1. Introduction
Entanglement is a key quantum resource for information tasks including timing/sensing [
1], communication and networking [
2], and computation [
3]. It is a fundamental quantum phenomenon, first discussed by Schrödinger [
4,
5] in response to the criticisms of the incompleteness of quantum mechanics by Einstein, Podolsky, and Rosen [
6], manifesting its effects at the atomic scale and possibly even the cosmic scale in theories of formation of spacetime itself [
7]. One of the important research areas in modern quantum information science is the difficult issue of the quantification and characterization of entanglement from bipartite to multi-partite quantum systems (see [
8,
9] and references therein).
For pure states, an important measure of bipartite entanglement is the von Neuman entropy (VNE) of the reduced subsystem of the composite state . This, of course, requires the diagonalization of to obtain its eigenvalues . Another widely used way to compute the measure of pure state bipartite entanglement is the linear entropy , whose popularity stems from not having to compute the eigenvalues of .
While the above measures of entanglement are applicable to pure states, entanglement measures for mixed states are harder to come by [
8]. Measures of mixed state entanglement exist only for particular systems, such as Wotter’s concurrence [
10] for a pair of qubits and for a qubit–qutrit system. A widely used “measure” of entanglement for both pure and mixed states, both discrete and continuous variable, is the Log Negativity (
) [
11,
12,
13] given by
where the negativity
is given by the sum of the absolute values of the negative eigenvalues of the partial transpose of
. This entanglement monotone is based on the fact that a separable state
remains positive under partial transpose. It is not a true entanglement measure since it does not detect bound entanglement (i.e., states that are entangled, yet have positive partial transposes).
In this work, we present numerical evidence for a pure state entanglement witness that exactly agrees with the
when the quantum amplitudes
of
(a
column vector) form a
Hermitian matrix,
,
, with normalization
. That is,
where
is the purity of
. Here, we denote our approximate expression for the Log Negativity as
(
a for
approximate), and distinguish it from the exact expression for the Log Negativity
(
e for
exact) obtained by numerical computation of the eigenvalues of the partial transpose of the pure state density matrix
).
Note that we use the term entanglement witness to mean a positive semi-definite approximation that acts as a lower bound (not necessarily the greatest lower bound) to the standard, computable, exact Log Negativity . To be a proper entanglement witness, the quantifier should not increase under local operations and classical communication (LOCC). We find that for the case of two qubits, for arbitrary complex C (which we derive analytically) and does not increase under local operations, and hence is a proper entanglement witness. For more than two qubits, it is only when C is Hermitian that again and does not increase under local operations. When C is an arbitrary complex matrix, does increase under local operations; however, it never exceeds the exact value . Thus, acts as a lower bound to the exact Log Negativity, and can be said to “witness” the presence of entanglement in the bipartite system. We compare our witness with that of linear entropy .
While we are not able to provide a bona fide analytic derivation of
, we do provide a plausibility argument modeled on the analytic diagonalization of correlated pure states of the form
by Agarwal [
13]. This form encompasses both discrete and continuous variable states (where the latter is truncated in each subspace to a maximum Fock number state
with
such that
for some arbitrary chosen
). Agarwal’s derivation can be interpreted as a generalization of the analytic diagonalization of the Schmidt decomposition of the pure state
, which yields
in terms of the magnitudes of the
complex quantum amplitudes
.
In brief, the goal and motivation of this article is to generalize and explore for higher bipartite states the curious exact form of an entanglement witness for two qubits in terms of its quantum amplitudes (vs. eigenvalues of a partially transposed density matrix), and to explore how well it might reveal (“witness”) entanglement present in such higher-dimensional bipartite states. The analytic plausibility argument we provide surprisingly reveals that a simple generalization of the exact two qubit Log Negativity formula non-trivially captures some of the entanglement for higher-dimensional bipartite states, which unexpectedly is exact and a proper entanglement witness when the coefficient matrix is Hermitian, .
We subsequently attempt to extend our witness from pure states to mixed states, with limited success, though with interesting, non-trivial special cases, in the sense that we are able to provided numerical evidence that
when the mixed state is written as a pure state decomposition (PSD)
with the quantum amplitude matrix
of each pure state component
uniformly generated (over the Haar measure) as a positive Hermitian matrix,
. In Equation (
2), we have defined the
average of our approximate Log Negativity on a PSD as
where the notation
is used to denote our witness formula for pure states, defined in Equation (11b). The rightmost term
in Equation (
2) is computed with our generalized mixed-state formula ansatz given in Equation (17c). Lastly, we find that the second inequality is saturated,
in Equation (
2), if the uniformly randomly generated
matrices above are real, i.e.,
. (A discussion of the uniform generation of Hermitian matrices over the Haar measure is given in
Appendix B).
