Abstract
Special load customers such as electric vehicles are emerging in modern power systems. They lead to a higher penetration of special load patterns, raising difficulty for short-term load forecasting (STLF). We propose a hierarchical STLF framework to improve load forecasting accuracy. An improved adaptive K-means clustering algorithm is designed for load pattern recognition and avoiding local sub-optimal clustering centroids. We also design bi-directional long-short-term memory neural networks with an attention mechanism to filter important load information and perform load forecasting for each recognized load pattern. The numerical results on the public load dataset show that our proposed method effectively forecasts the residential load with a high accuracy.
1. Introduction
1.1. Background
Load forecasting is an essential component of power system energy management and operation, with benefits to system reliability and security. With the fast development of renewable energy sources in distribution power systems, such as wind and photovoltaics (PVs), local power load requires more accurate forecasting with less controllable power supply sources. Furthermore, the increasing penetration of electric vehicles (EVs) and the participation of demand response (DR) programs make it more challenging to forecast residential load. Therefore, accurate load forecasting ensures suitable economic dispatch decisions from system operators and reduces system operation costs.
Accurate load forecasting relies on historical load data to reveal practical electricity consumption patterns for load forecasting [1,2]. Traditional load forecasting methods include time series analyzing method and regression methods, which basically analyze current load states and extend them to the future. The autoregressive integrated moving average (ARIMA) model is designed to perform short-term load forecasting embedded with a lifting scheme. Both the seasonal autoregressive integrated moving average (SARIMA) model and artificial neural network (ANN) are utilized and compared in the real-time Turkish Market [3]. Although these methods only require few load data for analysis, they cannot reveal the real relationship between the historical and forecasted load data due to their simple mapping principles. Furthermore, their learning strategy may not suit complex load behaviors with patterns from EV and DR programs.
1.2. Literature Review
Machine-learning algorithms effectively forecast short-term load and reveal load behavior patterns with a huge amount of historical data. Measurement systems in distribution power systems provide adequate terminal load measurements with smart meter for load forecasting, making it possible to analyze customer electricity consumption patterns. The support vector machine (SVM) method is utilized to analyze and normalize critical factors to forecast short-term load [4]. A classification and regression tree data mining method is proposed to extract characteristic attributes in the frequency domain from various load profiles and is utilized for customer load classification [5]. In [6], the authors proposed an improved multi-task learning algorithm for a Bayesian spatiotemporal Gaussian process model (BSGP) to predict load. However, these methods usually face the difficulty of poor generalization performances.
More research focuses on combining deep learning methods with feature selection to deal with special load behavior patterns [7,8,9]. A deep learning method combing a recurrent neural network (RNN) with an input attention mechanism and hidden connection mechanism is utilized for a higher accuracy in short-term load forecasting [10]. Deep forest regression is utilized for STLF, combining a multi-grained scanning procedure and cascade forest procedure [11]. In [12], long-short-term memory (LSTM) is introduced into multiple load prediction for multi-task learning, with a single load feature and auxiliary coupling information learning. A convolutional neural network (CNN) and LSTM neural network are combined for load prediction in [13]. A hybrid neutral network composed of CNN and bidirectional grated recurrent units is designed for short-term load forecasting with immersing DR programs [14]. In [15], a Markov-chain mixture distribution model (MCM) is utilized for very short-term load forecasting and is used to forecast one step ahead half-hour resolution residential load. A deep belief network and bidirectional RNN deep learning method with a bisectin K-means algorithm is proposed to achieve unsupervised pre-training and supervised adjustment training [16]. These methods usually face the difficulty of over-fitting or still require more accurate preprocessing methods for load pattern analysis [17,18].
Clustering plays an important role in the preprocessing stage of deep-learning load forecasting methods. They enhance load forecasting accuracy by grouping similar load behaviors and providing categorizing conditions, leading to forecasting each load pattern separately. Various clustering algorithms are utilized in load forecasting to improve accuracy, such as K-means, C-means, and expectation maximization methods [19,20,21]. Clustering algorithms also benefit the performance of deep-learning load forecasting algorithms, such as graph neutral2 networks [22,23]. In [24], an optimal kernel function selection method is proposed for load forecasting, combining SVR and weighted votes. Although much research focuses on introducing clustering algorithms into deep-learning load forecast methods, the load behaviors of EV and DR programs with higher penetration require accurate recognition and forecasting.
