1. Introduction
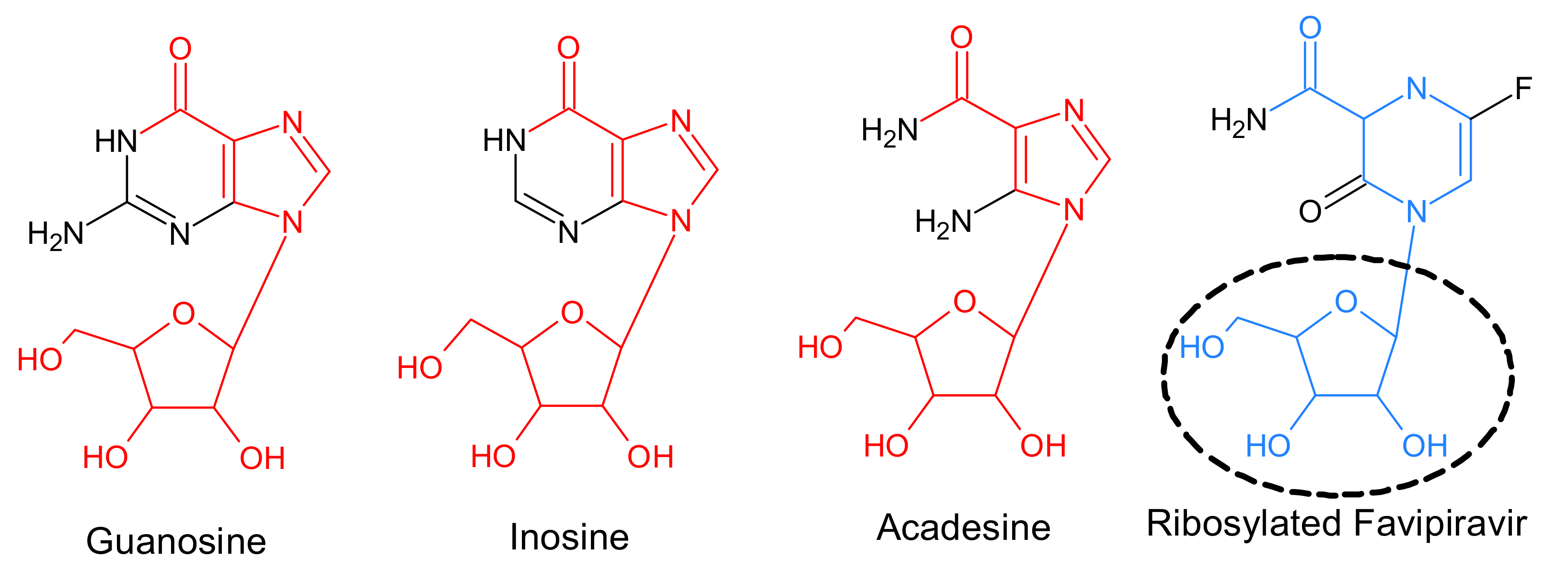
The coronavirus disease (COVID-19) has been spreading widely since 2019. In Japan, favipiravir (brand name: Avigan) has been examined as a promising antiviral medication against COVID-19. Favipiravir was initially developed as a medication to treat influenza. When Favipiravir is ribosylated, its structure resembles acadesine, which is a precursor to inosine. Inosine is the previous stage of guanosine and adenosine, which are components of RNA [
1]. With this treatment, the RNA synthetase of a virus mistakenly incorporates favipiravir, instead of guanosine, into the replicating virus. This causes RNA synthesis to stop and limits the replication of viruses inside the body.
Figure 1 shows the chemical structures of guanosine, inosine, acadesine, and ribosylated favipiravir. The substructure
, drawn in red, is common to all of guanosine, inosine, and acadesine. Therefore, in order to find candidate compounds for a new drug, it may be useful to search for compounds containing a substructure, provided as a query, in a database that consist of many compounds (i.e., substructure search). Conversely, if many substructures relevant to new drug development are known, it can be useful to search for substructures contained in a newly developed chemical compound, provided as a query, in a database recording these substructures (i.e., superstructure search). This paper discusses methods related to the latter task. The substructure drawn in blue in
Figure 1 is similar to the substructure
, but they do not match perfectly. In the situation shown, the substructure
, which contributes to anti-influenza agents, is registered in a database. The database contains various substructures for which its medicinal effects, side effects and so on are known. If ribosylated favipiravir is given as the query and the substructure
is the output as the search result, we may be able to discover that ribosylated favipiravir is anti-influenza. Therefore, such a search engine for chemical compounds would be very useful and effective.
A compound can be represented as a graph, in which the vertices and edges correspond to the atoms and chemical bonds, respectively. The aforementioned substructure and superstructure search correspond to subgraph search [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14] and supergraph search [
15,
16,
17,
18,
19,
20,
21,
22], respectively, which are actively being studied by researchers. A graph is a highly versatile data structure for representing information in many fields. It can be used to represent human relationship networks, protein interaction networks, resource description frameworks (RDF), computer-aided designs (CAD), and computer vision images; moreover, subgraph and supergraph search are used for many applications in addition to searching for compounds. However, there is no method for searching for graphs that are similar to subgraphs of a query graph and no method applicable to the resemblance between substructures shown in
Figure 1. This paper proposes the problem of similar supergraph search and also proposes a method to solve it.
In this paper, we measure the similarity between two graphs
g and
by the graph edit distance. The graph edit distance is the minimum number of edits required to transform g to another
, where an edit is either an insertion, deletion, or relabeling of a vertex or edge. The number of graphs obtained by editing the graph
g times increases drastically, especially when the numbers of vertices and edges are large and the varieties of vertex and edge labels are wide. Such a drastic increase in edited graphs makes it difficult to find similar graphs. However, some real applications need to obtain a subset of graphs edited
times. For example, editing the substructure in a broken ellipse of
Figure 1 is not admissible, whereas editing the remainder of the blue substructure is admissible. By restricting an editable part in the structure, the number of graphs obtained by editing the graph
g times is decreased. In our proposed method, users can search for their desired type of similar graphs in a database containing graphs and this search can be realized by simply rewriting only one function without the need to modify our proposed algorithm. Therefore, the method proposed in this paper is a general and flexible framework for searching for similar subgraphs of query graphs and is easily customizable for searching for the types of graphs desired by the user.
The remainder of the paper is organized as follows.
Section 2 formalizes the novel problem of searching for graphs contained in a query graph in a database storing many graphs and
Section 3 discusses related work. In
Section 4 and
Section 5, we propose straightforward methods for a simpler problem in which the searched graphs are constrained. In
Section 6 and
Section 7, we propose a novel method for solving the original problem by extending the above methods. In
Section 8, we analyze the computational efficiency of the proposed method by using real-world datasets. Finally, we conclude the paper in
Section 9.
2. Problem Definition
A labeled graph is expressed as , where V is a set of vertices, is a set of edges, is a set of labels for the vertices and edges, and is a function to assign the labels to the vertices and edges. We denote the set of all vertices in graph g as . A graph g is called a directed graph if the edges in g have directions; otherwise, g is called an undirected graph. A sequence of edges from to is called a path and a graph (for a directed graph, all edges in the graph are replaced with undirected edges.) and a path that exists between any two vertices is called connected.
Given graphs and , , when an injective function fulfills the following conditions, is called a subgraph of g, which is denoted as :
if ;
;
.
In addition, when iff , we call an induced subgraph of g, which is denoted as . Although this paper focuses only on undirected and connected graphs, the methods proposed can easily be extended to directed or unconnected graphs.
The graph edit distance is the minimum number of edits required to transform a graph
g to another graph
, where an edit is either an insertion, deletion, or relabeling of a vertex or edge. In this paper, we assume that the cost of each edit is 1. The number of edits between graphs
and
is defined as follows:
where we assume that
and
V is extended to
[
23]. In addition, when
g is transformed to
, the mapping between
V and
is expressed as a bijective mapping
.
is the cost to edit the vertex
to
and
is the cost to edit edge
to
. Editing
to
means performing a vertex insertion in
. Therefore, the graph edit distance
between the graphs
g and
is defined as follows:
where
is a set of all possible
-permutations of the integers
. The solution to Equation (
2) is one of the quadratic assignment problems, which are known to be NP-complete.
Given a set of graphs
, a query graph
q, and a threshold
as input, the problem tackled in this paper is to output a set of graphs.
In Equation (
3), note that
is a subgraph of
q but not an induced subgraph of
q. When
is 0 in Equation (
3), the problem is equivalent to the original supergraph search problem. Therefore, our problem, represented by Equation (
3), is an extension of the supergraph search problem.
3. Related Work
In
Section 2, we defined the problem tackled in this paper. Recently, much attention has been focused on searching for graphs satisfying some conditions in a database consisting of multiple graphs.
Table 1 summarizes graph search problems and the publications that tackle each problem. The subgraph search problem is to find graphs that contain the query graph and can be expressed as follows:
whereas the supergraph search problem is to find graphs that the query graph contains and it can be expressed as follows.
These problems contain the subgraph isomorphism problem, which is known to be NP-complete. The similar graph search problem is to find graphs that are similar to the query graph, and can be expressed as
This problem contains the graph edit distance problem, which is known to be NP-complete. Various methods have been proposed to solve these problems. The problem tackled in this paper is to find graphs that are similar to subgraphs of the query graph and contains both the subgraph isomorphism problem and graph edit distance problem. This problem is a novel one, to the best of our knowledge. Since the subgraph isomorphism problem and graph edit distance problem are NP-complete, a naive method for solving either of the problems for a given query graph and for each graph in the database would be unrealistic.
Most of the methods proposed in the articles cited in
Table 1 are based on filtering and verification and an index in each of the methods has a set of patterns
P extracted from the database in advance. For example, for the supergraph search problem, in the filtering phase,
is obtained. Subsequently, the verification phase checks whether
, for each graph
.
