Abstract
A grammar-based compressor is an algorithm that receives a word and outputs a context-free grammar that only produces this word. The approximation ratio for a single input word is the size of the grammar produced for this word divided by the size of a smallest grammar for this word. The worst-case approximation ratio of a grammar-based compressor for a given word length is the largest approximation ratio over all input words of that length. In this work, we study the worst-case approximation ratio of the algorithms Greedy, RePair and LongestMatch on unary strings, i.e., strings that only make use of a single symbol. Our main contribution is to show the improved upper bound of for the worst-case approximation ratio of Greedy. In addition, we also show the lower bound of for the worst-case approximation ratio of Greedy, and that RePair and LongestMatch have a worst-case approximation ratio of .
1. Introduction
The goal of grammar-based compression is to represent a word w by a small context-free grammar that produces exactly . Such a grammar is called a straight-line program (SLP) for w. In the best case, one gets an SLP of size for a word of length n, where the size of an SLP is the total length of all right-hand sides of the rules of the grammar. A grammar-based compressor is an algorithm that produces an SLP for a given word w. There are various grammar-based compressors that can be found in many places in the literature. A well-known example is the classic LZ78-compressor of Lempel and Ziv [1]. Although it was not introduced as a grammar-based compressor, it is straightforward to compute from the LZ78-factorization of w an SLP for w of roughly the same size. Other examples include BISECTION [2] and SEQUITUR [3]. In this work, we study the global grammar-based compressors Greedy [4,5,6], RePair [7] and LongestMatch [8], to which we will also refer to as global algorithms. Global algorithms are important in practice because they show excellent compression results in various fields. For example, Greedy is used in [5] to compress DNA sequences. Among all global algorithms, RePair is probably the most used one. Examples include compressing web graphs [9], searching compressed text [10], suffix array compression [11] and compressing XML [12]. A key concept of global compressors are maximal strings. A maximal string of an SLP is a word that has length at least two and occurs at least twice without overlap as a factor of the right-hand sides of the rules of . Furthermore, no strictly longer word appears at least as many times without overlap as a factor of the right-hand sides of . For an input word w, a global grammar-based compressor starts with the SLP that has a single rule , where S is the start nonterminal of the grammar. The SLP is then recursively updated by choosing a maximal string of the current SLP and replacing a maximal set of pairwise nonoverlapping occurrences of by a new nonterminal X. Additionally, a new rule is introduced. The algorithm stops when the obtained SLP has no maximal string. In the case of Greedy the chosen maximal string minimizes the size of the SLP in each round, while RePair selects in each round a most frequent maximal string, and LongestMatch chooses a longest maximal string. Please note that the Greedy algorithm as originally presented in [4,5,6] is different from the version studied in this work as well as in [13]: The original Greedy algorithm only considers the right-hand side of the start rule for the choice and the replacement of the maximal string. In particular, all other rules do not change after they are introduced.
In [13] the worst-case approximation ratio of grammar-based compressors is studied. For a grammar-based compressor that computes an SLP for a given word w, one defines the approximation ratio of on w as the quotient of the size of and the size of a smallest SLP for w. The approximation ratio is the maximal approximation ratio of among all words of length n. In [13] the authors provide upper and lower bounds for the approximation ratios of several grammar-based compressors (among them are all compressors mentioned so far), but for none of the compressors the lower and upper bounds match. For LZ78 and BISECTION these gaps were closed in [14]. For all global algorithms the best upper bound on the approximation ratio is [13], while the best known lower bounds so far are for RePair [15], for LongestMatch and for Greedy [13]. In general, the achieved bounds “leave a large gap of understanding surrounding the global algorithms" as the authors in [13] conclude.
Unary words have the form for some symbol a and integer . Grammar-based compression on unary words is strongly related to the field of addition chains, which has been studied for decades (see [16] (Chapter 4.6.3) for a survey) and still is an active topic due to the strong connection to public key cryptosystems (see [17] for a review from that point of view). An addition chain for an integer n of size m is a sequence of integers such that for each d (), there exists () such that . It is straightforward to compute from an addition chain for an integer n of size m an SLP for of size . Vice versa, an SLP for of size m yields an addition chain for n of size m. Therefore, grammar-based compressors on unary inputs can also be thought of as addition chain solvers, i.e., algorithms that find a (small) addition chain for a given integer.
The worst-case approximation ratio for global algorithms is difficult to analyze. A good starting point is therefore to analyze them on unary words because of their simplicity. Even though unary words are not interesting to compress, it is still interesting to look at how global algorithms perform on them. The improved upper bound we show for Greedy uses unary words and is the first improvement that happened in 15 years.
We show the worst-case approximation ratio of RePair and LongestMatch for unary words to be . Both algorithms are basically identical to the binary method that produces an addition chain for n by creating powers of two using repeated squaring, and then the integer n is represented as the sum of those powers of two that correspond to a one in the binary representation of n. Based on that information, we show that for any unary input w the produced SLPs of RePair and LongestMatch have size at most and we also provide a lower bound.
We improve the upper bound for the approximation ratio of Greedy on unary words to . In [18], which is the previous version of this article, the authors showed an upper bound for the approximation ratio of Greedy of for unary inputs, by only analyzing the first three rounds. Here, we present a more in-depth analysis that makes use of every round. We can prove that Greedy produces an SLP of size on input , which together with the fact that a smallest SLP for has size then yields the improved upper bound of . To prove the size bound on the SLP produced by Greedy, we distinguish unary and nonunary nonterminals. A nonterminal X is called unary if its right-hand side is of the form when it is first introduced. Otherwise, it is nonunary. We bound the total number of occurrences of all unary and nonunary nonterminals in the grammar produced by Greedy separately. For the unary nonterminals, we bound their total number to be , while each of them contributes a size of , which yields a total size contribution of . We then bound the number of occurrences of nonunary nonterminals using the already established number of unary nonterminals, which comes out to be . Thus, we obtain the desired upper bound on the size of the grammar.
