Abstract
With escalating global environmental challenges and worsening air quality, there is an urgent need for enhanced environmental monitoring capabilities. Low-cost sensor networks are emerging as a vital solution, enabling widespread and affordable deployment at fine spatial resolutions. In this context, machine learning for the calibration of low-cost sensors is particularly valuable. However, traditional machine learning models often lack interpretability and generalizability when applied to complex, dynamic environmental data. To address this, we propose a causal feature selection approach based on convergent cross mapping within the machine learning pipeline to build more robustly calibrated sensor networks. This approach is applied in the calibration of a low-cost optical particle counter OPC-N3, effectively reproducing the measurements of and as recorded by research-grade spectrometers. We evaluated the predictive performance and generalizability of these causally optimized models, observing improvements in both while reducing the number of input features, thus adhering to the Occam’s razor principle. For the calibration model, the proposed feature selection reduced the mean squared error on the test set by 43.2% compared to the model with all input features, while the SHAP value-based selection only achieved a reduction of 29.6%. Similarly, for the model, the proposed feature selection led to a 33.2% reduction in the mean squared error, outperforming the 30.2% reduction achieved by the SHAP value-based selection. By integrating sensors with advanced machine learning techniques, this approach advances urban air quality monitoring, fostering a deeper scientific understanding of microenvironments. Beyond the current test cases, this feature selection method holds potential for broader applications in other environmental monitoring applications, contributing to the development of interpretable and robust environmental models.
1. Introduction
The human quality of life is intricately intertwined with the physical environment surrounding us. We are now experiencing an era marked by unprecedented, widespread, and intense changes in the global environmental state [1]. Driven by human activities and population growth, significant global warming and consequent climate change are disrupting the usual balance of nature, posing a fundamental threat to various aspects of life. Human health is particularly affected, most significantly through its relationship with air quality. Global change and air quality are intertwined [2,3], and air quality is intricately related to human health. Air pollution is one of the greatest environmental risks to health. The World Health Organization (WHO) estimates that 4.2 million deaths annually can be attributed to air pollution [4]. Poor air quality due to pollutants such as ozone, particulate matter (PM), and sulfur dioxide can lead to a variety of health problems, including asthma, heart disease, and lung cancer. Associations have been reported between the concentrations of various air pollutants and diabetes, mumps, and epilepsy [5]. While the effects of climate change on air quality vary by region, many areas suffer a decline in air quality in parallel with global environmental change. Shifting weather patterns, including changes in temperature and precipitation, is expected to raise levels of PM. Robust evidence from models and observations shows that climate change is worsening ozone pollution. Climate change is expected to affect indoor heating and cooling demand due to temperature changes, altering fuel use, and consequently the composition of the emitted air pollutants. Evidence suggests that without additional air pollution controls, climate change will increase the risk of poor air quality in the US [6]. Therefore, the current state of global change and the concurrent exacerbation of air quality degradation emphasize the need for enhanced environmental monitoring capabilities at appropriate spatial scales.
The Internet of Things (IoT) has proved pivotal in this respect, enabling real-time data collection with high spatio-temporal resolution through networks of interconnected sensors. However, accessible, wide-scale deployment for environmental monitoring at more localized scales requires low-cost air quality sensor systems (LCSs) [7]. Although LCSs have the potential to bridge the gaps in sensor networks, thus facilitating dense monitoring networks capturing the relevant spatial variations in pollutants, they are less precise and have several sources of greater uncertainty compared to research-grade monitors. They are also more sensitive to environmental conditions. This makes them more likely to introduce potential measurement discrepancies compared to their reference sensors [8,9]. Therefore, LCSs require calibration prior to field deployment in order to improve the reliability and accuracy of the data being collected. This process involves the collocation of the LCS alongside a reference monitor at a representative location/s and then using the collected data to develop a calibration model that maps the raw output of the LCS to the measurements from the reference monitor. While several calibration mechanisms exist, machine learning is gaining popularity as a leading approach to LCS calibration [10,11,12].
Machine Learning and the Need for Causality
Machine learning (ML) is a subset of artificial intelligence. It involves creating algorithms and statistical models that allow computers to learn from data and make predictions without the need for explicit programming. That is, learning through examples. ML has now gained immense popularity, and almost all sectors in the industrial arena leverage machine learning solutions to enhance productivity, decision-making processes, and other aspects [13,14,15,16].
It has proved useful in a wide variety of applications in science and engineering as well, especially for those applications where we do not have a complete theory, yet which are of significance. In the field of Atmospheric Science and Climate Physics, ML techniques are being used as an automated approach to build empirical models from data alone [17,18,19], and especially in air quality prediction [20,21,22,23].
Despite their wide usage and relative success, most traditional ML methodologies are constrained in their performance due to inherent limitations. One such limitation is the lack of interpretability [24,25,26]. Although adept at extracting patterns from data, ML systems develop complex models with numerous inputs that are often challenging to interpret. These models typically function as opaque black boxes, lacking the capability to elucidate the rationale behind their predictions or recommendations, or why a specific feature is prioritized compared to others in a model. Although model interpretation techniques such as SHAP values [27] are beneficial, they offer information solely on the functioning of the model that was learned, but not necessarily on how the variables under consideration relate to each other in the physical world. Empirical risk minimization commonly practiced in ML is designed to minimize a loss function on observed data, aimed at optimizing some performance metric. This approach is suboptimal since blindly optimizing for the performance on a finite dataset runs the risk of prioritizing associations within the dataset rather than actual cause and effect instances, thus leading to an incomplete problem formulation. In most scientific applications where we may seek to empirically model a phenomenon being studied, or where decisions are being made based on predictions from an ML model, and therefore unfavorable results have significant implications, interpretable ML models are essential. This is to foster not only scientific understanding and justification for model predictions, but also safety and reliability, since fully testing an end-to-end system, exhaustively anticipating every potential scenario where the system could fail, is not feasible for most complex tasks. In such cases, the incompleteness associated with the absence of sufficient interpretability can lead to unquantified bias [25]. This is one motivation for ensuring that feature–target pairs utilized by an ML model reflect genuine causal relationships in the real world and not mere statistical correlations present within a finite dataset. This closely ties to the other drawback, which is a lack of robustness or generalizability. That is the ability to be deployed in a different environment or domain than the one in which it was trained, and yield equivalent performance [28,29,30]. In supervised learning, the objective is to predict unknowns using available information by learning a mapping between a set of inputs and corresponding outputs. If due caution is not exercised, there is a risk of overfitting, where the algorithm fits too closely or even exactly to its training data. An overfit model would have learned and potentially prioritized the spurious correlations present within the dataset, specific to that particular distribution of data. Once the prediction environment diverges from the training environment, performance degradation should be anticipated since the model has learned to rely on superficial features that are no longer present. This is due to variations in the feature–target correlations between different environments. Determining whether the data generation process at the prediction time matches the training time is often uncertain, especially once deployed. In this vein, there are several studies in the literature that cite instances where ML models prioritize feature–target correlations specific to the datasets they have seen, and consequently generalize poorly to new unseen data [31,32,33]. ML models are by nature sensitive to spurious correlations [32]. Models relying on spurious correlations that do not always hold for minority groups can cause the model to fail when the data distribution is shifted in real-world applications. This is especially concerning for machine learning applications involving atmospheric and other environmental data, as is the case in LCS calibration for environmental monitoring, since the dynamic nature of the data renders it constantly shifting, sometimes even abruptly reaching extremes. This makes it virtually impossible to assert with certainty that the training data perfectly align with real-world instances once the model is deployed in the long term. Hence, in order to ensure that predictions made by ML models outside of the immediate domain of the training dataset remain accurate, we need models that are invariant to distributional shifts. That is, a model that would have learned a mapping which does not prioritize mere correlations, but rather features that affect the target in all environments. This need for invariance in ML models is another motivation for integrating causality into ML pipelines. This is because causal relationships are invariant. Mere correlation does not imply causation. If two variables are causally related, it should remain consistent across all environments. The invariance of causal variables is well established in the literature [34,35,36]. Consequently, a model making predictions exclusively using features directly causally related to the target should be more robust compared to general models.
