1. Introduction
An American Call/Put option is a contract issued by a financial institution allowing the holder (owner) of the American Option to exercise the option to buy (in the case of Call) or sell (in the case of Put) at a given strike price on or before the expiration date. These contract types are found in all major financial markets, including equity, commodity, insurance, energy, and real estate. The American Option differs from the European Option, where the European Option can only be exercised at the expiration date.
Having the “flexibility” to exercise the option at any time before the expiration date makes it more complex to value the American Option than the European Option. At each time step before its expiry when the American Option is in-the-money (the positive payoff upon exercise), the option owner faces the decision to either exercise the option and collect the payoff or consider “continuing” thinking that if she waits, the payoff might become more in-the-money (the bigger payoff). This dilemma (”When to Exercise?”) is the core challenge of the American Option problem.
At each time step, the option owner must compare the “immediate exercise value” against the “expected payoff from continuation”. Consequently, the valuation of the American Option hinges upon “conditional expectation”, dictating the decision between “exercising” or “continuing” the option. As will be demonstrated in the subsequent section, the fair value of the American Option can be conceptualized within the framework as an “Optimal Stopping Time” problem and Sequential Decision-Making.
In [
1], a finite difference method was proposed for pricing Black–Scholes [
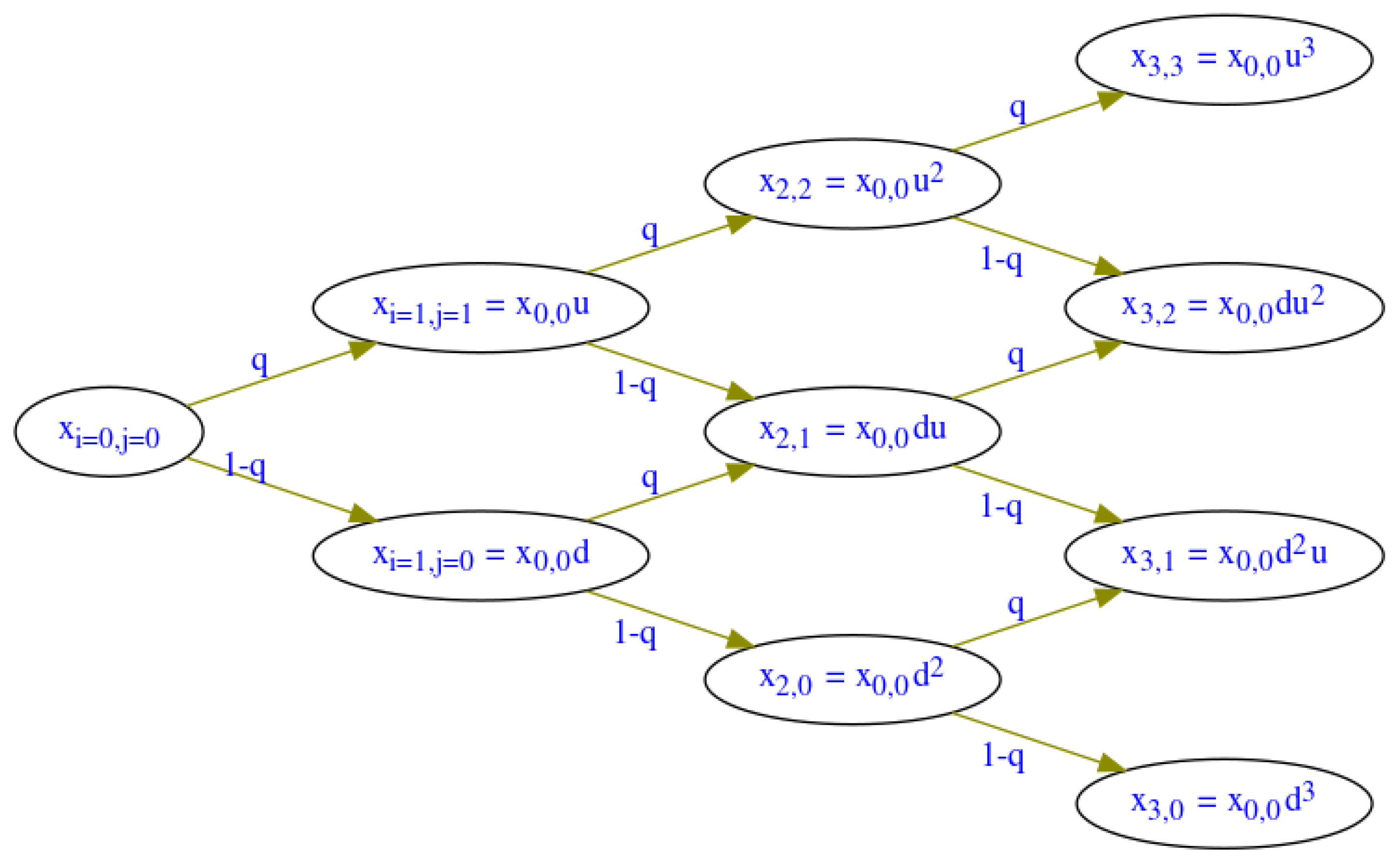
2] partial differential Equation (PDE) in American Put Option. The Binomial Option Pricing Model (BOPM) is another method for pricing the American Option proposed by [
3]. The key idea is to represent the underlying uncertainty in discrete time using a binomial lattice (Tree), then move backward from
to
to find the option value. In [
4], derived an analytical approximation for the American Option pricing by fitting the empirical function to the results of the American put option prices generated by BOPM.
Following a different approach, if the underlying asset is modeled as the Markov Process, the Bellman principle of Dynamic Programming (DP) [
5] can be used to compute the option value. However, this approach becomes impractical when the state space has many dimensions since the DP algorithm requires an exponential memory space in the number of dimensions. This problem is known as the “curse of dimensionality” for DP. To overcome this problem, ref. [
6] proposed that the state space domain was partitioned into a finite number of regions, and the continuation value was approximated. Similarly, Least Squares Monte Carlo (LSM) method was proposed to approximate the continuation value with regression on a set of basis functions to develop a low-dimensional approximation to the expected continuation value [
