Abstract
The milling machine serves an important role in manufacturing because of its versatility in machining. The cutting tool is a critical component of machining because it is responsible for machining accuracy and surface finishing, impacting industrial productivity. Monitoring the cutting tool’s life is essential to avoid machining downtime caused due to tool wear. To prevent the unplanned downtime of the machine and to utilize the maximum life of the cutting tool, the accurate prediction of the remaining useful life (RUL) cutting tool is essential. Different artificial intelligence (AI) techniques estimate the RUL of cutting tools in milling operations with improved prediction accuracy. The IEEE NUAA Ideahouse dataset has been used in this paper for the RUL estimation of the milling cutter. The accuracy of the prediction is based on the quality of feature engineering performed on the unprocessed data. Feature extraction is a crucial phase in RUL prediction. In this work, the authors considers the time–frequency domain (TFD) features such as short-time Fourier-transform (STFT) and different wavelet transforms (WT) along with deep learning (DL) models such as long short-term memory (LSTM), different variants of LSTN, convolutional neural network (CNN), and hybrid models that are a combination of CCN with LSTM variants for RUL estimation. The TFD feature extraction with LSTM variants and hybrid models performs well for the milling cutting tool RUL estimation.
1. Introduction
Machining is an important process in the manufacturing industry [1]. Machining process monitoring plays a vital role in improving the industry’s productivity by reducing unscheduled downtime caused due to failure of the cutting tool [2]. A proper predictive maintenance strategy must be defined to estimate the cutting tool’s life reduced due to tool wear caused during the machining operation [3]. With the evolving artificial intelligence (AI) techniques and advancements in sensor technology, data-driven prediction models are widely used for tool wear and remaining useful life (RUL) prediction [4]. The RUL of a cutting tool is how long it can accomplish the function effectively before it begins considerably deteriorating to perform its purpose. Multiple factors, including the material being cut, the cutting speed, the tool geometry, and the cutting fluid, can affect the RUL of a cutting tool. This paper mainly focuses on the RUL of cutting tools caused by changes in tool geometry due to tool wear. There are numerous approaches for estimating the RUL of a cutting tool, including physics-based models and machine learning (ML) or deep learning (DL)-based methods. Physics-based models, also known as mechanistic models, are based on fundamental physics principles and laws regulating the system. These models seek to describe the behavior of the system using mathematical equations that represent the physical processes involved. In ML/DL models, typically, these methods include monitoring the cutting tool’s condition and performance during use and utilizing this data to anticipate how long the tool can be used before it must be replaced. In the ML/DL-based method, the data-driven approach is an effective technique for forecasting the RUL of the equipment [5].
To prevent the machine’s unplanned downtime and utilize the cutting tool’s maximum life, the accurate prediction of the RUL cutting tool plays an important role [6,7]. Sayyad et al. discussed the effect of unplanned downtime on the equipment cost and profit of the industries [4]. Accurate RUL prediction has the potential to considerably increase the dependability and operational safety of industrial components or systems, thereby reducing the costs of maintenance and preventing severe breakdowns. Figure 1 illustrates the generalized concept of RUL of the equipment.
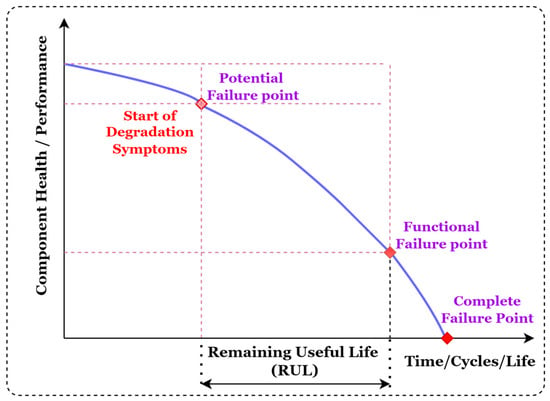
Figure 1.
Concept of remaining useful life (RUL) of the equipment.
The prediction accuracy of the RUL estimation plays an important role as accurate prediction helps to utilize the maximum life of the cutting tool. Many researchers aim to predict the tool wear instead of the RUL of the cutting tool. In the case of tool wear prediction, the frequent measurements of the flank or crater wear values are pretty tricky. In manual tool measurement using a tool maker’s microscope, the cutting tool must frequently remove for sensor data and wear mapping, which disturbs the machining process. In comparison, the RUL prediction provides continuous data mapping with sensor data in terms of time. As compared to tool wear as target output, a few research works on the RUL as a target variable in milling cutting tools. Additionally, consolidated comparative studies of the different time–frequency-based feature extraction techniques with various decision-making algorithms are not much addressed in previous works. So, the significant contribution of the work is as follows:
- To estimate the RUL of the milling cutting tool using the NUAA idea-house dataset [8];
- To use the time–frequency feature extraction techniques such as STFT, CWT, and WPT to get useful insights from data with reduced data dimensions;
- To use the different machine learning and deep learning decision-making algorithms for cutting tool RUL prediction and check the performance of each model using different evaluation parameters.
2. Related Work
This comprehensive literature analysis aims to investigate the present state of research, various approaches used for RUL estimation in the context of cutting tools, and the different feature extraction and selection techniques used to improve the RUL estimation accuracy. As the physics-based and data-driven driven models are widely used for tool wear and RUL predictions [9,10,11], this section discussed the physics-based and data-driven approaches. Different feature extraction techniques, such as time, frequency, and time–frequency domain and various feature selection techniques, are discussed for RUL prediction.
2.1. Physics-Based Model
In physics-based modeling for prediction, fundamental principles and mathematical equations need to be considered to model the system’s behavior. For accurate predictions, a number of factors, such as understanding the system, formulating the equations based on the system’s behavior, assumptions for simplification, estimation of system parameters etc., need to be studied deeply.
In the case of RUL prediction of the cutting tool, the tool geometry, cutting tool, and material materials must be considered. The cutting forces model, degradation mechanism, and wear rate estimation equations are required for estimation; based on this, the health indicators are developed. Model refinement and continuous improvement in the model are required in physics-based modeling to improve prediction accuracy.
Physics-based techniques suffer from a scarcity of accurate analytical models to characterize tool wear processes due to the cutting process’s intrinsic complexity and the machining process’s imperfect understanding [9]. The data-driven modeling approach is preferred in the tool wear and RUL predictions to avoid the modeling uncertainty in the physics-based model [12].
2.2. Data-Driven Model
The data-driven makes use of machine learning and statistical approaches to extract patterns and relationships from accessible data. In a data-driven model, the sensor data is collected from the machine by mounting the sensors at the appropriate position to understand the condition of the cutting tool. The dataset should encompass a wide range of tool life spans and operating conditions to capture the variation in tool deterioration patterns. The raw data need to be pre-processed before performing the feature extraction. The data pre-processing ensures the data’s integrity and suitability for modeling. This step entails dealing with missing values, anomalies, and data normalization or standardization to create a consistent scale for the variables. The extracted features from the pre-processed data are provided to decision-making algorithms to get output as the desired RUL prediction value. Figure 2 shows the generalized data-driven model for RUL prediction.
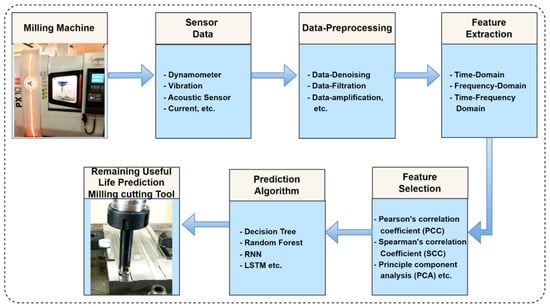
Figure 2.
Generalized data-driven model for RUL prediction.
In a data-driven model, the machining signals are gathered using different sensors such as acoustic, dynamometer, current, vibration, etc., using the indirect sensing technique [13,14]. These collected signals are used for RUL prediction by applying feature extraction, feature selection, and prediction algorithms on data.
Many researchers used the data-driven modeling approach for the tool wear and RUL prediction using single or multi-sensors with different feature extraction approaches [15,16,17]. Feature extraction and selection play an essential role in the accuracy of the prediction models in the data-driven models.
2.3. Feature Extraction and Selection
Proper feature extraction and selection are crucial in the training phase of any machine and deep learning model. Generally, features are extracted in the time domain (TD), frequency domain (FD), and time–frequency domains (TFD) [18]. TD features mainly represent the change in signal amplitude concerning time. Generally, signals are converted from the TD to the FD spectrum in the FD using the fast Fourier-transform (FFT) technique. The FFT is the sine wave function that provides the transient nature of spectral signal in terms of amplitude and frequency distribution [19]. In the frequency domain, FFT does not consider the abrupt change in the signal. The FD provides the time distribution information in the Fourier-transform (FT) phase characteristics. It is not easy to use this time distribution information of signal in the FD in signal processing [20]. The FFT lacks the ability to provide frequency information over the localized signal region in time. Both TD and FD-based feature extraction techniques are more suitable for stationary signals application where the spectral component of the signal does not change with time [21]. However, most real-time-generated signals are non-stationary types with varied spectral components with time [22]. The TFD feature extraction process is preferred for non-stationary signals generated in the machining process [23]. TFD-based feature extraction techniques mainly include STFT, WT, empirical mode decomposition (EMD), Hilbert–Huang transform (HHT), etc. The STFT and WT, TFD feature extraction techniques provide a good result for tool wear and RUL prediction [23,24,25].
