Abstract
To overcome the shortcomings of the lightning attachment procedure optimization (LAPO) algorithm, such as premature convergence and slow convergence speed, an enhanced lightning attachment procedure optimization (ELAPO) algorithm was proposed in this paper. In the downward leader movement, the idea of differential evolution was introduced to speed up population convergence; in the upward leader movement, by superimposing vectors pointing to the average individual, the individual updating mode was modified to change the direction of individual evolution, avoid falling into local optimum, and carry out a more fine local information search; in the performance enhancement stage, opposition-based learning (OBL) was used to replace the worst individuals, improve the convergence rate of population, and increase the global exploration capability. Finally, 16 typical benchmark functions in CEC2005 are used to carry out simulation experiments with LAPO algorithm, four improved algorithms, and ELAPO. Experimental results showed that ELAPO obtained the better convergence velocity and optimization accuracy.
1. Introduction
The optimization problems in engineering field can be expressed by mathematical models and solved by mathematical or numerical methods. With the development of science and technology, more and more engineering optimization problems are developing in the direction of large-scale, multi-peak, non-linear, and complex. It is difficult to solve them by traditional numerical methods. Meta-heuristic algorithm is an algorithm designed to solve approximate large-scale difficult optimization problems without deep adaptation to each problem. In recent decades, in order to overcome the shortcomings of slow computation speed and low reliability of traditional numerical methods in solving engineering problems, researchers have proposed a large number of meta-heuristic algorithms [1,2,3], which are widely used to solve complex problems in industries and services, from planning to production management and even engineering [4,5,6,7,8].
Meta-heuristic algorithms have some differences in the optimization mechanism, but they are similar in the optimization process. They are all “neighborhood search” structures. The algorithm starts from an initial solution (or a group of) and generates several neighborhood solutions through the neighborhood function under the control of the key parameters of the algorithm. It updates the current state according to the acceptance criteria (deterministic, probabilistic, or chaotic) and then adjusts the key parameters according to the key parameters modification criteria. Repeat the above search steps until the convergence criteria of the algorithm are satisfied, and finally the optimization results of the problem are obtained. Meta-heuristic optimization algorithms can be divided into evolutionary heuristic algorithm, group heuristic algorithm, and physical heuristic algorithm according to different inspiration sources.
Evolutionary heuristic algorithms are algorithms inspired by biological evolution in nature. Genetic algorithm [9] is the earliest and representative evolutionary heuristic algorithm, which inspired by Darwin’s evolutionary theory, it updates the individual through three processes: selection, crossover, and mutation. Differential evolutionary algorithm (DE) [10], evolution strategy (ES) [11], genetic programming (GP) [12], covariance-matrix adaptation evolution strategy [13], and biogeography-based optimizer (BBO) [14] are other methods under this category.
Group heuristic algorithms simulate the population behavior of insects, cattle, birds, and fish. These groups seek food in a cooperative way. Each member of the population constantly changes the direction of search by learning from his own experience and the experience of other members. The prominent feature of group heuristic algorithm is to use individuals in the population to search cooperatively, so as to find the optimal solution in the solution space. Particle swarm optimization (PSO) is the most representative algorithm. It is inspired by the foraging behavior of birds. For each individual, the position is updated according to its current speed, optimal position, and global optimal position [15]. The other methods that could be classified in this group are the artificial bee colony algorithm (ABC) [16], monkey search algorithm (MSA) [17], firefly algorithm (FA) [18], grey wolf optimization algorithm (GWO) [19], moth-flame optimization algorithm (MFO) [20], and so on.
The physical heuristic evolutionary algorithms are inspired by physical phenomena in nature and in these methods, the physical rules were used to update the solutions in each iteration. For example, in 2011, inspired by the spiral motion of galaxies in the universe, Shah-Hosseini H proposed a galaxy-based search algorithm (GbSA) [21]; in 2012, inspired by Newton’s second law, Rashedi E and others proposed gravitational search algorithms (GSA) [22]; in the same year, Kaveh A et al. were inspired by the refraction of light and proposed the ray optimization algorithms (RO) [23]; Hatamlou proposed a heuristic algorithm, which was named the black hole algorithms (BH) based on the black hole phenomenon in 2013 [24]; in 2016, inspired by the evaporation of water molecules on solid surfaces, Kaveh A et al. proposed an algorithm named the water evaporation optimization algorithm (WEO) [25].
