


Trivariate Joint Distribution Modelling of Compound Events Using the Nonparametric D-Vine Copula Developed Based on a Bernstein and Beta Kernel Copula Density Framework



Abstract
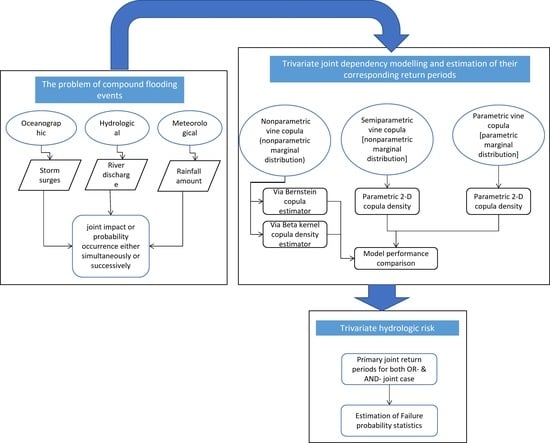
1. Introduction
2. Methodology
2.1. Nonparametric Copula Density Estimator
2.2. Univariate Kernel Density Estimation of Flood Margins
2.3. D-Vine Copula Structure in the Trivariate Modelling
2.4. Trivariate Joint Return Periods
2.5. Failure Probability in the Hydrologic Risk Evaluation
3. Application
3.1. Study Area and Defining the Compound Hazard Scenario
3.2. Nonparametric Estimation in the Univariate Flood Marginals
3.3. Incorporation of Nonparametric Vine Structure in the Trivariate Flood Dependence
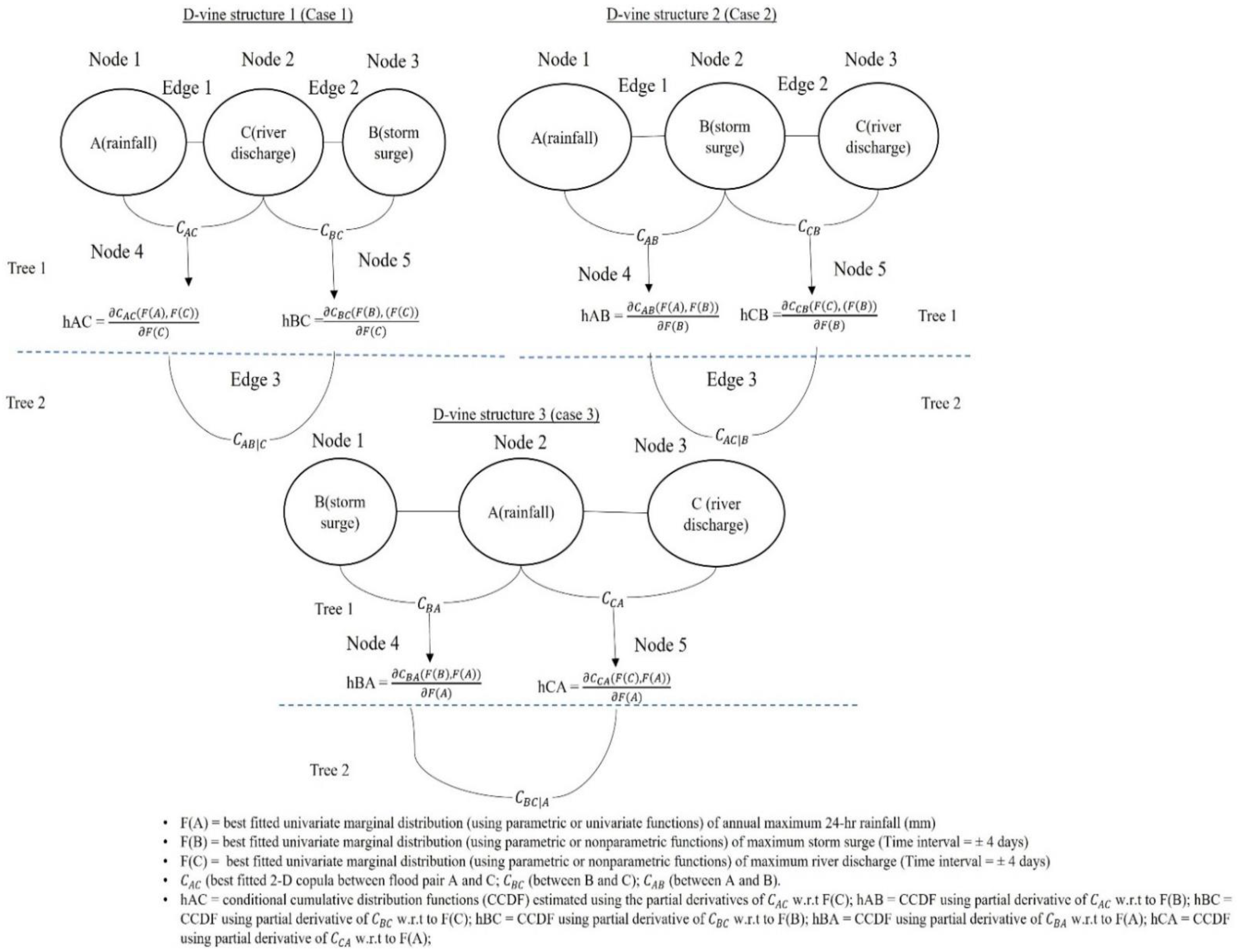
- D-Vine structure 1 (case 1) considers river discharge observation as a conditioning variable by placing it at the centre of the vine structure (refer to Figure 2 and Table 3 and Table 4). In this structure, at first, the 2D beta kernel copula density and 2D Bernstein copula estimator, which were selected as best-fitted from Table 3 for flood pair rainfall–river-discharge and storm surge–river-discharge in the first tree level (Tree 1), were now employed in the estimation of conditional cumulative distribution functions (CCDFs); and (refer to Equation (14)). The copula in the second tree level (Tree 2) was then identified using the above estimated CCDDFs values as input. It was found that the Bernstein copula estimator outperformed the beta kernel density to model joint dependence for the flood pair (RAIN, STORM SURGE|RIVER DISCHARGE) (which exhibited the minimum value of MSE, RMSE, MAE and KS and the higher value of NSE test statistics). Finally, the full 3D trivariate joint density was obtained using Equation (15).
- Similarly, D-vine structure 2 (case 2) comprises storm surge events as a conditioning variable (refer to Table 3 and Table 4 and Figure 2). In this vine framework, at first, in the first tree level (Tree 1), the Bernstein estimator is identified as the most justifiable and thus is employed in the estimation of CCDFs and , followed by Equation (14). Secondly, in the second tree level (Tree 2), the Bernstein copula estimator is selected as the most parsimonious in establishing the dependence between of flood pair (RAIN RIVER DSICHARGE|STORM SURGE) . Finally, using Equation (15), the full trivariate joint density of the fitted vine structure is estimated.
