
In-Field Automatic Detection of Grape Bunches under a Totally Uncontrolled Environment



Abstract
1. Introduction
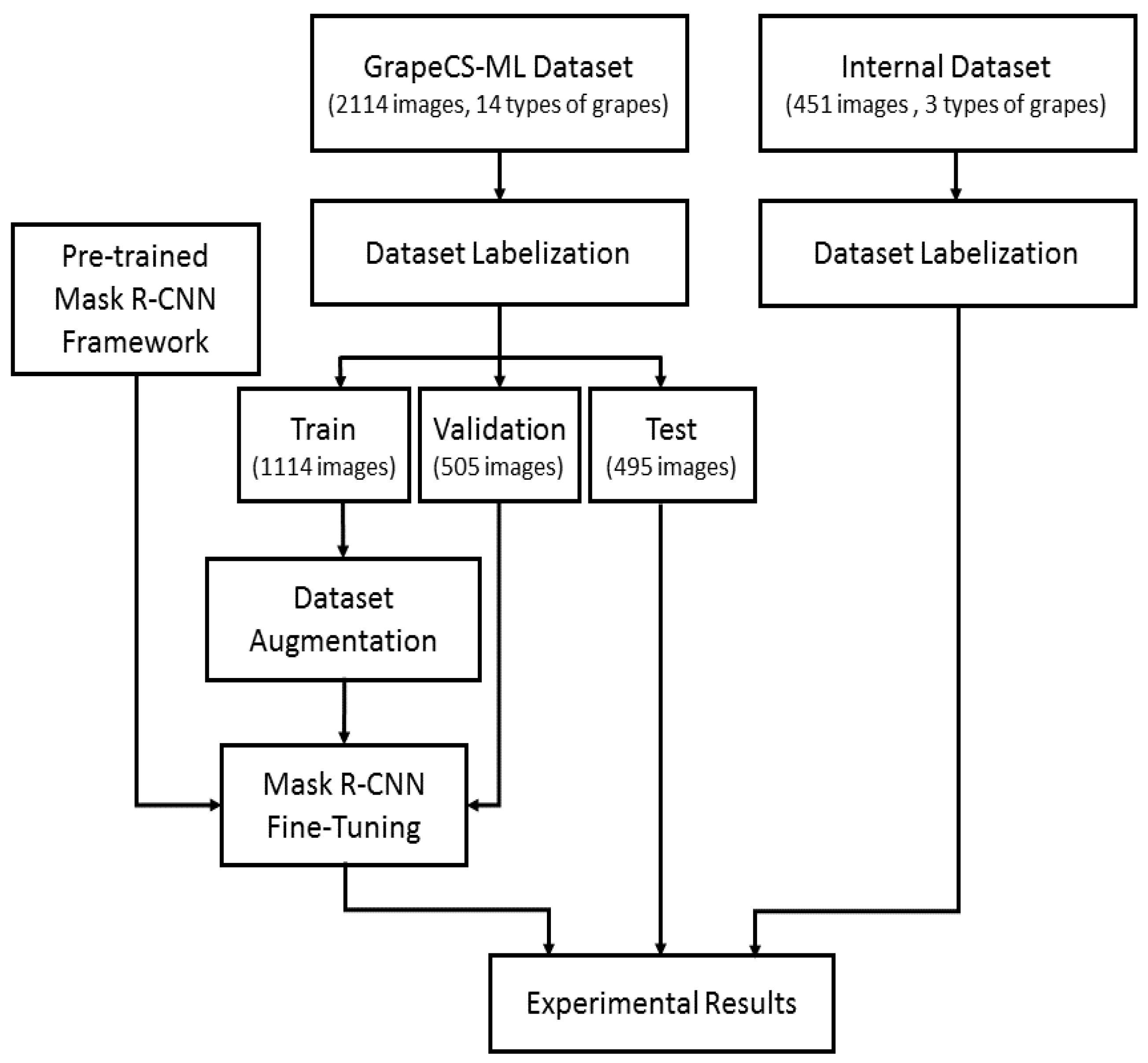
2. Materials and Methods
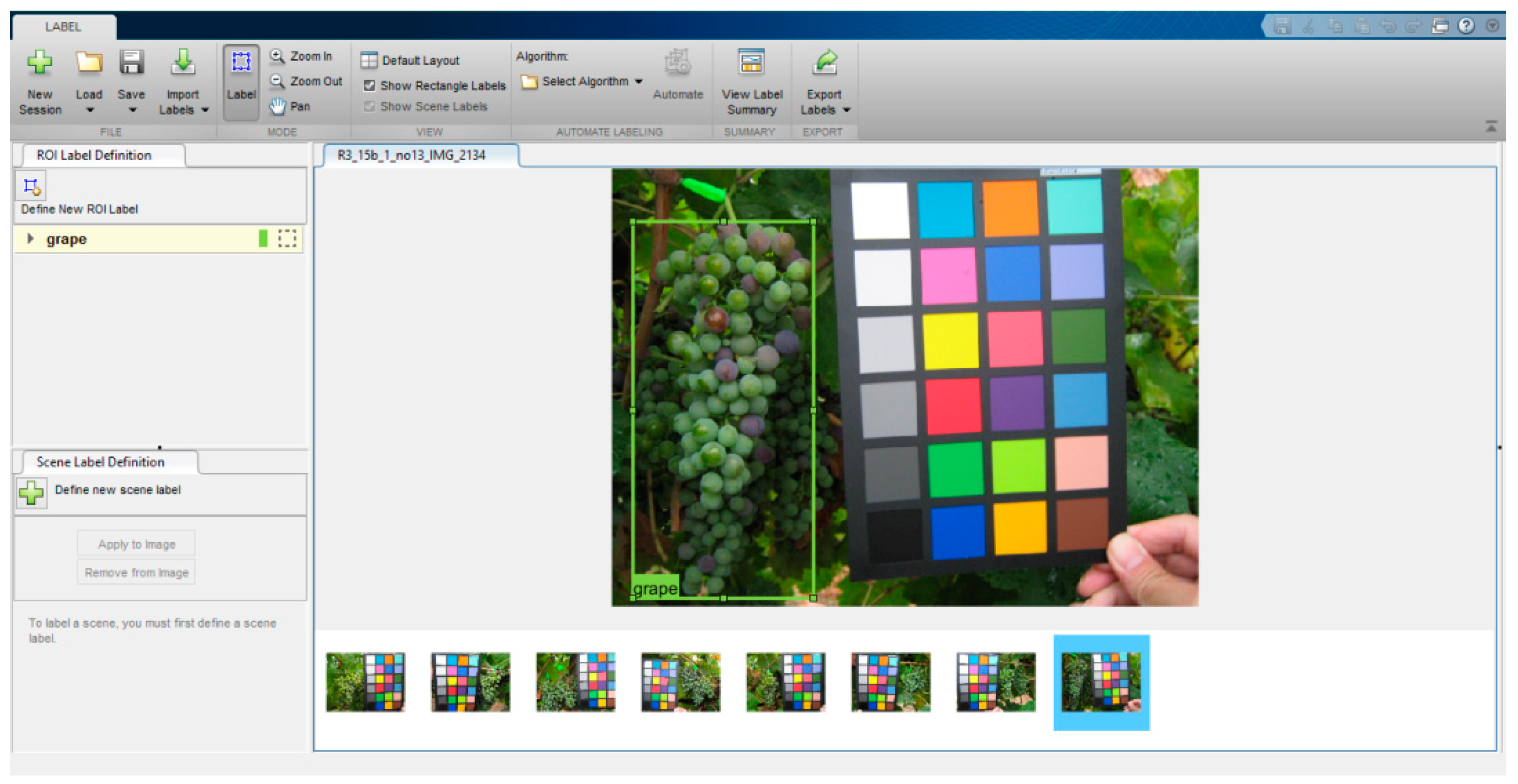
2.1. Dataset
- Set 1: Merlot cv. bunches, taken in seven rounds from the period January to April 2017;
- Set 2: Designed for research on berry and bunch volume and color as the grapes mature, featuring Merlot, Cabernet Sauvignon, Saint Macaire, Flame Seedless, Viognier, Ruby Seedless, Riesling, Muscat Hamburg, Purple Cornichon, Sultana, Sauvignon Blanc, and Chardonnay cvs;
- Set 3: Subsets for two cultivars (Cabernet Sauvignon and Shiraz) taken at dates close to maturity;
- Set 4: Subsets of images for two cultivars (Pinot Noir and Merlot) taken at dates close to maturity, with the focus on the color changes with the onset of ripening;
- Set 5: Sauvignon Blanc cv. bunches taken on three different dates. Each image also contains a hand-segmented region defining the boundaries of the grape bunch to serve as the ground truth for evaluating computer vision techniques such as image segmentation.
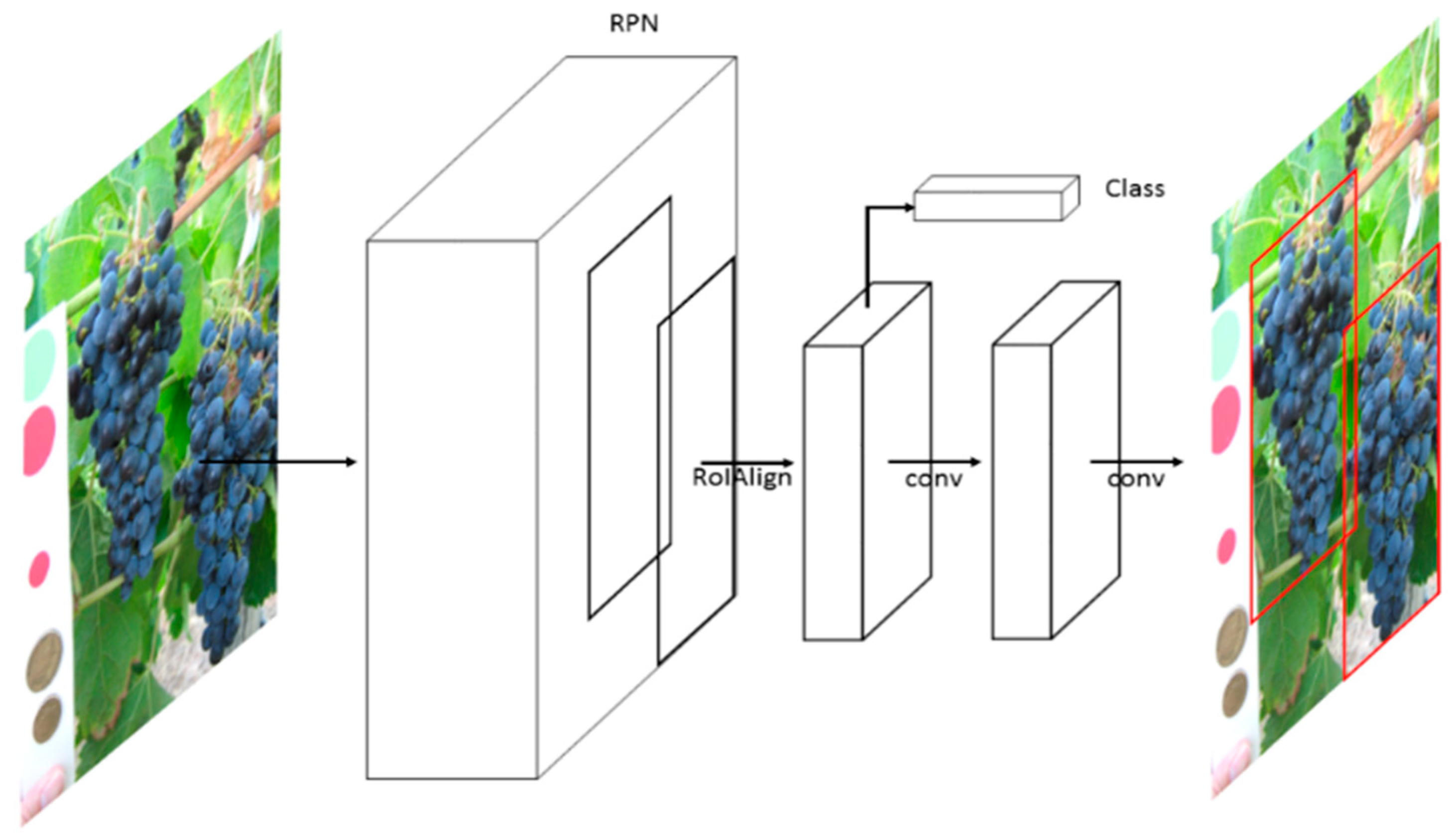
2.2. Mask R-CNN Framework for Grape Detection
2.3. Training Procedure
3. Results
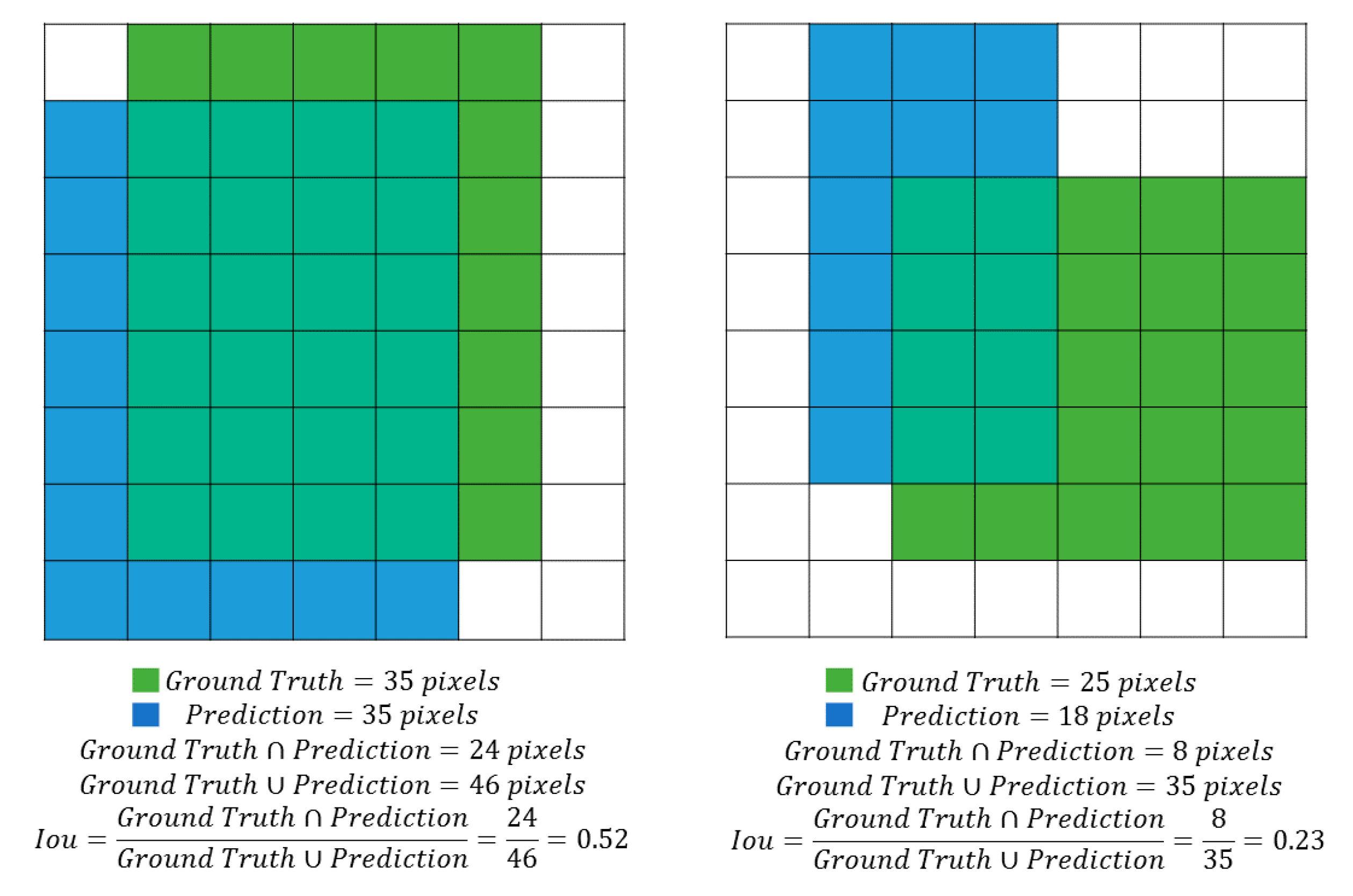
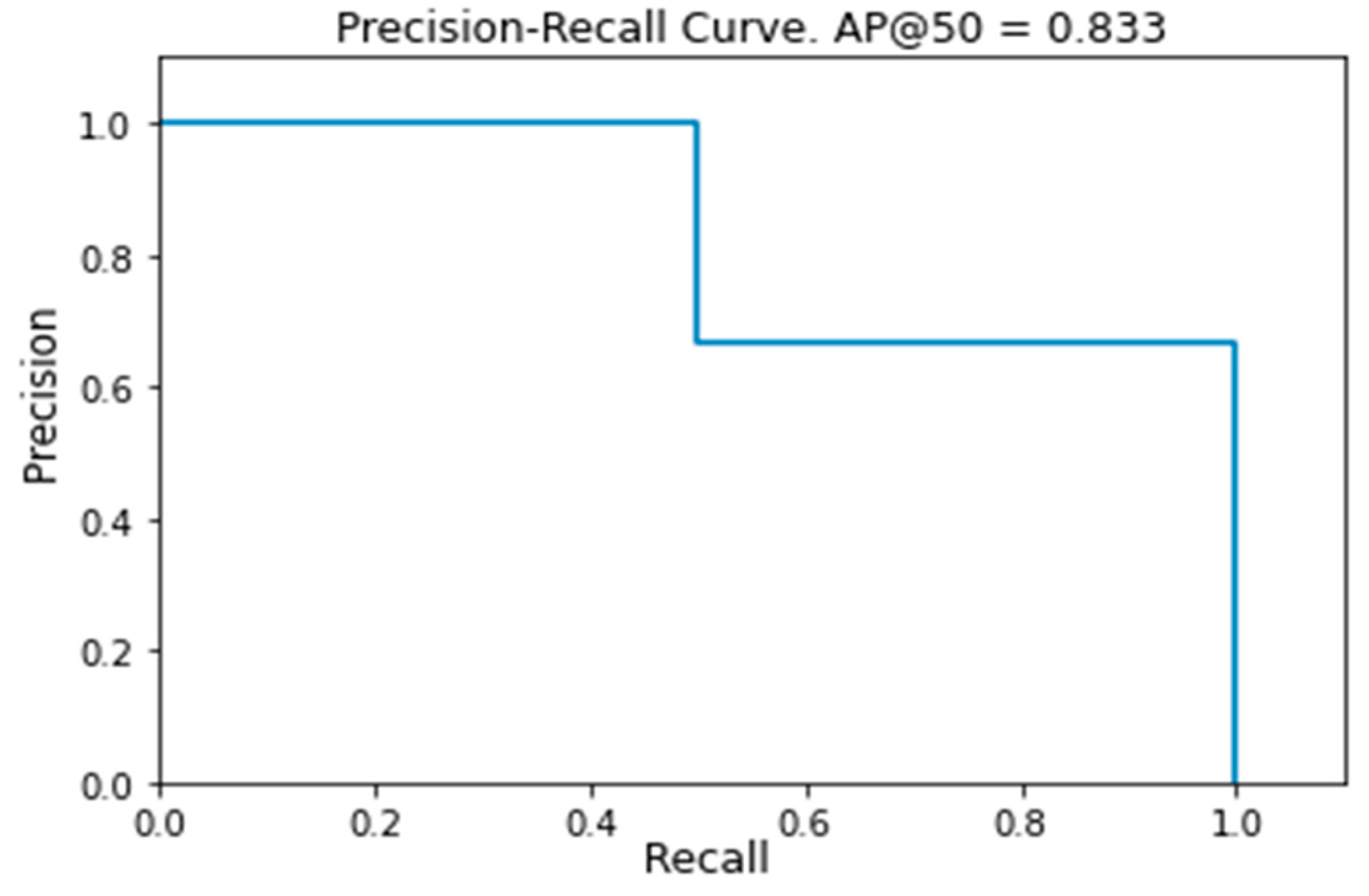
3.1. Performance Evaluation
- TP (True Positive): bounding boxes correctly detected (IoU > 50%);
- FP (False Positive): bounding boxes wrongly detected (there are no bunches or IoU < 50%);
- FN (False Negative): bounding boxes not detected where the bunches are present.
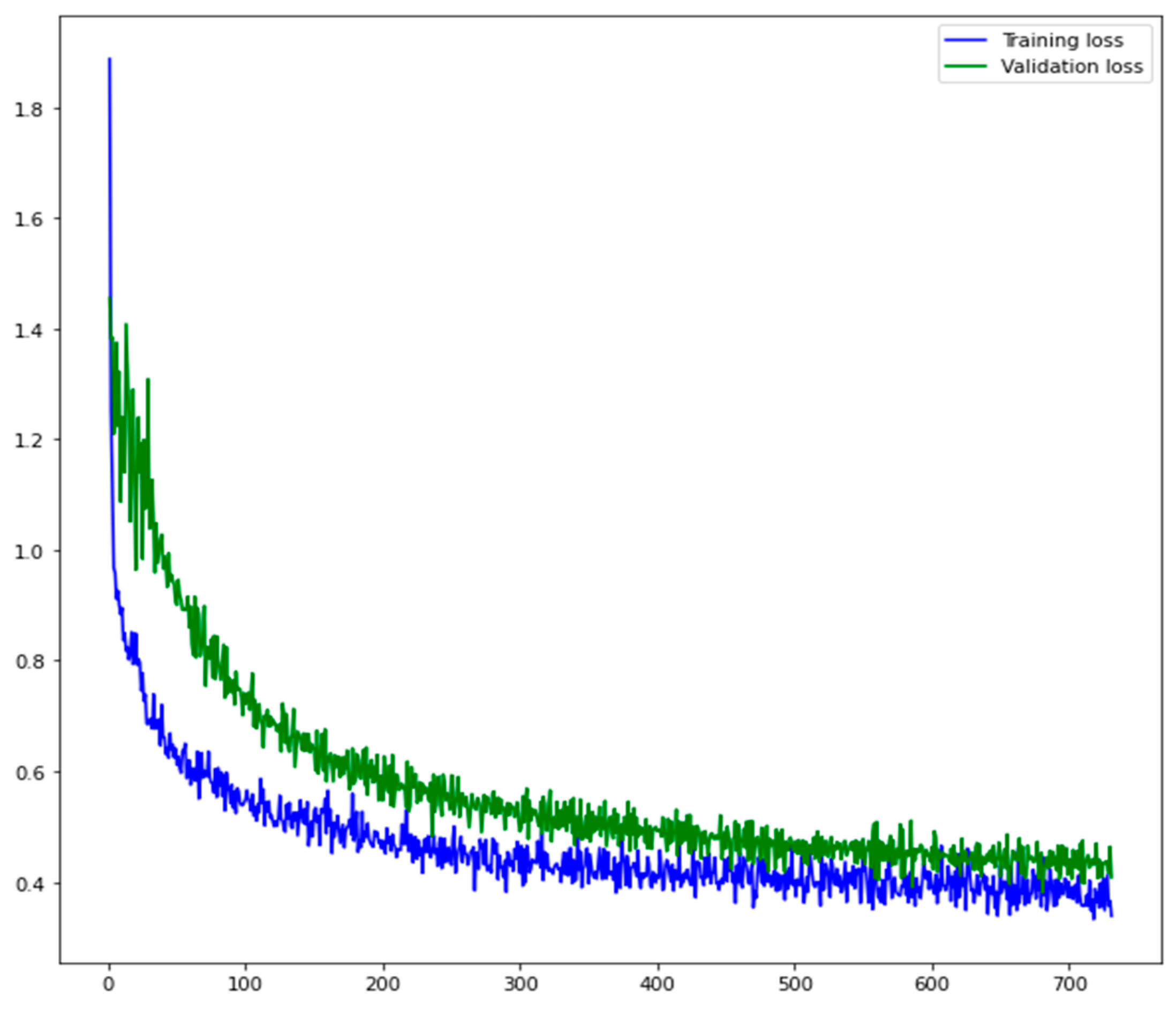
3.2. Loss Function
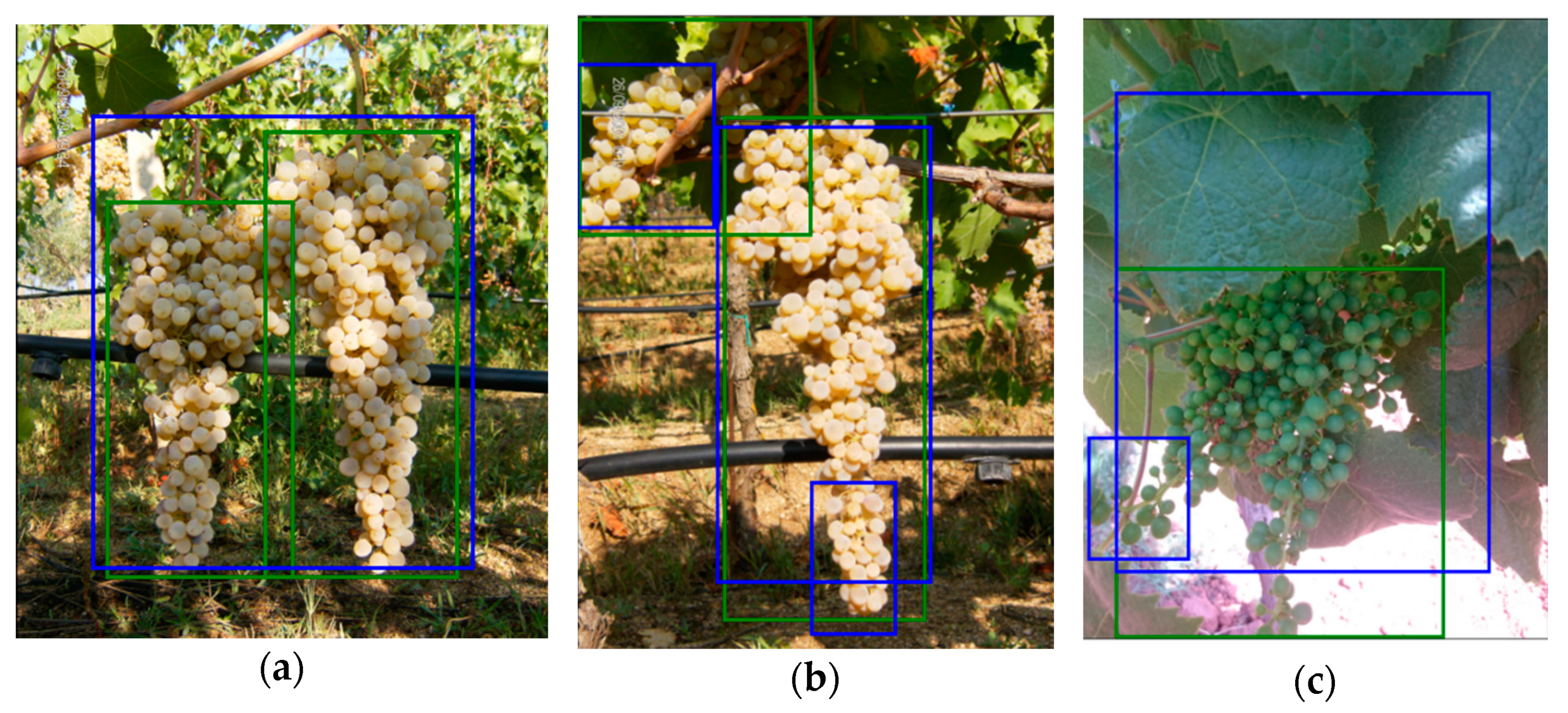
3.3. Detection Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Blackmore, S. Developing the Principles of Precision Farming. In Proceedings of the International Conference on Agropoles and Agro-Industrial Technological Parks (Agrotech 99), Barretos, Brazil, 15–19 November 1999. [Google Scholar]
- Sudduth, K.A. Engineering technologies for precision farming. In Proceedings of the International Seminar on Agricultural Mechanization Technology for Precision Farming, Suwon, Korea, 27 May 1999; pp. 5–27. [Google Scholar]
