

Graph-Based Conversation Analysis in Social Media




Abstract
1. Introduction
1.1. Problem Statement and Objective
- How to build a proper graph for describing the conversational aspect of online SM?
- How to reconstruct conversations from comments belong to an SM post/update that does not follow reply feature?
- How to assign an appropriate category label to an SM comment that represents the author’s intention?
- How to uncover micro topics that are discussed under one main topic.
- How are the topics, stance, and sentiments propagate on the discussion forums?
- What frequent patterns can be found in conversation graphs of online SM?
1.2. Method
1.3. Contribution
1.4. Structure of the Work
2. Related Work and Background
2.1. Related Work
2.1.1. Social Media
2.1.2. Graph Analysis of Social Network
2.1.3. Conversation Graphs on Social Media
2.1.4. Proposed Network Analysis of Conversation Graphs
2.2. Background
2.2.1. Web Scraping
2.2.2. Text Classification
2.2.3. Naïve Bayes
2.2.4. Support Vector Machines
2.2.5. Multi Layer Perceptron (MLP)
2.2.6. Random Forest
2.2.7. Graph
2.2.8. Network
2.2.9. Implementation for Graph Analysis
3. Methodology
3.1. Data Collection
3.2. Data Cleaning and Preprocessing
3.3. Text Classification Design
3.3.1. Category Specification
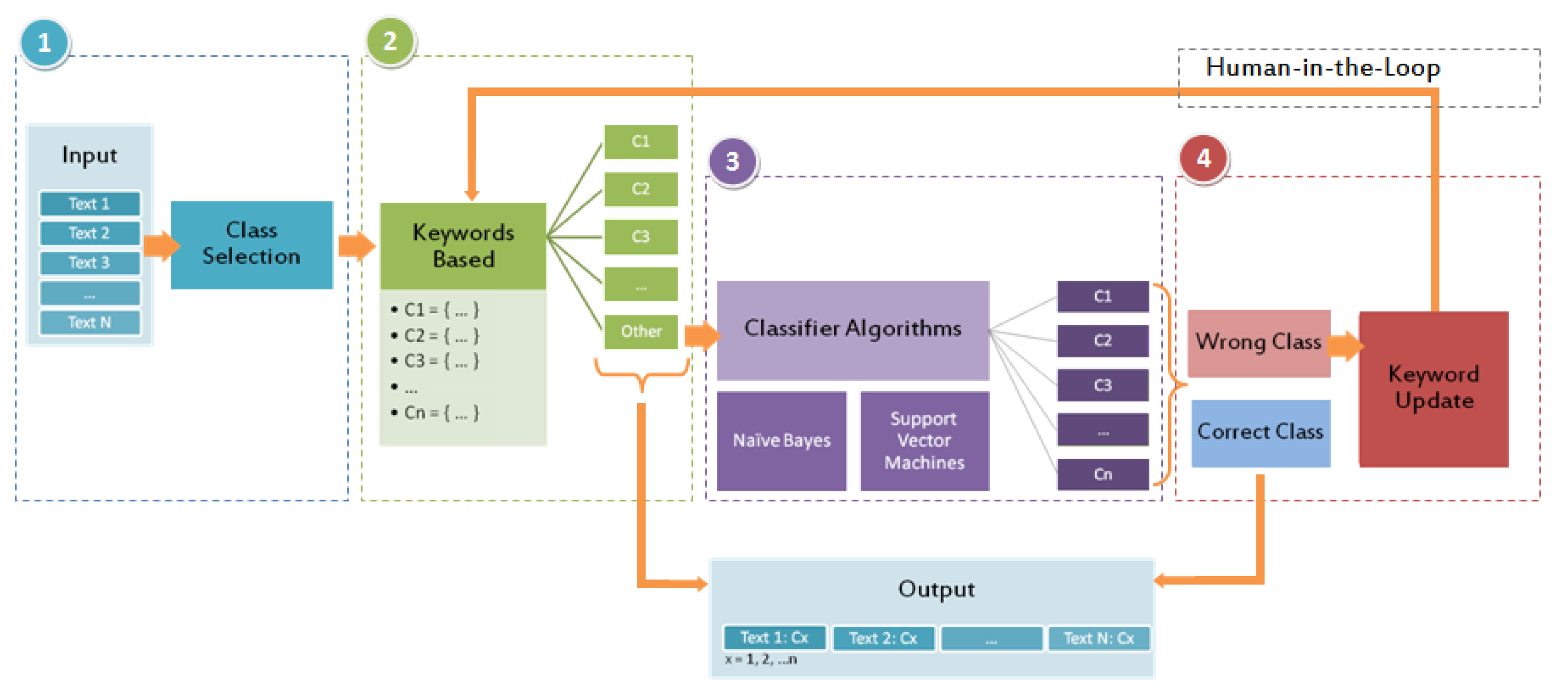
3.3.2. Keyword-Based Classification
3.3.3. Classifiers Algorithms
3.3.4. Human-in-The-Loop
3.4. Sentiment Analysis
3.5. Topic Modeling
3.6. Stance Detection
3.7. Network and Conversation Graph Design
3.7.1. General Network
- Post A post refers to an SM update that may consist of media, such as image or video, and text such as the caption of a tweet.
- User A user can be the author of a post or comment, a liker, and a new user that is intentionally called by a writer of a comment or a photo (by means of a caption section).
