Abstract
The primary purpose of video surveillance is to monitor public indoor areas or the boundaries of secure facilities to safeguard them against theft, unauthorized access, fire, and various other potential threats. Security cameras, equipped with integrated video surveillance systems, are strategically placed throughout critical locations on the premises, allowing security personnel to observe all areas for specific behaviors that may signal an emergency or a situation requiring intervention. A significant challenge arises from the fact that individuals cannot maintain focus on multiple screens simultaneously, which can result in the oversight of crucial incidents. In this regard, artificial intelligence (AI) video analytics has become increasingly prominent, driven by numerous practical applications that include object identification, detection of unusual behavior patterns, facial recognition, and traffic management. Recent advancements in this technology have led to enhanced functionality, remarkable accuracy, and reduced costs for consumers. There is a noticeable trend towards upgrading security frameworks by incorporating AI into pre-existing video surveillance systems, thus leading to modern video surveillance that leverages video analytics, enabling the detection and reporting of anomalies within mere seconds, thereby transforming it into a proactive security solution. In this context, the AiWatch system introduces digital twin (DT) technology in a modern video surveillance architecture to facilitate advanced analytics through the aggregation of data from various sources. By exploiting AI and DT to analyze the different sources, it is possible to derive deeper insights applicable at higher decision levels. This approach allows for the evaluation of the effects and outcomes of actions by examining different scenarios, hence yielding more robust decisions.
1. Introduction
Security is a critical component of contemporary life, where public and private spaces are increasingly monitored through the pervasive deployment of cameras and video surveillance systems. Despite this extensive monitoring, the data generated by these surveillance devices require human analysis to identify potential anomalies, thereby limiting the overall security that can be assured.
Recent advances in machine learning and the emergence of sophisticated artificial intelligence systems are significantly transforming the methodology employed in video surveillance, aiming to support or, where feasible, replace human oversight. A key characteristic of an effective video surveillance system is its responsiveness, which can only be realized if the system can anticipate the progression of activities within the monitored environment. In this context, one of the most promising innovations is the concept of digital twins, particularly the variant known as human digital twins. The ability of digital twins to continuously adapt to the state of a physical entity, simulate forthcoming events, and actively influence feedback and decision-making processes extends far beyond traditional digital models, which merely serve as representations. Furthermore, the real-time monitoring and simulation capabilities of digital twins are increasingly being integrated into surveillance applications.
Although the imperative of security is evident in various aspects of daily life, it must be balanced against the fundamental right to privacy, which individuals are unlikely to relinquish and is increasingly safeguarded by contemporary legislation. The protection of privacy has significantly influenced the design of video surveillance systems, which must adhere to stringent security standards in the collection and storage of data.
Consequently, modern video surveillance systems must incorporate technologies that ensure these standards, which the CIA Triad fundamentally encapsulates: confidentiality, integrity, and availability. Among the technologies used to achieve these objectives, blockchain technology has emerged as a prominent solution, demonstrating its ability to maintain high-security standards in systems tasked with managing substantial volumes of data [1].
The integration of digital twins and blockchain technology yields a highly effective and adaptable surveillance solution. Specifically, the data captured by surveillance cameras can be exploited to create and continuously update in real time a digital twin of people and physical environments. This integration facilitates more precise and comprehensive monitoring and analysis of the surrounding environment than simply observing the camera streams.
In this context, AiWatch has been designed and implemented, a system that allows for the identification of anomalous accesses and positioning of people identified within the monitored environment. To the best of the authors’ knowledge, this is the first attempt to introduce the concept of the human digital twin in the context of video surveillance systems. Its operation is articulated through a chain of modules, each responsible for a specific task of the final system. The environmental data extracted from the video stream are used to build digital models of people and the monitored environment. Subsequently, the data are analyzed through the use of artificial intelligence techniques to identify anomalies so that the latter can be recorded and notified to the competent personnel. Finally, the data are presented in a virtual environment that creates the 3D environment of the monitored space, integrated with the detected individuals.
The paper is organized as follows: Section 2 analyzes the relevant literature in the context of AI-based video surveillance systems; Section 3 describes AiWatch and its modules; Section 4 presents example views of the proposed system and its key characteristics; Section 5 concludes the work, highlighting the future developments of AiWatch.
2. Related Works
Ensuring public safety in public indoor environments is a complex challenge that encompasses many different technologies. This section presents an overview of the current approaches and technologies at the state of the art in video surveillance. Many works have described the vast availability of video surveillance systems in different scenarios. The authors in [2] provide an overview of recent artificial intelligence techniques employed in video surveillance. The work analyzes video surveillance systems in different contexts like smart home, maritime, and public transportation surveillance, focusing on deep neural networks for anomaly and motion detection. Smart home surveillance is analyzed in [3], drawing attention to how a system’s intelligence goes beyond traditional surveillance, promptly alerting customers through smart devices in case of unusual or potentially threatening activity. Surveillance Video Anomaly Detection (SVAD) systems are discussed in [4], a comprehensive survey of state-of-the-art AI approaches for SVAD that shows different applications as well as challenges in the use of AI.
An important characteristic of video surveillance is the ability to analyze human actions and behaviors to detect dangerous or anomalous situations [5]. In this context, the concepts of behavioral digital twin and human digital twin [6] have been developed. The former is described in [7], where the complexity of modeling human behavior and the challenges that arise when developing a behavioral DT are highlighted. Integrating data related to human actions, decision-making, and system responses under varying conditions makes the development of a behavior DT a complex task. An overview of the latter can be found in [8], where the human digital twin is described as an extension of the traditional understanding of digital twins by representing humans as the underlying physical entity. Human digital twins are referred to as a fast-emerging technology with significant potential in different application fields. For instance, in [9], the authors propose the use of DT and AI for real-time healthcare monitoring. In [10], the virtual twin integrates human modeling and AI engines to enable model–data-hybrid-enabled simulation. Human digital twin can potentially enable intelligent services through real-time analysis, timely feedback, and bidirectional interactions.
In the context of safety and security, in [11], a system that combines digital twin technology and 3D visualization is proposed for detecting safety and security threats in buildings. Concerning surveillance, ref. [12] proposes the use of digital twins for air surveillance infrastructure. The digital twin technology was also applied to intelligent security systems in large stadiums in [13], where the modeling method of the physical model is presented for the security equipment and building entities.
For a systematic review of the literature on combining AI and machine learning with DT technology and its applications, the reader may refer to [14] and the references therein.
To the best of our knowledge, AiWatch is the first video surveillance system to integrate the human digital twin and artificial intelligence technologies in a privacy-preserving distributed environment exploiting blockchain technology.
