
Probability Models of Distributed Proof Generation for zk-SNARK-Based Blockchains

 ,
,  , and
, and 
Abstract
:1. Introduction
- To estimate the number of steps (or to find its expectation and variance) needed to build a complete set of zk-SNARK-proofs for base assertions corresponding to the transactions, which the blockforger includes in the block he creates;
- Using these results, to recommend the maximal number of transactions that the blockforger should include in the block, to guarantee that the corresponding proof tree will be created with high probability during one time slot.
2. Preliminaries
- falling factorials:
- binomial and multinomial coefficients:
2.1. Stirling Numbers of the Second Kind
2.2. Factorisation of Markov Chains
- 1.
- for any the sum is locally constant on for each ;
- 2.
- .
- 1.
- Then, one can define a new stochastic matrix over a state-space T with entries
- 2.
- The lumped k-fold transition matrix can be written as
2.3. Coupon Collector Model via Products and Factorizations
- The number of distinct coupons selected after m steps;
- The number of steps required to obtain exactly r distinct coupons.
3. Distributed Generation of Sets of Proofs
3.1. Models of Distributed Generation of Sets of Proofs
- uniform distribution of in the set of functions , and
- uniform distribution of .
- 1.
- After m, , steps all coupons drown, during the last m steps, which are removed from the urn permanently.
- 2.
- Each time when collector drown m new distinct coupons, these m coupons are removed from the urn permanently.
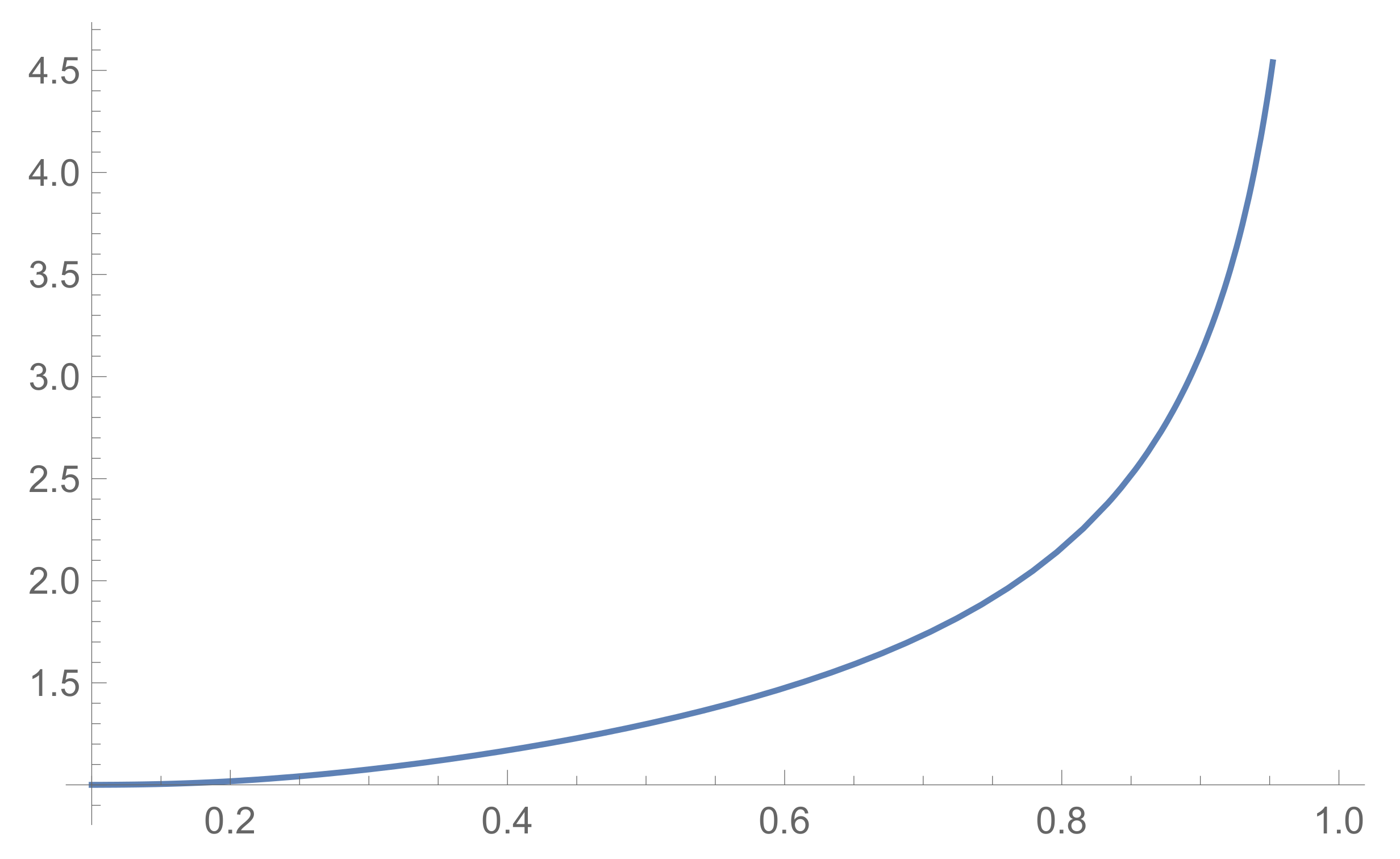
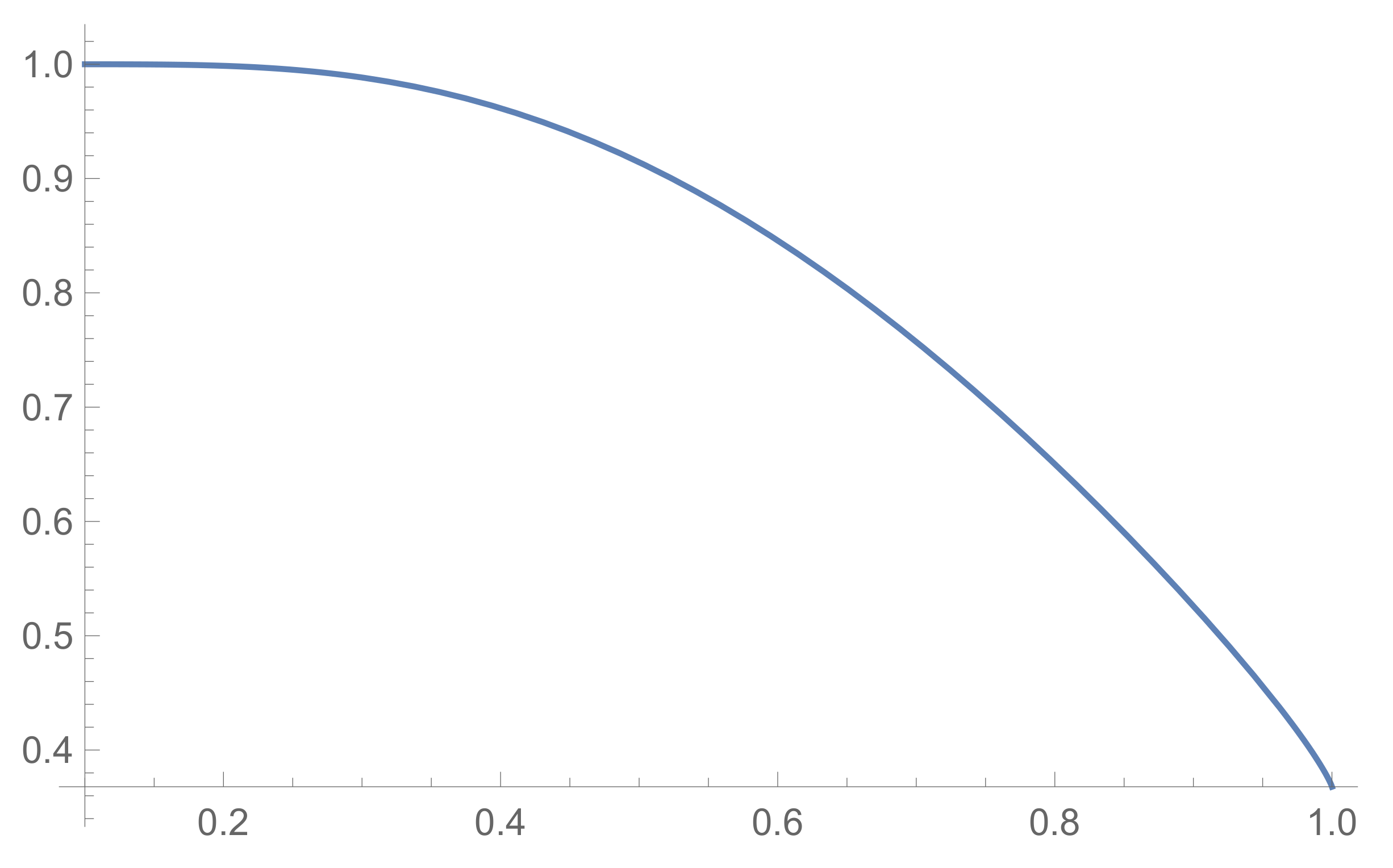
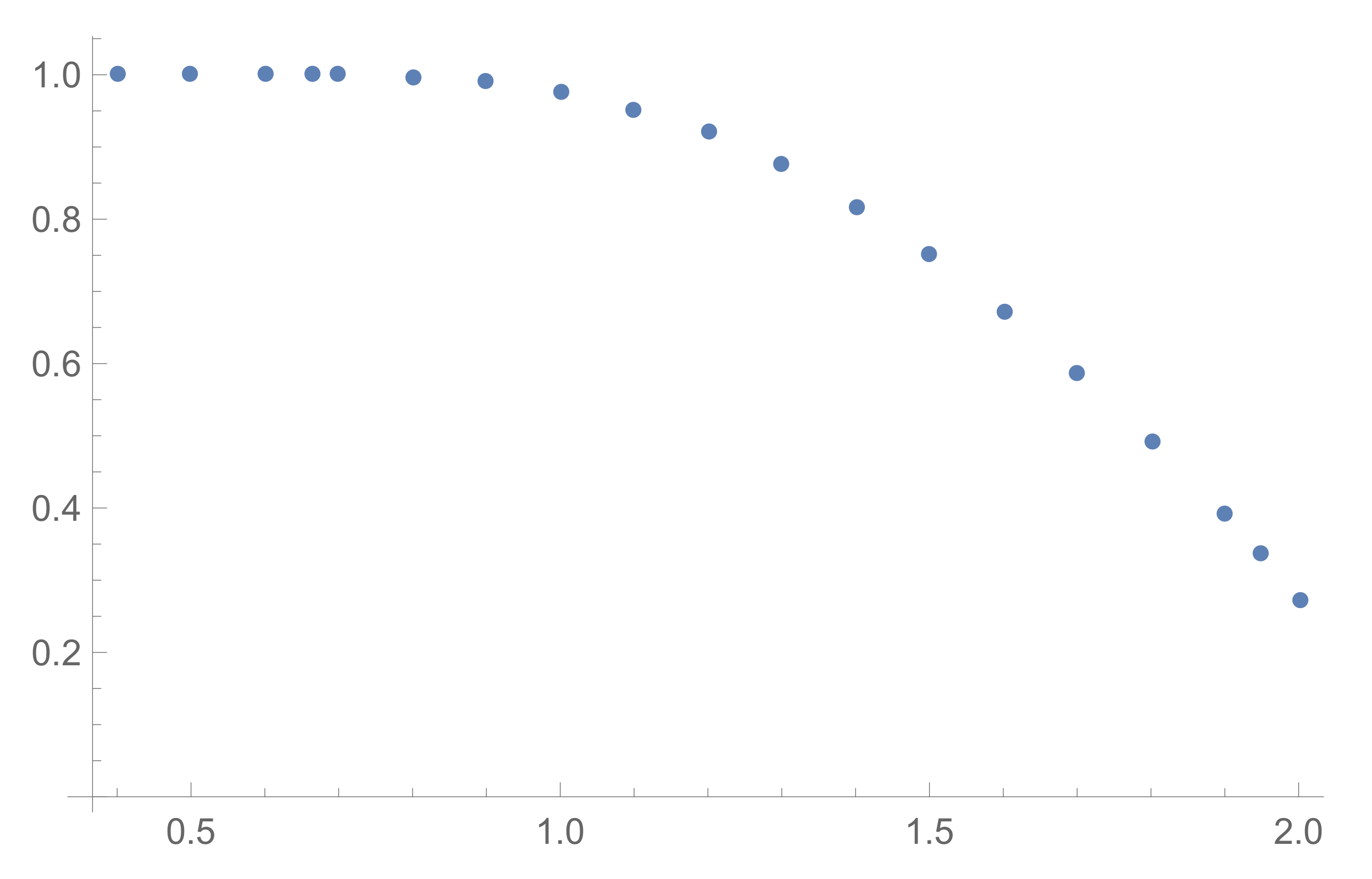
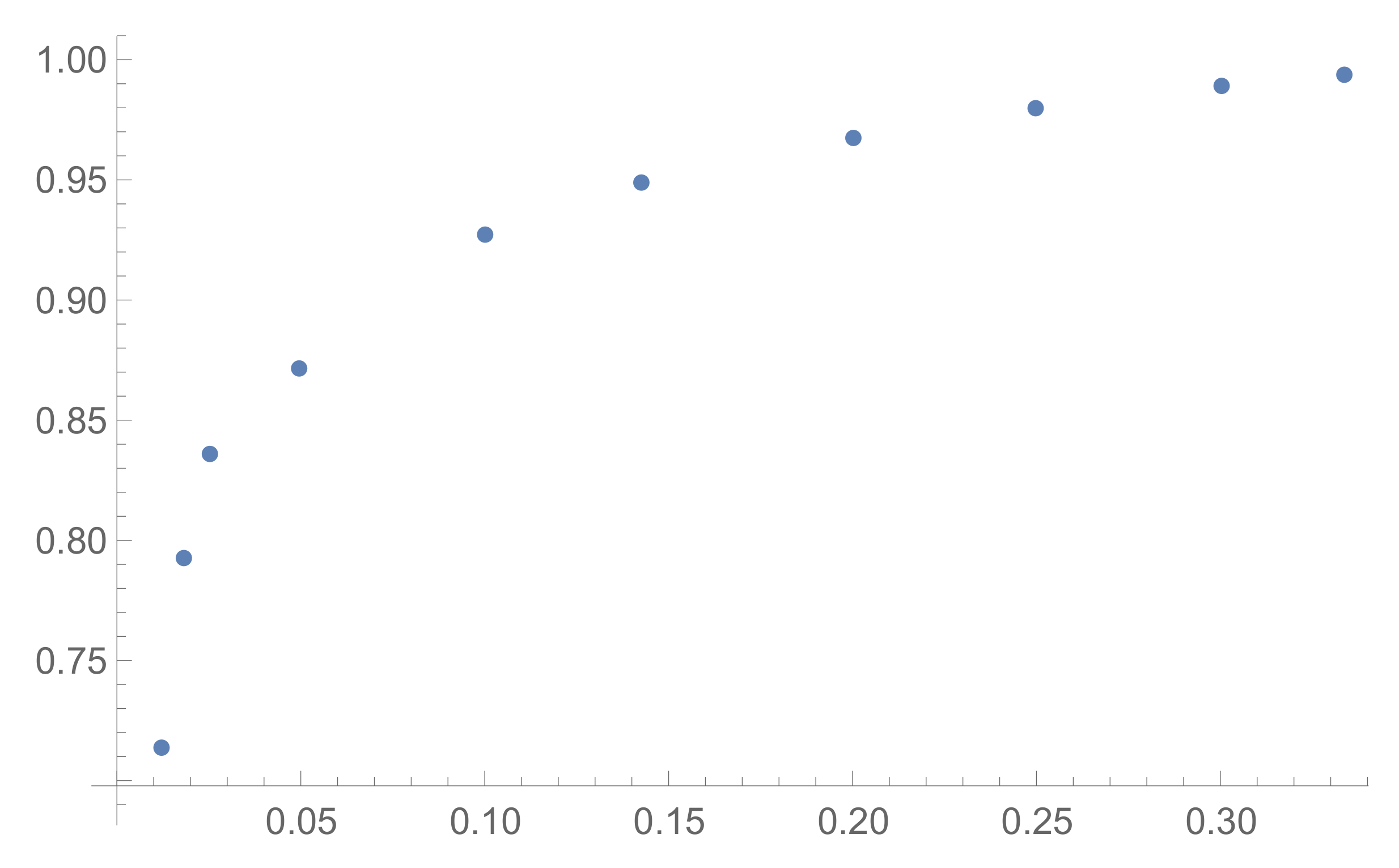
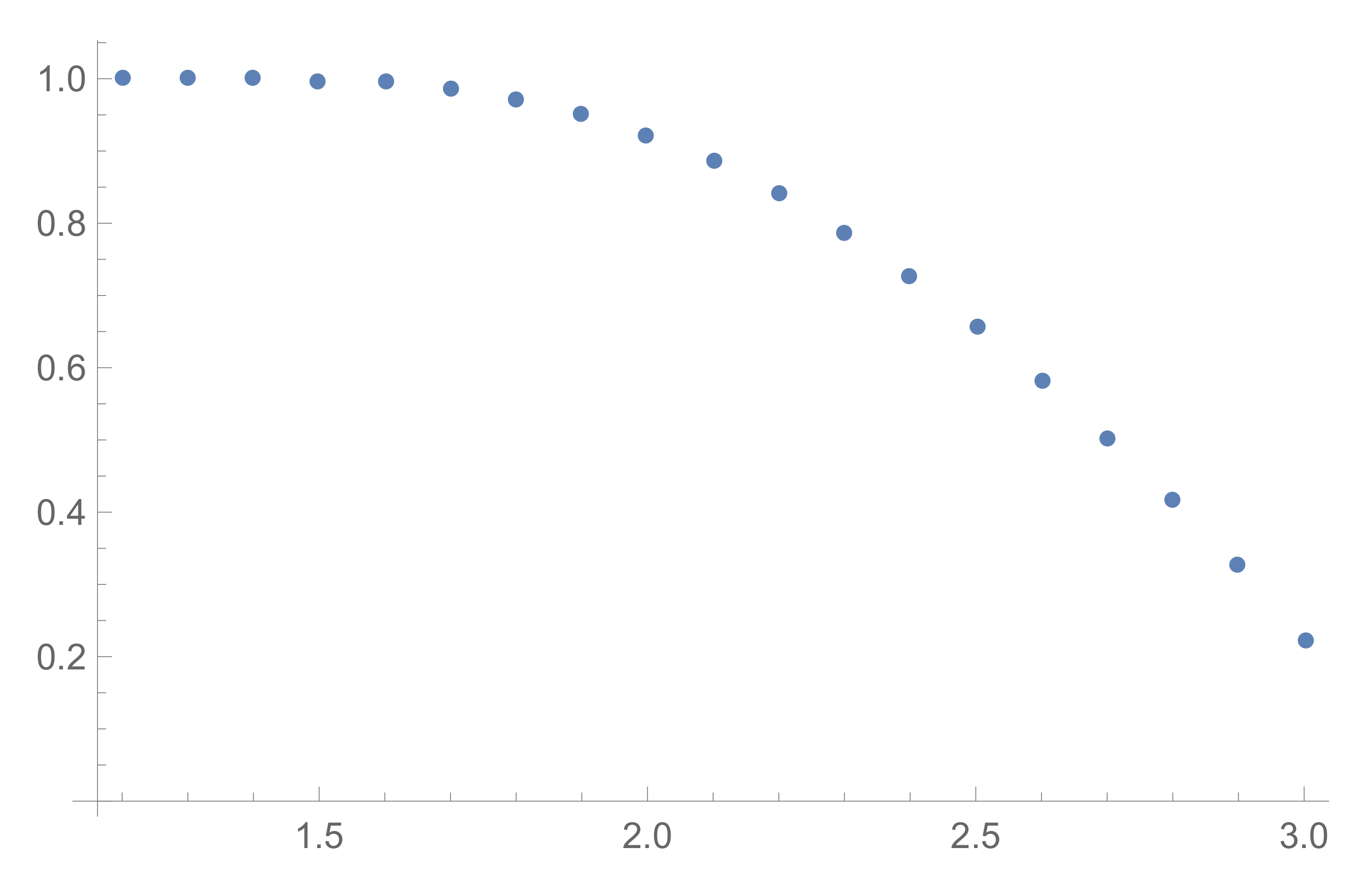
3.2. Asymptotics of
3.2.1. Large Number of Provers
3.2.2. Asymptotics of the Stirling Numbers and Probabilities
3.2.3. Dependence on the Ratio
- 1.
