
On the Distribution of the Information Density of Gaussian Random Vectors: Explicit Formulas and Tight Approximations


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction and Main Theorems
2. Special Cases
2.1. Equal Canonical Correlations
2.2. More on Special Cases with Simplified Formulas
3. Mutual Information and Information Density in Terms of Canonical Correlations
4. Proof of Main Results
4.1. Auxiliary Results
4.2. Proof of Theorem 1
4.3. Proof of Theorem 2
4.4. Proof of Theorem 3
4.5. Proof of Part (iii) of Corollary 1
5. Recurrence Formulas and Finite Sum Approximations
5.1. Recurrence Formulas
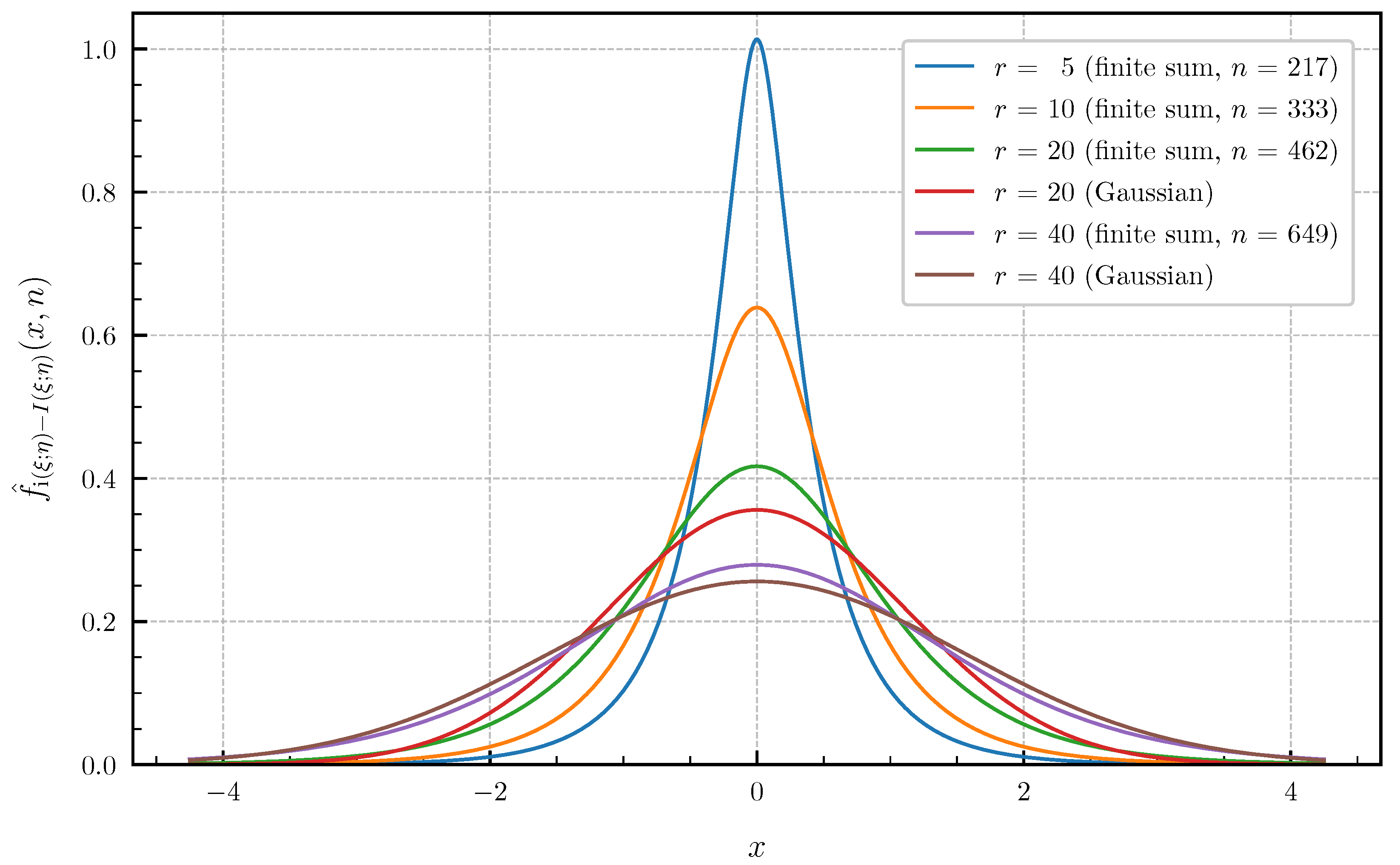
5.2. Finite Sum Approximations
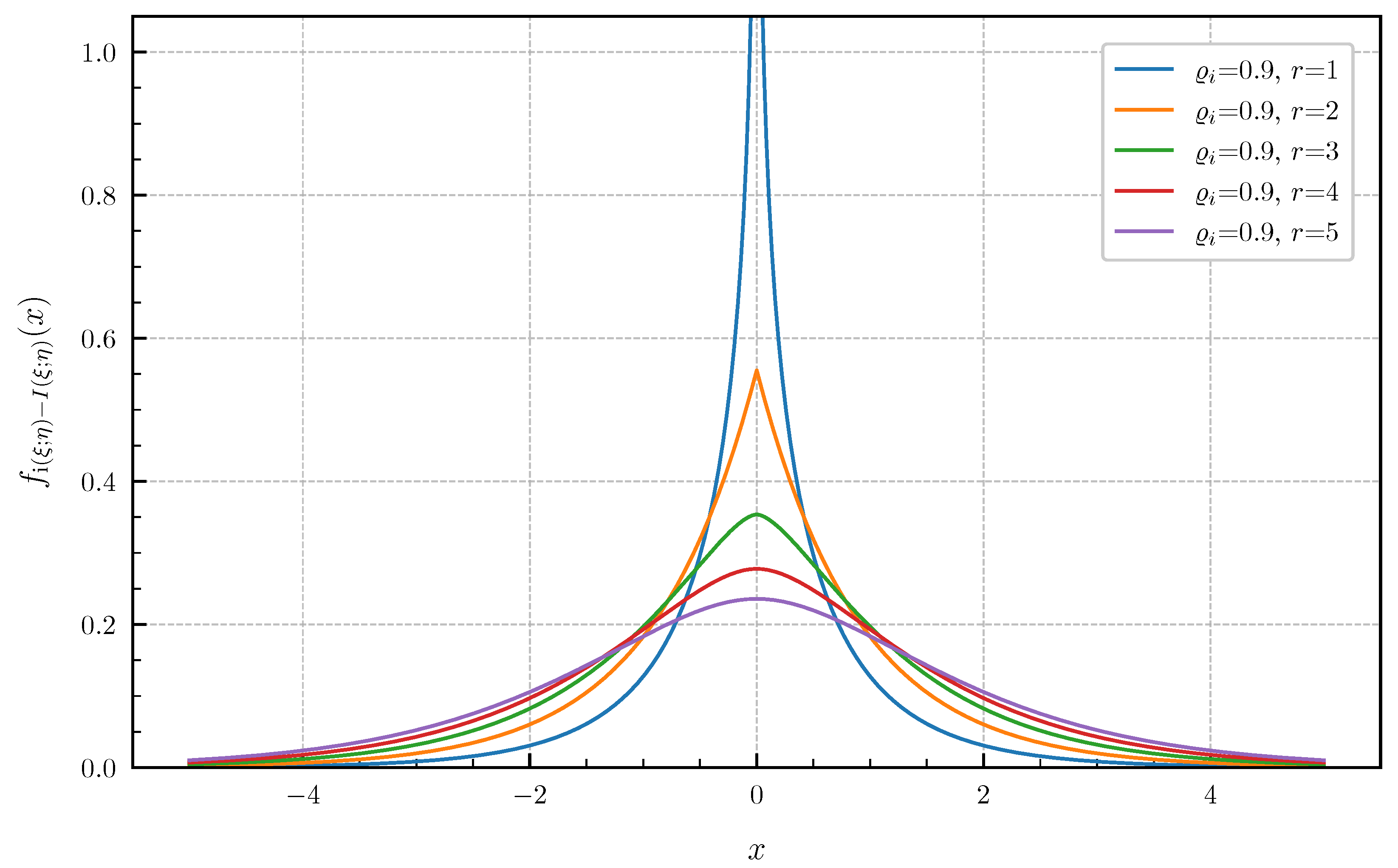
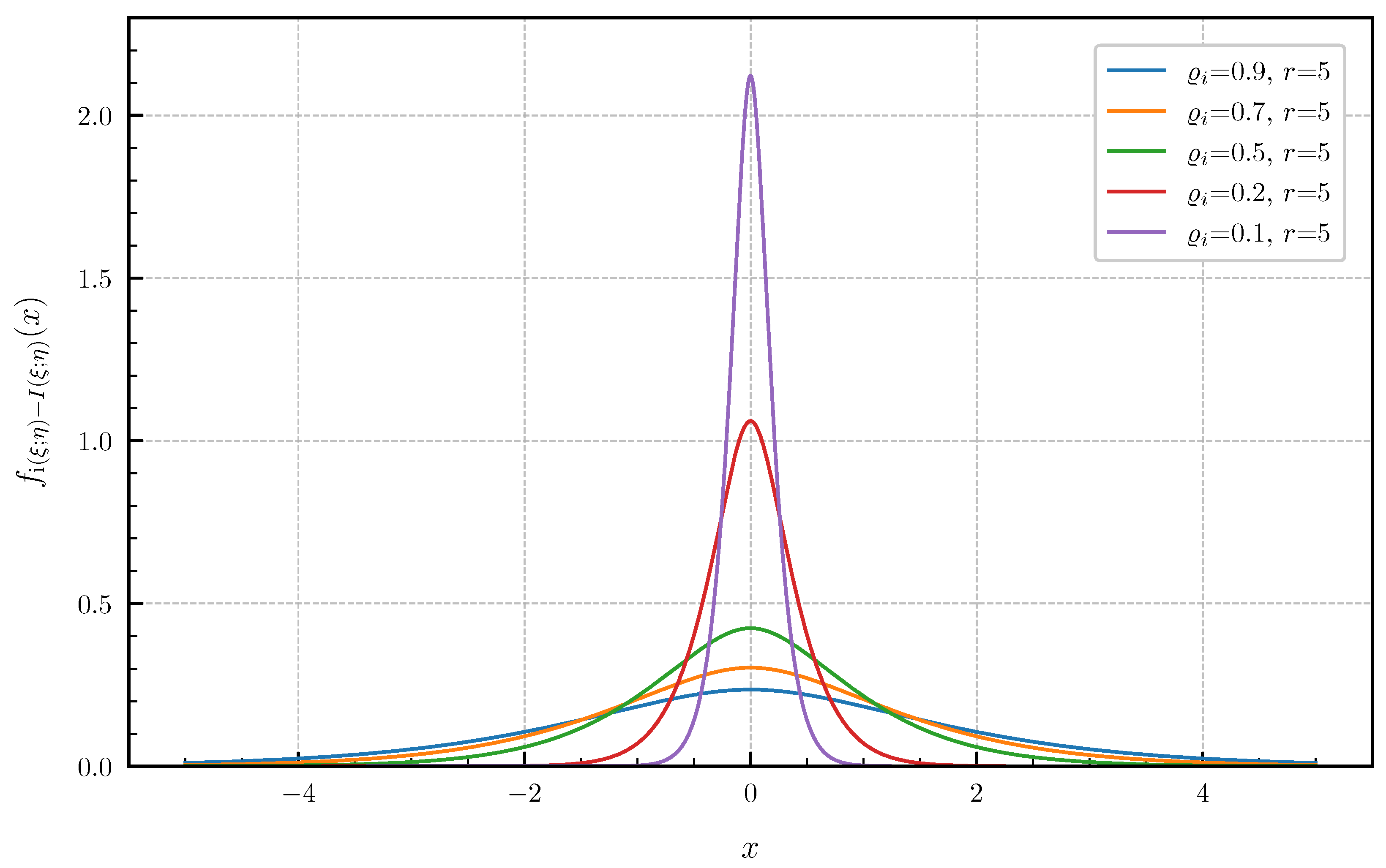
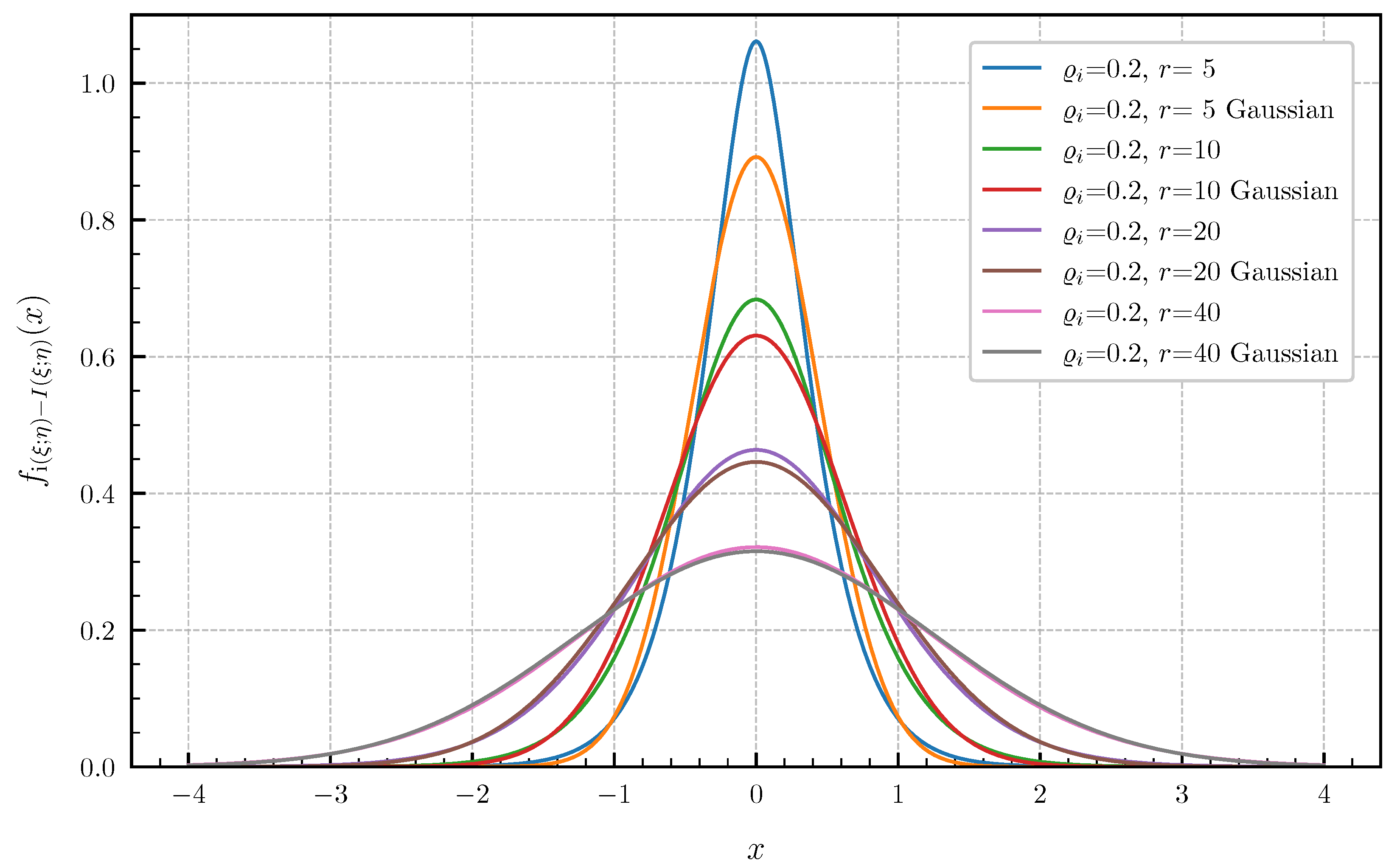
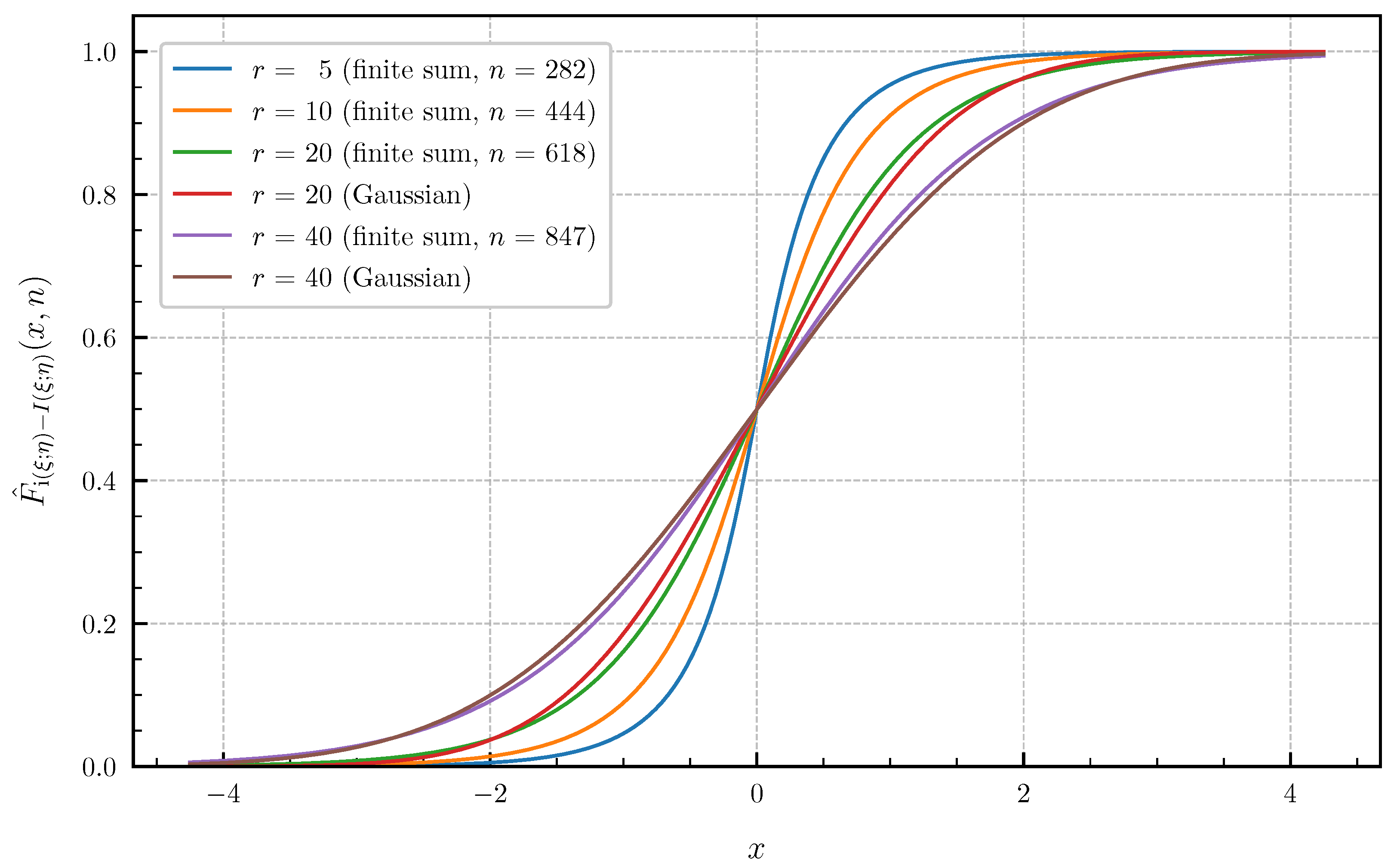
6. Numerical Examples and Illustrations
7. Summary of Contributions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Han, T.S.; Verdú, S. Approximation Theory of Output Statistics. IEEE Trans. Inf. Theory 1993, 39, 752–772. [Google Scholar] [CrossRef] [Green Version]