Rafezi et al. use vibration and sound signals to monitor the tool condition in CNC lathe drilling operations [26]. The author uses both TD and TFD features for tool condition monitoring and found that the TFD’s wavelet packet decomposition approach correlates better with tool conditions. Hong et al. use a dynamometer for gathering torque and forces generated during the micro-milling machine [24]. The WPT method extracts the features from the raw signals to monitor the tool wear in micro-milling. Xiang et al. used the accelerometer to capture the vibration signals during milling [27]. To extract features from the input vibration data, the WPT is employed. The extracted WPT features are provided to the backpropagation neural network (BPNN) and LSTM to predict the tool wear class. LSTM shows a higher testing accuracy (up to 95.67%) than the BPNN model for estimating the type of tool wear.
From the literature, it was found that the time–frequency domain feature extraction will provide better prediction results for the non-stationary signals generated during the machining. At the same time, deep learning models such as the LSTM show better prediction results in the time-series data analysis. From the previous work, it was found that limited comparative research has been carried out in the RUL prediction using the TFD feature extraction technique with different feature selection and ML and DL decision-making models. In this work, the time–frequency domain techniques are used for feature extraction with PCC and RF feature selection methods. The various predictions ML and DL models, including SVM, RFR, GBR, LSTM, CNN, LSTM variants, and hybrid models such as CNN with LSTM variants, are used to improve the prediction accuracy of the RUL estimation.
3. Time–Frequency Domain Feature Extraction
The non-stationary signals with different time-varying frequency characteristics show poor time-localization in the spectral domain. The TFD analysis is preferred to overcome the TD and FD limitations. Figure 3 shows the signal windowing approach’s comparison of the TD, FD, STFT, and WT [28,29].
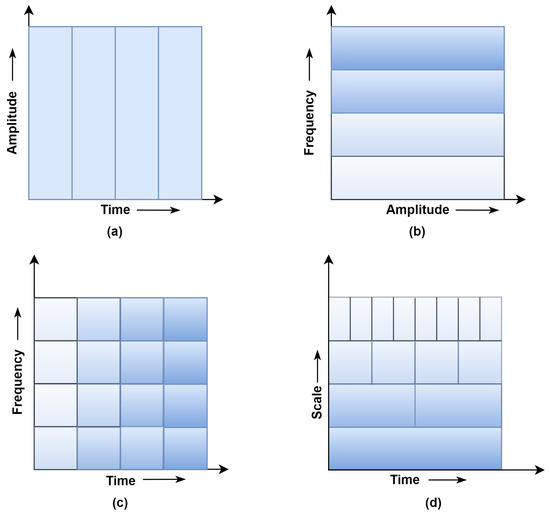
Figure 3.
Comparison of windowing approach (a) Time-domain, (b) Frequency-domain (Fast Fourier Transform) (c) Short Time Fourier Transform (STFT) (d) Wavelet Analysis.
In this study, the author used the STFT and WT methods for feature extraction purposes, as these methods show promising results in RUL prediction during machining.
3.1. Short-Time Fourier-Transform (STFT)
The poor time-localization problem of the spectral domain’s non-stationary signals is overcome by dividing the original signal into multiple short-duration windows in Fourier-transform; this technique is called window Fourier-transform (WFT) or STFT. FFT does not use the windowing function for signal transformation, as shown in Equation (1). In contrast, for calculating the STFT of the signal, the windowing function is used that is mathematically expressed using Equation (2) [30].
where ‘f(t)’ is the signal to be analyzed, ‘w(t − τ)’ is the window function, ‘τ’ is the translation parameter for time localization, ‘ω’ is the frequency component of the signal.
For computing STFT, different equal-length windowing functions, such as Hamming or Gaussian windows, are used. Discrete Fourier-transform (DFT) is performed on each section separately to form the time–frequency (TF) spectral signal. Reducing window size improves the time resolution resulting in more accurate TF resolution with increased computation time. At the same time, a wide window size results in poor time resolution with good frequency resolutions. The windowing function used in STFT does not vary (not scalable and movable) as the window size chosen before STFT operation.
3.2. Wavelet Transforms (WT)
WT is an extension of the FT. WT is the type of TF feature extraction technique. WT uses the family of ‘wavelets’ to decompose the signal. The wavelet is used as a windowing function in WT. Selecting the wavelet family uses different windowing functions such as Symlets, Morlets, Daubechies, Harr, etc. The wavelet functions can be shifted and scaled according to signal requirements. Due to the property of scaling and shifting, WT is adaptable to a wide range of time and frequency resolutions, making it a better alternative to STFT in non-stationary signal analysis. Equation (3) shows the mother wavelet ψ(t) used to calculate the wavelet transform function [23].
ψ(t) = mother wavelet, τ = transformation parameter, z = scaling factor, t = time stamp of generated signal. In the original mother wavelet value of z = 1 and τ = 0. This WT is mainly divided into CWT, DWT, and WPT [31].
3.2.1. Continuous Wavelet Transform (CWT)
CWT is an effective signal transformation technique in stationary and non-stationary signal analysis. The mathematical representation of the CWT of the signal is expressed by Equation (4)
where ‘’ is the signal for wavelet transform, ‘’ is the complex conjugate of mother wavelet Ψ(t), z is the scaling parameter used for zooming the wavelet, τ is the translation parameter used to define the location of the window. The integral compares the shape of the generated wavelet with the original signal. The equation generates the wavelet coefficient, which shows the correlation between the waveform and generated wavelet used at various scaling and shifting values [32]. However, its computation time is slow and generates redundant signals during its transformation.
3.2.2. Wavelet Packet Transform (WPT)
WPT is an enhancement in DWT. In which both the detailed and approximate coefficient obtained in the DWT is further decomposed at every stage [33].
Figure 4 shows the WPT with three levels of decomposition. Here, LP and HP are the low-pass and high-pass filters of the signals. The LP and HP are again divided into approximate and detailed coefficients. WPT uses Equation (3) to decompose the signal to calculate the wavelet transform function. WPT uses the two-scale difference to construct scaling and wavelet functions from a single scaling function. The coefficients related to the scaling function, also known as approximation coefficients, are linked with low-frequency data.
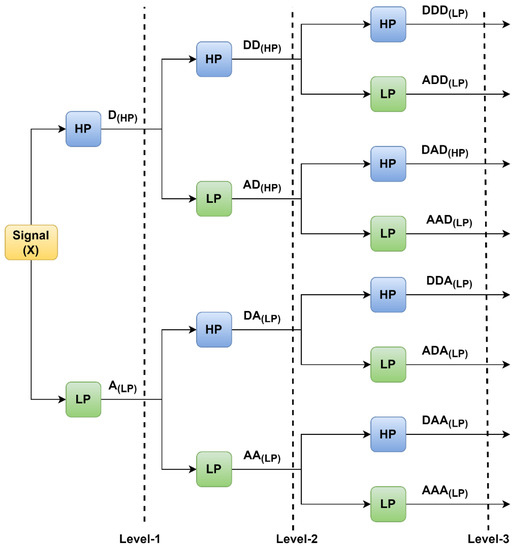
Figure 4.
WPT with three levels of decomposition.
In contrast, wavelet function coefficients are correlated with information with high frequency or detail coefficients. Figure 4 shows that 1st level of the decomposition signal is decomposed into D(HP) and A(LP). Similarly, in the second level of decomposition, the approximate signal is decomposed into (AA(LP) and DA(LP)), and the detailed coefficient decomposes into DD(HP) and AD(HP).
4. Proposed Methodology
The overall methodology section is divided into four sub-sections. As the online dataset is used in this work, Section 4.1 discusses the dataset description, Section 4.2 discusses the feature extraction and selection, and Section 4.3 discusses the models used for RUL prediction. Finally, evaluation parameters are discussed that are used for the model comparison. The detailed methodology for RUL prediction is shown in Figure 5.
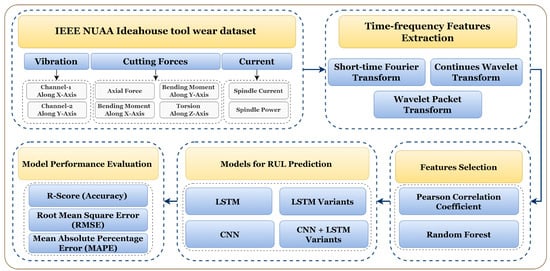
Figure 5.
Methodology for tool RUL prediction using different TFD feature extraction methods and LSTM variants.
4.1. Dataset Description
The IEEE NUAA Ideahouse [8] dataset is used to predict the RUL of the cutting tool. In this dataset, the vibration sensor (PCBTM-W356B11), sensory tool holder (SpikeTM sensory tool holder), and PLC are used to collect the vibration, cutting forces, and current/power from the milling machine (DMU™ 80P douBlock) during the machining of titanium alloy (TC4) with solid carbide and high-speed steel endmill cutters (12 mm diameter and 75 mm length). Figure 6 shows the schematic representation test rig of the NUAA Ideahouse dataset. The sensory tool holder is connected to the milling machine’s spindle to collect the cutting forces. The vibration sensor is mounted near the workpiece to be machined to collect the vibration signals.
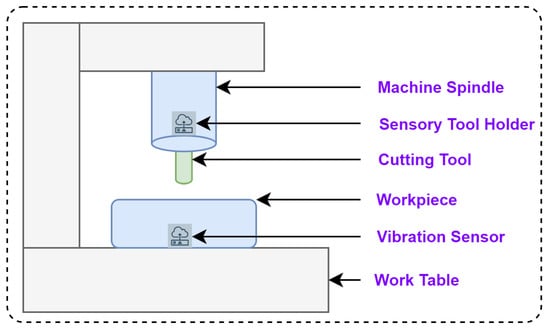
Figure 6.
