
Search on an NK Landscape with Swarm Intelligence: Limitations and Future Research Opportunities


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
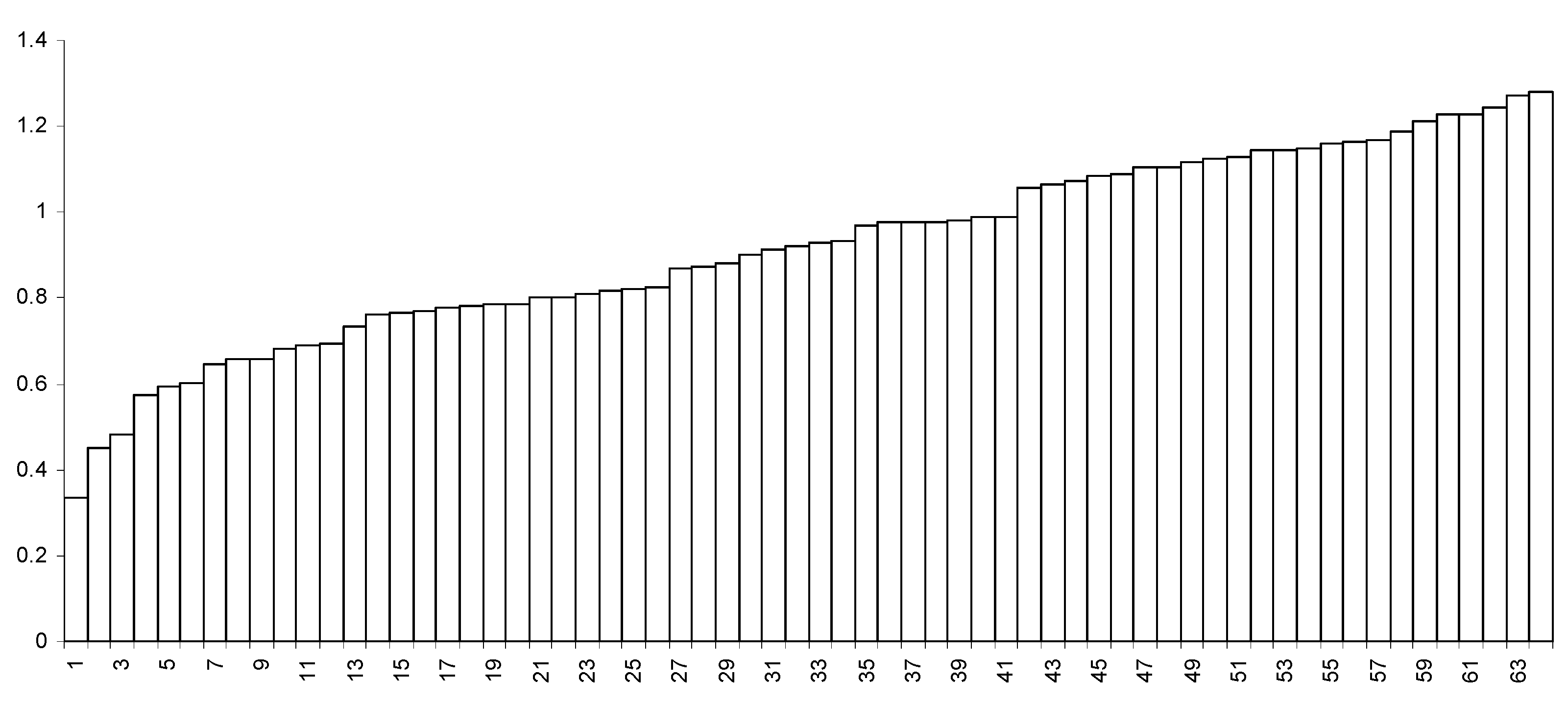{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Future Research Directions
- A payoff landscape or function that allows for continuous movement so that the full value of swarm in modeling agent (firm or human) behavior can be realized.
- Endogenous landscapes that allow payoffs to change as a function of agents positions on the landscape.
- Agent-specific landscapes that allow for researchers to explore heterogeneous returns to agent actions.
- Allowing information between agents, their locations, and their performance to be uncertain or incomplete.
- Including the cost of movements into the framework rather than implicitly assuming free movements on the landscape.
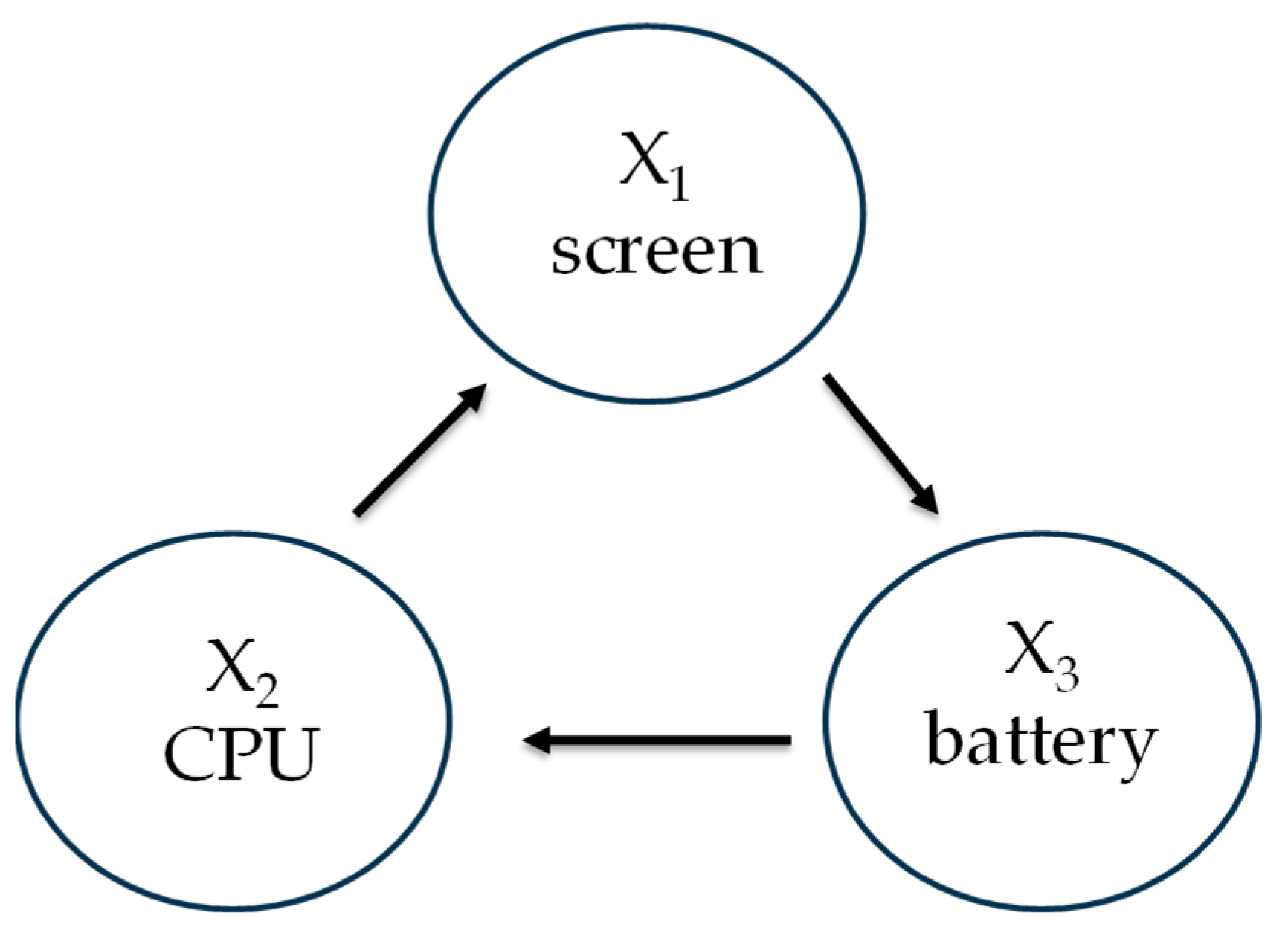
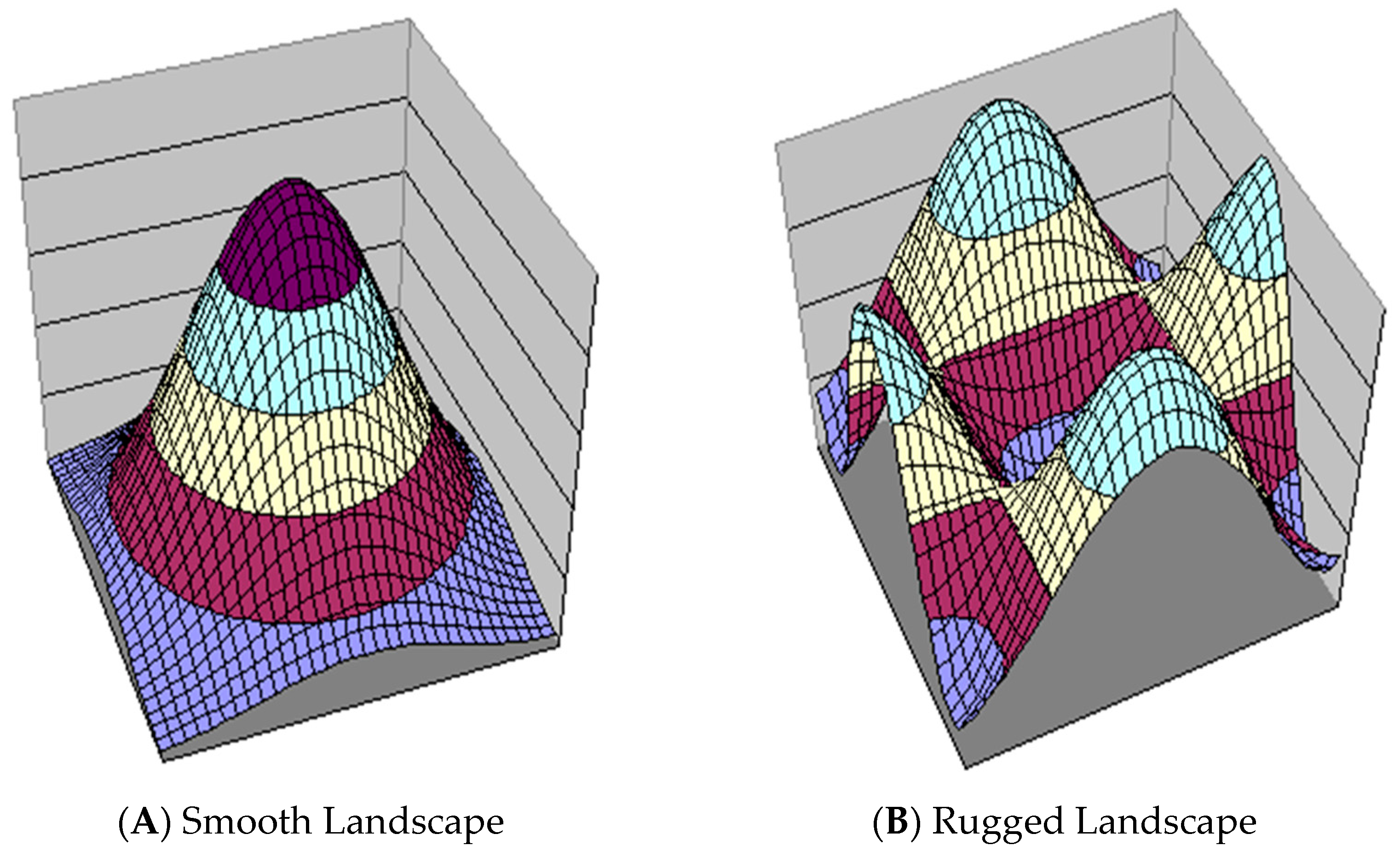
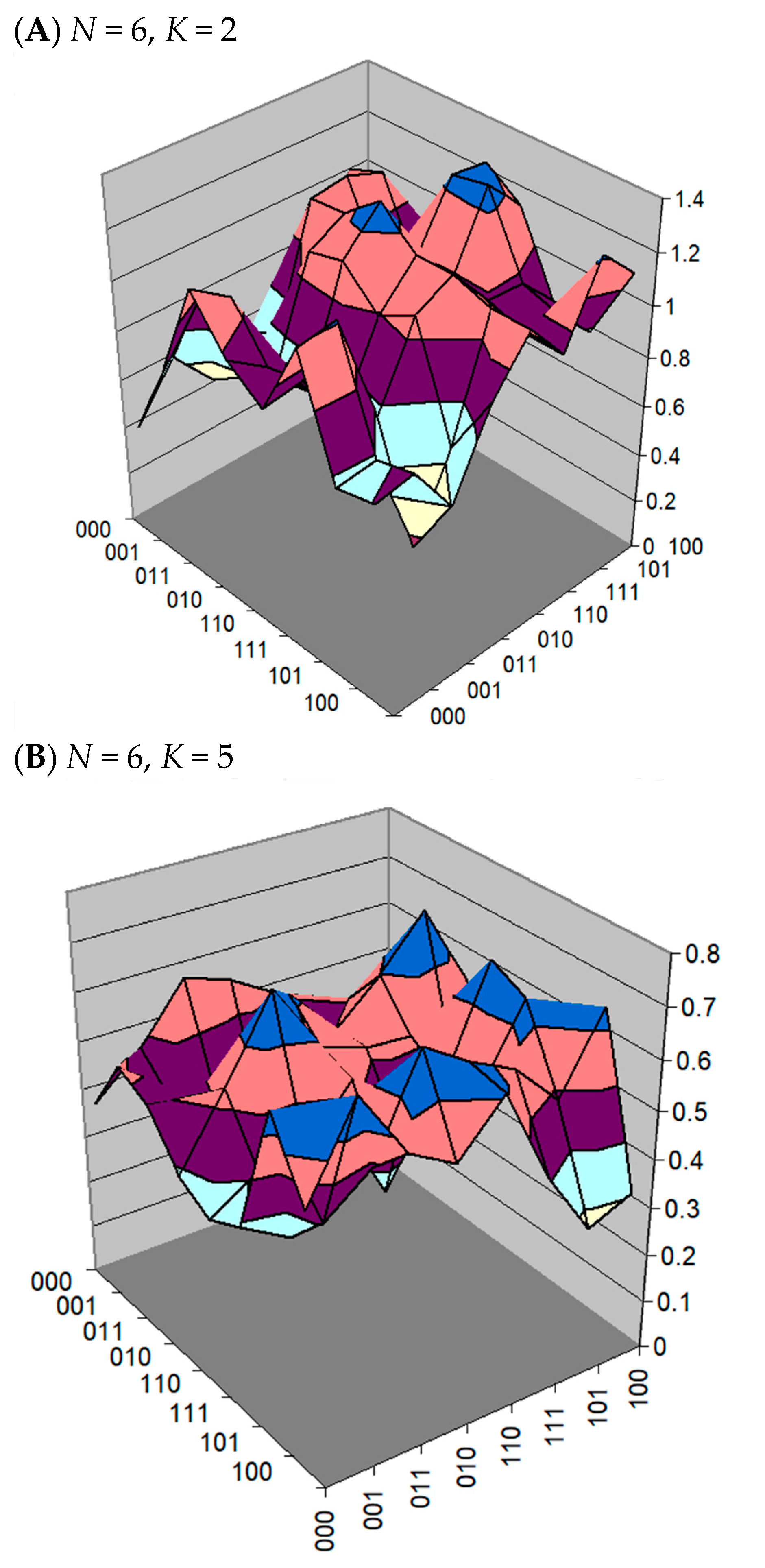
2. NK Landscape
2.1. Background
2.2. Mathematical Development of NK
3. Swarm Intelligence Algorithms
3.1. Background
3.2. Swarm Intelligence to Model Agent Behavior
3.3. Mathematical Development of Swarm


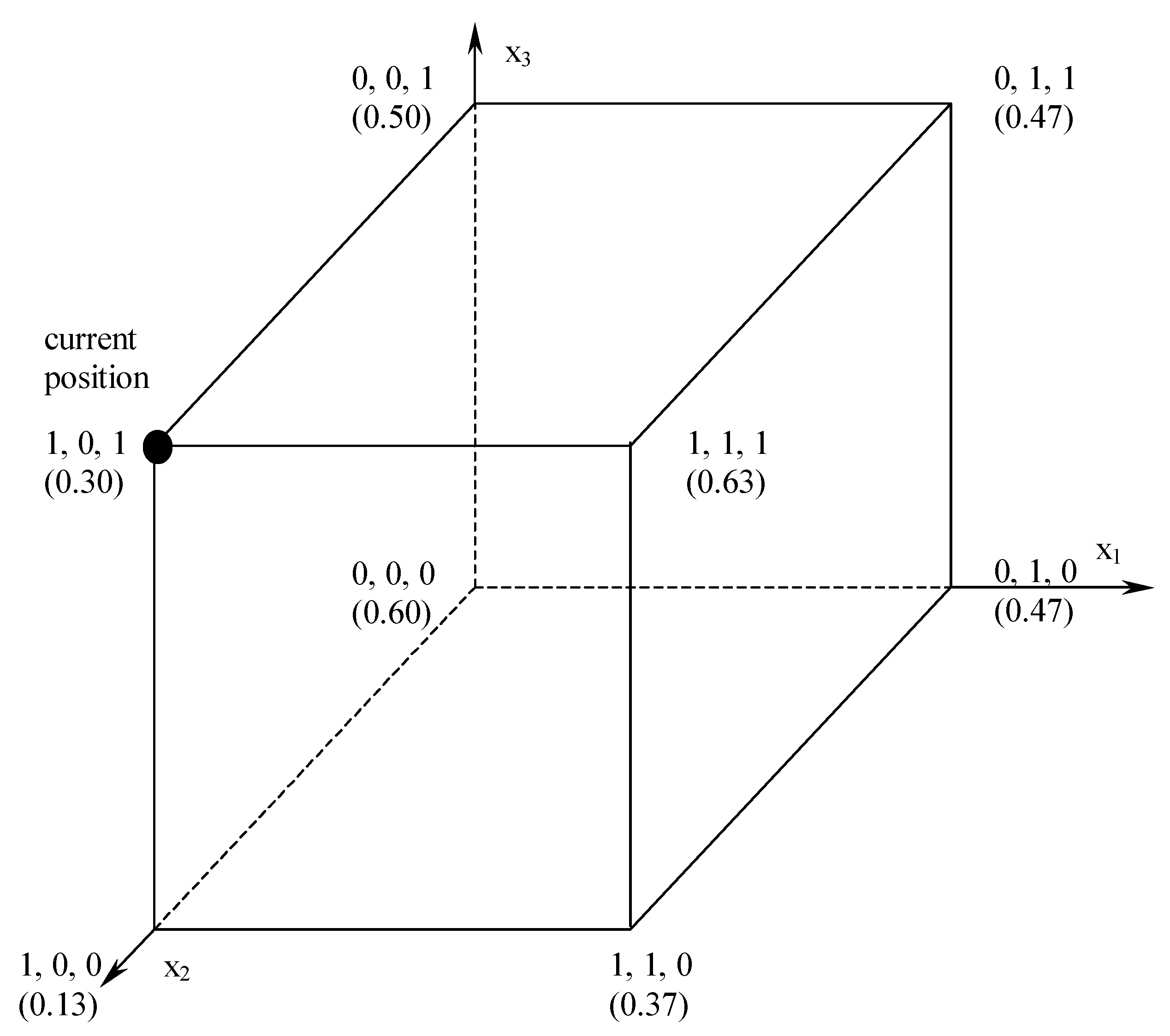
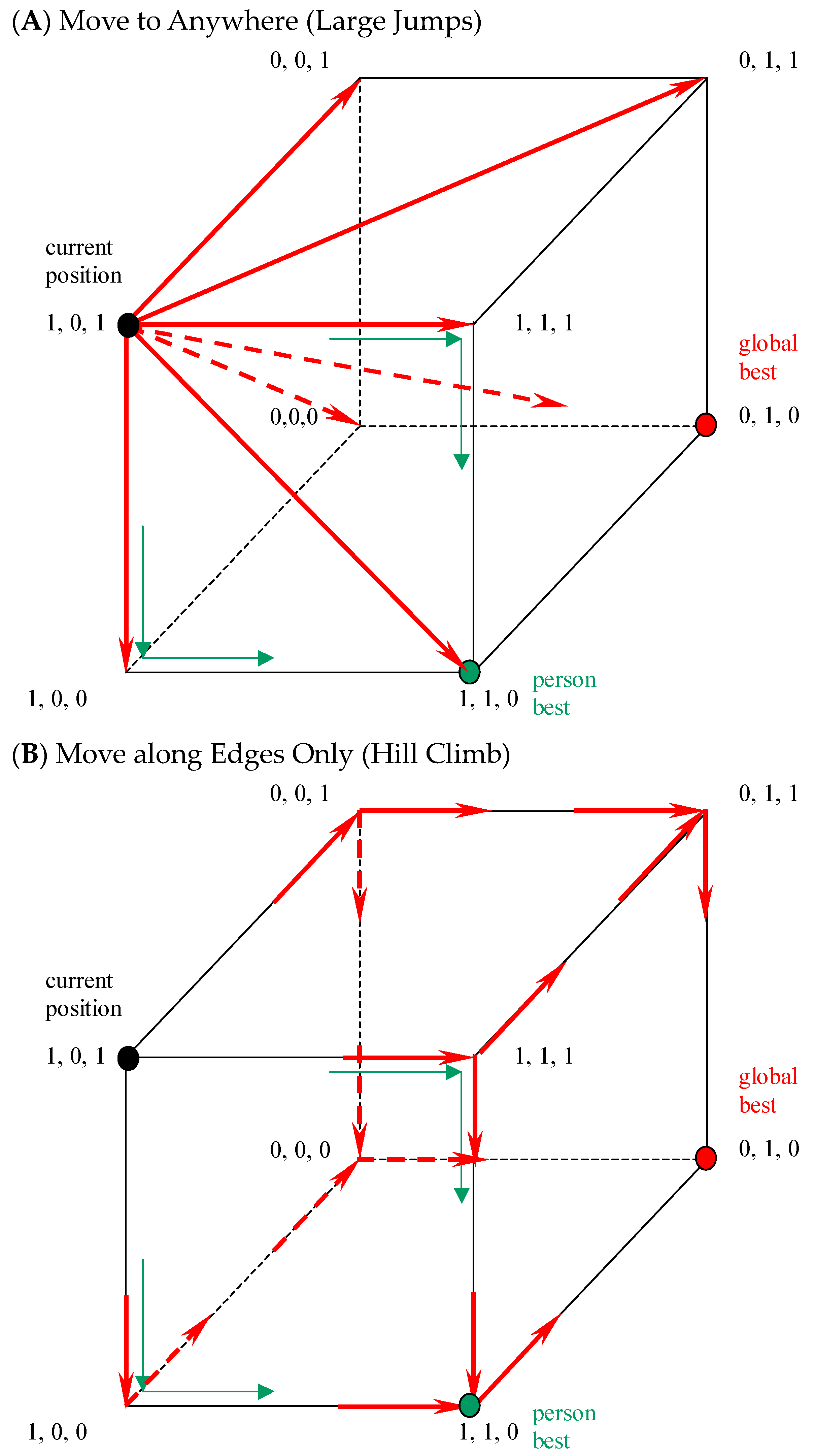
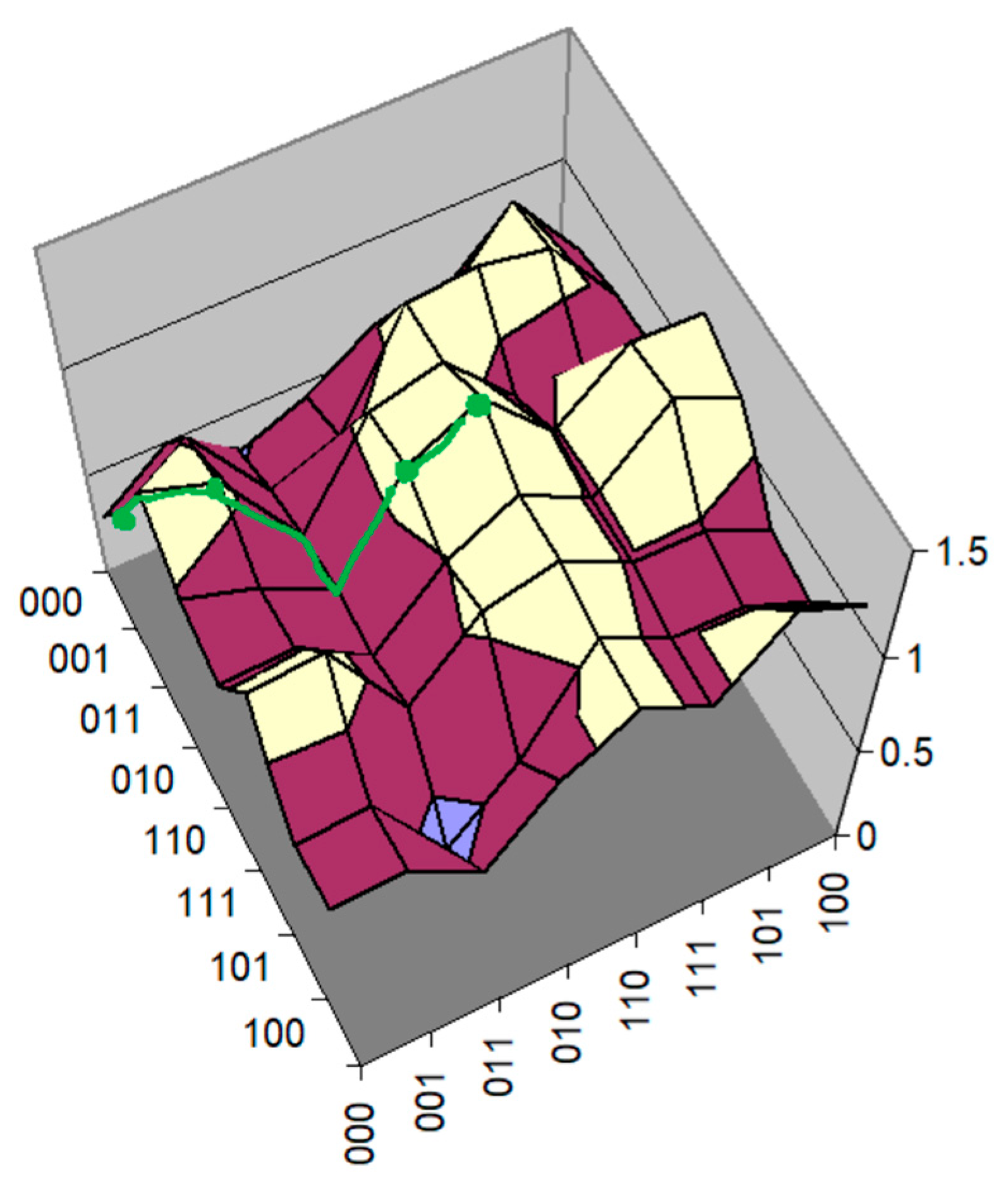
4. Search Algorithms
- One-mutant change or hill climb, where an agent chooses a new location from one of its one-mutant neighbors, such as 101 to 001, 111, or 100, if the fitness value of the new location is higher.
- Fitter-dynamics: an agent chooses a new location from the best of its one-mutant neighbors.
- Greedy dynamics (i.e., large or long jump), where an agent chooses a new location from all of its mutant neighbors, whoever has the highest fitness value.
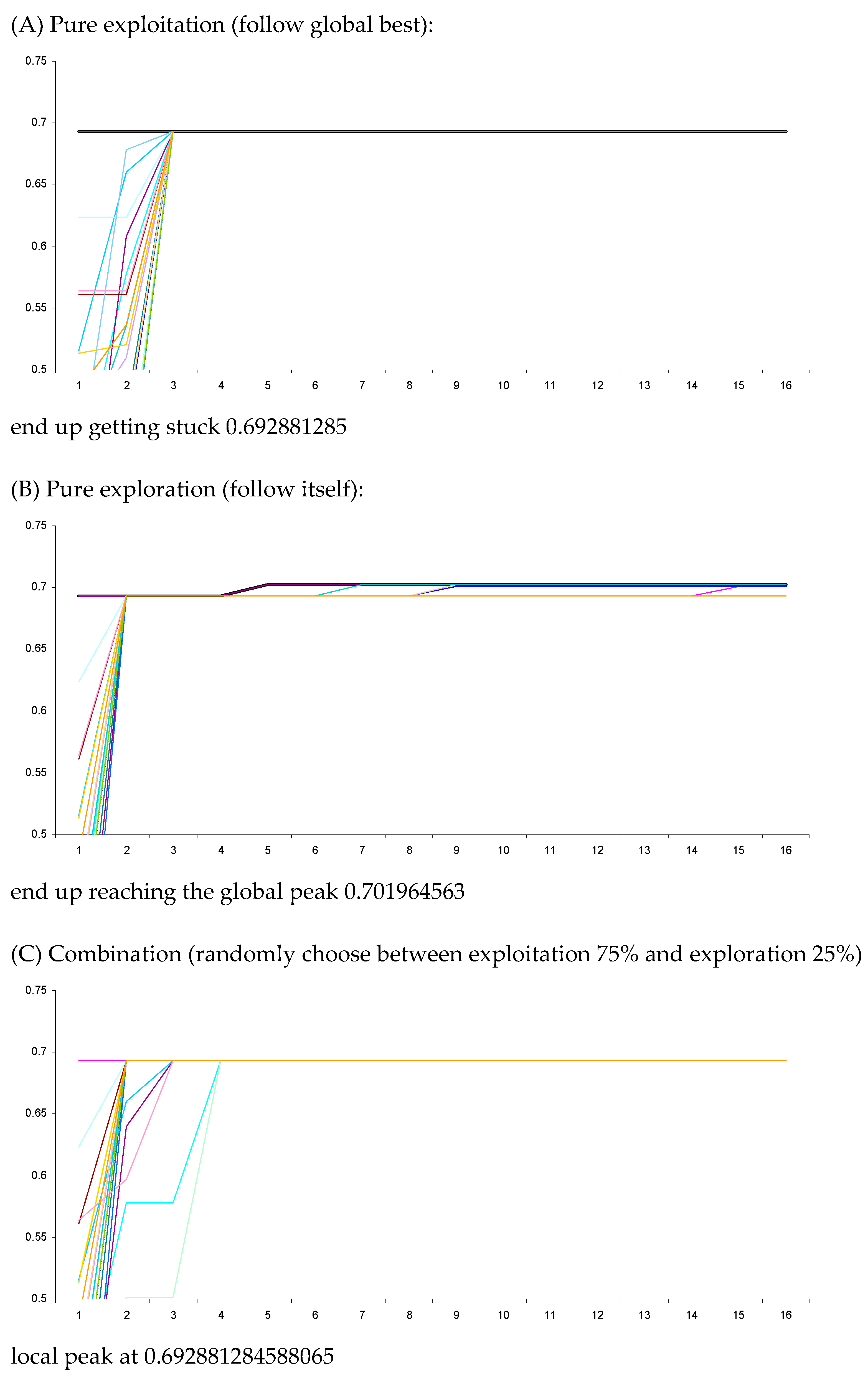