- Challenge/Topic This is an extra node that can be applied when the data used for implementation has such information about a particular topic. Here challenge node is used since we are going to apply the proposed framework on a challenge event.
- Comment A comment node is a comment posted by a user-related to an SM post. Thus this node is linked to a post node. A category attribute in this node is the implementation of intent analysis, which is performed beforehand.
- Hashtag A post or a comment node can contain one or more hashtags.
- Location A post can have a location stating where the update is published.
| Algorithm 1 Generating the graph representation of the relationship among SM content |
|
3.7.2. Conversation Design and Retrieval
- User mention recognition:The aim is to identify if a comment has mentioned one or more. A mentioned (tagged) user can be extracted by identifying a term beginning with “@” character in a comment or caption, which is linked to a user.
- Search tagged users: From all the comments posted before the current comment, we build a list of authors to find a similar user from the mentioned users list.
- Reply assignment: After finding a comment that its author is mentioned in the current comment, reply edge is assigned between the two comments.
4. Experiments
4.1. Expo Milan on Instagram
4.1.1. Case Study and Data Collection
4.1.2. Intent Analysis
Text Preprocessing
Keyword-Based Classification on Social Media Comments
Classifiers Algorithms Application
Human–in–the-Loop
4.1.3. Network Analysis
Graph Generation
Conversation Graphs
4.2. COVID-19 Vaccine Discussions on Reddit
4.2.1. Case Study and Data Collection
4.2.2. Topic Detection
Fine-graining results using repetitive modeling
4.2.3. Stance Detection
Labeling the Dataset
Classification Algorithms
5. Analysis Results
5.1. Analysis Results of the Expo Milan Experiment
5.1.1. Statistical Analysis of Conversation
Statistical Analysis
Comment Category Distribution
5.1.2. Time Space Analysis
5.1.3. Conversation Patterns Retrieval
Two-Node Patterns
Three- and Four-Nodes Patterns
5.2. Analysis Results of the COVID Vaccine Discussions Experiment
5.2.1. Statistical Analysis
5.2.2. Time Space Analysis
5.2.3. Sentiment Analysis
5.2.4. Topics Analysis
5.2.5. Stance Analysis
5.2.6. Time Analysis for Topics, Sentiments, and Stances
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qualman, E. How Social Media Transforms the Way We Live and Do Business; Business Book Summaries: Ipswich, MA, USA, 2011. [Google Scholar]
- Friedman, L.W.; Friedman, H. Using social media technologies to enhance online learning. J. Educ. Online 2013, 10, 1–22. [Google Scholar] [CrossRef]
- Al-Atabi, M.; DeBoer, J. Teaching entrepreneurship using massive open online course (MOOC). Technovation 2014, 34, 261–264. [Google Scholar] [CrossRef]
- Vasilescu, B.; Serebrenik, A.; Devanbu, P.; Filkov, V. How social Q&A sites are changing knowledge sharing in open source software communities. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, MD, USA, 15–19 February 2014; pp. 342–354. [Google Scholar]
- Diakopoulos, N.; Naaman, M. Towards Quality Discourse in Online News Comments. In Proceedings of the ACM 2011 Conference on Computer Supported Cooperative Work, Hangzhou, China, 19–23 March 2011; CSCW ’11. Association for Computing Machinery: New York, NY, USA; pp. 133–142. [Google Scholar] [CrossRef]
- He, W.; Zha, S.; Li, L. Social media competitive analysis and text mining: A case study in the pizza industry. Int. J. Inf. Manag. 2013, 33, 464–472. [Google Scholar] [CrossRef]
- Godey, B.; Manthiou, A.; Pederzoli, D.; Rokka, J.; Aiello, G.; Donvito, R.; Singh, R. Social media marketing efforts of luxury brands: Influence on brand equity and consumer behavior. J. Bus. Res. 2016, 69, 5833–5841. [Google Scholar] [CrossRef]
- Dong, J.Q.; Wu, W. Business value of social media technologies: Evidence from online user innovation communities. J. Strateg. Inf. Syst. 2015, 24, 113–127. [Google Scholar] [CrossRef]
- Bessis, N.; Dobre, C. Big Data and Internet of Things: A Roadmap for Smart Environments; Springer: Berlin/Heidelberg, Germany, 2014; Volume 546. [Google Scholar]
- Brambilla, M.; Javadian Sabet, A.; Masciadri, A. Data-driven user profiling for smart ecosystems. In Smart Living between Cultures and Practices. A Design Oriented Perspective; Mandragora: Milan, Italy, 2019; pp. 84–98. ISBN 978-88-7461-496-7. [Google Scholar]
- Tufekci, Z. Big questions for social media big data: Representativeness, validity and other methodological pitfalls. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Ruths, D.; Pfeffer, J. Social media for large studies of behavior. Science 2014, 346, 1063–1064. [Google Scholar] [CrossRef] [PubMed]
- Schreck, T.; Keim, D. Visual analysis of social media data. Computer 2012, 46, 68–75. [Google Scholar] [CrossRef]
- Leskovec, J.; Sosič, R. Snap: A general-purpose network analysis and graph-mining library. ACM Trans. Intell. Syst. Technol. (TIST) 2016, 8, 1–20. [Google Scholar] [CrossRef]
- Brambilla, M.; Javadian Sabet, A.; Hosseini, M. The role of social media in long-running live events: The case of the Big Four fashion weeks dataset. Data Brief 2021, 35, 106840. [Google Scholar] [CrossRef]