The schematic diagram of the test rig setup for the NUAA Ideahouse dataset.
Figure 7 shows the signal acquisition system for the NUAA Ideahouse milling dataset. Table 1 shows sampling frequencies for each acquisition equipment. The sampling rates were chosen based on the cutting and spindle speeds. The vibration, cutting forces, and spindle current/power are collected with the sampling rate of 400 Hz, 600 Hz, and 300 Hz, respectively. During the collection process, the low-frequency signals gathered by the software were autonomously interpolated, so the volume of data stored for each signal type is the same. Data synchronization software synchronizes the sampling frequencies at 300 hertz for all the signals.
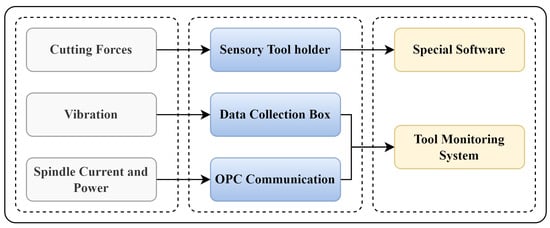
Figure 7.
Monitoring signals acquisition for NUAA Ideahouse milling dataset.

Table 1.
Signal acquisition equipment and sampling frequency.
In the IEEE NUAA Ideahouse [8] dataset, the experiment L9 orthogonal array is created using the experiment design, as shown in Table 2. Out of nine cases, the first two cases, W1 and W2, are considered for the RUL prediction.
Table 2.
Details of the orthogonal experiment of IEEE NUAA Ideahouse.
A total of thirty runs are taken in case-1 (W1), as shown in Table 3, and the flank wear of the tool is measured after each run. The maximum width of the flank wear is decided based on the ISO-8688 standards. In this dataset, the machining data is collected until the maximum value of the tool wear (maximum flank wear, i.e., VBmax) reaches up to 0.30 mm. The 0.30 mm is considered the cutting tool’s functional failure during machining in this dataset. The RUL of the cutting tool is estimated based on the value of flank wear. The additional time (in seconds) column is added to the sensor data based on the sampling rate of the data to generate the RUL column for each run. For the W1 run, the maximum value of flank wear is reached up to 0.27 mm. So, all 30 runs are considered for generating the RUL column based on the sampling frequency.
Table 3.
Tool wear labels for W1 case.
Figure 8 shows the raw data representation (scaled raw data between 0 to 1) of the individual sensor signal with respect to time. For raw data representation, all 30 runs of the W1 case are merged. The total time span to reach the maximum flank tool wear (VBmax) value from 0 mm to 0.27 mm is 3004 s. The TFD features are extracted from the raw data, and selected features are divided for the model training and testing. The data are split into 70–30% for training and testing. The different ML and DL models are trained on the test data, and the model’s performance is evaluated based on the test data. Figure 9 shows the training and testing phases of the RUL prediction approach.
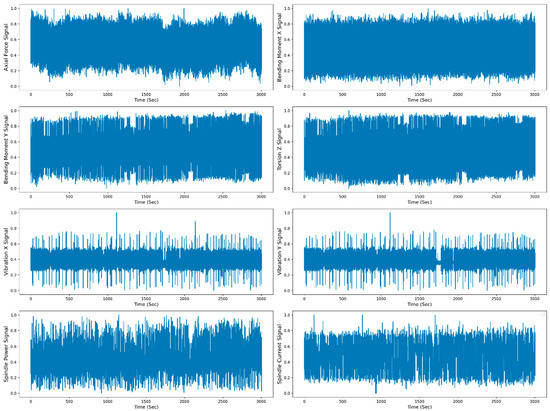
Figure 8.
Raw data representation of all the sensor signals to time for the W1 case.
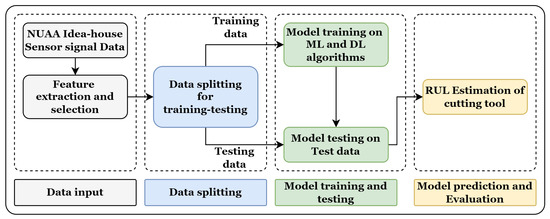
Figure 9.
Flowchart of training and testing phases of the RUL prediction approach.
4.2. Feature Extraction and Selection
The raw data in the dataset are normalized and provided for time–frequency feature extraction. The data are extracted in different TFDs such as STFT, CWT, and WPT. The statistical features shown in Table 4 are extracted from the TFD features coefficients vectors.
Table 4.
The statistical features and their formulae.
The extracted statistical TFD features are selected using Pearson’s correlation coefficient (PCC) and random forest regressor (RFR) methods. PCC [34] is extensively used in machining for feature selection in tool wear and RUL prediction. Equation (5) determines the linear correlations between signals and output variables.
where = input feature, = average of input feature, = target variable, = average of the target variable. The value of “r” can range from −1 to 1, with −1 denoting a high degree of negative correlation and 1 denoting a high degree of positive correlation [35].
Another method used for feature selection is the RF method. RF is the embedded feature selection method that lowers the danger of overfitting and performs quicker operations by overcoming the limitations of wrapper and filter feature selection methods [36]. RF is made up of a number of decision trees that were created by randomly extracting characteristics from the data. The significance of a feature is determined by the decrease in impurity or the increase in node purity that results from dividing a specific feature. Whenever a division is made during the building of each decision tree, the decrease in impurity is noted. This decrease is accumulated for every feature across the entire forest. The final step is to normalize the accumulated diminution by dividing it by the total number of trees, providing the feature importance score. The model creates a set containing the necessary features by trimming trees below a given node. The selected features using PCC and RF methods are provided for different RUL prediction models.
4.3. Models for RUL Prediction
The different models are used for RUL prediction, including ML models such as SVM, RFR, and GBR and DL models such as LSTM, LSTM variants, CNN, and hybrid models, which combine CNN and LSTM variants. This section discussed the brief about the LSTM, LSTM variants, and CNN with the LSTM model.
The LSTM [37] shows promising performance in tool wear and RUL prediction [38,39,40]. LSTM is an advancement of the recurrent neural network (RNN) [41]. The RNN’s gradient vanishing drawback was reduced in the LSTM structure [42]. The architecture of an LSTM unit is depicted in Figure 10. Long-range dependencies are exploited due to the improvements in the LSTM.
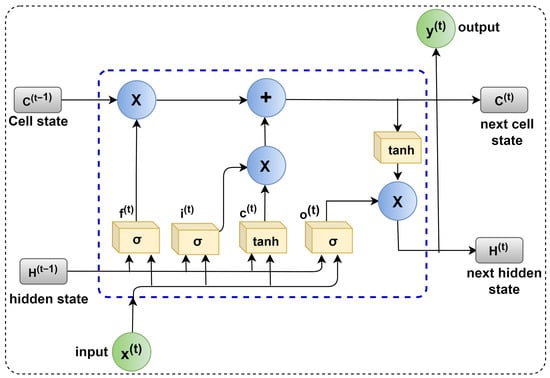
Figure 10.
The architecture of the LSTM unit.
The LSTM modifies the memory at each step rather than overwriting it. The LSTM’s main component is the cell. To add or change cell memory, the LSTM employs sigmoidal gates. ‘Input gate-I’, ‘candidate gate-C’, ‘output gate-O’, and ‘forget gate F’ make up a sigmoidal gate. A(t − 1) and A(t) denote the memory of the previous and subsequent units, respectively. The previous and next cell is hidden state outputs represented by B(t) and B(t − 1). X(t) is the input value, whereas X is element-wise multiplication. The Y(t) indicates the output generated by the LSTM cell. The next unit cell is updated by the gate parameters by modifying or adjusting the parameters and filtering the information. Le et al. [43] discussed the detailed working of the LSTM model.
Figure 11 depicts several LSMT model versions. The vanilla LSTM comprises a single hidden layer of LSTM units that can only access sequential data in one way [44]. The stack LSTM model, on either hand, considers the many hidden LSTM layers. Whereas the forward and backward LSTMs are combined to form the Bi-directional LSTM. The architecture of different LSTM versions is also discussed by Kolekar et al., Chandra et al., and Zhao et al. [45,46,47].
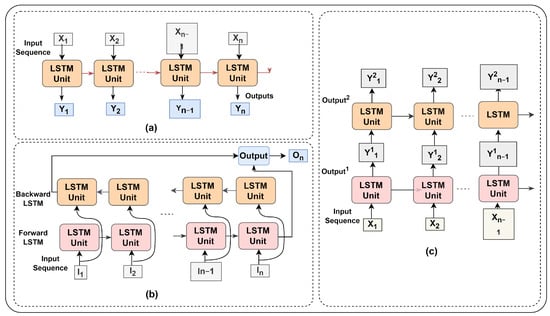
Figure 11.
LSTM variants. (a) Normal (Vanilla), (b) Bi-Directional, and (c) Stack.
Figure 12 shows the combination of the CNN-LSTM architecture [48] for the RUL prediction of the cutting tool. Zhang X et al. and Agga A et al. discussed the architecture of the CNN-LSTM in detailed [48,49]. In this work, along with the CNN-LSTM, the different variants of the SLTM are combined with the CNN model, such as CNN-Vanilla LSTM, CNN-Bidirectional LSTM, and CNN-stack LSTM.
