1. Introduction
According to Benford’s law, the frequency of the first digits of numbers are larger for digit 1 (about 30%) than 2 (about 18%) and so on up to 9 (about 5%). The “law” that governs these probabilities
is
where
. This law originated with Simon Newcomb [
1] and was popularized by Frank Benford [
2]. In 1995, T. P. Hill [
3] proved a theorem that helps explain the success of Benford’s first digit law. According to Hill’s theorem, the frequency of the first digits of numbers randomly drawn from randomly chosen distributions converge to
in the limit of large numbers. Several books introduce and summarize findings on the subject [
4,
5,
6].
Benford illustrated Equation (
1) with “found” or empirical datasets drawn from a number of sources. Many empirical sets of numbers observe or approximate Benford’s first digit law, particularly those that (1) span several decades; (2) have positive skewness; (3) have many entries; and (4) are not intentionally designed. Such datasets have been called “Benford suitable” by Goodman [
7].
Even so, some numerically generated datasets that are Benford suitable do not observe Benford’s law in detail. In particular, consider numbers drawn from an exponential probability density
where
and
are the rate or, equivalently, the inverse mean of the exponential probability density given by
The first digits of numbers drawn from Equation (
2) oscillate with
around
with amplitudes of about 10%.
Random numbers drawn from the exponential probability density (
2) are important because they approximate pieces of a quantity that is randomly partitioned [
8]. Suppose, for instance, that a population
P is to be divided, without bias, into
M cities and towns in such a way that the mean city size
is a definite quantity. If this partition is done so as to maximize the entropy of the partition, we find that the probability of city size
t is given by (
2), where
. See
Appendix A for a derivation of this claim that is inspired by a similar derivation by Iafrate, Miller, and Strach [
9]. Miller and Nigrini [
10] also explore relations between the exponential probability density (
2) and Benford’s law (
1).
We might expect the oscillations in the exponential probability density (
2) with
to have been observed in real-world data. However, our analysis shows that the predicted oscillations emerge from finite-sample noise only with a sample number
10,000. We also describe a real-world example of this first digit oscillation in the populations of US towns and cities as they have evolved over the last hundred years.
2. First Digit Probabilities
The probability
that a number drawn from the exponential distribution (
2) has a first digit
d is given by
According to Equation (4), the first digit probability
is periodic in
in the sense that
. Reference [
11], from whose paper the contents of this section originate, demonstrated that the averages of
over one decade of
are the Benford frequencies
. The
and
terms of a Fourier expansion of (
4) produce the formula
where
r and
are, respectively, the absolute value and argument of the gamma function
.
The first two factors in the second term on the right hand side of (
5) characterize an oscillation amplitude of approximately 10% of the non-oscillating term
, while the last factor is periodic in
. The
Fourier coefficients are approximately
times smaller than the
coefficients. Higher order coefficients are even smaller. Indeed, formula (
5) produces curves visually identical to those produced by the more complete expression (
4).
3. Sample Noise
Because the magnitude of the oscillating term in Equation (
5) is approximately 10% of the non-oscillating term
, its effect can easily be swamped by the noise inherent in finite datasets and finite samples from the exponential probability distribution (
2). We see this in the following way.
Assume a list of
N identically distributed, statistically independent, random numbers indexed with
. Now let
be an indicator random variable defined so that
when the number subscripted
j begins with digit
d and
when the number subscripted
j does not begin with digit
d. We then define the frequency
of the first digit
d among
N numbers as
The expectation value of both sides of Equation (
6) is
since the
are identically distributed,
, and, therefore, we may denote each of these terms by
. When the numbers determining the indicator random variables
are drawn from an exponential distribution,
and
are equal to
.
The variance of
is generated from
Since the
are statistically independent and identically distributed, the
are identical and, therefore, can be denoted by
. Consequently, we find that
Therefore, the variance
is given by
However, because
is an indicator random variable with only two possible values, 0 and 1,
. In this case, the variance (
10) becomes
and the relative standard deviation becomes
Recall that
and that the analysis resulting in Equations (
11) and (
12) applies generally to any distribution with indicator random variable
and expectation value
. Relations (
11) and (
12), between variance and mean, are, of course, not new. They also follow from the binomial probability distribution that governs the indicator variables.