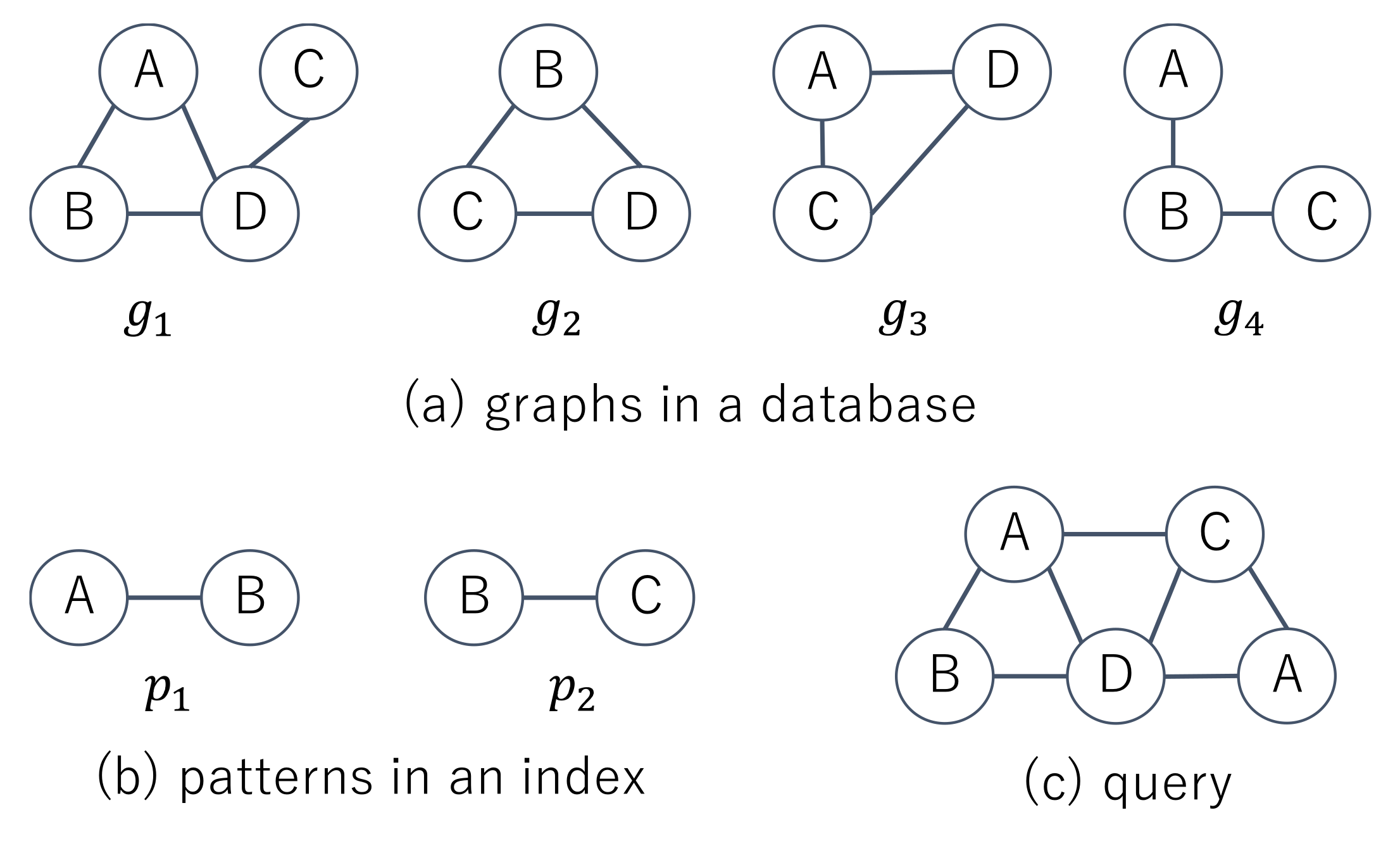
Figure 2a shows four graphs in a database and two patterns contained in an index. The index has the information that
,
,
, and
. Given the query shown in
Figure 2c, supergraph search methods first check whether
and
and then obtain
in the filtering phase. In the verification phase, they test whether
and
. Since the number of vertices in
is less than one for
, the computation time to check whether
becomes less than one for
and we do not need to check whether
in the filtering phase. The patterns in
P are either paths, trees, cycles, or graphs extracted from databases. The patterns are extracted by the enumeration or mining method. The enumeration method enumerates all subgraphs in graphs in a database, where the subgraphs are restricted to either paths, trees, cycles, or graphs. In contrast, the mining method enumerates all frequent patterns [
24], which are defined as
from graphs in a database, where
is defined as the number of graphs in
G containing pattern
p:
The extracted patterns are stored in a tree or lattice structure in the index of the graph database. Enumerating patterns and mining patterns from a database are time-consuming processes.
CodeTree [
17] is a method for the supergraph search problem. It does not distinguish between filtering and verification phases; it filters out graphs that are not contained in a given query graph while verifying unfiltered graphs. In addition, CodeTree does not enumerate or mine patterns in a database. All graphs in a database are stored in the form of one of the graph codes, such as AcGM [
33] code or DFS [
34] code, in the index in CodeTree. The AcGM and DFS codes are based on adjacency matrices and adjacency lists, which are alternatives to graph representations. The algorithms for constructing an index for a database and searching graphs in the index are independent of the graph codes and, thus, the method can be integrated and extended with various graph codes for representing graphs in accordance with the intended characteristics of those codes. For this reason, the method proposed in this paper is based on CodeTree.
In this paper, we focus on the problems in which each database consists of multiple graphs. Other subgraph search problems are to search for a database which consists of “a single large graph”. Since the number of graphs given as input is two, we need not distinguish the subgraph and supergraph searches. A typical problem of the graph search with a single large graph is to output all embeddings (or occurrences)
in a large graph
g for a query
q consisting of vertices
when the query
q is a subgraph of the large graph
g. This problem is applicable to RDFs (Resource Description Frameworks), where each subject or object and predicate corresponds to a vertex and edge in a graph, respectively; PPI (Protein-Protein Interaction) networks, where each protein and interaction correspond to a vertex and edge, respectively; and intrusion alert networks where each computer and possible attack such as Denial-of-Service and TCP Service Sweep correspond a vertex and edge, respectively. Some of the methods for solving these kinds of problems use not only exact matching [
35,
36,
37] but also approximate matching [
38,
39,
40,
41] with various similarity measures.
The most representative metric for measuring similarity between two graphs is the graph edit distance. Most of methods for graph search problems use this graph edit distance to measure similarities among graphs. Other most representative measures are to use maximum common subgraphs or graph kernels [
42,
43] between two graphs. There are two types of problems called maximum common induced subgraph problem [
44] and maximum common edge subgraph problem [
45] and the problems for finding the maximum common subgraphs in two graphs is NP-complete. In contrast, graph kernels have been proposed to classify graphs in the machine learning domain. The random walk graph kernel [
46] returns a high similarity of graphs if random walks on the graphs produce similar sequences of vertex and edge labels. The Weisfeiler–Lehman graph kernel [
47] uses the Weisfeiler–Lehman test, which was proposed to solve the graph isomorphism problem. The kernel iteratively relabels each vertex
v by concatenating a label of
v and labels of
v’s adjacent vertices and returns high similarity for two relabeled graphs if the graphs have many common labels.
4. Straightforward Method for Constrained Problem
In
Section 2, we defined the problem tackled in this paper. Here, for the sake of simplicity, we first provide methods for outputting the following:
by constraining the original problem. In the subsequent sections, we explain how the method can be extended to solve the original problem.
Definition 1 (AcGM code [
33]).
Given a graph , we assign vertex identifiers to vertices in g and assume that a subgraph of g induced by vertices is connected. g is represented by an adjacency matrix of dimension for which its elements are if or 0 otherwise. The AcGM code of graph g is defined by concatenating the elements in the upper-right part of the adjacency matrix, as follows:where each code fragment is defined as follows: is called a prefix of Equation (
5). In addition,
means that a prefix of an AcGM code
is equal to another AcGM code
and a graph expressed by AcGM code
c is denoted as
.
Definition 2 (Linear ordering between AcGM codes). When two AcGM codes and fulfill either of the following conditions, we say that :
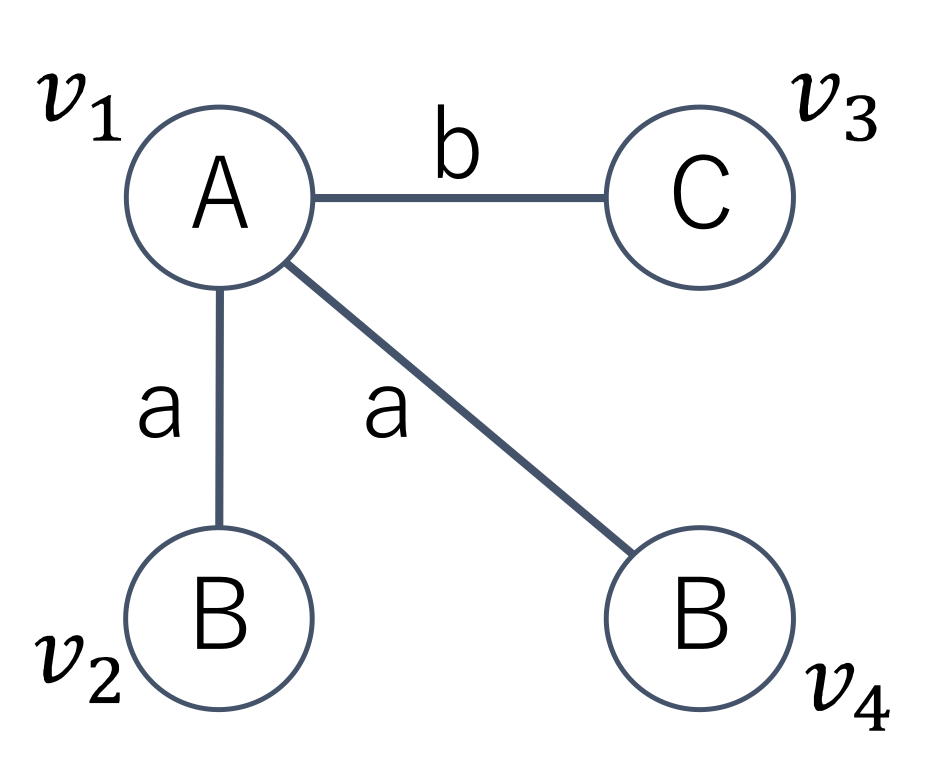
where is a linear ordering between code fragments [34]. Example 1. Given the graph with four vertices shown in Figure 3, we have possible permutations of the four vertices. Among the permutations, according to Definition 1, does not generate an AcGM code because a subgraph induced by is not connected. We can generate 12 AcGM codes from the graph and we show three AcGM codes as follows. Symbols on the left side of the following adjacent matrices are vertex IDs and the letters on the upper side of the matrices are vertex labels. In addition, letters in the matrices are edge labels and zeros in the matrices and they indicate that there are no edges.
