
Predicting Grape Sugar Content under Quality Attributes Using Normalized Difference Vegetation Index Data and Automated Machine Learning




Abstract
:1. Introduction
2. Materials and Methods
2.1. Solution Workflow
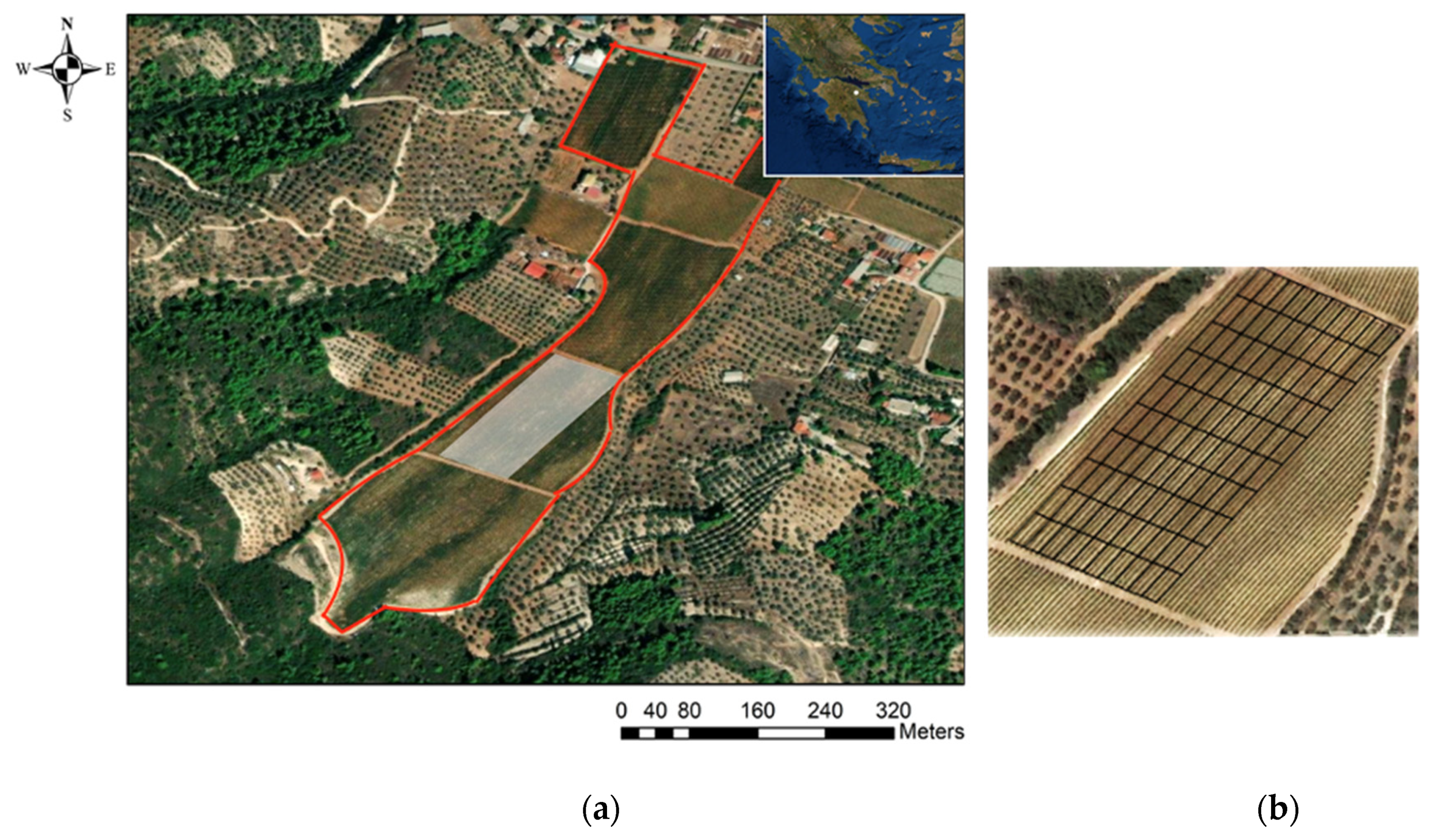
2.2. Study Area
2.3. Canopy Reflectance Data Collection
2.4. Data Preparation
2.5. Qualitative Characters Analysis
2.6. Statistical Analysis
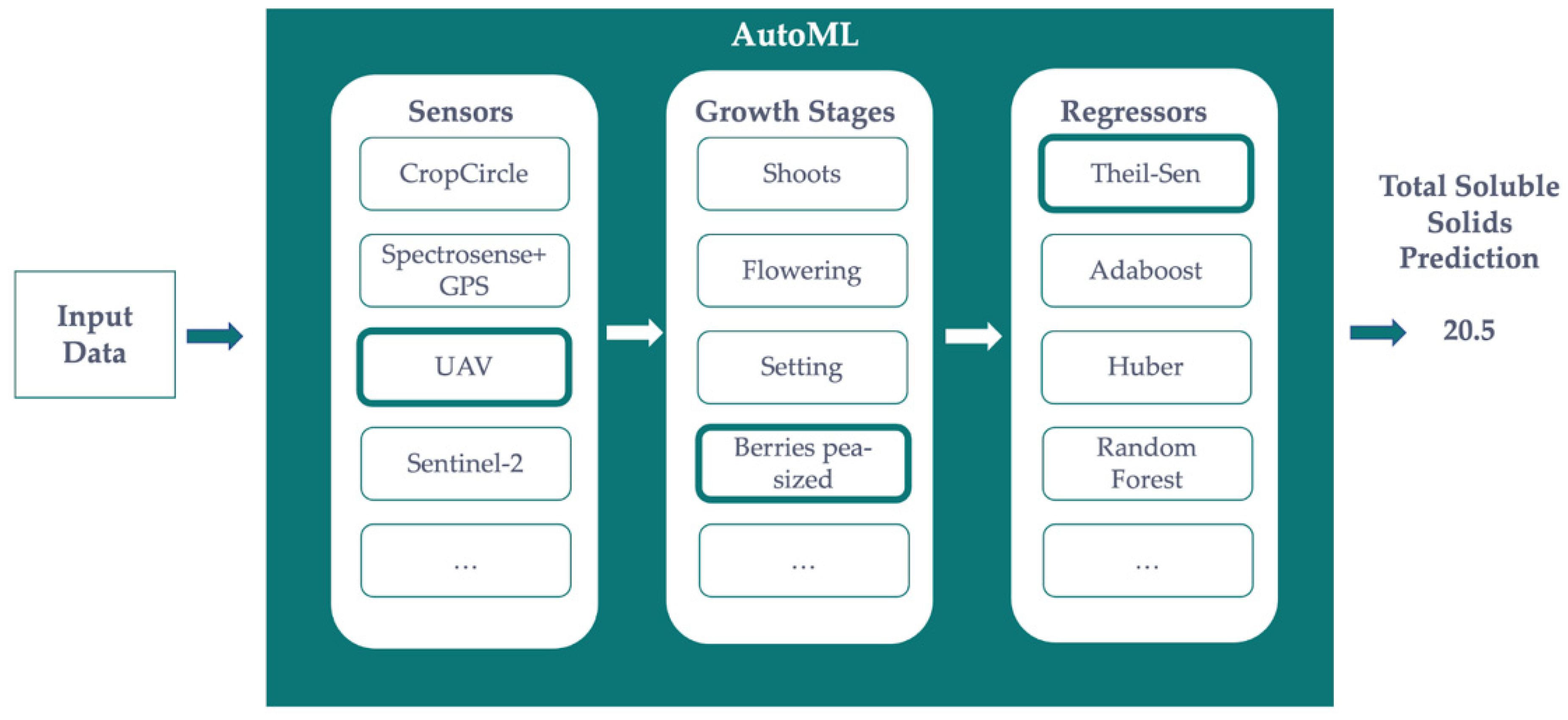
2.7. Architecture of the Solution
2.8. Regression Methods and AutoML Setup
- Ordinary Least Square (OLS): The most common estimation method for computing linear regression models, which can be found in related works such as, Prasetyo et al. (2018) [32].
- Theil-Sen Estimator Method: It is the most popular non-parametric technique for estimating a linear trend, and makes no assumption about the underlying distribution of the input data [33].
- Huber Regression: It is aware of the possibility of outliers in a dataset and assigns them less weight than other samples, unlike Theil-Sen, which ignores them [34].
- Decision Trees: This method uses a non-parametric learning approach. Its main advantage is that it is easy to interpret. Unless the model is too complicated, it can be visualized to better understand why the classifier made a particular decision.
- AdaBoost: The AdaBoost algorithm (adaptive boosting) uses an ensemble learning technique known as boosting, in which a decision tree is retrained several times, with greater emphasis on data samples where regression is imprecise [35].
- Random Forest: A supervised learning approach in which the ensemble learning method is used for regression. This combines numerous decision tree regressors into a single model trained on many data samples collected on the input feature (in this case, NDVI) using the bootstrap sampling method [36].
- Extremely Randomized Trees: Extra Trees is similar to Random Forest in that it combines predictions from many decision trees, but instead of bootstrap sampling, it uses the entire original input sample [37].
- Support Vector Machines: It is one of the most robust prediction methods. The (non-linear) model produced by this algorithm depends only on a subset of the training data because the cost function does not take into account any training data close to the model predictions [38].
- Automatic Relevance Determination: It is the regularization of the solution space using a parameterized, data-dependent priority distribution that effectively removes redundant or superfluous features [39].