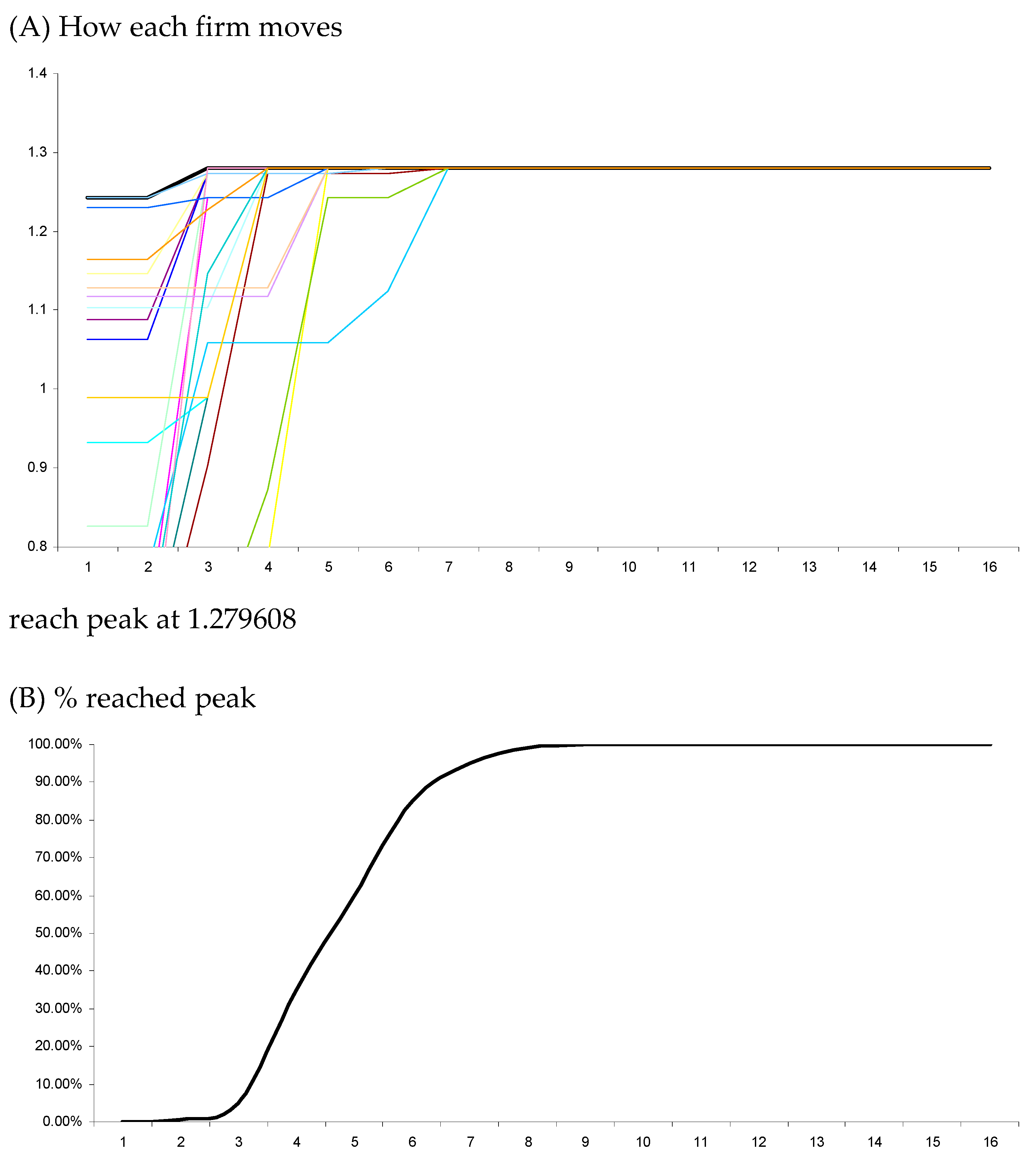
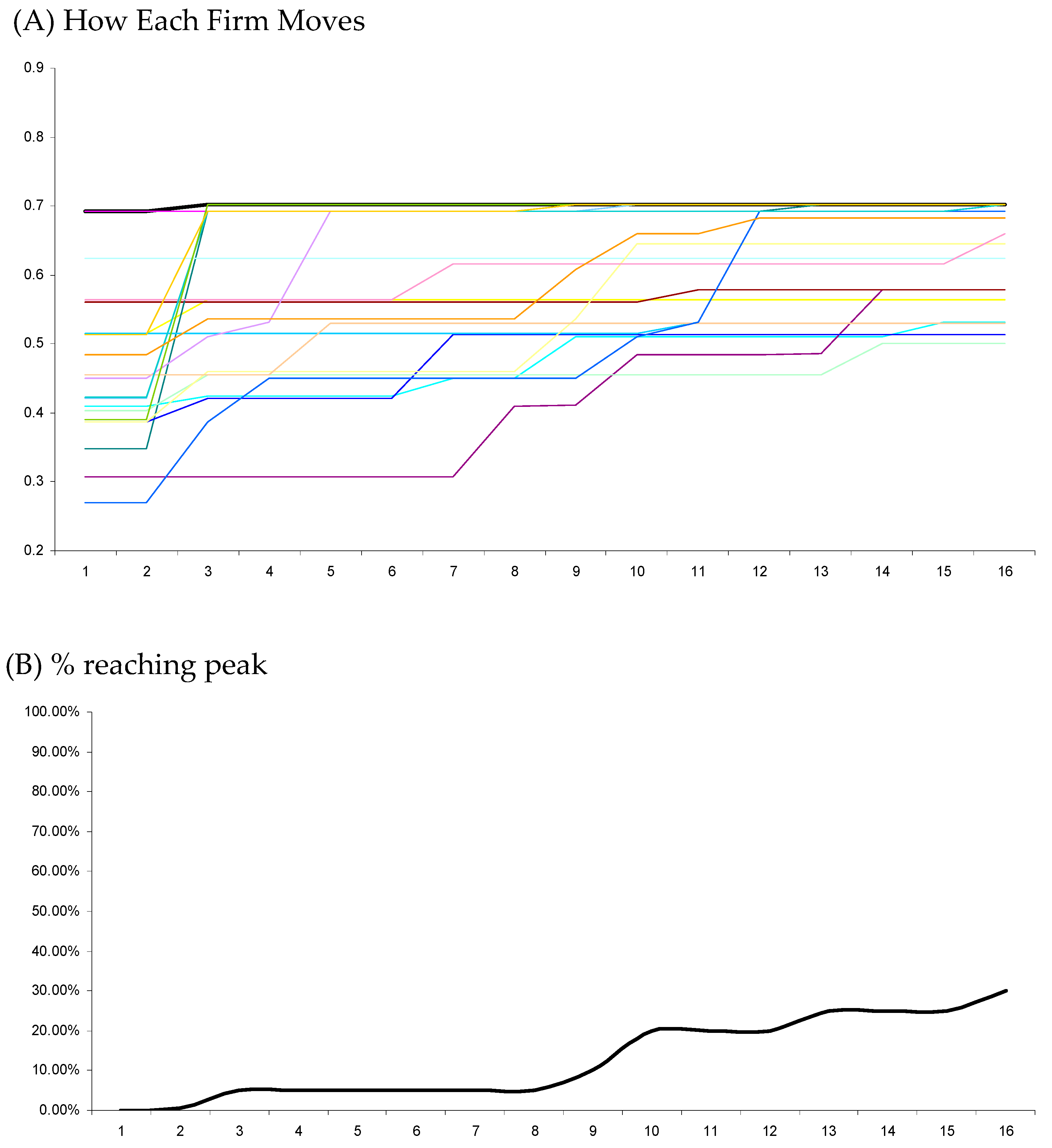
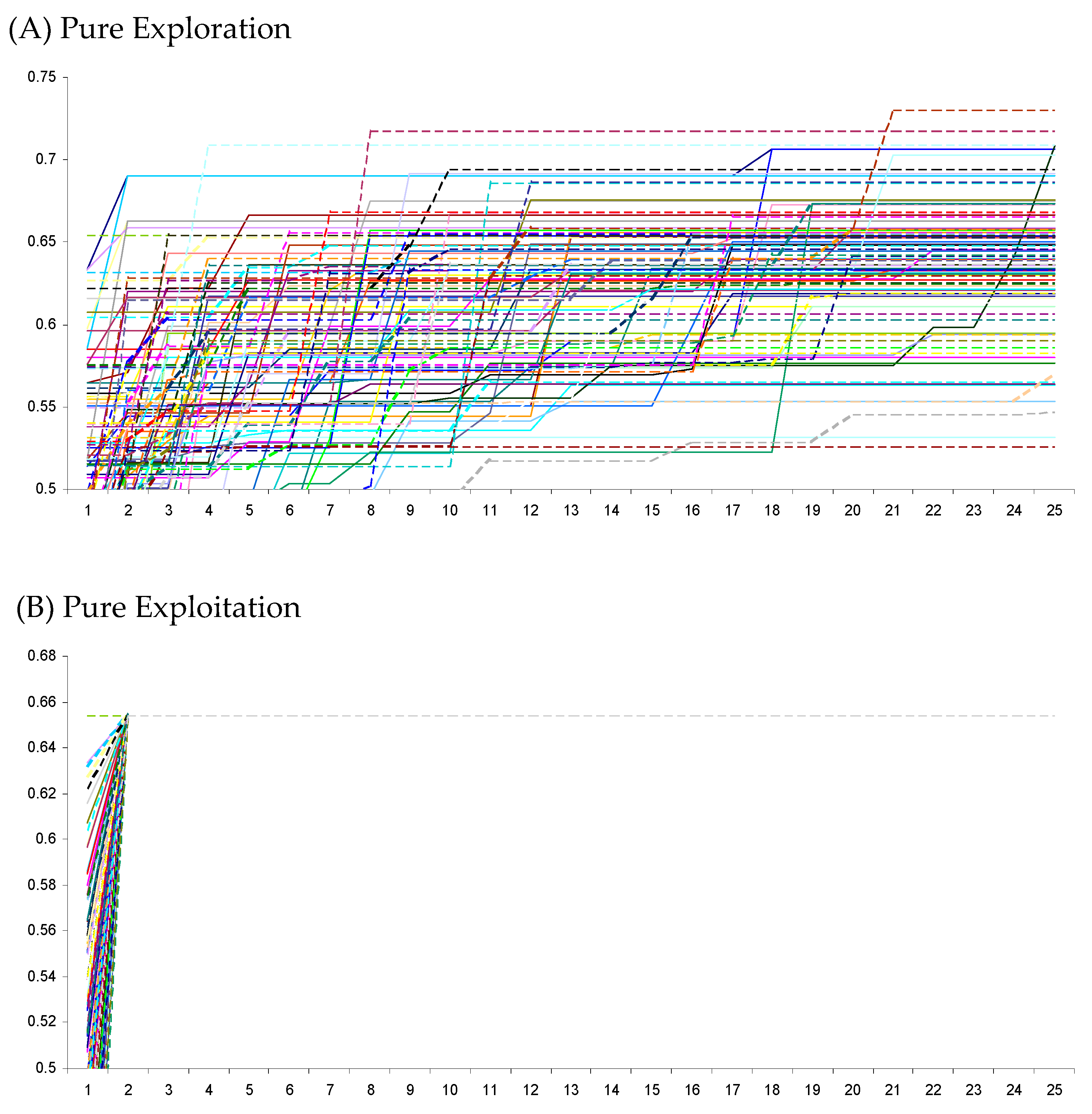
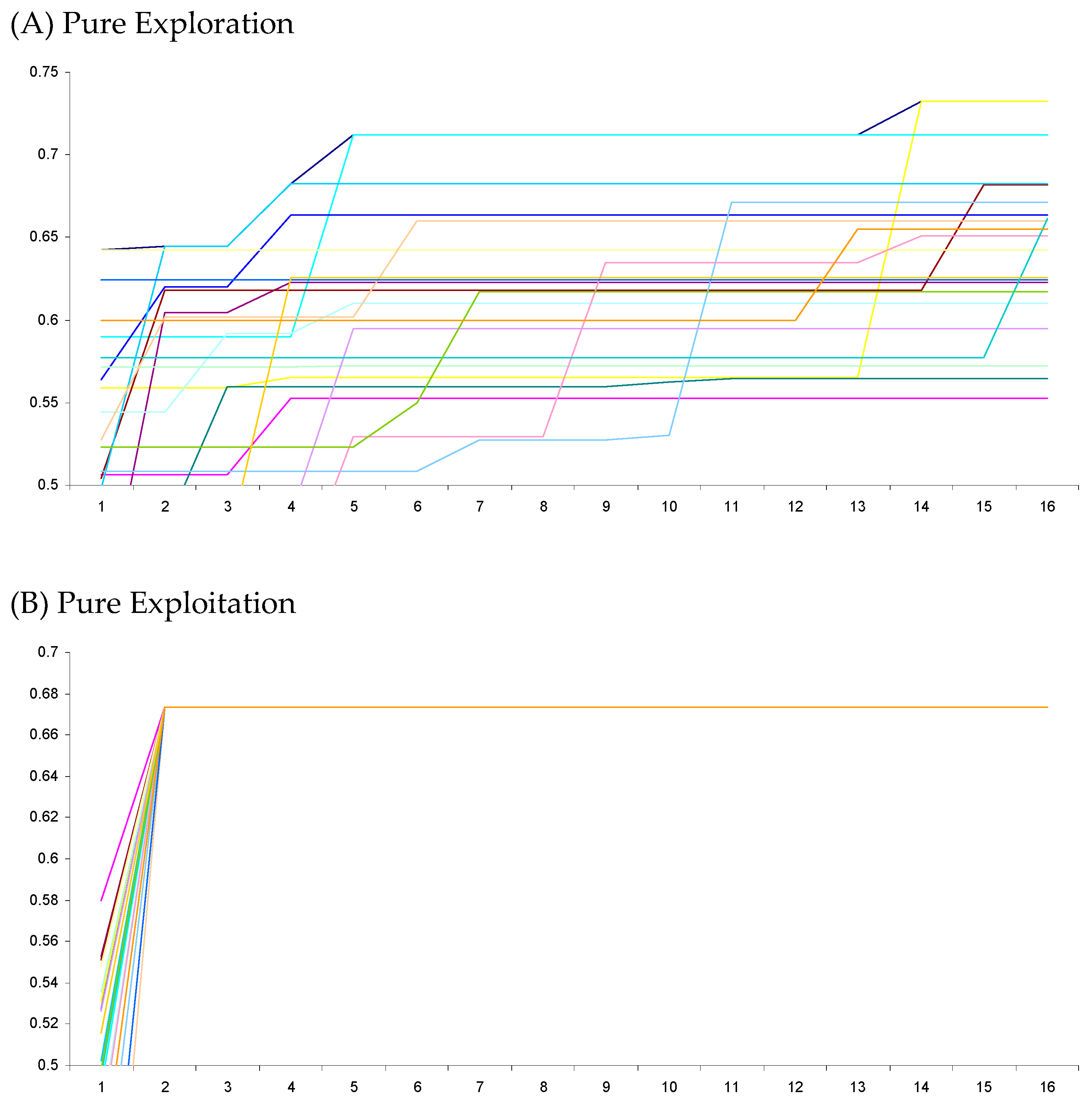
5. Results
5.1. Global Search
5.2. Local Search
5.3. Large N
6. Discussion of Simulation Results and Identification of Limitations of the NK Landscape for Swarm-Based Search
6.1. Discussion of Simulation Results
6.2. Further Discussion of NK Limitations for Swarm-Based Search Studies
7. Directions for Future Research
7.1. The Need for a Flexible Landscape
7.2. Landscape and Search Process Extensions
7.2.1. Endogenous Landscapes
7.2.2. Agent-Specific Landscapes
7.2.3. Incomplete Information
7.2.4. Costly Movements
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Buamann, O.; Schmitd, J.; Stieglitz, N. Effective search in rugged performance landscapes: A review and outlook. J. Manag. 2019, 45, 285–318. [Google Scholar] [CrossRef]
- Levinthal, D.A.; Marengo, L. Simulation modelling and business strategy research. In The Palgrave Encyclopedia of Strategic Management; Palgrave Macmillan: London, UK, 2018; pp. 1–5. [Google Scholar]
- Ganco, M.; Hoetker, G. NK modeling methodology in the strategy literature: Bounded search on a rugged landscape. In Research Methodology in Strategy and Management; Emerald Group Publishing Limited: Bingley, UK, 2009; Volume 5, pp. 237–268. [Google Scholar] [CrossRef]
- Csaszar, F.A. A note on how NK landscapes work. J. Organ. Des. 2018, 7, 15. [Google Scholar] [CrossRef]
- Chen, R.-R.; Miller, C.D.; Toh, P.K. Modeling firm search and innovation trajectory using swarm Intelligence. Algorithms 2023, 16, 72. [Google Scholar] [CrossRef]
- Kauffman, S.; Levin, S. Towards a general theory of adaptive walks on rugged landscapes. J. Theor. Biol. 1987, 128, 11–45. [Google Scholar] [CrossRef]
