
Fault Detection of Diesel Engine Air and after-Treatment Systems with High-Dimensional Data: A Novel Fault-Relevant Feature Selection Method



Abstract
1. Introduction
- This paper proposes a novel EGA–CCA scheme for fault detection, in which the EGA is used to optimize variables for the specific fault conditions for improving detection performance, while the CCA is used to extract the correlations between variables to establish a detection model.
- The EGA–CCA scheme is applied to establish fault detection models with operating data of the heavy diesel vehicle in practice, which successfully detects three faults in the air and after-treatment systems of the diesel engine.
2. Process and Problem Description
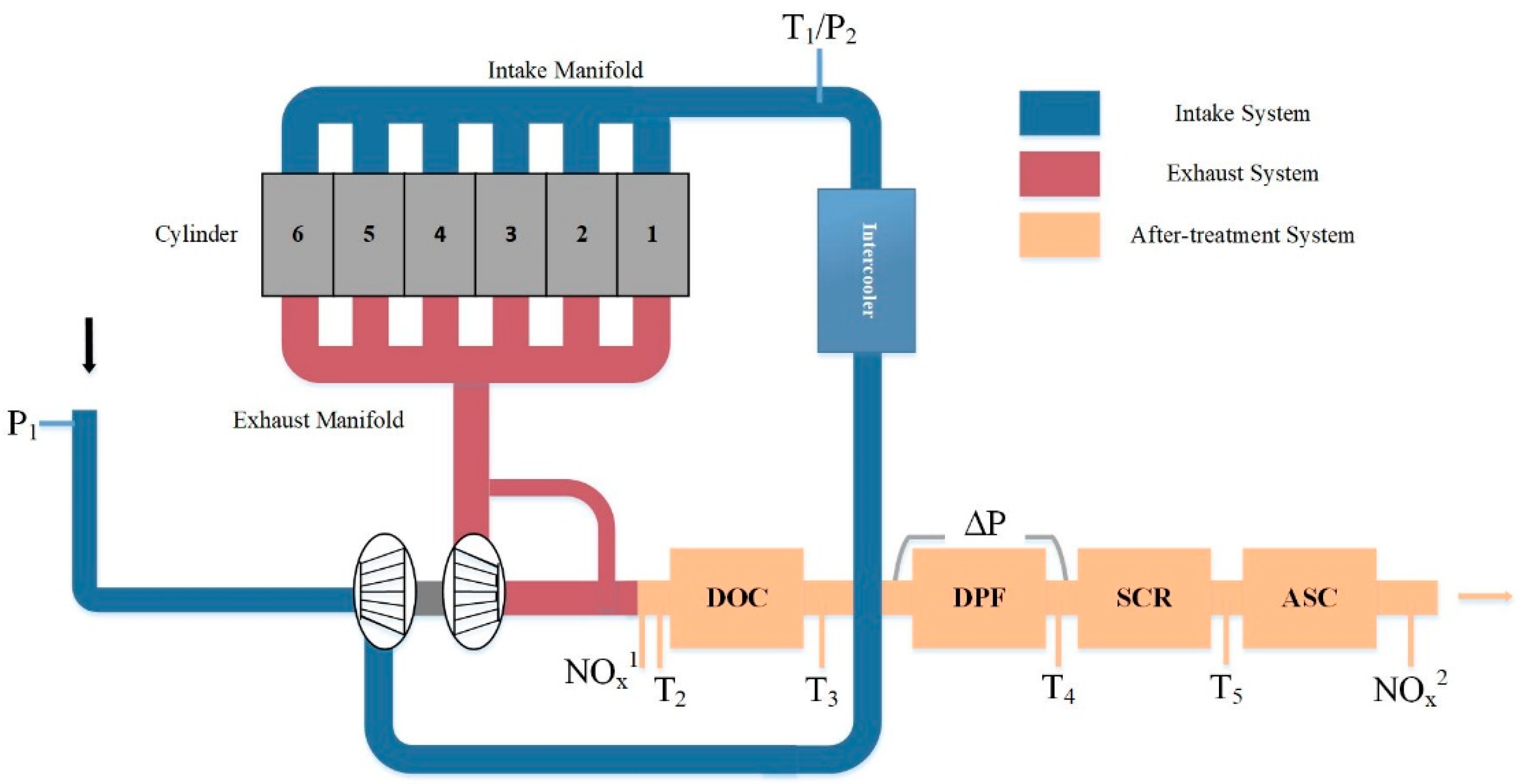
2.1. Process Description
