
Renewable Electricity Management Cloud System for Smart Communities Using Advanced Machine Learning



Abstract
1. Introduction
2. Related Works
2.1. Literature Review
2.1.1. Electricity Consumption/Usage Forecasting
2.1.2. Electricity Generation Forecasting
2.1.3. Shortage Analysis
2.2. Technology Survey
2.3. Research Gap and Contributions
2.3.1. Identified Research Gaps
- Models for forecasting shortages have limited accuracy:Traditional machine learning techniques or static rule-based approaches are the mainstays of existing models, which fall short in capturing intricate patterns of energy output and consumption. High-precision shortfall prediction mechanisms are lacking in research experiments that concentrate on load forecasting. Furthermore, the use of reinforcement learning to improve decision-making in shortage forecasting has not been extensively used.
- Absence of a Community-Based, Generalized Model: The majority of current research creates energy forecasting models for small-scale or single-building configurations. These models frequently do not generalize to other places, times of year, or populations. Their practicality is limited by the lack of a community-based, scalable forecasting mechanism.
- Inadequate Hybrid AI Technique Utilization: The benefits of hybrid models are not utilized by traditional forecasting techniques, which mostly rely on either machine learning (e.g., SVM, Random Forest) or deep learning (e.g., CNN, LSTM). When maximizing forecasting accuracy and decision-making, studies hardly ever combine reinforcement learning with AI techniques.
- Inadequate Real-Time Energy Trading Decision Support: Although many models forecast energy production and consumption, they do not provide useful information about when to purchase, sell, or store electricity. This restricts their usefulness in real-world energy markets.
- Lack of Distributed and Aggregated Decision Models: The majority of current research assesses centralized energy management systems, which are not flexible enough for multi-building or multi-meter settings. Distributed training models that support both localized and aggregated decision-making are required.
2.3.2. Contributions of This Research
