1. Introduction
Recently, distributed optimization has emerged as a significant research area in drones, leading to substantial advances. During past years, although several attempts were made to employ distributed optimization algorithms to address the decision problems involved in drones (see [
1,
2]), their usage in multi-robot systems is still limited to only a handful of examples, as discussed in [
3]. On the other hand, it is also mentioned in [
3] that many problems, including multi-robot target tracking, cooperative estimation, distributed simultaneous localization and mapping, and collaborative motion planning in multi-robot coordination and collaboration, can be formulated and solved within the framework of distributed optimization. Therefore, in this paper, we focus on designing novel distributed optimization algorithms and explore their potential applications in drones.
Recently, numerous influential results of distributed optimization have been achieved in this domain, encompassing both continuous-time distributed optimization algorithms (see [
4,
5,
6,
7,
8,
9,
10,
11]) and discrete-time distributed optimization algorithms (see [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30]). Notably, significant attention has been attracted by distributed constrained optimization, particularly with discrete-time algorithms designed for closed convex set constraints.
Initially, research primarily centered on distributed optimization algorithms that employed nonnegative decaying step-sizes, leading to algorithms with sub-linear convergence rates. The earliest studies addressed unconstrained optimization problems, with distributed algorithms over balanced graphs developed in [
12]. Subsequent work expanded these methods to include closed convex set constraints in [
13] and global general constraints in [
14]. When fixed unbalanced graphs were considered, distributed algorithms were developed to handle optimization problems with
N non-identical set constraints in [
15] and those with additional equality and inequality constraints in [
16]. Under time-varying unbalanced graph sequences, the Push-sum framework facilitated the design of distributed algorithms for unconstrained optimization in [
17], while an improved push–pull framework enabled solutions to problems with equality constraints and set constraints in [
18].
More recent efforts have emphasized the design of distributed optimization algorithms achieving linear convergence rates. In [
19], a distributed algorithm over balanced graphs was developed for unconstrained optimization, while further studies addressed the case of fixed unbalanced graphs in [
20,
21,
22]. For time-varying unbalanced graphs, the Push-DIGing algorithm and a push–pull-based algorithm were proposed in [
23,
24]. These methods, however, are limited to solving unconstrained optimization problems. For constrained cases, an algorithm over a fixed unbalanced graph was developed for problems with a closed convex set constraint in [
25].
Then, for further accelerating the convergence of the designed algorithms, the momentum terms were introduced in the proposed distributed optimization algorithms in [
27,
28,
29], where only the unconstrained optimization problems were studied. Moreover, the approach of employing momentum terms was later extended in the case with a global closed convex set constraint in [
30]. Although the momentum-based algorithm in [
30] achieves linear convergence, its use of dual iterative scales adds computational complexity. Thus, this paper aims to design novel distributed optimization algorithms for solving the constrained optimization problem with only one iterative scale and thus with lower computational complexity.
This paper’s main contribution lies in proposing the distributed optimization algorithms with linear convergence and momentum terms for problems with a global closed convex set constraint. Utilizing the method of feasible directions to handle the constraint, this approach eliminates the need for the dual iterative scales used in [
30], thus reducing computational complexity.
We structure the remainder of the paper as follows.
Section 2 introduces the relevant notations, graph theory, and matrix theory.
Section 3 presents the decision problem of drones, the proposed distributed algorithm, the main theorem, and a detailed convergence analysis. In
Section 4 and
Section 5, the results of simulation and conclusions are given, respectively.
2. Preliminaries
2.1. Notations
In this paper, the n-dimensional real vectors set is denoted by the . Especially, denotes the vectors with a proper dimension and all entries being 1. Let be a vector; denotes its i-th entry, and denotes its transpose. Moreover, stands for its 2-norm. Especially, if all , are positive (non-negative), x is called positive (non-negative). Moreover, stands for the vectors with a proper dimension and with its i-th entry being 1 and other entries being 0. Additionally, for a function defined on , represents the gradient of f at x. Let denote the -dimensional real matrices set. Especially, denotes the real identity matrix with a proper dimension. Let be a matrix; its transpose and the 2-norm induced matrix norm are, respectively, denoted by and . Moreover, its -th is denoted by . Especially, if all , , are positive (non-negative), M is called positive (non-negative). Moreover, for a closed convex set and a vector w, denotes the projection of w on .
2.2. Graph Theory
In this paper, the notations and definitions associated with the graph are the same as those described in [
25] and thus are omitted here.
2.3. Matrix Theory
This subsection gives the definition of doubly stochastic matrices and the significant results of doubly stochastic matrices and non-negative matrices.
Definition 1. Let be a non-negative matrix. A is called a non-negative stochastic matrix if . Moreover, A is called a non-negative doubly stochastic matrix if and .