- Zhang, N.; Wang, M.; Wang, N. Precision agriculture—A worldwide overview. Comput. Electron. Agric. 2002, 36, 113–132. [Google Scholar] [CrossRef]
- Lindblom, J.; Lundström, C.; Ljung, M.; Jonsson, A. Promoting sustainable intensification in precision agriculture: Review of decision support systems development and strategies. Precis. Agric. 2017, 18, 309–331. [Google Scholar] [CrossRef]
- Ghiani, L.; Sassu, A.; Lozano, V.; Brundu, G.; Piccirilli, D.; Gambella, F. Use of UAVs and Canopy Height Model Applied on a Time Scale in the Vineyard. In Proceedings of the International Mid-Term Conference of the Italian Association of Agricultural Engineering, Matera, Italy, 12–13 September 2019; pp. 837–844. [Google Scholar]
- Ghiani, L.; Sassu, A.; Piccirilli, D.; Marcialis, G.L.; Gambella, F. Development of a matlab code for the evaluation of spray distribution with water-sensitive paper. In Proceedings of the International Mid-Term Conference of the Italian Association of Agricultural Engineering, Matera, Italy, 12–13 September 2019; pp. 845–853. [Google Scholar]
- Pierce, F.J.; Nowak, P. Aspects of precision agriculture. In Advances in Agronomy; Elsevier: Amsterdam, The Netherlands, 1999; Volume 67, pp. 1–85. [Google Scholar]
- Matese, A.; di Gennaro, S.F. Technology in precision viticulture: A state of the art review. Int. J. Wine Res. 2015, 7, 69–81. [Google Scholar] [CrossRef]
- Sartori, L.; Gambella, F. Comparison of mechanical and manual cane pruning operations on three varieties of grape (Cabernet Sauvignon, Merlot, and Prosecco) in Italy. Trans. ASABE 2014, 57, 701–707. [Google Scholar]
- Guido, V.; Mercenaro, L.; Gambella, F. Application of proximal sensing in viticulture: Comparison of different berry state conditions. Chem. Eng. Trans. Open Access 2017, 58, 613–618. [Google Scholar]
- Sassu, A.; Ghiani, L.; Pazzona, A.; Gambella, F. Development and Implementation of an Ultra-Low Volume (ULV) Spraying Equipment Installed on a Commercial UAV. In Proceedings of the International Mid-Term Conference of the Italian Association of Agricultural Engineering, Matera, Italy, 12–13 September 2019; pp. 563–571. [Google Scholar]
