1. Introduction
The miniaturization and reduction in cost of the relevant control components in aircraft, as well as the development and progress of computer and sensing and measurement technologies, have improved the stability of flight control systems and greatly facilitated the development of quadrotors [
1]. The high operability, strong mobility and flexibility of quadrotors allow them to meet the specific needs of many projects, generally used in military, industrial and other fields [
2,
3]. A quadrotor system is multivariable, nonlinear and strongly coupled, and quadrotors will also be disturbed by the surrounding environment during flight [
4]. These factors can affect the accuracy of quadrotor control systems. The requirements for high-accuracy and robust flight control in the design of controllers for quadrotors are stringent, and the design of a core control algorithm is a prerequisite for quadrotors to achieve a stable and high-precision flight performance. Therefore, the research and development of controllers for quadrotor systems is of great significance.
At present, it is no longer a problem to ensure the uniformity of quadrotors through control algorithms. Many controllers for quadrotors have been designed and are already in application [
5]. Since the dynamics of quadrotors can be linearized around the equilibrium point, traditional linear control methods are used for a designed controller [
6]. On this basis, linear techniques are employed in the flight control of quadrotors, such as linear quadratic regulator (LQR) control [
7]. However, quadrotors need to be controlled away from the equilibrium point to accomplish complex control tasks and withstand external disturbances. As a result, a technique has been devised that is regarded as a robust feedback linearization method that uses extended state observers to estimate the nonlinear state feedback term online, containing aerodynamic forces, moments and unknown disturbances, and obtains the desired closed-loop dynamics via pole assignment [
8]. Moreover, several robust controllers relying on nonlinear techniques have been proposed, such as sliding mode control [
9], adaptive control [
10], backstepping-based control [
11] and robust control [
12]. These control methods ensure the stability and robustness of nonlinear systems and have generally been used for the tracking control of these systems, but their optimal properties have not been considered. Therefore, the concept of optimization has been introduced into control design.
To derive the optimal control policy for the infinite horizon optimal control problem, solving the Hamilton–Jacobi–Bellman (HJB) equation or the Hamilton–Jacobi–Isaacs (HJI) equation for the
optimal control problem considering uncertainties is essential. Nevertheless, it is difficult to mathematically derive the corresponding analytical solutions in most cases. Neural networks are an optional method to overcome this problem [
13,
14,
15]. The approximation property of neural networks makes it possible to find approximate solutions to partial differential equations. The convergence of neural networks can be ensured by penalizing them to ensure they satisfy the given partial differential equations. The ADP method is the combination of reinforcement learning, dynamic programming and neural network adaptive methods to derive approximate solutions of the HJB/HJI equations using function approximate structures to address nonlinear optimal control problems [
16,
17]. The ADP method is used for control design with suitable performance index functions to derive the desired dynamic performance and stabilize a nominal system with uncertainties. However, most nonlinear optimal control methods using the ADP method are aimed at nominal systems or uncertain systems satisfying specific conditions [
18,
19,
20], while the immunity to disturbances is still weak for such systems with external time-varying disturbances independent of the state, and the control effect under stronger disturbances is not ideal. The ADP method has been used in the design of controllers for quadrotors and efforts have been made to improve the robustness, but the designed controllers are more geared towards linear systems and design uncertainty is a unique problem [
21,
22]. Quadrotors will often experience various external effects in flight, requiring strong adaptive and anti-disturbance capabilities in flight control. The disturbance observer technique achieves disturbance suppression of the target utilizing feedback regulation [
23], which can attenuate compound disturbances containing external disturbances and model uncertainties, thus improving the system robustness. A disturbance observer can accurately estimate compound disturbances in a system, which greatly reduces the conservatism of the control. In addition, since a disturbance observer can usually be designed independently of the controller, this ensures that the method can be easily combined with other advanced control methods and more flexible in its application. There are experiments suggesting that the introduction of a disturbance observer significantly improves performance, which is a good reference for methods for quadrotors to overcome disturbances [
24].
