Abstract
Stem removal from harvested fruits remains one of the most labor-intensive tasks in fruit harvesting, directly affecting the fruit quality and marketability. Accurate and rapid fruit and stem segmentation techniques are essential for automating this process. This study proposes an enhanced You Only Look Once (YOLO) model, AppleStem (AS)-YOLO, which uses a ghost bottleneck and global attention mechanism to segment apple stems. The proposed model reduces the number of parameters and enhances the computational efficiency using the ghost bottleneck while improving feature extraction capabilities using the global attention mechanism. The model was evaluated using both a custom-built and an open dataset, which will be later released to ensure reproducibility. Experimental results demonstrated that the AS-YOLO model achieved high accuracy, with a mean average precision (mAP)@50 of 0.956 and mAP@50–95 of 0.782 across all classes, along with a real-time inference speed of 129.8 frames per second (FPS). Compared with state-of-the-art segmentation models, AS-YOLO exhibited superior performance. The proposed AS-YOLO model demonstrates the potential for real-time application in automated fruit-harvesting systems, contributing to the advancement of agricultural automation.
1. Introduction
Recently, advancements in agricultural technology have become crucial for improving efficiency and reducing costs through mechanized harvesting techniques. Apples, one of the world’s most economically significant crops, present a challenge for automated systems in accurately identifying both the fruit and its stem, which is essential for maintaining freshness and minimizing damage during postharvest processing [1]. Despite technological progress, stem removal remains labor-intensive, requiring significant labor within a short period. Automation of this process requires accurate segmentation techniques that utilize computer vision and deep-learning technologies [2,3]. Rapid advancements in computer vision technology have been crucial in addressing the challenge of accurately segmenting fruit and stems. Traditional detection methods [4,5,6,7,8,9,10] primarily focus on identifying the location or boundaries of fruits, however, accurately recognizing smaller regions such as stems remains a significant challenge. As depicted in Figure 1, stems occupy a considerably smaller area than fruits, requiring higher precision for recognition. To overcome these limitations, deep learning-based detection and segmentation models have evolved progressively, offering more refined and precise solutions to segmentation tasks.

Figure 1.
Sample images from AppleStem-Segmentation (AS-Seg) dataset used in the experiments.
Existing deep learning-based studies on apple and stem segmentation, such as those employing multimodal approaches [11] or two-step convolutional neural networks (CNN) [12,13], have shown promising results in terms of accuracy. However, there are significant limitations in terms of processing speed. In particular, two-stage segmentation architecture models such as Mask R-CNN [14] are not suitable for real-time application due to the substantial computational burden at each stage. In [13], Mask R-CNN was applied to experiments across various environments and achieved high segmentation accuracy. However, its processing time was still 1.18 s per image, which is not enough for real-time applications. Moreover, multimodal models that integrate RGB and near-infrared (NIR) imagery [11] showed high accuracy but it took time to align images between the two modalities. Any misalignment between the modalities can lead to degraded performance. Furthermore, RGB and NIR cameras are required to acquire images, and in the case of the NIR camera additional lighting device is required, making them less practical for deployment in real-world agricultural environments. In this way, as the module becomes more complex, the performance improves, but it does not meet the critical requirement of real-time processing, which is essential for agricultural automation.
In this paper, we propose AS-YOLO, an enhanced YOLO model developed to optimize the balance between performance and processing time for solving the problem of stem segmentation in apples. We reduce the number of parameters and improves computational efficiency through ghost bottleneck module [15]. Additionally, the Global Attention Mechanism (GAM) [16] is utilized to enhance the feature extraction capability of the model, enabling finer differentiation between stems and fruits. To validate the performance of the proposed AS-YOLO model, we used the AppleStem-Segmentation (AS-Seg) dataset [17], which includes both a self-constructed dataset and open datasets, as shown in Figure 1. This dataset was collected under various environmental conditions and includes diverse apple data. These variations enhance the reliability of the experimental results, ensuring the robustness of the model across different scenarios. Through comparative experiments using the dataset, we confirmed that AS-YOLO showed superior performance than existing methods.
Therefore, the proposed AS-YOLO model demonstrates the potential for real-time application in stem removal tasks performed by fruit-harvesting robots, laying the groundwork for significant advancements in agricultural automation. This approach is expected to substantially improve the efficiency of labor-intensive fruit harvesting work, further contributing to the automation of the agricultural field.
To address the limitations of existing deep learning-based fruit and stem segmentation methods, we propose an AS-YOLO model for fruit and stem segmentation. Our work presents four key contributions that distinguish it from previous research.
- -
- We propose a novel AS-YOLO model specifically designed for the segmentation of fruits and stems. This model ensures high processing speed, making it suitable for real-time applications in agricultural automation and fruit-harvesting robots, thereby contributing to enhanced harvest efficiency. The model also incorporates improvements in both accuracy and efficiency over the standard YOLO architecture.
- -
- The AS-YOLO model integrates a ghost bottleneck module to improve computational efficiency by reducing the number of model parameters. This optimization results in faster processing times, achieving real-time performance on an NVIDIA GeForce RTX 3070, with a throughput of 48.78 FPS.
- -
- To overcome the limitations of local feature extraction in conventional YOLO models, we introduce a global attention module (GAM). This module allows the model to better capture the overall context within images, significantly enhancing segmentation accuracy, particularly for smaller objects like stems.
- -
- We constructed and annotated a new dataset, AppleStem-Segmentation (AS-Seg) database, including both public and custom-built data, specifically for the segmentation of apples and their stems. This dataset will be made publicly available to support future research ensuring that future studies can benchmark performance against our work.
