Abstract
Moving target detection (MTD) is a crucial task in computer vision applications. In this paper, we investigate the problem of detecting moving targets in infrared (IR) surveillance video sequences captured using a steady camera in a maritime setting. For this purpose, we employ robust principal component analysis (RPCA), which is an improvement of principal component analysis (PCA) that separates an input matrix into the following two matrices: a low-rank matrix that is representative, in our case study, of the slowly changing background, and a sparse matrix that is representative of the foreground. RPCA is usually implemented in a non-causal batch form. To pursue a real-time application, we tested an online implementation, which, unfortunately, was affected by the presence of the target in the scene during the initialization phase. Therefore, we improved the robustness by implementing a saliency-based strategy. The advantages offered by the resulting technique, which we called “saliency-aided online moving window RPCA” (S-OMW-RPCA) are the following: RPCA is implemented online; along with the temporal features exploited by RPCA, the spatial features are also taken into consideration by using a saliency filter; the results are robust against the condition of the scene during the initialization. Finally, we compare the performance of the proposed technique in terms of precision, recall, and execution time with that of an online RPCA, thus, showing the effectiveness of the saliency-based approach.
1. Introduction
Automatic surveillance is a vast field which is expanding more and more and deepening its capabilities and applications due to the availability of low-cost sensors on the market and to an increase in computational capabilities. Recently, there have been many studies conducted on object detection [1,2]. In this study, we focus on a maritime scenario that presents some challenges which are mostly related to the non-stationarity of the background and to the changes in lighting conditions. An infrared (IR) band is used that tends to limit the effect due to clutter motion (especially in the long wavelength band); however, extraction of the foreground, which is intended as the target, is still a difficult task. In such a non-stationary background condition, it is usually possible to refer to frame-based techniques as well as dynamic background subtraction techniques. Frame-based techniques take advantage of the spatial features within a single frame to highlight the portions of an image that are likely to attract the attention of the observer. There are many methods described in the literature that are usually based on contrast [3,4,5], on the emulation of center-surround mechanism characteristics of the human retina [5,6,7], on spatial frequency analysis [5,8], as well as on neural networks [9]. Additionally, dynamic background subtraction techniques exploit the temporal features and can be classified into frame difference methods [10,11,12,13,14,15], statistical methods such as single Gaussian [16] and Gaussian mixture model (GMM) [15,17,18], domain transform-based techniques such as fast Fourier transform [19] and wavelet transform [20,21], machine learning models such as principal component analysis (PCA) [22,23,24] and robust principal component analysis (RPCA) [25,26,27,28,29,30], optical flow [31], and neural networks and deep learning techniques [32,33,34,35,36,37]. Frame difference methods assume that the background is unimodal and provide good performance only when the scene is really steady. Statistical methods are more robust to changes in the background. Domain transform-based techniques isolate the anomalies in the sequences by taking advantage of the characteristics of the transformed domain. Machine learning models consider the multimodality of the sequences and adapt to the specific background. Optical flow follows the changes in the gradient of the signal and it is robust against camera motion, but very time consuming; therefore, it is mainly used for tracking few regions instead of detection. Neural networks and deep learning techniques are more recent techniques which are promising, but require significant quantities of labeled data for training, which, in the specific field of marine infrared video, so far, have not been easily found.
In this paper, we describe, in detail, a RPCA-based technique, which is an unsupervised data-driven method, first, by introducing the simplest batch implementation, and then moving forward to a real-time approach by evaluating the online RPCA approach [38,39,40]. After considering the limits of the online implementation, we present an improved version of the method that exploits the information obtained by a saliency extraction algorithm. The idea of incorporating a saliency map into the RPCA cost function was inspired by the work of Oreifej et al. [41]. The novelty in the proposed strategy, which we call saliency-aided online moving window RPCA (S-OMW-RPCA), is the implementation of RPCA based on saliency maps in an online fashion to pursue real-time moving target detection in video sequences. We test the abovementioned technique with two saliency algorithms, namely spectral residual (SR) [8] and fine grained (FG) [7]. The choice was essentially driven by the noticeable speed of the mentioned techniques, which did not significantly increase the overall computational load. The last contribution of this paper is the evaluation of the proposed technique compared with a broadly used technique based on GMM [18], on a vast dataset of operationally significant video sequences, collected by the NATO Science and Technology Organization, Centre for Maritime Research and Experimentation (NATO STO-CMRE) during the Interactive Extreme-Scale Analytics and Forecasting (INFORE) project campaign led in Portovenere (La Spezia, Italy) during February 2022 [42]. The area of operation is shown in Figure 1. For the evaluation of the detection algorithms, some of the most representative sequences have been manually labeled through rectangular regions of interest (ROIs) surrounding the targets.
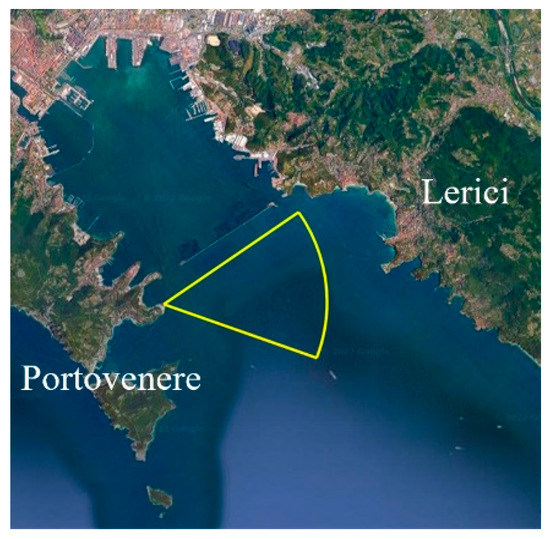
Figure 1.
Area of operations of the experimental activity trial (WGS84 Coordinates: 44.062057° N, 9.852161° E).