This paper is outlined as follows. In
Section 2, we discuss Agarwal’s derivation [
13] of the analytic diagonalization of correlated pure states of the form
and present an analytic formula for
in terms of the the Schmidt coefficients of the pure state. In
Section 3, we present our ansatz for an entanglement witness
and numerical evidence for it on the pure state
based solely on its quantum amplitudes
without the need for numerical diagonalization of
. We present numerical evidence that
when
, considered a complex matrix, is positive and Hermitian and that
on separable pure states. While not a formal proof, we present a plausibility argument leading to our formula for an approximate Log Negativity
inspired by the previous Agarwal’s derivation [
13] in
Section 2, based on an ansatz for the dominant analytic contributions to the negativity. For
C, an arbitrary complex matrix (subject to normalization), we present numerical evidence that
acts as a lower bound to
(better than
) and hence acts as an entanglement witness. For the case of two arbitrary qubits, we analytically show that our approximate formula for the Log Negativity agrees with the exact formula. In
Section 4, we attempt to provide a generalization of
to mixed states that reduces to the original formula for pure states, and again does not require the numerical diagonalization of matrices derived from
. This generalization is zero on separable states
only when either or both
are real. While this witness does detect a wide class of separable states, it does not detect them all (a notoriously difficult problem in its own right [
8,
9]). By examining Werner states of arbitrary dimension (mixing a generalized Bell state with a maximally mixed state of appropriate dimension), we are led to an ansatz for a mixed-state witness, for which we can numerically show that Equation (
2) holds over pure state decompositions (PSDs) for which the quantum amplitudes of the pure state components, when considered
matrices, are positive and Hermitian. In
Section 5, we discuss other approaches to bipartite pure-state entanglement quantities without matrix diagonalization, and possible relationship to our proposed approximate Log Negativity. In
Section 6, we summarize our results and present our conclusions. This work also include several appendices provided to explore and further clarify certain topics raised in the main text. In
Appendix A we explore various forms of our approximate Negativity and Log Negativity formulas for pure bipartite states. In
Appendix B we provide a discussion of the methods used for the uniform generation of Hermitian matrices over the Haar measure utilized in the numerical explorations in this work. In
Appendix C we provide a list and description of the various Log Negativity formulas, for both pure and mixed states used in this work. Finally, in
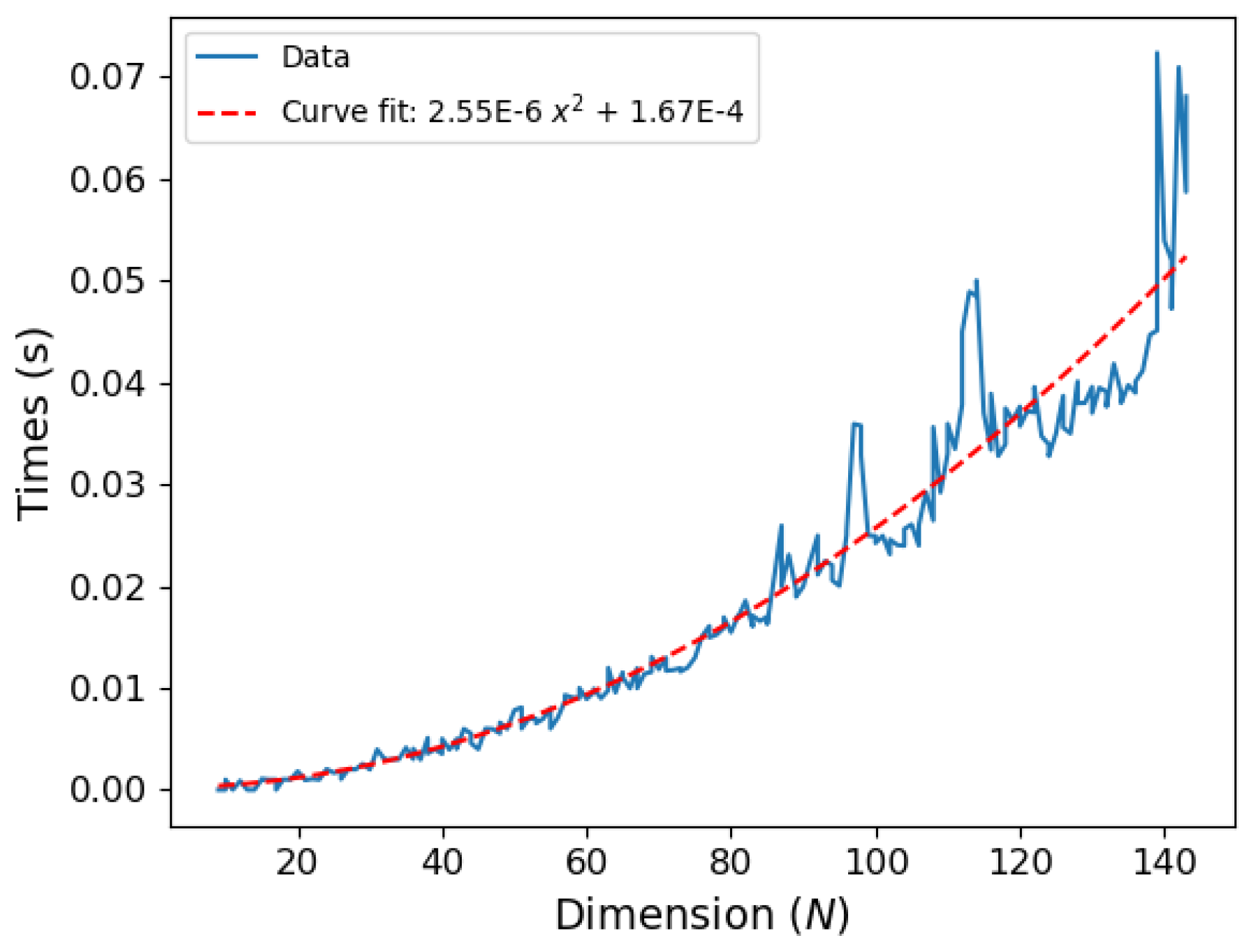
Appendix D we provide a numerical analysis of the computational scaling for computation of our approximate Log Negativty formula for pure bipartite states, versus the exact Log Negativity involving the computation of the eigenvalues of the partially transposed bipartite density matrix, as well as the computation of the linear entropy involving matrix multiplication.
