Genome Mining as New Challenge in Natural Products Discovery



Abstract
1. Introduction on Bioactive Natural Products Isolation
Genome Mining
2. The Significance Genome Mining in Drug Discovery
2.1. Strengths and Weaknesses of Genome Mining
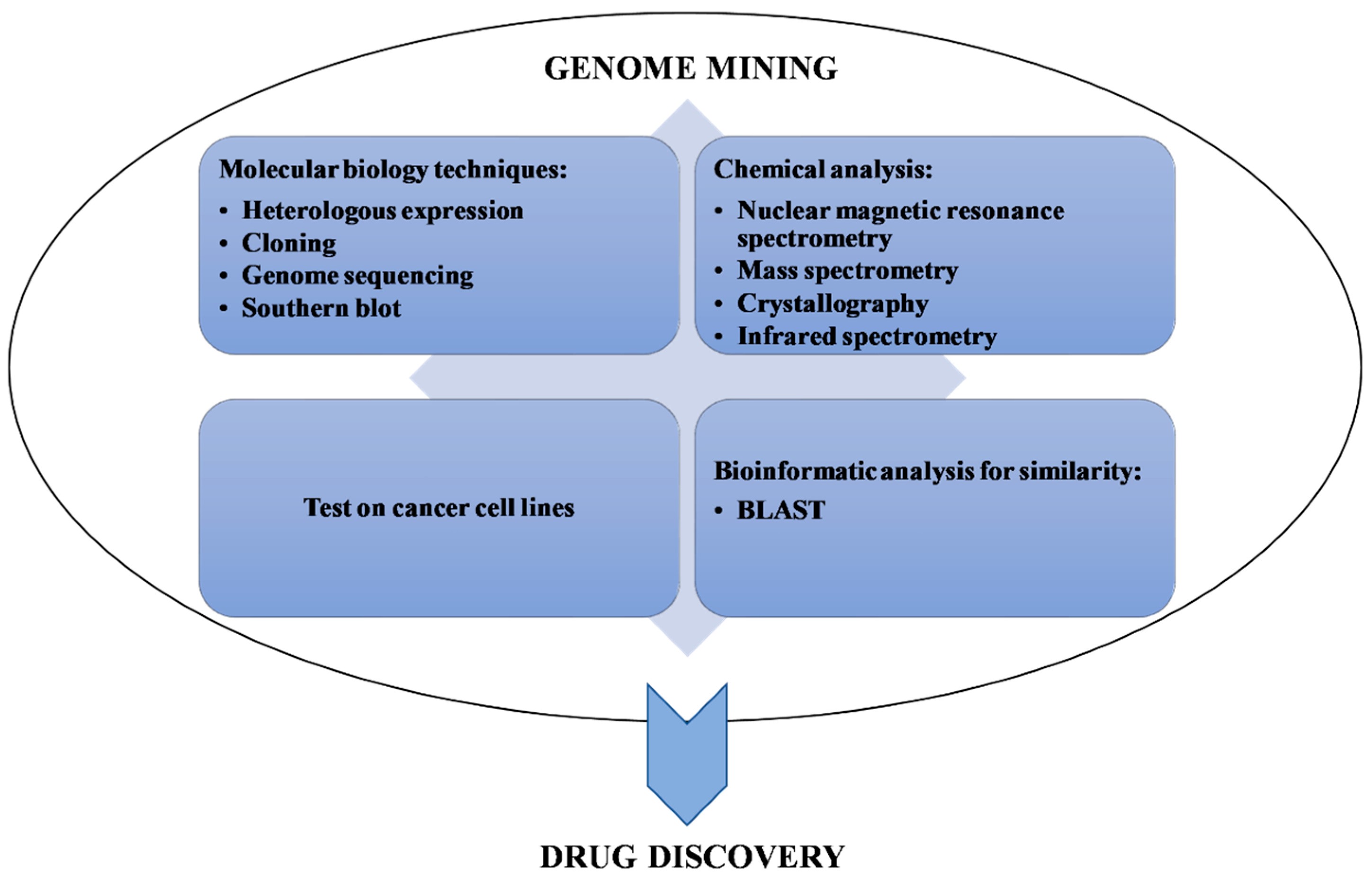
2.2. Synthetic Biology and Other Experimental Techniques Associated with Genome Mining
Examples of Other Experimental Techniques
2.3. Bacteria
Cyanobacteria
2.4. Fungi
2.5. Other Organisms
3. General Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ren, H.; Wang, B.; Zhao, H. Breaking the silence: New strategies for discovering novel natural products. Curr. Opin. Biotechnol. 2017, 48, 21–27. [Google Scholar] [CrossRef]
- Newman, D.J.; Cragg, G.M. Marine-sourced anti-cancer and cancer pain control agents in clinical and late preclinical development. Mar. Drugs 2014, 255–278. [Google Scholar] [CrossRef]
- Gruber, C.W. Global cyclotide adventure: A journey dedicated to the discovery of circular peptides from flowering plants. Pept. Sci. 2010, 94, 565–572. [Google Scholar] [CrossRef]
- Gruber, C.W.; Muttenthaler, M. Discovery of defense- and neuropeptides in social ants by genome-mining. PLoS ONE 2012, 7, 1–12. [Google Scholar] [CrossRef]
- Boddy, C.N. Bioinformatics tools for genome mining of polyketide and non-ribosomal peptides. J. Ind. Microbiol. Biotechnol. 2014, 443–450. [Google Scholar] [CrossRef]
- Wohlleben, W.; Mast, Y.; Stegmann, E.; Ziemert, N. Antibiotic drug discovery. Microb. Biotechnol. 2016, 9, 541–548. [Google Scholar] [CrossRef]
- Peláez, F. The historical delivery of antibiotics from microbial natural products—Can history repeat? Biochem. Pharmacol. 2006, 71, 981–990. [Google Scholar] [CrossRef]
- Maansson, M.; Vynne, N.G.; Klitgaard, A.; Nybo, J.L.; Melchiorsen, J.; Nguyen, D.D.; Sanchez, L.M.; Ziemert, N.; Dorrestein, P.C.; Andersen, M.R.; et al. An integrated metabolomic and genomic mining workflow to uncover the biosynthetic potential of bacteria. Am. Soc. Microbiol. 2016, 1, 1–14. [Google Scholar] [CrossRef]
- Gulder, T.A.M.; Moore, B.S. Chasing the treasures of the sea-bacterial marine natural products. Curr. Opin. Microbiol. 2009, 12, 252–260. [Google Scholar] [CrossRef]
- Almeida, E.L.; Kaur, N.; Jennings, L.K.; Felipe, A.; Rinc, C.; Jackson, S.A.; Thomas, O.P.; Dobson, A.D.W. Genome mining coupled with OSMAC-based cultivation reveal differential production of Surugamide A by the marine sponge isolate Streptomyces sp. SM17 when compared to its terrestrial relative S. albidoflavus J1074. Microorganisms 2019, 7, 394. [Google Scholar] [CrossRef]
- Tracanna, V.; De Jong, A.; Medema, M.H.; Kuipers, O.P. Mining prokaryotes for antimicrobial compounds: From diversity to function. FEMS Microbiol. Rev. 2017, 41, 417–429. [Google Scholar] [CrossRef]
- Durand, G.A.; Raoult, D.; Dubourg, G. Antibiotic discovery: History, methods and perspectives. Int. J. Antimicrob. Agents 2019, 53, 371–382. [Google Scholar] [CrossRef]
