Abstract
It is common practice to employ returns, price differences or log returns for financial risk estimation and time series forecasting. In De Prado’s 2018 book, it was argued that by using returns we lose memory of time series. In order to verify this statement, we examined the differences between fractional differencing and logarithmic transformations and their impact on data memory. We employed LSTM (long short-term memory) recurrent neural networks and an XGBoost regressor on the data using those transformations. We forecasted risk (volatility) and price value and compared the results of all models using original, unmodified prices. From the results, models showed that, on average, a logarithmic transformation achieved better volatility predictions in terms of mean squared error and accuracy. Logarithmic transformation was the most promising transformation in terms of profitability. Our results were controversial to Marco Lopez de Prado’s suggestion, as we managed to achieve the most accurate volatility predictions in terms of mean squared error and accuracy using logarithmic transformation instead of fractional differencing. This transformation was also most promising in terms of profitability.
1. Introduction
It is common practice to make statistical measures of time series invariant over time to describe data points more precisely using traditional regression methods. Moreover, various data transformations affect how much memory or similarity will remain between modified and unmodified series. However, it is unknown how important data transformation and correlation is to the original form and how they can affect the accuracy of predictions in machine learning. In this research, we compare how well recurrent neural networks perform with and without different data transformations in terms of forecasting prices and volatility, which will be evaluated using different metrics. We will also look into the accuracy of next-day prediction, create a strategy by using different strategies and seek to maximize our profit. These metrics will be the main criteria to determine how well the recurrent neural networks can be applied in daily trading.
To understand detrending (making time series stationary), we have to understand the reasoning for that and how transformation affects time series. In general, we detrend time series to make their mean, variance, and autocorrelation constant over time or, in other words, to decompose them into parts and remove their trend and seasonality components. Removing these parts makes time series more suitable for linear regression, where linear models such as ARIMA benefit the most (more discussed by Millionis (2004)). In general, this implies that the relationship between previous data points and the following ones holds the same relationship; thus, they perform poorly on long-term forecasting because they strongly depend on previous values. On the contrary, we have recurrent neural networks, which are not dependent on a condition for linearity to be satisfied. The best example would be LSTM cells, which excel at remembering long-term dependencies, meaning that with sufficient training data, they can determine the changing fluctuations of the time series.
Like any other model, RNNs are susceptible to a sudden change in financial market behavior. If you train your model using time series when the market was under the influence of certain properties, your testing set can differ from reality if new externalities occur that drastically reshape how the market acts without any similarity in the past. This can also take some time for the model to relearn. However, if a detrended time series were used, then despite the drastic change, the model will likely have better results since it is easier to learn stationary data, or at the very least, use inverse transformation to apply previous day information to have a more accurate prediction. This is also suggested by Salles et al. (2019) in “Non-stationary time series transformation methods: An experimental review”, where the author concludes that to obtain more accurate results, time series transformations in machine learning are necessary.
2. Fractional Differencing for Stationarity and Memory
In “Advances in financial machine learning” de Prado (2018), the author justifies the loss of memory in a time series by examining the relation between non-stationary time series and its stationary transformation, specifically by comparing using first-order logarithmic and fractional differencing usually used for long memory analysis Carreno Jara (2011), Maynard et al. (2013), Sadaei et al. (2016), Baillie (1996). To fully understand this, we have to look into the fractional differentiation of order d:
and rewrite it for our time series at time t with weights; then, we obtain its transformation
with
Given , all weights after will be negative and greater than . When , all weights are 0 except for , and when , we have a standard first-order differentiation because weights sequence .
In his book de Prado (2018), de Prado provides an example of E-mini S&P log-prices, where the statistic of the Augmented Dickey–Fuller test with (original time series) is and with , while the critical value of 5% is , meaning that the null hypothesis of the unit root can be rejected after fractional differentiation transformation. Furthermore, the correlation between the two datasets (original and transformed) is around , indicating that the memory is still preserved. In comparison, a transformation with gives an ADF statistic of , but correlation with the original set falls to 0.05. Thus, to achieve stationarity, it is sufficient to fractionally differentiate.
It is easy to see that weights are a recursive sequence that is decreasing and bounded. This means that is has limit , and we can show that . By solving equation , we obtain . This can also be seen from Figure 1, as k increases, the weights converge to zero; in other words, the present time variable dependence on historical values decreases and memory fades.
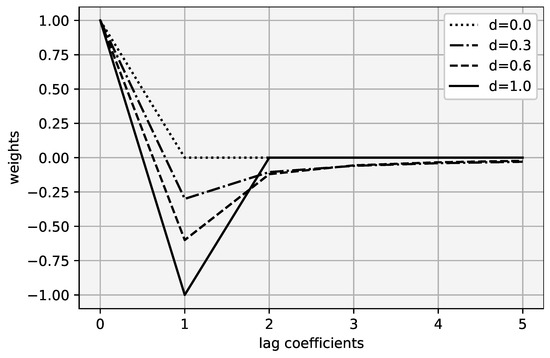
Figure 1.
