Edge Machine Learning for AI-Enabled IoT Devices: A Review




Abstract
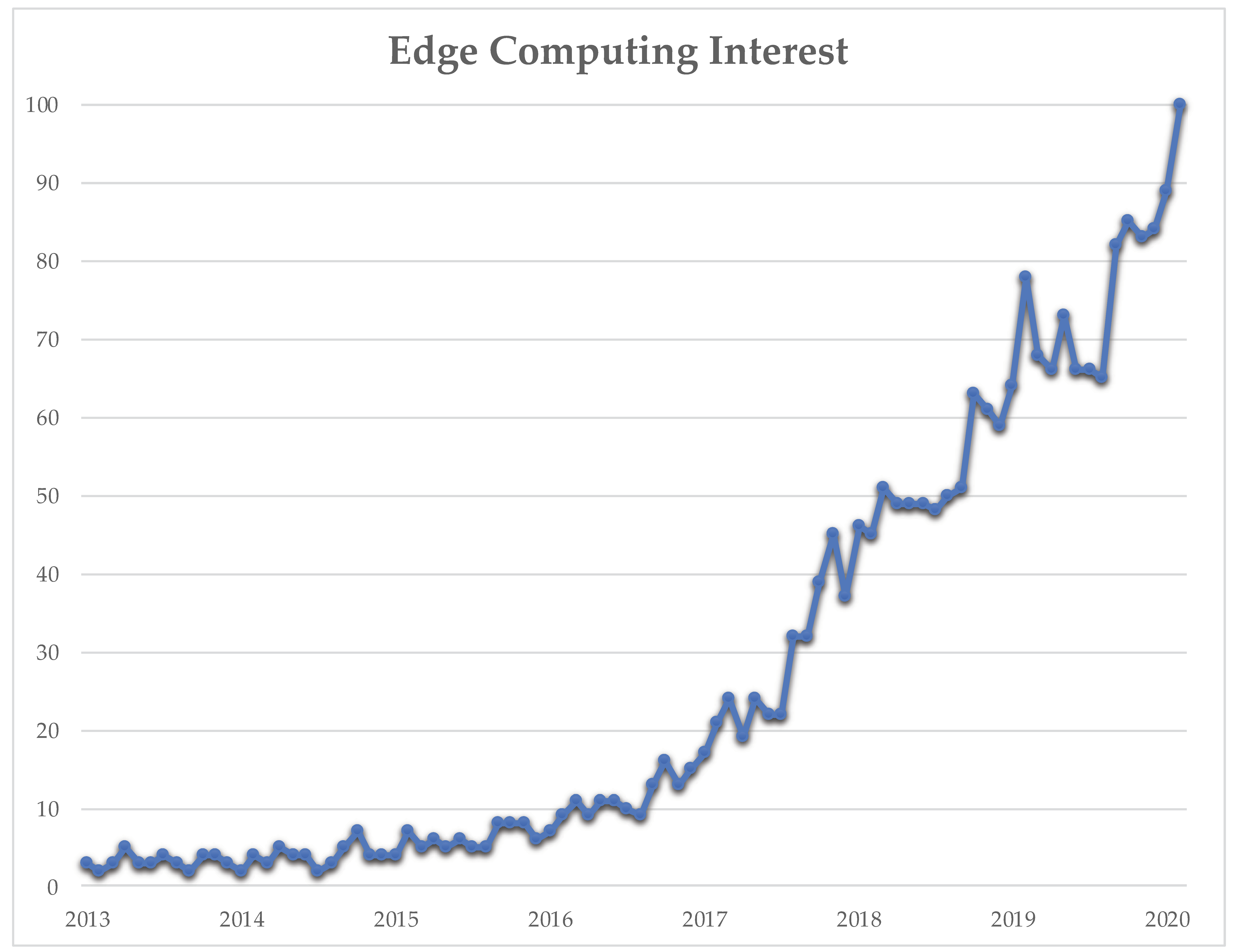
1. Introduction
2. Machine Learning Algorithms
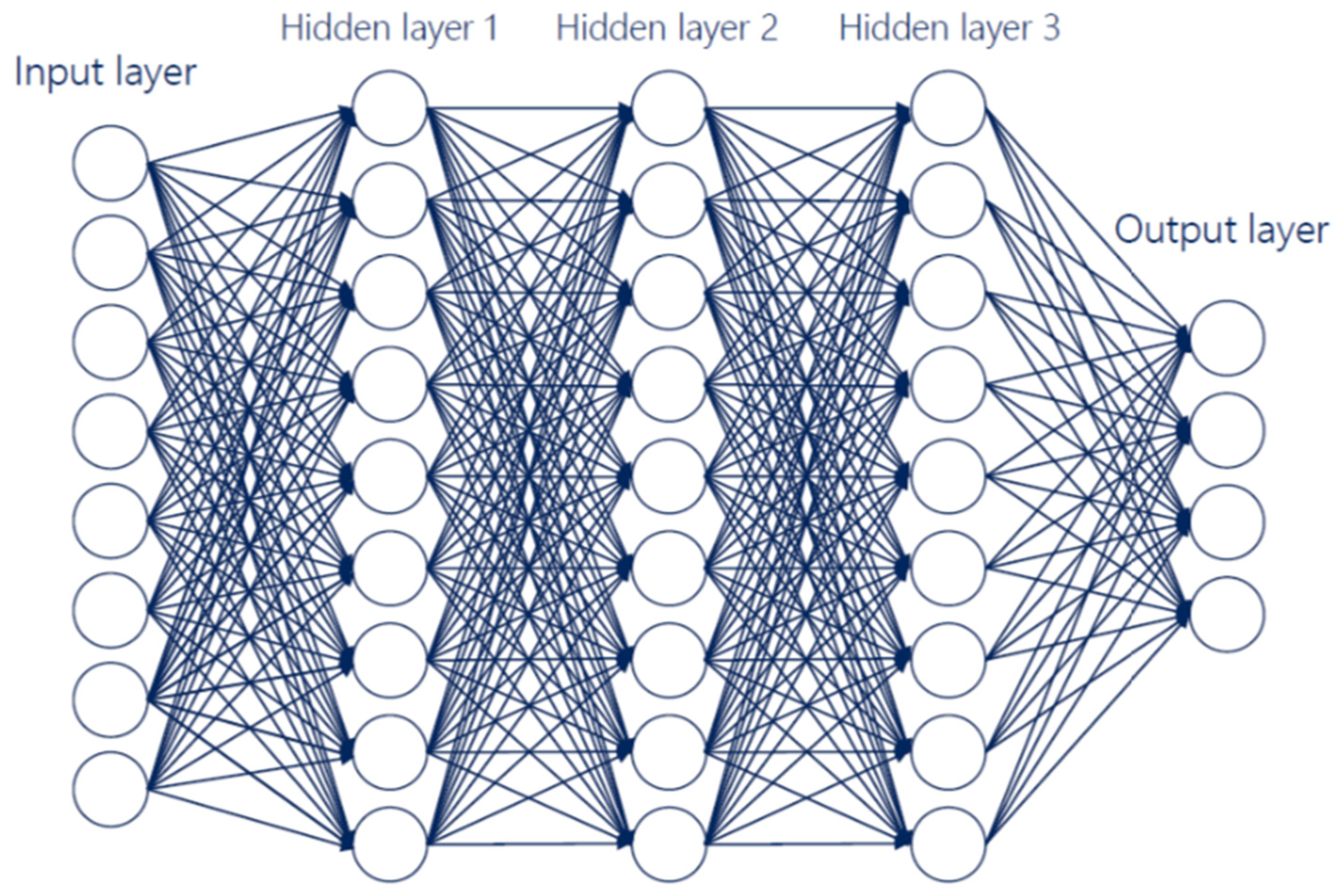
2.1. Deep Learning
2.2. RNN, GAN, K-NN
2.3. Tree-Based ML Algorithms
2.4. SVM
3. Bringing Machine Learning to the Edge
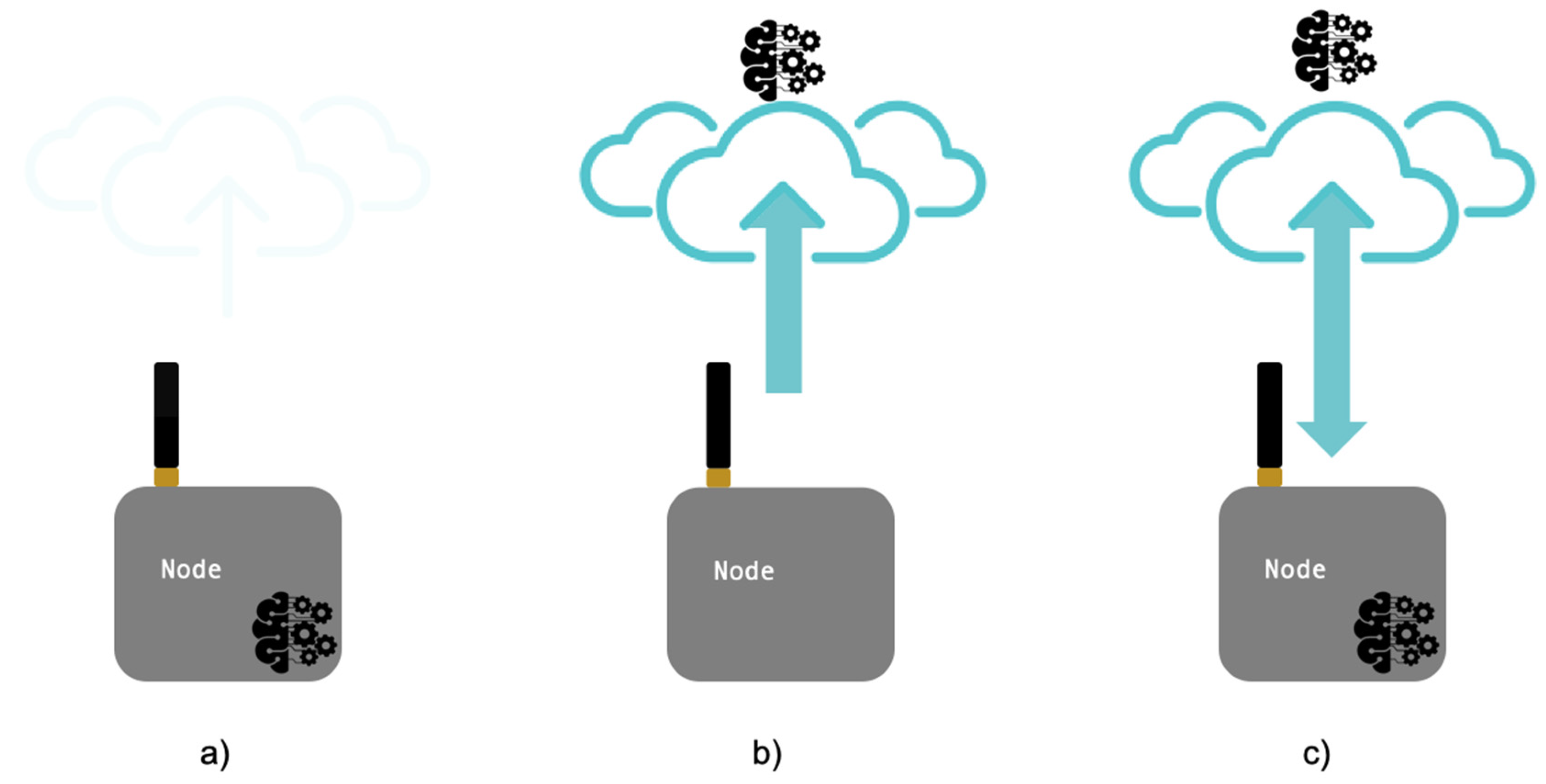
3.1. Architectures
3.2. Model and Hardware
3.2.1. Model Design
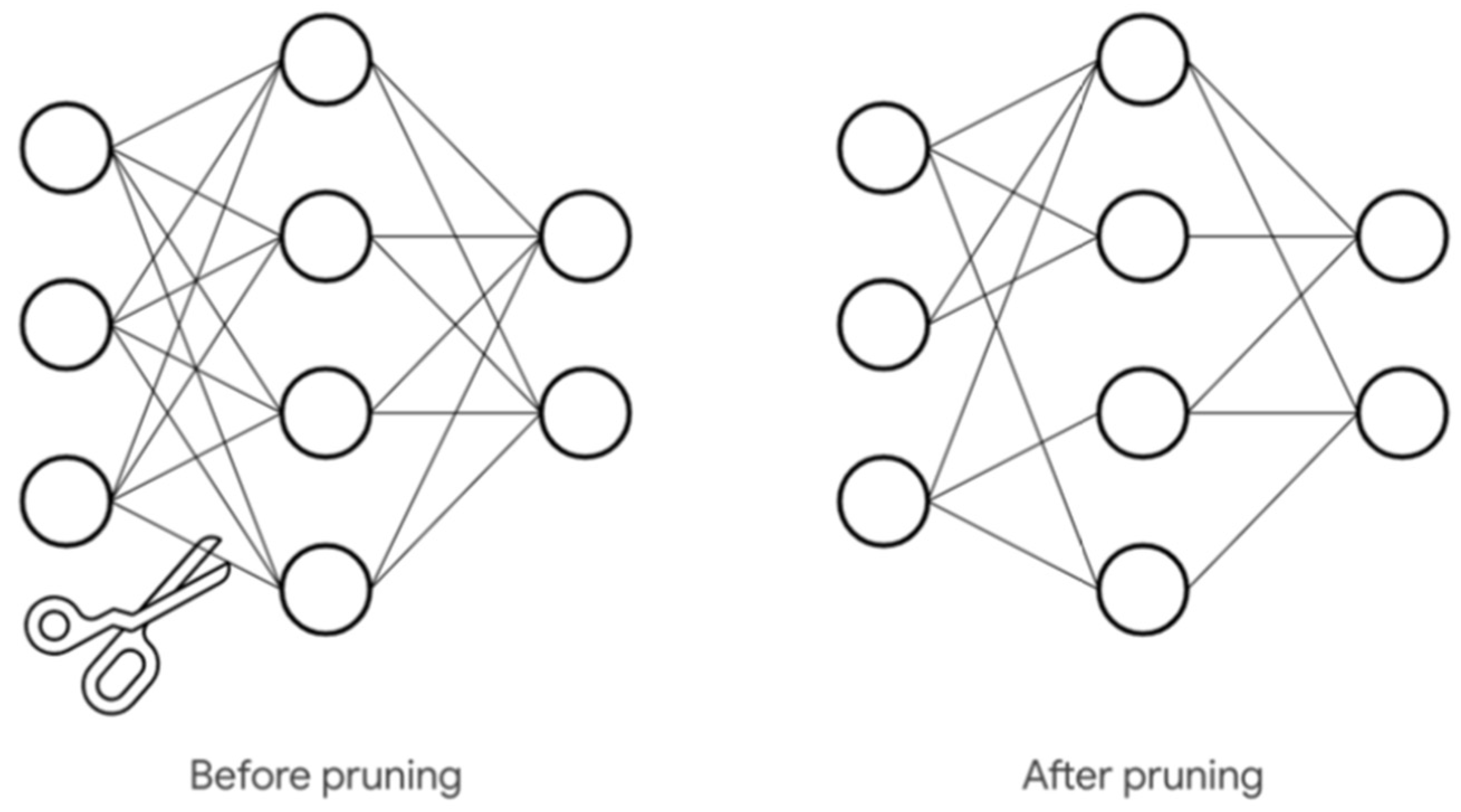
3.2.2. Model Compression
3.2.3. Hardware Choice
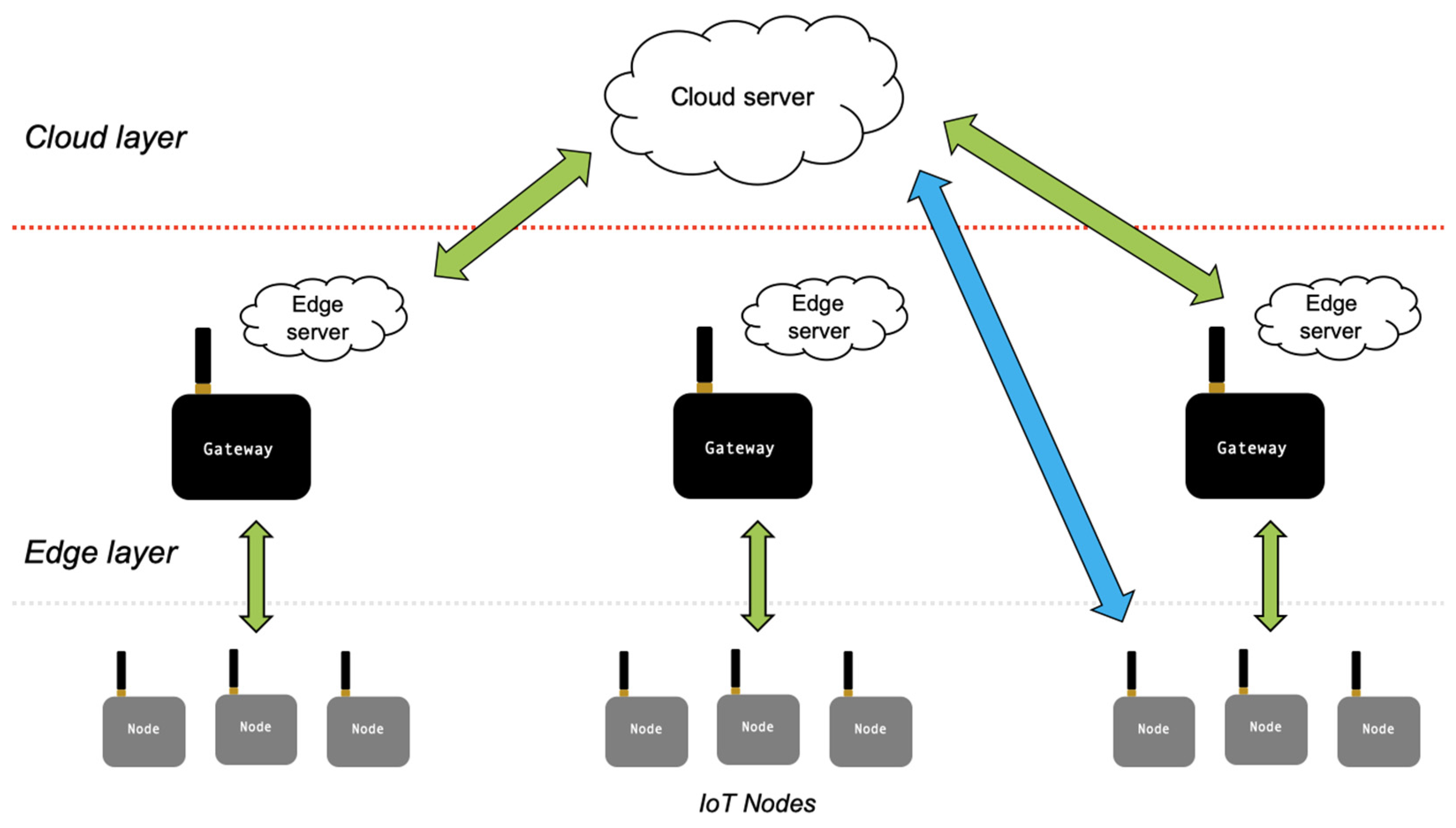
4. Edge Server-Based Architectures
5. Wireless Standards for AI-Enabled IoT Devices
- -
- high data rate;
- -
- high scalable and fine-grained networks, to increase network scalability;
- -
- very low latency;
- -
- long battery lifetime, to support billions of low-power and low-cost IoT devices.
6. Joint Computation
6.1. Partial Offload
6.2. Hierarchical Architectures
6.3. Distributed Computing
7. Privacy
7.1. Add Noise to Data
7.2. Cryptographic Techniques
8. Training
8.1. Training Algorithms
- ‘Important’ updating: After each mini-batch, only a small fraction of the gradient coordinates need to be updated. The algorithm determines main gradients, which will then be updated by the server. This process significantly reduces communication cost.
- Momentum residual accumulation: This mechanism is applied for tracking and accumulating out-of-date residual gradients, which helps to avoid low convergence rate caused by the previous important updating method.