We also show the lower bound of for the approximation ratio of Greedy. The key to achieve this bound is the sequence with , which has been studied in [19] (among other sequences), where it is shown that for . To prove the lower bound, we show that the SLP produced by Greedy on input has size , while a smallest SLP for has size (this follows from a construction used to prove the lower bound for Greedy in [13]).
This paper is an extended version of our paper published in the proceedings of SPIRE 2019 [18].
Related Work
One of the first appearances of straight-line programs in the literature are [20,21], where they are called word chains (since they generalize addition chains from numbers to words). In [20] it is shown that the function is in . Recall that is the size of a smallest SLP for the word w and thus measures the worst-case SLP-compression over all words of length n over a k-letter alphabet.
The smallest grammar problem is the problem of computing a smallest SLP for a given input word. It is known from [13,22] that in general no grammar-based compressor can solve the smallest grammar problem in polynomial time unless . Even worse, unless one cannot compute in polynomial time for a given word w an SLP of size at most [13]. One should mention that the constructions to prove these hardness results use alphabets of unbounded size. Although in [13] it is remarked that the construction in [22] works for words over a ternary alphabet, in [23] it is argued that this is not clear at all and a construction for fixed alphabets of size at least 24 is given. However, for grammar-based compression on unary strings as studied in this work (as well as for the problem of computing a smallest addition chain), there is no -hardness result, so there might be an optimal polynomial-time algorithm even though it is widely believed that there is none.
Other notable systematic investigations of grammar-based compression are provided in [8,24]. However, in [8], grammar-based compressors are used for universal lossless compression (in the information-theoretical sense), it is shown in [24] that the size of so-called irreducible SLPs (that include SLPs produced by global algorithms) can be upper-bounded by the (unnormalized) k-th order empirical entropy of the produced string plus some lower order terms.
2. Preliminaries
For we write for and otherwise. For we denote by the integer division of m and n. We denote by the modulo of m and n, i.e., and
If or is used, then this refers to the standard division over . Please note that and .
An alphabet is a finite set of symbols. For a word or string over with and we write to denote w’s length. The set of consists of all words over and , where is the word of length 0. A unary word is a word of the form with and . All other words are called nonunary. For words we say that v is a factor of w if there are such that .
A context-free grammar is a tuple , where N is the finite set of nonterminals, is the alphabet with , P is the set of productions of the form , where and , and is the start symbol. An SLP is a context-free grammar , where
- every has exactly one production, i.e.,
- the relation is acyclic.
This way, for every there exists a unique word with . We say that produces w if . Please note that some authors require SLPs to be in Chomsky Normal Form (CNF), i.e., every production is of the form , where or , where . We do not make this assumption here because, in general, grammar-based compressors produce SLPs that are not in CNF. Furthermore, every SLP can easily be transformed into an SLP that is in CNF, produces the same word and has roughly the same size. A grammar-based compressor is an algorithm that given an input outputs an SLP that produces w. The size of an SLP is defined as . For a word we write for the size of a smallest SLP that produces w. The worst-case approximation ratio of is the maximal approximation ratio over all words of length n over an alphabet of size k:
For a given SLP , a word is called a maximal string of if
- ,
- appears at least twice without overlap as a factor of the right-hand sides,
- and no strictly longer word appears at least as many times as a factor of the right-hand sides without overlap.
Example 1.
Let such that P contains
- ,
- ,
- , and
- .
The maximal strings of are , and . The factors and occur four times on the right-hand sides without overlap and occurs twice without overlap.
A global grammar-based compressor (or simply global algorithm) starts on input w with the SLP . In each round , the algorithm selects a maximal string of and updates to by replacing a largest set of pairwise nonoverlapping occurrences of in by a new nonterminal X. Additionally, the algorithm introduces the rule in . The algorithm stops when no maximal string occurs. Please note that the replacement is not unique, e.g., the word has a unique maximal string , which yields SLPs with rules , or , or , . We assume the first variant here, i.e., maximal strings are replaced from left to right. The compressor Greedy that we study in this work chooses a maximal string in each round such that the size of is minimal.
Example 2(Greedy).
Let . We have
- ,
- , ,
- , , ,
- , , , ,
- , , , , .
Please note that in the first round, instead of the maximal string the algorithm could also choose the maximal string , because both choices yield SLPs of minimal size 15. In the second round, instead of the algorithm could also choose , because both choices yield SLPs of size 14. Finally, the order of the choices (round 3) and (round 4) could be swapped because both choices yield SLPs of unchanged size 14.
The following lemma from [13] provides a lower bound on the size of an SLP for a word of length n.
Lemma 1
([13] (Lemma 1)). For every word of length n, we have .
3. Upper Bound for Greedy
To show our improved upper bound for the approximation ratio of Greedy on unary words, we are first going to prove that the size of the SLP produced by Greedy for the input is upper-bounded by .
Proposition 1.
For all n, we have
First, we need to prove several lemmas that are fulfilled for any global algorithm. When we apply specific arguments to Greedy, we draw attention to it. For better readability, we will use , i.e., the input is . Furthermore, let be the SLP obtained by the global algorithm on input after i rounds. Please note that until the algorithm stops, we have since exactly one new nonterminal is introduced in each round. If we quantify over the rounds of the algorithm, we always implicitly mean that the statements hold until the algorithm stops. If i is mentioned without a quantification, then the statement holds for any constructed after some round i of the algorithm.
Lemma 2.
For every i, there is a fixed order of the nonterminals in such that every right-hand side of a rule satisfies
Proof.