The remainder of this paper is organized as follows. Section 2 reviews related works on fruit and stem detection and segmentation. Section 3 describes the proposed AS-YOLO model and its key components. Section 4 presents experimental results, including ablation studies and comparisons with other methods. Finally, Section 5 discusses limitations and future research directions and Section 6 concludes the paper.
2. Related Works
Recently, various deep-learning-based methods and classical image processing algorithms have been studied in the detection and segmentation of fruit and stem. Each study improves detection and segmentation performance by addressing environmental factors, such as lighting variations, occlusions, and complex backgrounds, as well as accounting for the diverse shapes and sizes of fruits. Traditional image processing methods utilize color-based models, texture features, and geometric shape information to improve detection performance in complex environments. However, their effectiveness is limited by factors such as lighting variations and fruit shape. Recent deep-learning-based studies have demonstrated robust detection and segmentation performance in various environments using CNNs. However, they have limitations such as high computational cost and difficulty in real-time applications; thus, researchers are investigating lightweight models to address these problems. These studies can be categorized into detailed methods based on each approach.
2.1. Fruit Detection Approaches
Various methodologies have been developed for fruit detection, including color-based, texture-based, and multimodal-based methods, with each study improving detection performance by addressing environmental constraints and fruit-specific characteristics. In an early study, RGB-thermal fusion [4] was used because its performance was limited when relying solely on color information. By incorporating thermal channels, this method exhibited more accurate detection and boundary recognition performance under challenging lighting conditions. However, thermal cameras are expensive and are difficult to implement in real-world scenarios. Consequently, ref. [5] we propose a method that enhances edges using Laplacian filters [18] while combining color features, enabling accurate fruit detection in complex backgrounds using only RGB images. This method identifies fruit centers and expands them from the initial regions using a combination of texture and color features. Later studies [6,7] proposed a method that initially detects fruit pixels using only color information without texture features, followed by seed region expansion for more accurate segmentation. However, relying solely on color information is inadequate for capturing essential features, resulting in performance limitations and requiring complex post-processing to achieve accurate results. To address these limitations, studies have proposed extracting and combining various features to improve detection performance. One study introduced the EigenFruit method [8], a principal component analysis (PCA)-based method that applies the EigenFace [19] method for fruit detection. Additionally, ref. [10] proposed a method for detecting fruit regions by extracting texture features using a scale-invariant feature transform (SIFT) [20], speeded-up robust features (SURF) [21], and oriented fast and rotated brief (ORB) [22], subsequently classifying the detected regions using a support vector machine (SVM) [23]. While numerous studies have focused on improving fruit-detection performance across various environments, challenges remain owing to computational costs and variations in fruit size and shape.
2.2. Fruit Segmentation Approaches
Fruit segmentation is essential in automated fruit detection systems, enabling precise identification and extraction of fruit shapes. Various studies have been conducted to enhance the segmentation performance, with earlier research proposing a simple method using color histograms [24]. This study proposes a segmentation method that analyzes the color differences between the fruit and background using a color histogram, establishing an optimal threshold for segmentation. However, this study is limited to fruits with distinct colors, such as red, making it difficult to apply in environments where the fruit and background have similar colors. To overcome the limitations, thermal imaging methods [25] using a thermal camera have been proposed to achieve robust performances by segmenting the fruit based on the temperature differences between the object and the background, even when their colors are similar. Furthermore, a hyperspectral imaging [26] method has been proposed to effectively segment fruits and backgrounds by analyzing spectral data using multiple wavelengths. However, thermal and hyperspectral cameras are expensive, which makes their practical applications challenging. Subsequently, deep-learning-based approaches have been introduced to solve these problems. In [27], the study applied Mask R-CNN [14] and improved segmentation performance for elongated fruits by improving anchor boxes and the region proposal network (RPN) [28]. This optimization enables a more accurate detection and segmentation of fruits with elongated shapes. Additionally, attention modules [16] and deformable convolutions [28] are integrated into the Mask R-CNN, demonstrating high accuracy for complex backgrounds. However, the structural limitations of the Mask R-CNN, along with the added modules, make real-time implementation difficult. Consequently, ref. [29] introduced a MobileNetV3 model [30] as the backbone network of the Mask R-CNN, significantly improving the computational efficiency, and the boundary patch refinement (BPR) module was used [31] to improve the segmentation performance. Additionally, the proposed method operates robustly for lighting variations through a multimodule CNN [32] that combines image correction and shape completion modules. However, owing to its complex structure, the computational cost increases, making real-time applications difficult. Given the limitations of previous deep learning methods, which have difficulties operating in real time owing to their complex structures, ref. [33] the YOLOv5-LiNet model was proposed. This model significantly reduces the computational cost by redesigning the network structure of YOLOv5 [34]. Various approaches, from color-based methods to advanced deep learning methods, have been explored to improve the fruit segmentation performance. However, most studies have focused primarily on fruit segmentation, with relatively less emphasis on simultaneous fruit and stem segmentation. Stem segmentation is critical in automated systems, and related studies are discussed in the following section.