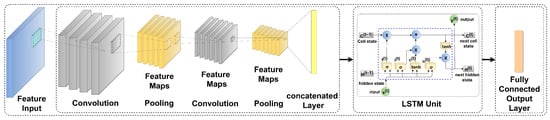
Figure 12.
Hybrid CNN-LSTM architecture for RUL prediction.
4.4. Performance Evaluation Parameters
Different performance measurement parameters, such as ‘R-squared score (R2)’, ‘Root Mean Square Error (RMSE)’, and ‘Mean Absolute Percent Error (MAPE)’, are used to measure the extent to which these prediction models work. The R2 is a metric that assesses the accuracy of a forecast based on real and predicted data [50].
It is used to evaluate the regression model performance by determining how far the predicted points are from the actual data points. Whereas the RMSE provides the square root of the average of predicted and actual values. Finally, MAPE is used to calculate the percentage prediction errors. The formulae for all the performance parameters are provided in Table 5, where n = number of data points, = predicted value, and = true or actual value.
Table 5.
Model performance parameters.
5. Results and Discussion
The NUAA Ideahouse dataset is in raw signal format with eight incoming signals, including four cutting forces, two vibrations, and one current and power signal, as mentioned in Section 4. From the L9 orthogonal array, the first two cases, W1 and W2, are considered in this work. The results related to case W1 are thoroughly elaborated in this section, and the summarized results table is provided for the W2 case at the end of the result section.
The time column is added to the dataset based on the sampling frequency (300 Hz/per signal). The actual values of the RUL are calculated based on the time column. The features are extracted and selected based on the sensor data as input and RUL as a target feature for the RUL prediction models. The data are normalized using the z-score data normalization technique before passing them to the model. This result section is organized into three parts, i.e.,:
- The feature extraction based on different TFD techniques such as CWT, STFT, and WPT and feature selection using PCC and RFR methods is discussed;
- Model performance for each TFD feature using PCC and RF feature selection techniques using different ML (SVM, RFR, and GBR) and DL models (LSTM, LSTM variants, CNN, and hybrid model consisting of CNN with LSTM variants) are evaluated;
- Finally, the graphs indicating the actual and predicted RUL of the cutting tool versus the actual machining time of milling are plotted for each condition, and a summary of all the obtained results is discussed.
5.1. Feature Extraction and Selection
The features are extracted in the TFD using STFT, CWT, and WPT. The statistical features are extracted from the generated time–frequency coefficient vectors. A total of 64 features are extracted in STFT and CWT each, as the number of input signals is eight (Figure 5), and eight statistical features (Table 3) are generated from each signal. In the WPT, the extracted coefficients are divided into approximate and detailed coefficients, generating a total of 128 features (64 approximate and 64 detailed). The extracted features in each method are shown in Table 6.
Table 6.
Feature extraction and its feature count.
After feature extraction, the features are selected using PCC and RF methods. In PCC, features with a correlation greater than 0.2 are chosen, whereas in RF, features with a weightage greater than 0.5 are chosen. The selection of threshold values for PCC and RF is finalized after many iterations. The threshold values are kept constant for all the feature extraction techniques to compare model performance.
Figure 13 shows the change in the mean STFT representation of the individual sensor signal with respect to time. Table 7 shows the selected features using the PCC feature selection technique for extracted STFT-based features. The feature names are indicated by the type of feature extraction technique followed by the type of statistical feature considered and the signal considered for feature extraction. A total of twenty-one features are selected that are having correlation coefficient greater than 0.2. Similarly, Table 8 shows the selected features using RF for STFT feature extraction. Out of 64 features, 31 high-weightage features are selected.
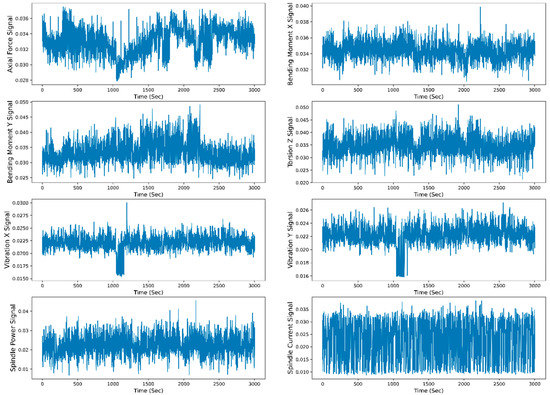
Figure 13.
Extracted mean STFT sensor signals representation with time.
Table 7.
Selected features using PCC from STFT feature extraction technique.
Table 8.
Selected features using RF from STFT feature extraction technique.
Figure 14 shows the change in the mean CWT representation of the individual sensor signal with respect to time. Table 9 and Table 10 indicate the feature selected using PCC and RF from extracted CWT features. The eleven features having a PCC value higher than 0.2 are selected for prediction model training and testing. Forty-three features are selected based on RF weightage greater than 0.5.
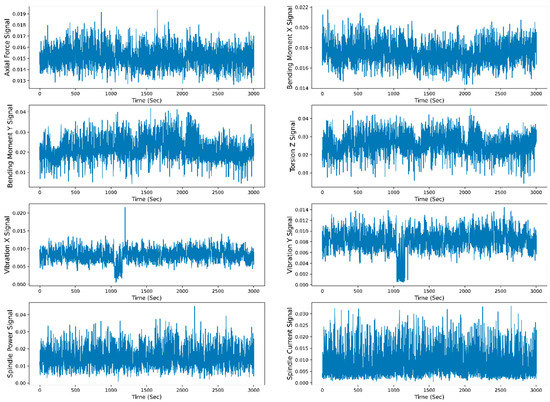
Figure 14.
Extracted mean CWT sensor signals representation with time.
Table 9.
Selected features using PCC from CWT feature extraction technique.
Table 10.
Selected features using RF from CWT feature extraction technique.
Figure 15 shows the change in the mean WPT representation of the individual sensor signal with respect to time. Table 11 indicates the selected 26 features using the PCC technique from the extracted 128 WPT features at the first level of decomposition. The ‘a’ and ‘d’ indicate the extracted approximate and detailed feature coefficients, followed by the extracted statistical details and signal names.
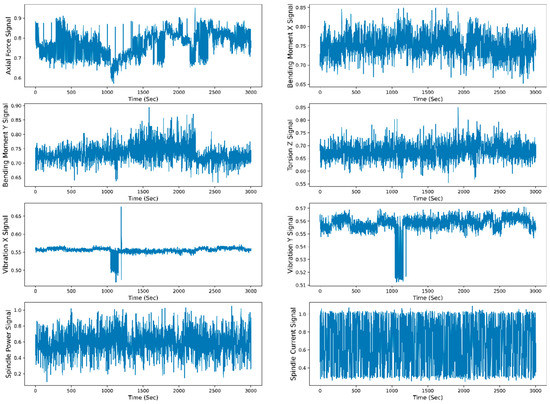
Figure 15.
Extracted mean WPT sensor signals representation with time.
Table 11.
Selected features using PCC from WPT feature extraction technique.
Table 12 indicates the selected features using the RF feature selection method from extracted WPT features. A total of 19 features are selected, with a weightage greater than 0.5.
Table 12.
Selected features using RF from WPT feature extraction technique.
5.2. Machine Learning Models Performance
The extracted and selected features are initially provided to different machine learning (ML) algorithms to check each model’s performance for RUL prediction. Various approaches for selecting features, including PCC and RFR methods, are used to assess the efficacy of each prediction model. In ML models, support vector machine (SVM), random forest regressor (RFR), and gradient boosting regressor (GBR) are used for RUL prediction.
Table 13 shows the performance evaluation for the different ML models using the PCC feature selection technique. The RUL prediction based on the ML model performs poorly compared to DL algorithms. The maximum value of R2 is 0.366 for the PCC-based feature selection method given by the RFR model for WPT feature extraction. Whereas, for the same extracted feature, the features are selected using the RF, and the performance of the ML models is slightly improved, as shown in Table 14. The WPT shows the maximum R2 of 0.496 for the RFR model in the RF base features selection method. The different DL models, such as LSTM, LSTM variants, CNN, and a combination of CNN with different LSTM variants, are used to improve the performance of the prediction models.
Table 13.
RUL prediction for PCC-based feature selection techniques using different ML models.
Table 14.
RUL prediction for RFR-based feature selection techniques using different ML models.
5.3. Deep Learning Model Performance
In the DL models, the extracted and selected features are initially provided to the different LSTM variants, such as Vanilla, Bi-directional, and Stack LSTM models, to check each model’s performance for RUL prediction. Similarly, the selected features are passed to the CNN model along with the hybrid model of CNN with different LSTM variants.
In this work, the call-backs and early-stopping approach are used to increase the performance and efficiency of DL models. Call-backs are functions that can be set to execute at certain points during training, such as after each epoch or after a given number of batches have been processed. These capabilities can be utilized to carry out a range of operations, including altering the learning rate, tracking training progress, and preserving model checkpoints, whereas early stopping, on the other hand, is a technique that is used to prevent overfitting. A call-back that checks the validation performance at the end of each epoch and stops training if the performance has not increased for a given number of epochs can be used to enable early stopping in deep learning models. These two approaches increase the effectiveness of the training process by preventing overfitting, conserving time, and reducing the amount of computational resources needed.
In this work, different performance evaluation parameters, such as R-squared (R2), RMSE, and MAPE, are considered to check the performance of each model. Generally, in regression, the R2 values above 0.90 and MAPE values below 10% are considered models showing good prediction values.