- Development of a High-Accuracy Model for Forecasting Shortages: This research presents a unique framework for shortage prediction that combines AI models with reinforcement learning (Q-learning and SARSA), which outperforms conventional machine learning models by achieving a 98.2% accuracy rate in shortage predicting.
- Community-Based Energy Forecasting System: This model is generalized and scalable, making it suitable for a range of geographic areas and seasonal fluctuations. Our method allows for forecasting over numerous buildings in a neighborhood, in contrast to current single-building models.
- Using Hybrid AI to Enhance Prediction: To maximize performance, our model combines the output of CNN, LSTM, SVM, and XGBoost with reinforcement learning. This model’s results ultimately show a 20% improvement in accuracy over stand-alone machine learning or deep learning models.
- Energy Trading Decision Support in Real Time: Based on forecasts of energy shortages, it offers practical advice on when to purchase, sell, or store energy. This increases the effectiveness of energy management while lowering dependency on non-renewable resources.
- Using Aggregated and Distributed Decision Models: This model structure creates a distributed training methodology in which separate buildings generate forecasts on their own. This ultimately establishes a structure of collective decision-making that offers a comprehensive perspective on community energy management.
3. Electricity Management System Design
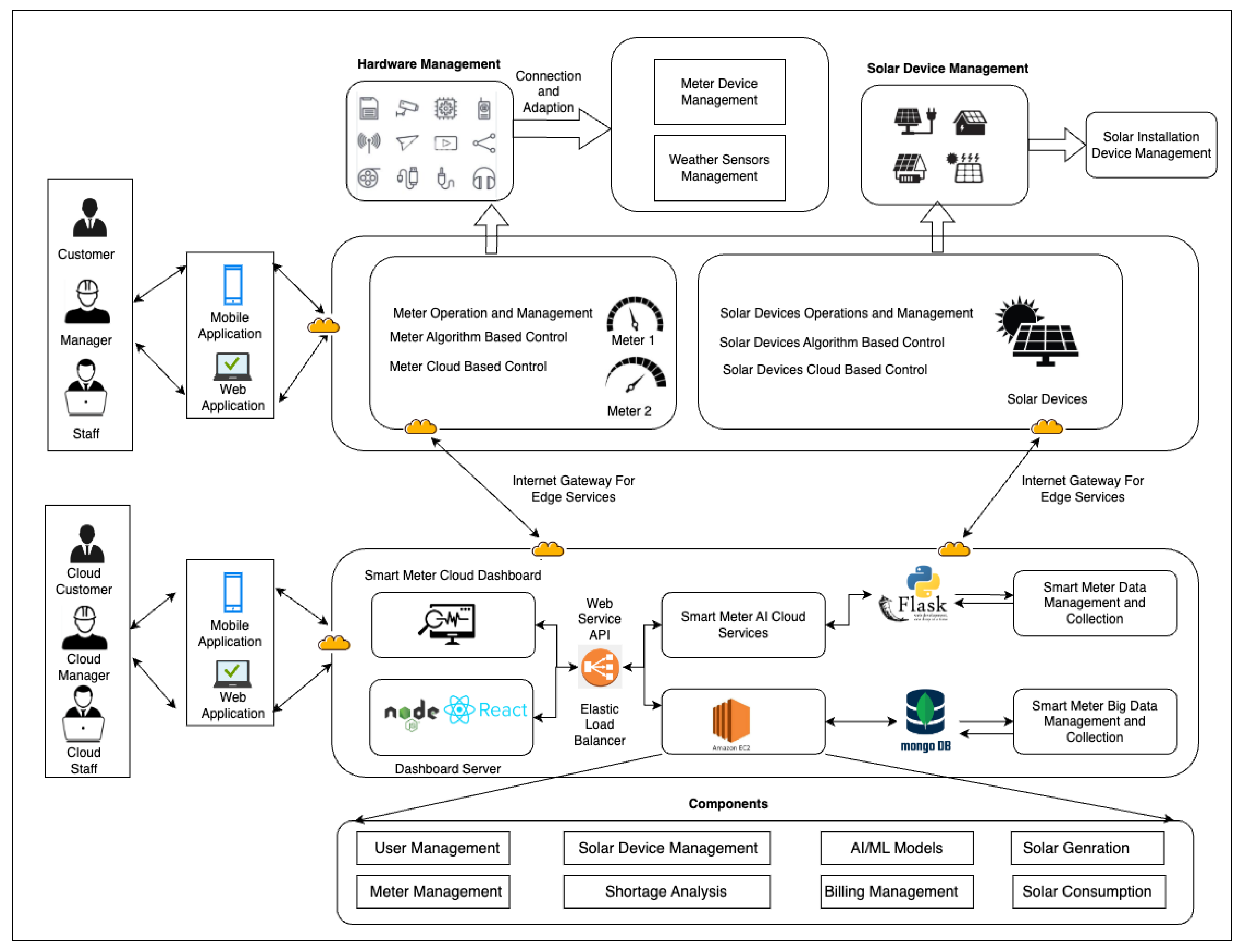
3.1. System Architecture
3.2. Cloud AI
3.3. Front End
3.4. Database
4. System Use Cases
4.1. Use Case 1: Making Data-Driven Decisions
4.2. Use Case 2: Managing System Hardware
4.3. Use Case 3: Consolidated Dashboard for Generation, Consumption, and Shortage Analysis
5. Data Engineering
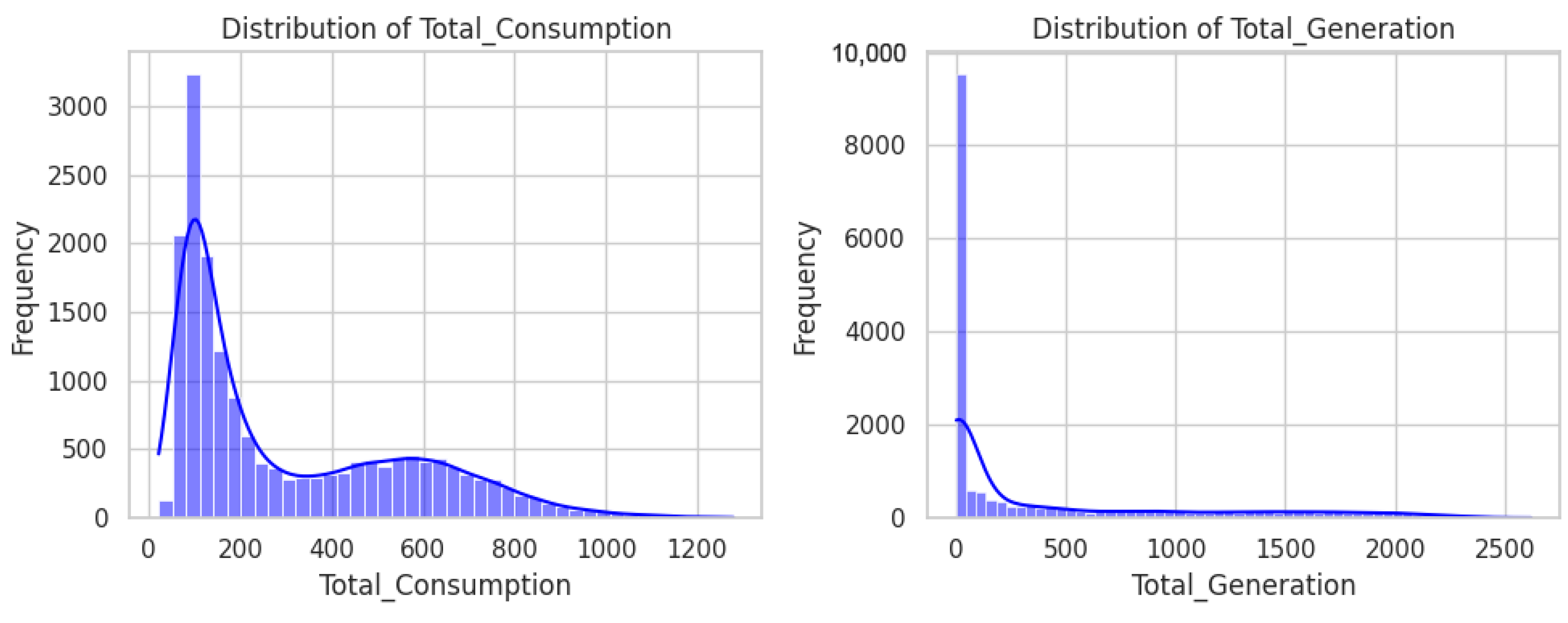
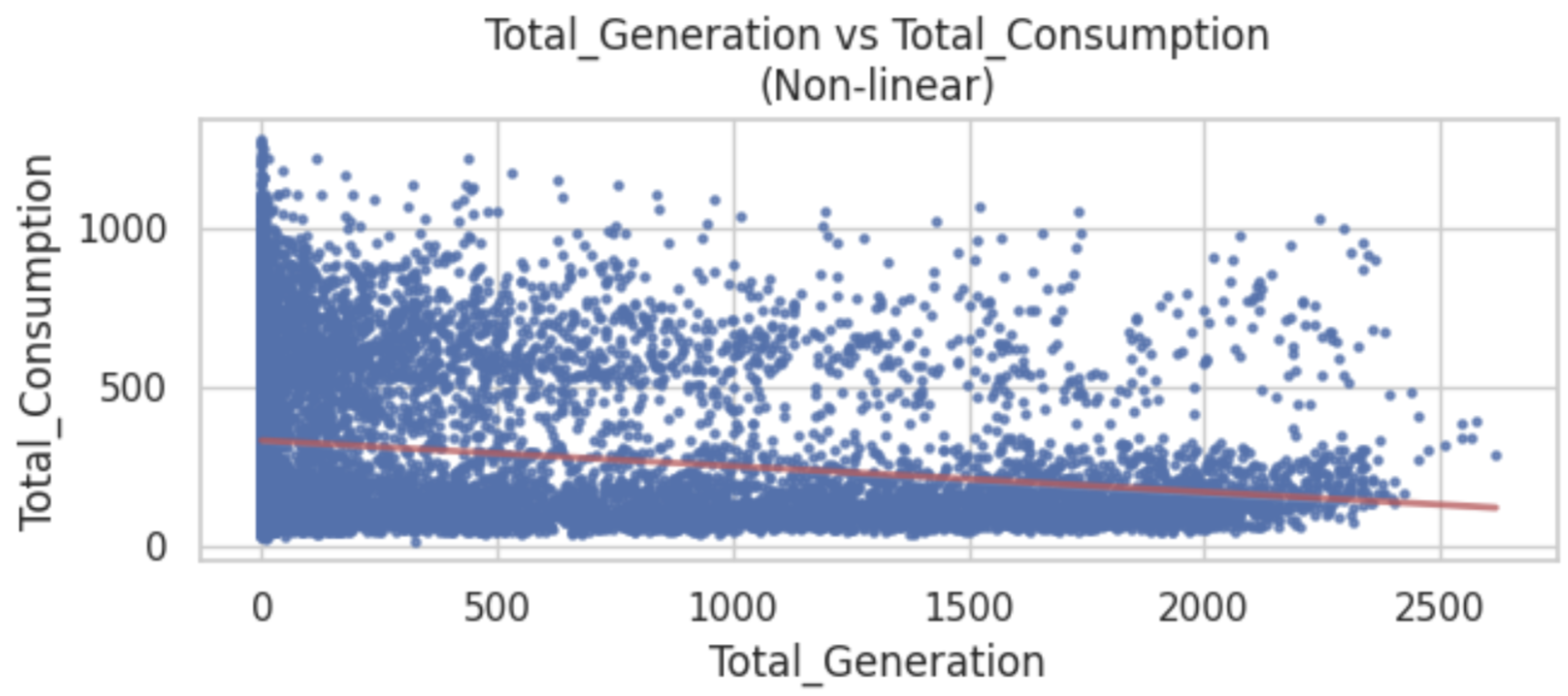
5.1. Data Collection
5.2. Data Pre-Processing
- Gb(i): Beam irradiance on the inclined plane (plane of the array) ().
- Gd(i): Diffuse irradiance on the inclined plane (plane of the array) ().
- Gr(i): Reflected irradiance on the inclined plane (plane of the array) ().
