Abstract
Ozone concentrations are key indicators of air quality. Modeling ozone concentrations is challenging because they change both spatially and temporally with complicated structures. Missing data bring even more difficulties. One of our interests in this paper is to model ozone concentrations in a region in the presence of missing data. We propose a method without any assumptions on the correlation structure to estimate the covariance matrix through a dimension expansion method for modeling the semivariograms in nonstationary fields based on the estimations from the hierarchical Bayesian spatio-temporal modeling technique (Le and Zidek). Further, we apply an entropy criterion (Jin et al.) based on a predictive model to decide if new stations need to be added. This entropy criterion helps to solve the environmental network design problem. For demonstration, we apply the method to the ozone concentrations at 25 stations in the Pittsburgh region studied. The comparison of the proposed method and the one is provided through leave-one-out cross-validation, which shows that the proposed method is more general and applicable.
1. Introduction
Ozone concentrations are the daily maximum 8 h moving averages of hourly ozone concentration data recorded in micrograms per cubic meter, g/m, which are key indicators of air quality. Monitoring the changes both spatially and temporally is very important for the assessment of air quality change, which has a great impact on our environment, society and economy. However, modeling the ozone concentrations is not an easy task since the ozone concentrations vary over space and time with complicated spatial structures, temporal structures and spatio-temporal interactions. Furthermore, the presence of missing data brings even more difficulties. As commented in [1], although we cannot escape the “curse of dimensionality”, we can take advantage of recent developments in computing speed and numerical advances (e.g., Markov chain Monte Carlo) that allow us to implement Bayesian spatio-temporal dynamical models in a hierarchical framework. Such a framework provides simple strategies for incorporating complicated spatio-temporal interactions at different stages of the models’ hierarchy, and the models are feasible to be implemented for high-dimensional data. Two popular hierarchical Bayesian spatio-temporal models can be found in [1,2], among others. The latter one was used in [3].
Ref. [3] studied the ozone concentrations within to longitude and to latitude around the Pittsburgh region (, ), in which all of the monitoring stations have missing data. That paper dealt with the missing problems in two steps. First, it filled in some of the missing measurements by using linear models so that the pattern of missing data became monotone (the monotone missing is also referred to as the staircase pattern). Second, it applied hierarchical Bayesian spatio-temporal (HBST) modeling proposed in [2] on this staircase of missing data to estimate the hyperparameters of the spatial-temporal model. Based on the estimated hyperparemeters, it estimated the spatial correlation function for the monitoring stations. Then, it estimated the covariance matrix for all of the stations and derived the predictive distribution for the ungauged sites.
Generalized linear models can be used to accommodate non-Gaussian geostatistical data (e.g., see [4]). Ref. [3] selected the generalized linear model with the quasi-Poisson family as an appropriated spatial correlation function by examining the pattern of spatial correlations obtained via the hierarchical model in the plot. However, their link function is not appropriate if there are negative correlations. This is a strong restriction because negative correlations are common for the ozone concentrations and other spatial-temporal data. Moreover, choosing a model by examining the plots derived in terms of the observed data set is not rigorous enough and may only be suitable just for a particular data set.
In this paper, we propose a method to estimate the covariance matrix through a dimension expansion method for modeling the semivariograms in nonstationary fields based on the estimations from hierarchical Bayesian spatio-temporal modeling. For demonstration, we apply the proposed method on the same data as in Jin et al. [3]. Without any assumption on the correlation structure, the proposed method is more general than the method in [3] such that it is applicable to other spatio-temporal data sets. Using the covariance matrix estimated by the proposed method on the entropy criterion in the environmental network design problem, our study provides interesting findings, and the locations of the selected ungauged stations are more reasonable. We provide comparison of these two methods through leave-one-out cross-validation, which shows that the proposed method provides improved results.
The paper is arranged as follows. In Section 2, we briefly introduce hierarchical Bayesian spatio-temporal modeling. In Section 3, we describe the ozone concentrations in the Pittsburgh region and apply the hierarchical Bayesian spatio-temporal modeling techniques for filling in missing measurements following [3]. In Section 4, we model the ozone concentrations in the Pittsburgh region. We first introduce the method for estimating the covariance matrix through a dimension expansion method for modeling the semivariograms in nonstationary fields, and we then give spatial predictive distributions on the ungauged sites using the covariance matrix estimated by the proposed method. In Section 5, we present the results of the entropy of the predictive distributions and an optimality criterion for extending an environmental network. In Section 6, we provide the model evaluation through leave-one-out cross-validation. We conclude this paper with a conclusion in Section 7.