The intent and focus of this work is on demonstrating that the information contained solely within the pure (mixed) state quantum amplitudes (matrix elements) directly provides inherent entanglement information that is normally associated with the eigenvalues of matrices derived from the quantum state (e.g., partial transpose, and reduced density matrices). While the numerical computation of eigenvalues does not present a practical impediment to the calculation of entanglement measures, it is the surprising relationship (and unexpected equality for certain classes of physically relevant pure and mixed states) of the proposed entanglement witness
to the exact (numerically computed) Log Negativity
, that was the impetus for this current investigation (see
Appendix C for a list and usage of the various Log Negativity functions used in this work).
3. Ansatz for an Entanglement Witness
From the previous section, we identify two types of states in the PT
and their contributions to the negativity: (without loss of generality and for notational simplicity, we treat
as real for now, and re-insert the absolute values at the very end of the discussion)
where Equation (10a) comes from states eigenstates
from Equation (5b) leading to the negativity in Equation (6b) (where
), and Equation (10b) comes from eigenstates
from Equation (8c) leading to the negativity in Equation (10b).
The main premise of our proposed entanglement witness (EW) is that these two types of terms constitute the majority contributions to the negativity for the general pure state
. Below we argue that the LN can be lower bounded by the following expression built solely from the wavefunction amplitudes
,
At first glance Equation (11a) looks a bit odd since if one were to take
(again, subscript
a for
approximate) one would expect to sum over the permanent
as opposed to the determinant
(We note that the closest related antisymmetric structure we have found is the norm-squared of the wedge product
used in Meyer and Wallach’s multiparticle global entanglement monotone
Q [
14] involving the pure states
and
.) However, using
enforces
on separable (product) pure states (i.e., the Det is identically zero if
). As mentioned previously, the set of eigenstates
giving rise to
forms an orthonormal subset, while the set of eigenstates
giving rise to
does not. Thus,
is being “overcounted” in
and we find that
produces much better results. Additionally, the use of the latter minus sign assures that if
then we obtain
, the
d-dimensional maximally entangled Bell state, for which
.
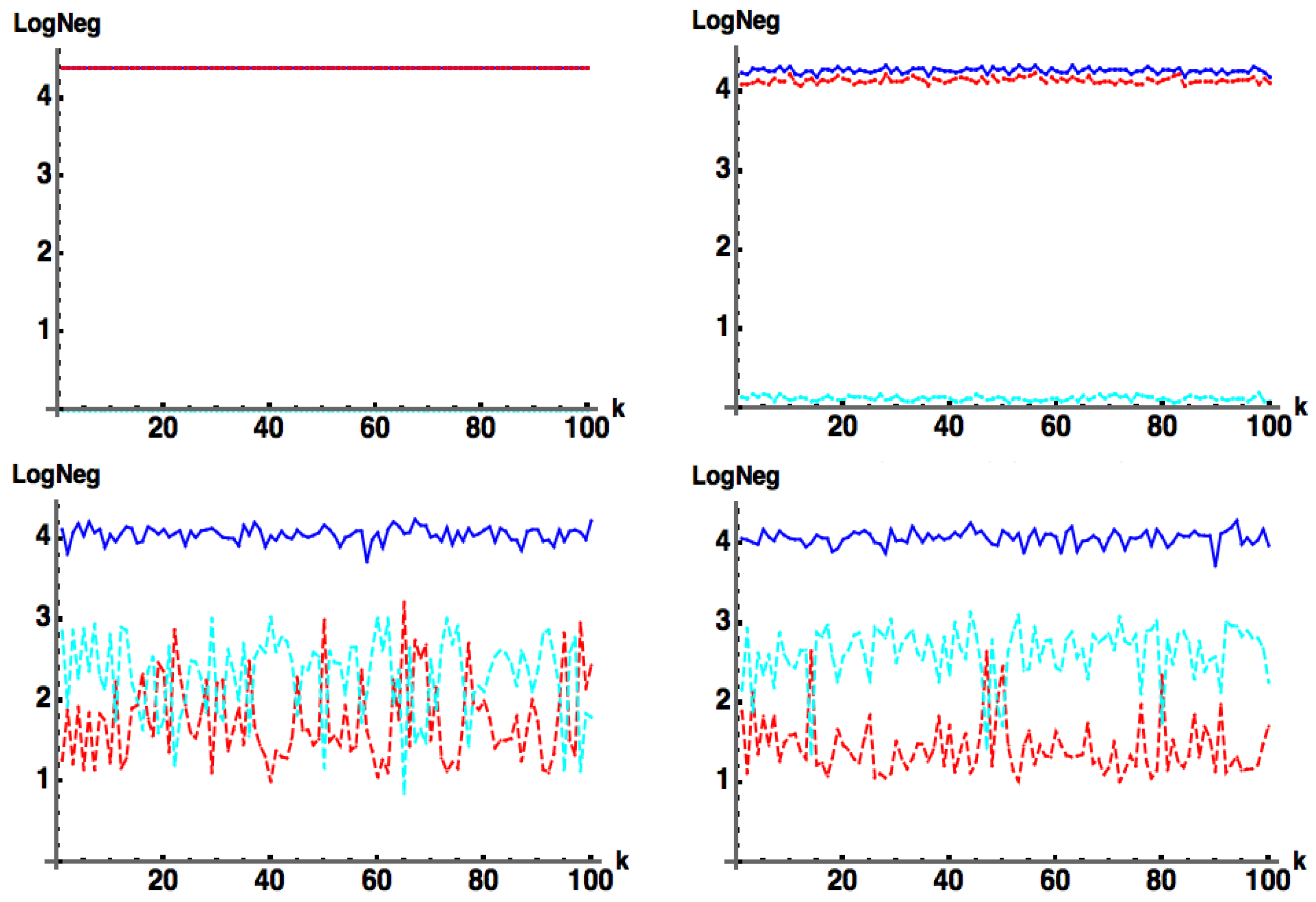
3.1. : Results
Surprisingly, we have found that Equation (11a,b) produces
exactly (obtained from numerically computed eigenvalues) of pure states, for which
is a
positive Hermitian matrix with both deterministic and random entries as shown in
Figure 1. Further, for the case when
is a positive Hermitian matrix
, we can derive (see Equation (A7a) and Equation (A7b)) the
non-trivial result
where the second equalities in the above
cannot be derived analytically, but rather are demonstrated numerically from plots such as
Figure 1. Here,
, which is then flattened (stripped by rows) into an
column vector representing
.