2.3. Detection and Segmentation Approaches for Fruit and Stem
The detection and segmentation of the fruit and stem is crucial in automated agricultural robots and management systems, with recent studies making significant progress. An earlier study [35] proposed an algorithm to separate fruits from the background by combining the opposition histogram and tiling adaptive (OHTA) color space with an SVM classifier [23]. By using the OHTA color space instead of RGB, this method accentuated the color differences between the object and background, enabling the SVM classifier to detect fruits and stems. However, this method was only effective with simple backgrounds, such as white or black, and its performance decreased significantly with more complex backgrounds. Consequently, this study [36] proposed a method that combines deep-learning-based You Only Look Once version 3 (YOLOv3) [37] with U-Net [38]. After detecting the main objects using YOLOv3, which offered relatively fast detection performance, U-Net was employed to refine the boundary between the fruit and stem for more precise accuracy. This study showed an accuracy of over 80%; however, it required a special lighting system. Subsequently, studies have progressed beyond merely detecting the boundaries or locations of fruits and stems, advancing toward their segmentation of fruits and stems at the pixel level. A study [39] proposed a pixel-level segmentation method using a multi-class SVM to classify pixels as fruits, stems, or backgrounds. It demonstrated high performance on small datasets but struggled to learn complex features, resulting in limited performance on large datasets compared with deep learning-based methods. Later studies, such as [12,13] applied a Mask R-CNN to segment fruits, stems, and backgrounds more effectively. While Mask R-CNN significantly reduced processing time from over 10 s to less than 1 s, making it much faster, it still required excessive time for real-time applications. Other studies have fused RGB and NIR images, utilizing a parallel attention mechanism [40] to fuse the features of both modalities and improve the segmentation performance. A study [11] proposed a method that improves segmentation performance by fusing RGB and NIR images to create multimodal images. Subsequently, it applied a parallel attention mechanism [40] to effectively fuse features between the two modalities. However, this method faced challenges with pixel misalignment between the two image types, leading to reduced accuracy when the images were imperfectly aligned.
Considering the limitations of previous studies, we proposed the AS-YOLO model, which segmented fruits and stems in real-time using only RGB images. Table 1 compares the proposed method with previous studies.

Table 1.
Comparison of previous researches and proposed method.
3. Materials and Methods
3.1. Overview of Proposed Method
Figure 2 illustrates a flowchart of the proposed method. The input consists of RGB images of apples acquired under various environmental conditions (Step 1 in Figure 2). Given that the input images varied in size, image-size normalization is applied to ensure consistent input dimensions for the model (Step 2 in Figure 2). After image-size normalization, the input image is resized to 640 × 640 (width and height) pixels. The proposed AS-YOLO model segments the fruit and stem (Step 3 in Figure 2). The output of the model consists of segmented results (step 4 in Figure 2), which are presented as binary masks that separate the boundaries and areas of the detected objects (steps 5 and 6 in Figure 2). A detailed description of the AS-YOLO architecture is provided in Section 3.2, while the core components of the model—the ghost bottleneck and global attention module—are explained in Section 3.3 and Section 3.4, respectively.
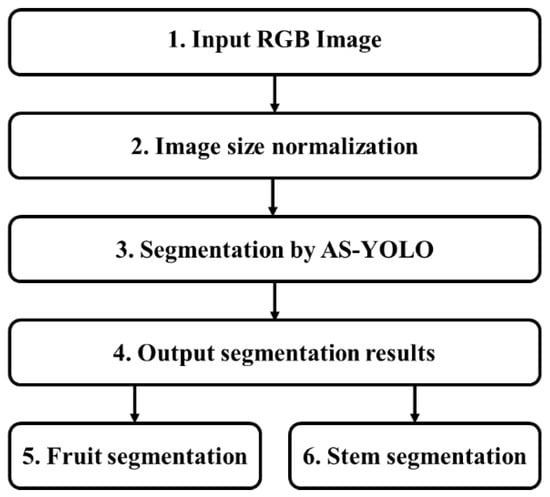
Figure 2.
Flowchart of proposed method.
3.2. AS-YOLO Model
The AS-YOLO model is based on the YOLOv8 [42] architecture, with enhanced segmentation performance achieved through the integration of ghost bottlenecks and a GAM. The AS-YOLO model demonstrates both high performance and fast speed for real-time fruit and stem segmentation. The architecture of AS-YOLO is illustrated in Figure 3, with detailed information, such as the kernel, stride, and padding for each layer, provided in Table 2.
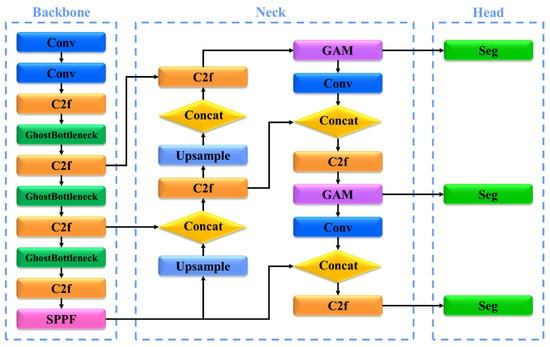
Figure 3.
Architecture of AS-YOLO.
Table 2.
Structure of Figure 3. Conv refers to convolutional layer, C2f refers to cross stage partial bottleneck with 2 convolutions—faster, SPPF refers to spatial pyramid pooling fusion, and GAM refers to global attention mechanism.
The backbone of the AS-YOLO model utilizes the YOLOv8 [42] architecture, incorporating a ghost bottleneck to reduce the computational cost and improve computational efficiency. A ghost bottleneck is a lightweight technique that replaces conventional convolution operations while preserving critical features, reducing the number of parameters, and ensuring real-time performance. The backbone processes input images at multiple resolutions, extracting key features through convolutional layers and ghost bottlenecks to maximize efficiency. A detailed description of ghost bottlenecks is presented in Section 3.3.
The neck of the AS-YOLO model combines a cross-stage partial bottleneck with two convolutions: a faster (C2f) block and a GAM, designed to learn the global features of an image. The GAM enables the model to focus more on key regions of the image, enhancing the segmentation performance of complex objects, such as apples, and smaller objects, such as apple stems. The neck structure combines multi-scale features extracted from the backbone through upsampling and concatenation operations, improving object detection accuracy. A detailed description of the GAM is provided in Section 3.4.
The head of the AS-YOLO model produces the final segmentation results, which include a detailed boundary delineation between the fruit and its stem. The segmentation head is designed to separate the apples and stems with high precision, ensuring distinct class predictions. Additionally, it supports multiclass predictions, enabling the model to accurately detect and segment the boundaries of different objects in a scene. The design of the head ensures that the model can handle fine-grained segmentation of both large and small objects, such as apples and stems.