- is a sum of Iverson brackets
- 2.
4. Distributed Generation of Proof Trees
4.1. Ordered Sets and Lattices
- the product , where iff in P and in Q. The product of distributive latices is a distributive lattice;
- the co-product which is the disjoint union, orders restricted on P and Q coincide with the initial, the elements from different sets are incomparable;
- linear sum which is disjoint union where, orders restricted on P and Q coincide with initial and for each , . The linear sum of distributive latices is a distributive lattice;

4.2. Poset Version of Coupon Collector Model
- If N is a discrete poset (where any two distinct elements are incomparable), then elements of are arbitrary subsets of N. The symmetry group is isomorphic to a full permutation group of N and acts transitive on subsets of fixed cardinality, and orbits are identified with cardinalities . So this is the Coupon collector’s model from Example 4.
- Consider the cases when are natural numbers with the usual linear order. The lattice can be naturally identified with via cardinality. The symmetry group is trivial, all orbits are singletons. The non-zero transition probabilities are:
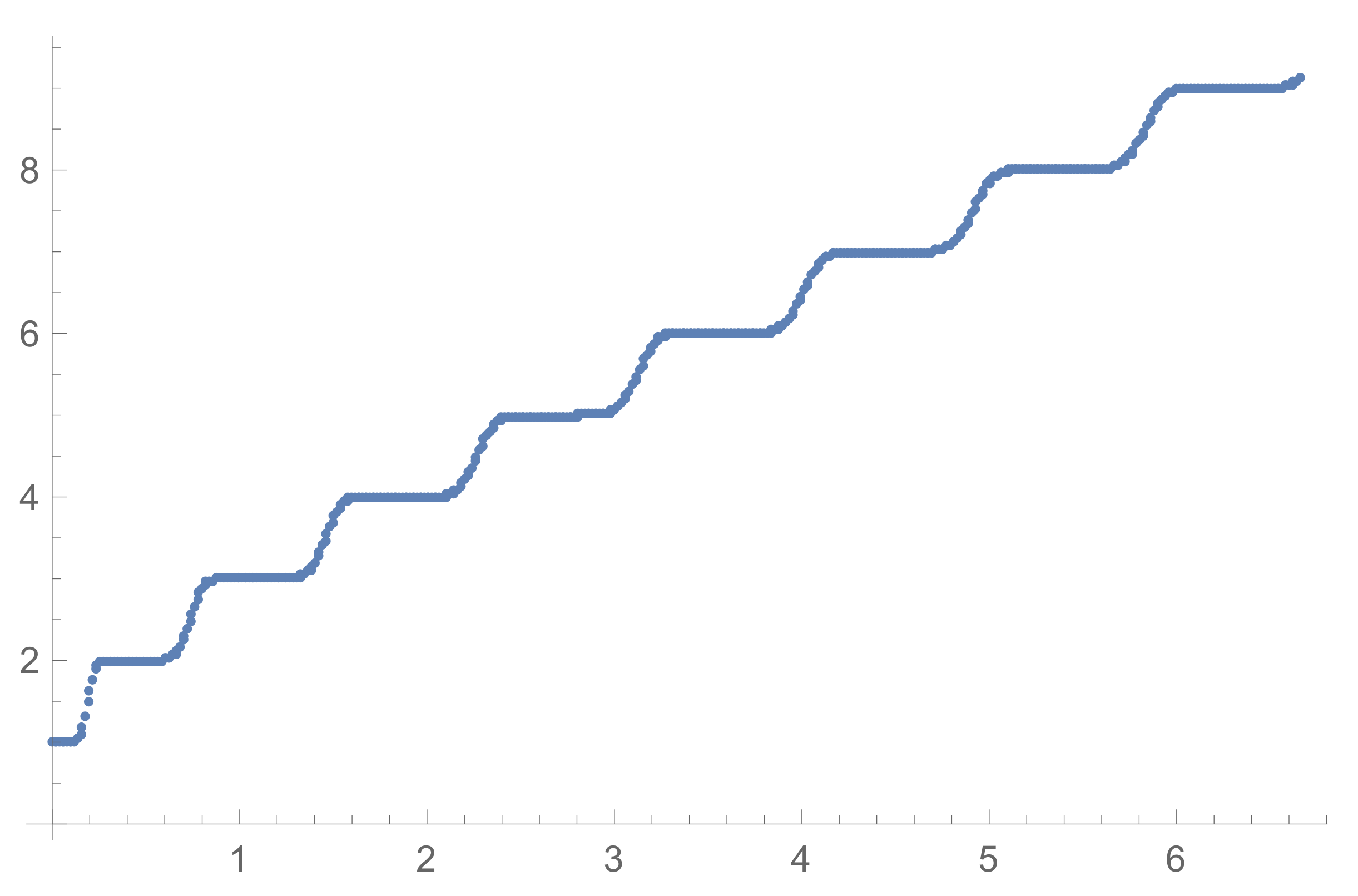
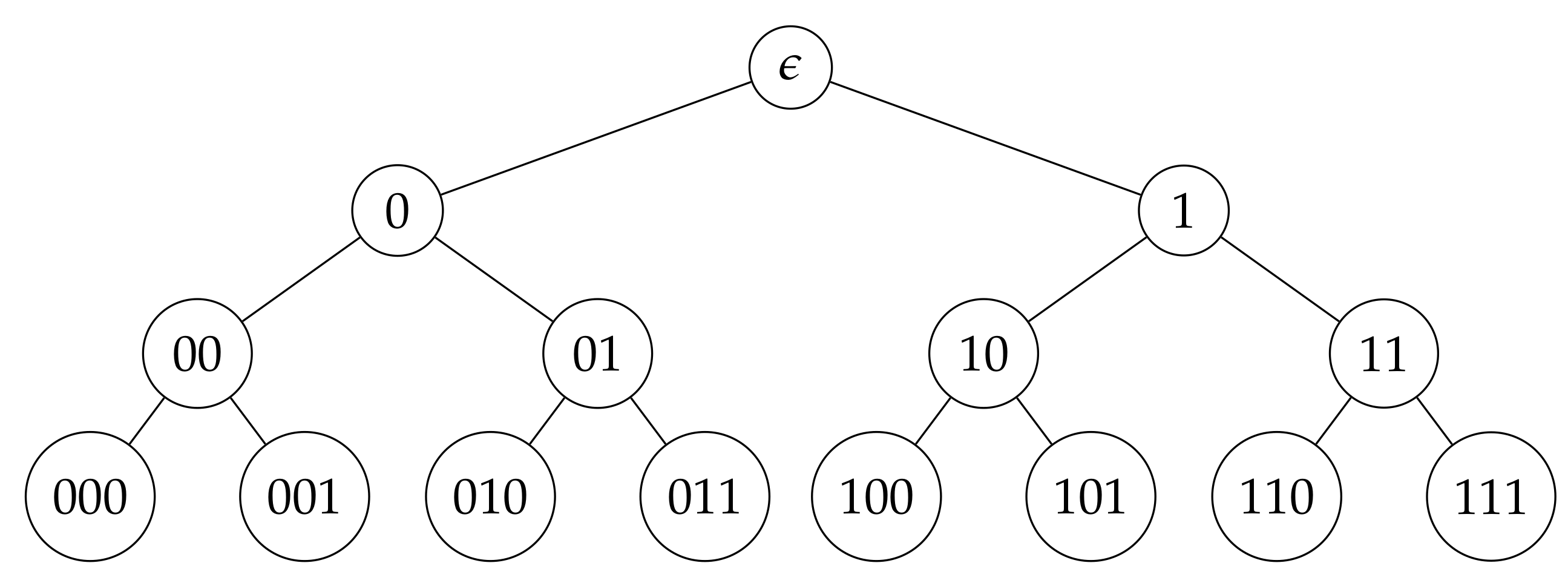
4.3. Around Perfect Binary Trees
4.4. Distributed Generation of Posets
- In the case of discrete poset N, elements of are all subsets of N, the symmetry group consists of all permutations and orbits are just integers identified with cardinalities of subsets. So we obtain a Markov chain from Example 7.
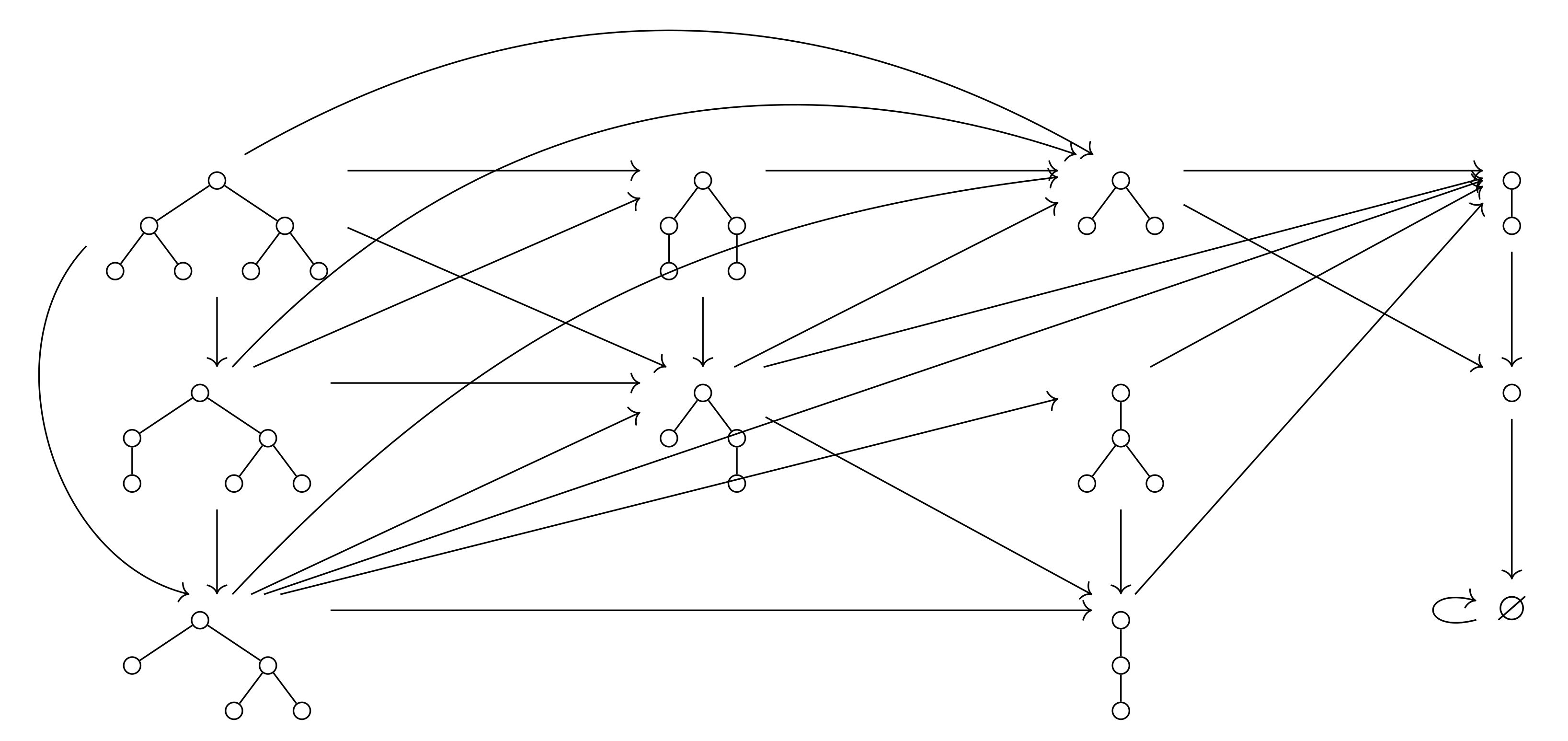
- In the case of perfect binary tree with ℓ levels the states of the Markov chain from Example 11 (resp. from Example 13) are up-sets in (res. orbits of such up-sets under action of ). According to Proposition 7 the numbers of such up-sets or orbits of up-sets grow rapidly depending on ℓ. Moreover, if we decide to consider not only uniform probability distributions on anti-chains we obtain a lot of additional parameters.For the case , the oriented graph of the Markov chain from Example 13 for is presented on Figure 11. It has 11 states, has no cycles including loops (except of the loop for the final state ⌀); the transition matrix is triangular; -invariant probability measures on different depends totally on 3 parameters.