3. Proposed System
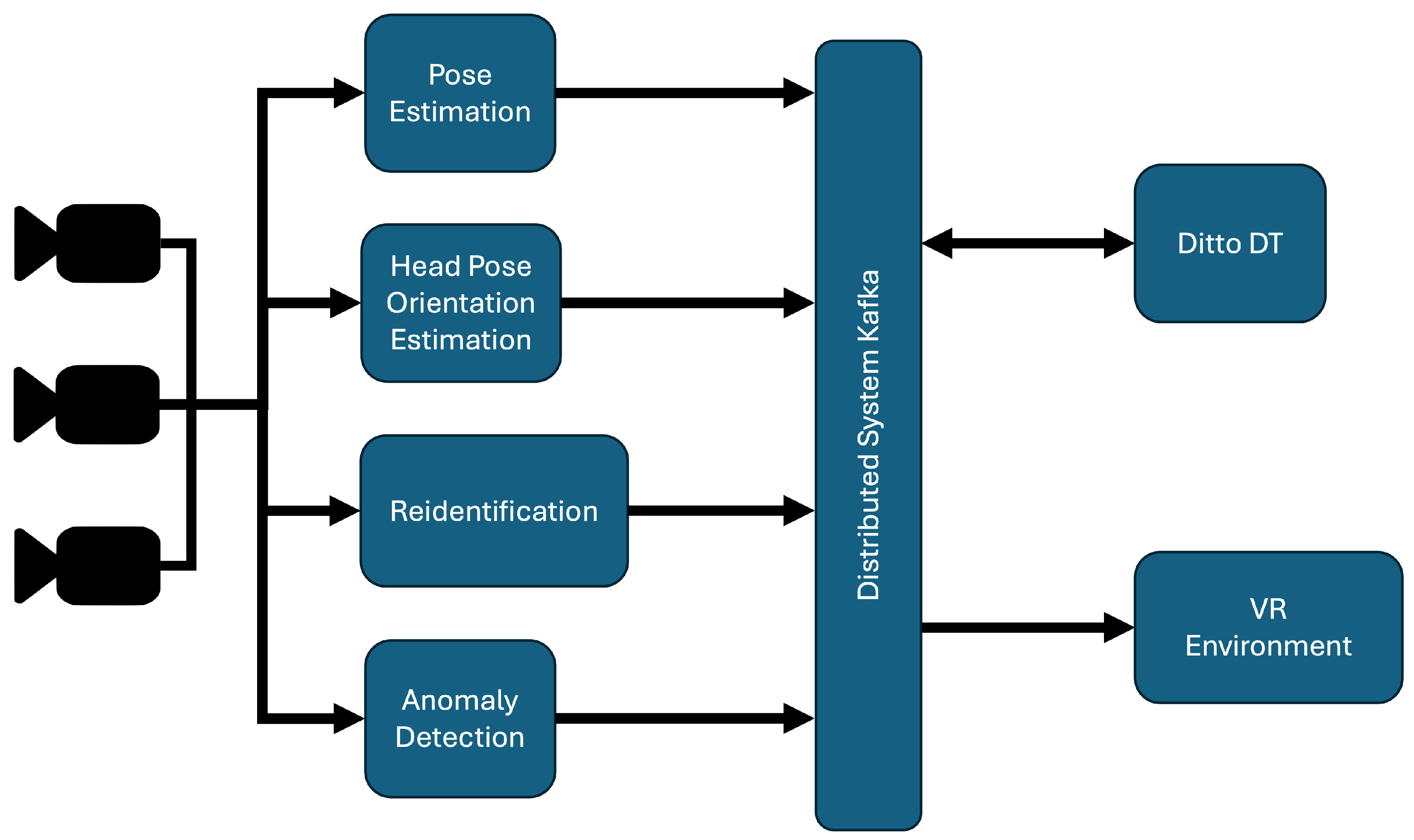
Before diving into the description of the single modules of AiWatch, we give a brief overview of the communication infrastructure that sits at the heart of the system. To facilitate efficient and reliable communication among modules within the system, Apache Kafka is employed as the primary communication channel [1]. The system’s data flow is managed through Kafka topic-based infrastructure, which enables the security system to concentrate on validation tasks at the component level. To ensure consistent data exchange across the system components, JSON format is adopted as the communication standard for each data transmission within Kafka topics. By continuously exchanging and processing data streams from different modules, AiWatch updates the digital twin models with real-time actionable insights. This intricate and dynamic flow of data presents several key challenges, such as ensuring the integrity and authenticity of data being transmitted, maintaining system reliability during periods of high transaction volumes, and offering scalability to handle rising data amounts or system growth. The proposed blockchain-based solution addresses these issues by providing a decentralized and tamper-resistant layer for data validation while also granting local autonomy to the involved components, thereby increasing both the security and transparency of the system. Within the AiWatch system, depicted in Figure 1, each component is assigned a specific identifier that is used consistently throughout the data flow. Specifically, the camera modules are responsible for the initial processing of image frames, while the final destination server, tasked with managing digital twin information, is designated as Ditto, as a reference to the Eclipse Ditto 1.1.0 software, which implements the module’s functionality.
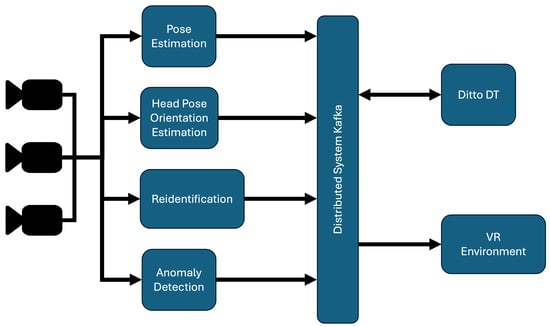
Figure 1.
AiWatch architecture.
Each module returns a complex structure originated from the necessity of extracting key information from the captured frames corresponding to the entities detected in the scene. At this stage, a critical function is the transformation of extracted data into structured JSON files, followed by their transmission to a designated Apache Kafka topic. The hash validation architecture integrates with this process before the data are transmitted through the Kafka topic. Afterward, the connection to the blockchain is initialized, and the data are stored within a smart contract.