- D-Vine structure 3 (case 3) is defined by considering rainfall events as a conditioning variable placed in the centre of the selected D-vine structure (refer to Figure 2, and Table 3 and Table 4). The Bernstein estimator and beta kernel density were identified as most justifiable and thus employed in the estimation the CCDFs and (followed by Equation (14)) in Tree 1. In the second level (Tree 2), again the Bernstein copula estimator was identified as the most parsimonious in modelling joint dependence of flood pair (STORM SURGE RIVER DSICHARGE|RAINFALL) (refer to Table 4). Finally, followed by Equation (15), the full trivariate joint density of the fitted vine structure was defined.
3.4. Comparing the Adequacy of Fitted Nonparametric D-Vine with Parametric and Semiparametric Approaches in the D-Vine Copula Framework
3.4.1. Constructing D-Vine Structure in the Parametric Fitting Procedure
3.4.2. Constructing a D-Vine Structure with the Semiparametric Settings
3.4.3. Comparison of the Models’ Performances (Nonparametric vs. Semiparametric vs. Parametric Vine)
3.5. Compound Flooding Events Risk Assessments
4. Research Summary and Conclusions
- This study compounded the joint relationship between annual maximum 24 h rainfall and their associated storm surge and river discharge observed within a time lag of ±4 days from the date of highest rainfall events. Our previous study [63] already examined the degree of mutual concurrencies and confirmed a significant positive correlation between selected flood contributing-variables.
- Our previous study confirmed that rainfall and storm surge events did not exhibit any significant trend or serial correlation (or autocorrelation). From our present study [63], it was also confirmed that both variables are homogenous. However, the storm surge events exhibited nonstationary behaviour (time trend with non-homogeneity), but no serial correlation was identified.
- The nonparametric Normal KDE is selected as the most parsimonious for all three targeted flood variables (refer to Table 2a–c). Additionally, the results were the same when comparing the performance with the best-fitted parametric function (GEV, NORMAL, GEV [63]; refer to Table 2a–c. This further reveals that a lack of prior distributional assumption can result in a better explanation of the targeted flood marginal distribution behaviour.
- The 3-D vine copula was constructed by permutating the conditioning variable’s location, which resulted in three different D-vine structures. In constructing the D-vine copula nonparametrically, it was found that the Bernstein copula fit best for flood pairs rainfall–storm surge and storm surge and river discharge, and the beta kernel estimator fit best for pair rainfall–river-discharge. All the selected nonparametric 2D copulas were employed in the 3D vine construction for three different D-vine structures. The fitness test statistics confirmed that nonparametric D-vine structure-2 (case-2) performs better when considering storm surge as a conditioning variable (with the Bernstein copula estimator fitted in both the first and second tree levels). It is important to note that it is much more practical to consider each targeted variable separately as a conditioning variable instead of just fixing it in the vine construction. This approach can generate multiple possible structures for selecting the most justifiable one.
- Best-fitted models have been compared analytically, such as nonparametric, semiparametric, and parametric fitting-based D-vine structures. Results confirmed the adequacy of the proposed nonparametric vine density. The model’s reliability was investigated analytically by comparing the theoretical and empirical Kendall’s tau. Results revealed that the selected D-vine structure-2, in the nonparametric fitting procedure, outperformed the others. In other words, the selected vine structure regenerates historical flood events efficiently. The adequacy of D-vine structure-2 (Nonparametric framework) was further investigated graphically through overlapped scatterplots between historical observation and generated samples. It is clearly noted that the fitted model effectively captured the natural mutual dependencies of historical flood events. In conclusion, our proposed vine copula density in the nonparametric fitting is a much better alternative to the traditional parametric vine approach.
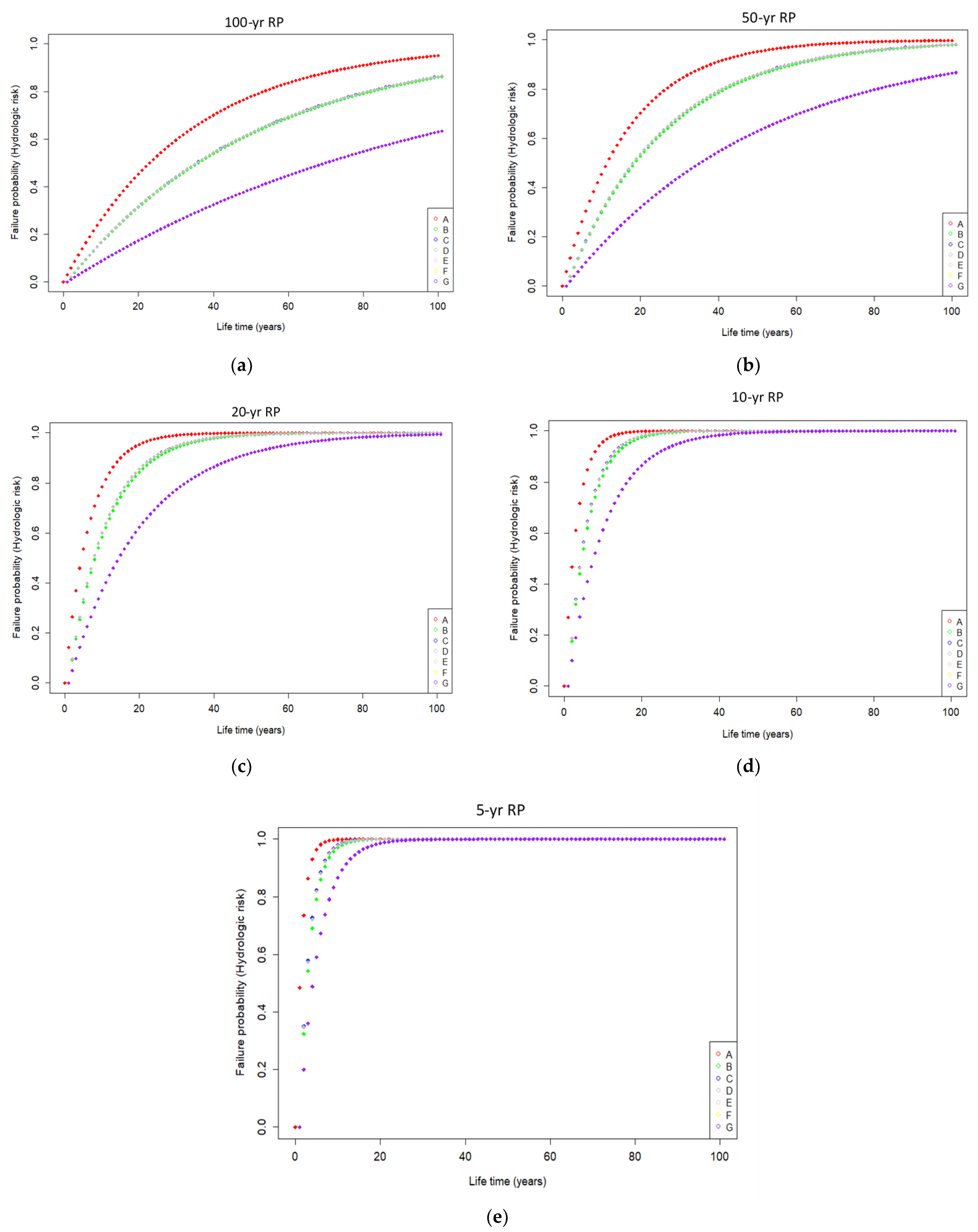
- The best-fitted nonparametric vine density was employed to estimate trivariate primary joint return periods for OR- and AND-joint cases. The OR-joint case resulted in lower return periods than the AND-joint case for the same flood combinations. It was noted how important it is to take accountability for trivariate return periods rather than just considering a bivariate (or univariate) approach, which would be problematic and less efficient for solving different water-related decision-making.
