
Command Recognition Using Binarized Convolutional Neural Network with Voice and Radar Sensors for Human-Vehicle Interaction





Abstract
1. Introduction
2. Related Works
3. Materials and Methods
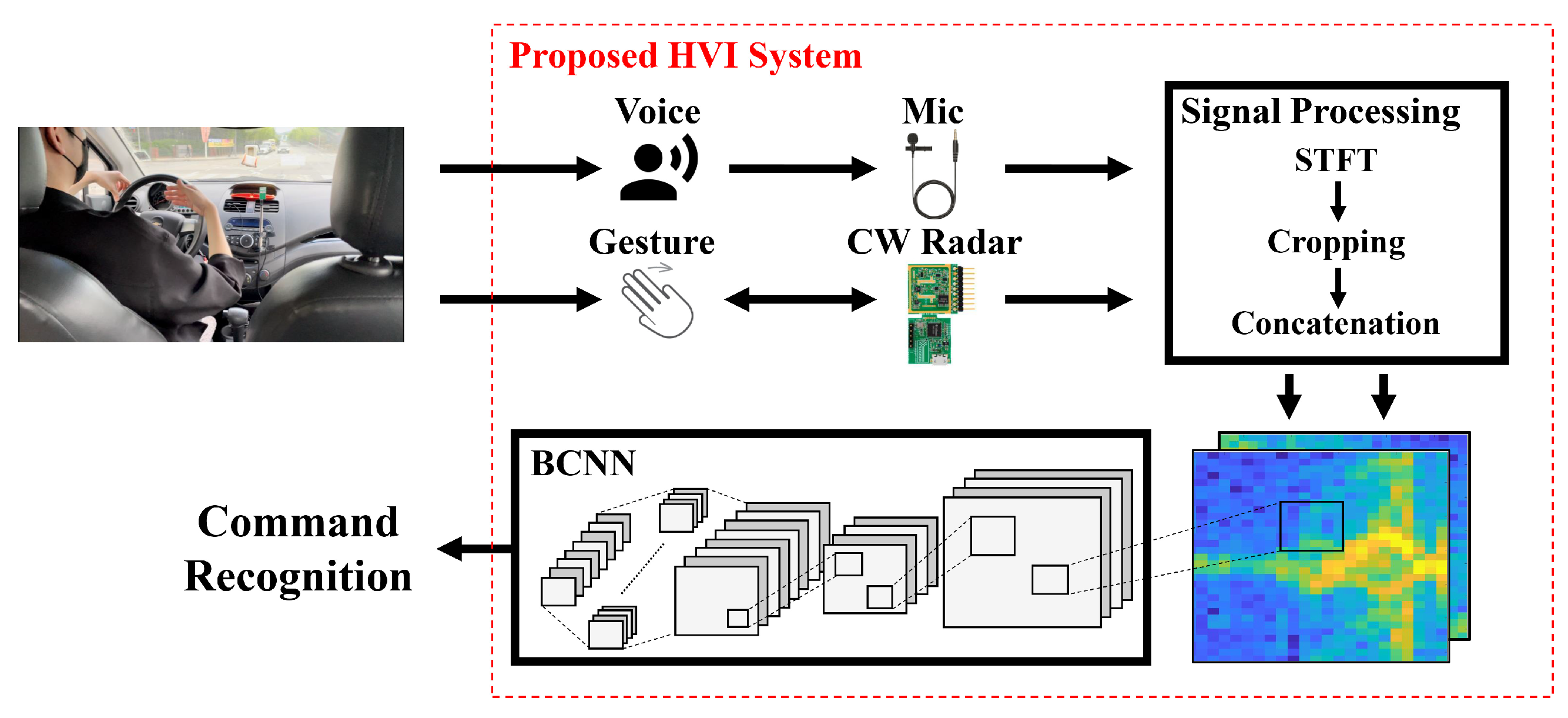
3.1. Proposed System
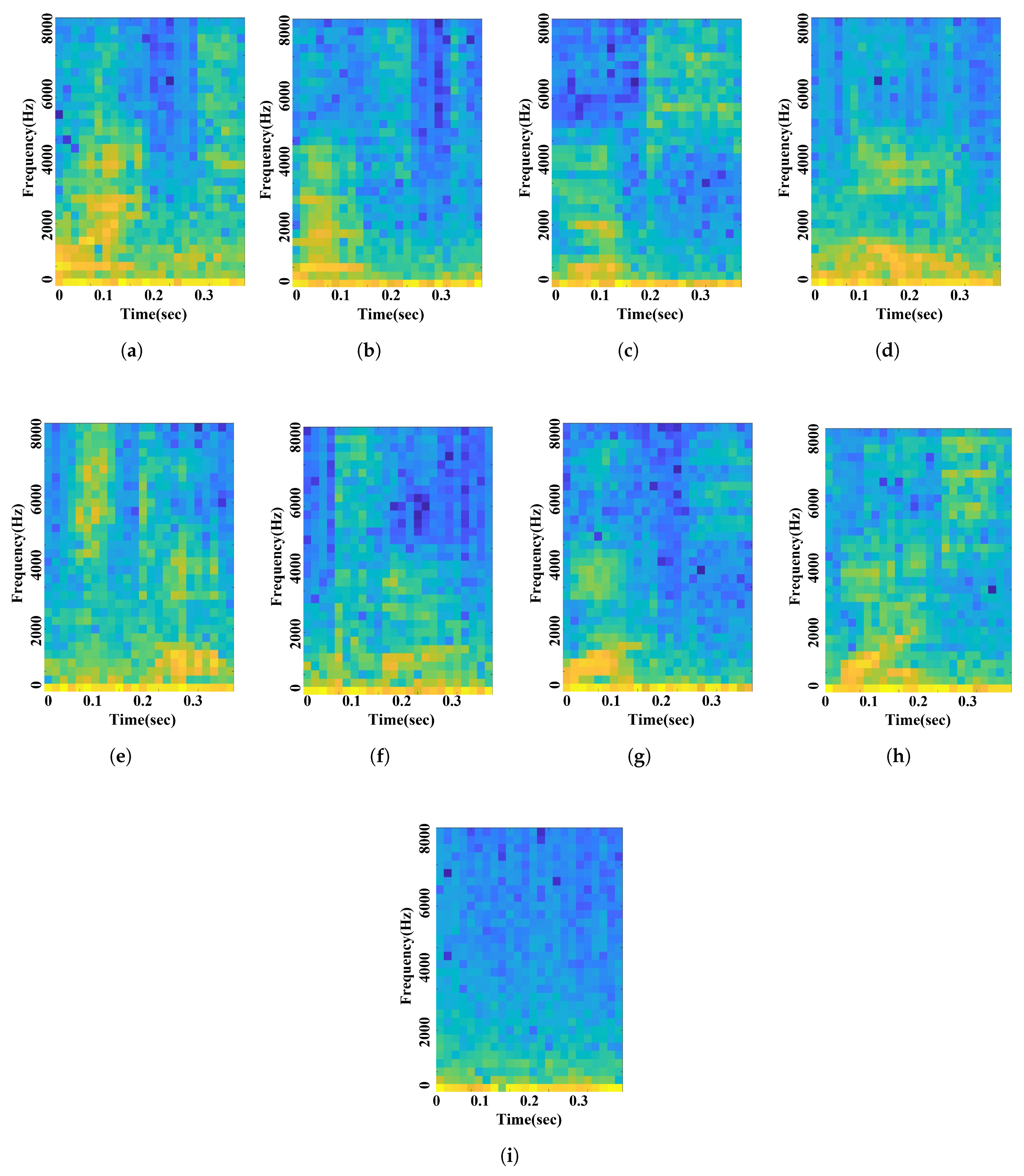
3.2. Voice Signal Processing
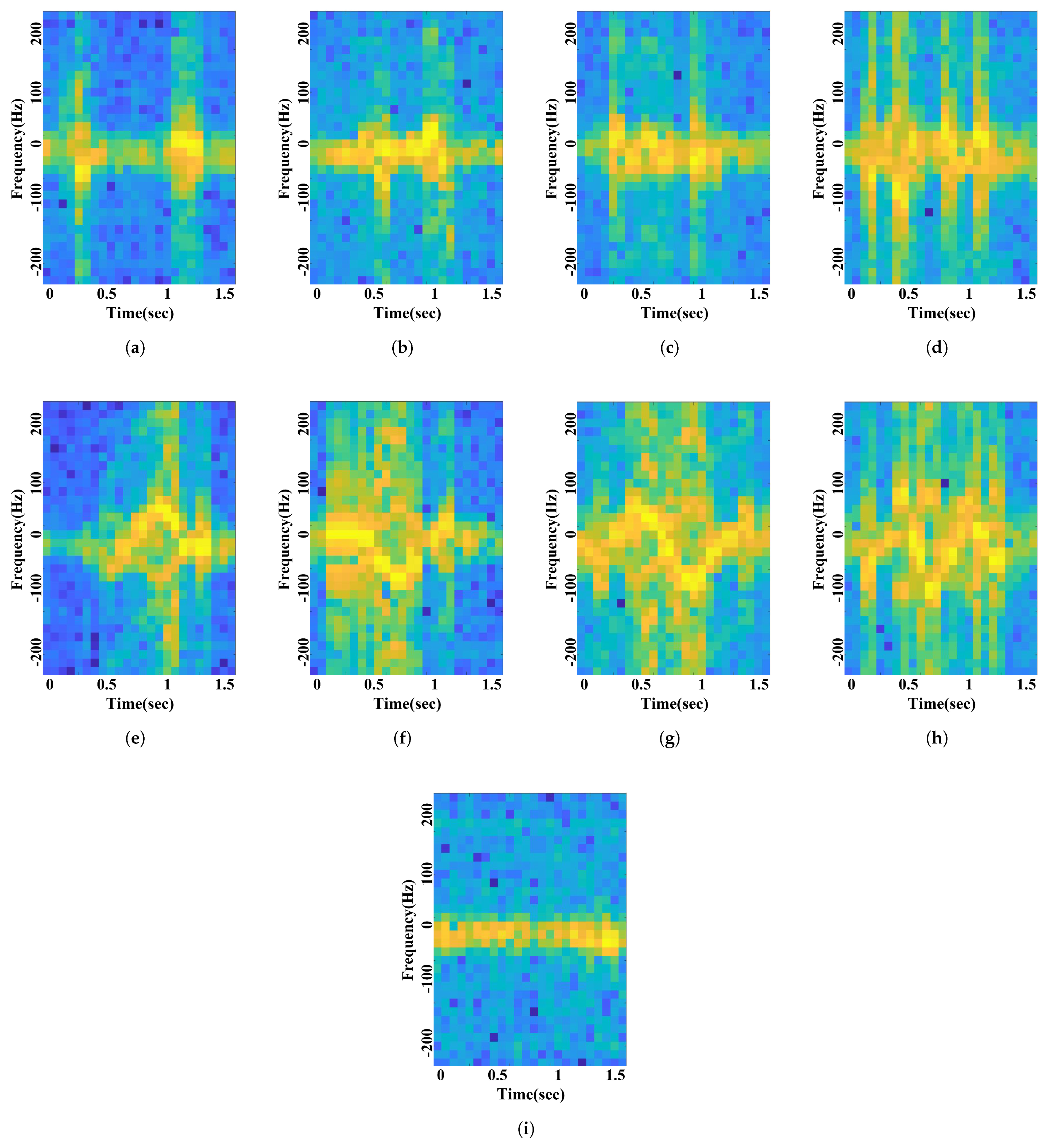
3.3. Radar Signal Processing
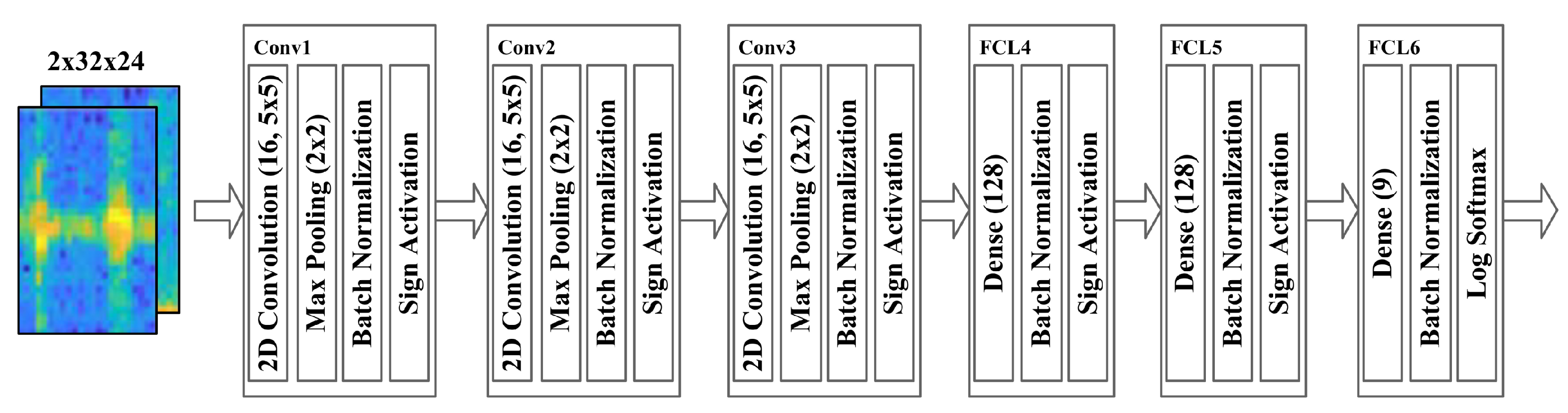
3.4. Binarized Convolutional Neural Network
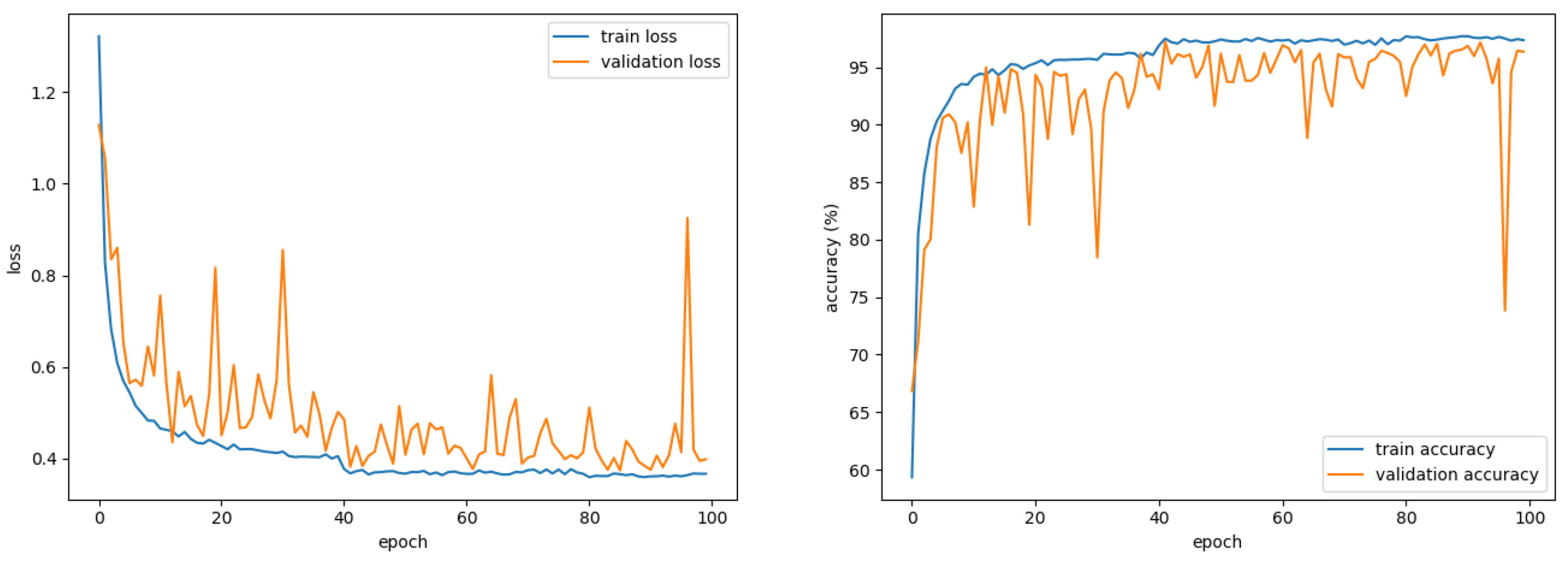
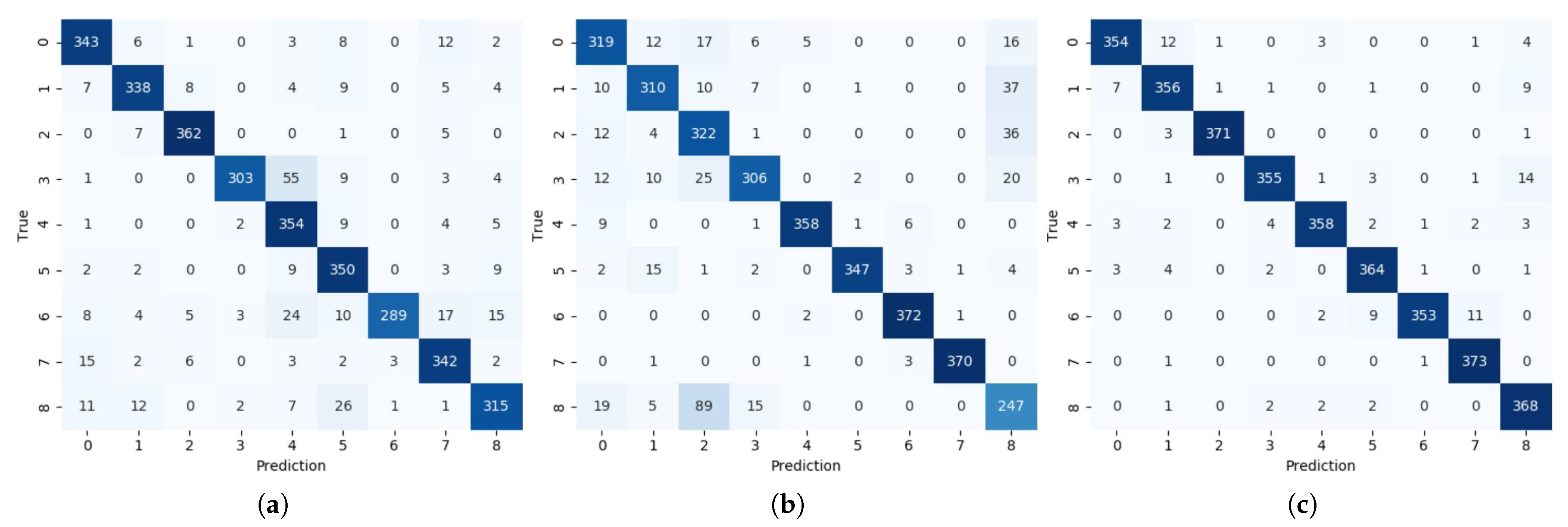
4. Experimental Results
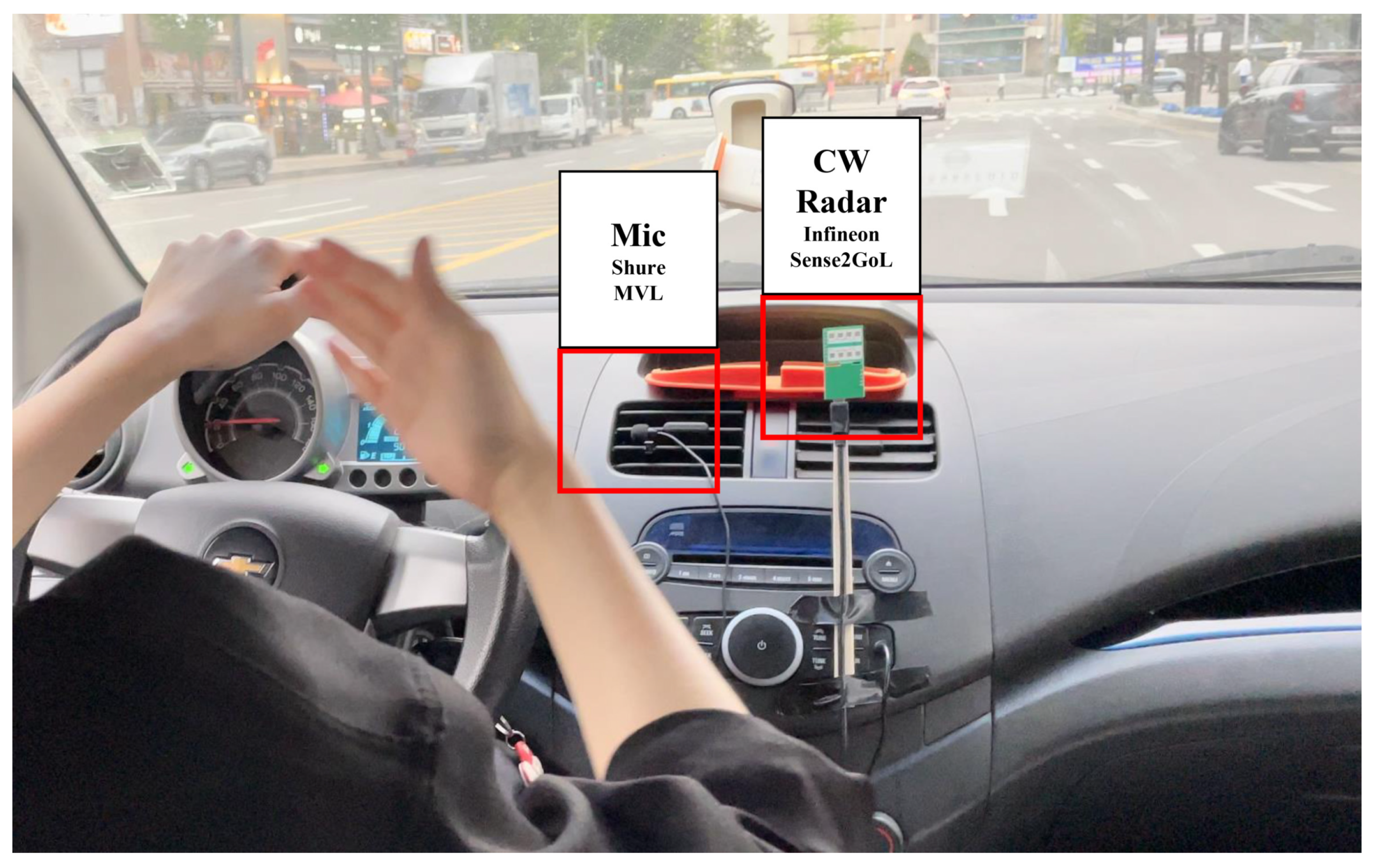
4.1. Environment
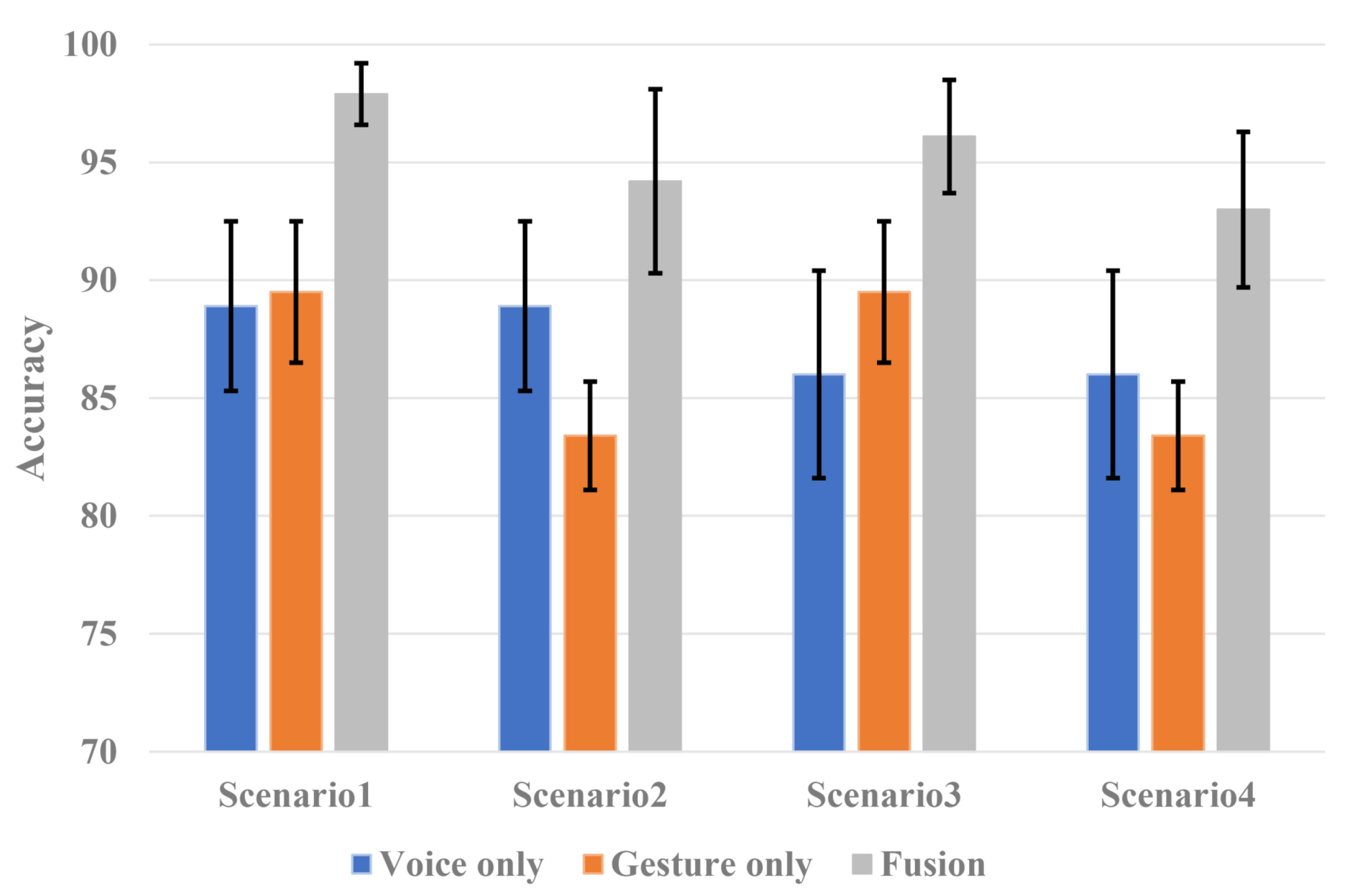
4.2. Evaluation
- Scenario 1: simple driving with less noise and no movement of passengers with less clutter;
- Scenario 2: simple driving with less noise and significant movement of passengers with clutter;
- Scenario 3: opening a window or turning on the air conditioner with significant noise and no passenger movement with less clutter;