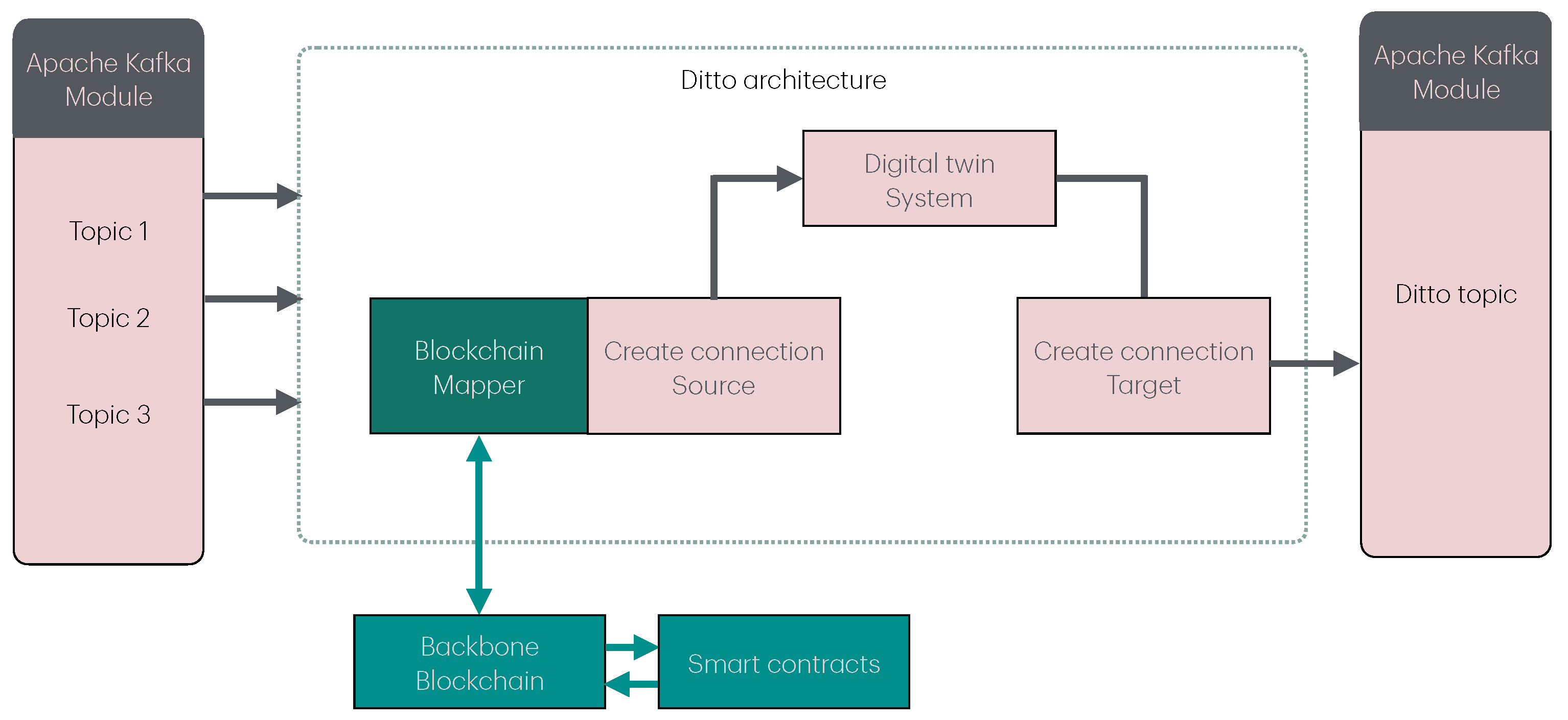
The proposed integration of the Ditto module involves the extension of its connectivity capabilities to enable more advanced functionalities required for interaction with blockchain technologies. The integration of the module required the design and implementation of a new mapping component that retains the original core functionality while extending its capabilities. The redesigned component is built upon the original mapper and is sketched in Figure 2.
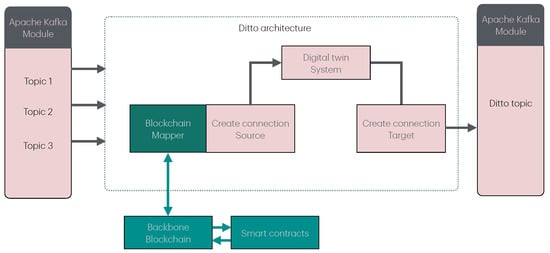
Figure 2.
Schematic path followed by data in the AiWatch system, with particular emphasis on the Ditto sub-components and the integrated mapper. “Topic 1”, “Topic 2”, and “Topic 3” in the Apache Kafka module refer to the Kafka topics in which each module writes the JSON file.
To emphasize the interconnected and clear integration of blockchain communication, the proposed implementation ensures that all interactions related to blockchain are directly incorporated within the Ditto module. By not depending on external or third-party software, the design ensures a smooth integration of blockchain functionalities into the fundamental operational processes. This close relationship improves the clarity of data movement and minimizes possible points of failure, facilitating secure and reliable communication. The strategy leverages the inherent advantages of Ditto’s modular design while maintaining the independence and integrity of the blockchain connection mechanism. The validation mechanism relies on a private blockchain that records the entities interacting with the digital twin, enhancing the overall security of the system. Regarding the data integrity, a validation component is integrated to ensure that received data correspond to the data sent by the originating entity. The system incorporates a data validation mechanism within the smart-contract subsystem, complemented by a middleware component integrated into the communication infrastructure. Off-chain transaction signing is employed, thereby maintaining the locality of the operation and avoiding unnecessary data transfers. In particular, the hash of the data is computed and transmitted alongside the signed transaction so that the digital twin module only accepts pre-validated information on the blockchain through the middleware component. Additionally, data transmission from the digital twin occurs only after undergoing an additional layer of validation. This approach ensures that the logical layer retains only the “fingerprint” of the shared information, enriching the overall data locality while minimizing the stored volume of data on the blockchain. A detailed description of the digital twins’ integration with the blockchain can be found in [1].
