Abstract
Depth-first search (DFS) is a well-known graph traversal algorithm and can be performed in time for a graph with n vertices and m edges. We consider the dynamic DFS problem, that is, to maintain a DFS tree of an undirected graph G under the condition that edges and vertices are gradually inserted into or deleted from G. We present an algorithm for this problem, which takes worst-case time per update and requires only bits of space. This algorithm reduces the space usage of dynamic DFS algorithm to only 1.5 times as much space as that of the adjacency list of the graph. We also show applications of our dynamic DFS algorithm to dynamic connectivity, biconnectivity, and 2-edge-connectivity problems under vertex insertions and deletions.
1. Introduction
Depth-first search (DFS) is a fundamental algorithm for searching graphs. As a result of performing DFS, a rooted tree (or forest, for disconnected graphs) which spans all vertices is constructed. This rooted tree (forest) is called DFS tree (DFS forest), which is used as a tool for many graph algorithms such as finding strongly connected components of digraphs and detecting articulation vertices or bridges of undirected graphs. Generally, for a graph with n vertices and m edges, DFS can be performed in time, and a DFS tree (forest) can be constructed in the same time.
The graph structure that appears in the real world often changes gradually with time. Therefore, we consider DFS on dynamic graphs, not on static graphs. This problem is called dynamic DFS problem, and the goal for this problem is to design a data structure which can rebuild, for any on-line sequence of updates on G, a DFS tree (forest) for G after each update. Here single update on the graph is one of the following four operations: inserting a new edge, deleting an existing edge, inserting a new vertex and its incident edges (simultaneously), and deleting an existing vertex and its incident edges.
The problem of computing a DFS tree can be classified into two settings. For an undirected graph G, a DFS tree is generally not unique even if a root vertex is fixed. However, if the order of adjacent vertices to visit is fixed for every vertex, the DFS tree will be unique. The ordered DFS tree problem is to compute the order in which the vertices are visited in this setting. Contrary to this, the general DFS tree problem is, given an undirected graph G, to compute any one of DFS trees. In this paper, we focus on the general DFS tree problem. Meanwhile, dynamic graph algorithms can be classified into three types. If an algorithm supports only insertion of edges, it is said to be incremental. If an algorithm supports only deletion of edges, it is called decremental. If an algorithm supports both insertion and deletion updates, it is called fully dynamic. We consider the incremental and fully dynamic settings. Generally, dynamic graph algorithms focus on only edge insertions and deletions. However, for the fully dynamic setting we also consider the vertex insertions and deletions.
1.1. Existing Results
All the works described in this section focus on the general DFS tree problem, not the ordered DFS tree problem. Until recently, there were few papers for the dynamic DFS problem, despite of the simplicity of DFS in static setting. For directed acyclic graphs, Franciosa et al. [1] proposed an incremental algorithm and later Baswana and Choudhary [2] proposed a randomized decremental algorithm. For undirected graphs, Baswana and Khan [3] proposed an incremental algorithm. However, these algorithms support only either of insertion or deletion, and do not support vertex updates. Moreover, none of these algorithms achieve the worst-case time complexity of per single update though the amortized update time is better than the static DFS algorithm. This means in the worst case the computational time becomes the same as the static algorithm.
In 2016, Baswana et al. [4] proposed a dynamic DFS algorithm for undirected graphs which overcomes these two problems. Their algorithm supports all four types of graph updates, edge/vertex insertions/deletions, and achieves worst case time per update. They also proposed an incremental (supporting only edge insertions) dynamic DFS algorithm with worst case time per update. Later Chen et al. [5] improved the fully dynamic worst-case update time by a factor. Baswana et al. also showed in the full version [6] of their paper the conditional lower bounds for fully dynamic DFS problems: time per update, under strong exponential time hypothesis, for any fully dynamic DFS under vertex updates, and time per update, under the condition the DFS tree is explicitly stored, for any fully dynamic DFS under edge updates. Now the recently proposed incremental dynamic DFS algorithm of Chen et al. [7] has worst-case update time and thus meets the lower bound of the incremental setting.
Recently, Baswana et al. [8] conducted an experimental study for the incremental (not fully dynamic) DFS problem. Besides this, Khan [9] proposed a parallel algorithm for the fully dynamic DFS (including vertex updates), which can compute the DFS tree after each update in time using m processors.
Please note that after the preliminary version [10] of this paper was published, Baswana et al. [11] proposed an improved algorithm for the fully dynamic DFS in undirected graphs. This algorithm has worst-case update time and requires bits of space.
1.2. Our Results
We develop algorithms for incremental (i.e., under edge insertions) and fully dynamic (i.e., under edge/vertex insertions/deletions) DFS problems in undirected graphs, based on the algorithms Baswana et al. [4] proposed (an overview of their algorithms is in Section 3). The dynamic DFS algorithms of both Baswana et al. [4] and Chen et al. [5,7] require bits of space, which is times larger than the space usage of the adjacency list of the graph G and thus do not seem to be optimal. Thus, we seek to compress the required space of the dynamic DFS.
Besides this, we focus on relatively dense graphs, i.e., graphs with , because in sparse graphs, i.e., , DFS can be performed in time, which meets the conditional lower bound Baswana et al. [6] suggests. Here please note that they showed an example of a graph in which any dynamic DFS algorithm under edge update takes time. Since this graph has only edges, the (conditional) lower bound holds even for the sparse graphs.
We develop two algorithms for the dynamic DFS algorithm, namely algorithms A and B. Algorithm A is a simple modification of the work of Baswana et al. [4], while algorithm B is designed to reduce the space usage more and more. The comparison of the required space and worst-case update time of these algorithms with those of Baswana et al. [4] and Chen et al. [5,7] is given in Table 1. Both of our algorithms compress the required space by a factor of and improve the worst-case update time by a factor under the fully dynamic case (i.e., supporting all four types of updates). Even under the incremental case (i.e., supporting only edge insertions), the update time is improved from [4], and close to [7]. Our main ingredient is the space usage of algorithm B: it is asymptotically only 1.5 times as much space as that of the adjacency list of G. Here note that since G is undirected, the adjacency list of G should have two elements for each edge in G and thus requires bits of space. We also show that if amortized update time is permitted instead of worst-case update time, the required space of algorithm B can be reduced to only bits.

Table 1.
Comparison of required space and worst-case update time for dynamic DFS algorithms.
Here note that the new dynamic DFS algorithm of Baswana et al. [11] does not subsume algorithm B in terms of the space usage. However, it subsumes algorithm A because the space usage is the same, but the update time is faster. Even so, we describe the details of algorithm A in this paper because, as described below, our algorithm A (as well as algorithm B) can be applied to dynamic biconnectivity and 2-edge-connectivity problems including vertex insertions and deletions.
Our work can be summarized as follows. First, we improve the way to solve a query that is frequently used in the algorithm of Baswana et al. [4] (Section 4), by using the idea of Chen et al. [5] partially. By this improvement, we propose a linear space (i.e., requiring bits of space) algorithm, algorithm A, for the incremental and fully dynamic DFS problems (Theorem 1 in Section 5). Second, we further compress the data structures used in [4,5] using wavelet tree [12] (Section 6). In this contribution, we develop an efficient method for solving a kind of query on integer sequences, named range leftmost (rightmost) value query, and give a space-efficient method for solving a variant of orthogonal range search problems, which has been studied in the computational geometry community. These queries are of independent interest. Third, we consider a space-efficient method to implement the algorithm of Baswana et al. [4] (Section 7). By combining them, we propose a more space-efficient algorithm with worst-case update time, algorithm B, for the incremental and fully dynamic DFS problems (Theorems 4 and 5). Simultaneously, results for the amortized update time algorithms are also obtained (Theorems 2 and 3).
1.3. Applications
For static undirected graphs, connectivity, biconnectivity and 2-edge-connectivity queries can be answered by using a DFS tree (details for these queries are in Section 8). The existing fully dynamic DFS algorithms [4,5] can be applied to solve these queries in fully dynamic graphs including vertex updates. Our algorithms can also be extended to answer these queries under the fully dynamic setting including vertex updates. Though we need some additional considerations for our algorithms (Section 8), the worst-case update time complexity and the required space can be kept same as the dynamic DFS algorithms in Table 1 (Theorems 6 and 7). Moreover, as well as the existing fully dynamic DFS algorithms, our algorithms can solve these queries in worst-case time.