- Kauffman, S.; Weinberger, E. The NK Model of rugged fitness landscapes and its application to the maturation of the immune response. J. Theor. Biol. 1989, 141, 211–245. [Google Scholar] [CrossRef]
- Levinthal, D.A. Adaptation on Rugged Landscapes. Manag. Sci. 1997, 43, 934–950. [Google Scholar] [CrossRef]
- Kaul, H.; Jacobson, S.H. Global optima results for the Kauffman NK model. Math. Program. 2005, 106, 319–338. [Google Scholar] [CrossRef]
- Rivkin, J.W.; Siggelkow, N. Patterned interactions in complex systems: Implications for exploration. Manag. Sci. 2007, 53, 1068–1085. [Google Scholar] [CrossRef]
- Bahceci, E. Competitive Multi-Agent Search. Ph.D. Dissertation, University of Texas at Austin, Austin, TX, USA, December 2014. [Google Scholar]
- Beni, G.; Wang, J.; Iglesias, A. Swarm Intelligence in Cellular Robotic Systems. In Proceedings of the NATO Advanced Workshop on Robots and Biological Systems, Tuscany, Italy, 26–30 June 1989; Springer: Berlin/Heidelberg, Germany, 1989; pp. 703–712. [Google Scholar] [CrossRef]
- Bonabeau, E.; Dorigo, M.; Theraulaz, G. Swarm Intelligence: From Natural to Artificial Systems; OUP: Cary, NC, USA, 1999. [Google Scholar]
- Beni, G. Swarm Intelligence. In Encyclopedia of Complexity and Systems Science; Meyers, R.A., Ed.; Springer: New York, NY, USA, 2009; pp. 1–32. [Google Scholar] [CrossRef]
- Reynolds, C. Flocks, herds and schools: A distributed behavioral model. In SIGGRAPH ’87, Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques, Anaheim, CA, USA, 27–31 July 1987; Association for Computing Machinery: New York, NY, USA, 1987; pp. 25–34. [Google Scholar]
- Eberhart, R.; Kennedy, J. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Shi, Y.; Eberhart, R.C. A modified particle swarm optimizer. In Proceedings of the IEEE International Conference on Evolutionary Computation, Anchorage, AK, USA, 4–9 May 1998; pp. 69–73. [Google Scholar]
