Abstract
As the population in the Western world is rapidly aging, the remote monitoring solutions integrated into the living environment of seniors have the potential to reduce the care burden helping them to self-manage problems associated with old age. The daily routine is considered a useful tool for addressing age-related problems having additional benefits for seniors like reduced stress and anxiety, increased feeling of safety and security. In this paper, we propose a solution for identifying the daily routines of seniors using the monitored activities of daily living and for inferring deviations from the routines that may require caregivers’ interventions. A Markov model-based method is defined to identify the daily routines, while entropy rate and cosine functions are used to measure and assess the similarity between the daily monitored activities in a day and the inferred routine. A distributed monitoring system was developed that uses Beacons and trilateration techniques for monitoring the activities of older adults. The results are promising, the proposed techniques can identify the daily routines with confidence concerning the activity duration of 0.98 and the sequence of activities in the interval of [0.0794, 0.0829]. Regarding deviation identification, our method obtains 0.88 as the best sensitivity value with an average precision of 0.95.
1. Introduction
In Europe, it is estimated that the number of older adults will continue to increase from 90.5 million at the start of 2019 to reach 129.8 million by 2050 [1]. At the same time, the number of formal and informal caregivers will not grow to match the increasing need, resulting in higher care costs and a decrease in quality of life [2]. The remote monitoring and assessment solutions integrated into the living and working environment of seniors have the potential to reduce the care burden, helping them to self-manage problems associated with old age. Moreover, older adults’ chronic condition is an important factor that should be considered, being complicated by additional risk factors such as deficits in activities of daily living, social situations exposing them to isolation and lack of support, cognitive decline and emotional anxiety [3]. Poorly managed care often inadequately considers the seniors’ health decline due to the lack of remote objective monitoring and does not address promptly potential problems.
Studies show that slowing the cognitive decline and maintaining independent functioning in conducting the activities of daily living (ADL) are important goals in supporting the care and wellbeing of older adults [4]. Using ambient assistive technologies in older adults’ homes is a promising solution for better managing their condition, helping them to live independently with as little support as possible from caregivers. In this context, the daily routine is considered a useful tool for addressing cognitive decline and self-management of chronic conditions having additional benefits like reduced stress and anxiety, increased feeling of safety and security. The use of IoT sensors and statistical and computational intelligence methods is promising as they allow formal and informal caregivers to establish and monitor the daily routines of older adults in an objective manner and to detect potential deviations requiring intervention. Following a daily routine induces a state of calm and comfort, for older adults reducing the level of anxiety and stress, and can increase the likelihood of being transferred into the long-term memory, this being very important in case of cognitive decline. By performing regular activities from the daily routine, their self-esteem and confidence may increase, as they are able to perform activities independently.
Equally important is the continuous monitoring of daily routine and any deviations from it. This can contribute to the identification of decreasing functionality in activities of daily living as well as of cognitive decline [5]. The traditional screening methods for assessing the capacity to conduct daily activities are usually based on self-reporting and they lack contextual information, not allowing for wider adoption. The use of innovative non-invasive monitoring solutions may allow the identification of sudden or gradual deviations from the baseline routines, allowing the setup of personalized intervention processes prolonging the autonomy and well-being of older adults. Such solutions could also improve the quality of life and could help older adults to live more years in a meaningful and dignified manner. Unfortunately, even when the older adult with noticeable decline symptoms visits the healthcare professional for an assessment, research shows that, in many cases, such deviations are difficult to identify due to a lack of information.
In this paper, we propose a solution for identifying the daily routines of seniors using the monitored activities of daily living and for inferring deviations from the baseline routines that may require professional or informal caregiver interventions. The paper’s novel contributions are the following:
- Markov model-based method for identifying the daily routines of older adults considering the daily living activity probability transitions and activity length.
- Technique for identifying relevant deviations from daily routines using entropy rate and cosine functions to measure and assess the similarity between the sequence of activities registered in a specific day and the baseline routine.
- Distributed system for testing and evaluation of the proposed methods which uses Beacons and trilateration techniques for monitoring the activities of the daily living of older adults.
The paper is structured as follows: Section 2 reviews some of the existing approaches in the field of daily routine assessment and anomalous behavior detection, Section 3 presents the daily routine assessment method, Section 4 presents the solution for deviation from baseline routine identification, Section 5 presents validation and the experimental results, while Section 6 concludes the paper.
2. Related Work
In the studied literature, the existing approaches for behavior anomaly detection differ based on the number of daily activities considered, strategies used to detect normal/abnormal behaviors and the features considered as relevant in the process [6,7,8]. The simplest type of anomaly is the punctual anomaly. In this case, each daily activity is considered independent, and the anomaly identification does not consider the potential relations with other activities. Several approaches aim to identify such anomalies in the case of elders with mild cognitive impairments living in smart homes. They use rule-based induction [9], statistical and knowledge-based methods [10,11] or combine clustering algorithms with recurrent neural networks [12].
A prerequisite in this case is the accurate detection of daily activities. In [13] a two-layer Hidden Markov Model (HMM) is used to learn and recognize basic activities. In the first layer, location data from sensors is used to predict the activity class and in the second layer the prediction is refined for activities under the same class. It obtains better accuracy than approaches that use Naive Bayes or Conditional Random Field, but it does not consider the model integration with sensor-based monitoring infrastructure. In [14] a hybrid approach for recognizing ADL is proposed using smartphone sensors combined with ambient ones. A coupled Hidden Markov model is used to model the temporal evolution of each person’s activity, while specific spatiotemporal constraints are used to limit the viable state space of activities. The approach features good results; however, it is difficult to use with older adults, as they will have to carry their smartphone with them all the time. A deep-learning framework to recognize complex ADL leveraging onto activity state representation while considering motion and environment sensor data is proposed in [15]. The results obtained are better compared with HMM and LSTM (Long Short-Term Memory) approaches, but it does not feature any anomaly detection. In [16] the authors propose a solution, which is the use of wearable sensors, convolutional and LSTM recurrent units to learn ADL features and temporal dependencies. It offers better accuracy compared with Convolutional Neural Networks (CNNs) based approaches, but limited results have been provided considering monitored data.
In the case of collective anomalies, a group of activities is analyzed together to identify whether the group or sequence is normal or abnormal. Authors of [17] uses data collected from wearable sensors to detect anomalies in elders’ behavior. The authors define a probabilistic model based on several parameters such as location, duration, start time and activities sequences. In [18] signals collected from an accelerometer are combined with ECG signals to detect users’ behavioral anomalies, while in [19] a supervised machine learning algorithm to classify anomalous sequences of activities is proposed. In the classification of contextual anomalies, daily activities are analyzed considering contextual features such as weekday or weekend, medication, etc. Solutions are proposed for real-time anomaly detection, with the contextual features being used for pruning the identified anomalies [20,21]. The daily patterns are detected with machine learning techniques and heuristics are employed to select relevant contextual features and fine-tune the learning parameters [22]. The spatial, temporal and contextual features are used to detect other types of anomalies such as incomplete activities, confusion in performing the activities, repeating activities or disruption of sleep [10,23,24]. Regardless of the anomaly type, two classes of strategies can be used for abnormal behavior detection. The profiling strategy supposes learning a model showing normal behavior [11,25]. The model is then used to detect anomalies in the new incoming data. The behavior is considered abnormal if there is a deviation from the learned model. In the case of the discriminating strategy, the abnormal behavior is included in the training data and the learned model is used then on incoming data [24,26].
The algorithms used for implementing the abnormal behavior detection strategies are either statistical or based on machine learning techniques. In the first case, statistical methods are used to detect abnormal behaviors. In [27], Hidden Markov Models (HMMs) are constructed from monitored data to predict the changes that could appear in the health status of older adults. The solution presented in [11] detects abnormal behavior in the case of elders using Bayesian statistics. Three types of likelihoods are considered: the sensor activation, the sensor sequence firing, and the event duration. In [28] a transition probability-based matrix which models the daily activity inside a room and room-to-room transitions is presented. A transition probability matrix is defined and used to model the daily mobility behavior of a person. Authors of [29] use a probabilistic Spatio-temporal statistical model to identify the daily behavior of an elder, and a cross-entropy measure to determine significant deviations. The daily routine of an elder is modeled as a collection of behavioral places located arbitrarily in a generic space [30]. Virtual pheromones are used to build images of the distribution maps which describe the evolution in space and time of the interactions between the elder and the environment. The deviations from the daily routine are detected by applying statistical analysis on top.
Computational intelligence methods such as supervised, semi-supervised and unsupervised learning have been used in the literature to detect normal and abnormal behavior patterns. In [31] Random Forest algorithms are used to create clusters of human behavior patterns, while agglomerative clustering is used to reveal data clusters into a 2D space. In [32], the kernel K-means algorithm is combined with a novel nominal matrix factorization method to detect the daily living routine of an elder. A behavior-aware flow graph is built to represent the trajectory data, then a kernel k-means algorithm is used to identify sub-flows representing behavioral patterns, and finally, a nominal matrix factorization method is used to identify the daily routine. In [33] the k-means clustering algorithm is applied to extract the daily behavior model of a person, and then the model and a cross-entropy measure are used to detect anomalies. Neural networks are used for behavioral anomaly detection [24]. Vanilla Recurrent Neural Networks (VRNNs), Long Short Term RNNs (LSTMs) and Gated Recurrent Unit RNNs (GRUs) are used in the case of elders with dementia to recognize daily life activities and to learn daily life behavioral routines. Authors of [24] propose a method based on Convolutional Neural Networks (CNNs) to identify abnormal behaviors such as repetitive activities, sleeping problems and confusion in performing an activity, etc. In [26] Long Short-Term Memory (LSTM), Convolutional Neural Network (CNN), CNN-LSTM and Autoencoder-CNN-LSTM are used to identify and predict the abnormal behavior of elders. The four networks have been applied on two public data sets, namely SIMADL Dataset [34] and MobiAct Dataset [35], and the experimental results demonstrate that hybridization of CNN with LSTM provides the best results in the case of detecting temporal and spatial abnormal behavior. In [36] an unsupervised approach for learning the ADL routine of elders living alone and detecting deviations from it is proposed. The daily living activities are identified by correlating the elder’s location in the house with the location’s power consumption. The approach deals with identifying the activities of daily living, modeling the basic routine of the elder and detecting the deviations from the routine in new sensor data using a fuzzy inference system to detect deviations from the routine. A Probabilistic Neural Network for activity recognition and an H2O autoencoder to identify anomalies about activity duration and the number of subevents are combined in [25]. In [37] the daily routine is sketched in collaboration with the monitored person, who is asked to describe the activities carried out daily. Based on the identified routine, a score is calculated that reflects how well an activity fits with the daily routine. In [7] the normal behavior of a person is defined as a sequence of four activities (sleeping, eating, taking a shower and leaving home), which are performed at specific times of the day. For detecting the behavior model, an unsupervised approach based on the DBSCAN algorithm is applied and the deviations are detected by computing a similarity score between the current behavior of the elder and her/his normal behavioral pattern. Other methods are based on a graph or task models. In [38], a graph that represents the sequence of performed activities and the duration corresponding to each activity for a specific participant is built and used to detect abnormal behavioral anomalies. In [39] a method for detecting behavioral changes in the daily routine of a person is defined by comparing activity curves that model the daily activity routines of a person between different points of time. In [40] the authors propose a method that compares the elder’s expected behavior with the elder’s actual behavior registered as a sequence of events unfolded in the current context. The elder expected behavior is represented as a task model which consists of sequences of tasks performed by an elder in a day (i.e., wake up, go to the bathroom, take medicine without food, prepare breakfast, take another medicine).