- Nett, M. Genome mining: Concept and strategies for natural product discovery. Prog. Chem. Org. Nat. Prod. 2014, 99, 199–245. [Google Scholar]
- Challis, G.L. Genome mining for novel natural product discovery. J. Med. Chem. 2008, 51, 2618–2628. [Google Scholar] [CrossRef]
- Ziemert, N.; Alanjary, M.; Weber, T. The evolution of genome mining in microbes—A review. Nat. Prod. Rep. 2016, 33, 988–1005. [Google Scholar] [CrossRef]
- Trivella, D.B.B.; De Felicio, R. The tripod forbacterial natural product discovery: Genome mining, silent pathway induction, and mass spectrometry-based molecular networking. mSystems 2018, 3, e00160–e17. [Google Scholar] [CrossRef]
- Koonin, E.V. Evolution of genome architecture. Int. J. Biochem. Cell Biol. 2009, 41, 298–306. [Google Scholar] [CrossRef]
- Timmermans, M.L.; Paudel, Y.P.; Ross, A.C. Investigating the biosynthesis of natural products from marine proteobacteria: A survey of molecules and strategies. Mar. Drugs 2017, 15, 235. [Google Scholar] [CrossRef]
- Blin, K.; Medema, M.H.; Kazempour, D.; Fischbach, M.A.; Breitling, R.; Takano, E.; Weber, T. antiSMASH 2.0—A versatile platform for genome mining of secondary metabolite producers. Nucleic Acids Res. 2013, 41, 204–212. [Google Scholar] [CrossRef]
- Skinnider, M.A.; Dejong, C.A.; Rees, P.N.; Johnston, C.W.; Li, H.; Webster, A.L.H.; Wyatt, M.A.; Magarvey, N.A. Genomes to natural products PRediction Informatics for Secondary Metabolomes (PRISM). Nucleic Acids Res. 2015, 43, 9645–9662. [Google Scholar] [CrossRef]
- Machado, H.; Tuttle, R.N.; Jensen, P.R. Omics-based natural product discovery and the lexicon of genome mining. Curr. Opin. Microbiol. 2017, 39, 136–142. [Google Scholar] [CrossRef]
- Hadjithomas, M.; Chen, I.A.; Chu, K.; Huang, J.; Ratner, A.; Palaniappan, K.; Andersen, E.; Markowitz, V.; Kyrpides, N.C.; Ivanova, N. IMG-ABC: New features for bacterial secondary metabolism analysis and targeted biosynthetic gene cluster discovery in thousands of microbial genomes. Nucleic Acids Res. 2017, 45, 560–565. [Google Scholar] [CrossRef]
- Helfrich, E.J.N.; Reite, S.; Piel, J. Recent advances in genome-based polyketide discovery. Curr. Opin. Biotechnol. 2014, 29, 107–115. [Google Scholar] [CrossRef]
- Olano, C.; Méndez, C.; Salas, J.A. Molecular insights on the biosynthesis of antitumour compounds by actinomycetes. Microb. Biotechnol. 2011, 4, 144–164. [Google Scholar] [CrossRef]
- Nett, M.; Ikeda, H.; Moore, B.S. Genomic basis for natural product biosynthetic diversity in the actinomycetes. Nat. Prod. Rep. 2009, 26, 1362–1384. [Google Scholar] [CrossRef]
- Olano, C.; Méndez, C.; Salas, J.A. Strategies for the design and discovery of novel antibiotics using genetic engineering and genome mining. In Antimicrobial Compounds: Current Strategies and New Alternatives; Villa, T.G., Veiga-Crespo, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–25. [Google Scholar]
- Mody, K.H.; Haldar, S. Genome mining for bioactive compounds. In Springer Handbook of Marine Biotechnology; Kim, S.K., Ed.; Springer Handbooks; Springer: Berlin/Heidelberg, Germany, 2015; pp. 531–539. [Google Scholar]
