




Sensors 2026, 26(5), 1418; https://doi.org/10.3390/s26051418 - 24 Feb 2026
Viewed by 562
Abstract
►
Show Figures
Public transportation is the core of easing urban traffic congestion, reducing pollution and advancing smart city transportation intellectualization. Its refined operation relies heavily on accurate, real-time passenger origin–destination (OD) data. However, traditional manual surveys are costly with low sampling rates, while smart card
[...] Read more.
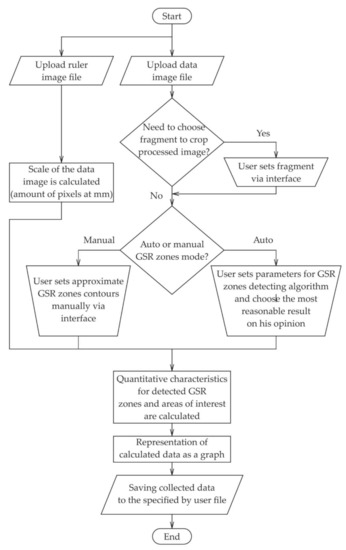
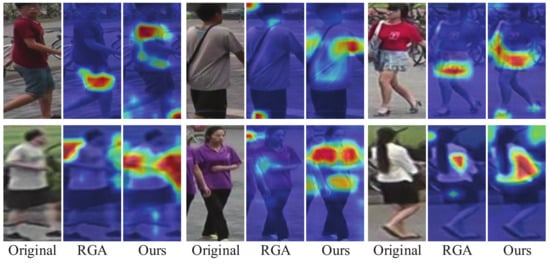
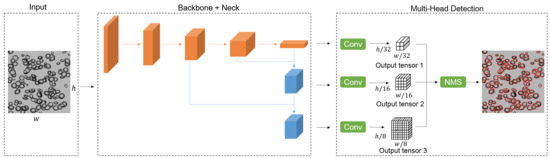
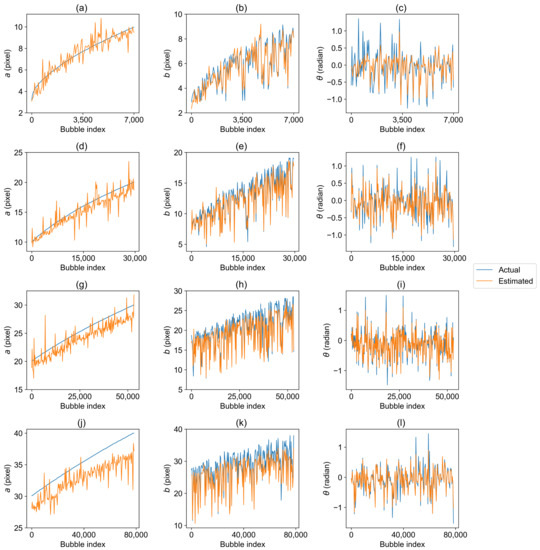
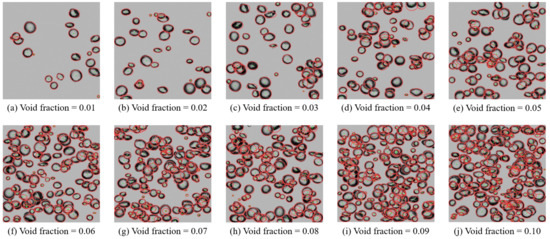
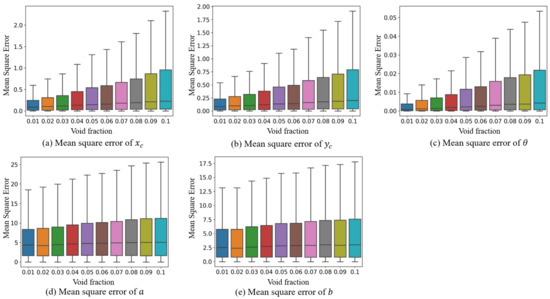
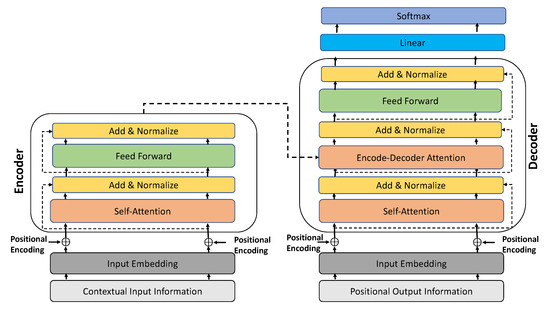
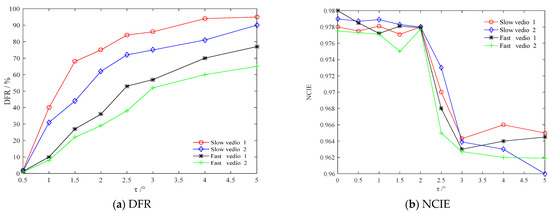
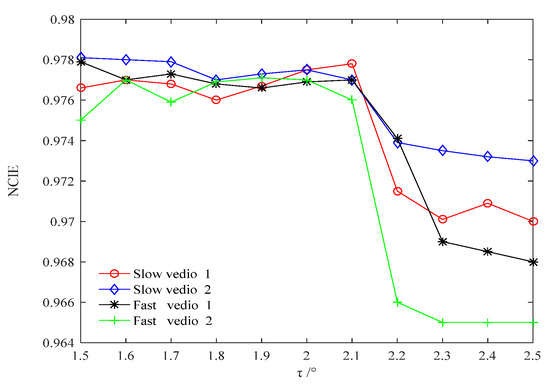