5.3.1. RUL Prediction Using STFT Feature Extraction Technique
The RUL of the cutting tool is predicted using the STFT feature extraction technique. Table 15 shows the performance evaluation parameters of the different LSTM variants model using STFT time–frequency-based feature extraction techniques for RUL prediction. For the PCC-based feature selection technique, the stack LSTM shows the maximum testing accuracy of 0.802, with 0.125 and 7.372% as RMSE and MAPE values, respectively. In RFR feature selection, stack LSTM provides a maximum R2 score value of 0.782 as testing accuracy with 0.131 RMSE value and 08.52% MAPE value.
Table 15.
STFT feature extraction-based RUL prediction for PCC and RFR feature selection techniques using different LSTM variants.
Figure 16 shows the learning curves for the RUL prediction, indicating the loss vs. the number of epochs for each model using PCC and RFR feature extraction in the STFT feature extraction technique. The graph shows that the losses are minimum for the highest R2 and minimum RMSE or MAPE values. Stack LSTM model offers a minimum loss for the PCC and RFR-based feature selection.
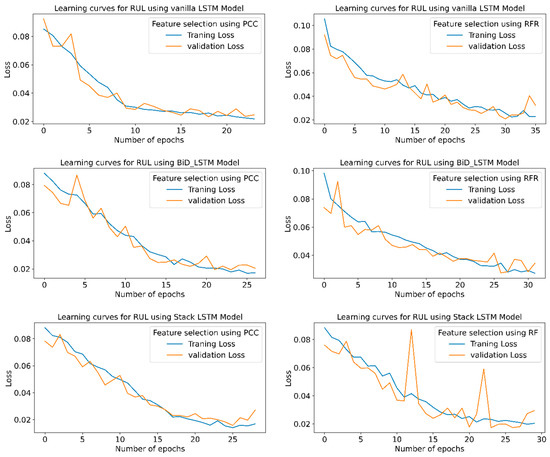
Figure 16.
RUL prediction learning curves using STFT-based feature extraction for different LSTM variants.
Figure 17 and Figure 18 show the graphs of the actual and predicted RUL of the cutting tool concerning total machining time for PCC-based and RFR-based feature selection. The stack LSTM shows the minimum deviation in RUL prediction for both feature selection techniques.
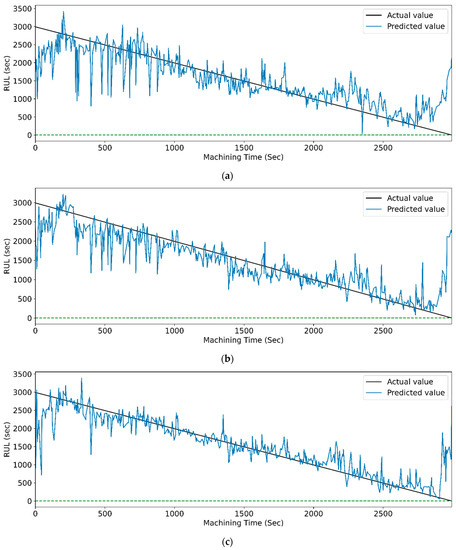
Figure 17.
The actual and predicted value of RUL versus machining time for STFT and PCC-based feature selection using different LSTM variants. (a) Vanilla. (b) Bi-directional, and (c) Stack.
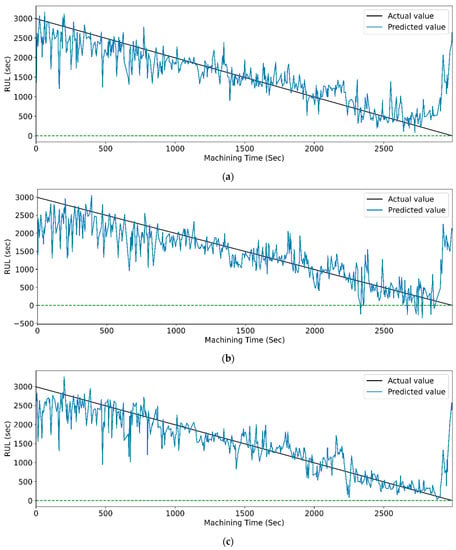
Figure 18.
The actual and predicted value of RUL versus machining time for STFT and RFR-based feature selection using different LSTM variants. (a) Vanilla, (b) Bi-directional, and (c) Stack.
Similarly, Table 16 shows the performance evaluation parameters of the CNN and CNN-LSTM variants models using STFT time–frequency-based feature extraction techniques for RUL prediction. For the PCC-based feature selection technique, the CNN-LSTM shows the maximum testing accuracy of 0.881, with 0.097 and 6.877% as RMSE and MAPE values, respectively. In RFR feature selection, CNN-bidirectional LSTM provides a maximum R2 score of 0.951 as testing accuracy with 0.062 RMSE value and 04.161% MAPE value.
Table 16.
STFT feature extraction-based RUL prediction for PCC and RFR feature selection techniques using CNN and CNN-LSTM variants.
Figure 19 and Figure 20 show the actual and predicted values of the RUL for the PCC-based and RF-based feature selection techniques, respectively. In PCC-based feature selection, as the CNN-LSTM shows the maximum accuracy, Figure 19b shows the minimum deviation between the actual and predicted RUL values. Similarly, in RFR-based feature selection, Figure 20d, the CNN-Stack-LSTM shows the minimum deviation in actual and predicted RUL values with maximum accuracy.
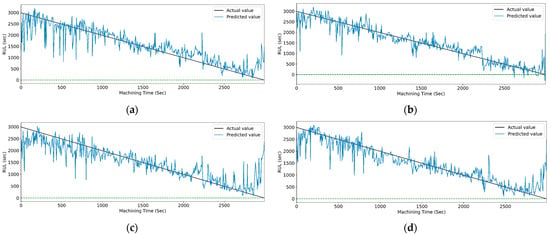
Figure 19.
The actual and predicted values of RUL versus machining time for STFT and PCC-based feature selection using different models. (a) CCN, (b) CNN-LSTM, (c) CNN-bidirectional LSTM, and (d) CNN-Stack LSTM.
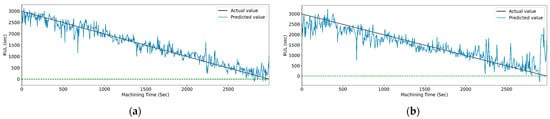
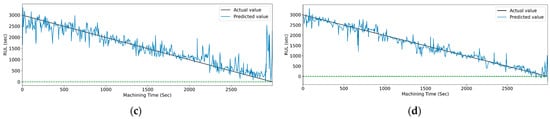
Figure 20.
The actual and predicted value of RUL versus machining time for STFT and RF-based feature selection using different models. (a) CCN, (b) CNN-LSTM, (c) CNN-bidirectional LSTM, and (d) CNN-Stack LSTM.
5.3.2. RUL Prediction Using CWT Feature Extraction Technique
Table 17 shows the performance evaluation parameters of the different LSTM variants model using CWT time–frequency-based feature extraction techniques for RUL prediction. In CWT, for vanilla LSTM, the maximum testing accuracy is 0.851, with 0.104 and 7.359 as RMSE and MAPE values, respectively. In RFR feature selection, stack LSTM provides a maximum R2 score value of 0.927 as testing accuracy with 0.075 and 5.781 as RMSE and MAPE values, respectively.
Table 17.
CWT feature extraction-based RUL prediction for PCC and RFR feature selection techniques using different LSTM variants.
Figure 21 shows the learning curves for all six conditions of the model.From the learning curves, it is clear that the model which shows maximum accuracy provides the minimum training and testing losses.
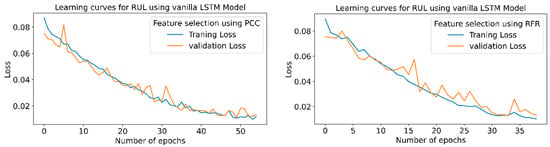
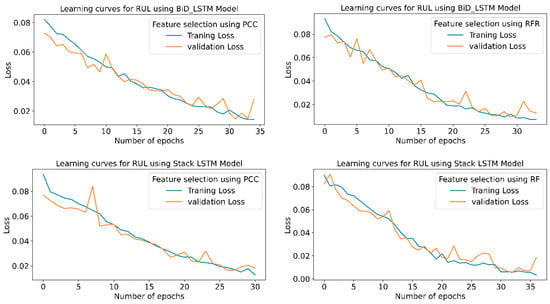
Figure 21.
RUL prediction learning curves using CWT-based feature extraction for different LSTM variants.
Figure 22 and Figure 23 show the graphical representation that indicates the actual and predicted RUL of different LSTM models with respect to machining time. Models with the highest accuracies for both feature selection methods demonstrate the least deviation between the real and anticipated values of RUL concerning machining time.
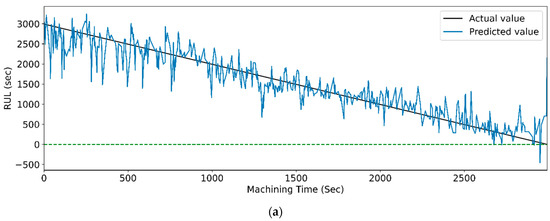
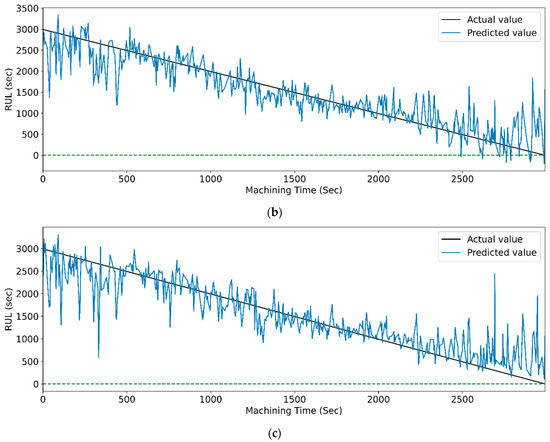
Figure 22.
