1. Introduction
Grapes, known as the queen of fruits, have high economic value. The short fruit period of grapes means that timely picking is essential for quality. Currently, hand grape harvesting is the most common method, which takes a lot of time and labor. With the transfer of rural labor from agriculture to non-agricultural industries, the rural surplus labor is gradually decreasing [
1]. Therefore, developing grape-picking robots has important research prospects. At present, picking robots mainly rely on the vision system to realize the location of fruits. Accurately detecting the location of the fruit is the key to achieving picking [
2]. Especially in the complex environment of grape orchards, is disturbed by factors such as illumination change, leaf occlusion, and fruit overlapping, which bring huge challenges to picking robots.
Traditional fruit detection methods, such as support vector machine [
3], template matching [
4], edge detection [
5], and threshold segmentation [
6], mainly extract inherent features, such as geometric shape [
7], color [
8,
9,
10], spectral information [
11], texture [
12] and edge [
13], to realize the detection of the grape region. Liu et al. [
14] used the least square method to fit the elliptic boundary of pomelo, to realize the segmentation of pomelo. Lin et al. [
4] proposed a local template matching algorithm and trained a new vector machine classifier by using color and texture, which can detect tomatoes, pumpkins, mangoes, and oranges. Nazari et al. [
15] designed an RGB classifier based on the color difference between red grapes and the background, which can segment red grapes. Pérez-Zavala et al. [
16] extracted the edge gradient information and surface texture information of grapes as classification features and used the support vector machine classifier to realize the segmentation of grapes and the background. Behroozi-Khazaei et al. [
8] put forward a method combining an artificial neural network and genetic algorithms, which can overcome the problem that greens grapes are similar to the background. Traditional grape detection methods can achieve good segmentation results when only a few fruits with a specified color and shape. At the same time, traditional image processing techniques rely on high-quality images and require complex artificial features. However, when there are complex scenes, such as scenes with changing illumination, scenes with dense fruits, and scenes with hidden fruits, the performance of fruit detection becomes poor. Under the circumstances, multiple overlapping grapes may be detected as one.
In the recent ten years, with the wide application of deep learning, great breakthroughs have been made in the object detection field [
17,
18,
19,
20,
21,
22]. Gao et al. [
23] divided the blocked apples into three categories, including apples occluded by leaves, apples occluded by branches, and apples occluded by other apples, and used the Faster R-CNN algorithm to detect the occluded apples. Tu et al. [
24] proposed a multi-scale feature fusion MS-FRCNN algorithm, which combined the semantic information of the deep network and the location information of the shallow network to improve the detection accuracy in the case of dense passion fruit. Mai et al. [
25] increased the single classifier in Faster-RCNN to three classifiers, which effectively enhanced the detection performance of dense fruit targets. Ding et al. [
26] improved the SSD model by using the receptive field block and attention mechanism, which effectively reduced the missed detection rate of occluded apples. Behera et al. [
27] changed IOU to MIOU in the loss function of Fast RCNN, which improved the recognition performance of occluded and dense fruits. Tu et al. [
24] and Ding et al. [
26] improved the feature fusion module of the model, and Behera et al. [
27] improved the loss function to solve the issue of difficult recognition of occluded and dense targets. However, due to the slow detection speed and a large number of parameters, the above models are difficult to deploy on the mobile end of harvesting robots.
In order to solve the issues of large parameters and slow detection speed, some scholars have studied in the field of lightweight. Generally speaking, the detection speed increases with the decrease in the model parameters. The main methods to reduce the parameters are replacing the convolution module and reducing the convolution layer [
28,
29,
30,
31]. Mao et al. [
32] proposed the Mini-YOLOv3 model, which used depthwise separable convolution and point group convolution to decrease the parameters. A lightweight YOLOv4 model was proposed by Zhang et al. [
33], the backbone network Darknet-53 of YOLOv4 is replaced with the GhostNet network and the basic convolution is replaced with a depthwise separable convolution in the neck and head. Ji et al. [
34] took YOLOVX-Tiny as the baseline, adopted a lightweight backbone network, and proposed a method for apple detection based on Shufflenetv2-YOLOX. Fu et al. [
35] used 1 × 1 convolution to decrease the parameters of the original model and proposed the DY3TNet model to detect kiwifruit. Li et al. [
36] reduced the calculations and parameters by introducing deep separable convolution and ghost modules. Liu et al. [
37] proposed the YOLOX-RA model, which pruned part of the network structure in the backbone network and used depth separable convolution in the neck network. Cui et al. [
38] changed the backbone network from CSPdarknet-Tiny to ShuffleNet in YOLOv4-tiny and reduced the three detection heads to one detection head. Zeng et al. [
39] replaced CSPdarknet with Mobilenetv3 and compressed the neck network of YOLOv5s by pruning technology [
40].