2.2. Faults in the Air and after-Treatment Systems
3. Fault Detection Scheme Based on Optimal Selection of Fault-Relevant Variables
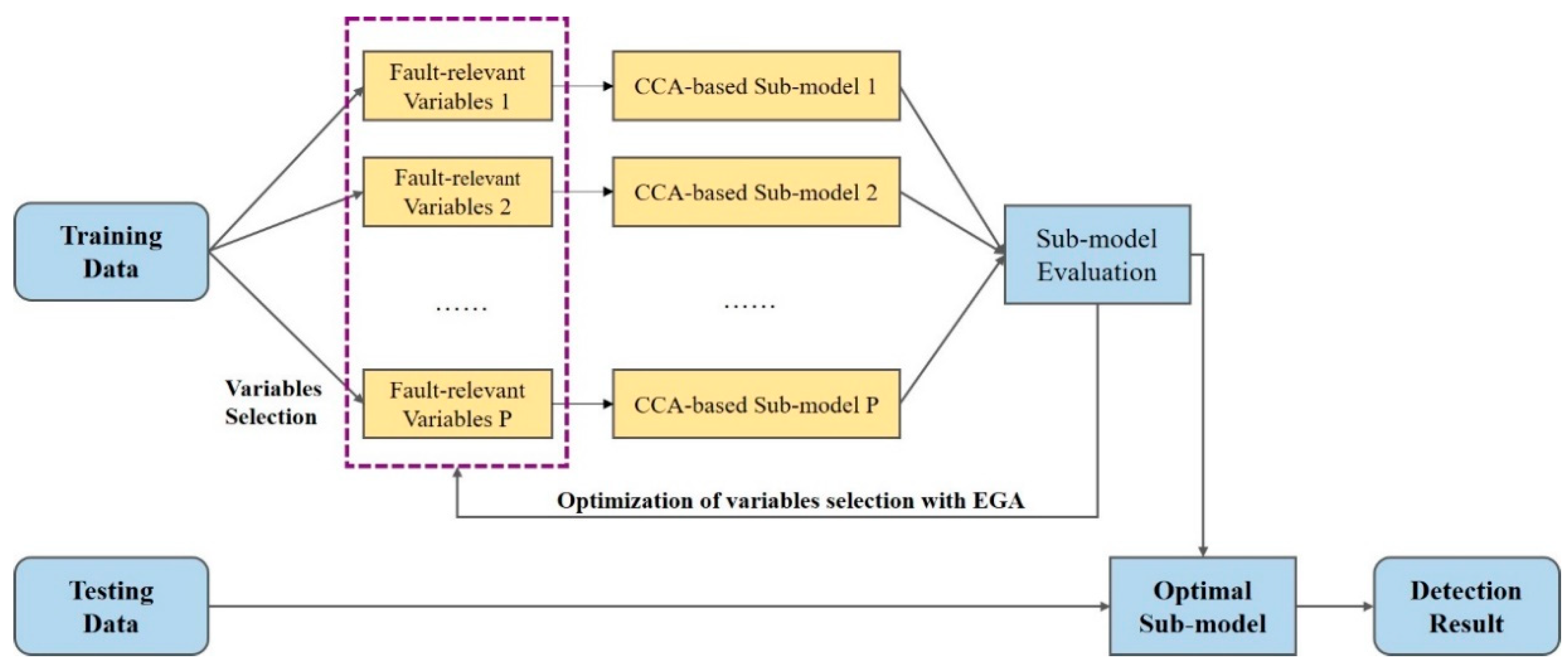
3.1. The Framework for Optimal Selection of Fault-Relevant Variables
3.2. CCA-Based Fault Detection Method
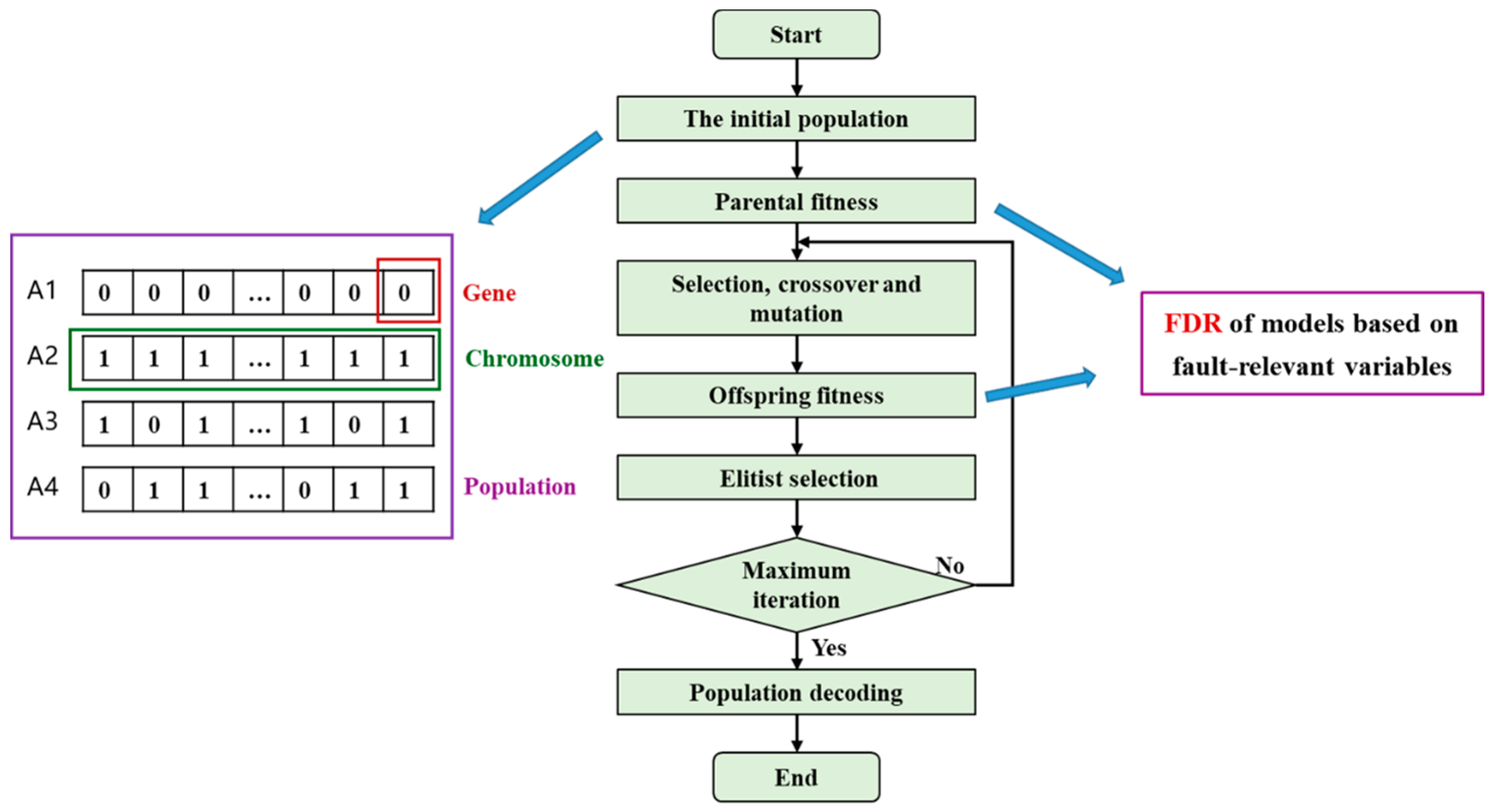
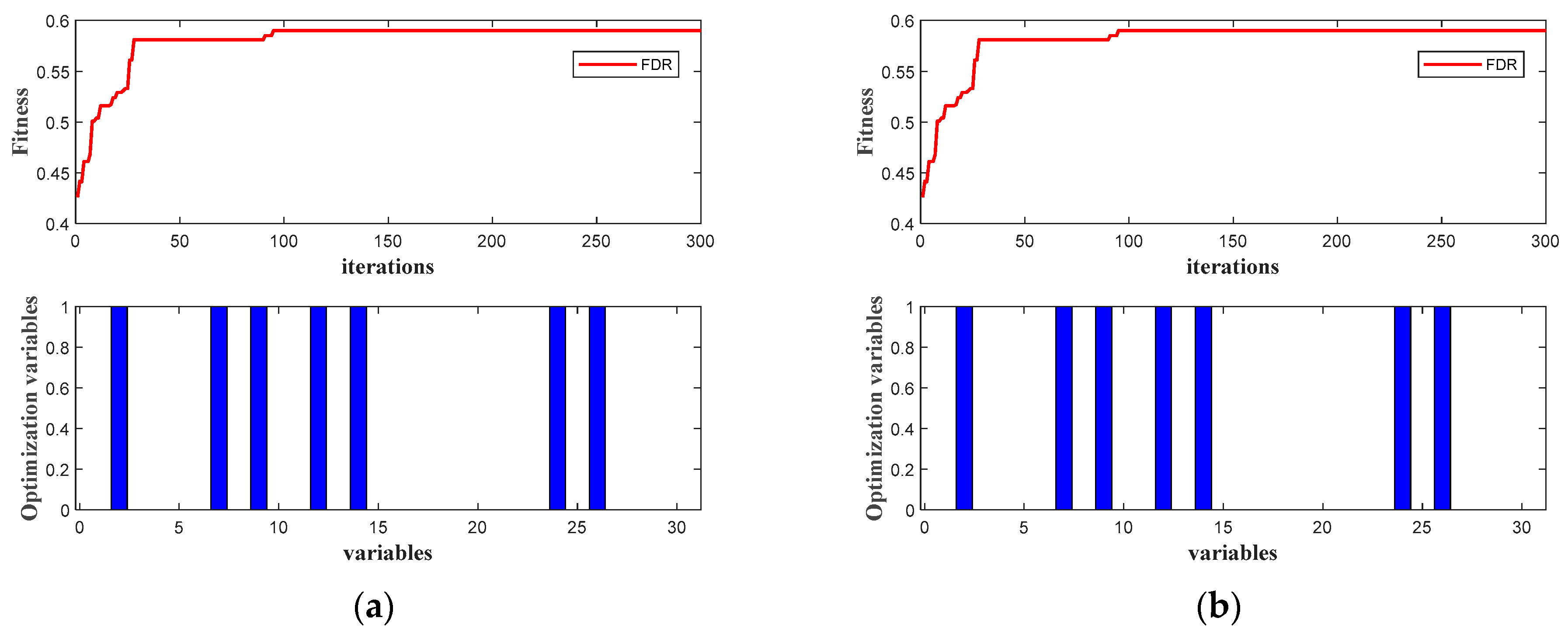
3.3. The Optimal Selection of Fault-Relevant Variables with EGA
