1. Introduction
Unmanned Aerial Vehicles (UAVs), commonly referred to as drones, have experienced a significant surge in popularity due to their versatility, cost-effectiveness, and ability to access hard-to-reach areas. In search-and-rescue (SAR) operations, UAVs provide real-time aerial surveillance, enabling fast response in challenging terrains such as forests, mountains, or disaster-stricken zones. Being equipped with thermal imaging and high-resolution cameras allows them to operate in low-visibility and obstructed environments. In the commercial sector, UAVs are revolutionizing delivery services by offering faster, contactless transportation of goods, especially in remote or urban areas where traditional delivery methods face logistical challenges. Additionally, in geographical mapping [
1], UAVs enable the creation of highly accurate topographical maps and 3D models by capturing detailed aerial imagery [
2] and LiDAR data, aiding in urban planning, agriculture [
3], and environmental monitoring [
4]. UAVs also offer a viable alternative to conventional platforms for acquiring high-resolution remote sensing data [
5]. In military operations, UAVs play a critical role in reconnaissance [
6,
7], surveillance [
8,
9], target acquisition [
10], detecting mines [
11], and even precision strikes [
12], offering strategic advantages while minimizing the risk to human personnel.
Traditionally, UAVs are controlled through methods such as remote piloting via radio frequency (RF) links, ground control stations (GCS) with dedicated software interfaces, and pre-programmed GPS waypoint navigation. In manual control modes, human operators rely on handheld transmitters or laptops connected to the drone to manage flight paths, altitude, and onboard sensors. The manual control mode often requires constant line of sight, stable communication channels, and skilled human operators, especially for complex maneuvers or in unpredictable environments. Traditional control methods present several challenges that can limit the effectiveness and scalability of UAV operations. RF communication is susceptible to signal interference, latency, and range limitations, particularly in urban or mountainous regions where signal obstruction is common. This can compromise the drone’s responsiveness or even result in its loss. Ground control stations, while powerful, are often bulky and rely on stable network connections, making rapid deployment in disaster zones or battlefield conditions more difficult. Pre-programmed GPS navigation, though useful for repetitive tasks like mapping, lacks adaptability to real-time changes such as dynamic obstacles or weather conditions. In all cases, manual piloting requires trained personnel, which can be a bottleneck in emergency situations whenever fast deployment is critical. These challenges highlight the need for more intelligent, autonomous UAV systems that can operate reliably with minimal human intervention, adapt to changing environments, and maintain operational continuity even under adverse conditions.
The limitations of traditional UAV control methods have led researchers to integrate Machine Learning (ML) techniques to enhance drone autonomy, adaptability, and performance [
13,
14]. ML algorithms enable UAVs to interpret complex environmental data, make decisions in real time, and learn from previous experiences without requiring constant human input [
15]. For instance, in search-and-rescue operations, ML-based image recognition can analyze live video feeds to detect human shapes or anomalies in terrain more accurately and faster than human operators [
16]. In navigation, Machine Learning allows drones to dynamically adjust their flight paths in response to obstacles, changing weather, or GPS signal loss, outperforming rigid, pre-programmed routes [
17]. Additionally, ML techniques used for optimal sensor fusion and predictive modeling can improve situational awareness by combining data from multiple onboard sensors (e.g., cameras, LiDAR, IMUs) to infer surroundings and anticipate future decisions, thereby reducing collision risks and enhancing stability [
18,
19,
20].
The use of ML also reduces the reliance on high-bandwidth, low-latency communication channels by allowing the UAV to operate semi- or fully autonomously [
21,
22,
23,
24]. This is especially beneficial in remote areas or signal-compromised environments like dense forests, urban canyons, or disaster zones. Furthermore, Machine Learning can support fleet-level coordination or swarms [
25], enabling multiple UAVs to collaborate, optimize coverage areas, and share learned experiences across missions. By embedding intelligence directly into the UAV’s onboard systems, these approaches not only address the shortcomings of traditional control methods but also unlock new levels of operational efficiency, scalability, and resilience. As hardware capabilities continue to improve and ML algorithms become more sophisticated, their integration into UAV systems is becoming not just a technological advancement but a necessity for meeting the demands of increasingly complex aerial missions.
The methodology used to analyze the surveyed papers in this study was structured around a systematic and comparative framework to evaluate the effectiveness of Multi-Agent Reinforcement Learning (MARL) techniques in UAV control applications. First, a comprehensive collection of recent and relevant peer-reviewed papers was assembled from high-impact journals and conferences, focusing on those that implemented MARL for UAV coordination, navigation, exploration, target tracking, and area coverage. Each paper was then examined based on a set of predefined systematic performance metrics, including environment type (e.g., discrete, continuous, simulated, or real-world), training technique (centralized, decentralized, or hybrid), swarm size, success rate, scalability, fault tolerance, and convergence speed.
For consistency, quantitative values such as swarm size and success rate were extracted directly from experimental results or approximated when reported in graphical form. Qualitative attributes like scalability were categorized as high, moderate, or low based on the authors’ claims, observed performance under varying conditions, and robustness to agent failure or environmental changes. When possible, convergence behavior was assessed through reported training curves or episode counts. This structured comparison enabled a cross-paper analysis, revealing trends, strengths, and limitations of existing approaches. The findings were tabulated and used to identify promising methods, gaps in current research, and areas requiring further investigation.
This paper is organized as follows: first, in
Section 2, we present the different methods of drone control, followed by
Section 3 on Reinforcement Learning (RL) and how it could be used in drone control.
Section 4 presents Value-Based Multi-Agent Reinforcement Learning Techniques, followed by Policy-Based Multi-Agent Reinforcement Learning Techniques in
Section 5. Multi-agent Federated Reinforcement Learning Techniques are presented in
Section 6. A comparison between all three of the techniques is presented in
Section 7. Open research problems and discussions are presented in
Section 8 followed by the Conclusion in
Section 9.
3. Reinforcement Learning
To possibly overcome the previously discussed limitations, researchers have turned to the use of Reinforcement Learning (RL), one of the three main paradigms of Machine Learning. Unlike data-training-based Machine Learning, RL uses learning through experience in which an agent learns to accomplish a goal by performing actions and receiving feedback in the form of rewards or penalties. The rewards inform the agent of the effectiveness of the action, influencing subsequent decisions [
46]. The goal is to maximize the total reward over time. This approach is inspired by behavioral psychology and is commonly used in areas such as robotics, game playing, and autonomous systems, where learning from direct experience is essential. RL, particularly Deep Reinforcement Learning (DRL), has been instrumental in enabling Unmanned Aerial Vehicles (UAVs) to autonomously execute specific tasks with minimal human oversight. This advancement is evident across various applications, including navigation, obstacle avoidance, and mission planning [
47,
48]. However, a major ongoing challenge is managing a group of these UAVs, each tasked with individual and collective tasks, particularly under demanding conditions like high turbulence and severe storms. In [
49], a DRL algorithm known as Proximal Policy Optimization (PPO) was implemented to control two drones equipped with distinct memory capabilities. Additionally, Curriculum Learning was employed to progressively train the drones to navigate environments ranging from those with few obstacles to others featuring multiple and complex obstacles. For example, in [
50], the authors present a path planning method that combines goal-conditioned Reinforcement Learning (RL) with Curriculum Learning to enable Unmanned Aerial Vehicles (UAVs) to handle increasingly complex missions. The training begins with simple tasks, such as reaching a single target, and progressively advances to more challenging scenarios, including round-trip navigation involving multiple sub-goals. This structured approach allows the UAVs to build upon foundational skills, leading to improved performance in environments with varying levels of complexity. This method demonstrated remarkable improvements with a 92% success rate in relatively complex tasks and a 77% success rate in round-trip missions. However, the agent did not take the most efficient route to the goal in some cases. This efficiency limitation becomes more evident in complex missions involving multiple waypoints or round-trip scenarios.