The remainder of this paper is organized as follows: In Section 2, we summarize the theoretical foundations of RPCA and its application as a background subtraction method, along with its online version; in Section 3, we present the modification proposed in this work; in Section 4, we present the dataset and discuss the qualitative and quantitative performance analysis; in Section 5, we provide concluding remarks.
2. Theoretical Framework and Related Works
2.1. Notation and Pixel Model
Throughout this paper, lowercase letters represent scalar variables, bold lowercase letters are used for vectors, capital letters represent matrices, and Greek letters are used for the coefficients.
As shown in Figure 2, the video sequences are organized in the form of three-dimensional arrays. Each element in the array represents the IR intensity value associated with the corresponding pixel. Since the IR images are monochromatic, each element carries just one value, instead of the triad of RGB videos.
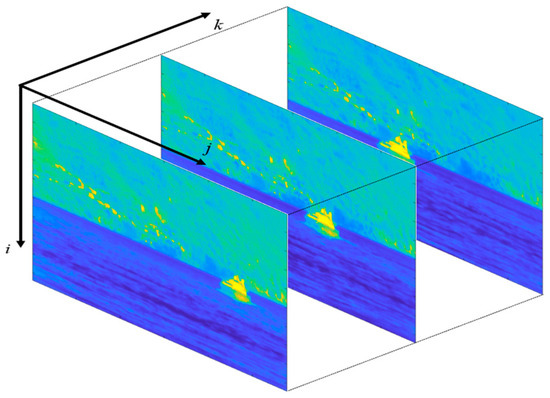
Figure 2.
A video sequence organized in the form of a three-dimensional array. The frames are shown in false colors according to the MATLAB “parula” colormap in which the lowest values are represented in blue, and the highest values are represented in yellow.
Referring to [3], we model the signal carried by a single pixel of spatial coordinates and at the quantized time instant as:
where is the background signal; is the target signal; and are the height and the width of each frame, respectively; is the number of collected frames. We also introduce the matrices , , and , in which , , and denote the -th frame, the corresponding background, and the target, respectively, reorganized in lexicographic order, while is the number of pixels. Given such a model, the objective of target detection is to separate the target signal from the background . In the literature, such a task is commonly referred to as background subtraction.
2.2. RPCA for Background Subtraction
RPCA is a well-known technique that improves PCA [43] by making it robust against outliers. In fact, while PCA can be used to effectively purge the input matrix from the additive white Gaussian noise, it fails in detecting outliers. In the case of MTD, according to the previously introduced model, the input matrix , which is representative of the input video, can be seen as the sum of a background matrix, represented by , and an outlier matrix , which represents the target. The idea behind using RPCA is that is low rank, while is sparse. Mathematically, the problem can be reformulated as that of finding and that satisfy Equation (2):
where denotes the l0-pseudo-norm, which counts the total number of non-zero elements in the matrix , while is a regularization parameter. Since both and are non-convex, the problem is not tractable as it is. For this reason, a convex relaxation makes it possible to find the optimal and with high probability. Such relaxation is given in Equation (3):
which is further relaxed in:
where is the nuclear norm of , which is a convex envelope of the function ; is the l1-norm of , which is a convex approximation of the l0-pseudo norm which promotes sparsity; as well, is another regularization parameter which, along with , controls the balance of the three terms. The convex problem in Equation (3) is known as principal component pursuit (PCP); it converges to the problem in Equation (2) and can be solved using an augmented Lagrange multiplier (ALM) algorithm [25,44]. The implementation is exposed in Algorithm 1.
| Algorithm 1: RPCA by ALM | |
| 1 | Input:
|
| 2 | Initialize: , |
| 3 | while not converged do |
| 4 |
|
| 5 |
|
| 6 |
|
| 7 | return:
|
In Algorithm 1:
- denotes the shrinkage operator applied on the matrix , which is the proximal operator for the l1-norm minimization problem [45];
- > denotes the singular value thresholding operator applied on the matrix , whose singular value decomposition (SVD) is , which is the proximal operator for the nuclear-norm minimization problem [45].
RPCA is usually implemented in a batch form. In this implementation, the video is divided into batches of fixed length of frames and RPCA is applied on each batch. The length of the batches has to be chosen taking into consideration the minimum speed of the target we are interested in as well as the stationarity of the background. This method is affected by non-causality, and therefore, it does not meet the real-time requirements. In fact, we would need to wait for the collection of the entire batch before obtaining background and target estimates. A possible solution is to apply a sliding window to the input video, resulting in a moving window RPCA (MW-RPCA) [40] which, for each new collected frame, calculates the batch RPCA on the last frames to provide the background/foreground separation of the last frame. This implementation in the analysis of the video sequences usually has quite a large computational burden.
2.3. Online Moving Window RPCA
In the literature, there are a few proposals of online RPCA implementations [38,39,40]. For this study, we referred to online moving window RPCA (OMW-RPCA) proposed by Xiao et al. [40], which is an improvement of online robust PCA via stochastic optimization (RPCA-STOC) proposed by Feng et al. [39]. We, hereinafter, summarize the ideas behind OMW-RPCA, which, by relaxing (3), solves the following problem:
where and are regularization parameters. It is worth noting that, even though by dividing the three terms in (5) by we could reconduct to a form that is more similar to the one in Equation (4), which is relative to batch implementation, online implementation requires a different proportion of the regularization parameters. For this reason and in order to comply with the notation used in the reference paper, we decided to keep the notations distinguished. Therefore, hereinafter, and will refer to batch RPCA, while and will refer to online implementation.
According to [39], the nuclear norm of respects the relation in Equation (6), which means that, given two matrices and such that with , the nuclear norm of is always lower than .
This means that solving the minimization problem in Equation (7) by plugging (6) into (5) also solves the minimization problem in Equation (5).
The above-depicted nuclear norm factorization is a well-established solution for online optimization problems [39,40,46,47] and is particularly elegant since can be seen as the basis for the low-rank subspace, in which case, would represent the coefficients of observations with respect to the basis . Given the input matrix , solving Equation (7) minimizes the following so called “empirical cost function”:
where is the empirical loss function for each frame, which is defined as:
The vectors and and the matrix are updated in two steps.
