Optimized Deep Convolutional Neural Networks for Identification of Macular Diseases from Optical Coherence Tomography Images


Abstract
:1. Introduction
2. Architectures of the Modified Deep Neural Networks (DNNs)
2.1. Sub-Networks of Inception-v3
2.2. Sub-Networks of ResNet50
2.3. Sub-Networks of DenseNet121
3. Experiments and Results
3.1. Performance of the Sub-Networks on Large-Scale Dataset
3.2. Performance of the Sub-Networks on Small-Scale Dataset
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bourne, R.R.; Jonas, J.B.; Flaxman, S.R.; Keeffe, J.; Leasher, J.; Naidoo, K.; Parodi, M.B.; Pesudovs, K.; Price, H.; White, R.A.; et al. Prevalence and causes of vision loss in high-income countries and in Eastern and Central Europe: 1990–2010. Br. J. Ophthalmol. 2014, 98, 629–638. [Google Scholar] [CrossRef] [PubMed]
- Romero-Aroca, P. Current status in diabetic macular edema treatments. World J. Diabetes 2013, 4, 165–169. [Google Scholar] [CrossRef] [PubMed]
- Rickman, C.B.; Farsiu, S.; Toth, C.A.; Klingeborn, M. Dry age-related macular degeneration: Mechanisms, therapeutic targets, and imaging. Investig. Ophthalmol. Vis. Sci. 2013, 54, ORSF68–ORSF80. [Google Scholar] [CrossRef] [PubMed]
- Ciulla, T.A.; Amador, A.G.; Zinman, B. Diabetic retinopathy and diabetic macular edema: Pathophysiology, screening, and novel therapies. Diabetes Care 2003, 26, 2653–2664. [Google Scholar] [CrossRef] [PubMed]
- Farsiu, S.; Chiu, S.J.; O’Connell, R.V.; Folgar, F.A.; Yuan, E.; Izatt, J.A.; Toth, C.A. Quantitative classification of eyes with and without intermediate age-related macular degeneration using optical coherence tomography. Ophthalmology 2014, 121, 162–172. [Google Scholar] [CrossRef] [PubMed]
- Gregori, G.; Wang, F.; Rosenfeld, P.J.; Yehoshua, Z.; Gregori, N.Z.; Lujan, B.J.; Puliafito, C.A.; Feuer, W.J. Spectral domain optical coherence tomography imaging of drusen in nonexudative age-related macular degeneration. Ophthalmology 2011, 118, 1373–1379. [Google Scholar] [CrossRef] [PubMed]
- Swanson, E.A.; Fujimoto, J.G. The ecosystem that powered the translation of OCT from fundamental research to clinical and commercial impact. Biomed. Opt. Express 2017, 8, 1638–1664. [Google Scholar] [CrossRef] [PubMed]