Considering the above analysis, a robust approximate optimal trajectory tracking control method is proposed for quadrotors to solve the optimal control problem under the conditions of compound disturbances. The main contributions are summarized as follows:
- (1)
The combination of modeling uncertainties and external time-varying disturbances is considered as compound disturbances. Disturbance observers are introduced to estimate the compound disturbances in the position and attitude subsystems, and the estimated values are used to design robust compensation inputs to suppress the effects of the compound disturbances and ensure the stability of a quadrotor system under the ADP method.
- (2)
To obtain optimal trajectory tracking control for a quadrotor without composite disturbances, the ADP method is used to design approximate optimal control inputs for the nominal system of a quadrotor.
The rest of the paper is organized as follows. In
Section 2, the quadrotor mathematical model is developed, and the quadrotor system is divided into two subsystems.
Section 3 describes the design of the robust approximate optimal trajectory tracking control and the stability analysis of the closed-loop system.
Section 4 describes the robust approximate optimal trajectory tracking control for the quadrotor. The results of the corresponding simulation and the results of the comparative simulation without disturbance observer are presented in
Section 5.
Section 6 gives the conclusion of the paper.
2. Mathematical Modeling of a Quadrotor
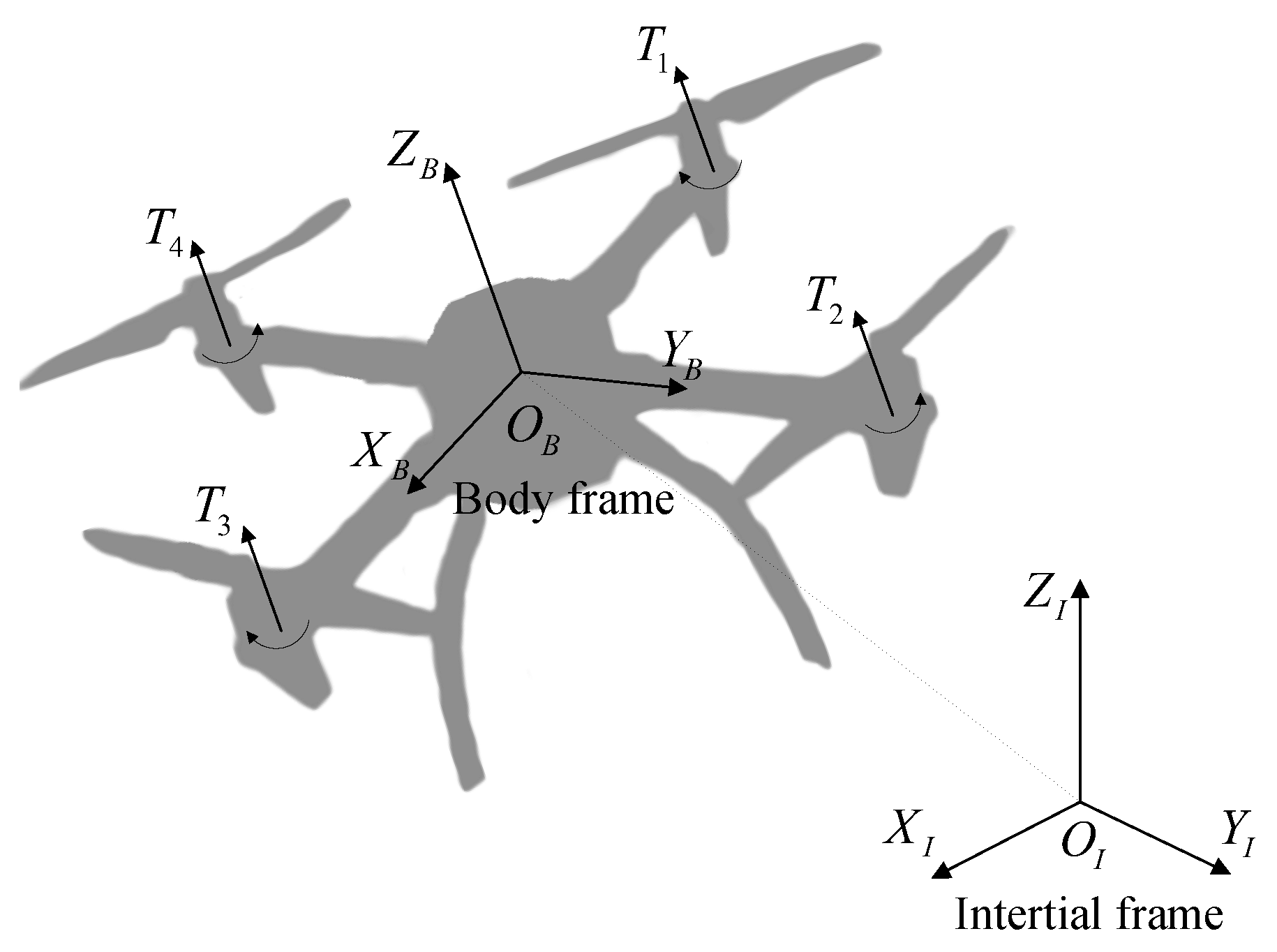
The quadrotor has four evenly spaced, cross-symmetrical brushless motors in the plane, The rotors of motor 1 and motor 3 rotate clockwise, while the rotors of motor 2 and motor 4 rotate counterclockwise. By changing the rotational speed of the four rotors, the quadrotor generates different magnitudes of lift forces and torques, which can control the takeoff, landing and attitude motions of the quadrotor. As a result, the location of the quadrotor can be altered in the three-dimensional space.
Figure 1 depicts the basic structure of the quadrotor.
To clarify the mathematical model of the quadrotor system and satisfy the implementation of the control method, the earth-fixed inertial frame
and the body-fixed body frame
are established. To ensure that the constructed mathematical model does not lose the generality, it is assumed that the deformation and elastic vibration properties of the rotors and body are neglected, and the quadrotor is considered as an ideal rigid body; the quadrotor’s structure is symmetrical, its mass is uniformly distributed, and its center of mass is located at the geometric center. The translational and rotational motions of the quadrotor are satisfied by [
25]
where