First, Equation (9) is solved in , to find and ; then, is updated by minimizing the following function:
whose minimum can be found in closed form:
which means that can be updated by block-coordinate descent with warm restart.
The advantage of online implementation with respect to the MW-RPCA lies in the fact that, for each new frame, only Equation (9) must be minimized with respect to two vectors, which requires remarkably less time than the minimization of Equation (4) with respect to two matrices. In addition, the update of is in closed form and does not have to be accomplished in an iterative way, therefore, adding very small computational load.
The implementation of OMW-RPCA, unfortunately, needs an initialization which provides both the estimated rank of the matrix and the initial basis . Such initialization, which is called the “burn-in” phase, is accomplished by applying batch RPCA on the first frames of the sequence, where is a user-specified window size that must be higher than the expected rank of the matrix . Although we suggest reading [40] for more details, we report in Algorithm 2 the steps of OMW-RPCA.
| Algorithm 2: Online Moving Window RPCA | |
| 1 | Input:
|
| 2 | Initialize:
|
| 3 | for to do |
| 4 | |
| 5 | for to do |
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 | return: |
Although OMW-RPCA solves the causality problem, the result is highly affected by the burn-in phase. In fact, in the burn-in sequence, if, on the one hand, no target is present, the successive iterations effectively isolate the target. On the other hand, if any target is present in the burn-in sequence, the successive iterations keep on considering the initial presence of the target as a part of the background. The result is that the estimated foreground and background contain a ghost of the target in the position it occupied during the burn-in phase. This problem is a sensitive issue since, in an operative context, we do not have any control of the scene during the initialization of the surveillance system. Figure 3 shows the effect of the burn-in ghosting in a sequence in which the target was present at the beginning of the recording. The upper row shows one of the first frames of the video sequence, which is included in the burn-in sequence, while the lower row shows a later frame, which is outside of the burn-in sequence. Alongside both frames, the corresponding background and foreground estimations are represented. It is worth noting that the presence of the target in the burn-in sequence affects the estimations and, even though the target is moving at a constant speed, the ghost remains in the position assumed by the boat in the burn-in sequence and does not move towards the successive positions.
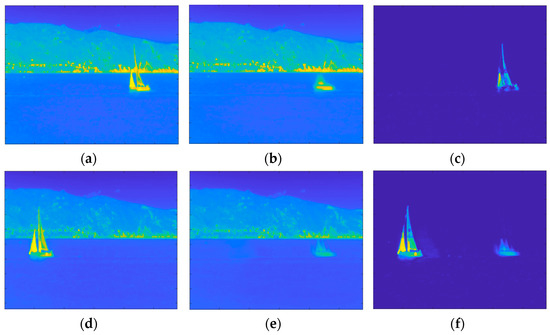
Figure 3.
Results of OMW-RPCA applied on one scene of INFORE dataset with a burn-in of 50 frames: (a) Frame 25 of the sequence; (b) background and (c) foreground estimated through the burn-in phase; (d) Frame 349 of the sequence; (e) background and (f) foreground estimated during the online iterations. The frames are shown in false colors according to the MATLAB “parula” colormap in which the lowest values are represented in blue, and the highest values are represented in yellow.
A trivial idea to solve the burn-in ghosting problem is to increase the value of the regularization parameter , which increases the weight of in the loss function in Equation (5). In fact, by increasing , we would increase the threshold of the proximal operator associated with the l1-norm, which is, indeed, the shrinkage operator. By doing this, we would cut the lower intensity pixels out of the foreground. Such pixels would hopefully belong to the ghost rather than to the actual target. In this way, the background estimation would also be modified, because of the condition , therefore, effectively deleting the ghost.
Increasing is, unfortunately, an unpleasant solution for the following reasons:
- The parameter would become much more dependent on the specific input matrix , while, in the practice, it is usually set as ;
- Along with the ghost pixels, a higher would also cause erosion of target associated pixels, affecting the detection probability as well.
In order to overcome those problems, we used a saliency-based approach, described in Section 2.4, which consisted of using a saliency map to modulate the regularization parameter associated with .
2.4. Saliency-Aided RPCA
The saliency-based approach in RPCA is not new in the literature [41,48,49]. Our approach was inspired by the approach proposed by Oreifej et al. in [41], which modified the minimization problem in Equation (3) as follows:
which is then relaxed to the form:
where is a matrix whose i-th column is the saliency map of the i-th frame, scaled in the range between 0 and 1 and organized in lexicographic order. The operator indicates the element-wise multiplication, while the operator denotes any function that:
- inverts the polarity of each element of , in the sense that a low value should address high objectness confidence, and vice versa;
- scales the resulting matrix in a wider modulation range (e.g., between 0 and 20).
We use , where and are tuning parameters controlling the slope of the negative exponential and the dynamic of the resulting matrix, respectively. For each new frame, the saliency map is calculated through one of the many saliency filters presented in the literature. In this work, we refer to the SR and the FG algorithms because of their very small execution time. In particular, SR takes advantage of the property of the natural images known as 1/f law, which states that the amplitude of the averaged Fourier spectrum of the ensemble of natural images obeys a distribution of the type .