- The trivariate and bivariate joint CDFs were employed in estimating failure probability (FP) statistics which highlight the hydrologic risk due to the compound effect of rainfall, storm surge and river discharge events in the trivariate flood events. Investigation revealed that FP statistics could be underestimated if neglecting the trivariate joint probability analysis between targeted flood characteristics compared to when considering the same flood variables in pairwise joint modelling. The FP statistics were higher when considering trivariate joint distribution for the OR-joint event than when considering bivariate joint dependency between flood pairs. The hydrologic risk (trivariate, bivariate and univariate events) decreases with an increase in the return periods. At the same time, hydrologic risk increases, followed by the service design lifetime of hydraulic infrastructure under consideration. The same investigation also found that the FP of univariate flood events is much lower than trivariate (and bivariate) events. These further reveals that compound events may not be devastating if each flood source variable is considered separately.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Seneviratne, S.; Nicholls, N.; Easterling, D.; Goodess, C.; Kanae, S.; Kossin, J.; Luo, Y.; Marengo, J.; McInnes, K.; Rahimi, M.; et al. Changes in climate extremes and their impacts on the natural physical environment, Manag. Risk Extrem. Events Disasters Adv. Clim. Change Adapt. 2012, 109–230. Available online: https://www.ipcc.ch/pdf/special-reports/srex/SREX-Chap3_FINAL.pdf (accessed on 6 July 2021).
- Wahl, T.; Jain, S.; Bender, J.; Meyers, S.D.; Luther, M.E. Increasing risk of compound flooding from storm surge and rainfall for major US cities. Nat. Clim. Chang. 2015, 5, 1093–1097. [Google Scholar] [CrossRef]
- Hendry, A.; Haigh, I.D.; Nicholls, R.J.; Winter, H.; Neal, R.; Wahl, T.; Joly-Laugel, A.; Darby, S.E. Assessing the characteristics and drivers of compound flooding events around the U.K. coast. Hydrol. Earth Syst. Sci. 2019, 23, 3117–3139. [Google Scholar] [CrossRef]
- Lucey, J.T.; Gallien, T.W. Characterizing multivariate coastal flooding events in a semi-arid region: The implications of copula choice, sampling, and infrastructure. Nat. Hazards Earth Syst. Sci. 2022, 22, 2145–2167. [Google Scholar] [CrossRef]
- Fritz, H.M.; Blount, C.D.; Thwin, S.; Thu, M.K.; Chan, N. Cyclone Nargis storm surge in Myanmar. Nat. Geosci. 2009, 2, 448–449. [Google Scholar] [CrossRef]
- Jonkman, S.N.; Maaskant, B.; Boyd, E.; Levitan, M.L. Loss of life caused by the flooding of New Orleans after hurricane Katrina: Analysis of the relationship between flood characteristics and mortality. Risk Anal. 2009, 29, 676–698. [Google Scholar] [CrossRef]
- Emanuel, K. Assessing the present and future probability of Hurricane Harvey’s rainfall. Proc. Natl. Acad. Sci. USA 2017, 114, 12681–12684. [Google Scholar] [CrossRef]
- Sweet, W.V.; Park, J. From the extreme to the mean: Acceleration and tipping points of coastal inundation from sea level rise. Earths Future 2014, 2, 579–600. [Google Scholar] [CrossRef]
- Kemp, A.C.; Horton, B.P. Contribution of relative sea-level rise to historical hurricane flooding in New York city: Historical hurricane flooding in New York City. J. Quat. Sci. 2013, 28, 537–541. [Google Scholar] [CrossRef]
- Moftakhari, H.R.; Salvadori, G.; Aghakouchak, A.; Sanders, B.F.; Matthew, R.A. Compounding effects of sea level rise and fluvial flooding. Proc. Natl. Acad. Sci. USA 2017, 114, 9785–9790. [Google Scholar] [CrossRef]
- Resio, D.T.; Westerink, J.J. Modeling the Physics of Storm Surges. Phys. Today 2008, 61, 33. [Google Scholar] [CrossRef]
- Coles, S.G. An Introduction to Statistical Modelling of Extreme Values; Springer: London, UK, 2001. [Google Scholar]
- Coles, S.; Heffernan, J.; Tawn, J. Dependence measures for extreme value analyses. Extremes 1999, 2, 339–365. [Google Scholar] [CrossRef]
- Svensson, C.; Jones, D.A. Dependence between extreme sea surge, river flow and precipitation in eastern Britain. Int. J. Climatol. 2002, 22, 1149–1168. [Google Scholar] [CrossRef]
- Cooley, D.; Davis, R.A.; Naveau, P. The pairwise beta distribution: A flexible parametric multivariate model for extremes. J. Multivar. Anal. 2010, 101, 2103–2117. [Google Scholar] [CrossRef]
- Zheng, F.; Westra, S.; Sisson, S.A. Quantifying the between extreme rainfall and storm surge in the coastal zone. J. Hydrol. 2013, 505, 172–187. [Google Scholar] [CrossRef]
- Zheng, F.; Seth, W.; Michael, L.; Sisson, S.A. Modeling dependence between extreme rainfall and storm surge to estimate coastal flooding risk. Water Resour. Res. 2014, 50, 2050–2071. [Google Scholar] [CrossRef]
- Joe, H. Multivariate Models and Dependence Concept; CRC Press: Boca Raton, FL, USA, 1997. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas; Springer: New York, NY, USA, 2006. [Google Scholar]
- Karmakar, S.; Simonovic, S.P. Bivariate flood frequency analysis. Part-2: A copula-based approach with mixed marginal distributions. J. Flood Risk Manag. 2009, 2, 32–44. [Google Scholar] [CrossRef]
- Latif, S.; Mustafa, F. Copula-based multivariate flood probability construction: A review. Arab J. Geosci. 2020, 13, 132. [Google Scholar] [CrossRef]
- Latif, S.; Mustafa, F. A nonparametric copula distribution framework for bivariate joint distribution analysis of flood characteristics for the Kelantan River basin in Malaysia. AIMS Geosci. 2020, 6, 171–198. [Google Scholar] [CrossRef]
- Lian, J.J.; Xu, K.; Ma, C. Joint impact of rainfall and tidal level on flood risk in a coastal city with a complex river network: A case study of Fuzhou City. China Hydrol. Earth Syst. Sci. 2013, 17, 679–689. [Google Scholar] [CrossRef]
- Xu, K.; Ma, C.; Lian, J.; Bin, L. Joint probability analysis of extreme precipitation and storm tide in a coastal city under changing environment. PLoS ONE 2014, 9, e109341. [Google Scholar] [CrossRef]
- Masina, M.; Lamberti, A.; Archetti, R. Coastal flooding: A copula-based approach for estimating the joint probability of water levels and waves. Coast. Eng. 2015, 97, 37–52. [Google Scholar] [CrossRef]