Based on the No-Free-Lunch theorem, it cannot be claimed that optimization methods could solve all the problems. In order to solve a wider range of optimization problems, a new method has been introduced, in 2017, Iranian scholar A. Foroughi Nematollahi and others, inspired by the nature of lightning attachment process, proposed the lightning attachment procedure optimization (LAPO) [26]. It is compared with nine algorithms, such as the particle swarm optimization (PSO), differential evolution (DE), gray wolf optimizer (GWO), and cuckoo search algorithms (CSA), on four sets of 29 standard test functions. The results show that the LAPO algorithm has obvious advantages in convergence speed and accuracy, but similar to other swarm intelligence optimization algorithms, the LAPO algorithm also has some shortcomings, such as slow convergence speed in the middle and later stages of the evolutionary search, and easy to fall into local optimum when solving high-dimensional and multi-peak problems. Since the LAPO algorithm was put forward shortly, it has not been paid enough attention by scholars in various fields, and the theoretical system of the LAPO algorithm is still far from perfect. In order to further improve the optimization performance of the LAPO algorithm, an enhanced lightning attachment procedure optimization algorithm (ELAPO) is proposed in this paper. The downward leader movement combines the renewal mechanism of differential evolution algorithm with the original renewal mechanism, and introduces the optimal individuals in the population to participate in the evolution. Speeds up the convergence rate of the population through the differential evolution mechanism on the basis of distinguishing the better and worse individuals in the original algorithm. The upward leader movement changes the direction and step size of individual learning, and makes the individual jump out of the local optimum. In the process of performance improvement, the dynamic opposition-based learning (OBL) [27] method is used to replace the original update operation. Experiments show that this method can effectively improve the convergence speed of the algorithm. At the same time, to test the ELAPO performance, we tested 16 benchmark functions, and compared the experimental results with LAPO and four improved optimization algorithms results.
The rest of this paper is organized as follows. Section 2 briefly introduces the principle and process of the standard LAPO algorithm. Section 3 describes the ELAPO algorithm combined with differential evolution and opposition-based learning in detail. The experiments and results analysis are reported in Section 4. Section 5 concludes this paper.
2. The Lightning Attachment Procedure Optimization Algorithm
In nature, there are a large number of positive charges on the upper surface of the thunderstorm clouds, and a large number of negative charges and a small number of positive charges on the lower surface. As the charge increases, the edge of the cloud breaks down, creating a trapezoidal downward pilot that gradually extends to the ground. Affected by this, the space electric field near ground objects such as lightning rods, conductors, poles, and towers will continue to increase. To a certain extent, it will lead to an upward return stroke through the ionization channel opened by the downward trapezoidal pilot, that is, from the ground to the bottom of the cloud, forming a flash-over. When three or four flash-overs occur, there will be a gap breakdown, accompanied by pulse discharge, forming thunder and lightning. In this process, many pulsed discharges were carried out. Since each pulse discharge consumes a large amount of charge accumulated in thunderstorm clouds, the discharge process will become weaker and weaker until the charge reserve in thunderstorm clouds is exhausted, the pulse discharge can stop. The point at which the breakdown discharge may occur is defined as the test point, and the point at which charge depletion occurs is called the strike point.
To simulate the process of lightning formation, the LAPO abstracts the test points between the cloud and ground as individuals, the electric field corresponding to the test points as fitness, and the downward trapezoidal pilot, upward return stroke and pulse discharge processes of lightning as three evolutionary operations, namely downward leader movement, upward leader movement, and branch fading. Branch decline runs through the other two evolutionary processes and gradually guides individual evolution. The key operation details of the LAPO algorithm are as follows:
2.1. Initialize the Population
Population is the set of all decision variables in the definition domain of optimization problems. In the LAPO algorithm, individuals in the population represent test points where breakdown may occur, and each individual in the population can serve as a starting point for downward or upward leaders. Suppose that the upper limit of the definition domain is ub and the lower limit is lb. Individuals are generated according to formula (1) to form the initial population.
In the formula represents the j-dimensional (j = 1, 2, 3, ……, D) particle of the i-th (i = 1, 2, 3, ……, NP) individual of the population in the t-th generation. In the initialization stage, t = 0, rand is a random number between [0,1].
2.2. Downward Leader Movement
During lightning downward leader movement, all test points are considered as potential next jump points for a particular test point. Since lightning has random behavior, individual j () is randomly selected in the population for test point i. If the electric field of j is higher than the average value, that is, the fitness of j is better than Fave, which is the fitness of the average individual , lightning will jump to that point, otherwise lightning will move in another direction, as shown in formula (2):
In the formula, rand is a random number between [0,1], and j is a randomly selected individual, which is not equal to i.