FG is an implementation of the well-known visual attention model, which emulates the behavior of the retina of the human eye, to highlight the spots within the image that are characterized by the highest center–surround contrast. After calculating the saliency maps, the problem in Equation (13) can be solved, again, using ALM. Referring to [41] for the details, the steps of the saliency-aided RPCA are reported in Algorithm 3.
| Algorithm 3: Saliency aided RPCA | |
| 1 | Input:
|
| 2 | Initialize: (empty matrix of size ) |
| 3 | for to do |
| 4 | Reshape in the frame form to get the matrix of size |
| 5 | Compute the saliency algorithm on the frame to get |
| 6 | Put in lexicographic order to get and update |
| 7 | while not converged do |
| 8 |
|
| 9 |
|
| 10 |
|
| 11 | return: |
3. Proposed Method: Saliency-Aided OMW-RPCA
By using a saliency-based approach, it is possible to modulate the regularization parameter controlling by considering the spatial features, which are not considered by RPCA. It is worth noting that, in practice, influences the threshold of the shrinkage operator in an inverse manner. In particular, is increased in those zones of the frame in which the confidence of finding an object is low, while it is maintained or even decreased where saliency maps suggest the presence of foreground. Considering the solutions in Section 2.3 and Section 2.4, the problem can be formulated as:
which is then relaxed to the form:
Plugging (6) into (15), we obtain:
Given the input matrix , solving Equation (16) minimizes the following “saliency-enhanced empirical cost function”:
where is the saliency-enhanced empirical loss function for each sample, defined as:
The vectors and and the matrix are updated in two steps:
- First, Equation (9) is solved in , to find and ;
- Then, is updated by block-coordinate descent with warm restart.
Note that, also in this case, it is necessary to initialize the iteration with a burn-in phase. We called the described algorithm “saliency-aided online moving window RPCA” or S-OMW-RPCA. The steps of S-OMW-RPCA are detailed in Algorithm 4.
| Algorithm 4: Saliency aided OMW-RPCA | |
| 1 | Input:
|
| 2 | Initialize:
|
| 3 | for to do |
| 4 | , |
| 5 | for to do |
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 |
|
| 11 |
|
| 13 |
|
| 14 | return: |
4. Results
4.1. Dataset and Qualitative Evaluation
In order to evaluate the performance of the proposed method, we used a valuable dataset containing video sequences depicting various scenarios of operational interest. In particular, the video sequences were collected by the NATO STO-CMRE during the execution of the INFORE project campaign led in the Gulf of La Spezia (Italy) during February 2022. Such a dataset includes 147 video sequences for a total of 54,363 frames. The characteristics of the sensor used to collect the sequences are shown in Table 1.

Table 1.
Hardware specifications of the IR camera.
The images collected by a static camera are characterized by heterogeneous backgrounds, mainly sea, and structured. The dataset also depicts different types of targets, including boats, ships, sailing ships, kayaks, and drones, covering a wide range of size (compared with the field-of-view of the camera) and speed. For the performance evaluation, a subset of six from the most valuable sequences, for a total number of 4706 frames were manually labeled. The labels, constituting ground truth (GT), are rectangular bounding boxes surrounding the target. The algorithms aim to provide estimated ROIs in the form of rectangular bounding boxes as close as possible to the GT ROIs. Figure 4 shows one frame of each labeled sequences, along with the relative GT ROIs.
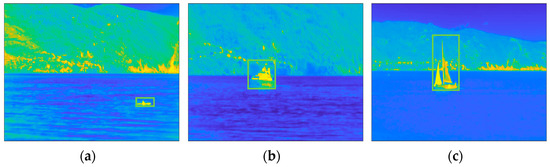
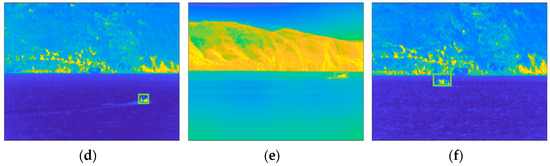
Figure 4.
Selection of six scenes of the INFORE dataset with the relative GT ROI (green rectangles): (a) Kayak; (b) speed boat; (c) sailing ship; (d) inflatable boat; (e) speed boat 2; (f) fishing boat. The frames are shown in false colors according to the MATLAB “parula” colormap in which the lowest values are represented in blue, and the highest values are represented in yellow.
For the sake of a qualitative comparison, Figure 5 shows the background and the foreground estimation resulting from OMW-RPCA applied on the first three video sequences shown in Figure 4, as well as from the proposed techniques implemented both with SR and FG saliency filters.
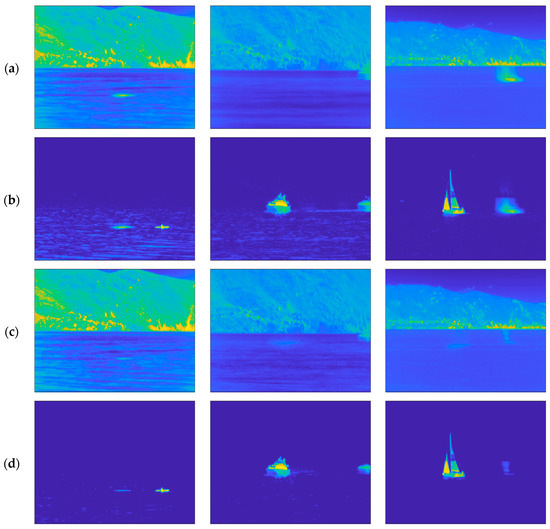
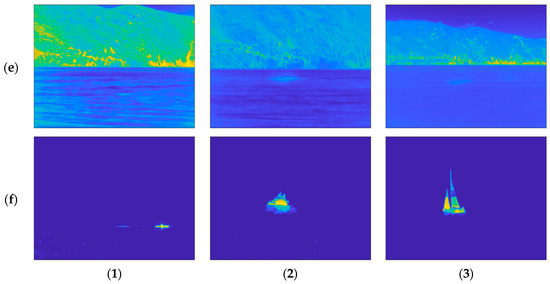
Figure 5.
Visual comparison on background subtraction results over three scenes of the INFORE dataset. From left to right: (1) Kayak; (2) speed boat; (3) sailing boat. From top to bottom: (a) background and (b) foreground estimation via OMW-RPCA; (c) background and (d) foreground estimation via S-OMW-RPCA with FG; (e) background and (f) foreground estimation via S-OMW-RPCA with SR. The frames are shown in false colors according to the MATLAB “parula” colormap in which the lowest values are represented in blue, and the highest values are represented in yellow.
Note that the size of the targets, along with their speed, as well as the warmth of the background and, in particular, the condition of the sea in all the sequences are different, which permits a more confident validation of the results. Referring to the sequences shown in Figure 5:
- The kayak is a very small target which covers 0.17% of the whole picture. The speed is such that the average permanence of the target on a single pixel is about 2 s. The background is quite hot and the waves on the sea are particularly evident.