The concept of RL is straightforward when applied to a single agent. In this setting, the agent interacts with an environment by making actions based on a policy, observes the impact of the actions, and receives rewards or penalties. The agent’s goal is to learn an optimal policy that maximizes the cumulative reward over time. The environment is typically considered stationary, meaning its dynamics do not change based on the agent’s actions. This allows the agent to gradually improve its decision-making through trial and error, leveraging algorithms like Q-learning [
51,
52], SARSA [
53], or policy gradient methods [
54]. The simplicity of this setup—one agent, one policy, one learning objective—makes it easier to model, analyze, and implement. It provides a controlled framework where concepts such as exploration vs. exploitation, reward shaping, and value estimation can be clearly defined and systematically improved. However, complexities arise when multiple agents are involved. Optimizing the learning process to train multiple agents efficiently, with minimal computational resources and script usage, becomes a challenge. Additionally, for parameters that provide a continuous action space—such as drone velocity, acceleration, or angular control—selecting the most suitable algorithm to handle such dynamics is crucial. In other words, adapting Reinforcement Learning (RL) algorithms for such scenarios requires the use of specialized methods beyond traditional discrete-action algorithms like Q-learning. In such environments, policy-based and actor–critic algorithms are preferred, as they are better suited for learning continuous control policies. More advanced actor–critic approaches like Deep Deterministic Policy Gradient (DDPG) [
55], Twin Delayed DDPG (TD3) [
56] and Soft Actor–Critic (SAC) [
57] offer improved stability and performance. These methods combine a value function (critic) with a policy function (actor), allowing for efficient learning in high-dimensional, continuous domains.
Reinforcement Learning (RL) relies on the assumption that an agent operates within a Markovian environment, leading to decision problems commonly modeled by the Markov Decision Process (MDP) [
58]. The foundational concept in this model is the Markov Property, which asserts that the probability of transitioning to the next state depends solely on the current state and not on any previous states [
59].
A Markov Decision Process (MDP) is a mathematical framework for modeling decision-making in environments where outcomes are partly random and partly under the control of an agent. A Markov Decision Process (MDP) is defined as a 5-tuple:
where
is a finite set of states.
is a finite set of actions.
is the transition probability function, giving the probability of transitioning to state from state s after taking action a.
is the reward function, specifying the expected reward received after taking action a in state s.
is the discount factor, representing the importance of future rewards.
The agent’s objective is to learn a policy
that maximizes the expected cumulative discounted reward:
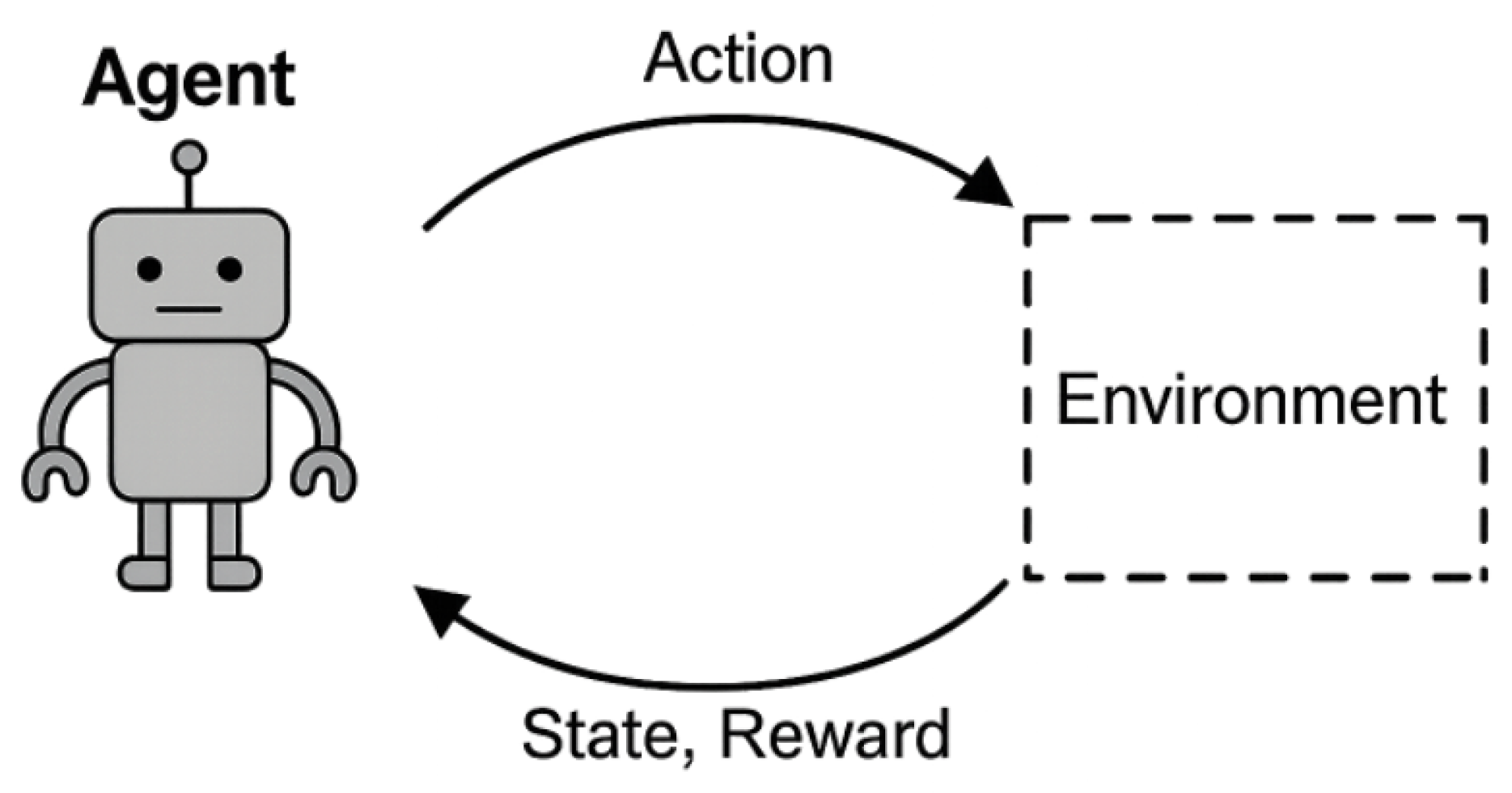
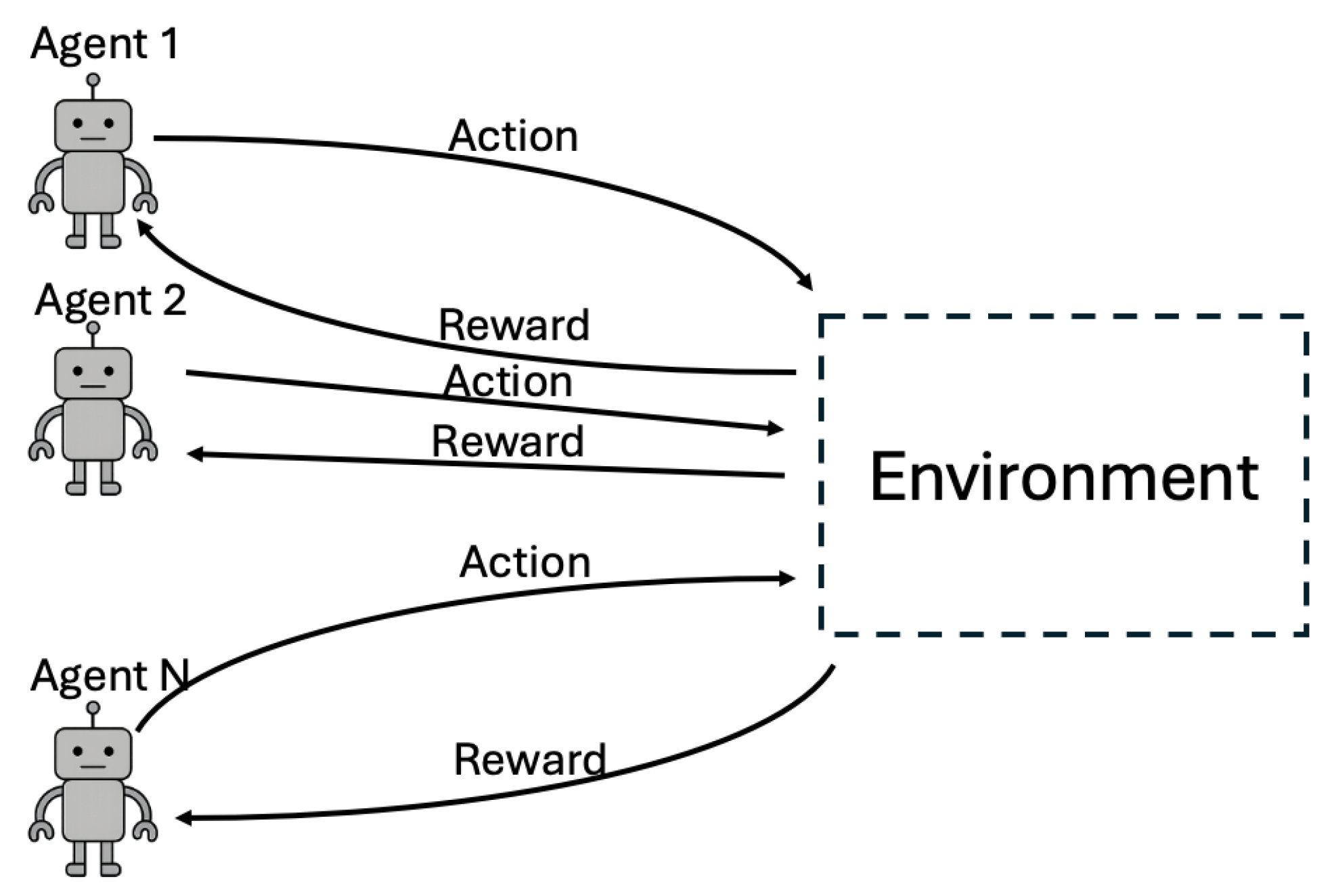
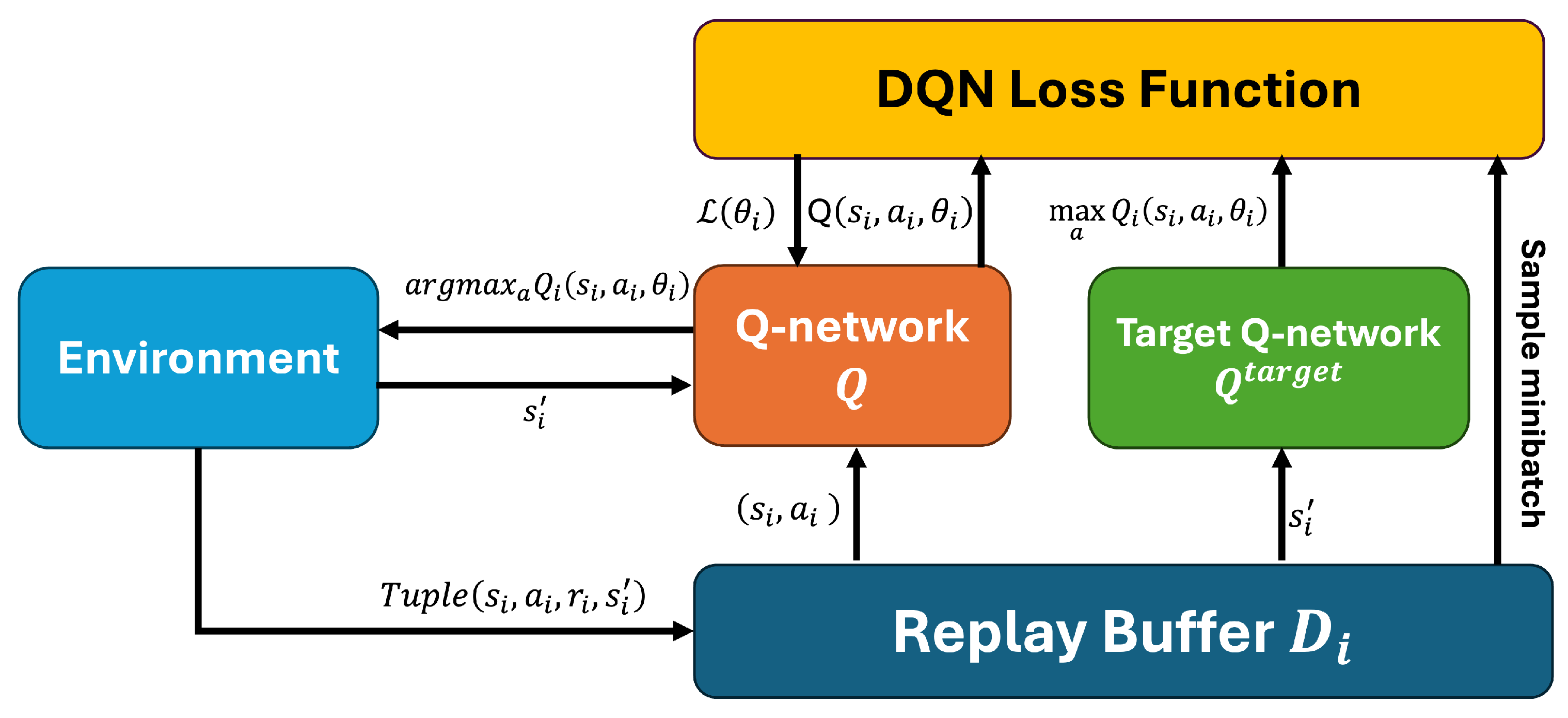