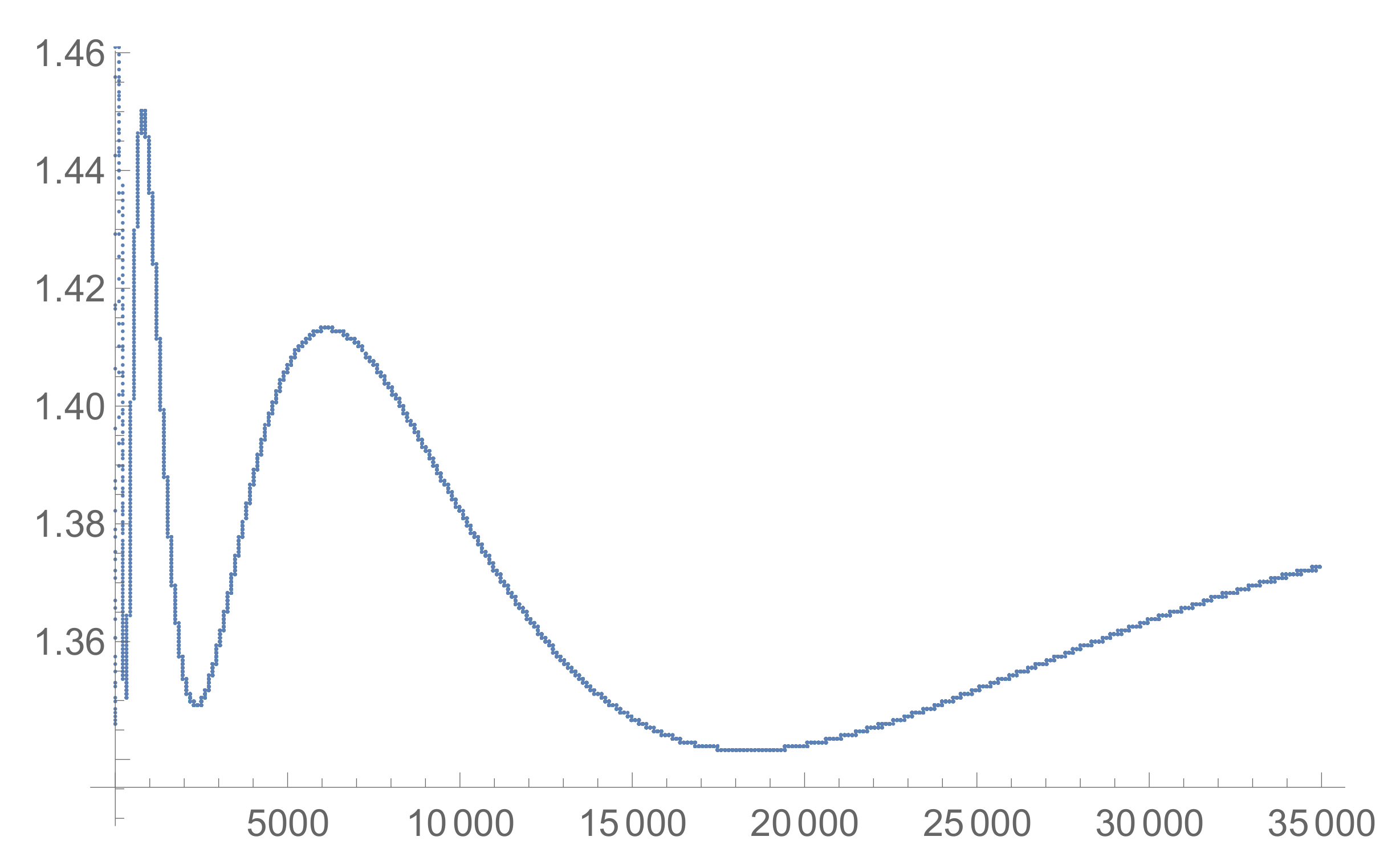
4.5. Some Asymptotics for
4.6. Practical Realization of Proof Trees Generation
- All transactions that the blockforger plans to include in the issued block must be processed within the time slot, i.e., the time allotted for the creation of this block, and the correspondent proof tree must be completely built;
- The number of these transactions should be the maximum possible, for which the probability of constructing the corresponding proof tree is close to 1.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| zk-SNARK | Zero-Knowledge Succinct Non-Interactive Argument of Knowledge |
| SC | Sidechain |
| MC | Mainchain |
| PoW | Proof of work |
| PoS | Proof of stake |
| UTXO | Unspent transaction output |
| iff | if and only if |
| poset | partially ordered set |
| ppm | parts per million |
References
- Rootstock: Smart Contracts on Bitcoin Network. 2018. Available online: https://www.rsk.co/ (accessed on 10 October 2021).
- Back, A.; Corallo, M.; Dashjr, L.; Friedenbach, M.; Maxwell, G.; Miller, A.; Poelstra, A.; Timón, J.; Wuille, P. Enabling Blockchain Innovations with Pegged Sidechains. 2014. Available online: https://blockstream.com/sidechains.pdf (accessed on 10 October 2021).
- Kiayias, A.; Zindros, D. Proof-of-Work Sidechains. 2018. Available online: https://ia.cr/2018/1048 (accessed on 11 October 2021).
- Garoffolo, A.; Kaidalov, D.; Oliynykov, R. Zendoo: A zk-SNARK Verifiable Cross-Chain Transfer Protocol Enabling Decoupled and Decentralized Sidechains. arXiv 2020, arXiv:2002.01847. [Google Scholar]
- Pass, R.; Shi, E. FruitChains: A Fair Blockchain. Cryptology ePrint Archive, Report 2016/916. 2016. Available online: https://ia.cr/2016/916 (accessed on 11 October 2021).
- VeriBlock Inc. Proof-of-Proof and VeriBlock Blockchain Protocol Consensus Algorithm and Economic Incentivization Specifications. 2019. Available online: http://bit.ly/vbk-wp-pop (accessed on 12 October 2021).
- Gaži, P.; Kiayias, A.; Russell, A. Tight consistency bounds for bitcoin. In Proceedings of the 2020 ACM SIGSAC Conference on Compute and Communications Security, Virtual Event, 9–13 November 2020; pp. 819–838. [Google Scholar]
- Karpinski, M.; Kovalchuk, L.; Kochan, R.; Oliynykov, R.; Rodinko, M.; Wieclaw, L. Blockchain Technologies: Probability of Double-Spend Attack on a Proof-of-Stake Consensus. Sensors 2021, 21, 6408. [Google Scholar] [CrossRef] [PubMed]
- Kovalchuk, L.; Kaidalov, D.; Nastenko, A.; Rodinko, M.; Oliynykov, R. Probability of double spend attack for network with non-zero synchronization time. In Proceedings of the 21th Central European Conference on Cryptology (CECC 2021), Budapest, Hungary, 23–25 June 2021; pp. 52–54. [Google Scholar]
- Kovalchuk, L.; Kaidalov, D.; Nastenko, A.; Rodinko, M.; Shevtsov, O.; Oliynykov, R. Decreasing security threshold against double spend attack in networks with slow synchronization. Comput. Commun. 2020, 154, 75–81. [Google Scholar] [CrossRef]
- Garoffolo, A.; Viglione, R. Sidechains: Decoupled Consensus Between Chains. arXiv 2018, arXiv:1812.05441. [Google Scholar]
- Kiayias, A.; Russell, A.; David, B.; Oliynykov, R. Ouroboros: A provably secure proof-of-stake blockchain protocol. In CRYPTO 2017, Part I; Lecture Notes in Computer Science; Springer: Heidelberg, Germany, 2017; Volume 10401, pp. 357–388. [Google Scholar]
- Garay, J.; Kiayias, A.; Leonardos, N. The bitcoin backbone protocol: Analysis and applications. In Advances in Cryptology-EUROCRYPT 2015, Part II; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9057, pp. 281–310. [Google Scholar]
- Ben-Sasson, E.; Chiesa, A.; Tromer, E.; Virza, M. Succinct Non-Interactive Zero Knowledge for a von Neumann Architecture. 2013. Available online: https://ia.cr/2013/879 (accessed on 10 October 2021).
