
DEPANet: A Differentiable Edge-Guided Pyramid Aggregation Network for Strip Steel Surface Defect Segmentation


Abstract
1. Introduction
- We propose a novel DEFP network consisting of stacked AFSFs to extract multiscale edge components from strip steel surface defects. Each AFSF utilizes a learnable Laplacian operator for edge feature extraction and a learnable Gaussian blurring mechanism for feature smoothing and enhancement.
- We propose EFAMs to generate edge-enhanced features, with each EFAM designed to integrate the backbone features with the edge components obtained from DEFP using a CBAM to enhance defect segmentation accuracy.
- Based on DEFP and EFAM, a novel network called DEPANet is proposed. Experimental results show that DEPANet achieves superior performance in segmenting and localizing complex defects on strip steel surfaces.
2. Related Work
2.1. ResNet-Based Methods
2.2. Edge Enhancement
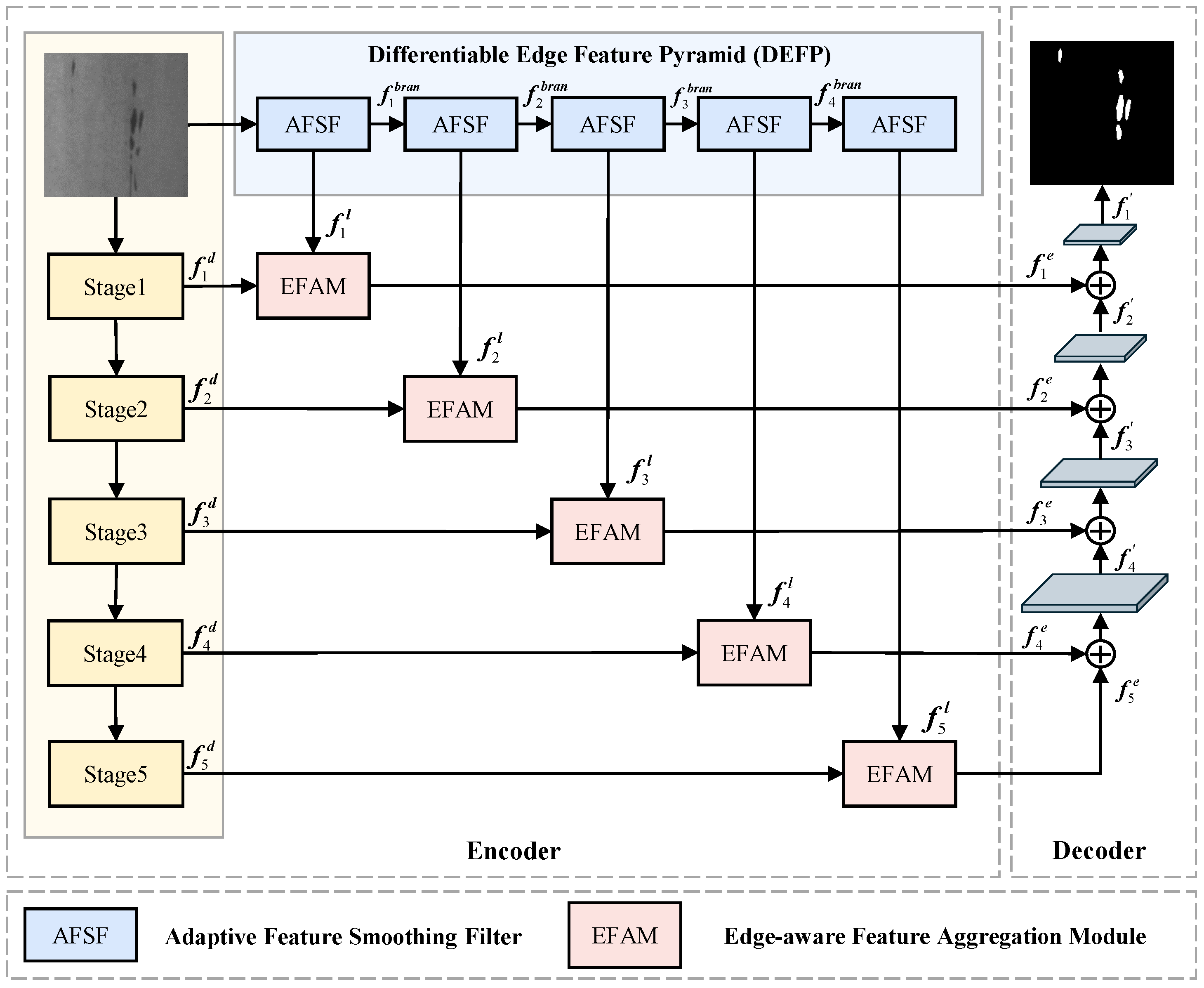
3. Methods
3.1. Overall Architecture
3.2. Differentiable Edge Feature Pyramid Network (DEFP)
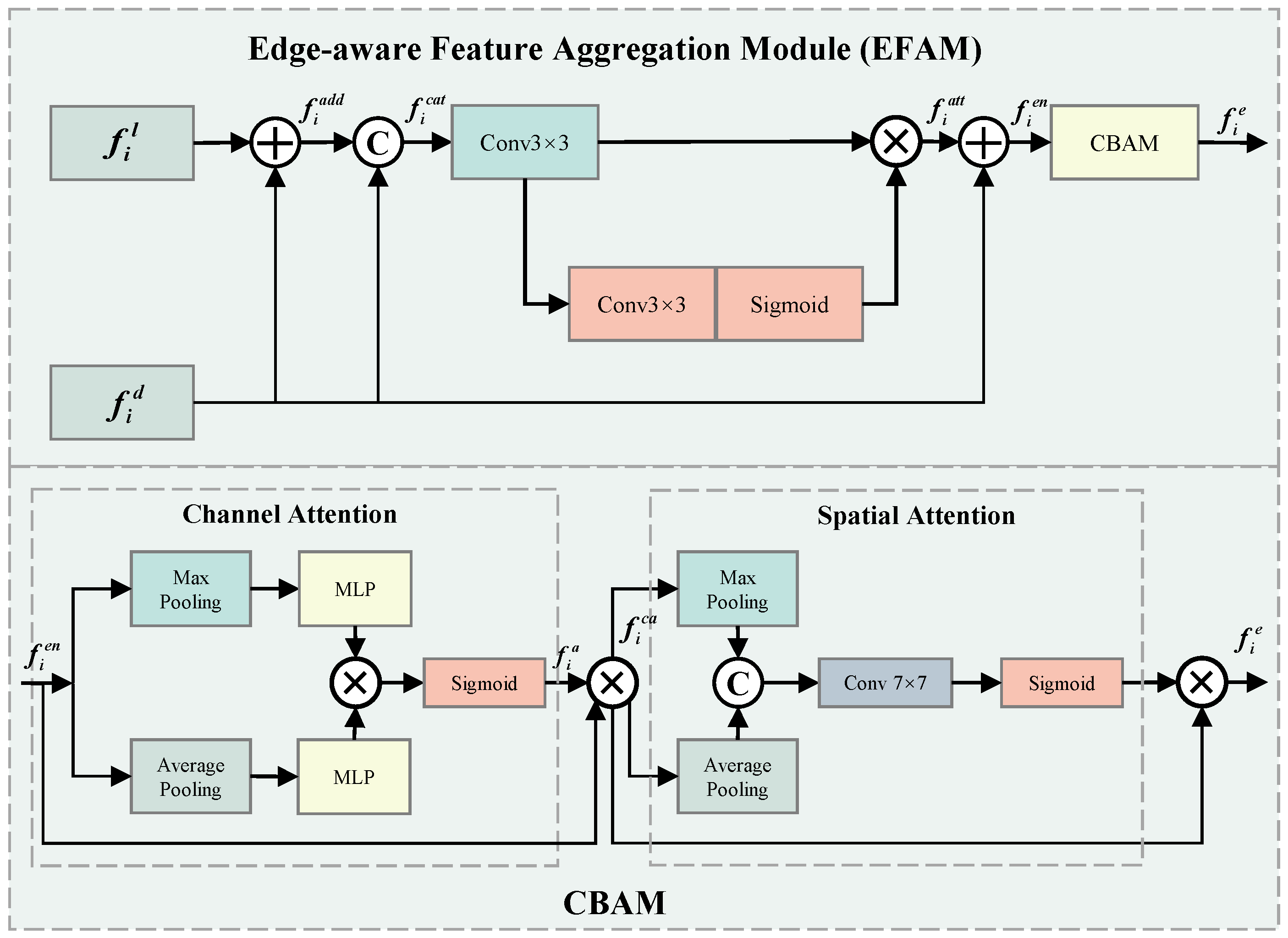
3.3. Edge-Aware Feature Aggregation Modules (EFAMs)
3.4. Loss Function
4. Experiment and Results
4.1. Datasets
4.2. Experimental Setup
4.3. Evaluation Metrics
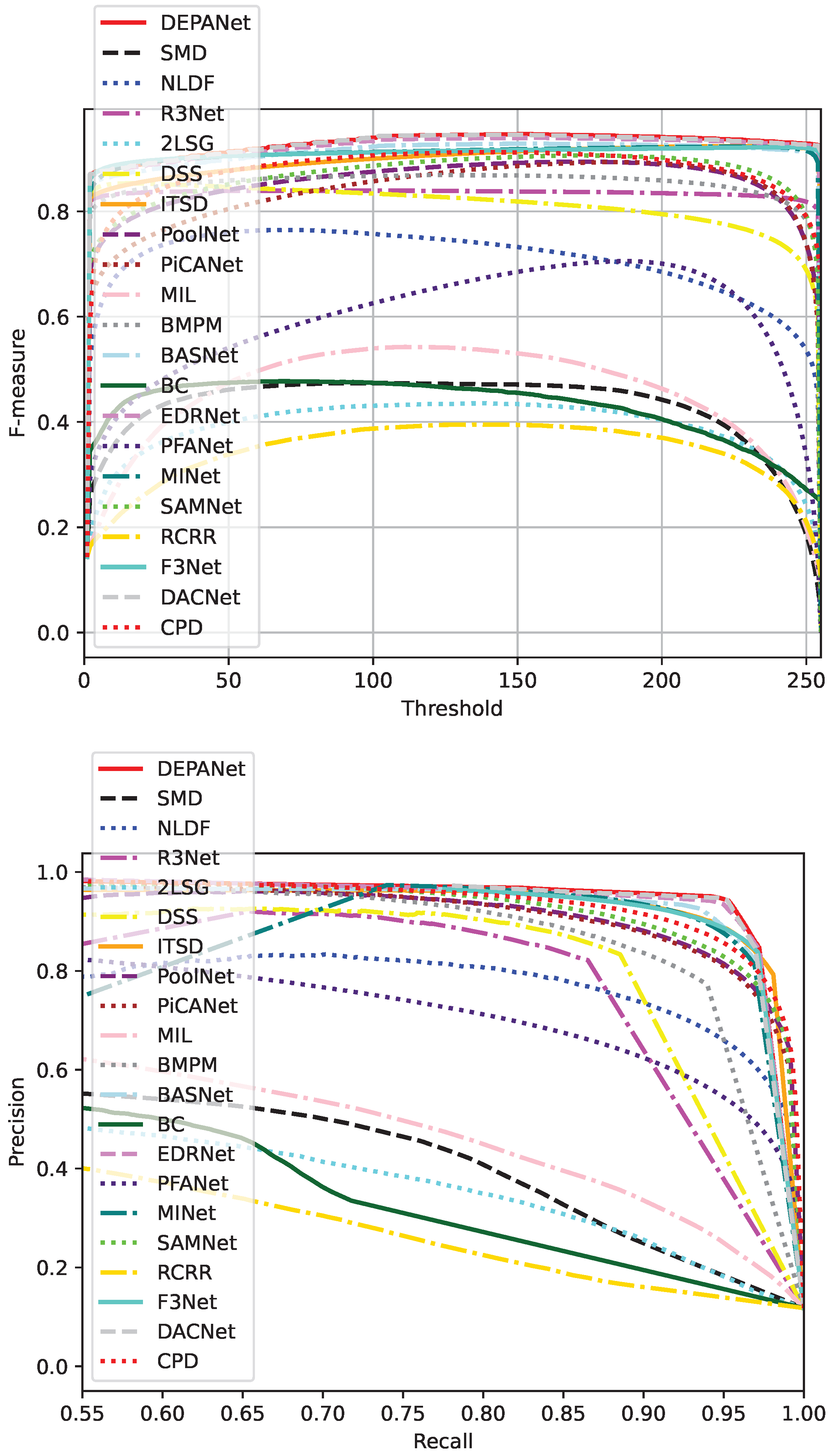
4.4. Comparison Results
4.5. Visualization Analysis
4.6. Ablation Studies
4.7. Generalization Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Liu, W. Surface Defect Detection Algorithm for Strip Steel Based on Improved YOLOv7 Model. IAENG Int. J. Comput. Sci. 2024, 51, 308–316. [Google Scholar]
- Ding, L.; Xiao, L.; Liao, B.; Lu, R.; Peng, H. An improved recurrent neural network for complex-valued systems of linear equation and its application to robotic motion tracking. Front. Neurorobotics 2017, 11, 45. [Google Scholar] [CrossRef] [PubMed]