- Smart, R.E. Principles of grapevine canopy microclimate manipulation with implications for yield and quality. A review. Am. J. Enol. Vitic. 1985, 36, 230–239. [Google Scholar]
- Bramley, R.G.V.; Lamb, D.W. Making Sense of Vineyard Variability in Australia. In Proceedings of the International Symposium on Precision Viticulture, Ninth Latin American Congr. on Viticulture and Oenology; 2003; pp. 35–54. Available online: https://docplayer.net/21684245-Making-sense-of-vineyard-variability-in-australia.html (accessed on 5 June 2021).
- Satorra, J.A.; Casasnovas, J.A.M.; Dasi, M.R.; Polo, J.R.R. Precision viticulture. Research topics, challenges and opportunities in site-specific vineyard management. Span. J. Agric. Res. 2009, 7, 779–790. [Google Scholar]
- Sassu, A.; Gambella, F.; Ghiani, L.; Mercenaro, L.; Caria, M.; Pazzona, A.L. Advances in Unmanned Aerial System Remote Sensing for Precision Viticulture. Sensors 2021, 21, 956. [Google Scholar] [CrossRef] [PubMed]
- Casasnovas, J.A.M.; Aymerich, X.B. Viticultura de precisión: Predicción de cosecha a partir de variables del cultivo e índices de vegetación. Rev. Teledetec. 2005, 24, 67–71. [Google Scholar]
- Dunn, G.M.; Martin, S.R. Yield prediction from digital image analysis: A technique with potential for vineyard assessments prior to harvest. Aust. J. Grape Wine Res. 2004, 10, 196–198. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Viola, P.; Jones, M. Robust real-time object detection. Int. J. Comput. Vis. 2001, 4, 4. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, E.C. Deepfruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed]
- Bresilla, K.; Perulli, G.D.; Boini, A.; Morandi, B.; Grappadelli, L.C.; Manfrini, E.L. Single-shot convolution neural networks for real-time fruit detection within the tree. Front. Plant Sci. 2019, 10, 611. [Google Scholar] [CrossRef]
- Safonova, A.; Guirado, E.; Maglinets, Y.; Alcaraz-Segura, D.; Tabik, E.S. Olive Tree Biovolume from UAV Multi-Resolution Image Segmentation with Mask R-CNN. Sensors 2021, 21, 1617. [Google Scholar] [CrossRef]