The Multi-Agent Reinforcement Learning (MARL) algorithm and its variations address the complexities of controlling multiple agents, such as a swarm of UAVs. This paper explores a broad spectrum of drone control methods, focusing on how MARL facilitates the coordination of UAV swarms during specific operations. Unlike Single-Agent Reinforcement Learning (SARL), which involves one agent interacting solely with its environment
Figure 2, MARL introduces multiple agents into the same environment
Figure 3. A Multi-Agent Reinforcement Learning (MARL) environment can be modeled as a Markov Game (Stochastic Game), defined by the tuple
where
is the set of global states.
is the action space for agent i, and the joint action space is .
is the transition function, determining the probability of transitioning to state given current state s and joint action .
is the reward function for agent i.
is the discount factor.
Figure 2.
Pictorial representation of Single-Agent Reinforcement Learning. The figure shows the flow of interaction in a typical Single-Agent Reinforcement Learning algorithm.
Figure 2.
Pictorial representation of Single-Agent Reinforcement Learning. The figure shows the flow of interaction in a typical Single-Agent Reinforcement Learning algorithm.
Figure 3.
Pictorial representation of Multi-Agent Reinforcement Learning. The figure shows the flow of interaction in a typical Multi-Agent Reinforcement Learning Algorithm.
Figure 3.
Pictorial representation of Multi-Agent Reinforcement Learning. The figure shows the flow of interaction in a typical Multi-Agent Reinforcement Learning Algorithm.
Each agent
i seeks to learn a policy
that maximizes its own expected return:
In MARL, these agents interact not only with the environment but also with each other [
60]. While each agent individually observes the shared environment’s state and decides on an action, it must also consider the actions and potential reactions of other agents. This scenario presents a unique challenge: although there is only one environment and one collective state, the presence of multiple agents necessitates individual policies and results in diverse rewards. Other major challenges arise from the non-stationarity of the environment and the scaling or dimensionality [
61,
62]. MARL algorithms can be broadly categorized into three types [
63]: value-based MARL, which focuses on updating the value functions of state–action pairs; policy-based MARL, which directly optimizes the policy functions guiding the agents’ actions; and actor–critic methods, which combine the strengths of both value-based and policy-based approaches. The “actor” updates the policy directly, while the “critic” evaluates the action by estimating value functions [
64]. This combination allows for more stable and efficient learning in complex environments [
65]. Actor–critic methods are generally considered a subclass of policy-based methods in the field of Reinforcement Learning [
66].
As mentioned before, Reinforcement Learning (RL) algorithms can be categorized based on several criteria. Firstly, they are divided into value-based and policy-based algorithms, depending on whether the updates are applied to value functions or policies. Secondly, they can be classified according to the nature of their state and action spaces into discrete- or continuous-time states and action RL algorithms. Lastly, RL algorithms are differentiated based on the number of agents they manage, categorized as Single-Agent and Multi-Agent Reinforcement Learning algorithms. In subsequent sections, these classifications are explored in greater detail.