Lemma 1 ([
31,
32])
. Let be a non-negative doubly stochastic matrix associated with the strongly connected directed graph . Especially, for all , suppose that are positive. Then, we have , with being a constant. Lemma 2 ([
32])
. For a non-negative matrix , if holds for a positive constant θ and a positive vector , then . 3. Main Results
We will give the decision problem of drones, the proposed distributed algorithm and main theorem, and the convergence analysis in this section.
3.1. Decision Problem of Drones
In recent years, drones have seen significant application across various practical fields such as the military, terrain exploration, and power grid fault detection. As multi-scenario tasks become more complex, task completion often requires the coordination of multiple drones. Due to the lengthy time required and the lack of robustness in solving large-scale optimization problems, centralized optimal decision-making methods cannot meet the intelligent demands of multi-drone clusters for handling complex tasks. Consequently, distributed optimization algorithms are increasingly employed to enable efficient autonomous decision-making in multi-drone clusters. For instance, in terrain exploration tasks, the influence of complex terrain requires that multi-drone clusters consider not only their inherent optimization objectives but also the impact of terrain constraints on drone actions. Therefore, the autonomous decision-making problem for multi-drone clusters can be formulated as the following mathematical model:
where
is the convex function representing the optimization objectives of drones and
is a set being convex and closed standing for the constraint observed by drones. As discussed in [
25], for a optimal solution
to problem Equation (
1), it holds that
with
being an arbitrary positive constant. Especially, let
in the subsequent analyses for convenience, and the case with
has been discussed in detail in [
25].
In the following, we first give a necessary assumption for problem Equation (
1), which is standard and usually introduced in the works researching the distributed optimization algorithms having linear convergence.
Assumption 1. All are L-smooth and α-strongly convex on , where α and L are positive constants.
3.2. Proposed Distributed Algorithm and Main Theorem
In this subsection, the distributed optimization algorithm is designed on the strongly connected balanced graph , and the main theorem about the proposed algorithm owing linear convergence is given.
Especially, motivated by [
26,
30], the discrete-time distributed algorithm is designed as in Algorithm 1, where
is the estimation on the optimal solution of node
i at
a;
A is the weighted matrix associated with
, which is assumed to be non-negative doubly stochastic;
is the estimation on the gradient of
h of node
i at
a; and
,
, and
are fixed step-sizes. Especially,
can be arbitrarily selected in
and
.
| Algorithm 1: Distributed Algorithm over Balanced Graph |
I: Input: , , , N, A;
II: Initialize: For all i, , ;
III: Iteration rule:
with
VI: Output |
For rewriting Equation (
3) in compact form and thus the convenience in the subsequent analysis, we introduce the following variable:
and
. Then, we can rewrite Equation (
3) as
Theorem 1. With the feasible step-sizes α, β, and η, whose feasible regions are detailedly defined in the subsequent convergence analysis, for all under Algorithm 1 converge to the unique optimal solution to problem Equation (1) linearly under Assumption 1. 3.3. Convergence Analysis for Algorithm 1
The detailed convergence analysis of Algorithm 1 is shown in this subsection, with the strict proof of Theorem 1 given.
Moreover, we introduce several variables necessarily involved in the subsequent convergence analysis, which are defined as
Proof. This proof is omitted here since it can be easily completed based on the proof of ([
25] [Lemma 6]). □
Next, by introducing the variable as
we give a key lemma for establishing the linear convergence property of Algorithm 1.
Lemma 4. Under Assumption 1 and when , there holdswhere In the following, the detailed proof of Theorem 1 is prepared.
Proof of Theorem 1. Clearly, it is sufficient for completing the proof to select the feasible step-sizes
,
,
in order to make
. Considering
, we can select
. Furthermore, noting Lemma 2, we can complete the proof by proving that there is a positive vector
satisfying
, i.e.,
Then, substituting
into Equation (
8), we can obtain
which is equivalent to
Since
,
, and
L are positive, if
,
,
,
, and
exist, which are positive constants, such that
holds, positive constants
,
,
,
,
, and
exist such that Equation (
10) holds. For arbitrary positive constant
, considering
with
, we select
,
, and
, with
,
, and
. Then, when
Equation (
11) holds. Then, with the selected
, we can select
to let Equation (
10) hold. Therefore, the proof has been completed. □
3.4. Distributed Algorithm on Unbalanced Graph
It can be noted that in
Section 3.2, we only consider the case that the communication graph between all drones is balanced, which means that any two directly connected drones (agents) can exchange information bidirectionally. However, in many cases that require privacy protection, the information exchange between two directly connected drones (agents) is unidirectional, which implies that the communication graph between all drones is unbalanced. Furthermore, it is difficult to design a nonnegative doubly stochastic matrix for an unbalanced graph, and a nonnegative stochastic matrix is always employed in the distributed optimization algorithms for cases involving the unbalanced graphs.