- Fuentes, A.; Yoon, S.; Kim, S.C.; Park, E.D.S. A robust deep-learning-based detector for real-time tomato plant diseases and pests recognition. Sensors 2017, 17, 2022. [Google Scholar] [CrossRef]
- Picon, A.; Alvarez-Gila, A.; Seitz, M.; Ortiz-Barredo, A.; Echazarra, J.; Johannes, E.A. Deep convolutional neural networks for mobile capture device-based crop disease classification in the wild. Comput. Electron. Agric. 2019, 161, 280–290. [Google Scholar] [CrossRef]
- Reis, M.J.C.S.; Morais, R.; Peres, E.; Pereira, C.; Contente, O.; Soares, S.; Valente, A.; Baptista, J.; Ferreira, P.J.; Cruz, J.B. Automatic detection of bunches of grapes in natural environment from color images. J. Appl. Log. 2012, 10, 285–290. [Google Scholar] [CrossRef]
- Diago, M.P.; Sanz-Garcia, A.; Millan, B.; Blasco, J.; Tardaguila, J. Assessment of flower number per inflorescence in grapevine by image analysis under field conditions: Grapevine flower number per inflorescence by image analysis. J. Sci. Food Agric. 2014, 94, 1981–1987. [Google Scholar] [CrossRef]
- Liu, S.; Cossell, S.; Tang, J.; Dunn, G.; Whitty, M. A computer vision system for early stage grape yield estimation based on shoot detection. Comput. Electron. Agric. 2017, 137, 88–101. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Diago, M.P.; Correa, C.; Millán, B.; Barreiro, P.; Valero, C.; Tardaguila, J. Grapevine Yield and Leaf Area Estimation Using Supervised Classification Methodology on RGB Images Taken under Field Conditions. Sensors 2012, 12, 16988–17006. [Google Scholar] [CrossRef]
- Font, D.; Tresanchez, M.; Martínez, D.; Moreno, J.; Clotet, E.; Palacín, J. Vineyard Yield Estimation Based on the Analysis of High Resolution Images Obtained with Artificial Illumination at Night. Sensors 2015, 15, 8284–8301. [Google Scholar] [CrossRef]
- Aquino, A.; Millan, B.; Gutiérrez, S.; Tardáguila, J. Grapevine flower estimation by applying artificial vision techniques on images with uncontrolled scene and multi-model analysis. Comput. Electron. Agric. 2015, 119, 92–104. [Google Scholar] [CrossRef]
