Abstract
A double-sided variant of the information bottleneck method is considered. Let be a bivariate source characterized by a joint pmf . The problem is to find two independent channels and (setting the Markovian structure ), that maximize subject to constraints on the relevant mutual information expressions: and . For jointly Gaussian and , we show that Gaussian channels are optimal in the low-SNR regime but not for general SNR. Similarly, it is shown that for a doubly symmetric binary source, binary symmetric channels are optimal when the correlation is low and are suboptimal for high correlations. We conjecture that Z and S channels are optimal when the correlation is 1 (i.e., ) and provide supporting numerical evidence. Furthermore, we present a Blahut–Arimoto type alternating maximization algorithm and demonstrate its performance for a representative setting. This problem is closely related to the domain of biclustering.
1. Introduction
The information bottleneck (IB) method [1] plays a central role in advanced lossy source compression. The analysis of classical source coding algorithms is mainly approached via the rate-distortion theory, where a fidelity measure must be defined. However, specifying an appropriate distortion measure in many real-world applications is challenging and sometimes infeasible. The IB framework introduces an essentially different concept, where another variable is provided, which carries the relevant information in the data to be compressed. The quality of the reconstructed sequence is measured via the mutual information metric between the reconstructed data and the relevance variables. Thus, the IB method provides a universal fidelity measure.
In this work, we extend and generalize the IB method by imposing an additional bottleneck constraint on the relevant variable and considering noisy observation of the source. In particular, let be a bivariate source characterized by a fixed joint probability law and consider all Markov chains . The Double-Sided Information Bottleneck (DSIB) function is defined as [2]:
where the maximization is over all and satisfying and . This problem is illustrated in Figure 1. In our study, we aim to determine the maximum value and the achieving conditional distributions (test channels) of (1) for various fixed sources and constraints and .
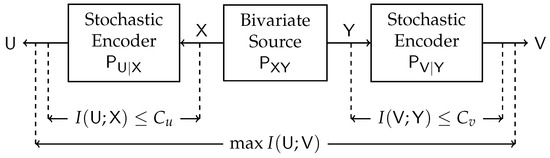
Figure 1.
Block diagram of the Double-Sided Information Bottleneck function.
The problem we consider originates from the domain of clustering. Clustering is applied to organize similar entities in unsupervised learning [3]. It has numerous practical applications in data science, such as: joint word-document clustering, gene expression [4], and pattern recognition. The data in those applications are arranged as a contingency table. Usually, clustering is performed on one dimension of the table, but sometimes it is helpful to apply clustering on both dimensions of the contingency table [5], for example, when there is a strong correlation between the rows and the columns of the table or when high-dimensional sparse structures are handled. The input and output of a typical biclustering algorithm are illustrated in Figure 2. Consider an data matrix . Find partitions and , , such that all elements of the “biclusters” [6] are homogeneous. The measure of homogeneity depends on the application.
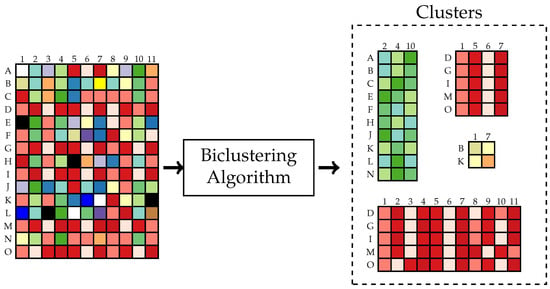
Figure 2.
Illustration of a typical biclustering algorithm.
This problem can also be motivated by a remote source coding setting. Consider a latent random variable , which satisfies and represents a source of information. We have two users that observe noisy versions of , i.e., and . Those users try to compress the observed noisy data so that their reconstructed versions, and , will be comparable under the maximum mutual information metric. The problem we consider also bears practical applications. Imagine a distributed sensor network where the different edges measure a noisy version of a particular signal but are not allowed to communicate with each other. Each of the nodes performs compression of the received signal. Under the DSIB framework, we can find the optimal compression schemes that preserve the reconstructed symbols’ proximity subject to the mutual information measure.
Dhillon et al. [7] initiated an information-theoretic approach to biclustering. They have regarded the normalized non-negative contingency table as a joint probability distribution matrix of two random variables. Mutual information was proposed as a measure for optimal co-clustering. An optimization algorithm was presented that intertwines both row and column clustering at all stages. Distributed clustering from a proper information-theoretic perspective was first explicitly considered by Pichler et al. [2]. Consider the model illustrated in Figure 3. A bivariate memory-less source with joint law generates n i.i.d. copies of . Each sequence is observed at two different encoders, and each encoder generates a description of the observed sequence, and . The objective is to construct the mappings and such that the normalized mutual information between the descriptions would be maximal while the description coding has bounded rate constraints. Single-letter inner and outer bounds for a general were derived. An example of a doubly symmetric binary source (DSBS) was given, and several converse results were established. Furthermore, connections were made to the standard IB [1] and the multiple description CEO problems [8]. In addition, the equivalence of information-theoretic biclustering problem to hypothesis testing against independence with multiterminal data compression and a pattern recognition problem was established in [9,10], respectively.
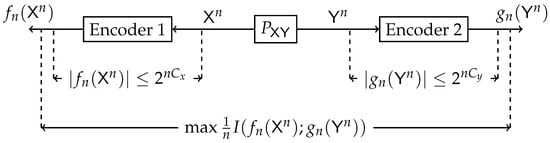
Figure 3.
Block diagram of the information-theoretic biclustering problem.
The DSIB problem addressed in our paper is, in fact, a single-letter version of the distributed clustering setup [2]. The inner bound in [2] coincides with our problem definition. Moreover, if the Markov condition is imposed on the multi-letter variant, then those problems are equivalent. A similar setting, but with a maximal correlation criterion between the reconstructed random variables, has been considered in [11,12]. Furthermore, it is sometimes the case that the optimal biclustering problem is more straightforward to solve than its standard, single-sided, clustering counterpart. For example, the Courtade–Kumar conjecture [13] for the standard single-sided clustering setting was ultimately proven for the biclustering setting [14]. A particular case, where are drawn from DSBS distribution and the mappings and are restricted to be Boolean functions, was addressed in [14]. The bound was established, which is tight if and only if and are dictator functions.
1.1. Related Work
Our work extends the celebrated standard (single-sided) IB (SSIB) method introduced by Tishby et al. [1]. Indeed, consider the problem illustrated in Figure 4. This single-sided counterpart of our work is essentially a remote source coding problem [15,16,17], choosing the distortion measure as the logarithmic loss. The random variable represents the noisy version () of the source () with a constrained number of bits (), and the goal is to maximize the relevant information in regarding (measured by the mutual information between and ). In the standard IB setup, is referred to as the complexity of , and is referred to as the relevance of .
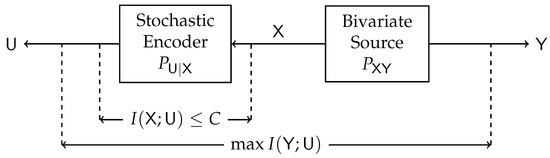
Figure 4.
Block diagram of the Single-Sided Information Bottleneck function.
For the particular case where are discrete, an optimal can be found by iteratively solving a set of self-consistent equations. A generalized Blahut–Arimoto algorithm [18,19,20,21] was proposed to solve those equations. The optimal test-channel was characterized using a variation principle in [1]. A particular case of deterministic mappings from to was considered in [22], and algorithms that find those mappings were described.
Several representing scenarios have been considered for the SSIB problem. The setting where the pair is a doubly symmetric binary source (DSBS) with transition probability p was addressed from various perspectives in [17,23,24]. Utilizing Mrs. Gerber’s Lemma (MGL) [25], one can show that the optimal test-channel for the DSBS setting is a BSC. The case where are jointly multivariate Gaussians in the SSIB framework was first considered in [26]. It was shown that the optimal distribution of is also jointly Gaussian. The optimality of the Gaussian test channel can be proven using EPI [27], or exploiting I-MMSE and Single Crossing Property [28]. Moreover, the proof can be easily extended to jointly Gaussian random vectors under the I-MMSE framework [29].
In a more general scenario where and only is fixed to be Gaussian, it was shown that discrete signaling with deterministic quantizers as test-channel sometimes outperforms Gaussian [30]. This exciting observation leads to a conjecture that discrete inputs are optimal for this general setting and may have a connection to the input amplitude constrained AWGN channels where it was already established that discrete input distributions are optimal [31,32,33]. One reason for the optimality of discrete distributions stems from the observation that constraining the compression rate limits the usable input amplitude. However, as far as we know, it remains an open problem.
