

Data, Volume 10, Issue 2 (February 2025) – 16 articles
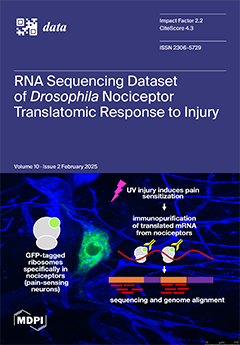
Cover Story (view full-size image):
To prepare to address the mechanisms of injury-induced nociceptor sensitization, which may underlie many types of abnormal pain (including chronic pain), we sequenced the translatome of the nociceptors, or pain-sensing neurons, of injured Drosophila larvae and, for comparison, those of uninjured larvae. Third-instar larvae were made to express a green fluorescent protein (GFP)-tagged ribosomal subunit RpL10Ab specifically in Class 4 dendritic arborization neurons, which are considered to be primary nociceptors. These larvae were then injured by ultraviolet light or were sham-injured. Ultraviolet light treatment induces a state of pain hypersensitivity that includes allodynia and hyperalgesia. Larvae were then homogenized and subjected to translating ribosome affinity purification (TRAP) using antibodies recognizing the GFP tag, and nociceptor-specific ribosome-bound RNA was sequenced. View this paper
- Issues are regarded as officially published after their release is announced to the table of contents alert mailing list.
- You may sign up for e-mail alerts to receive table of contents of newly released issues.
- PDF is the official format for papers published in both, html and pdf forms. To view the papers in pdf format, click on the "PDF Full-text" link, and use the free Adobe Reader to open them.
Previous Issue
Next Issue