For the dynamic connectivity problem under vertex updates, the dynamic subgraph connectivity problem [13,14] has been extensively studied. In this problem, given an undirected graph G, a binary status is associated with each vertex in G and we can switch it between “on” and “off”, and the query is to answer whether there is a path between two vertices in the subgraph of G induced by the “on” vertices. Indeed, our dynamic setting including vertex insertions and deletions is a generalization of this dynamic subgraph setting. Under the dynamic subgraph setting, we cannot change the topology of G, i.e., all edges and vertices in G are fixed, while under our setting we can. Under the generalized fully dynamic setting (i.e., our setting), we improve the deterministic worst-case update time bound of [4,5] (with keeping query time ) by a factor. We also compress the required space of their algorithms.
For the dynamic biconnectivity and 2-edge-connectivity problems, the setting including vertex updates was not well considered. Under the fully dynamic setting including vertex updates, we improve the deterministic worst-case update time bound of [4,5] (with keeping query time ) by a factor. We again compress the required space of their algorithms.
2. Preliminaries
Throughout this paper, n denotes the number of vertices and m denotes the number of edges. We assume that a graph is always simple, i.e., has no self-loops or parallel edges, since they make no sense in constructing DFS tree. With this assumption we can conclude and . We also assume that . We use as the base-2 logarithm. From now, the term “fully dynamic setting” includes vertex updates as well as edge updates, while “incremental setting” includes only edge insertions.
Given an undirected graph G and its DFS tree (forest) T, the parent vertex of a vertex v in T is denoted by . A subtree of T rooted at v is the subgraph of T induced by v and its descendants, and is denoted by . Two vertices x and y are said to have ancestor-descendant relation iff , x is an ancestor of y, or y is an ancestor of x. The path in T connecting two vertices x and y is denoted by . A path p in T is called an ancestor-descendant path iff the endpoints of p have ancestor-descendant relation.
Given a connected undirected graph G and its rooted spanning tree T, non-tree edges, i.e., the edges in G which are not included in T, can be classified into two types. A non-tree edge is called a back edge if it connects two vertices which have ancestor-descendant relation; otherwise it is called a cross edge. Then T is a DFS tree of G iff all non-tree edges are back edges. We call this DFS property.
We can assume that the graph G is always connected by the following way. At the beginning, we add a virtual vertex r, and edges for all vertices v in G, to the graph G. During our algorithm, we keep a DFS tree of this augmented graph rooted at r. The DFS tree (forest) of the original graph can be obtained by simply removing r from the DFS tree of the augmented graph.
Bit Vectors. Let be a 0,1-sequence of length l, and consider two queries on B: for , returns the number of occurrences of c in , and returns the position of the i-th occurrence of c in B if exists or ∅ otherwise. Then there exists a data structure such that rank and select queries for can both be answered in time and the required space is bits [15,16]. Moreover, the space can be reduced to bits while keeping query time [17], where is the zeroth-order empirical entropy of B. When 1 occurs k times in B, .
Wavelet Trees. Let be an integer sequence of symbols . A wavelet tree [12] for S is a complete binary tree with leaves and internal nodes, each internal node of which has a bit vector [15,16]. Each node v corresponds to an interval of symbols ; the root corresponds to and its left (right) child to (), and these intervals are recursively divided until leaves, each of which corresponds to one symbol. The bit vector corresponding to an internal node v is defined as follows. Let be the subsequence of S which consists of elements with symbols . Then if the symbol corresponds to the left child of v then ; otherwise . The wavelet tree requires bits of space, and can be built in time [18]. Using wavelet tree for S, the following queries can be solved in time for each: returns , returns the number of occurrences of c in , and returns the position of the i-th occurrence of c in B if exists or ∅ otherwise (here ).
3. Overview of the Algorithms of Baswana et al.
In this section, we give an overview of the DFS algorithms in dynamic setting proposed by Baswana et al. [4], and describe some lemmas used in this paper.
3.1. Fault Tolerant DFS Algorithm
We first refer to the algorithm for fault tolerant DFS problem. This problem is described as follows: given an undirected graph G and its DFS tree T, we try to rebuild a DFS tree for the new graph obtained by deleting edges and vertices (simultaneously) from G. In this part U denotes a set of vertices and edges we want to delete from G, and denotes the new graph obtained by deleting vertices and edges in U from G.
Their algorithm uses a partitioning technique which divides a DFS tree into connected paths and subtrees. This partitioning is called disjoint tree partitioning (DTP).
Definition 1 ([4]).
A DFS tree T of an undirected graph G and a set U of vertices and edges are given, and the forest obtained by removing the vertices and edges in U from T is considered. Given a vertex subset A of , a disjoint tree partitioning of defined by A is a partition of a subgraph of induced by A into a set of paths with and a set of trees. Here each is an ancestor-descendant path in T and each is a subtree of T.
Using DTP, their algorithm can be summarized as follows. First, the DTP of defined by (where V is the vertex set of and r is the virtual vertex in Section 2) is calculated. As a result, a set of paths and a set of subtrees are constructed. Now let be the partially constructed DFS tree of , and at first contains only r. Then their algorithm can be seen as if performing a static DFS traversal (start with r) on the graph whose vertex set is . When a path or a subtree is visited during the traversal, the algorithm extracts an ancestor-descendant path from x and attaches it to , which means the vertices of are marked as visited. Thereafter, the DTP of defined by the unvisited vertices is recalculated. This can be performed by local operations around x. More specifically, if the remaining part is divided into some subtrees and they are stored in ; otherwise is an ancestor-descendant path and is pushed back to . Then the traversal continues. If all vertices are visited, is indeed the DFS tree of .
The key point of reducing computational complexity is that taking advantage of partitioning, the number of edges accessed by this algorithm can be decreased from m. At this time, it must be ensured that the edges not accessed by this algorithm are not needed to construct the new DFS tree . To achieve this, they use a reduced adjacency list L and two kinds of queries Q and . Here Q and are defined as follows.
Definition 2 ([4]).
A connected undirected graph G, its DFS tree T, and a set U of vertices and edges are given. Then for any three vertices in , the following queries are considered. Among all edges in which directly connect a subtree and an ancestor-descendant path , returns one of the edges whose endpoint on is the nearest to x. Similarly, among all edges in which directly connect a vertex w and an ancestor-descendant path , returns one of the edges whose endpoint on is the nearest to x. If there are no connecting edges, these queries should return ∅. Here we can assume that (or ) and have no common vertices, and contain no vertices or edges in U.
During the construction of , the edges added to L are chosen carefully by Q and and, instead of the whole adjacency list of G, only L is accessed. Please note that in these queries, the virtual vertex r and its incident edges are not considered, i.e., there are no queries such that or contains r.
In fact, this fault tolerant DFS algorithm can be easily extended to handle insertion of vertices/edges as well as deletion updates [4]. Now we consider each of the situations: fully dynamic and incremental. Under the incremental case, the number of times the query Q is called is bounded by , and is not used. In this case, the number of edges in L is at most . Under the fully dynamic case, the number of times Q and is executed is bounded by and , respectively, and the number of edges in L is at most . Solving these queries Q and is the most time-consuming part of their algorithm. Therefore, the time complexity of their fault tolerant DFS algorithm can be summarized in the following lemma.
Lemma 1 ([4]).
An undirected graph G and its DFS tree T are given. Suppose that the query Q can be solved in time with a data structure constructed in time under the incremental case. Then with preprocessing time, a DFS tree for the graph obtained by applying any edge insertions to G can be built in time. Similarly, suppose Q and can be solved in and time (resp.) with a data structure built in time under the fully dynamic case. Then with preprocessing time, a DFS tree for the graph obtained by applying any updates (vertex/edge insertions/deletions) to G can be built in time.
3.2. Dynamic DFS Algorithm
Next we refer to the algorithm for the dynamic DFS. Baswana et al. [4] proposed an algorithm for this problem by using the fault tolerant DFS algorithm as a subroutine. Their result can be summarized in the following lemma.
Lemma 2 ([4]).
Suppose that for any updates on an undirected graph G, a new DFS tree can be built in time with a data structure constructed in time (i.e., with preprocessing time). Then for any on-line sequence of updates on the graph, a new DFS tree after each update can be built in amortized/worst-case time per update, if holds.
First we refer to the amortized (not worst-case) update time algorithm. Their idea is to rebuild the data structure , which is constructed at the preprocessing in the fault tolerant DFS algorithm, periodically. To explain this idea in detail, let be the graph obtained by applying first updates on G ( is later decided), and be the number of vertices and edges in , and be the DFS tree for reported by this algorithm. For the first updates, use the data structure constructed from the original graph G and DFS tree T. That is, after each arrival of graph update, we perform the fault tolerant DFS algorithm as if all previous updates come simultaneously. After updates are processed, build the data structure from and , and use for next updates. In other words, from -st to -th updates, we perform the fault tolerant DFS as if from -st to the latest updates come simultaneously. Similarly, after updates are processed, the data structure is built from and , and is used for next updates. We call the moment is used phasej of the amortized update time algorithm. In this way the construction time of the data structures is amortized over updates in phase j. Now suppose that for any updates on G, a new DFS tree can be built in time with built in time, where and are all functions of and . Then the update time complexity becomes by setting . Therefore, we can achieve the amortized update time bound in Lemma 2. Here in phase j, and h in Lemma 2 are indeed and , and are functions of and .
