
COIN: Counterfactual Image Generation for Visual Question Answering Interpretation


Abstract
:1. Introduction
- RQ1: How to change the answer of a VQA model with the minimum possible edit on the input image?
- RQ2: How to alter exclusively the region in the image on which the VQA model focuses to derive an answer to a certain question?
- RQ3: How to generate realistic counterfactual images?
2. Related Work
2.1. Interpretable Machine Learning
2.2. Visual Question Answering (VQA)
2.3. Interpretable VQA
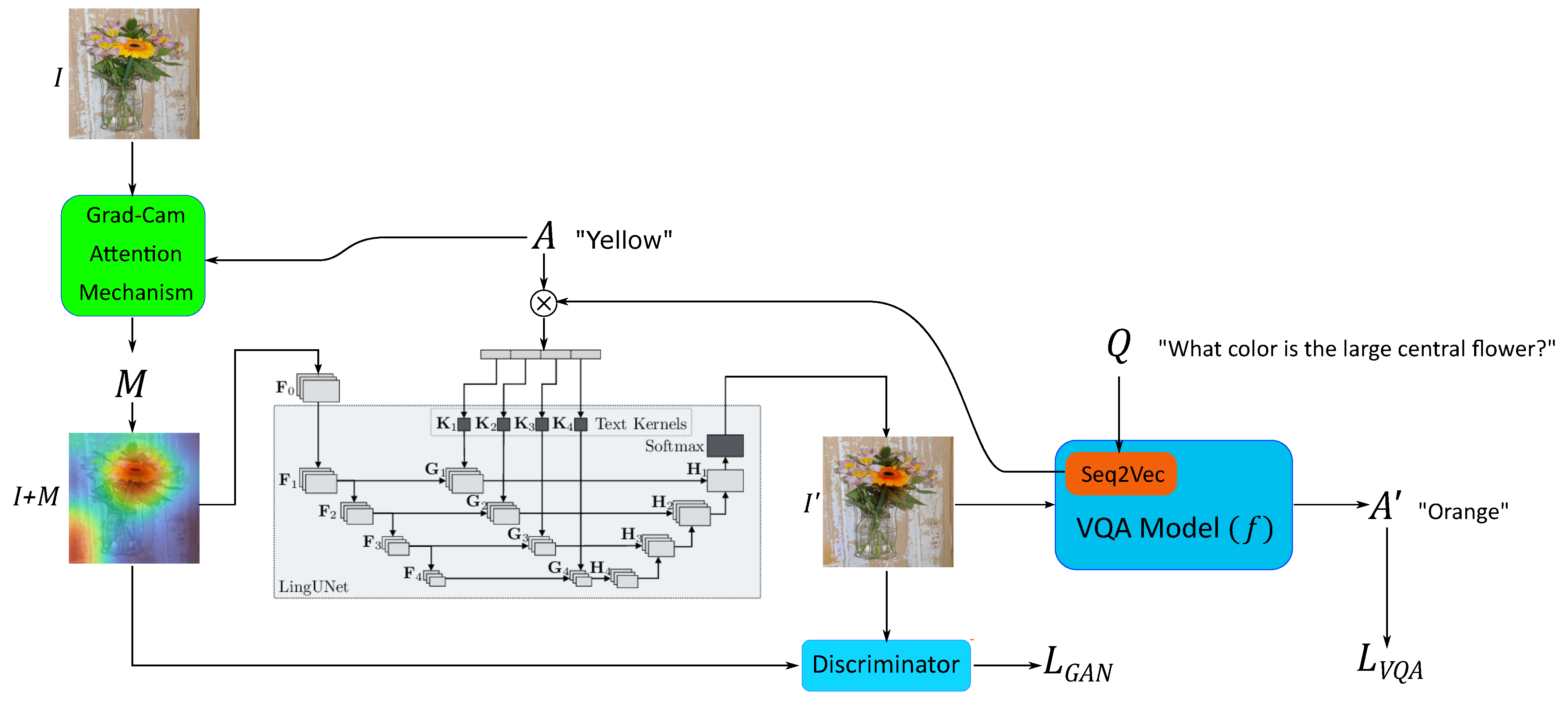
3. Method
3.1. ROI Guide
3.2. Language-Conditioned Counterfactual Image Generation
3.3. Minimum Change
3.4. Realism
Spectral Normalization for Stabilize Training
4. Experiments
4.1. Dataset
4.2. VQA System
4.3. Evaluation and Results
- Phase I: We present the participant with , Q and . The participant is requested then to answer the following questions:
- Is the answer correct?with three possible answers: Yes, No, and I am not sure.