3.1. Pose Estimation
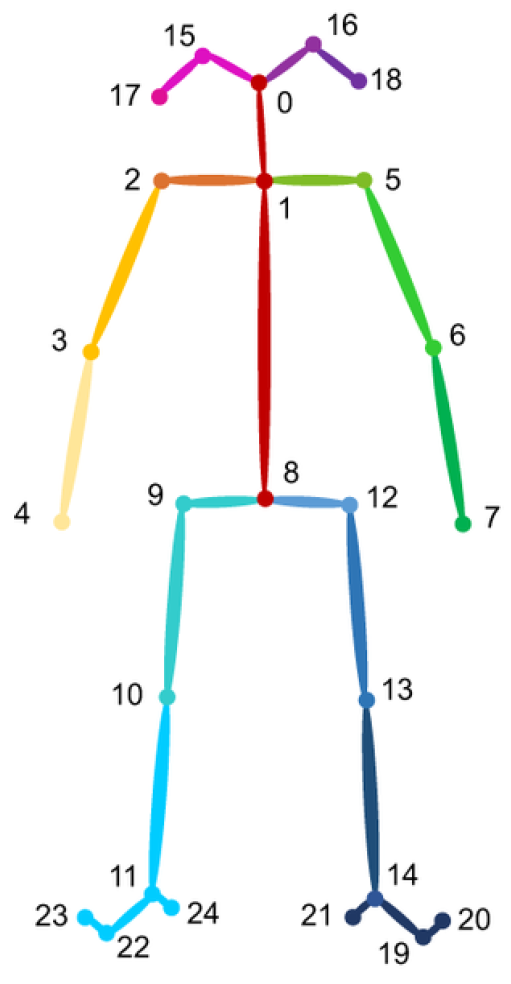
Estimating human 2D poses involves identifying the anatomical key points or “parts” of the human body. Determining the poses of multiple individuals in images involves significant challenges. First, each image may feature an undetermined number of people who can be positioned at various locations or scales. In addition, interactions among individuals create intricate spatial interferences due to contact, occlusion, or movements of limbs, complicating the association of body parts. Finally, the computational complexity tends to increase with the number of individuals in the image, making it difficult to achieve real-time performance. In the realm of multi-person pose estimation, the majority of methods have implemented a top–down approach that initially identifies individuals and then estimates the pose for each person separately within the detected areas. These methods are limited in their ability to capture spatial relationships between different individuals, which requires global inference. OpenPose [15] introduced the first bottom–up framework that uses Part Affinity Fields (PAFs), which are a series of 2D vector fields that represent the location and orientation of limbs throughout an image. By concurrently inferring these bottom–up detections and associations, it effectively incorporates a sufficient global context for a greedy parsing technique, achieving high-quality outcomes while significantly reducing computational requirements. OpenPose is made up of three distinct components: detection of the body and feet, detection of hands, and detection of faces. By using the results from the body detector, it is possible to roughly estimate facial bounding box proposals based on the locations of certain body parts, especially the ears, eyes, nose, and neck. Similarly, hand-bounding box proposals are derived from the key points of the arms. The output of the algorithm is a 25-keypoint skeleton for each person detected in the scene, as shown in Figure 3.
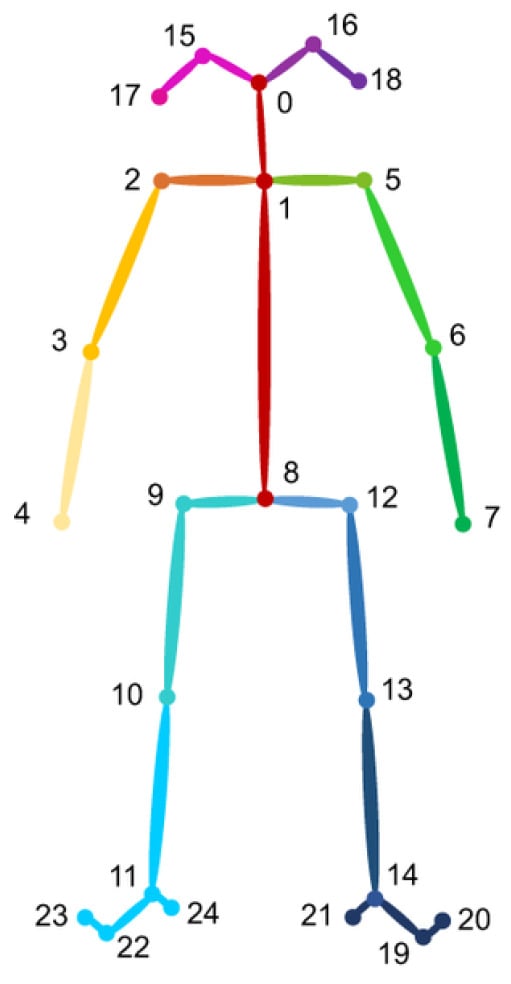
Figure 3.
The 25-keypoint skeleton representation.
To extract the 3D coordinates of each key point, AiWatch employs RGBD cameras, a type of depth camera that provides both depth (D) and color (RGB) data as the output in real time. Once retrieved, the skeleton is superimposed to the depth image so that each keypoint pixel can be assigned its depth. This is a fundamental step in storing the 3D pose of the detected people, which will then be reconstructed in the virtual environment. An example of the procedure is depicted in Figure 4.
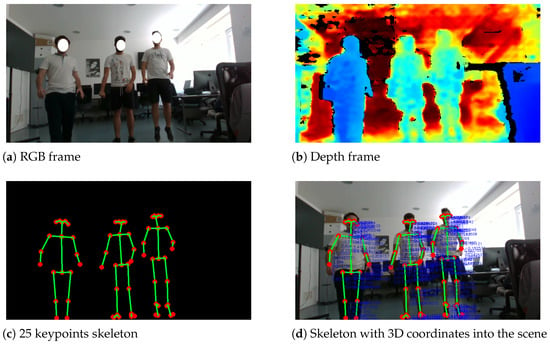
Figure 4.
Example of 3D pose extraction.
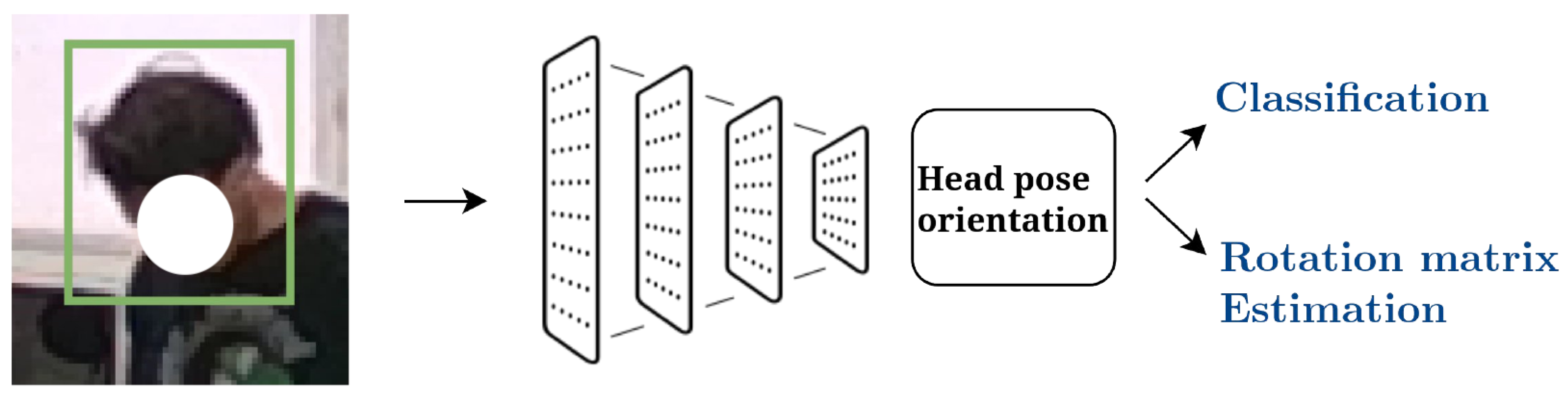
3.2. Head Pose Orientation Estimation
The Head Pose Orientation Estimation (HPOE) system is the AiWatch block that is in charge of estimating the head pose of each human detected by AiWatch. The structure of the HPOE component is described in Figure 5.