Hence, in this study, we propose a feature selection step within our ML pipeline, based on causality, suitable for complex systems. The objective is to select a subset of relevant features from a larger set of available features based on a causal relationship to the target. Feature selection is a crucial step in developing machine learning models, aligning with the principle of Occam’s razor, which favors simpler hypotheses. Most conventional feature selection approaches employ filter methods where features are ranked or scored based on measures such as SHAP or LIME values [37], with a threshold applied to select the top ranked features. However, if the model has learned and relies on spurious correlations, the feature importance derived from these methods will also reflect those spurious relationships [30]. Consequently, relying on potentially misleading feature explanations compromises the generalizability we aim to achieve in our LCS calibration models. Another widely used approach is to rank features based on mutual information with the target variable. This is inadequate, as mutual information captures general statistical dependence rather than causal relationships. By adopting a causal approach to balance simplicity and predictive accuracy, we aim to leverage the well-established invariance of causal variables, enabling the development of more robust, accurate, and interpretable calibration models.
The study is structured as follows: In Section 2, we outline the proposed methodology for feature selection, detailing the underlying principles and techniques employed. This methodology is then applied to two case studies: the calibration of a low-cost optical particle counter OPC-N3 to reproduce and measurements from a research grade sensor. For comparison, we also develop calibration models for both case studies using two alternative approaches: (1) with all available features as predictors and (2) feature selection based on SHAP values. Section 3 presents the results, comparing the performance of the three approaches across the two case studies.
2. Materials and Methods
We first briefly outline the principle of convergent cross mapping (CCM), as developed in [38] and elaborated in [39], which forms the backbone of the proposed feature selection mechanism. CCM is a method that can distinguish causality from correlation that is based on nonlinear state-space reconstruction. This approach is specifically designed for nonlinear dynamics, which are predominant in nature and exhibit deterministic characteristics. Deterministic systems differ from stochastic ones primarily in terms of separability. In purely stochastic systems, the effects of causal variables are separable, meaning that information associated with a causal factor is unique to that variable and can be excluded by removing it from the model. This implies that stochastic systems can be understood in parts rather than as an integrated whole. This does not hold true for most complex dynamic systems such as climate systems, ecological systems, biological systems, etc., which do not satisfy separability. Therefore, CCM provides a more rigorous and overarching causal mechanism more suited for the complex dynamics of the datasets commonly dealt with in machine learning problems, especially in environmental sciences.
CCM is based on the principle that if a system possesses deterministic aspects and its dynamics are not entirely random, then there exists a structured manifold that governs these dynamics, exhibiting coherent trajectories. In dynamical systems theory, two time-series variables, X and Y, are causally linked if they are coupled and part of the same underlying dynamic system, which is represented by a shared attractor manifold, M. In such a case, each variable contains information about the other. If X influences Y, then Y holds information that can be used to recover the states of X. CCM measures causality by determining how well the historical states of Y can estimate the states of X, which would only be possible if X causally influences Y.
Takens’ theorem [40] provides the theoretical foundation for this approach, stating that the essential information of a multidimensional dynamic system is preserved in the time series of any single variable. Therefore, a time series of one variable can be used to reconstruct the state space of the system (e.g., Figure 1). When X causally influences Y, the dynamics of the system can be represented by the shadow manifolds and , constructed from the lagged values of X and Y, respectively. These shadow manifolds map onto each other since X and Y should belong to the same dynamic system. Nearby points on should correspond to nearby points on , indicating a causal relationship. If so, Y can be used to estimate X, and vice versa. The degree to which Y can be used to estimate X is quantified by the correlation coefficient between the predicted and observed values of X, a process referred to as cross mapping. As the length of the time series increases, the shadow manifolds become denser, improving the precision of cross mapping, a phenomenon known as convergent cross mapping, which is the key criterion for establishing causality. The convergence property is crucial for distinguishing true causation from mere correlation. The degree to which the predictive skill converges can be interpreted as an estimate of the strength of the causal relationship.
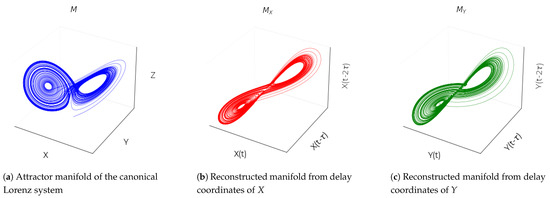
Figure 1.
(a) Attractor manifold of the canonical Lorenz system (M) plotted in 3D space, showing the trajectory of the original system in the state space with variables X, Y, and Z. (b) Reconstructed manifold using delay-coordinate embedding of the X variable. The coordinates , , and approximate the original attractor dynamics, capturing the structure of the system dynamics based only on the X time series. (c) Reconstructed manifold using delay-coordinate embedding of the Y variable. The coordinates , , and again form an attractor diffeomorphic to the original manifold, illustrating how the Y time series alone, through lagged coordinates, captures the dynamics of the system.
As detailed in [38], CCM is distinct from other cross-prediction methods, as it focuses on estimating the states of one variable from another, rather than forecasting the future states of the system. This distinction is particularly important in systems with chaotic dynamics, where prediction can be hampered by phenomena such as Lyapunov divergence. CCM also handles non-dynamic, random variables, making it a robust tool for causality detection in complex systems.
2.1. Proposed Feature Selection Mechanism
We now elaborate our novel feature selection scheme. It is important to note that there may be other causally inspired feature selection methods in the literature. An example would be the automatic feature selection method for developing data-driven soft sensors in industrial processes proposed in [41]. That approach asserts that the capacity of a feature to reduce the uncertainty of a target variable, as measured by Shannon entropy, quantifies the causal impact of that feature on the target. Our approach is not intended to compete with such methods; rather, ours is designed specifically to handle the complexity of environmental and climate data. While information theory and entropy-based causal inference methods might be well suited for random variables, for atmospheric and environmental variables exhibiting complex interplay between various factors, CCM provides comparatively more solid criteria for causation, rigorously rooted in dynamical systems theory. The more generalized approach of CCM is more compatible with atmospheric and climate data that possess both stochastic as well as deterministic aspects, and due to its ability to identify weakly coupled interactions, which can play a significant role in complex systems where components influence each other but do not directly cause drastic changes or exhibit intricate feedback relations, we deem this a more suitable causal approach for the type of intricate systems addressed in environmental monitoring [39,42,43,44].
Hence, we propose a feature selection process for machine learning in which we leverage the principle of causation as imposed by CCM. Given a set of features (in the case of LCS calibration, these would be individual output measurements from the LCSs along with external parameters such as ambient atmospheric pressure, temperature, and humidity to account for the sensitivity to environmental conditions) with the target variable Y (the target variable as measured by the reference instrument), our proposed work flow is as follows.
- 1:
- For each in , the causation criteria set by CCM for is evaluated. For the current study, the causal-ccm package [45] was used for this purpose. The implementation details and steps of the CCM algorithm are described in Appendix A.In evaluating the causal relationship from to Y, it is essential to select a sufficiently long time series for both variables in order to ascertain that the criterion of convergence is met and that the cross-map skill does not deteriorate significantly over time.
- 2:
- For each causality assessment, the causal-ccm package evaluates a p-value, representing the statistical significance of the result. All for which the p-value [46] and therefore not registered as a sufficiently rigorous causal connection are eliminated from the set of input features to the ML model
- 3:
- Next, the remaining features are ranked according to the strength of the causal relationship , from most causally related to Y to the least.
- 4:
- An appropriate threshold value is established for the strength of causality and the features exceeding this threshold are selected. The machine learning models are then constructed and trained for all possible subsets of the selected features as input variables to the model. After training, for each instance, the efficacy is tested using an independent validation dataset to assess how well it performs when presented with data that the algorithm has not previously seen, i.e., we test its generalizability.
By exploring various subsets of the most causally related features, as opposed to simply selecting the top-ranked ones, we aim to refine the selection process to retain to the most possible extent only the most direct causal influences. This approach seeks to enhance the generalizability of models by utilizing direct causal parents for predictions, as discussed in studies such as [35].