3.3. Ghost Bottleneck
The ghost bottleneck is a critical module in the AS-YOLO model that combines ghost modules with squeeze-and-excitation (SE) layers [43] and depthwise convolution (DWConv) [44] to maximize efficiency. This structure is designed to maintain high performance with low computational cost, making it essential for real-time processing.
As shown in Figure 4, the ghost bottleneck structure consists of two paths. In the main path, the input is processed by a ghost module that extracts the primary features. In this path, the features are transformed while emphasizing key information. The SE layer is selectively activated based on the stride condition, enhancing the most critical information for each channel. Subsequently, a second ghost module generates additional features, resulting in the final output. In the shortcut path, if the input and output dimensions are identical, an identity connection is used to process the unchanged data. However, if the dimensions differ or the stride is set to two, the data passes through DWConv and a 1 × 1 convolutional layer. The ghost bottleneck combines the outputs from both paths to generate the final output. This design minimizes feature loss while optimizing computational efficiency, establishing it as a critical element for achieving the real-time performance goals of the AS-YOLO network.
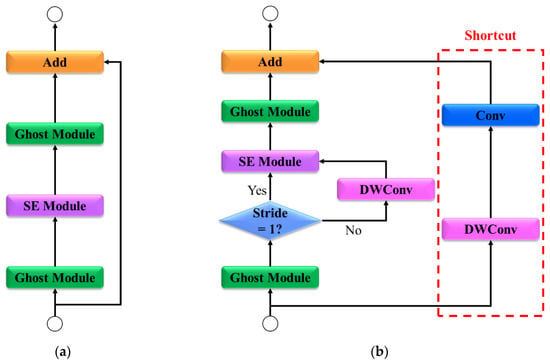
Figure 4.
Architecture of ghost bottleneck. (a) ghost bottleneck stride = 1 and M ≠ N, (b) ghost bottleneck stride = 2 or M ≠ N. SE refers to squeeze-and-excitation, Conv refers to convolution, and DWConv refers to Depth-wise convolution. M indicates the input dimension, while N indicates to the output dimension.
The computational process for the ghost bottleneck is mathematically expressed as: In the ghost module, the input feature map is reduced through a convolutional layer. This step captures the most critical features and produces a smaller feature map , as shown in Equation (1):
where and represent the number of input and output channels, respectively, and represents the filter reduction ratio. Subsequently, additional ghost features are generated through an inexpensive operation typically implemented using depth-wise convolution. Depthwise convolution applies convolution to each individual channel, operating similarly to traditional convolutional layers; however, computational costs are significantly reduced. The newly generated feature map is formulated as shown in Equation (2) and combined with to form a more expressive feature representation.
where k and s represent the kernel size and stride, respectively. The combined output of and can be expressed as shown in Equation (3). Through this process, expressive features are extracted while maintaining high computational efficiency, without the need for complex convolutional operations.
If downsampling is required in the ghost bottleneck owing to a stride s > 1, DWConv is applied to reduce the spatial resolution while preserving key features. This operation can be mathematically represented as shown in Equation (4), where represents the downsampled feature map.
where represents the number of channels in the input feature map. This operation adjusts the spatial resolution if necessary. When the stride is one, the operation is skipped, and an identity connection is used instead. The SE module performs squeezing and excitation by adjusting the importance of each channel. During the squeeze phase, global average pooling is applied to each channel to summarize the spatial information. In the excitation phase, the pooled data passes through two fully connected layers where weights are applied, emphasizing the important channels and suppressing the less important ones. The complete process is represented by Equation (5):
where represents to the global average pooling, represent the weights of the fully connected layer, and and represent rectified linear unit (ReLU) [45] and sigmoid function, respectively. The importance of each channel was determined using the sigmoid function, and the resulting weights were multiplied by the original feature map to generate the final output , as shown in Equation (6):
Subsequently, was processed by another ghost module to produce the final feature map, as expressed in Equation (7):
Additional refined features were extracted by reapplying the ghost module. Finally, the output from the ghost module , was combined with the output from the shortcut path to compute the final output, as shown in Equation (8). This residual connection enabled the network to learn effectively without losing important information.
The final output was generated by combining , which had passed through the ghost module twice, with an appropriate dimension-matched output from the shortcut path. This process enabled the ghost bottleneck to learn refined and detailed features, contributing to overall network efficiency and enhanced performance.
3.4. Global Attention Module
In the AS-YOLO architecture, the GAM is critical in applying attention mechanisms to both the channel and spatial information of the input feature maps, enabling the model to effectively extract important features. As shown in Figure 5, GAM consists of two primary components: channel attention and spatial attention. Each stage analyzes the input data and applies weights to emphasize the critical regions and channels, enabling the model to focus on the most relevant parts of the image and improve the overall segmentation performance.

Figure 5.
Architecture of global attention module. GAP refers to global average pooling, SiLU refers to sigmoid linear unit, and Conv refers to convolution.
Additionally, channel attention plays a critical role in assigning importance to each channel in the input feature map. Initially, the input feature map undergoes spatially compressed in the channel attention mechanism using GAP, which summarizes the spatial information into a single vector. Subsequently, the output passes through two convolutional layers with a sigmoid activation function applied at the end to compute the importance of each channel. Thus, the importance of each channel is determined, and the overall formula for channel attention is expressed in Equation (9):
where represent the weights of the convolutional layer, and and represent sigmoid linear unit (SiLU) [46] activation function and sigmoid function, respectively. The calculated channel attention map determines the importance of each channel in the input feature map. Ultimately, feature map , reflecting channel importance, can be obtained by multiplying channel attention map by input feature map , as shown in Equation (10):
After applying channel attention, GAM applies spatial attention to determine the importance of each spatial location. As shown in Equation (11), the input feature map passes through two convolutional layers, followed by the application of a sigmoid function to compute the importance of each spatial position.
where represent the weights of the convolutional layer. The spatial attention map , which represents the importance of each spatial position, is subsequently multiplied by to generate the final output , as expressed in Equation (12):
By applying attention to both key channels and spatial positions in the input feature map, the GAM enables the model to accurately detect important objects and fine-grained details.