- Javadian Sabet, A.; Brambilla, M.; Hosseini, M. A multi-perspective approach for analyzing long-running live events on social media. A case study on the “Big Four” international fashion weeks. Online Soc. Netw. Media 2021, 24, 100140. [Google Scholar] [CrossRef]
- Brambilla, M.; Javadian, A.; Sulistiawati, A.E. Conversation Graphs in Online Social Media. In Web Engineering; Brambilla, M., Chbeir, R., Frasincar, F., Manolescu, I., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 97–112. [Google Scholar]
- Planas, E.; Daniel, G.; Brambilla, M.; Cabot, J. Towards a model-driven approach for multiexperience AI-based user interfaces. Softw. Syst. Model. 2021, 20, 997–1009. [Google Scholar] [CrossRef]
- Arabghalizi, T.; Rahdari, B.; Brambilla, M. Analysis and Knowledge Extraction from Event-related Visual Content on Instagram. In Proceedings of the 3rd International Workshop on Knowledge Discoveryon the WEB-KD-WEB, Cagliari, Italy, 11–12 September 2017; Volume 1959, pp. 16–27. [Google Scholar]
- Balduini, M.; Brambilla, M.; Della Valle, E.; Marazzi, C.; Arabghalizi, T.; Rahdari, B.; Vescovi, M. Models and Practices in Urban Data Science at Scale. Big Data Res. 2019, 17, 66–84. [Google Scholar] [CrossRef]
- Boyd, D.M.; Ellison, N.B. Social network sites: Definition, history, and scholarship. J. Comput.-Mediat. Commun. 2007, 13, 210–230. [Google Scholar] [CrossRef]
- Rahdari, B.; Arabghalizi, T.; Brambilla, M. Analysis of online user behaviour for art and culture events. In International Cross-Domain Conference for Machine Learning and Knowledge Extraction; Springer: Berlin/Heidelberg, Germany, 2017; pp. 219–236. [Google Scholar]
- Zhan, L.; Sun, Y.; Wang, N.; Zhang, X. Understanding the influence of social media on people’s life satisfaction through two competing explanatory mechanisms. Aslib J. Inf. Manag. 2016, 68, 347–361. [Google Scholar] [CrossRef]
- Zhang, Y.; Leung, L. A review of social networking service (SNS) research in communication journals from 2006 to 2011. New Media Soc. 2015, 17, 1007–1024. [Google Scholar] [CrossRef]
- Henderson, A.; Edwards, L.; Bowley, R. Authentic dialogue? The role of “friendship” in a social media recruitment campaign. J. Commun. Manag. 2010, 14, 237–257. [Google Scholar] [CrossRef]
- Ellison, N.B.; Steinfield, C.; Lampe, C. The benefits of Facebook “friends”: Social capital and college students’ use of online social network sites. J. Comput.-Mediat. Commun. 2007, 12, 1143–1168. [Google Scholar] [CrossRef]
- Hudson, S.; Huang, L.; Roth, M.S.; Madden, T.J. The influence of social media interactions on consumer–brand relationships: A three-country study of brand perceptions and marketing behaviors. Int. J. Res. Mark. 2016, 33, 27–41. [Google Scholar] [CrossRef]
- Lai, L.S.; To, W.M. Content analysis of social media: A grounded theory approach. J. Electron. Commer. Res. 2015, 16, 138. [Google Scholar]
- Fono, D.; Baecker, R. Structuring and Supporting Persistent Chat Conversations. In Proceedings of the 2006 20th Anniversary Conference on Computer Supported Cooperative Work, Banff, AB, Canada, 4–8 November 2006; CSCW ’06. Association for Computing Machinery: New York, NY, USA; pp. 455–458. [Google Scholar] [CrossRef]
- Moro, S.; Rita, P.; Vala, B. Predicting social media performance metrics and evaluation of the impact on brand building: A data mining approach. J. Bus. Res. 2016, 69, 3341–3351. [Google Scholar] [CrossRef]
- Hosseini, M.; Sabet, A.J.; He, S.; Aguiar, D. Interpretable Fake News Detection with Topic and Deep Variational Models. arXiv 2022, arXiv:2209.01536. [Google Scholar] [CrossRef]
- Gasparini, M.; Ramponi, G.; Brambilla, M.; Ceri, S. Assigning users to domains of interest based on content and network similarity with champion instances. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Vancouver, BC, Canada, 27–30 August 2019; pp. 589–592. [Google Scholar]
- Javadian Sabet, A.; Rossi, M.; Schreiber, F.A.; Tanca, L. Towards Learning Travelers’ Preferences in a Context-Aware Fashion. In Ambient Intelligence—Software and Applications; Novais, P., Vercelli, G., Larriba-Pey, J.L., Herrera, F., Chamoso, P., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 203–212. [Google Scholar]
- Brena, G.; Brambilla, M.; Ceri, S.; Di Giovanni, M.; Pierri, F.; Ramponi, G. News Sharing User Behaviour on Twitter: A Comprehensive Data Collection of News Articles and Social Interactions. In Proceedings of the International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 6–9 June 2019; Volume 13, pp. 592–597. [Google Scholar]
- Javadian Sabet, A. Social Media Posts Popularity Prediction during Long-Running Live Events. A Case Study on Fashion Week. Master’s Thesis, Politecnico di Milano, Milan, Italy, 2019. [Google Scholar]
- Myers, S.A.; Sharma, A.; Gupta, P.; Lin, J. Information network or social network? The structure of the Twitter follow graph. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 493–498. [Google Scholar]
- Zhao, Z.; Wei, F.; Zhou, M.; Ng, W. Cold-start expert finding in community question answering via graph regularization. In International Conference on Database Systems for Advanced Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 21–38. [Google Scholar]
- Backstrom, L.; Kleinberg, J. Romantic partnerships and the dispersion of social ties: A network analysis of relationship status on facebook. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, ML, USA, 15–19 February 2014; pp. 831–841. [Google Scholar]