is chosen as a random positive diagonal matrix such that
, and
U is a uniformly generated (via the Haar measure)
random unitary matrix. (Note:
is chosen as the absolute value
squared of a random row of another randomly chosen unitary
.)
In
Figure 2, we relax the positivity condition on
C and change
to be chosen simply as a random row of separately generated randomly unitary
(vs. the absolute value squared of a random row of
for the previous case of
) so that
has random complex entries.
For any number of samples, we always find that
, i.e.,
acts as a proper lower bound to
. This behavior in
Figure 2 is the same if we simply take
as a matrix of random complex entries. This represents one of the main results of this work. In the following subsection we provide a plausibility argument for Equation (11b) indicating the logic of our “derivation”.
As discussed previously, the use of the Det in Equation (11a) enforces
on separable (product) pure states since the Det is identically zero if
. This is nicely illustrated for the case of pure states of the form
, where
. In
Figure 3 we show the superposition of two coherent states
. The state is separable when
where
(both exact and approximate).
Another way to show that Equation (11b) captures a separable pure state is shown in
Figure 4 In the left figure
and
are taken as two random rows of two different random unitary matrices, while in the right plot,
and
are taken as two random rows of the same random unitary matrix. In the latter, when the same row is chosen for both
and
, the state is separable and
.
3.2. Plausibility Argument for Equation (11a,b)
In this section we present a plausibility argument that led to the “derivation” of the negativity in Equation (11a) and hence the Log Negativity in Equation (11b).
We begin by considering a general pure state
. The pure state density matrix is given by
. Without loss of generality, and for ease of notation, we treat
as real in this subsection, and put in appropriate absolute values at the end of the calculation. Also, we drop the
subscript for now. We now write
as
The PT
is then given by
The first summation in Equation (14a) gives rise to the negativity (putting back in the absolute values) as discussed in Equation (10a) using the eigenstates .
The ansatz we employ is that the negativity is dominated by terms of the form (I), , giving rise to eigenstates , and terms (II), , giving rise to eigenstates , in the PT . We therefore approximate the negativity by only considering “matching terms” of types I and in .
Thus, in the second double summation in Equation (14a), we only consider the terms (i) which give rise to terms of the form .
The first two terms of this expression are diagonal, while the last term gives rise to the negativity as discussed in Equation (10b) using the eigenstates .
However, in the same term in the previous paragraph, we could also consider the case (ii) leading to terms of the form . The last two terms of this expression are diagonal, while the first two again contribute a Negativity of as in the previous paragraph. As part of our ansatz, we conjecture that the terms in Equation (14b) contribute no (significant) terms to the negativity.
Thus, the negativities that we have so far are
, which we can write as
where in the last line we have simply used the inequality that
with
and
. As discussed before, using
in Equation (15a) overestimates the negativities because the set of eigenstates
does not form an orthogonal subset. Thus, we instead use the lower bound
given by the determinant expression in Equation (15c).
is also the same expression as in Equation (11a), giving rise to the
given in Equation (11b).
While the above does not constitute a formal proof or a proper derivation , it is a plausibility argument borne out by numerical evidence. and in Equation (11a,b) also argue that the negativity in a general pure state is dominated by the states and found within , giving rise in the PT to the eigenstates and negativities and , respectively.
Finally, we return to the case when
is separable so that
. Let us now consider
, where we define
, with
and
Hermitian. If we further define
where
is an arbitrary
d-dimensional complex vector (such that
), then
represents an increasing random deviation away from the separable case. In
Figure 5 we show plots of
,
and
for
, such that
, with
for increasing values of
. We see that
acts as a lower bound for
. In
Figure 6 we show plots of
,
and
for
, such that
, with
for increasing values of
. We again see that
acts as a lower bound for
. Similar behavior occurs for arbitrary values of
M.