- Scheffler, R.J.; Colmer, S.; Tynan, H.; Demain, A.L.; Gullo, V.P. Antimicrobials, drug discovery, and genome mining. Appl. Microbiol. Biotechnol. 2013, 97, 969–978. [Google Scholar] [CrossRef]
- Zerikly, M.; Challis, G.L. Strategies for the discovery of new natural products by genome mining. ChemBioChem 2009, 10, 625–633. [Google Scholar] [CrossRef]
- Breitling, R.; Takano, E. Synthetic biology advances for pharmaceutical production. Curr. Opin. Biotechnol. 2015, 35, 46–51. [Google Scholar] [CrossRef]
- Keasling, J.D. Synthetic biology for dynthetic chemistry. ACS Chem. Biol. 2008, 3, 64–76. [Google Scholar] [CrossRef]
- Quin, M.B.; Schmidt-Dannert, C. Designer microbes for biosynthesis. Curr. Opin. Biotechnol. 2014, 29, 55–61. [Google Scholar] [CrossRef]
- Singh, V. Recent advancements in synthetic biology: Current status and challenges. Gene 2014, 535, 1–11. [Google Scholar] [CrossRef]
- Sleator, R.D. The synthetic biology future. Bioengineered 2014, 5, 69–72. [Google Scholar] [CrossRef]
- Unkles, S.E.; Valiante, V.; Mattern, D.J.; Brakhage, A.A. Synthetic biology tools for bioprospecting of natural products in eukaryotes. Chem. Biol. 2014, 21, 1–7. [Google Scholar] [CrossRef]
- Wilson, M.C.; Piel, J. Metagenomic approaches for exploiting uncultivated bacteria as a resource for novel biosynthetic enzymology. Chem. Biol. 2013, 20, 636–647. [Google Scholar] [CrossRef]
- Wright, G. Synthetic biology revives antibiotics. Nature 2014, 509, S13. [Google Scholar]
- Medema, M.H.; Breitling, R.; Bovenberg, R.; Takano, E. production in microorganisms. Nat. Publ. Gr. 2010, 9, 131–137. [Google Scholar]
- Cobb, R.E.; Luo, Y.; Freestone, T.; Zhao, H. Drug discovery and development via synthetic biology. In Synthetic Biology—Tools and Applications; Zhao, H., Ed.; Elsevier: Oxford, UK, 2013; pp. 183–206. [Google Scholar]
- Hranueli, D.; Starcevic, A.; Zucko, J.; Rojas, J.D.; Diminic, J.; Baranasic, D.; Gacesa, R.; Padilla, G.; Long, P.F.; Cullum, J. Synthetic biology: A novel approach for the construction of industrial microorganisms. Food Technol. Biotechnol. 2013, 51, 3–11. [Google Scholar]
- Zakeri, B.; Lu, T.K. Synthetic biology of antimicrobial discovery. ACS Synth. Biol. 2012. [Google Scholar] [CrossRef]
- Cummings, M.; Breitling, R.; Takano, E. Steps towards the synthetic biology of polyketide biosynthesis. FEMS Microbiol. Lett. 2014, 351, 116–125. [Google Scholar] [CrossRef]
- Genilloud, O. The re-emerging role of microbial natural products in antibiotic discovery. Antonie Van Leeuwenhoek 2014, 106, 173–188. [Google Scholar] [CrossRef]
- Luo, Y.; Cobb, R.E.; Zhao, H. Recent advances in natural product discovery. Curr. Opin. Biotechnol. 2014, 30, 230–237. [Google Scholar] [CrossRef]
- Porro, D.; Branduardi, P.; Sauer, M.; Mattanovich, D. Old obstacles and new horizons for microbial chemical production. Curr. Opin. Biotechnol. 2014, 30, 101–106. [Google Scholar] [CrossRef]