Throughout the rest of the paper, the -norm of a vector is denoted by , a identity matrix is denoted by , the transpose of a matrix A is denoted by and the trace of a square matrix B is denoted by . In addition, ‘⊗’ represents the Kronecker product, refers to a matrix Gaussian distribution, denotes a matric-t distribution, stands for the inverted Wishart distribution (see (a) of the appendix for definitions of these distributions) and denotes the generalized inverted Wishart distribution.
2. Hierarchical Bayesian Spatio-Temporal Modeling
We briefly describe HBST modeling in this section, which is the same as that given in [3] excluding Step 3 in the HBST modeling procedure. It is noted that this modeling is a special case of the HBST modeling presented in Chapter 10 of Le and Zidek (2006) excluding Step 3 in the HBST modeling procedure.
Define the following notations:
d = number of different type stations (e.g., agricultural, residential, commercial and industrial);
n = number of time points (e.g., number of days);
u = number of locations with no monitors (i.e., ungauged sites);
g = number of locations with monitors (i.e., gauged sites).
The stations are organized into k blocks where the () sites in the jth block have the same number of timepoints at which no measurements are taken. These blocks are numbered so that the measurements correspond to a monotone data pattern or a staircase structure, that is,
The response variables are written as
Here, of dimension denotes the unobserved responses at ungauged sites while of dimension is given by
where is an matrix of missing measurements at the gauged sites for the time points and is an matrix of observed measurements at the gauged sites for the time points.
We assume that the response matrix Y follows the Gaussian and generalized inverted Wishart model specified by
where B is an coefficient matrix with the hyperparameter mean matrix and the variance components , X is the matrix of covariates which is defined in (4) and is a set of model parameters specified below.
We partition B corresponding to the l time-varying covariates in conformance with the block structure as
By assuming an exchangeable structure across sites, B can be written as , where is the hyperparameter matrix and with for Station j under Class i and otherwise.
Likewise, we partition the covariance matrix over gauged and ungauged sites conformably as
where is a matrix being for the ungauged sites. Further, we partition the covariance matrix for the gauged site blocks as follows:
Similarly, for , we put
We reparametrize the matrix through the recursive one-to-one Bartlett transformation for the two blocks:
where and . Similarly, by applying the Bartlett decomposition, we can represent the submatrix , for , as
where and for ,
with
Therefore, the GIW prior distribution for in (1) is equivalently defined in terms of and , as follows:
where is the slope of the optimal linear predictor of based on and is the residual covariance of the optimal linear predictor. Similar interpretations can be applied to and , for
Let be the set of the hyperparameters in (1) and (2), i.e., , where , with degrees of freedom parameters . Write . Here, , which represents the hyperparameters involved in the marginal distribution of .
If a data matrix appears to be an ascending staircase, the HBST modeling procedure is given as follows:
- Step 1.
- Compute the hyperparameter values that maximize the marginal distribution using an empirical Bayesian approach (see (b) of Appendix A). The EM algorithm is used to obtain .
- Step 2.
- Obtain the predictive distributions of missing measurements as in (c) of Appendix A. Fill in the missing data by using the predictive distributions.
- Step 3.
- Obtain the estimate from the estimate of . In terms of , obtain the estimate of the covariance matrix by using a dimension expansion method given in Qin et al. [5] and the thin-plate spline method given in Wabba and Wendelberger (1980). The details are given in Section 4.1.
- Step 4.
- Estimate the hyperparameters and obtain the conditional predictive distribution (see Section 4.2).
3. Ozone Concentrations from the Monitoring Stations in Pittsburgh Region
The ozone concentrations were recorded within to longitude and to latitude around the Pittsburgh region (, ) for four consecutive summer months, June, July, August and September, over the period from 1995 to 2007. There were 25 monitoring stations in the region as shown in Figure 1, which is the same as Figure 1 in [3]. The original data set was collected from 25 stations, and there were a total of 1586 (13 years × 122 days) measurements at each station. The number of missing data in is shown by N1.Miss in Table 1, which is the same as Table 1 in [3]. In this section, we fill in missing measurements.