This paper builds upon the existing state of the art by proposing a solution for identifying the daily routines of older adults considering the length of the monitored activities and transition probabilities among activities as relevant features. The daily activity monitoring is done using Beacon technology, which offers an affordable, easy-to-install solution with a high potential of personalization since it may be associated with specific objects and related to activities that are being conducted. For identifying the daily routine, we have proposed a Markov-based model. Since the daily routine of a person is defined as the sequence of activities it is suitable to use a probabilistic model in which the transitions between activities are modeled using probabilities. Existing approaches in the reviewed literature based on probabilistic models such as [11,17] consider a few types of probabilities as parameters in their models, identifying a limited precision of the potential deviations. In our approach, new parameters have been considered to improve the model precision such as (i) the activity length probability used to identify the most likely length for the daily routine, (ii) the probability of conducting an activity is used to identify the most likely activities to be part of the routine and (iii) the probabilities of an activity to be the start or end activity of the routine. For anomaly detection, we used a two steps approach that is based on entropy rate and cosine similarity measure. The entropy rate offers the flexibility to consider the days for which we have only minor fluctuations compared to the daily routine in terms of the sequence of activities performed as normal and those for which there are major fluctuations as abnormal. In this way, we introduce the concept of flexibility in defining the daily routine of a person and the days that follow the daily routine. The cosine similarity measure was used to reduce the false-positive rate that could be generated by using the entropy rate. The days that are classified as being normal thus without significant deviation using the entropy metric are then further assessed using the cosine similarity metric to improve the precision of deviation detection. As a result, the precision of our approach is better, as shown in the experimental evaluation section of this paper.
3. Daily Routine Detection
For baseline evaluation, we used a Markov model considering activity sequencing, (i.e., the order in which they are conducted) and activity transition probabilities. Four types of probabilities were considered.
The first one is the transition probability, , which refers to the probability of activity succeeding activity . To calculate the transition probabilities, we considered the number of times the specific activity transition appears () and divided it by the number of all transitions starting with the same activity but not having as successor activity :
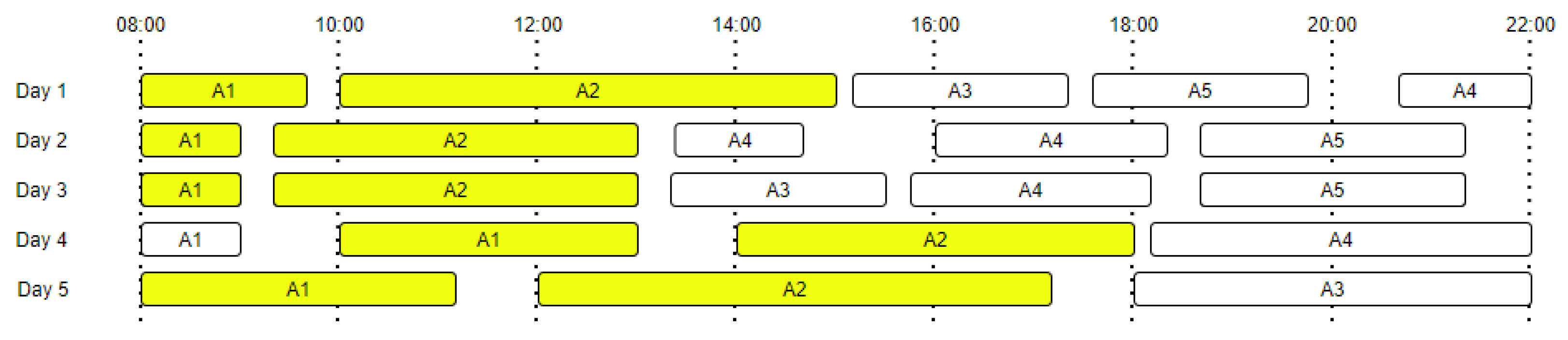
Figure 1 presents an example of daily activity transitions for five days, highlighting all the activity transitions from to . The number of transitions starting from a specific activity is equal with the total number of occurrences of that activity, which means that even if the activity is the last one from a day and has no activity following it, we will still count it in the total number of events. In our approach we have considered daily routines; thus, the last activity of one day does not transition into the first activity of the following day.
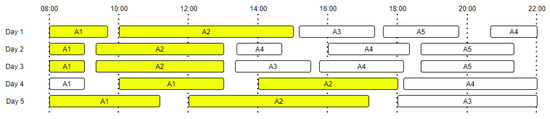
Figure 1.
Daily activities and transition probabilities ( to transitions are marked with yellow).
The second probability is the occurrence probability of an activity , , which represents the probability with which an activity is executed by an older adult. It is computed as:
where represents the number of occurrences of the activity , represents the number of occurrences of an activity (including activity) in the training data set and represents the total number of activities from the training data set.
The third and fourth probabilities are the probability of activity being the first activity of the day () and the probability of activity being the last activity of the day (). They are computed by dividing the number of days starting with activity and, respectively, ending with activity by the total number of days.
For baseline detection we construct the transition probability matrix (which corresponds to the Markov model) with each position in the matrix, with representing the probability that activity follows activity :
The baseline is modeled as the most likely sequence of activities that the older adult will do in a specific day:
The baseline detection algorithm iterates through the whole set of daily living activities and considers for each activity the probabilities to be first or last in the day as well as the transition probabilities. The iteration is started from the most likely activity to be the first one in a specific day (the activity with the highest ). For each activity we compare the probability that the activity is the last one in the daily sequence, , with all the transition probabilities . If a transition probability higher than is found, then the activity becomes the current activity and and are added in sequence to the daily baseline. The algorithm stops and returns the baseline when no other activity can be found such that , where is the last activity in the baseline sequence. The variable is used to fine tune the importance of the activity in the baseline detection algorithm.
However, when individuals always end their days with the same activity or follow a strict transition activity the algorithm stopping condition might be affected. If the end activity probability is not evenly distributed, the algorithm tends to favor a shorter baseline, stopping whenever the most likely ending activity is reached (i.e., no transition probability is greater than the end probability in this case). Alternatively, if two activities with high transition probability between each other are encountered, the algorithm would tend to bounce from one activity to the next indefinitely, thus favoring longer baselines. To address this issue, we considered another feature, the activity length probability. We determine the most likely length for a baseline using a weighted average of the length of daily activities, and then discount the end probability with respect to the relative distance between the average length and the length of the baseline which is currently constructed. Algorithm 1 presents the pseudocode for the baseline detection. The closer we get to the median length, the smaller the discount should be, thus we used an inversely proportional mapping function denoted “interpolate”.
| Algorithm 1: Baseline detection considering both activity sequence and activity length |
| Inputs:—transition probability matrix, —set holding each activity probability to be the first one of the day, —set holding each activity probability to be the last one of the day, —end probability weight, —length median, —length probability weight, —the transition probability from an activity to an activity ; Outputs: —activity sequence representing the baseline. Begin 1 3 4 4 5 6 while do 7 8 9 10 11 12 foreach do 13 14 if then 15 16 17 end 18 end 19 end 20 return End |
First, the probability of occurrence of each potential baseline length is computed and then it is used to determine the median length of the daily baseline using a weighted average. Linear interpolation is used to map in an inversely proportional manner the interval to the interval, where acts as a weight allowing us to tune the emphasis put by the algorithm on the length of the baseline. The value is used to proportionally discount the end probability based on the current length difference between the median and the baseline. As the baseline’s length approaches the median the discount is reduced. When the median length is reached the discount is set to 0, thus effectively removing any notion of length from the algorithm’s logic. As a result, the length probability parameter ensures the termination logic is not affected by unevenly distributed data. The length discount, , will be calculated by interpolating in each step the current length of the baseline in the interval, and then mapping it to the [, 0] interval.
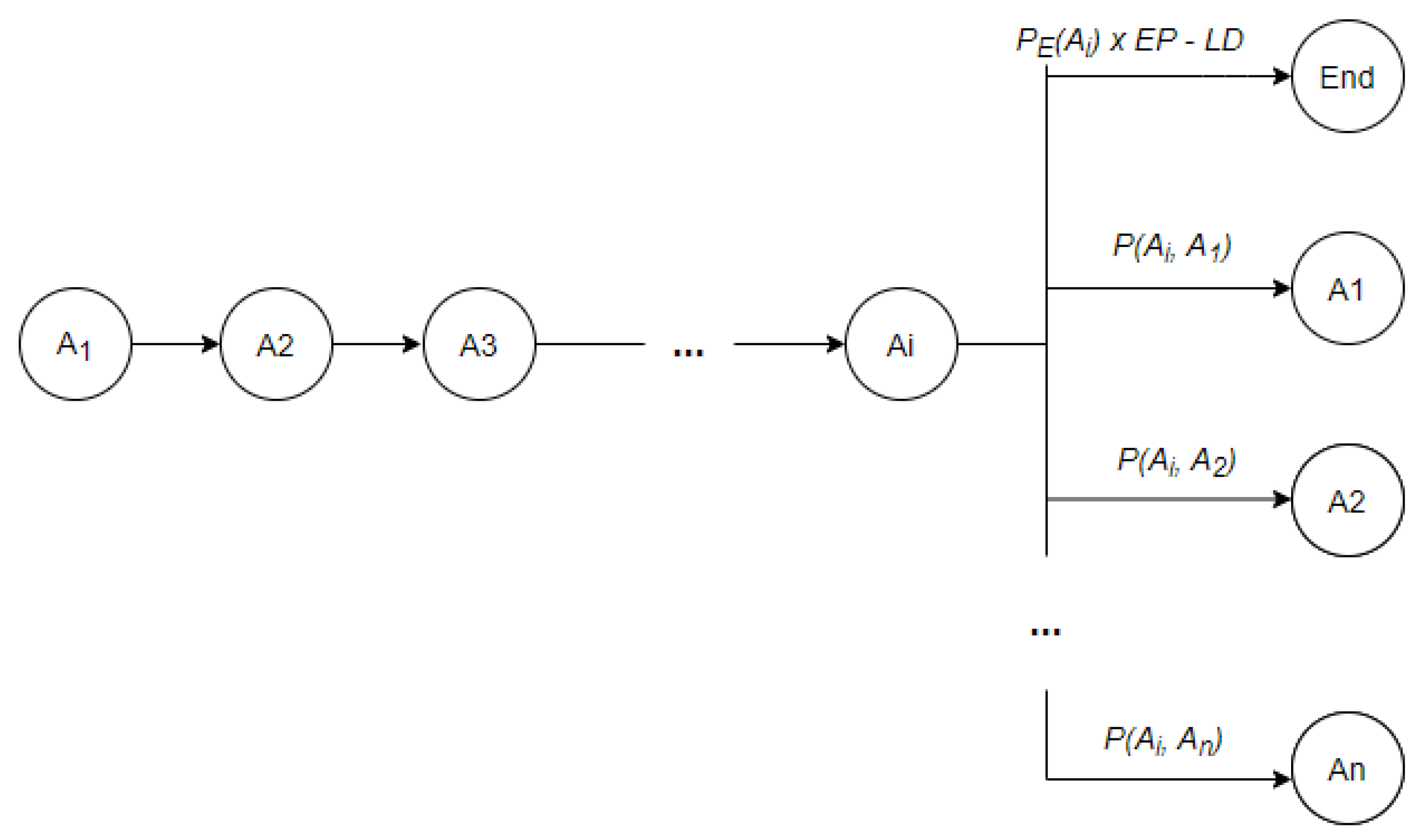
Finally, the importance of the baseline length and of the activity end probability can be tuned considering the data at hand using variables and . Their values can vary between minimum importance and maximum importance concerning the algorithm. Irrespective of the chosen parameters’ configuration the baseline should have the highest Markov product. For example, let us consider that is the last activity chosen as part of the baseline sequence at step . At step the algorithm has options to choose from, where is the number of distinct daily activities (see Figure 2). To yield the maximum Markov product, we need to choose the option with the highest associated probability. The probability to end the sequence with as the last activity is calculated as weighted with and discounted by the length discount factor LD. If the algorithm cannot find another activity to add to the baseline such that then is chosen as the end activity of the baseline and the algorithm’s execution finalizes. Otherwise, if an activity satisfying the above condition is found, is added to the baseline sequence and the process is repeated with step .