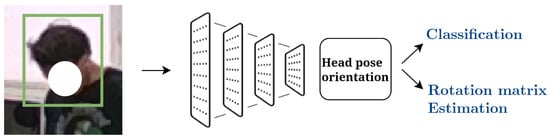
Figure 5.
The structure of the HPOE system.
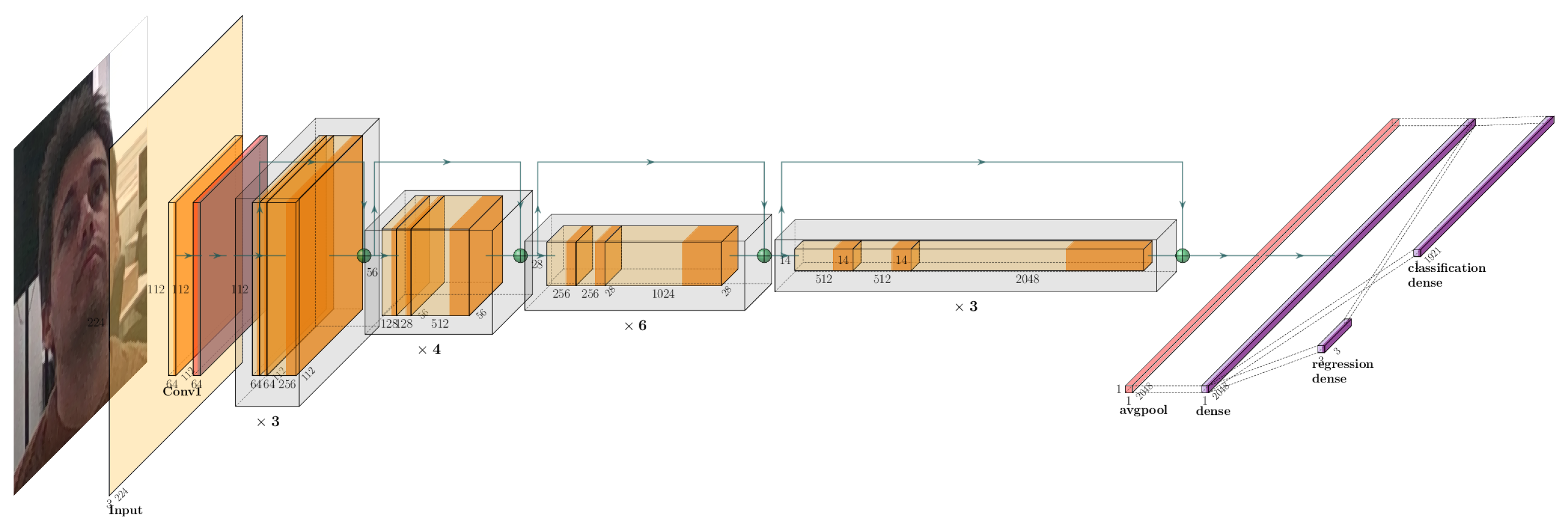
The first module extracts face crops using a Multi-Task Cascaded Convolutional Neural Network (MCTNN) [16]. An MCTNN consists of a cascade of three convolutional neural networks (CNNs). First, (P-net) individuates a set of bounding-box candidates; the second refines the candidate set, eliminating false positives. Furthermore, the final layer (O-net) produces the bounding boxes for the ultimate candidates with a notably low false candidate rate of about ∼1%. The second module of the HPOE system is composed of a Resnet50 [17] backbone (see Figure 6).
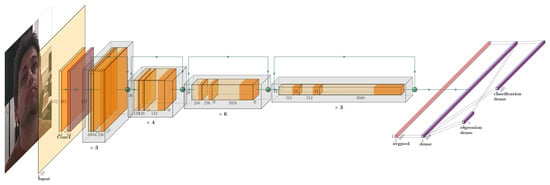
Figure 6.
The second module of HPOE. Gray boxes represent convolutional units, with 2D convolution operations and batch normalization operations in yellow and orange, respectively. Moreover, the green arrows and the purple layer represent residual connections and fully connected layers, respectively.
Then, the feature maps are linearized using an average pooling (pink layer in Figure 6) and feed consecutive layers (purple layers in Figure 6). In particular, the first dense layer improves the extracted feature representation to catch nonlinear patterns using a ReLu activation function. The features from this layer are fed into dense layers for both classification and regression tasks. In the classification task of the neural network, the goal is to assign an input (such as a facial crop) to one of the head poses that a person may adopt, with the number of these poses being empirically determined to be 1921 [18]. The regression task of the neural network resides in the computation of the rotation matrix values. With respect to HPOE’s state of the art, the main peculiarity of the proposed system resides in having both a regression and classification task, whereas in the literature, there are studies that focus exclusively either on a regression task (estimation of Euler angles or rotation matrix) or on a classification task (i.e., identification of a given human pose).
The loss function of the neural network is defined as follows:
where is the minimum square error, and are the k-th predicted and target rotation matrix columns, N is the number of classes, , are the true class i and the predicted class i, is the identity matrix, T denotes the transpose operator, and is the Frobenius norm; whereas and are trade-off parameters that can be set up using model selection techniques [19].
The aforementioned loss function is derived in the following way:
- The cross-entropy term constrains the model towards one of the possible orientations that a human can assume.
- The MSE term provides a fine-grained regression of the rotation matrix elements, ensuring continuous orientation predictions.
- The orthogonality constraint enforces the mathematical requirement of the rotation matrix orthogonality.