4. Experiment and Analysis
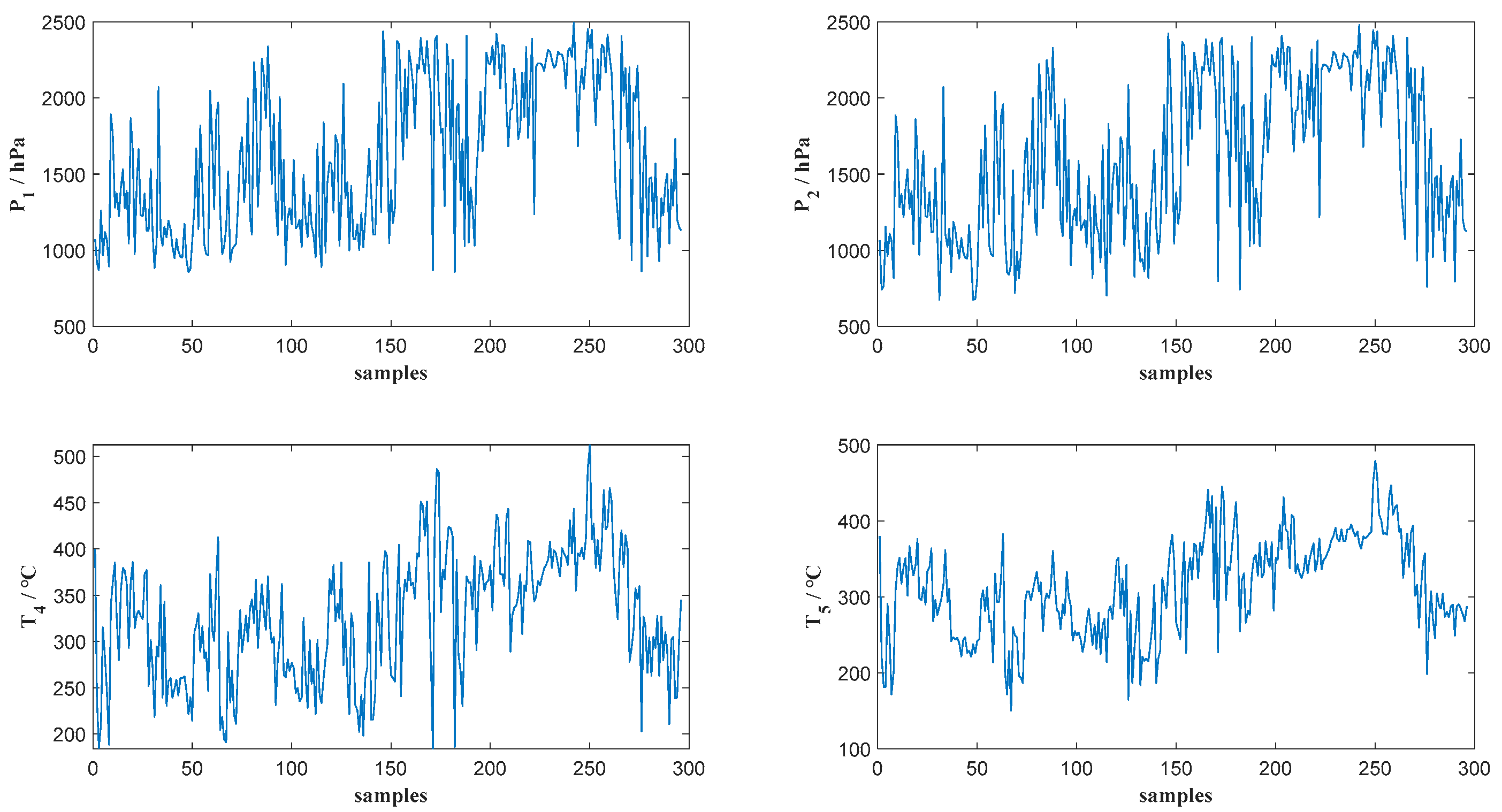
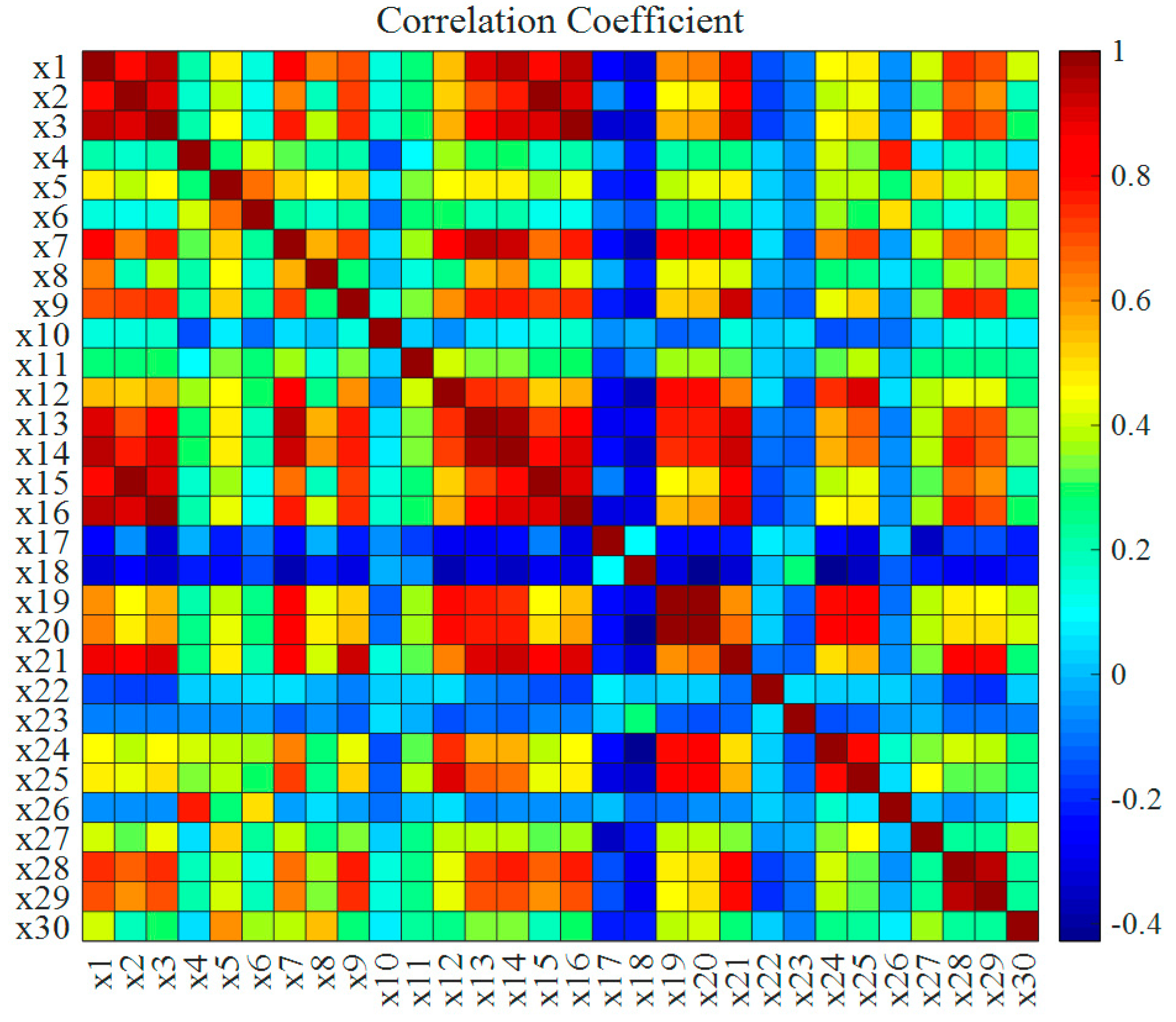
4.1. Data Description and Analysis
- (1)
- Cleansing: the Boolean variables, fault codes, and unsatisfactory variables for which the ratio of null exceed over 50%, would be filtered out. Moreover, the null and outliers in the remaining variables would be deleted as well.