7].
Since the optimal exercise time of the American Option is a Sequential Decision-Making problem, with two possible actions at each time step, the Reinforcement Learning (RL) [
8] approach has been used to find the fair value of option price by learning the optimal policy.
Reinforcement learning (RL) is a model-free approach for Sequential Decision-Making, where explicit modeling of the environment (quantifying uncertainty) is no longer needed. The initial significant contribution to the field of RL was the advent of Q-Learning by [
9]. Further, the integration of the RL algorithm and neural networks led to the development of Deep Reinforcement Learning (DRL), particularly with the introduction of the Deep Q-Network (DQN) [
10], enabling RL to be applied to more complex tasks like Atari games using deep convolutional neural networks for approximating Q value function in them. Later developments, such as Proximal Policy Optimization (PPO) by [
11] and Soft Actor–Critic (SAC) by [
12], further advanced the field of RL by introducing policy gradient methods as a new form of finding an optimal policy in Sequential Decision-Making. More recently, model-based RL like DreamerV2 [
13] that learn policy through building the latent space of the world model has improved the sample efficiency of the method. Multi-task Reinforcement Learning [
14] has also enhanced the scalability and data efficiency of RL methods.
Least Squares Policy Iteration (LSPI) was proposed to learn the optimal policy for pricing the American Option [
15]. They considered both Geometric Brownian Motion (GBM) and a stochastic volatility model as the underlying asset price models and showed good quality of the policy learned by RL. The work of [
16] employed a deep learning method to learn the optimal stopping times from Monte Carlo samples. They showed that the resulting stopping policy (neural network policy) can approximate the optimal stopping times. Iteration algorithm for pricing American Options based on Reinforcement Learning was proposed in [
17]. At each iteration, the method approximates the expected discounted payoff of stopping times and produces those closer to optimal. A thorough literature review of the modeling and pricing of the American Option (both classical and RL-based methods) can be found in [
18]. Reinforcement learning has also been applied to dynamic stock option hedging in markets calibrated with stochastic volatility models [
19]. A comprehensive review of the application of Reinforcement Learning for option hedging, as well as recent advances in utilizing Reinforcement Learning for various decision-making processes in finance, can be found in [
20,
21].
