1. Introduction
Turkey is the homeland of hazelnut culture. Hazelnuts, which are the nut of the hazel tree, are also called cobnuts and filbert nuts, depending on the species. There is a smooth shell surrounding a fibrous husk covering the cob, which is generally round or oval and about 15–25 mm (0.59–0.98 in) in length and 10–15 mm (0.39–0.59 in) in diameter. Globally, hazelnuts come in second place to almonds as far as cultivation is concerned. They have an important place in human nutrition and are mainly used in confectionery, but they are also used as table nuts and in oil production [
1].
According to data from the Food and Agriculture Organization, the world hazelnut production area is 966,196 hectares; approximately 75.4% of hazelnut production is in Turkey, about 8.1% is in Italy, 4.0% is in Azerbaijan, 1.9% is in Turkey, and 1.8% is in the USA. The hazelnut is therefore a valuable economic commodity. Turkey is the largest hazelnut producer in the world, with 69% of the global hazelnut production (about 776 000 tons out of the total world production of about 1,125,000 tons) [
2]. Additionally, Turkey is the largest exporter of hazelnuts, conducting about 80% of the world’s hazelnut exports [
3].
Considering the importance of hazelnuts for Turkey, the systems used in the process—from harvest to reaching the consumer—should be designed in an optimum way to increase work efficiency, save time, and prevent labor losses. In this chain, the aerodynamic properties of the hazelnut for the optimum design of the machinery and systems used for the classification, drying, transportation, and cleaning of the hazelnuts under suitable conditions are important factors to know. Additionally, in order to harvest hazelnuts, perhaps using a stationary thresher and cleaning unit, the physical and aerodynamic properties of hazelnuts are also important to know [