5.3. Training Data Preparation
6. Model Development
6.1. Approach 1: Traditional Models
6.1.1. Long Short-Term Memory (LSTM)
6.1.2. Convolutional Neural Network (CNN)
6.1.3. Support Vector Regressor (SVR)
6.1.4. Random Forest Regressor (RFR)
6.1.5. Extreme Gradient Boosting (XGBOOST)
6.1.6. Shortage Forecasting Model Development
6.2. Approach 2: Aggregated Training Learning Models
6.3. Approach 3: Distributed Training Learning Models
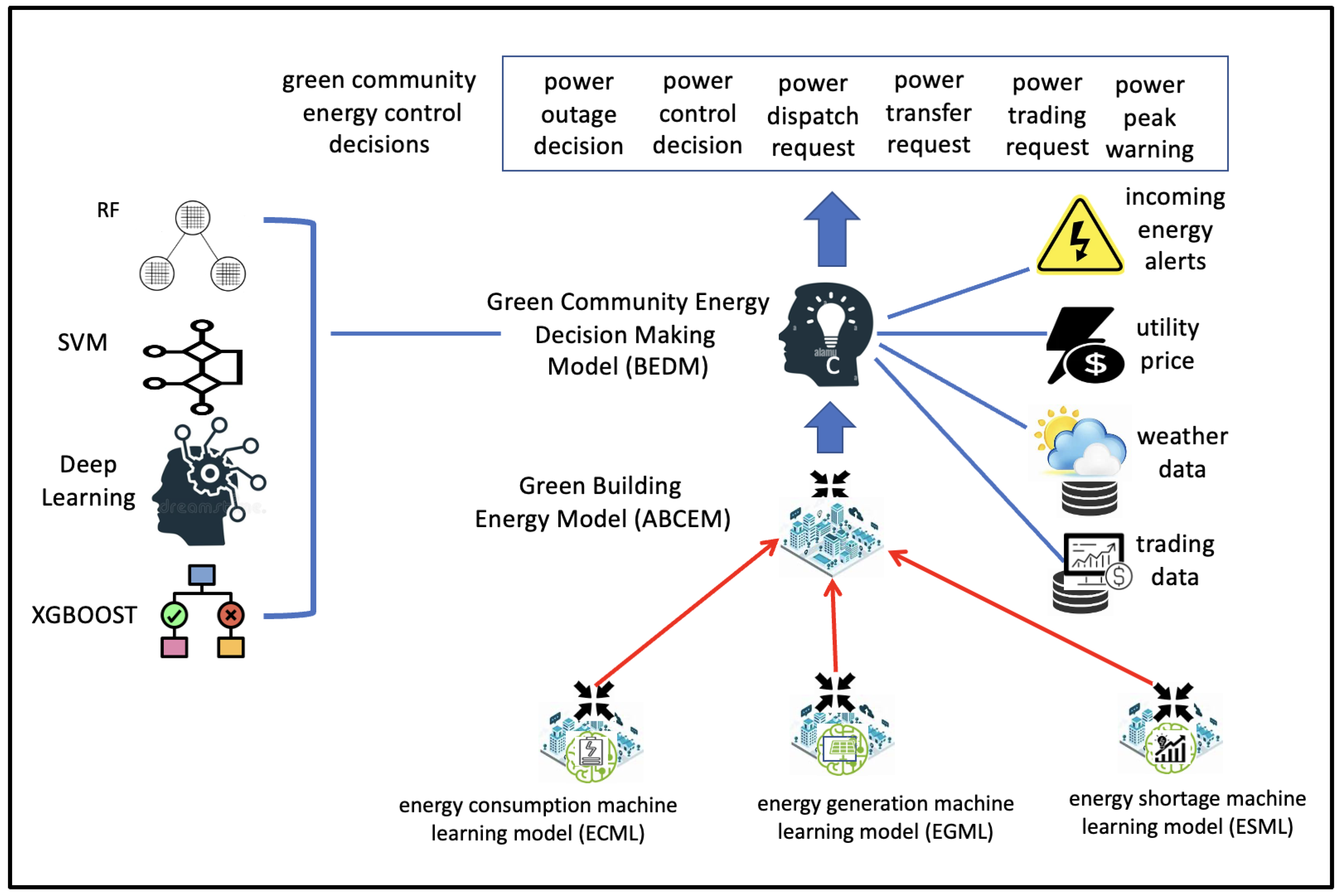
7. Decision-Making
7.1. Distributed Decision-Making
7.2. Aggregated Decision-Making
8. Results
9. Conclusions
Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MAE | Mean Absolute Error |
| RMSE | Root Mean Squared Error |
References
- Allied Market Research. Green Energy Market to Reach $2.4 Trillion, Globally, by 2032 at 8.9% CAGR: Allied Market Research. Cision PR Newswire, 11 December 2023. Available online: https://www.prnewswire.com/news-releases/green-energy-market-to-reach-2-4-trillion-globally-by-2032-at-8-9-cagr-allied-market-research-302011705.html (accessed on 11 December 2023).
- Calero, I.; Cañizares, C.A.; Bhattacharya, K.; Baldick, R. Duck-Curve Mitigation in Power Grids With High Penetration of PV Generation. IEEE Trans. Smart Grid 2022, 13, 314–329. [Google Scholar] [CrossRef]
- Powerwall. Tesla. (n.d.). Available online: https://www.tesla.com/powerwall (accessed on 13 June 2024).
- Ahmad, A.; Javaid, N.; Mateen, A.; Awais, M.; Khan, Z.A. Short-term load forecasting in smart grids: An intelligent modular approach. Energies 2019, 12, 164. [Google Scholar] [CrossRef]
- Bano, H.; Tahir, A.; Ali, I.; Khan, R.J.U.H.; Haseeb, A.; Javaid, N. Electricity load and price forecasting using enhanced machine learning techniques. In Innovative Mobile and Internet Services in Ubiquitous Computing; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 255–267. [Google Scholar]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M. Optimal deep learning LSTM model for electric load forecasting using feature selection and genetic algorithm: Comparison with machine learning approaches. Energies 2018, 11, 1636. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Multi-sequence LSTM-RNN deep learning and metaheuristics for electric load forecasting. Energies 2020, 13, 391. [Google Scholar] [CrossRef]