We prove this property by induction. Initially, the property holds for the SLP since and the only rule satisfies . Now assume the claim is true for , i.e., each right-hand side of a rule in is a word from . Please note that any nonempty factor of such a right-hand side is a word from for some . Therefore, assume the global algorithm chooses a maximal string in round and is the corresponding new rule. We show that for all rules , i.e., the order of the nonterminals after round is obtained by inserting the new nonterminal X directly before in the previous order. First, this is obviously true for the new rule as well as for all rules that have not been modified during round . It remains to check the rules that are obtained from a rule by replacing a largest set of pairwise nonoverlapping occurrences of in by the new nonterminal X. If () is unary and is the single maximal -block that occurs in , then replacing occurrences of from left to right yields as the new maximal blocks of X and in w. It follows that . If otherwise is not a unary word, i.e., for , then has exactly one occurrence of as a factor. It follows that and thus v satisfies the claim. This finishes the induction. □
In other words, there is at most one maximal block for each symbol on each right-hand side and the order of these blocks is the same for all rules. Similar to the case distinction in the last steps of the proof of Lemma 2, we will distinguish two types of nonterminals. Let be the introduced rule in some round of the algorithm. If is unary, then we call X a unary nonterminal. Otherwise, we call X nonunary. We categorize as a unary nonterminal, although formally is not a nonterminal. Please note that the type of a nonterminal is decided when it is introduced and does not change later, i.e., even if the right-hand side of a unary nonterminal becomes nonunary during the execution of the algorithm, the type of the nonterminal stays the same. Our strategy to prove Theorem 1 is to bound the total number of occurrences of unary nonterminals and nonunary nonterminals on right-hand sides independently. It follows from Lemma 2 that every factor that occurs more than once on the right-hand side of a single rule is unary. The following lemma is a direct consequence of that fact.
Lemma 3.
Every nonunary nonterminal occurs at most once on the right-hand side of each rule at any time of the algorithm.
Corollary 1.
If a unary nonterminal X is introduced and with is the corresponding rule for X, then Z is a unary nonterminal.
Next, we bound the number of rules that contain a unary nonterminal X on the right-hand side. For a nonterminal X, including , let be the number of rules of where X occurs on the right-hand side, or more formally
The next two lemmas describe how evolves depending on the type of the introduced nonterminal.
Lemma 4.
If a nonunary nonterminal X is introduced in some round , then for every (including ), we have .
Proof.
To prove this point, we use that all rules satisfy (Lemma 2). Since X is nonunary, the chosen maximal string satisfies for . If a nonterminal does not occur in , then . So, assume the nonterminal occurs in , i.e., for . Note first that occurs on the right-hand side of the new rule . It follows that to prove the claimed result, we must show that for at least one rule such that occurs in v, all occurrences of must disappear, i.e., does not occur in for . Let
be the set of nonterminals of where the corresponding rule is modified in round . Please note that since a maximal string occurs at least twice on all right-hand sides and occurs at most once as factor of each rule since X is nonunary (Lemma 3). If then for all and , the nonterminal does not occur in anymore since the complete -block (among other symbols) has been replaced. This means that since one new rule contains on the right-hand side, while for at least two rules the occurrences of have been removed in round . If otherwise or , then the same argument fails since for and , the right-hand side could still contain since it is not necessarily true that the complete -block has been replaced. However, due to the properties of a maximal string, we show that does not occur in for at least one and . Towards a contradiction, assume occurs in for all and . This means that for all and , the length of the maximal -block that occurs in v is strictly larger than the length of the maximal -block that occurs in . If , it follows that is a factor of v for all and , and symmetrically, if then is a factor of v for all and . This contradicts the property that no strictly longer string than occurs at least as often on the right-hand sides of the rules. It follows that in this case , which finishes the proof. □
Lemma 5.
If a unary nonterminal X is introduced in some round and with is the corresponding rule, then and .
Proof.
Both points are straightforward: A rule only contains X on the right-hand side if is a factor of for , which shows that . For the second point, note that if does not contain Z on the right-hand side, then the same is true for (the unchanged rule) . The only rule where Z occurs new is the new rule , and thus . □
So far, we have shown that when a unary nonterminal X is introduced and with is the corresponding rule, then Z is a unary nonterminal as well (Corollary 1). Furthermore, we argued that introducing a nonunary nonterminal does not increase the number of rules where a unary nonterminal occurs on the right-hand side (Lemma 4). It follows that we can upper-bound the number of unary nonterminals and the number of rules where those nonterminals occur on right-hand sides independently of the nonunary nonterminals.
To do so, we inductively define a binary tree that describes how the unary nonterminals evolve until is reached. All nodes in the tree are labeled with , where X is a unary nonterminal and k is an upper bound on for some j.
- (1)
- Initially, the tree only contains a single node that is labeled with .
- (2)
- If a rule is introduced in round for some , then we update to by adding two children to the unique leaf that is labeled with for some k. The new left child is labeled with and the new right child is labeled with as depicted on the left of Figure 1.
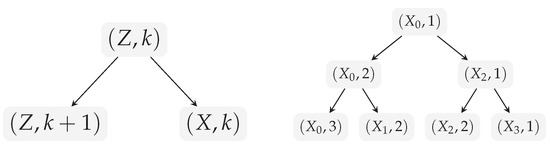 Figure 1. On the left, the general pattern that is applied during the construction of is illustrated, where the split refers to a rule that has been introduced by the global algorithm. On the right, the tree that corresponds to the introduced rules of Example 3 is shown.
Figure 1. On the left, the general pattern that is applied during the construction of is illustrated, where the split refers to a rule that has been introduced by the global algorithm. On the right, the tree that corresponds to the introduced rules of Example 3 is shown. - (3)
- If otherwise a nonunary nonterminal is introduced in round , then , i.e., nonunary nonterminals are ignored.