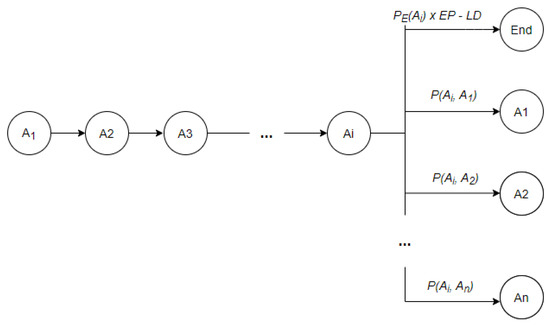
Figure 2.
Activity selection in baseline detection process.
4. Deviation Identification
As defined in the previous section the baseline is a sequence of daily living activities executed by an older adult, representing their normal routine. Therefore, to be able to automatically detect anomalies in terms of deviations from the daily routine, a function that associates the sequence of activities registered for a day to a certain similarity value in relation to the baseline is needed. Moreover, an interval of acceptance should be defined in such a way that whenever the value resulting from the mapping falls inside the interval, we accept it as a sequence of activities similar to the daily routine baseline. Alternatively, the day will be flagged as an anomaly or with a deviation from the normal routine.
The entropy rate is a function that has been extensively studied for similarity measures and its pattern detection capabilities [41]. Entropy is usually used as a measure for quantifying information and indicating the degree of randomness in a sequence of activities. Thus, the entropy rate function can be applied to our daily sequence of activities leveraging the already computed transition probability matrix. The following formula is used in similarity computation:
where is the entropy value and is the transition probabilities from an activity to an activity in the Markov model associated with the day.
The higher the entropy value, the higher the uncertainty (randomness). If all the daily recorded activity transitions occur with equal probability, then the entropy value reaches its maximum. The entropy rate function value is proven to work well for pattern matching [42,43], but the downside in our case is the fact that it relies only on transition probabilities. For instance, let for two arbitrary activities and ; then, the entropy value used above assigns the same value to both transitions. We could improve the discrimination ability in the case of daily deviation from baseline detection by incorporating the probability of occurrence of each registered activity. In this case the entropy rate is determined as:
The interval of confidence, , is calculated using the entropy rates, using the following formula:
where is the entropy rate of the daily routine baseline, is the entropy rate of the new registered daily sequence of activities and is a confidence index empirically determined considering the size and variance of the data. If the data is scarce and/or has a high deviation, we use a higher confidence index, thus effectively increasing the boundaries of the confidence interval to reduce the false positive rate (days detected erroneously as anomalous). Otherwise, if the data is uniform and in sufficient quantity, we reduce the confidence index for better accuracy. The anomalies are identified as days in which entropy rates of the registered sequence of activities exceed the confidence interval boundaries.
Anyway, considering only the transition probabilities of the daily registered activities in a day is not always sufficient; thus, the duration in time of each activity is also considered. Introducing this second dimension will potentially reduce the false positive rate, therefore improving the accuracy of deviation detection. In this case the daily routine baseline is augmented by associating each activity in the original sequence with its average duration.
The average duration of a specific activity is calculated considering all available historical data by adding the lasting time associated with each activity registration and dividing it by the number of occurrences of that activity. The following formula is used:
where represents the time duration of the jth occurrence of activity Ai and m the total number of activity j occurrences.
Moreover, in this case comparison measure and a threshold need to be defined and used in the same way in which the confidence interval and the entropy rate were used for the unidimensional deviation detection. The function used to quantify a day similarity in relation to the baseline considering the duration of registered activities is cosine similarity. Cosine similarity is a measure used to quantify the similarity between two or more vectors measuring the “distance” between two vectors in space. The formula below has been used:
where B represents the daily routine baseline, d is the day for which the sequence of activities is analyzed, is the duration of the activity in the day to be assessed and is the duration of the activity recorded in the baseline. If the two vectors for the current day and for the baseline are 90 degrees apart, the cosine will be 0, indicating maximum discrepancy between the two vectors. Alternatively, if the two vectors are perfectly similar, the angle between them will be 0 degrees, yielding a cosine of 1. Essentially the closer the cosine similarity measurement is to 1, the more similar the two vectors are.
Algorithm 2 shows the pseudocode for the duration-based anomaly detection. The Davg variable stores the average duration for each activity. We assume the functions for computing the average duration, computeAverageDuration, and the one used to compute the cosine similarity of two days, cosineSimilarity, have already been defined.
| Algorithm 2: Anomaly detection |
| Inputs: TD—testing data set, NDT—days that respect the baseline from the training data set, [c1,c2]—confidence interval, DSMax—duration similarity threshold. Outputs: AND—days deviated from baseline, APD—days that respect the baseline 1 ND ← []; 2 AND ← []; 3 APD ← []; 4 Davg ← computeAverageDuration(NDT); 5 foreach dayi in TD do 6 E ← computeEntropy(dayi); 7 if c1 ≤ E ≤ c2 then 8 append(ND, dayi); 9 else 10 append(AND, dayi); 11 end 12 end 13 foreach dayi in ND do 14 Dt ← Davg 15 if len(Davg)! = len(dayi) then 16 CA ← union(dayi, Davg); 17 dayi ← difference(dayi, difference(dayi, CA)); 18 Dt ← difference(Davg, difference(Davg, CA)); 19 endif 20 CS ← computeCosinesSimilarity(dayi, Dt); 21 if CS > DSMax then 22 append(APD, dayi); 23 else 24 append(AND, dayi); 25 end 26 end 27 return AND, APD |
We might have a different length in terms of number of activities for the baseline and the day being compared. In this case, we compute the minimum distance of the two and simply discard the remaining values in the bigger duration sequence. Using this approach, we ensure that a day that has already passed the initial anomaly check (based on ordering and transition probabilities, described in the previous subsection) will not be penalized again. Otherwise, take for example the 0-padding approach (pad the smaller sequence with 0 s), if the day would mimic the baseline up to the second to last entry, with the last activity in the baseline missing, we would have to add a 0 corresponding to the last entry in the duration sequence of the day. When calculating the cosine similarity in this case, the 0 would strongly affect the result of the duration check step. However, the missing activity was already accounted for in the previous step, ordering anomaly detection, and it passed as a day respecting the baseline.
5. Evaluation Results
This section describes the system developed for the monitoring and identification of older adults, ADLs, and the results obtained in relation with daily routine detection and deviation identification.
5.1. Activity of Daily Living Identification
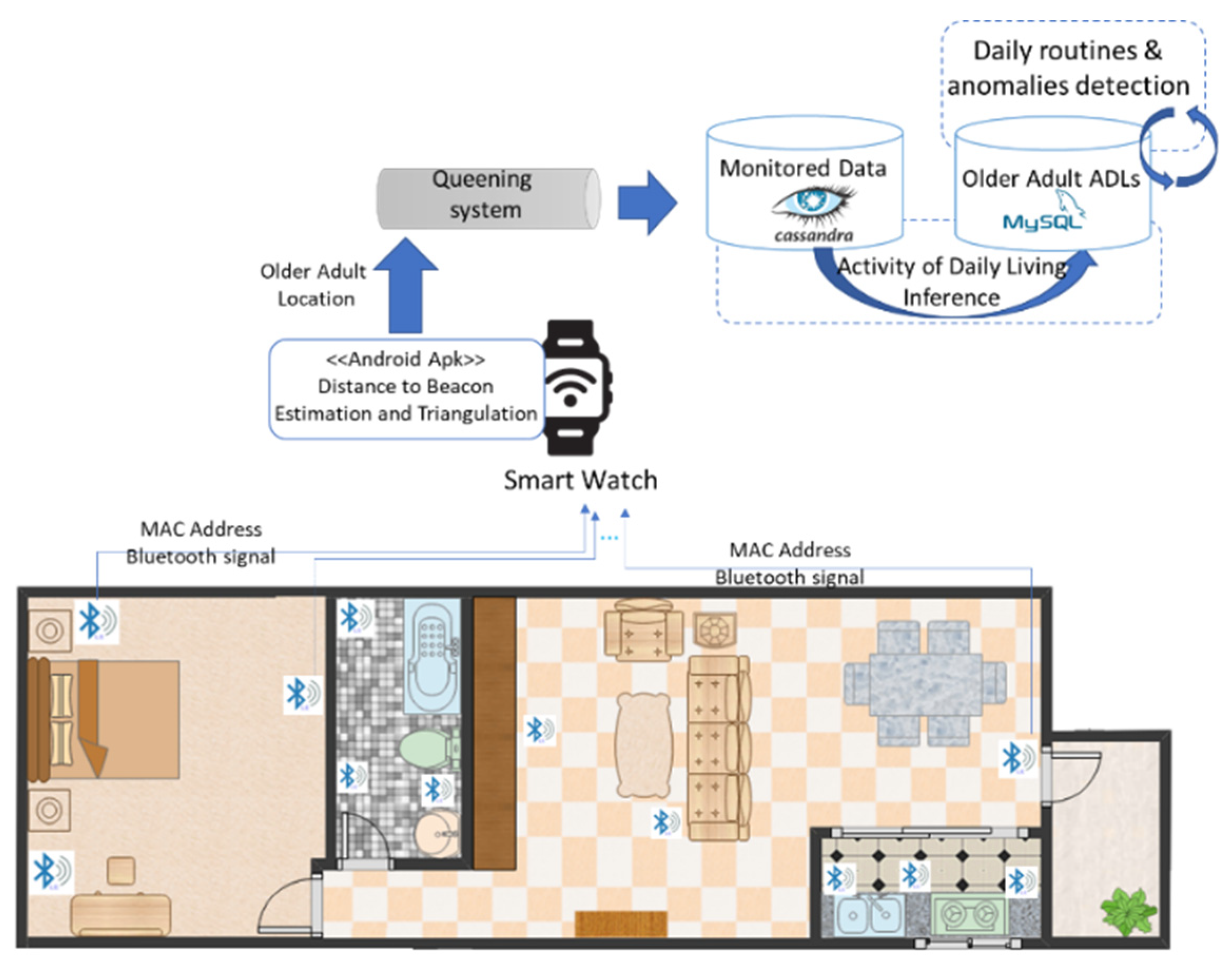
To test our proposed solution, we designed and implemented a distributed system that allows for the identification of daily life activities out of sensors data. The system design is based on stream processing principles for supporting the reliable acquisitions of potential big volumes of data from IoT sensors (see Figure 3).