- The speed boat is medium size and covers 0.72% of the picture. The average permanence is about 10 s. The background is colder, and the waves are less evident but still present.
- The sailing ship is an extended target which covers 2.21% of the picture. The average permanence is about 3 s. The background presents some hot spots near the horizon, while the sea is calm.
The permanence of the target on a single pixel is a very important parameter in the MTD, since targets with very long permanence may appear as still objects belonging to the background. To achieve the best performance, the MTD algorithm should be tuned on the exact speed of the object to be detected. Of course, this is not always possible since, in most cases, no a priori information about the target is available. For this reason, we want our algorithm to be effective in as many situations as possible. To match that requirement, we did not tune the algorithms on the specific video sequences. It is immediately evident that the proposed algorithm outperforms OMW-RPCA in estimating the background. In fact, the waves that affect the foreground estimation of OMW-RPCA in Figure 5b are almost completely absent in the estimation provided by the proposed technique in Figure 5d,f. Furthermore, the ghost caused by the presence of the target in the burn-in phase is greatly reduced. In particular, S-OMW-RPCA with FG has a slightly worse performance because the relative saliency map highlights the horizon regions as well, therefore, deceiving the detector in those regions.
For the sake of completeness, the values of the parameters used for the tests are listed in Table 2.
Table 2.
Values of the parameters used for the test.
The choice of the values of was driven by the operative consideration of having the first result after a couple of seconds after turning on the system, which, considering the frame rate of the used camera, whose characteristics are listed in Table 1, corresponds to exactly 50 frames. The choice of and was driven by the following considerations:
- After some experiments, we noted that the ghosts of the target were effectively deleted by increasing by a factor higher than 10;
- The original dynamic of the saliency map is in the range and we can assume that the lowest values (i.e., ) address the background, the middle values (i.e., ) indicate an uncertainty area, while the highest values (i.e., ) address the targets.
We, therefore, need to find a couple such that the values of the rescaled dynamic which correspond to the first third are much higher than the unity, the values that correspond to the second third are roughly unitary, while the values corresponding to the last third should tend to zero. With and , we obtain the scaling function graphed in Figure 6, which matches the above-reported considerations. To clarify, in order to adhere to our self-imposed requirement of not fine-tuning the algorithms, we did not engage in any empirical parameter optimization process. Instead, our approach solely relied on the aforementioned considerations.
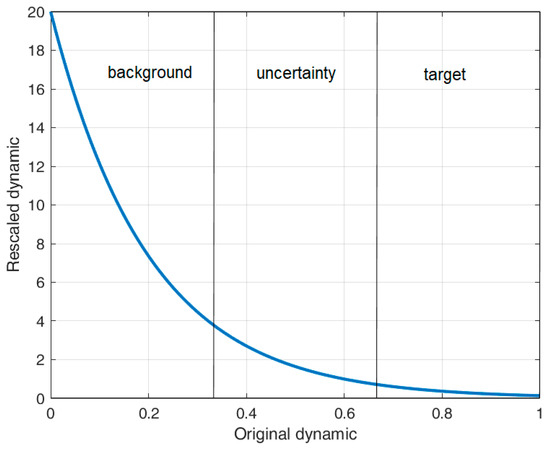
Figure 6.
Graph of the scaling function with and .
4.2. Precision-Recall Curves
For the quantitative evaluation, we refer to the precision and recall scores, which are defined in Equation (19).
where indicates the number of true positives (i.e., detected targets), indicates the number of false positives (i.e., false alarms), and indicates the number of false negatives (i.e., undetected targets).
In order to define the , , and scores, let us consider Figure 7. The is easily represented by the area of the intersection between the GT ROI (green rectangle) and the estimated ROIs (red rectangles). The is represented by the area of the estimated ROIs minus the . Therefore, the precision denominator corresponds to the whole area of the estimated ROIs. The is represented by the area of the GT ROI minus the . Therefore, the recall denominator corresponds to the whole area of the GT ROI.

Figure 7.
Example of ground truth ROI (green) vs. estimated ROI (red). The frames are shown in false colors according to the MATLAB “parula” colormap in which the lowest values are represented in blue, and the highest values are represented in yellow.
Precision and recall are broadly used performance indices, which are mostly provided as a pair of values in correspondence of a preventively chosen threshold [48,49]. Such a practice is adequate when the choice of the threshold is included in the evaluation, which is not the case. For this reason, we prefer to present the results in the form of curves obtained by varying the thresholds in a range covering all the conditions from 0% to 100% of the pixels denoted as positives. This approach (which is inspired by the receiver operating characteristics, broadly used in statistical decision theory), has already been utilized in [15] and has the advantage of decorrelating the results from the choice of the threshold, which can be, therefore, demanded to any suitable decision criteria. In addition to the comparison between the proposed technique with OMW-RPCA, we also provide the results of the moving object detector based on the improved adaptive Gaussian mixture model (GMM) [18] as a benchmark. The results for the six labeled sequences are reported in Figure 8, while Figure 9 depicts the average curves.
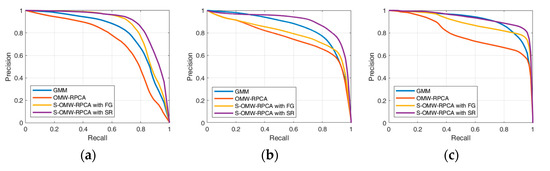
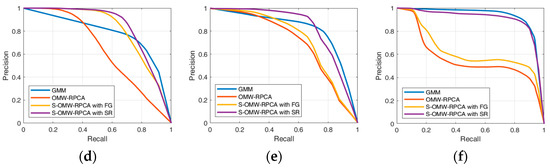
Figure 8.
Precision/recall curves over six scenes of INFORE dataset: (a) Kayak; (b) speed boat; (c) sailing ship; (d) inflatable boat; (e) speed boat 2; (f) fishing boat.