- Buntain, C.; Golbeck, J. Identifying social roles in reddit using network structure. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 615–620. [Google Scholar]
- Mcauley, J.; Leskovec, J. Discovering social circles in ego networks. ACM Trans. Knowl. Discov. Data (TKDD) 2014, 8, 1–28. [Google Scholar] [CrossRef]
- Rao, B.; Mitra, A. A new approach for detection of common communities in a social network using graph mining techniques. In Proceedings of the 2014 International Conference on High Performance Computing and Applications (ICHPCA), Bhubaneswar, India, 22–24 December 2014; pp. 1–6. [Google Scholar]
- Yang, J.; McAuley, J.; Leskovec, J. Community detection in networks with node attributes. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 1151–1156. [Google Scholar]
- Paranjape, A.; Benson, A.R.; Leskovec, J. Motifs in temporal networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 601–610. [Google Scholar]
- Shang, Y. Modeling epidemic spread with awareness and heterogeneous transmission rates in networks. J. Biol. Phys. 2013, 39, 489–500. [Google Scholar] [CrossRef]
- Odiete, O.; Jain, T.; Adaji, I.; Vassileva, J.; Deters, R. Recommending programming languages by identifying skill gaps using analysis of experts. a study of stack overflow. In Proceedings of the Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–12 July 2017; pp. 159–164. [Google Scholar]
- Ning, K.; Li, N.; Zhang, L.J. Using Graph Analysis Approach to Support Question & Answer on Enterprise Social Network. In Proceedings of the 2012 IEEE Asia-Pacific Services Computing Conference, Guilin, China, 6–8 December 2012; pp. 146–153. [Google Scholar]
- Aumayr, E.; Chan, J.; Hayes, C. Reconstruction of Threaded Conversations in Online Discussion Forums. ICWSM 2011, 11, 26–33. [Google Scholar]
- Cogan, P.; Andrews, M.; Bradonjic, M.; Kennedy, W.S.; Sala, A.; Tucci, G. Reconstruction and analysis of twitter conversation graphs. In Proceedings of the First ACM International Workshop on Hot Topics on Interdisciplinary Social Networks Research, Beijing, China, 12–16 August 2012; pp. 25–31. [Google Scholar]
- Zayats, V.; Ostendorf, M. Conversation modeling on Reddit using a graph-structured LSTM. Trans. Assoc. Comput. Linguist. 2018, 6, 121–132. [Google Scholar] [CrossRef]
- Kumar, R.; Mahdian, M.; McGlohon, M. Dynamics of conversations. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington DC, USA, 25–28 July 2010; pp. 553–562. [Google Scholar]
- Aragón, P.; Gómez, V.; Kaltenbrunner, A. To thread or not to thread: The impact of conversation threading on online discussion. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Association for the Advancement of Artificial Intelligence (AAAI): Palo Alto, CA, USA, 2017; pp. 12–21. [Google Scholar]
- Dave, K.; Wattenberg, M.; Muller, M. Flash Forums and ForumReader: Navigating a New Kind of Large-Scale Online Discussion. In Proceedings of the 2004 ACM Conference on Computer Supported Cooperative Work, Chicago, IL, USA, 6–10 November 2004; CSCW ’04. Association for Computing Machinery: New York, NY, USA; pp. 232–241. [Google Scholar] [CrossRef]
- Beenen, G.; Ling, K.; Wang, X.; Chang, K.; Frankowski, D.; Resnick, P.; Kraut, R.E. Using Social Psychology to Motivate Contributions to Online Communities. In Proceedings of the 2004 ACM Conference on Computer Supported Cooperative Work, Chicago, IL, USA, 6–10 November 2004; CSCW ’04. Association for Computing Machinery: New York, NY, USA; pp. 212–221. [Google Scholar] [CrossRef]
- Dillahunt, T.R.; Mankoff, J. Understanding Factors of Successful Engagement around Energy Consumption between and among Households. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, ML, USA, 15–19 February 2014; CSCW ’14. Association for Computing Machinery: New York, NY, USA; pp. 1246–1257. [Google Scholar] [CrossRef]
- Farzan, R.; Dabbish, L.A.; Kraut, R.E.; Postmes, T. Increasing Commitment to Online Communities by Designing for Social Presence. In Proceedings of the ACM 2011 Conference on Computer Supported Cooperative Work, Hangzhou, China, 19–23 March 2011; CSCW ’11. Association for Computing Machinery: New York, NY, USA; pp. 321–330. [Google Scholar] [CrossRef]
- Budak, C.; Garrett, R.K.; Resnick, P.; Kamin, J. Threading is sticky: How threaded conversations promote comment system user retention. Proc. ACM Hum.-Comput. Interact. 2017, 1, 1–20. [Google Scholar] [CrossRef]
- Samory, M.; Cappelleri, V.M.; Peserico, E. Quotes reveal community structure and interaction dynamics. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing, Portland, OR, USA, 25 February–1 March 2017; pp. 322–335. [Google Scholar]
- Garimella, K.; Weber, I.; De Choudhury, M. Quote RTs on Twitter: Usage of the new feature for political discourse. In Proceedings of the 8th ACM Conference on Web Science, Hannover, Germany, 22–25 May 2016; pp. 200–204. [Google Scholar]
- Hutto, C.J.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Zhang, L.; Ghosh, R.; Dekhil, M.; Hsu, M.; Liu, B. Combining lexicon-based and learning-based methods for Twitter sentiment analysis. HP Lab. Tech. Rep. HPL-2011 2011, 89. Available online: https://www.semanticscholar.org/paper/Combining-lexicon-based-and-learning-based-methods-Zhang-Ghosh/ab9a7687ab7c90707f863e54afe12fd99f2deb11 (accessed on 20 May 2022).