1.3. Contributions
This work aims to forecast short-term load with a high penetration of EV and DR programs. We focus on designing a load recognition and forecasting framework to achieve special load pattern recognition and simplify the forecasting process. The contributions of this work are summarized as follows:
- (1)
- We propose a hierarchical short-term load forecast (STLF) framework to accurately forecast system load with a high penetration of EV and DR programs. The framework combines clustering and deep-learning methods to recognize load behavior patterns and improve forecasting accuracy.
- (2)
- We design an improved adaptive K-means clustering algorithm for load pattern recognition. By incorporating exploration probability into the centroid results, the proposed adaptive K-means clustering algorithm avoids local optimal searching. We utilize multiple indexes (mean square error, Davies–Bouldin, and separation index) to evaluate the algorithm performance.
- (3)
- We design bi-directional LSTM neural networks with an attention mechanism to forecast each recognized load pattern. The designed bi-directional LSTM neutral network effectively utilizes the observed factors and captures long-term temporal characteristics.
The remainder of this paper is organized as follows. In Section 2, we formulate the improved adaptive K-means clustering algorithm for load pattern recognition. We also design bi-directional LSTM neural networks with an attention mechanism for load forecasting. Section 3 provides different case studies. Finally, Section 4 summarizes the conclusions and future research directions.
2. Hierarchical STLF Framework
2.1. Framework Structure
The proposed hierarchical STLF framework is shown in Figure 1. Data preparation fills missing load data and filters noisy data, which are further wrangled into daily load curves for the convenience of clustering and forecasting. An improved adaptive K-means algorithm clusters load data into several groups by adding an exploration step and iteratively changing the clustering number. The recognized load patterns are further forecasted separately using the bi-directional LSTM neutral network with an attention mechanism.
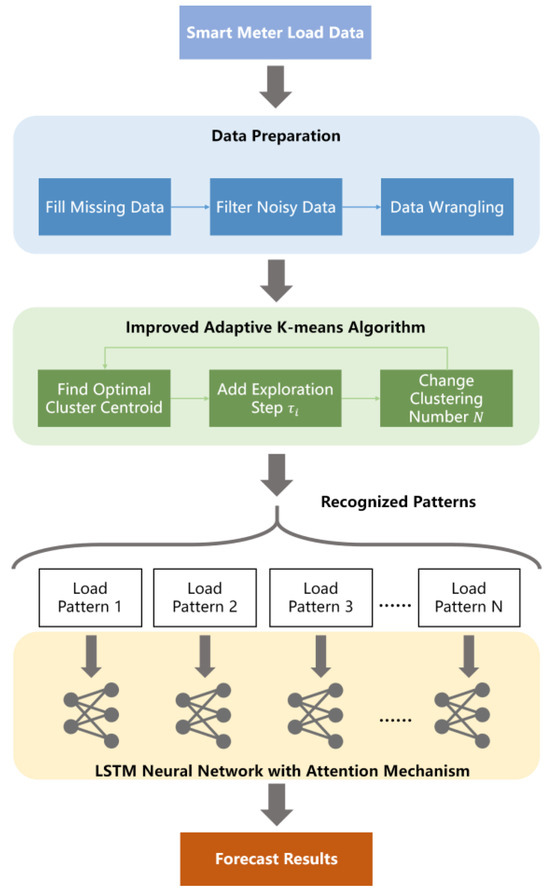
Figure 1.
The hierarchical STLF framework structure.