2.3. Upward Leader Movement
In the process of upward leader movement, all particles move upward along the charge channel opened by the downward leader and distribute exponentially in the channel. The updating mode of each particle’s position is shown in formula (3).
Among them, Xmin and Xmax are represented as the best and the worst individual of the current population respectively, and the exponential factor S is shown in formula (4).
t and tmax represent the number of iterations and the maximum number of iterations respectively.
2.4. Branch Fading
In the whole process of lightning formation, if the electric field of the new test point is higher than that of the previous point, the lightning branch will be generated and the pulse discharge will continue. On the contrary, the branch will disappear and the lightning formation will stop.
The LAPO algorithm simulates the above-mentioned fading process and chooses individuals according to formula (5).
The above two parts of the evolutionary operations, the downward leader movement and the upward leader movement, are selected and updated by branch fading, and for the individuals beyond the boundary generated in the downward and upward leader searches, the boundary absorption method is used, that is, the individuals beyond the boundary are placed on the boundary.
2.5. Enhancement of the Performance
In order to improve the performance of the algorithm, the average of the whole population was calculated and the fitness of the average solution was obtained in each generation. If the fitness of the worst individual was worse than the fitness of the average individual, the worst individual was replaced by the average solution.
In summary, LAPO performs the enhancement of the performance, the downward leader movement, and the upward leader movement in turn in each iteration, and each evolutionary process is accompanied by branch fading and boundary value processing, as shown in Figure 1.
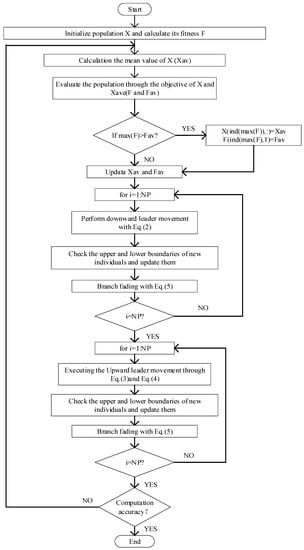
Figure 1.
Flow chart of the lightning attachment procedure optimization (LAPO) algorithm.
3. The Enhanced Lightning Attachment Procedure Optimization Algorithm
To further improve the convergence accuracy and speed of the LAPO algorithm, a lightning attachment procedure optimization algorithm based on combined differential learning and opposition-based learning was proposed.
3.1. Improved Downward Leader Movement
In the downward leader movement of the LAPO algorithm, the individual updates according to formula (2). After an in-depth analysis, it was found that the updating method had the following defects:
Firstly, since individual i is not directly related to the evolutionary information of individual j and the average individual, it seems unreasonable to determine the updating mode of individual i based solely on the fitness relationship between individual j and the average individual.
Secondly, because of the multiplication of individual j and rand, the evolution of each individual is more dependent on the average individual. With the evolution, each individual will gather near the average individual, that is to say, the overall population diversity maintenance ability of the algorithm is not good and easy to fall into local optimum.
Thirdly, only one random individual is selected to learn from the average individual and the current individual, which does not guarantee the “best selection”. If the selected individual is the worst individual or the poorer individual, it will affect the evolution speed of the downward leader.
In view of this, this paper improves formula (2), as shown in formula (6).
In the formula, is a randomly selected particle different from individual i, Xbest represents the best individual in the current population, Xave and Fave are represented as the average individual and the fitness value of the average individual respectively.
As can be seen from formula (6), it has the following advantages:
Firstly, we regard individuals whose fitness value was better than the average fitness value as better individuals. For these individuals, they used themselves as base vectors to search around themselves. For the other solutions whose evolutionary information was not good enough, they used the central individual as base vectors to update and search around the average individuals. Obviously, compared with the LAPO algorithm, which only searches near the individual itself, the improved update method converged faster.
Secondly, compared with LAPO’s over-learning mode to the average individual, the proposed method integrated the individual j, the average individual, and the optimal individual, and introduced more combinations to enable the particles to obtain more local information, which was more conducive to maintaining the diversity of the population.
Thirdly, compared with the original update method, formula (6) refers to the update strategy of differential evolution algorithm, by adding two differential vectors to control the directive of evolution, avoiding over-learning to a particle and falling into local optimum, and removing the step factor rand before individual j in the original LAPO algorithm, thus avoiding the blindness of random step size, and individual j directly participates in the evolution process, which further accelerated the convergence speed of the algorithm.