- Jin, J. Multi-function current differencing cascaded transconductance amplifier (MCDCTA) and its application to current-mode multiphase sinusoidal oscillator. Wirel. Pers. Commun. 2016, 86, 367–383. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, J.; Mai, W. VPT: Video portraits transformer for realistic talking face generation. Neural Netw. 2025, 184, 107122. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Mo, Z.; Yan, F.; Xia, L.; Shan, F.; Ding, Z.; Song, B.; Gao, W.; Shao, W.; Shi, F.; et al. Adaptive feature selection guided deep forest for COVID-19 classification with chest CT. IEEE J. Biomed. Health Inform. 2020, 24, 2798–2805. [Google Scholar] [CrossRef]
- Guo, Y.; Wei, J.; Feng, X. TSEDNet:Task-specific encoder–decoder network for surface defects of strip steel. Measurement 2025, 239, 115438. [Google Scholar] [CrossRef]
- Liu, R.; Huang, M.; Gao, Z.; Cao, Z.; Cao, P. MSC-DNet: An efficient detector with multi-scale context for defect detection on strip steel surface. Measurement 2023, 209, 112467. [Google Scholar] [CrossRef]
- Du, Y.; Chen, H.; Fu, Y.; Zhu, J.; Zeng, H. AFF-Net: A strip steel surface defect detection network via adaptive focusing features. IEEE Trans. Instrum. Meas. 2024, 73, 2518514. [Google Scholar] [CrossRef]
- Dong, X.; Li, Y.; Fu, L.; Liu, J. Edge-aware interactive refinement network for strip steel surface defects detection. Meas. Sci. Technol. 2024, 36, 016222. [Google Scholar] [CrossRef]
- Hui, M.; Yuqin, L.; Tianjiao, H.; Yihua, L. Research on a Multiscale U-Net Lung Nodule Segmentation Model Based on Edge Perception and 3D Attention Mechanism Improvement. IEEE Access 2024, 12, 165458–165471. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lu, K.; Wang, W.; Pan, X.; Zhou, Y.; Chen, Z.; Zhao, Y.; Wang, B. Resformer-Unet: A U-shaped Framework Combining ResNet and Transformer for Segmentation of Strip Steel Surface Defects. ISIJ Int. 2024, 64, 67–75. [Google Scholar] [CrossRef]
- Fan, Z.; Liu, Y.; Xia, M.; Hou, J.; Yan, F.; Zang, Q. ResAt-UNet: A U-shaped network using ResNet and attention module for image segmentation of urban buildings. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2023, 16, 2094–2111. [Google Scholar] [CrossRef]