The initial tree reflects that the only unary nonterminal of is and . If the tree is modified according to point (2) of the definition, this refers to Lemma 5, where and is shown when a rule for is introduced.
The level of a node is the length of the path from the node to the root. For a unary nonterminal , we denote by leveli the level of the unique leaf of that is labeled with for some k.
Example 3.
Assume that the first three rules introduced by a global algorithm are in the first round, in the second round and in the third round for . The tree that corresponds to this introduced rules is depicted on the right of Figure 1. The indices for the introduced nonterminals are chosen such that the ordering of the nonterminals in (see Lemma 2) is , i.e., all right-hand sides of rules are contained in . The corresponding SLPs , , and are depicted next, where we simply use ∗ instead of the exact exponents of the symbols due to better readability.
Please note that in this example, we have , , and , which is exactly the information contained in the second components of the leaf labels in . Furthermore, we havelevel3 for in this example.
The following lemma is a direct consequence of the fact that the maximal k that occurs for some label is incremented from one level to the next level (as described in Lemma 5).
Lemma 6.
For each node of at level m that is labeled with for some unary nonterminal , we have . Also, let be a unary nonterminal. Then we have .
So far, we provided information about the number of rules where a unary nonterminal occurs. Next, we move on to the total number of occurrences of a unary nonterminal on all right-hand sides. We denote by the total number of occurrences of X on right-hand sides of rules in . We have by the definition of both functions and for a nonunary nonterminal X, we have due to Lemma 3.
Lemma 7.
Let be the rule that is introduced in some round and let . We have
- (1)
- for all , and
- (2)
- .
Proof.
Point (1) is straightforward: For let be the maximal Y-block that occurs as a factor in for some . Replacing on right-hand sides yields that at least two occurrences of are eliminated while only is added as a part of the new rule . If otherwise , then because the occurrences of Y are not affected by the new rule.
Point (2) is also based on a simple observation. Please note that describes the part of the SLP that is affected by the replacement of in round , and is the size of that part in after the occurrences of are replaced by X plus the new occurrences in the introduced rule. All other parts of are not affected by the new rule. Now the properties of a maximal string ensure that . The extreme case where has length two and occurs only twice without overlap on the right-hand sides of rules in satisfies . All other cases even satisfy . Point (2) directly follows. □
Our next goal is to bound depending on for a unary nonterminal X. To do so, we now apply arguments specific to Greedy. Recall that Greedy selects a maximal string that minimizes the size of the obtained SLP in each round.
Lemma 8.
Let be a unary nonterminal and assume a rule for some is introduced byGreedyin round . We have
Proof.
If a unary nonterminal X and a rule with are introduced in round , then the choice of d only depends on the maximal Z-blocks occurring on all right-hand sides of rules in since the remaining part of does not change. Assume that and let be the lengths of the maximal Z-blocks occurring on right-hand sides of , i.e., . Then Greedy minimizes , where d is the size of the new rule and for each a maximal block on the right-hand side of a rule in is transformed into . Due to the greedy nature of the algorithm, the following equation holds for all :
Please note that the chosen maximal string has length at least 2, but the upper bound also holds for since in this case we have due to Lemma 7 (point (2)). If we apply , we get
Together with this proves the lemma. □
The following lemma is essential for the proof of Theorem 1 since we bound the total number of occurrences of a unary nonterminal depending on its level.
Lemma 9.
Let be a unary nonterminal with . We have
Proof.
We prove the lemma by induction on and we start with . The only SLP that contains a unary nonterminal X such that is the initial SLP and the unary nonterminal is . Please note that the maximal string chosen by any global algorithm in the first round on input trivially satisfies and thus the two unary nonterminals of have level one. We have and this is exactly what we obtain when is used on the right side of Equation (1) (the empty product is considered to be 1).
Now assume any unary nonterminal that has level m satisfies the claimed bound and we consider a unary nonterminal X such that for some i. It follows from the definition that there is a leaf node at level in that is labeled with for some k. There are two cases that need to be distinguished. Either this leaf is a left child or a right child of its parent node. Assume that is the label of a right child and let be the label of the left sibling of that node. To prove both cases simultaneously, we prove the upper bound for X and for Z, i.e., we use Z to cover the second case where the node is a left child. The parent node of and is labeled with (see Figure 1 on the left). Let be the maximal such that , i.e., for is the introduced rule in round and is the label of a leaf at level m in . By induction, we have . Now by Lemma 8, we have
Together with (Lemma 6), this yields
Using the fact that (there are at least two nonoverlapping occurrences of a maximal string) and (the new rule contains Z at least twice) yields the claimed upper bound on and . Finally, this upper bound holds for due to Lemma 7 (point (1)). □
Corollary 2.
Let be a unary nonterminal with . We have
Proof.
Please note that for all . We upper-bound the right side of Equation (1) (Lemma 9) as follows:
□
What we achieved so far is to bound the total size that a unary nonterminal X contributes on right-hand sides of the rules depending on . Next, we bound the size that nonunary nonterminals contribute to depending on the levels of all unary nonterminals. To do so, we need the following definitions. Let be the number of distinct right neighbors of X (which are not equal to X) on right-hand sides plus the number of occurrences of X as the last symbol of a right-hand side in , i.e.,
Let be the number of distinct left neighbors of X (which are not equal to X) on right-hand sides plus the number of occurrences of X as the first symbol of a right-hand side in , i.e.,
Also, let and . Please note that and since for each right-hand side of a rule there is at most one right (respectively, left) neighbor for some occurrence of X due to Lemma 2 and each right-hand side can contain X at most once as the last (respectively, first) symbol. Also, means that all maximal X-blocks on right-hand sides are either at the end of the right-hand side or are followed by a distinct symbol. Similarly, means that all maximal X-blocks on right-hand sides are either at the beginning of the right-hand side or are preceded by a distinct symbol. The following lemmas describe how the functions and evolve.