A reasonable choice of threshold for most cases would be , since any feature with retained for an appropriate duration of time would have established a causation guaranteed above chance and thus beyond being wholly attributed to noise, systematic error, or biases in the observational data. However, depending on the complexity of the system being modeled, the threshold may need to be adjusted to accommodate features with comparatively lower values representing weak couplings that might offer important information to the model. Especially in climate systems, weakly coupled interactions are ubiquitous. An example of weakly coupled interactions can be found in the relationship between soil moisture and precipitation patterns. While soil moisture levels can influence local precipitation through mechanisms like evapotranspiration and land–atmosphere interactions, the coupling between soil moisture and precipitation is often not straightforward. However, understanding these weakly coupled interactions is crucial for accurate hydrological and climate modeling. By incorporating the nuanced effects of soil moisture on precipitation, models can better simulate regional water cycles, drought patterns, and the impacts of land surface changes on local climate conditions.
- 5:
- The model that demonstrates the best predictive performance is selected as the final calibration model. Performance metrics are compared with the full model to assess any improvement in generalizability. If no improvement is observed, the process in Step 4 is repeated using a lower threshold.
Figure 2 gives a concise representation of the proposed feature selection.
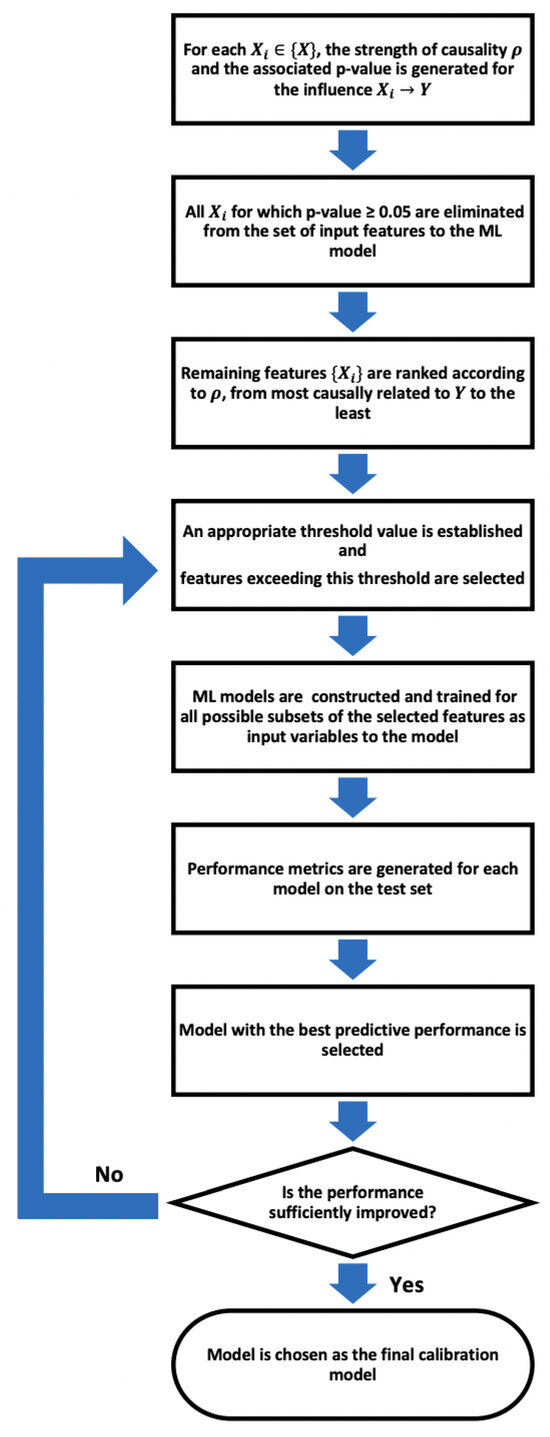
Figure 2.
Proposed causality-driven feature selection pipeline.
2.2. Experimental Test Cases
In order to validate the proposed feature selection method, it was applied on two real-world LCS calibration instances.
2.2.1. Experimental Setup and Datasets Used
The two test instances were the calibration of a low-cost optical particle counter (OPC) to reproduce the and counts from a research-grade OPC.
The dataset was obtained from a previous study in [10]. The low-cost OPC used was a readily available but much less accurate Alpha Sense OPC-N3 (http://www.alphasense.com/) (accessed on 8 November 2024), together with a cheaper environmental sensor (Bosch BME280) (Bosch, Baden-Württemberg, Germany). The OPC-N3 adheres to the method defined by the European Standard EN 481 in calculating its PM values. A low-power micro-fan enables sufficient airflow through the sensor, at a sample flow rate of 280 mL/min. The OPC-N3, similar to conventional OPCs, measures the light scattered by individual particles passing through a laser beam in the sample air stream. Based on Mie scattering theory, the intensity of scattered light is used to determine the particle size and concentration. The OPC-N3 categorizes particles into 24 size bins that cover 0.35 to 40 m, detecting nearly 100% of particles at 0.35 m and around 50% at 0.3 m, with a processing capacity of up to 10,000 particles per second. From these data, the mass concentrations of , and are calculated, assuming particle density and refractive index. To convert each particle’s recorded optical size into mass, the OPC-N3 assumes an average refractive index at the laser wavelength (658 nm) of . It is capable of on-board data logging and the on-board data are saved within an SD card which can be accessed through a micro-USB cable connected to the OPC [47].
The research-grade reference OPC used was a GRIMM Laser Aerosol Spectrometer and Dust Monitor Model 1.109 (Germany). It is capable of measuring particulates of diameters between 0.25 and 32 m distributed within 32 size channels. The sensor operates at a flow rate of 1.21 L/min, and particulates entering the sensor are detected by scattering a 655 nm laser beam through a light trap. The scattered light pulse from each particle is counted, and the intensity of the scattered light signal is used to classify it into a specific particle size. A curved optical mirror, positioned at a 90° scattering angle, redirects scattered light to a photo sensor, with its wide angle (120°) enhancing light collection and reducing the minimum detectable particle size. The optical setup also optimizes the signal-to-noise ratio and compensates for Mie scattering undulations caused by monochromatic illumination, allowing a definite particle sizing [48,49].
The data were collected by collocating the LCSs and the reference sensor unit at a field calibration station in an ambient environment from 2 December 2019 to 4 October 2019. There were in total 42 initial input features to our ML model, which included the particle counts for each of the 24 size bins measured by the OPC-N3; the OPC-N3 estimates of , , and ; a collection of OPC performance metrics, including the reject ratio, in-chamber temperature and humidity; and the ambient atmospheric pressure, temperature, and humidity from the BME280. The target outputs for estimation were the and abundance as measured by the reference instrument, each with its own empirical model. The data were first resampled at a frequency of 60 s, and the different data sources merged by matching the time.
We resampled the data for several key reasons. First, to ensure an evenly sampled time series for causal analysis using CCM, which relies on time-delay embeddings. Second, since this study involved constructing and training several benchmark models for comparison, a compact dataset was necessary to minimize computational time. A resampling frequency of 60 s was chosen to create a compact dataset without undersampling, while still adequately capturing temporal variability in PM levels. Finally, instances with missing values (NaN) were dropped from the dataset.
The genre of ML used was multivariate nonlinear nonparametric regression. According to [10], the best-suited class of regression algorithms for the task is an ensemble of decision trees with hyperparameter optimization. Therefore, the GradientBoostingRegressor implementation of Python 3.10 was used for ML tasks. Of the final cleaned and data-matched dataset, 2130 data instances were isolated for hyperparameter optimization using cross-validation, a subset of which, a continuous time series of 600 time steps, was used for the causal feature ranking. The remaining dataset, consisting of 31,361 instances, was randomly partitioned into 80% for training and 20% for testing. We employed the train_test_split function from sklearn.model_selection with the shuffle parameter at its default value of True, for this purpose. To ensure the rigor of the process, there was no overlap between the training and testing datasets and the data used for causal analysis.
Separate calibration models were developed for each of and . For each case, three approaches were employed and the results compared: (a) Using all 42 variables from the LCS as input features to the ML model; (b) using feature selection based on SHAP values; (c) using the proposed causality-based feature selection.
2.2.2.