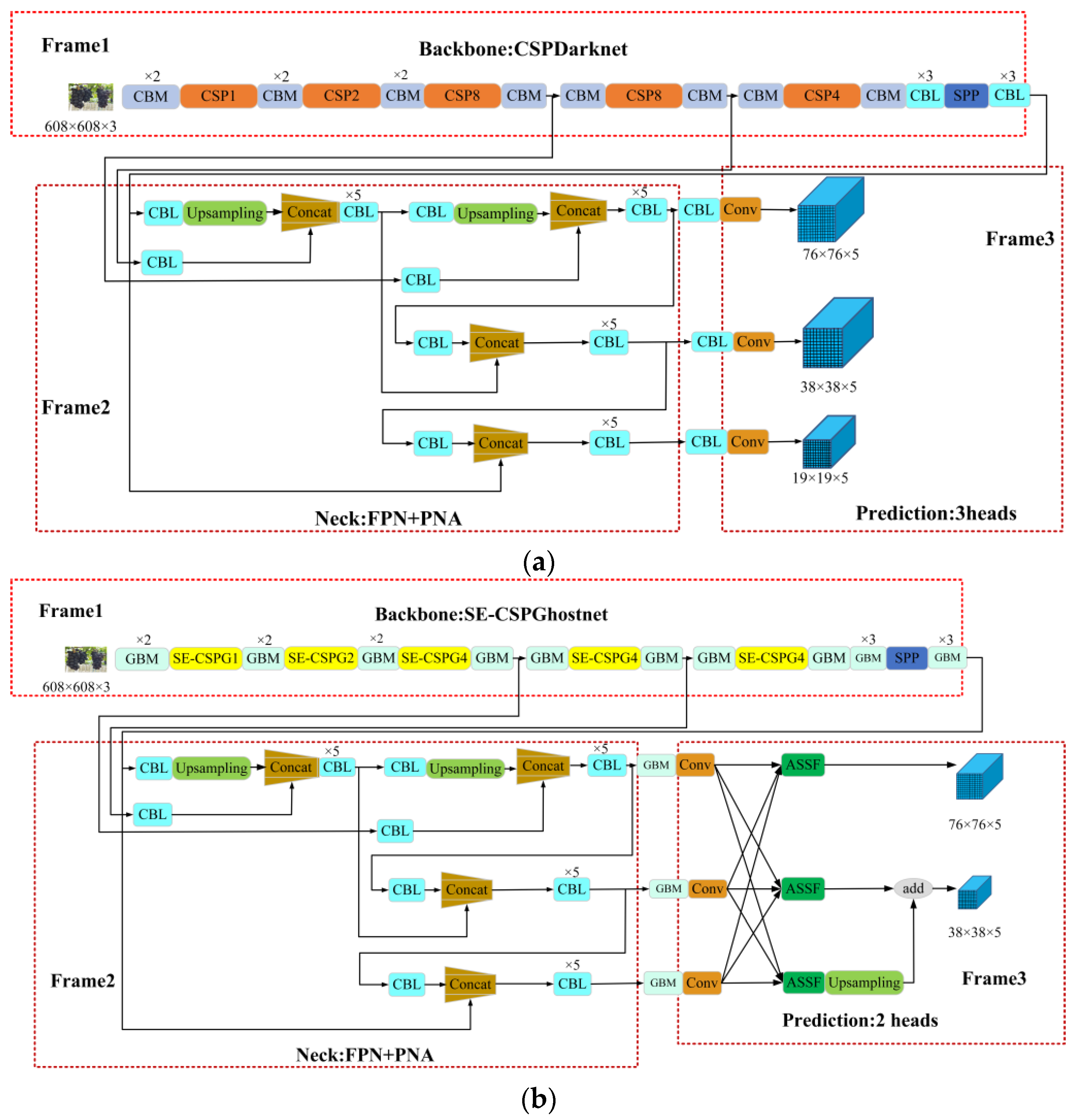
Although these models achieve lightweight, the detection accuracy suffers. In the vineyard, clusters of grapes grow densely and overlap each other, and the huge leaves easily cover the grapes. The complex growing environment leads to a low recall rate of the deep learning detection model for grape detection. In addition, the model parameters with high detection accuracy are redundant, which makes it difficult to deploy to the mobile end of the picking robots. The existing detection model can hardly meet the two advantages of detection accuracy and detection