The actual and predicted values of RUL versus machining time for CWT and PCC-based feature selection using different LSTM variants. (a) Vanilla, (b) Bi-directional, and (c) Stack.
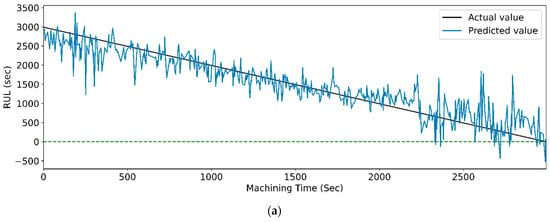
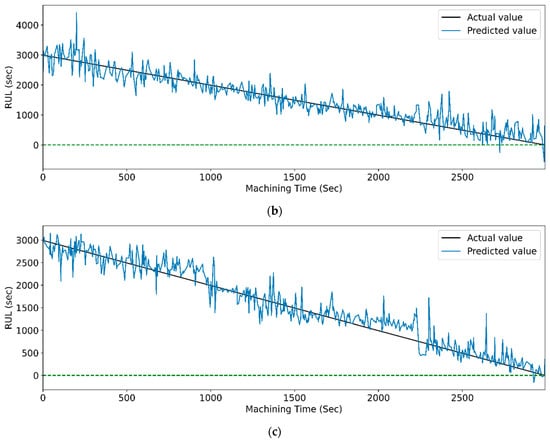
Figure 23.
The actual and predicted value of RUL versus machining time for CWT and RFR-based feature selection using different LSTM variants. (a) Vanilla, (b) Bi-directional, and (c) Stack.
Similarly, Table 18 shows the performance evaluation parameters of the CNN and CNN-LSTM variants models using CWT time–frequency-based feature extraction techniques for RUL prediction. For the PCC-based feature selection technique, the CNN-Bidirectional-LSTM shows the maximum testing accuracy of 0.960, with 0.051 and 3.576% as RMSE and MAPE values, respectively. In RFR feature selection, CNN-bidirectional LSTM provides a maximum R2 score of 0.971 as testing accuracy with 0.048 RMSE value and 3.428% MAPE value.
Table 18.
CWT feature extraction-based RUL prediction for PCC and RFR feature selection techniques using CNN and CNN-LSTM variants.
Figure 24 and Figure 25 show the actual and predicted values of the RUL for the PCC-based and RF-based feature selection techniques, respectively, for extracted features using the CWT method. In PCC-based feature selection, Figure 24c shows the minimum deviation between the actual and predicted RUL values, as the CNN-bidirectional-LSTM shows the maximum accuracy. Similarly, in RFR-based feature selection, Figure 25c, the CNN-bidirectional-LSTM shows the minimum deviation in actual and predicted RUL values with a maximum R-squared value of 0.96.
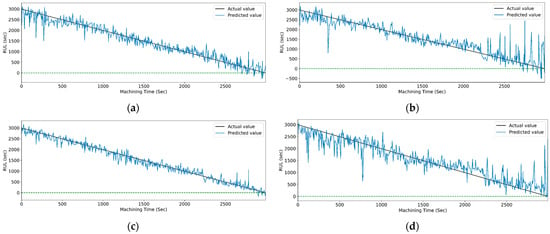
Figure 24.
The actual and predicted value of RUL versus machining time for CWT and PCC-based feature selection using different models. (a) CCN, (b) CNN-LSTM, (c) CNN-bidirectional LSTM, and (d) CNN-Stack LSTM.
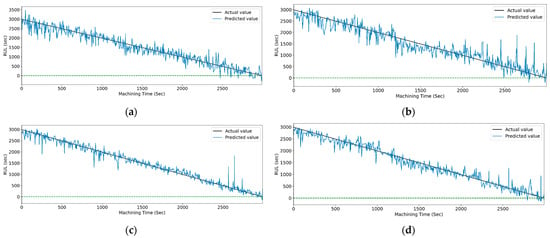
Figure 25.
The actual and predicted value of RUL versus machining time for CWT and RFR-based feature selection using different models. (a) CCN, (b) CNN-LSTM, (c) CNN-bidirectional LSTM, and (d) CNN-Stack LSTM.
5.3.3. RUL Prediction Using WPT Feature Extraction Technique
The WPT is used to estimate the RUL of the cutting tool. Table 19 shows the performance evaluation parameters of the different LSTM variants model using WPT time–frequency-based feature extraction techniques for RUL prediction. For the PCC-based feature selection technique, the stack LSTM shows the maximum testing accuracy of 0.857, with 0.102 and 7.140% as RMSE and MAPE values, respectively. In RFR feature selection, stack LSTM provides a maximum R2 score value of 0.978 as train accuracy and 0.967 as testing accuracy with 0.051 RMSE value and 03.676% MAPE value.
Table 19.
WPT feature extraction-based RUL prediction for PCC and RFR feature selection techniques using different LSTM variants.
Figure 26 indicates the training and validation loss learning curves for the prediction of RUL employing various LSTM variants for PCC and RFR-based feature selection techniques. In PCC-based feature selection, vanilla LSTM shows minimum training losses at 51 epochs. The model uses early stopping to avoid overfitting using a three-patient level in the call-back function. At the same time, in RFR based feature selection technique, the Stack LSTM shows minimum training losses at the 52 epochs and indicates the maximum accuracy for the same epochs.
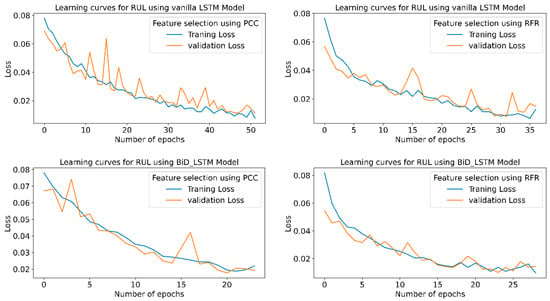
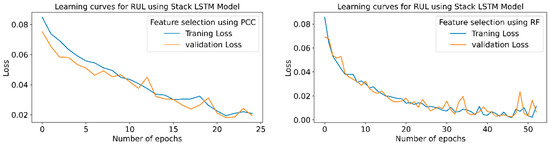
Figure 26.
RUL prediction learning curves using WPT-based feature extraction for different LSTM variants.
Figure 27 and Figure 28 show the actual and predicted RUL vs. machining time of the cutting tool using the WPT feature extraction technique for PCC and RFR-based feature selection, respectively, for different LSTM variants. From the graphical representation, it is clear that the model with the highest prediction accuracy shows a slight variation between the real and predicted RUL. Figure 14, vanilla LSTM, shows the minimum deviation between the actual and predicted RUL. Whereas, in Figure 15, stack LSTM shows the lowest variation between real and predicted RUL values.
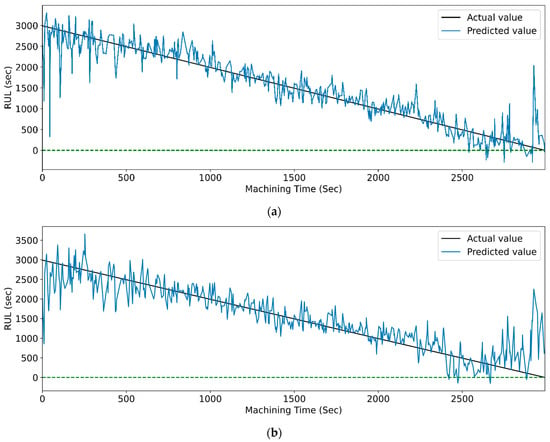
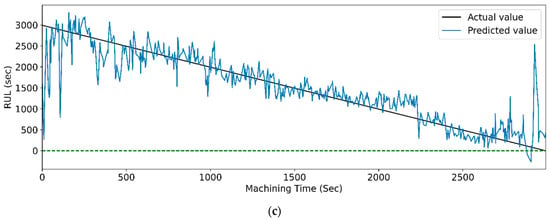
Figure 27.
The actual and predicted values of RUL versus machining time for WPT and PCC-based feature selection using different LSTM variants. (a) Vanilla, (b) Bi-directional, and (c) Stack.
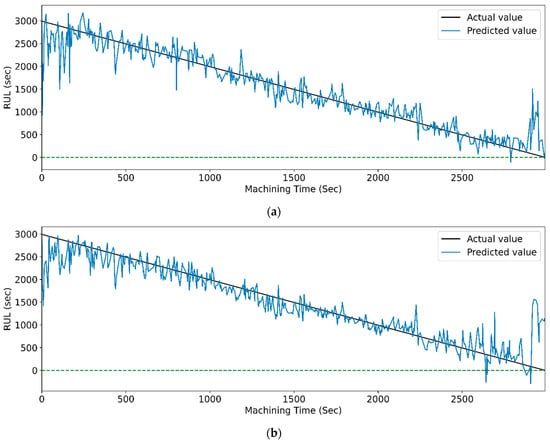
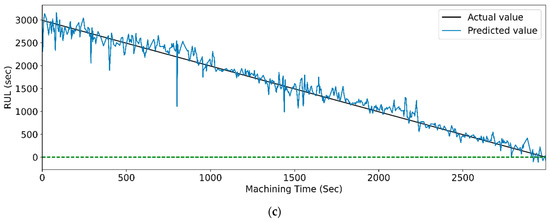
Figure 28.