3.3. Human Identification and Reidentification
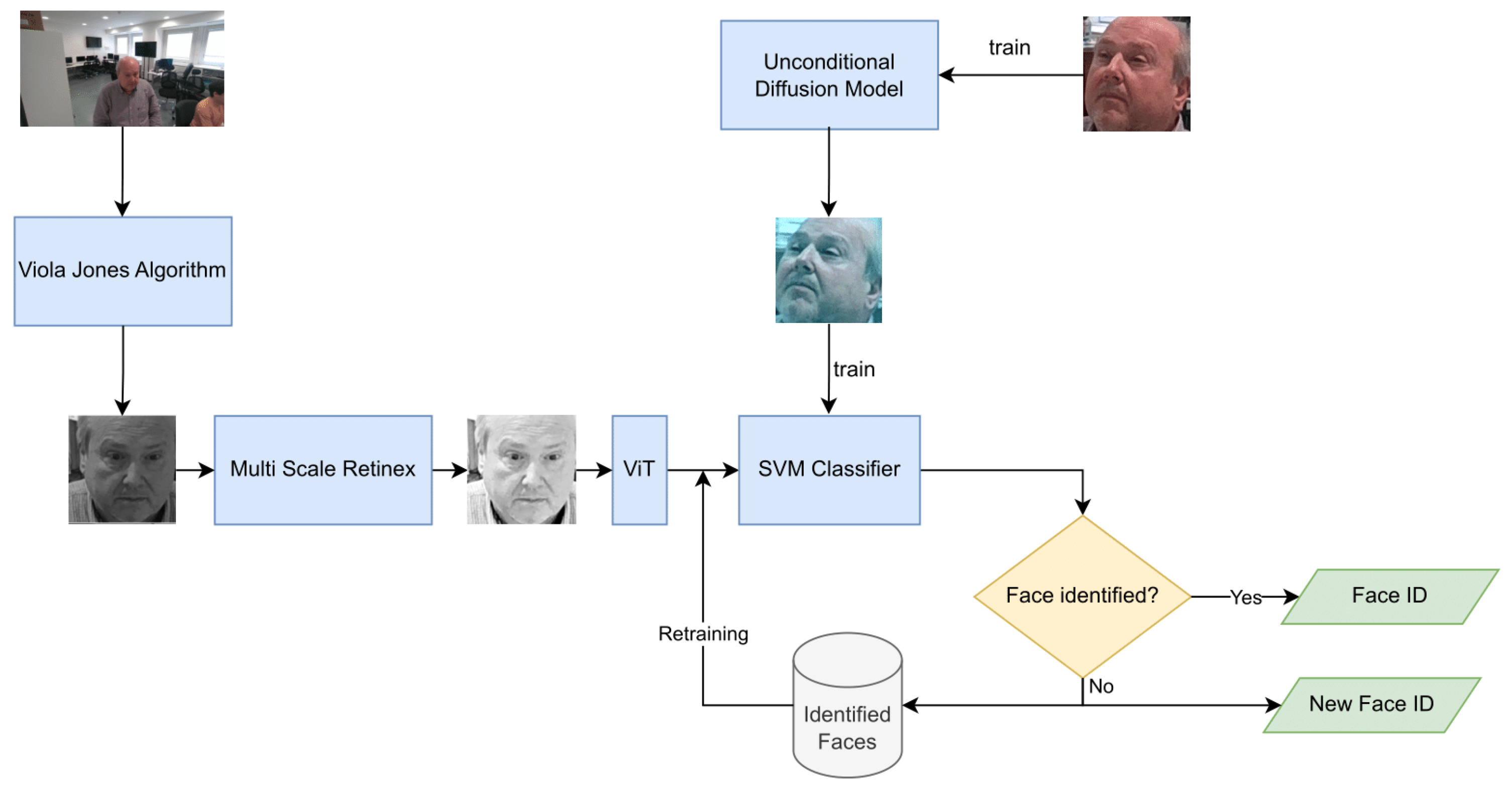
The Human Identification and Reidentification (HPR) system is the AiWatch block that is in charge of the identification and reidentification of each human detected by AiWatch. The HPR system receives as input the face of a human person, detected previously by the HPOE system, and it yields the identifier if the person was previously identified and recorded in AIWatch; otherwise, it associates a new identifier to the person. The HPR system, described in Figure 7, has four modules. The first stage receives by OpenPose the image containing the detected person, and it yields, as output, the face of the person, found by the Viola–Jones algorithm [20]. The second component is devoted to the input preprocessing and performs the light normalization of the input, i.e., the face of the human person, using the Multi Scale Retinex algorithm [21]. The third module performs the feature extraction with a pre-trained Visual Transformer (VIT) [22]. The last component is a Support Vector Machine (SVM) [23] classifier, trained on a dataset of identified faces, that performs an open-set identification task [24]. If the face of the human person is identified, the classifier returns its associated identity number (ID); otherwise, it creates a new identity number, adds the face to the Identified Faces dataset, and starts the retraining of the SVM classifier on the new Identified Faces dataset, augmented by a Diffusion Model [25].
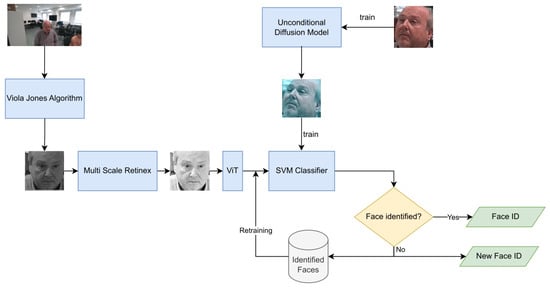
Figure 7.
The structure of the Human Identification and Reidentification system.