5. Policy-Based Multi-Agent Reinforcement Learning Techniques
Policy-based methods, also known as policy gradient methods, aim to directly model and optimize the policy. The parameterized policy, represented as
, is defined as a function of
[
82]. The objective function’s value depends on this policy, and various algorithms are employed to optimize the parameter
to maximize the reward, as outlined in [
82]. Policy-Based Multi-Agent Reinforcement Learning (MARL) techniques are a pivotal framework in the field of Reinforcement Learning, especially when dealing with environments involving multiple interacting agents [
67,
83]. These methods synergize policy-based (actor) and value-based (critic) approaches, enabling agents to learn optimal behaviors in complex, dynamic, and often partially observable settings [
84,
85]. At the core of policy-based methods lies the direct optimization of policies, which can be particularly advantageous in high-dimensional or continuous action spaces [
86,
87]. Unlike value-based methods that derive policies indirectly through value functions, policy-based approaches adjust the policy parameters directly to maximize expected returns. This direct optimization can lead to more stable and efficient learning, especially in scenarios where value estimation is challenging [
88]. In multi-agent scenarios, policy-based methods must account for the non-stationarity introduced by concurrently learning agents, making the design of effective algorithms particularly challenging [
83,
89]. Techniques such as Centralized Training with Decentralized Execution (CTDE) have been proposed to address these challenges, allowing agents to learn coordinated behaviors while operating independently during execution [
84,
90]. Policy-based MARL techniques have been applied across various domains, including autonomous driving, robotic coordination, and resource management [
91,
92]. For instance, in network load balancing, these methods have been utilized to dynamically distribute traffic, optimizing performance and reducing congestion [
92]. In robotic swarms, policy-based algorithms facilitate coordinated behaviors without centralized control, enhancing adaptability and robustness [
93,
94]. One can conclude that these methods are particularly well-suited for applications requiring continuous action control, such as robotic manipulations and drone speed adjustments. Despite their successes, policy-based MARL methods face challenges such as scalability to large agent populations, efficient communication protocols, and robustness to partial observability [
62,
67]. Future research is directed toward developing more scalable architectures, incorporating meta-learning for adaptability, and designing algorithms that can operate effectively with limited communication [
67,
68]. In the following subsections, we will explore three Policy-Gradient Multi-Agent Reinforcement Learning (MARL) algorithms and their applications in UAV control.
5.1. Deep Deterministic Policy Gradient (DDPG)
Deep Deterministic Policy Gradient (DDPG) is a model-free, off-policy actor–critic algorithm that employs a deterministic policy to address the challenge of discrete action spaces inherent in Deep Q-Networks (DQNs) [
95]. In contrast, DQNs stabilize the Q-function learning process through experience replay and a frozen target network. Multi-agent DDPG (MADDPG) extends the DDPG framework to environments with multiple agents operating synchronously, each using locally observed information [
84]. In MADDPG, each agent perceives the environment as dynamic due to the continuous policy updates from other agents, whose policies are unknown. It was designed to address the challenges posed by decentralized decision-making and non-stationarity in multi-agent systems. It was introduced by [
84] as an extension of the Deep Deterministic Policy Gradient (DDPG) algorithm [
55] to cooperative and competitive environments involving multiple agents. In Single-Agent Reinforcement Learning, DDPG has been shown to perform well in continuous action spaces using a deterministic actor–critic architecture. However, applying DDPG independently in multi-agent environments leads to non-stationary learning dynamics, as the environment’s state distribution changes with the evolving policies of other agents [
83,
89]. This non-stationarity can degrade learning performance or even lead to divergence. To address this, MADDPG introduces a centralized training and decentralized execution (CTDE) paradigm. During training, each agent has access to a centralized critic that takes into account the global state and actions of all agents. This allows the critic to estimate more accurate gradients despite the non-stationarity caused by other learning agents. However, the actor (policy network) for each agent uses only local observations during execution, enabling scalability and applicability in real-world distributed systems [
84].
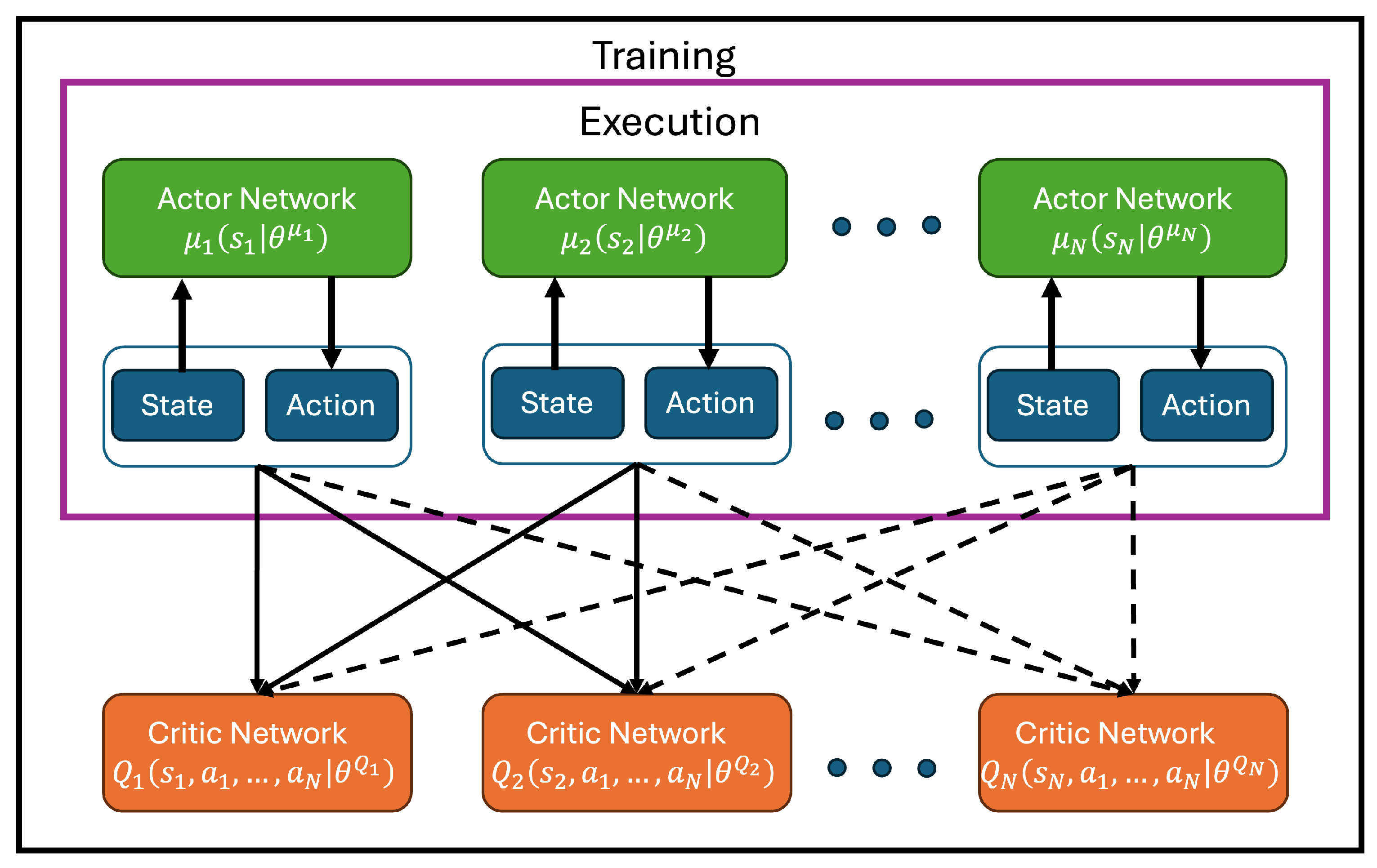
The Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm structure is shown in
Figure 6, while the algorithm is shown in Algorithm 3. It extends the Deep Deterministic Policy Gradient (DDPG) method to multi-agent environments by adopting the Centralized Training with Decentralized Execution (CTDE) paradigm. In MADDPG, each agent
learns a deterministic policy (actor)
, where
is the local observation of agent
i and
represents the parameters of the actor network. The corresponding action is given by
.