- Sahli, H.; Ben Slama, A.; Zeraii, A.; Labidi, S.; Sayadi, M. ResNet-SVM: Fusion based glioblastoma tumor segmentation and classification. J. X-Ray Sci. Technol. 2023, 31, 27–48. [Google Scholar] [CrossRef] [PubMed]
- Abdelrahman, A.; Viriri, S. FPN-SE-ResNet model for accurate diagnosis of kidney tumors using CT images. Appl. Sci. 2023, 13, 9802. [Google Scholar] [CrossRef]
- Yang, B.; Yang, S.; Wang, P.; Wang, H.; Jiang, J.; Ni, R.; Yang, C. FRPNet: An improved Faster-ResNet with PASPP for real-time semantic segmentation in the unstructured field scene. Comput. Electron. Agric. 2024, 217, 108623. [Google Scholar] [CrossRef]
- Wang, Y.; Yin, T.; Chen, X.; Hauwa, A.S.; Deng, B.; Zhu, Y.; Gao, S.; Zang, H.; Zhao, H. A steel defect detection method based on edge feature extraction via the Sobel operator. Sci. Rep. 2024, 14, 27694. [Google Scholar] [CrossRef]
- Zhang, Z.; Ding, C.; Zhang, M.; Luo, Y.; Mai, J. DCDLN: A densely connected convolutional dynamic learning network for malaria disease diagnosis. Neural Netw. 2024, 176, 106339. [Google Scholar] [CrossRef]
- Allah, A.M.G.; Sarhan, A.M.; Elshennawy, N.M. Edge U-Net: Brain tumor segmentation using MRI based on deep U-Net model with boundary information. Expert Syst. Appl. 2023, 213, 118833. [Google Scholar] [CrossRef]
- Jin, J.; Zhou, W.; Yang, R.; Ye, L.; Yu, L. Edge Detection Guide Network for Semantic Segmentation of Remote-Sensing Images. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Wang, J.; Chen, G.; Zhang, T.J.; Wu, N.; Wang, X. An Efficient Muscle Segmentation Method via Bayesian Fusion of Probabilistic Shape Modeling and Deep Edge Detection. IEEE Trans. Biomed. Eng. 2024, 71, 3263–3274. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Gedraite, E.S.; Hadad, M. Investigation on the Effect of a Gaussian Blur in Image Filtering and Segmentation. In Proceedings of the 53rd International Symposium ELMAR-2011, Zadar, Croatia, 14–16 September 2011; pp. 393–396. [Google Scholar]