We would like to point out that this research addresses a specific gap in the existing literature on American Options, and while there has been extensive research on American Options, there is a lack of focus on the analysis, emphasis, visualization, and comparison of the “policies (set of exercise decisions)” generated by different algorithms: (1) BOMP: Binomial Option Pricing Model, (2) LSM: Least Squares Monte Carlo, and (3) Reinforcement Learning. Our work is the first to concentrate on the final policy decisions generated by these algorithms, exploring how these policies differ and evolve during the training process (in the RL-based method). To implement this idea and conduct an analysis, we considered three distinct pricing models, encompassing both constant and calibrated stochastic volatility models. The results provide new insights into final policy behaviors under various market conditions (represented by different uncertainty models) and a comparison of their resulting values obtained from these algorithms. These findings offer a better understanding of decision-making processes in the context of American options.
The main contributions of this work are threefold: (a) We explored and implemented three methods for pricing the American Option for both constant and stochastic volatility models of underlying uncertainty. (b) The RL method was studied to understand and shed light on how learning in RL contributes to updating “Decisions” at each batch. (c) We replicated
Table 1 from the study by [
7] utilizing the Least Squares Monte Carlo Method for pricing American Options, facilitating a comparative analysis with the outcomes derived from the RL approach.
This paper is organized as follows:
Section 2 presents the “Problem Statement”.
Section 3 discusses the modeling of the uncertainty of underlying price dynamics.
Section 4 presents and briefly reviews the three methods for pricing the American Option.
Section 5 presents the work results. This paper concludes with
Section 6, “Discussion”, and
Section 7, “Conclusions”.
5. Results
5.1. Pricing Methods and Experimental Setup
In this section, the results of applying the three pricing methods—BOPM, LSM, and RL—to the following cases are presented as follows:
The underlying price is modeled using GBM (
Section 5.1).
The underlying price is modeled using GARCH (
Section 5.2).
The underlying price is modeled using EGARCH (
Section 5.3).
The parameters for each pricing model, including their calibration (for GARCH and EGARCH models), are provided within each respective section.
It is worth mentioning that the Binomial Option Pricing Model (BOPM) is appropriate for the Geometric Brownian Motion (GBM) price model because GBM assumes constant volatility and a log-normal price distribution, fitting well with BOPM’s discrete time steps and constant volatility assumptions. However, stochastic volatility models like GARCH and EGARCH feature time-varying volatility, which complicates the BOPM framework to be applicable. Therefore, BOPM is not suitable for these models, and only the RL and LSM methods have been applied to GARCH and EGARCH price models.
5.2. Option Price for GBM Price Model
The use of the GBM price model facilitates comparability with previous studies [
7] in the field. In addition, the exact solution of the AO valuation with the GBM price model can be solved using BOPM as the number of steps in the binomial tree approaches infinity.
5.2.1. Comparison of AO Valuation by BOPM, LSM, and RL
We first replicate
Table 1 in Longstaff and Schwartz’s work [
7] for BOPM and LSM. Then, RL is used to solve the same cases. In all cases (rows of
Table 1), the option’s strike price is
, the number of available opportunities to exercise is
(i.e., T = 1,
) and the risk-free discount rate is set to
.
In BOPM, each node branches out into two distinct paths: one upward movement and the other a downward movement. Furthermore,
, denotes the total number of time steps in the model. In
Table 1, the BOPM results are the exact solutions as a benchmark for comparing the results of the other two methods. The comparison shows that LSM and RL yield consistent results to BOPM, often matching to at least two decimal places.