First, all 42 output variables from the LCS described in Section 2.2.1 were used as input features with count from the reference sensor as the target variable for the ML model. The hyperparameters: the number of estimators (n_estimators), the learning rate (learning_rate), the maximum depth of the trees (max_depth), the minimum number of samples required to be at a leaf node (min_samples_leaf), and the number of features considered for splitting (max_features) were optimized using the GridSearchCV function of Python 3.10. To reduce the risk of overfitting, we constrained our grid search to smaller values of the learning rate (≤0.1) and a minimal range of 3–5 for the maximum depth of the trees. The optimized model was then trained on the training dataset and applied on the independent test dataset, and the performance of the model was assessed using the mean squared error (MSE) and the coefficient of determination (R²), two widely employed performance evaluation metrics in ML.
The SHAP values were then generated on the training dataset for the model to assess the model-specific contribution of each feature in predicting the count, and the features were ranked according to importance. A commonly used threshold for SHAP value-based feature selection is 0.5, indicating a significant influence on predictions. However, in our case, that would have eliminated most features (Figure 3) leading to underfitting. Therefore, for a fair comparison with the causality-based feature selection, the 10 highest-ranked features (highlighted in red in Figure 3) were chosen. ML models were then constructed with hyperparameter optimization and trained for all possible subsets of the selected features as inputs. Each instance was applied on the independent test dataset, and the performance metrics were generated. The best model was selected based on the MSE on the test set.
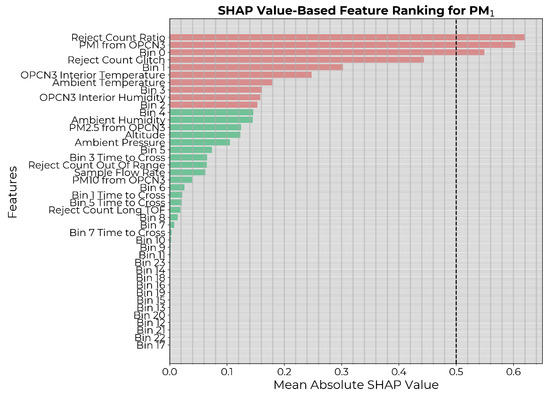
Figure 3.
Input features to the calibration model ranked in descending order of mean absolute SHAP values. The 10 highest-ranked features are highlighted in red.
Next, the causality-based feature selection described in Section 2.1 was applied with threshold . A higher threshold of 0.7 was selected in this case because mapping LCS readings to reference-grade measurements is a relatively straightforward task, making it less likely that weakly coupled variables would have significant effects. Therefore, as an initial attempt, we used a threshold of 0.7 to include the top 10 highest-ranked features (Figure 4). Then, the best model was selected based on the MSE on the test set. For the time-delay embedding for CCM, since the time series were not overly sampled in time, the lag () was set to one. The optimal embedding dimension (E) was empirically determined by applying simplex projection to the time series of the target counts from the reference sensor [44,50].
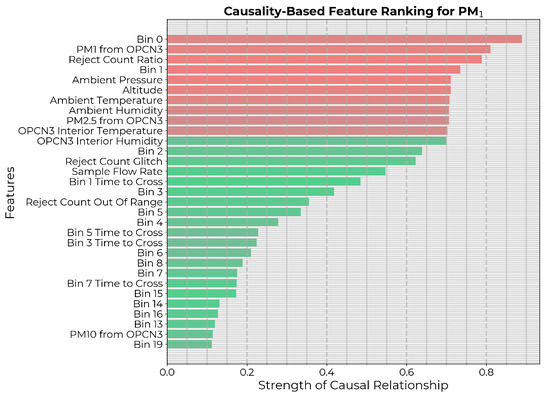
Figure 4.
Potential input features to the calibration model ranked in descending order of strength of causal influence after eliminating features with p-value . The 10 highest-ranked features are highlighted in red.
2.2.3.
The same procedure was followed for the estimation of particle counts, now with the count from the reference sensor as the target variable.
The feature importance ranking based on SHAP values is depicted in Figure 5. Since only two of the features placed above the threshold of 0.5, there also, the 10 highest-ranked features were considered for the subsequent feature refining.
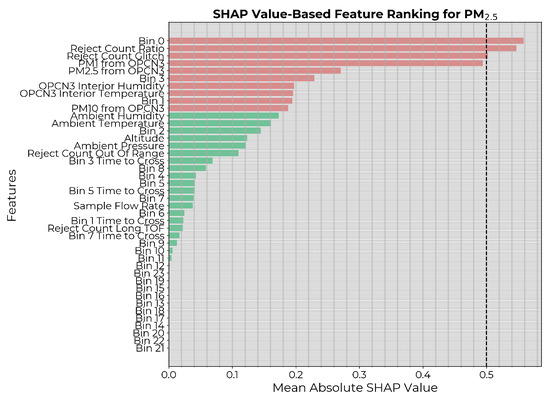
Figure 5.
Input features to the calibration model ranked in descending order of mean absolute SHAP values. The 10 highest-ranked features are highlighted in red.
The causality-based feature ranking is depicted in Figure 6, with threshold , that includes the top 10 ranked features.
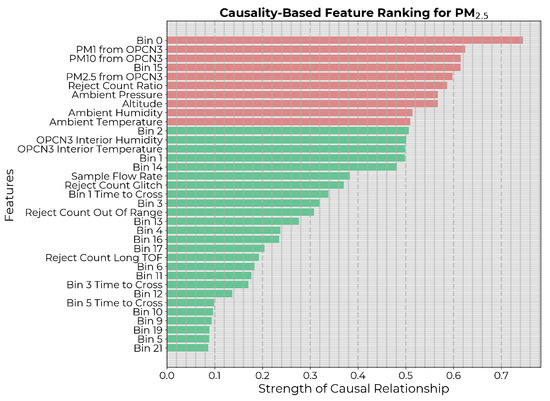
Figure 6.
Potential input features to the calibration model ranked in descending order of strength of causal influence after eliminating features with p-value . The 10 highest-ranked features are highlighted in red.
3. Results
In this section, we present the results from each of the three approaches across the two test cases.
3.1.
Figure 7 presents a scatter diagram comparing the estimates from the OPC-N3 against those from the reference instrument prior to any calibration. As expected, the estimates from the OPC-N3 sensor showed substantial disparity compared to the reference instrument values, highlighting the need for calibration.
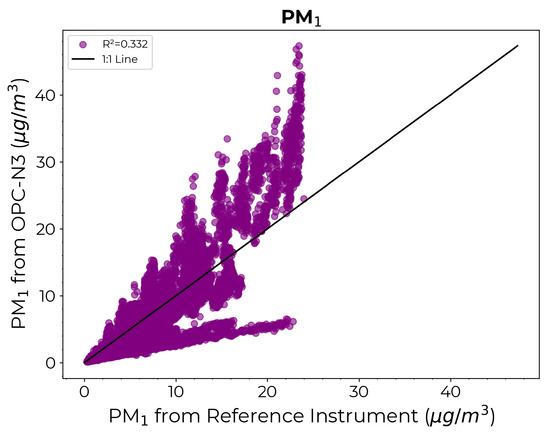
Figure 7.
Scatter diagram comparing the measurements from the reference instrument on the x-axis against the estimates from OPC-N3 on the y-axis prior to calibration.
Table 1 depicts the performance evaluation metrics of the calibration model for derived from each approach, when applied on the independent test dataset. The causality-based feature selection was observed to yield the lowest MSE as well as the highest on the test dataset, demonstrating superior generalizability to unseen data and enhanced predictive performance. Therefore, the causality-based approach was clearly more adept at extracting the causal variables while eliminating the redundant, non-causal, and/or indirect influences on the target. It also used the least number of input features to the model out of the three. This improved computational efficiency, which is particularly valuable when sensors are deployed in the long term and at finer spatial resolutions in order to reduce the computational load of handling large datasets over extended periods.

Table 1.
The performance evaluation metrics for the estimation of .
Figure 8 shows the density plots of the residuals (that is, differences between the actual and predicted values) for each approach.
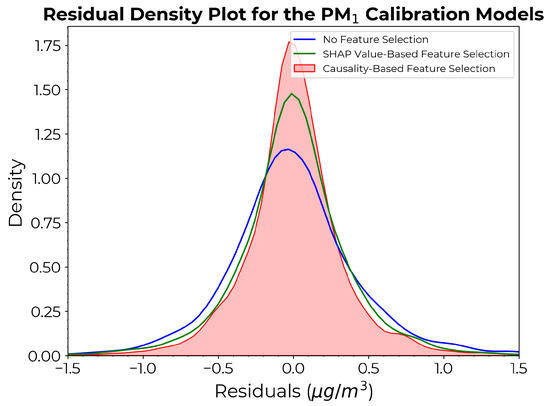
Figure 8.