There are various related problems considered in the literature that are equivalent to the SSIB; namely, they share a similar single-letter optimization problem. In the conditional entropy bound (CEB) function, studied in [17], given a fixed bivariate source and an equality constraint on the conditional entropy of given , the goal is to minimize the conditional entropy of given over the set of such that constitute a Markov chain. One can show that CEB is equivalent to SSIB. The common reconstruction CR setting [34] is a source coding with a side-information problem, also known as Wyner–Ziv coding, as depicted in Figure 5; with an additional constraint, the encoder can reconstruct the same sequence as the decoder. Additional assumption of log-loss fidelity results in a single-letter rate-distortion region equivalent to the SSIB. In the problem of information combining (IC) [23,35], motivated by message combining in LDPC decoders, a source of information, , is observed through two test-channels and . The IC framework aims to design those channels in two extreme approaches. For the first, IC asks what those channels should be to make the output pair maximally informative regarding . On the contrary, IC also considers how to design and to minimize the information in regarding . The problem of minimizing IC can be shown to be equivalent to the SSIB. In fact, if is a DSBS, then by [23], is a binary symmetric channel (BSC), recovering similar results from (Section IV.A of [17]).

Figure 5.
Block diagram of Source Coding with Side Information.
The IB method has been extended to various network topologies. A multilayer extension of the IB method is depicted in Figure 6. This model was first considered in [36]. A multivariate source generates a sequence of n i.i.d. copies . The receiver has access only to the sequence while are hidden. The decoder performs a consecutive L-stage compression of the observed sequence. The representation at step k must be maximally informative about the respective hidden sequence , . This setup is highly motivated by the structure of deep neural networks. Specific results were established for the binary and Gaussian sources.
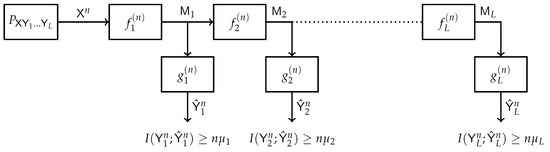
Figure 6.
Block diagram of the Multi-Layer IB.
The model depicted in Figure 7 represents a multiterminal extension of the standard IB. A set of receivers observe noisy versions of some source of information . The channel outputs are conditionally independent given . The receivers are connected to the central processing unit through noiseless but limited-capacity backhaul links. The central processor aims to attain a good prediction of the source based on compressed representations of the noisy version of obtained from the receivers. The quality of prediction is measured via the mutual information merit between and . The Distributive IB setting is essentially a CEO source coding problem under logarithmic loss (log-loss) distortion measure [37]. The case where are jointly Gaussian random variables was addressed in [20], and a Blahut–Arimoto-type algorithm was proposed. An optimized algorithm to design quantizers was proposed in [38].
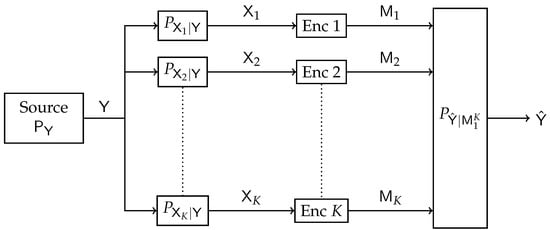
Figure 7.
Block diagram of the Distributive IB.
A cooperative multiterminal extension of the IB method was proposed in [39]. Let be n i.i.d. copies of the multivariate source . The sequences and are observed at encoders 1 and 2, respectively. Each encoder sends a representation of the observed sequence through a noiseless yet rate-limited link to the other encoder and the mutual decoder. The decoder attempts to reconstruct the latent representation sequence based on the received descriptions. As shown in Figure 8, this setup differs from the CEO setup [40] since the encoders can cooperate during the transmission. The set of all feasible rates of complexity and relevance were characterized, and specific regions for the binary and Gaussian sources were established. There are many additional variations of multi-user IB in the literature [20,26,35,36,37,39,40,41,42,43,44].
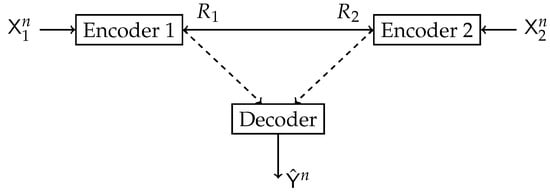
Figure 8.
Block diagram of the Collaborative IB.
The IB problem connects to many timely aspects, such as capital investment [43], distributed learning [45], deep learning [46,47,48,49,50,51,52], and convolutional neural networks [53,54]. Moreover, it has been recently shown that the IB method can be used to reduce the data transfer rate and computational complexity in 5G LDPC decoders [55,56]. The IB method has also been connected with constructing good polar codes [57]. Due to the exponential output-alphabet growth of polarized channels, it becomes demanding to compute their capacities to identify the location of “frozen bits". Quantization is employed in order to reduce the computation complexity. The quality of the quantization scheme is assessed via mutual information preservation. It can be shown that the corresponding IB problem upper bounds the quantization technique. Quantization algorithms based upon the IB method were considered in [58,59,60]. Furthermore, a relationship between the KL means algorithm and the IB method has been discovered in [61].
A recent comprehensive tutorial on the IB method and related problems is given in [24]. Applications of IB problem in machine learning are detailed in [26,45,46,47,51,52,62].
1.2. Notations
Throughout the paper, random variables are denoted using a sans-serif font, e.g., , their realizations are denoted by the respective lower-case letters, e.g., x, and their alphabets are denoted by the respective calligraphic letters, e.g., . Let stand for the set of all n-tuples of elements from . An element from is denoted by and substrings are denoted by . The cardinality of a finite set, say , is denoted by . The probability mass function (pmf) of , the joint pmf of and , and the conditional pmf of given are denoted by , , and , respectively. The expectation of is denoted by . The probability of an event is denoted as .
Let and be an n-ary and m-ary random variables, respectively. The marginal probability vector is denoted by a lowercase boldface letter, i.e.,
The probability vector of an n-ary uniform random variable is denoted by . We denote by T the transition matrix from to , i.e.,
The entropy of n-ary probability vector is given by , where
Throughout this paper all logarithms are taken to base 2 unless stated otherwise. We denote the ones complemented with a bar, i.e., . The binary convolution of is defined as . The binary entropy function is defined by , i.e., , and its inverse, restricted to .
Let and be a pair of random variables with joint pmf and marginal pmfs and . Furthermore, let T () be the transition matrix from () to (). The mutual information between and is defined as:
1.3. Paper Outline
Section 2 gives a proper definition of the DSIB optimization problem, mentions various results directly related to this work, and provides some general preliminary results. The spotlight of Section 3 is on the binary , where we derive bounds on the respective DSIB function and show a complete characterization for extreme scenarios. The jointly Gaussian is considered in Section 4, where an elegant representation of an objective function is presented, and complete characterization in the low-SNR regime is established. A Blahut–Arimoto-type alternating maximization algorithm will be presented in Section 5. Representative numerical evaluation of the bounds and the proposed algorithm will be provided in Section 6. Finally, a summary and possible future directions will be described in Section 7. The prolonged proofs are postponed to the Appendix A.
2. Problem Formulation and Basic Properties
The DSIB function is a multi-terminal extension of the standard IB [1]. First, we briefly remind the latter’s definition and give related results that will be utilized for its double-sided counterpart. Then, we provide a proper definition of the DSIB optimization problem and present some general preliminaries.
2.1. The Single-Sided Information Bottleneck (SSIB) Function
Definition 1
(SSIB). Let be a pair of random variables with , , and fixed . Denote by the marginal probability vector of , and let T be the transition matrix from to , i.e.,
Consider all random variables satisfying the Markov chain . The SSIB function is defined as:
Remark 1.
The SSIB problem defined in (6) is equivalent (has similar solution) to the CEB problem considered in [17].
Although the optimization problem in (6) is well defined, the auxiliary random variable may have an unbounded alphabet. The following lemma provides an upper bound on the cardinality of , thus relaxing the optimization domain.
Lemma 1
(Lemma 2.2 of [17]). The optimization over in (6) can be restricted to .
Remark 2.
A tighter bound, namely , was previously proved in [63] for the corresponding dual problem, namely, the IB Lagrangian. However, since is generally not a strictly convex function of C, it cannot be directly applied for the primal problem (6).
Note that the SSIB optimization problem (6) is basically a convex function maximization over a convex set; thus, the maximum is attained on the boundary of the set.