The Actual and predicted values of RUL versus machining time for WPT and RFR-based feature selection using different LSTM variants. (a) Vanilla, (b) Bi-directional, and (c) Stack.
Similarly, Table 20 shows the performance evaluation parameters of the CNN and CNN-LSTM variants models using WPT time–frequency-based feature extraction techniques for RUL prediction. For the PCC-based feature selection technique, the CNN-Bidirectional-LSTM shows the maximum testing accuracy of 0.908, with 0.086 and 5.90% as RMSE and MAPE values, respectively. In RFR feature selection, CNN-bidirectional-LSTM provides a maximum R2 score of 0.955 as testing accuracy with 0.056 RMSE value and 03.59% MAPE value.
Table 20.
WPT feature extraction-based RUL prediction for PCC and RFR feature selection techniques using CNN and CNN-LSTM variants.
Figure 29 and Figure 30 show the graphical representation of actual and predicted values of the RUL for the PCC-based and RF-based feature selection techniques, respectively, for extracted features using the WPT method. In PCC-based feature selection, Figure 29c shows the minimum deviation between the actual and predicted RUL values, as the CNN-bidirectional-LSTM shows the maximum accuracy. Similarly, as shown in Figure 30d, RFR-based feature selection, the CNN-bidirectional-LSTM, shows the minimum deviation in actual and predicted RUL values.
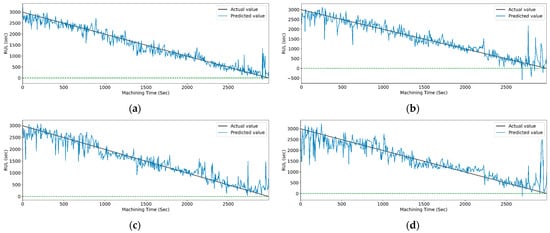
Figure 29.
The actual and predicted value of RUL versus machining time for WPT and PCC-based feature selection using different models. (a) CCN, (b) CNN-LSTM, (c) CNN-bidirectional LSTM, and (d) CNN-Stack LSTM.
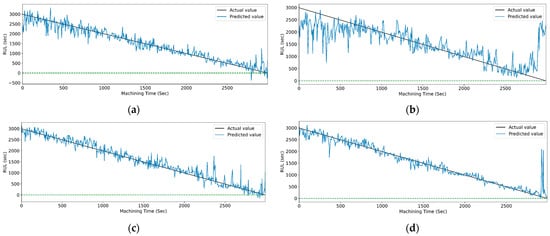
Figure 30.
The actual and predicted value of RUL versus machining time for WPT and RFR-based feature selection using different models. (a) CCN, (b) CNN-LSTM, (c) CNN-bidirectional LSTM, and (d) CNN-Stack LSTM.
Table 21 summarizes all the results from the prediction models, including LSTM, LSTM variants, CNN, and CNN with LSTM variants for case W1. In the STFT feature extraction technique, the CNN-stack-LSTM provides the maximum R2 value of 0.951 using the RF feature selection technique. In CWT feature extraction, the CNN-bidirectional LSTM provides a maximum R2 value of 0.971. In the WPT feature extraction technique, stack-LSTM provides the maximum R2 value of 0.967.
Table 21.
Summarized performance evaluation for different feature extraction techniques and DL models for RUL prediction using PCC and RFR-based feature selection techniques (Case-W1).
Similarly, the model performance is verified on case W2. In the case of W2, 18 runs are required to reach the maximum tool wear value of 0.30 mm. The DL models for RUL predictions provide good results, as summarized in Table 22.
Table 22.
Summarized performance evaluation for different feature extraction techniques and LSTM variants for RUL prediction using PCC and RFR-based feature selection techniques (Case-W2).
The results show that the RF feature selection technique performs slightly better than the PCC-based feature selection technique. Tool wear, or RUL, is a non-linear and complex phenomenon. The PCC feature selection technique provides better results for linear relationships than non-linear ones. The RF feature selection technique gives better results for non-linear relationships and complex models. In the case of RUL prediction models, ML models show poor prediction performance as the model struggles to capture complex and non-linear relationships in the cutting tool RUL data. In comparison, the DL models show fairly good prediction results in RUL prediction. In this work, based on the results, it is observed that, compared to the normal CCN and LSTM models, LSTM variants and hybrid models (CNN with LSTM variants) provide better results. The LSTM variants and CNN with LSTM variants easily and more accurately understand the temporal or time-related aspects of sequential or time series signals captured for RUL prediction of cutting tool.
6. Conclusions
In this work, the IEEE NUAA Ideahouse dataset is used for the cutting tool’s remaining useful life (RUL) prediction. Time–frequency feature extraction techniques such as STFT and WT are used to avoid the limitations of TD and FD feature extraction. The model prediction results are verified using the two cases (W1 and W2) from the dataset. The following conclusions are drawn from the obtained results:
- The RF feature selection technique performs slightly better than the PCC-based feature selection technique. The RF feature selection technique gives better results for non-linear relationships and complex models;
- The DL models such as LSTM, LSTM variants, CNN, and CNN with LSTM variants provide better prediction accuracies than ML models, as these models are effective for the time-series and complex non-linear cutting tool data for RUL estimation;
- In STFT, CWT, and WPT feature extraction techniques, the highest value of R2 score is more than 0.95 for LSTM variants and hybrid (CNN with LSTM variants) prediction models;
- The result shows that the TFD feature extraction technique is effective for RUL prediction with deep learning models such as LSTM, LSTM variants, CNN, and hybrid model CNN with LSTM variants.
Author Contributions
Conceptualization, S.S. and S.K.; methodology, S.S. and S.K.; validation, A.B., K.K. and A.A.; formal analysis, K.K. and A.A.; investigation, A.B.; resources, S.K. and K.K.; data curation, S.S.; writing—original draft preparation, S.S. and S.K.; writing—review and editing, A.B., K.K. and A.B.; visualization, S.K.; supervision, A.B.; project administration, K.K. and A.A.; funding acquisition, A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tong, X.; Liu, Q.; Pi, S.; Xiao, Y. Real-time machining data application and service based on IMT digital twin. J. Intell. Manuf. 2019, 31, 1113–1132. [Google Scholar] [CrossRef]
- Javed, K.; Gouriveau, R.; Li, X.; Zerhouni, N. Tool wear monitoring and prognostics challenges: A comparison of connectionist methods toward an adaptive ensemble model. J. Intell. Manuf. 2016, 29, 1873–1890. [Google Scholar] [CrossRef]
- Zonta, T.; da Costa, C.A.; Righi, R.D.R.; de Lima, M.J.; da Trindade, E.S.; Li, G.P. Predictive maintenance in the Industry 4.0: A systematic literature review. Comput. Ind. Eng. 2020, 150, 106889. [Google Scholar] [CrossRef]
- Sayyad, S.; Kumar, S.; Bongale, A.; Kamat, P.; Patil, S.; Kotecha, K. Data-Driven Remaining Useful Life Estimation for Milling Process: Sensors, Algorithms, Datasets, and Future Directions. IEEE Access 2021, 9, 110255–110286. [Google Scholar] [CrossRef]
- Liu, Y.C.; Chang, Y.J.; Liu, S.L.; Chen, S.P. Data-driven prognostics of remaining useful life for milling machine cutting tools. In Proceedings of the 2019 IEEE International Conference on Prognostics and Health Management, ICPHM 2019, San Francisco, CA, USA, 17–20 June 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Tian, Z. An artificial neural network method for remaining useful life prediction of equipment subject to condition monitoring. J. Intell. Manuf. 2009, 23, 227–237. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, Y.; Addepalli, S. Remaining Useful Life Prediction using Deep Learning Approaches: A Review. Procedia Manuf. 2020, 49, 81–88. [Google Scholar] [CrossRef]
- Li, Y.; Liu, C.; Li, D.; Hua, J.; Wan, P. Documentation of Tool Wear Dataset of NUAA_Ideahouse. IEEE Dataport. 2021. Available online: https://ieee-dataport.org/open-access/tool-wear-dataset-nuaaideahouse (accessed on 6 January 2023).
- Hanachi, H.; Yu, W.; Kim, I.Y.; Liu, J.; Mechefske, C.K. Hybrid data-driven physics-based model fusion framework for tool wear prediction. Int. J. Adv. Manuf. Technol. 2018, 101, 2861–2872. [Google Scholar] [CrossRef]
- Liang, Y.; Wang, S.; Li, W.; Lu, X. Data-Driven Anomaly Diagnosis for Machining Processes. Engineering 2019, 5, 646–652. [Google Scholar] [CrossRef]
- Wu, D.; Jennings, C.; Terpenny, J.; Gao, R.; Kumara, S. Data-Driven Prognostics Using Random Forests: Prediction of Tool Wear. 2017. Available online: http://proceedings.asmedigitalcollection.asme.org/pdfaccess.ashx?url=/data/conferences/asmep/93280/ (accessed on 6 January 2023).