By concatenating the letters and zeros on sides of arrows in the matrices, three AcGM codes are generated as follows. The order between the codes is .
Lemma 1. If two AcGM codes are the same, the graphs represented by the codes are isomorphic.
Proof. If two adjacency matrices are the same, the graphs represented by the matrices are isomorphic. Since each AcGM code of a graph g corresponds one-to-one with an adjacency matrix of g, if two AcGM codes are the same, the graphs represented by the codes are isomorphic. □
In contrast, if two graphs are isomorphic, their AcGM codes are not necessarily the same. This means that there are multiple AcGM codes of g that fulfill Definition 1. Thus, we denote the set of all AcGM codes of graph g as .
Lemma 2. When an AcGM code c is a prefix of another code , is connected and is an induced subgraph of .
Proof. Given an AcGM code
c of a graph
g, let its corresponding adjacency matrix be
A. All submatrices
of
A obtained by iteratively deleting the last row and column of
A represent induced and connected subgraphs of
g. According to Definition
5, AcGM codes for the matrices
must be prefices of the AcGM code for
A. □
From the above discussion, one straightforward method for outputting the subgraphs defined by Equation (
4) is to compute the graph edit distance between a graph
and a graph
, represented by a prefix
for
. However, computing the edit distance between
and
by Equation (
2) is not feasible. Therefore, we discuss a method for computing the edit distance by using the codes of
and
.
Lemma 3. Given the following AcGM codes:where a and b are the numbers of vertices in and , respectively, and the i-th vertex in maps to the i-th vertex in , the number of edits to transform to is the following:where δ is the Kronecker delta and . The complexity of solving Equation (8) is . The function is symmetric: . Proof. The first term of Equation (
8) is the sum of the numbers of edits that occur because of differences between the
i-th (
) vertices in
and
and its second term is the sum of the numbers of edits that occur because of differences between edges
(
) in
and
. Its third term is the sum of the numbers of edits to insert vertices in
or
and its fourth term is the sum of the numbers of edits to insert edges in
or
. □
Since Equation (
8) defines the number of edits between two graphs under the known mapping such that
for all
, it corresponds to Equation (
1). Therefore, Equation (
2) is formalized by using Equation (
8) as the following lemmas.
Lemma 4. Given the two AcGM codes c and defined in Equations (6) and (7), we have the following. Proof. According to Equation (
2),
is obvious. □
Lemma 5. Given an arbitrary AcGM code of a graph , the graph edit distance between g and is the following. Proof. Let
be codes generated from all possible permutations of vertices in
g. So
. Some codes
in
are not AcGM codes because a prefix of the permutation from which
is generated may not induce a connected subgraph of
g. Since
are codes generated from all possible permutations of vertices in
g, we have
. In addition, because
, we have
. Therefore,
is satisfied. □
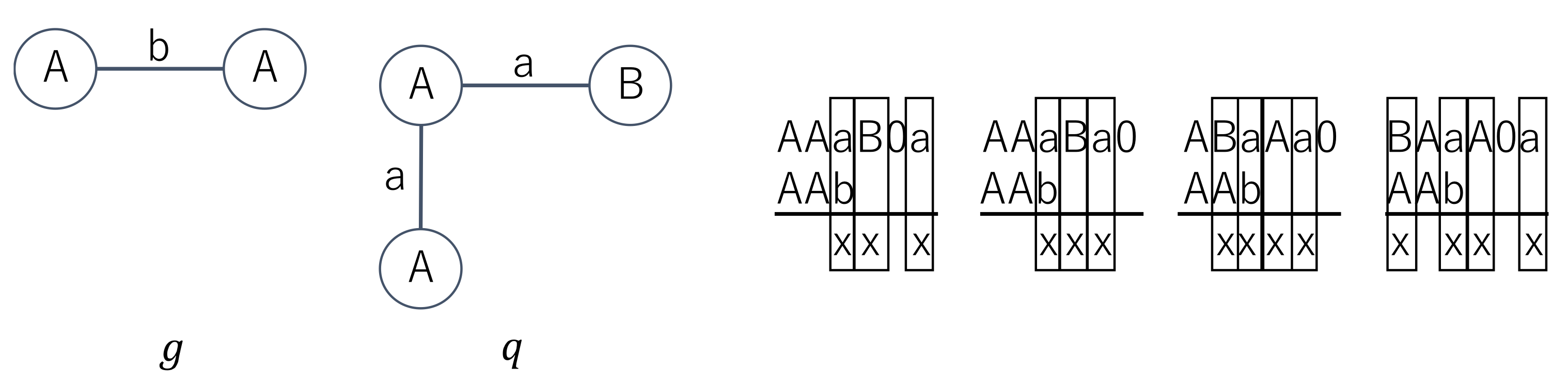
Example 2. As shown in Figure 4, given two graphs g and q for which the edit distance is 3, let an arbitrary AcGM code of g be AAb. is . When the code AAb is compared with , we need three edits which are indicated as × in Figure 4. By comparing AAb and all elements in , we obtain the graph edit distance between q and g according to Lemma 10. From Lemma 5, we have the following corollary.
Collorary 1. If for two AcGM codes c and , then .
Algorithm 1 shows the pseudocode for solving the problem defined by Equation (
4). In Line 3, an arbitrary AcGM code from
is generated for graph
in database
G. After one of all possible AcGM codes for
q is obtained in Line 4, a prefix
, which consists of
j fragments
, is generated in Line 6. Since
is a prefix of
c,
must be a connected and is an induced subgraph of
q. Subsequently,
is added to the set of output graphs
S if
, which indicates that
is a solution in the set defined by Equation (
4) according to Corollary 1. Once
is added to
S, any procedures for
are stopped and procedures for the next graph
are started. These steps are repeated for all of the graphs in
G. The time complexity of Algorithm 1 is
and the algorithm has some drawbacks, as follows.
- (1)
Although the algorithm produces
prefixes in Line 6 for each AcGM code
c in
and computes Equation (
8)
times in Line 7 for the prefixes, some of the repeated calculations of Equation (
8) are redundant because two prefixes
and
produced from
c satisfy
. Using the result of computing
to compute
would render Algorithm 1 efficient.
- (2)
Let
be the set of codes produced in Line 3. AcGM codes
and
, for which their prefixes are the same, are included in
. The repeated calculations of Equation (
8) between these AcGM codes and
are redundant. If the common prefix of
and
is
, using the result of computing
to compute
and
would make Algorithm 1 efficient.
| Algorithm 1: Straightforward Algorithm for Searching (4) |
 |
5. Method for Traversing Prefix Tree for Constrained Problem
In order to overcome drawback (1), described in the previous section, we introduce the following lemma.
Lemma 6. Given two AcGM codes c and , we have the following: In the case that i is greater than the number of fragments in c, we assume that is equivalent to c itself.
Proof. is the sum of and the number of edits between the -th fragments of and . Since the number of edits is non-negative, increases monotonically when i is increased. Therefore, for , we have . □
Collorary 2. According to Lemma 6, if , then .
As a consequence of Lemma 6 and Corollary 11, when , we can stop the computation in Line 7 of Algorithm 1.
Lemma 7. Given the two following fragments:for which their lengths are equal, the number of edits to equalize the fragments is as follows: Since is a symmetric function, .
Proof. Please see the proof for Lemma 3. □
Algorithm 2 shows the pseudocode for solving the problem defined by (
4), which overcomes the aforementioned drawback (1). After obtaining the
j-th fragments of AcGM codes
and
c in Line 7 of the algorithm, the number of edits between the fragments is calculated according to Lemma 7. The number of edits is then added to the accumulated edit count
. According to Corollary 2, the algorithm stops the calculation of the number of edits between
and one of the AcGM codes of
q in Line 8. However, because
is a member of the set defined in Equation (
4) if the edited distance between
and at least one AcGM code in
is less than
, these steps are repeated for all AcGM codes of
q. The time complexity of Algorithm 2 is
.
| Algorithm 2: Straightforward Algorithm 2 for Searching (4) |
 |
In order to overcome drawback (2), described in the previous section, we use a prefix tree for the AcGM codes for G.
Definition 3 (Code Tree [
17] (The detailed algorithm for constructing a code tree from a graph database
G is given in [
17].)).