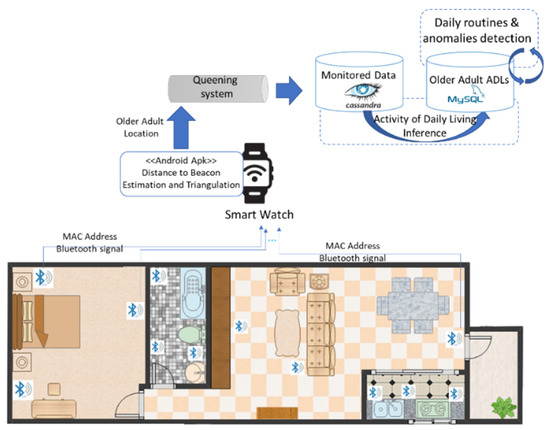
Figure 3.
Experimental system for ADL monitoring.
As sensors, we used Bluetooth Beacons to detect the presence of older adults in different rooms inside their homes and to infer the potential daily activity conducted. The Beacons were configured as shown in Table 1 where the Advertising Interval represents the time between advertising packets that are sent periodically by the Beacon on each advertising channel, txPower is used to adjust a device transmit power level based on the Received Signal Strength Indicator (RSSI) and Cal. power 0 m indicates the level of power received after any possible loss in the environment from the antenna level to the receiver.

Table 1.
Beacon’s configuration.
In such a Beacon-based monitoring system, data privacy and providing a secured data link between the sensors and the software tools is rather challenging. By default, the Beacons do not send encrypted data and the data can be tampered with. To deal with this type of concern in our system two state-of-the-art methods can be implemented to protect the Beacons against potential attacks: Time-varying IDs [44] and anomaly detection in ID transitions [45]. The first one aims to program the Beacons to broadcast IDs that are not fixed but vary in time and cryptographic techniques such as pseudorandom functions are used to generate such IDs. The downside of this approach is that it may lead to reducing the lifespan of the Beacon’s battery. The second one aims to detect anomalies in Beacon ID transitions by investigating the hypothesis of possible hacked smartwatches. When a user’s smartwatch is moved in the area of the Beacon, the transitions of consecutive Beacon IDs registered by the system should follow a specific probability distribution. The advantage, in this case, is that this method does not require Beacon modification and does not shorten Beacon lifespan.
An Android application was developed and deployed on a Smartwatch with internet capabilities to acquire and process data from the Bluetooth devices in the room and send it to a monitoring database using a messaging system. The Smartwatch watch is worn on the hand of the older adult whose activity we want to detect. The application processes the RSSI signal coming from the Beacons to determine the distance and position using trilateration.
To determine the distance between the Smartwatch from the Bluetooth Beacons installed in a room using the strength of the RSSI signal the following relation was used [46]:
where is established by the device manufacturer and set during its configuration and is the fluctuation of the power of the received signal directly affecting the value of the calculated distance.
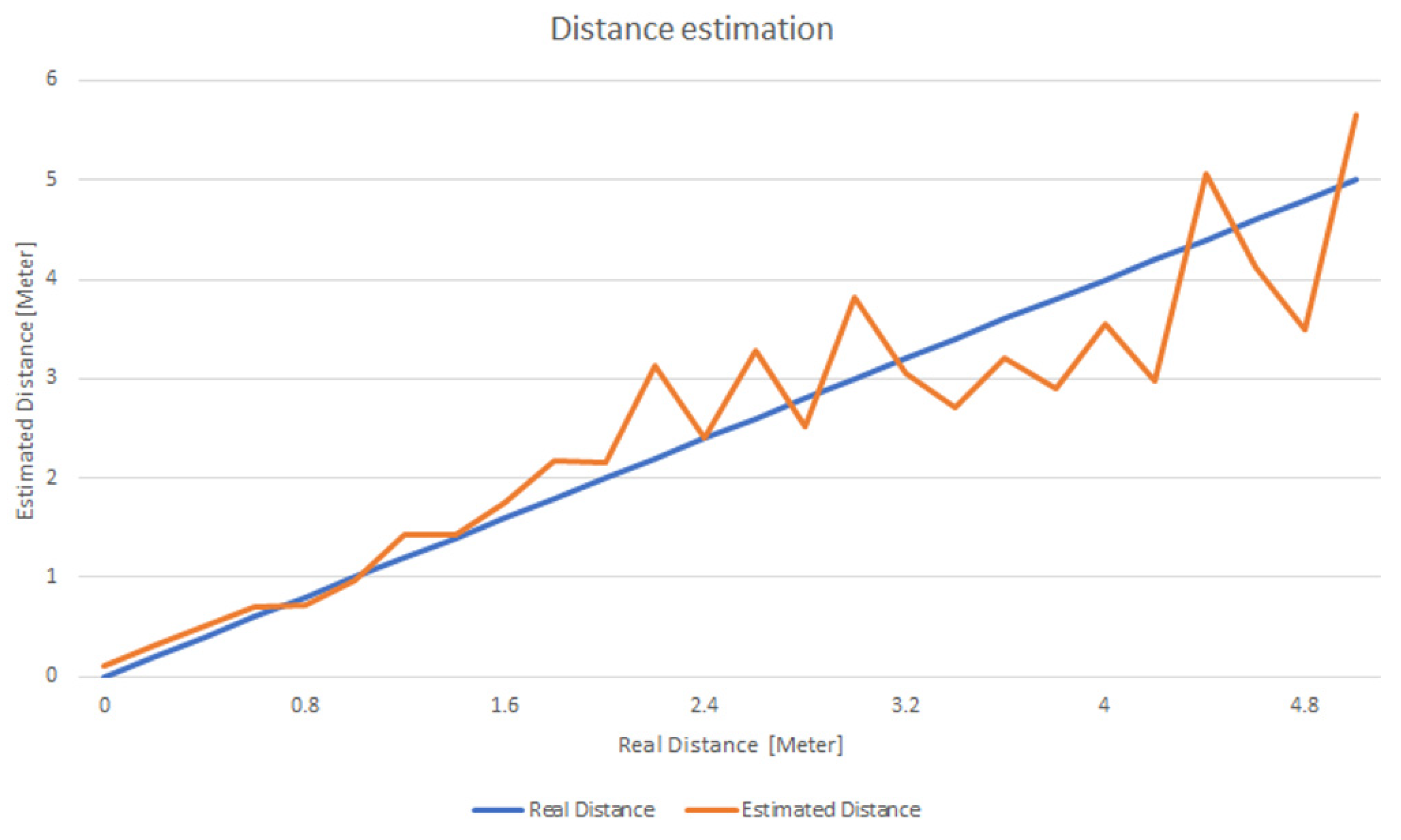
To evaluate the accuracy of the distance determination method, we calculated the distance at a granularity of 0.2 m, gradually moving away from the Beacon (see Figure 4). At each point, data was collected at a granularity of 100 ms for 2 s and the average was calculated. As can be seen the distance estimation works well especially when the distance is smaller than 2 m, making it feasible for use in house rooms. As the distance increases the assessment error also increases but even in this case the average error is below 42 cm.
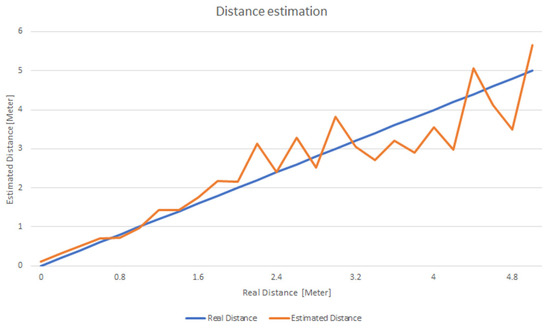
Figure 4.
Variation of assessed distance from the Beacon compared with the actual one.
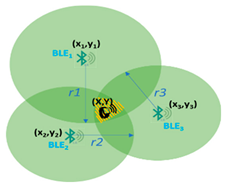
For daily activity detection minimum three devices are deployed in each room and trilateration techniques are used [47,48] which determine the point of intersection of the three circles generated by the Bluetooth Beacons emitting signals in the room. Table 2 shows the point of intersection representing the older adult location inside the room. The central points ) representing the coordinates of the Beacons deployed in the room and circulus radius of the emitted signals are already known. To ease the calculation and activity identification processes the Beacons are installed in the corners of the room or attached to the objects relevant for the activity carried out (e.g., TV, bed, fridge, book, etc.).
Table 2.
Trilateration technique used for determining the location in a room (adapted from [47,48]).
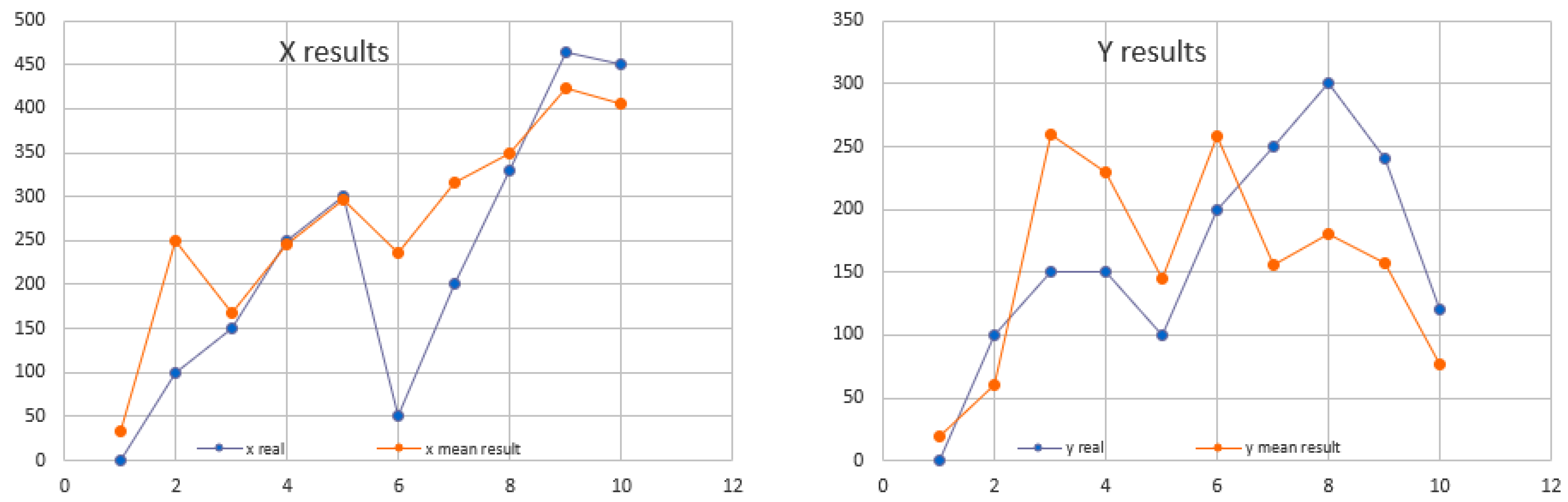
The results of using the trilateration technique to determine the location are good, with the average error reported on the x-axis being 61.630 cm, and for y-axis 69.273 cm (see Figure 5).
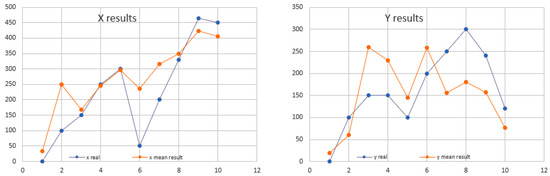
Figure 5.
Location results on x and y-axis using trilateration for three Beacons.