4. Experimental Results and Analysis
4.1. Experimental Database—AppleStem-Segmentation Database
In this experiment, we constructed the AS-Seg database by manually labeling portions of the fruit recognition dataset [47,48] along with data from our acquisition process. The camera used for data acquisition was an Intel RealsenseTM D405 [49], which operates optimally at distances ranging from 7 to 50 cm with a field of view (FOV) of 87° × 58° and a maximum resolution of 1280 × 720 pixels. Data acquisition was conducted in three different environments: an open table setup, an enclosed dark chamber setup, and a transparent box with a turntable setup (Figure 6). In the open-table setup, data were collected from various angles of apples placed on a table. In an enclosed dark chamber, the camera captured images in a light-controlled environment to minimize external light interference. Finally, the rotating apples were captured within a transparent acrylic box with a turntable. The images acquired using these settings are shown in Figure 1.

Figure 6.
Various experimental setups for apple image acquisition. (a) Open table setup, (b) Enclosed dark chamber, (c) Transparent box with turn table.
Descriptions of the AS-Seg database used in the experiments are listed in Table 3. The database was divided into training, test, and validation datasets, comprising 70%, 20%, and 10% of the total data, respectively, and used in the model learning, performance evaluation, and final verification stages. Various data-augmentation techniques have been applied to prevent overfitting during the training process, including dropout, mosaic augmentation [50], flipping, and pixel shifting. These augmentations enhanced the robustness of the model by introducing variations into the training data, thereby ensuring better generalization to unseen data.
Table 3.
Description of AS-Seg database.
4.2. Training of AS-YOLO
The AS-YOLO model was trained using training and validation datasets from the AS-Seg dataset. The training was conducted for 500 epochs, and an early stopping technique was applied, which was terminated if the validation loss did not improve for 100 epochs. This method ensured that the model avoided overfitting. The momentum parameter, weight decay, and initial learning rate were set to 0.937, 0.0005, and 0.01, respectively. Figure 7 shows the loss and mAP on the training data, along with the loss on the validation data. The x-axis represents the number of epochs, the left y-axis represents the loss values, and the right y-axis represents the mAP. As the training progressed, the performance of the model in both bounding box and mask segmentation improved steadily. The bounding box, mask segmentation, classification, and distribution focal losses on both the training and validation datasets continuously decreased and converged, indicating effectively learning by the proposed model from the AS-Seg dataset. This confirms the successful training of the AS-YOLO model on the AS-Seg dataset, demonstrating its ability to optimize the performance for both bounding box detection and mask segmentation tasks.
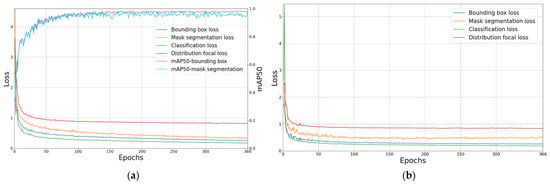
Figure 7.
Loss and accuracy curves for training and validation data. (a) Loss and accuracy curves for training data, (b) Loss curves for validation data.
4.3. Testing of AS-YOLO
To evaluate the performance of the proposed AS-YOLO model, the key metrics used are precision, recall, mAP@50, and mAP@50–95 for both bounding box and mask segmentation. These performance metrics are crucial in evaluating the accuracy of a model in predicting objects and performing segmentation. Precision refers to the proportion of predicted objects that are correctly detected as true positives. High precision indicates accurate identification of the predicted objects by the model. The recall measures the number of ground-truth objects in a dataset detected by the model. A high recall indicates that the model is effective in detecting most of the objects present in the dataset. mAP@50 calculates the mean average precision across all classes using an intersection over union (IoU) threshold of 0.5. This metric indicates how effectively the model detects objects by measuring the overlap between the predicted and ground truth objects, typically using the IoU as a threshold for accuracy. mAP@50–95 averages precision across multiple IoU thresholds from 0.5 to 0.95 in steps of 0.05. This serves as a more stringent evaluation, testing the consistency and robustness of the model for detecting objects under varying conditions. These metrics are used to compare the performance of the AS-YOLO model with those of other methods in both object detection and segmentation tasks.
4.4. Ablation Studies
To evaluate the contributions of the proposed modules to the performance of YOLOv8, we conducted an ablation study. The models were trained and evaluated on the apple and stem segmentation under consistent experimental conditions, with performance measured using precision, recall, mAP@50, and mAP@50–95. The results of the ablation study are presented in Table 4, which provides performance comparisons of different module configurations.
Table 4.
Performance comparisons of ablation studies.
The baseline YOLOv8 model achieved an overall mAP@50 of 0.935 and mAP@50–95 of 0.757. While the model performed well on apple segmentation, its performance on stem segmentation was comparatively lower, likely due to challenges such as small object size and occlusions.
Incorporating Ghost bottleneck into YOLOv8 improved the overall mAP@50 to 0.941 and mAP@50–95 to 0.761. Notably, precision of stem segmentation increased significantly from 0.886 to 0.939, demonstrating the ability of the Ghost bottleneck to enhance computational efficiency while improving segmentation accuracy for complex features.