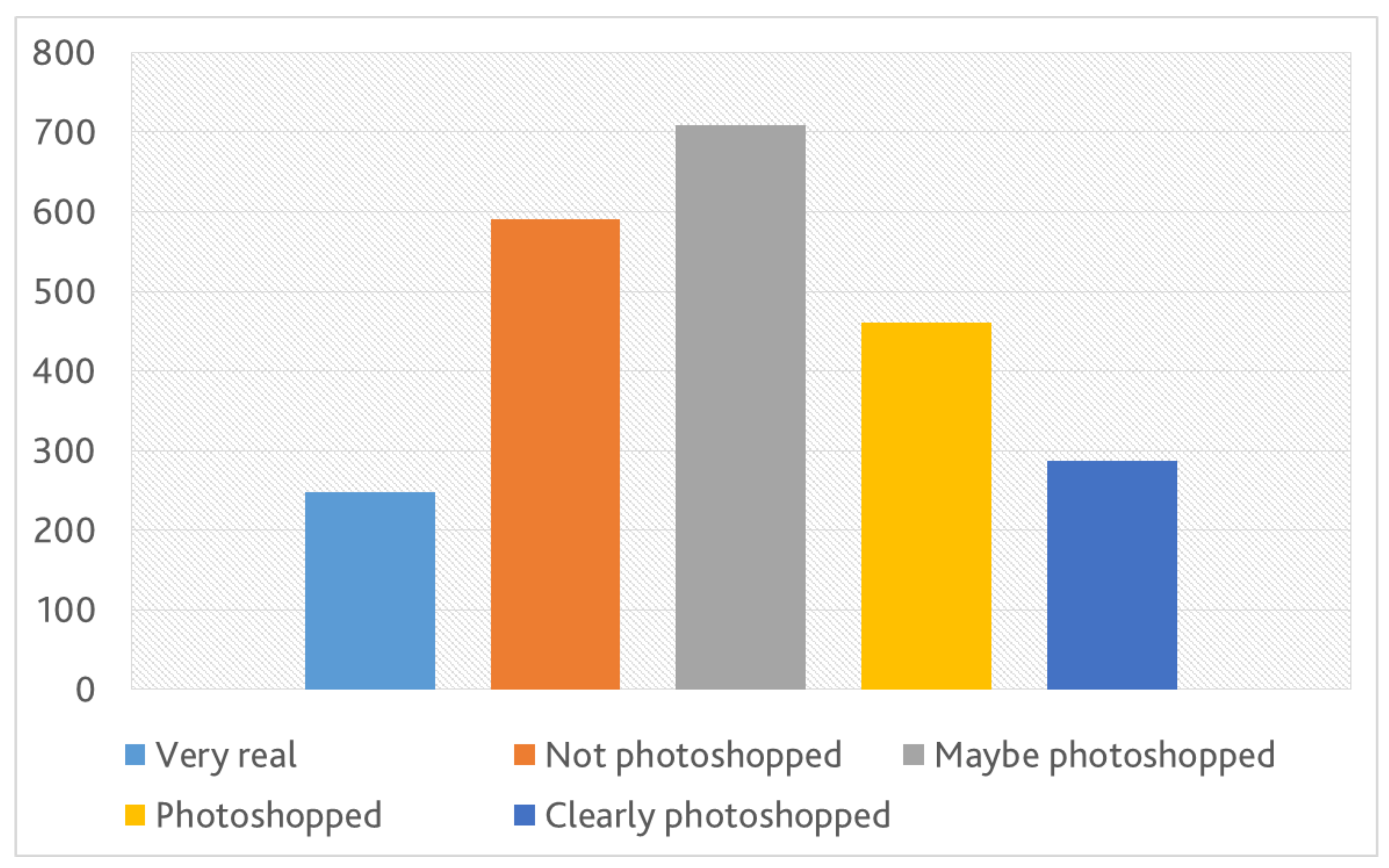
- Does the picture look photoshopped: any noticeable edit or distortion (automatic or manual)? with five possible answers (i.e., from Very real to Clearly photoshopped).