- Scenario 4: opening a window or turning on the air conditioner with significant noise and passenger movement with clutter.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Guo, J.; Song, B.; He, Y.; Yu, F.R.; Sookhak, M. A survey on compressed sensing in vehicular infotainment systems. IEEE Commun. Surv. Tutor. 2017, 19, 2662–2680. [Google Scholar] [CrossRef]
- Kazmi, S.A.; Dang, T.N.; Yaqoob, I.; Ndikumana, A.; Ahmed, E.; Hussain, R.; Hong, C.S. Infotainment enabled smart cars: A joint communication, caching, and computation approach. IEEE Trans. Veh. Technol. 2019, 68, 8408–8420. [Google Scholar] [CrossRef]
- Ohn-Bar, E.; Trivedi, M.M. Hand gesture recognition in real time for automotive interfaces: A multimodal vision-based approach and evaluations. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2368–2377. [Google Scholar] [CrossRef]
- May, K.R.; Gable, T.M.; Walker, B.N. A multimodal air gesture interface for in vehicle menu navigation. In Proceedings of the 6th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Seattle, WA, USA, 17–19 September 2014; pp. 1–6. [Google Scholar]
- Deo, N.; Rangesh, A.; Trivedi, M. In-vehicle hand gesture recognition using hidden markov models. In Proceedings of the IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2179–2184. [Google Scholar]
- Wang, H.; Ye, Z.; Chen, J. A Front-End Speech Enhancement System for Robust Automotive Speech Recognition. In Proceedings of the 2018 11th International Symposium on Chinese Spoken Language Processing (ISCSLP), Taipei, Taiwan, 26–29 November 2018; pp. 1–5. [Google Scholar]
- Loh, C.Y.; Boey, K.L.; Hong, K.S. Speech recognition interactive system for vehicle. In Proceedings of the 2017 IEEE 13th International Colloquium on Signal Processing & Its Applications (CSPA), Batu Ferringhi, Malaysia, 10–12 March 2017; pp. 85–88. [Google Scholar]
- Feng, X.; Richardson, B.; Amman, S.; Glass, J. On using heterogeneous data for vehicle-based speech recognition: A DNN-based approach. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4385–4389. [Google Scholar]