- Roscher, R.; Herzog, K.; Kunkel, A.; Kicherer, A.; Töpfer, R.; Förstner, W. Automated image analysis framework for high-throughput determination of grapevine berry sizes using conditional random fields. Comput. Electron. Agric. 2014, 100, 148–158. [Google Scholar] [CrossRef]
- Aquino, A.; Diago, M.P.; Millán, B.; Tardáguila, J. A new methodology for estimating the grapevine-berry number per cluster using image analysis. Biosyst. Eng. 2017, 156, 80–95. [Google Scholar] [CrossRef]
- Liu, S.; Whitty, M. Automatic grape bunch detection in vineyards with an SVM classifier. J. Appl. Log. 2015, 13, 643–653. [Google Scholar] [CrossRef]
- Nuske, S.; Wilshusen, K.; Achar, S.; Yoder, L.; Narasimhan, S.; Singh, S. Automated visual yield estimation in vineyards. J. Field Robot. 2014, 31, 837–860. [Google Scholar] [CrossRef]
- Mirbod, O.; Yoder, L.; Nuske, S. Automated Measurement of Berry Size in Images. IFAC-PapersOnLine 2016, 49, 79–84. [Google Scholar] [CrossRef]
- Coviello, L.; Cristoforetti, M.; Jurman, G.; Furlanello, C. GBCNet: In-Field Grape Berries Counting for Yield Estimation by Dilated CNNs. Appl. Sci. 2020, 10, 4870. [Google Scholar] [CrossRef]
- Seng, K.P.; Ang, L.-M.; Schmidtke, L.M.; Rogiers, S.Y. Computer Vision and Machine Learning for Viticulture Technology. IEEE Access 2018, 6, 67494–67510. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. Github. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 16 October 2020).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. airXiv 2015, arXiv:1405.0312[cs]. [Google Scholar]
- Mercenaro, L.; Usai, G.; Fadda, C.; Nieddu, G.; del Caro, A. Intra-varietal agronomical variability in Vitis vinifera L. cv. cannonau investigated by fluorescence, texture and colorimetric analysis. S. Afr. J. Enol. Vitic. 2016, 37, 67–78. [Google Scholar] [CrossRef]
- Nieddu, G.; Chessa, I.; Mercenaro, L. Primary and secondary characterization of a Vermentino grape clones collection. In Proceedings of the 2006 First International Symposium on Environment Identities and Mediterranean Area, Corte-Ajaccio, France, 10–13 July 2006; pp. 517–521. [Google Scholar] [CrossRef]
