Abstract
This paper proposes a two-stage maximum entropy prior to elicit uncertainty regarding a multivariate interval constraint of the location parameter of a scale mixture of normal model. Using Shannon’s entropy, this study demonstrates how the prior, obtained by using two stages of a prior hierarchy, appropriately accounts for the information regarding the stochastic constraint and suggests an objective measure of the degree of belief in the stochastic constraint. The study also verifies that the proposed prior plays the role of bridging the gap between the canonical maximum entropy prior of the parameter with no interval constraint and that with a certain multivariate interval constraint. It is shown that the two-stage maximum entropy prior belongs to the family of rectangle screened normal distributions that is conjugate for samples from a normal distribution. Some properties of the prior density, useful for developing a Bayesian inference of the parameter with the stochastic constraint, are provided. We also propose a hierarchical constrained scale mixture of normal model (HCSMN), which uses the prior density to estimate the constrained location parameter of a scale mixture of normal model and demonstrates the scope of its applicability.
Keywords:
hierarchical constrained scale mixture of normal model; rectangle-screened normal distribution; two-stage maximum entropy prior; uncertain constraint; 62H30; 62F15 MSC:
62H30; 62F15
1. Introduction
Suppose ’s are independent observations from a scale mixture of a p-variate normal distribution with the location parameter and known scale matrix. Then, a simple location model for the p-variate observations with is:
where the distribution of the vector variable is with:
where η is a mixing variable with the cdf and is a suitably-chosen weight function.
Bayesian analysis of the model (1) begins with the specification of a prior distribution, which represents the information about the uncertain parameter that is combined with the joint probability distribution of ’s to yield the posterior distribution. When there are no constraints on the location parameter, then usual priors (e.g., Jeffreys invariant prior or an informative normal conjugate prior) can be used, and posterior inference can be performed without any difficulty. In some practical situations, however, we may have prior information that have a multivariate interval constraint, and thus, the value of needs to be located in a restricted space where is a p-variate interval with and For the remainder of this paper, we use to denote the multivariate interval constraint:
When we have sufficient evidence that the constraint condition on the model (1) is true, then a suitable restriction on the parameter space, such as using a truncated prior distribution, is expected. See, e.g., [1,2,3,4], for various applications of the truncated prior distribution in Bayesian inference. However, it is often the case that prior information about the constraint is not certain for Bayesian inference. Further, even the observations from the assumed model (1) often do not provide strong evidence that the constraint is true and, therefore, may appear to contradict the assumption of the model associated with the constraint. In this case, it is expected that the uncertainty about the constraint is taken into account in eliciting a prior distribution of When the parameter constraint is not certain for Bayesian estimation in the univariate normal location model, the seminal work by [5] proposed the use of a two-stage hierarchical prior distribution by constructing a family of skew densities based on the positively-truncated normal prior distribution. Generalizing the framework of the prior hierarchy proposed by [5,6,7,8,9,10], among others, various priors were considered for the Bayesian estimation of normal and scale mixture of normal models with uncertain interval constraints. In particular, [7] obtained the prior of as the normal selection distribution (see, e.g., [11]) and, thus, exploited the class of weighted normal distribution by [12] for reflecting the uncertain prior belief on On the other hand, there are situations to set up a prior density of on the basis of information regarding the moments of the density, such as the mean and covariance matrix. A useful method of dealing with this situation is through the concept of entropy by [13,14]. Other general references where moment inequality constraints have been considered include [15,16]. To the best of our knowledge, however, a formal method to set up a prior density of consistent with information regarding the moments of the density, as well as the uncertain prior belief on the location parameter, has not previously been investigated in the literature. Thus, such practical considerations motivate us to develop a prior density of which is tackled in this paper.
As discussed by [17,18,19,20], the entropy has a direct relationship to information theory and measures the amount of uncertainty inherent in the probability distribution. Using this property of the entropy, we propose a two-stage hierarchical method for setting up the two-stage maximum entropy prior density of The method will enable us to elicit information regarding the moments of the prior distribution, as well as the degree of belief in the constraint Furthermore, this paper also suggests an objective method to measure the degree of belief regarding the multivariate interval constraint accounted for by using the prior. We also propose a simple way of controlling the degree of belief regarding the constraint of in Bayesian inference. This is done by investigating the relation between the degree of belief and the enrichment of the hyper-parameters of the prior density. In this respect, the study concerning the two-stage maximum entropy prior is interesting both from a theoretical and an applied point of view. On the theoretical side, it develops yet another conjugate prior of constrained based on the maximum entropy approach. The study provides several properties of the proposed prior, which advocate the idea of two stages of a prior hierarchy to elicit information regarding the moments of the prior and the stochastic constraint of From the applied view point, the prior is especially useful for a Bayesian subjective methodology for inequality constrained multivariate linear models.
The remainder of this paper is arranged as follows. In Section 2, we propose the two-stage maximum entropy prior of by applying Boltzmann’s maximum entropy theorem (see, e.g., [21,22]) to the frame of the two-stage prior hierarchy by [5]. We also suggest an objective measure of uncertainty regarding the stochastic constraint of that is accounted for by the two-stage maximum entropy prior. In Section 3, we briefly discuss the properties of the proposed prior of which will be useful for the Bayesian analysis of subject to uncertainty regarding the multivariate interval constraint . Section 4 provides a hierarchical scale mixture of normal model of Equation (1) using the two-stage prior, referred to as the hierarchical constrained scale mixture of normal model (HCSMN). Section 4 explores the Bayesian estimation model (1) by deriving the posterior distributions of the unknown parameters under the HCSMN and discusses the properties of the proposed measure of uncertainty that can be explained in the context of the HCSMN. In Section 5, we compare the empirical performance of the proposed prior based on synthetic data and real data applications with the HCSMN models for the estimation of with a stochastic multivariate interval constraint. Finally, the concluding remarks along with a discussion are provided in Section 6.