Lemma 2
(Theorem 2.5 of [17]). The inequality constraint in (6) can be replaced by equality constraint, i.e., .
2.2. The Double-Sided Information Bottleneck (DSIB) Function
Definition 2
(DSIB). Let be a pair of random variables with , and fixed . Consider all the random variables and satisfying the Markov chain . The DSIB function is defined as:
The achieving conditional distributions and will be termed as the optimal test-channels. Occasionally, we will drop the subscript denoting the particular choice of the bivariate source .
Note that (7) can be expressed in the following equivalent form:
Evidently, we can define (8) using (6). Indeed, fix so that it satisfies . Denote by the transition matrix from to and by the transition matrix from to , respectively, i.e.,
Denote by and the marginal probability vectors of and , respectively, and consider the inner maximization term in (8). Since and are fixed, then is also fixed. Denote by the transition matrix from to . Therefore, the inner maximization term in (8) is just the SSIB function with parameters and , namely, . Hence, our problem can also be interpreted in the following two equivalent ways:
or, similarly, by interchanging the order of maximization in (8), it can be expressed as follows:
where is the transition matrix from to , and is the transition matrix from to . This representation gives us a different perspective on our problem as an optimal compressed representation of the relevance random variable for the IB framework.
Remark 3.
The bound from Lemma 1 can be utilized to give cardinality bounding for the double-sided problem.
Proposition 1.
For the DSIB optimization problem defined in (7), it suffices to consider random variables and with cardinalities and .
Proof.
Let and be two arbitrary transition matrices. By Lemma 1, there exists with such that and . Similarly, can be replaced with , such that , and . Therefore, there exists an optimal solution with and . □
In the following two sections, we will present the primary analytical outcomes of our study. First, we consider the scenario where our bivariate source is binary, specifically DSBS. Then, we handle the case where and are jointly Gaussian.
3. Binary
Let be a DSBS with parameter p, i.e.,
We entitle the respective optimization problem (7) as the binary double-sided information bottleneck (BDSIB) and emphasize its dependence on the parameter p as .
The following proposition states that the cardinality bound from Lemma 1 can be tightened in the binary case.
Proposition 2.
Considering the optimization problem in (6) with and , binary is optimal.
The proof of this proposition is postponed to Appendix A. Using similar justification for Proposition 1 combined with Proposition 2, we have the following strict cardinality formula for the BDSIB setting.
Proposition 3.
For the respective DSBS setting of (7), it suffices to consider random variables and with cardinalities .
Note that the above statement is not required for the results in the rest of this section to hold and will be mainly applied to justify our conjectures via numerical simulations.
We next show that the specific objective function for the binary setting of (7), i.e, the mutual information between and , has an elegant representation which will be useful in deriving lower and upper bounds.
Lemma 3.
The mutual information between and can be expressed as follows:
where the expectation is taken over the product measure , and are binary random variables satisfying:
the kernel is given by:
and the reverse test-channels are defined by: , . Furthermore, since , utilizing Taylor’s expansion of , we obtain:
The general cascade of test-channels and the DSBS, defined by , and p, is illustrated in Figure 9. The proof of Lemma 3 is postponed to Appendix B.
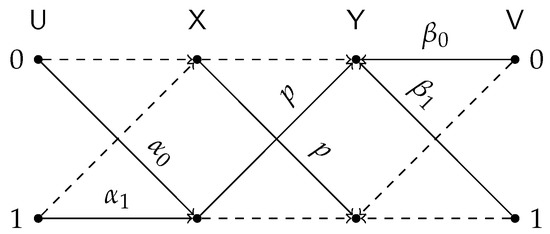
Figure 9.
General test-channel construction of the BDSIB function.
We next examine some corner cases for which is fully characterized.
3.1. Special Cases
A particular case where we have a complete analytical solution is when p tends to .
Theorem 1.
Suppose , and consider . Then
and it is achieved by taking and as BSC test-channels satisfying the constraints with equality.
This theorem follows by considering the low SNR regime in Lemma 3 and is proved in Appendix D. For the lower bound we take and to be BSCs.
In Section 6 we will give a numerical evidence that BSC test-channels are in fact optimal provided that p is sufficiently large. However, for small p this is no longer the case and we believe the following holds.
Conjecture 1.
Let , i.e., . The optimal test-channels and that achieve are Z-channel and S-channel respectively.
Remark 4.
Our results in the numerical section strongly support this conjecture. In fact they prove it within the resolution of the experiments, i.e., for optimizing over a dense set of test-channels rather then all test-channels. Nevertheless, we were not able to find an analytical proof for this result.
Remark 5.
Suppose , , and . Since (as form a Markov chain in this order) then maximizing is equivalent to minimizing , namely, minimizing information combining as in [23,35]. Therefore, Conjecture 1 is equivalent to the conjecture that among all channels with and , Z and S are the worst channels for information combining.
This observation leads us the following additional conjecture.
Conjecture 2.
The test-channels and that maximize are both Z channels.
Remark 6.
Suppose now that p is arbitrary and assume that one of the channels or is restricted to be a binary memoryless symmetric (BMS) channel (Chapter 4 of [64]), then the maximal is attained by BSC channels, as those are the symmetric channels minimizing [23]. It is not surprising that once the BMS constraint is removed, symmetric channels are no longer optimal (see the discussion in (Section VI.C of [23])).
Consider now the case () with an additional symmetry assumption . The most reasonable apriori guess is that the optimal test-channels and are the same up to some permutation of inputs and outputs. Surprisingly, this is not the case, unless they are BSC or Z channels, as the following negative result states.
Proposition 4.
Suppose and the transition matrix from to , given by
satisfies . Consider the respective SSIB optimization problem
The optimal that attains (6) with and does not equal to or any permutation of , unless is a BSC or a Z channel.
The proof is based on [17] and is postponed to Appendix E.
As for the case of , i.e., , we have the following conjecture.
Conjecture 3.
For every , there exists , such that for every the achieving test-channels and are BSC with parameters and respectively.
We will provide supporting arguments for this conjecture via numerical simulations in Section 6.
3.2. Bounds
In this section we present our lower and upper bounds on the BDSIB function, then we compare them for various channel parameters. The proofs are postponed to Appendix F. For the simplicity of the following presentation we define
denote as its inverse restricted to , and .
Proposition 5.
The BDSIB function is bounded from below by
where , , , and .
All terms in the RSH of (20) are attained by taking test-channels that match the constraints with equality and plugging them in Lemma 3. In particular: the first term is achieved by BSC test channels with transition probabilities and ; the second term is achieved by taking be a channel and be an channel. The aforementioned test-channel configurations are illustrated in Figure 10.
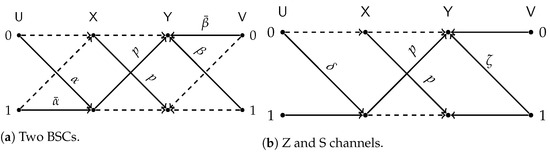
Figure 10.
Test-channel that achieve the lower bound of Proposition 5.
We compare the different lower bounds derived in Proposition 5 for various values of constraints. The achievable rate vs channel transition probability p is shown in Figure 11. Our first observation is that BSC test-channels outperform all other choices for almost all values of p. However, Figure 12 gives a closer look on small values of p. It is evident that the combination of Z and S test-channels outperforms any other schemes for small values of p. We have used this observation as one supporting evidence to Conjecture 1.
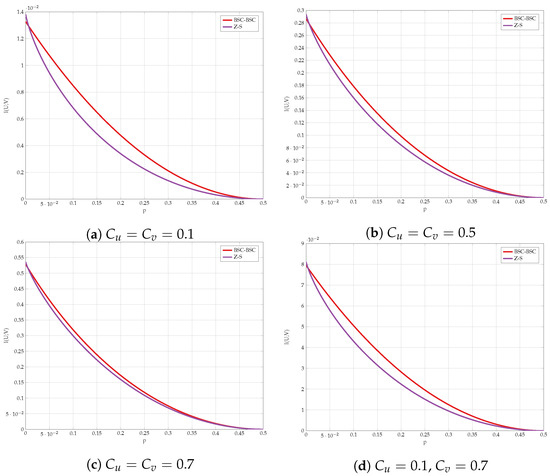
Figure 11.
Comparison of the lower bounds.