3.3. and for Perturbed Pure States vs. Purity of a Hermitian
In the previous sections, we examined
vs.
for pure bipartite states and found that
when
is considered a uniformly random (with respect to the Haar measure) Hermitian matrix, i.e.,
C “acts like a
density matrix”. We examined this equivalence (random) shot by shot. In this section, we examine the situation when we treat
C as a
density matrix of fixed purity
, for which
, but then perturb it away from this result by adding a uniformly random density matrix
multiplied by a small “noise” coefficient
. In particular we let
where
. Here
is a real, uniformly random, diagonal density matrix of fixed
chosen purity value [
15]
(abscissa),
U is a uniformly random unitary,
is random Hermitian density matrix, and
is a small real parameter. For
,
C is a Hermitian matrix of fixed purity
, and for each uniformly selected
C, we have
. By allowing
, and thus mixing in a uniformly random Hermitian
, we perturb
C away from its original fixed purity value at
. This allows us to sit at a fixed purity
and randomly select samples of
, and then calculate and compare the mean and standard deviations of
and
, which are no longer equal for
.
In
Figure 7 we consider two values of
(left and right columns, respectively), for two different values of
(top and bottom rows, respectively). The blue-dashed line is the mean of
for 100 sample points for each chosen value of the purity
. The extreme edges of the shaded blue band about the dashed blue line represent the mean value plus and minus the standard deviation. Similar remarks hold for the solid red line/bands representing
, and the solid cyan line/bands representing the difference
. From the latter difference cyan curve/band, we see that
, namely that even in these statistically perturbed cases (where again,
for
), our approximate Log Negativity formula for pure bipartite states where
is Hermitian, and
acts as a lower bound to
.
In examining the statistics of
Figure 7, note that as in
Figure 5 where
and the pure
d-dimensional state
has the highest purity
, the bipartite pure state
is (counterintuitively) separable, and hence corresponds to
, i.e., with minimum value (right side of the abscissa). In addition, as in
Figure 6, where
, with
having the lowest purity
, the bipartite pure state
corresponds (again, counterintuitively) to the maximally entangled Bell state, and hence to
with maximum value (left side of the abscissa).
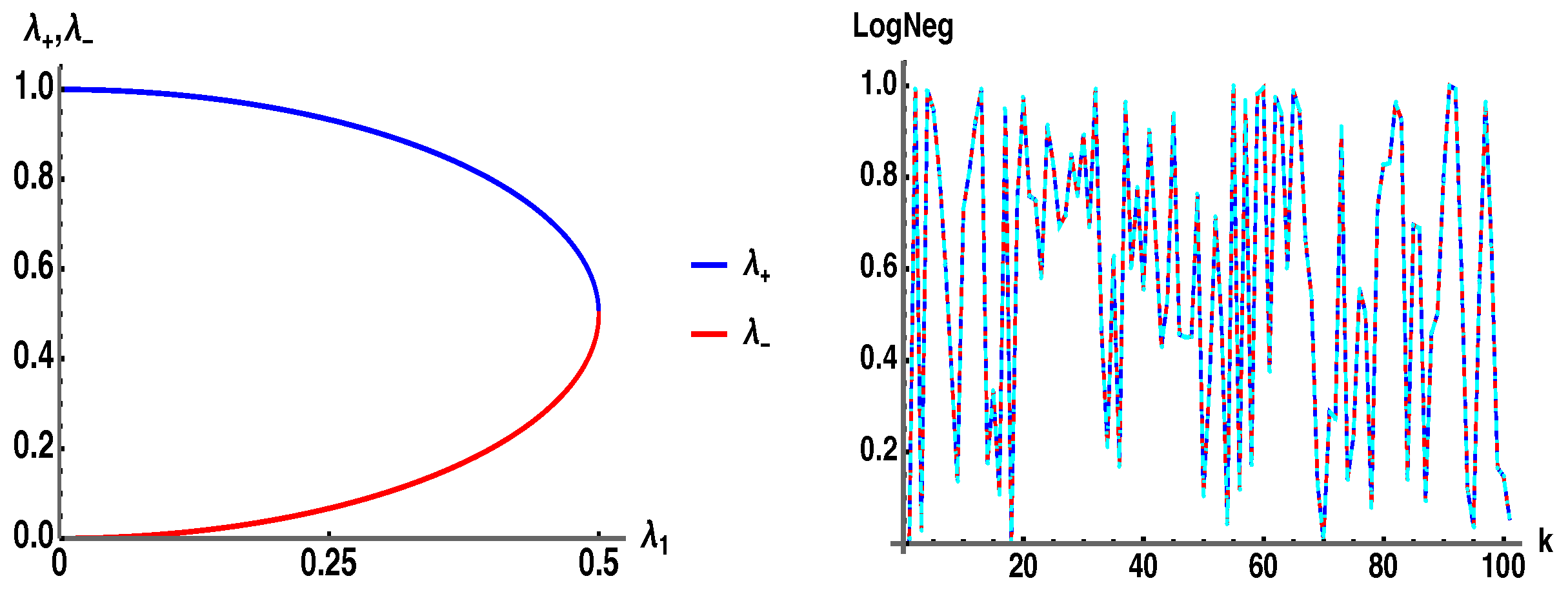
3.4. Analytic Derivation of for the Bipartite Case of Two Qubits,
For the case of two qubits (
), take
to be an arbitrary
complex matrix, for which we can analytically obtain the eigenvalues of the
partial transpose
, Equation (14b), in terms of the
. After using the normalization of the state
, the eigenvalues
of
can be written as
Thus, and contributes to the Log Negativity. Since is Hermitian with real eigenvalues, the radical under the square root must be positive , requiring that .
In
Figure 8 (left) we plot
. In
Figure 8 (right) we plot
(blue),
(red) from Equation (11b), and
(cyan) using the analytic eigenvalue
in Equation (16b), for the bipartite state of two qubits,
. The end result is that for the case of the pure bipartite case of two qubits there is only a single negative eigenvalue of the PT that contributes to the negativity, and it has the precise form of
as given in Equation (11a), which has two terms in the sum
summing to
. For higher dimensions
, it is then somewhat unexpected and surprising that
in Equation (11a) produces the exact negativity
when
of dimension
d.