2. Two-Stage Maximum Entropy Prior
2.1. Maximum Entropy Prior
Sometimes, we have a situation in which partial prior information is available, outside of which it is desirable to use a prior that is as non-informative as possible. Assume that we can specify the partial information concerning in Equation (1) with continuous space That is:
The maximum entropy prior can be obtained by choosing that maximizes the entropy:
in the presence of the partial information in the form of Equation (4). A straightforward application of the calculus of variation leads us to the following theorem.
Lemma 1.
(Boltzmann’s maximum entropy theorem): The density that maximizes , subject to the constraints takes the k-parameter exponential family form:
where can be determined, via the k-constraints, in terms of …,
Proof.
See, [22] for the proof. ☐
When the partial information is about the mean and covariance matrix of outside of which it is desired to use a prior that is as non-informative as possible, then the theorem yields the following result.
Corollary 1.
As partial prior information, let the parameter have a probability distribution on with mean vector and covariance matrix then the maximum entropy prior of is:
a density of the distribution.
Proof.
In practical situations, we sometimes have partial information about a multivariate interval constraint (i.e., ) in addition to the first two moments as given in Corollary 1.
Corollary 2.
Assume that the prior distribution of has the mean vector and covariance matrix Further assume, a priori, that the space of is constrained to a multivariate interval, given in Equation (3). Then, a constrained maximum entropy prior of is given by:
a density of the distribution, which is a p-dimensional truncated distribution with the space
Proof.
The certain multivariate interval constraint, can be expressed in terms of moment, Upon applying Lemma 1 with and for and and and we see that and Setting , and obtaining the normalizing constant, we obtain Equation (7). ☐
2.2. Two-Stage Maximum Entropy Prior
This subsection considers the case where the maximum entropy prior of has stochastic constraint in the form of a multivariate interval, i.e., Pr where is defined by Equation (3) and Here, is Pr calculated by using the maximum entropy prior distribution in Equation (6). We develop a two-stage prior of , denoted by , which has a different formula according to the degree of belief, regarding the constraint.
Suppose we have only partial information about the covariance matrix, of the parameter in the first stage of a prior elicitation. Then, for a given mean vector , we may construct the maximum entropy prior, Equation (6), so that the first stage maximum entropy prior will be , which is the density of the distribution. In addition to the information, suppose we have collected prior information about the unknown , which gives a value of the mean vector and covariance matrix , as well as a stochastic (or certain) constraint, indicating Pr Then, in the second stage of the prior elicitation, one can elicit the additional prior partial information by using the constrained maximum entropy prior in Equation (7).
Analogous to the work of [5], we can specify all of the partial information about by following two stages of the maximum entropy prior hierarchy over
where is a truncated normal density, i.e., the density of the variate, and Thus, the two stages of prior hierarchy are as follows. In the first stage, given has a maximum entropy prior that is the distribution as in Equation (6). In the second stage, has a distribution obtained by truncating the maximum entropy prior distribution to elicit uncertainty about the prior information that It may be sensible to assume that the value of is located in the multivariate interval or in the centroid of the interval.
Definition 1.
The marginal prior density of , obtained from the two stages of the maximum entropy prior hierarchy Equations (8) and (9), is called as a two-stage maximum entropy prior of .
Since if the constraint is completely certain (i.e., ), we may set to get the from the two stages of maximum entropy prior, while the two-stage prior yields with for the case where Thus, the hyper-parameters and may need to be assessed to achieve the degree of belief γ about the stochastic constraint. When and the above hierarchy of priors yields the following marginal prior of
Lemma 2.
The two stages of the prior hierarchy of Equations (8) and (9) yield the two-stage maximum entropy prior distribution of given by:
where denotes the pdf of and denotes a p-dimensional rectangle probability of the distribution of , i.e., and
Proof.
because and ☐
In fact, the density belongs to the family of rectangle screened multivariate normal () distributions studied by [23].
Corollary 3.
The distribution law of with the density in Equation (10) is:
which is a p-dimensional distribution with respective location and scale parameters and Ψ and the rectangle screening space Here, the joint distribution of and is where and .
Proof.
The density of is:
where and By use of the binomial inverse theorem (see, e.g., [24] p. 23), one can easily see that and are respectively equivalent to and in Equation (10), provided that is changed to ☐
According to [23], we see that the stochastic representation for the vector is:
where and are independent random vectors. Here, denotes a doubly-truncated multivariate normal random vector whose distribution is defined by with and This representation enables us to implement a one-for-one method for generating a random vector with the distribution. For generating the doubly-truncated multivariate normal vector the R package tmvtnorm by [25] can be used, where R is a computer language and an environment for statistical computing and graphics.
2.3. Entropy of a Maximum Entropy Prior
Suppose we have partial a priori information that we can specify values for the covariance matrices and where
2.3.1. Case 1: Two-stage Maximum Entropy Prior
When the two-stage maximum entropy prior is assumed for the prior distribution of its entropy is given by:
where and the denotes the expectation with respect to the distribution with the density Equation (12) shows that and Here, and are the mean vector and covariance matrix of the doubly-truncated multivariate normal random vector, . Readers are referred to [25] with the R package tmvtnorm and [26] with the R package mvtnorm for implementing the respective calculations of doubly-truncated moments and integrations. As seen in Equation (13), an analytic calculation of involves a complicated integration. Instead, by using a Monte Carlo integration, we may calculate it approximately. According to Equation (12), it follows that the stochastic representation of the prior distribution with density is useful for generating ’s from the prior distribution by using the R packages mvtnorm and tmvtnorm and, hence, implementing the Monte Carlo integration.