- Estebsari, A.; Rajabi, R. Single residential load forecasting using deep learning and image encoding techniques. Electronics 2020, 9, 68. [Google Scholar] [CrossRef]
- Guo, N.; Chen, W.; Wang, M.; Tian, Z.; Jin, H. Appling an improved method based on ARIMA model to predict the short-term electricity consumption transmitted by the Internet of Things (IoT). Wirel. Commun. Mob. Comput. 2021, 2021, 6610273. [Google Scholar] [CrossRef]
- Kuo, P.-H.; Huang, C.-J. A high precision artificial neural networks model for short-term energy load forecasting. Energies 2018, 11, 213. [Google Scholar] [CrossRef]
- Nepal, B.; Yamaha, M.; Yokoe, A.; Yamaji, T. Electricity load forecasting using clustering and ARIMA model for energy management in buildings. Jpn. Archit. Rev. 2020, 3, 62–76. [Google Scholar] [CrossRef]
- Rai, S.; De, M. Analysis of classical and machine learning based short-term and mid-term load forecasting for smart grid. Int. J. Sustain. Energy 2021, 40, 821–839. [Google Scholar] [CrossRef]
- Tong, C.; Li, J.; Lang, C.; Kong, F.; Niu, J.; Rodrigues, J.J.P.C. An efficient deep model for day-ahead electricity load forecasting with stacked denoising auto-encoders. J. Parallel Distrib. Comput. 2018, 117, 267–273. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Khan, N.; Hussain, T.; Lee, M.Y.; Baik, S.W. Diving deep into short-term electricity load forecasting: Comparative analysis and a novel framework. Mathematics 2021, 9, 611. [Google Scholar] [CrossRef]
- Zhang, J.; Wei, Y.-M.; Li, D.; Tan, Z.; Zhou, J. Short term electricity load forecasting using a hybrid model. Energy 2018, 158, 774–781. [Google Scholar] [CrossRef]
- Mehta, Y.; Xu, R.; Lim, B.; Wu, J.; Gao, J. A Review for Green Energy Machine Learning and AI Services. Energies 2023, 16, 5718. [Google Scholar] [CrossRef]
- BP Statistical Review of World Energy 2018. BP Statistical Review of World Energy 2018: Two Steps Forward, One Step Back,” bp Global. [Online]. Available online: https://www.bp.com/en/global/corporate/news-and-insights/press-releases/bp-statistical-review-of-world-energy-2018.html (accessed on 17 July 2024).