Lemma 10.
If then . If a nonunary, maximal string is selected in round for some , then .
Proof.
Let be the introduced rule in round . If X does not occur in , then it is straightforward to see that since and . The new nonterminal Y could be a new right neighbor for some occurrences of X, but all occurrences of X which have this new right neighbor Y in shared the same right neighbor in (the first symbol of ).
If otherwise X occurs in , then first assume that for some . Please note that replacing an occurrence of on the right-hand side of a rule either removes all occurrences of X on this right-hand side (in case u contains a maximal X-block of length for some integer ) or the right neighbor of the maximal X-block in u does not change in the modified rule since occurrences of are replaced from left to right. It follows that the only way to obtain is to remove all occurrences of X on a right-hand side, but then decreases by the same value. Additionally, the new rule adds a new right-hand side to , but since X is the last symbol on this right-hand side it follows that is incremented as well. Together this yields in this case.
The case remains where is nonunary and X occurs in . Here, we have due to Lemma 4 and occurs at most once on each right-hand side due to Lemma 2. However, again, the only way to reduce compared to is to remove all occurrences of X on a right-hand side, but then again decreases by the same value. This yields .
Assume now that a nonunary, maximal string for some is selected in round . We show that . If X only occurs in the new rule in after occurrences of are replaced on all right-hand sides in , i.e., all modified rules do not contain X anymore, then because at least two right-hand sides do not contain X as a factor anymore while only the new rule adds a new right-hand side which contains X to . Also, we have in this case and thus because all rules where the maximal X-block is removed shared the same right neighbor due to the fact that is the chosen maximal string. However, still occurs in the new rule of and thus . If otherwise at least one of the modified rules still contains X on the right-hand side, then is a factor of this right-hand side in after the replacement of . It follows that in this case and thus because each distinct right neighbor of X in is still a right neighbor of X in as argued above, but additionally is new since Y is a new nonterminal. □
The same result does not hold for . In particular, is possible when a rule is introduced in round for some due to the assumption that global algorithms replace occurrences of the maximal string from left to right. For example, assume that , and are the maximal X-blocks on right-hand sides of including distinct left neighbors for each X-block (A, B and C). Therefore, we have , and thus in this example. If now a rule is introduced, then this yields , and after replacing . Hence we have , and thus . We show in the following lemma that this is the only case where occurs.
Lemma 11.
Let . If a rule is introduced in round such that , then . If a nonunary, maximal string is selected in round for some , then
Proof.
The arguments are similar to the corresponding cases in Lemma 10. Let be the introduced rule in round . If X does not occur in , then since and . The new nonterminal Y could be a new left neighbor for some occurrences of X in , but all these occurrences of X shared the same left neighbor in (the last symbol of ).
If otherwise is nonunary and contains X, then we have due to Lemma 4 and occurs at most once on each right-hand side due to Lemma 2. The only way to obtain is again to remove all occurrences of X on a right-hand side, but then decreases by the same value. Please note that due to the assumption that is nonunary, it is not possible to modify two (or more) rules such that the maximal X-blocks have different left neighbors in and after the replacement these X-blocks share the same left neighbor in . This yields .
Assume now that a nonunary, maximal string is selected in round for some word . We show that . If X only occurs in the new rule in , i.e., X does not occur in the modified rules, then we have because at least two right-hand sides do not contain X as a factor anymore while only the new rule adds a new right-hand side which contains X to . Moreover, we have in this case because all rules where the maximal X-block is removed shared the same left neighbor since is the selected nonunary, maximal string. However, still occurs on the right-hand side of the new rule of . It follows that . If otherwise at least one of the modified rules still contains X on the right-hand side, then is a factor of this right-hand side in after the replacement of . It follows that and thus because each distinct left neighbor of X in is still a left neighbor of X in for some occurrence of X. Additionally, Y is a new left neighbor. □
In the following proof, we use the notation
for all unary nonterminals that appear in and for all nonunary nonterminals that appear in .
Lemma 12.
We have
Proof.
Let be the total size that all nonunary nonterminals contribute to the size of . We first bound the number of rounds where the function s increases, i.e., we bound . If a unary nonterminal is introduced in some round , then , i.e., we can ignore these rules. So, consider some round where a nonunary nonterminal X is introduced and let be the introduced rule. Let be the set of nonterminals that occur at least once in . We first show that if , then . In other words, if two nonunary nonterminals occur in , then . Let r be the number of rules such that is a factor of v. Recall that nonunary factors and nonterminals occur at most once on the right-hand side of a single rule (Lemma 3). We have because the new nonunary nonterminal X occurs now on r right-hand sides, contains k nonunary nonterminals which occur exactly once in each, and the replacement of on right-hand sides deletes these k nonterminals on r right-hand sides. We have (due to the properties of a maximal string) which together with yields . Hence we can assume that . The maximal string has length and is not unary, so the first and the last symbol of are different and at least one of them is unary due to our assumption that at most one nonunary nonterminal occurs in . Let Y be this unary nonterminal and assume that Y is the first symbol, i.e., the nonunary, maximal string is for some (nonempty) v. Afterwards we discuss the case where Y is the last symbol, i.e., .
We bound the number of rounds where a nonunary, maximal string is selected for some v. Let be the round where the unary nonterminal Y has been introduced. We have
due to Lemma 6 and for all . We also have for by Lemma 10. In addition to that, if is the selected nonunary, maximal string in round for some v, then we have again by Lemma 10. It follows that after at most many rounds where the chosen maximal string is nonunary and has the form for some (nonempty) v, we have . In this case, all maximal Y-blocks have distinct right neighbors or occur at the end of a right-hand side. Hence there is no possibility to select a nonunary, maximal string anymore.