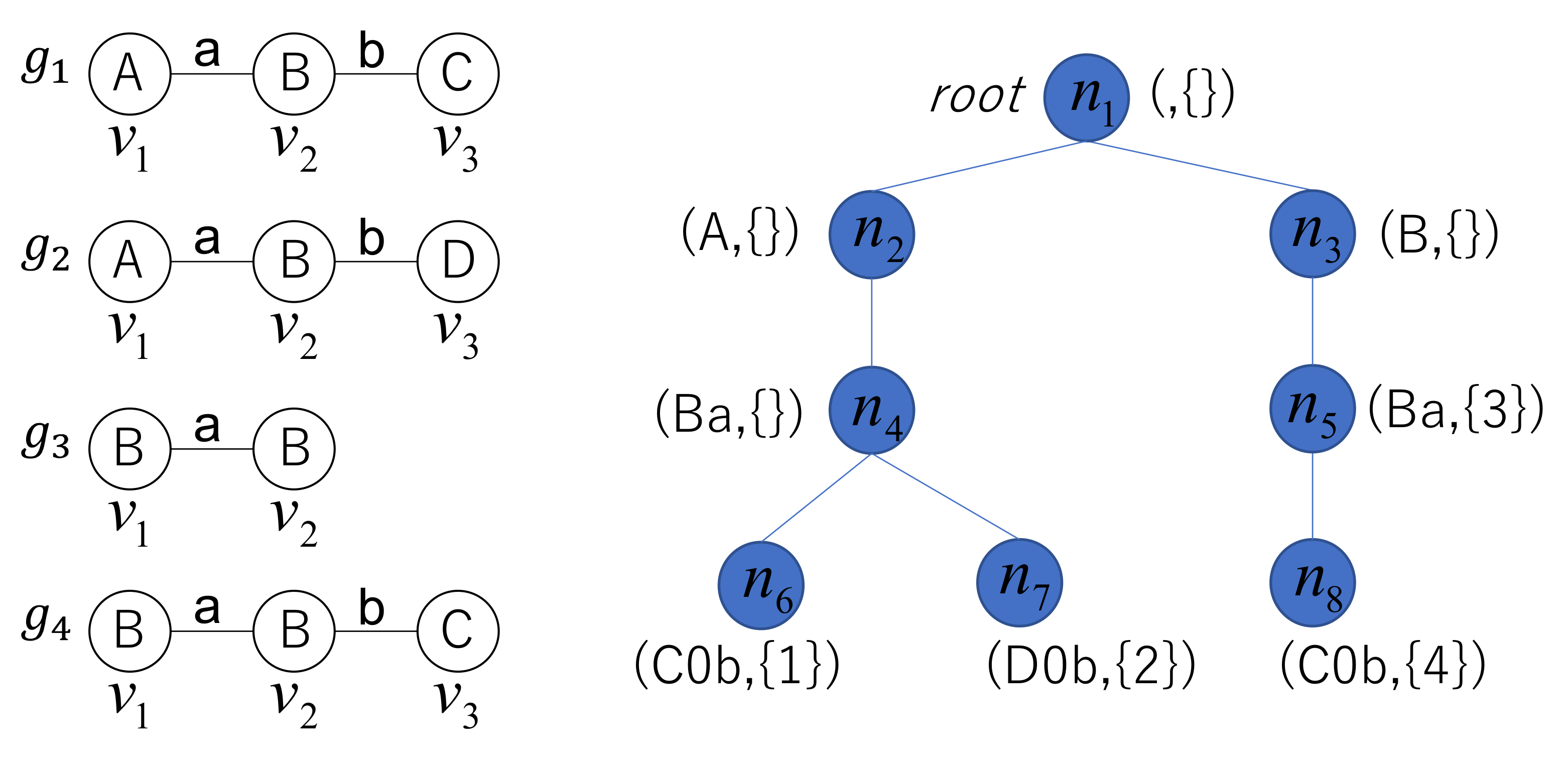
A code tree T is defined as the triplet , where is the root node of the tree, N is a set of the nodes of the tree, and B is a set of the branches of the tree. In addition, each node is associated with a code fragment and a set of graph identifiers. Let be the concatenation of the fragments associated with nodes on the path from the root to node n. When one of the AcGM codes of is the same as , the set of graph identifiers for node n contains i, which is the identifier of graph . The code fragment and graph identifiers associated with node n are denoted as and , respectively. For the root node, and . We present an example of a code tree below.
Example 3. A graph database consists of four graphs, as shown in Figure 5. When one of the AcGM codes for each graph in G is generated, the AcGM codes for the four graphs are as follows. From these AcGM codes, a code tree is constructed, as shown in the right part of Figure 5. Node of the tree is associated with the code fragment and the set of graph identifiers . The concatenation of fragments associated with nodes on the path from the root to node is , which represents graph in G. Algorithm 3 shows the pseudocode for searching for members of the set defined in Equation (
4) by traversing the code tree. At node
n, Algorithm 3 adds vertex
w of
q to
, from which the fragment
s is generated, with the addition of the prefix
of an AcGM code of
q. The algorithm then recursively traverses the children of
n that have fragments similar to fragment
s. In contrast to Algorithm 2, which iteratively checks whether each individual graph in the graph database is a solution, Algorithm 3 checks whether multiple graphs in the database are simultaneously solutions. This is because each node in the code tree is associated with the common prefix of the AcGM codes of multiple graphs in the database. This simultaneous checking renders our search very efficient. The worst case time complexity of Algorithm 3 is the same as the time complexity of Algorithm 2. When AcGM codes of graphs in the database do not have common prefixes as one another, the time complexity of Algorithm 3 becomes worst. However, the codes usually have common prefixes as one another and the computation time that this algorithm needs is proportional to the number of nodes that Algorithm 3 traverses. In addition, at each node, Algorithm 3 needs
.
| Algorithm 3: Code Tree Search for Finding Solutions to Equation (4) |
 |
6. Method for Traversing Prefix Tree for Original Problem
At node n, for which its depth is h in the code tree, Algorithm 3 retains the accumulated edit count for two concatenations c and of fragments of length h. c and have the following restrictions:
c is a concatenation of fragments associated with nodes on the path from the root of the code tree to n and is an AcGM code of a connected and induced graph that is a common subgraph of multiple graphs in the graph database;
is a prefix of one of the AcGM codes in . According to the definition of the AcGM code, must be connected and is an induced subgraph of q.
In order to solve the original problem for searching for solutions to Equation (
3), we relax the restrictions as follows. The restriction that
is connected is a consequence of the fact that
is a prefix of the AcGM codes
of
q. Therefore, in Line 4 of Algorithm 3., we relax this restriction by allowing
to be all possible
h-permutations of
in
q. Codes
by some of the permutations correspond to unconnected graphs.
Next, we relax the restriction that
is an induced subgraph of
q. Algorithm 1 produces prefixes of the AcGM codes of
q to obtain connected and induced subgraphs of
q. Suppose that we would like to obtain, in addition to the connected and induced subgraphs, all possible unconnected and non-induced subgraphs of
q. In this case, we may need, in addition to the prefixes of the AcGM codes of
q, all possible codes generated by replacing some elements
in the prefixes by 0. This requires us to solve both the permutation problem among the vertices of
q and the combination problem among the edges of
q. However, we do not need to solve the latter problem for the following reasons. We consider a graph
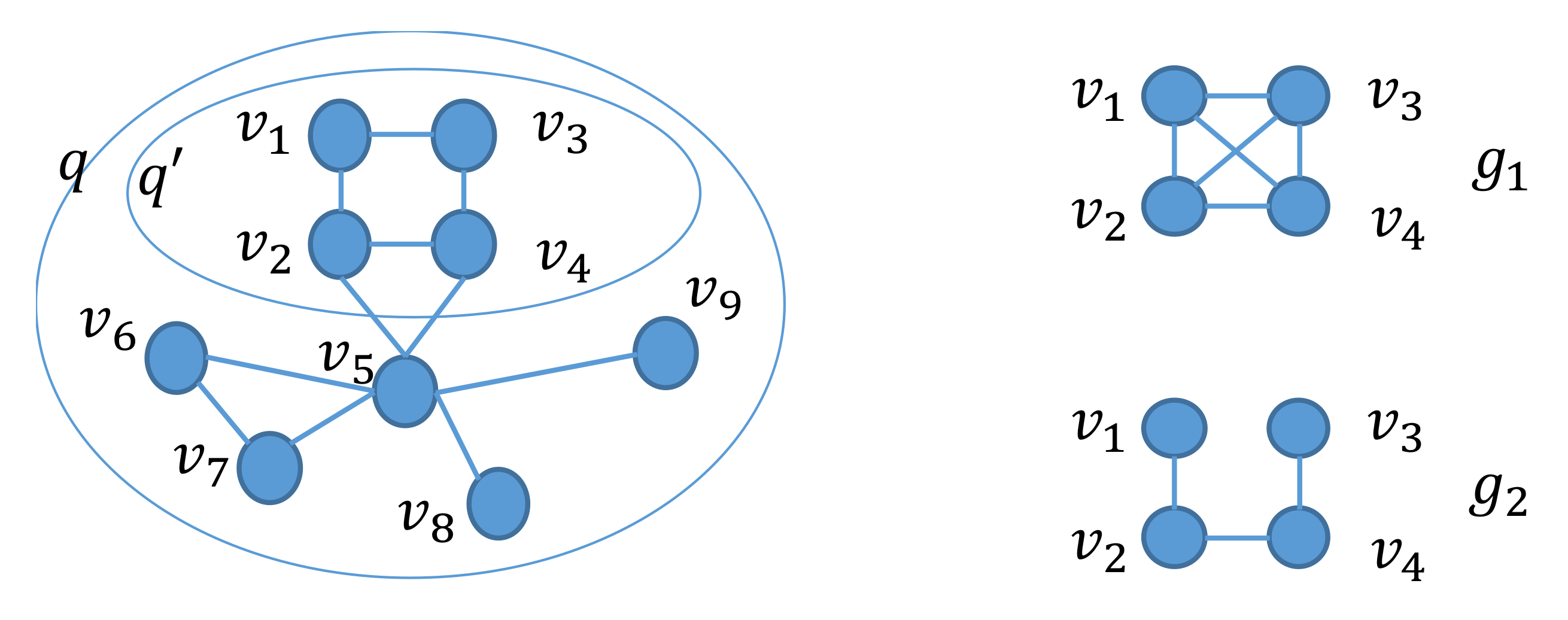
q, its induced subgraph
, and two graphs
and
, shown in
Figure 6. We refer to two vertices in
as
and
.
. Given a graph
obtained by removing an edge from
, we have
. In the problem of finding solutions to Equation (
3), we check whether there exists a subgraph of
q such that
and this subgraph need not be an induced subgraph of
q. Therefore, in the case that there is an edge between two vertices
and
in
and there is also an edge in
between the two corresponding vertices, we do not need to consider the graph
obtained by removing an edge from
. That is, we do not need to replace any elements
in prefixes of the AcGM codes of
by 0.
. For the above , we have . Therefore, in the case that there is an edge between two vertices and in and there is no edge in between the two corresponding vertices, we do not need to consider the graph that does not have an edge corresponding to edge in .
In all other cases, there is no edge between and in . Since , we do not need to replace by 0.
From the above discussion, we rewrite Lemma 7 as follows.
Lemma 8. This function is asymmetric. Since we consider all possible subgraphs of
q by the function defined in Equation (
8), we need to produce only the prefixes underlined above.
Algorithm 4 shows the pseudocode for searching for members of the set defined in Equation (
3) by traversing the code tree. The part from Lines 4–9 searches
, whereas the part from Lines 10–13 searches
. The other difference between Algorithm 3 and Algorithm 4 is Line 4, which produces codes from one of all possible
h-permutations of vertices of the query graph
q. The codes produced are not limited to AcGM codes, but are AGM codes [
24]. In Lines 7 and 11, Equation (
15) is used to calculate the similarity between two fragments. Since the codes produced in Line 4 are limited to prefixes of the AGM codes of
q, we do not need to solve the combination problem among the edges of
q, which enables our proposed method to be very efficient. The time complexity of Algorithm 4 is the same as one of Algorithm 3; nevertheless, the problem that Algorithm 3 solves is a constrained problem of the problem that Algorithm 4 solves.
| Algorithm 4: Code Tree Search for Finding Solutions to Equation (3) |
 |
7. Customization of Solutions
In the previous section, we proposed a method for searching for the set of graphs
S defined by Equation (
3). The number of graphs reachable by editing graph
times in Equation (
3) increases exponentially as
is increased. Therefore, for a large
, the computation time required to search for the graphs in
S becomes excessively long. However, some real applications need to obtain the following sets of constrained graphs rather than obtaining all the graphs in
S.