During training, each agent also maintains a centralized critic network
, where
x is the global state (which may include all agents’ observations),
are the actions of all agents, and
are the critic’s parameters. The target value for critic training is computed as
where
is the reward received by agent
i,
is the discount factor,
is the target critic network, and
are the actions predicted by the target actor networks at the next state
for all agents
j.
The critic network is updated by minimizing the following loss function:
where
K is the minibatch size and
are sampled from the replay buffer.
| Algorithm 3 Multi-Agent Deep Deterministic Policy Gradient (MADDPG) |
- 1:
Initialize environment with N agents - 2:
for each agent do - 3:
Initialize actor network and critic network - 4:
Initialize target networks: , - 5:
Initialize replay buffer - 6:
end for - 7:
for episode = 1 to M do - 8:
Initialize random process for exploration - 9:
Receive initial State - 10:
for time step to T do - 11:
for each agent i do - 12:
Select action - 13:
end for - 14:
Execute joint action and observe reward and next State for each agent - 15:
for each agent i do - 16:
Store in - 17:
Sample a minibatch of K transitions from - 18:
- 19:
where for all agents j - 20:
Update critic by minimizing: - 21:
Update actor using the policy gradient: - 22:
- 23:
end for - 24:
end for - 25:
end for
|
The actor is updated using the deterministic policy gradient, given by
Target networks for both the actor and critic are updated using soft updates as follows:
where
is the soft update rate.
MADDPG has demonstrated significant success in cooperative navigation tasks, autonomous vehicle coordination, and multi-robot systems. In the Multi-Agent Particle Environment (MPE) benchmark, MADDPG outperformed independent DDPG and Q-learning baselines by enabling agents to learn coordinated strategies [
84]. It has also been adopted in domains such as autonomous drone swarms [
67] and smart grid energy management [
92], showcasing its flexibility. Despite its success, MADDPG is not without limitations. The use of separate critics for each agent limits scalability to large agent populations. Furthermore, it assumes that agents can access the actions and observations of others during training, which may not always be feasible in partially observable settings. These limitations have inspired variants and improvements, such as MAAC and MAPPO, that aim to improve coordination, scalability, and robustness [
90,
93]. In [
77], MADDPG was compared with the Multi-agent Deep Q-Network (MADQN) algorithm, incorporating three learning strategies to enhance the speed and accuracy of UAV training for combat tasks. MADDPG demonstrated superior performance, achieving better convergence and providing more decision-making options for UAVs due to its operation in the continuous domain and the use of a continuous action space. Article [
96] compares the implementation of the DDPG, TRPO, and PPO algorithms in drone control against each other and a well-tuned PID controller. Specifically, DDPG was used to train drones for flight and stability maintenance. Although DDPG required a lengthy training period, it achieved convergence more quickly than TRPO. MADDPG works well for drones as it supports continuous action spaces, suitable for the control of thrust, pitch, and yaw, and it allows decentralized execution, which is necessary for independent UAV operation. It also enables the scalable training of multiple drones via centralized critics and finally, it is adaptable to partial observability and communication-constrained environments. In [
67], MADDPG was used to train quadrotors to maintain formations while avoiding collisions, using only partial observations in simulated environments like AirSim or Gazebo. In [
92] MADDPG allows drones to navigate between buildings and through air lanes by learning optimal control under flight constraints in urban air mobility simulations. In [
97], an artificial intelligence approach called Simultaneous Target Assignment and Path Planning (STAPP) is used to solve the multi-UAV target assignment and path planning (MUTAPP problem), which leverages the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm to model and train agents to handle both target assignment and path planning concurrently, guided by a specially designed reward structure.
5.2. Multi-Agent Trust Region Policy Optimization (MATRPO)
Trust Region Policy Optimization (TRPO) aims to limit excessive changes in policy updates by incorporating a KL divergence constraint, thereby reducing the number of parameter updates per step [
98]. However, TRPO has not fully resolved the issue of minimizing parameter updates, making it less reliable for controlling hardware agents. This limitation led to the development of the PPO algorithm.