2.9. Evaluation Methodology
2.10. Software and Hardware
3. Results
3.1. Exploratory Correlation Analysis
3.2. Regression Analysis
3.2.1. Comparing Manually Fine-Tuned ML and AutoML
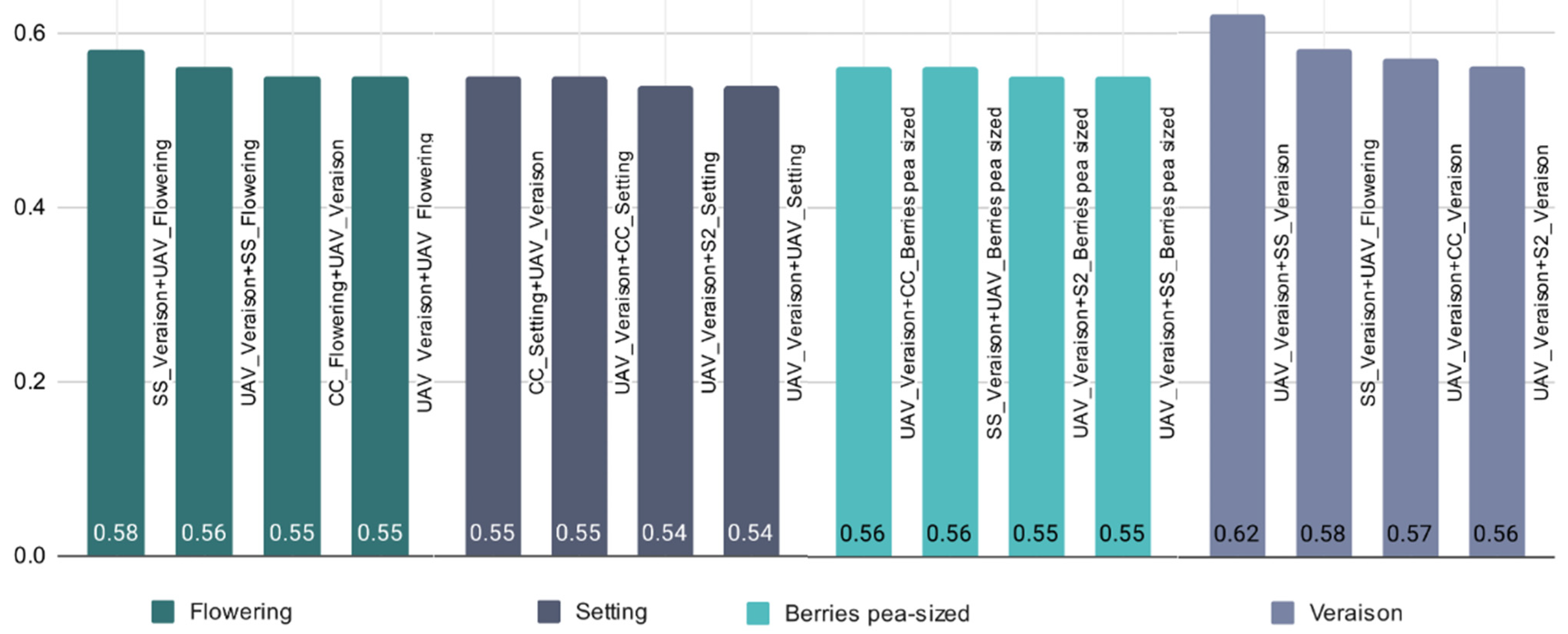
3.2.2. Combination of Sensors and Growth Stages
3.2.3. Combinations over the Two Growing Seasons, 2019 and 2020
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Balafoutis, A.; Beck, B.; Fountas, S.; Vangeyte, J.; Wal, T.; Soto, I.; Gómez-Barbero, M.; Barnes, A.; Eory, V. Precision Agriculture Technologies Positively Contributing to GHG Emissions Mitigation, Farm Productivity and Economics. Sustainability 2017, 9, 1339. [Google Scholar] [CrossRef] [Green Version]
- Balafoutis, A.; Koundouras, S.; Anastasiou, E.; Fountas, S.; Arvanitis, K. Life Cycle Assessment of Two Vineyards after the Application of Precision Viticulture Techniques: A Case Study. Sustainability 2017, 9, 1997. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, S.; Sadistap, S. Non-Destructive Sensing Methods for Quality Assessment of on-Tree Fruits: A Review. Food Meas. 2018, 12, 497–526. [Google Scholar] [CrossRef]
- Dai, Z.W.; Ollat, N.; Gomès, E.; Decroocq, S.; Tandonnet, J.-P.; Bordenave, L.; Pieri, P.; Hilbert, G.; Kappel, C.; van Leeuwen, C.; et al. Ecophysiological, Genetic, and Molecular Causes of Variation in Grape Berry Weight and Composition: A Review. Am. J. Enol. Vitic. 2011, 62, 413–425. [Google Scholar] [CrossRef] [Green Version]
- Iland, P. Chemical Analysis of Grapes and Wine: Techniques and Concepts; Patrick Iland Wine Promotions: Adelaide, Australia, 2013; ISBN 978-0-9581605-1-3. [Google Scholar]
- Cortez, P.; Teixeira, J.; Cerdeira, A.; Almeida, F.; Matos, T.; Reis, J. Using Data Mining for Wine Quality Assessment. In Discovery Science; Gama, J., Costa, V.S., Jorge, A.M., Brazdil, P.B., Eds.; Lecture Notes in Computer Science; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2009; Volume 5808, pp. 66–79. ISBN 978-3-642-04746-6. [Google Scholar]
- Acevedo-Opazo, C.; Tisseyre, B.; Guillaume, S.; Ojeda, H. The Potential of High Spatial Resolution Information to Define Within-Vineyard Zones Related to Vine Water Status. Precis. Agric. 2008, 9, 285–302. [Google Scholar] [CrossRef] [Green Version]
- Hall, A.; Lamb, D.W.; Holzapfel, B.P.; Louis, J.P. Within-Season Temporal Variation in Correlations between Vineyard Canopy and Winegrape Composition and Yield. Precis. Agric. 2011, 12, 103–117. [Google Scholar] [CrossRef]
- Baluja, J.; Diago, M.P.; Goovaerts, P.; Tardaguila, J. Assessment of the Spatial Variability of Anthocyanins in Grapes Using a Fluorescence Sensor: Relationships with Vine Vigour and Yield. Precis. Agric. 2012, 13, 457–472. [Google Scholar] [CrossRef]
- Sun, L.; Gao, F.; Anderson, M.; Kustas, W.; Alsina, M.; Sanchez, L.; Sams, B.; McKee, L.; Dulaney, W.; White, W.; et al. Daily Mapping of 30 m LAI and NDVI for Grape Yield Prediction in California Vineyards. Remote Sens. 2017, 9, 317. [Google Scholar] [CrossRef] [Green Version]
- Anastasiou, E.; Balafoutis, A.; Darra, N.; Psiroukis, V.; Biniari, A.; Xanthopoulos, G.; Fountas, S. Satellite and Proximal Sensing to Estimate the Yield and Quality of Table Grapes. Agriculture 2018, 8, 94. [Google Scholar] [CrossRef] [Green Version]
- Darra, N.; Psomiadis, E.; Kasimati, A.; Anastasiou, A.; Anastasiou, E.; Fountas, S. Remote and Proximal Sensing-Derived Spectral Indices and Biophysical Variables for Spatial Variation Determination in Vineyards. Agronomy 2021, 11, 741. [Google Scholar] [CrossRef]