Density plots of the residuals for the calibration models derived from each approach.
Figure 9 depicts the scatter diagrams of the calibration model for under different feature selection approaches. Figure 9a–c show the scatter plots of true vs. estimated count for each model on the training (blue) and independent test (red) sets. Figure 9d compares the performance of each model on the test set, with the causality-based approach yielding a comparatively thinner divergence from the 1:1 line. The density curve derived from the causality-based method exhibits a prominent density peak and narrower spread compared to the other two, indicating the most accurate predictions of the three, with fewer large residuals, thus producing a more reliable and robust model with fewer prediction errors.
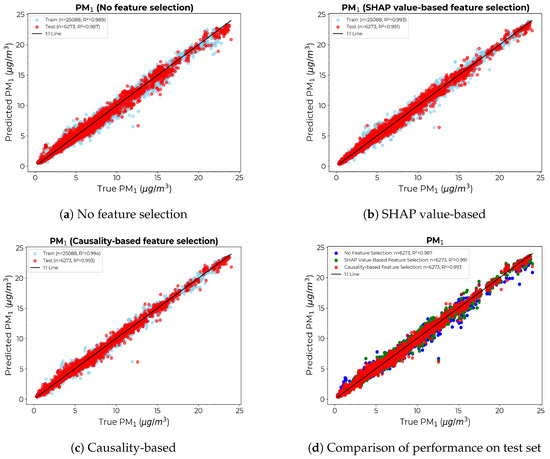
Figure 9.
Scatter diagrams for the calibration models with the x-axis showing the count from the reference instrument and the y-axis showing the count provided by calibrating the LCS: (a) Without any feature selection. (b) SHAP value-based feature selection. (c) Causality-based feature selection. (d) Comparison of true vs. predicted values for the test set across models.
3.2. PM2.5
Figure 10 depicts the scatter diagram comparing the estimates from the OPC-N3 against those from the reference instrument prior to calibration. Again, the necessity for calibration is underscored by the significant deviation in the estimates from the OPC-N3 sensor from the reference instrument values.
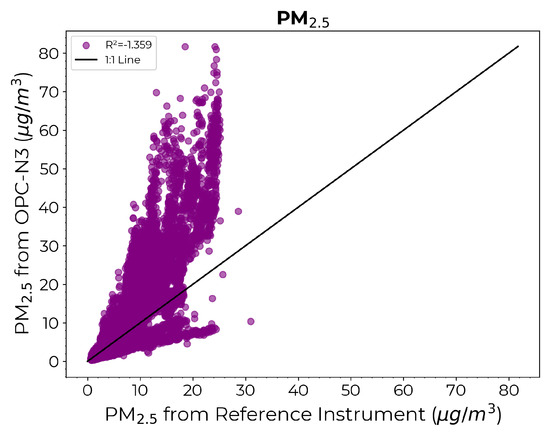
Figure 10.
Scatter diagram comparing the measurements from the reference instrument on the x-axis against the estimates from OPC-N3 on the y-axis prior to calibration.
Table 2 presents the performance metrics of the calibration model derived from each approach evaluated on the independent test dataset.
Table 2.
The performance evaluation metrics for the estimation of .
Although MSEs were higher and the values were lower across all three approaches compared to calibration models, the causality-based feature selection method consistently yielded the lowest MSE and the highest by a reasonable margin, with the least number of input features to the model.
Figure 11 depicts the density plots of the residuals for the estimation. Both models incorporating feature selection exhibited improved accuracy compared to the model without feature selection. Although less pronounced than in the case of models, the causality-based model continued to exhibit the narrowest residual distribution over larger values, characterized by a smaller base spread and a slightly higher peak compared to the SHAP value-based approach.
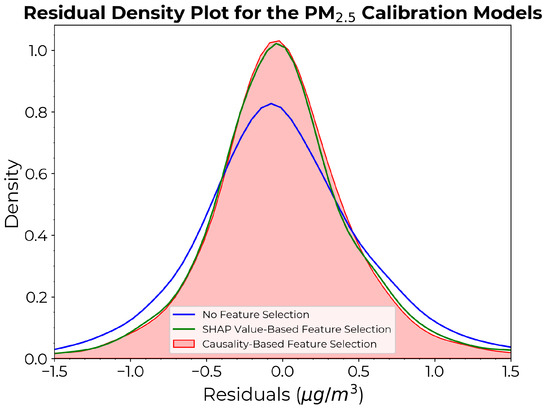
Figure 11.
Density plots of the residuals for the calibration models derived from each approach.
Figure 12 gives the scatter diagrams of the calibration model for under different feature selection approaches, along with the comparison of the models’ performance on the test set. Again, though less pronounced than in the case of models, the causality-based approach yielded the thinnest divergence from the 1:1 line.
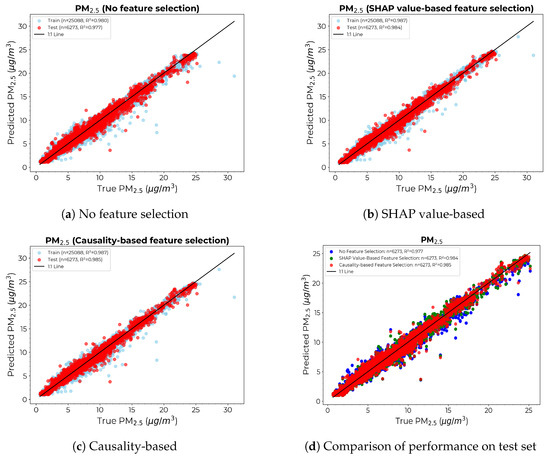
Figure 12.
Scatter diagrams for the calibration models with the x-axis showing the count from the reference instrument and the y-axis showing the count provided by calibrating the LCS: (a) Without any feature selection. (b) SHAP value-based feature selection. (c) Causality-based feature selection. (d) Comparison of true vs. predicted values for the test set across models.
4. Discussion
Our results demonstrate the efficacy of the causality-based feature selection method in building more accurate and robust calibration models for LCSs that generalize better to unseen data.
We compared the performance of the proposed method with feature selection based on SHAP values, a common approach for machine learning practitioners [51]. The proposed causality-based feature selection method consistently outperformed the SHAP value-based approach. It is important to note that in an effort to provide a rigorous and thorough comparison with the proposed method, we opted for a minimal threshold (<0.2 in both test cases) for feature selection based on SHAP values. Therefore, the observed underperformance of the SHAP-based approach highlights its limitations in extracting causal information and reinforces the susceptibility of machine learning models to spurious correlations.
The proposed feature selection method was validated on the calibration of two OPC instances. This provided a compelling case study for assessing the novel approach, since the working principle of OPCs (see Section 2.2.1) involves the estimation of particle size distributions based on light scattering, and not only is the relationship between scattered light intensity and particle characteristics (such as size, shape, and refractive index) nonlinear, but particle behavior and optical properties can often be influenced by environmental conditions. These complexities provide a strong basis for utilizing CCM, which is specifically designed to uncover causal influences in complex, nonlinear systems with subtle dependencies. In both case studies, the features chosen as predictors from the proposed causal approach validated its ability to extract the most direct causal influences from mere correlations and indirect influences. In both instances, the reject count ratio was extracted as an important predictor. This can be attributed to the operational principles of the OPC-N3. The OPC-N3 comprises two photo diodes that record voltages which are subsequently translated into particle count data. Particles partially within the detection beam or passing near its edges are rejected, and that is reflected on the parameter “Reject count ratio”. Consequently, this parameter enhances particle sizing accuracy, hence having a direct influence on the PM count [10]. Several studies have recorded the impact of meteorological parameters such as atmospheric pressure, temperature, and humidity on atmospheric levels of PM [52,53,54,55,56,57,58]. Atmospheric pressure affects PM levels through its impact on air density, vertical mixing, and the transport and dispersion of particles. Atmospheric pressure obstructs the upward movement of particles. Under high-pressure systems, air tends to be more stable, trapping pollutants near the surface, increasing PM levels. In contrast, in lower-pressure conditions, particles may disperse more easily due to reduced air density. Temperature also affects atmospheric stability, changing how pollutants disperse. Hot weather often results in stagnant air conditions, which can trap PM and hinder its dispersion. In addition, elevated temperatures can speed up chemical reactions that generate PM, particularly in areas with vehicle and industrial emissions. Humidity influences ambient levels of PM significantly through hygroscopic growth: certain atmospheric species absorb water and increase in size once the relative humidity exceeds the deliquescence point of the substance. This phenomenon can shift smaller particles into larger PM-size categories, resulting in changed PM levels. High humidity can also promote chemical reactions, such as the conversion of sulfur dioxide to sulfate aerosols [59], leading to higher PM levels. In addition to the direct impact of meteorological factors on ambient PM levels, the performance of LCSs can also be influenced by these environmental conditions [60]. Therefore, naturally, ambient temperature, pressure, and humidity should be important predictors to the calibration model, which causality-based feature selection was able to extract, as opposed to the SHAP value-based approach, which placed greater import on temperature and humidity in the interior of the OPC leading to less accurate predictions on the test data. This also demonstrates the versatility and robustness of a causal feature selection method underpinned by CCM, as it precisely identifies the significance of causal relationships between sensor readings and ambient environmental variables consistently across both cases. Tangentially, as a control comparison to verify CCM’s superior compatibility, we implemented Granger causality [61], which failed to identify any statistically significant causal influence from ambient environmental factors on the PM abundance (see Appendix B).