speed. To sum up, our research objective is to solve the problem that targets are difficult to identify while ensuring the accuracy of model detection and reducing the parameters of the model. In this paper, a GA-YOLO model with fast detection speed, small parameters, and a low missed detection rate is proposed for dense and occluded grapes.
In short, our innovations are as follows:
- (1)
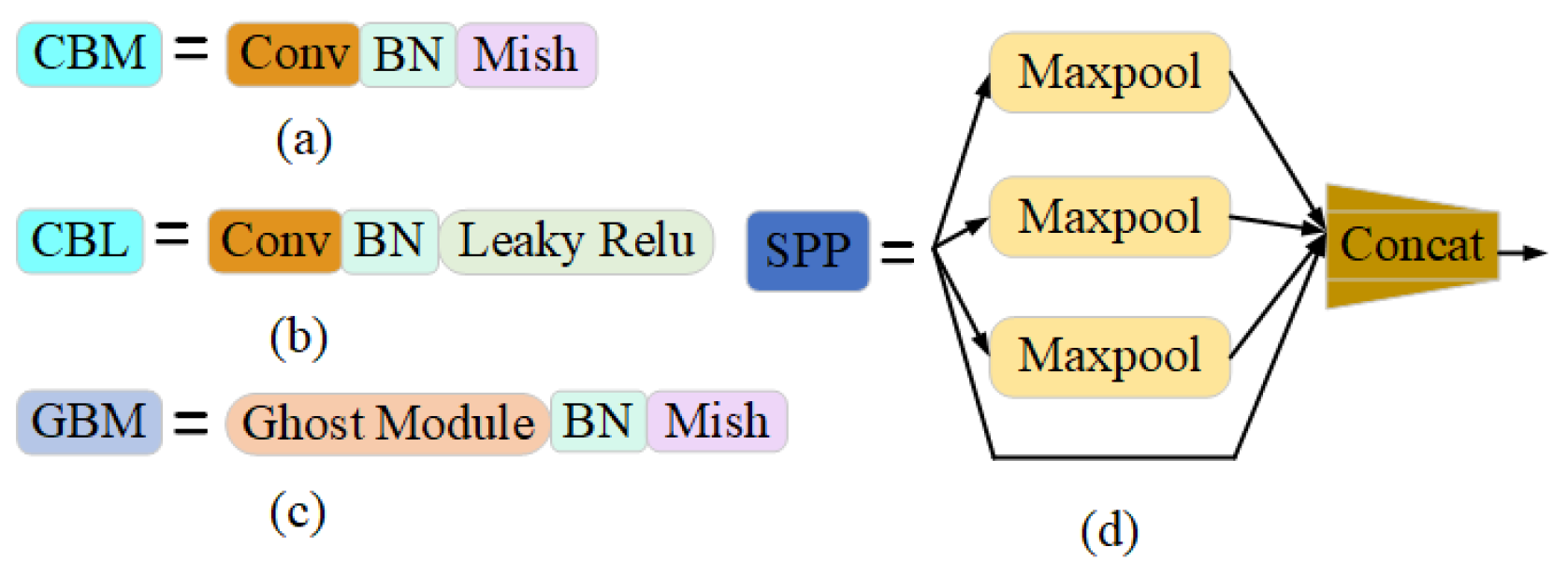
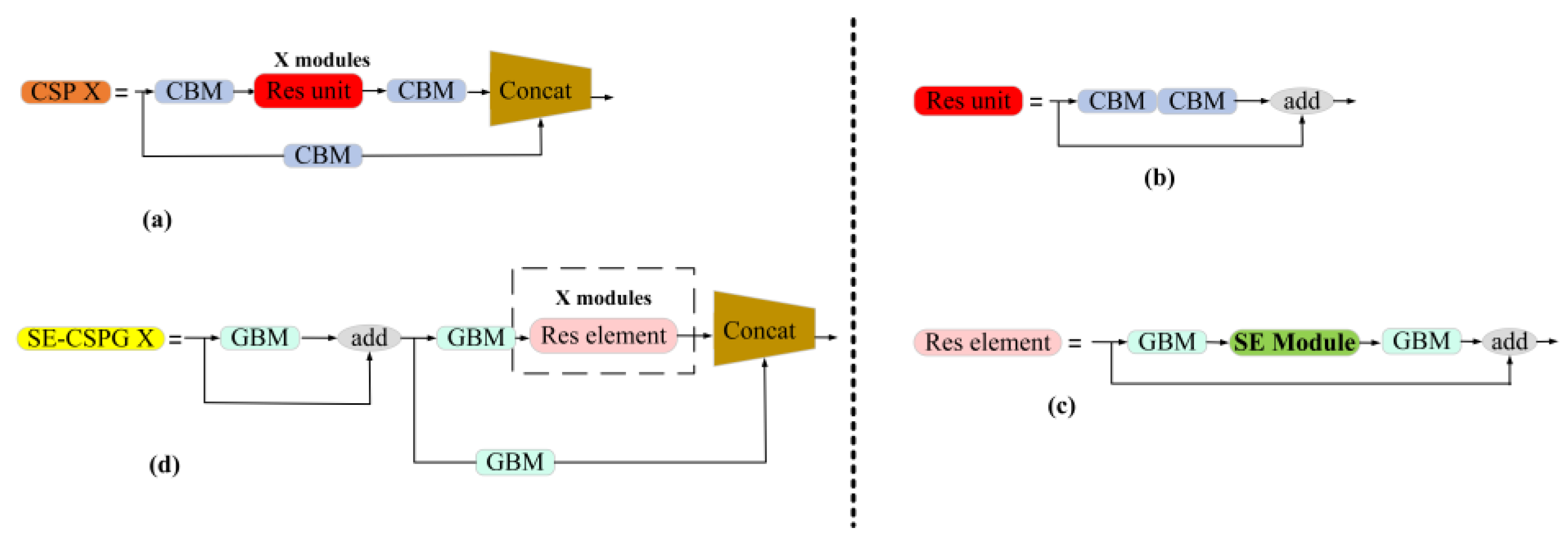
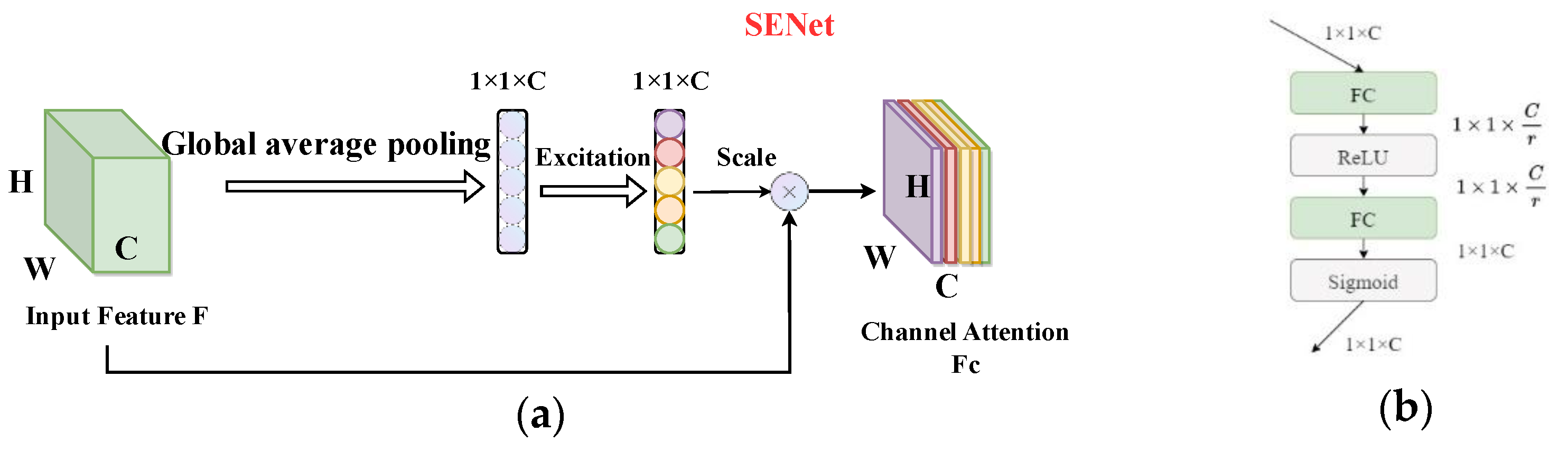
A new backbone network SE-CSPGhostnet is designed, which greatly reduces the parameters.