2.2. Improved Adaptive K-Means Algorithm
The traditional K-means clustering algorithm aims to cluster data into groups in an unsupervised manner. Each data belongs to the group with the closest clustering centroid. We design the improved adaptive K-means clustering algorithm as shown in Algorithm 1. We randomly select data points as the initial clustering centroids, which are at first given the clustering number . The whole dataset is divided into groups based on the distance, and we calculate the new clustering centroid as the average value of all data points in each group.
| Algorithm 1 Improved Adaptive K-means Clustering Algorithm |
| Input: Load vector set P |
| Output: Clustering group G 1: Initialize ; 2: While , do 3: Initialize clustering number and clustering centroid ; 4: Adjust ; 5: Calculate and update clustering centroid ; 6: If , then 7: Adjust ; 8: End if 9: ; 10: ; |
| 11: End while |
When giving a load vector set and with dimension and data, the K-means algorithm divides it into groups by minimizing the square sum of distances between each data and clustering centroid of group :
Each clustering centroid is optimized and used to calculate distances, where Equation (1) can be turned into:
We introduce exploration probability into the optimized results to avoid easily converging toward local optimal results. The traditional K-means clustering algorithm is sensitive to the initial clustering centroid, and the special type of load with frequent variations leads to large noises and outliers. These abnormal values may reduce the effectiveness of the traditional K-means algorithm. A random exploration vector is added to the clustering centroid:
is the random exploration vector, defined as:
where is the exploration factor, is the uniform distribution function with upper bound and lower bound . , and are two independent 0–1 distribution functions with probability . is randomly chosen from the multiplied individual distribution functions with the exploration factor controlling the exploration regions. controls the exploration directions by choosing −1, 0, 1, whose value represents the backward direction (−1), no direction (0), and forward direction (1), respectively. Hence, we guarantee that the exploration direction is evenly determined.
We introduce various evaluation indexes to assess the performance of the proposed algorithm. The mean square error () index calculates the average value of the square estimation error:
The index measures the diversity between data and clusters without considering the internal density of each cluster.
The Davies–Bouldin () index calculate the clustering density:
where is the diversity of cluster internal diversity:
The index measures the internal clustering density, while the distances between different clusters are not considered.
The separation () index calculates the average distance between cluster centroids:
The index only measures the diversity of different clusters. Here, we design the convergence tolerance of the inner-level iteration as:
where is calculated using the indexes of inner-level and th iterations. Other indexes are also utilized to evaluate clustering performances. We gradually narrow the probabilistic bound [, ] after each inner loop iteration and decrease the exploration factor . For each iteration, , , , and are adjusted as follows:
The clustering number is adjusted during each outer-level iteration by assessing the relative changes of . Other indexes, such as and SP, are compared to evaluate the clustering results’ performance. The initialized is 1 and plus 1 after each outer-level iteration:
Iteration stops when , as more clustering groups will not lead to a better performance for load forecasting. The improved adaptive K-means clustering algorithm provides output .
2.3. Bi-Directional LSTM Neural Network with Attention Mechanism
We design the bi-directional LSTM neutral network with an attention mechanism for the load forecasting of each recognized load pattern. Bi-directional LSTM neural networks with an attention mechanism analyze the input sequential load data of each load pattern and minimize its objective function to improve the load forecasting performance, as shown in Figure 2.
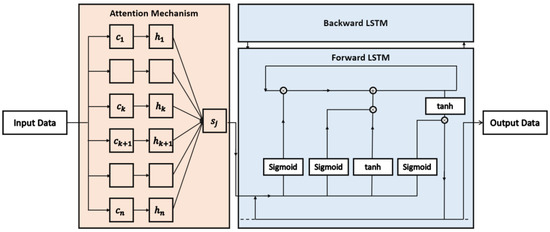
Figure 2.
The structure of bi-directional LSTM with attention mechanism.
The LSTM neural network is designed based on recurrent neutral networks (RNNs) and maintains a long-term memory for prediction. Each LSTM neuron has four inputs, where two inputs belong to the input gate and the other two inputs belong to the forget gate and output gate, respectively. Input gates update their states by combining the outputs of the last neuron and the current observation into:
and are the weights and offsets of the input gates. Forget gates update their states as:
and are the weights and offsets of the forget gates. Output gates update their states as:
and are the weights and offsets of the output gates. Candidate state values are calculated as:
and are the weights and offsets of the candidate state updates. Current state values are updated by old state values and candidate state values:
Output values are determined by and :
Single forward LSTM cannot extract information from the end to the start, which may cause difficulty for higher-resolution forecasting. We introduce the backward LSTM to extract the backward information from input features. Bi-directional LSTM can utilize future data information rather than only past information. We establish two LSTM neural networks, forward LSTM and backward LSTM, which share the same hidden states. The forward LSTM utilizes the input data to forecast the future data, and the backward LSTM forecasts the past data with the same inputs. It should be noted that of bi-directional LSTM includes both forward and backward . The bi-directional LSTM further extracts more information from both directions. The hidden state outputs of the forward and backward layers are combined to forecast the outputs.