Next we proceed to the worst-case update time algorithm. The idea to achieve the efficient “worst-case” update time described in [4] is to actually divide the construction process of data structure over updates. Here we assume that the number of edges is not dramatically changed during each phase, i.e., holds for all with some constants l and h. With this assumption we can say and differs only by a constant factor (since the number of vertices is not dramatically changed during each phase). In our algorithm described in Section 5 and Section 7, we can say this assumption always holds on condition that , so later we do not touch it.
Let us go into detail. For the first updates, use the data structure built from the original graph G and DFS tree T. For the next updates, use again and build gradually from and . Similarly, from -st to -th updates on the graph (), use for fault tolerant DFS and build gradually from and . In this way the construction time of data structures is divided, and the efficient worst-case update time in Lemma 2 is achieved.
4. Query Reduction to Orthogonal Range Search Problem
In this section, we show an efficient reduction from the queries Q and to orthogonal range search queries. Generally speaking, given some points on the grid points, an orthogonal range search problem (in a 2-dimensional plane) is to answer queries about the points within any rectangular region . Queries of this kind are extensively studied in the computational geometry community, e.g., counting the number of points (orthogonal range counting) or reporting all points (orthogonal range reporting) within R. Now we consider the following query.
Definition 3.
On grid points in a 2-dimensional plane, k points are given. Then for any rectangular region , the orthogonal range successor (predecessor) query returns one of the points whose y-coordinate is the smallest (largest) within R. If there are no points within R, the query should return ∅. We abbreviate it as ORS (ORP) query.
4.1. Original Reduction
First we describe the original reduction of queries Q and [4] proposed by Baswana et al. In their paper, the ORS (ORP) query is not explicitly used, but is implicitly used. Indeed, their method to answer Q and is equivalent to solving ORS (ORP) queries on the adjacency matrix of G; details are described below. We later use part of their ideas.
Now we describe that how a set of points is constructed from G. The high-level idea is quite simple: the vertices in G are numbered from 0 to , and an adjacency matrix according to this numbering is constructed. Let us go into detail. First, a heavy-light (HL) decomposition [19] of T is calculated. Then the order of vertices is decided according to the pre-order traversal of T, such that for the first time a vertex v is visited, the next vertex to visit is one that is directly connected with a heavy edge derived from the HL decomposition. Next, the vertices of G (except r) are numbered from 0 to according to ; here the vertex id of v is denoted by . Finally, on a 2-dimensional grid , for each edge of , we put two points on the coordinates and in . This is equivalent to considering the adjacency matrix of G, and thus points are placed.
The order has some good features. First, for any subtree of T, the vertex ids of the vertices of occupy single consecutive interval since is a pre-order traversal of T. Second, for any ancestor-descendant path in T, those of occupy at most intervals . This is because contains at most light edges (i.e., non-heavy edges) thanks to the property of HL decomposition [19]. Therefore, all edges in G between and are within rectangular regions on . Then if (e.g., the incremental case), the answer for can be obtained by searching them. More specifically, if we solve ORS queries on with and return the point with the smallest y-coordinate among the ORS queries’ answers. Otherwise, we solve ORP queries with the same rectangles and return the point with the largest y-coordinate among the ORP queries’ answers. If all ORS (ORP) queries return ∅, the answer for is also ∅. The same argument can be applied for except that the rectangular regions are .
If (e.g., the fully dynamic case), deletion of points on should be supported, since the edges in U and the incident edges of the vertices in U must be removed from to prevent Q and from reporting already deleted edges. To achieve this, Baswana et al. [4] uses a kind of range tree data structures to solve Q and , which supports deleting a point.
4.2. Efficient Reduction
Next we show the following: (a) the query can be converted to single (not ) ORS/ORP query for any , and (b) the deletion of points from need not be supported. Note that the idea to partially achieve (a) is first proposed by Chen et al. [5] and we use a part of it. However, the solution of the query Q of Chen et al. [5] deals with only the case is hanging from (that is, the case (ii) in Figure 1 explained later). Thus we here extend this to deal with an arbitrary case. The goal is to prove the following lemma.
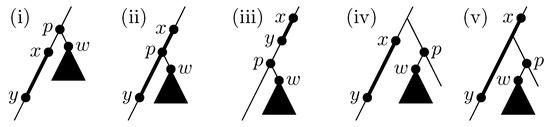
Figure 1.
The configurations of and in T that can appear in .
Lemma 3.
Suppose there exists a data structure which can solve both ORS and ORP queries on in time for each. Then for any three vertices , the query can be solved in time with . Similarly, for any the query can be answered in time with . Please note that need not support deletion of points from .
First we show (a) when (later this assumption is removed). Here we define some symbols for convenience: for two vertices a and b in G, means a is an ancestor of b in T, means or , and means neither nor holds, i.e., a and b have no ancestor-descendant relation. Let . Please note that it is confirmed that w always has a parent because if w is the root of T, spans all vertices of G and has some common vertices with any , which contradicts the assumption (see Definition 2). Now we assume (the case is considered at last). Then the configurations of and can be classified into five patterns in terms of and p as drawn in Figure 1: (i) , (ii) , (iii) , (iv) and , and (v) and . Now we show the following.
Claim 1.
For all cases from (i) to (v), the answer for can be obtained by solving the ORS query on with , where is the interval the vertices of occupy in the vertex numbering and is the lowest common ancestor of y and w in T.
Proof.
First, for the cases (i) and (iv), the answer for is ∅ since if such edge exists, it becomes a cross edge and thus refutes DFS property. For these cases, since comes above x and thus , the ORS query also returns ∅, which correctly answers . For other cases ((ii), (iii) and (v)), lies on . Here all edges between and are indeed between and due to DFS property. It may be that the interval contains some vertex ids of the vertices of branches forking from , which happens when these branches are traversed prior to y and w in . This does not cause trouble because there are no edges between and these branches again due to DFS property. Hence R contains all edges between and and no other edges, when we see as an adjacency matrix of G. Thus, reporting a point whose y-coordinate is the smallest within R yields an answer for . Here note that the LCA query can be solved in time with a data structure of bits built in time [20]. Therefore Claim 1 holds. ☐
From Claim 1 we prove (a) under and . Lastly, if , all we must do is swap x and y and perform almost the same as described above, except that we solve an ORP (not ORS) query on .
Next we show (b). First we assume that U consists of only vertices and contains no edges. In this setting we can confirm from Definition 2 that for the query , and have no vertices in U. Thus, contains no vertex ids of the vertices in U. We can also say that even if in Claim 1 contains some vertex ids of the vertices in U, these vertices are all in the branches forking from and cause no trouble. Therefore, even if U contains some vertices, Claim 1 also holds. For the query , we use the original reduction described in Section 4.1. We can also say from Definition 2 that and have no vertices in U. Thus, and contain no vertex ids of the vertices in U.
Finally, we consider the case U contains some edges. In this case, it seems that deletion of these edges from is needed. However, deleting one edge can be simulated by one vertex deletion and one vertex insertion as follows: first record u’s incident edges excluding itself, second delete v, and then insert a vertex with its incident edges . In the algorithm of Baswana et al. [4], vertex insertions are treated separately from the queries Q and . Thus, in this way we can avoid deleting e from . This completes the proof of Lemma 3.
Lastly we briefly explain that cannot be converted to single ORS (ORP) query in the same way as Q. The five patterns of configuration of vertices drawn in Figure 1 can also appear in . However, there is a corner case that can appear in but cannot appear in : , as drawn in Figure 2. This pattern cannot appear in since if then overlaps with . This corner case is relatively hard to convert to single ORS/ORP query on , since every vertex of a branch forking from has ancestor-descendant relation with w. Please note that it does not matter if is solved times slower than (see Lemma 1).
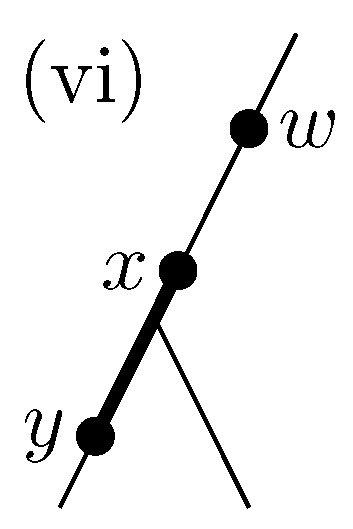
Figure 2.