Given a Benford probability
or Benford probability plus oscillation
and standard deviation
, Equation (
12) tells us how many samples
N from a distribution are required to resolve the mean frequency in the presence of finite-sample noise. For instance, in order that the relative standard deviation be small enough for the Benford frequency
of digit
to emerge from noise, say, about
of
,
, which means that
. However, if one also wants the oscillation of
around the Benford frequency
to emerge from sample noise, another
reduction in relative standard deviation is needed. In this case,
or
20,000. We illustrate these calculations in the next section.
4. Sampling
The cumulative probability of the exponential probability density defined in Equation (
2) is
and can be replaced by the uniform random variable
, or, equivalently, by
. Simultaneously,
becomes the random variable
T drawn from the exponential probability density (
2). Therefore, Equation (
13) implies that
The first digit random variable frequency
as determined from the random variables generated by Equation (
14) should reflect the
oscillations with period
as predicted by (
5), and so they do, as long as the number of samples
N is large enough. For more details concerning sampling consult reference [
12].
According to (
12), the relative standard deviation
is smallest for a given sample size
N when
is largest. For exponentially distributed probabilities this means the oscillation in
will most easily be seen in samples of the random variable
, that is, when
.
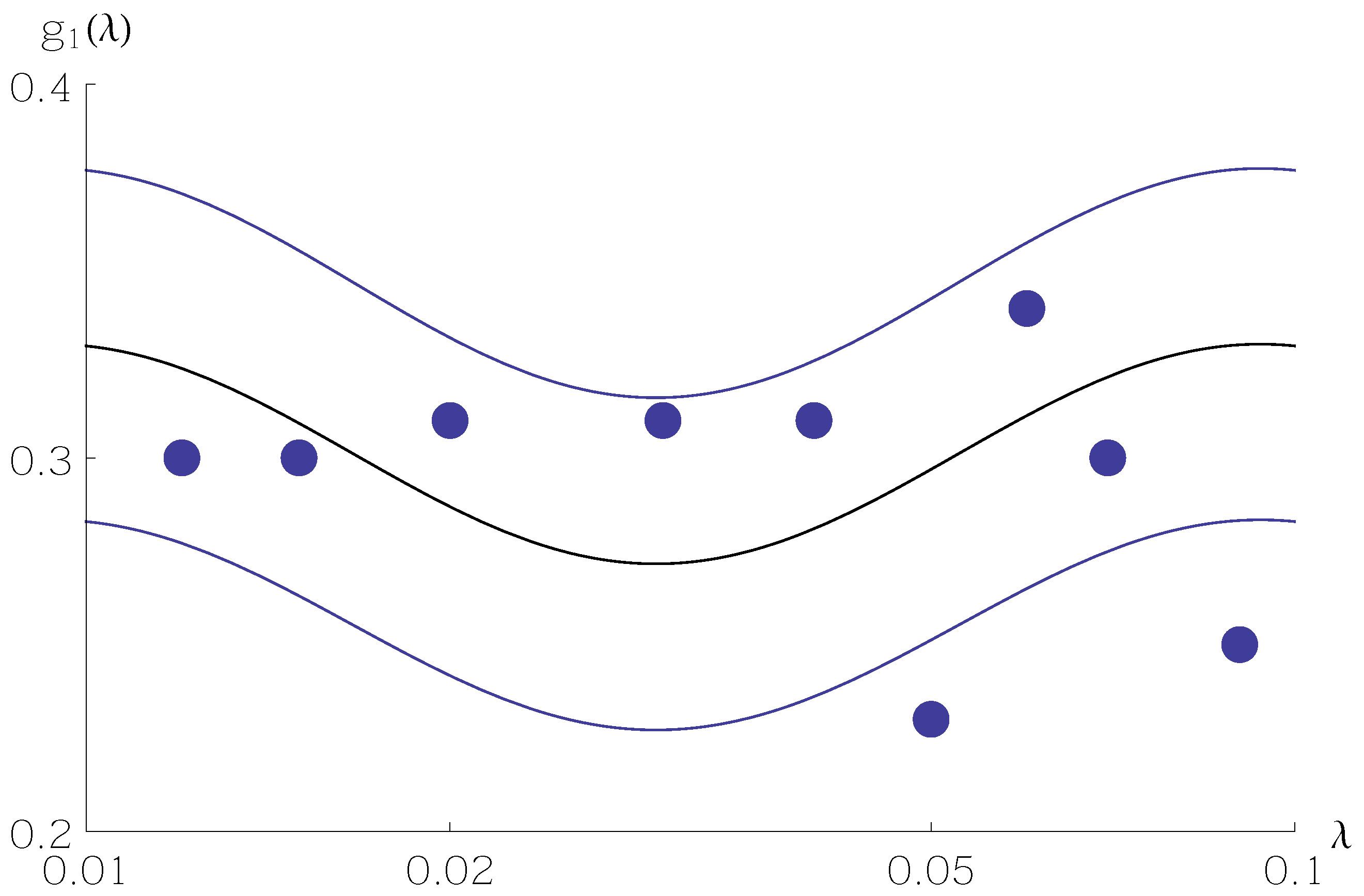
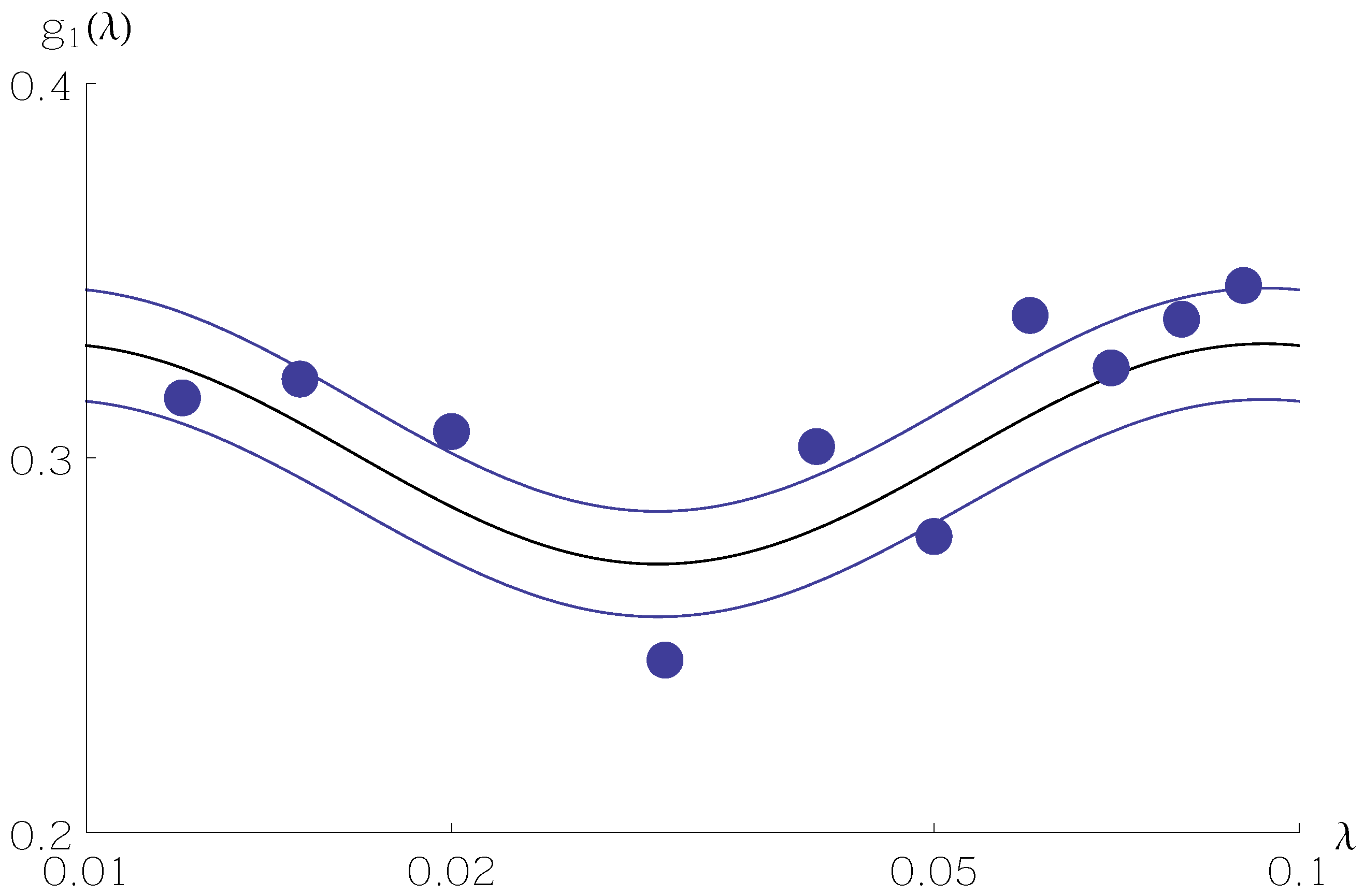
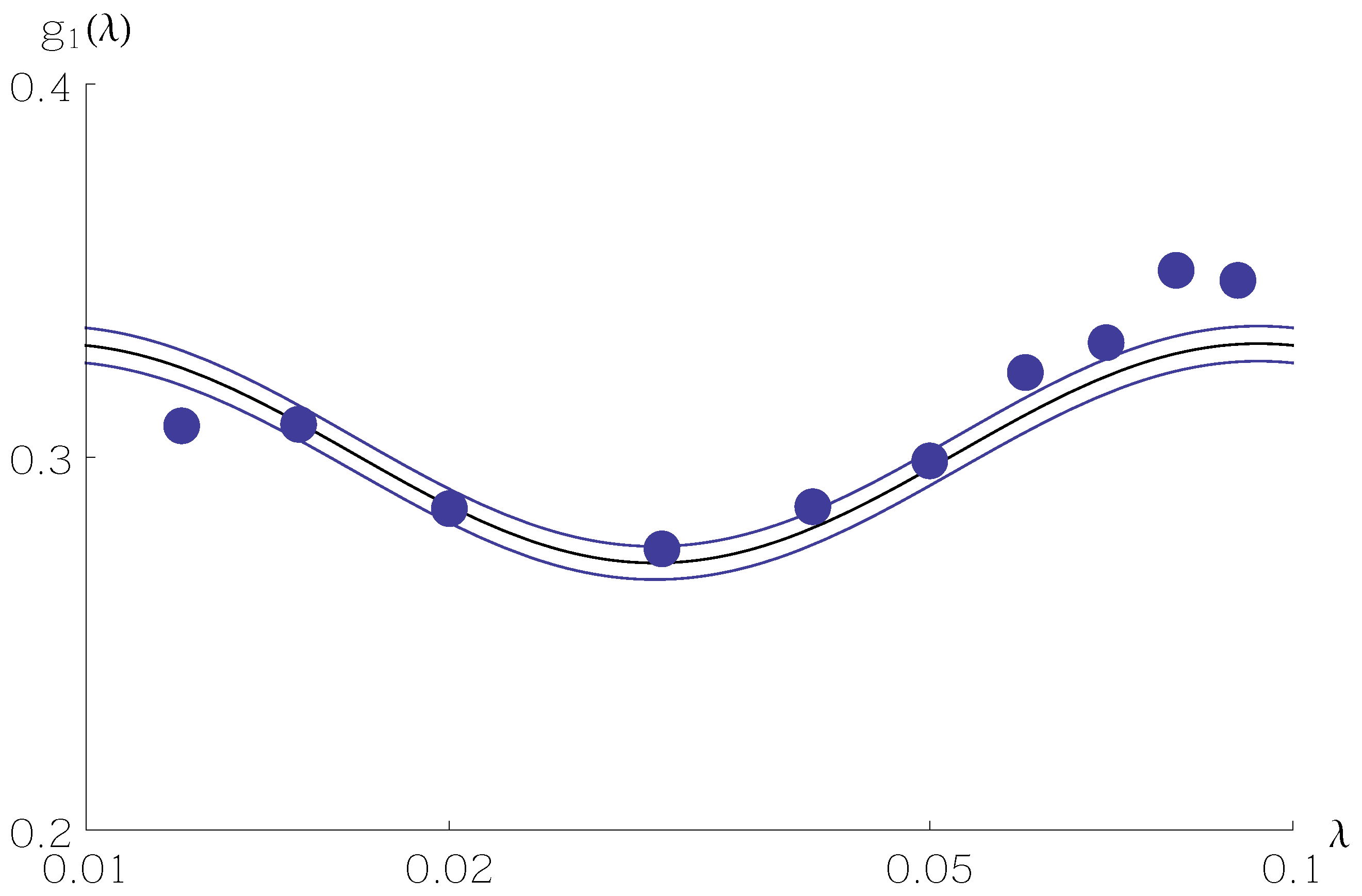
Figure 1,
Figure 2 and
Figure 3 show sample values of
for
N as a function of
between
and
. Values of the random variable
are shown as filled circles. The central curve is
from Equation (
5), and the two surrounding curves are
from Equation (
11) or Equation (
12) with
. Values of the random variable
mainly stay within the standard deviation curves.