Now we similarly bound the number of rounds such that a nonunary, maximal string is selected for some v. However, care must be taken in this case, because it is possible that when a rule for is introduced in round as explained above. Fortunately, rules of this form (the selected maximal string is from ) are introduced at most many times up to round i by the definition of . Let be the round where the unary nonterminal Y has been introduced. We have
for each due to Lemma 6 and for all . Furthermore, if the selected maximal string in round () is not from , we have due to Lemma 11. Moreover, if the maximal string is nonunary and for some (nonempty) v, then . It follows that between two rounds where maximal strings from are selected, there are at most many rounds where a nonunary, maximal string of the form is chosen because then is reached (for some j) and thus all maximal Y blocks have distinct left neighbors or occur at the beginning of a right-hand side. Hence no nonunary string of the form for some v occurs twice on right-hand sides. Since maximal strings from are chosen at most many times up to round i, it follows that the number of rounds where a nonunary, maximal string of the form for some v is selected is at most .
Furthermore, the maximal increase in a single round is at most , because the new nonunary nonterminal occurs in on at most many right-hand sides of rules for any and the total number of occurrences of all other (nonunary) nonterminals does not increase (Lemma 7, point (1)).
We conclude that for each unary nonterminal Y, at most
many rules are introduced such that the nonunary, maximal string satisfies or for some v and each of those rules increases the total size that nonunary nonterminals contribute by at most . In all other cases, we showed that the size that nonunary nonterminals contribute does not increase. □
Now we are able the prove Proposition 1.
Proof of Proposition 1.
Let be the final SLP obtained by Greedy, i.e., after f rounds the algorithm stops because has no maximal string. First, we want to bound the level of unary nonterminals occurring in . Assume there is a unary nonterminal X such that after some round of the algorithm. By Corollary 2, we have
Consider the unique leaf node in the tree which has level and label for some k. If in some round two children with labels and are attached to , i.e., the introduced rule in round j is for some , then we have by Lemma 7. To be more specific, if the length of the chosen maximal string is exactly and this maximal string occurs exactly twice without overlap in , then we have (and ). Please note that in this case, there does not exist a maximal string or of for all (since Y occurs only twice and does not occur on right-hand sides of ), i.e., the children of the node in are leaves for . Otherwise, if the maximal string has length or occurs at least three times without overlap, then we have since holds in this setting. This means that when a new branch occurs in the tree for some j, then the new children of the branching node are either leaves of the final tree or the corresponding nonterminals contribute strictly less to the size of the current SLP than the nonterminal which corresponds to the parent node did before the branch. We can iterate this argument for the children of the children of and so on, i.e., if we consider the subtree rooted at in , then from level to level the size that the nonterminals contribute decreases until only leaves occur at some level. Since , it follows that the subtree of rooted at has depth at most and thus the maximal level of any unary nonterminal in is bounded by
Consequently, the number of unary nonterminals (the number of leaves of ) is bounded by since is a binary tree of depth at most . Furthermore, each unary nonterminal X in satisfies . If there is a round such that we obtain by Corollary 2 and Lemma 7, point (1). Otherwise, let . Then , because there is at most one nonoverlapping occurrence of on right-hand sides of (otherwise there would exist a maximal string of ) and the number of rules where X occurs on the right-hand side is by Lemma 6. To be more precise, a single right-hand side of could have a maximal X-block of length 3 and all other right-hand sides must have at most one occurrence of X since two different right-hand sides where X-blocks of length 2 occur as well as one right-hand side where an X-block of length 4 occurs would contradict the fact that has no maximal string. It follows that the size which unary nonterminals contribute to is . By Lemma 12, we can bound the size that nonunary nonterminals contribute by since there are at most many unary nonterminals and each has level at most as argued above. It follows that , which proves the proposition. □
The following theorem follows directly from Proposition 1 and Lemma 1, where is shown for words w of length n.
Theorem 1.
For all n, we have
4. Lower Bound for Greedy
We proceed with the lower bound on the approximation ratio of Greedy. The best lower bound [13] (Theorem 11) that was known previously was
for all and infinitely many n. This bound was shown using unary words, which we will also use in our proof for the improved lower bound. A key concept for doing this is the sequence described in the following lemma by [19]:
Lemma 13
([19] (Example 2.2)). Let with and
We have .
In this work, we use the shifted sequence , i.e., we start with . It follows that , where . Additionally, we need the following lemma:
Lemma 14.
Let be an integer. Let with
We have for all .
Proof.
The unique minimum of is for . It follows that . □
Now we can prove the new lower bound for Greedy:
Theorem 2.
For all and infinitely many n, we have
Proof.
Let be a unary alphabet. We define . By Lemma 13, we have . Applying Lemma 1 yields
In the remaining proof we show that on input , Greedy produces an SLP of size , which directly implies . We start with the SLP which has the single rule . Consider now the first round of the algorithm, i.e., we need to find a maximal string of such that the grammar with rules
has minimal size. We have . By the definition of we have . Applying Lemma 14 yields . Please note that for this minimum is achieved, i.e., we can assume that Greedy selects the maximal string and is
Each maximal string of is either a unary word over X or a unary word over a, i.e., we can analyze the behavior of Greedy on both rules independently. The rule is obviously treated similarly as the initial SLP , so we continue with analyzing . However, again, the same arguments as above show that Greedy introduces a rule which yields as the new start rule. This process can be iterated using the same arguments for the leading unary strings of length for some .