The configuration of and w in T that can appear in and cannot appear in .
5. Linear Space Dynamic DFS
In this section, we propose a linear space fast dynamic DFS algorithm. In Section 4.2, we prove that there is no need to support deletion of points from even if there are some deletion updates of edges and vertices. This means we can bring a static data structure for the queries Q and rather than a dynamic one. Indeed, the data structure by Belazzougui and Puglisi [21] can solve the ORS query in rank space. The rank space with k points is a grid where all points differ in both x- and y-coordinates. For the rank space with k points, their data structure can solve ORS query in time for an arbitrary , can be constructed in time, and occupies bits of space. Though is not a rank space, we can convert to the rank space by using bit vectors. Please note that this kind of conversion is regularly employed for various orthogonal range search data structures (e.g., see [22]). So, in the proof below we do not show the conversion from to a rank space, but show that from the adjacency list of G to a rank space directly.
Lemma 4.
There exists a data structure which can solve both ORS and ORP queries on in time for each for arbitrary . This data structure requires bits of space and can be built in time.
Proof.
Let be the degree of a vertex v in G whose vertex id is i and (). Now we have , since G is an undirected graph. We construct a rank space satisfying the following condition: for two vertices with and , there exists an edge between v and w in G iff there exists a point within in . This can be done by the following procedure. First, prepare two arrays with for . Then for each edge in G, increment and by one and then place two points on the coordinates and in . When all edges are processed, satisfies the above condition.
Besides , we construct a bit vector with . Here for , and for . These mean that the bit vector for B enables us to interconvert between the vertex id and the coordinate in in time. Therefore, given an ORS query with a rectangle R on we can solve it as follows. First, convert the coordinates of R into that in by the bit vector for B. Second, solve the converted ORS query on by the data structure of Belazzougui and Puglisi [21]. Finally, if the answer is ∅ then the original answer is also ∅. Otherwise the answer is again converted to the vertex id by the bit vector for B. The overall cost for single ORS query is thus . Please note that the bit vector requires only bits of space.
We above mentioned only the ORS query, but the data structure for the ORP query can be built in a similar way. Let be a rank space constructed by flipping vertically; i.e., is constructed by putting a point on coordinates for every point on . can also be built directly from the adjacency list of G, and the ORP query on can be converted to the ORS query on in the same manner as described above. ☐
Figure 3 is an example of an undirected graph G and its corresponding rank space . In this example, the rectangles and have a point inside, which corresponds to the edge connecting 0 and 1. Conversely, the rectangles and do not have a point inside, which indicates the absence of the edge connecting 0 and 2.
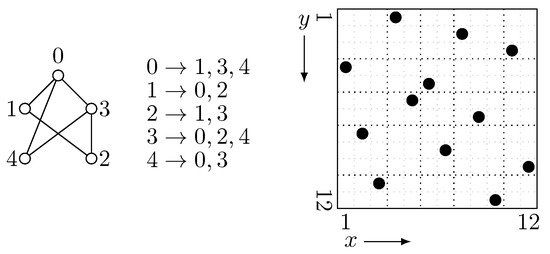
Figure 3.
An example of an undirected graph with vertex numbering, its adjacency list, and the corresponding rank space .
Combining Lemma 4 with Lemma 3 implies the following corollary.
Corollary 1.
There exists a data structure of bits such that for any , can be solved in time and in time. This data structure can be built in time.
This corollary directly gives a fault tolerant DFS algorithm when combining with Lemma 1. Here we must consider the space requirement of this algorithm, but it is simple. Information used in the algorithm other than the data structure to solve Q and and the reduced adjacency list L takes only bits: there are words of information for the original DFS tree T (including the data representing the disjoint tree partition), words of information attached to each vertex and each edge in T, a stack which has at most elements, and a partially constructed DFS tree, but these sum up to only words. Moreover, since the reduced adjacency list L contains at most edges, the required space for L is bounded by bits. From Corollary 1, the data structure to solve Q and occupies bits. Hence the following lemma holds.
Lemma 5.
An undirected graph G and its DFS tree T are given. Then there exists an algorithm such that with preprocessing time, a DFS tree for the graph obtained by applying any edge insertions to G can be built in time. Similarly, there exists an algorithm such that with preprocessing time, a DFS tree for the graph obtained by applying any updates (vertex/edge insertions/deletions) to G can be built in time. These algorithms require bits of space.
Linear space dynamic DFS algorithms are obtained by combining Lemma 5 with Lemma 2. For the incremental case, we set , and for Lemma 2 (here the condition must be satisfied). Then the update time is . We can say the update time is if , or otherwise. For the fully dynamic case, we set , and , and, therefore, the update time is .
Theorem 1.
There exists an algorithm such that given an undirected graph G and its DFS tree T, for any on-line sequence of updates on G, a new DFS tree after each update can be built in worst-case time per update under the incremental case, and time per update under the fully dynamic case, where is an arbitrary constant. This algorithm requires bits.
6. Compression of Data Structures
In this section, we show a way to solve Q and more space-efficiently, which is later used in the space-efficient dynamic DFS algorithm in Section 7.
6.1. Range Next Value Query
First, we show a data structure of bits, which can be derived immediately from the existing results.
It is already known that the ORS (ORP) query on a grid with k points, where all points differ in x-coordinates, can be solved efficiently with wavelet tree [23]. Now we describe this method in detail. The method is to build an integer array where is the y-coordinate of the point whose x-coordinate is i. Then the ORS (ORP) query is converted to the following query on S.
Definition 4.
An integer sequence is given. Then for any interval and integer p , the range next (previous) value query returns one of the smallest (largest) elements among the ones in which are not less than p (not more than q). If there is no such element, the query should return ∅. We abbreviate it as RN (RP) query.
These queries can be efficiently solved with the wavelet tree for S; if for all , they can be solved with rank and select queries on [23]. The pseudocode for solving RN query by the wavelet tree for S is given in Algorithm 1. In Algorithm 1, and stand for the left and right child of the node v, respectively. When calling , we can obtain the answer for the RN query with and p. Here a pair of the position and the value of the element is returned. If is returned, the answer for the RN query is ∅. The RP queries on S can be solved in a similar way using the same wavelet tree as the RN queries.
| Algorithm 1 Range Next Value by Wavelet Tree |
| 1: function RN() |
| 2: if or then return |
| 3: if then return |
| 4: |
| 5: if then |
| 6: |
| 7: if then return |
| 8: end if |
| 9: |
| 10: if then return |
| 11: else return |
| 12: end function |
The ORS query on with can be answered by solving the RN query on S with and . If the RN query returns ∅, the answer for the ORS query is also ∅. If the RN query returns an element, the answer is ∅ if the value of this element is larger than , or the point corresponding to this element otherwise. Similarly, the ORP query on can be converted to the RP query on S.
Although in the grid , on which we want to solve ORS (ORP) queries, some points share the same x-coordinate, it is addressed by preparing a bit vector B in the same way as the proof of Lemma 4. B enables us to convert x-coordinates. Here the integer sequence consists of the y-coordinates of the points on sorted by the corresponding x-coordinates. The required space of the wavelet tree is bits since there are points on and the y-coordinates vary between . Hence now we obtain a data structure of bits to solve Q and (note that the bit vector requires only bits as described in the proof of Lemma 4).
6.2. Halving Required Space
Next, we propose a data structure of bits to solve Q and . The data structure shown in Section 6.1 has information of both directions for each edge of G since G is an undirected graph. This seems to be redundant, thus we want to hold information of only one direction for each edge. In fact, the placement of points on is symmetric since the adjacency matrix of G is also symmetric. So now we consider, of the grid , the upper triangular part and the lower triangular part ; a grid inherits from the points within the region the x-coordinate is larger than the y-coordinate, and is defined in the same manner. Since G has no self-loops, and have m points for each. Now we show that we can use as a substitute for .
Let be an integer sequence which contains the y-coordinates of the points on sorted by the corresponding x-coordinates. Let be a bit vector , where is the number of occurrences of i in . enables us to convert the x-coordinate on to the position in and vice versa in time. Figure 4 is an example of the grid and its upper triangular part . Here we should observe that has half as much point as and thus the length of is halved from S.

Figure 4.
(Left) an example of the grid and its corresponding array S and bit vector B. Please note that this grid corresponds to the graph in Figure 3. (Right) the upper triangular part and its corresponding array and bit vector .