In this study, the number of paths for training RL is 5000. In our experiments, we increased the number of paths to over 10,000 and up to 50,000; however, these modifications did not yield significant improvements in the results. Due to the stochastic nature of GBM during RL training, the RL results in
Table 1 are the mean option prices of ten repetitions of the valuation process (for each case, the option is priced ten times, and the results are averaged). For LSM, the number of paths is 100,000, similar to Longstaff and Schwartz’s work [
7].
5.2.2. Decision Boundary
In
Table 1, the fair price of each option has been computed using the three methods. These three methods lead to slightly different values because their decision boundaries (the decisions to continue and exercise) are slightly different.
To delve into and understand this difference more,
Figure 2 illustrates the decision boundary for the GBM price model with
,
, and
. At any point in time (during the exercise window), if the price of the underlying asset is lower than the decision boundary curve, the option should be exercised. In
Figure 2, the
x-axis has been normalized (Time = t/Expiration Time), and the y-axis is the price of the underlying asset. The “locally jagged” nature of the decision boundary in the BOMP method is noteworthy. This boundary results from the discrete, stepwise structure of underlying asset price within the binomial lattice. The “diamond-like” local structure of these prices forms clusters, leading to jumps along the decision boundary curve, a phenomenon similarly discussed in [
23].
5.2.3. Decision Frequency
In this section, we look into the frequency of exercise time for each method. The “frequency of exercise time” in this context is the distribution of exercise time (time of stopping) for 10,000 paths (generated from the GBM model), based on a method (LSM or RL).
Figure 3 shows the frequency of exercise time for the case where spot price
, strike price
, and volatility
are used in GBM. For example, at time step 5, the number of paths, for which the option is exercised, is around 500 for both LSM and RL. That is, for around 500 out of 10,000 paths (5%), LSM and RL suggest exercising the option at step 5.
Note that in
Figure 3, the bars after time step 50 represent the paths where the option is not exercised at the expiry time step or before (i.e., the option is never exercised). Both LSM and RL suggest not exercising the option at the expiry time step or before for around 25% of paths, leading to zero payoff for those paths.
LSM and RL lead to similar frequencies of exercise time in general, implying that RL can solve for a decision policy similar to LSM does.
We consider another case with larger uncertainty in the underlying asset prices over time, by using spot price
, strike price
, and volatility
in GBM.
Figure 4 shows the resulting frequency of exercise time for each method. Compared to the case with volatility
(
Figure 3), the frequencies of exercise time (
Figure 4) are different.
For the case with
(
Figure 4), RL leads to a different frequency of exercise time compared to LSM; especially for early time steps, RL does not suggest exercising the option before time step 24 for any path, whilst LSM suggests exercising the option before time step 24 for some paths. This behavior contrasts with
Figure 3, where the RL and LSM methods exhibited similar frequencies of early exercises across all time steps.
5.2.4. How Well Does RL Decision Policy Improve Throughout Training?
Figure 5 shows the change in the frequency of exercise time for RL, indicating the evolution of RL decision policy throughout the training. At the beginning of the training, the weights are equal. As the training progresses (more batches), the weights converge to optimal values, and the decision policy also converges to the optimal one. The training is conducted with 5000 paths in five batches. As shown in
Figure 5, the frequency of exercise time has almost no change after “Batch 2”, which indicates the decision policy converges to the optimal one. As explained in greater detail in the next subsection, the Option Value was computed after each batch and compared with the results from the BOMP method. If the final policy from the RL training resembles this value, it is considered an optimal policy.
5.2.5. How Option Values Change during Training?
Figure 6 shows the change in option value with each batch during the RL training process. In this example, the initial weights were set to
. Subsequently, new weights are found in each batch. The new weights are then applied to a set of test paths to find the resulting option value option.
5.3. Option Price for GARCH Price Model
This section discusses the outcomes of implementing the two option valuation methods when the underlying price is modeled using the Generalized Autoregressive Conditional Heteroskedasticity (GARCH) model. The GARCH price model was selected to test the robustness of the RL method because GARCH is more complex and volatile than GBM. We calibrate the GARCH to historical Brent Crude Oil price data. In this section, Brent Crude Oil price acts as the Underlying Asset for the American Option. Subsequently, this calibrated GARCH model is utilized to simulate underlying asset price paths.