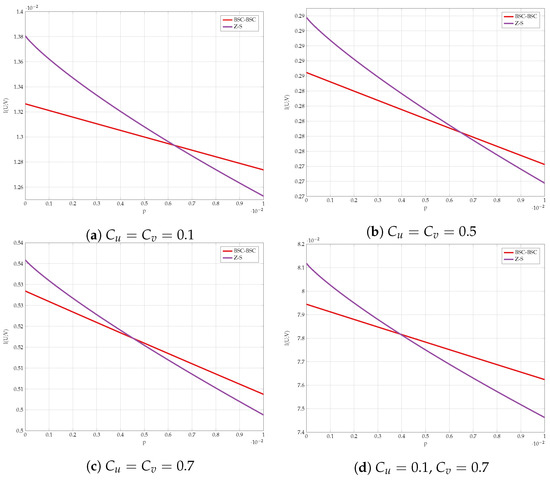
Figure 12.
Comparison of the lower bounds in high SNR regime.
We proceed to give an upper bound.
Proposition 6.
A general upper bound on BDSIB is given by
Note that the first term can be derived by applying Jensen’s inequality on (12), and the second term is a combination of the standard IB and the cut-set bound. We postpone the proof of Proposition 6 to Appendix F.
Remark 7.
Since , we have a factor 2 loss in the first term compared to the precise behavior we have found for in Theorem 1. This loss comes from the fact that the bound in (21) actually upper bounds the χ-squared mutual information between and . It is well-known that for very small we have that , see [65].
We compare the different upper bounds from Proposition 6 in Figure 13 for various bottleneck constraints, and in Figure 14 for various values of channel transition probabilities p. We observe that there are regions of C and p for which Jensen’s based bound outperforms the standard IB bound.
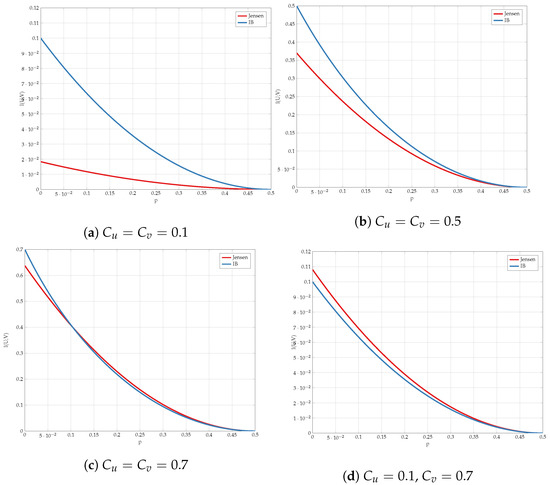
Figure 13.
Comparison of the upper bounds for various values of .
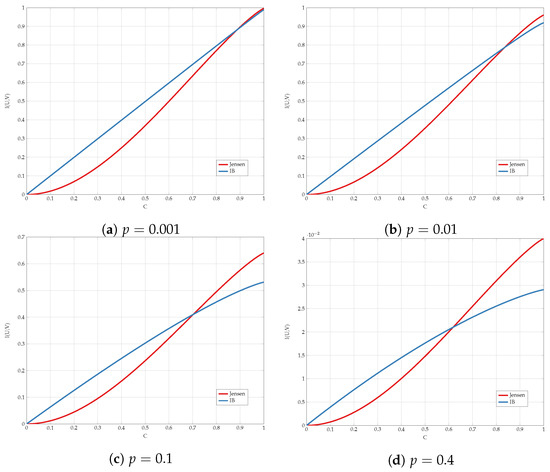
Figure 14.
Comparison of the upper bounds for various values of p.
Finally, we compare the best lower and upper bounds from Propositions 5 and 6 for various values of channel parameters in Figure 15. We observe that the bounds are tighter for asymmetric constraints and high transition probabilities.
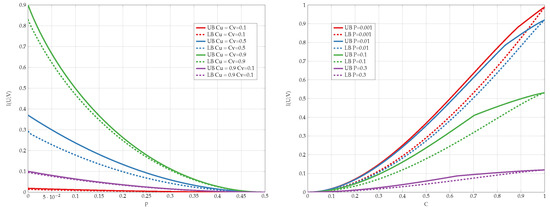
Figure 15.
Capacity bounds for various values of p and .
4. Gaussian
In this section we consider a specific setting where is the normalized zero mean Gaussian bivariate source, namely,
We establish achievability schemes and show that Gaussian test-channels and are optimal for vanishing SNR. Furthermore we show an elegant representation of the problem through probabilistic Hermite polynomials which are defined by
We denote the Gaussian DSIB function with explicit dependency on as .
Proposition 7.
Let be the nth order probabilistic Hermite polynomial, then the objective function of (7) for the Gaussian setting is given by
This representation follows by considering and expressing using Mehler Kernel [66]. Mehler Kernel decomposition is a special case of a much richer family of Lancaster distributions [67]. The proof of Proposition 7 is relegated to Appendix G.
Now we give two lower bounds on . Our first lower bound is established by choosing and to be additive Gaussian channels, satisfying the mutual information constraints with equality.
Proposition 8.
A lower bound on is given by
The proof of this bound is developed in Appendix H.
Although it was shown in [26] that choosing the test-channel to be Gaussian is optimal for the single-sided variant, it is not the case for its double-sided extension. We will show this by examining a specific set of values for the rate constraints, . Furthermore, we choose the test channels and to be deterministic quantizers.
Proposition 9.
Let , then
The proof of this bound is developed in Appendix I.
We compare the bounds from Propositions 8 and 9 with in Figure 16. The most unexpected observation here is that the deterministic quantizers lower bound outperform the Gaussian test-channels for high values of . The crossing point of those bounds is given by
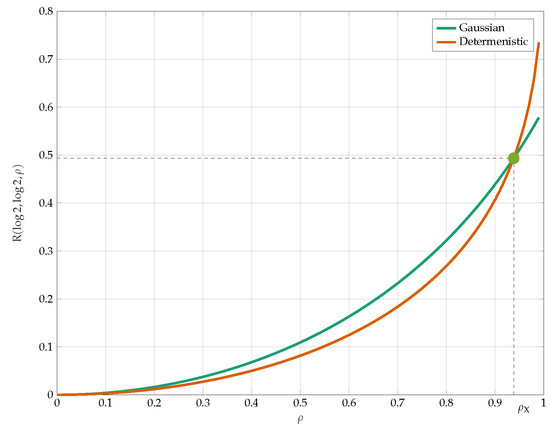
Figure 16.
Comparison of the lower bounds from Propositions 8 and 9.
We proceed to present our upper bound on . This bound is a combination of the cutset bound and the single-sided Gaussian IB.
We compare the best lower and upper bounds from Propositions 8–10 in Figure 17. We observe that the bounds become tighter as the constraint increases and in the low-SNR regime.
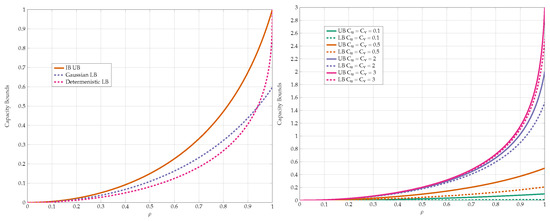
Figure 17.
Capacity bounds for various values of p and .
4.1. Low-SNR Regime
For , the exact asymptotic behavior of the Gaussian (Proposition 8) and deterministic (Proposition 9) test-channels, respectively, for is given by:
Hence, the Gaussian choice outperforms the second lower bound for vanishing SNR. The following theorem establishes that Gaussian test-channels are optimal for low-SNR.
Theorem 2.
For small ρ, the GDSIB function is given by:
The lower bound follows from Proposition 8. The upper bound is established by considering the kernel representation from Proposition 7 in the limit of vanishing . The detailed proof is given in Appendix J.
4.2. Optimality of Symbol-by-Symbol Quantization When
Consider an extreme scenario for which . Taking the encoders and as a symbol-by-symbol deterministic quantizers satisfying:
we achieve the optimum
5. Alternating Maximization Algorithm
Consider the DSIB problem for DSBS with parameter p analyzed in Section 3. The respective optimization problem involves simultaneous search of the maximum over the sets and . An alternating maximization, namely, fixing , then finding the respective optimal and vice versa, is sub-optimal in general and may result in convergent to a saddle point. However, for the case with symmetric bottleneck constraints, Proposition 4 implies that such point exists only for the BSC and Z/S channels. This motivates us to believe that performing an alternating maximization procedure on (9) will not result in sub-optimal saddle point, but rather converge to the optimal solution also for the general discrete .
Thus, we propose an alternating maximization algorithm. The main idea is to fix and then compute that attains the inner term in (9). Then, using , we find the optimal that attains the inner term in (10). Then, we repeat the procedure in alternating manner until convergence.