- Phase II: We present the participant with Q and both images I and together with the answers of the VQA system A and . The participant is requested then to answer the following questions:
- Which of the images is the original? with three possible answers: Image 1, Image 2 and I am not sure. Note that we do not indicate which of the images is I and which one is
- Is the difference between both images related to the question-critical object? with three possible answers: Yes, No and I am not sure
- Which pair (Image, Answer) is correct? with four possible answers: Image 1 (Note that we do not which of the images is I and which one is ), Image 2 (Note that we do not which of the images is I and which one is ), Both and None
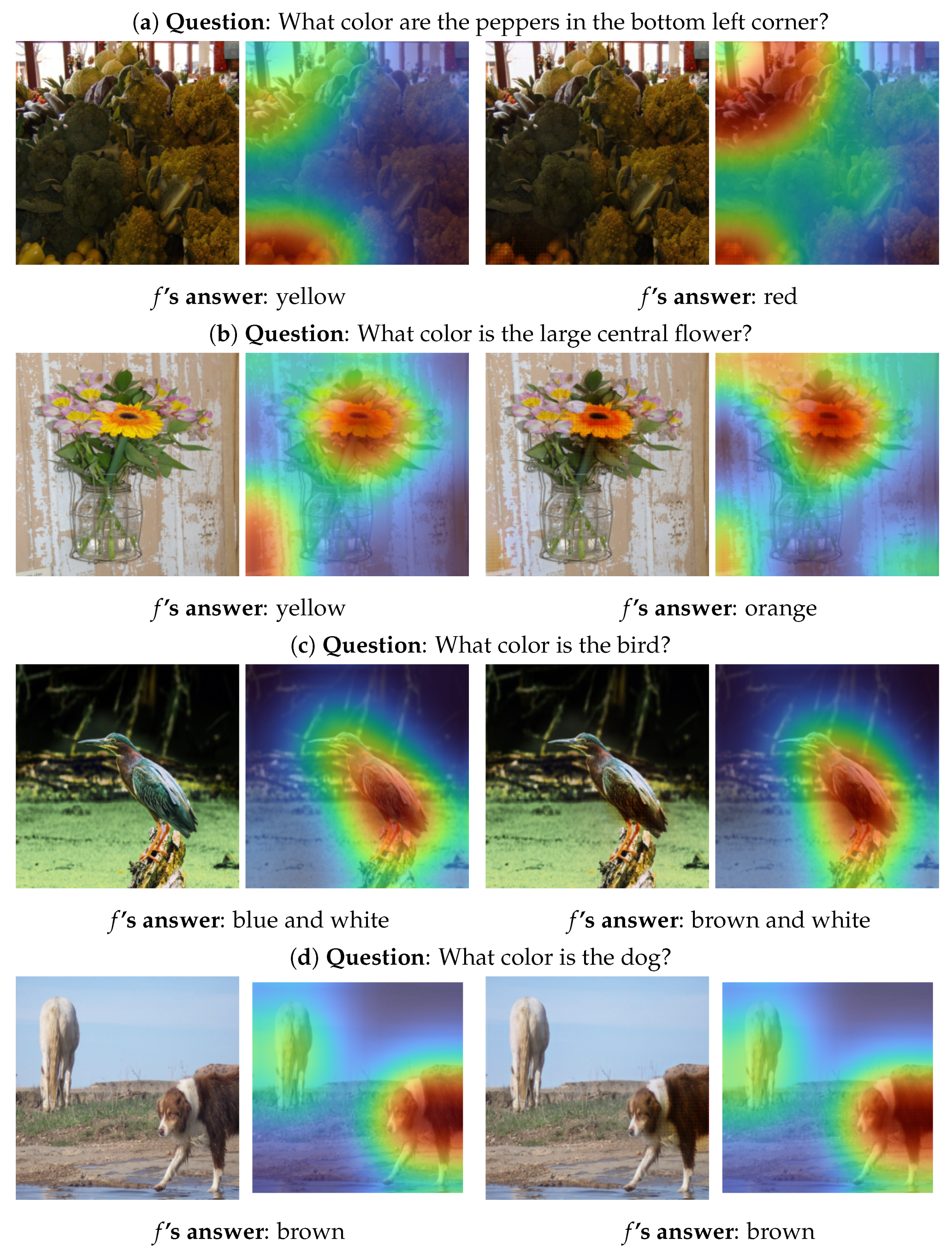
4.3.1. Semantic Change (RQ1)
- The question-critical region is very large but the VQA system focuses on a very small region. Once altering that region, the VQA system slightly deviates its focus to another region (see the example in Figure 5b and result discussion in RQ2). Although the answer does not change, it interprets the outcome of the VQA system and its behaviour. Specifically, why the model outputs the answer A and whether the model sticks to a specific region for answering a question Q.
- The image requires a significant change so that the answer is changed but due to the other constraints (e.g., minimum change, realism, etc), the generator cannot alter the image more. Here also, the interpretation would be that the VQA system is confident about the answer and a lot of change is required to change its answer.
- The VQA system does not rely on the image while deriving the answer (see Section 2.2).
4.3.2. Question-Critical Object (RQ2)
- If the object relevant to answering a question is relatively small compared to the rest of the image, the attention mechanism focuses on it completely in most cases. In other words, the computed intensities are higher for pixels belonging to the object than for the rest of the pixels. Under these circumstances, the generator can make larger changes to the entire object than to the rest of the image.
- Contrarily, if the object is very large or MUTAN pays attention to the background, the projection usually focuses only on a part of it. Consequently, the information that the generator receives allows it to apply more significant changes to a segment of the object or the background than to the rest of it.
- If MUTAN makes an incorrect prediction, this is often reflected by the projection not focusing on the question-critical object, but another element of the image, such as in Figure 5c.
4.3.3. Realism (RQ3)
4.3.4. Minimality of Image Edits
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, L.; Yan, X.; Xiao, J.; Zhang, H.; Pu, S.; Zhuang, Y. Counterfactual samples synthesizing for robust visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10800–10809. [Google Scholar]
- Niu, Y.; Tang, K.; Zhang, H.; Lu, Z.; Hua, X.S.; Wen, J.R. Counterfactual vqa: A cause-effect look at language bias. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12700–12710. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6904–6913. [Google Scholar]