- Nakov, P.; Rosenthal, S.; Kiritchenko, S.; Mohammad, S.M.; Kozareva, Z.; Ritter, A.; Stoyanov, V.; Zhu, X. Developing a successful SemEval task in sentiment analysis of Twitter and other social media texts. Lang. Resour. Eval. 2016, 50, 35–65. [Google Scholar] [CrossRef]
- Jayasanka, R.; Madhushani, T.; Marcus, E.; Aberathne, I.; Premaratne, S. Sentiment analysis for social media. In Information Technology Research Symposium; University of Moratuwa: Moratuwa, Sri Lanka, 5 December 2013. [Google Scholar]
- Mitchell, R. Web Scraping with Python: Collecting More Data from the Modern Web; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Aggarwal, C.C.; Zhai, C. Aggarwal, C.C.; Zhai, C. A survey of text classification algorithms. In Mining Text Data; Springer: Berlin/Heidelberg, Germany, 2012; pp. 163–222. [Google Scholar]
- Joachims, T.; Sebastiani, F. Guest editors’ introduction to the special issue on automated text categorization. J. Intell. Inf. Syst. 2002, 18, 103. [Google Scholar] [CrossRef]
- Knight, K. Mining online text. Commun. ACM 1999, 42, 58–61. [Google Scholar] [CrossRef]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. (CSUR) 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TA, USA, 25–30 January 2015. [Google Scholar]
- Zhang, H. The optimality of naive Bayes. AA 2004, 1, 3. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Gardner, M.W.; Dorling, S. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Zhang, C.; Ma, Y. Ensemble Machine Learning: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Bondy, J.A.; Murty, U.S.R. Graph Theory with Applications; Macmillan: London, UK, 1976; Volume 290. [Google Scholar]
- Godsil, C.; Royle, G.F. Algebraic Graph Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 207. [Google Scholar]
- Bollobás, B. Modern Graph Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 184. [Google Scholar]
- Estrada, E. Graph and network theory in physics. arXiv 2013, arXiv:1302.4378. [Google Scholar]
- Milo, R.; Kashtan, N.; Itzkovitz, S.; Newman, M.E.; Alon, U. On the uniform generation of random graphs with prescribed degree sequences. arXiv 2003, arXiv:cond-mat/0312028. [Google Scholar]
- Benson, A.R.; Gleich, D.F.; Leskovec, J. Higher-order organization of complex networks. Science 2016, 353, 163–166. [Google Scholar] [CrossRef]
- Jackson, M.O. Social and Economic Networks; Princeton University Press: Oxford, UK, 2010. [Google Scholar]
- Newman, M. Networks; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Kirkpatrick, A.; Onyeze, C.; Kartchner, D.; Allegri, S.; Nakajima An, D.; McCoy, K.; Davalbhakta, E.; Mitchell, C.S. Optimizations for Computing Relatedness in Biomedical Heterogeneous Information Networks: SemNet 2.0. Big Data Cogn. Comput. 2022, 6, 27. [Google Scholar] [CrossRef]
- Allegri, S.A.; McCoy, K.; Mitchell, C.S. CompositeView: A Network-Based Visualization Tool. Big Data Cogn. Comput. 2022, 6, 66. [Google Scholar] [CrossRef]
- Shannon, P.; Markiel, A.; Ozier, O.; Baliga, N.S.; Wang, J.T.; Ramage, D.; Amin, N.; Schwikowski, B.; Ideker, T. Cytoscape: A software environment for integrated models of biomolecular interaction networks. Genome Res. 2003, 13, 2498–2504. [Google Scholar] [CrossRef]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An open source software for exploring and manipulating networks. In Proceedings of the Third International AAAI Conference on Weblogs and Social Media, San Jose, CA, USA, 17–20 May 2009. [Google Scholar]
- Heymann, S.; Le Grand, B. Visual analysis of complex networks for business intelligence with gephi. In Proceedings of the 2013 17th International Conference on Information Visualisation, London, UK, 16–18 July 2013; pp. 307–312. [Google Scholar]
- Jacomy, M.; Venturini, T.; Heymann, S.; Bastian, M. ForceAtlas2, a continuous graph layout algorithm for handy network visualization designed for the Gephi software. PLoS ONE 2014, 9, e98679. [Google Scholar] [CrossRef]
- Robins, G. A tutorial on methods for the modeling and analysis of social network data. J. Math. Psychol. 2013, 57, 261–274. [Google Scholar] [CrossRef]
- MonkeyLearn. Sentiment Analysis: A Definitive Guide; MonkeyLearn, 2018. Available online: https://monkeylearn.com/sentiment-analysis/ (accessed on 18 May 2021).
