
Finding Closure Models to Match the Time Evolution of Coarse Grained 2D Turbulence Flows Using Machine Learning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Method
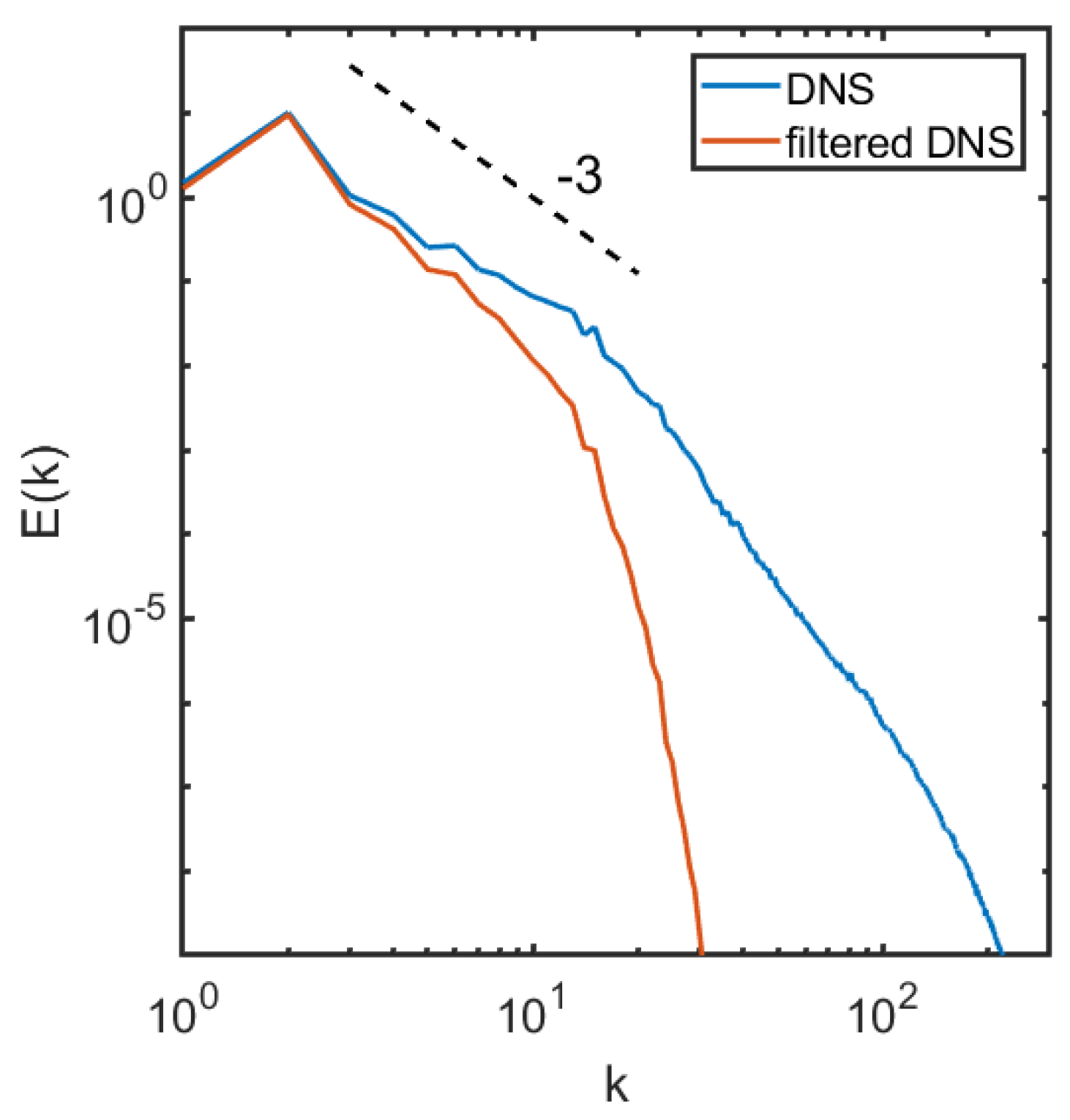
2.1. The Coarse Field
2.2. Neural Network (NN) Architecture
3. Results and Discussion
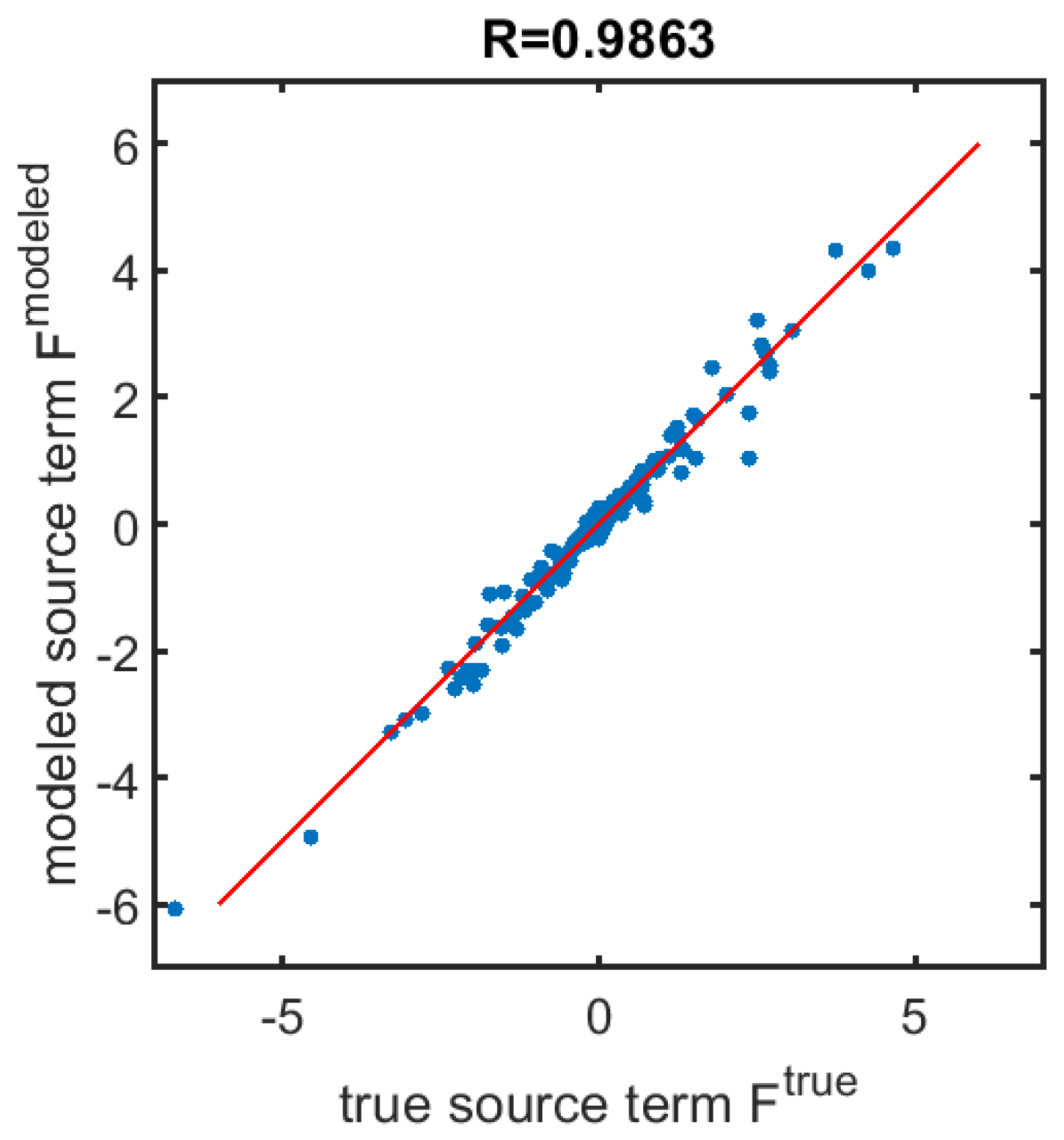
3.1. NN Learning
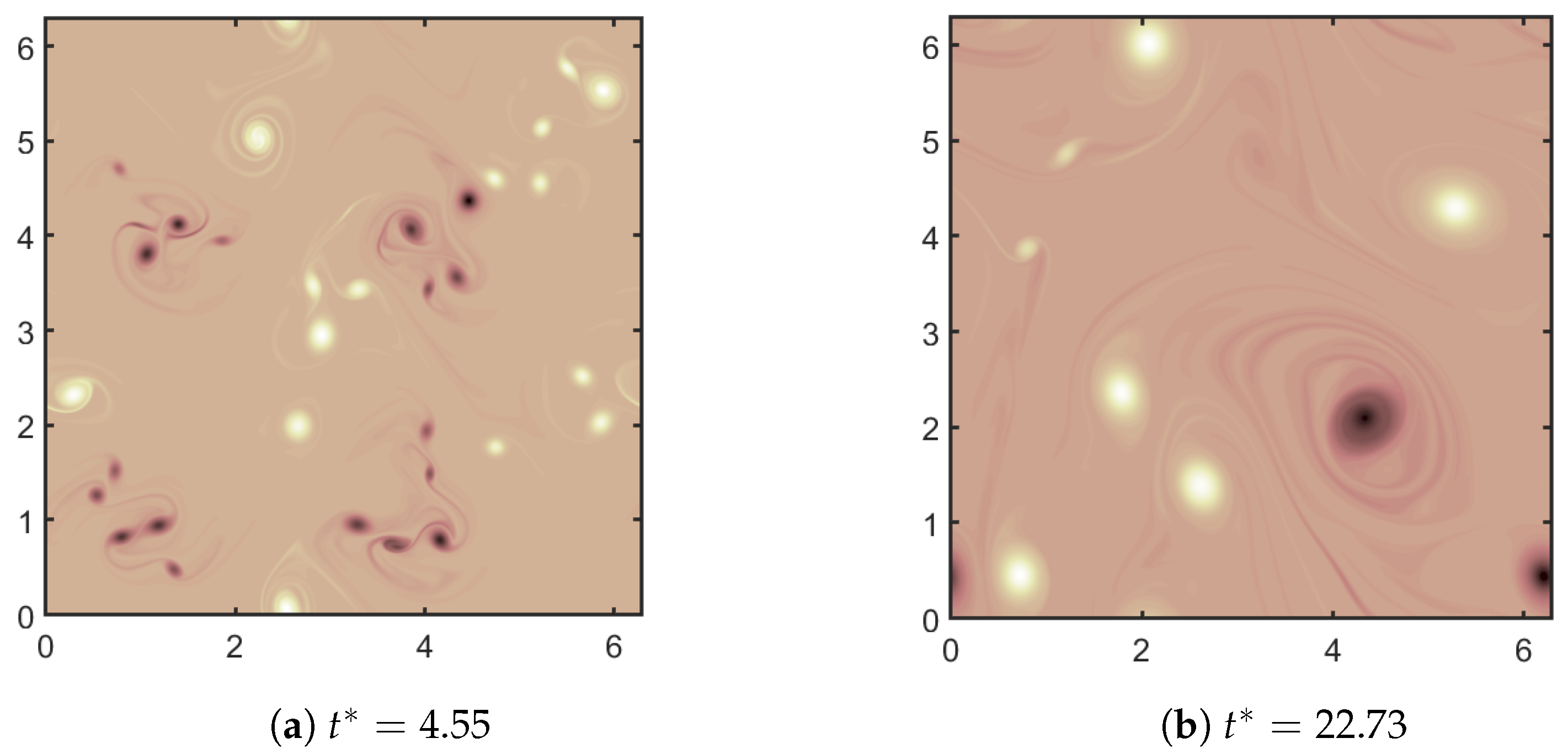
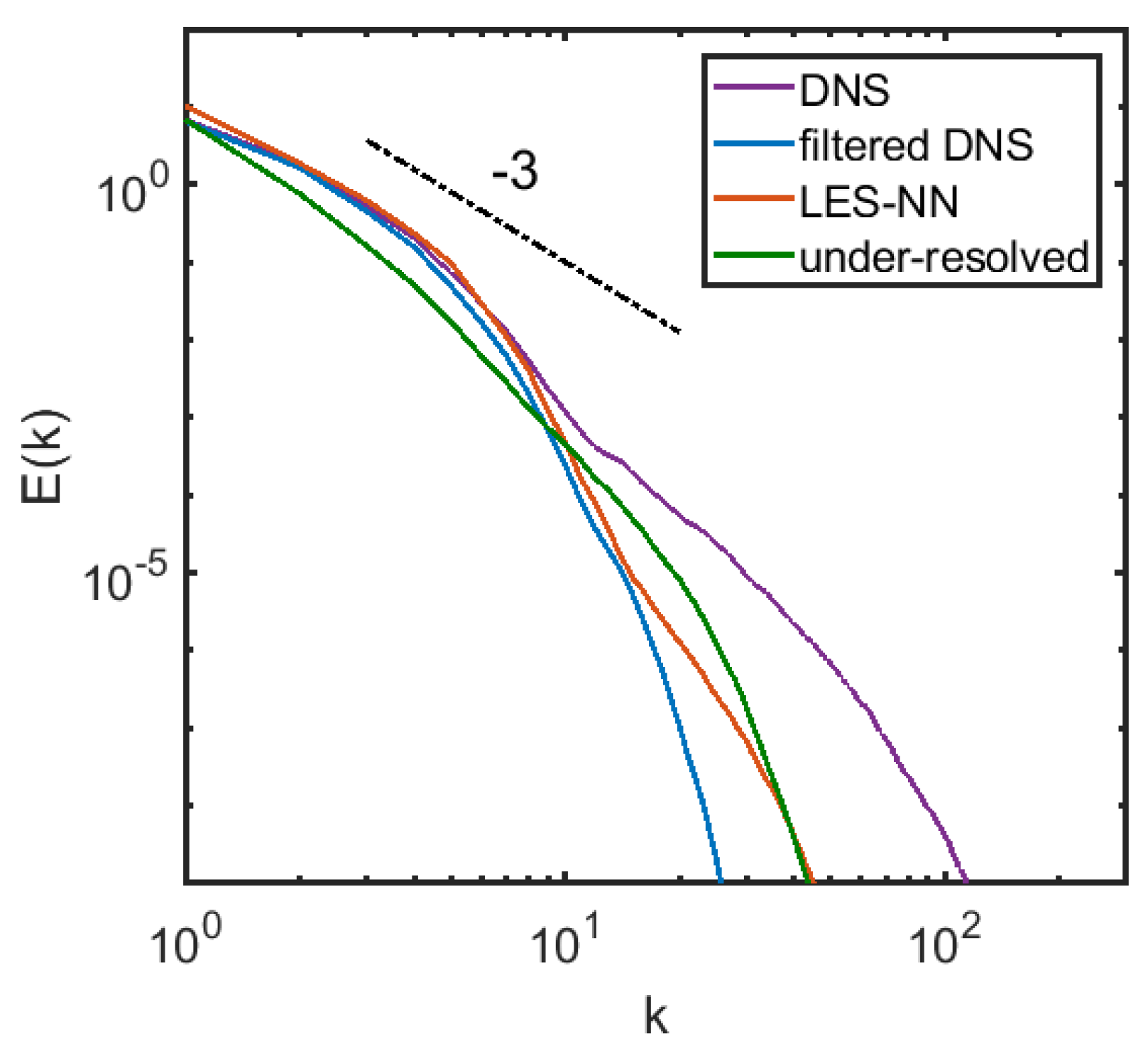
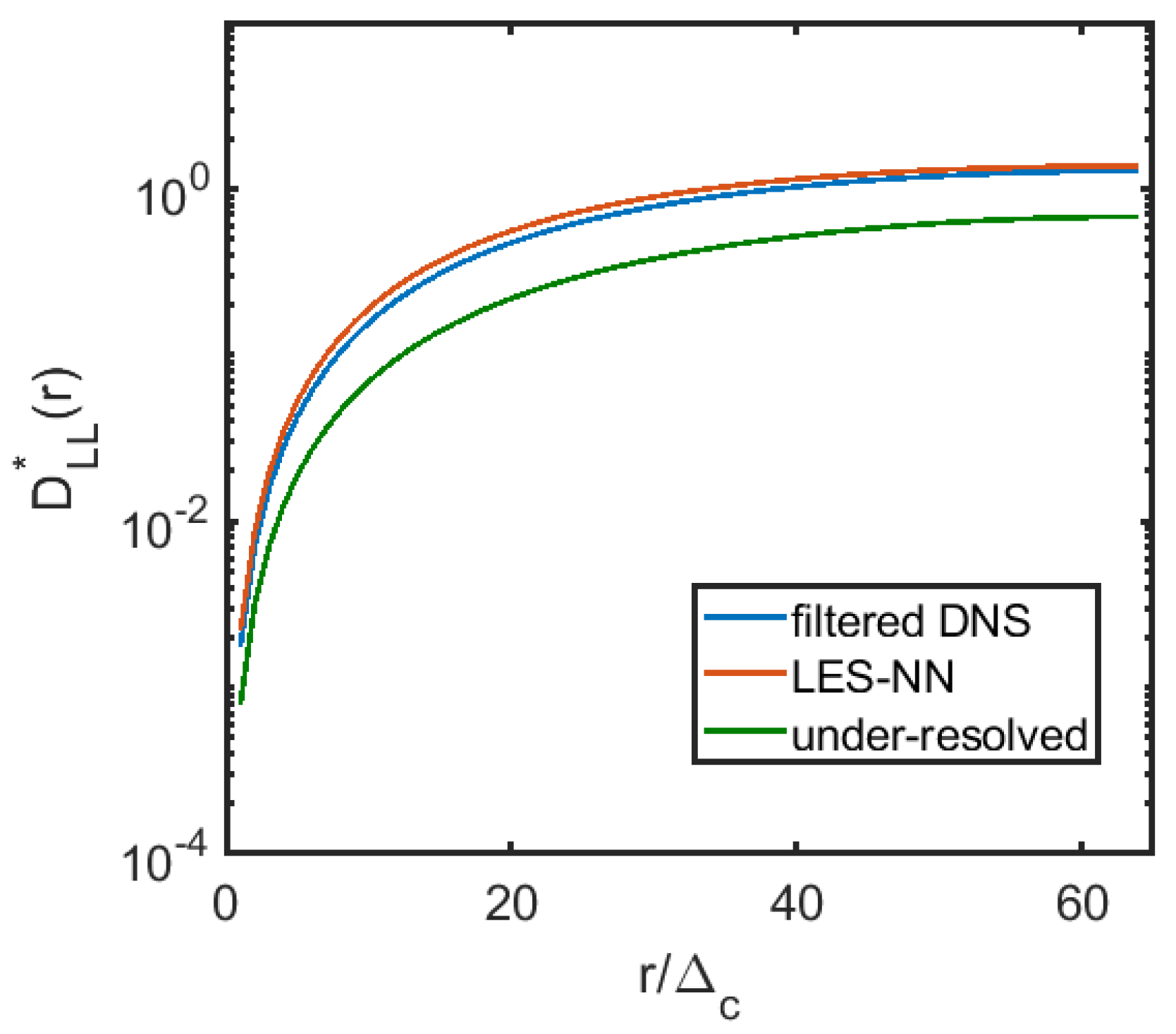
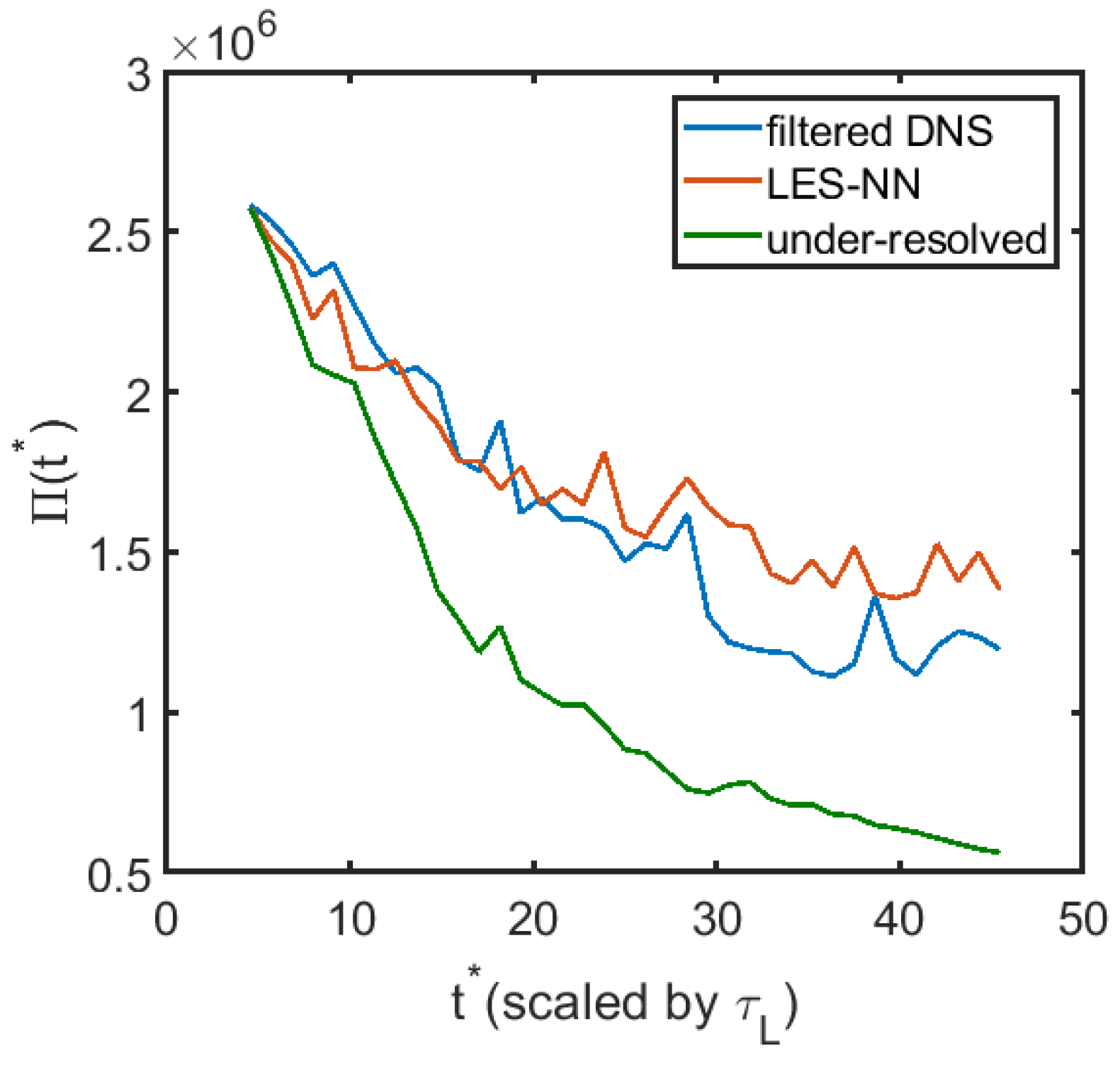
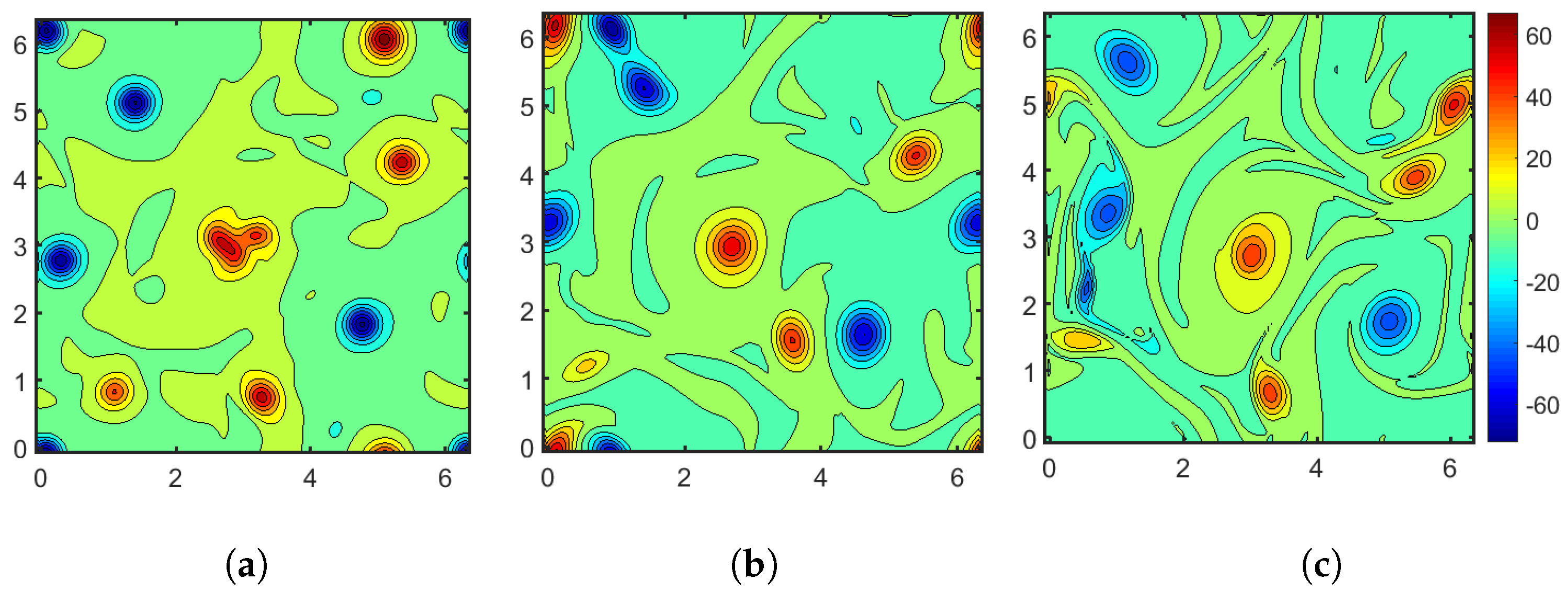
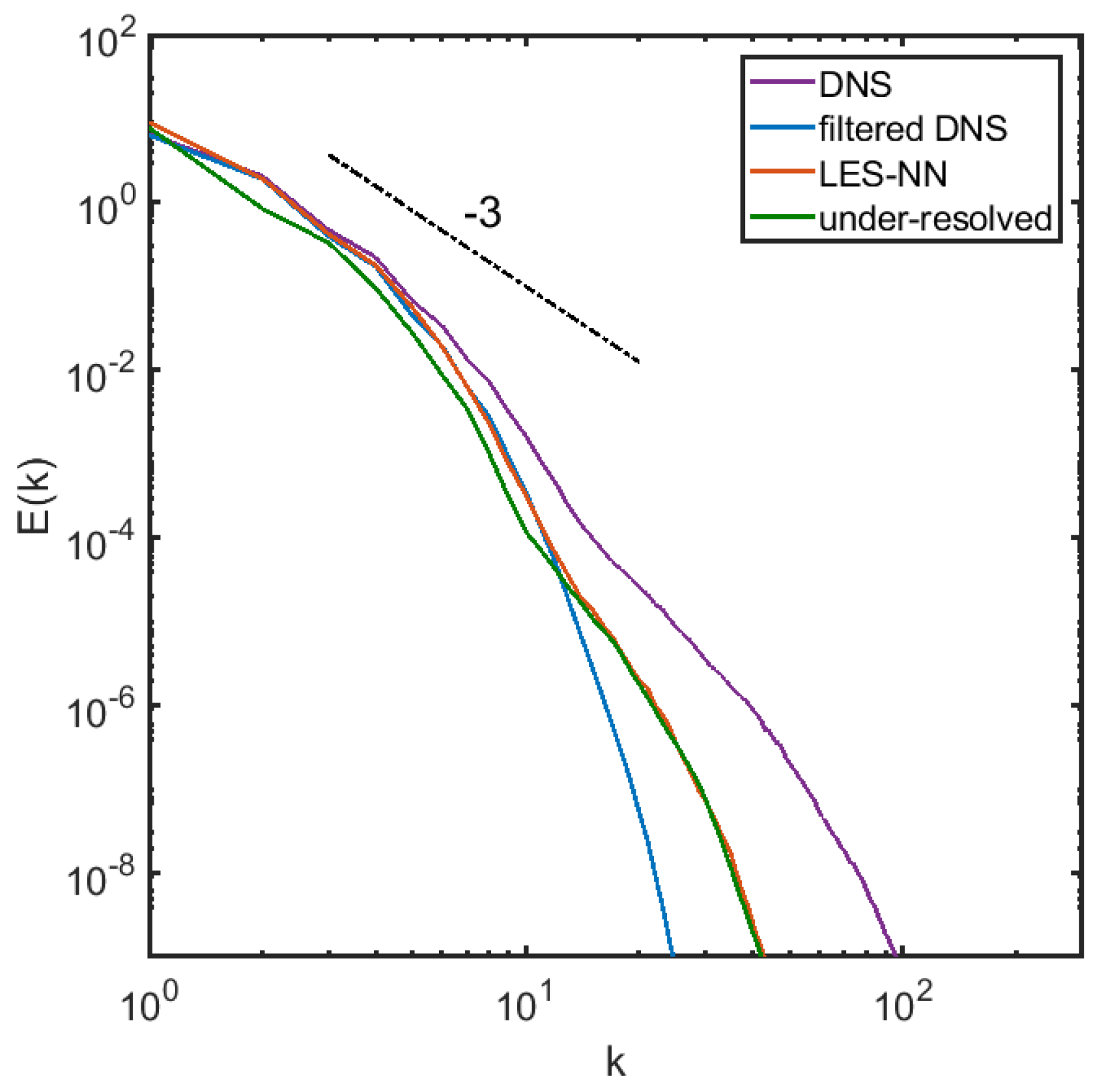
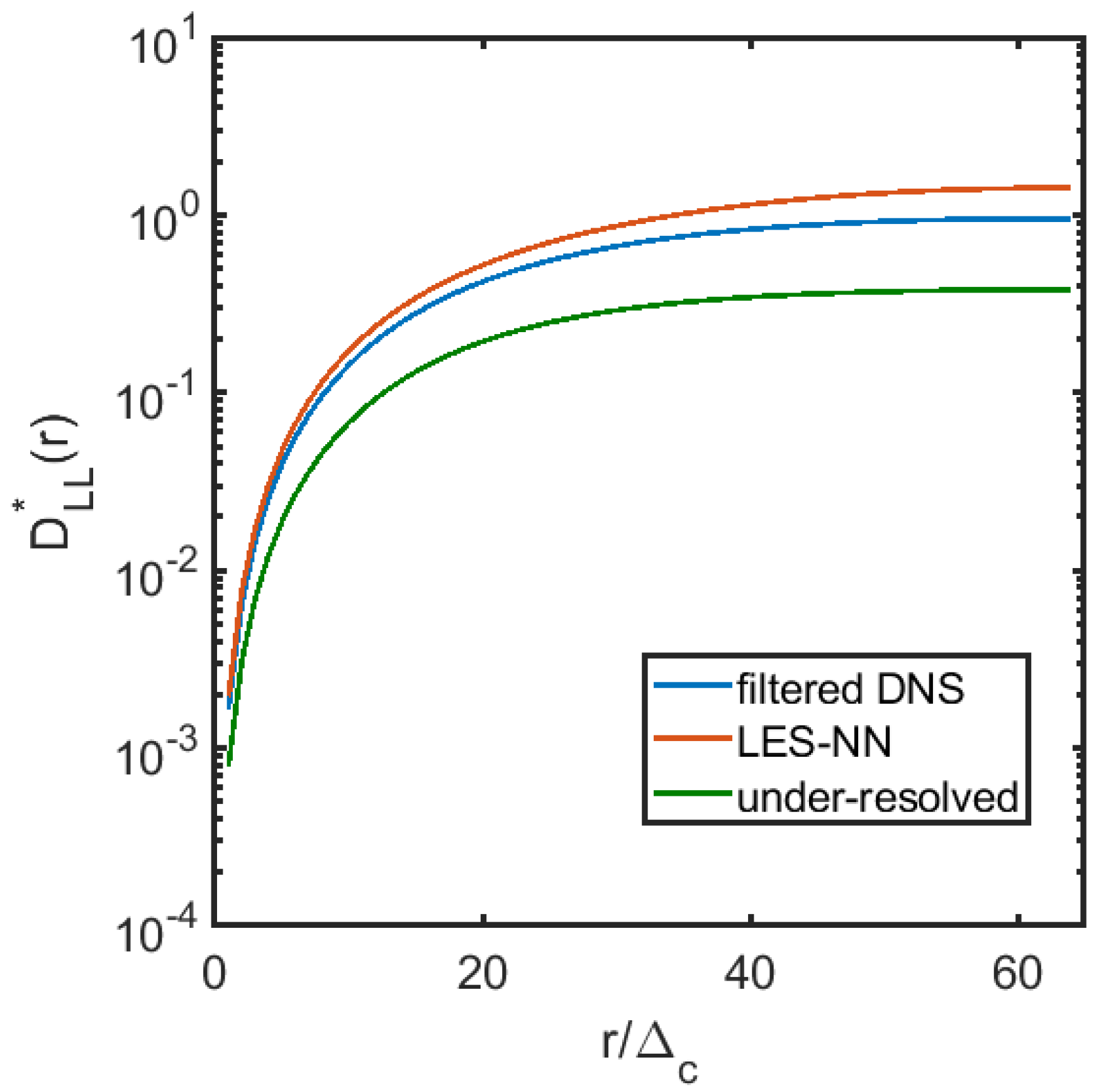
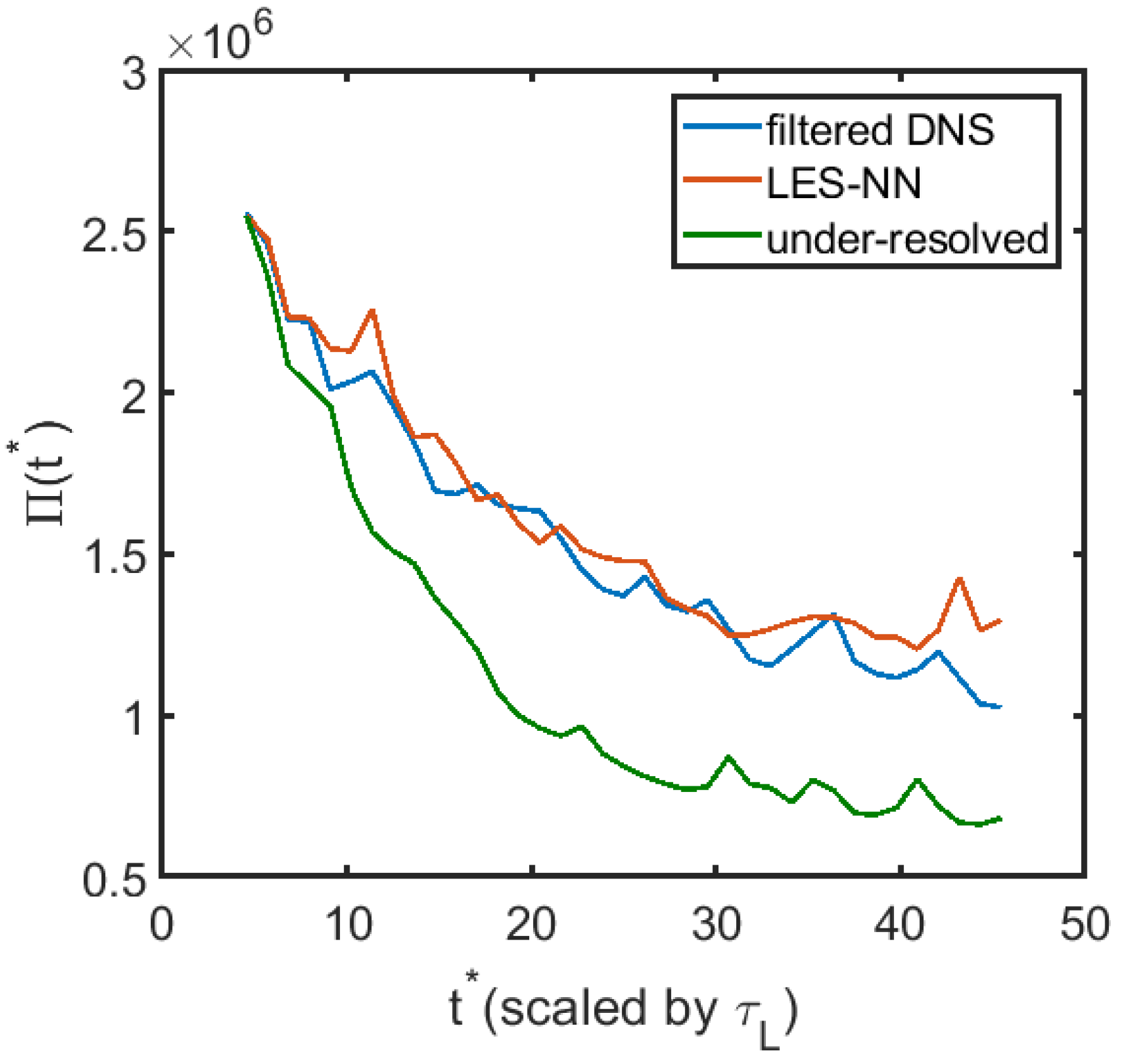
3.2. A Posteriori Tests
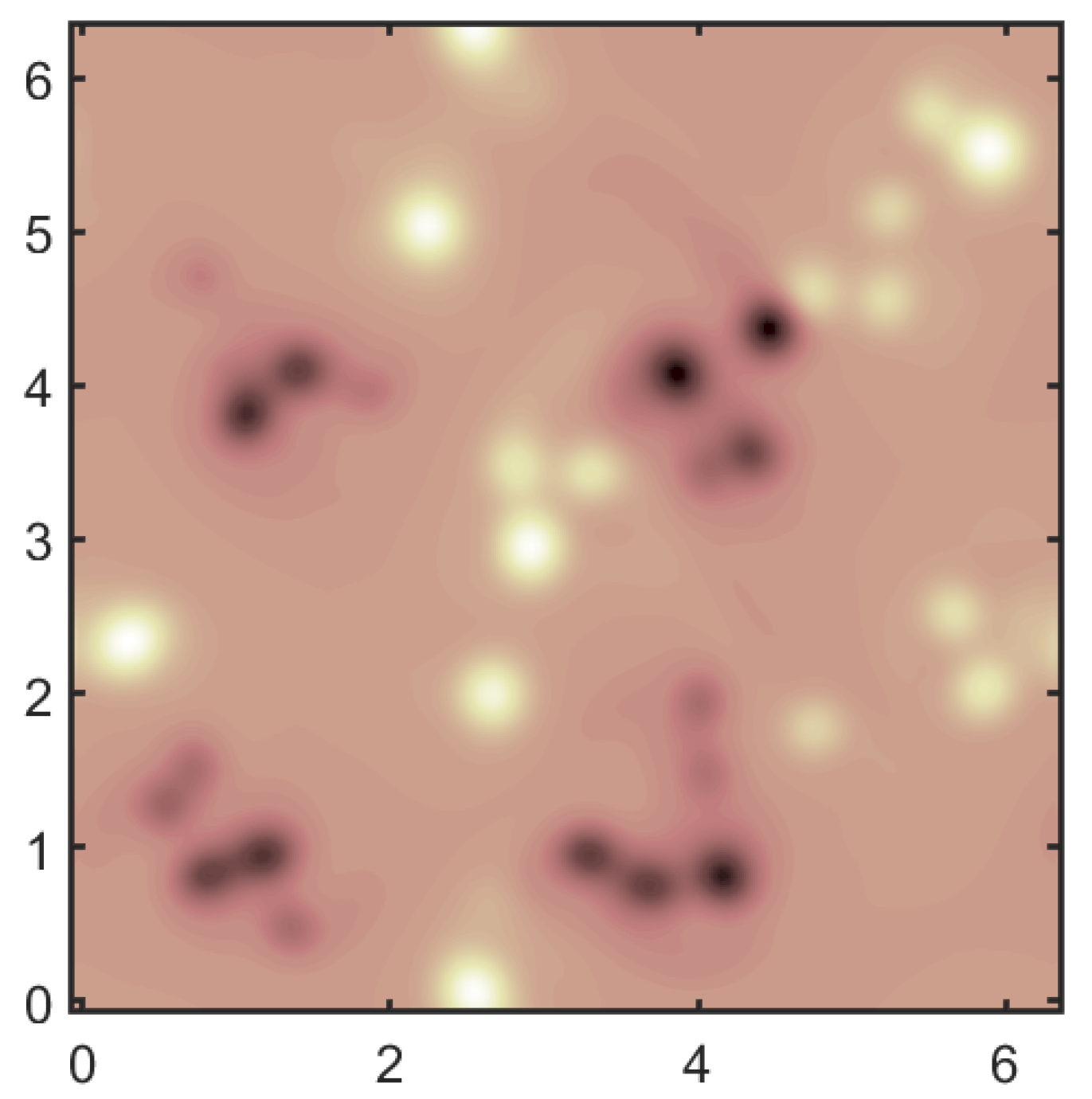
3.2.1. The Training Data
3.2.2. Non-Training Data