- Zhang, Y.; Niebles, J.C.; Soto, A. Interpretable visual question answering by visual grounding from attention supervision mining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (Wacv), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 349–357. [Google Scholar]
- Li, Q.; Fu, J.; Yu, D.; Mei, T.; Luo, J. Tell-and-Answer: Towards Explainable Visual Question Answering using Attributes and Captions. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1338–1346. [Google Scholar]
- Pan, J.; Goyal, Y.; Lee, S. Question-conditioned counterfactual image generation for vqa. arXiv 2019, arXiv:1911.06352. [Google Scholar]
- Teney, D.; Abbasnedjad, E.; van den Hengel, A. Learning what makes a difference from counterfactual examples and gradient supervision. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 580–599. [Google Scholar]
- Fernández-Loría, C.; Provost, F.; Han, X. Explaining data-driven decisions made by AI systems: The counterfactual approach. arXiv 2020, arXiv:2001.07417. [Google Scholar]
- Chakraborty, S.; Tomsett, R.; Raghavendra, R.; Harborne, D.; Alzantot, M.; Cerutti, F.; Srivastava, M.; Preece, A.; Julier, S.; Rao, R.M.; et al. Interpretability of deep learning models: A survey of results. In Proceedings of the 2017 IEEE Smartworld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (Smartworld/SCALCOM/UIC/ATC/CBDcom/IOP/SCI), San Francisco, CA, USA, 4–8 August 2017; pp. 1–6. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- Kim, B.; Khanna, R.; Koyejo, O.O. Examples are not enough, learn to criticize! criticism for interpretability. Adv. Neural Inf. Process. Syst. 2016, 29, 2288–2296. [Google Scholar]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Tsang, M.; Liu, H.; Purushotham, S.; Murali, P.; Liu, Y. Neural interaction transparency (nit): Disentangling learned interactions for improved interpretability. Adv. Neural Inf. Process. Syst. 2018, 31, 5804–5813. [Google Scholar]
- Zhang, Q.S.; Zhu, S.C. Visual interpretability for deep learning: A survey. Front. Inf. Technol. Electron. Eng. 2018, 19, 27–39. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Wang, X.; Wu, Y.N.; Zhou, H.; Zhu, S.C. Interpretable CNNs for object classification. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3416–3431. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moraffah, R.; Karami, M.; Guo, R.; Raglin, A.; Liu, H. Causal interpretability for machine learning-problems, methods and evaluation. ACM SIGKDD Explor. Newsl. 2020, 22, 18–33. [Google Scholar] [CrossRef]
- Nóbrega, C.; Marinho, L. Towards explaining recommendations through local surrogate models. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 1671–1678. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Montavon, G.; Lapuschkin, S.; Binder, A.; Samek, W.; Müller, K.R. Explaining nonlinear classification decisions with deep taylor decomposition. Pattern Recognit. 2017, 65, 211–222. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Interpretable machine learning: Definitions, methods, and applications. arXiv 2019, arXiv:1901.04592. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Denton, E.; Hutchinson, B.; Mitchell, M.; Gebru, T.; Zaldivar, A. Image counterfactual sensitivity analysis for detecting unintended bias. arXiv 2019, arXiv:1906.06439. [Google Scholar]