Adding the GAM module to YOLOv8 significantly improved recall and mAP@50–95, with this improvement attributed to GAM module’s ability to capture global contextual information, particularly benefiting stem segmentation.
The combination of ghost bottleneck and GAM in AS-YOLO achieved the best overall performance, with an mAP@50 of 0.956 and mAP@50–95 of 0.782. The model maintained high precision and recall for apple segmentation while significantly improving the balance between precision and recall for stem segmentation.
4.5. Comparisons with Other Methods
This study compared the performance of the proposed model with state-of-the-art methods, such as Mask R-CNN [14], YOLACT [51], HTC [52], YOLOv5 [34], PointRend [53], and YOLOv8 [42], YOLOv11 [54]. Table 5 presents a comparison of the detection and segmentation performances, and the inference speeds of the test set. The results demonstrated that the proposed model outperformed the other methods across most metrics while achieving the fastest inference speed. We primarily conducted experiments using YOLO-based methods, as they have consistently demonstrated high performance across various domains [55].
Table 5.
Performance comparisons of detection and segmentation methods on the test set.
The state-of-the-art methods performed reasonably well for the apple class, achieving high precision and recall across various architectures. However, there was a clear performance gap between these models and the AS-YOLO models, particularly for the stem class. AS-YOLO achieved the highest mAP@50–95 score of 0.674 for bounding box detection in the stem class, outperforming the scores of YOLOv8 at 0.597 and YOLOv11 at 0.664. This highlight its superior ability to segment small objects like stems, whereas other models encountered challenges.
AS-YOLO also demonstrated the highest speed among the compared methods, processing at 129.8 frames per second. This was approximately 13 percent faster than YOLOv8, which processed at 114.9 frames per second, and 16 percent faster than YOLOv11, which achieved 111.4 frames per second. Methods like Mask R-CNN and PointRend, with speeds of 49.5 and 57.2 frames per second respectively, lagged significantly due to their heavier architecture and reliance on iterative processes that are less suited for real-time tasks.
For the apple class, AS-YOLO achieved outstanding precision and recall, reaching values of 0.999 and 1.0 respectively. Its performance for the stem class was similarly impressive, with a precision of 0.888 and an mAP@50–95 of 0.574. In comparison, YOLOv11 showed competitive results, achieving an overall mAP@50–95 of 0.827 for bounding box detection, but it still lagged behind AS-YOLO in segmenting small objects such as stems. One of the reasons for YOLOv11’s lower performance on small object segmentation can be attributed to its increased computational complexity due to the integration of advanced transformer modules and adaptive spatial fusion mechanisms, as discussed in [56]. While these additions improve contextual understanding and feature fusion, they can introduce challenges in detecting fine-grained structures such as stems due to increased inference time and higher model capacity requirements. Moreover, YOLOv11 exhibited a slight decline in recall, which may indicate that it struggles to generalize well on smaller object classes with limited representation.
The effective balance between accuracy and speed in AS-YOLO is primarily achieved through the incorporation of the GAM module and ghost bottleneck structures. These components enhance global feature extraction and minimize computational overhead, enabling AS-YOLO to process both large and small objects efficiently. This makes it a practical solution for real-time applications, outperforming more complex methods such as Mask R-CNN.
In conclusion, AS-YOLO outperforms other state-of-the-art methods by providing exceptional accuracy for small object detection while maintaining real-time performance.
Figure 8 presents the segmentation results compared with other state-of-the-art method. The result shows that the proposed AS-YOLO model in this paper effectively segments the stem area overall, with no false positives of the hand being misidentified as a stem. The results demonstrate that the proposed method achieves robust performance in the fruit class, with particularly strong results in the segmentation of the stem class. This demonstrates that the AS-YOLO model achieves superior numerical performance, with its visualized results indicating the effectiveness of the model.
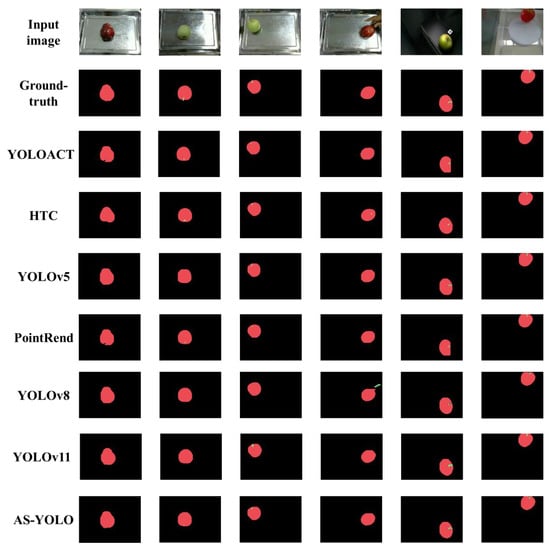
Figure 8.
Comparison of segmentation result images in AS-Seg dataset.
5. Limitations and Future Works
In our study, we proposed the AS-YOLO model to detect and segment apple and stem regions in 2D images. Although the performance of the proposed AS-YOLO model was confirmed to be higher than that of the existing method, there are some limitations in applying it to the actual apple post-harvest processing system.
First, while the AS-YOLO model demonstrates strong performance on the AppleStem-Segmentation database, its generalization to other fruit types or datasets with significantly different environmental conditions has not been extensively evaluated. Second, when applied to an actual apple post-processing automation system, there is a problem that it is difficult to precisely recognize and remove the stem based only on the detection results on the 2D image.
Considering these points, future research will focus on enhancing the generalization capabilities of the AS-YOLO model to ensure robust performance across diverse fruit types and varying environmental conditions. This will involve expanding the dataset to include a wider range of fruit species and conditions. In addition, based on the results of this study, we plan to study a deep learning model that estimates the actual 3D coordinates of the apple and stem using 3D point cloud data to apply to the apple post-processing automation system.