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Piomelli, U.; Zang, T.A. Large-eddy simulation of transitional channel flow. Comput. Phys. Commun. 1991, 65, 224–230. [Google Scholar] [CrossRef] [Green Version]
- Ling, J.; Kurzawski, A.; Templeton, J. Reynolds averaged turbulence modelling using deep neural networks with embedded invariance. J. Fluid Mech. 2016, 807, 155–166. [Google Scholar] [CrossRef]
- Xiao, H.; Wu, J.L.; Wang, J.X.; Sun, R.; Roy, C. Quantifying and reducing model-form uncertainties in Reynolds-averaged Navier–Stokes simulations: A data-driven, physics-informed Bayesian approach. J. Comput. Phys. 2016, 324, 115–136. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.X.; Wu, J.L.; Xiao, H. Physics-informed machine learning approach for reconstructing Reynolds stress modeling discrepancies based on DNS data. Phys. Rev. Fluids 2017, 2, 034603. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Xiao, H.; Sun, R.; Wang, Q. Reynolds-averaged Navier–Stokes equations with explicit data-driven Reynolds stress closure can be ill-conditioned. J. Fluid Mech. 2019, 869, 553–586. [Google Scholar] [CrossRef] [Green Version]
- Tracey, B.D.; Duraisamy, K.; Alonso, J.J. A machine learning strategy to assist turbulence model development. In Proceedings of the 53rd AIAA Aerospace Sciences Meeting, Kissimmee, FL, USA, 5–9 January 2015; p. 1287. [Google Scholar]
- Weatheritt, J.; Sandberg, R.D. Hybrid Reynolds-averaged/Large-Eddy Simulation methodology from symbolic regression: Formulation and application. AIAA J. 2017, 55, 3734–3746. [Google Scholar] [CrossRef]
- Ma, M.; Lu, J.; Tryggvason, G. Using statistical learning to close two-fluid multiphase flow equations for a simple bubbly system. Phys. Fluids 2015, 27, 092101. [Google Scholar] [CrossRef]