2.3.2. Case 2: Constrained Maximum Entropy Prior
When the constrained maximum entropy prior in Equation (7) is assumed for the prior distribution of its entropy is given by:
The denotes the expectation with respect to the doubly-truncated multivariate normal distribution with the density , and its analytic calculation is not possible. Instead, the R packages tmvtnorm and mvtnorm are available for calculating the respective moment and integration in the expression of
2.3.3. Case 3: Maximum Entropy Prior
On the other hand, if the maximum entropy prior is assumed for the prior distribution of the location parameter its entropy is given by:
The following theorem asserts the relationship among the degrees of belief, accounted for by the three priors, about the a priori uncertain constraint
Theorem 1.
The degrees of belief and about the a priori constraint accounted for by and , have the following relation:
provided that the parameters of in Equation (10) satisfy:
where denotes the -variate interval of random vector the equality holds for holds for and holds for
3. Properties
3.1. Objective Measure of Uncertainty
In constructing the two stages of prior hierarchy over the usual practice is to set the value of as the centroid of the uncertain constrained multivariate interval In this case, we have the following result.
Corollary 4.
In the case where the value of in is the centroid of the multivariate interval
Proof.
The following are immediate from Theorem 1 and Corollary 4: (i) The two-stage maximum entropy prior achieves for the degree of belief about the uncertain multivariate interval constraint , and its value satisfies if the condition in the theorem is satisfied. Note that the equality holds for ; (ii) The degree of belief about the multivariate interval constraint is a function of the covariance matrices and Thus, if we have the partial a priori information that specifies values of the covariance matrices and the degree of belief associated with can be assessed.
Figure 1 compares the degrees of belief about the uncertain multivariate interval constraint accounted for by the three priors of The figure is obtained in terms of with and and where is an intra-class covariance matrix, and denotes a summing vector whose every element is unity. When the constraint is changed to in this comparison, one can easily check that the degrees of belief do not change and give the same results seen in Figure 1. The figure depicts exactly the same inequality relationship given in Theorem 1. In comparison with and we see that the degree of belief in the uncertain constraint, accounted for by using becomes large as (or equivalently In particular, this tendency is more evident for small and large ρ values. Third, the difference in and in the right panel suggests that the difference becomes large as tends to In particular, for fixed values of δ and the figure shows that the difference increases as the value of decreases, while it decreases as the value of ρ increases for fixed values of δ and Therefore, the figure confirms that the two-stage maximum entropy prior accounts for the a priori uncertain constraint with the degree of belief The figure also notes that the magnitude of depends on both the first stage covariance and the second stage covariance in the two stages of prior hierarchy in Equations (8) and (9). All other choices of the values of and satisfying the condition in Theorem 1, produced similar graphics depicted in Figure 1, with the exception of the magnitude of the differences among the degrees of belief.
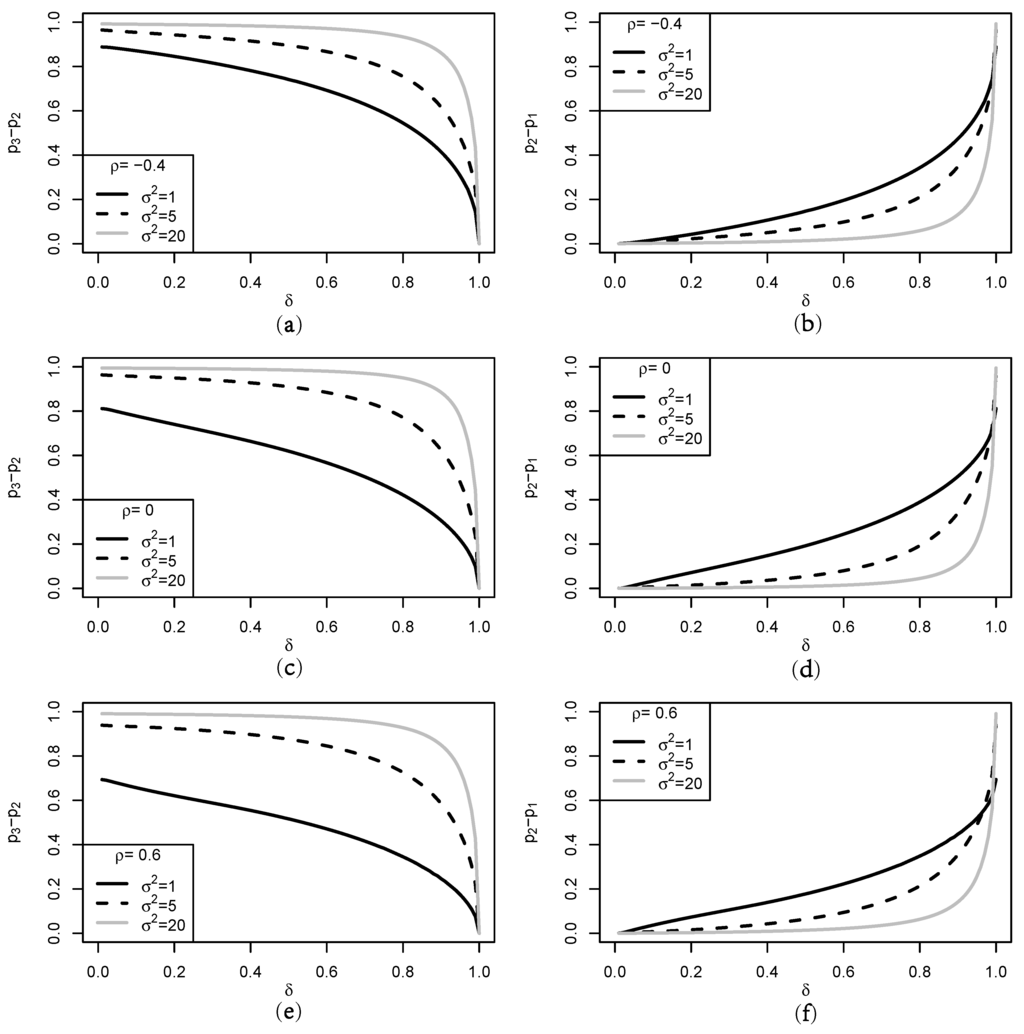
Figure 1.