Lemma 6.
Any ORS (ORP) query which appears in the reduction of Lemma 3 can be answered by solving one RN (RP) query, or by solving onerankand oneselectqueries, on .
Proof.
We give a proof for only ORS queries since that for ORP queries is almost same. It can be observed that if the query rectangle of the ORS query is inside the upper triangular part of , this ORS query can be converted to an RN query on in the same way as Section 6.1, since contains all points inside the upper triangular part in . The below claim ensures us that any ORS query related to Q can be converted to the RN query on .
Claim 2.
The rectangles appearing in Claim 1 are all inside the upper triangular part of , i.e., these rectangles are of the form: with .
Proof.
It can be easily observed that , appearing in the interval corresponding to the vertices of a subtree , equals to . Since , and thus is inside the upper triangular part. ☐
In solving , there may be query rectangles inside the lower triangular part. However, these rectangles are of the form: with . Transposing this rectangle, it is inside the upper triangular part and the problem becomes like the following: for a rectangle (with ) on , we want to know the point whose “x-coordinate” is the smallest within R. Converting the x-coordinate to the position in by , this problem is equivalent to the following problem: to find the leftmost element among ones in with a value just c.
Claim 3.
Finding the leftmost element among ones in with a value just c can be done by onerankand oneselectqueries on for any .
Proof.
Let . It is observed that the -st occurrence of c in is the answer if it exists and its position is in . So, if returns ∅ or a value more than then the answer is “not exist”. Otherwise the answer can be obtained by this select query itself. ☐
This completes the proof of Lemma 6. ☐
Since rank, select, RN and RP queries on can be solved in time for each with a wavelet tree for , we immediately obtain a data structure of bits for the queries Q and . Here the required space of is again bits and does not matter.
Corollary 2.
There exists a data structure of bits such that for any , can be solved in time and in time. This data structure can be built in time.
Please note that the above corollary does not mention working space for the construction of the data structure. Therefore, obtaining space-efficient dynamic DFS algorithm requires consideration of the building process, since in the algorithm of Baswana et al. we need to rebuild this data structure periodically. We further consider this in Section 7.
6.3. Range Leftmost Value Query
Next, we show another way to compress the data structure to bits. This is achieved by solving range leftmost (rightmost) value query with a wavelet tree. This query appears in the preliminary version [10] of this paper. In the preliminary version, this query and the RN (RP) query (Definition 4) is used simultaneously to obtain a data structure of bits. Although we no longer need to use this query to halve the required space as described in Section 6.2, this query still gives us another way to compress the data structure. Moreover, this query is of independent interest since its application is beyond the dynamic DFS algorithm, as described later.
The range leftmost (rightmost) value query is defined as follows.
Definition 5.
An integer sequence is given. Then for any interval and two integers , the range leftmost (rightmost) value query returns the leftmost (rightmost) element among the ones in with a value not less than p and not more than q. If there is no such element, the query should return ∅. We abbreviate it as RL (RR) query.
This RL (RR) query is a generalization of the query of Claim 3 in the sense that the value of elements we focus varies between instead of being fixed to just c. Moreover, the RL (RR) query is a generalization of a prevLess query [24], which is the RR query with and . It is already known that the prevLess query can be efficiently solved with the wavelet tree for S [24].
First we describe the idea to use RL (RR) query for solving Q and . Here we consider the symmetric variant of ORS (ORP) query, which is almost the same as ORS (ORP) query except that it returns one of the points whose “x-coordinate” is the smallest (largest) within R (we call it symmetric ORS (ORP) query). The motivation to consider symmetric ORS (ORP) queries comes from transposing the query rectangle of normal ORS (ORP) queries. Since is symmetric, the (normal) ORS query on with rectangle is equivalent to the symmetric ORS query on with rectangle . When transposing the rectangle, we can focus on the lower triangular part instead of the upper triangular part , as described below.
Let and be an integer sequence and a bit vector constructed from in the same manner as and . enables us to convert between the x-coordinate on and the position in . Then it can be observed that the symmetric ORS query on with can be answered by solving the RL query on with and , where is the interval of the position in corresponding to . If the RL query returns ∅, the answer for the symmetric ORS query is also ∅. Otherwise the answer can be obtained by converting the returned position in to the x-coordinate on by . In this reduction “leftmost” means “the smallest x-coordinate”. Similarly, a symmetric ORP query on can be converted to an RR query on . With this conversion from the symmetric ORS (ORP) query to the RL (RR) query, we can prove the following lemma which is a lower triangular version of Lemma 6.
Lemma 7.
Any ORS (ORP) query which appears in the reduction of Lemma 3 can be answered by solving one RL (RR) query, or by solving onerankand oneselectqueries, on .
Proof.
From Claim 2, the rectangles of the ORS queries corresponding to Q is all inside the upper triangular part. Therefore, when we transpose them, they are inside the lower triangular part. Since the symmetric ORS query can be converted into the RL query as described above, it is enough for solving Q. In solving , there may be query rectangles inside the upper triangular part. However, they are solved by one rank and one select queries on , in the same way as Claim 3. ☐
Next we describe how to solve RL (RR) queries with a wavelet tree. We prove the following lemma, by referring to the method to solve prevLess [24] by a wavelet tree.
Lemma 8.
An integer sequence is given. Suppose that for all . Then using the wavelet tree for S, both RL and RR queries can be answered in time for each.
Proof.
We show that with the pseudocode given in Algorithm 2. First we show the correctness. In the arguments of , v is the node of the wavelet tree we are present, and is the interval of symbols v corresponds to (i.e., ). We claim the following, which ensures us that the answer for the RL query can be obtained by calling . ☐
Claim 4.
For any node v of wavelet tree and four integers , calling yields the position of the answer for the RL query on . If the answer for the RL query is ∅, this function returns 0.
Proof.
We use an induction on the depth of the node v. The base case is or (note that either of them must occur when , so if v is a leaf node the basis case must happen). For the former case, the answer is obviously ∅. For the latter case, the answer is a since all elements in have value between . In these cases, the answer is correctly returned with lines 2–3 of Algorithm 2.
Now we proceed to the general case. Let , and . Then and . Therefore, the elements in with a value between appear in the left child , and those with a value between appear in the right child . Here and can be calculated by rank queries on : and . It can be observed that the element of corresponding to the leftmost element in with a value within is also the leftmost element in with a value within . Here i can be obtained by (induction hypothesis) and . Similarly, the element of corresponding to the leftmost element in with a value within is also the leftmost element in with a value within . Again j can be obtained by (induction hypothesis) and . Hence is the leftmost element we want to know. Now the answer is correctly returned with lines 4–10 of Algorithm 2: lines 7–10 cope with the case the function returns 0. ☐
Next we discuss the time complexity when calling . We show that for each level (depth) of the wavelet tree the function visits at most four nodes. At the top level we visit only one node . At level k, the general case occurs at most two times: it may occur when contains the endpoints of . Thus, at level the function is called at most times. Since the wavelet tree has depth , function is called times. For each node, all calculation other than the recursion can be done in time, so the overall time complexity is .
The same argument can be applied for the RR query. This completes the proof. ☐
| Algorithm 2 Range Leftmost Value by Wavelet Tree |
| 1:function RL() |
| 2: if or then return 0 |
| 3: if then return a |
| 4: |
| 5: |
| 6: |
| 7: if and then return |
| 8: else if then return |
| 9: else if then return |
| 10: else return 0 |
| 11: end function |
Lemmas 7 and 8 imply another way to achieve Corollary 2.
Finally, we discuss the application of RL (RR) query beyond the dynamic DFS algorithm. Let us consider ORS and ORP queries on an grid whose placement of points is symmetric. Suppose that there are d points on a diagonal line of (we call them diagonal points) and points within the other part of . Generally, there is no assumption on query rectangles such as Claim 2, so with only RN (RP) queries we cannot remove the points within the lower triangular part of . However, using RL (RR) queries as well as RN (RP) queries, we can consider only the upper triangular and the diagonal parts of . The idea, which is very similar to the method in the preliminary version [10] of this paper, is as follows. First, for a query rectangle of the ORS (ORP) query, we solve the corresponding RN (RP) query. Second, for the transposed query rectangle , we solve the corresponding RL (RR) query, and “transpose” the answer. Finally, we combine these two answers: choose the one with smaller (larger) y-coordinate. Let and be an integer sequence and a bit vector constructed from the upper triangular and the diagonal parts of in the same manner as and . A wavelet tree for can solve RN, RP, RL and RR queries on and occupies bits, since the diagonal part has d points and the upper triangular part has k points. Because the space required for is not a matter, now we obtain a space-efficient data structure for solving ORS and ORP queries on . If , the required space of the data structure is actually halved from using wavelet tree directly ( bits).