- Mercenaro, L.; Oliveira, A.; Cocco, M.; Nieddu, E.G. Biodiversity of Sardinian grapevine collection: Agronomical and physiological characterization. Acta Hortic. 2017, 65–72. [Google Scholar] [CrossRef]
- Komm, B.; Moyer, M. Vineyard Yield Estimation. 2015. Available online: https://research.libraries.wsu.edu:8443/xmlui/handle/2376/5265 (accessed on 16 October 2020).
- Sabbatini, P.; Dami, I.; Howell, G.S. Predicting Harvest Yield in Juice and Wine Grape Vineyards. Ext. Bull. 2012, 3186, 12. [Google Scholar]
- Nuske, S.; Achar, S.; Bates, T.; Narasimhan, S.; Singh, S. Yield estimation in vineyards by visual grape detection. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 2352–2358. [Google Scholar] [CrossRef]
- Palacios, F.; Diago, M.P.; Tardaguila, J. A Non-Invasive Method Based on Computer Vision for Grapevine Cluster Compactness Assessment Using a Mobile Sensing Platform under Field Conditions. Sensors 2019, 19, 3799. [Google Scholar] [CrossRef] [PubMed]
- Nezan, J.F.; Siret, N.; Wipliez, M.; Palumbo, F.; Raffo, L. Multi-purpose systems: A novel dataflow-based generation and mapping strategy. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Seoul, Korea, 20–23 May 2012; pp. 3073–3076. [Google Scholar]
- Li, L.; Sau, C.; Fanni, T.; Li, J.; Viitanen, T.; Christophe, F.; Palumbo, F.; Raffo, L.; Huttunen, H.; Takala, J.; et al. An integrated hardware/software design methodology for signal processing systems. J. Syst. Archit. 2019, 93, 1–19. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Fully Automated Detection Process | Large Data Set (More Than a Thousand) | Large Grape Variety (More Than Ten) |
|---|---|---|---|
| [34] | Yes (by camera internal flash at night) | No (190 images of white grapes, 35 images of red grapes) | No (Port) |
| [35] | No (using a uniform background of black color) | No (90 images) | No (Tempranillo, Graciano, and Carignan) |
| [36] | Yes | Yes (thousands of images extracted from hundreds of videos) | No (Chardonnay and Shiraz) |
| [38] | Yes | No (70 images) | No (Tempranillo) |
| [39] | Yes (with artificial illumination at night) | No (40 images) | No (Flame Seedless) |