4].
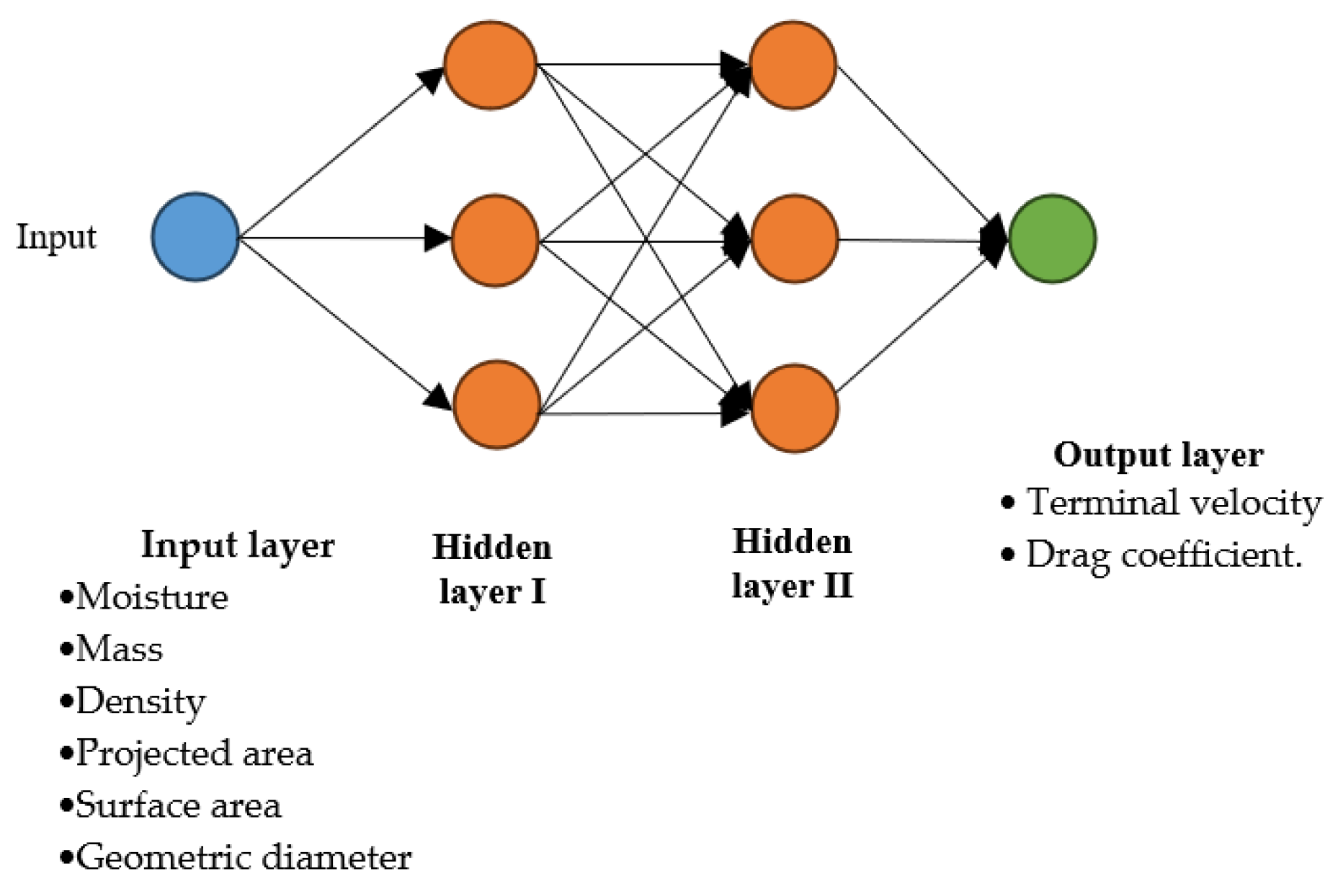
For the optimization of the systems used in hazelnut processing, the aerodynamic properties such as the terminal velocity and drag coefficient are important factors to consider. These properties (the terminal velocity and drag coefficient) are affected by numerous factors such as the humidity, mass, density, projected area, surface area, and geometric diameter [
5].
Aerodynamic tests with different agricultural products have determined terminal velocity as a function of moisture content. However, some studies showed that the terminal velocity of an agricultural product also changes according to the mass, geometric diameter (form), volume, density, and superficial projected area of the product [
4,
6,
7]. In addition, in a study on the separation of both damaged and undamaged seeds, the drag coefficient was determined as a function of the mean geometric diameter [
8].
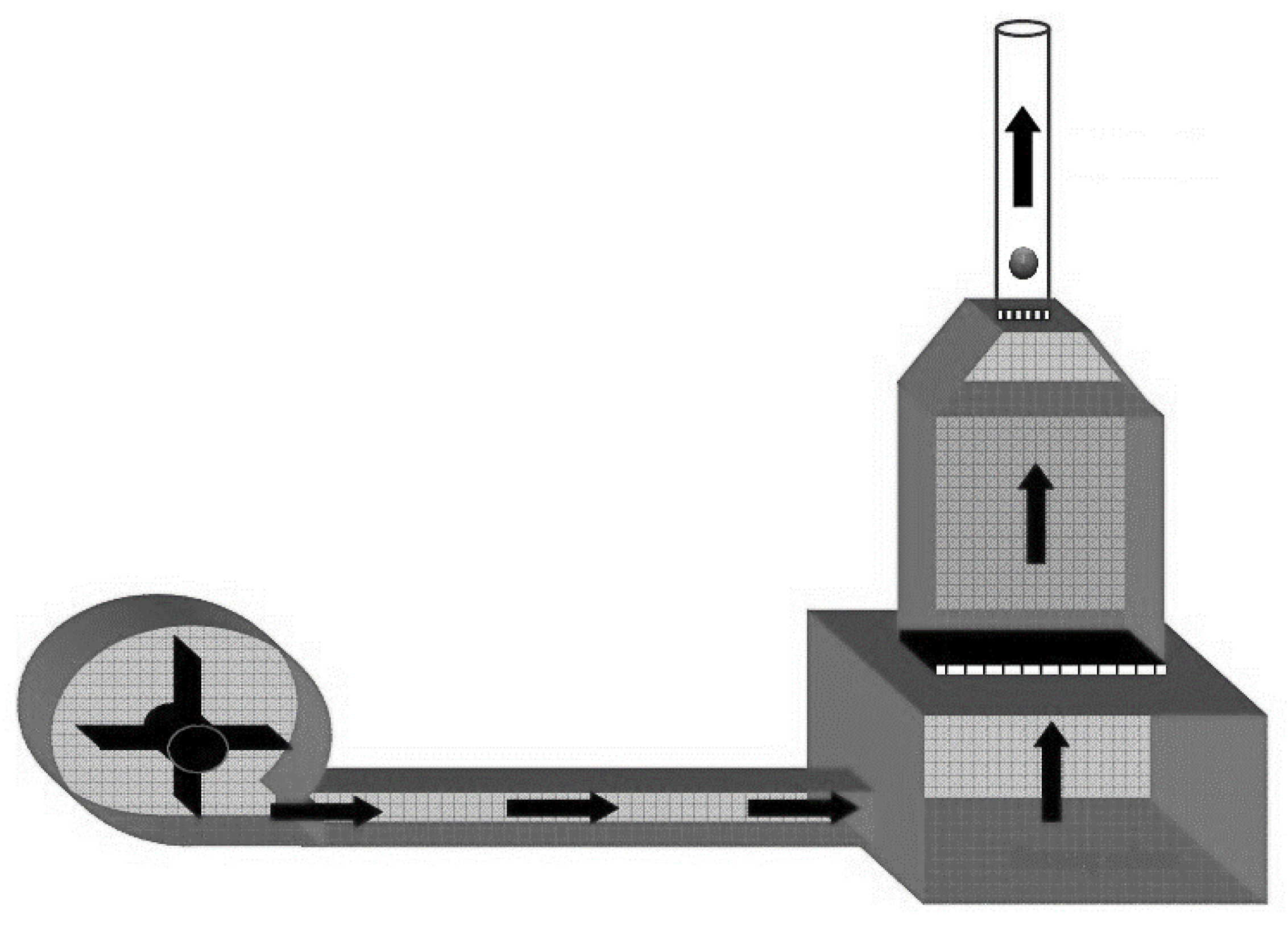
The terminal velocity and drag coefficient can be calculated or measured in the laboratory according to the specified fruit characteristics (humidity, mass, density, projected area, surface area, and geometric diameter). Two commonly used methods for the experimental measurement of terminal velocity are the drop and suspension methods [
9]. Both methods involve a very long, laborious process, and they are also very time consuming and labor intensive. In current times, when energy and labor are crucial and time is of the essence, nontraditional methods can be used, instead of experimental methods, to accurately predict these desired properties.
It is frequently challenging to establish the relationship between the dependent variables and independent variables in system/process phenomena [