If d is large, we can further compress the space from bits by treating diagonal points separately. Let be a bit vector such that if there exists a point on coordinates and otherwise. For a query rectangle , let . Then it can be easily observed that R contains diagonal lines from to if and R has no diagonal points otherwise. Therefore if , a diagonal point with smallest (largest) y-coordinate within R can be obtained by one rank and one select query on . Now we do not retain the information of the diagonal points in the wavelet tree, so the overall required space of data structures is bits.
7. More Space-Efficient Dynamic DFS
In this section, we show algorithms to solve the dynamic DFS problem space-efficiently. Our algorithm is based on the algorithms of Baswana et al. [4], but there is much consideration in compressing the working space of it.
7.1. Fault Tolerant DFS
We begin with the algorithm for the fault tolerant DFS problem. Following the original algorithm described in Section 3.1, the important point is that once a data structure for answering Q and is built, the reduced adjacency list L is used and the whole adjacency list of the original graph is no longer needed. Moreover, information used in the algorithm other than the data structure and the reduced adjacency list takes only bits, as described in Section 5. Since we have already shown in Corollary 2 that the data structure takes bits, we have only to consider the size of the reduced adjacency list L. From Section 3.1, for any graph updates, the number of edges in L is at most under the incremental case, and under the fully dynamic case. The time complexity of this algorithm can be calculated from Lemma 1 and Corollary 2. The required space of this algorithm is bits plus the space required for L, that is, bits (with standard linked lists) where is the upper bound of the number of edges in L. To sum up, we can obtain the following lemma.
Lemma 9.
An undirected graph G and its DFS tree T are given. Then there exists an algorithm such that with preprocessing time, a DFS tree for the graph obtained by applying any edge insertions to G can be built in time. This algorithm requires bits once the preprocessing is finished. Similarly, there exists an algorithm such that with preprocessing time, a DFS tree for the graph obtained by applying any updates (vertex/edge insertions/deletions) to G can be built in time. This algorithm requires bits once the preprocessing is finished.
7.2. Amortized Update Time Dynamic DFS
Next, we focus on the amortized update time dynamic DFS algorithm. During the “amortized time” algorithm described in Section 3.2, we should perform the reconstruction of the data structure to solve the fault tolerant DFS problem besides the fault tolerant DFS itself, and store information of up to last c updates. Here is indeed a bit vector and a wavelet tree described in Section 6. Therefore, we must consider (a) how many edges the reduced adjacency list L may have, (b) how much space is required to store information of updates, and (c) how to rebuild the data structure space-efficiently. We analyze these issues one by one.
First we consider (a). Since we rebuild periodically, we solve the fault tolerant DFS problem with at most updates in phase j. Therefore, we can obtain an upper bound on the number of edges in L. Under the incremental case, we can say and for Lemma 2 (here holds), and the size of L is bounded by , as described in Section 7.1. Under the fully dynamic case, we can say and , thus the upper bound is which is under the assumption . Hence we can conclude that L takes only bits under any conditions.
Next we consider (b), but this is almost the same as (a). Under the incremental case, the number of edges inserted during updates is up to which is . Under the fully dynamic case, the number of edges inserted or deleted during updates is up to , since insertion or deletion of one vertex involves those of incident edges. This is smaller than the maximum size of L, and thus it does not affect the bound. Please note that in the analysis of (a) and (b), we write in Section 3.2 as for simplicity.
Finally, we consider (c). Let be the order of vertices in defined by the pre-order traversal of , where and are the graph and its reported DFS tree at the beginning of phase j of the amortized update time algorithm, and let be the grid like constructed from and (in our algorithm we do not retain , but it helps the description of our algorithm clear). In addition to these, let and be an integer sequence and a bit vector built from the upper (or lower) triangular part of in the same manner as Section 6 (in Section 6, they are written as and (or and )). Now we focus on the end of phase j, i.e., the time is reported. Using these symbols, the rebuilding process at this moment is briefly described as follows. First, the order of vertices is decided according to the pre-order traversal of , and information attached to each vertex and edge of is initialized. Second, a grid is considered, and and are built. Finally, a wavelet tree for is constructed.
The main difficulty in this rebuilding process is that the whole adjacency list is not retained. That means the information of all edges in is not explicitly stored at this moment. It is stored in the wavelet tree for , the bit vector , and the information of the last updates. In our algorithm, we additionally retain the integer sequence during phase j of the algorithm. Then the main job in this moment is to construct and from , and the information of last updates.
To do this, we also retain during phase j an integer sequence , where is the number of points in the upper (or lower) triangular part of whose x-coordinate is less than i. Then holds. The y-coordinates of the points whose x-coordinate is i are stored in ; we call this subsequence a block i of . We impose a condition on that each block of is sorted in ascending order. Please note that takes bits and takes bits.
Now we describe the way to rebuild the data structures space-efficiently at the end of phase j. First, destroy and . Second, sort the information of last updates, i.e., the inserted or deleted edges during the last c updates, in the same order as . This can be performed as follows. First convert this information to tuples where is the vertex ids (according to ) of the endpoints of the edge with (or in the lower triangular case), and is information of 1 bit which represents whether the edge is inserted or deleted (here if there are inserted vertices, they are numbered from ). Second sort them by the ascending order of . If there are some tuples which share , they are sorted by the ascending order of . Please note that since the number of edges inserted or deleted during updates is up to , sorting can be performed in linear time (i.e., time) and bits of working space by radix sort. Third, create a new array and , which retains information of all edges in with the vertex numbering from . This can be done by simply scanning the tuples and simultaneously and merging them, since they are sorted in the same order. Fourth, destroy and , and decide the order of vertices in according to the pre-order traversal of . Fifth, create and from and , and destroy and . The detail of this process is described later. Finally, build and from and . Then we are ready for phase .
The remaining part is creating and from and . For simplicity, let , and suppose that we now focus on the upper triangular part of as in Section 6.2 (even if we focus on the lower triangular part of as in Section 6.3, we can perform this in almost the same way). First, construct an old-to-new correspondence table N of vertex numbering: is the vertex id from of a vertex whose vertex id from is i. Then the pseudocode for converting and to and is given in Algorithm 3. Here and stand for the increment and decrement (resp.) of this variable by one. This seems to be a bit complicated, but is equivalent to performing a kind of counting sort for two times. In the first part (lines 1–12 of Algorithm 3), we convert the old vertex id to the new one, let the points (i.e., edges in ) in the “lower” triangular part of , and sort them by their x-coordinates. In the second part (lines 14–21), we sort them by their y-coordinates and record their x-coordinates (see line 19) in . In this way their x- and y-coordinates are swapped, and finally they are in the upper triangular part of . In these processes, things get complicated since their x-coordinates are stored implicitly in and while y-coordinates are explicitly stored in and , but we manage to perform two counting sortings by this coordinate swapping method.
| Algorithm 3 Creating and from and |
| 1: , create and with all elem. 0 |
| 2: for to do |
| 3: while do |
| 4: |
| 5: end for |
| 6: for to do |
| 7: |
| 8: for down to 1 do |
| 9: while do |
| 10: |
| 11: |
| 12: end for |
| 13: destroy and , create and with all elem. 0 |
| 14: for to do |
| 15: for to do |
| 16: |
| 17: for down to 1 do |
| 18: while do |
| 19: |
| 20: |
| 21: end for |
| 22: destroy and |
Finally, we consider the time complexity and the required space of this building process. In this analysis we write as simply since from (b), the number of edges is changed by only during phase j when . The whole process to rebuild data structures takes time, since building single wavelet tree takes time and the others take only time. In the whole process, data structures or arrays which take bits are , , , , and , and at any time, this algorithm retains at most two of them. The working space for constructing wavelet tree in time [18] is at most bits. This can be written as . Here the integer sequence S has m elements and n symbols (). Since we assume as in Section 2, the pointers to form a complete binary tree shape of the wavelet tree for S requires only bits, which is negligible. All other data take only bits, and thus the space required by the algorithm is bits. Combining these observations with Lemma 2 yields the following theorems. Theorem 2 proposes the incremental DFS algorithm, while Theorem 3 states the fully dynamic one.
Theorem 2.
There exists an algorithm such that given an undirected graph G and its DFS tree T, for any on-line sequence of edge insertions on G, a new DFS tree after each insertion can be built in amortized time per update, with preprocessing time. This algorithm requires only bits once data structures for the original graph are built.
Theorem 3.