- Han, T.S. Information-Spectrum Methods in Information Theory; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Shannon, C.E. Probability of Error for Optimal Codes in a Gaussian Channel. Bell Syst. Tech. J. 1959, 38, 611–659. [Google Scholar] [CrossRef]
- Dobrushin, R.L. Mathematical Problems in the Shannon Theory of Optimal Coding of Information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability; Volume 1: Contributions to the Theory of Statistics; University of California Press: Berkeley, CA, USA, 1961; pp. 211–252. [Google Scholar]
- Strassen, V. Asymptotische Abschätzungen in Shannons Informationstheorie. In Transactions of the Third Prague Conference on Information Theory, Statistical Decision Functions, Random Processes (Held 1962); Czechoslovak Academy of Sciences: Prague, Czech Republic, 1964; pp. 689–723. [Google Scholar]
- Polyanskiy, Y.; Poor, H.V.; Verdú, S. Channel Coding Rate in the Finite Blocklength Regime. IEEE Trans. Inf. Theory 2010, 56, 2307–2359. [Google Scholar] [CrossRef]
- Durisi, G.; Koch, T.; Popovski, P. Toward Massive, Ultrareliable, and Low-Latency Wireless Communication With Short Packets. Proc. IEEE 2016, 104, 1711–1726. [Google Scholar] [CrossRef] [Green Version]
- Pinsker, M.S. Information and Information Stability of Random Variables and Processes; Holden-Day: San Francisco, CA, USA, 1964. [Google Scholar]
- Olver, F.W.J.; Lozier, D.W.; Boisvert, R.F.; Clark, C.W. (Eds.) NIST Handbook of Mathematical Functions; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Mathai, A.M. Storage Capacity of a Dam With Gamma Type Inputs. Ann. Inst. Stat. Math. 1982, 34, 591–597. [Google Scholar] [CrossRef]
- Grad, A.; Solomon, H. Distribution of Quadratic Forms and Some Applications. Ann. Math. Stat. 1955, 26, 464–477. [Google Scholar] [CrossRef]
- Kotz, S.; Johnson, N.L.; Boyd, D.W. Series Representations of Distributions of Quadratic Forms in Normal Variables. I. Central Case. Ann. Math. Stat. 1967, 38, 823–837. [Google Scholar] [CrossRef]