8.2. Training Hardware
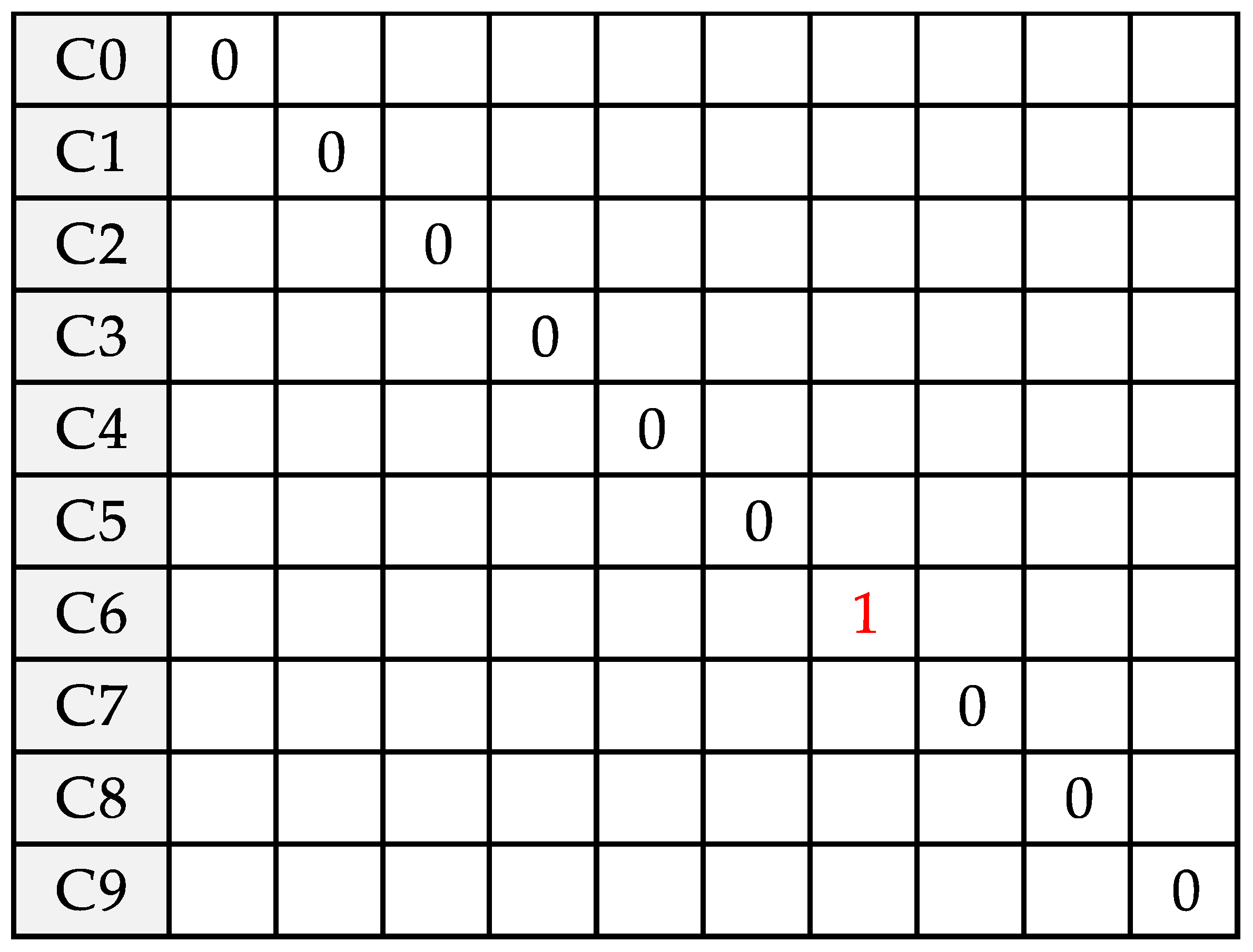
9. MNIST Example
9.1. Dataset
9.2. Model with Tensorflow
- -
- Definition of the model in Keras (using Tensorflow backend),
- -
- Conversion of the model from Keras to TFLite,
- -
- Implementation of a post-training quantization to further decrease the dimension of the NN,
- -
- Design of a Graphical User Interface (GUI) to draw the digit, and
- -
- Test on hardware devices.
9.3. Keras Model
9.4. Tensorflow Lite
- -
- The interpreter runs the optimized models on different hardware types (including mobile phones, low computational capacity devices, and microcontrollers), and
- -
- The converter, which converts the model to a more efficient format for use by the interpreter.
- model = ‘Model_Keras_MNIST_CNN_Test.h5’.
- converter = tf.lite.TFLiteConverter.from_keras_model_file(model)
- tflite_model = converter.convert()
- -
- Reduce latency and inference costs, and
- -
- Implement IA models on edge devices with limited capacity and low-power profile.
9.5. Pruning
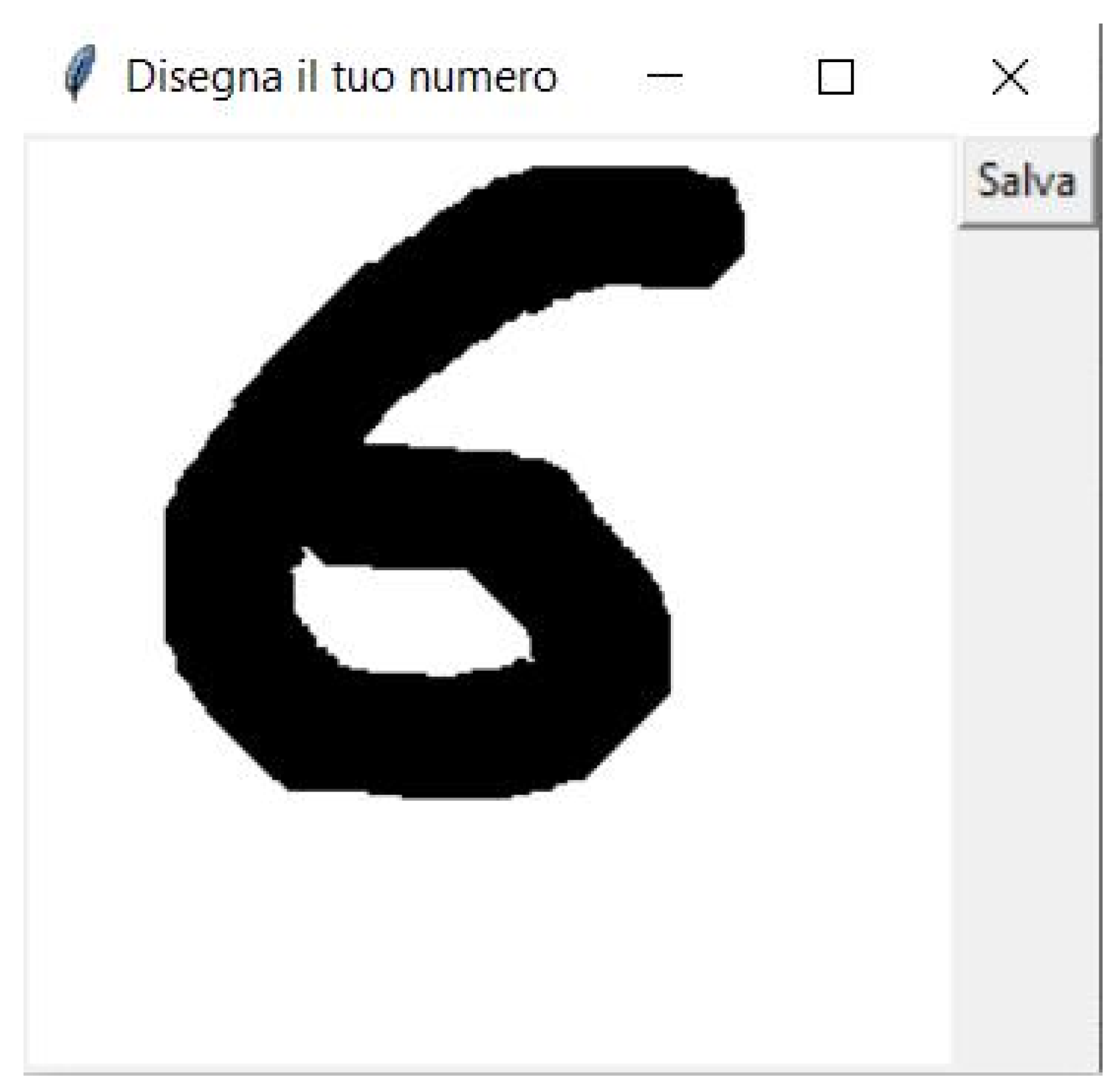
9.6. Graphical User Interface
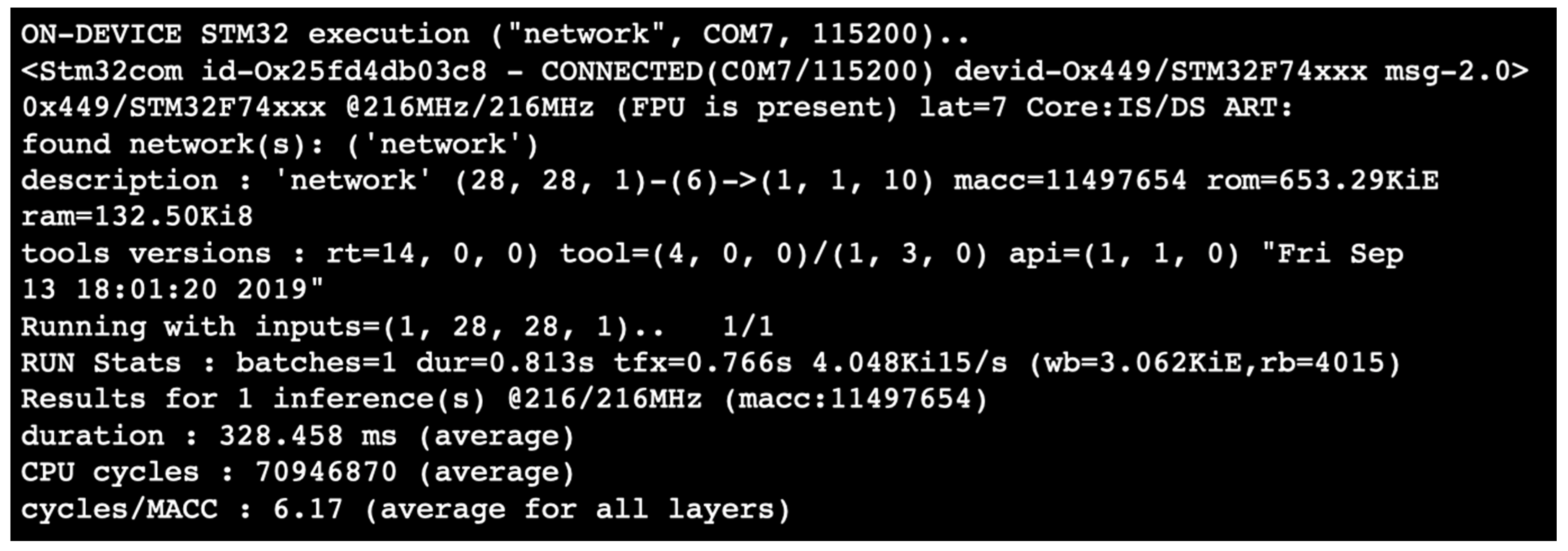
9.7. Validation on Target
- -
- Weight compression: It is applicable only to dense layers (or fully connected layers) and is based on weight-sharing algorithms such as K-means clustering.
- -
- Layers fusion: It allows merging two layers to optimize data placement, decreasing the number of the DNNs layers (e.g., nonlinearities or pooling after a convolutional layers).
- -
- Activation function optimization: Part of the memory is used to store temporary hidden layers values, so activation memory is reused across different layers.
- -
- Once the model is compressed (in this example we opted for a x4 compression), the tool gives the possibility to make an analysis of the NN to understand if it is loadable on the chosen microcontroller and to visualize the diagram of the loaded model. The Table 6 reports the output analysis of the network implemented in the example. It includes:
- -
- RAM: Indicates the size of the memory required to store the intermediate calculations;
- -
- ROM/Flash: Indicates the memory size needed to store weight and bias after compression; and
- -
- Complexity: Reports the complexity of the model in MAC (multiply-accumulate operations), unit of measure used also to express the complexity of the activation functions.
- -
- Validation on desktop: The model in C is executed on the PC.
- -
- Validation on target: The generated model is executed on the device of interest. It is necessary to load the code on the microcontroller and set a serial communication to communicate with the host.
10. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A survey. Comput. Networks 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Mahdavinejad, M.S.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A.P. Machine learning for internet of things data analysis: A survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
- IoT: Number of Connected Devices Worldwide 2012–2025 | Statista. Available online: https://www.statista.com/statistics/471264/iot-number-of-connected-devices-worldwide/ (accessed on 21 February 2020).
- Vahid Dastjerdi, A.; Buyya, R. Fog Computing: Helping the Internet of Things Realize. IEEE Comput. Soc. 2016, 49, 112–116. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, C.; Jiang, L.; Xie, S.; Zhang, Y. Intelligent Edge Computing for IoT-Based Energy Management in Smart Cities. IEEE Netw. 2019, 33, 111–117. [Google Scholar] [CrossRef]
- Wang, X.; Han, Y.; Wang, C.; Zhao, Q.; Chen, X.; Chen, M. In-edge AI: Intelligentizing mobile edge computing, caching and communication by federated learning. IEEE Netw. 2019, 33, 156–165. [Google Scholar] [CrossRef]
- Savaglio, C.; Ganzha, M.; Paprzycki, M.; Bădică, C.; Ivanović, M.; Fortino, G. Agent-based Internet of Things: State-of-the-art and research challenges. Futur. Gener. Comput. Syst. 2020, 102, 1038–1053. [Google Scholar] [CrossRef]
- Neto, A.R.; Soares, B.; Barbalho, F.; Santos, L.; Batista, T.; Delicato, F.C.; Pires, P.F. Classifying Smart IoT Devices for Running Machine Learning Algorithms. In Anais do XLV Seminário Integrado de Software e Hardware; SBC: Nashville, TN, USA, 2018. [Google Scholar]
- Edge Computing—Explore—Google Trends. Available online: https://trends.google.com/trends/explore?date=all&q=edgecomputing (accessed on 5 March 2020).
- Scopus Preview - Scopus - Welcome to Scopus. Available online: https://www.scopus.com/ (accessed on 15 March 2020).
- 1.4. Support Vector Machines—Scikit-Learn 0.22.2 Documentation. Available online: https://scikit-learn.org/stable/modules/svm.html (accessed on 5 March 2020).
- Guestrin, C. SVMs, Duality and the Kernel Trick. Mach. Learn. 2006, 10701, 15781. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Neapolitan, R.E.; Jiang, X. Neural Networks and Deep Learning. In Artificial Intelligence; CRC Press Taylor& Francis Group: Boca Raton, FL, USA, 2018. [Google Scholar]
- Jordan, M.I.; Bishop, C.M. Neural networks. In Computer Science Handbook, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2004; ISBN 9780203494455. [Google Scholar]
- Merenda, M.; Praticò, F.G.; Fedele, R.; Carotenuto, R.; Corte, D.; Della Corte, F.G. A Real-Time Decision Platform for the Management of Structures and Infrastructures. Electronics 2019, 8, 1180. [Google Scholar] [CrossRef]
- Anandhalli, M.; Baligar, V.P. A novel approach in real-time vehicle detection and tracking using Raspberry Pi. Alex. Eng. J. 2018, 57, 1597–1607. [Google Scholar] [CrossRef]
- Arasteh, H.; Hosseinnezhad, V.; Loia, V.; Tommasetti, A.; Troisi, O.; Shafie-Khah, M.; Siano, P. Iot-based smart cities: A survey. In Proceedings of the 2016 IEEE 16th International Conference on Environment and Electrical Engineering (EEEIC), Florence, Italy, 7–10 June 2016; pp. 2–7. [Google Scholar]
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, L.; Zorzi, M. Internet of Things for Smart Cities. IEEE Internet Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]
- Bibri, S.E. The IoT for smart sustainable cities of the future: An analytical framework for sensor-based big data applications for environmental sustainability. Sustain. Cities Soc. 2018, 38, 230–253. [Google Scholar] [CrossRef]
- Kim, T.H.; Ramos, C.; Mohammed, S. Smart City and IoT. Futur. Gener. Comput. Syst. 2017, 76, 159–162. [Google Scholar] [CrossRef]
- Sajjad, M.; Nasir, M.; Muhammad, K.; Khan, S.; Jan, Z.; Sangaiah, A.K.; Elhoseny, M.; Baik, S.W. Raspberry Pi assisted face recognition framework for enhanced law-enforcement services in smart cities. Futur. Gener. Comput. Syst. 2017, 108, 995–1007. [Google Scholar] [CrossRef]
- Zhang, T.; Chowdhery, A.; Bahl, P.; Jamieson, K.; Banerjee, S. The design and implementation of a wireless video surveillance system. In Proceedings of the Annual International Conference on Mobile Computing and Networking, MobiCom’15: The 21th Annual International Conference on Mobile Computing and Networking, Paris, France, 7–11 September 2015. [Google Scholar]
- Borgia, E. The Internet of Things vision: Key features, applications and open issues. Comput. Commun. 2014, 54, 1–31. [Google Scholar] [CrossRef]
- Magrini, M.; Moroni, D.; Palazzese, G.; Pieri, G.; Leone, G.; Salvetti, O. Computer Vision on Embedded Sensors for Traffic Flow Monitoring. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Las Palmas, Spain, 15–18 September 2015; pp. 161–166. [Google Scholar]
- Arshad, B.; Ogie, R.; Barthelemy, J.; Pradhan, B.; Verstaevel, N.; Perez, P. Computer Vision and IoT-Based Sensors in Flood Monitoring and Mapping: A Systematic Review. Sensors 2019, 19, 5012. [Google Scholar] [CrossRef]
- Fafoutis, X.; Marchegiani, L.; Elsts, A.; Pope, J.; Piechocki, R.; Craddock, I. Extending the battery lifetime of wearable sensors with embedded machine learning. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; pp. 269–274. [Google Scholar]
- Ieracitano, C.; Mammone, N.; Hussain, A.; Morabito, F.C. A novel multi-modal machine learning based approach for automatic classification of EEG recordings in dementia. Neural Netw. 2020, 123, 176–190. [Google Scholar] [CrossRef]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine learning in medicine. N. Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef]
- Ngiam, K.Y.; Khor, I.W. Big data and machine learning algorithms for health-care delivery. Lancet Oncol. 2019, 20, e262–e273. [Google Scholar] [CrossRef]
- Beam, A.L.; Kohane, I. Big Data and Machine Learning in Health Care. JAMA 2018, 319, 1317. [Google Scholar] [CrossRef] [PubMed]
- Amato, F.; López, A.; Peña-Méndez, E.M.; Vanhara, P.; Hampl, A.; Havel, J. Artificial neural networks in medical diagnosis. J. Appl. Biomed. 2013, 11, 47–58. [Google Scholar] [CrossRef]
- Syafrudin, M.; Alfian, G.; Fitriyani, N.L.; Rhee, J. Performance Analysis of IoT-Based Sensor, Big Data Processing, and Machine Learning Model for Real-Time Monitoring System in Automotive Manufacturing. Sensors 2018, 18, 2946. [Google Scholar] [CrossRef] [PubMed]
- Kihei, B.; Copeland, J.A.; Chang, Y. Automotive Doppler sensing: The Doppler profile with machine learning in vehicle-to-vehicle networks for road safety. In Proceedings of the IEEE Workshop on Signal Processing Advances in Wireless Communications, SPAWC, Sapporo, Japan, 3–6 July 2017. [Google Scholar]
- Gharib, M.; Lollini, P.; Botta, M.; Amparore, E.; Donatelli, S.; Bondavalli, A. On the Safety of Automotive Systems Incorporating Machine Learning Based Components: A Position Paper. In Proceedings of the 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops, DSN-W 2018, Luxembourg, 25–28 June 2018. [Google Scholar]
- Luckow, A.; Kennedy, K.; Manhardt, F.; Djerekarov, E.; Vorster, B.; Apon, A. Automotive big data: Applications, workloads and infrastructures. In Proceedings of the 2015 IEEE International Conference on Big Data, IEEE Big Data 2015, Santa Clara, CA, USA, 29 October–1 November 2015. [Google Scholar]
- OpenCV. Available online: https://opencv.org/ (accessed on 3 January 2020).
- Viola, P.; Jones, M.J. Robust Real-Time Object Detection; Technical Reports; Cambridge Research Laboratory: Cambridge, MA, USA, 2001. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Shashua, A. Introduction to Machine Learning: Class Notes 67577. arXiv 2009, arXiv:0904.3664. [Google Scholar]
- Transactions, E.A.I.E.; Health, P. Designing wearable sensing platforms for healthcare in a residential environment. EAI Endorsed Trans. Pervasive Health Technol. 2017, 3, 12. [Google Scholar]
- Shoeb, A.; Carlson, D.; Panken, E.; Denison, T. A micropower support vector machine based seizure detection architecture for embedded medical devices. In Proceedings of the 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009; pp. 4202–4205. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning in intelligent embedded systems. In WOES’99: Proceedings of the Workshop on Embedded Systems on Workshop on Embedded Systems; USENIX Association: Berkeley, CA, USA, 1999; p. 9. [Google Scholar]
- Li, H.; Ota, K.; Dong, M. Learning IoT in Edge: Deep Learning for the Internet of Things with Edge Computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef]
- Yazici, M.; Basurra, S.; Gaber, M. Edge Machine Learning: Enabling Smart Internet of Things Applications. Big Data Cogn. Comput. 2018, 2, 26. [Google Scholar] [CrossRef]
- Praticò, F.G.; Della Corte, F.G.; Merenda, M. Self-powered sensors for road pavements. In Proceedings of the Functional Pavement Design—4th Chinese-European Workshop on Functional Pavement Design, CEW 2016, Delft, The Netherlands, 29 June–1 July 2016. [Google Scholar]
- Iero, D.; Della Corte, F.G.; Felini, C.; Merenda, M.; Minarini, C.; Rubino, A. RF-Powered UHF-RFID Analog Sensors Platform. In Proceedings of the 2015 XVIII AISEM Annual Conference, Trento, Italy, 3–5 February 2015. [Google Scholar]
- Fedele, R.; Merenda, M.; Giammaria, F.; Praticò, F.G. Energy harvesting for IoT road monitoring systems. Instrumentation Mesure Métrologie 2018, 18, 17. [Google Scholar] [CrossRef]
- Merenda, M.; Iero, D.; Pangallo, G.; Falduto, P.; Adinolfi, G.; Merola, A.; Graditi, G.; Della Corte, F.G. Open-Source Hardware Platforms for Smart Converters with Cloud Connectivity. Electronics 2019, 8, 367. [Google Scholar] [CrossRef]
- Della Corte, F.G.; Merenda, M.; Bellizzi, G.G.; Isernia, T.; Carotenuto, R. Temperature Effects on the Efficiency of Dickson Charge Pumps for Radio Frequency Energy Harvesting. IEEE Access 2018, 6, 65729–65736. [Google Scholar] [CrossRef]
- Tatarinova, T.V.; Editors, Y.N.; Raschka, S.; Verdier, C.F.J.E.S.O.; Hearty, J.; Huffman, J.; Pajankar, A. Python Machine Learning; Packt Publishing: Birmingham, UK, September 2015; ISBN 978-1-78439-390-8. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Pdf ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Caterini, A.L.; Chang, D.E. Recurrent neural networks. In SpringerBriefs in Computer Science; Springer International Publishing: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Beil, J.; Perner, G.; Asfour, T. Speech Recognition With Deep Recurrent Neural Networks. In Proceedings of the IEEE International Conference on Rehabilitation Robotics, Singapore, 1–14 August 2015; pp. 119–124. [Google Scholar]
- Hochreiter, S.; Urgen Schmidhuber, J. Long Shortterm Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Genrative Adversial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems–Volume 2, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Gupta, C.; Suggala, A.S.; Goyal, A.; Simhadri, H.V.; Paranjape, B.; Kumar, A.; Goya, S.; Udupa, R.; Varma, M.; Jain, P. ProtoNN: Compressed and accurate kNN for resource-scarce devices. In Proceedings of the 34th International Conference on Machine Learning ICML, Sydney, Australia, 6–11 August 2017; Volume 3, pp. 2144–2159. [Google Scholar]
- Gope, D.; Dasika, G.; Mattina, M. Ternary Hybrid Neural-Tree Networks for Highly Constrained IoT Applications. arXiv 2019, arXiv:1903.01531. [Google Scholar]
- Kumar, A.; Goyal, S.; Varma, M. Resource-efficient machine learning in 2 KB RAM for the Internet of Things. In Proceedings of the 34th International Conference on Machine Learning ICML, Sydney, Australia, 6–11 August 2017; Volume 4, pp. 3062–3071. [Google Scholar]
- Haigh, K.Z.; Mackay, A.M.; Cook, M.R.; Lin, L.G. Machine Learning for Embedded Systems: A Case Study; Technical Report; BBN Technologies: Cambridge, MA, USA, 2015. [Google Scholar]
- Chen, J.; Ran, X. Deep Learning With Edge Computing: A Review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.H.; Emer, J.; Suleiman, A.; Zhang, Z. Hardware for machine learning: Challenges and opportunities. In Proceedings of the 2017 IEEE Custom Integrated Circuits Conference (CICC), Austin, TX, USA, 30 April–3 May 2017; pp. 1–8. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 11 November 2019).