There exists an algorithm such that given an undirected graph G and its DFS tree T, for any on-line sequence of graph updates on G, a new DFS tree after each update can be built in amortized time per update under fully dynamic setting, with preprocessing time. This algorithm requires only bits under once data structures for the original graph are built.
7.3. Worst-Case Update Time Dynamic DFS
Finally, we consider the worst-case update time algorithm for the dynamic DFS, following the “worst-case time” algorithm described in Section 3.2. To implement this space-efficiently, again we must consider (a), (b) and (c) described in Section 7.2, but two of them are almost the same argument. In the worst-case time algorithm, we should solve the fault tolerant DFS problem with at most updates and thus store information of last updates. Therefore, the required space for the reduced adjacency list and the information of updates are multiplied by some constant, but these are absorbed in the big O notation.
Therefore, we have only to consider (c). Let be the pair of the bit vector and the wavelet tree . Then during phase 0, is used to perform fault tolerant DFS and rebuilding of data structures is not needed. During phase , is used and the following processes are done gradually: first destroy (this is not needed for phase 1), and then build , and from , in the same way as Section 7.2. At the end of phase j there exist , , and , and we can continue to the next phase .
Finally, we consider how much space is needed to implement this algorithm. In phase j, takes bits, and rebuilding the data structures requires at most bits as described in Section 7.2. Therefore, the total required space is bits. These results can be summarized in the following theorems.
Theorem 4.
There exists an algorithm such that given an undirected graph G and its DFS tree T, for any on-line sequence of edge insertions on G, a new DFS tree after each insertion can be built in worst-case time per update, with preprocessing time. This algorithm requires only bits once data structures for the original graph are built.
Theorem 5.
There exists an algorithm such that given an undirected graph G and its DFS tree T, for any on-line sequence of graph updates on G, a new DFS tree after each update can be built in worst-case time per update under fully dynamic setting, with preprocessing time. This algorithm requires only bits under once data structures for the original graph are built.
8. Applications
In this section, we show the applications of our fully dynamic DFS algorithms to dynamic connectivity, dynamic biconnectivity, and dynamic 2-edge-connectivity. The description for these applications also appears in the full version of the paper of Baswana et al. [6]. We basically follow their description, but now we must consider the additional space required by calculating them. Moreover, in dynamic biconnectivity and 2-edge-connectivity, we have some additional considerations to keep the update time same as Theorems 1 and 5.
8.1. Dynamic Connectivity
For the dynamic connectivity problem, we deal with an on-line sequence of graph updates and connectivity queries. The query takes two vertices as an input and asks whether these two vertices are in the same connected component or not. This can be easily done by the following way. For each graph update, perform dynamic DFS and obtain a new DFS tree rooted at the virtual vertex r. By removing r from , becomes a forest each tree of which is a spanning tree for one connected component. Then simply traversing from r, we can number the connected components of G, and attach to each vertex v in G the id of the connected component v belongs to. The query can be solved by simply checking the connected component id of two vertices; connected if they are same, or disconnected otherwise. Since traversing takes time and the additional required space is only bits, these operations do not violate the update time and space complexity of dynamic DFS algorithms. Since the initial DFS tree can be obtained in time which is absorbed in the preprocessing time, we obtain the following theorem.
Theorem 6.
Given an undirected graph G, there exists an algorithm such that with preprocessing time, for any on-line sequence of graph updates (edge/vertex insertion/deletion) and connectivity queries, each update can be processed in worst-case time ( time) and each query can be answered in worst-case time. This algorithm requires bits ( bits) once the preprocessing is finished.
8.2. Dynamic Biconnectivity/2-Edge-Connectivity
For the dynamic biconnectivity (2-edge-connectivity) problems, we first formally define the problem. A set S of vertices in an undirected graph G is called a biconnected component iff it is the maximal set such that the removal of any one vertex in S keeps S connected. Similarly, a set S of vertices is said to be a 2-edge-connected component iff it is the maximal set such that the removal of any one edge whose endpoints are both in S keeps S connected. The biconnectivity (2-edge-connectivity) query takes two vertices as an input and asks whether these two vertices are in the same biconnected (2-edge-connected) component or not. The goal of the dynamic biconnectivity (2-edge-connectivity) problem is to design an algorithm which can process any on-line sequence of graph updates and biconnectivity (2-edge-connectivity) queries.
The concepts related to biconnectivity and 2-edge-connectivity are articulation points and bridges. A vertex v (an edge e) in G is called an articulation point (a bridge) iff the removal of v (e) increases the number of connected components in G. Then we can say that for any DFS tree T of G, two vertices u and v are in the same biconnected component iff the path from u to v in T (excluding u and v themselves) includes no articulation points. Similarly, two vertices u and v are in the same 2-edge-connected component iff the path from u to v in T contains no bridges. Therefore, now we can reduce the dynamic biconnectivity (2-edge-connectivity) problem to the following problem: to design an algorithm which can enumerate, for any on-line sequence of updates on G, all articulation points and bridges after each update.
In static setting, the articulation points and bridges can be listed also by DFS. Given a connected undirected graph G and its DFS tree T, we first number the vertices from 0 to by the pre-order traversal of T; the id of a vertex v is denoted by . Then the high number of a vertex v is defined by . It can be said that a vertex v is an articulation point iff v is a root of T and has multiple children, or v is a non-root vertex of T and has at least one child w with . We can also say that a tree edge (v is a parent of w) is a bridge iff , and for all children x of w. Therefore, if we can calculate for all vertices, we can detect all articulation points and bridges in time by simply traversing T.
Now the problem we want to solve is to design an algorithm such that given an undirected graph G, it can compute a new DFS tree and for the graph obtained by applying any graph updates to G. Baswana et al. [6] proposed an efficient method for solving this by modifying the fault tolerant DFS algorithm. Before explaining this, let us recall the fault tolerant DFS algorithm. We state in Section 3.1 that during the construction of a new DFS tree , when a path or a subtree (derived from DTP) is visited, an ancestor-descendant path is extracted from x and the remaining part is pushed back to if originally or otherwise. Let () be a set of these extracted paths from (). The algorithm in Section 3.1 ensures us that . For an extracted path , let and be the endpoints of , where is an ancestor of in the new DFS tree .
We describe their method to calculate . They use the query defined in Definition 2. First, compute the initial DTP in the same way as fault tolerant DFS, and for each vertex v in some subtree , calculate the highest ancestor among vertices such that there is an edge in the updated graph. This is calculated by an ORS query on with where is the interval the vertices of occupy in the (old) vertex numbering . Second, obtain a new DFS tree by fault tolerant DFS tree algorithm. In constructing , simultaneously number the vertices to get the (new) vertex numbering . Third, for each vertex v except r, attach an integer which is initialized to some constant larger than any vertex numbering , e.g., the number of vertices. Fourth, for each inserted edge , update by and by . Here for a vertex v and an integer k, “update by k” means substituting for . Finally, these operations are performed.
- For each vertex v and each path , solve to get an edge and update by .
- For each vertex v and each path , solve to get and update by .
- For each vertex v that is in some subtree initially (i.e., when the initial DTP is calculated), let be the path which contains v. Then solve to get and update by .
- For each vertex v that is in some subtree initially, let be the path which contains . Then solve to get and update by .
Baswana et al. [6] show that after performing them, is calculated by . Thus, after calculating , can be computed in time by simply traversing the new DFS tree .
We bring their method to our situation. First we consider the time complexity. Except for the operations 1. to 4., we throw ORS queries, perform fault tolerant DFS and scan all inserted edges. The most time-consuming part among them is fault tolerant DFS, and takes time with ORS (ORP) query time (Lemmas 1 and 3). The operations 3. and 4. solves for n times, thus they take time which is absorbed. However, the operations 1. and 2. solves for times since , and therefore they seem to take time, which is larger than performing fault tolerant DFS. This is because is solved times slower than Q is. Here we show the following lemma, which implies that they take only time.
Lemma 10.
The operations 1. and 2. can be performed by solving ORS (ORP) queries in total.
Proof.
In solving , we solve ORS (ORP) queries with , where is the intervals occupies in the (old) vertex numbering . For , let be the number of intervals of vertex ids is divided into. Then it suffices to show that , since it can be said that for each vertex v, and are solved for all by ORS (ORP) queries. Let us recall that the union of all paths in equals to the union of paths in , a set of ancestor-descendant paths of the initial DTP. Let S be the vertices of the union of all paths in . Since (see Definition 1), S occupies at most intervals. Thus, even if S is divided into paths, the number of intervals to consider is at most . Hence . ☐
In this way we can say the time complexity is .