- Di Gennaro, S.F.; Toscano, P.; Cinat, P.; Berton, A.; Matese, A. A precision viticulture UAV-based approach for early yield prediction in vineyard. In Precision Agriculture’19, Proceedings of the 12th European Conference on Precision Agriculture, Montpellier, France, 8–11 July; Wageningen Academic Publishers: Wageningen, The Netherlands, 2019; pp. 373–379. [Google Scholar]
- Ballesteros, R.; Intrigliolo, D.S.; Ortega, J.F.; Ramírez-Cuesta, J.M.; Buesa, I.; Moreno, M.A. Vineyard Yield Estimation by Combining Remote Sensing, Computer Vision and Artificial Neural Network Techniques. Precis. Agric. 2020, 21, 1242–1262. [Google Scholar] [CrossRef]
- Arab, S.T.; Noguchi, R.; Matsushita, S.; Ahamed, T. Prediction of Grape Yields from Time-Series Vegetation Indices Using Satellite Remote Sensing and a Machine-Learning Approach. Remote Sens. Appl. Soc. Environ. 2021, 22, 100485. [Google Scholar] [CrossRef]
- Kasimati, A.; Espejo-Garcia, B.; Vali, E.; Malounas, I.; Fountas, S. Investigating a Selection of Methods for the Prediction of Total Soluble Solids Among Wine Grape Quality Characteristics Using Normalized Difference Vegetation Index Data From Proximal and Remote Sensing. Front. Plant Sci. 2021, 12, 683078. [Google Scholar] [CrossRef] [PubMed]
- Nuske, S.; Wilshusen, K.; Achar, S.; Yoder, L.; Narasimhan, S.; Singh, S. Automated Visual Yield Estimation in Vineyards: Automated Visual Yield Estimation. J. Field Robot. 2014, 31, 837–860. [Google Scholar] [CrossRef]
- Liu, S.; Li, X.; Wu, H.; Xin, B.; Tang, J.; Petrie, P.R.; Whitty, M. A Robust Automated Flower Estimation System for Grape Vines. Biosyst. Eng. 2018, 172, 110–123. [Google Scholar] [CrossRef]
- Aquino, A.; Millan, B.; Diago, M.-P.; Tardaguila, J. Automated Early Yield Prediction in Vineyards from On-the-Go Image Acquisition. Comput. Electron. Agric. 2018, 144, 26–36. [Google Scholar] [CrossRef]
- Sirsat, M.S.; Mendes-Moreira, J.; Ferreira, C.; Cunha, M. Machine Learning Predictive Model of Grapevine Yield Based on Agroclimatic Patterns. Eng. Agric. Environ. Food 2019, 12, 443–450. [Google Scholar] [CrossRef]
- Smith, M.L.; Smith, L.N.; Hansen, M.F. The Quiet Revolution in Machine Vision-a State-of-the-Art Survey Paper, Including Historical Review, Perspectives, and Future Directions. Comput. Ind. 2021, 130, 103472. [Google Scholar] [CrossRef]
- Krauß, J.; Pacheco, B.M.; Zang, H.M.; Schmitt, R.H. Automated Machine Learning for Predictive Quality in Production. Procedia CIRP 2020, 93, 443–448. [Google Scholar] [CrossRef]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. Adv. Neural Inf. Processing Syst. 2015, 28, 2755–2763. [Google Scholar]
- Kotthoff, L.; Thornton, C.; Hoos, H.H.; Hutter, F.; Leyton-Brown, K. Auto-WEKA. In Automated Machine Learning; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; The Springer Series on Challenges in Machine Learning; Springer International Publishing: Cham, Switzerland, 2019; pp. 81–95. ISBN 978-3-030-05317-8. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No Free Lunch Theorems for Optimization. IEEE Trans. Evol. Computat. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Mohr, F.; Wever, M.; Tornede, A.; Hullermeier, E. Predicting Machine Learning Pipeline Runtimes in the Context of Automated Machine Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3055–3066. [Google Scholar] [CrossRef] [PubMed]