- Loria, S. textblob Documentation. Release 0.15 2018, 2, 269. Available online: https://textblob.readthedocs.io/en/dev/ (accessed on 15 July 2021).
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Steinbauer, T. Information and Social Analysis of Reddit. 2011. Available online: http://snap.stanford.edu/class/cs224w-2011/proj/tbower_Finalwriteup_v1.pdf (accessed on 17 May 2021).
- pj. How to Scrap Reddit Using pushshift.io via Python. 2018. Available online: https://github.com/pushshift/api (accessed on 15 April 2022).
- Brambilla, M.; Kharmale, K. COVID-19 Vaccine Discussions on Reddit with Sentiment, Stance, Topics, and Timing. 2022. Available online: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/XJTBQM (accessed on 28 August 2022).
- Xu, B.; Guo, X.; Ye, Y.; Cheng, J. An Improved Random Forest Classifier for Text Categorization. JCP 2012, 7, 2913–2920. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Oliveira, L.S.; de Melo, P.O.; Amaral, M.S.; Pinho, J.A.G. When politicians talk about politics: Identifying political tweets of brazilian congressmen. arXiv 2018, arXiv:1805.01589. [Google Scholar]
- Shang, Y. Generalized k-core percolation in networks with community structure. SIAM J. Appl. Math. 2020, 80, 1272–1289. [Google Scholar] [CrossRef]
- Brankovic, A.; Hosseini, M.; Piroddi, L. A Distributed Feature Selection Algorithm Based on Distance Correlation with an Application to Microarrays. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 16, 1802–1815. [Google Scholar] [CrossRef]
- Hosseini, M. Feature Selection for Microarray Classification Problems. Master’s Thesis, Politecnico di Milano, Milan, Italy, 2018. [Google Scholar]
- Cha, Y.; Kim, J.; Park, S.; Yi, M.Y.; Lee, U. Complex and Ambiguous: Understanding Sticker Misinterpretations in Instant Messaging. Proc. ACM Hum.-Comput. Interact. 2018, 2, 3274299. [Google Scholar] [CrossRef]
- Jiang, J.A.; Fiesler, C.; Brubaker, J.R. ‘The Perfect One’: Understanding Communication Practices and Challenges with Animated GIFs. Proc. ACM Hum.-Comput. Interact. 2018, 2, 3274349. [Google Scholar] [CrossRef]
- Scotti, V.; Tedesco, R.; Sbattella, L. A Modular Data-Driven Architecture for Empathetic Conversational Agents. In Proceedings of the 2021 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 17–20 January 2021; pp. 365–368. [Google Scholar] [CrossRef]
- Galitsky, B. Adjusting Chatbot Conversation to User Personality and Mood. In Artificial Intelligence for Customer Relationship Management; Springer: Berlin/Heidelberg, Germany, 2021; pp. 93–127. [Google Scholar]
- O’Brien, M.; Dyché, J. The CRM Handbook: A Business Guide to Customer Relationship Management; Addison-Wesley Professional: Boston, MA, USA, 2002. [Google Scholar]




































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Word | # | Word | # | Word | # | Word | # |
|---|---|---|---|---|---|---|---|
| graz | 8268 | buongiorn | 1278 | fatt | 923 | instagood | 732 |
| buon | 4298 | foodporn | 1262 | brav | 919 | like | 729 |
| thank | 2876 | piac | 1203 | meravigl | 909 | far | 725 |
| bell | 2551 | nice | 1178 | buonissim | 904 | dolc | 699 |
| Yourexpo-2015 | 2204 | molt | 1171 | igersital | 897 | davver | 690 |
| food | 1844 | foto | 1160 | ved | 865 | ver | 688 |
| ricett | 1841 | tua | 1141 | trov | 840 | vai | 678 |
| bellissim | 1810 | prov | 1121 | expo-stuporesapor | 789 | follow | 677 |
| fot | 1686 | timoebasil | 1114 | mayazetac | 778 | ser | 666 |
| car | 1523 | me | 1094 | son | 773 | expo-italianlife | 655 |
| instafood | 1480 | giorn | 1078 | sol | 773 | tropp | 650 |
| mill | 1479 | compl | 1076 | poi | 767 | foodblog | 649 |
| expo2015 | 1388 | wow | 1066 | blog | 761 | beauti | 643 |
| good | 1374 | i | 1041 | tant | 749 | dev | 640 |
| love | 1283 | sempr | 1030 | expo | 748 | … | … |
| Category | Keywords |
|---|---|
| Thank | grac, graz, thank |
| Congratulation | augur, complean, felic, tanti, congrat |
| Agreement | cert, concordi, convenir, accord, si, true, conferm, agree, certain, ok, right, sure, yes, of course, esattamente |
| Positive | amar, amor, bac, great, bei, bell, ben, fabulous, bravissim, buon, cool, cute, gorgeous, enjoy, dear, cellent, good, darling, bont, bacion, kind, like, love, magnif, nice, prett |
| Invitation | canali, invit, pagin, segui, sito, venir, vien, blog, check, click, come, follow, http, link, mail, page, site, tag, visit, invite, web |