represents the position of the quadrotor in the inertial frame and
represents the corresponding velocity.
denotes the vector of Euler angles.
denotes the angular velocity of the quadrotor in the body frame.
is the rotation matrix for the angular velocity in the form of
in which
,
and
.
Relying on the Newton–Euler method, the dynamical equation of quadrotor with compound disturbances is represented by [
26]
where
represents the mass of the quadrotor.
represents the inertia matrix of the quadrotor. As the assumptions of the quadrotor structure, its inertia matrix can be defined as the diagonal array
.
is the drag coefficient matrix.
represents the resultant force consisting of the gravity and the total lift in the inertial frame.
represents the torque in the body frame.
and
are the compound disturbances in position and attitude dynamic models, which contain modeling uncertainties and external time-varying disturbances.
According to the mechanical analysis, the quadrotor is affected by gravity and lift forces. Since the special structure of the quadrotor, the lift forces are along the z-axis direction of the body frame. Then, the resultant force expressed in the inertial frame is [
27]
where
represents the total lift force and
represents the gravity acceleration.
.
is the rotation matrix of the body frame transformed into the inertial frame in the form of
Assumption 1 ([
28])
. The pitch and roll angles hold the conditions and to avoid the singularities of the matrices and . Assumption 2 ([
29])
. In the control process, the total compound disturbance has finite energy. In addition, is a continuous function and its norm is bounded such that , where is an unknown positive constant. Simultaneously, the compound disturbances are usually considered to be superimposed by the low-frequency period signals. Hence, it is assumed that the total compound disturbance has a low change rate and its rate of change is slow compared to the dynamic properties of the disturbance observer, which can be considered that . Assumption 3 ([
30])
. The desired trajectory of position and the desired trajectory of yaw angle and their higher order derivatives are known, continuous and bounded. Remark 1. Assumption 2 is common in control studies using disturbance observers [31,32,33], while there are different considerations for compound disturbances in [34]. In the case of this paper, the considerations in Assumption 2 are used. Assumption 3 ensures that the ADP method can be utilized for the control design and the stability analysis. The total lift and torque of the quadrotor are related to the force and torque of the four rotors as follows [
35]:
where
and
are the lift and torque generated by the four rotors of the quadrotor, respectively.
l represents the length from each rotor to the center of the body.