- Huffmann, J.E.W.; Mittelbach, M. On the Distribution of the Information Density of Gaussian Random Vectors: Explicit Formulas and Tight Approximations. Entropy 2022, 24, 924. [Google Scholar] [CrossRef]
- Simon, M.K. Probability Distributions Involving Gaussian Random Variables: A Handbook for Engineers and Scientists; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Laneman, J.N. On the Distribution of Mutual Information. In Proceedings of the Workshop Information Theory and Its Applications (ITA), San Diego, CA, USA, 13 February 2006. [Google Scholar]
- Wu, P.; Jindal, N. Coding Versus ARQ in Fading Channels: How Reliable Should the PHY Be? IEEE Trans. Commun. 2011, 59, 3363–3374. [Google Scholar] [CrossRef] [Green Version]
- Buckingham, D.; Valenti, M.C. The Information-Outage Probability of Finite-Length Codes Over AWGN Channels. In Proceedings of the 42nd Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 19–21 March 2008. [Google Scholar]
- Hotelling, H. Relations Between Two Sets of Variates. Biometrika 1936, 28, 321–377. [Google Scholar] [CrossRef]
- Gelfand, I.M.; Yaglom, A.M. Calculation of the Amount of Information About a Random Function Contained in Another Such Function. In AMS Translations, Series 2; AMS: Providence, RI, USA, 1959; Volume 12, pp. 199–246. [Google Scholar]
- Härdle, W.K.; Simar, L. Applied Multivariate Statistical Analysis, 4th ed.; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Koch, I. Analysis of Multivariate and High-Dimensional Data; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Timm, N.H. Applied Multivariate Analysis; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Ibragimov, I.A.; Rozanov, Y.A. On the Connection Between Two Characteristics of Dependence of Gaussian Random Vectors. Theory Probab. Appl. 1970, 15, 295–299. [Google Scholar] [CrossRef]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products, 7th ed.; Elsevier: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Prudnikov, A.P.; Brychov, Y.A.; Marichev, O.I. Integrals and Series, Volume 2: Special Functions; Gordon and Breach Science: New York, NY, USA, 1986. [Google Scholar]