| [40] | No (capturing inflorescences facing the Sun and casting a shadow on the scene to create a homogeneous illumination) | No (40 images) | No (Airen, Albariño, Tempranillo, and Verdejo) |
| [41] | Yes | No (139 images) | No (Riesling, Pinot Blanc, Pinot Noir, and Dornfelder) |
| [42] | No (using a dark cardboard behind the cluster) | No (152 images) | Yes (Tempranillo, Semillon, Merlot, Grenache, Cabernet Sauvignon, Chenin Blanc, and Sauvignon Blanc) |
| [43] | Yes | No (160 images) | No (Shiraz and Cabernet Sauvignon) |
| [44] | Yes (with natural illumination, flash illumination, and cross-polarized flash illumination) | Yes (more than one thousand images) | No (Traminette, Riesling, Chardonnay, Petite Syrah, Pinot Noir, and Flame Seedless) |
| [45] | Yes | Yes (more or less 100,000 images) | No (Petite Syrah and Cabernet Sauvignon) |
| [47] | Yes | Yes (GrapeCS-ML dataset: more than 2000 images) | Yes (Merlot, Cabernet Sauvignon, Saint Macaire, Flame Seedless, Viognier, Ruby Seedless, Riesling, Muscat Hamburg, Purple Cornichon, Sultana, Sauvignon Blanc, Chardonnay, Shiraz, Pinot Noir) |
| This work | Yes | Yes (GrapeCS-ML dataset: more than 2000 images + Internal dataset: 451 images) | Yes (Merlot, Cabernet Sauvignon, Saint Macaire, Flame Seedless, Viognier, Ruby Seedless, Riesling, Muscat Hamburg, Purple Cornichon, Sultana, Sauvignon Blanc, Chardonnay, Shiraz, Pinot Noir, Vermentino, Cannonau (i.e., Granache), Cagnulari (i.e., Graciano)) |
| GrapeCS-ML Dataset | ||
|---|---|---|
| Train | Set 1 | 1114 images |
| Validation | Set 2 | 505 images |
| Test | Set 3 | 204 images |
| Set 4 | 242 images | |
| Set 5 | 49 images | |
| Internal Dataset | 451 images | |
| GrapeCS-ML Dataset | |
|---|---|
| Set 1 | 480 × 640 (1102), 640 × 480 (7), 1200 × 1600 (5) |
| Set 2 | 480 × 640 (253), 640 × 480 (198), 1200 × 1600 (28), 1600 × 1200 (26) |
| Set 3 | 480 × 640 (81), 640 × 480 (81), 1200 × 1600 (21), 1600 × 1200 (21) |
| Set 4 | 480 × 640 (35), 640 × 480 (206) |
| Set 5 | 640 × 480 (1), 3024 × 3024 (12), 3024 × 4032 (36), 3402 × 3752 (1) |