- Woodside-Oriakhi, M.; Lucas, C.; Beasley, J. Heuristic algorithms for the cardinality constrained efficient frontier. Eur. J. Oper. Res. 2011, 213, 538–550. [Google Scholar] [CrossRef]
- Zhu, H.; Wang, Y.; Wang, K.; Chen, Y. Particle swarm optimization (PSO) for the constrained portfolio optimization problem expert systems with applications. Exp. Syst. Appl. 2011, 38, 10161–10169. [Google Scholar] [CrossRef]
- Cura, T. Particle swarm optimization approach to portfolio optimization. Nonlinear Anal. Real World Appl. 2009, 10, 2396–2406. [Google Scholar] [CrossRef]
- Raei, R.; Alibeiki, H. Portfolio optimization using particle swarm optimization method. Financ. Res. J. 2010, 12, 1–20. [Google Scholar]
- Thakkar, A.; Chaudhari, K. A comprehensive survey on portfolio optimization, stock price and trend prediction using particle swarm optimization. Arch. Comput. Methods Eng. 2021, 28, 2133–2164. [Google Scholar] [CrossRef]
- Erwin, K.; Engelbrecht, A. Multi-guide set-based particle swarm optimization for multi-objective portfolio optimization. Algorithms 2023, 16, 62. [Google Scholar] [CrossRef]
- Erwin, K.; Engelbrecht, A.P. Set-Based particle swarm optimization for portfolio optimization. In Proceedings of the International Conference on Swarm Intelligence, ANTS Conference, Barcelona, Spain, 26–28 October 2020; pp. 333–339. [Google Scholar]
- Lahmiri, S. Interest rate next-day variation prediction based on hybrid feedforward neural network, particle swarm optimization, and multiresolution techniques. Phys. A Stat. Mech. Its Appl. 2016, 444, 388–396. [Google Scholar] [CrossRef]
- Gao, W.; Su, C. Analysis of earnings forecast of blockchain financial products based on particle swarm optimization. J. Comput. Appl. Math. 2020, 372, 112724. [Google Scholar] [CrossRef]