- Hayashi, M.; Tamai, K.; Owashi, Y.; Miura, K. Automated Machine Learning for Identification of Pest Aphid Species (Hemiptera: Aphididae). Appl. Entomol. Zool. 2019, 54, 487–490. [Google Scholar] [CrossRef]
- Koh, J.C.O.; Spangenberg, G.; Kant, S. Automated Machine Learning for High-Throughput Image-Based Plant Phenotyping. Remote Sens. 2021, 13, 858. [Google Scholar] [CrossRef]
- Espejo-Garcia, B.; Malounas, I.; Vali, E.; Fountas, S. Testing the Suitability of Automated Machine Learning for Weeds Identification. AI 2021, 2, 4. [Google Scholar] [CrossRef]
- Taylor, J.A.; McBratney, A.B.; Whelan, B.M. Establishing Management Classes for Broadacre Agricultural Production. Agron. J. 2007, 99, 1366–1376. [Google Scholar] [CrossRef]
- Stavrakaki, M.; Biniari, K.; Daskalakis, I.; Bouza, D. Polyphenol Content and Antioxidant Capacity of the Skin Extracts of Berries from Seven Biotypes of the Greek Grapevine Cultivar Korinthiaki Staphis’(Vitis Vinifera’L.). Aust. J. Crop Sci. 2018, 12, 1927–1936. [Google Scholar] [CrossRef]
- Prasetyo, Y.; Sukmono, A.; Aziz, K.W.; Prakosta Santu Aji, B.J. Rice Productivity Prediction Model Design Based On Linear Regression of Spectral Value Using NDVI and LSWI Combination On Landsat-8 Imagery. IOP Conf. Ser. Earth Environ. Sci. 2018, 165, 012002. [Google Scholar] [CrossRef] [Green Version]
- Sen, P.K. Estimates of the Regression Coefficient Based on Kendall’s Tau. J. Am. Stat. Assoc. 1968, 63, 1379–1389. [Google Scholar] [CrossRef]
- Huber, P.J. Robust Regression: Asymptotics, Conjectures and Monte Carlo. Ann. Stat. 1973, 1, 799–821. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests Machine Learning. View Artic. PubMed/NCBI Google Sch. 2001, 45, 5–32. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Neal, R.M. Bayesian Learning for Neural Networks; Springer Science & Business Media: New York, NY, USA, 2012; Volume 118, ISBN 1-4612-0745-2. [Google Scholar]
- Gupta, Y. Selection of Important Features and Predicting Wine Quality Using Machine Learning Techniques. Procedia Comput. Sci. 2018, 125, 305–312. [Google Scholar] [CrossRef]
- Cheng, C.-L.; Shalabh; Garg, G. Coefficient of Determination for Multiple Measurement Error Models. J. Multivar. Anal. 2014, 126, 137–152. [Google Scholar] [CrossRef] [Green Version]
- Anastasiou, E.; Castrignanò, A.; Arvanitis, K.; Fountas, S. A Multi-Source Data Fusion Approach to Assess Spatial-Temporal Variability and Delineate Homogeneous Zones: A Use Case in a Table Grape Vineyard in Greece. Sci. Total Environ. 2019, 684, 155–163. [Google Scholar] [CrossRef]
- Fiorillo, E.; Crisci, A.; De Filippis, T.; Di Gennaro, S.F.; Di Blasi, S.; Matese, A.; Primicerio, J.; Vaccari, F.P.; Genesio, L. Airborne High-Resolution Images for Grape Classification: Changes in Correlation between Technological and Late Maturity in a Sangiovese Vineyard in Central Italy: Precision Viticulture—Central Italy. Aust. J. Grape Wine Res. 2012, 18, 80–90. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bramley, R.G.V.; Trought, M.C.; Praat, J.-P. Vineyard Variability in Marlborough, New Zealand: Characterising Variation in Vineyard Performance and Options for the Implementation of Precision Viticulture. Aust. J. Grape Wine Res. 2011, 17, 72–78. [Google Scholar] [CrossRef]
- Primicerio, J.; Di Gennaro, S.F.; Fiorillo, E.; Genesio, L.; Lugato, E.; Matese, A.; Vaccari, F.P. A Flexible Unmanned Aerial Vehicle for Precision Agriculture. Precis. Agric. 2012, 13, 517–523. [Google Scholar] [CrossRef]