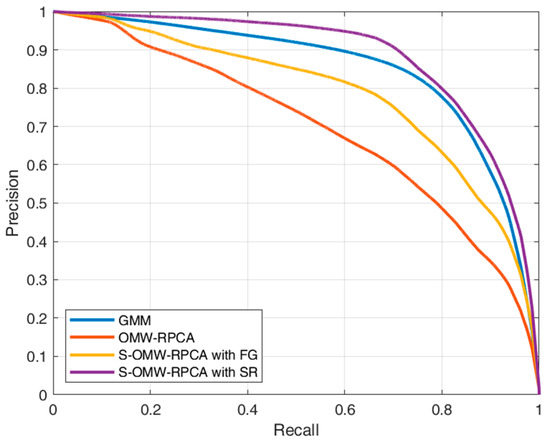
Figure 9.
Precision/recall average curves calculated over six sequences of INFORE dataset.
The aim of the algorithms in terms of precision and recall is to reach the highest possible precision, given an acceptable level of recall (e.g., 0.8), which means that the curve must tend to the top-right corner of the graph. From the curves in Figure 8, it emerges that the proposed S-OMW-RPCA always outperforms the simple OMW-RPCA and, in particular, S-OMW-RPCA with SR always outperforms S-OMW-RPCA with FG. Furthermore, as compared with the MTD based on GMM, S-OMW-RPCA with SR also performs remarkably well in the first three sequences, in the fourth and fifth sequences it loses precision in correspondence of high recalls, while in the sixth sequence it provides quite similar results. Figure 9 shows the average curves, and the results confirm that S-OMW-RPCA outperforms OMW-RPCA and, on average, performs slightly better than GMM.
Finally, for a more synthetic comparison, in Table 3, we show the precision obtained by each algorithm in each sequence by setting the recall to a value of 0.8, which, when working with ROIs, is usually considered to be an acceptable result. The bold scores represent the best precision performance for each sequence on average, while the red scores represent the best performance among the RPCA-based techniques.
Table 3.
Precision score, measured at a recall of 0.8 for each tested algorithm (rows), over six sequences of INFORE dataset (columns), singularly and on average. The best score for each column is highlighted by using bold numbers, while the best score over the RPCA techniques is shown in red.
The results in Table 3, confirm that, for an acceptable value of recall, S-OMW-RPCA, especially the version with SR, yields much higher precision than the simple OMW-RPCA. Furthermore, compared to the widely used GMM approach, the performance of the proposed algorithm depends on the specific sequence; nonetheless, on average, it manifests the highest precision.
4.3. Execution Time
Regarding the execution time, as previously mentioned, the SR and FG saliency algorithms were chosen not only for their quality but also for their speed. In fact, for a 22k pixel frame, such as those of the used sequences, the average execution time of the SR and FG is 4.86 × 10−7 and 1.65 × 10−5 s per frame, respectively. Such values are several orders of magnitude lower than the execution time of OMW-RPCA, which, in the online phase is in the order of 10−2 s per frame. This fact may mislead one to think that the execution time of OMW-RPCA and the execution time of the proposed S-OMW-RPCA should be approximately equal. On the contrary, the different weights given by the saliency maps lead to a significant variation in the time required for the convergence of the ALM used to solve the burn-in phase, and for the minimization of Equation (18) for the solution of the online phase. The experiments were conducted using the MATLAB environment with a computer whose specifications are indicated in Table 4. The results are shown in Table 5. The bold scores represent the minimum execution time achieved by the competing algorithms for each sequence and in each phase. We would like to clarify that the algorithms used in this study were not optimized. Therefore, it is important to interpret the results solely for the purpose of comparison.
Table 4.
Hardware specifications of the computer.
Table 5.
Comparison between the execution time of OMW-RPCA and the proposed S-OMW-RPCA with SR and FG, both during the burn-in and the online phases. The values are expressed in seconds per frame. The best scores are highlighted by bold numbers.
Counterintuitively, the results show that, while the speed of the ALM used to solve the burn-in phase is always increased by the use of saliency maps, the minimization of Equation (18) for the solution of the online phase is slowed down. It is worth noting that, even though the execution time of the online phase is slightly higher than the frame collection period, which is the inverse of the frame rate, an optimization of the algorithms in a leaner programming environment would easily permit real-time implementation. We are currently working on methods to distribute the computational tasks so that the execution time is minimized.
5. Conclusions
In this paper, we investigated the problem of online moving target detection in marine scenarios with infrared sequences captured using steady cameras. We particularly focused on RPCA, which is a data-driven technique with many fields of application, broadly used, especially in its batch implementation, for object detection. We started by analyzing the online implementation and, after considering their limitations, we proposed an improvement based on the use of a saliency map to modulate the regularization parameters of RPCA. For the saliency maps, we used the FG and SR algorithms, which are very fast saliency filters that did not significantly increase the computational load of the whole technique. Finally, we compared the performance of the proposed technique with that of the online implementation, as well as with another broadly used technique based on GMM, which serves as a benchmark for the state-of-the-art MTD techniques. The algorithms were tested through a valuable dataset of video sequences collected by NATO STO-CMRE during the INFORE Project, during February 2022, in the Gulf of La Spezia. The comparisons were conducted both qualitatively and quantitatively, the latter through the widely used metrics of precision and recall. The results showed that the proposed saliency-aided technique greatly improved online RPCA especially when the SR filter was used for saliency map extraction. Furthermore, the proposed technique also performed better than GMM, on average. The execution time was also evaluated. Specifically, S-OMW-RPCA was faster than OMW-RPCA in the burn-in phase, while it was slower in the online phase. Finally, we specified that the algorithms were not optimized with respect to their computational load, but it is our belief that a careful optimization on a leaner programming language would make the proposed algorithm suitable for real-time surveillance purposes.