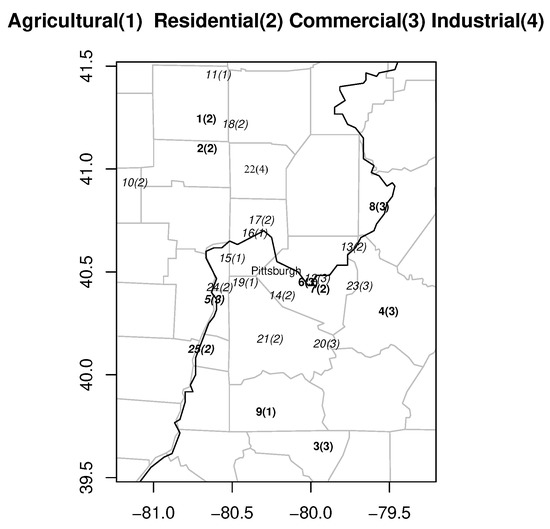
Figure 1.
Monitoring stations in the Pittsburgh region.

Table 1.
Location of the stations and number of missing data.
3.1. Filling in the Missing Measurements for Each Monitoring Station within the Period of Monitoring Blocks
Since there are missing data in the dataset, we follow the steps in [3] in filling in some missing measurements occurred during the operation of each monitoring station, using the regression model as
for and , where a and b are regression coefficients, , for , are the categorical factors and is a sequence of independently and identically distributed Gaussian random variables with mean 0 and variance . The model (3) assigns different means to the years with a yearly cycle of 122 days. We re-express the 13 factors in the model via Helmert contrasts, which compare the first level of the factor with all later levels, the second level with all later levels, and so forth. The Helmert matrix, , is defined as follows.
Let X, the matrix of covariates, be
where and
and let and denote the response variables, regression coefficient vector and error variables, respectively. The model (3) is written as .
We then fill in the missing measurements within the blocks by the least squares predictions plus errors and obtain a new data set in which the unfilled missing measurements are either in the end of the time period or in the beginning of the time period. The number of missing data in is shown in Table 1 by N2.Miss.
3.2. Filling in the Missing Measurements in
To fill in the missing measurements in , we can proceed as follows [3]:
- (i)
- Obtain a new data set from by filling in the 488 missing measurements at Stations 5 and 25 during the end of the time period by using the HBST modeling technique. N3.Miss in Table 1 displays the number of missing data in the data set , which shows that has a staircase data structure, as all of the missing data are located in the beginning of the time period.
- (ii)
- Put , , , , , , , , , , , , , , , , and . Fill in the remaining missing values in by executing Steps 1–2 of the HBST modeling procedure.
4. Model the Ozone Concentrations in the Pittsburgh Region
To model ozone concentrations in the Pittsburgh region by spatial interpolation, we cover the region by the 100 grid boxes of a spatial resolution of latitude longitude . Thus, . The grid points are ungauged sites, and their classes are displayed in Figure 4. To derive the predictive distributions for these grid points, a key step is to estimate the covariance matrix.
4.1. Estimation of the Covariance Matrix
In this subsection, we introduce a method for estimating the covariance matrix through a dimension expansion method for modeling the semivariograms in nonstationary fields in terms of from Step 1 of the HBST procedure.
Let , be an environmental random process, where is a d-dimensional spatial index that varies continuously throughout the region . At n spatial locations denoted by , we observe realizations of the random process , i.e., . We are interested in learning the spatial dependency of the process through the observed data. The semivariogram function which describes the degree of spatial dependency of an intrinsic stationary random process is a cornerstone in spatial statistics. An intrinsic stationary random process satisfies the following two conditions (Cressie [6]):
- ,
- ,
where a semivariogram is defined as for two different locations, and , in the monitored region. The estimated covariance matrix of the monitoring stations is based on the estimation of from Step 1 of the HBST procedure. We estimate the semivariograms of the ozone concentrations from the monitoring stations by
From Figure 2, we notice that the estimated semivariograms related to Station 3 (marked by “×”) are much higher than the other stations. We examine the location of Station 3 and notice that it was on the edge of the monitored region. Moreover, there were over ten airports around this station. According to Xue et al. [7], there is a great impact of high-altitude aircrafts on the ozone layer in the stratosphere. This becomes an influential factor in modeling the ozone concentrations. Next, we introduce how this factor is considered in the proposed modeling technique.