The signal strength of the Beacons, together with the calculated distances and coordinates of the location in the house plan, is sent from the Android application to a messaging system and then saved in a non-relational database. This type of message queue offers an asynchronous publish–subscribe mechanism that has the role of maintaining persistent data and ensures high performance and reliability especially in times when the volume of data is very high when the data comes from multiple clients simultaneously, and the database server cannot process them all at the same time.
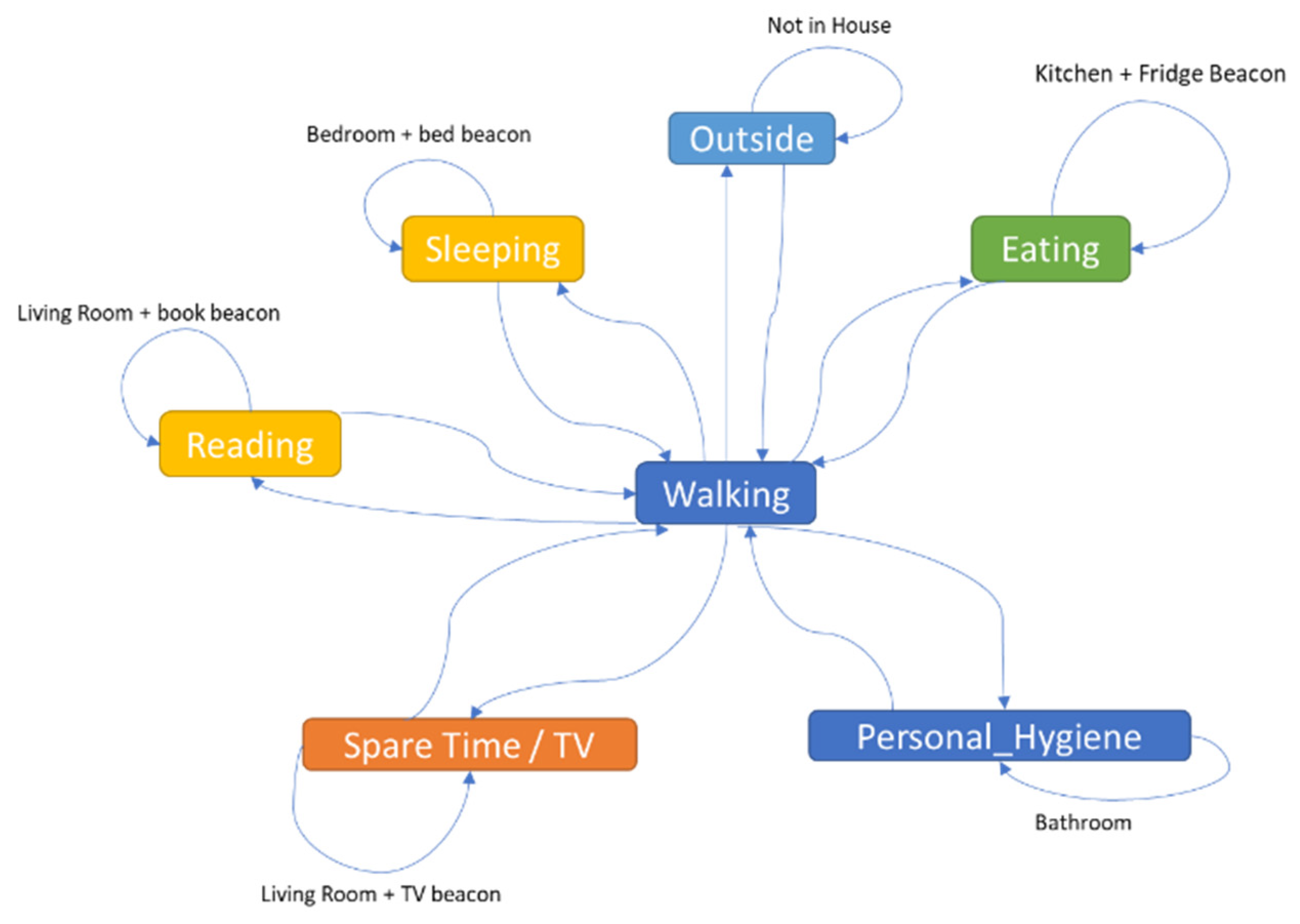
The data saved in the database were then processed using an inference system to detect the ADLs of the older adult. The daily activities associated with each room of the house and specific objects are (see Figure 6): (i) Sleeping—the older adult is located in the bedroom and then on the bed; (ii) eating—the older adult is in the kitchen and the fridge is used; (iii) personal hygiene—the older adult is in the bathroom; (iv) reading—the older adult is located in the living room and the book is used; (v) spare time/TV—the older adult is in the living room and close to the TV; (vi) walking—the older adult is inside the house and is moving around; (vii) outside—the older adult leaves the house.
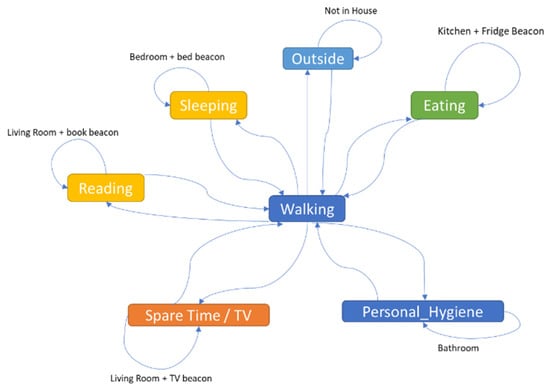
Figure 6.
Activity of daily living identification rules.
5.2. Routine and Deviation Assessment
To validate the proposed algorithms for baseline and deviation detection we constructed a data set named ADLS (i.e., the activity of daily living set), which contains information about daily life activities of 10 older adults and was generated using the system described in Section 5.1.
The ADLS data set contains information about daily life activities performed by 10 older adults collected throughout various time frames. We have used it to validate and assess the efficiency of the baseline and deviation detection algorithms in different settings. Table 3 provides a more detailed description of the data including the link to the older adult, which was monitored, the total number of monitored days and out of these the number of days with sequence and duration anomalies.
Table 3.
ADLS data used in experiments.
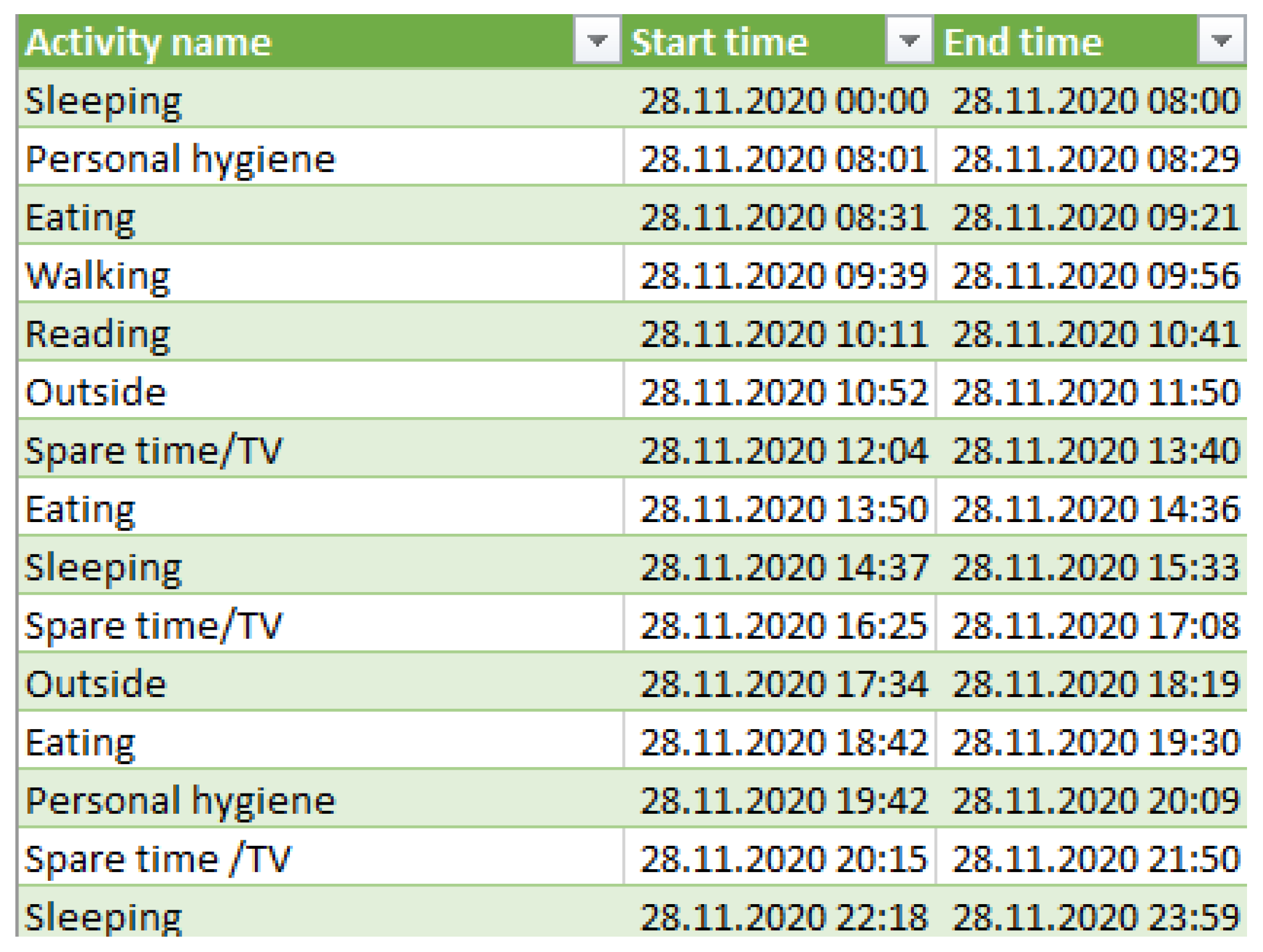
For each older adult, the data set contains the start time and end time of a monitored activity together with the activity label. Figure 7 shows a snippet from the ADLS data set corresponding to the older adult M1, which contains the activities performed during the day of 28 November 2020, together with their start and end time of each activity.
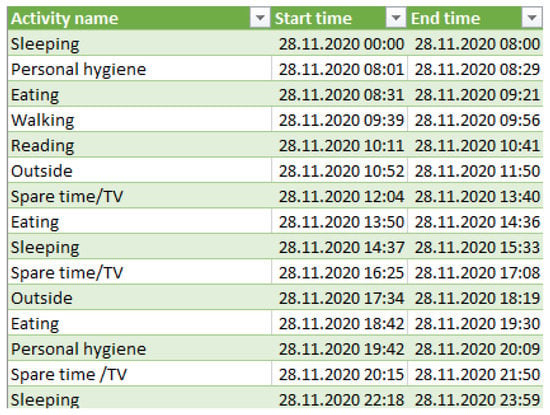
Figure 7.
Activities of daily living monitored for a day.
To evaluate the proposed algorithms’ success rate of abnormal behaviour detection, we applied the k-fold cross-validation technique and the results were evaluated using the precision, recall, F-measure, specificity and accuracy metrics. For each older adult, we split the dataset containing the daily monitored activities into k folds, where one fold contains the daily activities monitored for two weeks. For each fold, we performed the following steps:
- -
- The fold was considered as a test data set on which the deviation detection algorithm was applied to detect the days with deviations.
- -
- The remaining folds were considered as part of the training set on which the baseline learning algorithm was applied to identify the routine of the older adult.