Note that BOMP is not applicable to GARCH, so only LSM and RL are implemented for the GARCH case. In addition, in this example, the strike price is .
5.3.1. Hitorical Brent Crude Oil Price Data and GARCH Calibration
The historical Brent Crude Oil price data from 1987 to 2024, as shown in
Figure 7, are used to calibrate the GARCH price model.
Figure 8 contrasts the realized volatilities of the Brent Crude Oil price data and the forecasted volatilities of the calibrated GARCH model.
5.3.2. Decision Boundary
The decision boundary curves solved using LSM and RL for the case with the calibrated GARCH price model are plotted in
Figure 9. The decision boundary curves for the LSM and RL methods follow a similar trend, where the boundary curves at the expiry time
approach the strike price (
).
5.3.3. Decision Frequency
The resulting LSM and RL decision policies, as illustrated in
Figure 9, are applied to 20,000 price paths sampled from the calibrated GARCH price model with the spot price
. The frequency of exercise time for each method is shown in
Figure 10. Again, RL leads to a similar frequency of exercise time as LSM does. For approximately 7000 out of the 20,000 paths, LSM and RL suggest not exercising the option within the expiry time; in other words, the option is suggested to be exercised before/at the expiry time for around 14,000 paths.
5.3.4. How Well Does RL Decision Policy Improve Throughout Training?
Figure 11 shows the development of the frequency of exercise time, implying the development of the RL decision policy over the course of training. Initially (batch 0), the RL decision policy predominantly recommends exercising the option during the middle stages of the timeline (time steps between 15 and 30). However, with more batches of training, adjustments to the RL decision policy result in progressively fewer middle-stage exercises and more early-stage exercises. By the end of the fourth batch (Number 3 on the right side of
Figure 11), the frequency of exercise time stabilizes, which indicates the RL decision policy converges.
5.3.5. Final Option Values
The two methods, RL and LSM, were used to find the decision boundary (policy) shown in
Figure 9. The resulting decision boundaries from both methods were then tested on 10,000 paths to estimate the option value. Each method was repeated ten times to account for the stochastic nature of underlying price uncertainty (modeled by GARCH(1,1)). The average option value (
,
) was USD 10.75 for the RL method and USD 10.72 for the LSM method.
5.4. Option Price for EGARCH Price Model
This section discusses the implementation of RL and LSM methods for pricing AO, where the underlying price is modeled using the Exponential Generalized Autoregressive Conditional Heteroskedasticity (EGARCH) model. The EGARCH price model was selected since it can handle situations where negative returns increase future volatility more than positive returns. The GARCH model does not easily capture this feature. It makes EGARCH better suited for modeling real-world financial data where such asymmetry is common. We calibrate the EGARCH to historical Brent Crude Oil price data, the same as in the previous section. Subsequently, this calibrated EGARCH model is utilized to simulate underlying asset price paths.
5.4.1. EGARCH Price Model Calibration
Similar to the GARCH method, the Maximum Likelihood Estimation (MLE) method was used to estimate the parameters of the EGARCH model by calibrating it to oil price data (
Figure 7). The estimated parameters of the EGARCH model are presented in
Table 2.
Figure 12 contrasts the realized volatilities of Brent Crude Oil price data with the forecasted volatilities from the calibrated EGARCH model. In
Figure 12, the EGARCH(1,1,1) price model, due to its short memory (1,1,1), does not perfectly reconstruct the data. However, it is important to clarify that the primary focus of this paper is not on forecasting or developing models that perfectly fit the data. Rather, our work is centered on “Sequential Decision-Making” in American Options, where these models are used to simulate future paths as inputs to different pricing methods. Thus, even though the EGARCH(1,1,1) model may not reconstruct the data with high accuracy, it still serves as a consistent input for all methods under comparison.