- Home—Keras Documentation. Available online: https://keras.io/ (accessed on 11 November 2019).
- Yao, S.; Zhao, Y.; Zhang, A.; Su, L.; Abdelzaher, T. DeepIoT: Compressing Deep Neural Network Structures for Sensing Systems with a Compressor-Critic Framework. In Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems, Delft, The Netherlands, 6–8 November 2017. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning Convolutional Neural Networks for Resource Efficient Inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- Anwar, S.; Sung, W. Compact Deep Convolutional Neural Networks With Coarse Pruning. arXiv 2016, arXiv:1610.09639. [Google Scholar]
- Yang, T.J.; Chen, Y.H.; Sze, V. Designing energy-efficient convolutional neural networks using energy-aware pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6071–6079. [Google Scholar]
- Narang, S.; Elsen, E.; Diamos, G.; Sengupta, S. Exploring Sparsity in Recurrent Neural Networks. arXiv 2017, arXiv:1704.05119. [Google Scholar]
- Guo, Y.; Yao, A.; Chen, Y. Dynamic network surgery for efficient DNNs. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16); Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 1387–1395. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- X-CUBE-AI—AI Expansion Pack for STM32CubeMX—STMicroelectronics. Available online: https://www.st.com/en/embedded-software/x-cube-ai.html#overview (accessed on 18 November 2019).
- TensorFlow Lite for Microcontrollers. Available online: https://www.tensorflow.org/lite/microcontrollers (accessed on 15 March 2020).
- Arduino Nano 33 BLE Sense with Headers | Arduino Official Store. Available online: https://store.arduino.cc/arduino-nano-33-ble-sense-with-headers (accessed on 15 March 2020).
- SparkFun Edge Development Board—Apollo3 Blue—DEV-15170—SparkFun Electronics. Available online: https://www.sparkfun.com/products/15170 (accessed on 15 March 2020).
- Artificial Intelligence (AI)—STMicroelectronics. Available online: https://www.st.com/content/st_com/en/about/innovation---technology/artificial-intelligence.html (accessed on 15 March 2020).
- Adafruit EdgeBadge—TensorFlow Lite for Microcontrollers ID: 4400—$35.95: Adafruit Industries, Unique & fun DIY Electronics and Kits. Available online: https://www.adafruit.com/product/4400 (accessed on 15 March 2020).
- Overview | Espressif Systems. Available online: https://www.espressif.com/en/products/hardware/esp32-devkitc/overview (accessed on 15 March 2020).
- Overview | Espressif Systems. Available online: https://www.espressif.com/en/products/hardware/esp-eye/overview (accessed on 15 March 2020).
- High-Performing AI Solutions to Transform our Digital World—Arm. Available online: https://www.arm.com/solutions/artificial-intelligence (accessed on 15 March 2020).
- New AI technology from Arm delivers intelligence for IoT—Arm. Available online: https://www.arm.com/company/news/2020/02/new-ai-technology-from-arm (accessed on 15 March 2020).
- Zhao, Z.; Barijough, K.M.; Gerstlauer, A. DeepThings: Distributed adaptive deep learning inference on resource-constrained IoT edge clusters. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2018, 37, 2348–2359. [Google Scholar] [CrossRef]
- Nikouei, S.Y.; Chen, Y.; Song, S.; Xu, R.; Choi, B.Y.; Faughnan, T. Smart surveillance as an edge network service: From harr-cascade, SVM to a Lightweight CNN. In Proceedings of the 2018 IEEE 4th International Conference on Collaboration and Internet Computing (CIC), Philadelphia, PA, USA, 18–20 October 2018; pp. 256–265. [Google Scholar]
- Xu, R.; Nikouei, S.Y.; Chen, Y.; Polunchenko, A.; Song, S.; Deng, C.; Faughnan, T.R. Real-Time Human Objects Tracking for Smart Surveillance at the Edge. In Proceedings of the IEEE International Conference on Communications, Kansas City, MO, USA, 20–24 May 2018. [Google Scholar]
- Chand, G.; Ali, M.; Barmada, B.; Liesaputra, V.; Ramirez-Prado, G. Tracking a person’s behaviour in a smart house. In International Conference on Service-Oriented Computing; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Rosato, D.; Comai, S.; Masciadri, A.; Salice, F. Non-invasive monitoring system to detect sitting people. In Proceedings of the 4th EAI International Conference on Smart Objects and Technologies for Social Good, Bologna, Italy, 28–30 November 2018; pp. 261–264. [Google Scholar]
- SparkFun Edge Hookup Guide—learn.sparkfun.com. Available online: https://learn.sparkfun.com/tutorials/sparkfun-edge-hookup-guide/all (accessed on 14 April 2020).
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Yu-han, T.; Ravindranath, L.; Deng, S.; Chen, T.Y. Continuous, Real-Time Object Recognition on Mobile Devices Categories and Subject Descriptors. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems (SenSys ‘15). Association for Computing Machinery, New York, NY, USA; 2015; pp. 155–168. [Google Scholar]
- Hung, C.C.; Ananthanarayanan, G.; Bodik, P.; Golubchik, L.; Yu, M.; Bahl, P.; Philipose, M. VideoEdge: Processing camera streams using hierarchical clusters. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25–27 October 2018; pp. 115–131. [Google Scholar]
- Jiang, A.H.; Wong, D.L.K.; Canel, C.; Tang, L.; Misra, I.; Kaminsky, M.; Kozuch, M.A.; Pillai, P.; Labs, I.; Andersen, D.G.; et al. Mainstream: Dynamic Stem-Sharing for Multi-Tenant Video Processing. In Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018. [Google Scholar]
- Radio Regulations. Available online: https://www.itu.int/pub/R-REG-RR/en (accessed on 22 February 2020).
- Radio Versions | Bluetooth® Technology Website. Available online: https://www.bluetooth.com/learn-about-bluetooth/bluetooth-technology/radio-versions/ (accessed on 11 March 2020).
- Dekimpe, R.; Xu, P.; Schramme, M.; Flandre, D.; Bol, D. A Battery-Less BLE IoT Motion Detector Supplied by 2.45-GHz Wireless Power Transfer. In Proceedings of the 2018 IEEE 28th International Symposium on Power and Timing Modeling, Optimization and Simulation, PATMOS, Platja d’Aro, Spain, 2–4 July 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 68–75. [Google Scholar]
- Bluetooth 5: Go Faster, Go Further. Available online: https://www.bluetooth.com/wp-content/uploads/2019/03/Bluetooth_5-FINAL.pdf (accessed on 9 April 2020).
- Bluetooth Special Interest Group (SIG). Bluetooth Core Specification Version 5.0. In Bluetooth Core Specif. Version 5.2; Bluetooth Special Interest Group (SIG): Kirkland, WA, USA, 2019; Available online: https://www.bluetooth.com/wp-content/uploads/2020/01/Bluetooth_5.2_Feature_Overview.pdf (accessed on 20 April 2020).
- Zigbee Alliance Website. Available online: https://zigbeealliance.org/ (accessed on 11 March 2020).
- 802.15.4v-2017—IEEE Standard for Low-Rate Wireless Networks—Amendment 5: Enabling/Updating the Use of Regional Sub-GHz Bands. Available online: https://standards.ieee.org/standard/802_15_4v-2017.html (accessed on 11 March 2020).
- Pan, M.S.; Tseng, Y.C. ZigBee and Their Applications. In Sensor Networks and Configuration, Fundamentals, Standards, Platforms, and Applications; Springer: Berlin/Heidelberg, Germany, 2007; Volume 16, pp. 349–368. [Google Scholar]
- Islam, M.L.; Faizan, C.; Quavi, S.M.A. IOT Based Smart Garbage Monitoring System. Int. J. Comput. Sci. Eng. 2019, 7, 649–651. [Google Scholar] [CrossRef]
- Yaqoob, I.; Hashem, I.A.T.; Mehmood, Y.; Gani, A.; Mokhtar, S.; Guizani, S. Enabling communication technologies for smart cities. IEEE Commun. Mag. 2017, 55, 112–120. [Google Scholar] [CrossRef]
- Sahitya, G.; Balaji, N.; Naidu, C.D.; Abinaya, S. Designing a wireless sensor network for precision agriculture using zigbee. In Proceedings of the 7th IEEE International Advanced Computing Conference, IACC 2017, Hyderabad, India, 5–7 January 2017. [Google Scholar]
- Hidayat, T. Internet of Things Smart Agriculture on ZigBee: A Systematic Review. J. Telekomun. dan Kompʹût. 2017, 8, 75–86. [Google Scholar] [CrossRef]
- Lei, Y.; Wang, T.; Wu, J. Vehicles relative positioning based on ZigBee and GPS technology. In Proceedings of the ICEIEC 2016 IEEE 6th International Conference on Electronics Information and Emergency Communication, Beijing, China, 17–19 June 2016. [Google Scholar]
- Dong, C.; Chen, X.; Dong, H.; Yang, K.; Guo, J.; Bai, Y. Research on intelligent vehicle infrastructure cooperative system based on zigbee. In Proceedings of the 2019 5th International Conference on Transportation Information and Safety (ICTIS), Liverpool, UK, 14–17 July 2019; pp. 1337–1343. [Google Scholar]
- Lee, H.J.; Lee, S.H.; Ha, K.S.; Jang, H.C.; Chung, W.-Y.C.; Kim, J.Y.; Chang, Y.-S.; Yoo, D.H. Ubiquitous healthcare service using Zigbee and mobile phone for elderly patients. Int. J. Med Inform. 2009, 78, 193–198. [Google Scholar] [CrossRef]
- Chae, M.J.; Yoo, H.; Kim, J.; Cho, M. Development of a wireless sensor network system for suspension bridge health monitoring. Autom. Constr. 2012, 21, 237–252. [Google Scholar] [CrossRef]
- Z-Wave | Safer, Smarter Homes Start with Z-Wave. Available online: https://www.z-wave.com/ (accessed on 12 March 2020).