Figure 2 takes the better individuals as an example to further describe the downward leader’s update strategy.
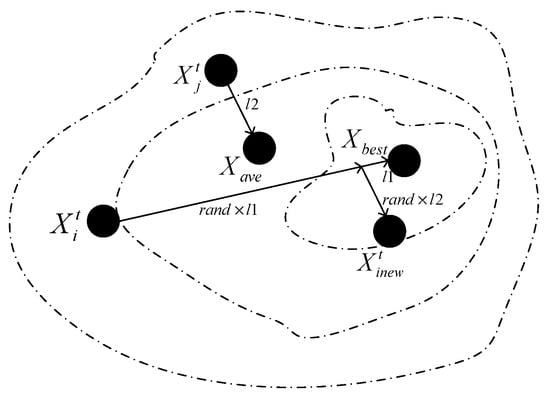
Figure 2.
Diagram of the better individual renewal.
Take individual i as an example, if it is a better one, individual i adds the difference vector , which is from individual to the best individual, close to the search area where the optimal individual is located, and then adds the difference vector which is from individual j to the average individual, reach to . Since the j individual is randomly selected and the direction of the second difference vector is randomly generated, the current individuals can get more evolutionary directions and traverse the search interval where the excellent individuals are located more quickly.
3.2. Improvement of Upward Leader Movement
It can be seen from formula (4) that in the upward leader movement of LAPO, individuals are updated by learning from the best and worst individuals. As we all know, the worst individual carries relatively less information for evolution, there is a low probability of producing excellent individuals through them, which results in ineffective search and reduces the convergence speed of the algorithm.
Since the average individual contains evolutionary information of all individuals to some extent. Using average individuals instead of the worst individual to participate in evolution will inevitably increase the probability of obtaining better individuals and maintain the diversity of the population while improving the convergence rate. To this end, the updated formula of the upward leader, formula (4), is adjusted as follows:
Combining formula (5), comparison formula (4), and formula (7), we can find that: In the early stage of evolution, S value is relatively large, and the proportion of learning results from other individuals is relatively large, while the average individual is much better than the worst one, and carries more information conducive to evolution, so learning from is obviously faster than learning from , and as evolution proceeds, each solution tends to be optimal, the range of is obviously smaller than , with the value of S decreases. That is to say, formula (7) has a relatively small search range, which is more conducive to the fine search near itself and improves the convergence accuracy of the algorithm. Moreover, is a vector pointing to the average individual, which can effectively jump out of the local optimum by superposition it.
3.3. The Improved Enhancement Performance
The original algorithm updates the worst individual in each generation by comparing the fitness values of the newly generated average individual with the worst individual in the population and retaining the better one of them. According to the analysis of the experimental results and formulas, this operation can increase the convergence speed of the algorithm to a certain extent, but there is still room to improve its convergence speed.
Literature [27] points out that the opposition-based learning (OBL) of a particle is usually better than that of the original particle, so the probability of the average particle after the OBL is better than that of the original average individual. It is possible that the average individual after the OBL will take part in the evolution instead of the worst individual, which will lead to a faster convergence rate. In order to further accelerate the convergence speed of the algorithm, an improved opposition-based learning strategy as shown in formula (8) was adopted.
where represents the component of the first solution on the j-dimension, is its corresponding reverse solution, , are the minimum and maximum values of the current search interval on the j-dimension, . The learning strategies obtained by different values of k are also different. Three strategies, k = 0.5, 1, and rand, are given in [27]. To verify the effectiveness of the improved strategy, the dynamic opposition-based learning strategy LAPO algorithm combined with k = 0.5, 1, rand, and the original LAPO algorithm were compared when the number of iterations was set to 500 generations. Experiments were carried out on typical single-peak function Sphere and multi-peak function Ackley, respectively. The results are shown in Figure 3, which show that for LAPO, when k = 0.5 and k = rand, the dynamic opposition-based learning strategy converged faster than the original algorithm, where k = rand had a relatively faster convergence rate. In order to improve the convergence speed of the algorithm, the formula (9) with k = rand was used to update the worst particle in this paper.
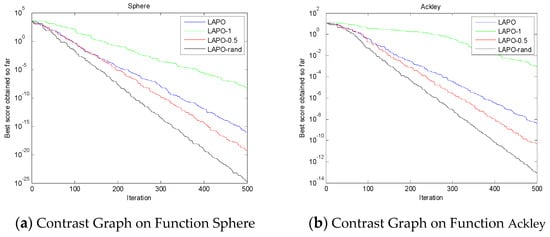
Figure 3.