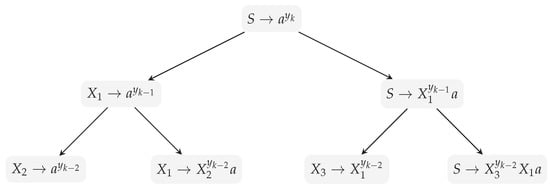
The reader might think of this process as a binary tree, where each node is labeled with a rule (the root is labeled with ) and the children of a node are the two rules obtained by Greedy when the rule has been processed. We assume that the left child represents the rule for the chosen maximal string and the right child represents the parent rule where all occurrences of the maximal string are replaced by the new nonterminal. In Figure 2 this binary tree is depicted for the steps we discussed above.
Figure 2.
Three rounds of Greedy on input .
Please note that when a rule is processed, the longest common factor of the two new rules has length 1 (the remainder). More generally, after each round there is no word of length at least two that occurs as a factor in two different rules, since a possibly shared remainder has length 1 and otherwise only new nonterminals are introduced. It follows that we can iterate this process independently for each rule until no maximal string occurs. This is the case when each rule starts with a unary string of length or, in terms of the interpretation as a binary tree, when a full binary tree of height k is produced. Each right branch occurring in this tree adds a new remainder to those remainders that already occur in the parent rule and a left branch introduces a new (smaller) instance of the start problem. We show by induction that at level of this full binary tree of height k, there is one rule of size and many rules of size for . At level 0, this is true since there is only a single rule of size . Assuming that our claim is true at level , we derive from each rule at level i two new rules at level : A right branch yields a rule that starts with a leading unary string of size and adds a new remainder to the parent rule. A left branch yields a rule that contains only a unary string of size . If we first consider the left branches, we derive that each of the many rules at level i adds a rule of size at level . For the right branches, the single rule of size at level i yields a rule of size at level . Furthermore, each of the many rules of size () yields a rule of size . When we put everything together, we get that at level there is a single rule of size and many rules of size for . That finishes the induction. It follows that the final SLP (which consists of the rules at level k) has a single rule of size and many rules of size for . This gives a total size of
□
5. RePair and LongestMatch
In this section, we analyze the global grammar-based compressors RePair and LongestMatch. In each round i, RePair selects a most frequent maximal string of and LongestMatch selects a longest maximal string of .
We will abbreviate the approximation ratio by for better readability. We will first show that RePair and LongestMatch produce SLPs of equal size for unary inputs and we show what the exact size of these SLPs depending on n is. We then use this information to obtain our result for and , respectively. Fix an integer and consider the binary representation
of n, where for . We denote by the number of 1’s in the binary representation of n, i.e.,
For example, we have and thus , and .
Proposition 2.
For , let be the SLP produced by RePair on input and be the SLP produced by LongestMatch on input . We have
Proof.
If or then has no maximal string and thus the final SLP of any global algorithm has a single rule . The reader can easily verify the claimed result for these cases.
We now assume that . Let . We prove the claim for RePair first and for LongestMatch after. On input , RePair runs for exactly m rounds and creates rules and for , i.e., the nonterminal produces the string . These rules have a total size of . After these steps, the start rule is
where the ’s are the coefficients occurring in the binary representation of n, see equation (2). In other words, the symbol a only occurs in the start rule if the least significant bit is , and the nonterminal () occurs in the start rule if and only if . Since RePair only replaces words with at least two occurrences, the most significant bit is represented by . A third occurs in the start rule if and only if . The size of the start rule is . It follows that the total size of the SLP produced by RePair on input is , which together with and (the most significant bit is always 1) yields the claimed size.
Now we prove the same result for LongestMatch. In the first round, the chosen maximal string is , which yields rules and , i.e., the symbol a occurs in the start rule if and only if n is odd and thus the least significant bit is . Assuming that , this procedure is now repeated for the rule (for there is no maximal string, and the algorithm stops after the first round). This yields , and (note that ). After steps, the iteration of this process results in the final SLP with rules , for and . The size of this SLP is , which directly implies the claimed result for LongestMatch. □
Using Proposition 2, we prove the matching bounds for and :
Theorem 3.
For all n, we have .
Proof.
As a consequence of Proposition 2, RePair and LongestMatch produce on input SLPs of size at most , since . By Lemma 1, we have . The equality finishes the proof. □
Theorem 4.
For infinitely many n, we have .
Proof.
Let . We have and thus . By Proposition 2, the size of the SLPs produced by RePair and LongestMatch is . By Lemma 1, we have
The equality finishes the proof. □
6. Discussion
Although we improved the upper bound on the approximation ration for Greedy, the lower bound remains quite weak. We might be able to improve it by finding a similar sequence such that Greedy produces larger remainders in each round. However, care must be taken since for larger remainders it is not true anymore that the rules can be analyzed independently because the rules could share factors of length greater than one. Concerning the upper bound, we conjecture that Greedy achieves logarithmic compression for all unary inputs and thus the approximation ratio is constant, but we have not been able to prove this so far. For arbitrary alphabets, a nonconstant lower bound for Greedy as well as an improvement of the upper bound of for any global algorithm seems to be natural starting points for future work.