| Food | acqua, carot, cavol, cena, cibo, ciocco, colazion, cottur, crem, croccant, cucchi, cucin, cuoc, delica, deliz, diet, dolc, dolci, espresso, fagiol, salad, salmon, salt, seafood |
| Greeting | arriv, buon, sera, buongiorn, ciao, mattin, nott, salv, giorn, night, morning, afternoon, hello, good, giorn, hey |
| Question | ? |
| Hashtag | # |
| Predicted | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Naïve Bayes | thank | congratulation | agreement | positive | invitation | food | greeting | question | |
| Actual | thank | 1765 | 0 | 0 | 271 | 0 | 67 | 29 | 0 |
| congratulation | 6 | 1 | 0 | 56 | 0 | 0 | 1 | 0 | |
| agreement | 15 | 0 | 0 | 79 | 0 | 23 | 0 | 0 | |
| positive | 51 | 0 | 0 | 4320 | 2 | 164 | 18 | 1 | |
| invitation | 7 | 0 | 0 | 177 | 201 | 73 | 0 | 4 | |
| food | 54 | 0 | 0 | 561 | 5 | 3311 | 12 | 2 | |
| greeting | 52 | 0 | 0 | 413 | 1 | 125 | 875 | 1 | |
| question | 20 | 0 | 0 | 554 | 6 | 239 | 15 | 45 | |
| Predicted | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| SVM | thank | congratulation | agreement | positive | invitation | food | greeting | question | |
| Actual | thank | 2084 | 0 | 0 | 30 | 0 | 8 | 10 | 0 |
| congratulation | 3 | 37 | 0 | 22 | 0 | 1 | 1 | 0 | |
| agreement | 4 | 0 | 23 | 60 | 0 | 26 | 2 | 2 | |
| positive | 95 | 0 | 2 | 4136 | 7 | 185 | 122 | 9 | |
| invitation | 8 | 0 | 1 | 124 | 251 | 62 | 14 | 2 | |
| food | 126 | 3 | 4 | 517 | 11 | 3221 | 54 | 9 | |
| greeting | 35 | 0 | 0 | 138 | 2 | 70 | 1219 | 3 | |
| question | 85 | 1 | 0 | 380 | 28 | 221 | 91 | 73 | |
| a Naïve Bayes | b SVM | ||||||||||||
| Predicted | Predicted | ||||||||||||
| Naïve Bayes | thank | positive | invitation | food | question | SVM | thank | positive | invitation | food | question | ||
| Actual | thank | 1491 | 567 | 0 | 34 | 0 | thank | 2012 | 77 | 0 | 3 | 0 | |
| positive | 40 | 6415 | 3 | 145 | 1 | positive | 107 | 6436 | 4 | 57 | 0 | ||
| invitation | 1 | 215 | 193 | 49 | 0 | invitation | 8 | 226 | 191 | 29 | 4 | ||
| food | 49 | 846 | 0 | 2746 | 0 | food | 126 | 1528 | 1 | 1985 | 1 | ||
| question | 13 | 647 | 5 | 134 | 28 | Actual | question | 64 | 650 | 24 | 65 | 24 | |
| Comment | Sentiment | Stance |
|---|---|---|
| Vaccine triggers a stronger immunity than the infection. They almost always do. This is not how a vaccine work. On a mild case your immune system does not fight an army it’s just a small scouting team. A vaccine is like training your immune system with a very elaborate vr system mimicking the strength of a full army | Positive | Favor |
| Im scared I really want to be able to trust the vaccine and see it as hope for the world but I don’t. I simply feel like it was way too quickly developed and Ive heard a lot of bad things. Theres no way to know the long term effects of this yet and I just don’t know what to do. | Positive | Against |
| What will the effect of mRNA have? | Neutral | None |
| AMA I got the first dose of the Pfizer vaccine today. I work for a small hospital and I was given dose 1 of 2 of the Pfizer vaccine today. It was my choice. No it didnt hurt any worse than a normal shot. I signed a consent form. And Ill be given dose 2 in 3 weeks. | Negative | Favor |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Against | 0.65 | 0.68 | 0.67 | 19 |
| Favor | 0.67 | 0.53 | 0.59 | 15 |
| None | 0.67 | 0.75 | 0.71 | 16 |
| Accuracy | 0.66 | 50 | ||
| Macro Avg | 0.66 | 0.66 | 0.66 | 50 |
| Weighted Avg | 0.66 | 0.66 | 0.66 | 50 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Against | 0.92 | 0.58 | 0.71 | 19 |
| Favor | 0.77 | 0.67 | 0.71 | 15 |
| None | 0.60 | 0.94 | 0.73 | 16 |
| Accuracy | 0.72 | 50 | ||
| Macro Avg | 0.76 | 0.73 | 0.72 | 50 |
| Weighted Avg | 0.77 | 0.72 | 0.72 | 50 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Against | 0.72 | 0.68 | 0.70 | 19 |
| Favor | 0.57 | 0.53 | 0.55 | 15 |
| None | 0.67 | 0.75 | 0.71 | 16 |
| Accuracy | 0.66 | 50 | ||
| Macro Avg | 0.65 | 0.66 | 0.65 | 50 |
| Weighted Avg | 0.66 | 0.66 | 0.66 | 50 |
| Previous Comment | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| replies to ↱ | thank | positive | food | greeting | question | congratulation | agreement | invitation | hashtag | |
| Subsequent comment | thank | 1830 | 9299 | 1783 | 1150 | 397 | 149 | 88 | 790 | 143 |