Graphs of the difference between and . (a), (c), and (e) for the difference between and ; (b), (d), and (f) for the difference between and .
3.2. Properties of the Entropy
The expected uncertainty in the multivariate interval constraint of the location parameter , accounted for by the two-stage prior , is measured by its entropy , and information about the constraint is defined by Thus, as considered by [20,28], the difference between the Shannon measures of information, before and after applying the uncertain constraint can be explained by the following property.
Corollary 5.
When is the centroid of the multivariate interval
where reduces to for while is equal to for All of the equalities hold for
Proof. It is straightforward to check the equalities by using the stochastic representation in Equation (12). Since is the maximum entropy prior, it is sufficient to show that First, implies that by the lemma of [27]. Second, by Corollary 4. This and the lemma of [27] indicate that is a positive-semi-definite, and hence, by ([29], p. 54), where and for These two results give the inequality because
Figure 2 depicts the difference between and using the same parameter values used in constructing Figure 1. Figure 2 coincides with the inequality relation given in Corollary 5 and indicates the following consequences: (i) Even though is not the centroid of the multivariate interval we see that for (ii) The difference is a monotone decreasing function of while is a monotone increasing function. (iii) The differences get bigger the larger becomes for This indicates that the entropy of is associated not only with the covariance of the first stage prior , but that of the second stage prior in Equations (8) and (9), respectively. (iv) Upon comparing Figure 1 and Figure 2, the entropy is closely related to the degree of belief , such that:
where is obtained by using Equations (13) and (16) and denotes the degree of uncertainty in a priori information regarding the multivariate interval constraint elicited by These consequences and Corollary 5 indicate that stands between and Thus, the two-stage prior is useful for eliciting uncertain information about the multivariate interval constraint. Theorem 1 and the above statements produce an objective method for eliciting the stochastic constraint via
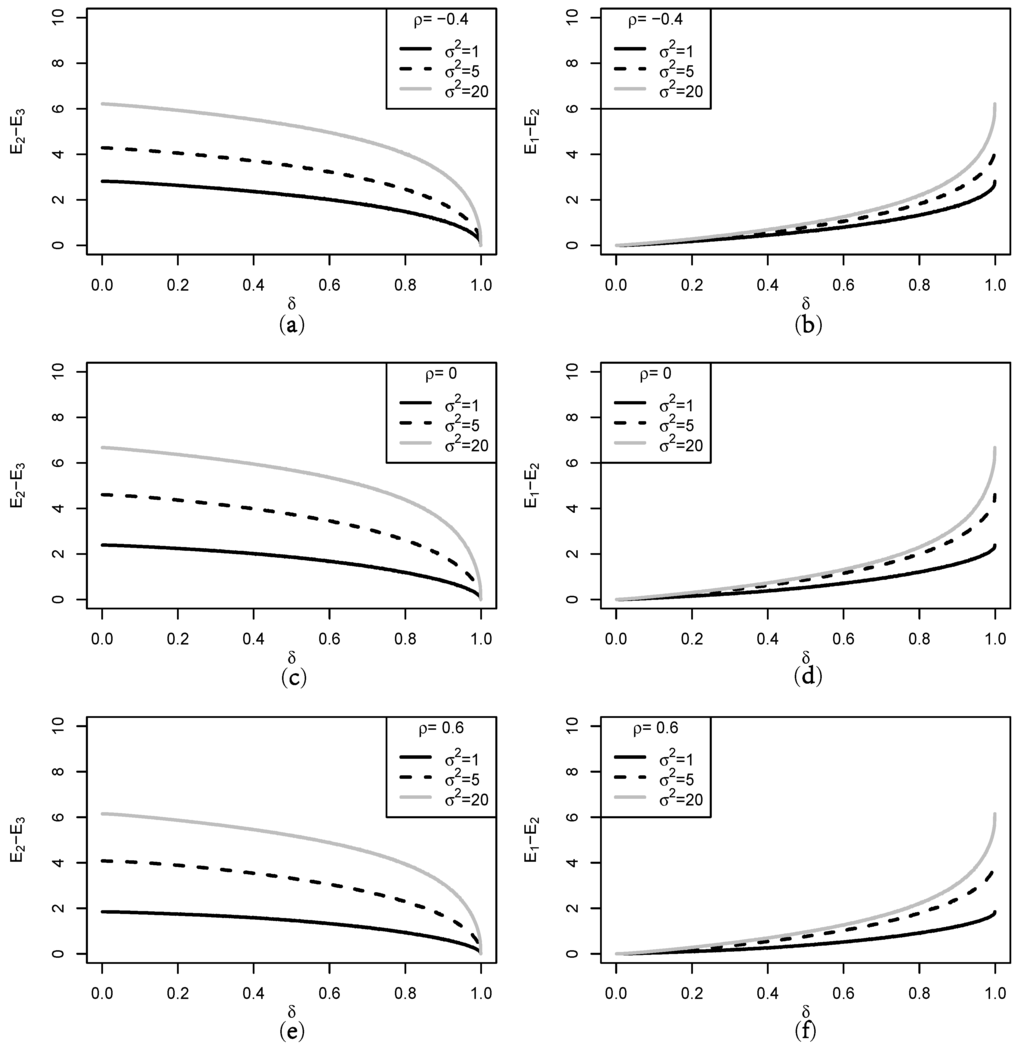
Figure 2.