- Van Velthoven, M.E.; Faber, D.J.; Verbraak, F.D.; van Leeuwen, T.G.; de Smet, M.D. Recent developments in optical coherence tomography for imaging the retina. Prog. Retin. Eye Res. 2007, 26, 57–77. [Google Scholar] [CrossRef] [PubMed]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.S.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 2018, 172, 1122–1131. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.Y.; Chen, M.; Ishikawa, H.; Wollstein, G.; Schuman, J.S.; Rehg, J.M. Automated macular pathology diagnosis in retinal OCT images using multi-scale spatial pyramid and local binary patterns in texture and shape encoding. Med. Image Anal. 2011, 15, 748–759. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Hijazi, M.H.A.; Coenen, F. Automated ‘disease/no disease’ grading of age-related macular degeneration by an image mining approach. Investig. Ophthalmol. Vis. Sci. 2012, 53, 8310–8318. [Google Scholar] [CrossRef] [PubMed]
- Hijazi, M.H.A.; Coenen, F.; Zheng, Y. Data mining techniques for the screening of age-related macular degeneration. Knowl. Based Syst. 2012, 29, 83–92. [Google Scholar] [CrossRef]
- Srinivasan, P.P.; Kim, L.A.; Mettu, P.S.; Cousins, S.W.; Comer, G.M.; Izatt, J.A.; Farsiu, S. Fully automated detection of diabetic macular edema and dry age-related macular degeneration from optical coherence tomography images. Biomed. Opt. Express 2014, 5, 3568–3577. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Li, S.; Sun, Z. Fully automated macular pathology detection in retina optical coherence tomography images using sparse coding and dictionary learning. J. Biomed. Opt. 2017, 22, 016012. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 22–25 June 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems conference, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erjam, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115. [Google Scholar] [CrossRef] [PubMed]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. Jama 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Abdolmanafi, A.; Duong, L.; Dahdah, N.; Adib, I.R.; Cheriet, F. Characterization of coronary artery pathological formations from OCT imaging using deep learning. Biomed. Opt. Express 2018, 9, 4936–4960. [Google Scholar] [CrossRef] [PubMed]
- Karri, S.P.K.; Chakraborty, D.; Chatterjee, J. Transfer learning based classification of optical coherence tomography images with diabetic macular edema and dry age-related macular degeneration. Biomed. Opt. Express 2017, 8, 579–592. [Google Scholar] [CrossRef] [PubMed]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [PubMed]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Yosinski, J.; Clune, J.; Nguyen, A.; Fuchs, T.; Lipson, H. Understanding neural networks through deep visualization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv, 2017; arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Keras. Available online: https://github.com/keras-team/keras (accessed on 20 July 2018).