- (2)
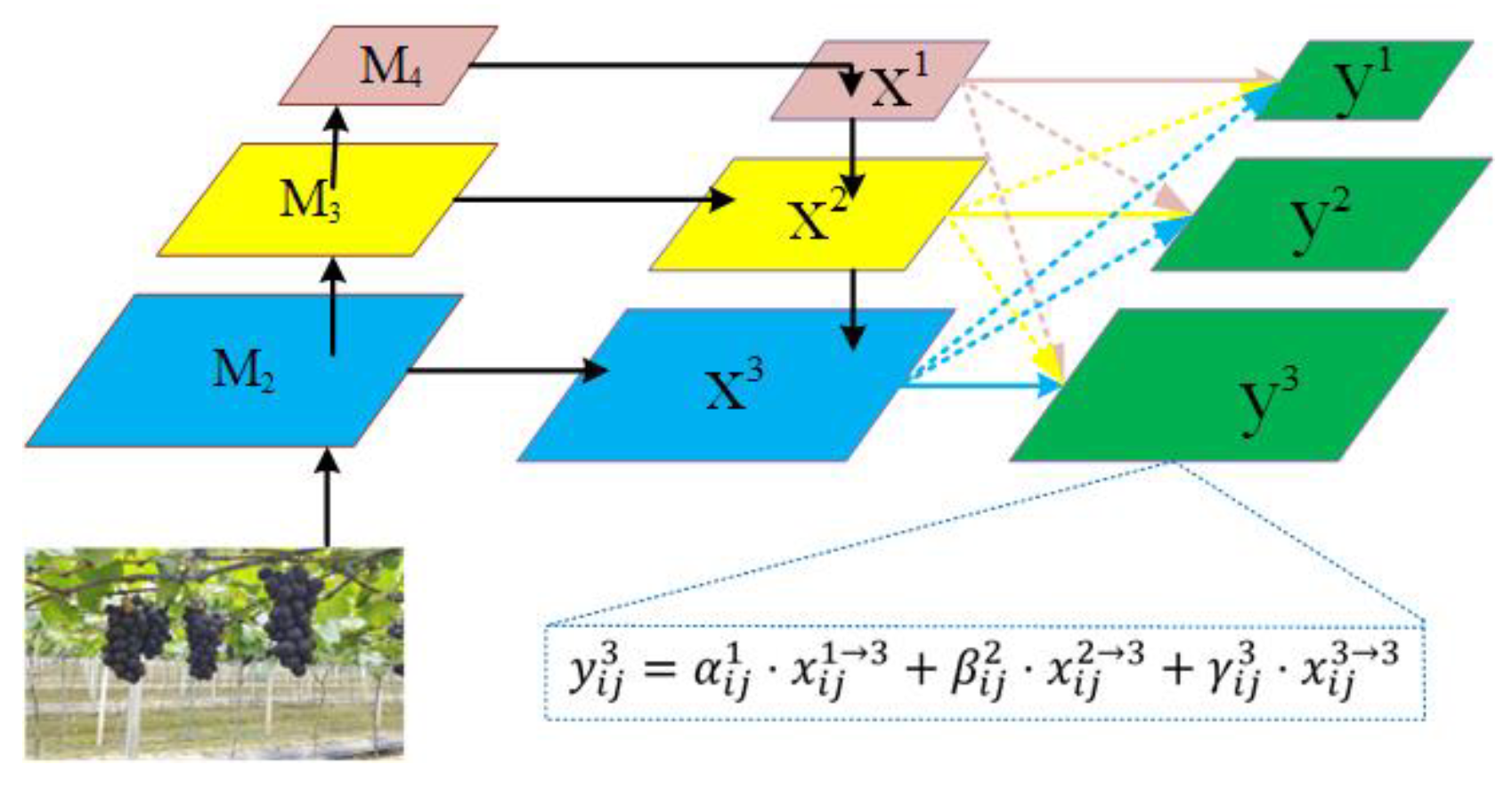
ASFF mechanism is used to address the issues of difficult detection of occluded and dense targets, and the model’s detection accuracy is raised.
- (3)
A novel loss function is constructed to improve detection efficiency.
The architecture of this paper is as follows:
Section 1 introduces the background, significance, and current status.
Section 2 introduces dataset collection, annotation, and augmentation.
Section 3 introduces the GA-YOLO algorithm.
Section 4 contains the experimental process, the comparison of model performance, and the analysis of the results.
Section 5 describes the use of human–computer interaction interface.
Section 6 discusses the experimental results and points out the limitations of the algorithm.
Section 7 concludes the paper and provides future research plans.
In the paper, the full names and acronyms are displayed in
Table 1.
6. Discussion of Experiment
The problems of agricultural health monitoring [
49,
50,
51,
52,
53,
54,
55] and harvesting [
56,
57] have always been hot spots of scientific research. In particular, the deep learning algorithm has become the mainstream research algorithm of the vision system of fruit-picking robots. Compared with the Faster RCNN algorithm [
20], the YOLO algorithm [
17,
18,
19,
22] has the advantage of high speed because it unifies regression and classification into one stage. In recent years, some scholars [
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39] have applied the YOLO algorithm to the visual detection of fruit-picking robots, which provides technical help to solve the picking problem in agriculture. However, the YOLO algorithm still has some shortcomings, such as large parameters and low detection accuracy of occluded targets, which are exactly what we want to solve.