Author Contributions
Conceptualization, D.H.; methodology, D.H.; validation, D.H. and C.P.R.; formal analysis, D.H.; writing—original draft preparation, D.H.; writing—review and editing, C.P.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the DFG research project LO 748/10-2.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef]
- Kieffer, J.C.; Yang, E.; Nelson, G.J.; Cosman, P.C. Universal lossless compression via multilevel pattern matching. IEEE Trans. Inf. Theory 2000, 46, 1227–1245. [Google Scholar] [CrossRef]
- Nevill-Manning, C.G.; Witten, I.H. Identifying Hierarchical Structure in Sequences: A linear-time algorithm. CoRR 1997, 7, 67–82. [Google Scholar] [CrossRef]
- Apostolico, A.; Lonardi, S. Some Theory and Practice of Greedy Off-Line Textual Substitution. In Proceedings of the Data Compression Conference, DCC 1998, IEEE Computer Society, Snowbird, UH, USA, 30 March–1 April 1998; pp. 119–128. [Google Scholar] [CrossRef]
- Apostolico, A.; Lonardi, S. Compression of Biological Sequences by Greedy Off-Line Textual Substitution. In Proceedings of the Data Compression Conference, DCC 2000, IEEE Computer Society, Snowbird, UH, USA, 28–30 March 2000; pp. 143–152. [Google Scholar] [CrossRef]
- Apostolico, A.; Lonardi, S. Off-line compression by greedy textual substitution. Proc. IEEE 2000, 88, 1733–1744. [Google Scholar] [CrossRef]
- Larsson, N.J.; Moffat, A. Offline Dictionary-Based Compression. In Proceedings of the Data Compression Conference, DCC 1999, IEEE Computer Society, Snowbird, UH, USA, 29–31 March 1999; pp. 296–305. [Google Scholar] [CrossRef]
- Kieffer, J.C.; Yang, E. Grammar-based codes: A new class of universal lossless source codes. IEEE Trans. Inf. Theory 2000, 46, 737–754. [Google Scholar] [CrossRef]
- Claude, F.; Navarro, G. Fast and Compact Web Graph Representations. ACM Trans. Web 2010, 4, 16:1–16:31. [Google Scholar] [CrossRef]
- Kida, T.; Matsumoto, T.; Shibata, Y.; Takeda, M.; Shinohara, A.; Arikawa, S. Collage system: a unifying framework for compressed pattern matching. Theor. Comput. Sci. 2003, 298, 253–272. [Google Scholar] [CrossRef]
- González, R.; Navarro, G. Compressed Text Indexes with Fast Locate. In Proceedings of the Combinatorial Pattern Matching, 18th Annual Symposium, CPM 2007, London, ON, Canada, 9–11 July 2007; In Lecture Notes in Computer Science. Ma, B., Zhang, K., Eds.; Springer: Berlin, Germany, 2007; Volume 4580, pp. 216–227. [Google Scholar] [CrossRef]
- Lohrey, M.; Maneth, S.; Mennicke, R. XML tree structure compression using RePair. Inf. Syst. 2013, 38, 1150–1167. [Google Scholar] [CrossRef]
- Charikar, M.; Lehman, E.; Liu, D.; Panigrahy, R.; Prabhakaran, M.; Sahai, A.; Shelat, A. The smallest grammar problem. IEEE Trans. Inf. Theory 2005, 51, 2554–2576. [Google Scholar] [CrossRef]
- Hucke, D.; Lohrey, M.; Reh, C.P. The Smallest Grammar Problem Revisited. In Proceedings of the String Processing and Information Retrieval—23rd International Symposium, SPIRE 2016, Beppu, Japan, 18–20 October 2016; In Lecture Notes in Computer Science. Inenaga, S., Sadakane, K., Sakai, T., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9954, pp. 35–49. [Google Scholar] [CrossRef]
- Hucke, D.; Jez, A.; Lohrey, M. Approximation ratio of RePair. arXiv 2017, arXiv:1703.06061. [Google Scholar]
- Knuth, D.E. The Art of Computer Programming, Volume II: Seminumerical Algorithms, 3rd ed.; Addison-Wesley: Boston, MA, USA, 1998. [Google Scholar]
- Noma, A.M.; Muhammed, A.; Mohamed, M.A.; Zulkarnain, Z.A. A Review on Heuristics for Addition Chain Problem: Towards Efficient Public Key Cryptosystems. J. Comput. Sci. 2017, 13, 275–289. [Google Scholar] [CrossRef]
- Hucke, D. Approximation Ratios of RePair, LongestMatch and Greedy on Unary Strings. In Proceedings of the String Processing and Information Retrieval—26th International Symposium, SPIRE 2019, Segovia, Spain, 7–9 October 2019; In Lecture Notes in Computer Science. Brisaboa, N.R., Puglisi, S.J., Eds.; Springer: Berlin, Germany, 2019; Volume 11811, pp. 3–15. [Google Scholar] [CrossRef]
- Aho, A.V.; Sloane, N.J.A. Some doubly exponential sequences. Fibonacci Quart. 1973, 11, 429–437. [Google Scholar]
- Berstel, J.; Brlek, S. On the Length of Word Chains. Inf. Process. Lett. 1987, 26, 23–28. [Google Scholar] [CrossRef]
- Diwan, A.A. A New Combinatorial Complexity Measure for Languages; Tata Institute: Bombay, India, 1986. [Google Scholar]
- Storer, J.A.; Szymanski, T.G. Data compression via textual substitution. J. ACM 1982, 29, 928–951. [Google Scholar] [CrossRef]
- Casel, K.; Fernau, H.; Gaspers, S.; Gras, B.; Schmid, M.L. On the Complexity of Grammar-Based Compression over Fixed Alphabets. In Proceedings of the 43rd International Colloquium on Automata, Languages, and Programming, ICALP 2016, Rome, Italy, 11–15 July 2016; Chatzigiannakis, I., Mitzenmacher, M., Rabani, Y., Sangiorgi, D., Eds.; Schloss Dagstuhl—Leibniz-Zentrum für Informatik. 2016; Volume 55, p. 122. [Google Scholar] [CrossRef]
- Ochoa, C.; Navarro, G. RePair and All Irreducible Grammars are Upper Bounded by High-Order Empirical Entropy. IEEE Trans. Inf. Theory 2019, 65, 3160–3164. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).