- Huffmann, J.E.W.; Mittelbach, M. Efficient Python Implementation to Numerically Calculate PDF, CDF, and Moments of the Information Density of Gaussian Random Vectors. Source Code Provided on GitLab. 2021. Available online: https://gitlab.com/infth/information-density (accessed on 24 June 2022). Source Code Provided on GitLab.
- Moschopoulos, P.G. The Distribution of the Sum of Independent Gamma Random Variables. Ann. Inst. Stat. Math. 1985, 37, 541–544. [Google Scholar] [CrossRef]
- Comtet, L. Advanced Combinatorics: The Art of Finite and Infinite Expansions, Revised and Enlarged ed.; D. Reidel Publishing Company: Dordrecht, The Netherlands, 1974. [Google Scholar]
- Grenander, U.; Szegö, G. Toeplitz Forms and Their Applications; University of California Press: Berkeley, CA, USA, 1958. [Google Scholar]
- Huffmann, J.E.W. Canonical Correlation and the Calculation of Information Measures for Infinite-Dimensional Distributions. Diploma Thesis, Department of Electrical Engineering and Information Technology, Technische Universität Dresden, Dresden, Germany, 2021. Available online: https://nbn-resolving.org/urn:nbn:de:bsz:14-qucosa2-742541 (accessed on 24 June 2022).





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huffmann, J.E.W.; Mittelbach, M. On the Distribution of the Information Density of Gaussian Random Vectors: Explicit Formulas and Tight Approximations. Entropy 2022, 24, 924. https://doi.org/10.3390/e24070924
Huffmann JEW, Mittelbach M. On the Distribution of the Information Density of Gaussian Random Vectors: Explicit Formulas and Tight Approximations. Entropy. 2022; 24(7):924. https://doi.org/10.3390/e24070924
Chicago/Turabian StyleHuffmann, Jonathan E. W., and Martin Mittelbach. 2022. "On the Distribution of the Information Density of Gaussian Random Vectors: Explicit Formulas and Tight Approximations" Entropy 24, no. 7: 924. https://doi.org/10.3390/e24070924
APA StyleHuffmann, J. E. W., & Mittelbach, M. (2022). On the Distribution of the Information Density of Gaussian Random Vectors: Explicit Formulas and Tight Approximations. Entropy, 24(7), 924. https://doi.org/10.3390/e24070924