We introduce attention mechanisms in the LSTM neural networks to filter and update important load information. The attention mechanism simulates the human thinking process by calculating attention weights in neural networks, representing the importance of each hidden state for outputs. Given the hidden states , the attention mechanism calculates attention weights as:
represents the compatibility between the hidden states and :
The weighted sum of the hidden states is calculated with attention weights:
The final output value considers the weighted sum of the hidden states, current input values and last hidden states:
where is the LSTM function.
3. Case Study
3.1. Data Preparation
We utilize the customer load data from the Ausgrid distribution network in Sydney and the NSW region, including 300 customers’ load and PV data with 365 days [25]. We select 200 customers’ data with 300 days and aggregate them into 5 aggregated customers, with a time resolution of 30 min. Each aggregated customer includes 35–45 m’ data, with the consideration of avoiding overly large or small load values. We divide these data into the training set, validation set, and test set, with 150 days, 40 days, and 10 days, respectively.
3.2. Clustering Results
We utilize the improved adaptive K-means clustering algorithm to recognize load patterns. For each aggregated customer, the proposed method adaptively recognizes the optimal clustering groups with a tolerance of . The error index of each aggregated customer is shown in Table 1. rapidly drops with increasing and soon satisfies the tolerance of convergence.

Table 1.
of each aggregated customer.
The clustering number of each aggregated customer is 6, 8, 5, 5, 7, respectively. We calculate their and indexes with a clustering number ranging from 2 to , as shown as Table 2 and Table 3. Nearly all indexes with the chosen clustering number reach the lowest values, representing the closer internal density of each clustering group. The obtained clustering number has a relatively larger index for each aggregated customer. The index results show that the clustering results contribute to improvements with larger results.
Table 2.
index of each aggregated customer.
Table 3.
index of each aggregated customer.
The clustering centroids of each aggregated customer with the improved adaptive K-means clustering algorithm using the training dataset are shown in Figure 3. Customer names and clustering group centroids are shown above each figure and shown in the legend. For example, “C1” represents the aggregated customer 1 with six clustering group centroids –. These clustering results have large differences in the late afternoon peak load and forenoon load. Meanwhile, the loads at mid-night and early morning in different clustering groups have similar values.
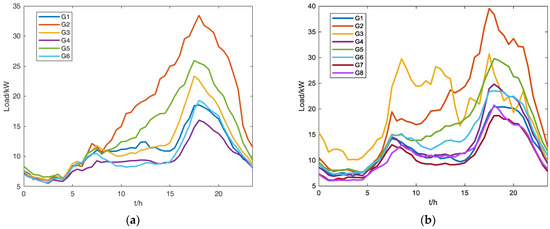
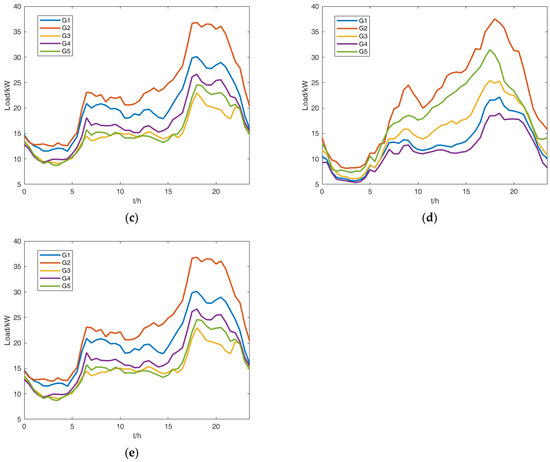
Figure 3.
(a) Clustering centroids of aggregated customer C1; (b) Clustering centroids of aggregated customer C2; (c) Clustering centroids of C3; (d) Clustering centroids of C4; (e) Clustering centroids of C5.