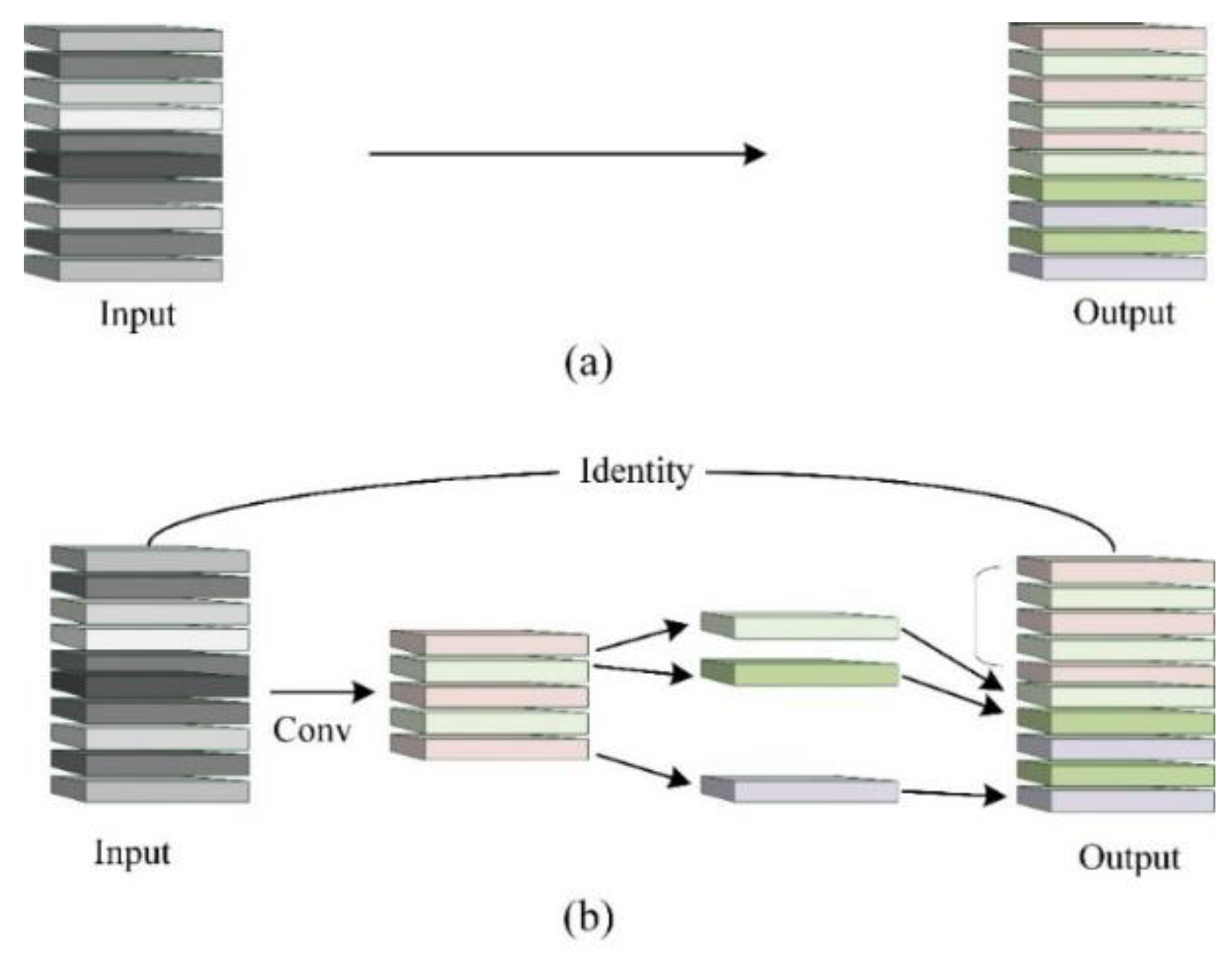
In fact, in recent years, some scholars have begun to study the lightweight model while ensuring the detection accuracy of complex objects. Zhao et al. [
58] changed the backbone network in YOLOV4 from CSPdarknet53 to MobileNet53 to obtain a lightweight model, and at the same time, the deformable convolution was used to achieve dense target detection. Betti [
59] and others pruned Darknet53 and compressed the backbone network from 53 layers to 20 layers. In addition, YOLO-S replaces the maximum pooling with cross-border convolution, which reduces the information loss in the transmission process and improves the detection accuracy of small targets. Huang et al. [
60] proposed a GCS-YOLOv4-tiny model based on YOLOV4-Tiny. In this model, grouping convolution is used to reduce the parameter of the model by 1.7 M, and the attention mechanism is used to improve the mAP of F. margarita to 93.42%. Sun et al. [
61] designed a shuffle module, lightened YOLOv5s and obtained the YOLO-P model. What is more, the YOLO-P model adopts a Hard-Swish activation function and CBAM attention mechanism. The research methods of the above scholars mainly use lightweight modules to partially replace the original network to achieve the purpose of reducing parameters. Meanwhile, methods such as the replacement of activation functions and the addition of attention mechanisms ensure the detection accuracy of the model for occlusions and dense objects. To conclude, using lightweight convolution modules (such as depth separable convolution, group convolution, etc.), and replacing backbone networks are the most frequently used to reduce the parameters of the model. Mao et al. [
32], Fu et al. [
35], Li et al. [
36], and Liu et al. [
37] used depth separable convolution to reduce the parameters of the model by 77%, 18.18%, 49.15%, and 10.03%, respectively. Moreover, Zhang et al. [
33], Cui et al. [
38], Zeng et al. [
39], and Zhao et al. [
58] replaced the backbone network to reduce the parameters of the model by 82.3%, 52.3%, 78%, and 82.81%, respectively. Replacing backbone networks can reduce more parameters than using lightweight convolution modules, but the accuracy drops even more. Similar to using deep separable convolution to replace ordinary convolution, we use a ghost module to replace ordinary convolution, which reduces the parameters of the model by 82.79%, and the accuracy loss is less affected than replacing the backbone network. In order to solve the problem of decreasing accuracy, attention mechanisms and improving loss function are common methods, which have been adopted by most researchers [
26,
27,
33,
34,
36,
37,
38,
60,
61]. In addition to these two improved methods, we adopt the ASFF method [
42] in the head network to effectively improve the detection accuracy of the model. ASFF performs spatial filtering on the feature maps at all levels, thus retaining only useful information for combination. GA-YOLO is proposed under the guidance of similar design ideas. The GA-YOLO model is of great significance for improving the picking speed and picking quality (low missing picking rate) of the picking robot.