- Paddon, C.J.; Keasling, J.D. Semi-synthetic artemisinin: A model for the use of synthetic biology in pharmaceutical development. Nat. Rev. Microbiol. 2014, 12, 355–367. [Google Scholar] [CrossRef]
- Kurita, K.L.; Glassey, E.; Linington, R.G. Integration of high-content screening and untargeted metabolomics for comprehensive functional annotation of natural product libraries. Proc. Natl. Acad. Sci. USA 2015, 112, 11999–12004. [Google Scholar] [CrossRef]
- Wang, G.; Hosaka, T.; Ochi, K.; Wang, G.; Hosaka, T.; Ochi, K. Dramatic activation of antibiotic production in Streptomyces coelicolor by cumulative drug resistance mutations. Appl. Environ. Microbiol. 2008, 74, 2834. [Google Scholar] [CrossRef]
- Tang, X.; Li, J.; Milla, N.; Zhang, J.J.; Neill, E.C.O.; Ugalde, J.A.; Jensen, P.R.; Mantovani, S.M.; Moore, B.S. Identification of thiotetronic acid antibiotic biosynthetic pathways by target-directed genome mining. ACS Chem. Biol. 2015, 10, 2841–2849. [Google Scholar] [CrossRef]
- Craney, A.; Ozimok, C.; Pimentel-elardo, S.M.; Capretta, A.; Nodwell, J.R. Chemical perturbation of secondary metabolism demonstrates important links to primary metabolism. Chem. Biol. 2012, 19, 1020–1027. [Google Scholar] [CrossRef]
- Kwon, T.; Lee, G.; Rhee, Y.; Park, H.; Chang, M.; Lee, S.; Lee, J.; Lee, T. Identification of nickel response genes in abnormal early developments of sea urchin by differential display polymerase chain reaction. Ecotoxicol. Environ. Saf. 2012, 1–7. [Google Scholar]
- Newman, D.J.; Cragg, G.M. Natural products as sources of new drugs from 1981 to 2014. J. Nat. Prod. 2016, 79, 629–661. [Google Scholar] [CrossRef]
- Jin, J.; Yang, X.; Liu, T.; Xiao, H.; Wang, G.; Zhou, M.; Liu, F.; Zhang, Y.; Liu, D.; Chen, M.; et al. Fluostatins M–Q featuring a 6-5-6-6 ring skeleton and high oxidized A-rings from marine Streptomyces sp. PKU-MA00045. Mar. Drugs 2018, 16, 87. [Google Scholar] [CrossRef]
- Hornung, A.; Bertazzo, M.; Dziarnowski, A.; Schneider, K.; Welzel, K.; Wohlert, S.; Holzenkämpfer, M.; Nicholson, G.J.; Bechthold, A.; Süssmuth, R.D.; et al. A genomic screening approach to the structure-guided identification of drug candidates from natural sources. ChemBioChem 2007, 8, 757–766. [Google Scholar] [CrossRef]
- Mcalpine, J.B.; Bachmann, B.O.; Piraee, M.; Tremblay, S.; Alarco, A.; Zazopoulos, E.; Farnet, C.M. Microbial genomics as a guide to drug discovery and structural elucidation: ECO-02301, a novel antifungal agent, as an example. J. Nat. Prod. 2005, 68, 493–496. [Google Scholar] [CrossRef]
- Liu, W.; Kersten, R.D.; Yang, Y.; Moore, B.S.; Dorrestein, P.C. Imaging mass spectrometry and genome mining via short sequence tagging identified the anti-infective agent arylomycin in Streptomyces roseosporus. J. Am. Chem. Soc. 2011, 133, 18010–18013. [Google Scholar] [CrossRef]
- Liu, W.; Lamsa, A.; Wong, W.R.; Boudreau, P.D.; Kersten, R.; Peng, Y.; Moree, W.J.; Duggan, B.M.; Moore, B.S.; Gerwick, W.H.; et al. MS/MS-based networking and peptidogenomics guided genome mining revealed the stenothricin gene cluster in Streptomyces roseosporus. J. Antibiot. Tokyo 2014, 67, 99–104. [Google Scholar] [CrossRef]