The recognized patterns of each aggregated customer result in obvious differences in their load variations and are mainly divided into three types: large, medium, and small load variations. Large load variation patterns can be easily recognized in each aggregated customer, such as . Small load variation patterns usually have more differences in the afternoon and night. Some special load patterns are also recognized with the improved adaptive K-means algorithm, such as load pattern with morning and afternoon peak loads. These load patterns help forecast their load variation trends.
3.3. STLF Results
We design the bi-directional LSTM neural network with an attention mechanism and utilize the 150-day data for training using Pytorch. The bi-directional LSTM neural network performs STLF for each type of recognized load patterns. We validate this method on the 40-day validation dataset and test its performance on the 10-day test dataset. All the training and tests are running on a computer with an Intel i5-9300 h CPU with 2.4 GHz and 16 GB memory.
We assess the validation and test results using root mean squared error () and mean absolute percentage error ():
Their results are shown in Figure 4. In the validation set, the proposed method achieves an ranging from 0.1020 to 0.1721 and an ranging from 0.7019% to 0.8035%, while it performs worse in C1, C2, and C5 in the test set compared with the results in the validation set. In C3 and C4, the proposed method achieves a better performance in the test set with of 0.1587 and 0.1207 and of 0.8021% and 0.7874%.
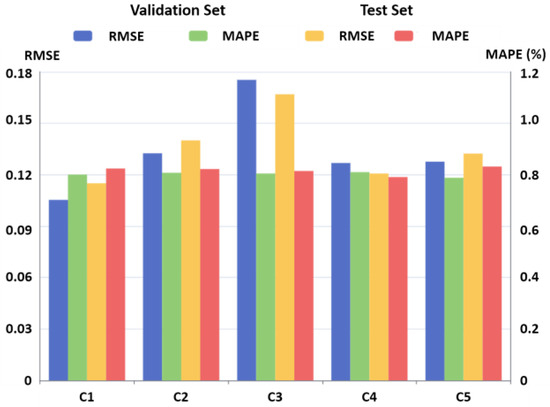
Figure 4.
and results of validation set and test set.
We display the STLF results of both the validation set and the test set, as shown as Figure 5. The STLF results show that the proposed method achieves a good performance on both the validation set and the test set of each aggregated customer. We also find that the load forecasting errors during 11:00–14:00 and 19:00–21:00 are usually higher than other time periods, as shown as Figure 6. We notice that forecasted load errors only exceed 0.4 kW in several specific time points and that most forecasted load errors are smaller than 0.2 kW. The reason may rely on the forecasting errors arising from multiple load patterns during these time periods, leading to higher . However, the slightly forecasting errors during mid-night or early morning may result in higher , as the load at these time periods are relatively lower.
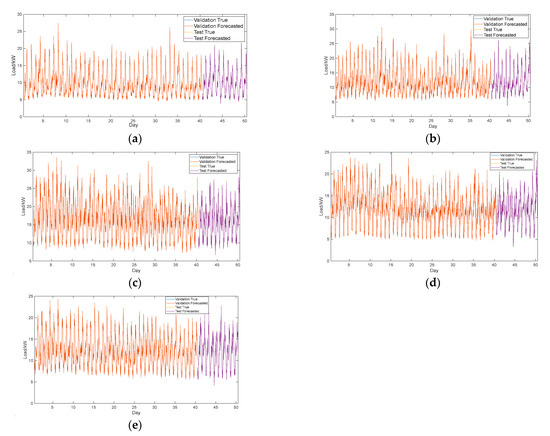
Figure 5.
(a) Forecasted and real load in the validation set and test set of C1; (b) Forecasted and real load in the validation set and test set of C2; (c) Forecasted and real load in the validation set and test set of C3; (d) Forecasted and real load in the validation set and test set of C4; (e) Forecasted and real load in the validation set and test set of C5.
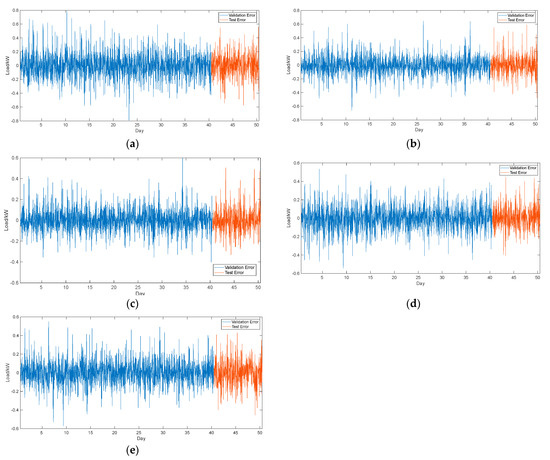
Figure 6.