- Bowe, S.; Gabizon, A. Making Groth’s zk-SNARK Simulation Extractable in the Random Oracle Model. 2018. Available online: https://ia.cr/2018/187 (accessed on 10 October 2021).
- Reitwiessner, C. zkSNARKs in a Nutshell. 2016. Available online: https://blog.ethereum.org/2016/12/05/zksnarks-in-a-nutshell/ (accessed on 17 October 2021).
- Goldwasser, S.; Micali, S.; Rackoff, C. The knowledge complexity of interactive proofs. SIAM J. Comput. 1989, 18, 186–208. [Google Scholar] [CrossRef]
- Bitansky, N.; Canetti, R.; Chiesa, A.; Tromer, E. From Extractable Collision Resistance to Succinct Non-Interactive Arguments of Knowledge, and Back Again. Cryptology ePrint Archive, Report 2011/443. 2011. Available online: https://ia.cr/2011/443 (accessed on 10 October 2021).
- Groth, J. Short pairing-based non-interactive zero-knowledge arguments. In ASIACRYPT 2010; Abe, M., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6477, pp. 321–340. [Google Scholar]
- Gennaro, R.; Gentry, C.; Parno, B.; Raykova, M. Quadratic Span Programs and Succinct NIZKs without PCPs. Cryptology ePrint Archive, Report 2012/215. 2012. Available online: https://ia.cr/2012/215 (accessed on 12 October 2021).
- Parno, B.; Gentry, C.; Howell, J.; Raykova, M. Pinocchio: Nearly Practical Verifiable Computation. Cryptology ePrint Archive, Report 2013/279. 2013. Available online: https://ia.cr/2013/279 (accessed on 12 October 2021).
- Groth, J. On the Size of Pairing-Based Non-interactive Arguments. In Advances in Cryptology–EUROCRYPT 2016; Fischlin, M., Coron, J.S., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9666, pp. 305–326. [Google Scholar]
- Hopwood, D.; Bowe, S.; Hornby, T.; Wilcox, N. Zcash Protocol Specification: Version 2021.2.16 [NU5 Proposal]. 2021. Available online: https://zips.z.cash/protocol/protocol.pdf (accessed on 12 October 2021).
- Mina. Started by O(1) Labs. 2021. Available online: https://minaprotocol.com (accessed on 17 October 2021).
- Grassi, L.; Khovratovich, D.; Rechberger, C.; Roy, A.; Schofnegger, M. Poseidon: New Hash Functions for Zero Knowledge Proof Systems. Cryptology ePrint Archive, Report 2019/458. 2019. Available online: https://ia.cr/2019/458 (accessed on 12 October 2021).
- Kovalchuk, L.; Oliynykov, R.; Rodinko, M. Security of the Poseidon Hash Function Against Non-Binary Differential and Linear Attacks. Cybern Syst. Anal. 2021, 57, 268–278. [Google Scholar] [CrossRef]
- Haböck, U.; Garoffolo, A.; Benedetto, D.D. Darlin: Recursive Proofs using Marlin. Cryptology ePrint Archive, Report 2021/930. 2021. Available online: https://ia.cr/2021/930 (accessed on 12 October 2021).
- Chiesa, A.; Hu, Y.; Maller, M.; Mishra, P.; Vesely, N.; Ward, N. Marlin: Preprocessing zkSNARKs with Universal and Updatable SRS. In Proceedings of the Advances in Cryptology-EUROCRYPT 2020-39th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Part I, Zagreb, Croatia, 10–14 May 2020; Canteaut, A., Ishai, Y., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2020; Volume 12105, pp. 738–768. [Google Scholar]
- Boneh, D.; Drake, J.; Fisch, B.; Gabizon, A. Halo Infinite: Recursive zk-SNARKs from Any Additive Polynomial Commitment Scheme. Cryptology ePrint Archive, Report 2020/1536. 2020. Available online: https://ia.cr/2020/1536 (accessed on 12 October 2021).
- Bespalov, Y.; Garoffolo, A.; Kovalchuk, L.; Nelasa, H.; Oliynykov, R. Models of distributed proof generation for zk-SNARK-based blockchains. In Theoretical and Applied Cryptography; Belarusian State University: Minsk, Belarus, 2020; pp. 112–120. [Google Scholar]
- Stanley, R.P. Enumerative Combinatorics, 2nd ed.; Cambridge Studies in Advanced Mathematics, 49; Cambridge University Press: Cambridge, UK, 2011; Volume 1. [Google Scholar]
- The OEIS Foundation Inc. The On-Line Encyclopedia of Integer Sequences. Available online: https://oeis.org (accessed on 17 October 2021).
- Kemeny, J.G.; Snell, J.L. Finite Markov Chains; Undergraduate Texts in Mathematics; Springer: Berlin/Heidelberg, Germany, 1976. [Google Scholar]
- Ben-Israel, A.; Greville, T.N. Generalized Inverses: Theory and Applications, 2nd ed.; CMS Books in Mathematics; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- D’Angeli, D.; Donno, A. Crested products of Markov chains. Ann. Appl. Probab. 2009, 19, 414–453. [Google Scholar] [CrossRef]
- Levin, D.A.; Peres, Y.; Wilmer, E.L. Markov Chains and Mixing Times, 2nd ed.; AMS: Providence, RI, USA, 2017. [Google Scholar]
- O’Neill, B. The Classical Occupancy Distribution: Computation and Approximation. Am. Stat. 2021, 75, 364–375. [Google Scholar] [CrossRef]
- Jiang, Z. An Upper Bound on Stirling Number of the Second Kind. 2015. Available online: https://blog.zilin.one/2015/02/25/an-upper-bound-on-stirling-number-of-the-second-kind/ (accessed on 12 October 2021).