- Wang, C.; Wang, Y.; Yuan, Y.; Peng, S.; Li, G.; Yin, P. Joint computation offloading and resource allocation for end-edge collaboration in internet of vehicles via multi-agent reinforcement learning. Neural Netw. 2024, 179, 106621. [Google Scholar] [CrossRef]
- Ruby, U.; Yendapalli, V. Binary cross entropy with deep learning technique for image classification. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 5393–5397. [Google Scholar]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice loss for data-imbalanced NLP tasks. arXiv 2019, arXiv:1911.02855. [Google Scholar]
- Song, G.; Song, K.; Yan, Y. Saliency Detection for Strip Steel Surface Defects Using Multiple Constraints and Improved Texture Features. Opt. Lasers Eng. 2020, 128, 106000. [Google Scholar] [CrossRef]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency Filters: Contrast-Based Filtering for Salient Region Detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Cheng, M.M.; Fan, D.P. Structure-Measure: A New Way to Evaluate Foreground Maps. Int. J. Comput. Vis. 2021, 129, 2622–2638. [Google Scholar] [CrossRef]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-Tuned Salient Region Detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-Alignment Measure for Binary Foreground Map Evaluation. arXiv 2018, arXiv:1805.10421. [Google Scholar]
- Zhou, L.; Yang, Z.; Zhou, Z.; Hu, D. Salient Region Detection Using Diffusion Process on a Two-Layer Sparse Graph. IEEE Trans. Image Process. 2017, 26, 5882–5894. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. BASNet: Boundary-Aware Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency Optimization from Robust Background Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar]