- World Energy Outlook 2018. (n.d.). IEA. Paris, France, 2018. Available online: https://www.iea.org/reports/world-energy-outlook-2018 (accessed on 17 July 2024).
- Mahmud, K.; Azam, S.; Karim, A.; Zobaed, S.; Shanmugam, B.; Mathur, D. Machine Learning Based PV Power Generation Forecasting in Alice Springs. IEEE Access 2021, 9, 46117–46128. [Google Scholar] [CrossRef]
- Liu, C.-H.; Gu, J.-C.; Yang, M.-T. A Simplified LSTM Neural Networks for One Day-Ahead Solar Power Forecasting. IEEE Access 2021, 9, 17174–17195. [Google Scholar] [CrossRef]
- Jebli, I.; Belouadha, F.-Z.; Kabbaj, M.I.; Tilioua, A. Prediction of Solar Energy Guided by Pearson Correlation Using Machine Learning. Energy 2021, 224, 120109. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, Q.; Yan, K.; Du, Y. Deep Learning Enhanced Solar Energy Forecasting with AI-Driven IoT. Wirel. Commun. Mob. Comput. 2021, 2021, 9249387. [Google Scholar] [CrossRef]
- Babbar, S.M.; Lau, C.Y.; Thang, K.F. Long Term Solar Power Generation Prediction Using Adaboost as a Hybrid of Linear and Non-Linear Machine Learning Model. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 536–546. [Google Scholar] [CrossRef]
- Chodakowska, E.; Nazarko, J.; Nazarko, Ł.; Rabayah, H.S.; Abendeh, R.M.; Alawneh, R. ARIMA models in solar radiation forecasting in different geographic locations. Energies 2023, 16, 5029. [Google Scholar] [CrossRef]
- Khan, W.; Walker, S.; Zeiler, W. Improved solar photovoltaic energy generation forecast using deep learning-based ensemble stacking approach. Energy 2022, 240, 122812. [Google Scholar] [CrossRef]
- Atique, S.; Noureen, S.; Roy, V.; Subburaj, V.; Bayne, S.; Macfie, J. Forecasting of total daily solar energy generation using ARIMA: A case study. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 0114–0119. [Google Scholar] [CrossRef]
- Kim, E.; Akhtar, M.S.; Yang, O.-B. Designing solar power generation output forecasting methods using time series algorithms. Electr. Power Syst. Res. 2023, 216, 109073. [Google Scholar] [CrossRef]
- Lim, S.-C.; Huh, J.-H.; Hong, S.-H.; Park, C.-Y.; Kim, J.-C. Solar power forecasting using CNN-LSTM hybrid model. Energies 2022, 15, 8233. [Google Scholar] [CrossRef]
- Maciejowska, K.; Nitka, W.; Weron, T. Enhancing load, wind and solar generation for day-ahead forecasting of electricity prices. Energy Econ. 2021, 99, 105273. [Google Scholar] [CrossRef]
- Pan, C.; Tan, J.; Feng, D. Prediction intervals estimation of solar generation based on gated recurrent unit and kernel density estimation. Neurocomputing 2021, 453, 552–562. [Google Scholar] [CrossRef]
- Kim, S.-G.; Jung, J.-Y.; Sim, M.K. A Two-Step Approach to Solar Power Generation Prediction Based on Weather Data Using Machine Learning. Sustainability 2019, 11, 1501. [Google Scholar] [CrossRef]
- Hameed, Z.; Hashemi, S.; Traholt, C. Applications of AI-based forecasts in renewable based electricity balancing markets. In Proceedings of the 2021 22nd IEEE International Conference on Industrial Technology (ICIT), Virtual, 10–12 March 2021; Volume 1, pp. 579–584. [Google Scholar]
- Bâra, A.; Oprea, S.-V. Intelligent system to optimally trade at the interference of multiple crises. Appl. Intell. 2023, 53, 25581–25604. [Google Scholar] [CrossRef]
- Bottieau, J.; Hubert, L.; De Greve, Z.; Vallee, F.; Toubeau, J.-F. Very-short-term probabilistic forecasting for a risk-aware participation in the single price imbalance settlement. IEEE Trans. Power Syst. Publ. Power Eng. Soc. 2020, 35, 1218–1230. [Google Scholar] [CrossRef]
- Essl, A.; Ortner, A.; Haas, R.; Hettegger, P. Machine learning analysis for a flexibility energy approach towards renewable energy integration with dynamic forecasting of electricity balancing power. In Proceedings of the 2017 14th International Conference on the European Energy Market (EEM), Dresden, Germany, 6–9 June 2017; pp. 1–6. [Google Scholar]
- Jaehnert, S.; Farahmand, H.; Doorman, G.L. Modelling of prices using the volume in the Norwegian regulating power market. In Proceedings of the 2009 IEEE Bucharest PowerTech, Bucharest, Romania, 28 June–2 July 2009; pp. 1–7. [Google Scholar]