The model proposed in this paper mainly aims at the target detection of dense and occluded grapes. The model can also be used for other fruits in the same growth state (clusters) such as tomatoes, bananas, and strawberries. According to the ablation experiments in
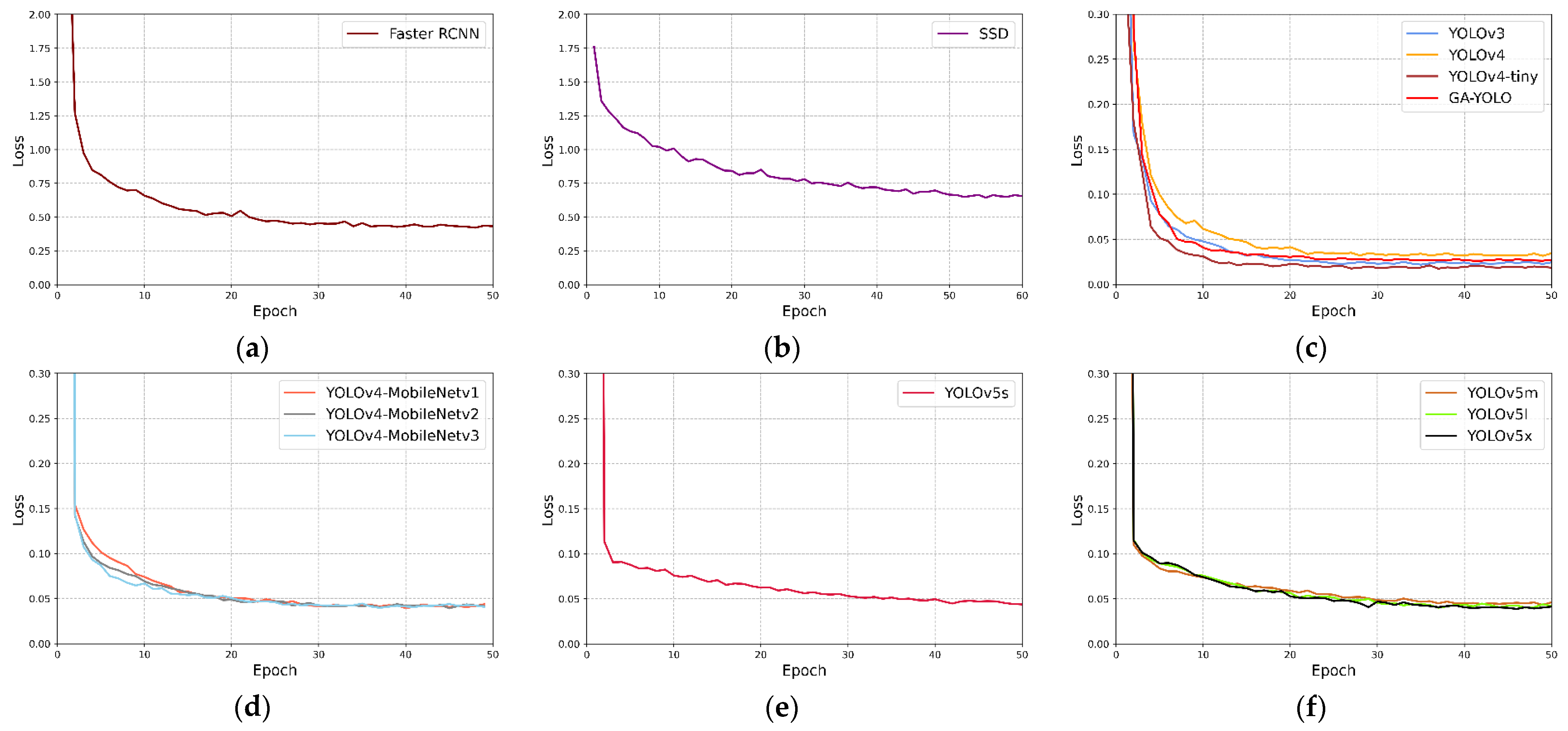
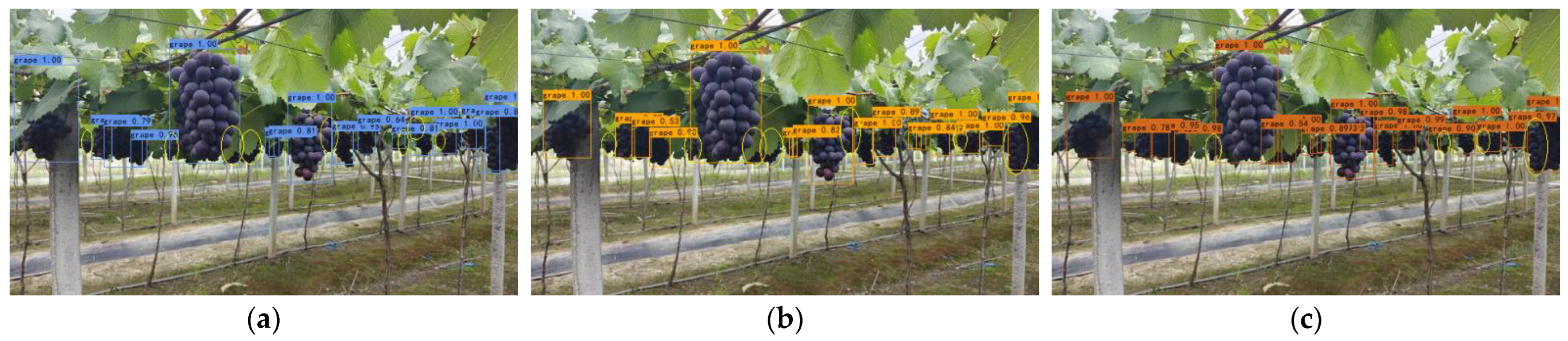
Section 4, we found that the detection accuracy of the model decreased by 0.94% after the model was lightened by 82.79%. Yet, we can add an ASFF module and improve the loss function to heighten accuracy. The model is lightweight, which is of great significance to solve the deployment problem of the mobile end of the model. In addition, the recall rate of the GA-YOLO model and other target detection models is lower than the precision rate, which shows that the problem of missed detection is puzzling grape detection. By lowering the confidence threshold for prediction, it is easier for the model to detect grapes and reduce the missed detection rate. However, this will increase the risk of false detection, so subsequent debugging of the model is required. Finally, it may be possible to increase the size of the input image to obtain more abundant location features and semantic features to reduce the missed detection rate, but this method will increase the number of parameters of the model, so it is necessary to find the optimal input image size.
There are still some problems to be considered when picking grapes by picking robots.
- (1)
We need to distinguish the maturity of grapes to avoid picking immature grapes.
- (2)