- Paprotny, D.; Vousdoukas, M.I.; Morales-Nápoles, O.; Jonkman, S.N.; Feyen, L. Compound flood potential in Europe. Hydrol. Earth Syst. Sci. Discuss. 2018. [Google Scholar] [CrossRef]
- Zellou, B.; Rahali, H. Assessment of the joint impact of extreme rainfall and storm surge on the risk of flooding in a coastal area. J. Hydrol. 2019, 569, 647–665. [Google Scholar] [CrossRef]
- Ghanbari, M.; Arabi, M.; Kao, S.; Obeysekera, J.; Sweet, W. Climate Change and Changes in Compound Coastal-Riverine Flooding Hazard Along the U.S. Coasts. Earth’s Future 2021, 9, e2021EF002055. [Google Scholar] [CrossRef]
- Serinaldi, F.; Grimaldi, S. Fully nested 3-copula procedure and application on hydrological data. J. Hydrol. Eng. 2007, 12, 420–430. [Google Scholar] [CrossRef]
- Grimaldi, S.; Serinaldi, F. Asymmetric copula in multivariate flood frequency analysis. Adv. Water Resour. 2006, 29, 1155–1167. [Google Scholar] [CrossRef]
- Reddy, M.J.; Ganguli, P. Probabilistic assessments of flood risks using trivariate copulas. Theor. Appl. Climatol. 2013, 111, 341–360. [Google Scholar]
- Kao, S.; Govindaraju, R. Trivariate statistical analysis of extreme rainfall events via the Plackett family copulas. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Fan, L.; Zheng, Q. Probabilistic modelling of flood events using the entropy copula. Adv. Water Resour. 2016, 97, 233–240. [Google Scholar]
- Genest, C.; Favre, A.C.; Beliveau, J.; Jacques, C. Metaelliptical copulas and their use in frequency analysis of multivariate hydrological data. Water Resour. Res. 2007, 43, W09401. [Google Scholar] [CrossRef]
- Whelan, N. Sampling from Archimedean copulas. Quant. Financ. 2004, 4, 339–352. [Google Scholar] [CrossRef]
- Savu, C.; Trede, M. Hierarchies of Archimedean copulas. Quant Financ. 2010, 10, 95–304. [Google Scholar] [CrossRef]
- Hofert, M.; Pham, D. Densities of nested Archimedean copulas. J. Multivar. Anal. 2013, 118, 37–52. [Google Scholar] [CrossRef]
- Bedford, T.; Cook, R.M. Vines-a new graphical model for dependent random variables. Ann. Stat. 2002, 30, 1031–1068. [Google Scholar] [CrossRef]
- Aas, K.; Berg, D. Models for construction of multivariate dependence—A comparison study. Eur. J. Financ. 2009, 15, 639–659. [Google Scholar] [CrossRef]
- Aas, K.; Czado, K.C.; Frigessi, A.; Bakken, H. Pair-copula constructions of multiple dependence. Insur. Math. Econ. 2009, 44, 182–198. [Google Scholar] [CrossRef]
- Graler, B.; Berg, M.J.V.; Vandenberg, S.; Petroselli, A.; Grimaldi, S.; Baets, B.D.; Verhost, N.E.C. Multivariate return periods in hydrology: A critical and practical review focusing on synthetic design hydrograph estimation. Hydrol. Earth Sys. Sci. 2013, 17, 1281–1296. [Google Scholar] [CrossRef]
- Bevacqua, E.; Maraun, D.; Hobæk Haff, I.; Widmann, M.; Vrac, M. Multivariate statistical modelling of compound events via pair-copula constructions: Analysis of floods in Ravenna (Italy). Hydrol. Earth Syst. Sci. 2017, 21, 2701–2723. [Google Scholar] [CrossRef]
- Jane, R.; Cadavid, L.; Obeysekera, J.; Wahl, T. Multivariate statistical modelling of the drivers of compound flood events in South Florida. Nat. Hazards Earth Syst. Sci. Discuss. 2020, 20, 2681–2699. [Google Scholar] [CrossRef]
- Saghafian, B.; Mehdikhani, H. Drought characteristics using new copula-based trivariate approach. Nat. Hazards 2014, 72, 1391–1407. [Google Scholar] [CrossRef]
- Tosunoglu, F.; Gürbüz, F.; İspirli, M.N. Multivariate modeling of flood characteristics using Vine copulas. Environ. Earth Sci. 2020, 79, 459. [Google Scholar] [CrossRef]
- Latif, S.; Mustafa, F. Parametric vine copula construction for flood analysis for Kelantan River basin in Malaysia. Civ. Eng. J. 2020, 6, 1470–1491. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis, 1st ed.; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Moon, Y.-I.; Lall, U. Kernel function estimator for flood frequency analysis. Water Resour. Res. 1994, 30, 3095–3103. [Google Scholar] [CrossRef]
- Sharma, A.; Lall, U.; Tarboton, D.G. Kernel bandwidth selection for a first order nonparametric streamflow simulation model. Stoch. Hydrol. Hydraul. 1998, 12, 33–52. [Google Scholar] [CrossRef]
- Kim, T.W.; Valdes, J.B.; Yoo, C. Nonparametric approach for bivariate drought characterization using Palmer drought index. J. Hydrol. Eng. 2006, 11, 134–143. [Google Scholar] [CrossRef]
- Karmakar, S.; Simonovic, S.P. Bivariate food frequency analysis. Part-1: Determination of marginal by parametric and nonparametric techniques. J. Flood Risk Manag. 2008, 1, 190–200. [Google Scholar] [CrossRef]
- Charpentier, A.; Fermanian, J.; Scaillet, O. Copulas: From Theory to Application in Finance, 1st ed.; Chapter The Estimation of Copulas: Theory and Practice; Risk Books: Torquay, UK, 2006. [Google Scholar]
- Rauf, U.F.A.; Zeephongsekul, P. Analysis of Rainfall Severity and Duration in Victoria, Australia using Nonparametric Copulas and Marginal Distributions. Water Resour. Manag. 2014, 28, 4835–4856. [Google Scholar] [CrossRef]
- Harrell, F.E.; Davis, C.E. A new distribution-free quantile estimator. Biometrika 1982, 69, 635–640. [Google Scholar] [CrossRef]
- Chen, S.X. Beta kernel estimators for density functions. Comput. Stat. Data Anal. 1999, 31, 131–145. [Google Scholar] [CrossRef]
- Pfeifer, D.; Strassburger, D.; Philipps, J. Modelling and Simulation of Dependence Structures in Nonlife Insurance with Bernstein Copulas; Working Paper; Carl von Ossietzky University: Oldenburg, Germany, 2009. [Google Scholar]
- Sancetta, A.; Satchell, S. The Bernstein copula and its applications tomodeling and approximations of multivariate distributions. Econom. Theory 2004, 20, 535–562. [Google Scholar] [CrossRef]
- Weiss, G.N.F.; Scheffer, M. Smooth Nonparametric Bernstein Vine Copulas. SSRN Electron. J. 2012. [Google Scholar] [CrossRef]
- Kulpa, T. On approximation of copulas. Int. J. Math. Math. Sci. 1999, 22, 259–269. [Google Scholar] [CrossRef]