- Seo, M.; Zhu, D.; Endo, S.; Ikeda, H.; Cane, D.E. Genome mining in Streptomyces. Elucidation of the role of baeyer-villiger monooxygenases and non-heme iron-dependent dehydrogenase/oxygenases in the final steps of the biosynthesis of pentalenolactone and neopentalenolactone. Biochemistry 2011, 50, 1739–1754. [Google Scholar] [CrossRef]
- Tang, J.; Liu, X.; Peng, J.; Tang, Y.; Zhang, Y. Genome sequence and genome mining of a marine-derived antifungal bacterium Streptomyces sp. M10. Appl. Microbiol. Biotechnol. 2015, 99, 2763–2772. [Google Scholar] [CrossRef]
- Xu, M.; Wang, Y.; Zhao, Z.; Gao, G.; Huang, S.-X.; Kang, Q.; He, X.; Lin, S.; Pang, X.; Deng, Z.; et al. Functional genome mining for metabolites encoded by large gene clusters using heterologous expression of a whole genomic BAC library in Streptomyces. Appl. Environ. Microbiol. 2016, 82, 5795–5805. [Google Scholar] [CrossRef]
- Cano-prieto, C.; García-Salcedo, R.; Sánchez-Hidalgo, M.; Braña, A.F.; Fiedler, H.-P.; Méndez, C.; Salas, J.A.; Olano, C. Genome mining of Streptomyces sp. Tü 6176: Characterization of nataxazole biosynthesis pathway. ChemBioChem 2015, 16, 1461–1473. [Google Scholar] [CrossRef]
- Ye, S.; Molloy, B.; Braña, A.F.; Zabala, D.; Olano, C.; Cortés, J.; Morís, F.; Salas, J.A.; Méndez, C. Identification by genome mining of a Type I Polyketide gene cluster from Streptomyces argillaceus involved in the biosynthesis of pyridine and piperidine alkaloids Argimycins P. Front. Microbiol. 2017, 8, 1–18. [Google Scholar] [CrossRef]
- Paulo, B.S.; Sigrist, R.; Angolini, C.F.F.; Oliveira, L.G. De New cyclodepsipeptide derivatives revealed by genome mining and molecular networking. Chem. Sel. 2019, 4, 7785–7790. [Google Scholar]
- Purves, K.; Macintyre, L.; Brennan, D.; Hreggviðsson, G.Ó.; Kuttner, E.; Ásgeirsdóttir, M.E.; Young, L.C.; Green, D.H.; Edrada-ebel, R.; Duncan, K.R. Using molecular networking for microbial secondary metabolite bioprospecting. Metabolites 2016, 6, 2. [Google Scholar] [CrossRef]
- Deng, H.; Ma, L.; Bandaranayaka, N.; Qin, Z.; Mann, G.; Kyeremeh, K.; Yu, Y.; Shepherd, T.; Naismith, J.H.; O’Hagan, D. Identification of fluorinases from Streptomyces sp. MA37, Norcardia brasiliensis, and Actinoplanes sp. N902-109 by genome mining. ChemBioChem 2014, 15, 364–368. [Google Scholar] [CrossRef] [PubMed]
- Anoop, A.; Antunes, A. Whole genome sequencing of the symbiont Pseudovibrio sp. from the intertidal marine sponge Polymastia penicillus revealed a gene repertoire for host-switching permissive lifestyle. Genome Biol. Evol. 2015, 7, 3022–3032. [Google Scholar]
- Bertin, M.J.; Schwartz, S.L.; Lee, J.; Korobeynikov, A.; Dorrestein, P.C.; Gerwick, L.; Gerwick, W.H. Spongosine production by a Vibrio harveyi strain associated with the sponge Tectitethya crypta. J. Nat. Prod. 2014, 78, 493–499. [Google Scholar] [CrossRef]
- Jeske, O.; Jogler, M.; Petersen, J.; Sikorski, J.; Jogler, C. From genome mining to phenotypic microarrays: Planctomycetes as source for novel bioactive molecules. Antonie Van Leeuwenhoek 2013, 104, 551–567. [Google Scholar] [CrossRef]