- Zhang, L.; Dai, J.; Lu, H.; He, Y.; Wang, G. A Bi-Directional Message Passing Model for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1741–1750. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded Partial Decoder for Fast and Accurate Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Zhou, X.; Fang, H.; Liu, Z.; Zheng, B.; Sun, Y.; Zhang, J.; Yan, C. Dense Attention-Guided Cascaded Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Instrum. Meas. 2021, 71, 1–14. [Google Scholar] [CrossRef]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply Supervised Salient Object Detection with Short Connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3212. [Google Scholar]
- Song, G.; Song, K.; Yan, Y. EDRNet: Encoder-Decoder Residual Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Instrum. Meas. 2020, 69, 9709–9719. [Google Scholar] [CrossRef]
- Wei, J.; Wang, S.; Huang, Q. F3Net:Fusion, Feedback, and Focus for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12321–12328. [Google Scholar]
- Zhou, H.; Xie, X.; Lai, J.H.; Chen, Z.; Yang, L. Interactive Two-Stream Decoder for Accurate and Fast Saliency Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9141–9150. [Google Scholar]
- Huang, F.; Qi, J.; Lu, H.; Zhang, L.; Ruan, X. Salient Object Detection Via Multiple Instance Learning. IEEE Trans. Image Process. 2017, 26, 1911–1922. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-Scale Interactive Network for Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9413–9422. [Google Scholar]
- Luo, Z.; Mishra, A.; Achkar, A.; Eichel, J.; Li, S.; Jodoin, P.M. Non-Local Deep Features for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6609–6617. [Google Scholar]
- Zhao, T.; Wu, X. Pyramid Feature Attention Network for Saliency Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3085–3094. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. PiCANet: Learning Pixel-Wise Contextual Attention for Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3089–3098. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A Simple Pooling-Based Design for Real-Time Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3Net: Recurrent Residual Refinement Network for Saliency Detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; Volume 684690. [Google Scholar]