- (2)
- Filtering: the significant noise will be filtered by the moving the average method.
- (3)
- Resampling: the uniform sampling is selected to obtain appropriate modeling and test data sets.
- (4)
- Standardization: the original data subtract the mean and divide by the standard deviation to obtain normally distributed data, with a mean of 0 and standard deviation of 1, which makes different variables have the same weighted influence on the model.
4.2. Experimental Settings
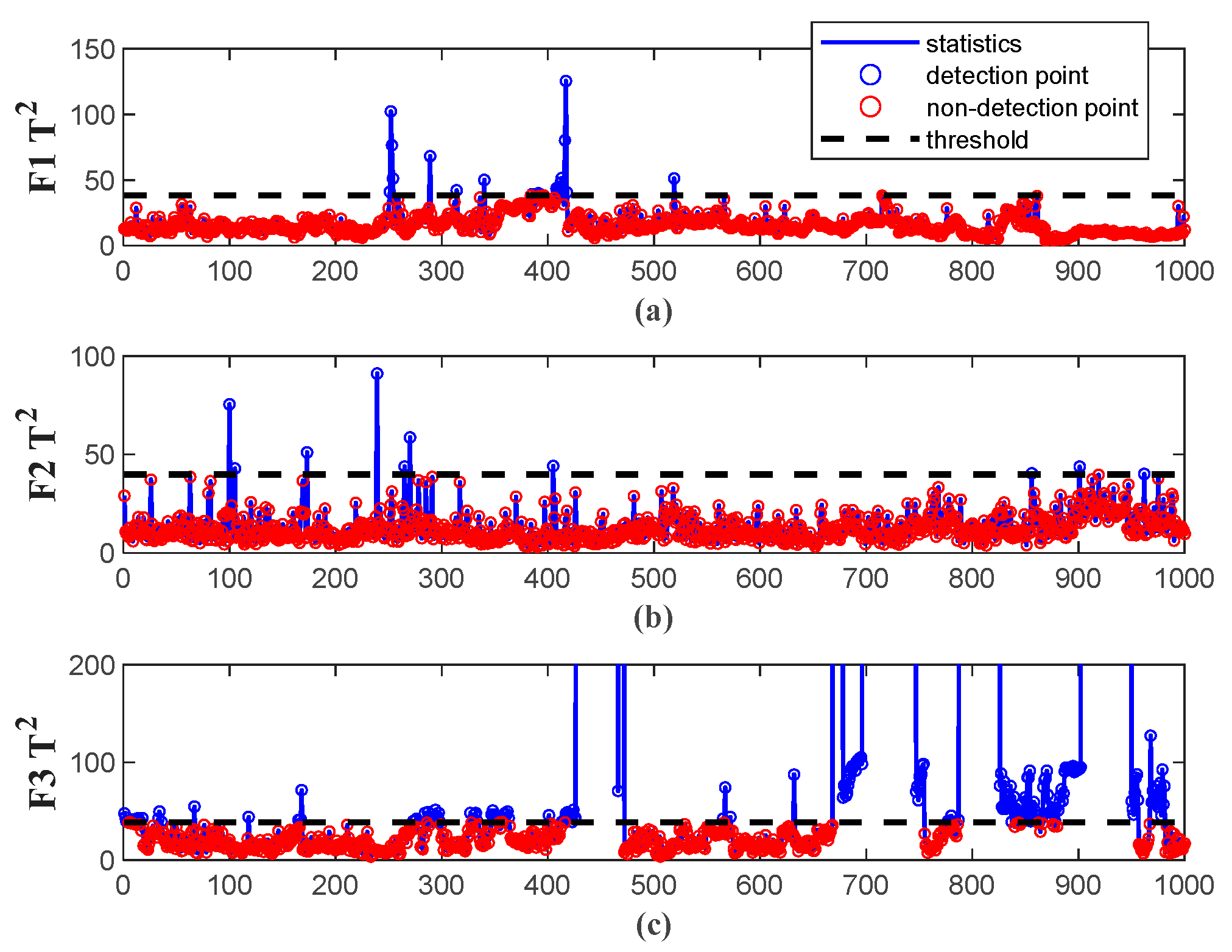
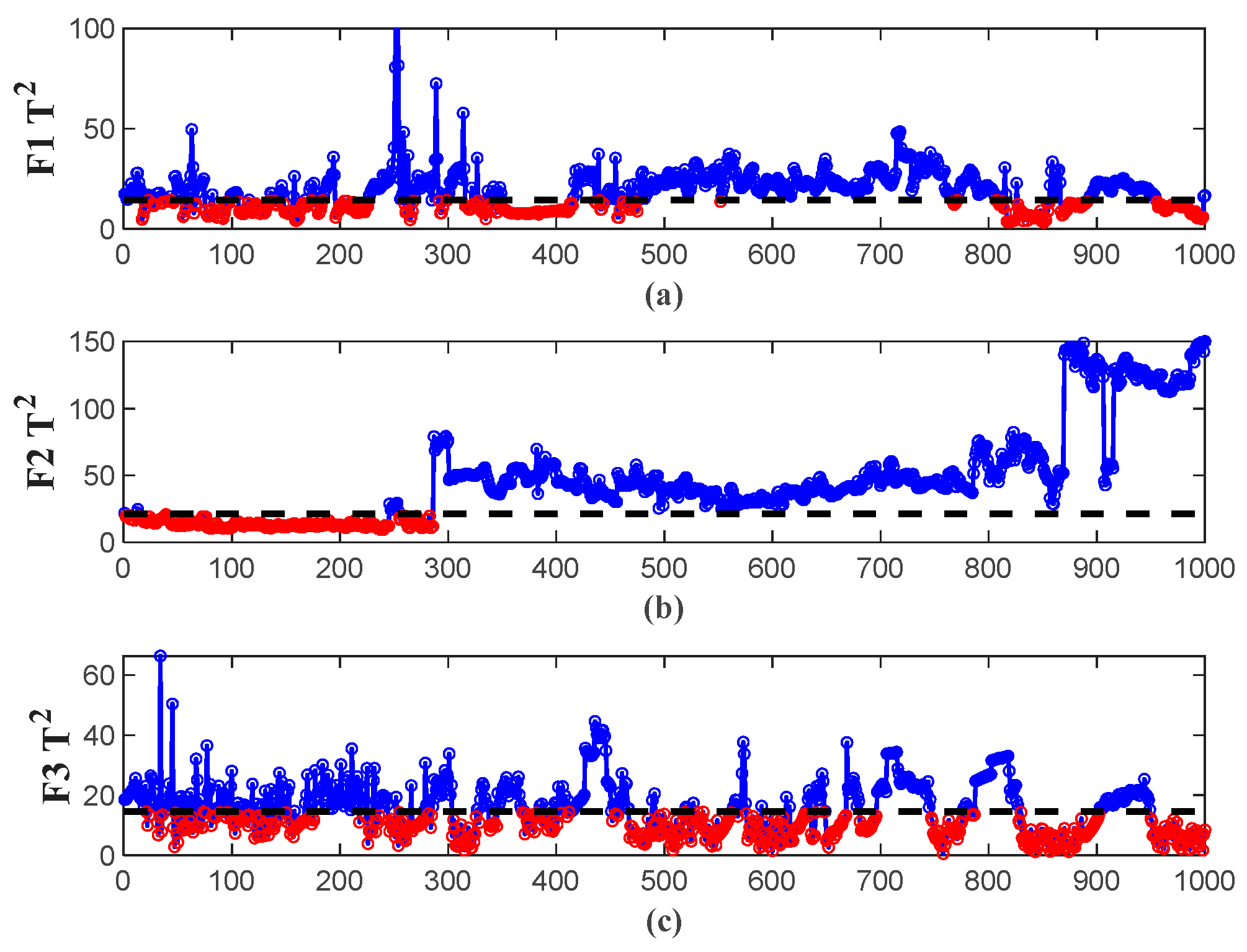
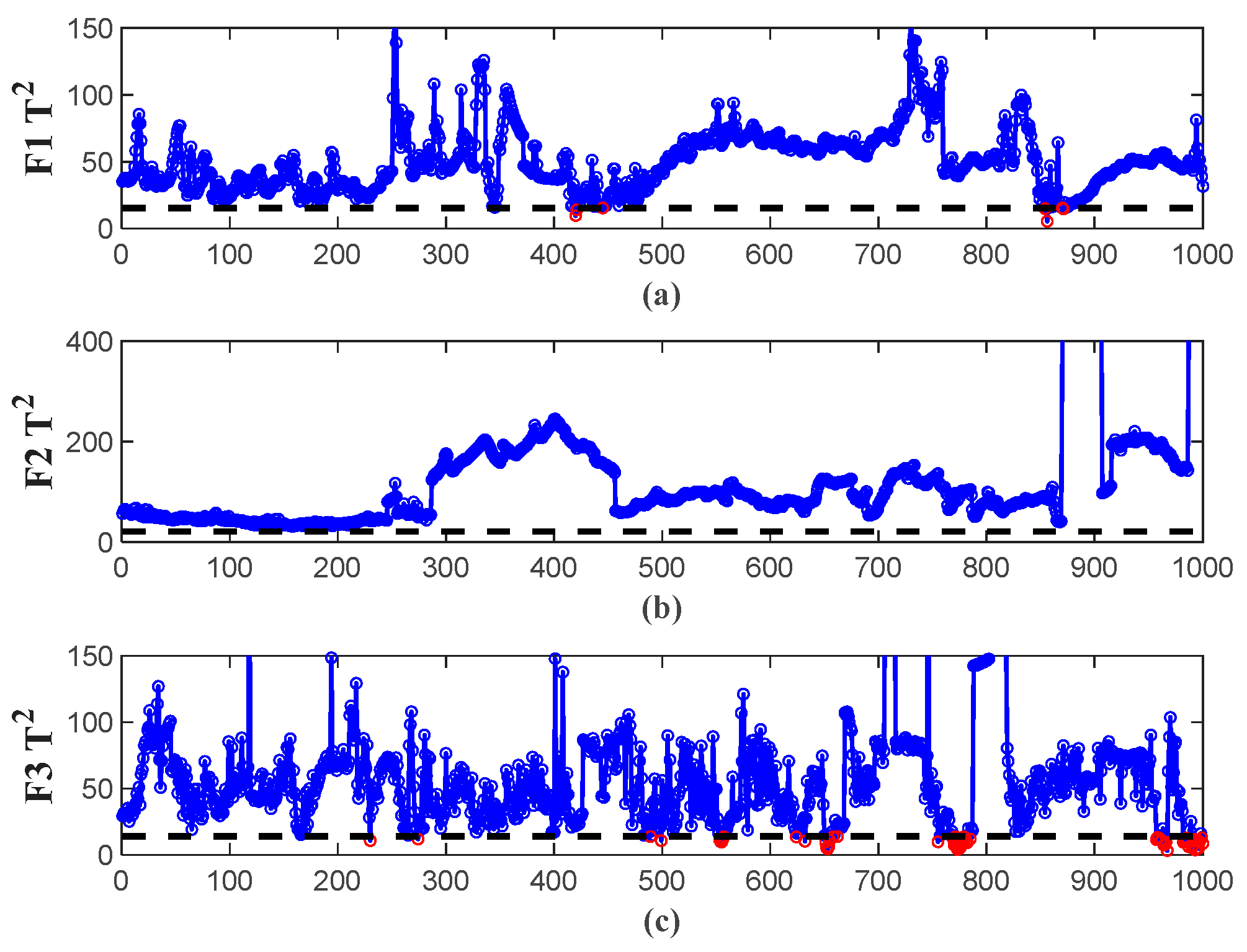
4.3. Experimental Results and Analysis Based on EGA–CCA
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Quiros, D.C.; Smith, J.; Thiruvengadam, A.; Huai, T.; Hu, S.H. Greenhouse gas emissions from heavy-duty natural gas, hybrid, and conventional diesel on-road trucks during freight transport. Atmos. Environ. 2017, 168, 36–45. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, S.; Hao, J.; Liu, H.; Wu, X.; Hu, J.; Walsh, M.P.; Wallington, T.J.; Zhang, K.M.; Stevanovic, S. On-road vehicle emissions and their control in China: A review and outlook. Sci. Total Environ. 2017, 574, 332–349. [Google Scholar] [CrossRef] [PubMed]
- Apicella, B.; Mancaruso, E.; Russo, C.; Tregrossi, A.; Oliano, M.M.; Ciajolo, A.; Vaglieco, B.M. Effect of after-treatment systems on particulate matter emissions in diesel engine exhaust. Exp. Therm Fluid Sci. 2020, 116, 110107. [Google Scholar] [CrossRef]
- Lao, C.T.; Akroyd, J.; Eaves, N.; Smith, A.; Morgan, N.; Nurkowski, D.; Bhave, A.; Kraft, M. Investigation of the impact of the configuration of exhaust after-treatment system for diesel engines. Appl. Energy 2020, 267, 114844. [Google Scholar] [CrossRef]
- Guan, B.; Zhan, R.; Lin, H.; Huang, Z. Review of state of the art technologies of selective catalytic reduction of NOx from diesel engine exhaust. Appl. Therm. Eng. 2014, 66, 395–414. [Google Scholar] [CrossRef]
- Naifeng, H.; Zhongfeng, J.; Zhi, N. On the Influencing Factors of Integrated Aftertreatment System in Diesel Engine. J. Phys. Conf. Ser. 2020, 1578, 012165. [Google Scholar]