Note that inner terms of (9) and (10) are just the standard IB problem defined in (6). For completeness, we state here the main result from [1] and adjust it for our problem. Consider the respective Lagrangian of (6) given by:
Lemma 4
(Theorem 4 of [1]). The optimal test-channel that maximizes (30) satisfies the equation:
where and is given via Bayes’ rule, as follows:
In a very similar manner to the Blahut–Arimoto algorithm [18], the self-consistent equations can be adapted into converging, alternating iterations over the convex sets , , and , as stated in the following lemma.
Lemma 5
(Theorem 5 of [1]). The self-consistent equations are satisfied simultaneously at the minima of the functional:
where the minimization is performed independently over the convex sets of , , and . The minimization is performed by the converging alternation iterations as described in Algorithm 1.
| Algorithm 1: IB iterative algorithm IBAM(args) |
 |
Next, we propose a combined algorithm to solve the optimization problem from (7). The main idea is to fix one of the test-channels, i.e., , and then find the corresponding optimal opposite test-channel, i.e., , using Algorithm 1. Then, we apply again Algorithm 1 by switching roles, i.e., fixing the opposite test-channel, i.e., , and then identifying the optimal . We repeat this procedure until convergence of the objective function . We summarize the proposed composite method in Algorithm 2.
Remark 8.
Note that every alternating step of the algorithm involves finding an optimal that corresponds to the respective problem constraints . We have chosen to implement this exploration step using a bisection-type method. This may result that the actual pair is ϵ-far away from the desired constraint.
| Algorithm 2: DSIB iterative algorithm DSIBAM(args) |
 |
6. Numerical Results
In this section, we focus on the DSBS setting of Section 3. In the first part of this section, we will show using a brute-force method the existence of a sharp, phase-transition phenomena in the optimal test-channels and vs. DSBS parameter p. In the second part of this section, we will evaluate the alternating maximization algorithm proposed in Section 5; then, we compare its performance to the brute-force method.
6.1. Exhaustive Search
In this set of simulations, we again fix the transition matrix from to characterized by the parameters:
chosen such that . This choice defines a path in the plain. Then, for every such T we optimize for different values of the DSBS parameter p. The results for a specific choice of vs. a for different values of p are plotted in Figure 18. Note that the region of a corresponds to the continuous conversion from a Z channel () to a BSC (). We observe here a very sharp transition from the optimality of Z-S channels to BSC channels configuration for a small change in p. This kind of behavior continues to hold with a different choice of , as can be seen in Figure 19.
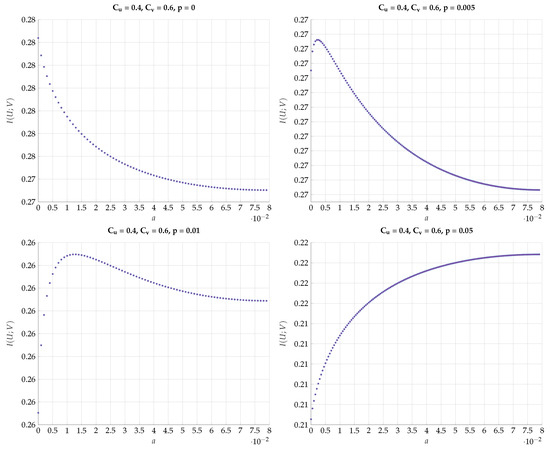
Figure 18.
Maximal for fixed values and different values of p.
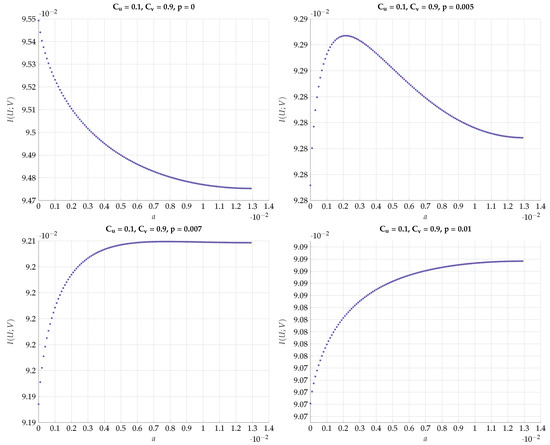
Figure 19.
Maximal for fixed values and different values of p.
Next, we would like to emphasize this sharp phase transition phenomena by plotting the optimal a that achieves the maximal vs the DSBS parameter p. The results for various combinations of and are presented in Figure 20 and Figure 21. We observe that the curves are convex for and constant for with . Furthermore, the derivative of for tends to ∞.
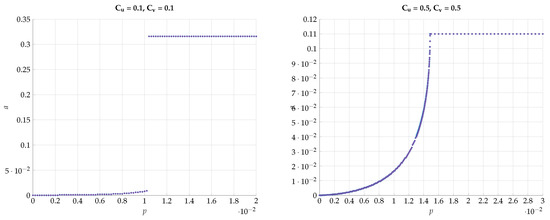
Figure 20.
Optimal value of a for various values of and .
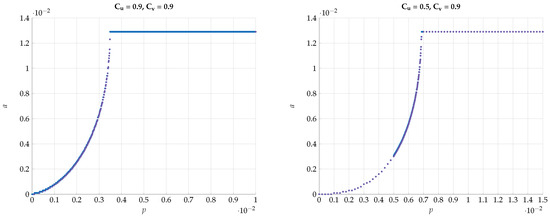
Figure 21.
Optimal value of a for various values of and .
One may further claim that there is no sharp transition to the BSC test-channels and as p grows away from zero, but rather only approaches BSC. To convince the reader that the optimal test channels are exactly BSC, we performed an alternating maximization experiment. We fixed , and . Then we have chosen as an almost BSC channel satisfying and found the channel that maximizes subject to . Then, we fixed the channel and found the that maximizes subject to . We have repeated this alternating maximization procedure until it converges. The transition matrices were parameterized as follows:
The results for different values of p, , and are shown in Figure 22, Figure 23 and Figure 24. We observe that and rapidly converge to their respective BSC values satisfying the mutual information constraints. Note that the last procedure is still an exhaustive search, but it is performed in alternating fashion between the sets and .
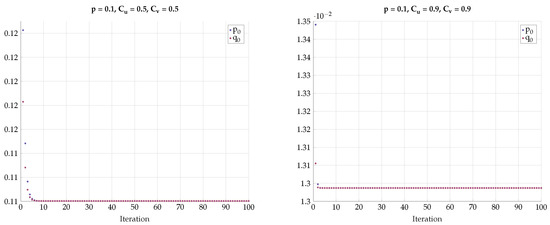
Figure 22.
Alternating maximization with exhaustive search for various p, , .
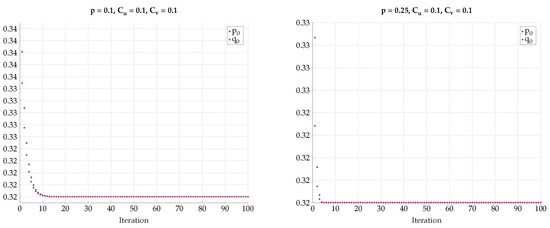
Figure 23.
Alternating maximization with exhaustive search for various p, , .
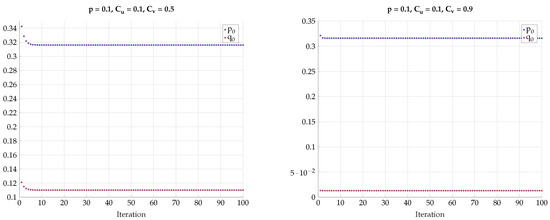
Figure 24.
Alternating maximization with exhaustive search for various p, , .
6.2. Alternating Maximization
In this section, we will evaluate the algorithm proposed in Section 5. We focus on the DSBS setting of Section 3 with various values of problem parameters.
First, we explore the convergence behavior of the proposed algorithm. Figure 25 shows the objective function on every iteration step for representative fixed-channel transition parameters p and the constraints and . We observe a slow convergence to a final value for and , but once the constraints and the transition probability are increased, the algorithm converges much more rapidly. The non-monotonic behavior in some regimes is justified with the help of Remark 8. In Figure 26, we see the respective test-channel probabilities , , , and . First, note that if , then is a BSC. Similarly, if , then is a BSC. Second, if , then is a Z-channel. Similarly, if , then is an S-channel. We observe that for , the test-channels and converge to Z- and S-channels, respectively. As for all other settings, the test-channels converge to BSC channels.