- Corless, R.; Gonnet, G.; Hare, D.; Jeffrey, D.; Knuth, D. On the Lambert W function. Adv. Comput. Math. 1996, 5, 329–359. [Google Scholar] [CrossRef]
- Moser, L.; Wyman, M. Stirling numbers of the second kind. Duke Math. J. 1958, 25, 29–48. [Google Scholar] [CrossRef]
- Bender, E.A. Central and local limit theorems applied to asymptotic enumeration. J. Combin. Theory Ser. A 1973, 15, 91–111. [Google Scholar] [CrossRef] [Green Version]
- Temme, N.M. Asymptotic estimates of Stirling numbers. Stud. Appl. Math. 1993, 89, 233–243. [Google Scholar] [CrossRef] [Green Version]
- Roman, S. Lattices and Ordered Sets; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Bespalov, Y. Categories: Between Cubes and Globes. Sketch I. Ukr. J. Phys. 2019, 64, 1125–1128. [Google Scholar] [CrossRef]
- Sidenko, S. Kac’s Random Walk and Coupon Collector’s Process on Posets. Ph.D. Thesis, MIT, Cambridge, MA, USA, 2008. [Google Scholar]
- Bespalov, Y.; Garoffolo, A.; Kovalchuk, L.; Nelasa, H.; Oliynykov, R. Game-Theoretic View on Decentralized Proof Generation in zk-SNARK Based Sidechains. In Proceedings of the Cybersecurity Providing in Information and Telecommunication Systems (CPITS 2021), CEUR Workshop Proceedings 2021, Online, 7–8 January 2021; Volume 2923, pp. 47–59. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| m\n | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 9 tics |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 1;0.750000 2;0.250000 | 2;0.810764 3;0.187500 4;0.001736 | 3;0.346759 4;0.598575 5;0.054020 6;0.000643 7;0.000003 | 4 0.948934 | |||||
| 4 | 1;0.875000 2;0.125000 | 1;0.093750 2;0.856554 3;0.049624 | 2;0.038452 3;0.791998 4;0.167602 5;0.001946 6;0.000002 | 4 0.998582 | |||||
| 9 | 1;0.996094 2;0.003906 | 1;0.711365 2;0.288588 3;0.000047 | 1;0.010815 2;0.928031 3;0.061145 4;0.000009 | 2;0.006789 3;0.824258 4;0.168743 5;0.000210 | 0.892535 | ||||
| 10 | 1;0.998047 2;0.001953 | 1;0.780602 2;0.219387 3;0.000011 | 1;0.028163 2;0.944047 3;0.027789 4;0.000001 | 2;0.036465 3;0.901558 4;0.061960 5;0.000017 | 0.951990 | ||||
| 16 | 1;0.999969 2;0.000031 | 1;0.960000 2;0.040000 | 1;0.306798 2;0.693034 3;0.000168 | 1;0.000001 2;0.720767 3;0.279205 4;0.000027 | 3;0.323989 4;0.673970 5;0.002041 | ||||
| 32 | 1;1.000000 | 1;0.999598 2;0.000402 | 1;0.891278 2;0.108722 | 1;0.073443 2;0.926430 3;0.000127 | 2;0.490645 3;0.509350 4;0.000005 | 0.948374 | |||
| 33 | 1;1.000000 | 1;0.999699 2;0.000301 | 1;0.904520 2;0.095480 | 1;0.089692 2;0.910235 3;0.000073 | 2;0.561396 3;0.438602 4;0.000002 | 0.961682 | |||
| 64 | 1;1.000000 | 1;1.000000 | 1;0.998446 2;0.001554 | 1;0.765182 2;0.234818 | 1;0.004182 2;0.995734 3;0.000084 | 2;0.226404 3;0.773595 4;0.000001 | |||
| 94 | 1;1.000000 | 1;1.000000 | 1;0.999972 2;0.000028 | 1;0.963319 2;0.036681 | 1;0.163487 2;0.836513 | 2;0.969308 3;0.030692 | 0.944377 | ||
| 95 | 1;1.000000 | 1;1.000000 | 1;0.999975 2;0.000025 | 1;0.965585 2;0.034415 | 1;0.173944 2;0.826056 | 2;0.973714 3;0.026286 | 0.950428 | ||
| 128 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;0.995870 2;0.004130 | 1;0.562887 2;0.437113 | 1;0.000013 2;0.999930 3;0.000057 | 2;0.048095 3;0.951905 | ||
| 256 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;0.999999 2;0.000001 | 1;0.990585 2;0.009415 | 1;0.304309 2;0.695691 | 2;0.999956 3;0.000044 | ||
| 451 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;0.999981 2;0.000019 | 1;0.948528 2;0.051472 | 1;0.018313 2;0.981687 | 0.949452 | |
| 452 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;0.999981 2;0.000019 | 1;0.949314 2;0.050686 | 1;0.018930 2;0.981070 | 0.950256 | |
| 512 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;0.999997 2;0.000003 | 1;0.980019 2;0.019981 | 1;0.088899 2;0.911101 | ||
| 1024 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;0.999994 2;0.000006 | 1;0.959185 2;0.040815 | ||
| 2175 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;0.999995 2;0.000005 | 1;0.949825 2;0.050175 | 0.949820 |
| 2176 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;1.000000 | 1;0.999995 2;0.000005 | 1;0.950016 2;0.049984 | 0.950011 |
| m | [1..3] | [4..9] | [10..32] | [33..94] | [95..451] | [452..2175] | ⩾2176 |
|---|---|---|---|---|---|---|---|
| 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bespalov, Y.; Garoffolo, A.; Kovalchuk, L.; Nelasa, H.; Oliynykov, R. Probability Models of Distributed Proof Generation for zk-SNARK-Based Blockchains. Mathematics 2021, 9, 3016. https://doi.org/10.3390/math9233016
Bespalov Y, Garoffolo A, Kovalchuk L, Nelasa H, Oliynykov R. Probability Models of Distributed Proof Generation for zk-SNARK-Based Blockchains. Mathematics. 2021; 9(23):3016. https://doi.org/10.3390/math9233016
Chicago/Turabian StyleBespalov, Yuri, Alberto Garoffolo, Lyudmila Kovalchuk, Hanna Nelasa, and Roman Oliynykov. 2021. "Probability Models of Distributed Proof Generation for zk-SNARK-Based Blockchains" Mathematics 9, no. 23: 3016. https://doi.org/10.3390/math9233016
APA StyleBespalov, Y., Garoffolo, A., Kovalchuk, L., Nelasa, H., & Oliynykov, R. (2021). Probability Models of Distributed Proof Generation for zk-SNARK-Based Blockchains. Mathematics, 9(23), 3016. https://doi.org/10.3390/math9233016