- Sohrabi, M.; Zandieh, M.; Shokouhifar, M. Sustainable inventory management in blood banks considering health equity using a combined metaheuristic-based robust fuzzy stochastic programming. Socio-Econ. Plan. Sci. 2023, 86, 101462. [Google Scholar] [CrossRef]
- Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997; pp. 4104–4108. [Google Scholar]
- Lee, S.; Soak, S.; Oh, S.; Pedrycz, W. Modified binary particle swarm optimization. Prog. Nat. Sci. 2008, 19, 1161–1166. [Google Scholar] [CrossRef]
- Di Caro, G. Lecture Notes (Chapter 16 of Collective Intelligence: From Multi-Agent Systems to Swarms); Carnegie Mellon University: Pittsburgh, PA, USA, 2019. [Google Scholar]
- Dehghani, M.; Samet, H. Momentum search algorithm: A new meta-heuristic optimization algorithm inspired by momentum conservation law. SN Appl. Sci. 2020, 2, 1720. [Google Scholar] [CrossRef]
- Nguyen, B.H.; Xue, B.; Andreae, P.; Zhang, M. A new binary particle swarm optimization approach: Momentum and dynamic balance between exploration and exploitation. IEEE Trans. Cybern. 2021, 51, 589–603. [Google Scholar] [CrossRef]
- Shokouhifar, A.; Shokouhifar, M.; Sabbaghian, M.; Soltanian-Zadheh, H. Swarm intelligence empowered three-stage ensemble deep learning for arm volume measurement in patients with lymphedema. Biomed. Signal Process. Control 2023, 85, 105027. [Google Scholar] [CrossRef]
- Kumar, A.; Kumar, S.A.; Dutt, V.; Dubey, A.K.; Garcia-Diaz, V. IoT-based ECG monitoring for arrhythmia classification using Coyote Grey Wolf optimization-based deep learning CNN classifier. Biomed. Signal Process. Control 2022, 76, 103638. [Google Scholar] [CrossRef]