- Smith, K.A.; Csech, C.; Murdoch, D.; Shaker, G. Gesture recognition using mm-wave sensor for human-car interface. IEEE Sens. Lett. 2018, 2, 1–4. [Google Scholar] [CrossRef]
- Wang, Y.; Ren, A.; Zhou, M.; Wang, W.; Yang, X. A novel detection and recognition method for continuous hand gesture using fmcw radar. IEEE Access 2020, 8, 167264–167275. [Google Scholar] [CrossRef]
- Sun, Y.; Fei, T.; Schliep, F.; Pohl, N. Gesture classification with handcrafted micro-Doppler features using a FMCW radar. In Proceedings of the 2018 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM), Munich, Germany, 15–17 April 2018; pp. 1–4. [Google Scholar]
- Kopinski, T.; Geisler, S.; Handmann, U. Gesture-based human-machine interaction for assistance systems. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 510–517. [Google Scholar]
- Neßelrath, R.; Moniri, M.M.; Feld, M. Combining speech, gaze, and micro-gestures for the multimodal control of in-car functions. In Proceedings of the 2016 12th International Conference on Intelligent Environments (IE), London, UK, 14–16 September 2016; pp. 190–193. [Google Scholar]
- Tateno, S.; Zhu, Y.; Meng, F. Hand gesture recognition system for in-car device control based on infrared array sensor. In Proceedings of the 2019 58th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Hiroshima, Japan, 10–13 September 2019; pp. 701–706. [Google Scholar]
- Ahmed, S.; Khan, F.; Ghaffar, A.; Hussain, F.; Cho, S.H. Finger-counting-based gesture recognition within cars using impulse radar with convolutional neural network. Sensors 2019, 19, 1429. [Google Scholar] [CrossRef] [PubMed]
- Khan, F.; Leem, S.K.; Cho, S.H. Hand-Based Gesture Recognition for Vehicular Applications Using IR-UWB Radar. Sensors 2017, 17, 833. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Toomajian, B. Hand gesture recognition using micro-Doppler signatures with convolutional neural network. IEEE Access 2016, 4, 7125–7130. [Google Scholar] [CrossRef]
- Molchanov, P.; Gupta, S.; Kim, K.; Pulli, K. Multi-sensor system for driver’s hand-gesture recognition. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–8. [Google Scholar]