- ANT Protocol | Dynastream Innovations. Available online: https://www.dynastream.com/solutions/ant-wireless/ (accessed on 9 April 2020).
- What is ANT+—THIS IS ANT. Available online: https://www.thisisant.com/consumer/ant-101/what-is-ant/ (accessed on 16 April 2020).
- Mulligan, G. The 6LoWPAN architecture. In Proceedings of the 4th Workshop on Embedded Networked Sensors, EmNets, Cork, Ireland, 25–26 June 2007. [Google Scholar]
- Unwala, I.; Taqvi, Z.; Lu, J. Thread: An IoT protocol. In Proceedings of the IEEE Green Technologies Conference, Austin, TX, USA, 4–6 April 2018. [Google Scholar]
- Shop Humidor Monitoring from Smartphone and Tablet Habueno. Available online: https://www.habueno.com/shop/?lang=en (accessed on 16 April 2020).
- WiFi HaLow | WiFi Alliance. Available online: https://www.WiFi.org/discover-WiFi/WiFi-halow (accessed on 12 March 2020).
- Flores, A.B.; Guerra, R.E.; Knightly, E.W.; Ecclesine, P.; Pandey, S. IEEE 802.11af: A standard for TV white space spectrum sharing. IEEE Commun. Mag. 2013, 51, 92–100. [Google Scholar] [CrossRef]
- Bellalta, B. IEEE 802.11ax: High-efficiency WLANS. IEEE Wirel. Commun. 2016, 23, 38–46. [Google Scholar] [CrossRef]
- Merenda, M.; Iero, D.; Della Corte, F.G. CMOS RF Transmitters with On-Chip Antenna for Passive RFID and IoT Nodes. Electronics 2019, 8, 1448. [Google Scholar] [CrossRef]
- Lazaro, A.; Villarino, R.; Girbau, D. A Survey of NFC Sensors Based on Energy Harvesting for IoT Applications. Sensors 2018, 18, 3746. [Google Scholar] [CrossRef] [PubMed]
- LoRa Alliance® Website. Available online: https://lora-alliance.org/ (accessed on 11 March 2020).
- Chiani, M.; Elzanaty, A. On the LoRa Modulation for IoT: Waveform Properties and Spectral Analysis. IEEE Internet Things J. 2019, 6, 8463–8470. [Google Scholar] [CrossRef]
- Augustin, A.; Yi, J.; Clausen, T.H.; Townsley, W.M. A Study of LoRa: Long Range & Low Power Networks for the Internet of Things. Sensors 2016, 16, 1466. [Google Scholar]
- Suresh, V.M.; Sidhu, R.; Karkare, P.; Patil, A.; Lei, Z.; Basu, A. Powering the IoT through embedded machine learning and LoRa. In Proceedings of the IEEE World Forum on Internet of Things, WF-IoT, Singapore, 5–8 February 2018. [Google Scholar]
- Merenda, M.; Felini, C.; Della Corte, F.G. A Monolithic Multisensor Microchip with Complete On-Chip RF Front-End. Sensors 2018, 18, 110. [Google Scholar] [CrossRef]
- Sigfox—The Global Communications Service Provider for the Internet of Things (IoT). Available online: https://www.sigfox.com/en (accessed on 5 January 2020).
- Huang, J.; Qian, F.; Guo, Y.; Zhou, Y.; Xu, Q.; Mao, Z.M.; Sen, S.; Spatscheck, O. An in-depth study of LTE: Effect of network protocol and application behavior on performance. Comput. Commun. Rev. 2013, 43, 363–374. [Google Scholar] [CrossRef]
- Akpakwu, G.A.; Silva, B.J.; Hancke, G.P.; Abu-Mahfouz, A.M. A Survey on 5G Networks for the Internet of Things: Communication Technologies and Challenges. IEEE Access 2018, 6, 3619–3647. [Google Scholar] [CrossRef]
- Li, S.; Xu, L.D.; Zhao, S. 5G Internet of Things: A survey. J. Ind. Inf. Integr. 2018, 10, 1–9. [Google Scholar] [CrossRef]
- GSMA | Narrowband – Internet of Things (NB-IoT) | Internet of Things. Available online: https://www.gsma.com/iot/narrow-band-internet-of-things-nb-iot/ (accessed on 11 March 2020).
- Ratasuk, R.; Mangalvedhe, N.; Zhang, Y.; Robert, M.; Koskinen, J.P. Overview of narrowband IoT in LTE Rel-13. In Proceedings of the 2016 IEEE Conference on Standards for Communications and Networking (CSCN), Berlin, Germany, 31 October–2 November 2016. [Google Scholar]
- Borkar, S.R. Long-term evolution for machines (LTE-M). In LPWAN Technologies for IoT and M2M Applications; Academic Press: Cambridge, MA, USA, 2020; pp. 145–166. [Google Scholar]
- Wang, D.; Chen, D.; Song, B.; Guizani, N.; Yu, X.; Du, X. From IoT to 5G I-IoT: The Next Generation IoT-Based Intelligent Algorithms and 5G Technologies. IEEE Commun. Mag. 2018, 56, 114–120. [Google Scholar] [CrossRef]
- Morocho-Cayamcela, M.E.; Lee, H.; Lim, W. Machine learning for 5G/B5G mobile and wireless communications: Potential, limitations, and future directions. IEEE Access 2019, 7, 137184–137206. [Google Scholar] [CrossRef]
- Al-Sarawi, S.; Anbar, M.; Alieyan, K.; Alzubaidi, M. Internet of Things (IoT) communication protocols: Review. In Proceedings of the ICIT 2017—8th International Conference on Information Technology, Amman, Jordan, 17–18 May 2017. [Google Scholar]
- Mahmoud, M.S.; Mohamad, A.A.H. A Study of Efficient Power Consumption Wireless Communication Techniques/ Modules for Internet of Things (IoT) Applications. Adv. Internet Things 2016, 6, 19–29. [Google Scholar] [CrossRef]
- Mekki, K.; Bajic, E.; Chaxel, F.; Meyer, F. A comparative study of LPWAN technologies for large-scale IoT deployment. ICT Express 2019, 5, 1–7. [Google Scholar] [CrossRef]
- Choi, C.S.; Jeong, J.D.; Lee, I.W.; Park, W.K. LoRa based renewable energy monitoring system with open IoT platform. In Proceedings of the International Conference on Electronics, Information and Communication, ICEIC, Honolulu, HI, USA, 24–27 January 2018. [Google Scholar]
- Zhou, Q.; Zheng, K.; Hou, L.; Xing, J.; Xu, R. Design and Implementation of Open LoRa for IoT. IEEE Access 2019, 7, 100649–100657. [Google Scholar] [CrossRef]
- Wang, S.Y.; Chen, Y.R.; Chen, T.Y.; Chang, C.H.; Cheng, Y.H.; Hsu, C.C.; Lin, Y.B. Performance of LoRa-based IoT applications on campus. In Proceedings of the IEEE Vehicular Technology Conference, Toronto, ON, Canada, 24–27 September 2017. [Google Scholar]
- Sarker, V.K.; Queralta, J.P.; Gia, T.N.; Tenhunen, H.; Westerlund, T. A survey on LoRa for IoT: Integrating edge computing. In Proceedings of the 2019 4th International Conference on Fog and Mobile Edge Computing, FMEC, Rome, Italy, 10–13 June 2019. [Google Scholar]
- Poursafar, N.; Alahi, M.E.E.; Mukhopadhyay, S. Long-range wireless technologies for IoT applications: A review. In Proceedings of the International Conference on Sensing Technology, ICST, Sydney, Australia, 4–6 December 2017. [Google Scholar]
- Vejlgaard, B.; Lauridsen, M.; Nguyen, H.; Kovacs, I.Z.; Mogensen, P.; Sorensen, M. Coverage and Capacity Analysis of Sigfox, LoRa, GPRS, and NB-IoT. In Proceedings of the IEEE Vehicular Technology Conference, Sydney, Australia, 4–7 June 2017. [Google Scholar]
- Ray, B. NB-IoT vs. LoRa vs. Sigfox. Available online: https://www.link-labs.com/blog/nb-iot-vs-lora-vs-sigfox (accessed on 16 April 2020).
- Zuniga, J.C.; Ponsard, B.; Sigfox System Description. Ietf 97. Available online: https://datatracker.ietf.org/meeting/97/materials/slides-97-lpwan-25-sigfox-system-description-00 (accessed on 16 April 2020).
- Froiz-Míguez, I.; Fernandez-Carames, T.M.; Fraga-Lamas, P.; Castedo, L. Design, Implementation and Practical Evaluation of an IoT Home Automation System for Fog Computing Applications Based on MQTT and ZigBee-WiFi Sensor Nodes. Sensors 2018, 18, 2660. [Google Scholar] [CrossRef]
- Ergen, S.C. ZigBee/IEEE 802.15.4 Summary. UC Berkeley September 2004. Available online: http://users.eecs.northwestern.edu/~peters/references/ZigtbeeIEEE802.pdf (accessed on 16 April 2020).