(a) Forecasted load errors in the validation set and test set of C1; (b) Forecasted load errors in the validation set and test set of C2; (c) Forecasted load errors in the validation set and test set of C3; (d) Forecasted load errors in the validation set and test set of C4; (e) Forecasted and real load in the validation set and test set of C5.
4. Conclusions
This work examines short-term load forecasting to reduce the forecasting errors of residential load with a higher penetration of EV and DR programs. We formulate the hierarchical STLF framework with three parts: data preparation, improved adaptive K-means algorithm, and bi-directional LSTM neural network with an attention mechanism. We propose the improved adaptive K-means algorithm for load pattern recognition, where exploration steps are introduced to avoid local sub-optimal clustering centroids. The adaptive clustering number choosing scheme is also designed to choose the acceptable clustering number while maintaining fewer clustering groups to alleviate the difficulty of load forecasting. We apply the absolutely relative changes as the tolerance for convergence and utilize , , and indexes to evaluate the algorithm performance. Bi-directional LSTM neural networks with an attention mechanism are designed for forecasting loads for each load pattern. We introduce the attention mechanism to filter and update important load information and improve forecasting accuracy. The bi-directional LSTM also benefits information utilization with both past and future information extraction. We test the performance of the proposed hierarchical STLF framework on actual load datasets. The results show that the proposed framework effectively recognizes load patterns and achieves around 0.75% in both validation and test sets. In future work, we would improve deep neural networks to reduce the training difficulty and improve accuracy. Traditional STLF methods should be combined with machine-learning methods to achieve a better performance.
Funding
This research received no external funding.
Data Availability Statement
Data sharing depends on acquisitions from readers.
Conflicts of Interest
The author declares no conflicts of interest.
References
- Trull, O.; García-Díaz, J.C.; Troncoso, A. One-day-ahead electricity demand forecasting in holidays using discrete-interval moving seasonalities. Energy 2021, 231, 120966. [Google Scholar] [CrossRef]
- Trull, Ó.; García-Díaz, J.C.; Troncoso, A. Application of discrete-interval moving seasonalities to spanish electricity demand forecasting during easter. Energies 2019, 12, 1083. [Google Scholar] [CrossRef]
- Bozkurt Ö, Ö.; Biricik, G.; Tayşi, Z.C. Artificial neural network and SARIMA based models for power load forecasting in Turkish electricity market. PLoS ONE 2017, 12, e0175915. [Google Scholar] [CrossRef] [PubMed]
- Dong, X.; Deng, S.; Wang, D. A short-term power load forecasting method based on k-means and SVM. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 5253–5267. [Google Scholar] [CrossRef]
- Zhong, S.; Tam, K.S. Hierarchical classification of load profiles based on their characteristic attributes in frequency domain. IEEE Trans. Power Syst. 2014, 30, 2434–2441. [Google Scholar] [CrossRef]
- Gilanifar, M.; Wang, H.; Sriram, L.M.K.; Ozguven, E.E.; Arghandeh, R. Multitask Bayesian spatiotemporal Gaussian processes for short-term load forecasting. IEEE Trans. Ind. Electron. 2019, 67, 5132–5143. [Google Scholar] [CrossRef]
- Li, C. Designing a short-term load forecasting model in the urban smart grid system. Appl. Energy 2020, 266, 114850. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, Z.A.; Ullah, A.; Hussain, T.; Ullah, W.; Lee, M.Y.; Baik, S.W. A novel CNN-GRU-based hybrid approach for short-term residential load forecasting. IEEE Access 2020, 8, 143759–143768. [Google Scholar] [CrossRef]