- Gomez, O.; Holter, S.; Yuan, J.; Bertini, E. ViCE: Visual counterfactual explanations for machine learning models. In Proceedings of the 25th International Conference on Intelligent User Interfaces, Cagliari, Italy, 17–20 March 2020; pp. 531–535. [Google Scholar]
- Goyal, Y.; Wu, Z.; Ernst, J.; Batra, D.; Parikh, D.; Lee, S. Counterfactual visual explanations. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 2376–2384. [Google Scholar]
- Hendricks, L.A.; Hu, R.; Darrell, T.; Akata, Z. Generating counterfactual explanations with natural language. arXiv 2018, arXiv:1806.09809. [Google Scholar]
- Sokol, K.; Flach, P.A. Glass-Box: Explaining AI Decisions With Counterfactual Statements Through Conversation with a Voice-enabled Virtual Assistant. Int. Jt. Conf. Artif. Intell. Organ. 2018, 5868–5870. [Google Scholar] [CrossRef] [Green Version]
- Verma, S.; Dickerson, J.; Hines, K. Counterfactual explanations for machine learning: A review. arXiv 2020, arXiv:2010.10596. [Google Scholar]
- Pearl, J. Theoretical Impediments to Machine Learning with Seven Sparks from the Causal Revolution. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; p. 3. [Google Scholar]
- Malinowski, M.; Fritz, M. A multi-world approach to question answering about real-world scenes based on uncertain input. Adv. Neural Inf. Process. Syst. 2014, 27, 1682–1690. [Google Scholar]
- Srivastava, Y.; Murali, V.; Dubey, S.R.; Mukherjee, S. Visual question answering using deep learning: A survey and performance analysis. arXiv 2019, arXiv:1909.01860. [Google Scholar]
- Zhang, P.; Goyal, Y.; Summers-Stay, D.; Batra, D.; Parikh, D. Yin and yang: Balancing and answering binary visual questions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5014–5022. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Geman, D.; Geman, S.; Hallonquist, N.; Younes, L. Visual turing test for computer vision systems. Proc. Natl. Acad. Sci. USA 2015, 112, 3618–3623. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.K. Survey of visual question answering: Datasets and techniques. arXiv 2017, arXiv:1705.03865. [Google Scholar]
- Wu, Q.; Teney, D.; Wang, P.; Shen, C.; Dick, A.; van den Hengel, A. Visual question answering: A survey of methods and datasets. Comput. Vis. Image Underst. 2017, 163, 21–40. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked attention networks for image question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 21–29. [Google Scholar]
- Zhu, X.; Mao, Z.; Liu, C.; Zhang, P.; Wang, B.; Zhang, Y. Overcoming language priors with self-supervised learning for visual question answering. arXiv 2020, arXiv:2012.11528. [Google Scholar]