Multi-Agent Trust Region Policy Optimization (MA-TRPO) extends the principles of Trust Region Policy Optimization (TRPO) to Multi-Agent Reinforcement Learning (MARL) scenarios. While TRPO has demonstrated stability and performance in single-agent settings by ensuring monotonic policy improvements through constrained updates, its direct application to multi-agent environments introduces challenges due to the dynamic interactions among multiple learning agents [
83]. In MARL, each agent’s learning process can affect and be affected by the learning processes of other agents, leading to a non-stationary environment from any individual agent’s perspective. This interdependence complicates the application of TRPO, which assumes a stationary environment for its theoretical guarantees to hold. To address this, researchers have developed adaptations of TRPO tailored for multi-agent settings. One such adaptation is the Multi-Agent Trust Region Policy Optimization (MATRPO) algorithm proposed by [
99], which reformulates the TRPO update as a distributed consensus optimization problem. This approach allows agents to optimize their policies based on local observations and private rewards without requiring access to other agents’ information, promoting a decentralized and privacy-preserving learning process. Empirical evaluations have demonstrated MATRPO’s robust performance in cooperative multi-agent tasks.
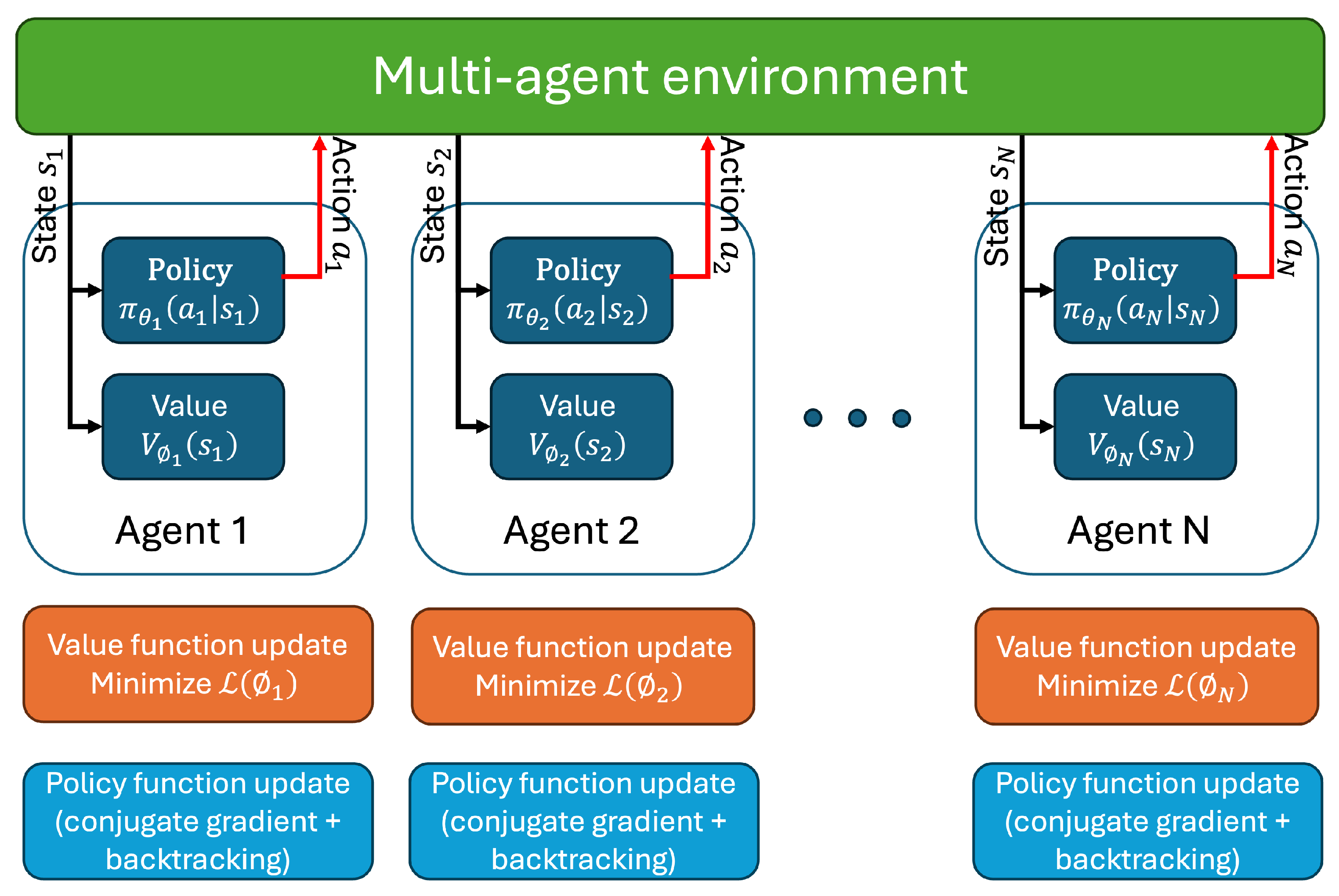
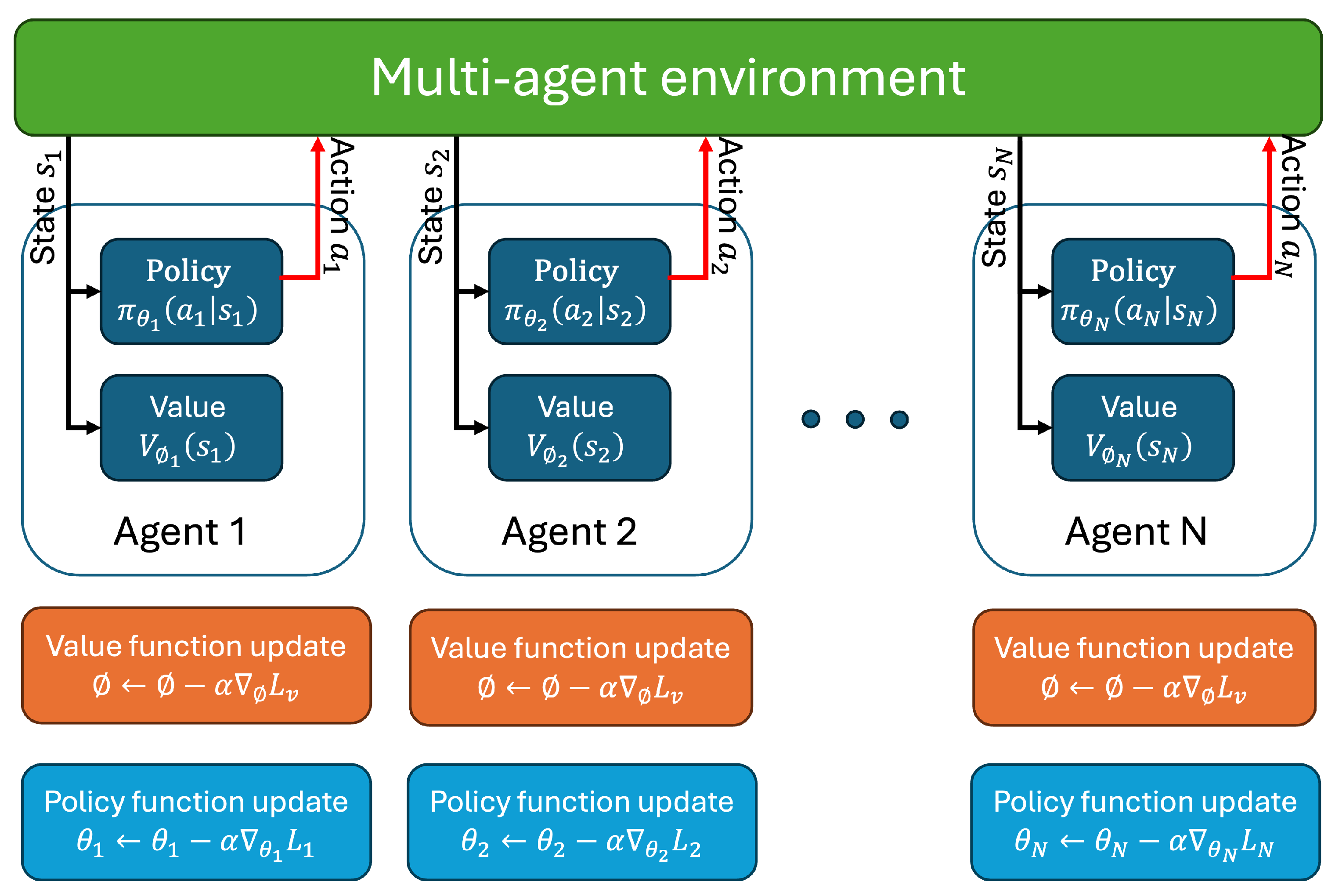
The
Multi-Agent Trust Region Policy Optimization (MATRPO) structure is shown in
Figure 7, while the algorithm is shown in Algorithm 4 [
100,
101]. In this framework, a set of agents
interact with a shared environment modeled as a Markov Game. Each agent
i has its own policy
and value function
, where
and
denote the respective parameter vectors. Agents observe local states
, take actions
, and receive rewards
, aiming to maximize the expected return
. Training is conducted under the Centralized Training with Decentralized Execution (CTDE) paradigm.
During each iteration, each agent collects trajectories
by executing its current policy in the environment. The advantage function
, often estimated using Generalized Advantage Estimation (GAE), is computed to evaluate the benefit of taking action
in state
s. The policy gradient for agent
i is computed as
To ensure stable updates, MATRPO imposes a trust region constraint using the Kullback–Leibler (KL) divergence between the old and new policies. This leads to the following constrained optimization problem:
where
is the Hessian of the sample average KL-divergence, approximated as
and
is a predefined KL-divergence bound. The optimal update direction
is computed using the conjugate gradient method, followed by a backtracking line search to enforce the KL constraint. Finally, each agent updates its value function by minimizing the mean squared error between predicted and actual returns:
MATRPO allows each agent to learn a stable and effective decentralized policy while leveraging centralized training to improve coordination and performance in multi-agent environments.
| Algorithm 4 Multi-Agent Trust Region Policy Optimization (MATRPO) |
- 1:
Initialize policy parameters and value function parameters - 2:
Set KL-divergence constraint - 3:
for each iteration do - 4:
for each agent do - 5:
Collect trajectories using policy in the environment - 6:
Estimate advantage function using value function - 7:
- 8:
Compute the Hessian of the sample average KL-divergence: - 9:
Solve constrained optimization: - 10:
Use conjugate gradient to compute step direction - 11:
Perform backtracking line search to ensure KL-divergence - 12:
Update policy: - 13:
Update value function parameters by minimizing: - 14:
end for - 15:
end for
|
Another significant development is the Heterogeneous-Agent Trust Region Policy Optimization (HATRPO) algorithm [
102], which introduces a sequential policy update scheme and a multi-agent advantage decomposition lemma. HATRPO enables agents with different policy and value function structures to learn effectively without sharing parameters or relying on restrictive assumptions about the decomposability of the joint value function. This method has shown superior performance in various benchmarks, including Multi-Agent MuJoCo and StarCraft II tasks. In parallel, Wen et al. [
103] proposed a game-theoretic formulation of trust-region optimization in multi-agent systems, resulting in the Multi-Agent Trust-Region Learning (MATRL) method. MATRL uses Nash equilibrium concepts to guide policy updates and ensure convergence in competitive and cooperative environments, further strengthening the theoretical underpinnings of trust-region approaches in multi-agent learning.