- Dimla, D.E. Sensor signals for tool-wear monitoring in metal cutting operations—A review of methods. Int. J. Mach. Tools Manuf. 2000, 40, 1073–1098. [Google Scholar] [CrossRef]
- Sick, B. Online and indirect tool wear monitoring in turning with artificial neural networks: A review of more than a decade of research. Mech. Syst. Signal Process. 2002, 16, 487–546. [Google Scholar] [CrossRef]
- Sayyad, S.; Kumar, S.; Bongale, A.; Bongale, A.M.; Patil, S. Estimating Remaining Useful Life in Machines Using Artificial Intelligence: A Scoping Review. Libr. Philos. Pract. 2021, 2021, 1–26. [Google Scholar]
- Zhou, Y.; Liu, C.; Yu, X.; Liu, B.; Quan, Y. Tool wear mechanism, monitoring and remaining useful life (RUL) technology based on big data: A review. SN Appl. Sci. 2022, 4, 232. [Google Scholar] [CrossRef]
- Tran, V.T.; Pham, H.T.; Yang, B.-S.; Nguyen, T.T. Machine performance degradation assessment and remaining useful life prediction using proportional hazard model and support vector machine. Mech. Syst. Signal Process. 2012, 32, 320–330. [Google Scholar] [CrossRef]
- Liu, M.; Yao, X.; Zhang, J.; Chen, W.; Jing, X.; Wang, K. Multi-Sensor Data Fusion for Remaining Useful Life Prediction of Machining Tools by iabc-bpnn in Dry Milling Operations. Sensors 2020, 20, 4657. [Google Scholar] [CrossRef]
- Zhang, C.; Yao, X.; Zhang, J.; Jin, H. Tool Condition Monitoring and Remaining Useful Life Prognostic Based on a Wireless Sensor in Dry Milling Operations. Sensors 2016, 16, 795. [Google Scholar] [CrossRef]
- Zhou, Y.; Xue, W. A Multi-sensor Fusion Method for Tool Condition Monitoring in Milling. Sensors 2018, 18, 3866. [Google Scholar] [CrossRef] [PubMed]
- Thirukkumaran, K.; Mukhopadhyay, C.K. Analysis of Acoustic Emission Signal to Characterization the Damage Mechanism During Drilling of Al-5%SiC Metal Matrix Composite. Silicon 2020, 13, 309–325. [Google Scholar] [CrossRef]
- da Costa, C.; Kashiwagi, M.; Mathias, M.H. Rotor failure detection of induction motors by wavelet transform and Fourier transform in non-stationary condition. Case Stud. Mech. Syst. Signal Process. 2015, 1, 15–26. [Google Scholar] [CrossRef]
- Delsy, T.T.M.; Nandhitha, N.M.; Rani, B.S. RETRACTED ARTICLE: Feasibility of spectral domain techniques for the classification of non-stationary signals. J. Ambient. Intell. Humaniz. Comput. 2020, 12, 6347–6354. [Google Scholar] [CrossRef]
- Zhu, K.; Wong, Y.S.; Hong, G.S. Wavelet analysis of sensor signals for tool condition monitoring: A review and some new results. Int. J. Mach. Tools Manuf. 2009, 49, 537–553. [Google Scholar] [CrossRef]
- Hong, Y.-S.; Yoon, H.-S.; Moon, J.-S.; Cho, Y.-M.; Ahn, S.-H. Tool-wear monitoring during micro-end milling using wavelet packet transform and Fisher’s linear discriminant. Int. J. Precis. Eng. Manuf. 2016, 17, 845–855. [Google Scholar] [CrossRef]
- Segreto, T.; D’addona, D.; Teti, R. Tool wear estimation in turning of Inconel 718 based on wavelet sensor signal analysis and machine learning paradigms. Prod. Eng. 2020, 14, 693–705. [Google Scholar] [CrossRef]
- Rafezi, H.; Akbari, J.; Behzad, M. Tool Condition Monitoring based on sound and vibration analysis and wavelet packet decomposition. In Proceedings of the 2012 8th International Symposium on Mechatronics and Its Applications, Sharjah, United Arab Emirates, 10–12 April 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Xiang, Z.; Feng, X. Tool Wear State Monitoring Based on Long-Term and Short-Term Memory Neural Network; Springer: Singapore, 2020; Volume 593. [Google Scholar] [CrossRef]
- Ganesan, R.; DAS, T.K.; Venkataraman, V. Wavelet-based multiscale statistical process monitoring: A literature review. IIE Trans. Inst. Ind. Eng. 2004, 36, 787–806. [Google Scholar] [CrossRef]
- Strackeljan, J.; Lahdelma, S. Smart Adaptive Monitoring and Diagnostic Systems. In Proceedings of the 2nd International Seminar on Maintenance, Condition Monitoring and Diagnostics, Oulu, Finland, 28–29 September 2005. [Google Scholar]
- Wang, L.; Gao, R. Condition Monitoring and Control for Intelligent Manufacturing; Springer: Berlin/Heidelberg, Germany, 2006; Available online: https://www.springer.com/gp/book/9781846282683 (accessed on 6 January 2023).
- Burus, C.S.; Gopinath, R.A.; Guo, H. Introduction to Wavelets and Wavelet Transform—A Primer; Prentice Hall: Upper Saddle River, NJ, USA, 1997. [Google Scholar]
- Hosameldin, A.; Asoke, N. Condition Monitoring with Vibration Signals; Wiley-IEEE Press: Piscataway, NJ, USA, 2020. [Google Scholar]
- Liu, M.-K.; Tseng, Y.-H.; Tran, M.-Q. Tool wear monitoring and prediction based on sound signal. Int. J. Adv. Manuf. Technol. 2019, 103, 3361–3373. [Google Scholar] [CrossRef]
- Li, X.; Lim, B.S.; Zhou, J.H.; Huang, S.; Phua, S.J.; Shaw, K.C.; Er, M.J. Fuzzy neural network modelling for tool wear estimation in dry milling operation. In Proceedings of the Annual Conference of the Prognostics and Health Management Society, PHM 2009, San Diego, CA, USA, 27 September–1 October 2009; pp. 1–11. [Google Scholar]
- Nettleton, D. Selection of Variables and Factor Derivation. In Commercial Data Mining; Morgan Kaufmann: Boston, MA, USA, 2014; pp. 79–104. [Google Scholar] [CrossRef]
- Sayyad, S.; Kumar, S.; Bongale, A.; Kotecha, K.; Selvachandran, G.; Suganthan, P.N. Tool wear prediction using long short-term memory variants and hybrid feature selection techniques. Int. J. Adv. Manuf. Technol. 2022, 121, 6611–6633. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chan, Y.-W.; Kang, T.-C.; Yang, C.-T.; Chang, C.-H.; Huang, S.-M.; Tsai, Y.-T. Tool wear prediction using convolutional bidirectional LSTM networks. J. Supercomput. 2021, 78, 810–832. [Google Scholar] [CrossRef]
- Lindemann, B.; Maschler, B.; Sahlab, N.; Weyrich, M. A survey on anomaly detection for technical systems using LSTM networks. Comput. Ind. 2021, 131, 103498. [Google Scholar] [CrossRef]
- An, Q.; Tao, Z.; Xu, X.; El Mansori, M.; Chen, M. A data-driven model for milling tool remaining useful life prediction with convolutional and stacked LSTM network. Measurement 2019, 154, 107461. [Google Scholar] [CrossRef]
- Wu, Z.; Christofides, P.D. Economic Machine-Learning-Based Predictive Control of Non-linear Systems. Mathematics 2019, 7, 494. [Google Scholar] [CrossRef]
- Chen, C.-W.; Tseng, S.-P.; Kuan, T.-W.; Wang, J.-F. Outpatient Text Classification Using Attention-Based Bidirectional LSTM for Robot-Assisted Servicing in Hospital. Information 2020, 11, 106. [Google Scholar] [CrossRef]
- Le, X.H.; Ho, H.V.; Lee, G.; Jung, S. Application of Long Short-Term Memory (LSTM) Neural Network for Flood Forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef]
- Chatterjee, A.; Gerdes, M.W.; Martinez, S.G. Statistical Explorations and Univariate Timeseries Analysis on COVID-19 Datasets to Understand the Trend of Disease Spreading and Death. Sensors 2020, 20, 3089. [Google Scholar] [CrossRef] [PubMed]
- Chandra, R.; Goyal, S.; Gupta, R. Evaluation of Deep Learning Models for Multi-Step Ahead Time Series Prediction. IEEE Access 2021, 9, 83105–83123. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Wang, J.; Mao, K. Learning to Monitor Machine Health with Convolutional Bi-Directional LSTM Networks. Sensors 2017, 17, 273. [Google Scholar] [CrossRef]
- Kumar, S.; Kolekar, T.; Kotecha, K.; Patil, S.; Bongale, A. Performance evaluation for tool wear prediction based on Bi-directional, Encoder–Decoder and Hybrid Long Short-Term Memory models. Int. J. Qual. Reliab. Manag. 2022, 39, 1551–1576. [Google Scholar] [CrossRef]
- Zhang, X.; Lu, X.; Li, W.; Wang, S. Prediction of the remaining useful life of cutting tool using the Hurst exponent and CNN-LSTM. Int. J. Adv. Manuf. Technol. 2021, 112, 2277–2299. [Google Scholar] [CrossRef]
- Agga, A.; Abbou, A.; Labbadi, M.; El Houm, Y.; Ali, I.H.O. CNN-LSTM: An efficient hybrid deep learning architecture for predicting short-term photovoltaic power production. Electr. Power Syst. Res. 2022, 208, 107908. [Google Scholar] [CrossRef]
- Lin, Y.-C.; Wu, K.-D.; Shih, W.-C.; Hsu, P.-K.; Hung, J.-P. Prediction of Surface Roughness Based on Cutting Parameters and Machining Vibration in End Milling Using Regression Method and Artificial Neural Network. Appl. Sci. 2020, 10, 3941. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).