A sample size of hardly allows one to discern the Benford frequency much less the oscillation around . Only with larger samples, on the order of 10,000, does the oscillation emerge from finite-sample noise.
5. Population of Towns and Cities in the USA
In order to observe the predicted first digit oscillations in real-world data, one must find datasets with more than approximately 10,000 entries and with several different values of the inverse mean
. For a first effort, no data seems more likely to reveal these oscillations than that of the US Census Bureau as described in [
13]; in particular, the populations of incorporated towns and cities at different 10-year intervals. However, only the decennial censuses from 1970 forward have been digitized. While the population of the USA has increased by
since 1970, the number of towns and cities has also increased. For this reason, the inverse mean of the municipal population
has changed very little between 1980 and 2010.
In order to find town and city population data with significantly different inverse means
, we reached back to the census of 1910. After making the considerable effort to digitize the 1910 populations of 14,000 incorporated towns and cities as listed in the pdf made available by the US Census Bureau [
14], we sorted these numbers (and others from the 1980–2010 period) according to first digits.
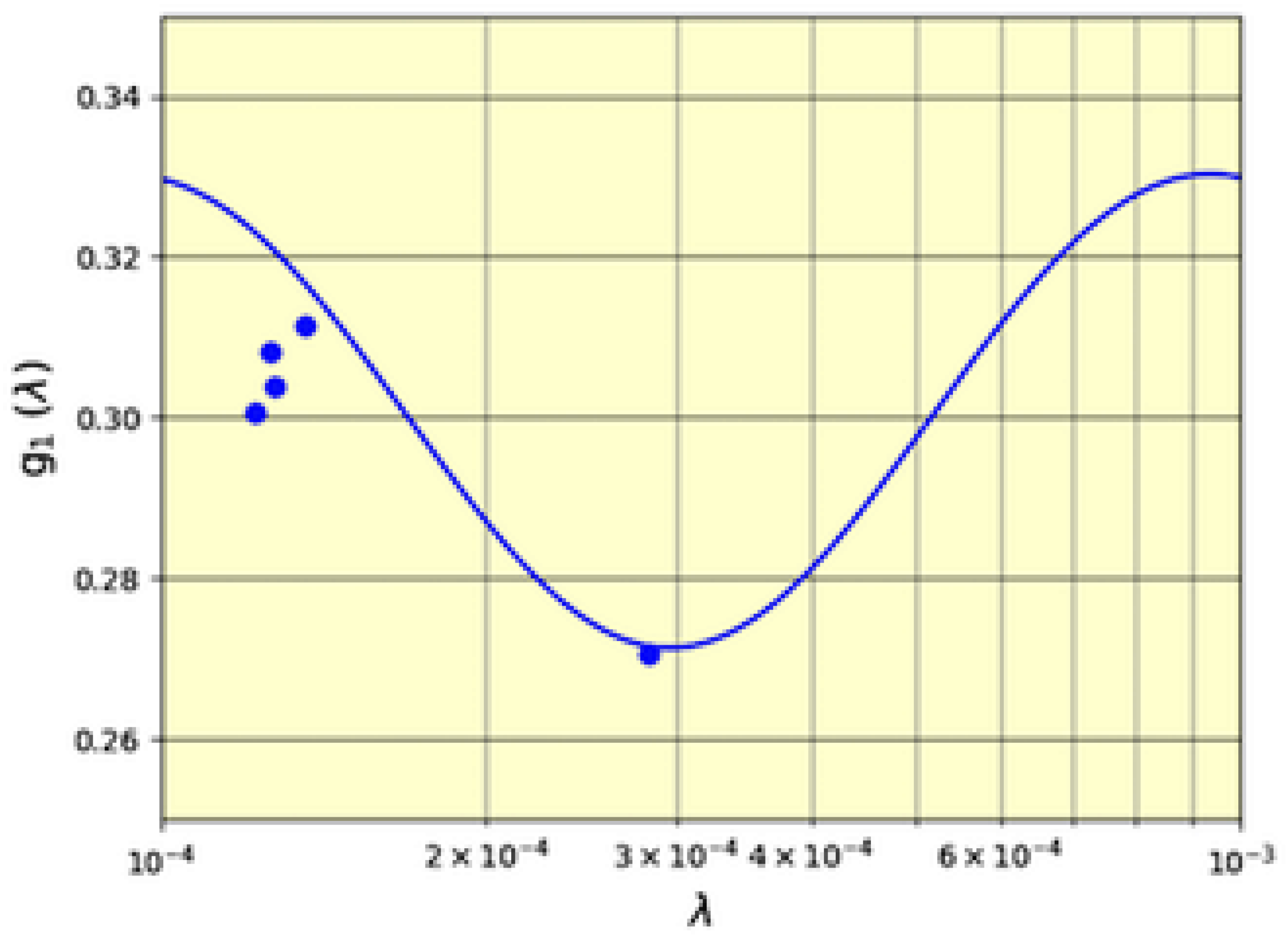
Figure 4 shows the result of our efforts. Here we see the frequency of leading digit 1 for the decennial censuses 1980–2010 (the leftmost group of filled circles) and for 1910 (the rightmost filled circle) versus their respective inverse mean population per town or city
. The probability
of first digit 1 as determined by formula (
5), which derives from the exponential distribution (
2) with parameter
, is also shown.
Figure 4 does not have standard deviation curves because the number of samples is different for each point.