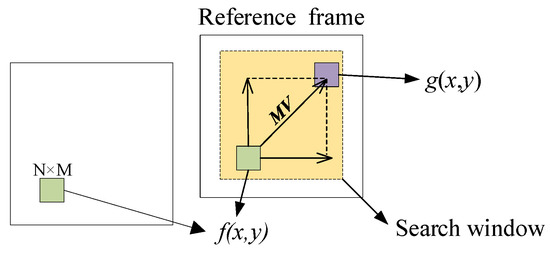
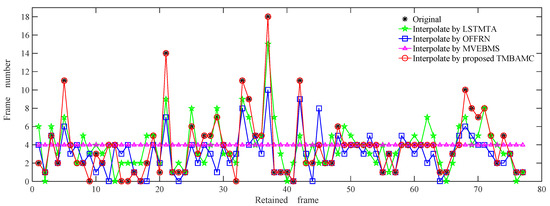
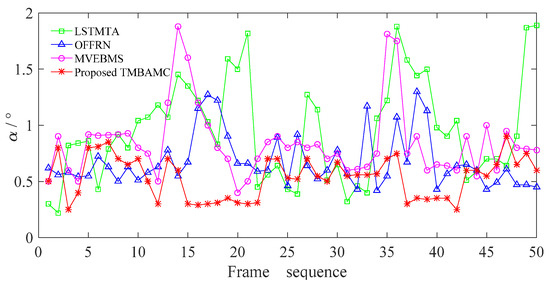
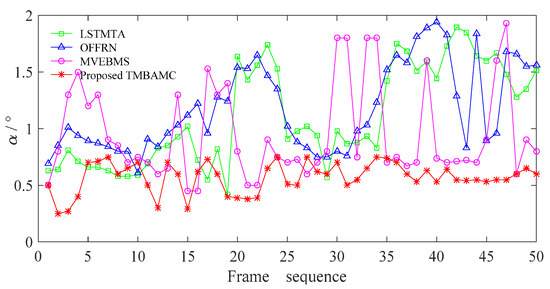
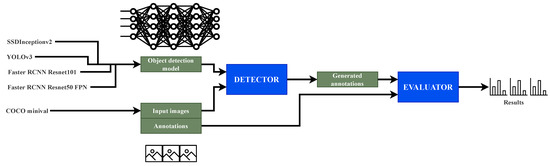
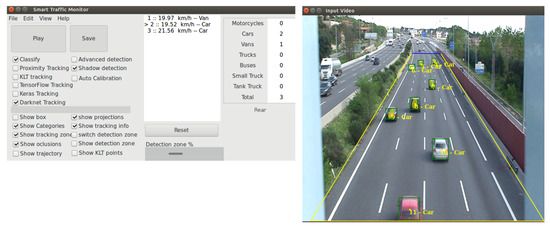
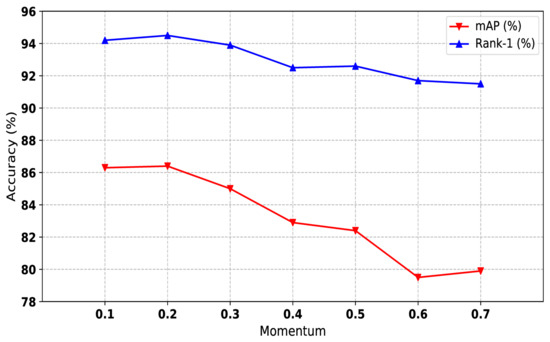
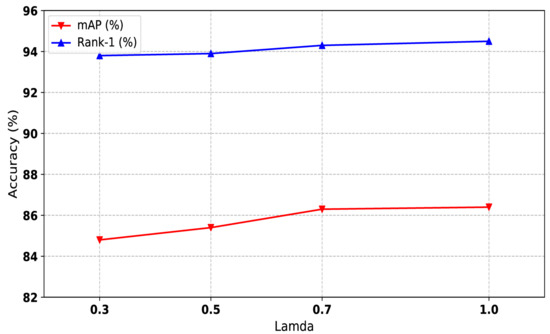
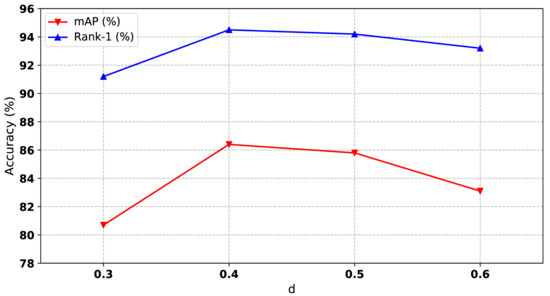
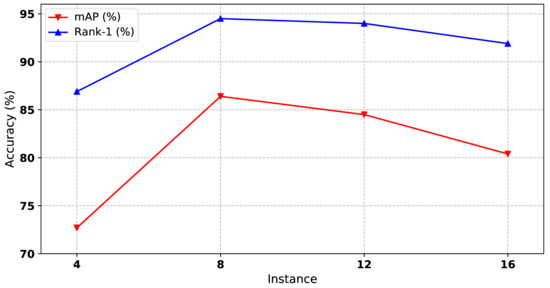
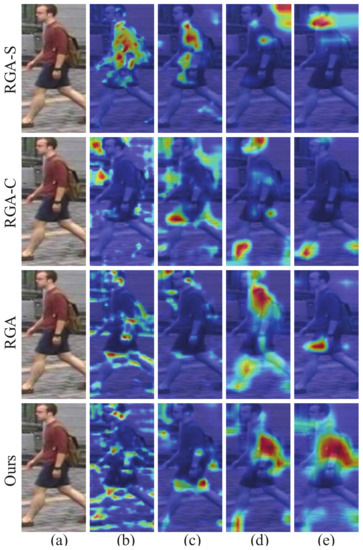
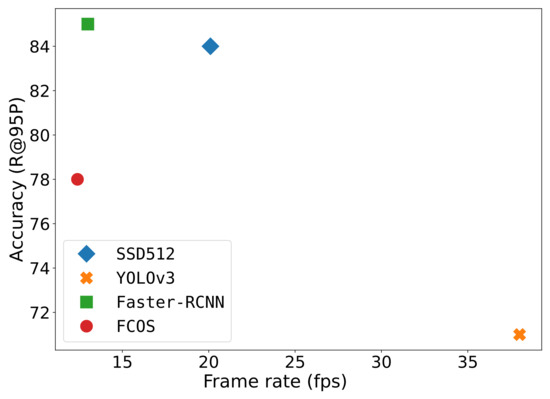
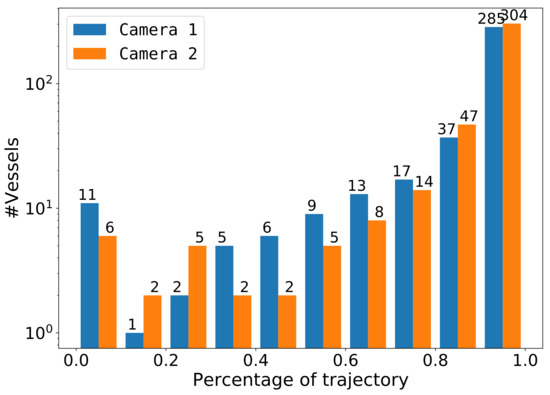
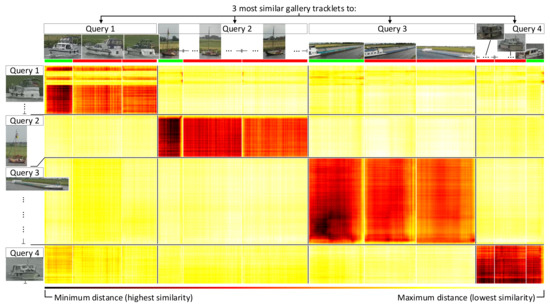
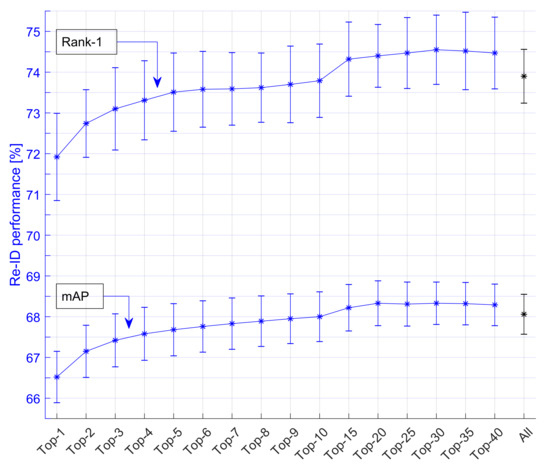
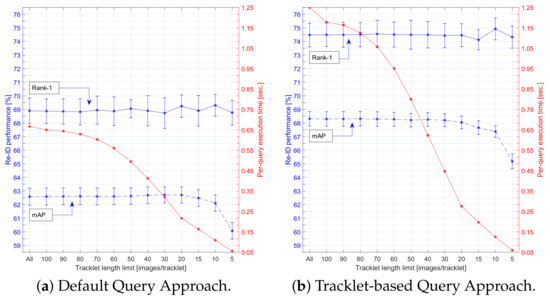
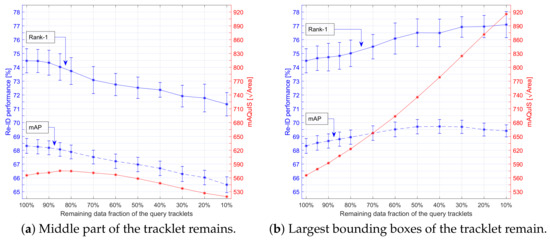
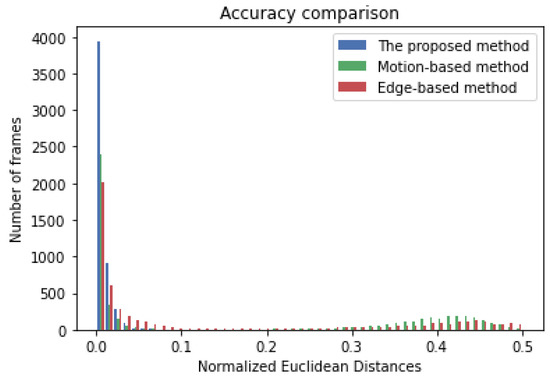