Although this study focused on the proposed feature selection method in the context of LCS calibration, it is broadly applicable to other machine learning tasks that involve time series data. The flexibility of CCM, which can handle both linear and nonlinear dynamics, as well as deterministic and random data without specific assumptions, enhances the utility of the proposed feature selection approach. However, a key limitation is that CCM requires a sufficiently long time series to reliably determine causality, which may pose challenges in cases where data are not collected in continuous intervals.
5. Conclusions
In this study, we proposed a causality-based feature selection method using convergent cross mapping for the calibration of low-cost air quality sensor systems using machine learning. The integration of causality improved the interpretability and generalizability of the environmental machine learning models. The application of this approach to real-world low-cost sensor calibration demonstrated significant improvements in predictive performance and generalizability, confirming the efficacy of the proposed methodology.
In future work, we aim to validate this approach across various types of sensors and datasets to assess its robustness and adaptability in a range of applications in atmospheric and climate sciences. In particular, the mathematical rigor and versatility of convergent cross mapping, which underpins our feature selection method, could prove advantageous in empirical climate modeling applications.
Author Contributions
Conceptualization, V.S. and D.J.L.; methodology, V.S. and D.J.L.; data curation, L.O.H.W.; software, V.S.; validation, D.J.L.; formal analysis, V.S.; investigation, V.S.; resources, D.J.L., L.O.H.W. and J.W.; writing—original draft preparation, V.S.; writing—review and editing, D.J.L., V.S., J.W. and L.O.H.W.; visualization, V.S. and J.W.; supervision, D.J.L.; project administration, D.J.L.; funding acquisition, D.J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by TRECIS CC* Cyberteam (NSF #2019135); NSF OAC-2115094 Award; and EPA P3 grant number 84057001-0; AFWERX AFX23D-TCSO1 Proposal # F2-17492.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The code and data are publicly available at https://github.com/mi3nts/Causality-Driven-Machine-Learning (accessed on 8 November 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
Correction Statement
This article has been republished with a minor correction to the readability of Table A3. This change does not affect the scientific content of the article.
Abbreviations
The following abbreviations are used in this manuscript:
| PM | Particulate matter |
| IoT | Internet of Things |
| LCS | Low-cost air quality sensor systems |
| ML | Machine learning |
| CCM | Convergent cross mapping |
| OPC | Optical particle counter |
| MSE | Mean squared error |
| GC | Granger Causality |
Appendix A. The CCM Algorithm
Here we present the algorithm for the determination of causality based on CCM, as outlined in [62].
Given two variables of interest, X and Y, with time series and , respectively, where L is the length of the time series, the CCM algorithm for determining the causal influence of X on Y is as follows:
- 1:
- Define the reconstructed shadow manifold :Then, the reconstructed shadow manifold is defined by (A2).
- 2:
- At t, locate in .
- 3:
- Identify nearest neighbors:Find the nearest neighbor vectors from selected vector ( is the minimum number of points needed for an embedding/simplex with E dimensions [38]).Let the time indices of the nearest neighbors of be denoted by .
- 4:
- Define the model that predicts X given :Construct a model that predicts X based on states of Y given bywhereandwith being the Euclidean distance between two reconstructed state vectors and .Here, the division by serves to scale distances relative to the nearest neighbor. In this approach, the more distant neighbors are assigned lower weights, with the weights decreasing exponentially as the distance increases.
- 5:
- Assess dynamical coupling between X and Y:If X and Y are dynamically coupled, nearby clusters of points in should correspond to nearby clusters in . As L increases, the density of neighbor points in both manifolds should increase, should converge to X. Therefore, the convergence of nearest neighbors can be examined to assess the correspondence between states on and .
- 6:
- Evaluate correlation for causality testing:Plot the correlation coefficients between X and . If a significant correlation is observed, this indicates that sufficient information from X is embedded in Y. In this case, we can conclude that X causally influences Y.
Appendix B. Granger Causality
Granger causality (GC) [61] is a mechanism that relies on predictability as the criterion to establish causation between time series variables as opposed to simple correlation. X is considered to “Granger cause” Y if knowledge of X’s past enhances the prediction accuracy of Y, beyond what can be achieved by using only Y’s own historical data [63]. While undoubtedly a key advancement in addressing the causation problem, there are several caveats to adopting this approach in the context of a causality-driven feature selection step for complex ML problems involving atmospheric and environmental variables.
The key requirement of GC is separability, i.e., information about a causative factor is uniquely associated with that variable and can be removed by excluding it from the model. While characteristic of stochastic and linear systems, as already elaborated in Section 2, this is not satisfied in deterministic systems, especially in dynamic systems with weak to moderate coupling. In such cases, GC may yield ambiguous results [38].
Tangential to the current study, we explored the viability of GC in the context of being the basis for a causality-driven feature selection in the calibration of OPCs. As is evident from the results of the current study, as well as the literature cited in Section 4, ambient environmental variables of humidity, temperature, and pressure are instrumental predictors in achieving an accurate and robust calibration model. In order to establish if GC is capable of identifying causal relationships between these ambient environmental variables and PM abundance, we implemented GC analysis on the relevant time-series data. The grangercausalitytests method of the statsmodels module [64] was implemented with Python 3.10 for the analysis. For an inclusive comparison, we implemented GC with lags from 1 through 10. The null hypothesis for the Granger causality test is that the time series of the second variable does not Granger cause the time series of the first variable. The null hypothesis is rejected if the p-values are below the chosen significance level. We implemented grangercausalitytests() with each of ambient humidity, temperature, and pressure as the second variable for each instance of and from the reference sensor as the first variable to assess the Granger causal influence of ambient environment variables on PM abundance. We present the results below:
Appendix B.1. PM1
As depicted in Table A1, Table A2 and Table A3, across all lag levels, the p-values remained consistently above the typical significance threshold of 0.05 [46], suggesting no statistically significant Granger causality was established from ambient environment variables to abundance levels.
Table A1.
Granger causality test results for ambient humidity.
Table A1.
Granger causality test results for ambient humidity.
| Lag Length | p-Value |
|---|---|
| 1 | 0.5231 |
| 2 | 0.0528 |
| 3 | 0.0616 |
| 4 | 0.0687 |
| 5 | 0.1191 |
| 6 | 0.1780 |
| 7 | 0.2919 |
| 8 | 0.3875 |
| 9 | 0.4419 |
| 10 | 0.4333 |
Table A2.
Granger causality test results for ambient temperature.
Table A2.
Granger causality test results for ambient temperature.
| Lag Length | p-Value |
|---|---|
| 1 | 0.5696 |
| 2 | 0.0943 |
| 3 | 0.1172 |
| 4 | 0.1448 |
| 5 | 0.2356 |
| 6 | 0.3174 |
| 7 | 0.4809 |
| 8 | 0.5799 |
| 9 | 0.6351 |
| 10 | 0.6192 |
Table A3.