- Huang, Y.H.; Ng, E.C.Y.; Yam, Y.S.; Lee, C.K.C.; Surawski, N.C.; Mok, W.C.; Organ, B.; Zhou, J.L.; Chan, E.F.C. Impact of potential engine malfunctions on fuel consumption and gaseous emissions of a Euro VI diesel truck. Energy Convers. Manag. 2019, 184, 521–529. [Google Scholar] [CrossRef]
- Mohammadpour, J.; Franchek, M.; Grigoriadis, K. A survey on diagnostic methods for automotive engines. Int. J. Engine Res. 2012, 13, 41–64. [Google Scholar] [CrossRef]
- Liu, S.X.; Lu, M. Fault Diagnosis of the Blocking Diesel Particulate Filter Based on Spectral Analysis. Processes 2019, 7, 943. [Google Scholar] [CrossRef]
- Wang, Y.Y.; Sun, Y.; Chang, C.F.; Hu, Y.R. Model-Based Fault Detection and Fault-Tolerant Control of SCR Urea Injection Systems. IEEE Trans. Vehicul. Technol. 2016, 65, 4645–4654. [Google Scholar] [CrossRef]
- Jhou, J.S.; Chen, S.H.; Tsay, W.D.; Lai, M.C. The Implementation of OBD-II Vehicle Diagnosis System Integrated with Cloud Computation Technology. In Proceedings of the 2013 Second International Conference on Robot, Vision and Signal Processing, Kitakyushu, Japan, 10–12 December 2013; pp. 9–12. [Google Scholar]
- He, K.X.; Hu, X.; An, X.P. The Design and Implementation of Heavy-Duty Diesel Vehicles Remote Monitoring and Control System. In 2018 International Conference on Electrical, Control, Automation and Robotics; DEStech Publications, Inc.: Xiamen, China, 2018; Volume 307, pp. 768–774. [Google Scholar]
- Park, Y.J.; Fan, S.K.S.; Hsu, C.Y. A Review on Fault Detection and Process Diagnostics in Industrial Processes. Processes 2020, 8, 1123. [Google Scholar] [CrossRef]
- Ge, Z.Q.; Song, Z.H.; Gao, F.R. Review of Recent Research on Data-Based Process Monitoring. Ind. Eng. Chem. Res. 2013, 52, 3543–3562. [Google Scholar] [CrossRef]
- Wang, G.Z.; Liu, J.C.; Li, Y.; Zhang, C. Fault diagnosis of chemical processes based on partitioning PCA and variable reasoning strategy. Chin. J. Chem. Eng. 2016, 24, 869–880. [Google Scholar] [CrossRef]
- Zeng, L.; Long, W.; Li, Y. A Novel Method for Gas Turbine Condition Monitoring Based on KPCA and Analysis of Statistics T-2 and SPE. Processes 2019, 7, 124. [Google Scholar] [CrossRef]
- Zhu, J.L.; Ge, Z.Q.; Song, Z.H. Distributed Parallel PCA for Modeling and Monitoring of Large-Scale Plant-Wide Processes With Big Data. IEEE Trans. Ind. Inform. 2017, 13, 1877–1885. [Google Scholar] [CrossRef]