- -
- In order to detect deviations, the test set was compared against the identified baseline.
- -
- The results obtained while detecting the deviations in daily life activities were evaluated with the precision, recall, F-measure, specificity and accuracy metrics.
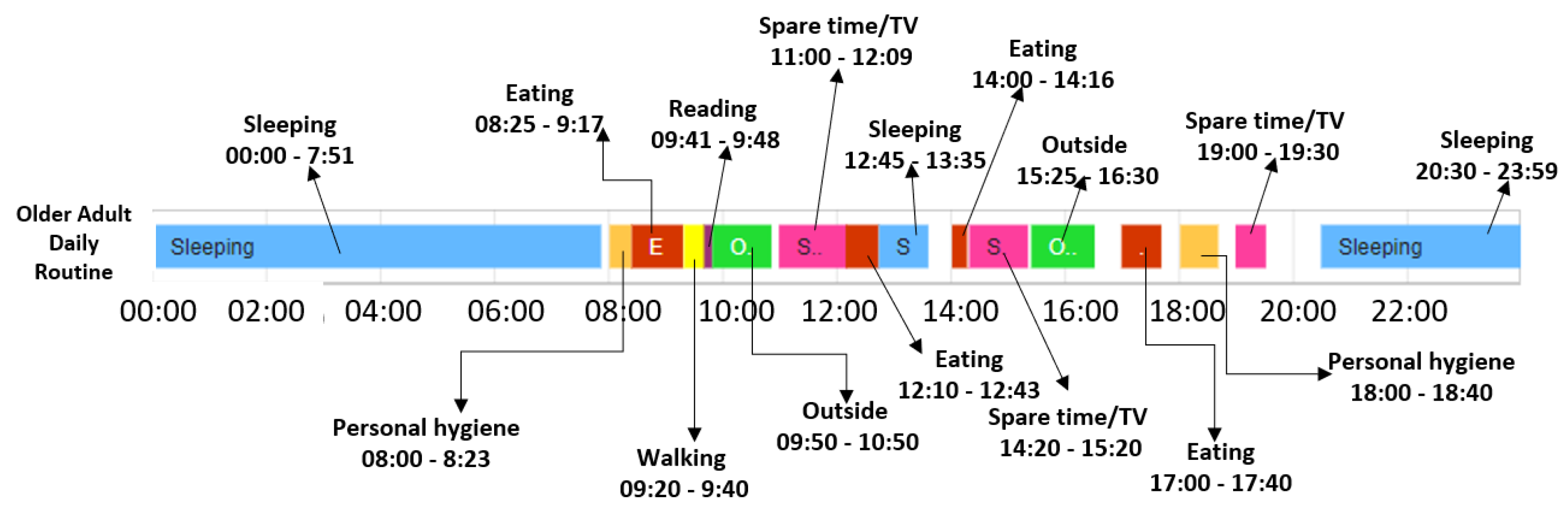
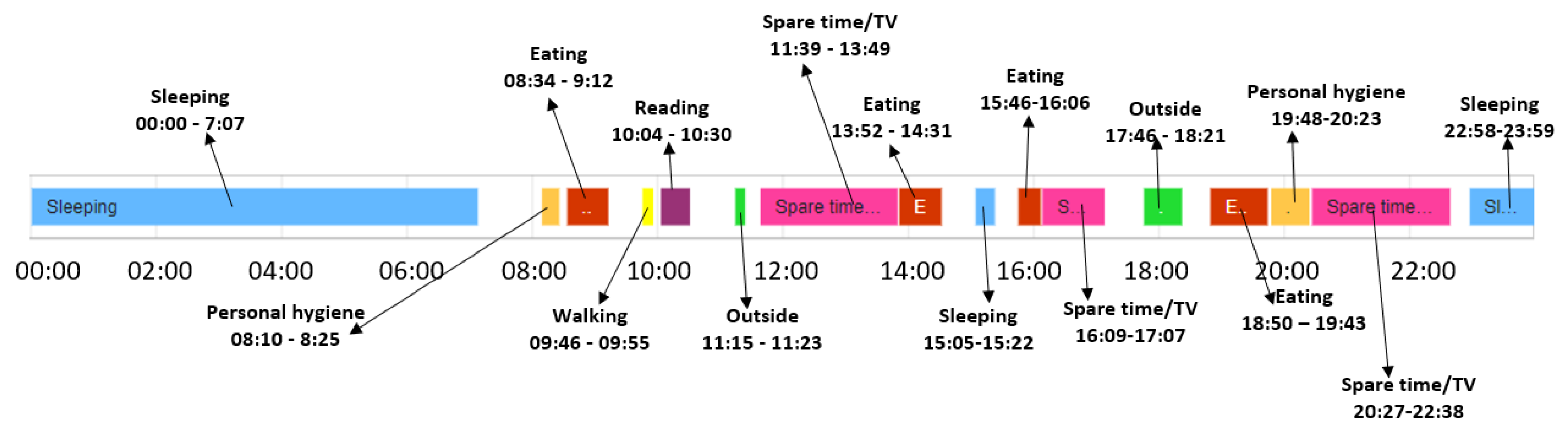
In what follows, we trace the baseline and deviation detection algorithms considering the k-fold cross validation technique in the case of the older adult M1. The older adult M1 was monitored for 84 days and the corresponding data was split in six folds, where each fold consists of 14 monitored days. Five folds are used to extract the normal behavior, also called the daily routine, while the remaining fold is used to detect the abnormal behavior of the monitored person (i.e., the days that do not follow the daily routine). Figure 8 shows an example of daily routine identified by our algorithm for the older adult M1 considering the start time and end time for each activity, and the duration and chronological order of the activities in the sequence.
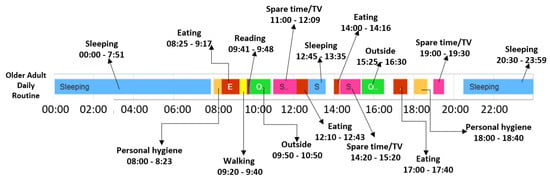
Figure 8.
Daily routine extracted for older adult M1.
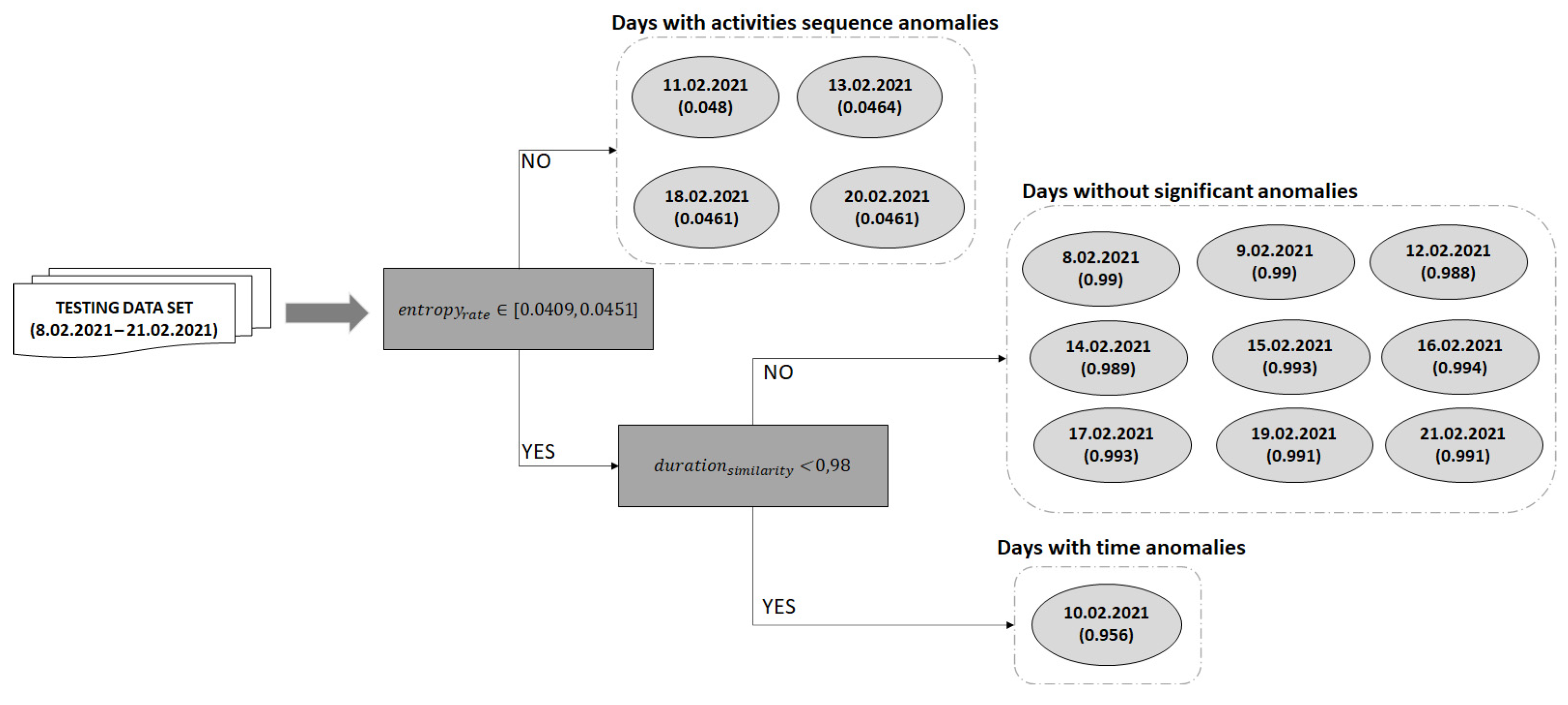
Based on the identified baseline and on the days from the five folds considered for baseline detection that are like the baseline in terms of sequence of activities, a confidence interval and a confidence duration were determined for each older adult considered. For example, in the case of the older adult M1, a confidence interval of [0.0794, 0.0829] was determined using Formula (7) while the confidence duration was determined as 0.98.
After the daily activities baseline is computed we used the remaining one fold to classify the days that feature deviations from the baseline. The entropy rate of each day from this fold is computed using Formula (6). Figure 9 illustrates the entropy rates computed for all the days in the fold used for detecting deviations for the older adult M1. The days on which the entropy rate does not fall in the confidence interval are classified as days with sequence anomalies.
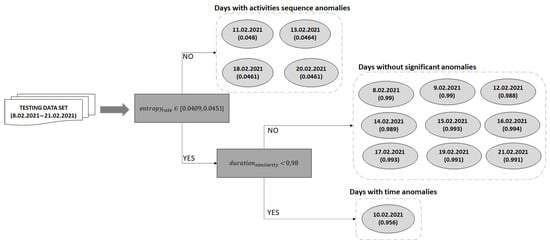
Figure 9.
Deviation detection process on the testing data set for older adult M1.