- Guérard-Hélaine, C.; de Berardinis, V.; Besnard-Gonnet, M.; Darii, E.; Debacker, M.; Debard, A.; Fernandes, C.; Hélaine, V.; Mariage, A.; Pellouin, V.; et al. Genome mining for innovative biocatalysts: New dihydroxyacetone aldolases for the Chemist’ s Toolbox. ChemCatChem 2015, 7, 1871–1879. [Google Scholar] [CrossRef]
- Singh, S.P.; Klisch, M.; Sinha, R.P.; Häder, D. Genomics genome mining of mycosporine-like amino acid (MAA) synthesizing and non-synthesizing cyanobacteria: A bioinformatics study. Genomics 2010, 95, 120–128. [Google Scholar] [CrossRef]
- Micallef, M.L.; Agostino, P.M.D.; Sharma, D.; Viswanathan, R.; Moffitt, M.C. Genome mining for natural product biosynthetic gene clusters in the Subsection V cyanobacteria. BMC Genom. 2015, 1–20. [Google Scholar] [CrossRef]
- Fuerst, J.A.; Sagulenko, E. Beyond the bacterium: Planctomycetes structure and function. Nat. Rev. Microbiol. 2011, 9, 13–18. [Google Scholar] [CrossRef]
- Oren, A.; Gunde-cimerman, N. Mycosporines and mycosporine-like amino acids: UV protectants or multipurpose secondary metabolites? FEMS Microbiol. Lett. 2007, 269, 1–10. [Google Scholar] [CrossRef]
- Keller, N.P.; Turner, G.; Bennett, J.W. Fungal secondary metabolism—from biochemistry to genomics. Nat. Rev. Microbiol. 2015, 3, 937–947. [Google Scholar] [CrossRef]
- Bergmann, S.; Schümann, J.; Scherlach, K.; Lange, C.; Brakhage, A.A.; Hertweck, C. Genomics-driven discovery of PKS-NRPS hybrid metabolites from Aspergillus nidulans. Nat. Chem. Biol. 2007, 3, 213–217. [Google Scholar] [CrossRef]
- Mao, X.; Xu, W.; Li, D.; Yin, W.; Chooi, Y.; Li, Y.; Tang, Y.; Hu, Y. Epigenetic genome mining of an endophytic fungus leads to the pleiotropic biosynthesis of natural products. Angew. Commun. 2015, 54, 7592–7596. [Google Scholar] [CrossRef]
- Ding, Y.; De Wet, J.R.; Cavalcoli, J.; Li, S.; Greshock, T.J.; Miller, K.A.; Finefield, J.M.; Sunderhaus, J.D.; Mcafoos, T.J.; Tsukamoto, S.; et al. Genome-based characterization of two prenylation steps in the assembly of the Stephacidin and Notoamide anticancer agents in a marine-derived Aspergillus sp. J. Am. Chem. Soc. 2010, 132, 12733–12740. [Google Scholar] [CrossRef]
- Ye, Y.; Minami, A.; Mándi, A.; Liu, C.; Taniguchi, T.; Kuzuyama, T.; Monde, K.; Gomi, K.; Oikawa, H. Genome mining for sesterterpenes using bifunctional terpene synthases reveals a unified intermediate of di/sesterterpenes. J. Am. Chem. Soc. 2015, 137, 11846–11853. [Google Scholar] [CrossRef]
- Mojib, N.; Amad, M.; Thimma, M.; Aldanondo, N.; Kumaran, M.; Irigoien, X. Carotenoid metabolic profiling and transcriptome-genome mining reveal functional equivalence among blue-pigmented copepods and appendicularia. Mol. Ecol. 2014, 23, 2740–2756. [Google Scholar] [CrossRef]
- Huang, A.C.; Kautsar, S.A.; Hong, Y.J.; Medema, M.H.; Bond, A.D.; Tantillo, D.J.; Osbourn, A. Unearthing a sesterterpene biosynthetic repertoire in the Brassicaceae through genome mining reveals convergent evolution. Proc. Natl. Acad. Sci. USA 2017, 114, 1–10. [Google Scholar] [CrossRef]