| Internal Dataset | 360 × 640 (1), 480 × 640 (29), 640 × 480 (17), 1600 × 2128 (2), 1904 × 2528 (3), 2048 × 1536 (36), 2112 × 2816 (23), 2304 × 3072 (1), 2320 × 3088 (120), 2560 × 1536 (3), 2816 × 2112 (139), 3072 × 2304 (9), 3088 × 2320 (43), 3456 × 4608 (2), 4160 × 2340 (1), 4608 × 3456 (22) |
| mAP | |||
|---|---|---|---|
| Dataset Name | Train Complete, with Augmentation | Train 10%, with Augmentation | Train 10%, without Augmentation |
| Validation (Set 2) | 93.97% | 90.95% | 85.24% |
| Test (Set 3 + Set 4 + Set 5) | 92.78% | 90.98% | 87.65% |
| Set 3 | 98.77% | 98.69% | 97.30% |
| Set 4 | 89.18% | 86.70% | 83.40% |
| Set 5 | 85.64% | 80.07% | 68.44% |
| Internal Dataset | 89.90% | 86.41% | 70.75% |
| Dataset Name | mAP (Total Number of Images) | |||||
|---|---|---|---|---|---|---|
| 1 bunch | 2 bunches | 3 bunches | 4 bunches | 5 bunches | 6 bunches | |
| Validation (Set 2) | 98.85% (369) | 82.61% (126) | 57.22% (10) | |||
| Test (Set 3, 4, 5) | 99.75% (395) | 65.41% (73) | 72.59% (15) | 51.72% (8) | 60.00% (2) | 64.63% (2) |
| Set 3 | 100.00% (195) | 72.22% (9) | ||||
| Set 4 | 99.45% (181) | 57.70% (53) | 65.28% (8) | |||
| Set 5 | 100.00% (19) | 96.97% (11) | 80.95% (7) | 51.72% (8) | 60.00% (2) | 64.63% (2) |
| Internal Dataset | 96.79% (218) | 85.39% (166) | 76.11% (46) | 80.89% (17) | 99.17% (4) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghiani, L.; Sassu, A.; Palumbo, F.; Mercenaro, L.; Gambella, F. In-Field Automatic Detection of Grape Bunches under a Totally Uncontrolled Environment. Sensors 2021, 21, 3908. https://doi.org/10.3390/s21113908
Ghiani L, Sassu A, Palumbo F, Mercenaro L, Gambella F. In-Field Automatic Detection of Grape Bunches under a Totally Uncontrolled Environment. Sensors. 2021; 21(11):3908. https://doi.org/10.3390/s21113908
Chicago/Turabian StyleGhiani, Luca, Alberto Sassu, Francesca Palumbo, Luca Mercenaro, and Filippo Gambella. 2021. "In-Field Automatic Detection of Grape Bunches under a Totally Uncontrolled Environment" Sensors 21, no. 11: 3908. https://doi.org/10.3390/s21113908
APA StyleGhiani, L., Sassu, A., Palumbo, F., Mercenaro, L., & Gambella, F. (2021). In-Field Automatic Detection of Grape Bunches under a Totally Uncontrolled Environment. Sensors, 21(11), 3908. https://doi.org/10.3390/s21113908