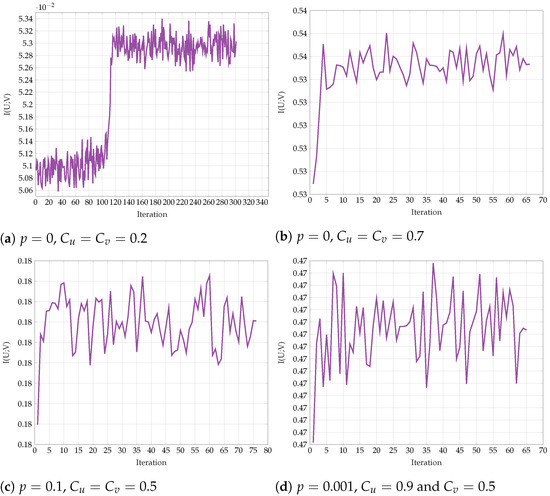
Figure 25.
Convergence of for various values of p, and .
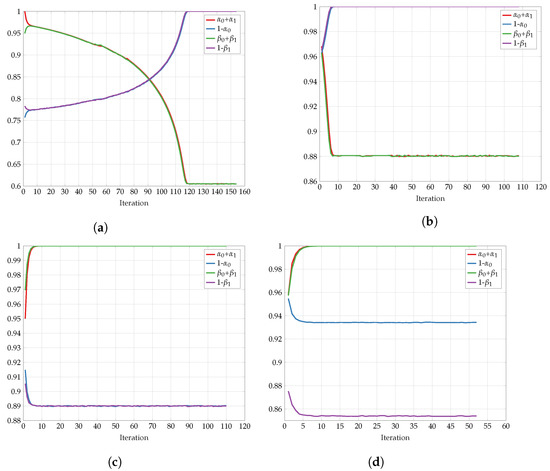
Figure 26.
Convergence of p with: (a) , ; (b) , ; (c) , ; (d) , .
Finally, we compare the outcome of Algorithm 2 to the optimal solution achieved by the brute-force method, namely, evaluating (12) for every and that satisfy the problem constraints. The results for various values of channel parameters are shown in Figure 27. We observe that the proposed algorithm achieves the optimum for any DSBS parameter p and some representative constraints and .
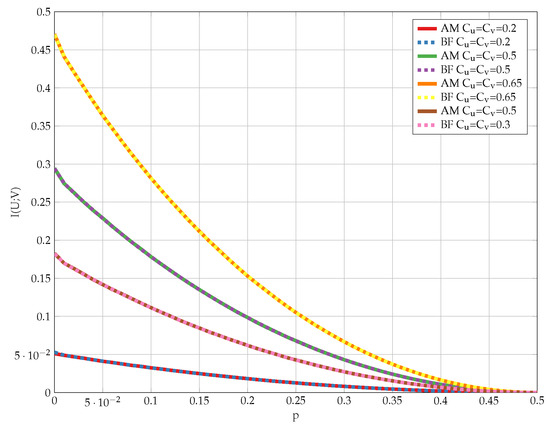
Figure 27.
Comparison of the proposed alternating maximization algorithm and the brute-force search method for various problem parameters.
7. Concluding Remarks
In this paper, we have considered the Double-Sided Information Bottleneck problem. Cardinality bounds on the representation’s alphabets were obtained for an arbitrary discrete bivariate source. When and are binary, we have shown that taking binary auxiliary random variables is optimal. For DSBS, we have shown that BSC test-channels are optimal when . Furthermore, numerical simulations for arbitrary p indicate that Z -and S-channels are optimal for . As for the Gaussian bivariate source, representation of utilizing Hermite polynomials was given. In addition, the optimality of the Gaussian test-channels was demonstrated for vanishing SNR. Moreover, we have constructed a lower bound attained by deterministic quantizers that outperforms the jointly Gaussian choice at high SNR. Note that the solution for the n-letter problem for under constraints and does not tensorize in general. For , we can easily achieve the cut-set bound . In addition, if time-sharing is allowed, the results change drastically.
Finally, we have proposed an alternating maximization algorithm based on the standard IB [1]. For the DSBS, it was shown that the algorithm converges to the global optimal solution.
Author Contributions
Conceptualization, O.O. and S.S.; methodology, M.D., O.O., and S.S.; software, M.D.; formal analysis, M.D.; writing—original draft preparation, M.D.; writing—review and editing, M.D.; supervision, S.S. All authors have read and agreed to the published version of the manuscript.
Funding
The work has been supported by the European Union’s Horizon 2020 Research And Innovation Programme, grant agreement no. 694630, by the ISF under Grant 1641/21, and by the WIN consortium via the Israel minister of economy and science.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Proposition 2
Before proceeding to proof Proposition 2, we need the following auxiliary results.
Lemma A1.
Let be an arbitrary binary-input, ternary-output channel, parameterized using the following transition matrix:
Consider the function defined on . This function has the following properties:
- 1.
- If is linear on a sub-interval of , then it is linear for every .
- 2.
- Otherwise, it is strictly convex over or there are points and such that where
We postpone the proof of this lemma to Appendix K.
Lemma A2.
The convex envelope of at any point can be obtained as a convex combination of only points in and .
We postpone the proof of this lemma to Appendix L and proceed to proof Proposition 2. Note that if is strictly convex in , then by the paragraph following (Theorem 2.3 of [17]) , we are done.
From now on, we consider the case where is not strictly convex. Then, there is an interval and such that
Let and represent the columns of T corresponding to and , respectively, Moreover let and be the probability vector of an arbitrary binary random variable, where .
Assume and . Then, there must be and such that
Lemma A3.
The set must contain at least three distinct points.
We postpone the proof of this lemma to Appendix M.
Consider the function defined on . We have that
In addition, if we define to be the lower convex envelope of , then . Thus, the lower convex envelope of at q is attained by two linear combinations.
By Lemma Lemma A3, the set must contain at least three distinct points, say . Due to Lemma A2, they are all in . Furthermore, by the pigeonhole principle, we must have that one of the intervals contains at least two points. Assume WLOG that . For any , let and consider the following set of weights/probabilities:
Note that
and
but since
thus, it attains a smaller value than a, provided that is strictly convex on . This contradicts our assumption that the convex envelope at q equals a, and thus must contain a linear segment in .
By Lemma A1, this can happen only if p is linear for every . In particular:
Note that for any choice of
Taking the expectation we obtain:
This implies that
and this is attained by any choice of satisfying . In particular the choice , where is statistically independent of and is chosen such that , attains . Thus, suffices even if is not strictly convex.
Appendix B. Proof of Lemma 3
Let and be the test-channels from to and from to , respectively. The joint probability function of and can be expressed via Bayes’ rule and the Markov chain condition as:
Since , we define as the ratio between the joint distribution of and relative to the respective product measure. Note that:
Denoting and , we obtain:
The last expression can also be represented as follows:
Thus,
Furthermore, note that since , we can utilize Taylor’s expansion of to obtain:
and
Therefore:
where follows since . This completes the proof.
Appendix C. Auxiliary Concavity Lemma
As a preliminary step to proving Theorem 1, we will need the following auxiliary lemma.
Lemma A4.
The function is concave.
Proof.
Denoting , we have . Since is twice differentiable, it is sufficient to show that is decreasing. The first derivative is given by:
Since
utilizing the inverse function derivative property, we obtain:
In addition, the second order derivative is given by:
Define
Note that . Since is increasing, in order to show that decreasing, it suffices to show that decreasing. The first order derivative of is given by:
Define such that . Note that . We obtain:
Now, making use of the expansion , we have:
Thus,
where follows since . Thus, and is concave. □
Appendix D. Proof of Theorem 1
Plugging () in (14), we obtain:
Now, we rewrite with explicit dependency on as:
We would like to expand with Taylor series around . Note that . Furthermore, the second derivative is given by:
Hence,
Now, note that
with similar relation for . Therefore,
where the first inequality follows since the function is concave by Lemma A4 and applying Jensen’s inequality, and the second inequality follows from rate constraints.
Appendix E. Proof of Proposition 4
Suppose that the optimal test-channel is given by the following transition matrix:
Assume in contradiction that the opposite optimal test-channel is symmetric to and is given by:
Applying Bayes’ rule on (A53), we obtain:
Appendix F. Proof of Proposition 6
By Lemma 3, the objective function of (7) for a DSBS setting, denoted here by , is given by:
where can be expressed as:
Since , we have the following upper bound on :
where the inequality in follows from Lemma A4 and inequality in follows from the problem constraints.
Appendix G. Proof of Proposition 7
We assume and are continuous RVs. The proof for the discrete case is identical. The joint density can be expressed with explicit dependency on as follows:
where [66]. Similarly, can also be written with explicit dependency on
Appendix H. Proof of Proposition 8
Let be jointly Gaussian Random variables, such that
where , , , . Due to Proposition 7, the mutual information for jointly Gaussian is given by
where and follow from the properties of Mehler Kernel [66].