6. Conclusions
We propose the AS-YOLO model as an efficient model for fruit and stem segmentation, facilitating the stem removal process by fruit-harvesting robots. By integrating ghost bottleneck and global attention modules into the YOLOv8 architecture, the proposed method achieves improved computational efficiency and enhanced detection accuracy, particularly for small objects such as stems. The experimental results demonstrate that the proposed AS-YOLO model achieves real-time inference performance at 129.8 FPS on a GPU while maintaining high accuracy, particularly in metrics such as mAP @50 and mAP @50–95. Compared with previous models, AS-YOLO provides faster and more accurate performance, highlighting its potential for real-time automation systems.
This research contributes to the automation of stem removal in fruit harvesting and provides a foundational technology that can be applied to other agricultural automation tasks. Future work will focus on extending the model to 3D image-based segmentation, enabling a more precise representation of the fruit shape, size, and depth. Additionally, we will enhance the robustness of the model in agricultural environments with varying lighting conditions, complex backgrounds, and obstacles, ensuring consistent performance under these challenging scenarios.
Author Contributions
Conceptualization, N.R.B.; Data curation, D.-h.N. and H.-M.L.; Methodology, N.R.B.; Supervision, S.W.C.; Validation, Y.L.; Writing—original draft, N.R.B.; Writing—review & editing, S.W.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Korea Institute of Planning and Evaluation for Technology in Food, Agriculture and Forestry (IPET) through Open Field Smart Agriculture Technology Short-term Advancement Program, funded by Ministry of Agriculture, Food and Rural Afairs (MAFRA) (322035-03), and by the Industrial Technology Innovation Program (20023014, Development of an Agricultural Robot Platform Capable of Continuously Harvesting more than 3 Fruits per minute and Controlling Multiple Transport Robots in an Outdoor Orchard Environment) funded by the Ministry of Trade, Industry & Energy (MOTIE, Korea).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets generated and/or analyzed during the current study will be made publicly available on GitHub upon acceptance of this manuscript for publication. The repository can be accessed at: https://github.com/BAN2ARU/AS-YOLO (accessed on 18 February 2025). To comply with data sharing requirements and transparency, a data usage agreement will be provided on the GitHub repository, and all users are requested to acknowledge and adhere to this agreement when accessing the data.
Acknowledgments
The authors extend their appreciation to the team members for their support in this work. They also acknowledge the financial support from IPET (322035-03, MAFRA) and MOTIE (20023014, Korea), which made this research possible.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ziv, C.; Fallik, E. Postharvest Storage Techniques and Quality Evaluation of Fruits and Vegetables for Reducing Food Loss. Agronomy 2021, 11, 1133. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, Z.; Mhamed, M.; Yuan, D.; Wang, X. Apple’s In-Field Grading and Sorting Technology: A Review. In Towards Unmanned Apple Orchard Production Cycle: Recent New Technologies; Springer: Berlin/Heidelberg, Germany, 2023; pp. 81–104. [Google Scholar]
- Valenzuela, J.L. Advances in Postharvest Preservation and Quality of Fruits and Vegetables. Foods 2023, 12, 1830. [Google Scholar] [CrossRef] [PubMed]
- Stajnko, D.; Lakota, M.; Hočevar, M. Estimation of Number and Diameter of Apple Fruits in an Orchard during the Growing Season by Thermal Imaging. Comput. Electron. Agric. 2004, 42, 31–42. [Google Scholar] [CrossRef]
- Zhao, J.; Tow, J.; Katupitiya, J. On-Tree Fruit Recognition Using Texture Properties and Color Data. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, Canada, 2–6 August 2005; IEEE: Piscataway, NJ, USA; pp. 263–268. [Google Scholar]
- Cohen, O.; Linker, R.; Naor, A. Estimation of the Number of Apples in Color Images Recorded in Orchards. In Proceedings of the Computer and Computing Technologies in Agriculture IV, Nanchang, China, 22–25 October 2010; Springer: Berlin/Heidelberg, Germany; pp. 630–642. [Google Scholar]
- Linker, R.; Cohen, O.; Naor, A. Determination of the Number of Green Apples in RGB Images Recorded in Orchards. Comput. Electron. Agric. 2012, 81, 45–57. [Google Scholar] [CrossRef]
- Kurtulmus, F.; Lee, W.S.; Vardar, A. Green Citrus Detection Using ‘Eigenfruit’, Color and Circular Gabor Texture Features under Natural Outdoor Conditions. Comput. Electron. Agric. 2011, 78, 140–149. [Google Scholar] [CrossRef]
- Zhou, R.; Damerow, L.; Sun, Y.; Blanke, M.M. Using Colour Features of Cv. ‘Gala’ Apple Fruits in an Orchard in Image Processing to Predict Yield. Precis. Agric. 2012, 13, 568–580. [Google Scholar] [CrossRef]
- Chaivivatrakul, S.; Dailey, M.N. Texture-Based Fruit Detection. Precis. Agric. 2014, 15, 662–683. [Google Scholar] [CrossRef]
- Liu, C.; Feng, Q.; Sun, Y.; Li, Y.; Ru, M.; Xu, L. YOLACTFusion: An Instance Segmentation Method for RGB-NIR Multimodal Image Fusion Based on an Attention Mechanism. Comput. Electron. Agric. 2023, 213, 108186. [Google Scholar] [CrossRef]
- Hussain, M.; He, L.; Schupp, J.; Lyons, D.; Heinemann, P. Green Fruit Segmentation and Orientation Estimation for Robotic Green Fruit Thinning of Apples. Comput. Electron. Agric. 2023, 207, 107734. [Google Scholar] [CrossRef]
- López-Barrios, J.D.; Escobedo Cabello, J.A.; Gómez-Espinosa, A.; Montoya-Cavero, L.-E. Green Sweet Pepper Fruit and Peduncle Detection Using Mask R-CNN in Greenhouses. Appl. Sci. 2023, 13, 6296. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA; pp. 2980–2988. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition; Seattle, WA, USA, 13–19 June 2020, pp. 1580–1589.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- AS-YOLO Model and AppleStem-Segmentation Dataset. Available online: https://github.com/BAN2ARU/AS-YOLO (accessed on 18 February 2025).