The comparison of LAPO and LAPO combined with opposition-based learning (OBL).
3.4. The Pseudo Code of the ELAPO Algorithm
| Initialize the first population of test points randomly in the specific range |
| Calculate the fitness of test points |
| while the end criterion is not achieved |
| Set the test point with the worst fitness as Xw |
| for j = 1:D |
| end |
| if the fitness of is better than the fitness of Xw |
| end |
| Obtain Xave which is the mean value of all the test points |
| Calculate the fitness of Xave as Fave |
| for i = 1:NP (each test point) |
| Select randomly which is not equal to |
| Set the test point with the best fitness as |
| for j = 1:D (number of variables) |
| Update the variables of based on Equation (6), as |
| Check the boundary. If the particle exceeds the boundary value, it is generated randomly within the boundary. |
| end |
| Calculate the fitness of |
| if the fitness of is better than |
| end |
| end |
| for i = 1:NP (each test point) |
| for j = 1:D (number of variables) |
| Update the variables of based on Equation (8) as |
| Check the boundary. If the particle exceeds the boundary value, it is generated randomly within the boundary. |
| end |
| Calculation the fitness of |
| if the fitness of is better than |
| end |
| end |
| XBEST = the test point with the best fitness |
| FBEST = the best fitness |
| end |
| return XBEST, FBEST |
4. Analysis of the Simulation Results
In order to test the performance of the proposed ELAPO, a series of experiments were carried out in this section. All experiments were implemented on CPU: Intel (R) Core (TM) i5-4200H, 4G memory, and 2.8GHz main frequency computer. The program was implemented in the language of Matlab R2014a.
The experiment selected 16 benchmark functions in CEC2005 [28]. Among them, f1–f8 were unimode functions, f9–f16 were multimodal functions, the dimensions of the test functions from f1 to f14 were all set in 30 dimensions, and the dimensions of the test functions f15 and f16 were set in two dimensions, the specific functions are shown in Table 1.

Table 1.
Test Functions.
In order to further validate the advantages of ELAPO, the ELAPO algorithm was compared with the basic LAPO algorithm and the other four algorithms that have better optimization results in recent years, including: All-dimension neighborhood based particle swarm optimization with randomly selected neighbors (ADN-RSN-PSO) [29], enhanced artificial bee colony algorithms with adaptive differential operators (ABCADE) [30], an optimization algorithm for teaching and learning based on hybrid learning strategies (DSTLBO) [31], and a self-adaptive differential evolution algorithm with improved mutation strategy (IMSaDE) [32].
During the experiment, the parameters of the contrast algorithm were set as those in the literature. Except the number of population and the maximum number of function evaluations LAPO and DSTLBO did not involve any parameters. For this reason, Table 2 gives the parameter settings of other algorithms, all from the original literature.
Table 2.
Arithmetic parameter settings.
In order to ensure fairness, the population number of each algorithm was 30, and the maximum number of function evaluations was 90,000. In order to avoid the harmful effect of the randomness of a single operation, each algorithm was run 30 times independently for each test function and recorded the maximum, average, minimum, variance of 30 experimental results, and the success rate of reaching the appointed precision and recorded Friedman ranking based on the average. The appointed precision was 10−10 for the benchmark functions whose optimal was 0, for the benchmark functions f14, f15, and f16 whose optimal was not equal to 0, the appointed precision was −78, −1.8, and −0.8 respectively. The statistical results are shown in Table 3.
Table 3.
Convergence accuracy.
At the same time, in order to compare the differences of each method, two non-parametric tests, Friedman and Holm [33,34], were used to check the data in Table 3. Firstly, Friedman rank mean of each algorithm was calculated and recorded from large to small. Friedman statistics were calculated to test whether there were significant differences between the six algorithms. If there were differences, the Holm test was used to further analyze whether there were significant differences between ELAPO algorithm and the other five algorithms. The test results are shown in Table 4.
Table 4.
The results of the non-parametric test.
It can be seen from Table 4 that ADN-RSN-PSO algorithm could reach global optimal only on f15 and f16; ABCADE algorithm could reach global optimal only on f14, f15, and f16, and had a certain probability to convergence to the optimal on f4, f11, and f13; DSTLBO could reach convergence to the optimal on f1, f9, f10, f13, f15, and f16, and had a certain probability to convergence to the optimal on f2, f3, f6, and f12; IMSaDE could reach convergence to the optimal on f15 and f16, but still had a certain probability to converge to the optimal on f11 and f12; the LAPO could reach convergence to the optimal on f13, f15, and f16, there was also a certain probability for f9 to converge to the optimal; for the ELAPO could reach convergence to the optimal on all the functions except f5, f6, f7, f8, and f12, but had a best convergence accuracy on f5, while for f6, f7, f8, and f12, the convergence accuracy was second best.