- Mahmoodzadeh, A.; Nejati, H.R.; Mohammadi, M.; Ibrahim, H.H.; Rashidi, S.; Rashid, T.A. Forecasting tunnel boring machine penetration rate using LSTM deep neural network optimized by grey wolf optimization algorithm. Expert Syst. Appl. 2022, 209, 118303. [Google Scholar] [CrossRef]
- Yang, X.; Zhao, D.; Yu, F.; Heidari, A.A.; Bano, Y.; Ibrohimov, A.; Liu, Y.; Cai, Z.; Chen, H.; Chen, X. An optimized machine learning framework for predicting intradialytic hypotension using indexes of chronic kidney disease-mineral and bone disorders. Comput. Biol. Med. 2022, 145, 105510. [Google Scholar] [CrossRef]
- Guerra, J.F.; Garcia-Hernandex, R.; Llama, M.A.; Santibanez, V. A comparative study of swarm intelligence metaheuristics in ukf-based neural training applied to the identification and control of robotic manipulator. Algorithms 2023, 16, 393. [Google Scholar] [CrossRef]
- Tomassetti, G.; Cagnina, L. Particle swarm algorithms to solve engineering problems: A comparison of performance. J. Eng. 2013, 2013, 435104. [Google Scholar] [CrossRef]
- Papazoglu, G.; Biskas, P. Review and comparison of genetic algorithm and particle swarm optimization in the optimal power flow problem. Energies 2023, 16, 1152. [Google Scholar] [CrossRef]
- Kicska, G.; Kiss, A. Comparing swarm intelligence algorithms for dimension reduction in machine learning. Big Data Cogn. Comput. 2021, 5, 36. [Google Scholar] [CrossRef]
- Selvaraj, S.; Choi, E. Survey of swarm intelligence algorithms. In ICSIM ’20, Proceedings of the 3rd International Conference on Software Engineering and Information Management, Sydney, NSW, Australia, 12–15 January 2020; ACM: New York, NY, USA, 2020; pp. 69–73. [Google Scholar] [CrossRef]
- Banerjee, S.; Agarwal, N. Analyzing collective behavior from blogs using swarm intelligence. Knowl. Inf. Syst. 2012, 33, 523–554. [Google Scholar] [CrossRef]