Editing graphs is constrained: for example, the relabeling of vertices or edges is admissible in
of Equation (
3), whereas insertions and deletions are not admissible. That is, when converting a labeled graph
g to an unlabeled graph
by removing label information from vertices and edges in
g,
and
in Equation (
3) are isomorphic.
Editing graphs is constrained: for example, editing some specific vertices and edges in a query graph
q is admissible, whereas editing other vertices and edges is not admissible. For example, in the substructure drawn with blue lines and labels in
Figure 1, editing its ring structure is admissible, whereas editing the remainder of the blue substructure is not admissible.
The problem for the above constraint
is formalized as follows.
In order to solve this problem, Equation (
15) is rewritten as follows.
For the case of
, the first and second terms in Equation (
17) are the numbers of edits that occur by relabeling the
i-th vertices and edges
, respectively, in
and
. The third term of Equation (
17) is the sum of the numbers of edits that occur by inserting or deleting edges. For this case, in containing such insertion or deletion operations, the
function returns values larger than
and Algorithm 4 (in Line 7) backtracks the code tree.
For the case of the above constraint
, let some specific vertices in query graph
q be
. When Algorithm 4 visits node
n in the code tree, it generates various codes by
, in Line 4. Some vertices in
are included in
, but others are not. In this case, Equation (
15) is rewritten as follows.
Thus, for the case of
, the first and second terms of Equation (
18) are the numbers of edits that occur by relabeling the
i-th vertices and edges
, respectively, in
and
, where
and
are elements in
. The third term of Equation (
18) is the sum of the numbers of edits that occur by editing the other vertices and edges.
In order to summarize the above discussion, the advantages of our proposed method are the following:
Therefore, the method proposed in this paper is a general and flexible framework for searching for similar subgraphs of query graphs and is easily customizable for searching for the types of graphs desired by the user.
8. Experimental Evaluation
For our experimental evaluation, we used the three real-world datasets used in [
18] which were downloadable from
https://github.com/SNUCSE-CTA/IDAR on 1 March 2021. The datasets consisting of chemical compounds are called AIDS, NCI, and PubChem. Each atom, chemical bond, atom type, and bond type in a chemical compound corresponds to a vertex, edge, vertex label, and edge label, respectively. Sets of queries and databases containing graphs were generated from each of the datasets. One hundred query graphs, each containing more than 100 vertices, were selected from each of the datasets. Each generated database contained between 10,000 and 100,000 graphs and each of the graphs was generated by one of two different methods [
18]. In the first method, each graph in a database consisted of vertices and edges on a random walk on a graph randomly selected from one of the datasets. This type of database is called
rand. In the second method, each graph in a database was a frequent subgraph with a minimum support value of 0.1% [
24] that is enumerated from one of the datasets. This type of database is called