- Latif, S.; Simonovic, S.P. Nonparametric approach to copula estimation in compounding the joint impact of storm surge and rainfall events in coastal flood analysis. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Pirani, F.J.; Najafi, M.R. Recent trends in individual and multivariate flood drivers in Canada’s Coasts. Water Resour. Res. 2020, 56. [Google Scholar] [CrossRef]
- Atkinson, D.E.; Forbes, D.L.; James, T.S. Dynamic coasts in a changing climate. In Canada’s Marine Coasts in a Changing Climate; Lemmen, D.S., Warren, F.J., James, T.S., Clarke, C.S.L.M., Eds.; Government of Canada: Ottawa, ON, Canada, 2016; pp. 27–68. [Google Scholar]
- Latif, S.; Simonovic, S.P. Compounding joint impact of rainfall, storm surge and river discharge on coastal flood risk: An approach based on 3D Fully Nested Archimedean Copulas. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Wand, M.P.; Marron, J.S.; Ruppert, D. Transformations in Density Estimation: Rejoinder (in Theory and Methods). J. Am. Stat. Assoc. 1991, 86, 360–361. [Google Scholar]
- Müller, H.G. Smooth Optimum Kernel Estimators near Endpoints. Biometrika 1991, 78, 521–530. [Google Scholar] [CrossRef]
- Schuster, E. Incorporating Support Constraints into Nonparametric Estimators of Densities. Commun. Stat. Theory Methods 1985, 14, 1123–1136. [Google Scholar] [CrossRef]
- Brown, B.M.; Chen, S.X. Beta-bernstein smoothing for regression curves with compact support. Scand. J. Stat. 1999, 26, 47–59. [Google Scholar] [CrossRef]
- Chen, S.X. Beta Kernel for Regression Curve. Stat. Sin. 2000, 10, 73–92. [Google Scholar]
- Bouezmarni, T.; Ghouch, E.; Taamouti, A. Bernstein estimator for unbounded copula densities. Stat. Risk Model. 2013, 30, 343–360. [Google Scholar] [CrossRef]
- Nagler, T.; Czado, C. Evading the curse of dimensionality in nonparametric density estimation with simplified vine copulas. J. Multivar. Anal. 2016, 151, 69–89. [Google Scholar] [CrossRef]
- Lorentz, G. Bernstein Polynomials; University of Toronto Press: Toronto, ON, Canada, 1953. [Google Scholar]
- Tenbusch, A. Two-dimensional Bernstein polynomial density estimation. Metrika 1994, 41, 233–253. [Google Scholar] [CrossRef]
- Diers, D.; Eling, M.; Marek, S. Dependence modeling in non-life insurance using the Bernstein copula. Insur. Math. Econ. 2012, 50, 430–436. [Google Scholar] [CrossRef]
- Santhosh, D.; Srinivas, V. Bivariate frequency analysis of flood using a diffusion kernel density estimator. Water Resour. Res. 2013, 49, 8328–8343. [Google Scholar] [CrossRef]
- Latif, S.; Mustafa, F. A nonparametric statistical framework using a kernel density estimator to approximate flood marginal distributions—A case study for the Kelantan River Basin in Malaysia. Water Supply 2020, 20, 1509–1533. [Google Scholar] [CrossRef]
- Jones, M.C.; Marron, J.S.; Sheather, S.J. A brief survey of bandwidth selection for density estimation. J. Am. Stat. Assoc. 1996, 91, 401–407. [Google Scholar] [CrossRef]
- Sheather, S.J.; Jones, M.C. A reliable data-based bandwidth selection method for kernel density estimation. J. R. Stat. Soc. Ser. B 1991, 53, 683–690. [Google Scholar] [CrossRef]
- Wand, M.P.; Jones, M.C. Kernel Smoothing; Chapman and Hall: London, UK, 1995. [Google Scholar]
- Chen, S. Optimal Bandwidth Selection for Kernel Density Functionals Estimation. J. Probab. Stat. 2015, 2015, 242683. [Google Scholar] [CrossRef]
- Czado, C.; Jeske, S.; Hofmann, M. Selection strategies for regular vine copulae. J. French Soc. Stat. 2013, 154, 174–190. [Google Scholar]
- Kurowicka, D.; Cooke, R. Uncertainty Analysis with High Dimensional Dependence Modelling; John Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Vernieuwe, H.; Vandenberghe, S.; Baets, B.D.; Verhost, N.E.C. A continuous rainfall model based on vine copulas. Hydrol. Earth Syst. Sci. 2015, 19, 2685–2699. [Google Scholar] [CrossRef]
- Yue, S.; Rasmussen, P. Bivariate frequency analysis: Discussion of some useful concepts in hydrological applications. Hydrol. Process 2002, 16, 2881–2898. [Google Scholar] [CrossRef]
- Shiau, J.T. Return period of bivariate distributed hydrological events. Stoch. Environ. Res. Risk Assess. 2003, 17, 42–57. [Google Scholar] [CrossRef]
- Salvadori, G. Bivariate return periods via-2 copulas. J. R. Stat. Soc. Ser. B 2004, 1, 129–144. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Frequency analysis via copulas: Theoretical aspects and applications to hydrological events. Water Resour. Res. 2004, 40, W12511. [Google Scholar] [CrossRef]
- Zhang, L.; Singh, V.P. Trivariate flood frequency analysis using the Gumbel-Hougaard copula. J. Hydrol. Eng. 2007, 12, 431–439. [Google Scholar] [CrossRef]
- Zhang, L.; Singh, V.P. Bivariate flood frequency analysis using copula method. J. Hydrol. Eng. 2006, 11, 150. [Google Scholar] [CrossRef]
- Reddy, M.J.; Ganguli, P. Bivariate flood frequency analysis of Upper Godavari River flows using Archimedean copulas. Water Resour. Manag. 2012, 26, 3995–4018. [Google Scholar] [CrossRef]
- Requena, A.; Flores, I.; Mediero, L.; Garrote, L. Extension of observed flood series by combining a distributed hydro-meteorological model and a copula based model. Stoch. Environ. Res. Risk Assess. 2016, 30, 1363–1378. [Google Scholar] [CrossRef][Green Version]
- Read, L.K.; Vogel, R.M. Reliability, return periods, and risk under nonstationarity. Water Resour. Res. 2015, 51, 6381–6398. [Google Scholar] [CrossRef]
- Salvadori, G.; Durante, F.; de Michele, C.; Bernardi, M.; Petrella, L. A Multivariate Copula-Based Framework for Dealing with Hazard Scenarios and Failure Probabilities. Water Resour. Res. 2016, 52, 3701–3721. [Google Scholar] [CrossRef]
- Serinaldi, F. Dismissing return periods! Stoch. Hydrol. Hydraul. 2014, 29, 1179–1189. [Google Scholar]
- Xu, Y.; Huang, G.; Fan, Y. Multivariate flood risk analysis for Wei River. Stoch. Hydrol. Hydraul. 2015, 31, 225–242. [Google Scholar] [CrossRef]
- British Columbia Ministry of Environment. Sea Level Rise Adaptation Primer: A Toolkit to Build Adaptive Capacity on Canada’s South Coasts. 2013. Available online: https://www2.gov.bc.ca/assets/gov/environment/climate-change/adaptation/resources/slr-primer.pdf (accessed on 15 December 2019).