| positive | 632 | 2158 | 997 | 439 | 581 | 27 | 73 | 98 | 95 | |
| food | 247 | 924 | 738 | 203 | 546 | 5 | 24 | 36 | 34 | |
| greeting | 109 | 625 | 180 | 644 | 136 | 8 | 12 | 15 | 13 | |
| question | 154 | 409 | 279 | 109 | 182 | 1 | 14 | 49 | 26 | |
| congratulation | 14 | 37 | 11 | 16 | 7 | 19 | 1 | 1 | 2 | |
| agreement | 21 | 128 | 57 | 37 | 92 | 1 | 10 | 6 | 5 | |
| invitation | 40 | 82 | 54 | 18 | 114 | 1 | 7 | 31 | 6 | |
| hashtag | 2 | 3 | 0 | 1 | 6 | 0 | 0 | 0 | 0 | |
| 3 Nodes | # | 4 Nodes | # |
|---|---|---|---|
| thank → thank → positive | 1254 | thank → thank → thank → positive | 386 |
| thank → thank → thank | 519 | thank → thank → thank → thank | 229 |
| thank → positive → positive | 416 | thank → positive → thank → positive | 138 |
| thank → positive → thank | 314 | thank → positive → thank → positive | 138 |
| positive → thank → positive | 305 | positive → positive → positive → positive | 81 |
| thank → thank → food | 256 | thank → thank → positive → positive | 79 |
| positive → positive → positive | 250 | thank → thank → thank → food | 74 |
| thank → positive → food | 219 | thank → positive → positive → positive | 53 |
| thank → thank → greeting | 194 | thank → thank → thank → greeting | 42 |
| thank → food → positive | 129 | thank → thank → positive → thank | 39 |
| thank → greeting → positive | 112 | positive → positive → thank → positive | 32 |
| positive → positive → food | 107 | positive → thank → positive → thank | 30 |
| thank → positive → question | 107 | positive → positive → positive → food | 26 |
| thank → food → food | 106 | thank → thank → positive → food | 24 |
| thank → greeting → greeting | 94 | thank → thank → food → thank | 22 |
| thank → positive → greeting | 89 | thank → positive → positive → food | 22 |
| thank → food → question | 85 | thank → positive → positive → question | 22 |
| thank → food → thank | 79 | thank → positive → thank → food | 21 |
| positive → positive → question | 79 | thank → thank → food → food | 21 |
| food → thank → positive | 74 | positive → positive → positive → thank | 20 |
| positive → positive → thank | 65 | positive → positive → positive → question | 20 |
| question → thank → positive | 64 | thank → positive → positive → thank | 17 |
| food → positive → positive | 60 | thank → thank → food → positive | 16 |
| thank → thank → question | 58 | thank → thank → positive → question | 15 |
| positive → thank → food | 52 | thank → positive → thank → greeting | 14 |
| greeting → thank → positive | 43 | positive → thank → positive → positive | 13 |
| question → positive → positive | 41 | positive → thank → positive → food | 13 |
| thank → thank → invitation | 35 | greeting → positive → thank → positive | 13 |
| positive → positive → greeting | 33 | thank → thank → thank → question | 13 |
| thank → positive → hashtag | 33 | food → positive → positive → positive | 11 |
| Description | Duration |
|---|---|
| Comments received in 1 h after posting the root discussion | 1 h |
| Comments received in between 1–6 h after posting the root discussion | 6 h |
| Comments received in between 6–12 h after posting the root discussion | 12 h |
| Comments received in between 12–24 h after posting the root discussion | 24 h |
| Comments received in between 24–48 h after posting the root discussion | 48 h |
| Comments received in between 48–168 h after posting the root discussion | 168 h |
| Comments received after 1 week | After a Week |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brambilla, M.; Javadian Sabet, A.; Kharmale, K.; Sulistiawati, A.E. Graph-Based Conversation Analysis in Social Media. Big Data Cogn. Comput. 2022, 6, 113. https://doi.org/10.3390/bdcc6040113
Brambilla M, Javadian Sabet A, Kharmale K, Sulistiawati AE. Graph-Based Conversation Analysis in Social Media. Big Data and Cognitive Computing. 2022; 6(4):113. https://doi.org/10.3390/bdcc6040113
Chicago/Turabian StyleBrambilla, Marco, Alireza Javadian Sabet, Kalyani Kharmale, and Amin Endah Sulistiawati. 2022. "Graph-Based Conversation Analysis in Social Media" Big Data and Cognitive Computing 6, no. 4: 113. https://doi.org/10.3390/bdcc6040113
APA StyleBrambilla, M., Javadian Sabet, A., Kharmale, K., & Sulistiawati, A. E. (2022). Graph-Based Conversation Analysis in Social Media. Big Data and Cognitive Computing, 6(4), 113. https://doi.org/10.3390/bdcc6040113