freq. In the experiments, vertices corresponding to hydrogen were removed, which is similar to the experiments in [
2,
14,
17,
30].
Table 2 summaries graphs in databses and queries in our experiments.
Since the problem of similar supergraph search is a novel problem proposed in this paper, there are no methods for solving this problem other than our proposed method to the best of our knowledge. Although we cannot compare our proposed method with other methods, our method is based on CodeTree (We use “CodeTree” to name the method proposed in [
17] and “code tree” to represent the index used in CodeTree). This is proposed in [
17] and our method with
is equivalent to CodeTree. Our proposed method was implemented in Java and the experiments reported in this section were conducted on a workstation with an AMD Ryzen Threadripper 3970X 3.7 GHz CPU and 64 GB main memory.
First, we conducted experiments for Algorithm 4 with Equation (
17).
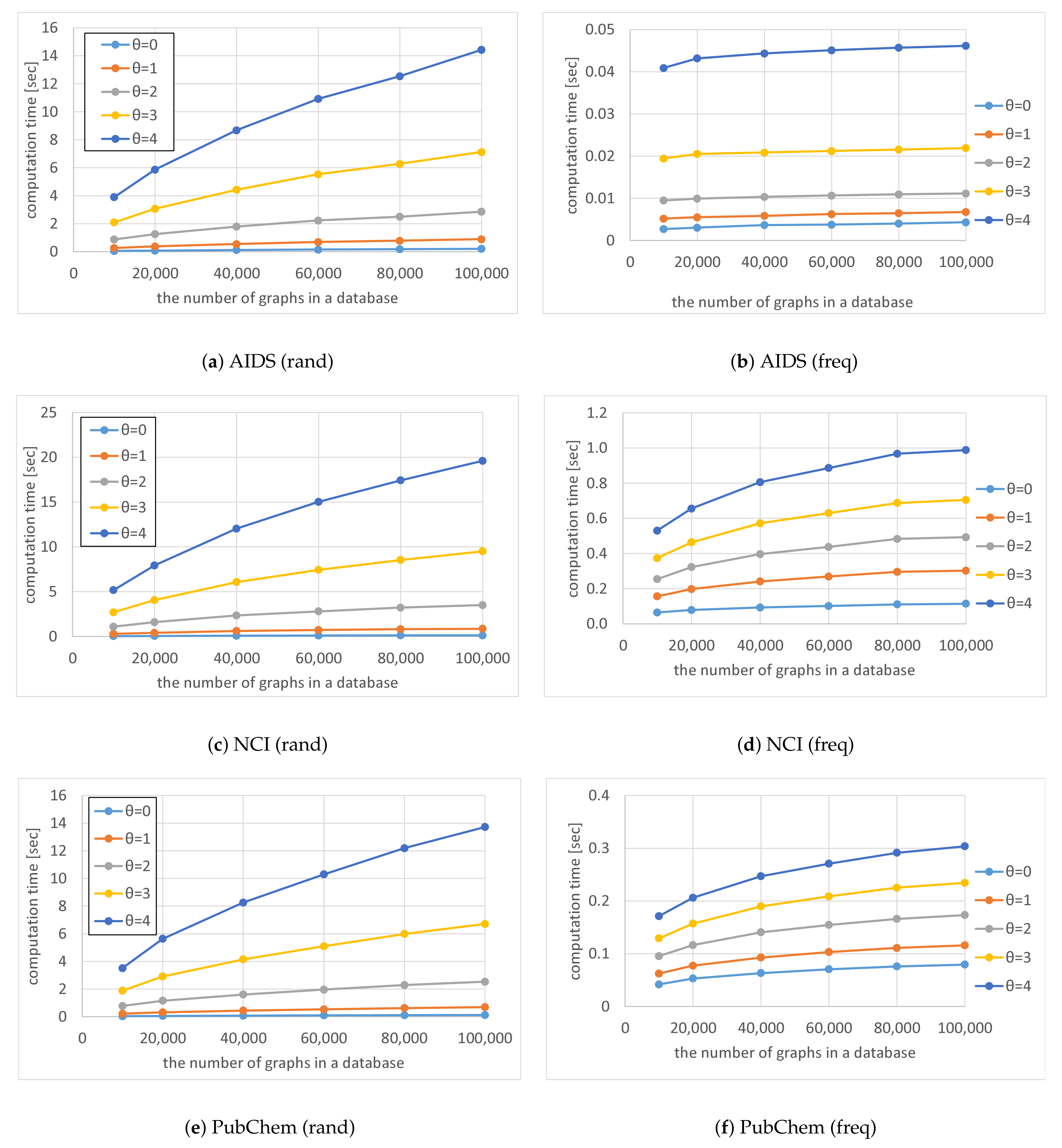
Figure 7,
Figure 8 and
Figure 9 show the average computation time (query processing time)
t, the average number of nodes
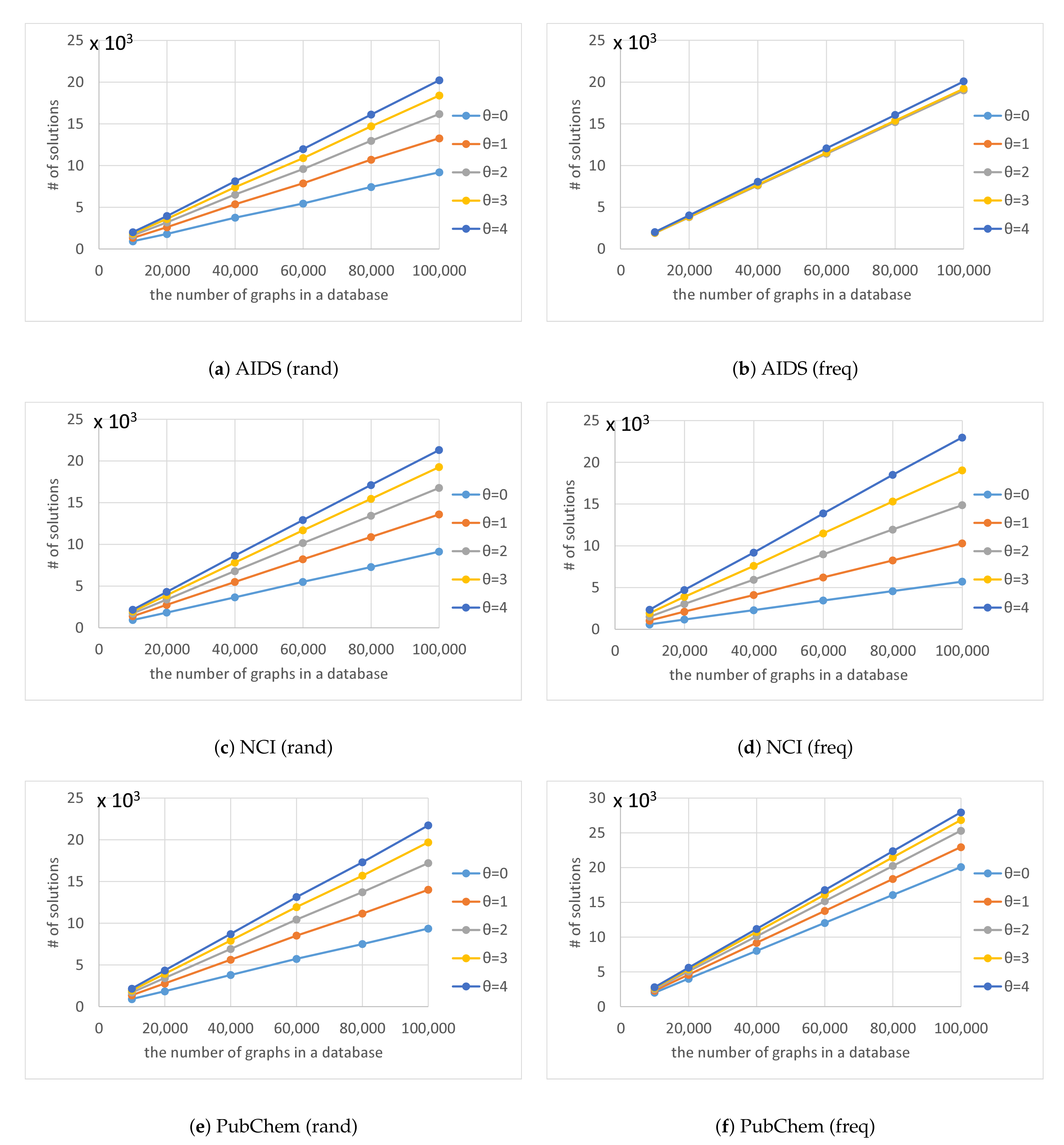
n in the code tree that our method traversed, and the average number of solutions
, respectively, for various numbers of graphs
in a database and various thresholds
. The computation time increased as the number of graphs in a database increased, as shown in
Figure 7. Although the time complexity of Algorithms 1 and 2 is linearly related to the number of graphs in the database, the computation time of our method was sublinear for the number of graphs in the database because Algorithm 4 maintains the correspondence between a vertex of a query graph and vertices of multiple graphs in the database simultaneously. In contrast, the computation time increased exponentially as
was increased, as shown in
Figure 7. This is because the number of graphs reachable by editing a graph
times increases exponentially. Although the computation time increased as the database size increased for
freq databases, the rate of increase was less than for
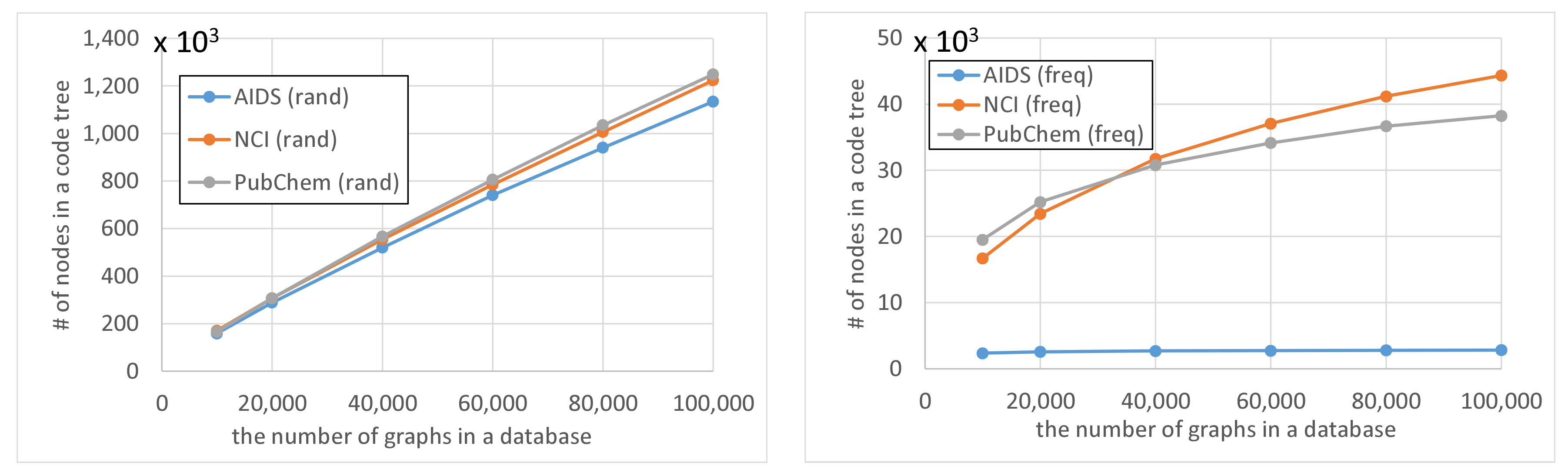
rand databases. This is because the numbers of nodes in code trees for
freq databases are smaller than those for
rand databases and the former numbers are relatively unchanged by the increase in database size, as shown in
Figure 10. The reason why the numbers of nodes in code trees are largely unaffected by database size is that frequent subgraphs enumerated from the datasets are similar to each other and the AcGM codes of similar frequent subgraphs have common prefixes. This is because a subgraph of a frequent subgraph is also a frequent subgraph, which is a consequence of the anti-monotonic property of the support value [
24].
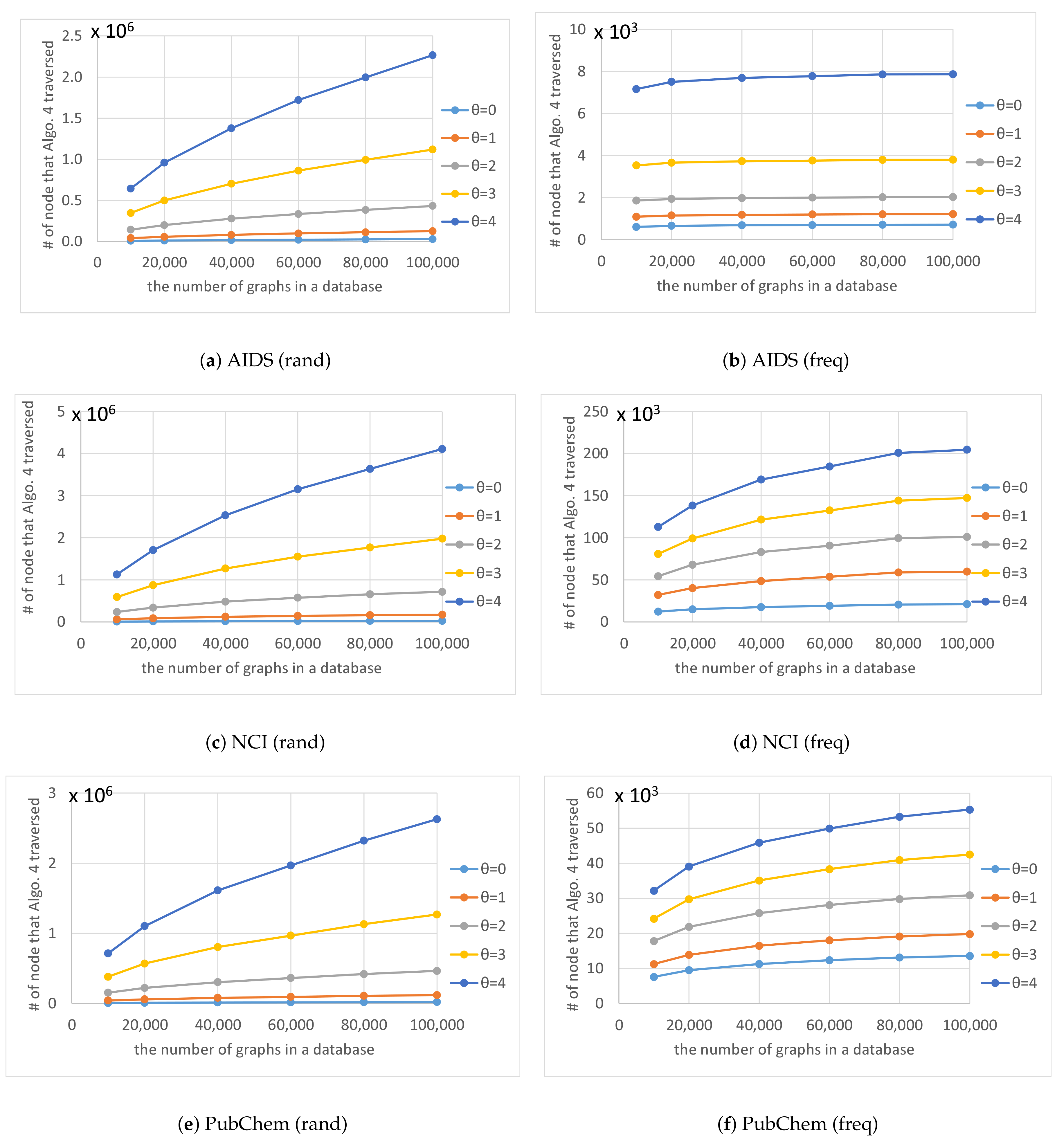
As shown in
Figure 8, the number of nodes in the code tree that Algorithm 4 traversed also increased exponentially as
increased. The shapes of the curves plotted in
Figure 8 are similar to those in
Figure 7 and the trend for the numbers
of graphs in databases and thresholds
in
Figure 8 are also similar to those in
Figure 7.
Figure 11 shows
for various numbers of graphs
in a database and various thresholds
. The figure shows that
is almost constant and unaffected by the number of graphs in a database, which indicates that the computation time of our method is proportional to the number of nodes in the code tree that Algorithm 4 traverses.