{kind=link}
| Strengths | Weaknesses |
|---|---|
| Easy to apply for experimental procedures in laboratory | Not to predict biotechnological potential of the natural compounds |
| Cheap and easy to apply in laboratory | Only known biosynthetic gene clusters |
| To predict chemical structures of bioactive natural products | Difficulty to formulate chemical structures |
| No particular skills and/or experience of the operators | Too new approach that needs to be deepened |
| Microorganism | Experimental Purpose | Associated Techniques | References |
|---|---|---|---|
| Actinomycetes | Identification of strains capable to produce halogen enzymes. | PCR screening and NMR spectroscopy | [54] |
| Streptomyces aizunensis NRRL B-11277 | Elucidation of new antibiotic ECO-02301 structure | HPLC, MIC | [55] |
| Streptomyces roseosporus | Anti-infective agent arylomycin and its BGCs | IMS, MS and SST | [56] |
| Streptomyces roseosporus | Identification of stenothricin and its BGCs | MS/MS spectra, antiSMASH, NMR, BioMAP, Cytological profiling | [57] |
| Streptomyces exfoliatus UC5319, Streptomyces arenae TU469 and Streptomyces avermitilis | Biosynthetic gene clusters involved in the synthesis of pentalenolactone | Cloning, MS/MS spectra, H-NMR spectroscopy | [58] |
| Streptomycetes sp. M10 | To determine biosynthetic gene clusters involved in the synthesis of natural products | PRC screening, BLASTP, antiSMASH, Artemis Release 12.0, RT-PCR, MALDI-TOF | [59] |
| Streptomyces sp., Streptomyces roche, Streptomyces lividans SBT5 | Streptothricin and borrelidin biosynthetic gene clusters | Heterologous expression, HPLC, LC-MS, LEXAS method, antiSMASH | [60] |
| Streptomyces sp. Tü 6176: | BGCs of nataxazole | antiSMASH 2.0 heterologous expression, gene inactivation, antibiotic disc diffusion assay, test on cancer cell lines | [61] |
| Strepmomyces argillaceus ATCC12956 | Argimycin biosynthetic gene cluster | AntiSMASH, test on cancer cell lines | [62] |
| Streptomyces sp. CBMAI 2042 | Valinomycin biosynthetic gene cluster | Test on pathogens, in silico analyses | [63] |
| Bacillus, Streptomyces, Micronospora, Paenibacillus, Kocuria, Verricosispora, Staphylococcus, Micrococcus | Influence of isolation location on secondary metabolite production | Test on cancer cell lines, MS, GNPS | [64] |
| Streptomyces sp. MA37, Norcardia brasiliensis, Actinoplanes sp. N902-109 | Identification of Fluorinases | overexpression of gene, vitro activity assay and 19F NMR | [65] |
| Streptomyces sp. PKU-MA00045 | Aromatic polyketides | 1H-NMR and 13C-NMR spectra, genome sequencing, BLAST | [53] |
| Streptomyces sp. SM17 | Identification of Surugamide A | NCBI BLASTN, antiSMASH, NMR | [10] |
| Pseudovibrio sp. POLY-S9 | BGCs of symbiotic bacteria and gene involved in symbiontic relationship | genome sequencing, antiSMASH | [66] |