Graphs of the entropy difference between and for different values of (a), (c), and (e) for the difference between and ; (b), (d), and (f) for the difference between and .
Corollary 6.
Suppose the degree () of uncertainty associated with the stochastic constraint is given. An objective way of eliciting the prior information by using is to choose the covariance matrices and in , such that where is known and with
Since , the degree of uncertainty ( ) is equal to The left panel of Figure 1 plots a graph of against The graph indicates that a δ value for can be easily determined for given and the value is in inverse proportion to the degree of uncertainty regardless of
3.3. Posterior Distribution
Suppose the distribution of the error vector in the model (1) belongs to the family of scale mixture of normal distributions defined in Equation (2); then, the conditional distribution of the data information from is It is well known that the priors and are conjugate priors for the location vector provided that η and Λ are known. That is, conditional on each prior satisfies the conjugate property that the prior and the posterior distributions of belong to the same family of distributions. The following corollary provides that the conditional conjugate property also applies to
Corollary 7.
Let with known Then, the two-stage maximum entropy prior in Equation (10) yields the conditional posterior distribution of given by:
where
Proof.
When the two-stage prior in Equation (10) is used, the conditional posterior density of given η is:
in that where and The last term of the proportional relations is a kernel of the density defined by Corollary 3. ☐
Corollaries 3 and 7 establish the conditional conjugate property of Suppose the location parameter is the normal mean vector, then the prior distribution, i.e., yields the conditional posterior distribution, which belongs to the class of distributions as given in Corollary 7. In the particular case where the distribution of η degenerates at i.e., the model (1) is a normal model, then the conditional conjugate property of reduces to the unconditional conjugate property.
Using the relation between the distribution of Equation (11) and that of Equation (12), we can obtain the stochastic representation for the conditional posterior distribution in Equation (17) as follows.
Corollary 8.
Conditional on the mixing variable η, the stochastic representation of is:
where and are independent and where and
4. Hierarchical Constrained Scale Mixture of Normal Model
For the model (1), if we are completely sure about a multivariate interval constraint on a suitable restriction on the parameter space such as using a truncated normal prior distribution, is expected for eliciting the information. However, there are certain cases where we have a priori information that the location parameter is highly likely to have a multivariate interval constraint, and thus, the value of needs to be located with uncertainty in a restricted space with . Then, we cannot be sure about the constraint, and then, the constraint becomes stochastic (or uncertain), as in our problem of interest. In this case, the uncertainty about the constraint must be taken into account in the estimation procedure of the model (1). This section considers a hierarchical Bayesian estimation of the scale mixture of normal models reflecting the uncertain prior belief on
4.1. The Hierarchical Model
Let us consider a hierarchical constrained scale mixture of normal model (HCSMN) that uses the hierarchy of the scale mixture of normal model (1) and includes the two stages of a prior hierarchy in the following way:
where denotes the inverted Wishart distribution with positive definite scale matrix D and d degrees of freedom whose pdf is:
with and
4.2. The Gibbs Sampler
Based on the HCSMN model structure with the likelihood and the prior distributions in Equation (19), the joint posterior distribution of Λ and given the data is:
where ’s denote the densities of the mixing variables ’s. Note that the joint posterior of Equation (20) is not simplified in an analytic form of the known density and, thus, intractable for the posterior inference. Instead, we use the Gibbs sampler for the posterior inference. See [30] for a reference. To run the Gibbs sampler, we need the following full conditional posterior distributions:
- (i)
- The full conditional posterior densities of ’s are given by:
- (ii)
- The full conditional distribution of is obtained by using the way analogous to the proof of Corollary 7. It is:where:and
- (iii)
- The full conditional posterior distribution of Λ is an inverse-Wishart distribution:where and
4.3. Markov Chain Monte Carlo Sampling Scheme
When conducting a posterior inference of the HCSMN model, using the Gibbs sampling algorithm with the full conditional posterior distributions of ’s, and Λ, the following points should be noted.
- note 1: Variable at i.e., the HCN (hierarchical constrained normal) model with the Gibbs sampler consists of two conditional distributions and To sample from the first full conditional posterior distribution, we can utilize the stochastic representations of the distribution in Corollary 8. The R package tmvtnorm and the R package mvtnorm can be used to sample from the distribution in Equation (22).
- note 2: According to choice of the distribution and the mixing function the HCSMN model may produce a different model other than the HCN model, such as hierarchical constrained multivariate (HC), hierarchical constrained multivariate , hierarchical constrained multivariate and hierarchical constrained multivariate models. See, e.g., [31,32], for various distributions of and corresponding function , which can be used to construct the HCSMN model.
- note 3: When the hierarchical constrained multivariate (HC) model is considered, the hierarchy of the model in Equation (19) consists of with and Thus, the Gibbs sampler comprises the conditional posterior Equations (21)–(23). Under the HC model, the distribution of Equation (21) reduces to:where and To limit model complexity, we consider only fixed ν, so that we can investigate different HC models. As suggested by [32], a uniform prior on () can be considered. However, this will bring additional computational burden.