- Yuan, Y.; Li, C.; Kim, J.; Cai, W.; Feng, D.D. Reversion Correction and Regularized Random Walk Ranking for Saliency Detection. IEEE Trans. Image Process. 2017, 27, 1311–1322. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Zhang, X.Y.; Bian, J.W.; Zhang, L.; Cheng, M.M. SAMNet: Stereoscopically Attentive Multi-Scale Network for Lightweight Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 3804–3814. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Li, B.; Ling, H.; Hu, W.; Xiong, W.; Maybank, S.J. Salient Object Detection Via Structured Matrix Decomposition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 818–832. [Google Scholar] [CrossRef] [PubMed]
- Cui, W.; Song, K.; Feng, H.; Jia, X.; Liu, S.; Yan, Y. Autocorrelation-aware aggregation network for salient object detection of strip steel surface defects. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, G.; Zhou, T.; Zhang, Y.; Liu, N. Context-aware cross-level fusion network for camouflaged object detection. arXiv 2021, arXiv:2105.12555. [Google Scholar]
- GongyangLi, Z.; Bai, Z.; Lin, W.; Ling, H. Lightweight salient object detection in optical remote sensing images via feature correlation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5617712. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MAE ↓ | SM ↑ | w- ↑ | ↑ | ↑ | ↑ | ↑ | ↑ | ↑ | Params (M) ↓ | FPS↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2LSG [32] | 0.2547 | 0.5723 | 0.2816 | 0.6745 | 0.5439 | 0.6572 | 0.4365 | 0.3954 | 0.4562 | 61.7 | 20.2 |
| BASNet [33] | 0.0159 | 0.9193 | 0.8955 | 0.9593 | 0.9603 | 0.9714 | 0.8694 | 0.9011 | 0.9223 | 52.1 | 23.1 |
| BC [34] | 0.1593 | 0.5861 | 0.3999 | 0.7264 | 0.6403 | 0.6836 | 0.4677 | 0.4227 | 0.4708 | —— | 18.0 |
| BMPM [35] | 0.0312 | 0.8513 | 0.8454 | 0.9298 | 0.8972 | 0.9301 | 0.8384 | 0.8417 | 0.8622 | 49.9 | 26.2 |
| CPD [36] | 0.0242 | 0.8981 | 0.7928 | 0.9299 | 0.9369 | 0.9744 | 0.8305 | 0.8701 | 0.9091 | 29.6 | 19.2 |