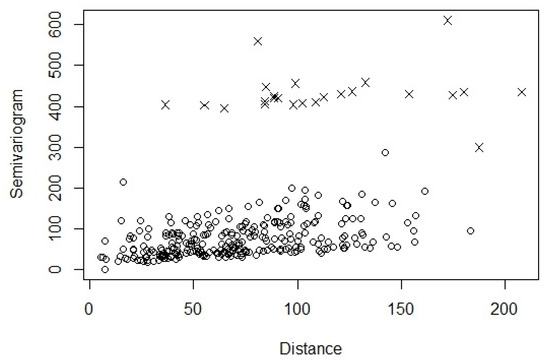
Figure 2.
Empirical semivariograms of the ozone concentrations from the monitoring stations versus the Euclidean distances between monitoring stations based on the Bayesian hierarchical model. The semivariograms related to Station 3 are marked by “×”.
It is obvious that this field is not stationary. Bornn et al. [8] proposed a novel approach to find the latent dimensions over which the nonstationary fields exhibit stationarity through dimension expansion. They justified that for a nonstationary Gaussian process , where , there exists a vector , , such that the expanded process is stationary under appropriate moment constraints. Note that is the concatenation of the vectors and . The stationary semivariogram with latent vectors can be expressed by
where is the expanded spatial index for the ith location. Qin et al. [5] improved the method in Bornn et al. [8] by considering the covariance structure of the , which are generally correlated. In our application, we use the lasso-penalized weighted least-squares criterion (WLS) in Qin et al. [5] as follows,
to estimate the parameters and the expanded dimensions. Here, is the estimated semivariogram by (5) and is the Euclidean distance between the locations and and is the kth column of . is the concatenation of the matrices and . The tuning parameter in the group lasso is used to determine the number of latent dimensions and regularize the estimation of to prevent overfitting. is a parametric stationary semivariogram model with parameter . The most popular ones are the exponential model, the spherical model and the Gaussian model (see Journel and Huijbregts [9] and Cressie [6]), among others). For example, the exponential model is defined as
where and .
The semivariogram plot with estimated expanded dimensions (Figure 3) of the monitoring stations shows that the field is in good agreement with the theoretical model, as most of the points are near the solid red line, the fitted exponential semivariogram model. Two extra dimensions are added to the original coordinate with . Figure 3 shows that with the extra dimensions, Station 3 is pushed much further out of the two-dimensional plane, reflecting the impact of high-altitude aircrafts on the ozone layer in the stratosphere we have mentioned earlier.
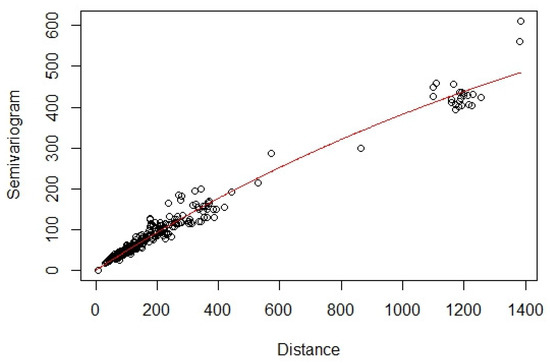
Figure 3.
Semivariogram plot of the ozone concentrations from the monitoring stations over a larger range of distances than the range shown in Figure 2, owing to the application of dimension expansion. The fitted exponential semivariogram model is shown by the red solid line.
After the expanded dimensions for the monitoring stations are obtained, we use the thin-plate spline method [10] to estimate the hidden dimensions for the ungauged sites. The semivariograms for the ungauged stations are estimated by the exponential model using the estimated parameter vector . Next, we estimate the semivariograms between stations and using the exponential model based on the distances over the space composed by the original and the expanded dimensions. Last, the covariance between any two sites can be estimated by
where and are estimates of and obtained by the thin-plate spline approach.
4.2. Prediction of the Daily Ozone Concentrations at the Grid Points
By Chapter 10 of Le and Zidek (2006), spatial predictive distributions at the grid points given the monitoring sites are as follows:
where , , and (see (a) of Appendix A for definition of the matric-t distribution).
We estimate the hyperparameters associated with the grid points and via
with
and .