Weights distributed to different lag coefficients.
Memory in Time Series
There are a lot of debates in the financial world about the stationary vs. memory dilemma. Some argue that these two concepts have no correlation Kom Samo (2018) as there are too many assumptions to be considered, while others oppose that opinion. Upon further reading, we tried to evaluate memory in time series before and after fractional differencing from a practitioner’s perspective.
The transformation of fractional differentiation is based on the idea that by transforming present values in relation to past values, the data series persist its trend. This implies that there is a significant connection between trends of original and transformed time series or that there is a correlation between those two sets.
In Figure 2, autocorrelations of fractionally different time series take some time to completely disappear, indicating longer memory compared to first-order difference of logarithmic time series where previous values have no significant relation to each other.
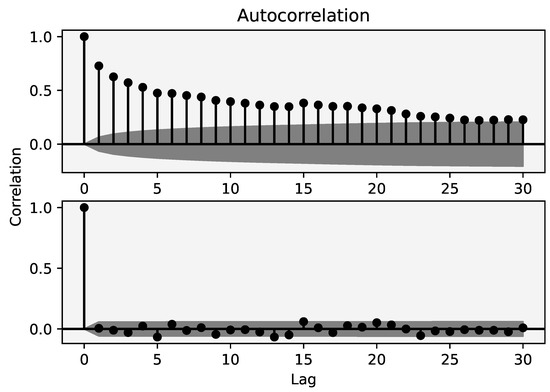
Figure 2.
Autocorrelation functions of time series transformation with d = opt (upper one) and d = 1 (lower one).
Hosking (1981) proposed that fractionally differenced processes exhibit long-term persistence and anti-persistence. One way to examine the persistence of time series is to use the Hurst exponent. The Hurst exponent H ranges between 0 and 1. If value , it implies an anti-persistent series, meaning that any positive movement will likely be followed by a negative step and vice versa. If value , it implies that any positive/negative change in time steps will be followed accordingly by positive/negative change. A value of indicates no correlation between a series variable and its past values. Since the Hurst exponent relates to the autocorrelations lag rate changes, we can further calculate the decrease in the Hurst exponent and time series trend. An important note is that after adapting the rescaled range analysis, we calculated the average Hurst exponent of all future contracts volatility and prices being on average at around and , respectively, indicating that the series of volatility consists of persistence, while prices consist of anti-persistence as well as lack of long memory in time series and the rapid decay of correlations in time. In theory, cases with short memory use ARIMA models as they are more suitable compared to ARFIMA (ARIMA with a fractionally differenced lag), which is used to represent long-range time series.
3. Methodology
In this research, we used 22 future contract close prices as our data. Out of those 22 symbols, 5 were from agricultural, 5 from currency, 5 from the interest rate, 3 from metal, 2 from stock, and 2 from energy sectors. Below, we present a brief description of each of the following experiments:
- Forecasting true range volatility with RNN;
- Forecasting close prices with RNN and implementing results with two strategies;
- Forecasting close prices with XGBoost regressor and implementing results with two strategies.
Each of the experiments was performed for three different time series transformations:
- I.
- Unmodified time series, without any manipulation, noted as d = 0;
- II.
- Fractional differenced time series with minimal order d to pass ADF test, noted as d = opt;
- III.
- Classical logarithmic transformation, noted as d = 1.
Implemented strategies We will be using two simple algorithmic trading strategies. The first strategy uses next-day predictions to determine new positions—if next-day prediction is higher (or lower) than our previous prediction, then the position will be 1 or (long or short). The second strategy is more intuitive; if the prediction is higher than today’s price, we will go long, and if the prediction is lower, we will go short. Let us denote our strategy , as real price and as predicted price, where t indicates time. When our strategies can be described as:
The reason to implement strategy no.1 is that in some cases, RNN can manage to minimize loss efficiently despite the fact that its prediction is below or above our target. However, we can still try to see how accurate predicted positions are.
Data Transformations
In Figure 3 and Figure 4, we will show a process of detrending a few selected symbols. Before any transformation, time series were randomly distributed Figure 4, indicating non-stationarity.
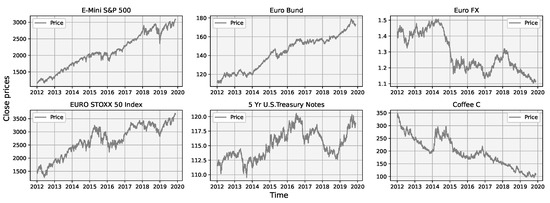
Figure 3.