- Li, Y.; Chi, Z.; Liu, X.; Zhu, T. Passive-ZigBee: Enabling zigbee communication in IoT networks with 1000X+ less power consumption. In Proceedings of the SenSys 2018—16th Conference on Embedded Networked Sensor Systems, Shenzhen, China, 4–7 November 2018. [Google Scholar]
- Patil, S.M.; Moiz Baig, M. Survey on Creating ZigBee Chain Reaction Using IoT. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2018, 3, 545–549. [Google Scholar]
- Hersent, O.; Boswarthick, D.; Elloumi, O. Z-Wave. In The Internet of Things: Key Applications and Protocols; John Wiley & Sons: Hoboken, NJ, USA, 2011; ISBN 9781119994350. [Google Scholar]
- Raza, S.; Misra, P.; He, Z.; Voigt, T. Building the Internet of Things with bluetooth smart. Ad Hoc Networks 2017, 57, 19–31. [Google Scholar] [CrossRef]
- Cha, S.-C.; Chen, J.-F.; Su, C.; Yeh, K.-H. A Blockchain Connected Gateway for BLE-Based Devices in the Internet of Things. IEEE Access 2018, 6, 24639–24649. [Google Scholar] [CrossRef]
- Jeon, K.E.; She, J.; Soonsawad, P.; Ng, P.C. BLE Beacons for Internet of Things Applications: Survey, Challenges, and Opportunities. IEEE Internet Things J. 2018, 5, 811–828. [Google Scholar] [CrossRef]
- Collotta, M.; Pau, G.; Talty, T.; Tonguz, O.K. Bluetooth 5: A Concrete Step Forward toward the IoT. IEEE Commun. Mag. 2018, 56, 125–131. [Google Scholar] [CrossRef]
- Ray, P.P.; Agarwal, S. Bluetooth 5 and Internet of Things: Potential and architecture. In Proceedings of the International Conference on Signal Processing, Communication, Power and Embedded System, SCOPES 2016, Paralakhemundi, India, 3–5 October 2016. [Google Scholar]
- Pau, G.; Collotta, M.; Maniscalco, V. Bluetooth 5 Energy Management through a Fuzzy-PSO Solution for Mobile Devices of Internet of Things. Energies 2017, 10, 992. [Google Scholar]
- López-Matencio, P.; Vales-Alonso, J.; Costa-Montenegro, E. ANT: Agent Stigmergy-Based IoT-Network for Enhanced Tourist Mobility. Mob. Inf. Syst. 2017, 2017, 1–15. [Google Scholar] [CrossRef]
- Shrivastava, V.; Rayanchu, S.; Yoon, J.; Banerjee, S. 802.11n under the microscope. In Proceedings of the ACM SIGCOMM Internet Measurement Conference, IMC, Vouliagmeni, Greece, 20–22 October 2008. [Google Scholar]
- IEEE. IEEE Std 802.11ah-2016 (Amendment to IEEE Std 802.11-2016, as Amended by IEEE Std 802.11ai-2016). IEEE Standard for Information Technology--Telecommunications and Information Exchange between Systems—Local and Metropolitan Area Networks--Specific Requirements—Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications Amendment 2: Sub 1 GHz License Exempt Operation; IEEE Computer Society: Washington, DC, USA, 14 December 2016. [Google Scholar] [CrossRef]
- Park, M. IEEE 802.11ah: Sub-1-GHz license-exempt operation for the internet of things. IEEE Commun. Mag. 2015, 53, 145–151. [Google Scholar] [CrossRef]
- Hossain, M.I.; Lin, L.; Markendahl, J. A Comparative Study of IoT-Communication Systems Cost Structure: Initial Findings of Radio Access Networks Cost. In Proceedings of the 11th CMI International Conference, 2018: Prospects and Challenges Towards Developing a Digital Economy within the EU, PCTDDE 2018, Copenhagen, Denmark, 29–30 November 2018. [Google Scholar]
- Chen, M.; Miao, Y.; Hao, Y.; Hwang, K. Narrow Band Internet of Things. IEEE Access 2017, 5, 20557–20577. [Google Scholar] [CrossRef]
- Sara, J.J.; Hossain, M.S.; Khan, W.Z.; Aalsalem, M.Y. Survey on Internet of Things and 4G. In Proceedings of the 2019 International Conference on Radar, Antenna, Microwave, Electronics, and Telecommunications (ICRAMET), Tangerang, Indonesia, 23–24 October 2019; pp. 1–6. [Google Scholar]
- Gemalto Introducing 5G Networks—Characteristics and Usages. 2016. Available online: Https://www.Gemalto.Com (accessed on 16 April 2020).
- Martinez, I.S.H.; Salcedo, I.P.O.J.; Daza, I.B.S.R. IoT application of WSN on 5G infrastructure. In Proceedings of the 2017 International Symposium on Networks, Computers and Communications, ISNCC, Marrakech, Morocco, 16–18 May 2017. [Google Scholar]
- Mumtaz, S.; Bo, A.; Al-Dulaimi, A.; Tsang, K.F. Guest Editorial 5G and beyond Mobile Technologies and Applications for Industrial IoT (IIoT). IEEE Trans. Ind. Inf. 2018, 14, 2588–2591. [Google Scholar] [CrossRef]
- Kang, Y.; Hauswald, J.; Gao, C.; Rovinski, A.; Mudge, T.; Mars, J.; Tang, L. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, Xi’an, China, 8–12 April 2017; pp. 615–629. [Google Scholar]
- Teerapittayanon, S.; McDanel, B.; Kung, H.T. Distributed Deep Neural Networks over the Cloud, the Edge and End Devices. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 328–339. [Google Scholar]
- Wang, J.; Zhu, X.; Zhang, J.; Cao, B.; Bao, W.; Yu, P.S. Not just privacy: Improving performance of private deep learning in mobile cloud. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2407–2416. [Google Scholar]
- Du, M.; Wang, K.; Xia, Z.; Zhang, Y. Differential Privacy Preserving of Training Model in Wireless Big Data with Edge Computing. IEEE Trans. Big Data 2018. [Google Scholar] [CrossRef]
- Abadi, M.; McMahan, H.B.; Chu, A.; Mironov, I.; Zhang, L.; Goodfellow, I.; Talwar, K. Deep learning with differential privacy. In Proceedings of the ACM Conference on Computer and Communications Security, Vienna, Austria, 25–27 October 2016. [Google Scholar]
- Xu, C.; Ren, J.; Zhang, D.; Zhang, Y. Distilling at the Edge: A Local Differential Privacy Obfuscation Framework for IoT Data Analytics. IEEE Commun. Mag. 2018, 56, 20–25. [Google Scholar] [CrossRef]
- Miao, Q.; Jing, W.; Song, H. Differential privacy–based location privacy enhancing in edge computing. Concurr. Comput. Pract. Exp. 2018, 31, e4735. [Google Scholar] [CrossRef]
- Dowlin, N.; Edu, N.; Gilad-Bachrach, R.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J.; Com, J.W. CryptoNets: Applying neural networks to Encrypted data with high throughput and accuracy—Microsoft research. Microsoft Res. Tech. Rep. 2016, 48, 1–12. [Google Scholar]
- Dias, M.; Abad, A.; Trancoso, I. Exploring Hashing and Cryptonet Based Approaches for Privacy-Preserving Speech Emotion Recognition. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Morris, A.; Mellis, C. Privacy-preserving classifification on deep neural network. IACR Cryptol. ePrint Arch. 2017, 2017, 35. [Google Scholar]
- Mao, J.; Chen, X.; Nixon, K.W.; Krieger, C.; Chen, Y. MoDNN: Local distributed mobile computing system for Deep Neural Network. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 1396–1401. [Google Scholar]
- Chandakkar, P.S.; Li, Y.; Ding, P.L.K.; Li, B. Strategies for Re-Training a Pruned Neural Network in an Edge Computing Paradigm. In Proceedings of the 2017 IEEE International Conference on Edge Computing (EDGE), Honolulu, HI, USA, 25–30 June 2017; pp. 244–247. [Google Scholar]
- Tao, Z.; Li, Q. eSGD: Communication efficient distributed deep learning on the edge. In Proceedings of the USENIX Workshop on Hot Topics in Edge Computing, HotEdge 2018, Co-Located with USENIX ATC 2018, Boston, MA, USA, 10 July 2018. [Google Scholar]
- Deep Learning Hardware: FPGA vs. GPU. Available online: https://semiengineering.com/deep-learning-hardware-fpga-vs-gpu/ (accessed on 18 February 2020).
- cuBLAS | NVIDIA Developer. Available online: https://developer.nvidia.com/cublas (accessed on 21 February 2020).
- NVIDIA cuDNN | NVIDIA Developer. Available online: https://developer.nvidia.com/cudnn (accessed on 21 February 2020).
- Mathieu, M.; Henaff, M.; LeCun, Y. Fast Training of Convolutional Networks through FFTs. arXiv 2013, arXiv:1312.5851. [Google Scholar]
- Cong, J.; Xiao, B. Minimizing in Convolutional Neural Networks. Int. Conf. Artif. Neural Networks 2014, 8681, 281–290. [Google Scholar]
- Lavin, A.; Gray, S. Fast Algorithms for Convolutional Neural Networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hailo–Top Performing AI Chip for Edge Devices. Available online: https://hailo.ai/ (accessed on 18 November 2019).
- Cloud TPU | Google Cloud. Available online: https://cloud.google.com/tpu/ (accessed on 18 November 2019).
- US8655815B2—Neural processing unit—Google Patents. Available online: https://patents.google.com/patent/US8655815B2/en (accessed on 6 March 2020).
- Farabet, C.; Poulet, C.; Han, J.Y.; LeCun, Y. CNP: An FPGA-based processor for Convolutional Networks. In Proceedings of the 2009 International Conference on Field Programmable Logic and Applications, Prague, Czech, 31 August–2 September 2009; Volume 1, pp. 32–37. [Google Scholar]
- Farabet, C.; Martini, B.; Corda, B.; Akselrod, P.; Culurciello, E.; LeCun, Y. NeuFlow: A runtime reconfigurable dataflow processor for vision. In Proceedings of the CVPR 2011 WORKSHOPS, Colorado Springs, CO, USA, 20–25 June 2011; pp. 109–116. [Google Scholar]
- Chakradhar, S.; Sankaradas, M.; Jakkula, V.; Cadambi, S. A dynamically configurable coprocessor for convolutional neural networks. In Proceedings of the 37th Annual International Symposium on Computer Architecture, Saint-Malo, France, 19–23 June 2010; pp. 247–257. [Google Scholar]
- Nuño-Maganda, M.; Torres-Huitzil, C. A temporal coding hardware implementation for spiking neural networks. ACM SIGARCH Comput. Archit. News 2011, 38, 2. [Google Scholar] [CrossRef]
- Chen, Y.; Luo, T.; Liu, S.; Zhang, S.; He, L.; Wang, J.; Li, L.; Chen, T.; Xu, Z.; Sun, N.; et al. DaDianNao: A Machine-Learning Supercomputer. In Proceedings of the 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014; pp. 609–622. [Google Scholar]
- Du, Z.; Fasthuber, R.; Chen, T.; Ienne, P.; Li, L.; Luo, T.; Feng, X.; Chen, Y.; Temam, O. ShiDianNao: Shifting vision processing closer to the sensor. In Proceedings of the 42nd Annual International Symposium on Computer Architecture, Portland, Oregon, 13–17 June 2015; pp. 92–104. [Google Scholar]
- Intel® Neural Compute Stick 2 | Intel® Software. Available online: https://software.intel.com/en-us/neural-compute-stick (accessed on 16 April 2020).
- Othman, N.A.; Aydin, I. A New Deep Learning Application Based on Movidius NCS for Embedded Object Detection and Recognition. In Proceedings of the 2018 2nd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 19–21 October 2018. [Google Scholar]
- Get Started with Intel® Neural Compute Stick 2 | Intel® Software. Available online: https://software.intel.com/en-us/articles/get-started-with-neural-compute-stick (accessed on 16 April 2020).