In order to compare the differences of each method, a Friedman test was taken to check the data in Table 3. First, we assumed that there was no significant difference between the six algorithms. It can be calculated in Table 4 by formula (9).
in which, k refers to the number of algorithms and n refers to the number of data sets of each algorithm and the result is , greater than the critical value 11.07 at the degree of freedom df = 6 − 1 = 5 and a = 0.05 in the chi-square distribution, rejecting the zero hypotheses, that is, the six algorithms in this experiment have significant differences at the 5% significant level.
To further compare the performance of the six algorithms, assuming that the convergence performance of ELAPO is better than the other five methods. Comparing and , if at the 5% significant level, then reject the original hypothesis, that is, the ELAPO have significant differences to the algorithm i. By observing the data in the table, we found that only , Holm Test rejects the other four hypotheses and accepts the fifth hypothesis, which means that the performance of the ELAPO algorithm in this paper was equivalent to that of DSTLBO in the above test functions, while the other four p values were less than , which means that the performance of ELAPO was obviously better than ADN-RSN-PSO, ABCADE, IMSaDE, and LAPO. Although the accuracy of the ELAPO algorithm was not significantly higher than that of DSTLBO, it had a smaller average rank. Comprehensive analysis of the experimental results of ELAPO in single-peak function and multi-peak function shows that ELAPO was relatively balanced in the search calculation of two kinds of functions, and for all functions, the improved ELAPO algorithm was superior to the LAPO algorithm in solving accuracy.
From the perspective of robustness, the ELAPO algorithm proposed in this paper had a low success rate only on f9 and f14, while the solution of other functions was relatively stable. DSTLBO had a low success rate on f4, f11, and f14 functions and belongs to sub-stability, while ADN-RSN-PSO, ABCADE, IMSaDE, and LAPO had a relatively low success rate in achieving the specified accuracy of the solution function. Through comparative analysis, the proposed ELAPO algorithm had better robustness.
In addition, in order to intuitively see the convergence of each algorithm, experiments were carried out with the number of evaluations of 30,000 times, and the following experimental comparison figures were obtained, in which the abscissa represents the number of evaluation times of the function and the ordinate represents the logarithmic value of the fitness values obtained.
It can be seen from Figure 4 that the convergence speed of ELAPO proposed in this paper was relatively fast when solving single-peak functions f2, f3, f4, and f5, while the convergence speed of f8 and DSTLBO was similar, f1, f6, and f7 were worse than DSTLBO, but the convergence speed of ELAPO was faster than ADN-RSN-PSO, ABCADE, IMSaDE, and LAPO when solving the above functions. When solving multimodal functions f9–f13, f15, and f16, the ELAPO algorithm in this paper had a faster convergence speed, while in function f14, the convergence speed in the early stage of evolution had no obvious advantage, but in the middle stage of evolution, there was a clear tendency to jump out of the local optimum.
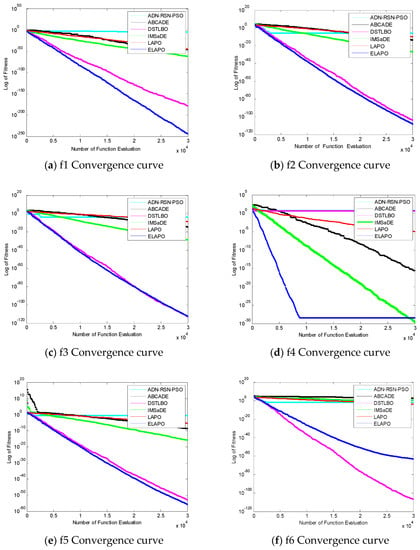
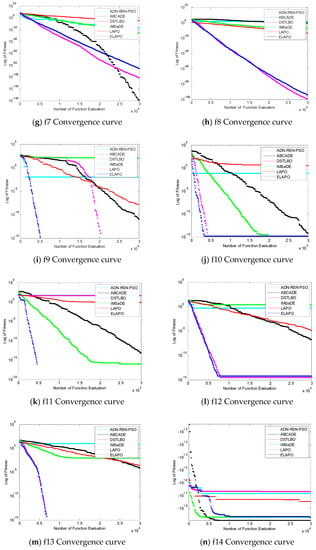
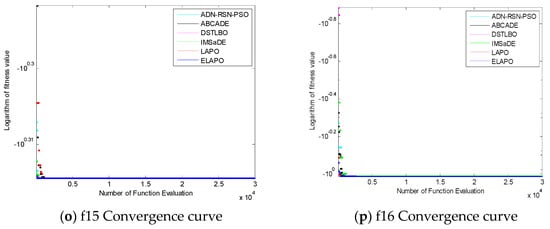
Figure 4.