Non-stationary prices of selected futures during an 8 year period.
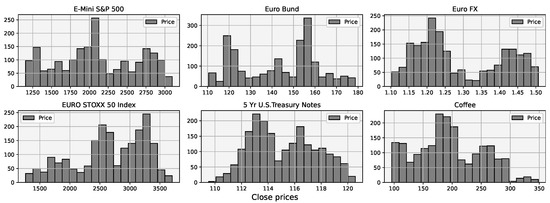
Figure 4.
Distribution of selected non-stationary futures prices during an 8 year period.
After the transformation to stationary prices, we can visually see the drastic change in their distributions in Figure 5 and Figure 6.
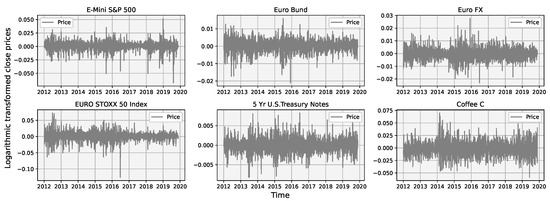
Figure 5.
Selected futures prices after logarithmic transformation during an 8 year period.
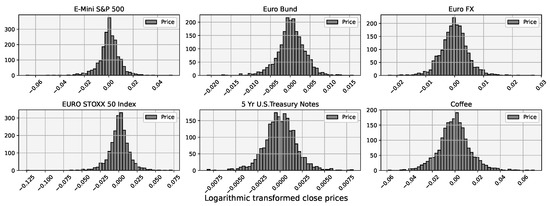
Figure 6.
Distribution of selected futures logarithmic returns during 8 year period.
To confirm stationarity, we applied the ADF test to check if there is a need for second-order differentiation as well as a measured correlation between the original set and transformed, see Table 1. Critical value being at the 95% confidence level.

Table 1.
First-order logarithmic differenced series ADF test results and correlation with original series.
According to de Prado (2018), all future contracts achieve stationarity at around , and most of them are stationary even at . We conducted the same experiment on 22 futures contracts, and all of them proved Marcos Lopez de Prado’s statement, passing the ADF test with , and a part of them achieved stationarity with . Furthermore, looking into those symbols that passed the ADF test, the average correlation between original and transformed data sets with is equal to 0.381 and with to , indicating that the time series with might be over-differentiated, removing unnecessary information to achieve stationarity. The results of selected symbols statistics after fractional differencing are seen in Table 2.
Table 2.
Statistics of fractional differenced series ADF test results and correlation with original series.
Evaluation metrics
For prediction evaluation, we are using three metrics.
- Profitability. We integrate predictions into the two strategies mentioned above to simulate how profitable each of them could be.
- Accuracy. Position accuracy calculates how many times our predictions from to will go in the same direction as the real price movement from to .
- MSE. Third metric mean squared error, which calculates how far the distance is from the true values of the time series to our estimated regression
The experiment was conducted with Python using the Keras library. Because of time consumption, we grouped similarly correlated time series and predicted each group with different models. The hyperparameters for models were selected using the tryout approach. The Adam optimizer was used for all models with MSE as our loss function.
The dataset of each symbol was divided into 3 parts: training, validation, and test samples with the following ratio: 5:1:1 varying from January of 2012 until November of 2019. To deal with underfitting, we monitored each symbol’s performance by looking at the training and validation loss graph, which indicates if there is room for improvement. We also implemented early stopping to stop the model at the inflection point in validation loss to prevent overfitting.
4. Results
Forecasting risk (volatility) using True Range
Table 3 shows the tabulated results of machine learning forecasted volatility using different time series transformations. We used accuracy and MSE for measuring predictions (Figure 7).
Table 3.
Accuracy and MSE results of predicted true range volatility.
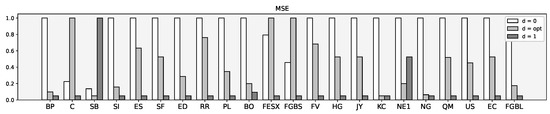
Figure 7.
MSE scaled between 0 and 1.
Forecasting prices with LSTM. Strategies returns
From Table 4 below, we can see the comparison between returns with a different order of differencing using both strategies. This shows how much each data manipulation affected each symbol’s profitability. Strategies with d = 1 provide the best outcome.
Table 4.
Strategy returns using LSTM predicted prices.
Forecasting prices with LSTM. Accuracy and MSE
Table 5 illustrates the results. Note that a huge variance between MSE was caused by a different tick size of future contracts and price range (Figure 8).
Table 5.
Accuracy and MSE results of predicted prices.
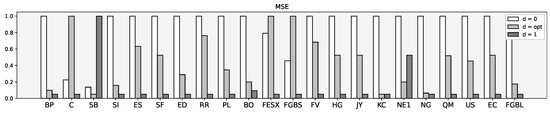
Figure 8.