After all of the hyperparameters in the predictive distributions are estimated, we can predict the daily ozone concentrations at all the grid points in the time period of study by generating samples from the predictive distributions.
5. Environmental Network Extension
Assume that Y has the density function f. The total reduction in uncertainty of Y can be presented by the entropy of its distribution, i.e., , where is a not necessarily integrable reference density (Jaynes [11]). According to the predictive distribution (7), the total entropy can be defined as
where is a constant depending on the degree of freedom and the dimension of the ungauged sites.
The key step in expanding an environmental network is to find appropriate ungauged sites to add to the existing network that maximizes the corresponding entropy. We use the following optimality criterion as given in [3]:
The sites, in a vector of dimension , are selected to maximize the entropy in (8). In [3], the grid points were selected with the highest entropy 11.3774. The proposed method selects the grid points with entropy 12.1207. This selection is more reasonable, as they are not gathered in the southeast corner of the region like The selected sites among 100 grid points by the two methods are shown in Figure 4 below.
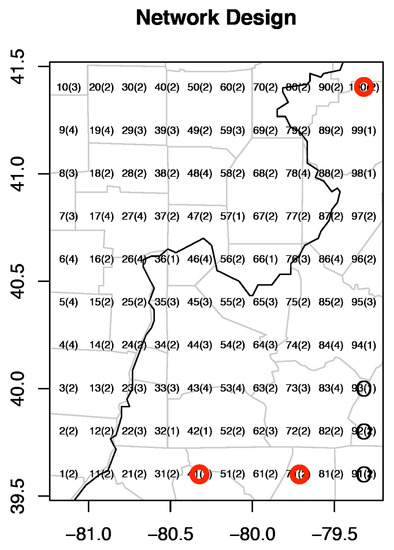
Figure 4.
The selected sites among 100 grid points (black circled points by [3] and red circled points by our method).
6. Model Evaluation
In this section, we use the leave-one-out cross-validation to evaluate the accuracy of the predictive model derived using the proposed method and compare the proposed method with the one in [3]. We select the observations from one of the original 25 stations as validation data, and observations in the remaining 24 stations are treated as training data. We use the data from day 855 to day 1586 at the end of the study from each station to evaluate the prediction because during this period, none of the stations has missing data. By choosing this period, we avoid using the Bayesian hierarchical modeling technique for estimating the missing data in the training data set, which is time-consuming and not our intention for evaluating the proposed method on estimating the covariance matrix. Station 22 is excluded because it is the only industrial station in the study. For each of the 24 stations, we generate 100 samples from the predictive distribution with parameters estimated using observations from the rest of the 23 stations. We compute the average of relative absolute bias (ARAB) as , where is the jth sample generated from the predictive distributions and is the observation from Station i on time t. The results are given in Table 2.
Table 2.
Mean and SD of the average of relative absolute bias.
In Table 2, “-” means that there is no prediction for the station because there are negative correlations and the method in [3] is not applicable to estimate the predictive distribution. The results in Table 2 show that the proposed method provides slightly more accurate predictions than the one in [3] for most of the stations. More important is that, when there are negative correlations obtained from the estimations of the hierarchical Bayesian spatio-temporal modeling technique, the method in [3] fails to estimate the covariance matrix, while the proposed method still provides accurate predictions except for Station 3. This is expected because Station 3 is an influential station. Therefore, if we use observations at Station 3 as the validation data set, it has a great impact on estimating the covariance matrix.
7. Conclusions
In this paper, we have derived a predictive model through the hierarchical Bayesian spatio-temporal modeling technique given in [12] at ungauged sites based on the covariance matrix estimated by a dimension expansion method for modeling semivariograms in nonstationary fields. Further, we have applied an entropy criterion (see [12] or [3] for details) based on the predictive model to decide if new stations need to be added. This entropy criterion helps to solve the environmental network design problem. For demonstration, we have applied the proposed method on ozone concentrations at 25 stations in the Pittsburgh region studied in [3]. The proposed method has provided satisfactory results. Moreover, the results have shown that the method is more general and applicable, as no assumption is imposed on the correlation structure.
Author Contributions
Conceptualization, B.S. and Y.W.; methodology, B.S. and Y.W.; software, B.S.; validation, B.S. and Y.W.; formal analysis, B.S.; investigation, B.S. and Y.W.; resources, Y.W.; data curation, B.S.; writing—original draft preparation, B.S. and Y.W.; writing—review & editing, Y.W.; supervision, Y.W.; project administration, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Natural Sciences and Engineering Research Council (NSERC) of Canada.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author, upon reasonable request.