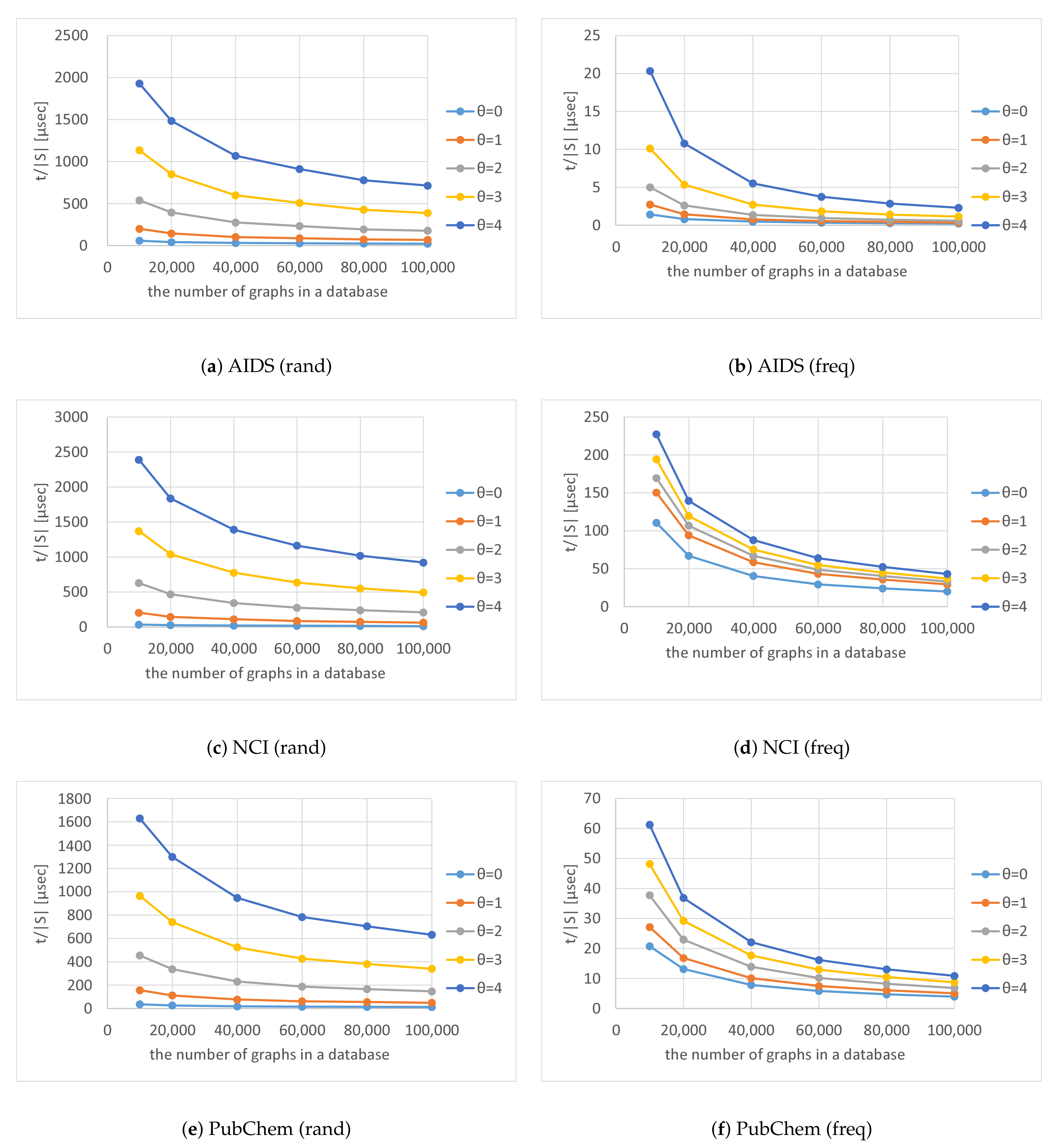
As shown in
Figure 9, the number of solutions found by Algorithm 4 was proportional to the number of graphs in the databases. Because there is a limit to the number of graphs in the database, the number of solutions did not increase exponentially as
increased. The rectangle in
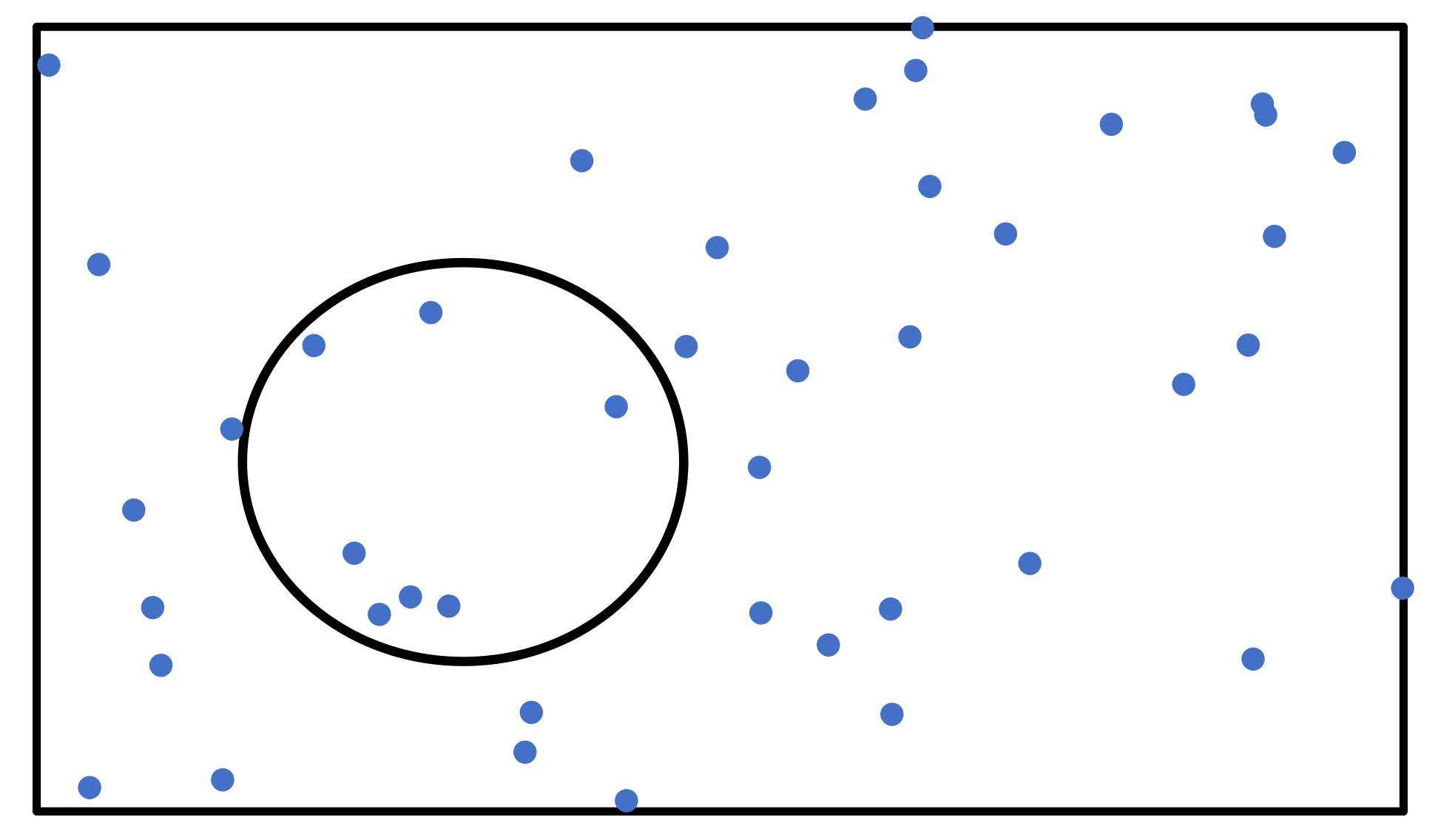
Figure 12 shows the space in which graphs in a database are distributed and each point in the rectangle shows a graph in the database. Points inside the circle are solutions for a given query
q and threshold
. If the number of graphs in database
G is doubled to
, such that
, the number of points surrounded by the circle doubles, if the distribution is not changed such that
. Thus, the number of solutions found by Algorithm 4 is proportional to the numbers of graphs in the databases.
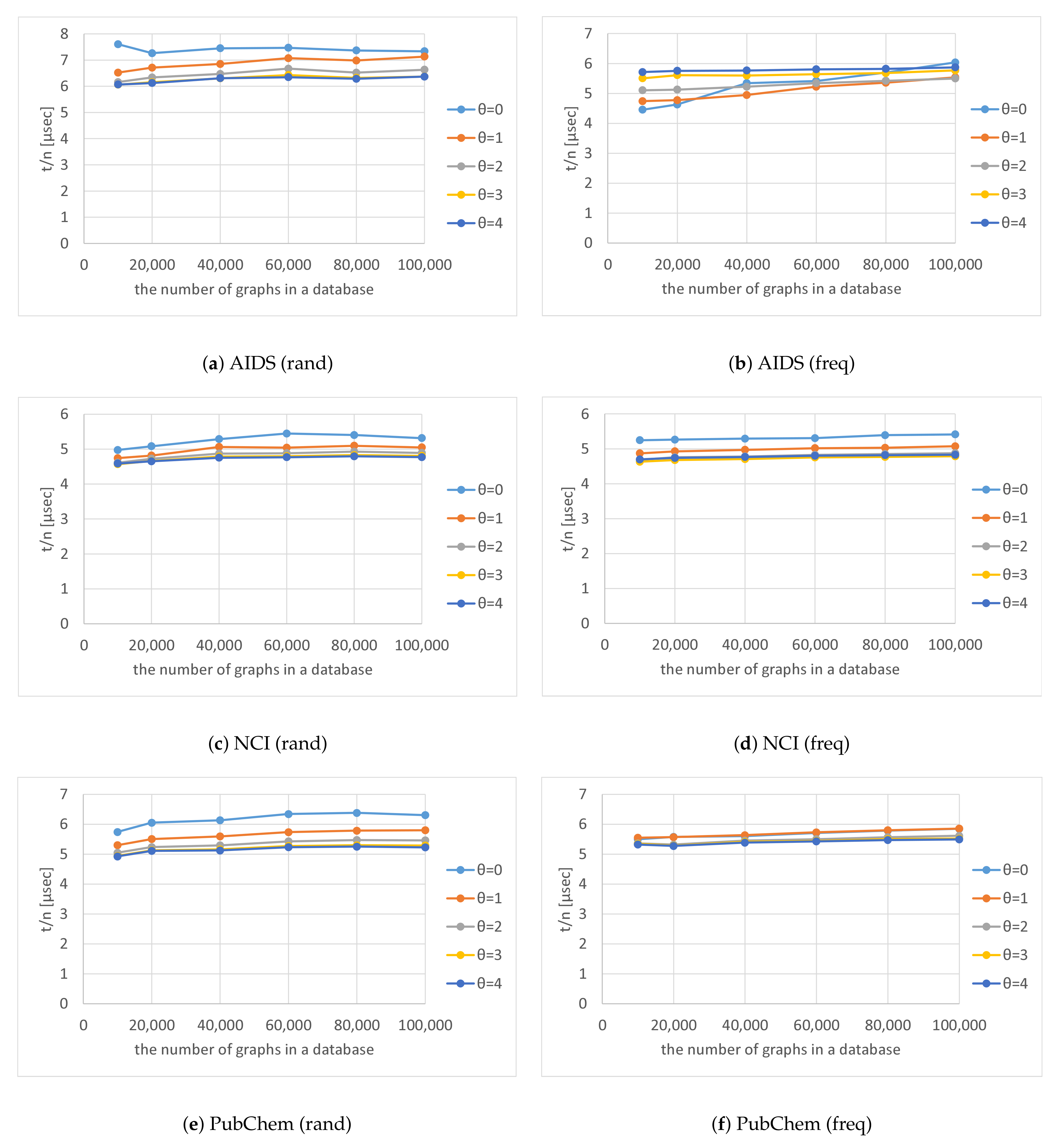
Figure 13 shows
for various numbers of graphs
in a database and various thresholds
; the figure indicates the average computation time to output each solution. As the numbers of graphs in the databases increased,
decreased exponentially. This is because
is proportional to the number of graphs in a database, whereas the overall computation time to search for solutions is sublinear.