Public transportation is the core of easing urban traffic congestion, reducing pollution and advancing smart city transportation intellectualization. Its refined operation relies heavily on accurate, real-time passenger origin–destination (OD) data. However, traditional manual surveys are costly with low sampling rates, while smart card big data lacks alighting information and has deviations, failing to reflect real travel behaviors and becoming a bottleneck for intelligent public transportation development. To address this, this paper proposes a bus passenger boarding/alighting detection and recognition study based on video images and the YOLO algorithm. Aiming at traditional YOLO’s shortcomings in on-vehicle scenarios (insufficient feature extraction, inefficient feature fusion, slow convergence), the baseline YOLOv8n is improved for bus scenarios’ high-density, high-occlusion and variable-target scales: (1) DAC2f structure (deformable attention + C2f) captures occluded passengers’ core features and suppresses background interference; (2) SWD-PAN enables bidirectional cross-scale feature interaction to adapt to scale differences; and (3) WIoUv3 balances sample weights for small targets and non-standard posture passengers. Experiments show that precision, recall and mAP increase by 3.68%, 5.12% and 6.26%, respectively, meeting real-time requirements. The improved YOLOv8 is deeply integrated with DeepSORT to enhance tracking stability. Tests show that MOTA reaches 31.24% (2.6% higher than YOLOv8n, 16.4% higher than YOLO-X) and MOTP reaches 88.06%, solving trajectory breakage and ID switching. This addresses traditional OD data collection pain points, providing technical support for intelligent public transportation refined management and smart city transportation optimization.