10]. It is challenging to map the behavior of a system or process with a mathematical model in such circumstances, and even when answers are established, such mathematical models are frequently complicated, nonlinear, and parallel. The physical characteristics of hazelnut fruits and their aerodynamic characteristics do not have a known numerical relationship. As a result, machine learning processes offer a more effective method of solving this kind of problem [
11]. In recent years, there has been an increase in the usage of some machine learning technologies to solve these problems. Using these techniques, solution-oriented approaches can be achieved via fast and simple simulations [
12]. Such effective methods are required for the precise representation and identification of descriptive parameters utilized in agricultural and food product quality evaluation. In an input–output coupling, machine learning provides nonlinear models that can forecast current and future values [
13]. The physical, mechanical, and qualitative aspects of fruit have been studied using various network architectures of artificial neural networks, including different inputs, network structures, training algorithms, iteration counts, and so on. Suitable ANN models for predicting physical and mechanical qualities have been identified by combining different combinations. The ANN method was applied to estimate the typical physiological changes in pears, and the ANN model produced the best estimation based on real data [
14]. An artificial neural network can be used to better estimate the volume and surface area of a fruit according to Ziaratban et al. [
15]. Lu et al. [
16] used single-hidden-layer ANNs in their asparagus investigation, and the number of neurons in the hidden layer was determined via a trial-and-error method.