- Tang, X.; Dai, Y.; Wang, T.; Chen, Y. Short-term power load forecasting based on multi-layer bidirectional recurrent neural network. IET Gener. Transm. Distrib. 2019, 13, 3847–3854. [Google Scholar] [CrossRef]
- Zhang, M.; Yu, Z.; Xu, Z. Short-term load forecasting using recurrent neural networks with input attention mechanism and hidden connection mechanism. IEEE Access 2020, 8, 186514–186529. [Google Scholar] [CrossRef]
- Yin, L.; Sun, Z.; Gao, F.; Liu, H. Deep forest regression for short-term load forecasting of power systems. IEEE Access 2020, 8, 49090–49099. [Google Scholar] [CrossRef]
- Sun, Q.; Wang, X.; Zhang, Y.; Zhang, F.; Zhang, P.; Gao, W. Multiple load prediction of integrated energy system based on long short-term memory and multi-task learning. Autom. Electr. Power Syst. 2021, 45, 63–70. [Google Scholar]
- Rafi, S.H.; Deeba, S.R.; Hossain, E. A short-term load forecasting method using integrated CNN and LSTM network. IEEE Access 2021, 9, 32436–32448. [Google Scholar] [CrossRef]
- Xuan, Y.; Si, W.; Zhu, J.; Sun, Z.; Zhao, J.; Xu, M.; Xu, S. Multi-model fusion short-term load forecasting based on random forest feature selection and hybrid neural network. IEEE Access 2021, 9, 69002–69009. [Google Scholar] [CrossRef]
- Munkhammar, J.; van der Meer, D.; Widén, J. Very short term load forecasting of residential electricity consumption using the Markov-chain mixture distribution (MCM) model. Appl. Energy 2021, 282, 116180. [Google Scholar] [CrossRef]
- Tang, X.; Dai, Y.; Liu, Q.; Dang, X.; Xu, J. Application of bidirectional recurrent neural network combined with deep belief network in short-term load forecasting. IEEE Access 2019, 7, 160660–160670. [Google Scholar] [CrossRef]
- Aly, H.H.H. A proposed intelligent short-term load forecasting hybrid models of ANN, WNN and KF based on clustering techniques for smart grid. Electr. Power Syst. Res. 2020, 182, 106191. [Google Scholar] [CrossRef]
- Atef, S.; Eltawil, A.B. Assessment of stacked unidirectional and bidirectional long short-term memory networks for electricity load forecasting. Electr. Power Syst. Res. 2020, 187, 106489. [Google Scholar] [CrossRef]
- Bian, H.; Zhong, Y.; Sun, J.; Shi, F. Study on power consumption load forecast based on K-means clustering and FCM–BP model. Energy Rep. 2020, 6, 693–700. [Google Scholar] [CrossRef]
- Sokhanvar, K.; Karimpour, A.; Pariz, N. Electricity price forecasting using a clustering approach. In Proceedings of the 2008 IEEE 2nd International Power and Energy Conference, Johor Bahru, Malaysia, 24–26 November 2008; pp. 1302–1305. [Google Scholar]
- Martínez-Álvarez, F.; Troncoso, A.; Riquelme, J.C.; Riquelme, J.M. Partitioning-clustering techniques applied to the electricity price time series. In Intelligent Data Engineering and Automated Learning-IDEAL 2007, Proceedings of the 8th International Conference, Birmingham, UK, 16–19 December 2007; Proceedings 8; Springer: Berlin/Heidelberg, Germany, 2007; pp. 990–999. [Google Scholar]
- Lin, W.; Wu, D.; Boulet, B. Spatial-temporal residential short-term load forecasting via graph neural networks. IEEE Trans. Smart Grid 2021, 12, 5373–5384. [Google Scholar] [CrossRef]
- Han, F.; Pu, T.; Li, M.; Taylor, G. Short-term forecasting of individual residential load based on deep learning and K-means clustering. CSEE J. Power Energy Syst. 2020, 7, 261–269. [Google Scholar]
- Che, J.X.; Wang, J.Z. Short-term load forecasting using a kernel-based support vector regression combination model. Appl. Energy 2014, 132, 602–609. [Google Scholar] [CrossRef]
- Ratnam, E.L.; Weller, S.R.; Kellett, C.M.; Murray, A.T. Residential load and rooftop PV generation: An Australian distribution network dataset. Int. J. Sustain. Energy 2017, 36, 787–806. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).