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Ji, Q.; He, W.; Huang, J.; Sun, Y. Efficient Deep Learning-Based Automated Pathology Identification in Retinal Optical Coherence Tomography Images. Algorithms 2018, 11, 88. [Google Scholar] [CrossRef]






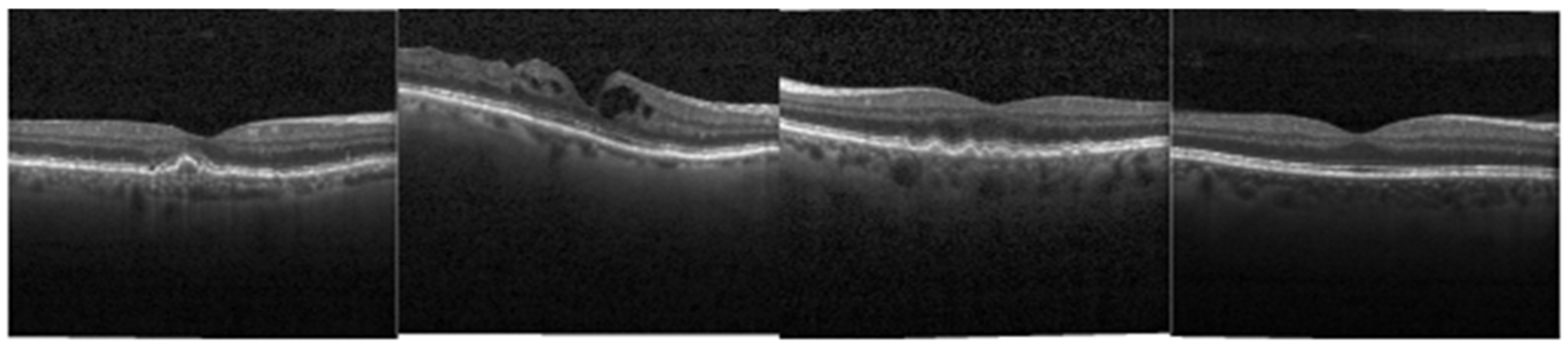{kind=link}
{kind=link}
{kind=link}
{kind=link}
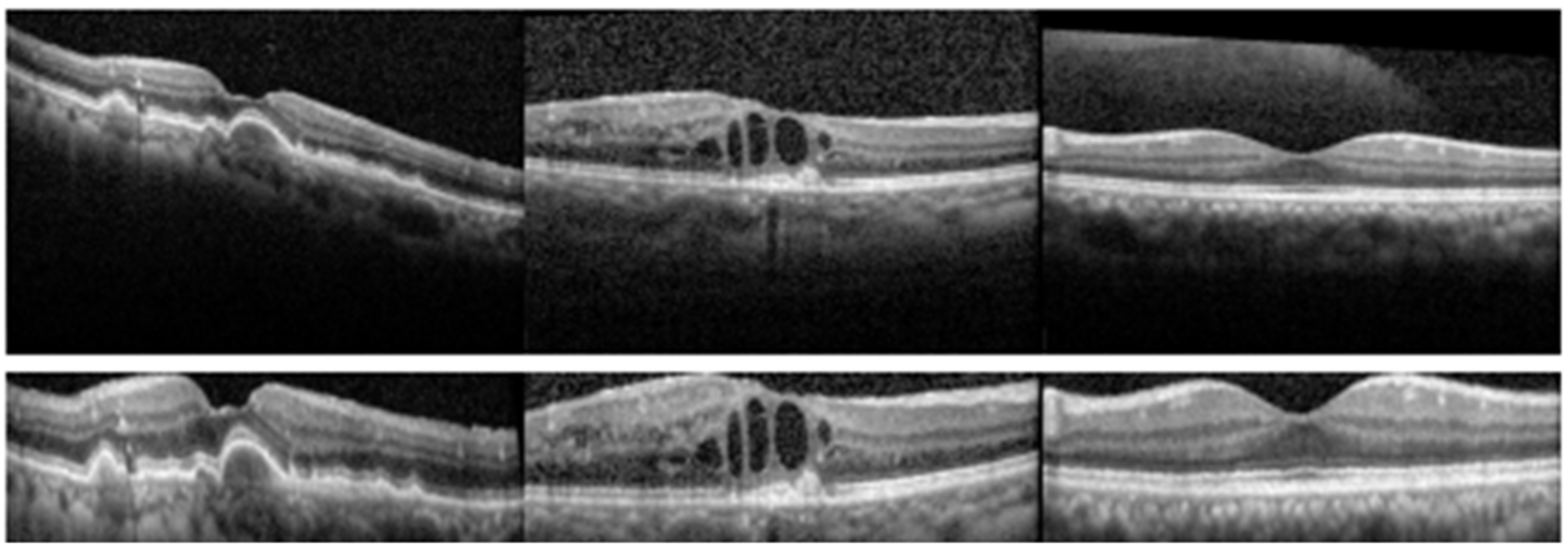{kind=link}
| Inception-v3 | Total | Trainable | Non-Trainable |
|---|---|---|---|
| Mixed6 | 6,834,468 | 6,819,492 | 14,976 |
| Mixed7 | 8,978,340 | 8,959,524 | 18,816 |
| Mixed8 | 10,679,972 | 10,658,596 | 21,376 |
| Mixed9 | 15,730,916 | 15,703,012 | 27,904 |
| Mixed10 | 21,810,980 | 21,776,548 | 34,432 |
| ResNet50 | Total | Trainable | Non-Trainable |
|---|---|---|---|
| Ac37 | 7,471,492 | 7,443,972 | 27,520 |
| Ac40 | 8,593,284 | 8,562,692 | 30,592 |
| Ac43 | 14,652,292 | 14,611,460 | 40,832 |
| Ac46 | 19,124,100 | 19,077,124 | 43,976 |
| Ac49 | 23,595,908 | 23,542,788 | 53,120 |
| DenseNet121 | Total | Trainable | Non-Trainable |
|---|---|---|---|
| C5_b2 | 5,063,620 | 5,007,556 | 56,064 |
| C5_b4 | 5,294,916 | 5,235,972 | 58,944 |
| C5_b6 | 5,543,108 | 5,481,028 | 62,080 |
| C5_b8 | 5,808,196 | 5,742,724 | 65,472 |
| C5_b10 | 6,090,180 | 6,021,060 | 69,120 |
| C5_b12 | 6,389,060 | 6,316,036 | 73,024 |
| C5_b14 | 6,704,836 | 6,627,652 | 77,184 |
| C5_b16 | 7,037,508 | 6,955,908 | 81,600 |
| Accuracy | Sensitivity | Specificity | ||
|---|---|---|---|---|
| IBDL [9] | 96.60 | 97.80 | 97.40 | |
| Sub-networks of Inception-v3 | Mixed6 | 99.70 | 99.40 | 99.80 |
| Mixed7 | 99.35 | 98.70 | 99.57 | |
| Mixed8 | 99.70 | 99.40 | 99.80 | |
| Mixed9 | 99.55 | 99.10 | 99.70 | |
| Mixed10 | 99.70 | 99.40 | 99.80 | |
| Sub-networks of ResNet50 | Ac37 | 99.60 | 99.20 | 99.73 |
| Ac40 | 99.65 | 99.30 | 99.77 | |
| Ac43 | 99.45 | 98.90 | 99.63 | |
| Ac46 | 99.60 | 99.20 | 99.73 | |
| Ac49 | 99.60 | 99.20 | 99.73 | |
| Sub-networks of DenseNet121 | C5_b2 | 99.50 | 99.00 | 99.67 |
| C5_b4 | 99.80 | 99.60 | 99.87 | |
| C5_b6 | 99.45 | 98.90 | 99.77 | |
| C5_b8 | 99.65 | 99.30 | 99.77 | |
| C5_b10 | 99.75 | 99.50 | 99.83 | |
| C5_b12 | 99.70 | 99.40 | 99.80 | |
| C5_b14 | 99.80 | 99.60 | 99.87 | |
| C5_b16 | 99.75 | 99.50 | 99.83 | |
| Accuracy | Sensitivity | Specificity | ||