By the Mutual Information constraints we have:
Hence,
Appendix I. Proof of Proposition 9
We choose and to be deterministic functions of and , respectively, i.e., and . In such case, the rate constraints are met with equality, namely, . We proceed to evaluate the achievable rate:
where equality in follows since by symmetry. We therefore obtain the following formula for the “error probability”:
where also follows from symmetry. Utilizing Sheppard’s Formula (Chapter 5, p.107 of [68]), we have This completes the proof of the proposition.
Appendix J. Proof of Theorem 2
We would like to approximate in the limit using a Taylor series up to a second order in . As a first step, we evaluate the first two derivatives of at . Note that and
Thus, ,
and
Expanding in Taylor series around gives us and
Thus,
Note that and
In addition, by (Corollary to Theorem 8.6.6 of [69]),
Moreover, from MI constraint, we have
and therefore . Thus, we obtain:
In a very similar method, one can show that .
Thus, for
Appendix K. Proof of Lemma A1
The function is a twice differentiable continuous function with respective second derivative given by
The former can also be written as a proper rational function [70], i.e., , where
and
Note that equals for and hence is positive for this set of points.
- Suppose is linear over some interval . In such case, its second derivative must be zero over this interval, which implies that is zero over this interval. Since is a degree 3 polynomial, it can be zero over some interval if and only if it is zero everywhere. Thus, if is linear over some interval , then it is non-linear for every .
- For , and is a degree 3 polynomial in p. Since and , this polynomial has no sign changes or has exactly two sign changes in . Therefore, either is convex or there are two points and , , such that is convex in and concave in .
Appendix L. Proof of Lemma A2
Let and assume in contradiction that attains the lower convex envelope at point q, and that . By assumption, we have that
We can write for some and still
However, due to concavity of in , we must have
This implies that there is a linear combination of point from that attains a lower value than , contradicting the assumption that is the lower convex envelope at point q. Since was arbitrary, the lemma holds.
Appendix M. Proof of Lemma A3
Assume in contradiction that there are no distinct points, i.e., it has , then and ,which contradicts the initial assumption that . Assume WOLG that but . Since implies , then must be q as well in contradiction to the initial assumption.
Consider the following cases:
- , : This implies . Furthermore,which holds only if in contradiction to our initial assumption.
- , : This implieswhich holds only if . In such casein contradiction to the assumption .
Thus, the lemma holds.
References
- Tishby, N.; Pereira, F.C.N.; Bialek, W. The information bottleneck method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- Pichler, G.; Piantanida, P.; Matz, G. Distributed information-theoretic clustering. Inf. Inference J. Ima 2021, 11, 137–166. [Google Scholar] [CrossRef]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall: Hoboken, NJ, USA, 1988. [Google Scholar]
- Gupta, N.; Aggarwal, S. Modeling Biclustering as an optimization problem using Mutual Information. In Proceedings of the International Conference on Methods and Models in Computer Science (ICM2CS), Delhi, India, 14–15 December 2009; pp. 1–5. [Google Scholar]
- Hartigan, J. Direct Clustering of a Data Matrix. J. Am. Stat. Assoc. 1972, 67, 123–129. [Google Scholar] [CrossRef]
- Madeira, S.; Oliveira, A. Biclustering algorithms for biological data analysis: A survey. IEEE/ACM Trans. Comput. Biol. Bioinform. 2004, 1, 24–45. [Google Scholar] [CrossRef] [PubMed]
- Dhillon, I.S.; Mallela, S.; Modha, D.S. Information-Theoretic Co-Clustering. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2003, (KDD ’03), Washington, DC, USA, 24–27 August 2003; pp. 89–98. [Google Scholar]
- Courtade, T.A.; Kumar, G.R. Which Boolean Functions Maximize Mutual Information on Noisy Inputs? IEEE Trans. Inf. Theory 2014, 60, 4515–4525. [Google Scholar] [CrossRef]
- Han, T.S. Hypothesis Testing with Multiterminal Data Compression. IEEE Trans. Inf. Theory 1987, 33, 759–772. [Google Scholar] [CrossRef]
- Westover, M.B.; O’Sullivan, J.A. Achievable Rates for Pattern Recognition. IEEE Trans. Inf. Theory 2008, 54, 299–320. [Google Scholar] [CrossRef]
- Painsky, A.; Feder, M.; Tishby, N. An Information-Theoretic Framework for Non-linear Canonical Correlation Analysis. arXiv 2018, arXiv:1810.13259. [Google Scholar]
- Williamson, A.R. The Impacts of Additive Noise and 1-bit Quantization on the Correlation Coefficient in the Low-SNR Regime. In Proceedings of the 57th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 24–27 September 2019; pp. 631–638. [Google Scholar]
- Courtade, T.A.; Weissman, T. Multiterminal Source Coding Under Logarithmic Loss. IEEE Trans. Inf. Theory 2014, 60, 740–761. [Google Scholar] [CrossRef]
- Pichler, G.; Piantanida, P.; Matz, G. Dictator Functions Maximize Mutual Information. Ann. Appl. Prob. 2018, 28, 3094–3101. [Google Scholar] [CrossRef]
- Dobrushin, R.; Tsybakov, B. Information transmission with additional noise. IRE Trans. Inf. Theory 1962, 8, 293–304. [Google Scholar] [CrossRef]
- Wolf, J.; Ziv, J. Transmission of noisy information to a noisy receiver with minimum distortion. IEEE Trans. Inf. Theory 1970, 16, 406–411. [Google Scholar] [CrossRef]
- Witsenhausen, H.S.; Wyner, A.D. A Conditional Entropy Bound for a Pair of Discrete Random Variables. IEEE Trans. Inf. Theory 1975, 21, 493–501. [Google Scholar] [CrossRef]
- Arimoto, S. An algorithm for computing the capacity of arbitrary discrete memoryless channels. IEEE Trans. Inf. Theory 1972, 18, 14–20. [Google Scholar] [CrossRef]
- Blahut, R. Computation of channel capacity and rate-distortion functions. IEEE Trans. Inf. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef]
- Aguerri, I.E.; Zaidi, A. Distributed Variational Representation Learning. IEEE Trans. Pattern Anal. 2021, 43, 120–138. [Google Scholar] [CrossRef]
- Hassanpour, S.; Wuebben, D.; Dekorsy, A. Overview and Investigation of Algorithms for the Information Bottleneck Method. In Proceedings of the SCC 2017: 11th International ITG Conference on Systems, Communications and Coding, Hamburg, Germany, 6–9 February 2017; pp. 1–6. [Google Scholar]
- Slonim, N. The Information Bottleneck: Theory and Applications. Ph.D. Thesis, Hebrew University of Jerusalem, Jerusalem, Israel, 2002. [Google Scholar]
- Sutskover, I.; Shamai, S.; Ziv, J. Extremes of information combining. IEEE Trans. Inf. Theory 2005, 51, 1313–1325. [Google Scholar] [CrossRef]
- Zaidi, A.; Aguerri, I.E.; Shamai, S. On the Information Bottleneck Problems: Models, Connections, Applications and Information Theoretic Views. Entropy 2020, 22, 151. [Google Scholar] [CrossRef]
- Wyner, A.; Ziv, J. A theorem on the entropy of certain binary sequences and applications–I. IEEE Trans. Inf. Theory 1973, 19, 769–772. [Google Scholar] [CrossRef]
- Chechik, G.; Globerson, A.; Tishby, N.; Weiss, Y. Information Bottleneck for Gaussian Variables. J. Mach. Learn. Res. 2005, 6, 165–188. [Google Scholar]
- Blachman, N. The convolution inequality for entropy powers. IEEE Trans. Inf. Theory 1965, 11, 267–271. [Google Scholar] [CrossRef]
- Guo, D.; Shamai, S.; Verdú, S. The interplay between information and estimation measures. Found. Trends Signal Process. 2013, 6, 243–429. [Google Scholar] [CrossRef]
- Bustin, R.; Payaro, M.; Palomar, D.P.; Shamai, S. On MMSE Crossing Properties and Implications in Parallel Vector Gaussian Channels. IEEE Trans. Inf. Theory 2013, 59, 818–844. [Google Scholar] [CrossRef]