- Santos, G.; Pinto, T.; Vale, Z.; Morais, H.; Praca, I. Balancing market integration in MASCEM electricity market simulator. In Proceedings of the 2012 IEEE Power and Energy Society General Meeting, San Diego, CA, USA, 22–26 July 2012; pp. 1–8. [Google Scholar]
- Wang, Y.; Wang, J.; Zhao, G.; Dong, Y. Application of residual modification approach in seasonal ARIMA for electricity demand forecasting: A case study of China. Energy Policy 2012, 48, 284–294. [Google Scholar] [CrossRef]
- Zhang, S.; Pandey, A.; Luo, X.; Powell, M.; Banerji, R.; Fan, L.; Parchure, A.; Luzcando, E. Practical adoption of cloud computing in power systems—drivers, challenges, guidance, and real-world use cases. IEEE Trans. Smart Grid 2022, 13, 2390–2411. [Google Scholar] [CrossRef]
- Hong, T.; Pinson, P.; Wang, Y.; Weron, R.; Yang, D.; Zareipour, H. Energy Forecasting: A Review and Outlook. IEEE Open Access J. Power Energy 2020, 7, 376–388. [Google Scholar] [CrossRef]
- Jaramillo, M.; Pavón, W.; Jaramillo, L. Adaptive Forecasting in Energy Consumption: A Bibliometric Analysis and Review. Data 2024, 9, 13. [Google Scholar] [CrossRef]
- Diamantoulakis, P.D.; Kapinas, V.M.; Karagiannidis, G.K. Big data analytics for dynamic energy management in smart grids. Big Data Res. 2015, 2, 94–101. [Google Scholar] [CrossRef]
- E-Land. CO2 Reduction at the Valahia University of Târgoviște. Available online: Https://Elandh2020.Eu/,2Apr.2020,elandh2020.eu/wp-content/uploads/2020/04/Dorin_CO2_reduction_at_UVTgv_v4.pdf (accessed on 29 July 2024).
- Photovoltaic Geographical Information System (PVGIS). (n.d.). EU Science Hub. Available online: https://joint-research-centre.ec.europa.eu/photovoltaic-geographical-information-system-pvgis_en (accessed on 28 July 2024).
- Historical Weather API. (n.d.). Open-meteo.com. Available online: https://open-meteo.com/en/docs/historical-weather-api (accessed on 28 July 2024).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Prediction Horizon | Best Model | RMSE | MAE | MSE | MAPE | Historical Data | Temp. | Humi-dity | Day Time | Cloud Cover | Wind Speed | Electricity Price |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [4] | Short Term | ANN | - | - | - | 1.23 | Y | Y | N | Y | N | N | N |
| [5] | Short Term | ANN | 146.07 | 109.3 | 320.07 | 45.41 | N | Y | N | Y | N | N | N |
| [6] | Short to Medium | LSTM | 0.56% | - | - | - | Y | N | N | Y | N | N | N |
| [7] | Short Term | LSTM | 0.621 | 231.50 | - | - | Y | N | N | N | N | N | N |
| [8] | Short Term | CNN | - | - | - | 12 | Y | Y | Y | N | N | Y | Y |
| [9] | Short Term | ARIMA | 0.097% | - | - | - | Y | Y | Y | N | N | N | N |
| [10] | Short Term | CNN | 11.66 | - | - | 9.77 | Y | Y | Y | Y | Y | Y | Y |
| [11] | Short Term | ARIMA | 413.1 | 299.9 | - | 18.4 | Y | N | N | Y | N | N | N |
| [12] | Short-Term and Mid Term | SVR | - | - | - | 3.60 | N | Y | N | Y | N | N | N |
| [13] | Short Term | Hybrid ANN | - | - | - | 2.6706 | N | Y | Y | N | N | Y | N |
| [14] | Short Term | LSTM | 0.4075 | - | 0.1661 | - | Y | Y | Y | N | N | Y | Y |
| [15] | Short Term | Hybrid Model | - | 38.61 | - | 0.6% | Y | Y | N | N | N | N | N |
| Proposed Model | Short Term | Distributed Model | 1.12 | 8.57 | - | - | Y | Y | Y | Y | Y | Y | Y |
| Aggregated Model | 14.72 | 12 | - | - | Y | Y | Y | Y | Y | Y | Y |
| Ref | Prediction Horizon | Best Model | RMSE | MAE | MSE | MAPE | Weather | Solar PV. | Historical Data | Solar Position Time | Consumption |
|---|---|---|---|---|---|---|---|---|---|---|---|
| [19] | Short-Term | LSTM | - | 0.1492 | - | −1.4027 | Y | Y | Y | N | N |
| [20] | Short-Term and Long-Term | LSTM | 0.512 | - | - | - | Y | Y | N | N | N |
| [21] | Short-Term | LR | 0.002 | 0.0013 | - | - | Y | Y | N | N | N |
| [22] | Short-Term | CNN-ALSTM | 1.30 | 0.70 | - | - | Y | Y | N | N | N |
| [23] | Medium-Term | Hybrid Adaboost | - | - | - | 8.88 | Y | Y | Y | N | N |
| [24] | Medium-Term | ARIMA | 381.09 | 19.52 | 16.59% | Y | Y | Y | Y | Y | N |
| [26] | Short-Term | ARIMA | - | - | - | 17.70 | Y | Y | Y | Y | Y |