- note 4: Except for the HCN and HC models, the Metropolis–Hastings algorithm within the Gibbs sampler is used for estimating the HCSMN models, because the conditional posterior densities Equation (20) do not have explicit forms of known distributions as in Equations (21) and (22). See, e.g., [22], for the algorithm for sampling from various mixing distributions, A general procedure for the algorithm is as follows: Given the current values , we independently generate a candidate from a proposal density as suggested by [33], which is used for a Metropolis–Hastings algorithm. Then, accept the candidate value with the acceptance rate:Because the target density is proportional to and is uniformly bounded for
- note 5: As noted from Equations (8) and (9), the second and third stage priors of the HCSMN model in Equation (19) reduce to the two-stage prior eliciting the stochastic multivariate interval constraint with degree of uncertainty Instead, if the maximum entropy prior and the constrained maximum entropy prior are used for the HCSMN, then the respective full conditional distributions of of the Gibbs sampler change from Equation (22) to:where and are the same as given in Equation (22).
4.4. Bayes Estimation
For a simple example, let us consider the HCN model with known When we assume a stochastic constraint obtained from a priori information, we may use the two-stage maximum entropy prior defined by the second and third stages of the HCSMN model (19) with where the value of δ is determined by using Corollary 6. This yields a Bayes estimate based on the two-stage maximum entropy prior. Corollary 8 yields:
and:
where I a truncated normal distribution with and and denotes i-th diagonal element of Here, and are the same as those in Equation (22), and denotes the univariate standard normal density function. See [25,34] for the first moment of the truncated multivariate normal distribution and for a numerical calculation of the posterior covariance matrix respectively.
On the other hand, when we have certainty about the constraint we may use the HCSMN model with which uses the constrained maximum entropy prior instead of in its hierarchy. This case gives the Bayes estimate:
and:
where I and denotes i-th diagonal element of
On the contrary, when we have completely no a priori information about the constraint in the space of the HCSMN model with the maximum entropy prior (equivalently, the HCSMN model with ) may be used for the posterior inference. In this model, the Bayes estimate of the location parameter is given by:
Comparing Equations (24) and (25) to Equation (26), we see that Equations (24) and (25) are the same for , and the last term in Equation (24) vanishes when we assume that there is no a priori information about the stochastic constraint, In this sense, the last term in Equation (24) can be interpreted as a shrinkage effect of the HCSMN model with This effect makes the Bayes estimator of shrink toward the stochastic constraint. In addition, we can calculate the difference between the estimates in Equations (24) and (25):
This difference vector is a function of the degree of belief or for Equation (25) is based on and and for Thus, the difference represents a stochastic effect of the multivariate interval constraint.
5. Numerical Illustrations
This section presents an empirical analysis of the proposed approach (using the HCSMN model) to the stochastic multivariate interval constraint on the location model. We provide numerical simulation results and a real data application comparing the proposed approach to the hierarchical Bayesian approaches, which use usual priors, and For numerical implementations, we develop our program written in R, which is available from the author upon request.
5.1. Simulation Study
To examine the performance of the HSCMN model for estimating the location parameter with a stochastic multivariate interval constraint, we conduct a simulation study. The study is based up 200 synthetic datasets for different sample sizes generated form each distribution of and a four-dimensional t with the location parameter scale matrix Λ and degrees of freedom For the simulation, we used the following choice of parameter values: and where and
To fit each of the 200 synthetic datasets (Dataset I) generated from the distribution, we implemented the Markov chain Monte Carlo (MCMC) posterior simulation with the three different HCN models with the multivariate interval constraint : the HCN models that use and We denote these models by HCN, HCN and HCN For each dataset, MCMC posterior sampling was based on the first 10,000 posterior samples as the burn-in, followed by a further 100,000 posterior samples with a thinning size of 10. Thus, the final MCMC posterior samples with a size of 10,000 were obtained for each of the three HCN models. Exactly the same MCMC posterior sampling scheme is applied to each of the 200 synthetic datasets (Dataset II) from the distribution based on the three HC models, HC, HC and HC To satisfy a subjective perspective of the hierarchical models, we set and to specify our information about the parameter while we set and to elicit no information about Λ (see, e.g., [32]). For the stochastic multivariate interval constraint, we set and and this constraint gives the degree of belief (or ) and (or ) for (or 2). Note that the degree of belief in the constraint, accounted for by is for all of the values of
Summary statistics of the posterior samples of the location parameters (the mean and the standard deviation of 200 posterior means of each parameter) along with the degrees of belief about the constraint ( and ) are listed in Table 1. For the sake of saving a space, we omit the summary statistics regarding Λ from the table. The table indicates the followings: (i) The MCMC method performs well in estimating the location parameters of all of the models considered. This can be justified by the estimation results of the HCN and HC models. Specifically, in the posterior estimation of the data information tends to dominate the prior information about for the large sample case (i.e., ), while the latter tends to dominate the former for the small sample case of Furthermore, the convergence of the MCMC sampling algorithm was evident, and a discussion about the convergence will be given in Subsection 5.2; (ii) The estimates of obtained from the HCN and HC models are uniformly closer to the stochastic constraint than those from the HCN and HC models. This confirms that induces an obvious shrinkage effect in Bayesian estimation of the location parameter with a stochastic multivariate interval constraint; (iii) Comparing the estimates of obtained from the HCN (or HC model to those from the HCN (or HC model, we see that the difference between their vector values is significant. Thus, we can expect an apparent stochastic effect if we use in Bayesian estimation of the location parameter with a stochastic multivariate interval constraint.

Table 1.
Summaries of posterior samples of obtained by using three different priors; and HCN, hierarchical constrained normal.