- Ma, M.; Lu, J.; Tryggvason, G. Using statistical learning to close two-fluid multiphase flow equations for bubbly flows in vertical channels. Int. J. Multiph. Flow 2016, 85, 336–347. [Google Scholar] [CrossRef] [Green Version]
- Duraisamy, K.; Iaccarino, G.; Xiao, H. Turbulence modeling in the age of data. Annu. Rev. Fluid Mech. 2019, 51, 357–377. [Google Scholar] [CrossRef] [Green Version]
- Sarghini, F.; De Felice, G.; Santini, S. Neural networks based subgrid scale modeling in Large Eddy Simulations. Comput. Fluids 2003, 32, 97–108. [Google Scholar] [CrossRef]
- Gamahara, M.; Hattori, Y. Searching for turbulence models by artificial neural network. Phys. Rev. Fluids 2017, 2, 054604. [Google Scholar] [CrossRef]
- Beck, A.; Flad, D.; Munz, C.D. Deep neural networks for data-driven LES closure models. J. Comput. Phys. 2019, 398, 108910. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Luo, K.; Li, D.; Tan, J.; Fan, J. Investigations of data-driven closure for subgrid-scale stress in Large-Eddy Simulation. Phys. Fluids 2018, 30, 125101. [Google Scholar] [CrossRef]
- Xie, C.; Wang, J.; Weinan, E. Modeling subgrid-scale forces by spatial artificial neural networks in Large Eddy Simulation of turbulence. Phys. Rev. Fluids 2020, 5, 054606. [Google Scholar] [CrossRef]
- Xie, C.; Wang, J.; Li, H.; Wan, M.; Chen, S. Spatially multi-scale artificial neural network model for Large Eddy Simulation of compressible isotropic turbulence. AIP Adv. 2020, 10, 015044. [Google Scholar]
- Kraichnan, R.H. Inertial ranges in two-dimensional turbulence. Phys. Fluids 1967, 10, 1417–1423. [Google Scholar] [CrossRef] [Green Version]
- Boffetta, G.; Ecke, R.E. Two-dimensional turbulence. Annu. Rev. Fluid Mech. 2012, 44, 427–451. [Google Scholar] [CrossRef]