The detection of grape clusters is only a part of picking steps, and we also need to realize the detection of picking points. Some scholars [
62,
63,
64] have developed the detection algorithm of grape picking points, the position errors between most predicted picking points and real points are within 40 pixels. However, the detected grapes are not in dense and shaded conditions, and the detection accuracy is low, so there is much room for improvement. The occlusion problem is not only solved by visual models but also requires appropriate planting strategies, such as farmers paying attention to thinning leaves and fruits when planting.
- (3)
The picking robot can work 24 h a day, so it is necessary to obtain the grape dataset at night. In fact, when the fruit is picked at night, it will not be exposed to the sun to cause water loss, so the quality of the fruit will be better. In addition, a richer dataset can increase the robustness of GA-YOLO.
Overall, the development of deep learning-based methods for fruit detection in agricultural settings has shown great promise in recent years. Other deep learning models (such as Faster RCNN and SSD, etc.), have their own unique advantages in specific fruit detection. In the future, we can also combine the design ideas of these models to better solve the identification problem of tropical fruits.
7. Conclusions
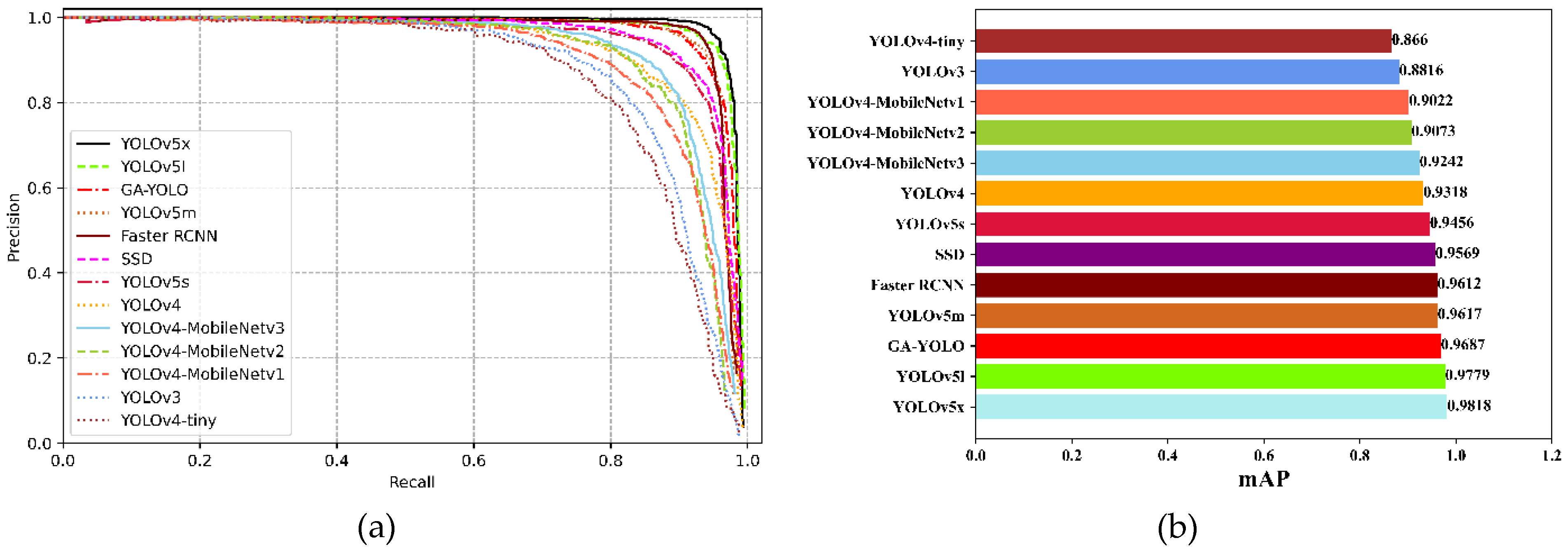
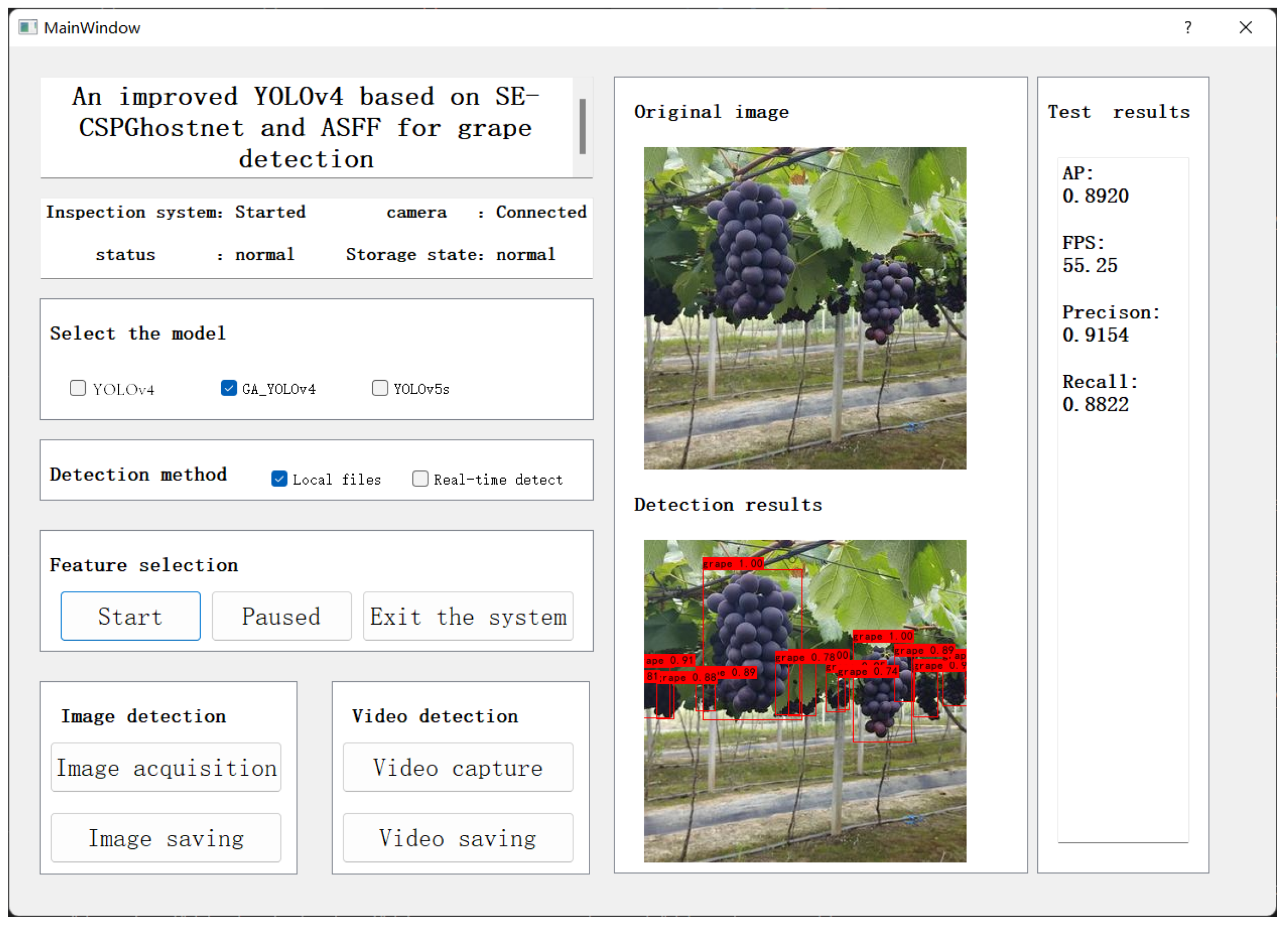