Granger causality test results for and ambient pressure.
Table A3.
Granger causality test results for and ambient pressure.
| Lag Length | p-Value |
|---|---|
| 1 | 0.8333 |
| 2 | 0.5366 |
| 3 | 0.6190 |
| 4 | 0.7315 |
| 5 | 0.5543 |
| 6 | 0.6514 |
| 7 | 0.7924 |
| 8 | 0.7104 |
| 9 | 0.7401 |
| 10 | 0.7885 |
Appendix B.2. PM2.5
In the case of as well, according to Table A4, Table A5 and Table A6, the p-values remained well above the typical threshold of 0.05 [46]. The GC analysis failed to identify the significance of the causal influence of ambient environment variables on abundance levels.
Table A4.
Granger causality test results for ambient humidity.
Table A4.
Granger causality test results for ambient humidity.
| Lag Length | p-Value |
|---|---|
| 1 | 0.3366 |
| 2 | 0.4009 |
| 3 | 0.7111 |
| 4 | 0.8371 |
| 5 | 0.9256 |
| 6 | 0.9664 |
| 7 | 0.9822 |
| 8 | 0.9843 |
| 9 | 0.9883 |
| 10 | 0.9756 |
Table A5.
Granger causality test results for ambient temperature.
Table A5.
Granger causality test results for ambient temperature.
| Lag Length | p-Value |
|---|---|
| 1 | 0.5113 |
| 2 | 0.6379 |
| 3 | 0.8674 |
| 4 | 0.9466 |
| 5 | 0.9821 |
| 6 | 0.9934 |
| 7 | 0.9970 |
| 8 | 0.9977 |
| 9 | 0.9984 |
| 10 | 0.9958 |
Table A6.
Granger causality test results for ambient pressure.
Table A6.
Granger causality test results for ambient pressure.
| Lag Length | p-Value |
|---|---|
| 1 | 0.4672 |
| 2 | 0.7967 |
| 3 | 0.9837 |
| 4 | 0.9656 |
| 5 | 0.9607 |
| 6 | 0.9762 |
| 7 | 0.9968 |
| 8 | 0.9990 |
| 9 | 0.9944 |
| 10 | 0.9990 |
References
- Intergovernmental Panel on Climate Change. Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Orru, H.; Ebi, K.; Forsberg, B. The interplay of climate change and air pollution on health. Curr. Environ. Health Rep. 2017, 4, 504–513. [Google Scholar] [CrossRef]
- Arshad, K.; Hussain, N.; Ashraf, M.H.; Saleem, M.Z. Air pollution and climate change as grand challenges to sustainability. Sci. Total Environ. 2024, 928, 172370. [Google Scholar]
- Shaddick, G.; Thomas, M.L.; Mudu, P.; Ruggeri, G.; Gumy, S. Half the world’s population are exposed to increasing air pollution. NPJ Clim. Atmos. Sci. 2020, 3, 23. [Google Scholar] [CrossRef]
- Li, Y.; Xu, L.; Shan, Z.; Teng, W.; Han, C. Association between air pollution and type 2 diabetes: An updated review of the literature. Ther. Adv. Endocrinol. Metab. 2019, 10, 2042018819897046. [Google Scholar] [CrossRef]
- Nolte, C. Air quality. In Impacts, Risks, and Adaptation in the United States: Fourth National Climate Assessment, Volume II; U.S. Global Change Research Program: Washington, DC, USA, 2018; Chapter 13; p. 516. [Google Scholar]
- Malings, C.; Archer, J.-M.; Barreto, Á.; Bi, J. Low-Cost Air Quality Sensor Systems (LCS) for Policy-Relevant Air Quality Analysis; Gaw Report No. 293; World Meteorological Organization: Geneva, Switzerland, 2024. [Google Scholar]
- Okafor, N.U.; Alghorani, Y.; Delaney, D.T. Improving data quality of low-cost IoT sensors in environmental monitoring networks using data fusion and machine learning approach. ICT Express 2020, 6, 220–228. [Google Scholar] [CrossRef]
- DeSouza, P.; Kahn, R.; Stockman, T.; Obermann, W.; Crawford, B.; Wang, A.; Crooks, J.; Li, J.; Kinney, P. Calibrating networks of low-cost air quality sensors. Atmos. Meas. Tech. 2022, 15, 6309–6328. [Google Scholar] [CrossRef]
- Wijeratne, L.O.; Kiv, D.R.; Aker, A.R.; Talebi, S.; Lary, D.J. Using machine learning for the calibration of airborne particulate sensors. Sensors 2019, 20, 99. [Google Scholar] [CrossRef]
- Zhang, Y.; Wijeratne, L.O.; Talebi, S.; Lary, D.J. Machine learning for light sensor calibration. Sensors 2021, 21, 6259. [Google Scholar] [CrossRef]
- Wang, A.; Machida, Y.; de Souza, P.; Mora, S.; Duhl, T.; Hudda, N.; Durant, J.L.; Duarte, F.; Ratti, C. Leveraging machine learning algorithms to advance low-cost air sensor calibration in stationary and mobile settings. Atmos. Environ. 2023, 301, 119692. [Google Scholar] [CrossRef]
- Kelly, B.; Xiu, D. Financial machine learning. Found. Trends Financ. 2023, 13, 205–363. [Google Scholar] [CrossRef]
- Mariani, M.M.; Borghi, M. Artificial intelligence in service industries: Customers’ assessment of service production and resilient service operations. Int. J. Prod. Res. 2024, 62, 5400–5416. [Google Scholar] [CrossRef]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine learning in medicine. N. Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef]
- Kang, Z.; Catal, C.; Tekinerdogan, B. Machine learning applications in production lines: A systematic literature review. Comput. Ind. Eng. 2020, 149, 106773. [Google Scholar] [CrossRef]
- Lary, D.J.; Zewdie, G.K.; Liu, X.; Wu, D.; Levetin, E.; Allee, R.J.; Malakar, N.; Walker, A.; Mussa, H.; Mannino, A.; et al. Machine learning applications for earth observation. In Earth Observation Open Science and Innovation; Springer: Cham, Switzerland, 2018; pp. 165–218. [Google Scholar]
- Malakar, N.K.; Lary, D.J.; Moore, A.; Gencaga, D.; Roscoe, B.; Albayrak, A.; Wei, J. Estimation and bias correction of aerosol abundance using data-driven machine learning and remote sensing. In Proceedings of the 2012 Conference on Intelligent Data Understanding, Boulder, CO, USA, 24–26 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 24–30. [Google Scholar]
- Albayrak, A.; Wei, J.; Petrenko, M.; Lary, D.; Leptoukh, G. Modis aerosol optical depth bias adjustment using machine learning algorithms. In Proceedings of the AGU Fall Meeting Abstracts, San Francisco, CA, USA, 4–8 December 2011; Volume 2011, p. A53C-0371. [Google Scholar]
- Shin, S.; Baek, K.; So, H. Rapid monitoring of indoor air quality for efficient HVAC systems using fully convolutional network deep learning model. Build. Environ. 2023, 234, 110191. [Google Scholar] [CrossRef]
- Ravindiran, G.; Hayder, G.; Kanagarathinam, K.; Alagumalai, A.; Sonne, C. Air quality prediction by machine learning models: A predictive study on the indian coastal city of Visakhapatnam. Chemosphere 2023, 338, 139518. [Google Scholar] [CrossRef]
- Wang, S.; McGibbon, J.; Zhang, Y. Predicting high-resolution air quality using machine learning: Integration of large eddy simulation and urban morphology data. Environ. Pollut. 2024, 344, 123371. [Google Scholar] [CrossRef]
- SK, A.; Ravindiran, G. Integrating machine learning techniques for Air Quality Index forecasting and insights from pollutant-meteorological dynamics in sustainable urban environments. Earth Sci. Inform. 2024, 17, 3733–3748. [Google Scholar]
- Rudner, T.G.J.; Toner, H. Key Concepts in AI Safety: Interpretability in Machine Learning; Center for Security and Emerging Technology: CSET: Washington, DC, USA, 2021. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Lipton, Z.C. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Lundberg, S. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Li, K.; DeCost, B.; Choudhary, K.; Greenwood, M.; Hattrick-Simpers, J. A critical examination of robustness and generalizability of machine learning prediction of materials properties. NPJ Comput. Mater. 2023, 9, 55. [Google Scholar] [CrossRef]
- Schölkopf, B. Causality for machine learning. In Probabilistic and Causal Inference: The Works of Judea Pearl; Association for Computing Machinery: New York, NY, USA, 2022; pp. 765–804. [Google Scholar]
- Cloudera Fast Forward Labs. Causality for Machine Learning: Applied Research Report. 2020. Available online: https://ff13.fastforwardlabs.com/ (accessed on 8 November 2024).