5.4.2. Decision Boundary
The decision boundary curves solved using LSM and RL for the case with the calibrated EGARCH price model are plotted in
Figure 13. A notable difference between these boundaries is that the RL method results in “more” early exercises before half the expiry date. In contrast, the LSM method has a lower value boundary (
), resulting in fewer paths below this value and, consequently, “fewer” early exercises.
5.4.3. Decision Frequency
The resulting decision policies using LSM and RL, illustrated in
Figure 13, were applied to 10,000 price paths sampled from the calibrated EGARCH price model with a spot price of
and strike price
. The frequency of exercise times for each method is shown in
Figure 14. In both methods, approximately 35% of the paths are not exercised early. However, the RL method exhibits more early exercises before time step 25, as indicated by its decision boundary (discussed in the previous section).
5.4.4. Final Option Values
The two methods, RL and LSM, were used to find the decision boundary (policy) shown in
Figure 13. The decision boundaries obtained from both methods were then tested on 10,000 paths to estimate the option value. Each method was repeated ten times to account for the stochastic nature of underlying price uncertainty, modeled by EGARCH(1,1,1). The average option value, with
, strike price = USD 80 was USD 15.01 for the RL method and USD 14.91 for the LSM method.
6. Discussion
The classical LSM method is based on a predefined probabilistic model of an underlying asset price. The LSM samples future paths of the underlying asset price from the predefined probabilistic model, estimates conditional expected values using regression, and derives the option value through backward induction.
Conversely, the Reinforcement Learning (RL) approach is model free, eliminating the need for a predefined probabilistic price model to value an option. Instead, RL can utilize historical underlying asset price data to train for the optimal decision policy, exemplifying a data-driven approach to pricing American Options. Our study demonstrates that the RL method is effective for valuing American Options and yields results comparable to those obtained using the BOPM and LSM methods.
A limitation of the RL method needs to be mentioned. The stability of the training process can be an issue in finding the optimal policy. Careful attention is required when designing the RL algorithm with the appropriate number of batches, iterations, and learning rates to avoid overfitting and underfitting.
Future work could explore the potential of different feature functions (in this study only Laguerre was considered) in improving policy and valuation of the American Option. Additionally, investigating other types of underlying price models, such as jump models or two-factor models, could provide further insight.
7. Conclusions
Identifying the optimal exercise time of an American Option is a Sequential Decision-Making problem. At each time step, the option holder must decide whether to exercise the option based on the immediate reward or wait for potential future rewards, considering downstream uncertainties and decisions.
Our analysis shows that decision boundaries derived from the Least Squares Method Monte Carlo (LSM) method tend to be non-smooth. Notably, for the EGARCH(1,1,1) price model, the decision boundary changes abruptly at certain time steps when the number of sampled prices in the training set is around 100,000 paths. This occurs because LSM performs regression at each time step, whereas RL embeds time (t) directly within the Q-value function. A further conclusion is that, in the EGARCH (1,1,1) model, the LSM and RL-based methods result in two different exercise policies. However, as demonstrated in
Section 5.4.4, applying these different final policies to test paths yields the same option valuation. Despite the different exercise policies, the final option values are identical. This contrasts with the cases of the GBM and GARCH (1,1) models, where both the final policies and the option values are similar.
Finally, the Reinforcement Learning (RL) method learns policies through an iterative process. During this learning process, an iteration step where policy “change” stops is observed, indicating convergence. In this work, by employing the experience-replay method in RL, convergence is achieved within a few batches. The key contributions of this work can be summarized as follows: (a) The implementation, illustration, comparison, and discussion of the three methods—BOPM, LSM, and RL—for valuing American Options in cases with constant and stochastic volatility models—GBM and GARCH—of underlying asset price uncertainty. (b) The study and evaluation of an RL implementation for Sequential Decision-Making sheds light on how learning in RL contributes to improving “decisions”. (c) The authors of [
7] presented twenty different GBM-based models and used the LSM technique to determine option values. In this work, we apply the RL method to the same models, as shown in
Table 1, and compare it with the LSM approach.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}