- Taskos, D.G.; Koundouras, S.; Stamatiadis, S.; Zioziou, E.; Nikolaou, N.; Karakioulakis, K.; Theodorou, N. Using Active Canopy Sensors and Chlorophyll Meters to Estimate Grapevine Nitrogen Status and Productivity. Precis. Agric. 2015, 16, 77–98. [Google Scholar] [CrossRef]
- Reynolds, A.G.; Lee, H.-S.; Dorin, B.; Brown, R.; Jollineau, M.; Shemrock, A.; Crombleholme, M.; Poirier, E.J.; Zheng, W.; Gasnier, M. Mapping Cabernet Franc Vineyards by Unmanned Aerial Vehicles (UAVs) for Variability in Vegetation Indices, Water Status, and Virus Titer. In Proceedings of the E3S Web of Conferences, Zaragoza, Spain, 18–22 June 2018; Volume 50, p. 02010. [Google Scholar]
- Sozzi, M.; Kayad, A.; Marinello, F.; Taylor, J.; Tisseyre, B. Comparing Vineyard Imagery Acquired from Sentinel-2 and Unmanned Aerial Vehicle (UAV) Platform. Oeno One 2020, 54, 189–197. [Google Scholar] [CrossRef] [Green Version]
- Matese, A.; Di Gennaro, S.F.; Miranda, C.; Berton, A.; Santesteban, L.G. Evaluation of Spectral-Based and Canopy-Based Vegetation Indices from UAV and Sentinel 2 Images to Assess Spatial Variability and Ground Vine Parameters. Adv. Anim. Biosci. 2017, 8, 817–822. [Google Scholar] [CrossRef]
- Arnó Satorra, J.; Martínez Casasnovas, J.A.; Ribes Dasi, M.; Rosell Polo, J.R. Precision Viticulture. Research Topics, Challenges and Opportunities in Site-Specific Vineyard Management. Span. J. Agric. Res. 2009, 7, 779–790. [Google Scholar] [CrossRef] [Green Version]
- Henry, D.; Aubert, H.; Véronèse, T. Proximal Radar Sensors for Precision Viticulture. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4624–4635. [Google Scholar] [CrossRef]
- Xue, J.; Su, B. Significant Remote Sensing Vegetation Indices: A Review of Developments and Applications. J. Sens. 2017, 2017, 1353691. [Google Scholar] [CrossRef] [Green Version]
- Lamb, D.W.; Weedon, M.M.; Bramley, R.G.V. Using Remote Sensing to Predict Grape Phenolics and Colour at Harvest in a Cabernet Sauvignon Vineyard: Timing Observations against Vine Phenology and Optimising Image Resolution. Aust. J. Grape Wine Res. 2004, 10, 46–54. [Google Scholar] [CrossRef] [Green Version]
- Kazmierski, M.; Glémas, P.; Rousseau, J.; Tisseyre, B. Temporal Stability of Within-Field Patterns of NDVI in Non Irrigated Mediterranean Vineyards. Oeno One 2011, 45, 61–73. [Google Scholar] [CrossRef]
- Tagarakis, A.; Liakos, V.; Fountas, S.; Koundouras, S.; Gemtos, T.A. Management Zones Delineation Using Fuzzy Clustering Techniques in Grapevines. Precis. Agric. 2013, 14, 18–39. [Google Scholar] [CrossRef]
- Fountas, S.; Anastasiou, E.; Balafoutis, A.; Koundouras, S.; Theoharis, S.; Theodorou, N. The Influence of Vine Variety and Vineyard Management on the Effectiveness of Canopy Sensors to Predict Winegrape Yield and Quality. In Proceedings of the Proceedings of the International Conference of Agricultural Engineering, Zurich, Switzerland, 6–10 July 2014; pp. 6–10. [Google Scholar]
- García-Estévez, I.; Quijada-Morín, N.; Rivas-Gonzalo, J.C.; Martínez-Fernández, J.; Sánchez, N.; Herrero-Jiménez, C.M.; Escribano-Bailón, M.T. Relationship between Hyperspectral Indices, Agronomic Parameters and Phenolic Composition of Vitis Vinifera Cv Tempranillo Grapes. J. Sci. Food Agric. 2017, 97, 4066–4074. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhatnagar, R.; Gohain, G.B. Crop Yield Estimation Using Decision Trees and Random Forest Machine Learning Algorithms on Data from Terra (EOS AM-1) & Aqua (EOS PM-1) Satellite Data. In Machine Learning and Data Mining in Aerospace Technology; Springer: Cham, Switzerland, 2020; pp. 107–124. [Google Scholar]