- Beery, S.; Van Horn, G.; Perona, P. Recognition in terra incognita. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 456–473. [Google Scholar]
- Ye, W.; Zheng, G.; Cao, X.; Ma, Y.; Hu, X.; Zhang, A. Spurious correlations in machine learning: A survey. arXiv 2024, arXiv:2402.12715. [Google Scholar]
- Ilyas, A.; Santurkar, S.; Tsipras, D.; Engstrom, L.; Tran, B.; Madry, A. Adversarial examples are not bugs, they are features. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2019; Volume 32. [Google Scholar]
- Haavelmo, T. The probability approach in econometrics. Econometrica 1944, 12, S1–S115. [Google Scholar] [CrossRef]
- Bühlmann, P. Invariance, causality and robustness. Stat. Sci. 2020, 35, 404–426. [Google Scholar] [CrossRef]
- Peters, J.; Bühlmann, P.; Meinshausen, N. Causal inference by using invariant prediction: Identification and confidence intervals. J. R. Stat. Soc. Ser. B Stat. Methodol. 2016, 78, 947–1012. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Sugihara, G.; May, R.; Ye, H.; Hsieh, C.H.; Deyle, E.; Fogarty, M.; Munch, S. Detecting causality in complex ecosystems. Science 2012, 338, 496–500. [Google Scholar] [CrossRef]
- Tsonis, A.A.; Deyle, E.R.; May, R.M.; Sugihara, G.; Swanson, K.; Verbeten, J.D.; Wang, G. Dynamical evidence for causality between galactic cosmic rays and interannual variation in global temperature. Proc. Natl. Acad. Sci. USA 2015, 112, 3253–3256. [Google Scholar] [CrossRef]
- Takens, F. Detecting strange attractors in turbulence. In Dynamical Systems and Turbulence, Warwick 1980: Proceedings of a Symposium Held at the University of Warwick 1979/80; Springer: Berlin/Heidelberg, Germany, 2006; pp. 366–381. [Google Scholar]
- Sun, Y.N.; Qin, W.; Hu, J.H.; Xu, H.W.; Sun, P.Z. A causal model-inspired automatic feature-selection method for developing data-driven soft sensors in complex industrial processes. Engineering 2023, 22, 82–93. [Google Scholar] [CrossRef]
- Chen, Z.; Cai, J.; Gao, B.; Xu, B.; Dai, S.; He, B.; Xie, X. Detecting the causality influence of individual meteorological factors on local PM2. 5 concentration in the Jing-Jin-Ji region. Sci. Rep. 2017, 7, 40735. [Google Scholar]
- Rybarczyk, Y.; Zalakeviciute, R.; Ortiz-Prado, E. Causal effect of air pollution and meteorology on the COVID-19 pandemic: A convergent cross mapping approach. Heliyon 2024, 10, e25134. [Google Scholar] [CrossRef]
- Ye, H.; Deyle, E.R.; Gilarranz, L.J.; Sugihara, G. Distinguishing time-delayed causal interactions using convergent cross mapping. Sci. Rep. 2015, 5, 14750. [Google Scholar] [CrossRef]
- Javier, P.J.E. causal-ccm: A Python Implementation of Convergent Cross Mapping, version 0.3.3; GitHub: San Francisco, CA, USA, 2021. [Google Scholar]
- Edwards, A.W. RA Fischer, statistical methods for research workers, (1925). In Landmark Writings in Western Mathematics 1640–1940; Elsevier: Amsterdam, The Netherlands, 2005; pp. 856–870. [Google Scholar]
- Alphasense. Alphasense User Manual OPC-N3 Optical Particle Counter; Alphasense: Great Notley, UK, 2018. [Google Scholar]
- Broich, A.V.; Gerharz, L.E.; Klemm, O. Personal monitoring of exposure to particulate matter with a high temporal resolution. Environ. Sci. Pollut. Res. 2012, 19, 2959–2972. [Google Scholar] [CrossRef]
- GRIMM Aerosol Technik. GRIMM Software for Optical Particle Counter, Portable Aerosol Spectrometer 1.108/1.109; GRIMM Aerosol Technik: Ainring, Germany, 2009. [Google Scholar]
- Sugihara, G.; May, R.M. Nonlinear forecasting as a way of distinguishing chaos from measurement error in time series. Nature 1990, 344, 734–741. [Google Scholar] [CrossRef]
- Marcílio, W.E.; Eler, D.M. From explanations to feature selection: Assessing SHAP values as feature selection mechanism. In Proceedings of the 2020 33rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Porto de Galinhas, Brazil, 7–10 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 340–347. [Google Scholar]
- Kirešová, S.; Guzan, M. Determining the correlation between particulate matter PM10 and meteorological factors. Eng 2022, 3, 343–363. [Google Scholar] [CrossRef]
- Yang, H.; Peng, Q.; Zhou, J.; Song, G.; Gong, X. The unidirectional causality influence of factors on PM2.5 in Shenyang city of China. Sci. Rep. 2020, 10, 8403. [Google Scholar] [CrossRef]
- Fu, H.; Zhang, Y.; Liao, C.; Mao, L.; Wang, Z.; Hong, N. Investigating PM2.5 responses to other air pollutants and meteorological factors across multiple temporal scales. Sci. Rep. 2020, 10, 15639. [Google Scholar] [CrossRef] [PubMed]
- Vaishali; Verma, G.; Das, R.M. Influence of temperature and relative humidity on PM2.5 concentration over Delhi. MAPAN 2023, 38, 759–769. [Google Scholar] [CrossRef]
- Hernandez, G.; Berry, T.A.; Wallis, S.L.; Poyner, D. Temperature and humidity effects on particulate matter concentrations in a sub-tropical climate during winter. Int. Proc. Chem. Biol. Environ. Eng. 2017, 102, 41–49. [Google Scholar]
- Kim, M.; Jeong, S.G.; Park, J.; Kim, S.; Lee, J.H. Investigating the impact of relative humidity and air tightness on PM sedimentation and concentration reduction. Build. Environ. 2023, 241, 110270. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, S.; Zhang, X.; Guo, S.; Wang, Y.; Zhao, F.; Chen, J.; Qi, P.; Lu, F.; Chen, M.; et al. Characters of particulate matter and their relationship with meteorological factors during winter Nanyang 2021–2022. Atmosphere 2023, 14, 137. [Google Scholar] [CrossRef]
- Zhang, S.; Xing, J.; Sarwar, G.; Ge, Y.; He, H.; Duan, F.; Zhao, Y.; He, K.; Zhu, L.; Chu, B. Parameterization of heterogeneous reaction of SO2 to sulfate on dust with coexistence of NH3 and NO2 under different humidity conditions. Atmos. Environ. 2019, 208, 133–140. [Google Scholar] [CrossRef]
- Raysoni, A.U.; Pinakana, S.D.; Mendez, E.; Wladyka, D.; Sepielak, K.; Temby, O. A Review of Literature on the Usage of Low-Cost Sensors to Measure Particulate Matter. Earth 2023, 4, 168–186. [Google Scholar] [CrossRef]
- Granger, C.W. Investigating causal relations by econometric models and cross-spectral methods. Econom. J. Econom. Soc. 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Javier, P.J.E. Chapter 6: Convergent Cross Mapping. In Time Series Analysis Handbook; GitHub: San Francisco, CA, USA, 2021. [Google Scholar]
- Clarke, H.D.; Granato, J. Time Series Analysis in Political Science. In Encyclopedia of Social Measurement; Kempf-Leonard, K., Ed.; Elsevier: Amsterdam, The Netherlands, 2005; pp. 829–837. [Google Scholar] [CrossRef]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28–30 June 2010. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).