Accordingly, when matrix
A is only the stochastic matrix, Algorithm 1 is ineffective to address the problem in Equation (
1), and we will take the case without the constraint and without the momentum terms
, for example, to explain the detailed reason. When the constraint and the momentum terms
are omitted, Algorithm 1 can be rewritten as
with the definition of
being the same as that in
Section 3.2.
It is worth noting from Lemma 3 that
can be approximatively seen as the gradient of the global objective function
h at
upon all
achieving consensus. Moreover, from the property of the non-negative doubly stochastic matrix as given in Lemma 2, we can obtain that all
achieve consensus linearly. Furthermore, for the consensus state
, we have
which can be approximatively seen as the classical gradient-decent iteration for obtaining the minimum of
. Therefore, all
under Algorithm 1 will converge to the minimum of
.
However, as discussed in [
25], when
A is only a non-negative doubly stochastic matrix, the result in Lemma 2 will become
where
is a nonnegative left eigenvector of
A with respect to the eigenvalue 1, satisfying
. Then, we should re-define
and
as
and can obtain that all
will converge to the consensus state
and
. Therefore,
can only be approximatively seen as the gradient of
rather than
, and thus Algorithm 1 will not converge to the minimum of the
.
Clearly, if the detailed information of
can be exactly obtained, the terms
in Algorithm 1 can be modified as
to ensure that Algorithm 1 is still effective, with
A being the only non-negative stochastic. However, it is difficult to exactly obtain the detailed information of
in most cases, and thus the iteration
with all
, is designed to estimate
. Furthermore, as discussed in [
25], all
will converge to
linearly, and thus
will converge to
linearly. Finally, with the idea of estimating
, we can modify the term
in Algorithm 1 as
to ensure that Algorithm 1 is still effective, with
A being only non-negative stochastic.
Finally, motivated by [
26,
30], the distributed algorithm over the unbalanced graph is designed as in Algorithm 2.
| Algorithm 2: Distributed Algorithm over Unbalanced Graph |
I: Input: , , , N, A;
II: Initialize: For all i, , , ;
III: Iteration rule:
with
VI: Output |
Let
we can rewrite Equation (17) with the unbalanced graph as
Theorem 2. With the feasible step-sizes α and η, for all under Algorithm 2 converge to the unique optimal solution to problem Equation (1) linearly under Assumption 1. 3.5. Convergence Analysis for Algorithm 2
Now, we can establish the convergence properties of Algorithm 2.
Lemma 5. With the given initial values, one has Let .
Proof. This proof is omitted here as it can be readily accomplished based on the proof of ([
25] [Lemma 8]). □
Next, define the following variable as
Lemma 6. Under Assumption 1 and when , there holdswhere and are defined as With Lemma 6, the proof of Theorem 2 can be similarly completed based on the proof of Theorem 1; therefore, we omit it.
Remark 1. It can be obtained from the proof of Theorem 1 that with the desired step-sizes α, β, and η, the optimal error satisfieswhere is a positive constant. Therefore, for an arbitrarily small positive constant ϵ, it is necessary to execute Algorithm 1 at least times to ensure that , while times are needed for Algorithm 1 in [30], where M is a positive constant satisfying with being a constant. Clearly, Algorithm 2 in this paper and Algorithm 2 in [30] have the similar case with respect to the computational complexity. 4. Simulations
Here, a simulation example is shown to verify the theoretical results developed in this paper. Especially, the multi-drones target tracking problem is considered for the simulation in this paper, which was also discussed in [
3] and can be simplistically formulated as
where
N represents the number of drones for tracking the moving target;
T represents the number of moving steps of the target; and
, with
being the real state of the target at step
t and
being the sampling value at step
t of the random variable
introduced to represent the measurement noise of the drone
i. The aim of this task is employing
N drones to track the real target trajectory
,
, ⋯,
. Especially, in this simulation,
N is selected as 8,
T is set as 5,
, and
takes values in
randomly and uniformly. For convenience, all values of the parameters involved in this simulation are collected in
Table 1.