3.4. Anomaly Detection of Human Behavior
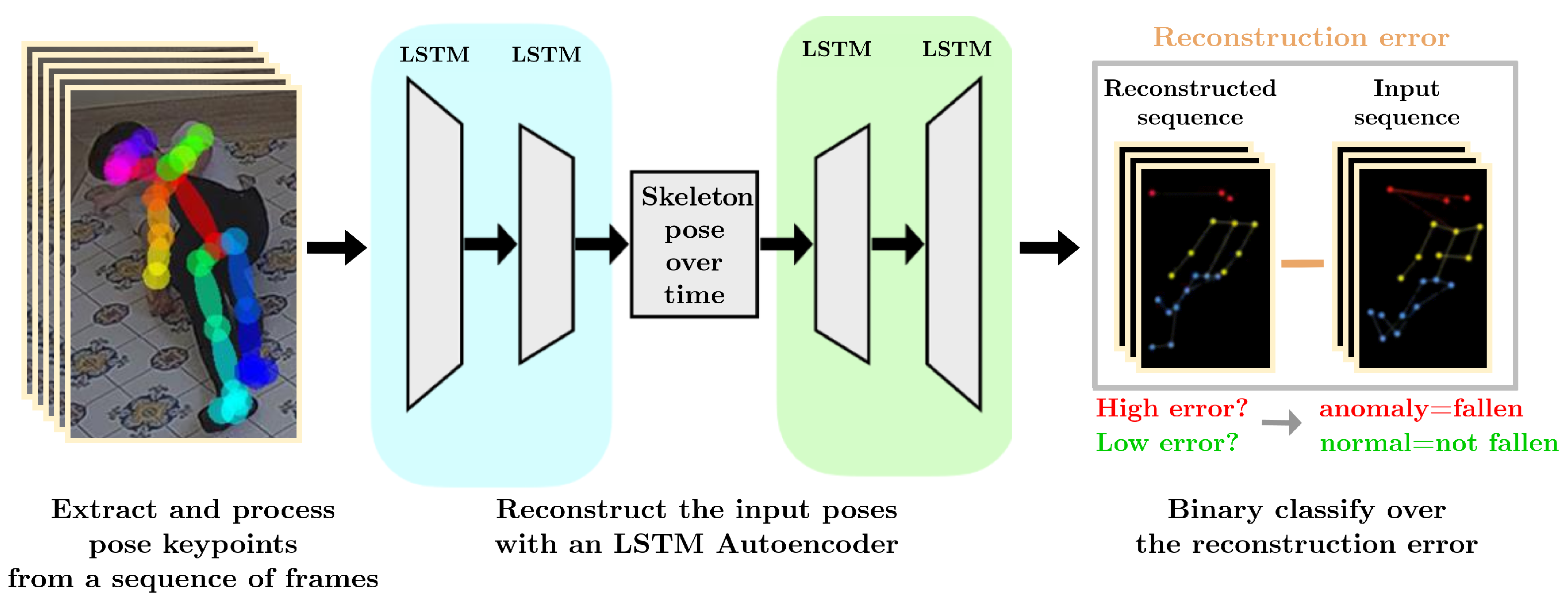
The Anomaly Detection of Human Behavior (ADH) system consists of a system devoted to detecting human falls in the video surveillance system. The ADH has two stages (see Figure 8).
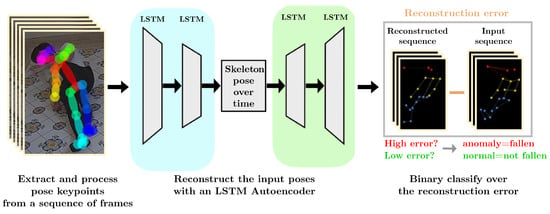
Figure 8.
The structure of the ADH system.
The first stage receives, as input, a sequence of 75 frames from the camera. This sequence of frames, using the OpenPose framework, is transformed into a sequence of human skeletons (see Figure 8), where each skeleton consists of the nineteen pairs of keypoint coordinates, since it is empirically proven that the remaining six keypoints (that is 15, 16, 20, 21, 23, 24 in Figure 3) are not relevant for the detection of anomaly pose. The output of this stage is a matrix , where each row contains the coordinates of the nineteen keypoints in the ith frame. The second stage consists of a Long Short-Term Memory (LSTM) [26] Autoencoder, whose input is the matrix , constructed in the previous stage. The LSTM autoencoder has an encoder–bottleneck–decoder structure with the encoding/decoding layers and the bottleneck having 128 LSTM and 64 LSTM units, respectively. The activation function among layers is the ReLU; the loss function is the mean squared error.
The training set consisted of 1010 3-second-long skeletal sequences, corresponding to roughly 1 h of human activities. The dataset aimed to cover the possible orientations, positions, and postures of a person in a normal indoor context, adding cases of occlusions. Moreover, data augmentation was applied in the form of y-axis mirroring. The training set was unlabeled since this information is unnecessary for the LSTM Autoencoder optimization.
The LSTM Autoencoder, during its training, learned the poses that humans assume in regular (that is, not anomalous) behaviors over time. The trained LSTM Autoencoder is capable of reconstructing every regular human pose, except the anomalous ones that are not present in the training set. In testing, the human pose sequences are reconstructed using the LSTM Autoencoder. Hence, the reconstruction error between the input and the reconstructed one, measured in terms of the mean square error, can be used to construct a binary classifier to detect anomalous poses.
4. Discussion
AiWatch was implemented and tested in the following computational environment:
- Operating System: Ubuntu 22.04 LTS;
- CPU: Intel i9 13900KF;
- GPU: NVIDIA RTX 4090, 24GB;
- RAM: 64GB.
This allows for a frame rate of 15/20 fps, depending on the number of persons detected. The digital twin of each person detected in the monitored environment is updated with information obtained from the pose estimation, head pose estimation, identification, and anomaly detection modules. Specifically, in the case of a first detection, a new digital twin is created, while in the case of reidentification, the digital twin associated with the identified person is updated. It is important to note that the images of the detected people are not saved into the system, while the aforementioned information about the detected people is encoded in the status of the digital twins, thus preserving their privacy.
To provide a visible representation of the monitored environment and the digital twins present in the scene, AiWatch is equipped with a virtual reality module that replicates in real time all the actions happening in the monitored environment. Following an update or the creation of a new digital twin, the corresponding avatar is updated or placed in the scene, as shown in Figure 9 and Figure 10.

Figure 9.
Detected person with skeleton.

Figure 10.
Avatar of the detected person in the virtual environment.
In Figure 11 and Figure 12, the update of the avatar related to the detection of a fallen person is shown.

Figure 11.
Detected fall event in the real environment.

Figure 12.
Avatar of the detected fallen person in the virtual environment.
The importance of the proposed system, by leveraging the past actions of each detected person encoded in the digital twin representation, resides in being a framework on which it will be possible to build new complex reasoning modules. Understanding and forecasting human behavior within decision-making contexts is essential for the creation of artificial intelligence systems that can proficiently collaborate with and assist individuals, thereby facilitating informed decision-making and mitigating cognitive biases and limitations. Recently, there has been an increasing interest in employing artificial intelligence to model human behavior, particularly within domains characterized by human interaction with this technology. While the majority of existing research works primarily model human behavior through aggregate behavioral cloning, AiWatch proposes an innovative methodology based on the modeling of behaviors at the individual level. This approach would exploit the idea behind recent approaches to behavioral stylometry [27], which involves the identification of individuals based on their actions, despite the limitations of these approaches in terms of scalability and generative capabilities, as they are unable to generate new actions. AiWatch has the potential to mitigate these constraints by conceptualizing behavioral stylometry as a learning framework, wherein each individual is treated as a distinct task, thereby facilitating the acquisition of tailored representations for each individual. From a generative standpoint, this approach would enable the synthesis of actions that emulate the distinctive styles of each individual, while also permitting the interpretation and manipulation of the associated representations to generate additional actions. By harnessing the cognitive reasoning and generative capacities to forecast human behavior, it would create an equilibrium between exploitative and exploratory actions, both of which are critical for simulating authentic decision-making processes in real-world scenarios.