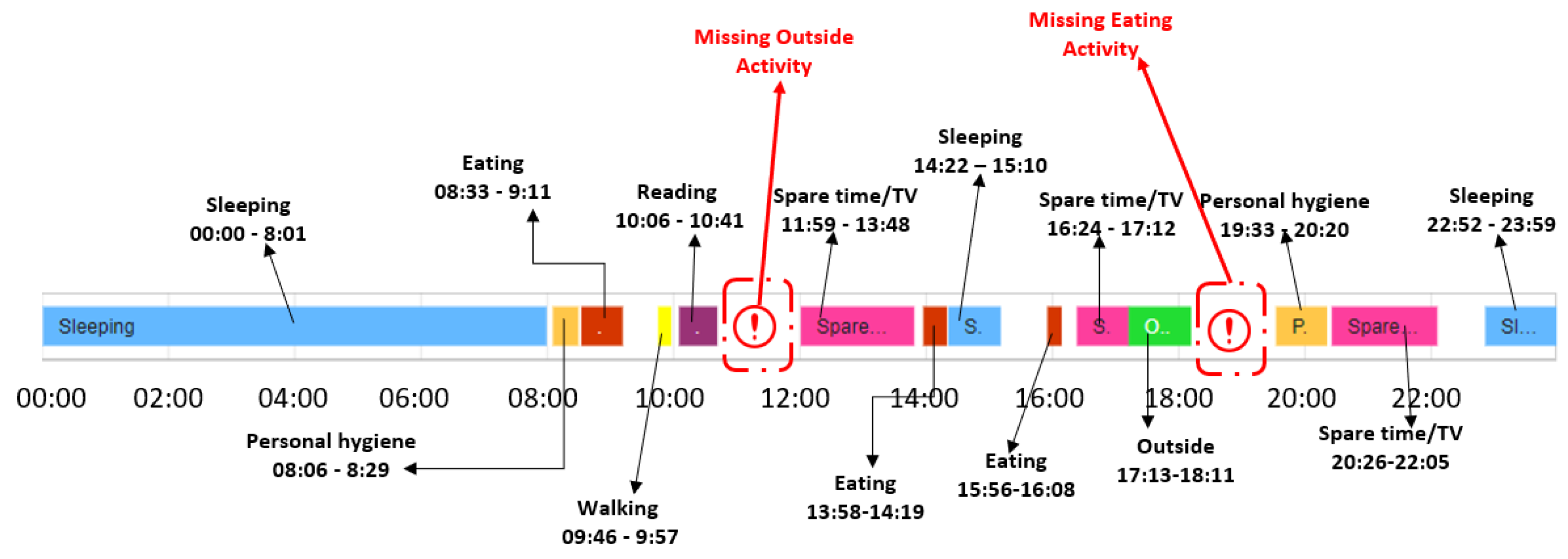
Figure 10 illustrates for the older adult M1 an example with the activities from the date 11 February 2021, which has been classified as a day with sequence anomalies.
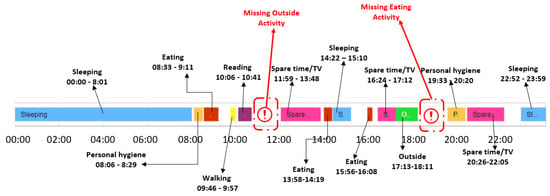
Figure 10.
Example of day with activity sequence anomalies for the older adult M1.
The days from the one fold that have not been classified as having activity sequence anomalies are further analyzed to detect the ones with activity duration anomalies. For each day a duration similarity is computed which is compared with the confidence duration value (i.e., 0.98). If the duration similarity is lower than the confidence duration, then the day is considered to have time anomalies (see Figure 9).
Figure 11 illustrates for the older adult M1 the activities from the date 10 February 2021, which has been classified as a day with activity duration anomalies. If the duration similarity is higher than the confidence duration, then the day conforms to the learned baseline, without any significant deviations (e.g., days February 8 and February 9 in Figure 9).
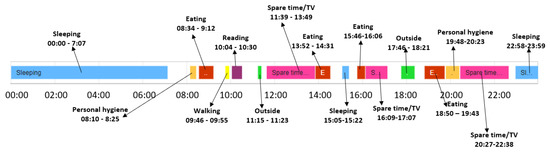
Figure 11.
Example of day classified as featuring activity duration anomalies.
Similarly, we applied the baseline and deviation detection algorithms for all the other folds corresponding to the M1 older adult and for each round of experiments we computed the values of the precision, recall, F-measure, specificity and accuracy metrics.
Finally, Table 4 illustrates the obtained experimental results for each of the 10 older adults of our data set, with the steps followed being the same as the ones presented for older adult M1. The metrics values represent averages of the results obtained when applying the k-fold cross validation technique. The last row in the table presents the overall average values of the considered metrics.
Table 4.
Cross-validation evaluation results.
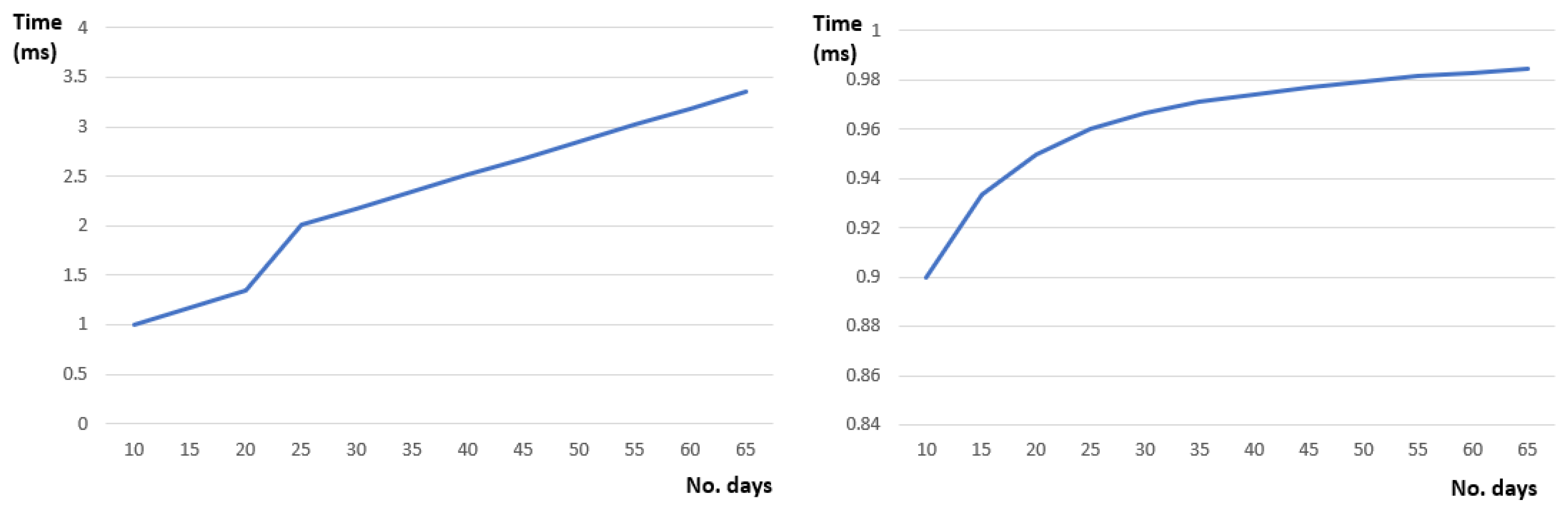
Figure 12 below shows the parameter learning features of our defined Hidden Markov model. Given a sequence of days each having a set of activities the defined model can learn the defined probability parameters with a minimum time overhead (Figure 12—right). Moreover, the learned probability parameter values converge after several iterations throughout consecutive days (see Figure 12—left).
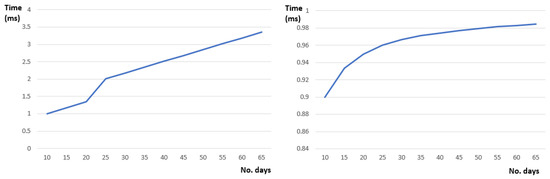
Figure 12.
Parameter learning features: (left) Learning time and (right) probability activity transition (sleep -> eating).
To determine the effectiveness of our approach for anomaly detection in daily life activities we compared the results obtained with the ones reported in the state of the art by [11,17] (see Table 5). As described in the related work section, Refs. [11,17] apply probabilistic models for detecting anomalies in elders’ behaviour. For comparison we considered the values of the precision, recall and F-measure metrics as they were reported by the two approaches. In case of [11] we have averaged the values reported for the above-mentioned metrics considering a sensor activation likelihood of 95% BCI (i.e., Bayesian credible interval) for both real and synthetic data. For [17] we averaged the obtained values for precision, recall and F-measure for various values of the threshold in anomaly detection, a configurable parameter used by authors. By analysing the results from Table 5 it can be noticed that our approach provides better precision than [11,17] with a slight penalty in recall.
Table 5.
Comparison results.
6. Conclusions
In this paper we proposed a solution for identifying the daily routines of older adults and potential deviations considering the length of the monitored activities and transition probabilities among activities as relevant features. The daily activity monitoring is done using Beacon technology, while for deviation from routine assessment a Markov model is employed. The entropy rate and cosine functions are used to determine the similarity between the sequence of activities registered in a specific day and the routine solution featuring good values of precision. The proposed techniques can identify the daily routines with confidence concerning the activity duration of 0.98 and confidence concerning the sequence of activities in the interval [0.0794, 0.0829]. Compared with other relevant approaches found in the state of the art our solution provides a recall value that is slightly lower and a higher precision value. Related to the baseline learning, the Hidden Markov model shows promising results in terms of determining the activity transition probabilities and learning time being dependent on the amount of data used in training.
Author Contributions
Conceptualization, V.R.C., C.B.P. and T.C.; Data curation, D.D. and D.T.; Formal analysis, V.R.C., M.A., T.C. and C.A.; Funding acquisition, T.C. and I.A.; Investigation, R.S.; Methodology, C.B.P., M.A. and I.A.; Software, D.D., R.S. and D.T.; Validation, V.R.C., C.B.P., D.D., R.S. and C.A.; Visualization, D.T., M.A. and I.A.; Writing—original draft, V.R.C., C.B.P., D.D., R.S. and T.C.; Writing—review & editing, I.A. and C.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by UEFISCDI Romania and the European Union AAL Programme with co-funding from the Horizon 2020 research and innovation programme, grant number AAL159/2020 H2HCare, AAL59/2018 ReMIND, AAL264/2021 engAGE and AAL162/2020 ReMember-Me. The APC was funded by the Technical University of Cluj-Napoca, Romania.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing is not applicable to this article.
Acknowledgments
This work was supported by three grants of the Romanian National Authority for Scientific Research and Innovation, CCCDI–UEFISCDI and of the AAL Programme with co-funding from the European Union’s Horizon 2020 research and innovation programme project number AAL159/2020 H2HCare, AAL59/2018 ReMIND, AAL264/2021 engAGE and AAL162/2020 ReMember-Me within PNCDI III.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ageing Europe—Statistics on Population Developments. Available online: https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Ageing_Europe_-_statistics_on_population_developments (accessed on 15 December 2021).