3.5. Comparison with Linear Entropy
The archetypal measure of entanglement of bipartite pure states that does not involve the computation of eigenvalues is the linear entropy where is the reduced density matrix obtained by tracing out over one of the subsystems. when is separable and when (a matrix) is maximally entangled, and hence (a matrix) is maximally mixed.
In
Figure 9 we plot
,
, and a variation on the approximate negativity formula Equation (11b) given by
(see Equation (
A2)), and the linear entropy
, when
is a positive Hermitian
matrix (with
) for
. In this case, both
and
identically equal
. The
is plotted below (in orange) and acts as a lower bound to
.
Figure 10 is identical to
Figure 9, except we now allow
to be a random complex
matrix. We see that
acts as a better lower bound than
, which is in turn a better lower bound than the
. As the dimension
d increases, the latter three measures are observed to converge to approximately the same lower bound values, with
still performing as a slightly better lower bound.
4. An Attempt to Extend to General Density Matrices
Extending the negativity and Log Negativity from Equation (11a,b) appropriate for pure states to mixed states is a non-trivial task. In principle the extension of an entanglement measure to mixed states is easy to state but computationally involved to perform [
16]. Given a pure state (ensemble) decomposition (PSD) of a mixed state
and an entanglement measure
E on pure states, one can form the average entanglement
. The entanglement measure on mixed states is then taken as the minimum of
over all possible PSDs
(the so-called
convex roof construction). This final result is sometimes referred to as the entanglement of formation, which quantifies the resource required to create a given entangled state. Since
is a convex function, one can apply Legendre transformations [
17] to transform the above difficult minimization into the “minmax” problem [
18]
, where the exterior maximum is taken over all Hermitian matrices
X. The dimension of the exterior optimization over
X can be reduced to a rather small number by the symmetry of the state
, which greatly simplifies the numerical task as was demonstrated in [
19].
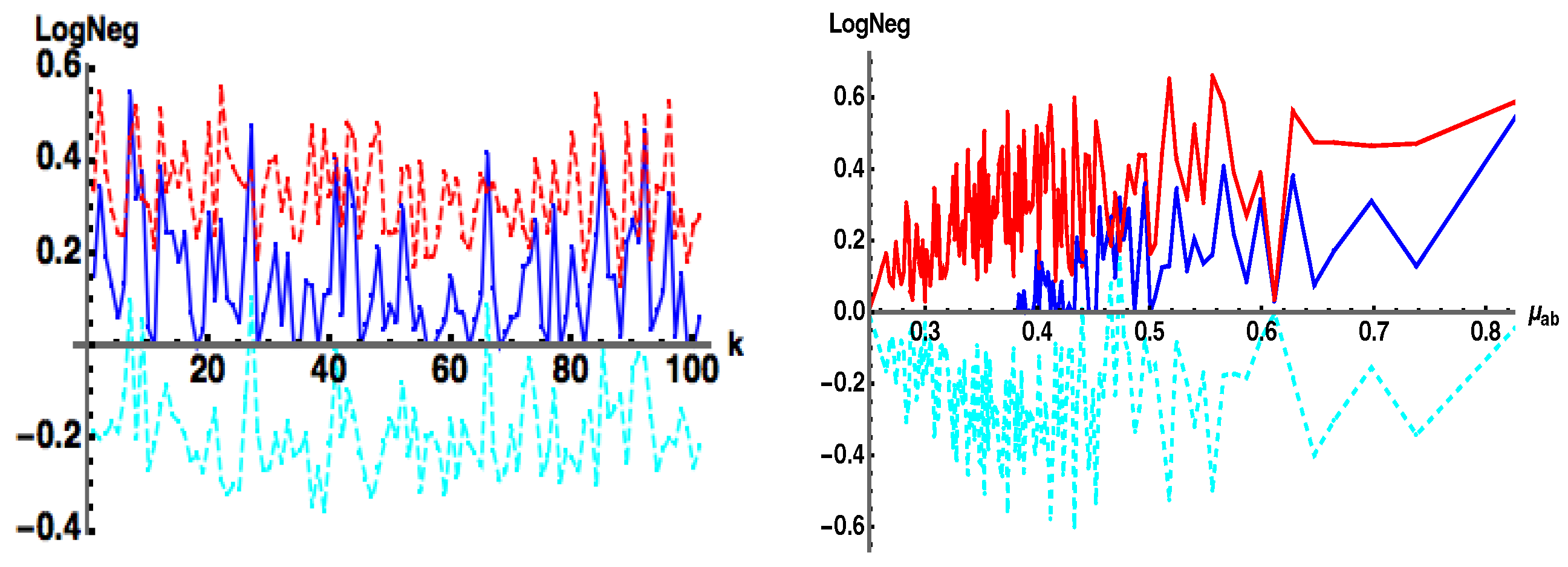
In this work we are not interested in forming a proper entanglement measure, rather a witness, that can lower bound the exact Log Negativity. Therefore, we will forgo the above computationally involved procedure and instead put forth (while somewhat simplistic but computationally tractable) an ansatz for a straightforward generalization of our pure state witness.