| Vibrio harveyi | BGCs of spongosine and potential secondary metabolites | MS/MS-based molecular networking, nitric oxide assay, MLSA and BLAST, genome sequencing and antiSMASH | [67] |
| Planctomyces | Metabolic properties of these bacteria | antiSMASH, MicroArray | [68] |
| Diverse prokaryotic species | New aldolase enzymes | LC–MS, cloning, FPLC, HTS | [69] |
| Pseudoalteromonas luteviolacea | Violacein biosynthetic pathway | LC-MS/MS, antiSMASH | [8] |
| Anabaena variabilis PCC 7937, Anabaena sp. PCC 7120, Synechocystis sp. PCC 6803 and Synechococcus sp. PCC 6301 | MAA biosynthetic gene cluster | MAA induction with radiation UVR, MAA extraction, HPLC, BLAST | [70] |
| Hapalosiphon welwitschii UH strain IC-52-3, Westiella intricate UH strain HT-29-1 and Fischerella sp. CC 9431 | Hapalosine biosynthetic pathway | PCR screening, antiSMASH, Geneious version 6.1.7 | [71] |
| Fungi | Experimental Purpose | Associated Techniques | References |
|---|---|---|---|
| Aspergillus nidulans | Detection of silent metabolic pathway | Southern blot, HPLC, NMR, IR, and MS | [75] |
| Calcarisporium arbuscula | Silent metabolic pathway involved in natural product biosynthesis | genome sequencing, LC-MS, chromatographic and NMR analysis, HPLC | [76] |
| Aspergillus MF297-2 | Identification of BGCs of ephacidin and notoamide | genome sequencing, BLAST, gene cloning, overexpression of protein, HPLC, LC-MS, 1H, and 13C NMR | [77] |
| Aspergillus oryzae and Neosartorya fischeri | Isolation of terpene synthases | heterologous expression, GC-MS, 1H- and 13C-NMR, LC-MS, and HR-MS | [78] |
| Organism | Experimental Purpose | Associated Techniques | References |
|---|---|---|---|
| Atta cephalotes, Camponotus floridanus and Harpegnathos saltator | Defense- and neuropeptides in Social Ants | tBLASTn, GeneWise algorithm, ClustalW | [4] |
| Calanus sp., Pontella sp., Oikopleura sp., Acartia sp., Acartia sp. and Corycaeus sp. | Metabolic pathway from conversion from β-carotene to astaxanthin. | LC-UV method, HPLC, Hhpred database | [79] |
| Arabidopsis thaliana, Capsella rubella, Brassica oleracea, Nicotiana benthamiana, Agrobacterium tumefaciens | Sesterterpene biosynthetic gene cluster | plantiSMASH, heteroloug expression, GC-MS, cristallography | [80] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albarano, L.; Esposito, R.; Ruocco, N.; Costantini, M. Genome Mining as New Challenge in Natural Products Discovery. Mar. Drugs 2020, 18, 199. https://doi.org/10.3390/md18040199
Albarano L, Esposito R, Ruocco N, Costantini M. Genome Mining as New Challenge in Natural Products Discovery. Marine Drugs. 2020; 18(4):199. https://doi.org/10.3390/md18040199
Chicago/Turabian StyleAlbarano, Luisa, Roberta Esposito, Nadia Ruocco, and Maria Costantini. 2020. "Genome Mining as New Challenge in Natural Products Discovery" Marine Drugs 18, no. 4: 199. https://doi.org/10.3390/md18040199
APA StyleAlbarano, L., Esposito, R., Ruocco, N., & Costantini, M. (2020). Genome Mining as New Challenge in Natural Products Discovery. Marine Drugs, 18(4), 199. https://doi.org/10.3390/md18040199