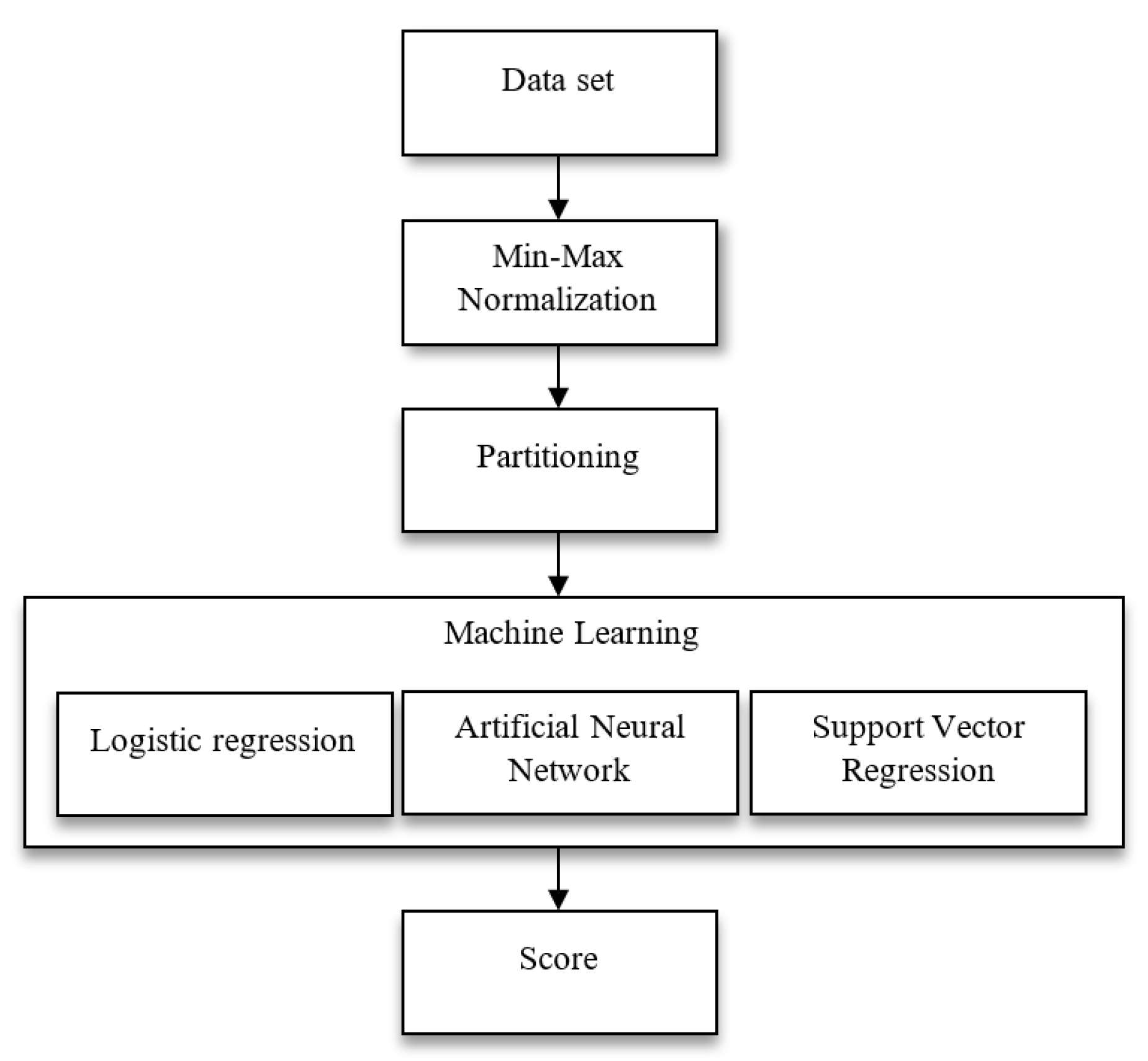
Machine learning, which can be defined as a type of application in which computer programs can learn patterns through training data and algorithms, is a sub-branch of artificial intelligence. Its application, which imitates human movements, aims to learn through experience without programming. The learning system of the machine learning algorithm is divided into three main parts. The decision process is used by machine learning algorithms to make a prediction or classification. Based on some input data, which may be labeled or unlabeled, an algorithm will generate a prediction about a pattern in the data. An error process is used to evaluate the prediction of the model. If there are known examples, an error function can perform a benchmark to evaluate the accuracy of the model. In the optimization process, if the model fits the data points in the training set better, then the weights are adjusted to reduce the discrepancy between the known sample and the model prediction. By repeating this evaluation and optimizing the process, the algorithm autonomously updates the weights until an accuracy threshold is reached [
17].
This study presents an accurate estimation of aerodynamic properties such as terminal velocity and drag coefficient depending on some fruit properties, such as humidity, mass, density, projection area, surface area, and geometric diameter, using a machine learning method. By using machine learning models, we aim to determine the most accurate model given different inputs and network structures. The results obtained can be considered a useful tool when the drying, harvesting, sorting, transportation, separation, trashing, and processing of hazelnuts is developed and optimized.
4. Conclusions
The aerodynamic properties of hazelnuts (terminal velocity and drag coefficient) are major parameters for harvesting and post-harvesting operations. These parameters are very important for the design and modification of machines used in many processes, such as harvesting, drying, transportation, classification, cleaning, etc. In order to determine these properties, measurements with a large number of samples are required. These types of measurements are time consuming, costly, and labor intensive. Additionally, they introduce several measurement errors. Identifying such features with machine learning systems leads to more datasets, attributes, and algorithms for further study, as well as faster and more reliable results for industrial applications such as discrimination, sorting, and prediction processes.