- O’Bryan, L.; Beier, M.; Salas, E. How approaches to animal swarm intelligence can improve the study of collective intelligence in human teams. J. Intell. 2020, 8, 9. [Google Scholar] [CrossRef]
- Minar, N.; Burkahrt, R.; Langston, C.; Askenzi, M. The Swarm Simulation System: A Toolkit for Building Multi-Agent Simulations. Santa Fe Institute Working Paper. 1996. Available online: https://EconPapers.repec.org/RePEc:wop:safiwp:96-06-042 (accessed on 13 October 2023).
- Coen, C.A.; Maritan, C.A. Investing in Capabilities: The Dynamics of Resource Allocation. Organ. Sci. 2011, 22, 99–117. [Google Scholar] [CrossRef]
- Padget, J.; Vidgen, R.; Mitchell, J.; Marshall, A.; Mellor, R. Sendero: An extended, agent-based implementation of Kauffman’s NKCS model. J. Artif. Soc. Soc. Simul. 2009, 12, 1–8. [Google Scholar]
- Arend, R.J. Balancing the Perceptions of NK Modeling with Critical Insights. J. Innov. Entrep. 2022, 11, 23. [Google Scholar] [CrossRef]
- Wu, J. Withholding Knowledge; Department of Logic and Philosophy of Science, University of California at Irvine: Irvine, CA, USA, 2022. [Google Scholar]
- Kauffman, S.A.; Macready, W.G. Search strategies for applied molecular evolution. J. Theor. Biol. 1995, 173, 427–440. [Google Scholar] [CrossRef]
- Merz, P. Memetic Algorithms for Combinatorial Optimization Problems: Fitness Landscapes and Effective Search Strategies. Ph.D. Dissertation, Fachbereich 12, Elektrotechnik und Informatik, Lemgo, Germany, 2006. [Google Scholar]
- Krasnogor, N.; Smith, J. Emergence of profitable search strategies based on a simple inheritance mechanism. In GECCO’01, Proceedings of the 3rd Annual Conference on Genetic and Evolutionary Computation, San Francisco, CA, USA, 7–11 July 2001; ACM: New York, NY, USA, 2001; pp. 432–439. [Google Scholar]