5.2. Car Body Assembly Data Example
John and Wichern consider car body assembly data (accessible through www.prenhall.com/statistics, [35]) obtained from a study of its sheet metal assembly process. A major automobile manufacturer uses sensors that record the deviation from the nominal thickness (millimeters ) at a specific location on a car, which has the following levels: the deviation of the car body at the final stage of assembly () and that at an early stage of assembly (). The data consist of 50 pairs of observations of (, ), and they provide summary statistics as listed in Table 2. The tests given by ([36], p. 148), using the measures of multivariate skewness and kurtosis, accept the bivariate normality of the joint distribution of The respective skewness and kurtosis are and which give respective p-values of 0.954 (chi-square test for the skewness) and 0.721 (normal test for the kurtosis), indicating the observation model for the dataset is:
where The Shapiro–Wilk (S-W) test is also implemented to see the marginal normality of each The test statistic values and corresponding p-values of the S-W test are listed in Table 2.
Table 2.
Summary statistics for the car body assembly data. S-W, Shapiro–Wilk.
In practical situations, we may have information about the mean vector of the observation model (i.e., mean deviation from the nominal thickness) from a past study of the sheet metal assembly process or a quality control report of the automobile manufacturer. Suppose that the information about the centroid of the mean deviation vector, is with Furthermore, there is uncertain information that where and This paper has proposed the two-stage maximum entropy prior to represent all of the information, which is not available with the other priors, such as and .
Using the three hierarchical models (i.e., the HCN HCN and HCN models), we obtain 10,000 posterior samples from the MCMC sampling scheme based on each of the three models with a 10 thinning period after a burn-in period of 10,000 samples. In estimating the Mote Carlo (MC) error, we used the batch mean method method with 50 batches; see, e.g., [37] (pp. 39–40). For a formal test for the convergence of the MCMC algorithm, we applied the Heidelberger–Welch diagnostic test of [38] to single-chain MCMC runs and calculated the p-values of the test. For the posterior simulation, we used the following choice of hyper-parameter values: and The posterior estimation and the convergence test results are shown in Table 3. Note that Columns 7–9 of the table list the values obtained from implementing the MCMC sampling for the posterior estimation of HCN(πtwo).
Table 3.
The posterior estimates and the convergence test results.
The small MC error values listed in Table 3 convince us of the convergence of the MCMC algorithm. Furthermore, the p-values of the Heidelberger–Welch test for the stationarity of the single MCMC run are larger than 0.1. Thus, both of the diagnostic checking methods advocate the convergence of the proposed MCMC sampling scheme. Similar to Table 1, this table also shows that induces the shrinkage and stochastic effects in the Bayesian estimation of with the uncertain multivariate interval constraint: (i) From the comparison of the posterior estimates obtained from HCN with those from HCN, we see that the estimates of and obtained from HCN shrink toward the stochastic interval The magnitude of shrinkage effect induced by using the proposed prior becomes more evident as the degree of belief in the interval constraint (or δ) gets larger; (ii) On the other hand, we can see the stochastic effect of the prior by comparing the posterior estimate of obtained from HCN with that from HCN The stochastic effect can be measured by the difference between the estimates, and we see that the difference becomes smaller as (or δ) gets larger.
6. Conclusions
In this paper, we have proposed a two-stage maximum entropy prior of the location parameter of a scale mixture of normal model. The prior is derived by using the two stages of a prior hierarchy advocated by [5] to elicit a stochastic multivariate interval constraint, With regard to eliciting the stochastic constraint, the two-stage maximum entropy prior has the following properties. (i) Theorem 1 and Corollary 4 indicate that the two-stage prior is flexible enough to elicit all of the degrees of belief in the stochastic constraint; (ii) Corollary 4 confirms that the entropy of the two-stage prior is commensurate with the uncertainty about the constraint ; (iii) As given in Corollary 6, the preceding two properties enable us to propose an objective way of eliciting the uncertain prior information by using From the inferential view point: (i) the two-stage prior for the normal mean vector has the conjugate property that the prior and posterior distributions belong to the same family of the distributions by [23]; (ii) the conjugate property enables us to construct an analytically simple Gibbs sampler for the posterior inference of the model (1) with unknown covariance matrix Λ; (iii) this paper also provides the HCSMN model, which is flexible enough to elicit all of the types of stochastic constraints and the scale mixture for Bayesian inference of the model (1). Based on the HCSMN model, the full conditional posterior distributions of unknown parameters were derived, and the calculation of posterior summary was discussed by using the Gibbs sampler and two numerical applications.
The methodological results of the Bayesian estimation procedure proposed in the paper can be extended to other multivariate models that incorporate functional means, such as linear and nonlinear regression models. For example, the seemingly unrelated regression (SUR) model and the factor analysis model (see, e.g., [24]) can be explained in the same framework of the proposed HCSMN in Equation (1). We hope to address these issues in the near future.
Acknowledgments
The research of Hea-Jung Kim was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2015R1D1A1A01057106).
Conflicts of Interest
The author declares no conflict of interest.