Author Contributions
Conceptualization, O.P., N.A. and R.G.; Data curation, R.G.; Formal analysis, O.P.; Funding acquisition, G.F., R.G. and D.Z.; Investigation, O.P.; Methodology, O.P., N.A. and R.G.; Project administration, N.A. and R.G.; Resources, G.F., R.G. and D.Z.; Software, O.P.; Supervision, N.A., M.D. and R.G.; Validation, O.P.; Visualization, O.P., N.A. and R.G.; Writing—original draft, O.P.; Writing—review and editing, O.P., N.A., M.D. and R.G. All authors have read and agreed to the published version of the manuscript.
Funding
The work described in this paper has been supported by the INFORE EU H2020 project, grant agreement No 825070, and by the NATO Allied Command Transformation under the Autonomous Anti-Submarine Warfare and the Data Knowledge Operational Effectiveness research programmes.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data set used in this work is owned by NATO and legal restrictions apply to its redistribution. The data set can be released to NATO Nations in accordance to the NATO data exploitation framework policy. A public sample of the data set is available as “INFORE22 sea trial open data set” at the URL https://zenodo.org/record/6372728 (accessed on 6 July 2023). under terms and conditions specified in the “Conditions for use and distributions” paragraph.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video Processing from Electro-Optical Sensors for Object Detection and Tracking in a Maritime Environment: A Survey. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1993–2016. [Google Scholar] [CrossRef]
- Chapel, M.-N.; Bouwmans, T. Moving Objects Detection with a Moving Camera: A Comprehensive Review. Comput. Sci. Rev. 2020, 38, 100310. [Google Scholar] [CrossRef]
- Acito, N.; Corsini, G.; Diani, M.; Pennucci, G. Comparative Analysis of Clutter Removal Techniques over Experimental IR Images. Opt. Eng. 2005, 44, 106401. [Google Scholar] [CrossRef]
- Cheng, M.-M.; Mitra, N.J.; Huang, X.; Torr, P.H.S.; Hu, S.-M. Global Contrast Based Salient Region Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef]
- Pulpito, O.; Acito, N.; Diani, M.; Ceglie, S.U.D.; Corsini, G. Infrared Saliency Enhancement Techniques for Extended Naval Target Detection in Open Sea Scenario. In Proceedings of the Electro-Optical Remote Sensing XVI, Berlin, Germany, 5–8 September 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12272, pp. 18–27. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A Model of Saliency-Based Visual Attention for Rapid Scene Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Montabone, S.; Soto, A. Human Detection Using a Mobile Platform and Novel Features Derived from a Visual Saliency Mechanism. Image Vis. Comput. 2010, 28, 391–402. [Google Scholar] [CrossRef]
- Hou, X.; Zhang, L. Saliency Detection: A Spectral Residual Approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Hu, W.-C.; Yang, C.-Y.; Huang, D.-Y. Robust Real-Time Ship Detection and Tracking for Visual Surveillance of Cage Aquaculture. J. Vis. Commun. Image Represent. 2011, 22, 543–556. [Google Scholar] [CrossRef]
- Smith, A.A.; Teal, M.K. Identification and Tracking of Maritime Objects in Near-Infrared Image Sequences for Collision Avoidance. In Proceedings of the 7th International Conference on Image Processing and Its Applications, Manchester, UK, 13–15 July 1999; pp. 250–254. [Google Scholar] [CrossRef]
- Sang, N.; Zhang, T. Segmentation of FLIR Images by Target Enhancement and Image Model. In Proceedings of the International Symposium on Multispectral Image Processing (ISMIP’98), Wuhan, China, 21–23 October 1998; SPIE: Bellingham, WA, USA, 1998; Volume 3545, pp. 274–277. [Google Scholar]
- Barnett, J. Statistical Analysis of Median Subtraction Filtering with Application To Point Target Detection In Infrared Backgrounds. In Proceedings of the Infrared Systems and Components III, Los Angeles, CA, USA, 16–17 January 1989; SPIE: Bellingham, WA, USA, 1989; Volume 1050, pp. 10–18. [Google Scholar]
- Voles, P.; Teal, M.; Sanderson, J. Target Identification in a Complex Maritime Scene. In Proceedings of the IEE Colloquium on Motion Analysis and Tracking (Ref. No. 1999/103), London, UK, 10 May 1999; p. 15. [Google Scholar] [CrossRef]
- Pulpito, O.; Acito, N.; Diani, M.; Corsini, G.; Grasso, R.; Ferri, G.; Grati, A.; Le Page, K.; Bereta, K.; Zissis, D. Real-Time Moving Target Detection in Infrared Maritime Scenarios. In Proceedings of the 2022 IEEE International Workshop on Metrology for the Sea; Learning to Measure Sea Health Parameters (MetroSea), Milazzo, Italy, 3–5 October 2022; pp. 456–461. [Google Scholar]
- Wren, C.R.; Azarbayejani, A.; Darrell, T.; Pentland, A.P. Pfinder: Real-Time Tracking of the Human Body. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 780–785. [Google Scholar] [CrossRef]
- Gupta, K.M.; Aha, D.W.; Hartley, R.; Moore, P.G. Adaptive Maritime Video Surveillance. SPIE Proc. 2009, 7346, 81–92. [Google Scholar]
- Zivkovic, Z. Improved Adaptive Gaussian Mixture Model for Background Subtraction. In Proceedings of the 17th International Conference on Pattern Recognition, 2004 (ICPR 2004), Cambridge, UK, 26 August 2004; Volume 2, pp. 28–31. [Google Scholar]
- Chen, Z.; Wang, X.; Sun, Z.; Wang, Z. Motion Saliency Detection Using a Temporal Fourier Transform. Opt. Laser Technol. 2016, 80, 1–15. [Google Scholar] [CrossRef]
- Strickland, R.N.; Hahn, H.I. Wavelet Transform Methods for Object Detection and Recovery. IEEE Trans. Image Process. 1997, 6, 724–735. [Google Scholar] [CrossRef] [PubMed]
- Infrared Image Segmentation by Combining Fractal Geometry with Wavelet Transformation. Available online: https://www.sensorsportal.com/HTML/DIGEST/P_2529.htm (accessed on 30 January 2023).