Multi-Agent Trust-Region Policy Optimization (MATRPO) has shown significant promise in the field of autonomous drones (UAVs), particularly in scenarios that require decentralized coordination, robustness, and policy stability in dynamic environments. MATRPO extends the Trust Region Policy Optimization (TRPO) framework into multi-agent systems by reformulating the policy optimization as a distributed consensus optimization problem [
99]. This formulation is particularly suitable for UAV applications where each drone must act autonomously using local observations while collectively achieving a global task. In many UAV missions, such as aerial surveying, disaster relief, and military surveillance, individual drones have access to only partial state information due to limited sensing and communication constraints. MATRPO enables each agent to update its policy independently without needing access to the policies or observations of other agents, a critical advantage over fully centralized algorithms [
83,
99]. This makes MATRPO ideal for distributed drone swarms operating in GPS-denied or bandwidth-constrained environments, where decentralized execution is not just efficient but also necessary [
104]. UAVs are often deployed in non-stationary environments, such as regions with changing wind patterns, moving obstacles, or adversarial interference. MATRPO’s trust region mechanism, which restricts the KL divergence between consecutive policies, ensures that policy updates are stable and conservative, avoiding performance collapses due to overly aggressive updates [
86,
99]. This is particularly important for aerial applications, where erratic behavior can lead to mission failure or hardware loss. Applications of MATRPO spans areas for coverage and exploration [
105], search and rescue (SAR) [
106], and emergency communication and network access [
107]. Compared to methods like MADDPG or MAPPO, which often require centralized critics or synchronized updates, MATRPO offers a fully decentralized and privacy-preserving framework with the stability benefits of trust region optimization. This makes it highly suitable for UAVs operating in real-world scenarios where central coordination is infeasible or unsafe [
99]. The major drawback is that TRPO exhibits the longest training times compared to MADDPG and MAPPO, explaining its infrequent use in UAV control. Despite this drawback, TRPO achieves precise convergence during training, making it beneficial for controlling ground vehicles and robotics.
5.3. Proximal Policy Optimization (PPO)
PPO performs optimization using a batch of navigation examples and minibatch stochastic gradient descent to maximize the objective [
87], simplifying the algorithm by eliminating the KL penalty and the need for versatile updates. It balances updates between the current policy
and the previous policy
that created the batch, preventing excessive updates beyond the region where the sample provides a reliable estimate. PPO also integrates with the actor–critic framework, where each agent uses one actor and multiple critic networks for faster and distributed learning. Multi-Agent Proximal Policy Optimization (MAPPO) is an extension of the Proximal Policy Optimization (PPO) algorithm tailored for Multi-Agent Reinforcement Learning (MARL) environments. It employs a Centralized Training with Decentralized Execution (CTDE) framework, where each agent learns its policy while a centralized critic evaluates the joint actions, facilitating stable learning in cooperative settings.
The Multi-Agent Proximal Policy Optimization (MAPPO)structure is shown in
Figure 8, while the algorithm is shown in Algorithm 5 [
108]. In MAPPO, each agent
i learns a decentralized policy
based on its own local observation
, while benefiting from a centralized critic
that has access to the global state
s during training.
| Algorithm 5 Multi-Agent Proximal Policy Optimization (MAPPO) |
- 1:
Initialize policy parameters for n agents - 2:
Initialize centralized value function parameters - 3:
for each iteration do - 4:
for each environment rollout do - 5:
for to T do - 6:
for each agent to N do - 7:
Observe local state - 8:
Sample action - 9:
end for - 10:
Execute joint action - 11:
Observe next state s and joint reward - 12:
Store in buffer - 13:
end for - 14:
end for - 15:
for each agent to N do - 16:
Compute advantages using Generalized Advantage Estimation (GAE): - 17:
Compute the PPO objective: - 18:
Update policy parameters: - 19:
end for - 20:
Update value function parameters by minimizing: - 21:
end for
|
The learning objective of each agent is adapted from PPO’s clipped surrogate loss, which stabilizes policy updates by preventing large deviations between the new and old policy. The surrogate loss function for agent
i is defined as
where the probability ratio
is given by
and
denotes the advantage function for agent
i, which is estimated using Generalized Advantage Estimation (GAE):
Here, is the discount factor and controls the bias-variance tradeoff in advantage estimation.
The centralized value function
is updated by minimizing the mean squared error between the predicted value and the actual return
R:
MAPPO has demonstrated strong empirical performance in several benchmark environments, such as the StarCraft Multi-Agent Challenge (SMAC) and Multi-Agent MuJoCo, by leveraging stable and efficient policy optimization for cooperative multi-agent systems. In [
49], PPO was used to train two UAVs individually and as a pair for navigation recommendations, while the drone control was manually handled by a remote pilot. This semi-autonomous control approach is suitable for military operations in war zones, where distinguishing between allies and foes is challenging, providing precise navigation paths for manual operation by a remote pilot. In [
109], PPO was employed to train 50 UAVs for cooperative persistent surveillance in an unknown environment. A neural network using PPO enabled the swarm to navigate and avoid collisions effectively in a complex environment with numerous obstacles. PPO was also used to train UAVs for stability in multi-agent environments in [
110], simulated using the PyBullet gym in OpenAI. The dynamic environment created various scenarios and obstacles, and PPO was found to be well-balanced in training time and convergence accuracy compared to other algorithms. In [
77], a complex UAV-to-UAV combat situation was simulated, requiring UAVs to gather information from teammates and enemies. A decentralized PPO approach with decentralized actors and a centralized critic was implemented in a four-UAV swarm combating a two-UAV swarm. This approach outperformed a centralized PPO, which struggled with convergence as the number of UAVs increased. PPO remains the most versatile training algorithm in robotics [
7]. In [
111], the authors introduce a multi-UAV escape target search algorithm based on MAPPO to address the escape target search difficulty problem. The authors of [
90] demonstrated the effectiveness of MAPPO across various MARL benchmarks, including the StarCraft Multi-Agent Challenge (SMAC) and Google Research Football, highlighting its superior performance over other algorithms like MADDPG and COMA. Further advancements, such as the MAPPO-PIS algorithm introduced in [
112], incorporates intent-sharing mechanisms to enhance cooperative decision-making among connected and autonomous vehicles (CAVs), showcasing improved safety and efficiency in complex traffic scenarios. Liu et al. [
113] presents a path planning approach utilizing an action-mask-based Multi-Agent Proximal Policy Optimization (AM-MAPPO) algorithm to coordinate multiple UAVs in the search for moving targets within three-dimensional (3D) environments. Specifically, it introduces a multi-UAV high–low altitude collaborative search architecture that combines the wide detection range offered by high-altitude UAVs with the enhanced detection accuracy provided by low-altitude UAVs. Multi-Agent Proximal Policy Optimization (MAPPO) has demonstrated significant potential in enhancing the coordination and control of multi-UAV systems, particularly in complex, dynamic, and partially observable environments. By leveraging the Centralized Training with Decentralized Execution (CTDE) paradigm, MAPPO allows for scalable and robust policy learning across fleets of autonomous drones [
90]. Despite this decentralized execution, the training process embeds cooperative behavior learned centrally, ensuring coordinated action across the fleet. This separation of training and execution allows MAPPO to scale to large numbers of agents, as the centralized training phase can efficiently exploit inter-agent dependencies while keeping the execution decentralized and lightweight, which enhances convergence speed. Applications of MAPPO in drone systems span a wide array of domains, including target tracking, surveillance, collaborative exploration, and search-and-rescue missions. These techniques not only improve search efficiency but also enhance mission safety and redundancy, which are critical in real-world deployments. Moreover, MAPPO’s ability to maintain stable policy updates through clipped objectives while effectively handling the non-stationarity inherent in multi-agent systems, makes it an ideal candidate for UAV Swarm Intelligence and autonomous aerial systems. As research continues, integrating MAPPO with communication-aware strategies, intent prediction, and sensor fusion is expected to further extend its capabilities in urban air mobility, precision agriculture, and disaster response operations.
The comparative analysis across Policy-Based Multi-Agent Reinforcement Learning (MARL) techniques reveals distinct performance trade-offs tied to each algorithm’s environment and coordination strategy.
Table 3 presents a brief comparison between the most common Policy Gradient-Based Algorithms for UAV Swarm Control in Multi-Agent Reinforcement Learning.