The main advantage of Equation (17b) is that upon reduction to a pure state
, the above formulas reduce to Equation (11a,b). However, as
Figure 11 shows, Equation (17b,c) now acts more as an approximate upper bound as the dimension
d increases (left), versus a desired lower bound, but typically at higher purity
values (right). Note that
does a fairly good job of tracking the up and down random fluctuations of
but the former does not do a very good job when the latter is zero. On the negative side, Equation (17b) does not capture separability when
. The issue of witnessing separability in general is a difficult, non-trivial problem [
12], so it is not surprising that a simple generalization from a pure state witness to a mixed state witness would not be valid. Nonetheless,
Figure 11 is intriguing for the relative tracking of
with
.
acts “almost” as an upper bound to
, (i.e., the cyan difference curve
), but there are places where it also acts as a lower bound, i.e.,
.
4.1. on Werner states
Because they are analytically tractable, it is informative to examine the proposed mixed-state witness Equation (17c) for the case of Werner states of dimension
(where
), i.e.,
(Note:
is a
vector, so
is a
matrix). In
Figure 12 we show
and
for Werner states with (top)
(two qubits) and (bottom)
using the approximation for the negativity given in Equation (17c).
Here we also introduce the Average Log Negativity (ALN) (for both exact and approximate
) given by
for mixed states of the form
. It is straightforward to compute that for the Werner state, the negative eigenvalues of the partial transpose are given by
Therefore, the negativity in this region is given by
yielding
Thus,
is entangled (
) for
, and separable (
) for
. Finally, one can also show that the purity
for the Werner states is given by
. This corresponds to a critical value
, equivalently
, where the value of the Log Negativity drops to zero. Some authors [
16] refer to phenomena as the “sudden death of entanglement” since in the region
,
is separable, while
is entangled for
.
On the other hand, for a given
, for Werner states, we have
yielding again
vs. at
as for
. Therefore,
(red curve) never detects separability, and for Werner states, acts as a strict upper bound for
(blue curve). Further, for Werner states
as demonstrated in the bottom plot in
Figure 12 with
. Note that in the limiting case of
, the Werner state is always entangled, and never has a region of separability.
The sudden death of entanglement at introduces a derivative discontinuity in that arises from the definition that the negativity is defined as non-zero only if some eigenvalues of the partial transpose of the density matrix are negative. Equivalently, such a discontinuity could also be introduced for the Werner states by declaring that iff . Our definition of the continuous function can never capture this derivative discontinuity. For Werner states one could attempt to capture this feature for any definition of a by simply defining for .
A symmetrization of Equation (17b) is given by
which also reduces to Equation (11a,b) for the case of pure states
. (Note that one could also add terms such as
which reduce to zero on the pure state case
. However, we have not found such additional terms useful). Equation (
24) also has the additional favorable property that it
does detect separability
iff, for each i, either or are zero. This occurs because if
, Equation (
24) reduces to
where the terms inside the absolute value are proportional to the product of
. This implies that either term in the product needs to be zero as a necessary and sufficient condition for the approximate negativity
in Equation (
19) to yield zero on separable states.
Equation (
24) does detect a wide class of separable states, but of course, not all. This is especially apparent since the application of Equation (
24) to the
produces exactly the same plots as shown in
Figure 12. We can understand this as follows. For the case of two qubits (
), we can write
While Equation (26a) is valid for all values of
, Equation (26b,c) is only valid mixed-state representations (since each of the four terms is diagonal in a separable basis, and positive semi-definite)
provided that . Now the term
involves density matrices
and
that are
both complex, for which our witness in Equation (
24) cannot detect separability since at least one of the
or
would need to be real
.
4.2. Average as a Lower Bound for
We note that for Werner states, the Average Log Negativity (ALN)
for both the exact
, and the approximate version
(using Equation (17c) on the right-hand side), are identically equal throughout all of
, even in the separable region
where
, as shown as the overlapping dashed blue and red lines in
Figure 13. This is because
on the
components of the pure symmetric Bell state density matrix, and also on the maximally mixed state (yielding value
on the latter). In fact, we see that the
is concave
in the region where entanglement is present, and is convex
in the region where the state is separable. On the other hand, our
is concave throughout all of
. Thus, as the dimension
increases,
becomes an increasingly better lower bound for
for a larger region of
p as the region of separability decreases as shown in
Figure 13 for
, and for
in (bottom)
Figure 12.
The above properties on Werner states prompt us to compare
to
for more general random density matrices written as a pure state ensemble decomposition (PSD),
, which we consider (only) for the remainder of this section. We also introduce an additional version of the average approximate Log Negativity given by
which now uses our approximation of the Log Negativity for pure states via Equation (11b) on the ensemble pure state components on the right-hand side, which is denoted as
. This is to be distinguished from the notation
, which we will reserve to denote the Log Negativity using our approximate mixed-state formula Equation (17c), and
which is the average approximate Log Negativity that also uses Equation (17c) on general mixed states
.
The trend seen in the above Werner state discussion appears to hold in general for PSDs, namely that as the dimension
of the pure state components
increases,
becomes an increasingly better proper lower bound of
as shown in
Figure 14 (top).