Next we consider the required space, but it is easy. The key point is again that the whole adjacency list of G is not needed due to the usage of the query . In these processes, we must store the endpoints of each path in . For each vertex v, we must retain , , , , and a pointer to a path in v is contained, and so on. However, these sum up to only words of information, thus these takes only bits. Therefore, we prove the following.
Lemma 11.
Given an undirected graph G and its DFS tree T, there exists an algorithm such that with preprocessing time, articulation points and bridges of the graph obtained by applying any updates (vertex/edge insertions/deletions) to G can be all enumerated in () time. This algorithm requires () bits of space once the preprocessing is finished.
We propose an efficient fully dynamic biconnectivity/2-edge-connectivity algorithm including vertex updates using Lemma 11. For 2-edge-connectivity, it can be observed from the definition that each vertex belongs to exactly one 2-edge-connected component. With the relation between 2-edge-connectivity and bridges, we can number the 2-edge-connected components of G, and attach to each vertex v the id of the 2-edge-connected component v belongs to, by simply traversing . Then the 2-edge-connectivity query can be answered in the same way as the connectivity query. For biconnectivity, we first build an LCA data structure [20] for after each update. We also compute, for each vertex v, the lowest ancestor among articulation points (excluding v itself). They can be all computed in time by simply traversing after each update. Then for the biconnectivity query with two input vertices , first get in by querying the LCA data structure. Now the path from v to w in is indeed two ancestor-descendant paths from v to x and from x to w in . We can check whether these paths contain articulation vertices or not by comparing to and to . For example, if , the path from v to x in contains at least one articulation points; otherwise does not. For one biconnectivity query the overall time is including the LCA query. The additional space required is also bits because the LCA data structure takes only bits. Therefore, we obtain the following theorem.
Theorem 7.
Given an undirected graph G, there exists an algorithm such that with preprocessing time, for any on-line sequence of graph updates (edge/vertex insertion/deletion), biconnectivity queries and 2-edge-connectivity queries, each update can be processed in worst-case time ( time) and each query can be answered in worst-case time. This algorithm requires bits ( bits) once the preprocessing is finished.
Author Contributions
Conceptualization, K.N.; methodology, K.N. and K.S.; software, K.N.; validation, K.N. and K.S.; formal analysis, K.N. and K.S.; investigation, K.N.; resources, K.N.; data curation, K.N.; writing—original draft preparation, K.N.; writing—review and editing, K.N. and K.S.; visualization, K.N.; supervision, K.S.; project administration, K.S.; funding acquisition, K.S.
Funding
This work was supported by JST CREST Grant Number JPMJCR1402, Japan.
Conflicts of Interest
The first author is now working at NTT laboratories. This work has been done when the first author is in the University of Tokyo.
Abbreviations
The following abbreviations are used in this manuscript:
| DFS | Depth-First Search |
| ORS query | Orthogonal Range Successor query |
| ORP query | Orthogonal Range Predecessor query |
| HL decomposition | Heavy-Light decomposition |
| LCA query | Lowest Common Ancestor query |
References
- Franciosa, P.G.; Gambosi, G.; Nanni, U. The incremental maintenance of a Depth-First-Search tree in directed acyclic graphs. Inf. Process. Lett. 1997, 61, 113–120. [Google Scholar] [CrossRef]
- Baswana, S.; Choudhary, K. On dynamic DFS tree in directed graphs. In Proceedings of the 40th International Symposium on Mathematical Foundations of Computer Science (MFCS), Milan, Italy, 24–28 August 2015; Volume 9235, pp. 102–114. [Google Scholar]
- Baswana, S.; Khan, S. Incremental algorithm for maintaining DFS tree for undirected graphs. In Proceedings of the 41st International Colloquium on Automata, Languages, and Programming (ICALP), Copenhagen, Denmark, 8–11 July 2014; Volume 8572, pp. 138–149. [Google Scholar]
- Baswana, S.; Chaudhury, S.R.; Choudhary, K.; Khan, S. Dynamic DFS in undirected graphs: Breaking the O(m) barrier. In Proceedings of the Twenty-Seventh Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), Arlington, VA, USA, 10–12 January 2016; pp. 730–739. [Google Scholar]
- Chen, L.; Duan, R.; Wang, R.; Zhang, H. Improved algorithms for maintaining DFS tree in undirected graphs. arXiv, 2016; arXiv:1607.04913. [Google Scholar]
- Baswana, S.; Chaudhury, S.R.; Choudhary, K.; Khan, S. Dynamic DFS in undirected graphs: Breaking the O(m) barrier. arXiv, 2015; arXiv:1502.02481. [Google Scholar]
- Chen, L.; Duan, R.; Wang, R.; Zhang, H.; Zhang, T. An improved algorithm for incremental DFS tree in undirected graphs. In Proceedings of the 16th Scandinavian Symposium and Workshops on Algorithm Theory (SWAT), Malmö, Sweden, 18–20 June 2018; pp. 16:1–16:12. [Google Scholar]
- Baswana, S.; Goel, A.; Khan, S. Incremental DFS algorithms: A theoretical and experimental study. In Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), New Orleans, LA, USA, 7–10 January 2018; pp. 53–72. [Google Scholar]
- Khan, S. Near optimal parallel algorithms for dynamic DFS in undirected graphs. In Proceedings of the 29th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), Washington, DC, USA, 24–26 July 2017; pp. 283–292. [Google Scholar]
- Nakamura, K.; Sadakane, K. A space-efficient algorithm for the dynamic DFS problem in undirected graphs. In Proceedings of the 11th International Conference and Workshops on Algorithms and Computation (WALCOM), Hsinchu, Taiwan, 29–31 March 2017; Volume 10167, pp. 295–307. [Google Scholar]
- Baswana, S.; Gupta, S.K.; Tulsyan, A. Fault tolerant and fully dynamic DFS in undirected graphs: Simple yet efficient. arXiv, 2018; arXiv:1810.01726. [Google Scholar]
- Grossi, R.; Gupta, A.; Vitter, J.S. High-order entropy-compressed text indexes. In Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), Baltimore, MD, USA, 12–14 January 2003; pp. 841–850. [Google Scholar]
- Frigioni, D.; Italiano, G.F. Dynamically switching vertices in planar graphs. Algorithmica 2000, 28, 76–103. [Google Scholar] [CrossRef]
- Chan, T.M.; Pătraşcu, M.; Roditty, L. Dynamic connectivity: Connecting to networks and geometry. SIAM J. Comput. 2011, 40, 333–349. [Google Scholar] [CrossRef]
- Jacobson, G. Space-efficient static trees and graphs. In Proceedings of the 30th Annual Symposium on Foundations of Computer Science (FOCS), Research Triangle Park, NC, USA, 30 October–1 November 1989; pp. 549–554. [Google Scholar]
- Clark, D. Compact Pat Trees. Ph.D. Thesis, University of Waterloo, Waterloo, ON, Canada, 1996. [Google Scholar]
- Raman, R.; Raman, V.; Rao, S.S. Succinct indexable dictionaries with applications to encoding k-ary trees, prefix sums and multisets. ACM Trans. Algorithms 2007, 3, 43. [Google Scholar] [CrossRef]
- Munro, J.I.; Nekrich, Y.; Vitter, J.S. Fast construction of wavelet trees. Theor. Comput. Sci. 2016, 638, 91–97. [Google Scholar] [CrossRef]
- Sleator, D.D.; Tarjan, R.E. A data structure for dynamic trees. J. Comput. Syst. Sci. 1983, 26, 362–391. [Google Scholar] [CrossRef]
- Bender, M.A.; Farach-Colton, M. The LCA problem revisited. In Proceedings of the 4th Latin American Symposium on Theoretical Informatics (LATIN), Punta del Esk, Uruguay, 10–14 April 2000; Volume 1776, pp. 88–94. [Google Scholar]
- Belazzougui, D.; Puglisi, S.J. Range predecessor and Lempel-Ziv parsing. In Proceedings of the Twenty-Seventh Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), Arlington, VA, USA, 10–12 January 2016; pp. 2053–2071. [Google Scholar]
- Yu, C.C.; Hon, W.K.; Wang, B.F. Improved data structures for the orthogonal range successor problem. Comput. Geom. 2011, 44, 148–159. [Google Scholar] [CrossRef]
- Navarro, G. Wavelet trees for all. J. Discret. Algorithms 2014, 25, 2–20. [Google Scholar] [CrossRef]
- Kreft, S.; Navarro, G. Self-indexing based on LZ77. In Proceedings of the 22nd Annual Symposium on Combinatorial Pattern Matching (CPM), Palermo, Italy, 27–29 June 2011; Volume 6661, pp. 41–54. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).