- Vos, E.E.; de Bruin, S.R.; van der Beek, A.J.; Proper, K.I. “It’s Like Juggling, Constantly Trying to Keep All Balls in the Air”: A Qualitative Study of the Support Needs of Working Caregivers Taking Care of Older Adults. Int. J. Environ. Res. Public Health 2021, 18, 5701. [Google Scholar] [CrossRef]
- Šare, S.; Ljubičić, M.; Gusar, I.; Čanović, S.; Konjevoda, S. Self-Esteem, Anxiety, and Depression in Older People in Nursing Homes. Healthcare 2021, 9, 1035. [Google Scholar] [CrossRef] [PubMed]
- Schneider, F.; Horowitz, A.; Lesch, K.-P.; Dandekar, T. Delaying memory decline: Different options and emerging solutions. Transl. Psychiatry 2020, 10, 13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Anghel, I.; Cioara, T.; Moldovan, D.; Antal, C.; Pop, C.D.; Salomie, I.; Pop, C.B.; Chifu, V.R. Smart Environments and Social Robots for Age-Friendly Integrated Care Services. Int. J. Environ. Res. Public Health 2020, 17, 3801. [Google Scholar] [CrossRef] [PubMed]
- Mshali, H.; Lemlouma, T.; Moloney, M.; Magoni, D. A survey on health monitoring systems for health smart homes. Int. J. Ind. Ergon. 2018, 66, 26–56. [Google Scholar] [CrossRef] [Green Version]
- Zekri, D.; Delot, T.; Thilliez, M.; LeComte, S.; Desertot, M. A Framework for Detecting and Analyzing Behavior Changes of Elderly People over Time Using Learning Techniques. Sensors 2020, 20, 7112. [Google Scholar] [CrossRef] [PubMed]
- Deep, S.; Zheng, X.; Karmakar, C.; Yu, D.; Hamey, L.G.C.; Jin, J. A Survey on Anomalous Behavior Detection for Elderly Care Using Dense-Sensing Networks. IEEE Commun. Surv. Tutor. 2020, 22, 352–370. [Google Scholar] [CrossRef]
- Janjua, Z.H.; Riboni, D.; Bettini, C. Towards automatic induction of abnormal behavioral patterns for recognizing mild cognitive impairment. In Proceedings of the 31st Annual ACM Symposium on Applied Computing, Pisa, Italy, 4–8 April 2016; pp. 143–148. [Google Scholar] [CrossRef]
- Riboni, D.; Bettini, C.; Civitarese, G.; Janjua, Z.H.; Helaoui, R. SmartFABER: Recognizing Fine-Grained Abnormal Behaviors for Early Detection of Mild Cognitive Impairment. Artif. Intell. Med. 2016, 67, 57–74. [Google Scholar] [CrossRef] [Green Version]
- Ordóñez, F.J.; De Toledo, P.; Sanchis, A. Sensor-based Bayesian detection of anomalous living patterns in a home setting. Pers. Ubiquitous Comput. 2015, 19, 259–270. [Google Scholar] [CrossRef]
- Casagrande, F.D.; Zouganeli, E. Activity Recognition and Prediction in Real Homes. In Nordic Artificial Intelligence Research and Development. NAIS 2019: Communications in Computer and Information Science; Springer: Cham, Switzerland, 2019; Volume 1056. [Google Scholar] [CrossRef] [Green Version]
- Kabir, M.H.; Hoque, M.R.; Thapa, K.; Yang, S.-H. Two-Layer Hidden Markov Model for Human Activity Recognition in Home Environments. Int. J. Distrib. Sens. Netw. 2016, 12, 4560365. [Google Scholar] [CrossRef] [Green Version]
- Roy, N.; Misra, A.; Cook, D.J. Ambient and smartphone sensor assisted ADL recognition in multi-inhabitant smart environments. J. Ambient Intell. Humaniz. Comput. 2016, 7, 1–19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, H.; Chen, H.; Brown, R. A sequence-to-sequence model-based deep learning approach for recognizing activity of daily living for senior care. J. Biomed. Inform. 2018, 84, 148–158. [Google Scholar] [CrossRef] [PubMed]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, C.; Sheng, W.; Liu, M. Wearable Sensor-Based Behavioral Anomaly Detection in Smart Assisted Living Systems. IEEE Trans. Autom. Sci. Eng. 2015, 12, 1225–1234. [Google Scholar] [CrossRef]
- Nadeem, A.; Mehmood, A.; Rizwan, K. A dataset build using wearable inertial measurement and ECG sensors for activity recognition, fall detection and basic heart anomaly detection system. Data Brief 2019, 27, 104717. [Google Scholar] [CrossRef]
- Azimi, H.; Xi, P.; Bouchard, M.; Goubran, R.; Knoefel, F. Machine Learning-Based Automatic Detection of Central Sleep Apnea Events from a Pressure Sensitive Mat. IEEE Access 2020, 8, 173428–173439. [Google Scholar] [CrossRef]
- Nassif, A.B.; Abu Talib, M.; Nasir, Q.; Dakalbab, F.M. Machine Learning for Anomaly Detection: A Systematic Review. IEEE Access 2021, 9, 78658–78700. [Google Scholar] [CrossRef]
- Parvin, P.; Chessa, S.; Kaptein, M.; Paternò, F. Personalized real-time anomaly detection and health feedback for older adults. J. Ambient Intell. Smart Environ. 2019, 11, 453–469. [Google Scholar] [CrossRef]
- Nath, R.K.; Thapliyal, H. Machine Learning-Based Anxiety Detection in Older Adults Using Wristband Sensors and Context Feature. SN Comput. Sci. 2021, 2, 1–12. [Google Scholar] [CrossRef]
- Parvin, P.; Paterno, F.; Chessa, S. Anomaly Detection in the Elderly Daily Behavior. In Proceedings of the 2018 14th International Conference on Intelligent Environments (IE), Rome, Italy, 25–28 June 2018; pp. 103–106. [Google Scholar] [CrossRef]
- Arifoglu, D.; Bouchachia, A. Detection of abnormal behaviour for dementia sufferers using Convolutional Neural Networks. Artif. Intell. Med. 2019, 94, 88–95. [Google Scholar] [CrossRef]
- Fahad, L.G.; Tahir, S.F. Activity recognition and anomaly detection in smart homes. Neurocomputing 2021, 423, 362–372. [Google Scholar] [CrossRef]
- Zerkouk, M.; Chikhaoui, B. Spatio-Temporal Abnormal Behavior Prediction in Elderly Persons Using Deep Learning Models. Sensors 2020, 20, 2359. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Forkan, A.R.M.; Khalil, I.; Tari, Z.; Foufou, S.; Bouras, A. A Context-Aware Ap-proach for Long-Term Behavioural Change Detection and Abnormality Prediction in Ambient Assisted Living. Pattern Recognit. 2015, 48, 628–641. [Google Scholar] [CrossRef]
- Eisa, S.; Moreira, A. A Behaviour Monitoring System (BMS) for Ambient Assisted Living. Sensors 2017, 17, 1946. [Google Scholar] [CrossRef] [Green Version]
- Aran, O.; Sanchez-Cortes, D.; Do, M.-T.; Gatica-Perez, D. Anomaly Detection in Elderly Daily Behavior in Ambient Sensing Environments. In International Workshop on Human Behavior Understanding, HBU 2016: Human Behavior Understanding; Springer: Cham, Switzerland; pp. 51–67. [CrossRef] [Green Version]
- Susnea, I.; Dumitriu, L.; Talmaciu, M.; Pecheanu, E.; Munteanu, D. Unobtrusive Monitoring the Daily Activity Routine of Elderly People Living Alone, with Low-Cost Binary Sensors. Sensors 2019, 19, 2264. [Google Scholar] [CrossRef] [Green Version]
- Lundström, J.; Järpe, E.; Verikas, A. Detecting and exploring deviating behaviour of smart home residents. Expert Syst. Appl. 2016, 55, 429–440. [Google Scholar] [CrossRef]
- Li, C.; Cheung, W.K.; Liu, J.; Ng, J.K. Automatic Extraction of Behavioral Patterns for Elderly Mobility and Daily Routine Analysis. ACM Trans. Intell. Syst. Technol. 2018, 9, 1–26. [Google Scholar] [CrossRef]
- Zhao, S.; Li, W.; Cao, J. A User-Adaptive Algorithm for Activity Recognition Based on K-Means Clustering, Local Outlier Factor, and Multivariate Gaussian Distribution. Sensors 2018, 18, 1850. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alshammari, T.; Alshammari, N.; Sedky, M.; Howard, C. SIMADL: Simulated Activities of Daily Living Dataset. Data 2018, 3, 11. [Google Scholar] [CrossRef] [Green Version]
- Vavoulas, G.; Chatzaki, C.; Malliotakis, T.; Pediaditis, M.; Tsiknakis, M. The MobiAct Dataset: Recognition of Activities of Daily Living using Smartphones. In Proceedings of the 2nd International Conference on Infor-mation and Communication Technologies for Ageing Well and e-Health (ICT4AWE), Rome, Italy, 21–22 April 2016; pp. 143–151. [Google Scholar]
- Pazhoumand-Dar, H.; Armstrong, L.J.; Tripathy, A.K. Detecting deviations from activities of daily living routines using kinect depth maps and power consumption data. J. Ambient Intell. Humaniz. Comput. 2019, 11, 1727–1747. [Google Scholar] [CrossRef]
- Caroux, L.; Consel, C.; Dupuy, L.; Sauzéon, H. Towards context-aware assistive applications for aging in place via real-life-proof activity detection. J. Ambient Intell. Smart Environ. 2018, 10, 445–459. [Google Scholar] [CrossRef]
- Paudel, R.; Eberle, W.; Holder, L.B. Anomaly Detection of Elderly Patient Activities in Smart Homes using a Graph-Based Approach. In Proceedings of the International Conference of Data Science, Las Vegas, NV, USA, 30 July–2 August 2018; pp. 163–169. [Google Scholar]
- Dawadi, P.N.; Cook, D.J.; Schmitter-Edgecombe, M. Modeling patterns of activities using activity curves. Pervasive Mob. Comput. 2016, 28, 51–68. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Manca, M.; Parvin, P.; Paternò, F.; Santoro, C. Detecting Anomalous Elderly Behaviour in Ambient Assisted Living. In Proceedings of the ACM SIGCHI Symposium on Engineering Interactive Computing Systems, Lisbon, Portugal, 26–29 June 2017; pp. 63–68. [Google Scholar] [CrossRef]
- Qin, S.M.; Verkasalo, H.; Mohtaschemi, M.; Hartonen, T.; Alava, M. Patterns, entropy, and predictability of human mobility and life. PLoS ONE 2012, 7, e51353. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Porta, A.; Valencia, J.F.; Cairo, B.; Bari, V.; De Maria, B.; Gelpi, F.; Barbic, F.; Furlan, R. Are Strategies Favoring Pattern Matching a Viable Way to Improve Complexity Estimation Based on Sample Entropy? Entropy 2020, 22, 724. [Google Scholar] [CrossRef] [PubMed]
- Markić, I.; Štula, M.; Zorić, M.; Stipaničev, D. Entropy-Based Approach in Selection Exact String-Matching Algorithms. Entropy 2020, 23, 31. [Google Scholar] [CrossRef]
- Chan, A.C.; Chung, R.M. Security and Privacy of Wireless Beacon Systems. arXiv 2021, arXiv:2107.05868. [Google Scholar]
- Atzori, L.; Iera, A.; Morabito, G. From “smart objects” to “social objects”: The next evolutionary step of the internet of things. IEEE Commun. Mag. 2014, 52, 97–105. [Google Scholar] [CrossRef]
- Bilbao-Jayo, A.; Almeida, A.; Sergi, I.; Montanaro, T.; Fasano, L.; Emaldi, M.; Patrono, L. Behavior Modeling for a Beacon-Based Indoor Location System. Sensors 2021, 21, 4839. [Google Scholar] [CrossRef]
- Li, J.; Yue, X.; Chen, J.; Deng, F. A Novel Robust Trilateration Method Applied to Ultra-Wide Bandwidth Location Systems. Sensors 2017, 17, 795. [Google Scholar] [CrossRef] [Green Version]
- Rose, N.D.R.; Tan, L.; Ahmad, M. 3D Trilateration Localization using RSSI in Indoor Environment. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 385–391. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).