| DACNet [37] | 0.0129 | 0.9321 | 0.9139 | 0.9671 | 0.9693 | 0.9627 | 0.8911 | 0.9217 | 0.9351 | 98.2 | 15.7 |
| DSS [38] | 0.0256 | 0.8202 | 0.8296 | 0.9339 | 0.8514 | 0.9326 | 0.8581 | 0.8033 | 0.8501 | 74.9 | 24.6 |
| EDRNet [39] | 0.0139 | 0.9343 | 0.9187 | 0.9635 | 0.9716 | 0.9790 | 0.8858 | 0.9177 | 0.9370 | 49.4 | 27.9 |
| F3Net [40] | 0.0157 | 0.9155 | 0.9065 | 0.9680 | 0.9671 | 0.9724 | 0.8943 | 0.9038 | 0.9178 | 35.8 | 23.5 |
| ITSD [41] | 0.0158 | 0.9201 | 0.8976 | 0.9561 | 0.9641 | 0.9733 | 0.8606 | 0.8923 | 0.9207 | 48.1 | 18.0 |
| MIL [42] | 0.1854 | 0.6143 | 0.3087 | 0.7216 | 0.5971 | 0.7079 | 0.4760 | 0.4472 | 0.5385 | 56.5 | 20.8 |
| MINet [43] | 0.0150 | 0.9202 | 0.9181 | 0.9604 | 0.9631 | 0.9701 | 0.8813 | 0.9011 | 0.8979 | 48.3 | 19.6 |
| NLDF [44] | 0.0491 | 0.8021 | 0.6911 | 0.671 | 0.8050 | 0.8734 | 0.7211 | 0.7007 | 0.7621 | 56.3 | 23.4 |
| PFANet [45] | 0.0876 | 0.7381 | 0.5322 | 0.7195 | 0.7500 | 0.8549 | 0.5545 | 0.5922 | 0.7089 | 88.0 | 17.6 |
| PiCANet [46] | 0.0289 | 0.8912 | 0.8902 | 0.8961 | 0.9199 | 0.9659 | 0.7580 | 0.8278 | 0.8022 | 49.1 | 26.7 |
| PoolNet [47] | 0.0244 | 0.9005 | 0.8322 | 0.9173 | 0.9311 | 0.9692 | 0.8062 | 0.8484 | 0.8905 | 54.4 | 25.0 |
| R3Net [48] | 0.0263 | 0.8374 | 0.8301 | 0.9298 | 0.9022 | 0.9341 | 0.8419 | 0.8280 | 0.8351 | 48.3 | 27.0 |
| RCRR [49] | 0.2455 | 0.5311 | 0.2317 | 0.6345 | 0.5465 | 0.6261 | 0.3327 | 0.3381 | 0.3923 | —— | 20.0 |
| SAMNet [50] | 0.0267 | 0.9013 | 0.8491 | 0.9270 | 0.9385 | 0.9700 | 0.8045 | 0.8577 | 0.9027 | 65.5 | 29.3 |
| SMD [51] | 0.2088 | 0.5808 | 0.3652 | 0.7093 | 0.5921 | 0.6467 | 0.4411 | 0.4233 | 0.4612 | 74.1 | 19.1 |
| Ours | 0.0132 | 0.9373 | 0.9247 | 0.9793 | 0.9765 | 0.9793 | 0.9223 | 0.9193 | 0.9256 | 47.6 | 22.3 |
| Exp. | DEPANet | SD-Saliency-900 | ||||||
|---|---|---|---|---|---|---|---|---|
| ResNet34 | DEFP | EFAM | CBAM | MAE ↓ | SM ↑ | ↑ | ↑ | |
| #1 | ✓ | X | X | X | 0.0191 | 0.8891 | 0.9231 | 0.8919 |