- Yin, S.; Zhu, X.P.; Kaynak, O. Improved PLS Focused on Key-Performance-Indicator-Related Fault Diagnosis. IEEE Trans. Ind. Electron. 2015, 62, 1651–1658. [Google Scholar] [CrossRef]
- Xie, X.C.; Sun, W.; Cheung, K.C. An Advanced PLS Approach for Key Performance Indicator-Related Prediction and Diagnosis in Case of Outliers. IEEE Trans. Ind. Electron. 2016, 63, 2587–2594. [Google Scholar] [CrossRef]
- Chen, Z.W.; Ding, S.X.; Zhang, K.; Li, Z.B.; Hu, Z.K. Canonical correlation analysis-based fault detection methods with application to alumina evaporation process. Control Eng. Pract. 2016, 46, 51–58. [Google Scholar] [CrossRef]
- Jiang, B.B.; Braatz, R.D. Fault detection of process correlation structure using canonical variate analysis-based correlation features. J. Proc. Contr. 2017, 58, 131–138. [Google Scholar]
- Chen, Z.W.; Yang, C.H.; Peng, T.; Dan, H.B.; Li, C.G.; Gui, W.H. A Cumulative Canonical Correlation Analysis-Based Sensor Precision Degradation Detection Method. IEEE Trans. Ind. Electron. 2019, 66, 6321–6330. [Google Scholar] [CrossRef]
- Chen, Z.W.; Zhang, K.; Ding, S.X.; Shardt, Y.A.W.; Hu, Z.K. Improved canonical correlation analysis-based fault detection methods for industrial processes. J. Proc. Contr. 2016, 41, 26–34. [Google Scholar] [CrossRef]
- Ghosh, K.; Ramteke, M.; Srinivasan, R. Optimal variable selection for effective statistical process monitoring. Comput. Chem. Eng. 2014, 60, 260–276. [Google Scholar] [CrossRef]
- Ming, L.; Zhao, J.S. Feature selection for chemical process fault diagnosis by artificial immune systems. Chin. J. Chem. Eng. 2018, 26, 1599–1604. [Google Scholar] [CrossRef]
- Qian, F.; Ma, D.; Zhu, N.; Li, P.; Xu, X.W. Research on Optimization Design of SCR Nozzle for National VI Heavy Duty Diesel Engine. Catalysts 2019, 9, 452. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Candidate Variables | Variable Meaning | Candidate Variables | Variable Meaning |
|---|---|---|---|
| Exhaust gas flow 1 | Actual value of intake pressure | ||
| Engine torque | Closed-loop control deviation of supercharging pressure | ||
| Intake pressure after the intercooler | DPF observation model carbon load Carbon load of DPF observation model | ||
| Intake temperature after the intercooler | Differential pressure of the DPF (filtered) | ||