- Lemmen, D.S.; Warren, F.J.; James, T.S.; Mercer Clarke, C.S.L. (Eds.) Canada’s Marine Coasts in a Changing Climate; Government of Canada: Ottawa, ON, Canada, 2016; 274p.
- Mann, H.B. Nonparametric test against trend. Econometrics 1945, 13, 245–259. [Google Scholar] [CrossRef]
- Kendall, M.G. Rank Correlation Methods, 4th ed.; Charles Griffn: London, UK, 1975; p. 1975. [Google Scholar]
- Pettitt, A.N. A Non-Parametric Approach to the Change-Point Problem. Appl. Stat. 1979, 28, 126–135. [Google Scholar] [CrossRef]
- Alexandersson, H. A homogeneity test applied to precipitation data. J. Clim. 1986, 6, 661–675. [Google Scholar] [CrossRef]
- Buishand, T.A. Some methods for testing the homogeneity of rainfall records. J. Hydrol. 1982, 58, 11–27. [Google Scholar] [CrossRef]
- Gringorten, I.I. A plotting rule of extreme probability paper. J. Geophys. Res. 1963, 68, 813–814. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G.E. Estimating the dimension of a model. Ann. Stat. 1978, 6, e461e–e464. [Google Scholar] [CrossRef]
- Hannan, E.J.; Quinn, B.G. The Determination of the order of an autoregression. J. R. Stat. Soc. Ser. B 1979, 41, 190–195. [Google Scholar] [CrossRef]
- Willmott, C.; Matsuura, K. Advantage of the Mean Absolute Error (M.A.E.) OVER THE Root Mean Square Error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Farrel, P.J.; Stewart, K.R. Comprehensive study of tests for normality and symmetry: Extending the Spiegelhalter test. J. Stat. Comput. Simul. 2006, 76, 803–816. [Google Scholar] [CrossRef]
- Nash, J.; Sutcliffe, J. River flow forecasting through conceptual models part i e a discussion of principles. J. Hydrol. 1970, 10, e282–e290. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 10 October 2022).
- Nagler, T. kdecopula: An R Package for the Kernel Estimation of Bivariate Copula Densities. J. Stat. Softw. 2018, 84, 1–22. [Google Scholar] [CrossRef]
- De Michele, C.; Salvadori, G.; Canossi, M.; Petaccia, A.; Rosso, R. Bivariate statistical approach to check the adequacy of dam spillway. J. Hydrol. Eng. 2005, 10, 50–57. [Google Scholar] [CrossRef]
- Klein, B.; Pahlow, M.; Hundecha, Y.; Schumann, A. Probability analysis of hydrological loads for the design of food control system using copulas. J. Hydrol. Eng. ASCE 2010, 15, 360–369. [Google Scholar] [CrossRef]
- Genest, C.; Rémillard, B. Validity of the parametric bootstrap for goodness-of-ft testing in semiparametric models. Ann l’Inst. Henri. Poincare Prob. Stat. 2008, 44, 1096–1127. [Google Scholar]
- Genest, C.; Rémillard, B.; Beaudoin, D. Goodness-of-ft tests for copulas: A review and a power study. Insur. Math Econ. 2009, 44, 199–214. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SI No. | Kernel Density Estimation | K(x) |
|---|---|---|
| 1 | Normal | = |
| 2 | Epanechnikov (or parabolic) | = 0, otherwise |
| 3 | Biweight (or Quartic) | otherwise |
| 4 | Triweight | otherwise |
| (a) | |||||||||
| Nonparametric KDE | Estimated Bandwidth (via Direct-Plug-in Method) | MSE (Mean Square Error) | RMSE (Root Mean Square Error) | AIC (Akaike Information Criterion) | BIC (Bayesian Information Criterion) | HQC (Hannan-Quinn Information Criterion) | MAE (Mean Absolute Error) | ||
| Normal * | 11.25 | 0.0003 | 0.0199 | −358.22 | −356.39 | −357.53 | 0.015 | ||
| Epanechnikov (or parabolic) | 24.90 | 0.0007 | 0.0281 | −326.36 | −324.53 | −325.67 | 0.023 | ||
| Biweight (or Quartic) | 29.50 | 0.0010 | 0.0316 | −315.56 | −313.73 | −314.88 | 0.026 | ||
| Triweight | 33.50 | 0.0011 | 0.0342 | −308.42 | −306.59 | −307.73 | 0.027 | ||
| Parametric GEV (Latif and Simonovic 2022a [63]) ** | Estimated parameters via Maximum likelihood estimation (MLE) | 0.0009 | 0.0312 | −312.97 | −307.48 | −310.91 | 0.024 | ||
| ) = 1494.64; scale (sigma = ) = 616.37; shape (xi = ) = 0.31 | |||||||||
| (b) | |||||||||
| Nonparametric KDE | Estimated Bandwidth (via Direct-Plug-in Method) | MSE (Mean Square Error) | RMSE (Root Mean Square Error) | AIC (Akaike Information Criterion) | BIC (Bayesian Information Criterion) | HQC (Hannan-Quinn Information Criterion) | MAE (Mean Absolute Error) | ||
| Normal * | 0.07 | 0.0003 | 0.0175 | −369.83 | −368.00 | −369.15 | 0.014 | ||
| Epanechnikov (or parabolic) | 0.16 | 0.0007 | 0.0265 | −331.95 | −330.12 | −331.26 | 0.020 | ||
| Biweight (or Quartic) | 0.20 | 0.0008 | 0.0288 | −324.17 | −322.34 | −323.48 | 0.022 | ||
| Triweight | 0.22 | 0.0009 | 0.0304 | −319.30 | −317.47 | −318.61 | 0.023 | ||
| Parametric Normal (Shahid and Simonovic 2022a [63]) ** | Estimated parameters via Maximum likelihood estimation (MLE) | 0.0011 | 0.034 | −306.56 | −302.90 | −305.19 | 0.026 | ||
| mean (mu = ) = 2.340757e−18; sd (sigma = ) = 1.676386e−01 | |||||||||
| (c) | |||||||||
| Nonparametric KDE | Estimated Bandwidth (via Direct-Plug-in Method) | MSE (Mean Square Error) | RMSE (Root Mean Square Error) | AIC (Akaike Information Criterion) | BIC (Bayesian Information Criterion) | HQC (Hannan-Quinn Information Criterion) | MAE (Mean Absolute Error) | ||