References
- O’Hagan, A. Bayes estimation of a convex quadratic. Biometrika 1973, 60, 565–572. [Google Scholar] [CrossRef]
- Steiger, J. When constraints interact: A caution about reference variables, identification constraints, and scale dependencies in structural equation modeling. Psychol. Methods 2002, 7, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Lopes, H.F.; West, M. Bayesian model assessment in factor analysis. Stat. Sin. 2004, 14, 41–67. [Google Scholar]
- Loken, E. Identification constraints and inference in factor models. Struct. Equ. Model. 2005, 12, 232–244. [Google Scholar] [CrossRef]
- O’Hagan, A.; Leonard, T. Bayes estimation subject to uncertainty about parameter constraints. Biometrika 1976, 63, 201–203. [Google Scholar] [CrossRef]
- Liseo, B.; Loperfido, N. A Bayesian interpretation of the multivariate skew-normal distribution. Stat. Probab. Lett. 2003, 49, 395–401. [Google Scholar] [CrossRef]
- Kim, H.J. On a class of multivariate normal selection priors and its applications in Bayesian inference. J. Korean Stat. Soc. 2011, 40, 63–73. [Google Scholar] [CrossRef]
- Kim, H.J. A measure of uncertainty regarding the interval constraint of normal mean elicited by two stages of a prior hierarchy. Sic. World J. 2014, 2014, 676545. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.J.; Choi, T. On Bayesian estimation of regression models subject to uncertainty about functional constraints. J. Korean Stat. Soc. 2015, 43, 133–147. [Google Scholar] [CrossRef]
- Kim, H.J.; Choi, T.; Lee, S. A hierarchical Bayesian regression model for the uncertain functional constraint using screened scale mixture of Gaussian distributions. Statistics 2016, 50, 350–376. [Google Scholar] [CrossRef]
- Arellano-Valle, R.B.; Branco, M.D.; Genton, M.G. A unified view on skewed distributions arising from selection. Can. J. Stat. 2006, 34, 581–601. [Google Scholar] [CrossRef]
- Kim, H.J. A class of weighted multivariate normal distributions and its properties. J. Multivar. Anal. 2008, 99, 1758–1771. [Google Scholar] [CrossRef]
- Jaynes, E.T. Prior probabilities. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 227–241. [Google Scholar] [CrossRef]
- Jaynes, E.T. Papers on Probability, Statistics, and Statistical Physics; Rosenkrantz, R.D., Ed.; Reidel: Boston, MA, USA, 1983. [Google Scholar]
- Smith, S.R.; Grandy, W. Maximum-Entropy and Bayesian Methods in Inverse Problems; Reidel: Boston, MA, USA, 2013. [Google Scholar]
- Ishwar, P.; Moulin, P. On the existence of characterization of the Maxent distribution under general moment inequality constraints. IEEE Trans. Inf. Theory 2005, 51, 3322–3333. [Google Scholar] [CrossRef]
- Rosenkrantz, R.D. Inference, Method, and Decision: Towards a Bayesian Philosophy and Science; Reidel: Boston, MA, USA, 1977. [Google Scholar]
- Rosenkrantz, R.D. (Ed.) E.T. Jaynes: Papers on Probability, Statistics, and Statistical Physics; Kluwer Academic: Dordrecht, The Netherlands, 1989.
- Yuen, K.V. Bayesian Methods for Structural Dynamics and Civil Engineering; John Wiley & Sons: Singapore, Singapore, 2010. [Google Scholar]
- Wu, N. The Maximum Entropy Method; Springer: New York, NY, USA, 2012. [Google Scholar]
- Cercignani, C. The Boltzman Equation and Its Applications; Springer: Berlin/Heidelberg, Germany, 1988. [Google Scholar]
- Leonard, T.; Hsu, J.S.J. Bayesian Methods: An Analysis for Statisticians and Interdisciplinary Researchers; Cambridge University Press: New York, NY, USA, 1999. [Google Scholar]
- Kim, H.J.; Kim, H.-M. A Class of Rectangle-Screened Multivariate Normal Distributions and Its Applications. Statisitcs 2015, 49, 878–899. [Google Scholar] [CrossRef]
- Press, S.J. Applied Multivariate Analysis, 2nd ed.; Dover Publications, Inc.: New York, NY, USA, 2005. [Google Scholar]
- Wilhelm, S.; Manjunath, B.G. Tmvtnorm: Truncated Multivariate Normal Distribution and Student t Distribution. Available online: http://CRAN.R-project.org/package=tmvtnorm (accessed on 17 May 2016).
- Genz, A.; Bretz, F. Computation of Multivariate Normal and t Probabilities; Springer: New York, NY, USA, 2009. [Google Scholar]
- Gupta, S.D. A note on some inequalities for multivariate normal distribution. Bull. Calcutta Stat. Assoc. 1969, 18, 179–180. [Google Scholar]
- Lindly, D.V. Bayesian Statistics: A Review; SIAM: Philadelphia, PA, USA, 1970. [Google Scholar]
- Khuri, A.I. Advanced Calculus with Applications in Statistics; John Wiley & Son: New York, NY, USA, 2003. [Google Scholar]
- Gamerman, D.; Lopes, H.F. Markov Chain Monte Carlo: Stochastic Simulation for Bayesian Inference, 2nd ed.; Chapman and Hall: New York, NY, USA, 2006. [Google Scholar]
- Branco, M.D. A general class of multivariate skew-elliptical distributions. J. Multivar. Anal. 2001, 79, 99–113. [Google Scholar] [CrossRef]
- Chen, M.-H.; Dey, D.K. Bayesian modeling of correlated binary response via scale mixture of multivariate normal link functions. Sankhyã 1998, 60, 322–343. [Google Scholar]
- Chib, S.; Greenberg, E. Understanding the Metropolis-Hastings algorithm. Am. Stat. 1995, 49, 327–335. [Google Scholar]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Distribution in Statistics: Continuous Univariate Distributions, 2nd ed.; John Wiley & Son: New York, NY, USA, 1994; Volume 1. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson Prentice Hall: London, UK, 2007. [Google Scholar]
- Mardia, K.V.; Kent, J.T.; Bibby, J.M. Multivariate Analysis; Academic Press: London, UK, 1979. [Google Scholar]
- Ntzoufras, I. Bayesian Modeling Using WinBUGS; John Wiley & Son: New York, NY, USA, 2009. [Google Scholar]
- Heidelberger, P.; Welch, P. Simulation run length control in the presence of an initial transient. Oper. Res. 1992, 31, 1109–1144. [Google Scholar] [CrossRef]
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).