- Gonzalez, R.C. Digital Image Processing; Pearson Education India: Chennai, India, 2009; ISBN 8131726959. [Google Scholar]
- Turk, M.; Pentland, A. Eigenfaces for Recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA; pp. 2564–2571. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Bulanon, D.M.; Kataoka, T.; Ota, Y.; Hiroma, T. AE—Automation and Emerging Technologies. Biosyst. Eng. 2002, 83, 405–412. [Google Scholar] [CrossRef]
- Bulanon, D.M.; Burks, T.F.; Alchanatis, V. Study on Temporal Variation in Citrus Canopy Using Thermal Imaging for Citrus Fruit Detection. Biosyst. Eng. 2008, 101, 161–171. [Google Scholar] [CrossRef]
- Okamoto, H.; Lee, W.S. Green Citrus Detection Using Hyperspectral Imaging. Comput. Electron. Agric. 2009, 66, 201–208. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, D.; Jia, W.; Ji, W.; Ruan, C.; Sun, Y. Cucumber Fruits Detection in Greenhouses Based on Instance Segmentation. IEEE Access 2019, 7, 139635–139642. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA; pp. 764–773. [Google Scholar]
- Jia, W.; Wei, J.; Zhang, Q.; Pan, N.; Niu, Y.; Yin, X.; Ding, Y.; Ge, X. Accurate Segmentation of Green Fruit Based on Optimized Mask RCNN Application in Complex Orchard. Front. Plant Sci. 2022, 13, 955256. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA; pp. 1314–1324. [Google Scholar]
- Tang, C.; Chen, H.; Li, X.; Li, J.; Zhang, Z.; Hu, X. Look Closer to Segment Better: Boundary Patch Refinement for Instance Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 13921–13930. [Google Scholar]
- Lei, H.; Huang, K.; Jiao, Z.; Tang, Y.; Zhong, Z.; Cai, Y. Bayberry Segmentation in a Complex Environment Based on a Multi-Module Convolutional Neural Network. Appl. Soft Comput. 2022, 119, 108556. [Google Scholar] [CrossRef]
- Lawal, O.M. YOLOv5-LiNet: A Lightweight Network for Fruits Instance Segmentation. PLoS ONE 2023, 18, e0282297. [Google Scholar] [CrossRef] [PubMed]
- YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 30 December 2024).
- Feng, G.; Qixin, C.; Yongjie, C.; Masateru, N. Fruit Location And Stem Detection Method For Strawbery Harvesting Robot. Trans. Chin. Soc. Agric. Eng. 2008, 24, 89–94. [Google Scholar]
- Liang, C.; Xiong, J.; Zheng, Z.; Zhong, Z.; Li, Z.; Chen, S.; Yang, Z. A Visual Detection Method for Nighttime Litchi Fruits and Fruiting Stems. Comput. Electron. Agric. 2020, 169, 105192. [Google Scholar] [CrossRef]
- Farhadi, A.; Redmon, J. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; proceedings, part III 18. Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Qiang, L.; Jianrong, C.; Bin, L.; Lie, D.; Yajing, Z. Identification of Fruit and Branch in Natural Scenes for Citrus Harvesting Robot Using Machine Vision and Support Vector Machine. Int. J. Agric. Biol. Eng. 2014, 7, 115–121. [Google Scholar] [CrossRef]
- Prabhakar, K.R.; Srikar, V.S.; Babu, R.V. DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA; pp. 4714–4722. [Google Scholar]
- Wang, D.; He, D. Fusion of Mask RCNN and Attention Mechanism for Instance Segmentation of Apples under Complex Background. Comput. Electron. Agric. 2022, 196, 106864. [Google Scholar] [CrossRef]
- YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 30 December 2024).
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Howard, A.G. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:1710.05941. [Google Scholar] [CrossRef]
- Hussain, D.; Hussain, I.; Ismail, M.; Alabrah, A.; Ullah, S.S.; Alaghbari, H.M. A Simple and Efficient Deep Learning-Based Framework for Automatic Fruit Recognition. Comput. Intell. Neurosci. 2022, 2022, 6538117. [Google Scholar] [CrossRef]
- Fruit Recognition Dataset. Available online: https://zenodo.org/records/1310165 (accessed on 30 December 2024).
- Intel Realsense D405 Camera. Available online: https://www.intelrealsense.com/depth-camera-d405/ (accessed on 30 December 2024).
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA; pp. 9156–9165. [Google Scholar]
- Chen, K.; Ouyang, W.; Loy, C.C.; Lin, D.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; et al. Hybrid Task Cascade for Instance Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA; pp. 4969–4978. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image Segmentation as Rendering. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA; pp. 9796–9805. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Saydirasulovich, S.N.; Mukhiddinov, M.; Djuraev, O.; Abdusalomov, A.; Cho, Y.I. An improved wildfire smoke detection based on YOLOv8 and UAV images. Sensors 2023, 23, 8374. [Google Scholar] [CrossRef]
- Sapkota, R.; Karkee, M. Comparing YOLO11 and YOLOv8 for Instance Segmentation of Occluded and Non-Occluded Immature Green Fruits in Complex Orchard Environment. arXiv 2024, arXiv:2410.19869. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).