- Coral. Available online: https://www.coral.ai/ (accessed on 16 April 2020).
- Examples | Coral. Available online: https://coral.ai/examples/ (accessed on 16 April 2020).
- Hochstetler, J.; Padidela, R.; Chen, Q.; Yang, Q.; Fu, S. Embedded deep learning for vehicular edge computing. In Proceedings of the 2018 3rd ACM/IEEE Symposium on Edge Computing, SEC 2018, Bellevue, WA, USA, 25–27 October 2018. [Google Scholar]
- Marantos, C.; Karavalakis, N.; Leon, V.; Tsoutsouras, V.; Pekmestzi, K.; Soudris, D. Efficient support vector machines implementation on Intel/Movidius Myriad 2. In Proceedings of the 2018 7th International Conference on Modern Circuits and Systems Technologies, MOCAST 2018, Thessaloniki, Greece, 7–9 May 2018. [Google Scholar]
- Barry, B.; Brick, C.; Connor, F.; Donohoe, D.; Moloney, D.; Richmond, R.; O’Riordan, M.; Toma, V.; Nicholls, D. Always-on Vision Processing Unit for Mobile Applications. IEEE Micro 2015, 35, 56–66. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, S.; Han, T. Demo: Fast and accurate object analysis at the edge for mobile augmented reality. In Proceedings of the 2017 2nd ACM/IEEE Symposium on Edge Computing, SEC 2017, San Jose, CA, USA, 12–14 October 2017. [Google Scholar]
- Lee, S.; Son, K.; Kim, H.; Park, J. Car plate recognition based on CNN using embedded system with GPU. In Proceedings of the 2017 10th International Conference on Human System Interactions, HSI 2017, Ulsan, Korea, 17–19 July 2017. [Google Scholar]
- Ezra Tsur, E.; Madar, E.; Danan, N. Code generation of graph-based vision processing for multiple CUDA Cores SoC Jetson TX. In Proceedings of the 2018 IEEE 12th International Symposium on Embedded Multicore/Many-Core Systems-on-Chip, MCSoC 2018, Hanoi, Vietnam, 12–14 September 2018. [Google Scholar]
- Rungsuptaweekoon, K.; Visoottiviseth, V.; Takano, R. Evaluating the power efficiency of deep learning inference on embedded GPU systems. In Proceedings of the 2017 2nd International Conference on Information Technology, INCIT 2017, Nakhonpathom, Thailand, 2–3 November 2017. [Google Scholar]
- Chinchali, S.; Sharma, A.; Harrison, J.; Elhafsi, A.; Kang, D.; Pergament, E.; Cidon, E.; Katti, S.; Pavone, M. Network Offloading Policies for Cloud Robotics: A Learning-Based Approach. In Proceedings of the Robotics: Science and Systems 2019, Freiburg im Breisgau, Germany, 22–26 June 2019. [Google Scholar]
- Jana, A.P.; Biswas, A. Mohana YOLO based detection and classification of objects in video records. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information and Communication Technology, RTEICT 2018, Bangalore, India, 18–19 May 2018. [Google Scholar]
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y.; Temam, O. DianNao: A small-footprint high-throughput accelerator for ubiquitous machine-learning. In Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems—ASPLOS, Salt Lake City, UT, USA, 1–5 March 2014. [Google Scholar]
- MNIST Handwritten Digit Database, Yann LeCun, Corinna Cortes and Chris Burges. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 16 April 2020).
- National Institute of Standards and Technology | NIST. Available online: https://www.nist.gov/ (accessed on 8 January 2020).
- Cook, L.T.; Zhu, Y.; Hall, T.J. Bioelasticity imaging: II. Spatial resolution. Med. Imaging 2000, 3982, 315–325. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Journal of Machine Learning Research, 2010, 13th International Conference on Artificial Intelligence and Statistics, AISTATS 2010, Sardinia, Italy, 13–15 May 2010; 2010. [Google Scholar]
- TensorFlow Lite models | TensorFlow. Available online: https://www.tensorflow.org/lite/models (accessed on 8 January 2020).
- Sequential—Keras Documentation. Available online: https://keras.io/models/sequential/ (accessed on 8 January 2020).
- TensorFlow Lite inference. Available online: https://www.tensorflow.org/lite/guide/inference (accessed on 16 April 2020).
- FlatBuffers: FlatBuffers. Available online: https://google.github.io/flatbuffers/ (accessed on 8 January 2020).
- Magnitude-Based Weight Pruning with Keras. Available online: https://www.tensorflow.org/model_optimization/guide/pruning/pruning_with_keras (accessed on 8 January 2020).
- Python Imaging Library (PIL). Available online: https://pythonware.com/products/pil/ (accessed on 8 January 2020).
- TkInter—Python Wiki. Available online: https://wiki.python.org/moin/TkInter (accessed on 8 January 2020).
- NUCLEO-F746ZG—STM32 Nucleo-144 Development Board with STM32F746ZG MCU, Supports Arduino, ST Zio and Morpho Connectivity—STMicroelectronics. Available online: https://www.st.com/en/evaluation-tools/nucleo-f746zg.html (accessed on 15 March 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | DNN Model | Application | End Devices | Key Metrics |
|---|---|---|---|---|
| This work (Section 9) | CNN | Image Recognition | STM32F401RE (ARM® Cortex® -M4) | fast inference |
| [23] | SVM | Image Recognition | Raspberry Pi model 3 (ARM® v8) | fast inference |
| [90] | DNN | Distributed Computing | Raspberry Pi model 3 (ARM® v8) | hierarchical |
| [91] | SVM, CNN | Video Analysis | Raspberry Pi model 3 (ARM® v8) | fast inference |
| [92] | SVM | Video Analysis | Raspberry Pi model 3 (ARM® v8) | fast inference |
| [28] | SVM | Battery Lifetime Estimation | SPHERE | energy |
| [44] | CNN | Image Recognition, Sensor Fusion | Motorola 68HC11 | fast inference |
| [65] | SVM | Code execution | ARM® v7 | accuracy |
| [93,94] | Logistic Regression | Human Activity Recognition | ESP32 | accuracy |
| [95] | CNN | Speech Recognition | Sparkfun Edge | accuracy |
| Group | Technology | Data Rate | Distance (Indoor/Outdoor) | Works |
|---|---|---|---|---|
| Contactless | NFC | 424 kbps | 0–4 cm | [126] |
| Contactless | RFID | 640 kbps | 10–20 m | [125] |
| LPWAN | LoRa | 0.3 to 50 kbps | 5–10 km | [127,128,144,145,146,147,148] |
| LPWAN | SigFox | 100 or 600 bps | 30–50km | [143,148,149,150,151] |
| WPAN | Zigbee | 250 kbps | 10–100 m | [152,153,154,155] |
| WPAN | Z-Wave | 100 kbps | 100 m | [116,156] |
| WPAN | Bluetooth LE | 1 Mbps | 10 m/50 m | [102,157,158,159] |
| WPAN | Bluetooth 5 | 2 Mbps | 40 m/200 m | [160,161,162] |
| WPAN | ANT | 60 kbps | 30 m | [163] |
| WiFi | IEEE 802.11n | 600 Mbps | 70 m/250 m | [164] |
| WiFi | IEEE 802.11ax | 9600 Mbps | 30 m/120 m | [124] |
| WiFi | IEEE 802.11af | 570 Mbps | 280 m/1 km | [165,166] |
| WiFi | IEEE 802.11ah | 347 Mbps | 140 m/500 m | [122,166,167] |
| Cellular | NB-IoT | 200 kbps | 280 m/1 km | [136,137,150,168] |
| Cellular | LTE-M1 | 1 Mbps | 5–100 km | [138] |
| Cellular | 4G/LTE | 150 Mbps | 15 km | [169] |
| Cellular | 5G | 10–50 Gbps | 2 km | [170,171,172] |
| Work | DNN Model | Application | End Devices |
|---|---|---|---|
| [206,207,208] | SVM/CNN | Image and Video Analysis | Movidius |
| [209,210,211] | CNN | Image and Video Analysis, Robotics | Jetson TX1 |
| [212,213] | YOLO [214] | Image Recognition, Robotics | Jetson TX2 |
| [98] | AlexNet | Image Classification | Nvidia Tegra K1 |
| [196] | CNN | Image Analysis | Neuflow |
| [215] | CNN, DNN | Image Recognition | DianNao |
| [200] | CNN | Vision Processing | ShiDianNao |
| First Level | Second Level | Accuracy on Test |
|---|---|---|
| relu | relu | 96.20% |
| tanh | tanh | 96.80% |
| sigmoid | sigmoid | 96.96% |
| relu | tanh | 97.18% |
| tanh | relu | 96.64% |
| sigmoid | relu | 96.88% |
| relu | sigmoid | 97.25% |
| tanh | sigmoid | 97.21% |
| sigmoid | tanh | 97.10% |
| Layer (Type) | Output Shape | Param # |
|---|---|---|
| conv2d_1 (Conv2D) | (None, 26, 26, 32) | 320 |
| conv2d_2 (Conv2D) | (None, 24, 24, 64) | 18496 |
| max_pooling2d_1 (MaxPooling2) | (None, 12, 12, 64) | 0 |
| dropout_1 (Dropout) | (None, 12, 12, 64) | 0 |
| flatten_1 (Flatten) | (None, 9216) | 0 |
| dense_l (Dense) | (None, 64) | 589888 |
| dropout_2 (Dropout) | (None, 64) | 0 |
| dense_2 (Dense) | (None, 10) | 650 |
| Name | RAM | FLASH | Complexity |
|---|---|---|---|
| Network | 135.68 kBytes | 668.97 kBytes | 11497654 MAC |
| Description | Shape | ms |
|---|---|---|
| 10004/(2D Convolutional) | (26, 26, 32) | 9.328 |
| 10011/(Merged Conv2d/Pool) | (12, 12, 64) | 299.524 |
| 10005/(Dense) | (1, 1, 64) | 19.562 |
| 10009/(Nonlinearity) | (1, 1, 64) | 0.006 |
| 10005/(Dense) | (1, 1, 10) | 0.022 |
| 10009/(Nonlinearity) | (1, 1, 10) | 0.014 |
| 328.458 (total) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Merenda, M.; Porcaro, C.; Iero, D. Edge Machine Learning for AI-Enabled IoT Devices: A Review. Sensors 2020, 20, 2533. https://doi.org/10.3390/s20092533
Merenda M, Porcaro C, Iero D. Edge Machine Learning for AI-Enabled IoT Devices: A Review. Sensors. 2020; 20(9):2533. https://doi.org/10.3390/s20092533
Chicago/Turabian StyleMerenda, Massimo, Carlo Porcaro, and Demetrio Iero. 2020. "Edge Machine Learning for AI-Enabled IoT Devices: A Review" Sensors 20, no. 9: 2533. https://doi.org/10.3390/s20092533
APA StyleMerenda, M., Porcaro, C., & Iero, D. (2020). Edge Machine Learning for AI-Enabled IoT Devices: A Review. Sensors, 20(9), 2533. https://doi.org/10.3390/s20092533