| [25] | Short-Term | Bagging | - | - | - | 0.9 | Y | Y | Y | N | N |
| [27] | Short-Term | LSTM | 5.90 | 5.55 | - | 6.70 | Y | N | Y | N | N |
| [28] | Short-Term | CNN-LSTM | 9.09 | 6.97 | - | - | Y | Y | N | Y | N |
| [29] | Short-Term | TSO | 1.077 | 0.74 | - | - | Y | N | N | N | N |
| [30] | Short-Term | LSTM | 0.032 | 0.026 | 0.001 | - | Y | N | N | N | N |
| Proposed Model | Short-Term | Distributed Model | 53.15 | 26.32 | - | - | Y | Y | Y | Y | Y |
| Proposed Model | Short-Term | Aggregated Model | 75.45 | 33.12 | - | - | Y | Y | Y | Y | Y |
| Ref | Prediction Horizon | Models | Model Performance | Load Consumption | Solar Generation | Electricity Price |
|---|---|---|---|---|---|---|
| [33] | Short, Medium, Long Term | ANN | MAPE: 2.34% RMSE: 4.18 | Y | Y | N |
| [34] | Short Term | Dynamic Day-Ahead Dimensioning Model | lower balancing costs | Y | Y | Y |
| [35] | Short and Long Term | Statistical Model | increased accuracy | Y | Y | N |
| [36] | Short Term | Multi-variate LSTM | improved: MAE by 14.63%, RMSE by 20.45%, MAPE by 9.5% | Y | Y | N |
| [37] | Short Term | Encoder–decoder, robust bi-model optimization | 94.1% accuracy | Y | Y | |
| [38] | Short Term | ARIMA | MAPE: 3.28% RMSE: 6.67 | Y | Y | Y |
| Proposed Model | Short Term | Campus model, with aggregated and distributed training | 98.2% accuracy | Y | Y | Y |
| Sr. No | Company Name | Electricity Consumption | Electricity Generation | Shortage Prediction |
|---|---|---|---|---|
| 1 | Tesla | Y | Y | Y |
| 2 | Sunrun | Y | Y | Y |
| 3 | NextEra Energy | Y | Y | Y |
| 4 | Enphase Energy | Y | Y | Y |
| 5 | Vivint Solar | Y | Y | N |
| 6 | First Solar | Y | Y | Y |
| 7 | SunPower | Y | Y | Y |
| 8 | Canadian Solar | Y | Y | Y |
| 9 | JinkoSolar | Y | Y | Y |
| 10 | Hanwha Q Cells | Y | Y | Y |
| 11 | Trina Solar | Y | Y | N |
| 12 | REC Group | Y | Y | N |
| 13 | SunEdison | Y | Y | N |
| 14 | SMA Solar Technology | Y | Y | N |
| 15 | SolarEdge Technologies | Y | Y | Y |
| 16 | LG Solar | Y | Y | N |
| 17 | Yingli Solar | Y | Y | N |
| 18 | GCL-Poly Energy | Y | Y | N |
| 19 | Sharp Solar | Y | Y | N |
| 20 | Panasonic Solar | Y | Y | N |
| Research Gap | Existing Limitations | Contribution of This Study |
|---|---|---|
| Shortage Forecasting | No reinforcement learning and poor accuracy | A new RL-enhanced model with an accuracy of 98.2% |
| Community-Based Model | Single-building models and their inability to scale | Multi-building generalized forecasting model |
| AI Techniques | Focus on either ML or DL | Combining ML, DL, and RL in a hybrid AI model |
| Real-Time Energy Trading | No actionable buy/sell/store insights | A decision-support tool for trading power |
| Aggregated-Distributed Models | Centralized models lack adaptability | Framework for distributed and aggregated decision-making |
| Time | Day | Month | Hour | Con1 | Con2 | Con3 | Gen1 | Gen2 | Gen3 |
|---|---|---|---|---|---|---|---|---|---|
| 1/1/19 0:30 | 1 | 1 | 0 | 263.93 | 119.97 | 100.38 | 0 | 0 | 0 |
| 1/1/19 1:30 | 1 | 1 | 1 | 261.38 | 128.87 | 98.78 | 0 | 0 | 0 |
| 1/1/19 2:30 | 1 | 1 | 2 | 289.59 | 130.39 | 129.99 | 0 | 0 | 0 |
| 1/1/19 3:30 | 1 | 1 | 3 | 340.86 | 143.53 | 129.51 | 0 | 0 | 0 |
| 1/1/19 4:30 | 1 | 1 | 4 | 399.54 | 174.59 | 150.48 | 0 | 0 | 0 |
| 1/1/19 5:30 | 1 | 1 | 5 | 359.57 | 251.32 | 135.99 | 0 | 0 | 0 |
| 1/1/19 6:30 | 1 | 1 | 6 | 352.05 | 247.05 | 147.60 | 0 | 0 | 0 |
| 1/1/19 7:30 | 1 | 1 | 7 | 344.88 | 239.04 | 147.82 | 0 | 0 | 0 |
| 1/1/19 8:30 | 1 | 1 | 8 | 329.57 | 237.91 | 135.97 | 14.36 | 254.63 | 17.34 |
| 1/1/19 9:30 | 1 | 1 | 9 | 314.84 | 230.92 | 129.75 | 70.62 | 644.55 | 85.29 |
| G(k) | G(d) | G(t) | Temp (°C) | Humidity (%) | Dew Point (°C) | Precip (mm) | Cloud Cover (%) | Cloud Class | Wind Speed (m/s) | Total Gen |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0.31 | 87 | −1.7 | 0 | 94 | Overcast | 7.2 | 486.9927752 |
| 0 | 0 | 0 | 0.24 | 88 | −1.6 | 0 | 94 | Overcast | 5.6 | 830.8305377 |
| 0 | 0 | 0 | 0.21 | 88 | −1.5 | 0 | 94 | Overcast | 5.8 | 533.8596574 |
| 0 | 0 | 0 | 0.32 | 88 | −1.5 | 0 | 94 | Overcast | 5.6 | 818.1938571 |