Full article

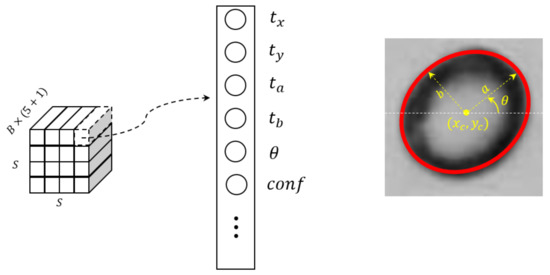
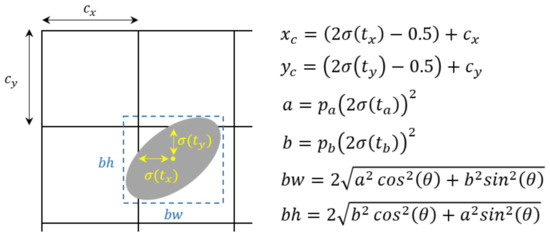
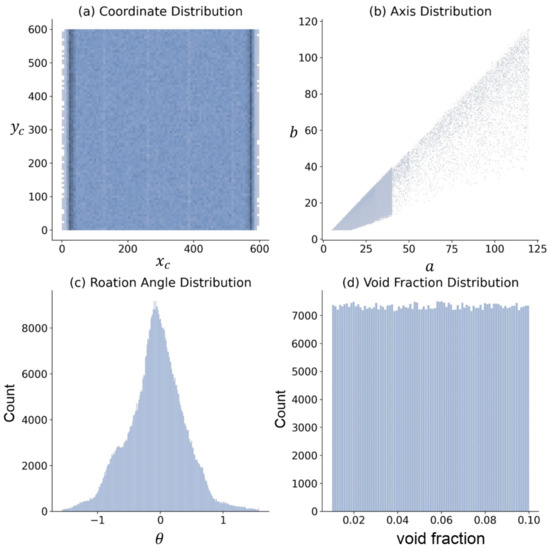
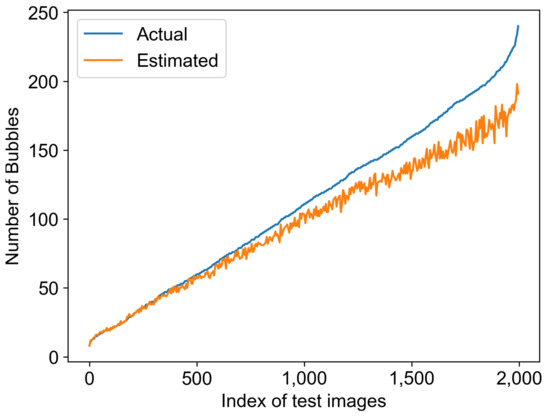
Figure 1





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
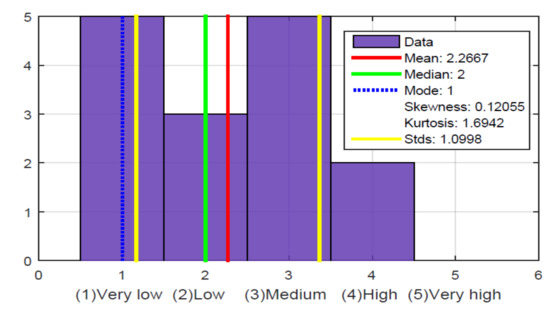{kind=link}
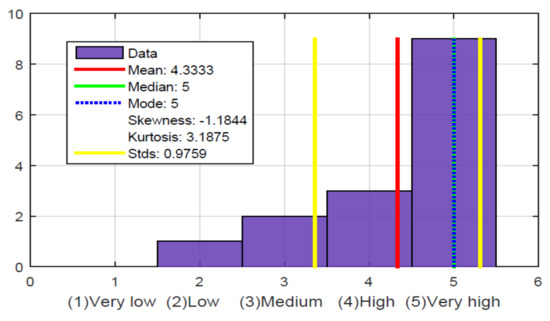{kind=link}