Table 4 presents a comparison between many of the research articles cited in this section. For example, [
113], using AM-MAPPO, demonstrates strong scalability and moderate convergence for multi-UAV target tracking by leveraging redundant coverage, while [
112] applies PIS-MAPPO in traffic merging scenarios, achieving enhanced safety but at the cost of slower convergence (>10,000 steps). In contrast, Liao et al. [
111] introduces ETS-MAPPO with STEE for obstacle-rich, moving-target environments, offering a 30% success rate improvement and moderate convergence (<1600 steps) due to dynamic agent reallocation. Classical methods such as Q-learning [
67] and DRL with reward shaping [
49] show moderate success (85%) but suffer from poor scalability and slower convergence due to their discrete and environment-specific designs. Transformer-based MARL in [
105] offers the highest coverage (97%) with fast convergence and high scalability, while centralized MADDPG in [
106] delivers 95% target coverage with rapid convergence (<100 steps) but limited fault tolerance. Chen et al. [
107] and Qie et al. [
97] explore urban and threat-aware UAV scenarios, respectively, where both demonstrate moderate convergence and fault resilience, with [
97] notably requiring over 150,000 steps due to its complex STAPP framework. Overall, advanced MARL frameworks such as AM-MAPPO, Transformer-based MARL, and ETS-MAPPO stand out in handling larger swarms and dynamic environments and achieving higher success rates with relatively stable training dynamics.
6. Multi-Agent Federated Reinforcement Learning Techniques
Federated Learning (FL) has emerged as a powerful framework for enabling decentralized intelligence, particularly in scenarios where data privacy and communication constraints are critical. When combined with Multi-Agent Reinforcement Learning (MARL), FL facilitates the training of distributed agents across multiple edge devices or environments without requiring direct access to local data. This synergy allows agents to collaboratively learn shared policies or value functions while preserving data locality and reducing bandwidth usage. In federated MARL, each agent or a group of agents independently interacts with its environment to collect experience and update local models, which are then periodically aggregated using techniques such as Federated Averaging (FedAvg) on a central server or coordinator. These methods help address key challenges in MARL, including scalability, heterogeneity of agent experiences, and security concerns. As such, federated MARL is increasingly being explored in domains such as autonomous vehicle coordination, distributed robotics, and smart IoT systems, where collaborative learning must occur without centralized data collection.
Multi-Agent Federated Reinforcement Learning (MAFRL) techniques have become a powerful paradigm for establishing stable [
114] and intelligent communication networks, particularly in scenarios involving distributed and mobile agents such as UAVs. By combining the decentralized decision-making capabilities of Multi-Agent Reinforcement Learning with the privacy-preserving and communication-efficient nature of federated learning, MAFRL enables each agent to learn locally from its environment while benefiting from global knowledge through periodic model aggregation. This architecture is particularly advantageous in dynamic wireless networks, where maintaining stability in terms of connectivity, data throughput, and fairness is critical. For instance, UAVs acting as aerial relays can collaboratively learn optimal flight paths, power allocations, and scheduling policies without sharing raw data, thereby reducing latency and enhancing scalability. Moreover, the federated approach ensures robustness against network failures or mobility-induced disruptions by enabling asynchronous updates and distributed training. As demonstrated in recent studies, MAFRL achieves improved convergence [
115], reduced interference, and enhanced fairness in access to limited communication resources [
116], making it a highly effective solution for the future of resilient and adaptive communication networks. It was also used to improve spectrum utilization [
117]. MAFRL was applied to optimize the quality of service in various LoRa network slices.
Recent research in Multi-Agent Federated Reinforcement Learning (MAFRL) for UAV applications has yielded a diverse range of frameworks aimed at optimizing communication efficiency, trajectory planning, and resource allocation in dynamic environments. Gao et al. [
118] introduced a federated Deep Reinforcement Learning framework for UAV trajectory design, enabling privacy-preserving collaboration across multiple UAVs serving mobile users. Their focus on trajectory learning demonstrated strong performance under mobile user scenarios. However, the study focused on a limited number of UAVs (only five), which raises questions about the scalability. It lacks real-life applications, as it was only validated by simulation. Nie et al. [
119] addressed semi-distributed resource management in UAV-aided mobile edge computing (MEC) systems by proposing an MAFRL algorithm that balances computation offloading and power minimization while preserving user privacy using Gaussian noise. But this framework has scalability concerns as it was validated by simulations on a limited number of UAVs, as well as its dependence on a central server. In contrast, Wang et al. [
120] applied a distributed federated Deep Reinforcement Learning (DFDRL) approach to optimize UAV trajectories in emergency communication networks, with an emphasis on adaptability and reduced latency in air–ground cooperation. Tarekegn et al. [
121] proposed a federated multi-agent DRL system for trajectory control and fair communication (TCFC), which uniquely emphasized fairness in user data rates and applied real channel measurements for link estimation—setting it apart in terms of practical realism. Finally, Han et al. [
122] proposed a collaborative learning model for UAV deployment and resource allocation using environment-centric learning, focusing on system-wide throughput and fair access. This framework poses potential privacy concerns as raw observations may still be shared among agents. While all papers demonstrate the scalability and privacy-preserving benefits of federated learning, they differ in primary focus: [
118,
119,
120] target performance and latency, [
121] centers on fairness and real-world deployment, and [
122] integrates collaborative policy learning for UAV deployment.
Table 5 presents a comparison between these different research articles.
7. Comparison Between MARL Learning Techniques
Table 6 presents a brief comparison between Multi-Agent Reinforcement Learning (MARL) techniques. This comparison summarizes the key points relevant to UAV control, depending on factors such as the environment, application, and performance requirements. The comparison of Value-Based, Policy-Based, and Federated Multi-Agent Reinforcement Learning (MARL) techniques reveals distinct strengths and limitations across key performance dimensions. Value-based methods, such as QMIX and QTRAN, focus on learning joint or decomposed value functions and are generally efficient in simpler or discrete environments, but they can suffer from scalability issues and instability in partially observable or dynamic settings. In contrast, policy-based approaches like MAPPO and MADDPG directly optimize decentralized or centralized policies, offering better adaptability to continuous control tasks such as UAV formation flying and cooperative maneuvering. These methods typically require more training episodes but yield greater robustness and flexibility in complex multi-agent scenarios. Federated MARL introduces an additional layer of scalability and privacy by enabling agents to train locally while sharing model parameters rather than raw data. Although convergence may be slower due to asynchronous updates and communication delays, federated approaches excel in settings where data locality, communication efficiency, or privacy is a concern—making them highly suitable for distributed UAV swarms or edge AI systems. Ultimately, the choice among these techniques depends on the application’s control complexity, environmental dynamics, system scale, and communication constraints.
When comparing some of the most common MARL techniques used for applications related to UAVs, as presented in
Table 7, one should note that the training time of Multi-Agent Reinforcement Learning (MARL) techniques is influenced by several critical factors. These include the number of agents involved, as more agents increase the dimensionality of the joint action space and coordination complexity. The algorithm type also plays a role; for example, value-based methods like QMIX may train faster but struggle with scalability, whereas policy-based methods like MAPPO can offer stability at the cost of longer convergence. Communication overhead, especially in centralized or hybrid systems, can slow training when agents frequently exchange state or policy information. Additionally, environmental complexity, such as dynamic obstacles or partial observability, and the reward structure (sparse vs. dense) significantly affect the sample efficiency and number of episodes required to reach optimal performance. This comparison also highlights a diverse landscape of algorithmic strengths tailored to different operational demands. SERT-QDN [
78] stands out with high scalability, robust fault tolerance, and high success rates, making it ideal for fault-tolerant swarm operations in harsh environments, although it demands moderate computational resources. QMIX [
68] and QTRAN [
79] present trade-offs; QMIX offers high success with moderate scalability but limited fault tolerance and lower training complexity, whereas QTRAN, while constrained in scalability and convergence, demands high computational and energy resources due to its constraint-based exploration. MAVEN [
81] and VDAC [
123] both feature moderate capabilities but diverge in exploration strategy, with MAVEN leveraging latent variables and VDAC using decentralized advantages suitable for entropy-regularized applications. ROMA [
124] and MAPPO [
90] deliver high performance in scalability and convergence, with ROMA employing role assignment for structured swarm behavior and MAPPO suited for formation control with general advantage estimation. HAPPO [
102], a hierarchical variant, matches MAPPO’s strengths and adds precision for coordinated missions. Lastly, FACMAC [
125,
126] and WQMIX [
127] focus on bandwidth-awareness and energy efficiency, respectively, with both showing strong success rates and scalability. Overall, the selection of a method depends on mission-specific requirements such as fault tolerance, deployment readiness, and computational constraints.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}