|---|---|---|---|---|
| ScSPM [14] | 97.75 | 96.67 | 98.30 | |
| DL-based CNN [35] | 98.86 | 98.30 | 99.15 | |
| IBDL [9] | 94.57 | 92.03 | 95.85 | |
| Sub-networks of Inception-v3 | Mixed6 | 99.67 ± 0.08 | 99.50 ± 0.12 | 99.75 ± 0.06 |
| Mixed7 | 99.51 ± 0.17 | 99.26 ± 0.25 | 99.63 ± 0.13 | |
| Mixed8 | 99.58 ± 0.13 | 99.37 ± 0.19 | 99.68 ± 0.10 | |
| Mixed9 | 99.56 ± 0.17 | 99.35 ± 0.25 | 99.67 ± 0.13 | |
| Mixed10 | 99.27 ± 0.41 | 98.90 ± 0.61 | 99.45 ± 0.31 | |
| Sub-networks of ResNet50 | Ac37 | 99.49 ± 0.18 | 99.24 ± 0.26 | 99.62 ± 0.13 |
| Ac40 | 99.35 ± 0.19 | 99.02 ± 0.28 | 99.51 ± 0.14 | |
| Ac43 | 99.34 ± 0.19 | 99.01 ± 0.29 | 99.50 ± 0.14 | |
| Ac46 | 99.27 ± 0.19 | 98.90 ± 0.28 | 99.45 ± 0.14 | |
| Ac49 | 99.09 ± 0.25 | 98.64 ± 0.38 | 99.32 ± 0.19 | |
| Sub-networks of DenseNet121 | C5_b2 | 99.53 ± 0.16 | 99.30 ± 0.24 | 99.65 ± 0.12 |
| C5_b4 | 99.56 ± 0.17 | 99.35 ± 0.26 | 99.67 ± 0.13 | |
| C5_b6 | 99.60 ± 0.18 | 99.40 ± 0.26 | 99.70 ± 0.13 | |
| C5_b8 | 99.53 ± 0.18 | 99.30 ± 0.27 | 99.65 ± 0.13 | |
| C5_b10 | 99.46 ± 0.23 | 99.19 ± 0.34 | 99.59 ± 0.17 | |
| C5_b12 | 99.48 ± 0.17 | 99.23 ± 0.26 | 99.61 ± 0.13 | |
| C5_b14 | 99.55 ± 0.16 | 99.33 ± 0.24 | 99.67 ± 0.12 | |
| C5_b16 | 99.58 ± 0.11 | 99.37 ± 0.17 | 99.68 ± 0.08 | |
| Average | Standard Deviation | F | p-Value | F Crit | |
|---|---|---|---|---|---|
| Mixed6 | 99.67 | 0.08 | 8.984 | 7.73 × 10−3 | 4.414 |
| Mixed10 | 99.27 | 0.41 | |||
| Ac37 | 99.49 | 0.18 | 16.690 | 6.94 × 10−4 | 4.414 |
| Ac49 | 99.09 | 0.25 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, Q.; Huang, J.; He, W.; Sun, Y. Optimized Deep Convolutional Neural Networks for Identification of Macular Diseases from Optical Coherence Tomography Images. Algorithms 2019, 12, 51. https://doi.org/10.3390/a12030051
Ji Q, Huang J, He W, Sun Y. Optimized Deep Convolutional Neural Networks for Identification of Macular Diseases from Optical Coherence Tomography Images. Algorithms. 2019; 12(3):51. https://doi.org/10.3390/a12030051
Chicago/Turabian StyleJi, Qingge, Jie Huang, Wenjie He, and Yankui Sun. 2019. "Optimized Deep Convolutional Neural Networks for Identification of Macular Diseases from Optical Coherence Tomography Images" Algorithms 12, no. 3: 51. https://doi.org/10.3390/a12030051
APA StyleJi, Q., Huang, J., He, W., & Sun, Y. (2019). Optimized Deep Convolutional Neural Networks for Identification of Macular Diseases from Optical Coherence Tomography Images. Algorithms, 12(3), 51. https://doi.org/10.3390/a12030051