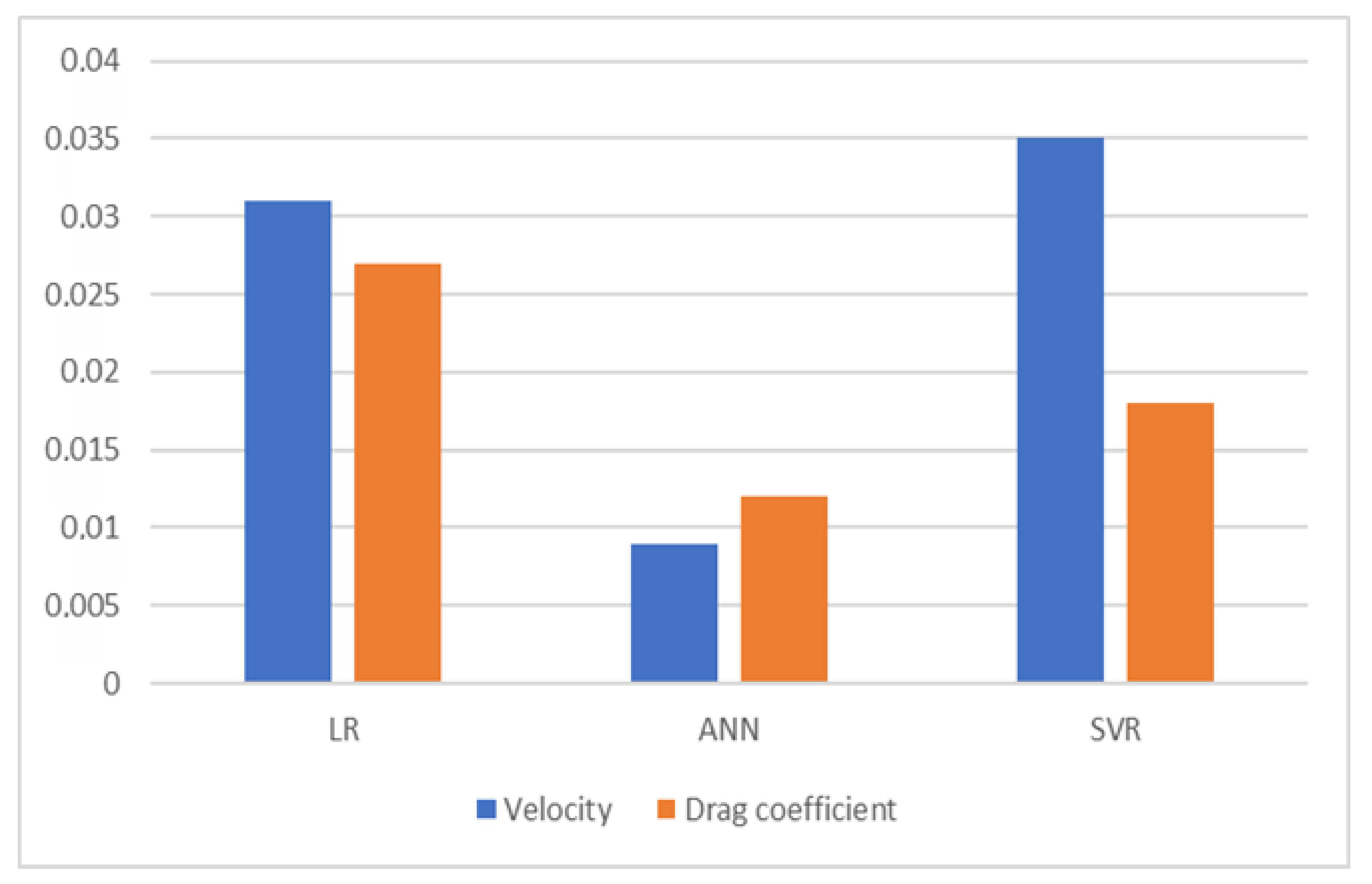
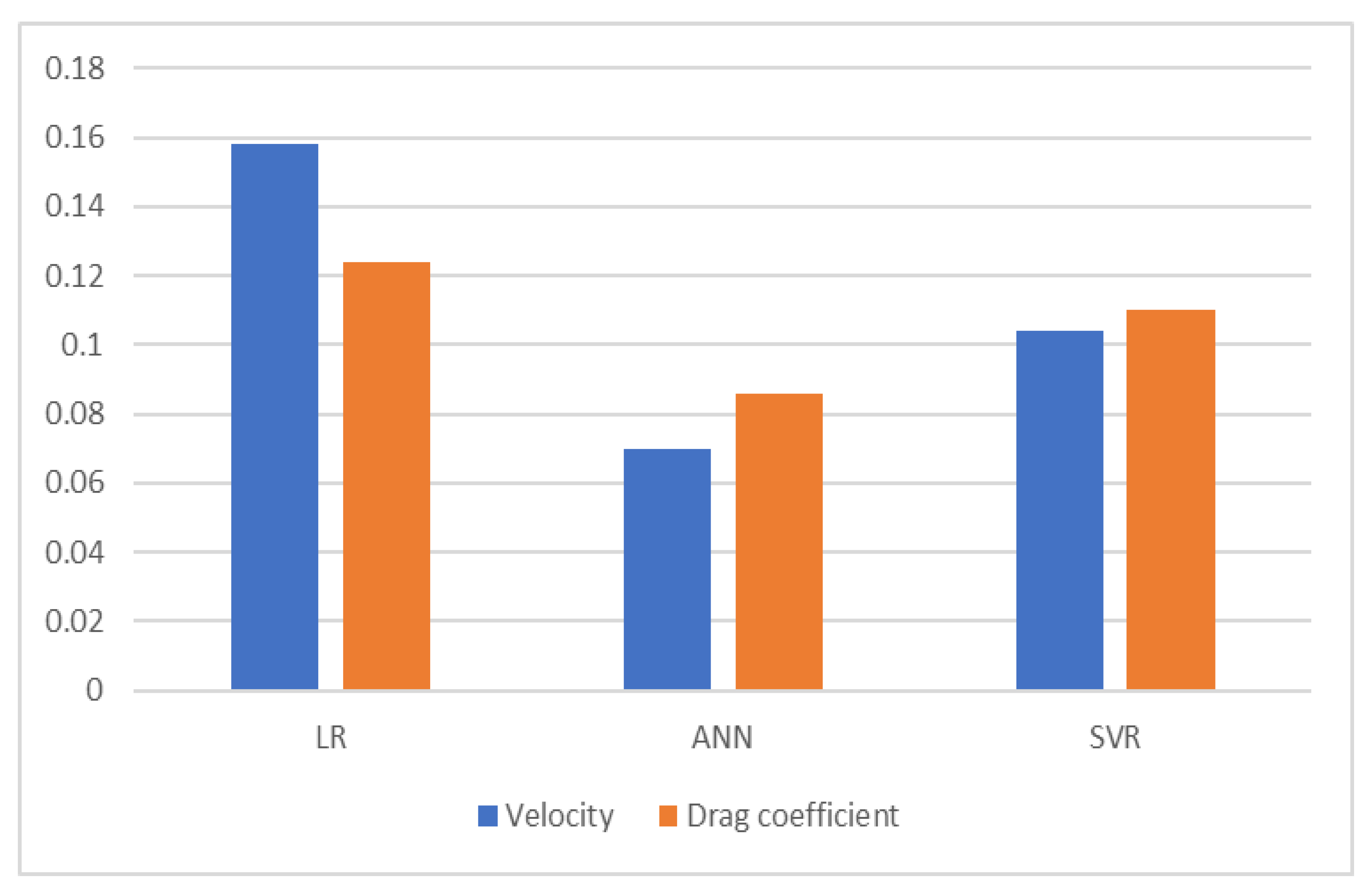
In this study, the terminal velocity and drag coefficient of hazelnuts were successfully predicted by models created using six different independent variables in three machine learning methods. Considering the R2 metric in the evaluation of the methods, it was seen that these models can be used to predict the terminal velocity and hazelnut drag coefficient using six independent variables. An MSE and MAE of zero indicate that the models are error free. Since the MSE and MAE metrics are close to zero in this study, it can be concluded that the findings of the study are acceptable and the error rate is low. As a result of the evaluation of the models, it was seen that the most successful methods with the lowest error were artificial neural networks, support vector regression, and logistic regression, respectively.
Machine learning can be used in the food processing industry in a highly practical, fast, and reliable way. In addition, it can help in the determination of physical and engineering properties of agricultural products and in quality assessment industries. The current models and findings will provide important contributions to researchers and designers.
In future studies, the prediction success can be increased by increasing the size of the data sets and adding independent variables to the models. In addition, the effect of using different machine learning methods such as deep learning on the accuracy of the method can be analyzed.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}