- Das, A.; Agrawal, H.; Zitnick, L.; Parikh, D.; Batra, D. Human attention in visual question answering: Do humans and deep networks look at the same regions? Comput. Vis. Image Underst. 2017, 163, 90–100. [Google Scholar] [CrossRef] [Green Version]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. arXiv 2016, arXiv:1602.07332. [Google Scholar] [CrossRef] [Green Version]
- Ben-Younes, H.; Cadene, R.; Cord, M.; Thome, N. Mutan: Multimodal tucker fusion for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2612–2620. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Bergholm, F. Edge focusing. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 6, 726–741. [Google Scholar] [CrossRef]
- Misra, D.; Bennett, A.; Blukis, V.; Niklasson, E.; Shatkhin, M.; Artzi, Y. Mapping Instructions to Actions in 3D Environments with Visual Goal Prediction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2667–2678. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Lin, Z.; Sekar, V.; Fanti, G. Why Spectral Normalization Stabilizes GANs: Analysis and Improvements. arXiv 2020, arXiv:2009.02773. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Nam, S.; Kim, Y.; Kim, S.J. Text-adaptive generative adversarial networks: Manipulating images with natural language. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 42–51. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. Adv. Neural Inf. Process. Syst. 2016, 29, 2234–2242. [Google Scholar]
- Zhu, D.; Mogadala, A.; Klakow, D. Image manipulation with natural language using Two-sided Attentive Conditional Generative Adversarial Network. Neural Netw. 2021, 136, 207–217. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| The counterfactual generator proposed in this paper. | |
| f | The VQA system (i.e., MUTAN [42] in this paper) |
| I | Original image |
| Q | Question about I |
| A | The answer of f to Q given I |
| h | I’s height |
| w | I’s width |
| The counterfactual image of I, generated by | |
| The answer of f to Q given | |
| An image generated by | |
| M | The attention map of I |
| The attention map of |
| Training Set | Validation Set | ||||
|---|---|---|---|---|---|
| All | |||||
| Color | |||||
| Shape | |||||
| Same VQA Answers | ALL | ||||
| Color | |||||
| Shape | |||||
| Different VQA Answers | ALL | ||||
| Color | |||||
| Shape | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boukhers, Z.; Hartmann, T.; Jürjens, J. COIN: Counterfactual Image Generation for Visual Question Answering Interpretation. Sensors 2022, 22, 2245. https://doi.org/10.3390/s22062245
Boukhers Z, Hartmann T, Jürjens J. COIN: Counterfactual Image Generation for Visual Question Answering Interpretation. Sensors. 2022; 22(6):2245. https://doi.org/10.3390/s22062245
Chicago/Turabian StyleBoukhers, Zeyd, Timo Hartmann, and Jan Jürjens. 2022. "COIN: Counterfactual Image Generation for Visual Question Answering Interpretation" Sensors 22, no. 6: 2245. https://doi.org/10.3390/s22062245
APA StyleBoukhers, Z., Hartmann, T., & Jürjens, J. (2022). COIN: Counterfactual Image Generation for Visual Question Answering Interpretation. Sensors, 22(6), 2245. https://doi.org/10.3390/s22062245