- Münzner, S.; Schmidt, P.; Reiss, A.; Hanselmann, M.; Stiefelhagen, R.; Dürichen, R. CNN-based sensor fusion techniques for multimodal human activity recognition. In Proceedings of the 2017 ACM International Symposium on Wearable Computers (ISWC’17), Maui, HI, USA, 11–15 September 2017; pp. 158–165. [Google Scholar]
- Alay, N.; Al-Baity, H.H. Deep Learning Approach for Multimodal Biometric Recognition System Based on Fusion of Iris, Face, and Finger Vein Traits. Sensors 2020, 20, 5523. [Google Scholar] [CrossRef] [PubMed]
- Oh, S.; Bae, C.; Kim, S.; Cho, J.; Jung, Y. Design and Implementation of CNN-based HMI System using Doppler Radar and Voice Sensor. J. IKEEE 2020, 24, 777–782. [Google Scholar]
- Nayak, P.; Zhang, D.; Chai, S. Bit efficient quantization for deep neural networks. arXiv 2019, arXiv:1910.04877. [Google Scholar]
- Jain, A.; Bhattacharya, S.; Masuda, M.; Sharma, V.; Wang, Y. Efficient execution of quantized deep learning models: A compiler approach. arXiv 2020, arXiv:2006.10226. [Google Scholar]
- Nalepa, J.; Antoniak, M.; Myller, M.; Ribalta Lorenzo, P.; Marcinkiewicz, M. Towards resource-frugal deep convolutional neural networks for hyperspectral image segmentation. Microprocess. Microsyst. 2020, 73, 102994. [Google Scholar] [CrossRef]
- Simons, T.; Lee, D.J. A Review of Binarized Neural Networks. Electronics 2019, 8, 661. [Google Scholar] [CrossRef]
- Lin, X.; Zhao, C.; Pan, W. Towards accurate binary convolutional neural network. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 345–353. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; pp. 525–542. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Cho, J.; Jung, Y.; Lee, S.; Jung, Y. Reconfigurable Binary Neural Network Accelerator with Adaptive Parallelism Scheme. Electronics 2021, 10, 230. [Google Scholar] [CrossRef]
- Yin, Y.; Liu, L.; Sun, X. SDUMLA-HMT: A multimodal biometric database. In Proceedings of the Chinese Conference on Biometric Recognition, Beijing, China, 3–4 December 2011; pp. 260–268. [Google Scholar]
- MVL Lavalier Microphone for Smartphone or Tablet. Available online: https://www.shure.com/en-US/products/microphones/mvl (accessed on 2 March 2021).