5. Conclusions
Herein, Aiwatch, a distributed video surveillance system, is proposed. Aiwatch combines artificial intelligence (AI) and digital twin technologies to take full control of video surveillance areas. The control is obtained by applying AI-based video analytics techniques whose usage is facilitated owing to the introduction of digital twin technologies that allow for the aggregation of data from diverse sources. A prototypical version of Aiwatch is currently in use at CVPR Lab “Alfredo Petrosino” of the University Parthenope of Naples, showing promising and encouraging performance.
In future works, two research lines will be investigated. The former will consist of empowering the anomaly detection module with the integration of audio analysis techniques (e.g., beamforming [28]) able to identify and locate anomalies (e.g., falling out of chairs). The latter will be related to the introduction of a further module in AiWatch, devoted to the human behavior analysis to predict in advance the occurrence of future, potentially dangerous human actions.
Author Contributions
Conceptualization, A.F., A.M., F.C., A.C. and A.S.; methodology, A.F., A.M., F.C., A.C. and A.S.; software, M.L., A.P., F.L. and A.J.S.; validation, M.L., A.P., F.L. and A.J.S.; formal analysis, A.F., A.M., F.C., A.C. and A.S.; investigation, A.F., A.M., F.C., A.C. and A.S.; resources, A.F., A.M., F.C., A.C. and A.S.; data curation, M.L., A.P. and A.J.S.; writing—original draft preparation, A.F., F.C., M.L. and A.S.; writing—review and editing, A.F., F.C. and A.S.; visualization, M.L., A.P., F.L. and A.J.S.; supervision, A.F., F.C. and A.S.; project administration, A.F., F.C. and A.S.; funding acquisition, A.F. and F.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Informed Consent Statement
Informed consent was obtained from all subjects (they are all authors of the manuscript) involved in the study.
Data Availability Statement
The code is available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ferone, A.; Verrilli, S. Exploiting Blockchain Technology for Enhancing Digital Twins’ Security and Transparency. Future Internet 2025, 17, 31. [Google Scholar] [CrossRef]
- Maheswari, U.; Karishma; Vigneswaran, T. Artificial Intelligence in Video Surveillance. In Advances in Computational Intelligence and Robotics; IGI Global: Hershey, PA, USA, 2023; pp. 1–17. [Google Scholar]
- E, S.; A, V.; A, S.; V N, S.; M, V. A Survey on AI Based Smart CCTV Surveillance System. In Proceedings of the 2024 10th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 14–15 March 2024; Volume 1, pp. 1–5. [Google Scholar] [CrossRef]
- Şengönül, E.; Samet, R.; Abu Al-Haija, Q.; Alqahtani, A.; Alturki, B.; Alsulami, A.A. An Analysis of Artificial Intelligence Techniques in Surveillance Video Anomaly Detection: A Comprehensive Survey. Appl. Sci. 2023, 13, 4956. [Google Scholar] [CrossRef]
- Joudaki, M.; Imani, M.; Arabnia, H.R. A New Efficient Hybrid Technique for Human Action Recognition Using 2D Conv-RBM and LSTM with Optimized Frame Selection. Technologies 2025, 13, 53. [Google Scholar] [CrossRef]
- Miller, M.E.; Spatz, E. A unified view of a human digital twin. Hum.-Intell. Syst. Integr. 2022, 4, 23–33. [Google Scholar] [CrossRef]
- Fang, W.; Love, P.E.; Luo, H.; Li, J.; Lu, Y. Moving beyond 3D digital representation to behavioral digital twins in building, infrastructure, and urban assets. Adv. Eng. Inform. 2025, 64, 103130. [Google Scholar] [CrossRef]
- Lauer-Schmaltz, M.W.; Cash, P.; Hansen, J.P.; Maier, A. Designing Human Digital Twins for Behaviour-Changing Therapy and Rehabilitation: A Systematic Review. Proc. Des. Soc. 2022, 2, 1303–1312. [Google Scholar] [CrossRef]
- Jameil, A.K.; Al-Raweshidy, H. A Digital Twin framework for real-time healthcare monitoring: Leveraging AI and secure systems for enhanced patient outcomes. Discov. Internet Things 2025, 5, 37. [Google Scholar] [CrossRef]
- He, Q.; Li, L.; Li, D.; Peng, T.; Zhang, X.; Cai, Y.; Zhang, X.; Tang, R. From digital human modeling to human digital twin: Framework and perspectives in human factors. Chin. J. Mech. Eng. 2024, 37, 9. [Google Scholar] [CrossRef]
- Khajavi, S.H.; Tetik, M.; Liu, Z.; Korhonen, P.; Holmström, J. Digital Twin for Safety and Security: Perspectives on Building Lifecycle. IEEE Access 2023, 11, 52339–52356. [Google Scholar] [CrossRef]
- Schreiber, H.; Bösch, W.; Paulitsch, H.; Schlemmer, A.; Schäfer, M.; Kraft, M. ESIT —ein Digitaler Zwilling für das zivile Flugsicherungsradar. e+i Elektrotechnik Inform. 2024, 141, 175–187. [Google Scholar] [CrossRef]
- Liu, Z.; Sun, X.; Sun, Z.; Liu, L.; Meng, X. The digital twin modeling method of the National Sliding Center for intelligent security. Sustainability 2023, 15, 7409. [Google Scholar] [CrossRef]
- Kreuzer, T.; Papapetrou, P.; Zdravkovic, J. Artificial intelligence in digital twins—A systematic literature review. Data Knowl. Eng. 2024, 151, 102304. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1558–2361. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Spoleto, A.; Staiano, A.; Hauber, G.; Lettiero, M.; Barra, P.; Camastra, F. Deep learning-based robust head pose estimation. In Proceedings of the 32th Italian Workshop on Neural Networks, to Appear, Salerno, Italy, 23–25 May 2013. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar] [CrossRef]
- Petro, A.; Sbert, C.; Morel, J. Multiscale retinex. Image Process. Line 2014, 4, 71–88. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Cortes, C.; Vapnik, V. Multiscale retinex. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Camastra, F.; Vinciarelli, A. Machine Learning for Audio, Image and Video Analysis, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- McIlroy-Young, R.; Wang, R.; Sen, S.; Kleinberg, J.; Anderson, A. Detecting Individual Decision-Making Style: Exploring Behavioral Stylometry in Chess. In Advances in Neural Information Processing Systems; Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: New York, NY, USA, 2021; Volume 34, pp. 24482–24497. [Google Scholar]
- Frost, O.L. An algorithm for linearly constrained adaptive array processing. Proc. IEEE 1972, 60, 926–935. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).