The figure of function convergence.
5. Conclusions and Future Research
In this paper, an improved physical heuristic algorithm ELAPO was proposed. In the downward leader movement by updating the better and the worse particles with a different way and replacing the worst particles in the population with opposition-based learning in the part of enhancement performance, the convergence speed of the algorithm was accelerated. The upward leader jumps out of the local optimum by changing the direction and step size of particle learning. In order to verify the performance of ELAPO, eight single-mode functions and eight multi-mode functions were tested, and the experimental results were compared with those of the better algorithms in recent years. The comparison and analysis of the results showed that the ELAPO algorithm proposed in this paper was superior in solving accuracy and speed, and its performance was stable. The ELAPO algorithm proposed in this paper had certain improvement significance compared with the original algorithm.
In this paper, we only considered the global optimization, and the algorithm could be extended to solve other problems such as constrained optimization problems. In future work, we plan to apply ELAPO to solve real-world domain-specific problems, such as computational offloading problems in mobile edge computing [35].
Author Contributions
Writing—original draft, X.J.; Writing—review & editing, Y.W. and X.J.
Funding
The authors disclosed receipt of the following financial support for the research, authorship of this article: This work was supported in part by the National Natural Science Foundation of China under grants NO.61501107and NO.61603073, and the Project of Scientific and Technological Innovation Development of Jilin NO.201750227 and NO.201750219.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Boussaid, I.; Lepagnot, J.; Siarry, P. A survey on optimization metaheuristics. Inf. Sci. 2013, 237, 82–117. [Google Scholar] [CrossRef]
- Gogna, A.; Tayal, A. Metaheuristics: Review and application. J. Exp. Theor. Artif. Intell. 2013, 25, 503–526. [Google Scholar] [CrossRef]
- Mahdavi, S.; Shiri, M.E.; Rahnamayan, S. Metaheuristics in large-scale global continues optimization: A survey. Inf. Sci. 2015, 295, 407–428. [Google Scholar] [CrossRef]
- Liu, Y.K.; Li, M.K.; Xie, C.L.; Peng, M.J.; Xie, F. Path-planning research in radioactive environment based on particle swarm algorithm. Prog. Nucl. Energy 2014, 74, 184–192. [Google Scholar] [CrossRef]
- Wari, E.; Zhu, W. A survey on metaheuristics for optimization in food manufacturing industry. Appl. Soft Comput. 2016, 46, 328–343. [Google Scholar] [CrossRef]
- Pyrz, M.; Krzywoblocki, M. Crashworthiness Optimization of Thin-Walled Tubes Using Macro Element Method and Evolutionary Algorithm. Thin Walled Struct. 2017, 112, 12–19. [Google Scholar] [CrossRef]
- Kadin, Y.; Gamba, M.; Faid, M. Identification of the Hydrogen Diffusion Parameters in Bearing Steel by Evolutionary Algorithm. J. Alloys Compd. 2017, 705, 475–485. [Google Scholar] [CrossRef]
- Shieh, M.D.; Li, Y.; Yang, C.C. Comparison of multi-objective evolutionary algorithms in hybrid Kansei engineering system for product form design. Adv. Eng. Inf. 2018, 36, 31–42. [Google Scholar] [CrossRef]
- Yang, J.H.; Honavar, V. Feature Subset Selection Using a Genetic Algorithm. In Feature Extraction, Construction and Selection; Springer: Boston, MA, USA, 1998; pp. 117–136. [Google Scholar]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Knowles, J.; Corne, D. The Pareto Archived Evolution Strategy: A New Baseline Algorithm for Pareto Multiobjective Optimisation. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99, Washington, DC, USA, 6–9 July 1999. [Google Scholar]
- Banzhaf, W.; Koza, J.R.; Ryan, C.; Spector, L.; Jacob, C. Genetic programming. IEEE Intell. Syst. 2000, 15, 74–84. [Google Scholar] [CrossRef]