- Bausseur, M.; Goeffon, A.; Lareux, F.; Saubion, F.; Vigneron, V. On the attainability of NK landscapes global optima. In Proceedings of the Seventh Annual Symposium on Combinatorial Search (SoCS 2014), Prague, Czech Republic, 15–17 August 2014; Association for the Advancement of Artificial Intelligence: Washington, DC, USA, 2021; Volume 5, pp. 28–34. [Google Scholar] [CrossRef]
- Geisendorf, S. Searching NK fitness landscapes: On the trade off between speed and quality in complex problem solving. Comput. Econ. 2010, 35, 395–406. [Google Scholar] [CrossRef]
- Li, W.; Meng, X.; Huang, Y. Fitness distance correlation and mixed search strategy for differential evolution. Neurocomputing 2021, 458, 514–525. [Google Scholar] [CrossRef]
- Harrison, J.R.; Kemp, A.; Saetre, A.S. Attraction-based fitness landscapes for computational decision search. In Proceedings of the PICMET ‘17: Technology Management for Interconnected World, PICMET, Portland, OR, USA, 9–13 July 2017. [Google Scholar]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, R.-R.; Miller, C.D.; Toh, P.K. Search on an NK Landscape with Swarm Intelligence: Limitations and Future Research Opportunities. Algorithms 2023, 16, 527. https://doi.org/10.3390/a16110527
Chen R-R, Miller CD, Toh PK. Search on an NK Landscape with Swarm Intelligence: Limitations and Future Research Opportunities. Algorithms. 2023; 16(11):527. https://doi.org/10.3390/a16110527
Chicago/Turabian StyleChen, Ren-Raw, Cameron D. Miller, and Puay Khoon Toh. 2023. "Search on an NK Landscape with Swarm Intelligence: Limitations and Future Research Opportunities" Algorithms 16, no. 11: 527. https://doi.org/10.3390/a16110527
APA StyleChen, R.-R., Miller, C. D., & Toh, P. K. (2023). Search on an NK Landscape with Swarm Intelligence: Limitations and Future Research Opportunities. Algorithms, 16(11), 527. https://doi.org/10.3390/a16110527