| Normal * | 340.21 | 0.0005 | 0.0223 | −347.61 | −345.78 | −346.93 | 0.017 | ||
| Epanechnikov (or parabolic) | 753.16 | 0.0017 | 0.0415 | −290.65 | −288.82 | −289.96 | 0.030 | ||
| Biweight (or Quartic) | 892.25 | 0.0019 | 0.0444 | −284.42 | −282.60 | −283.74 | 0.033 | ||
| Triweight | 1013.19 | 0.0022 | 0.0477 | −277.81 | −275.99 | −277.13 | 0.037 | ||
| Parametric GEV (Shahid and Simonovic 2022a [63]) ** | Estimated parameters via Maximum likelihood estimation (MLE) | 0.0008 | 0.0291 | −319.15 | −313.67 | −317.10 | 0.022 | ||
| ) = 1494.64; scale (sigma = ) 616.37; shape (xi = ) = 0.31 | |||||||||
| Flood Attribute Pairs | Nonparametric 2-D Copula Density | Estimated Bandwidth (Only for Beta Kernel Copula Density) | MSE (Mean Square Error) | RMSE (Root Mean Square Error) | MAE (Mean Absolute Error) | K-S (Kolmogorov–Smirnov) | NSE (Nash–Sutcliffe model Efficiency Coefficient) |
|---|---|---|---|---|---|---|---|
| Annual Maximum 24 h Rainfall (mm)-Maximum Storm surge (Time interval = ±4 days) (m) | Bernstein estimator * | 0.11 | 0.0013 | 0.0360 | 0.0290 | D = 0.0869, p-value = 0.99 | 0.980 |
| Beta kernel density | 0.0014 | 0.0371 | 0.0295 | D = 0.1521, p-value = 0.66 | 0.979 | ||
| Maximum Storm surge (Time interval = ±4 days) (m)-Maximum River discharge (Time interval = ±4 days) (m3/s) | Bernstein estimator * | 0.12 | 0.0012 | 0.0350 | 0.0270 | D = 0.1521, p-value = 0.66 | 0.981 |
| Beta kernel density | 0.0014 | 0.0375 | 0.0295 | D = 0.1521, p-value = 0.66 | 0.978 | ||
| Annual Maximum 24 h Rainfall (mm)-Maximum River discharge (Time interval = ±4 days) (m3/s) | Bernstein estimator | 0.17 | 0.0011 | 0.0338 | 0.0258 | D = 0.1956, p-value = 0.34 | 0.981 |
| Beta kernel density * | 0.0008 | 0.0298 | 0.0221 | D = 0.1521, p-value = 0.66 | 0.985 |
| Vine Structure (Conditioning Variable) | Tree Level | Flood Attribute Pairs | Fitted Nonparametric Copula Estimator | Estimated Bandwidth (for Beta Kernel Copula Density) | MSE (Mean Square Error) | RMSE (Root Mean Square Error) | MAE (Mean Absolute Error) | K-S (Kolmogorov–Smirnov) | NSE (Nash–Sutcliffe Model Efficiency Coefficient) | |
|---|---|---|---|---|---|---|---|---|---|---|
| Case 1 (1-3-2) | 3 or Maximum River Discharge (Time interval = ±4 days) placed in the centre | Tree 1 | 1-3 (Rain-River discharge) | Beta kernel | 0.11 | 0.0004 | 0.0223 | 0.017 | D = 0.086, p-value = 0.99 | 0.992 |
| 2-3 (storm surge-river discharge) | Bernstein | |||||||||
| Tree 2 | 12|3 | Bernstein | 0.0006 | 0.0249 | 0.019 | D = 0.087, p-value = 0.99 | 0.990 | |||
| Beta kernel | ||||||||||
| Case 2 (1-2-3) * | 2 or Maximum Storm Surge (Time interval = ±4 days) placed in the centre | Tree 1 | 1-2 (Rain–Storm Surge) | Bernstein | 0.17 | 0.0002 | 0.0153 | 0.013 | D = 0.152, p-value = 0.66 | 0.995 |
| 3-2 (Storm surge–river discharge) | Bernstein | |||||||||
| Tree 2 | 13|2 | Bernstein | 0.0003 | 0.0154 | 0.013 | D = 0.152, p-value = 0.66 | 0.995 | |||
| Beta kernel | ||||||||||
| Case 3 (2-1-3) | 1 or Annual Maximum 24 h Rainfall placed in the centre | Tree 1 | 2-1 (Storm surge-Rain) | Bernstein | 0.12 | 0.0004 | 0.0203 | 0.015 | D = 0.152, p-value = 0.66 | 0.993 |
| 3-1 (River discharge-Rainfall) | Beta kernel | |||||||||
| Tree 2 | 23|1 | Bernstein | 0.0005 | 0.0214 | 0.016 | D = 0.086, p-value = 0.99 | 0.992 | |||
| Beta kernel |
| Vine Structure (Conditioning Variable) | Tree Level | Flood Attribute Pairs | Most Parsimonious Fitted Copula | Copula Dependence Parameters via MPL | MSE | RMSE | MAE | K-S | NSE | Log-Likelihood (LL) | AIC | BIC | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case 1 (1-3-2) | 3 or Maximum River Discharge (Time interval = ±4 days) placed in the centre | Tree 1 | 1-3 (Rain-River discharge) | Survival BB7 | ; | 0.00086 | 0.0294 | 0.021 | D = 0.152 (0.66) | 0.982 | 10.51 | −11.02 | −1.87 |
| 3-2 (storm surge-river discharge) | Survival BB1 | θ = par = 0.23; δ = par2 = 1.29 | |||||||||||
| Tree 2 | 12|3 | Frank | 2.92 | ||||||||||
| Case 2 (1-2-3) | 2 or Maximum Storm Surge (Time interval = ±4 days) placed in the centre | Tree 1 | 1-2 (Rain–Storm Surge) | BB1 (Clayton-Gumbel) | θ = par = 0.19; δ = par2 = 1.36 | 0.00088 | 0.0297 | 0.022 | D = 0.173 (0.48) | 0.982 | 10.50 | −11.01 | −1.87 |
| 2-3 (Storm surge–river discharge) | Survival BB1 | θ = par = 0.23; δ = par2 = 1.29 | |||||||||||
| Tree 2 | 13|2 | Rotated BB6 270 degrees | θ = par = −1; δ = par2 = −1 | ||||||||||
| Case 3 (2-1-3) * | 1 or Annual Maximum 24 h Rainfall placed in the centre | Tree 1 | 2-1 (Storm surge-Rain) | BB1 (Clayton-Gumbel) | θ = par = 0.19; δ = par2 = 1.36 | 0.00084 | 0.0290 | 0.021 | D = 0.152 (0.67) | 0.982 | 10.85 | −11.71 | −2.57 |
| 3-1 (River discharge-Rainfall) | Survival BB7 | θ = par = 1.142; δ = par2 = 0.19 | |||||||||||
| Tree 2 | 23|1(Storm-River/Rainfall) | Frank | θ = par = 2.97 |