- Hansen, N.; Ostermeier, A. Completely Derandomized Self-Adaptation in Evolution Strategies. Evol. Comput. 2001, 9, 159–195. [Google Scholar] [CrossRef]
- Simon, D. Biogeography-based optimization. IEEE Trans. Evol. Comput. 2008, 12, 702–713. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Basturk, B.; Karaboga, D. An artificial bee colony (ABC) algorithm for numeric function optimization. In Proceedings of the IEEE Swarm Intelligence Symposium, Indianapolis, IN, USA, 12–14 May 2006; pp. 687–697. [Google Scholar]
- Mucherino, A.; Seref, O. Monkey search: A novel metaheuristic search for global optimization. AIP Conf. Proc. 2007, 953, 162–173. [Google Scholar]
- Yang, X.S. Firefly Algorithms for Multimodal Optimization. In Proceedings of the 5th International Symposium on Stochastic Algorithms, Foundations and Applications, Sapporo, Japan, 26–28 October 2009; pp. 169–178. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Shah-Hosseini, H. Principal components analysis by the galaxy-based search algorithm: A novel metaheuristic for continuous optimisation. Int. J. Comput. Sci. Eng. 2011, 6, 132–140. [Google Scholar]
- Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S. GSA: A Gravitational Search Algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Kaveh, A.; Khayatazad, M. A new meta-heuristic method: Ray Optimization. Comput. Struct. 2012, 112, 283–294. [Google Scholar] [CrossRef]
- Hatamlou, A. Black hole: A new heuristic optimization approach for data clustering. Inf. Sci. 2013, 222, 175–184. [Google Scholar] [CrossRef]
- Kaveh, A.; Bakhshpoori, T. Water Evaporation Optimization: A Novel Physically Inspired Optimization Algorithm. Comput. Struct. 2016, 167, 69–85. [Google Scholar] [CrossRef]
- Nematollahi, A.F.; Rahiminejad, A.; Vahidi, B. A Novel Physical Based Meta-Heuristic Optimization Method Known as Lightning Attachment Procedure Optimization. Appl. Soft Comput. 2017, 59, 596–621. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Z.; Liu, Y.; Wang, J.; Jiang, D.; Chen, L. Space transformation search: A new evolutionary technique. In Proceedings of the First ACM/SIGEVO Summit on Genetic and Evolutionary Computation, Shanghai, China, 12–14 June 2009; pp. 537–544. [Google Scholar]
- Suganthan, P.N.; Hansen, N.; Liang, J.J.; Deb, K.; Chen, Y.P.; Auger, A.; Tiwari, S. Problem Definitions and Evaluation Criteria for the CEC 2005 Special Session on Real-Parameter Optimization. Available online: https://www.researchgate.net/profile/Ponnuthurai_Suganthan/publication/235710019_Problem_Definitions_and_Evaluation_Criteria_for_the_CEC_2005_Special_Session_on_Real-Parameter_Optimization/links/0c960525d3990de15c000000/Problem-Definitions-and-Evaluation-Criteria-for-the-CEC-2005-Special-Session-on-Real-Parameter-Optimization.pdf (accessed on 29 June 2019).
- Sun, W.; Lin, A.; Yu, H.; Liang, Q.; Wu, G. All-dimension neighborhood based particle swarm optimization with randomly selected neighbors. Inf. Sci. 2017, 405, 141–156. [Google Scholar] [CrossRef]
- Liang, Z.; Hu, K.; Zhu, Q.; Zhu, Z. An Enhanced Artificial Bee Colony Algorithm with Adaptive Differential Operators. Appl. Soft Comput. 2017, 58, 480–494. [Google Scholar] [CrossRef]
- Bi, X.-J.; Wang, J.-H. Teaching-learning-based optimization algorithm with hybrid learning strategy. J. Zhejiang Univ. Eng. Sci. 2017, 51, 1024–1031. [Google Scholar]
- Wang, S.; Li, Y.; Yang, H.; Liu, H. Self-adaptive differential evolution algorithm with improved mutation strategy. Soft Comput. 2018, 22, 3433–3447. [Google Scholar] [CrossRef]
- Demišar, J.; Schuurmans, D. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Guo, F.; Zhang, H.; Ji, H.; Li, X.; Leung, V.C. An Efficient Computation Offloading Management Scheme in the Densely Deployed Small Cell Networks with Mobile Edge Computing. IEEE/ACM Trans. Netw. 2018, 26, 2651–2664. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).