Acknowledgments
The authors would like to thank the three anonymous reviewers for their helpful comments and constructive suggestions which led to the improvement of this article.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Hierarchical Bayesian Spatio-Temporal Modeling
The following is mainly based on Chapter 10 of Le and Zidek (2006).
(a) Somedistributions
Matrix normal distribution. If, for an matrix and positive definite matrices and , the density function of an random matrix X has the form
then X is said to have a matrix normal distribution and is denoted by .
Inverted Wishart distribution. If, for a positive definite matrix and a positive constant , the density function of a random matrix S has the form
then S is said to have an inverted Wishart distribution and is denoted by .
Matric-t distribution. If, for an matrix , positive definite matrices and and a positive constant , the density function of an random matrix X has the form
then X is said to have a matric-t distribution and is denoted by .
(b) Estimation of
Le and Zidek (2006) showed that the predictive distributions derived through the integrated framework above are completely characterized by their hyperparameters, which are estimated by an empirical Bayes approach, that is, to estimate them by maximizing the marginal likelihood of all the measured responses (conditional on those hyperparameters) evaluated at their observed values. This procedure is referred to as type-II maximum likelihood estimation (type-II MLE). To estimate , the following procedure can be employed: Compute the hyperparameter values that maximize the marginal distribution , where . The subscript g indicates that not all the hyperparameters are involved in this marginal distribution. The response matrix Y follows the GIW distribution specified by (1) and (2). The marginal distribution can be written as
where , , , with , for ,
and
Although can be written as a matric-t distribution as in (A1), direct maximization of this marginal density presents a challenge. The EM algorithm helps circumvent it.
(c) Predictive distributions of missing data
By Theorem 10.1 of Le and Zidek (2006), it follows that
where , , and .
References
- Wikle, C.K.; Berliner, L.M.; Cressie, N. Hierachichical Bayesian space-time models. Environ. Ecol. Stat. 1998, 5, 117–154. [Google Scholar] [CrossRef]
- Le, N.D.; Sun, W.; Zidek, J.V. Spatial prediction and temporal backcasting for environmental fields having monotone data patterns. Can. J. Stat. 2001, 29, 529–554. [Google Scholar] [CrossRef]
- Jin, B.; Wu, Y.; Chan, E. Hierarchical Bayesian spatial-temporal modeling of regional ozone concentrations and respecitve network design. J. Environ. Stat. 2012, 3, 1–32. [Google Scholar]
- Diggle, P.J.; Ribeiro, P.J., Jr. Model-Based Geostatistics; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Qin, S.; Sun, B.; Wu, Y.; Fu, Y. Generalized least-squares in dimension expansion method for nonstationary processes. Environmetrics 2021, 32, e2684. [Google Scholar] [CrossRef]
- Cressie, N. Statistics for Spatial Data, Revised Edition; Wiley: New York, NY, USA, 2015. [Google Scholar]
- Xue, X.T.; Guy, B.; Xing, L.; Pierre, F.; Claire, G.; Philip, R. The Impact of High Altitude Aircraft on the Ozone Layer in the Stratosphere. J. Atmos. Chem. 1994, 18, 103–128. [Google Scholar]
- Bornn, L.; Shaddick, G.; Zidek, J.V. Modeling non-stationary processes through dimension expansion. J. Am. Stat. Assoc. 2012, 107, 281–289. [Google Scholar] [CrossRef] [Green Version]
- Journel, A.G.; Huijbregts, C.J. Mining Geostatistics; Academic: London, UK, 1978. [Google Scholar]
- Wabba, G.; Wendelberger, J. Some new mathematical methods for variational objective analysis using splines and cross-validation. Mon. Weather Rev. 1980, 108, 1122–1143. [Google Scholar] [CrossRef] [Green Version]
- Jaynes, E.T. Information Theory and Statistical Mechanics, Statistical Physics, 3rd ed.; Ford, K.W., Ed.; Benjamin: New York, NY, USA, 1963. [Google Scholar]
- Le, N.D.; Zidek, J.V. Statistical Analysis of Environmental Space-Time Processes; Springer: New York, NY, USA, 2006. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).