- Kasimati, A.; Kalogrias, A.; Psiroukis, V.; Grivakis, K.; Taylor, J.A.; Fountas, S. 17. Are all NDVI maps created equal—Comparing vineyard NDVI data from proximal and remote sensing. In Precision Agriculture’21, Proceedings of the 13th European Conference on Precision Agriculture (ECPA), Budapest, Hungary, 19–22 July 2021; Wageningen Academic Publishers: Wageningen, The Netherlands, 2021; pp. 155–162. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dates | EL No-Stage | Description |
|---|---|---|
| 15 May–30 May | 12-Shoots | 5 leaves separated; shoots about 10 cm long; inflorescence clear |
| 1 June–20 June | 23-Flowering | 16–20 leaves separated; 50% caps off |
| 21 June–20 July | 27-Setting | Young berries enlarging, bunch at right angles to stem |
| 21 July–15 August | 31-Berries pea-sized | About 7 mm in diameter |
| 16 August–10 September | 35-Véraison | Berries begin to color and increase in size |
| 11 September–20 September | 38-Harvest | Berries ready for harvest |
| (a) Manually Fine-Tuned ML | (b) AutoML | |||||
|---|---|---|---|---|---|---|
| Sensor_Growth Stage | R² (avg) | RMSE | Sensor_Growth Stage | R² (avg) | RMSE | |
| 2019 | SS_Véraison | 0.51 ± 0.09 | 1.45 ± 0.19 | SS_Véraison | 0.57 ± 0.05 | 1.14 ± 0.29 |
| CC_Véraison | 0.42 ± 0.10 | 1.67 ± 0.35 | UAV_Véraison | 0.52 ± 0.04 | 1.22 ± 0.25 | |
| SS_Berries pea-sized | 0.41 ± 0.11 | 1.71 ± 0.24 | S2_Berries pea sized | 0.49 ± 0.06 | 1.30 ± 0.48 | |
| UAV_Véraison | 0.38 ± 0.10 | 1.95 ± 0.55 | CC_Véraison | 0.49 ± 0.08 | 1.25 ± 0.26 | |
| 2020 | UAV_Véraison | 0.61 ± 0.03 | 1.37 ± 0.19 | UAV_Véraison | 0.65 ± 0.04 | 1.22 ± 0.36 |
| UAV_Berries pea-sized | 0.57 ± 0.04 | 1.55 ± 0.32 | UAV_Flowering | 0.59 ± 0.05 | 1.30 ± 0.41 | |
| UAV_Flowering | 0.56 ± 0.06 | 1.75 ± 0.19 | UAV_Berries pea sized | 0.59 ± 0.05 | 1.31 ± 0.32 | |
| SS_Setting | 0.44 ± 0.0 | 1.73 ± 0.23 | SS_Setting | 0.54 ± 0.03 | 1.44 ± 0.53 | |
| Combined Sensor_Growth Stage | R² (avg) | RMSE | |
|---|---|---|---|
| 2019 | SS_Véraison + UAV_Véraison | 0.58 ± 0.06 | 1.08 ± 0.33 |
| SS_Véraison + UAV_Setting | 0.57 ± 0.06 | 1.08 ± 0.34 | |
| SS_Véraison + CC_Véraison | 0.57 ± 0.08 | 1.09 ± 0.3 | |
| SS_Véraison + S2_Véraison | 0.57 ± 0.07 | 1.10 ± 0.35 | |
| 2020 | UAV_Véraison + SS_Véraison | 0.66 ± 0.07 | 1.16 ± 0.36 |
| UAV_Véraison + S2_Véraison | 0.66 ± 0.07 | 1.17 ± 0.35 | |
| UAV_Véraison + S2_Flowering | 0.66 ± 0.06 | 1.17 ± 0.34 | |
| CC_Flowering + UAV_Véraison | 0.65 ± 0.07 | 1.19 ± 0.38 |
| Sensor-Based Combined Sensor_Growth Stages | R² (avg) | RMSE | ||
|---|---|---|---|---|
| 2019 | SS_Véraison + | SS_Flowering | 0.54 ± 0.06 | 1.13 ± 0.29 |
| SS_Véraison | 0.53 ± 0.08 | 1.14 ± 0.32 | ||
| SS_Berries pea sized | 0.52 ± 0.08 | 1.13 ± 0.21 | ||
| CC_Véraison + | CC_Véraison | 0.48 ± 0.15 | 1.20 ± 0.34 | |
| UAV_Véraison + | UAV_Flowering | 0.47 ± 0.12 | 1.21 ± 0.29 | |
| UAV_Berries pea sized | 0.46 ± 0.14 | 1.22 ± 0.19 | ||
| UAV_Setting | 0.46 ± 0.11 | 1.24 ± 0.33 | ||
| S2_Berries pea sized + | S2_Flowering | 0.44 ± 0.22 | 1.24 ± 0.38 | |
| 2020 | UAV_Véraison + | UAV_Flowering | 0.64 ± 0.08 | 1.20 ± 0.36 |
| UAV_Berries pea sized | 0.64 ± 0.07 | 1.20 ± 0.39 | ||
| UAV_Setting | 0.62 ± 0.11 | 1.22 ± 0.42 | ||
| SS_Setting + | SS_Flowering | 0.55 ± 0.07 | 1.35 ± 0.37 | |
| SS_Véraison | 0.53 ± 0.07 | 1.36 ± 0.38 | ||