- Sanderovich, A.; Shamai, S.; Steinberg, Y.; Kramer, G. Communication Via Decentralized Processing. IEEE Trans. Inf. Theory 2008, 54, 3008–3023. [Google Scholar] [CrossRef]
- Smith, J.G. The information capacity of amplitude-and variance-constrained scalar Gaussian channels. Inf. Control. 1971, 18, 203–219. [Google Scholar] [CrossRef]
- Sharma, N.; Shamai, S. Transition points in the capacity-achieving distribution for the peak-power limited AWGN and free-space optical intensity channels. Probl. Inf. Transm. 2010, 46, 283–299. [Google Scholar] [CrossRef]
- Dytso, A.; Yagli, S.; Poor, H.V.; Shamai, S. The Capacity Achieving Distribution for the Amplitude Constrained Additive Gaussian Channel: An Upper Bound on the Number of Mass Points. IEEE Trans. Inf. Theory 2019, 66, 2006–2022. [Google Scholar] [CrossRef]
- Steinberg, Y. Coding and Common Reconstruction. IEEE Trans. Inf. Theory 2009, 55, 4995–5010. [Google Scholar] [CrossRef]
- Land, I.; Huber, J. Information Combining. Found. Trends Commun. Inf. Theory 2006, 3, 227–330. [Google Scholar] [CrossRef][Green Version]
- Yang, Q.; Piantanida, P.; Gündüz, D. The Multi-layer Information Bottleneck Problem. In Proceedings of the IEEE Information Theory Workshop (ITW), Kaohsiung, Taiwan, 6–10 November 2017; pp. 404–408. [Google Scholar]
- Berger, T.; Zhang, Z.; Viswanathan, H. The CEO Problem. IEEE Trans. Inf. Theory 1996, 42, 887–902. [Google Scholar] [CrossRef]
- Steiner, S.; Kuehn, V. Optimization Of Distributed Quantizers Using An Alternating Information Bottleneck Approach. In Proceedings of the WSA 2019: 23rd International ITG Workshop on Smart Antennas, Vienna, Austria, 24–26 April 2019; pp. 1–6. [Google Scholar]
- Vera, M.; Rey Vega, L.; Piantanida, P. Collaborative Information Bottleneck. IEEE Trans. Inf. Theory 2019, 65, 787–815. [Google Scholar] [CrossRef]
- Ugur, Y.; Aguerri, I.E.; Zaidi, A. Vector Gaussian CEO Problem Under Logarithmic Loss and Applications. IEEE Trans. Inf. Theory 2020, 66, 4183–4202. [Google Scholar] [CrossRef]
- Estella, I.; Zaidi, A. Distributed Information Bottleneck Method for Discrete and Gaussian Sources. In Proceedings of the International Zurich Seminar on Information and Communication (IZS), Zurich, Switzerland, 21–23 February 2018; pp. 35–39. [Google Scholar]
- Courtade, T.A.; Jiao, J. An Extremal Inequality for Long Markov Chains. In Proceedings of the 52nd Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 1–3 October 2014; pp. 763–770. [Google Scholar]
- Erkip, E.; Cover, T.M. The Efficiency of Investment Information. IEEE Trans. Inf. Theory 1998, 44, 1026–1040. [Google Scholar] [CrossRef]
- Gács, P.; Körner, J. Common information is far less than mutual information. Probl. Contr. Inform. Theory 1973, 2, 149–162. [Google Scholar]
- Farajiparvar, P.; Beirami, A.; Nokleby, M. Information Bottleneck Methods for Distributed Learning. In Proceedings of the 56th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 2–5 October 2018; pp. 24–31. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep Learning and the Information Bottleneck Principle. In Proceedings of the Information Theory Workshop (ITW), Jeju Island, Korea, 11–15 October 2015; pp. 1–5. [Google Scholar]
- Alemi, A.; Fischer, I.; Dillon, J.; Murphy, K. Deep Variational Information Bottleneck. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Gabrié, M.; Manoel, A.; Luneau, C.; Barbier, j.; Macris, N.; Krzakala, F.; Zdeborová, L. Entropy and mutual information in models of deep neural networks. In Advances in NIPS; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Goldfeld, Z.; van den Berg, E.; Greenewald, K.H.; Melnyk, I.; Nguyen, N.; Kingsbury, B.; Polyanskiy, Y. Estimating Information Flow in Neural Networks. arXiv 2018, arXiv:1810.05728. [Google Scholar]
- Amjad, R.A.; Geiger, B.C. Learning Representations for Neural Network-Based Classification Using the Information Bottleneck Principle. IEEE Trans. Pattern Anal. 2020, 42, 2225–2239. [Google Scholar] [CrossRef]
- Saxe, A.M.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A.; Tracey, B.D.; Cox, D.D. On the information bottleneck theory of deep learning. J. Stat. Mech. Theory Exp. 2019, 2019, 1–34. [Google Scholar] [CrossRef]
- Cheng, H.; Lian, D.; Gao, S.; Geng, Y. Evaluating Capability of Deep Neural Networks for Image Classification via Information Plane. In Lecture Notes in Computer Science, Proceedings of the Computer Vision-ECCV 2018-15th European Conference, Munich, Germany, 8–14 September 2018, Proceedings, Part XI; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11215, pp. 181–195. [Google Scholar]
- Yu, S.; Wickstrøm, K.; Jenssen, R.; Príncipe, J.C. Understanding Convolutional Neural Networks with Information Theory: An Initial Exploration. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 435–442. [Google Scholar] [CrossRef]
- Lewandowsky, J.; Stark, M.; Bauch, G. Information bottleneck graphs for receiver design. In Proceedings of the IEEE International Symposium on Information Theory, Barcelona, Spain, 10–15 July 2016; pp. 2888–2892. [Google Scholar]
- Stark, M.; Wang, L.; Bauch, G.; Wesel, R.D. Decoding rate-compatible 5G-LDPC codes with coarse quantization using the information bottleneck method. IEEE Open J. Commun. Soc. 2020, 1, 646–660. [Google Scholar] [CrossRef]
- Bhatt, A.; Nazer, B.; Ordentlich, O.; Polyanskiy, Y. Information-distilling quantizers. IEEE Trans. Inf. Theory 2021, 67, 2472–2487. [Google Scholar] [CrossRef]
- Stark, M.; Shah, A.; Bauch, G. Polar code construction using the information bottleneck method. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Barcelona, Spain, 15–18 April 2018; pp. 7–12. [Google Scholar]
- Shah, S.A.A.; Stark, M.; Bauch, G. Design of Quantized Decoders for Polar Codes using the Information Bottleneck Method. In Proceedings of the SCC 2019: 12th International ITG Conference on Systems, Communications and Coding, Rostock, Germany, 11–14 February 2019; pp. 1–6. [Google Scholar]
- Shah, S.A.A.; Stark, M.; Bauch, G. Coarsely Quantized Decoding and Construction of Polar Codes Using the Information Bottleneck Method. Algorithms 2019, 12, 192. [Google Scholar] [CrossRef]
- Kurkoski, B.M. On the Relationship Between the KL Means Algorithm and the Information Bottleneck Method. In Proceedings of the 11th International ITG Conference on Systems, Communications and Coding (SCC), Hamburg, Germany, 6–9 February 2017; pp. 1–6. [Google Scholar]
- Goldfeld, Z.; Polyanskiy, Y. The Information Bottleneck Problem and its Applications in Machine Learning. IEEE J. Sel. Areas Inf. Theory 2020, 1, 19–38. [Google Scholar] [CrossRef]
- Harremoes, P.; Tishby, N. The Information Bottleneck Revisited or How to Choose a Good Distortion Measure. In Proceedings of the 2007 IEEE International Symposium on Information Theory, Nice, France, 24–29 June 2007; pp. 566–570. [Google Scholar]
- Richardson, T.; Urbanke, R. Modern Coding Theory; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Sason, I. On f-divergences: Integral representations, local behavior, and inequalities. Entropy 2018, 20, 383. [Google Scholar] [CrossRef] [PubMed]
- Mehler, F.G. Ueber die Entwicklung einer Function von beliebig vielen Variablen nach Laplaceschen Functionen höherer Ordnung. J. Reine Angew. Math. 1866, 66, 161–176. [Google Scholar]
- Lancaster, H.O. The Structure of Bivariate Distributions. Ann. Math. Statist. 1958, 29, 719–736. [Google Scholar] [CrossRef]
- O’Donnell, R. Analysis of Boolean Functions, 1st ed.; Cambridge University Press: New York, NY, USA, 2014. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Corless, M.J. Linear Systems and Control : An Operator Perspective; Monographs and Textbooks in Pure and Applied Mathematics; Marcel Dekker: New York, NY, USA, 2003; Volume 254. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).