Moreover, it is assumed that the state of the moving target at the step
t is contained in
, which is selected as
for all
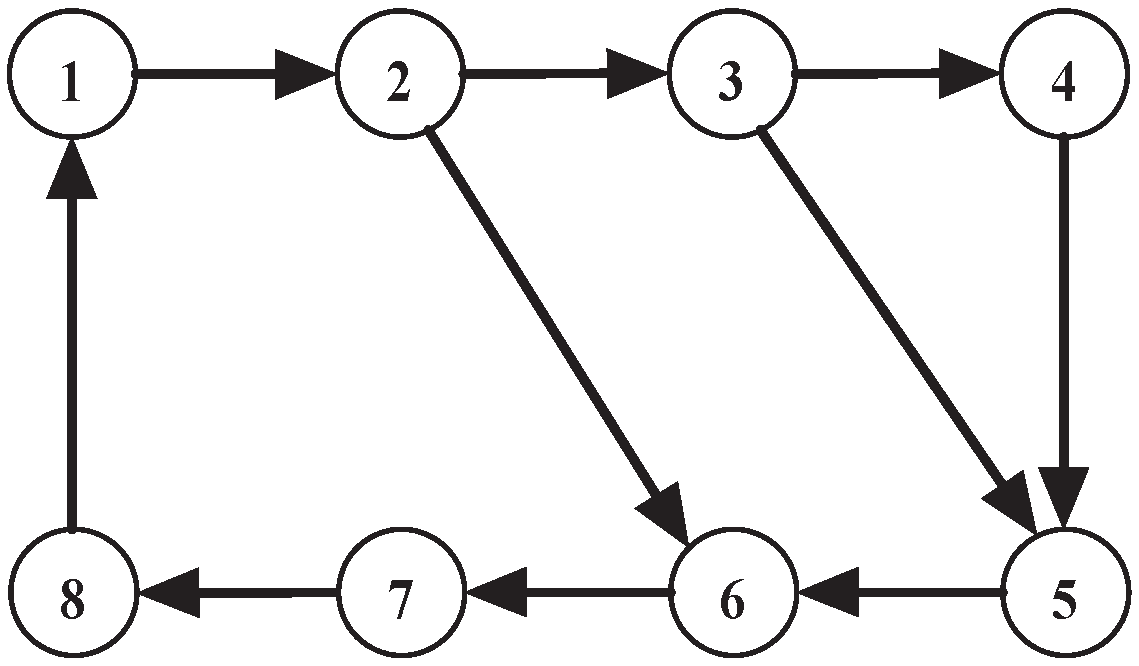
. Additionally, the balanced communication graph necessarily involved in the distributed Algorithm 1 is depicted as in
Figure 1. Accordingly, we selected the weighted matrix
A as
Moreover, the step-sizes are selected as
,
, and
in this simulation, respectively. Especially, in
Figure 2, the transient behaviors of all
under Algorithm 1 are shown, which shows that all
under Algorithm 1 converge to the unique optimal solution
.
Furthermore, with the same settings except that the unbalanced communication graph necessarily involved in the distributed algorithm (18) is depicted as in
Figure 3 and the weighted matrix
A is selected as
the transient behaviors of all
under Algorithm 2 are shown in
Figure 4, which shows that all
under Algorithm 2 converge to the unique optimal solution
.
Moreover, in order to highlight the good performance at reducing the computational complexity compared to Algorithm 1 in [
30], the simulations of Algorithm 1 in this paper and Algorithm 1 in [
30] under the same settings are further made. Especially, we introduce the convergence index (CI) as
with
and show the transient behaviors of CI under two Algorithms in
Figure 5 for comparison. It can be seen from
Figure 5 that two distinct Algorithms share a similar convergence rate. On the other hand, the operating time of GPU with different Algorithms is recoded during the simulations, which shows that for obtaining the similar convergence performance,
s is required for Algorithm 1 in this paper, while
s is needed for Algorithm 1 in [
30].
Additionally, in order to explore how the momentum parameters affect the convergence rate, the simulations of Algorithm 1 with different momentum parameters are further made under the same other settings. Furthermore, the transient behaviors of CI under Algorithm 1 with different momentum parameters are shown in
Figure 6 for comparison, which shows that the convergence rates in terms of the CI under Algorithm 1 with bigger momentum parameters are faster than that with smaller momentum parameters, and Algorithm 1 is nonconvergent when the momentum parameter is too big (
).
Remark 2. It is worth mentioning that although the definitions of the upper bound of the desired α, β, and η are given in Equations (
12)
and (
13)
, it is still difficult to exactly give the explicit bounds of the desired α, β, and η since the global information L, μ, and ρ are necessarily involved in the definitions. On the other hand, it can also be noted from Equations (
12)
and (
13)
that the proposed Algorithms would be convergent when α, β, and η are sufficient small. Therefore, when carrying out the simulation for the proposed Algorithms, arbitrarily positive constants can be selected for the step-sizes first. Then, if the Algorithms with the selected step-sizes are nonconvergent, the smaller positive constants could be selected for the step-sizes until the Algorithms converge. 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}