| Vine Structure (Conditioning Variable) | Tree Level | Flood Attribute Pairs | Most Parsimonious or Best-Fitted Copula | Copula Dependence Parameters | MSE | RMSE | MAE | K-S | NSE | Log-Likelihood (LL) | AIC (Akaike Information Criterion) | BIC (Bayesian Information Criterion) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case 1 (1-3-2) | 3 or Maximum River Discharge (Time interval = ±4 Days) placed in the centre | Tree 1 | 1-3 (Rain-River discharge) | Survival BB7 | ; | 0.0006 | 0.0236 | 0.0185 | D = 0.152 (0.66) | 0.9886 | 10.68 | −11.37 | −2.23 |
| 3-2 (storm surge-river discharge) | Survival BB1 | θ = par = 0.23; δ = par2 = 1.29 | |||||||||||
| Tree 2 | 12|3 | Frank | 2.89 | ||||||||||
| Case 2 (1-2-3) | 2 or Maximum Storm Surge (Time interval = ±4 days) placed in the center | Tree 1 | 1-2 (Rain–Storm Surge) | BB1 (Clayton-Gumbel) | 0.19; | 0.0006 | 0.0239 | 0.0192 | D = 0.130 (0.82) | 0.9883 | 10.81 | −9.62 | 1.34 |
| 2-3 (Storm surge–river discharge) | Survival BB1 | θ = par = 0.23; δ = par2 = 1.29 | |||||||||||
| Tree 2 | 13|2 | Rotated BB6 270 degrees | θ = par = −1; δ = par2 = −1 | ||||||||||
| Case 3 (2-1-3) * | 1 or Annual Maximum 24 h Rainfall placed in the center | Tree 1 | 2-1 (Storm surge-Rain) | BB1 (Clayton-Gumbel) | 0.19; | 0.0005 | 0.0232 | 0.0185 | D = 0.1303 (0.82) | 0.9890 | 11.38 | −12.77 | −3.62 |
| 3-1 (River discharge-Rainfall) | Survival BB7 | ; | |||||||||||
| Tree 2 | 23|1 | Frank | 2.75 |
| Best-Fitted D-Vine Structure | MSE | RMSE | MAE | K-S | NSE |
|---|---|---|---|---|---|
| Nonparametric settings (D-vine structure-2 (case-2) * | 0.0002 | 0.0153 | 0.0130 | D = 0.152, p-value = 0.66 | 0.995 |
| Semiparametric settings (D-vine structure-3 (case-3) | 0.0005 | 0.0232 | 0.0185 | D = 0.130 (0.82) | 0.989 |
| Parametric settings (D-vine structure-3 (case-3) | 0.00084 | 0.0290 | 0.0218 | D = 0.152 (0.67) | 0.982 |
| CF Pairs | Kendall’s Tau Estimated from Historical Flood Events (Empirical Estimates) | Kendall’s Tau Estimated from Best-Fitted D-Vine Copula (D-Vine Structure 3) in a Parametric Setting (Theoretical Estimates) | Kendall’s Tau Calculated from Best-Fitted D-Vine Copula (D-Vine Structure-3) in a Semiparametric Setting (Theoretical Estimates) | Kendall’s Tau Estimated from Best-Fitted D-Vine Copula (D-Vine Structure-2) in the Nonparametric Setting (Theoretical Estimates) |
|---|---|---|---|---|
| Annual maximum 24 h rainfall (mm) − Maximum Storm Surge (m) (Time interval = ±4 days) | 0.30 | 0.29 | 0.31 | 29 |
| Maximum Storm Surge (m) (Time interval = ±4 days) − Maximum River discharge (m3/s) (Time interval = ±4 days) | 0.29 | 0.34 | 0.31 | 29 |
| Annual maximum 24 h rainfall (mm) − Maximum Storm Surge (m) (Time interval = ±4 days) − Maximum River discharge (m3/s) (Time interval = ±4 days) | 0.14 | 0.16 | 0.15 | 0.14 |
| Estimated Flood Quantiles Using the Inverse Cumulative Distribution Functions (CDFs) of Best-Fitted Marginal Distribution via KDE | Bivariate Joint Return Periods (JRPs) | Trivariate Joint Return Periods (JRPs) Estimated Using the Best-Fitted D-Vine Structure (Case-2) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Return Period (Years), T | Annual Maximum 24 h Rainfall (R) (mm) | Maximum Storm Surge (m) (SS) (Time Interval = ±4 Days) | Maximum River Discharge (RD) (m3s−1) (Time Interval = ±4 Days)) | OR-JRP, | AND-JRP | OR-JRP, | AND-JRP | OR-JRP, | AND-JRP, | OR-JRP, | AND-JRP, |
| 5 | 97.04 | 0.151 | 2573.15 | 3.08 | 13.17 | 2.84 | 20.52 | 2.88 | 18.91 | 2.06 | 15.95 |
| 10 | 110.73 | 0.228 | 3367.54 | 5.69 | 40.97 | 5.32 | 81.46 | 5.34 | 77.23 | 3.70 | 50.42 |
| 20 | 128.04 | 0.277 | 5408.36 | 10.77 | 139.73 | 10.31 | 328.39 | 10.32 | 318.89 | 7.02 | 173.06 |
| 50 | 143.42 | 0.316 | 5854.64 | 25.85 | 760.16 | 25.29 | 2162.62 | 25.30 | 2063.98 | 17.00 | 950.29 |
| 100 | 147.54 | 0.337 | 5951.52 | 50.92 | 2744.23 | 50.26 | 9633.91 | 50.29 | 8517.88 | 33.66 | 3486.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Latif, S.; Simonovic, S.P. Trivariate Joint Distribution Modelling of Compound Events Using the Nonparametric D-Vine Copula Developed Based on a Bernstein and Beta Kernel Copula Density Framework. Hydrology 2022, 9, 221. https://doi.org/10.3390/hydrology9120221
Latif S, Simonovic SP. Trivariate Joint Distribution Modelling of Compound Events Using the Nonparametric D-Vine Copula Developed Based on a Bernstein and Beta Kernel Copula Density Framework. Hydrology. 2022; 9(12):221. https://doi.org/10.3390/hydrology9120221
Chicago/Turabian StyleLatif, Shahid, and Slobodan P. Simonovic. 2022. "Trivariate Joint Distribution Modelling of Compound Events Using the Nonparametric D-Vine Copula Developed Based on a Bernstein and Beta Kernel Copula Density Framework" Hydrology 9, no. 12: 221. https://doi.org/10.3390/hydrology9120221
APA StyleLatif, S., & Simonovic, S. P. (2022). Trivariate Joint Distribution Modelling of Compound Events Using the Nonparametric D-Vine Copula Developed Based on a Bernstein and Beta Kernel Copula Density Framework. Hydrology, 9(12), 221. https://doi.org/10.3390/hydrology9120221