| 0 | 10.29 | 0.56 | 0.56 | 91 | −2.5 | 0 | 91 | Overcast | 5.5 | 744.5520956 |
| 0 | 19.37 | 1.44 | 0.05 | 91 | −2.1 | 0 | 67 | Mostly Cloudy | 5.1 | 746.8227593 |
| 0 | 75.57 | 2.86 | −0.15 | 91 | −1.9 | 0 | 94 | Overcast | 4.2 | 828.5234751 |
| 0 | 79.57 | 3.85 | 0.42 | 91 | −1.9 | 0 | 94 | Overcast | 4.2 | 697.6937879 |
| 0 | 77.69 | 2.92 | 2.32 | 77 | 2.23 | 0 | 94 | Overcast | 4.6 | 606.5127888 |
| Stage | Action Performed | Rows × Columns |
|---|---|---|
| Pre-Raw Data Collection | Extraction of Solar power data for 2019 and 2020 | 17,520 × 11 |
| Extraction of Radiation data for 2019 and 2020 | 17,520 × 8 | |
| Extraction of Weather data for 2019 and 2020 | 17,520 × 23 | |
| Pre-Processing | Compiling solar power, radiation, weather data, removing unwanted columns, date formatting, feature extraction, and checking for null values and outliers. | 17,520 × 20 |
| Transformation | Converted the cloud cover column from numerical values to categorical values. | 17,520 × 20 |
| Data Preparation | Training dataset | 13,104 × 20 |
| Test dataset | 2208 × 19 | |
| Validation dataset | 2208 × 19 |
| Timestamp | Forecasted Consumption | Forecasted Generation | Predicted Shortage | Status | Action |
|---|---|---|---|---|---|
| 2020-12-01 08:30:00 | 662.52 | 605.46 | 57.05 | Shortage | Buy |
| 2020-12-01 09:30:00 | 638.81 | 1103.60 | −466.79 | Abundance | Sell/Store |
| 2020-12-01 10:30:00 | 638.08 | 1293.91 | −655.10 | Abundance | Sell/Store |
| 2020-12-01 11:30:00 | 607.37 | 1248.24 | −640.87 | Abundance | Sell/Store |
| 2020-12-01 12:30:00 | 595.18 | 1366.72 | −771.54 | Abundance | Sell/Store |
| 2020-12-01 13:30:00 | 591.22 | 995.87 | −404.64 | Abundance | Sell/Store |
| 2020-12-01 14:30:00 | 603.97 | 525.48 | 78.49 | Shortage | Buy |
| 2020-12-01 15:30:00 | 615.02 | 84.83 | 530.14 | Shortage | Buy |
| 2020-12-01 16:30:00 | 647.05 | 2.21 | 644.84 | Shortage | Buy |
| 2020-12-01 17:30:00 | 657.33 | 2.21 | 655.12 | Shortage | Buy |
| Component | Models | RMSE | MAE |
|---|---|---|---|
| Generation | XGBoost | 94.4 | 39.12 |
| RF | 100.28 | 39.54 | |
| SVM | 116.44 | 52.84 | |
| LSTM | 158.58 | 82.17 | |
| Consumption | XGBoost | 14.65 | 11.67 |
| RF | 18.08 | 14.33 | |
| SVM | 43.77 | 29.39 | |
| LSTM | 31.67 | 22.2 | |
| CNN | 37.21 | 24.76 | |
| Shortage Prediction | XGBoost | 79.08 | 45.88 |
| RF | 86.47 | 48.97 | |
| SVR | 147.34 | 74.17 |
| Model | Accuracy | Correct Prediction | Incorrect Prediction |
|---|---|---|---|
| RF | 91.44% | 673 | 63 |
| NN | 89.40% | 658 | 78 |
| SVM | 88% | 652 | 84 |
| Component | Training Type | Models | RMSE | MAE |
|---|---|---|---|---|
| Generation | Distributed | Building 1 | 53.15 | 26.32 |
| Building 2 | 42.08 | 21.59 | ||
| Building 3 | 30.25 | 18.74 | ||
| Aggregated | Aggregated Model | 75.45 | 33.12 | |
| Consumption | Distributed | Building 1 | 34.43 | 32.06 |
| Building 2 | 14.96 | 12.46 | ||
| Building 3 | 1.12 | 8.57 | ||
| Aggregated | Aggregated Model | 14.72 | 12.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehta, Y.; Lo, V.; Mehta, V.; Agrawal, K.; Madabathula, C.T.; Chang, E.; Gao, J. Renewable Electricity Management Cloud System for Smart Communities Using Advanced Machine Learning. Energies 2025, 18, 1418. https://doi.org/10.3390/en18061418
Mehta Y, Lo V, Mehta V, Agrawal K, Madabathula CT, Chang E, Gao J. Renewable Electricity Management Cloud System for Smart Communities Using Advanced Machine Learning. Energies. 2025; 18(6):1418. https://doi.org/10.3390/en18061418
Chicago/Turabian StyleMehta, Yukta, Vincent Lo, Vijen Mehta, Kunal Agrawal, Charan Teja Madabathula, Eugene Chang, and Jerry Gao. 2025. "Renewable Electricity Management Cloud System for Smart Communities Using Advanced Machine Learning" Energies 18, no. 6: 1418. https://doi.org/10.3390/en18061418
APA StyleMehta, Y., Lo, V., Mehta, V., Agrawal, K., Madabathula, C. T., Chang, E., & Gao, J. (2025). Renewable Electricity Management Cloud System for Smart Communities Using Advanced Machine Learning. Energies, 18(6), 1418. https://doi.org/10.3390/en18061418