| SS_Harvest | 0.51 ± 0.06 | 1.39 ± 0.32 | ||
| CC_Setting + | CC_Berries pea sized | 0.34 ± 0.1 | 1.62 ± 0.58 | |
| CC_Harvest | 0.32 ± 0.13 | 1.66 ± 0.82 | ||
| CC_Véraison | 0.31 ± 0.15 | 1.65 ± 0.66 | ||
|
Growth Stage-Based Combined Sensors_Growth Stage | R² (avg) | RMSE | ||
|---|---|---|---|---|
| 2019 | SS_Véraison + | UAV_Véraison | 0.58 ± 0.06 | 1.08 ± 0.33 |
| CC_Véraison | 0.57 ± 0.08 | 1.09 ± 0.3 | ||
| S2_Véraison | 0.57 ± 0.07 | 1.10 ± 0.35 | ||
| S2_Berries pea sized + | UAV_Berries pea sized | 0.47 ± 0.01 | 1.22 ± 0.31 | |
| SS_Berries pea sized | 0.42 ± 0.24 | 1.25 ± 0.29 | ||
| CC_Berries pea sized | 0.39 ± 0.18 | 1.31 ± 0.43 | ||
| UAV_Flowering + | SS_Flowering | 0.38 ± 0.17 | 1.32 ± 0.48 | |
| CC_Flowering | 0.38 ± 0.11 | 1.33 ± 0.48 | ||
| 2020 | UAV_Véraison + | SS_Véraison | 0.66 ± 0.07 | 1.16 ± 0.36 |
| S2_Véraison | 0.66 ± 0.07 | 1.17 ± 0.35 | ||
| CC_Véraison | 0.64 ± 0.07 | 1.20 ± 0.37 | ||
| UAV_Flowering + | S2_Flowering | 0.58 ± 0.08 | 1.29 ± 0.37 | |
| UAV_Flowering | 0.58 ± 0.07 | 1.29 ± 0.35 | ||
| CC_Flowering | 0.58 ± 0.07 | 1.29 ± 0.34 | ||
| UAV_Berries pea sized + | CC_Berries pea sized | 0.55 ± 0.08 | 1.33 ± 0.44 | |
| SS_Berries pea sized | 0.55 ± 0.08 | 1.34 ± 0.43 | ||
| SS_Setting + | UAV_Setting | 0.52 ± 0.09 | 1.38 ± 0.39 | |
| S2_Setting | 0.52 ± 0.07 | 1.39 ± 0.35 | ||
| Sensor | Combined Growth Stages | R² (avg) | RMSE |
|---|---|---|---|
| CropCircle | Setting + Véraison | 0.36 ± 0.18 | 1.47 ± 0.5 |
| Spectrosense + GPS | Véraison + Flowering | 0.53 ± 0.1 | 1.26 ± 0.3 |
| UAV | Véraison + Flowering | 0.55 ± 0.06 | 1.20 ± 0.31 |
| Sentinel-2 | Flowering + Berries pea sized | 0.24 ± 0.16 | 1.63 ± 0.55 |
| Sensor | Combined Growth Stages | R² (avg) | RMSE |
|---|---|---|---|
| Flowering | CC + UAV | 0.48 ± 0.04 | 1.31 ± 0.41 |
| Setting | CC + UAV | 0.36 ± 0.14 | 1.46 ± 0.48 |
| Berries pea-sized | SS + S2 | 0.30 ± 0.19 | 1.55 ± 0.47 |
| Véraison | UAV + SS | 0.62 ± 0.05 | 1.13 ± 0.34 |
| Algorithm | R² (avg) | Best Solution (Rank) |
|---|---|---|
| Adaboost | 0.44 ± 0.09 | 7 |
| ARD | 0.53 ± 0.09 | 3 |
| Decision Tree | 0.45 ± 0.11 | 8 |
| Extra Trees | 0.43 ± 0.08 | 9 |
| Huber Regression | 0.52 ± 0.12 | 4 |
| SVM | 0.52 ± 0.12 | 1 |
| Random Forest | 0.41 ± 0.09 | 2 |
| OLS | 0.51 ± 0.09 | 6 |
| Theil-Sen Regression | 0.51 ± 0.12 | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kasimati, A.; Espejo-García, B.; Darra, N.; Fountas, S. Predicting Grape Sugar Content under Quality Attributes Using Normalized Difference Vegetation Index Data and Automated Machine Learning. Sensors 2022, 22, 3249. https://doi.org/10.3390/s22093249
Kasimati A, Espejo-García B, Darra N, Fountas S. Predicting Grape Sugar Content under Quality Attributes Using Normalized Difference Vegetation Index Data and Automated Machine Learning. Sensors. 2022; 22(9):3249. https://doi.org/10.3390/s22093249
Chicago/Turabian StyleKasimati, Aikaterini, Borja Espejo-García, Nicoleta Darra, and Spyros Fountas. 2022. "Predicting Grape Sugar Content under Quality Attributes Using Normalized Difference Vegetation Index Data and Automated Machine Learning" Sensors 22, no. 9: 3249. https://doi.org/10.3390/s22093249
APA StyleKasimati, A., Espejo-García, B., Darra, N., & Fountas, S. (2022). Predicting Grape Sugar Content under Quality Attributes Using Normalized Difference Vegetation Index Data and Automated Machine Learning. Sensors, 22(9), 3249. https://doi.org/10.3390/s22093249