- 24 GHz Transceiver: BGT24LTR11. Available online: https://www.infineon.com/dgdl/Infineon-AN598_Sense2GOL_Pulse-ApplicationNotes-v01_00-EN.pdf?fileId=5546d4626e651a41016e82b630bc1571 (accessed on 2 March 2021).
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 18–21 June 2018; pp. 7132–7141. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Suganuma, M.; Shirakawa, S.; Nagao, T. A genetic programming approach to designing convolutional neural network architectures. In Proceedings of the Genetic and Evolutionary Computation Conference, Berlin, Germany, 15–19 July 2017; pp. 497–504. [Google Scholar]
- Lorenzo, P.R.; Nalepa, J.; Kawulok, M.; Ramos, L.S.; Ranilla Pastor, J. Particle swarm optimization for hyper-parameter selection in deep neural networks. In Proceedings of the Genetic and Evolutionary Computation Conference, Berlin, Germany, 15–19 July 2017; pp. 481–488. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Frequency response | 45 Hz–20 kHz |
| Polar pattern | Omnidirectional |
| Signal-to-noise ratio | 65 dB |
| Maximum sound pressure level | 124 dB |
| Parameter | Value |
|---|---|
| Center frequency | 24 GHz |
| Output power | 6 dBm |
| Antenna gain | 10 dBi |
| Maximum distance | 15 m |
| Horizontal field of view | 29 |
| Vertical field of view | 80 |
| Convolution Layer | Fully Connected Layer | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| 1 | 84.5 ± 4.5% | 89.5 ± 4.5% | 91 ± 3% | 90.5 ± 3.5% |
| 2 | 91 ± 3% | 91 ± 3% | 92.5 ± 2.5% | 95 ± 1% |
| 3 | 92 ± 2% | 92.5 ± 2.5% | 95 ± 1.5% | 94 ± 1% |
| 4 | 91 ± 3% | 92.5 ± 2.5% | 93 ± 3% | 94 ± 1% |
| 2CLs + 4FCLs | 3CLs + 3FCLs | |
|---|---|---|
| Number of parameters | 140,256 | 56,320 |
| Computation time | 0.581 ms | 0.622 ms |
| Right | Left | Yes | No | Stop | Pull | Once | Twice | Unknown | |
|---|---|---|---|---|---|---|---|---|---|
| Precision | 0.96 | 0.94 | 0.99 | 0.98 | 0.98 | 0.96 | 0.99 | 0.96 | 0.92 |
| Recall | 0.94 | 0.95 | 0.99 | 0.95 | 0.95 | 0.97 | 0.94 | 0.99 | 0.98 |
| F1 score | 0.95 | 0.94 | 0.99 | 0.96 | 0.97 | 0.96 | 0.97 | 0.98 | 0.95 |
| Validation Sets | Voice Only | Gesture Only | Fusion |
|---|---|---|---|
| Driver 1 | 87.6% | 84.4% | 95.2% |
| Driver 2 | 88.3% | 89.7% | 97.2% |
| Driver 3 | 85.2% | 83.5% | 94.0% |
| Driver 4 | 86.8% | 78.8% | 90.9% |
| Driver 5 | 84.9% | 88.6% | 96.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, S.; Bae, C.; Cho, J.; Lee, S.; Jung, Y. Command Recognition Using Binarized Convolutional Neural Network with Voice and Radar Sensors for Human-Vehicle Interaction. Sensors 2021, 21, 3906. https://doi.org/10.3390/s21113906
Oh S, Bae C, Cho J, Lee S, Jung Y. Command Recognition Using Binarized Convolutional Neural Network with Voice and Radar Sensors for Human-Vehicle Interaction. Sensors. 2021; 21(11):3906. https://doi.org/10.3390/s21113906
Chicago/Turabian StyleOh, Seunghyun, Chanhee Bae, Jaechan Cho, Seongjoo Lee, and Yunho Jung. 2021. "Command Recognition Using Binarized Convolutional Neural Network with Voice and Radar Sensors for Human-Vehicle Interaction" Sensors 21, no. 11: 3906. https://doi.org/10.3390/s21113906
APA StyleOh, S., Bae, C., Cho, J., Lee, S., & Jung, Y. (2021). Command Recognition Using Binarized Convolutional Neural Network with Voice and Radar Sensors for Human-Vehicle Interaction. Sensors, 21(11), 3906. https://doi.org/10.3390/s21113906