| #2 | ✓ | ✓ | ✓ | X | 0.0141 | 0.9267 | 0.9671 | 0.9298 |
| #3 | ✓ | ✓ | ✓ | ✓ | 0.0132 | 0.9373 | 0.9758 | 0.9396 |
| #4 | BCE | 0.0154 | 0.9015 | 0.9598 | 0.9116 | |||
| #5 | Dice | 0.0149 | 0.9141 | 0.9674 | 0.9180 | |||
| #6 | BCE + Dice | 0.0132 | 0.9373 | 0.9758 | 0.9396 | |||
| Methods | MAE ↓ | SM ↑ | ↑ | ↑ | Parameters (M) ↓ |
|---|---|---|---|---|---|
| C2FNet [53] | 0.0207 | 0.8982 | 0.9701 | 0.8835 | 26.4 |
| CPD [36] | 0.0254 | 0.8884 | 0.9627 | 0.8777 | 29.6 |
| DACNet [37] | 0.0226 | 0.8855 | 0.9570 | 0.8722 | 98.2 |
| EDRNet [39] | 0.0229 | 0.8651 | 0.9603 | 0.8769 | 49.4 |
| BC [34] | 0.1356 | 0.6004 | 0.6704 | 0.4976 | — |
| F3Net [40] | 0.0208 | 0.8977 | 0.9663 | 0.8910 | 35.8 |
| MINet [43] | 0.0221 | 0.8885 | 0.9604 | 0.8798 | 48.3 |
| RCRR [49] | 0.2194 | 0.5633 | 0.6198 | 0.4377 | — |
| CorrNet [54] | 0.0243 | 0.8776 | 0.9532 | 0.8785 | 39.3 |
| PiCANet [46] | 0.0449 | 0.8490 | 0.9317 | 0.8337 | 49.1 |
| Ours | 0.0202 | 0.9007 | 0.9654 | 0.8860 | 47.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Geng, S.; Zheng, C.; Xu, C.; Guo, H.; Feng, Y. DEPANet: A Differentiable Edge-Guided Pyramid Aggregation Network for Strip Steel Surface Defect Segmentation. Algorithms 2025, 18, 279. https://doi.org/10.3390/a18050279
Sun Y, Geng S, Zheng C, Xu C, Guo H, Feng Y. DEPANet: A Differentiable Edge-Guided Pyramid Aggregation Network for Strip Steel Surface Defect Segmentation. Algorithms. 2025; 18(5):279. https://doi.org/10.3390/a18050279
Chicago/Turabian StyleSun, Yange, Siyu Geng, Chengyi Zheng, Chenglong Xu, Huaping Guo, and Yan Feng. 2025. "DEPANet: A Differentiable Edge-Guided Pyramid Aggregation Network for Strip Steel Surface Defect Segmentation" Algorithms 18, no. 5: 279. https://doi.org/10.3390/a18050279
APA StyleSun, Y., Geng, S., Zheng, C., Xu, C., Guo, H., & Feng, Y. (2025). DEPANet: A Differentiable Edge-Guided Pyramid Aggregation Network for Strip Steel Surface Defect Segmentation. Algorithms, 18(5), 279. https://doi.org/10.3390/a18050279