Of course, these data merely suggest that the first digit oscillations around Benford frequencies are a feature of population and other real-world data. As such, we hope it encourages others to look for more conclusive evidence. However, as noted, the prerequisite for this search is a Benford suitable dataset with at least 10,000 entries.
6. Summary and Conclusions
In Equation (
5), we have made explicit the periodic dependence of the first digit frequencies
of numbers that are drawn from an exponential distribution with rate
. According to this relation, the amplitude of these oscillations is approximately
of the Benford frequencies
. We have also demonstrated that the number of data entries required to allow these
oscillations to emerge from sample noise in real-world data should be larger than about 10,000. We have illustrated this requirement in numerical realizations of the simulation algorithm in Equation (
14). The populations of US towns and cities spanning a century is real-world, if anecdotal, evidence of these first digit oscillations.
While the requirement of 10,000 numbers sets a high bar, sufficiently large Benford suitable datasets do exist and have been sorted according to first digit [
15]. The first digit frequencies reported in [
15] appear to be consistent with the predicted
oscillations around Benford values. However, the appropriate value of
, which determines the phase of these oscillations, was not reported.
Alternatively, one might repeat the same experiment many times in which a given quantity is partitioned in such a way that the inverse mean of the partition sizes
is constant. Then, according to the law of large numbers, the mean values of the frequency of first digits will converge to those described by formula (
5). Our analysis may explain why those mining specific datasets for evidence of Benford’s law may only fortuitously find agreement within
of
and then only for certain digits.



{kind=link}
{kind=link}
{kind=link}
{kind=link}