MSE scaled between 0 and 1.
Forecasting prices with XGBoost regressor: Strategy returns
XGBoost, also called Extreme Gradient Boosting, is a machine learning model that originated from Friedman et al. (2000) idea of gradient boosting used for regression and classification problems. We examined the XGBoost classifier for our datasets with window = 20. Each attempt was optimized accordingly on the validation sample. Results are depicted in Table 6.
Table 6.
Strategy returns using LSTM predicted prices.
Forecasting prices with XGBoost regressor: Accuracy and MSE
Table 7 illustrates the results. Note that a huge variance between MSE was caused by a different tick size of future contracts and price range (Figure 9).
Table 7.
Accuracy and MSE results of predicted prices.
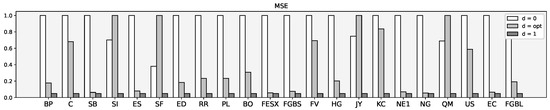
Figure 9.
MSE scaled between 0 and 1.
Evaluating portfolio volatility
We can further analyze the risk of each strategy in regard to its prediction method. As Table 8 shows, both strategies show similar results in terms of volatility. As expected, the most consistent method with the difference time series is the first-order logarithmic (d = 1), providing the least amount of variance between the returns.
Table 8.
Volatility.
Assuming returns are normally distributed, we can approximate the monthly value-at-risk with a 95% confidence level (Table 9).
Table 9.
VaR 95%.
Neither data transformation shows a significantly lower risk. However, returns using time series transformation with with both LSTM and XGBoost predictors are the most stable. On average, all methods indicate about at least 5–8% loss every 20 months.
5. Conclusions
According to our research, machine learning algorithms should consider stationary time series transformations as it improved their predicted values. To deal with unknown values, algorithms must have a pool of known variables to find the best fitting estimation. In most cases, first-order difference of logarithmic data transformation showed the best results for each metric as the vast majority of symbols (more than 80%) had the best MSE value. One exception was XGBoost regressor, which was most profitable using fractional differencing as 45.45% of and 50% of all symbols earned more using two different strategies compared with other time series modifications.
Both transformations improved forecasting results in comparison with unmodified series. However, concluded results contradicted Marco López de Prado’s suggestion that saving memory in time series can lead to more accurate and profitable results compared to other methods.
For future works, we suggest further analyzing this topic since both transformations and improved neural network predictions compared to raw data series . One of the possibilities is the absence of long memory in future contract prices. Determining memory impact on the order of transformation and using supplementary tests would be beneficial for future research.
Author Contributions
A.R. and E.G. authors contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be provided upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Baillie, Richard T. 1996. Long memory processes and fractional integration in econometrics. Journal of Econometrics 73: 5–59. [Google Scholar] [CrossRef]
- Carreño Jara, Emiliano. 2011. Long memory time series forecasting by using genetic programming. Genetic Programming and Evolvable Machines 12: 429–56. [Google Scholar] [CrossRef]
- de Prado, Marcos Lopez. 2018. Advances in Financial Machine Learning. Hoboken: John Wiley & Sons. [Google Scholar]
- Friedman, Jerome, Hastie Trevor, and Robert Tibshirani. 2000. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). The Annals of Statistics 28: 337–407. [Google Scholar] [CrossRef]
- Hosking, J. R. M. 1981. Fractional differencing. Biometrika 68: 165–76. [Google Scholar] [CrossRef]
- Kom Samo, Yves-Laurent. 2018. Stationarity and Memory in Financial Markets. October 15. Available online: https://towardsdatascience.com/non-stationarity-and-memory-in-financial-markets-fcef1fe76053 (accessed on 1 November 2022).
- Maynard, Alex, Aaron Smallwood, and Mark E. Wohar. 2013. Long memory regressors and predictive testing: A two-stage rebalancing approach. Econometric Reviews 32: 318–60. [Google Scholar] [CrossRef]
- Milionis, Alexandros E. 2004. The importance of variance stationarity in economic time series modelling. A practical approach. Applied Financial Economics 14: 265–78. [Google Scholar] [CrossRef]
- Sadaei, HosseinJavedani, Rasul Enayatifar, Frederico Gadelha Guimarães, Maqsood Mahmud, and Zakarya A. Alzamil. 2016. Combining ARFIMA models and fuzzy time series for the forecast of long memory time series. Neurocomputing 175: 782–96. [Google Scholar] [CrossRef]
- Salles, Rebecca, Kele Belloze, Fabio Porto, Pedro H. Gonzalez, and Eduardo Ogasawara. 2019. Nonstationary time series transformation methods: An experimental review. Knowledge-Based Systems 164: 274–91. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).