- Seki, M.; Wada, T.; Fujiwara, H.; Sumi, K. Background Subtraction Based on Cooccurrence of Image Variations. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; Volume 2, p. II. [Google Scholar]
- Power, P.; Schoonees, J. Understanding Background Mixture Models for Foreground Segmentation. In Proceedings of the Image and Vision Computing New Zealand 2002, Auckland, New Zealand, 26–28 November 2002. [Google Scholar]
- Oliver, N.M.; Rosario, B.; Pentland, A.P. A Bayesian Computer Vision System for Modeling Human Interactions. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 831–843. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust Principal Component Analysis? J. ACM 2011, 58, 1–37. [Google Scholar] [CrossRef]
- De la Torre, F.; Black, M.J. Robust Principal Component Analysis for Computer Vision. In Proceedings of the 8th IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Volume 1, pp. 362–369. [Google Scholar]
- Cao, X.; Yang, L.; Guo, X. Total Variation Regularized RPCA for Irregularly Moving Object Detection Under Dynamic Background. IEEE Trans. Cybern. 2016, 46, 1014–1027. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Zhao, Q.; Zhang, S.; Meng, D. A Tensor-Based Online RPCA Model for Compressive Background Subtraction. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15, early access. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, D.; Chen, M. Adaptive Cointegration Analysis and Modified RPCA With Continual Learning Ability for Monitoring Multimode Nonstationary Processes. IEEE Trans. Cybern. 2022, 1–14, early access. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Yang, Z.; Li, J. Novel RPCA with Nonconvex Logarithm and Truncated Fraction Norms for Moving Object Detection. Digit. Signal Process. 2023, 133, 103892. [Google Scholar] [CrossRef]
- Ablavsky, V. Background Models for Tracking Objects in Water. In Proceedings of the 2003 International Conference on Image Processing (Cat. No.03CH37429), Barcelona, Spain, 14–17 September 2003; Volume 3, p. III-125. [Google Scholar]
- Schofield, A.J.; Mehta, P.A.; Stonham, T.J. A System for Counting People in Video Images Using Neural Networks to Identify the Background Scene. Pattern Recognit. 1996, 29, 1421–1428. [Google Scholar] [CrossRef]
- Lim, L.A.; Yalim Keles, H. Foreground Segmentation Using Convolutional Neural Networks for Multiscale Feature Encoding. Pattern Recognit. Lett. 2018, 112, 256–262. [Google Scholar] [CrossRef]
- Maddalena, L.; Petrosino, A. A Self-Organizing Approach to Detection of Moving Patterns for Real-Time Applications. In Proceedings of the Advances in Brain, Vision, and Artificial Intelligence, Naples, Italy, 10–12 October 2007; Mele, F., Ramella, G., Santillo, S., Ventriglia, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 181–190. [Google Scholar]
- Lim, K.; Jang, W.-D.; Kim, C.-S. Background Subtraction Using Encoder-Decoder Structured Convolutional Neural Network. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Sharma, T.; Debaque, B.; Duclos, N.; Chehri, A.; Kinder, B.; Fortier, P. Deep Learning-Based Object Detection and Scene Perception under Bad Weather Conditions. Electronics 2022, 11, 563. [Google Scholar] [CrossRef]
- Yang, J.; Liu, S.; Li, Z.; Li, X.; Sun, J. Real-Time Object Detection for Streaming Perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5385–5395. [Google Scholar]
- He, J.; Balzano, L.; Lui, J.C.S. Online Robust Subspace Tracking from Partial Information. arXiv 2011, arXiv:1109.3827. [Google Scholar]
- Feng, J.; Xu, H.; Yan, S. Online Robust PCA via Stochastic Optimization. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NE, USA, 5–8 December 2013; Curran Associates, Inc.: Red Hook, NY, USA, 2013; Volume 26. [Google Scholar]
- Xiao, W.; Huang, X.; He, F.; Silva, J.; Emrani, S.; Chaudhuri, A. Online Robust Principal Component Analysis with Change Point Detection. IEEE Trans. Multimed. 2020, 22, 59–68. [Google Scholar] [CrossRef]
- Oreifej, O.; Li, X.; Shah, M. Simultaneous Video Stabilization and Moving Object Detection in Turbulence. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 450–462. [Google Scholar] [CrossRef] [PubMed]
- Ferri, G.; Grasso, R.; Faggiani, A.; de Rosa, F.; Camossi, E.; Grati, A.; Stinco, P.; Tesei, A.; Been, R.; LePage, K.D.; et al. A Hybrid Robotic Network for Maritime Situational Awareness: Results from the INFORE22 Sea Trial. In Proceedings of the OCEANS 2022, Hampton Roads, VA, USA, 17–20 October 2022; pp. 1–10. [Google Scholar]
- Pearson, K. LIII. On Lines and Planes of Closest Fit to Systems of Points in Space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Brunton, S.L.; Kutz, J.N. Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Parikh, N.; Boyd, S. Proximal Algorithms. Found. Trends Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Burer, S.; Monteiro, R.D.C. A Nonlinear Programming Algorithm for Solving Semidefinite Programs via Low-Rank Factorization. Math. Program. Ser. B 2003, 95, 329–357. [Google Scholar] [CrossRef]
- Recht, B.; Fazel, M.; Parrilo, P.A. Guaranteed Minimum-Rank Solutions of Linear Matrix Equations via Nuclear Norm Minimization. SIAM Rev. 2010, 52, 471–501. [Google Scholar] [CrossRef]
- Sobral, A.; Bouwmans, T.; ZahZah, E. Double-Constrained RPCA Based on Saliency Maps for Foreground Detection in Automated Maritime Surveillance. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar]
- Li, Y.; Liu, G.; Liu, Q.; Sun, Y.; Chen, S. Moving Object Detection via Segmentation and Saliency Constrained RPCA. Neurocomputing 2019, 323, 352–362. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).