Here
and
is given by the blue curve,
by the red curve, and
by the magenta curve. We are interested in the comparison of the red and magenta curves to the blue curve, based on how the
matrices are chosen in each pure state component of the PSD, where
, with
. In
Figure 14 (top), the
are chosen as a random complex matrices. For this case we have
(red, magenta, blue curves) as the dimension
increases. For
Figure 14 (middle), the
are chosen as random Hermitian matrices. Here there is a dramatic change in structure. For this case we have
(magenta, blue, red curves), for which
has switched to a proper upper bound of
, and these inequalities hold all the way down to
, the case of two qubits. Further, both
and
track the fluctuations of
surprisingly, extremely well. Finally, in
Figure 14 (bottom) the
are chosen as random orthogonal matrices, and now, very surprisingly, we find that we have
(magenta, blue overlapping red curves), namely that
becomes exactly equal to
, while
remains a lower bound (which appears somewhat tighter than in the previous Hermitian case). Again, these inequalities hold all the way down to
, the case of two qubits.
In general we have found that for
written as a PSD,
based on our pure state negativity approximation given in Equation (11b) does a better job of acting as a lower bound to
than
based on the mixed-state negativity approximation given in Equation (17c). As discussed in the Introduction, Equation (
2), and shown in
Figure 14, we have numerically found that
when the mixed state is written as a pure state decomposition (PSD)
,
and in addition, the quantum amplitude matrix
of each pure state component
is uniformly generated (over the Haar measure) as a positive Hermitian matrix,
. Further, we find that the second inequality is surprisingly saturated, i.e.,
in Equation (
28), if the uniformly randomly generated
matrices above are real, i.e.,
. A discussion of the uniform generation of Hermitian matrices over the Haar measure used in these numerical studies is given in
Appendix B.
6. Summary and Conclusions
In this work we presented numerical evidence for a witness for bipartite entanglement based solely on the coefficients of the pure state wavefunction as opposed to the eigenvalues of the partial transpose of , as appropriate for the Log Negativity. This is achieved by approximating the negativity by diagonally dominant determinants of the coefficients as given in Equation (11a). This agrees exactly with the exact negativity (given by the standard definition obtained by the sum of the absolute values of the negative eigenvalues of the partial transpose ) when is a positive Hermitian matrix (i.e., C is itself a non-unit trace density matrix). Interestingly, these include the cases when (i) C is considered a maximally mixed density matrix, then is the maximally entangled d-dimensional Bell state, while (ii) if C is a pure state density matrix, then is separable, and (iii) symmetric superpositions of pure states with real coefficients. In these cases, . Of particular relevance is that for C being a general complex matrix, we find that acts as proper (but not tight) lower bound for , i.e., .
In the second half of this work, we attempted to generalize our approximation of the negativity from pure states to mixed states via Equation (17b), which reduces to the diagonally dominant determinants formula Equation (11a) for pure states. We met with partial, yet still interesting, success. One of the key features of a negativity based on Equation (
24), a symmetrized version of Equation (11a), is that it yields
on separable states
when either one of the component separable states
or
is
, real. While this of course does not capture all separable states (a non-trivial task), it does capture a wide range of physically relevant density matrices.
In general, we found that a
based on Equation (
24) acts more as an (undesired) upper bound to
as demonstrated vividly on the analytically tractable
d-dimensional Werner states. However, for Werner states we saw that
as the dimension
d grew large, and the corresponding region of separability grew smaller as
.
This led us to consider
for pure state ensemble decomposition (PSD) of the density matrices
, now using our approximation of the pure state negativity via Equation (11a). Again, we saw that as the dimension
d of the pure state components
increased,
acted as a proper lower bound to
, i.e.,
. We speculate that this occurs for similar reasons to for the Werner states, namely that as the dimension
d increases, the region of separable states becomes vanishingly small [
9,
33], and simultaneously our negativity formula Equation (11a) is more accurate on pure states than Equation (17b) on mixed states, and hence the former does a better job of acting as a lower bound.
In summary, the main features of our proposed entanglement witness are (i) a simple formula for an approximate negativity Equation (11a) on bipartite pure states directly in terms of the quantum amplitudes of the quantum states that is also exact for a certain class of physical relevant states (with the Log Negativity related to the negative log of the purity of the quantum amplitude (matrix) when they have the properties of a normalized density matrix, Equation (12c)), and (ii) this negativity formula does not require the need to numerically compute eigenvalues of the partial transpose of the density matrix. An attempted generalization of this pure state negativity formula for pure states to mixed states yields that (iii) in simulations on pure state decompositions (PSDs) of density matrices where the quantum amplitudes
of each of the pure state components
act as positive Hermitian matrices,
Equation (
27), based on the Log Negativity approximation for pure states Equation (11b), yields a proper lower bound to
, and (iv) on the PSD of density matrices in (iii),
provides a proper upper bound to
(with equality when
are orthogonal matrices), and most interestingly, both
and
track, extremely well, the fluctuations in
for uniformly randomly generated states.
As stated in the introduction, the numerical computation of eigenvalues does not present a practical impediment to the calculation of entanglement measures. Rather, it is the surprising and unexpected relationship (and equality for certain physically relevant states, both pure and mixed) between the entanglement witness we propose and the exact Log Negativity that was the impetus for this current investigation. In essence, the main contribution of this work is an extension of the class of states that are amenable to Agarwal’s [
13] method of exact analytical diagonalization. Our conjecture is that these two types of exactly analytical diagonalizable states form the dominant contribution to the entangle of the state as measured by our approximate Log Negativity formula. What is unexpected and surprising is that (i) it yields exact results on a limited class of pure state, (ii) acts as a lower bound (what we refer to as an entanglement witness) on arbitrary pure states, and, even more surprisingly, (iii) yields exact results on a limited class of mixed states. It is our hope that this work might inspire further investigations into a more complete foundational (and proper) derivation underpinning the results presented in these numerical investigations.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}