- Maulik, R.; San, O. A neural network approach for the blind deconvolution of turbulent flows. J. Fluid Mech. 2017, 831, 151–181. [Google Scholar] [CrossRef] [Green Version]
- Maulik, R.; San, O.; Rasheed, A.; Vedula, P. Subgrid modelling for two-dimensional turbulence using neural networks. J. Fluid Mech. 2019, 858, 122–144. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, S.E.; Pawar, S.; San, O.; Rasheed, A.; Iliescu, T.; Noack, B.R. On closures for reduced order models—A spectrum of first-principle to machine-learned avenues. Phys. Fluids 2021, 33, 091301. [Google Scholar] [CrossRef]
- Siddani, B.; Balachandar, S.; Moore, W.C.; Yang, Y.; Fang, R. Machine learning for physics-informed generation of dispersed multiphase flow using generative adversarial networks. Theor. Comput. Fluid Dyn. 2021, 35, 807–830. [Google Scholar] [CrossRef]
- Jagtap, A.D.; Kawaguchi, K.; Karniadakis, G.E. Adaptive activation functions accelerate convergence in deep and physics-informed neural networks. J. Comput. Phys. 2020, 404, 109136. [Google Scholar] [CrossRef] [Green Version]
- Jagtap, A.D.; Kawaguchi, K.; Em Karniadakis, G. Locally adaptive activation functions with slope recovery for deep and physics-informed neural networks. Proc. R. Soc. A 2020, 476, 20200334. [Google Scholar] [CrossRef] [PubMed]
- Jagtap, A.D.; Shin, Y.; Kawaguchi, K.; Karniadakis, G.E. Deep Kronecker neural networks: A general framework for neural networks with adaptive activation functions. Neurocomputing 2022, 468, 165–180. [Google Scholar] [CrossRef]
- Piomelli, U.; Cabot, W.H.; Moin, P.; Lee, S. Subgrid-scale backscatter in turbulent and transitional flows. Phys. Fluids A Fluid Dyn. 1991, 3, 1766–1771. [Google Scholar] [CrossRef] [Green Version]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Lu, J.; Tryggvason, G. Finding Closure Models to Match the Time Evolution of Coarse Grained 2D Turbulence Flows Using Machine Learning. Fluids 2022, 7, 154. https://doi.org/10.3390/fluids7050154
Chen X, Lu J, Tryggvason G. Finding Closure Models to Match the Time Evolution of Coarse Grained 2D Turbulence Flows Using Machine Learning. Fluids. 2022; 7(5):154. https://doi.org/10.3390/fluids7050154
Chicago/Turabian StyleChen, Xianyang, Jiacai Lu, and Grétar Tryggvason. 2022. "Finding Closure Models to Match the Time Evolution of Coarse Grained 2D Turbulence Flows Using Machine Learning" Fluids 7, no. 5: 154. https://doi.org/10.3390/fluids7050154
APA StyleChen, X., Lu, J., & Tryggvason, G. (2022). Finding Closure Models to Match the Time Evolution of Coarse Grained 2D Turbulence Flows Using Machine Learning. Fluids, 7(5), 154. https://doi.org/10.3390/fluids7050154