| Calculated value of the intercooler cooling efficiency | Exhaust volume flow | ||
| Filter value of the intercooler cooling efficiency | Mass flow of NOx | ||
| Lower limit of particulate matter differential pressure | Pressure of urea pump | ||
| Rotating speed | Urea level | ||
| Upstream NOx | Downstream temperature of selective catalytic reduction (SCR) | ||
| Downstream NOx | upstream temperature of SCR | ||
| Upstream temperature of the diesel oxidation catalyst | Urea temperature | ||
| Upstream temperature of the diesel particulate filter (DPF) | Throttle opening | ||
| Differential pressure of the DPF (unfiltered) | Urea injection quantity | ||
| Exhaust gas flow 2 | Duty ratio of urea pump | ||
| Fuel-injection quantity | Speed |
| Fault No | ||
|---|---|---|
| 1 | ||
| 2 | ||
| 3 |
| Parameter Variable | Value |
|---|---|
| Chromosomal Gene | 30 |
| Population Size | 50 |
| Iterations | 300 |
| Crossover Rate | 1 |
| Mutation Rate | 0.01 |
| Fault No. | |||
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 |
| Methods | PCA | EGA–PCA | CCA | EGA–CCA | |
|---|---|---|---|---|---|
| Fault No. | |||||
| 1 | 2.1% | 62.2% | 88.4% | 99.3% | |
| 2 | 47.2% | 72.6% | 89.3% | 99.9% | |
| 3 | 38.5% | 46.4% | 46.2% | 94.1% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ran, Q.; Song, Y.; Du, W.; Du, W.; Peng, X. Fault Detection of Diesel Engine Air and after-Treatment Systems with High-Dimensional Data: A Novel Fault-Relevant Feature Selection Method. Processes 2021, 9, 259. https://doi.org/10.3390/pr9020259
Ran Q, Song Y, Du W, Du W, Peng X. Fault Detection of Diesel Engine Air and after-Treatment Systems with High-Dimensional Data: A Novel Fault-Relevant Feature Selection Method. Processes. 2021; 9(2):259. https://doi.org/10.3390/pr9020259
Chicago/Turabian StyleRan, Qilan, Yedong Song, Wenli Du, Wei Du, and Xin Peng. 2021. "Fault Detection of Diesel Engine Air and after-Treatment Systems with High-Dimensional Data: A Novel Fault-Relevant Feature Selection Method" Processes 9, no. 2: 259. https://doi.org/10.3390/pr9020259
APA StyleRan, Q., Song, Y., Du, W., Du, W., & Peng, X. (2021). Fault Detection of Diesel Engine Air and after-Treatment Systems with High-Dimensional Data: A Novel Fault-Relevant Feature Selection Method. Processes, 9(2), 259. https://doi.org/10.3390/pr9020259