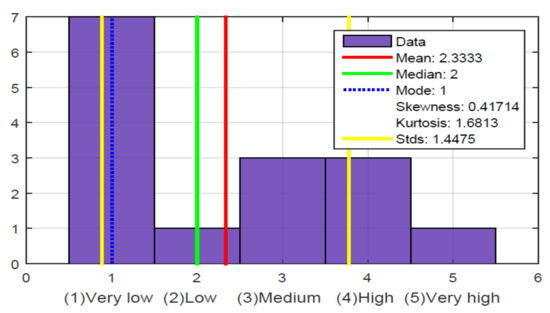{kind=link}
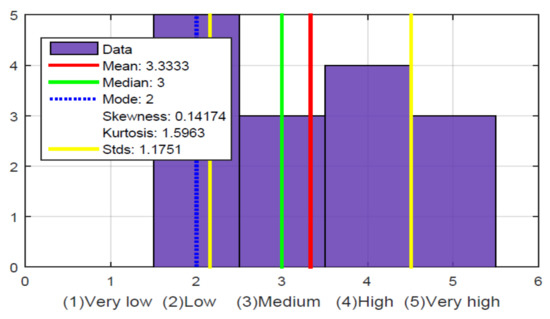{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
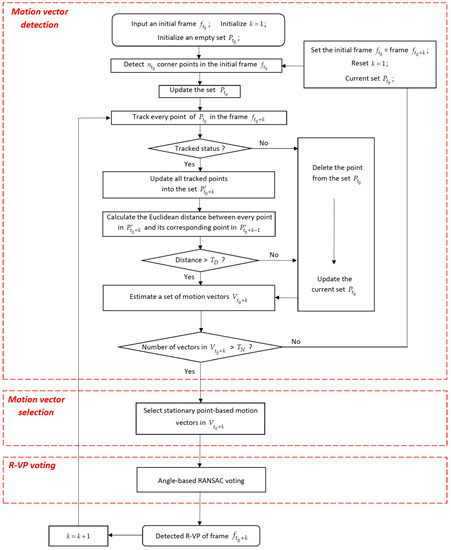{kind=link}
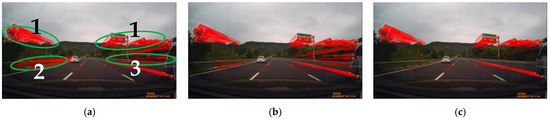{kind=link}
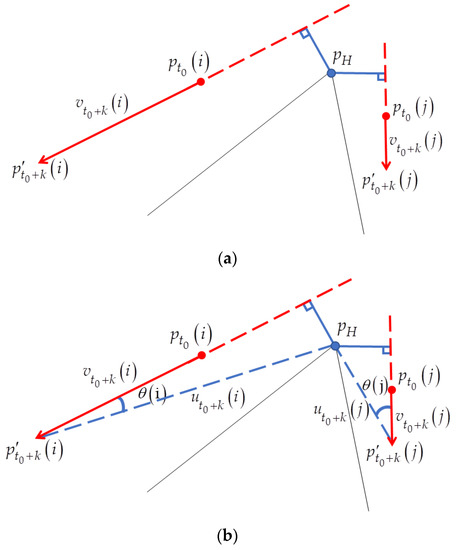{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}