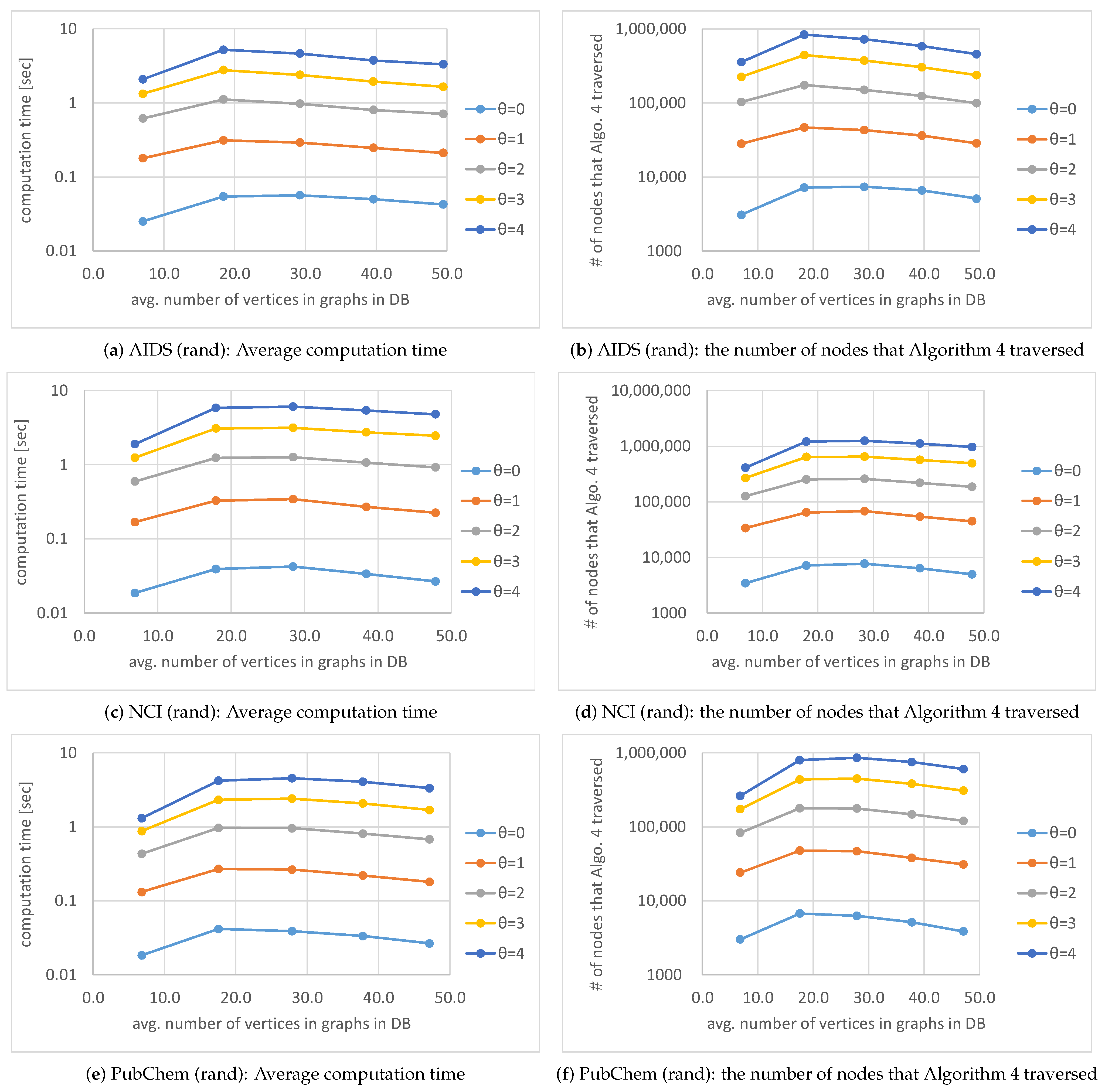
Figure 14 shows that average computation time and the number of nodes that Algorithm 4 traversed for various average numbers of vertices in graphs in a database and various thresholds
. When the average number of vertices in graphs in a database is increased, the average computation time of Algorithm 4 is largely unaltered because the computation time of Algorithm 4 is proportional to the number of nodes that Algorithm 4 traverses, as mentioned after Algorithm 3. The number is also largely unaltered with respect to the change of the average number of the vertices. The reason why the number of nodes that Algorithm 4 traversed is largely unaltered is because of the use of the function
shown in Equation (
17). By using Equation (
17), the relabeling of vertices or edges is admissible, whereas insertions and deletions of the vertices and edges are not admissible. Therefore, nodes that Algorithm 4 traverses are restricted. As mentioned in
Section 7, one of the advantages of our proposed method is the customizability for searching for the types of graphs desired by users. By customizing the search for the types of graphs, the users can reduce not only the number of solutions to be outputted but also computation time of our proposed method.
Next, we conducted experiments for Algorithm 4 with Equations (
15) and (
17).
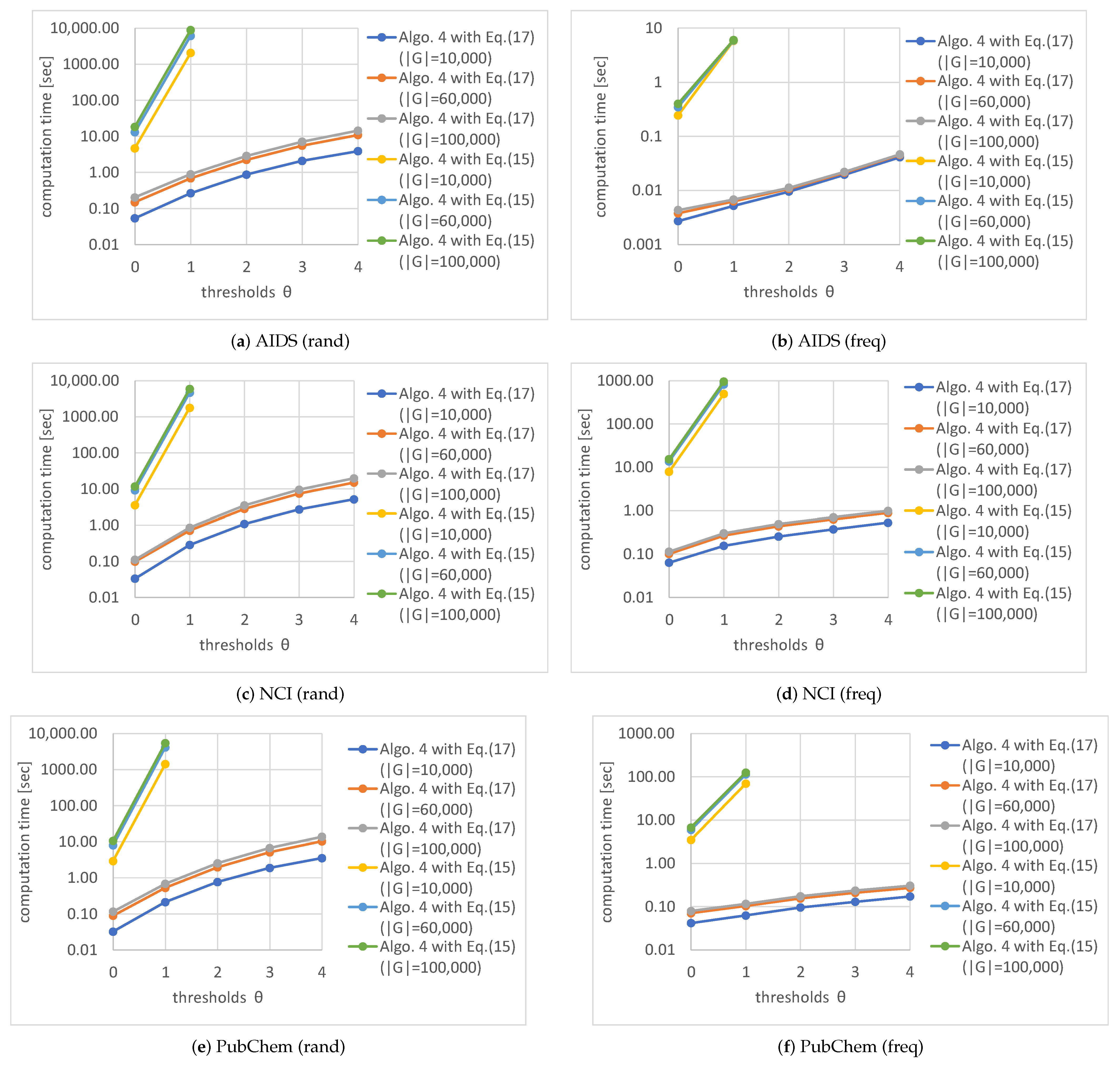
Figure 15 shows the computation times for various numbers of graphs in the databases and various thresholds. The computation times with Equation (
17) were much shorter than those with Equation (
15). This is because the number of graphs reachable by editing a graph
times increases exponentially and editing graphs with Equation (
17) is limited to the relabeling of vertices and edges, which is faster than the insertion and deletion of vertices and edges that are required with Equation (
15).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}