The goal of this paper is to decrease the parameters and calculations and raise the detection accuracy of the model. In this research, a lightweight network model named GA-YOLO was proposed. This model uses a backbone network of SE-CSPGhost, which reduces the parameter amount of the original model by 82.79% and improves the detection speed of the model by 20.245 FPS. This lightweight approach is of great significance for model deployment to mobile terminals. At the same time, although the lightweight model reduces the detection accuracy of dense and occluded grapes by 0.94%. By adding the attention mechanism and ASFF mechanism, and improving the loss function, the accuracy rate is increased by 3.69%. In short, the parameter quantity of the GA-YOLO model is 11.003 M, the mAP is 96.87%, the detection speed is 20.245 FPS and the F1 value is 94.78%. Compared with YOLOv4 and the other 11 commonly used models, the GA-YOLO has the advantages of high detection accuracy and low model parameters. It has excellent comprehensive performance and can meet the precision and speed requirements of picking robots. Finally, we use PyQt5 to design a human–computer interaction interface to facilitate the use of the GA-YOLO model by non-professionals. In future research, we will consider the mobile deployment of the model, and deploy the GA-YOLO model on small computing devices (Raspberry Pie, developed by the Raspberry Pie Foundation in Cambridge, England; Jetson Nano, developed by the NVIDIA Corporation in Santa Clara, CA, USA; Intel NCS 2, developed by the Intel Corp in Santa Clara, CA, USA), using the deep learning inference framework NCNN and TensorRT. In addition, we will consider collecting grape datasets under night illumination and training a widely used GA-YOLO model.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}