The rotor speeds are related to pulse-width modulated (PWM) signals through the motors. The lift forces and torques generated by the four motors are related to the pulse width of the input signals as follows [
36]:
where
and
are the positive gains of the lift coefficient and the inverse torque coefficient, respectively.
is the motor bandwidth and
represents the PWM signals of each corresponding motor, which should be limited between 0 and 1.
Assuming that the motors have a sufficiently fast response speed, then the motor model can be simplified as [
37]
Hence, (
8) can be rewritten as [
38]
Considering the trajectory tracking control for the quadrotor, the control objective is to design a controller that allows the position and attitude to track the desired trajectory asymptotically within a small error.
Combining (
1), (
2), (
4) and (
5), the overall model of the quadrotor can be decomposed into a position subsystem and an attitude subsystem. The position subsystem can be represented as
with
While the attitude subsystem is expressed in the form of
with
In the next section, (
12) and (
13) will be the focus of our research.
3. Robust Approximate Optimal Trajectory Tracking Control Design
Considering the convenience of describing the control design process, (
12) and (
13) is represented in the uniform form
in which
and
represent the drift dynamics and the input dynamics of the system, respectively.
denotes the observable state vector,
denotes the control input, and
denotes the compound disturbance.
Definition 1 ([
39])
. A state vector is said to be uniformly ultimately bounded (UUB) if there exists a compact set , a positive number and a time such that for all state variable initial value and all . Lemma 1 ([
40])
. is UUB if the time derivative of a positive definite function is negative when for a positive constant . To realize the trajectory tracking control with robustness for the system, the designed controller consists of two parts, the form of which is as follows:
where
is the robust compensation input designed through the disturbance observer for suppressing the effect of compound disturbances in the system.
is the control input designed based on the ADP method for the nominal system, which takes the form of
where
represents the steady-state control input and
represents the feedback control input.
3.1. Disturbance Observer Design
The disturbance observer is applied to derive the estimate of the compound disturbance. The estimated value is then used for the design of the robust compensation input to improve robustness. The disturbance observer is designed as
in which
represents the estimate of the unknown compound disturbance,
represents the designed vector-valued function,
is the observer gain and
represents the auxiliary variable vector of the disturbance observer.
Remark 2. In the disturbance observer (17), the derivative of the state is required, which is unknown because the compound disturbance is unknown. Then, the auxiliary variable vector is given to avoid calculating the derivative of the state. Define the estimation error of compound disturbance as
. With regard to Assumption
2 and the disturbance observer (
17), the time derivative of
is developed as
Combined with (
14), we have
Then, is convergent by appropriately designing the vector-valued function .
Theorem 1. Considering System (14), the disturbance observer is designed as (17). If is ensured to be positive definite for the design of the vector-valued function , then the estimated compound disturbance would follow the compound disturbance D, which means the estimation error could converge to zero. Proof. Select the candidate Lyapunov function as follows:
Combined with (
18), the time derivative of
is
In the case where
is positive definite, then we derive
where
and
denotes the minimum eigenvalue. Obviously,
when
. Hence, the disturbance observer (
17) can estimate
D and
will converge to zero. This completes the proof. □
Then, the robust compensation input
is designed as
3.2. Optimal Trajectory Tracking Control Design and Analysis
The compound disturbance is estimated by the disturbance observer. The robust compensation input is designed by the estimated value to suppress the effect of the compound disturbances. As a result, converting the trajectory tracking control problem of the nonlinear system with the compound disturbance into the trajectory tracking control problem of the nominal system is possible. In order to derive the optimal control for the nominal system, deriving the solution of the associated HJB equation is essential. Unfortunately, deriving the analytical solution is difficult for the nonlinear system by the direct solution method. Then, the ADP method is utilized for achieving the approximate optimal control by constructing the critic network. The weight update law designed for the critic network ensures the convergence of the weight and the stability of the closed-loop system.
For System (
14), the nominal system is represented by
Given the desired trajectory
, the steady-state control input
is obtained from (
24) as
in which
denotes the pseudo-inverse of
.
Define the tracking error as
. Combined with (
14) and (
15), the error system is developed as
Let
and
, then we have
Noting that , the norm of is bounded such that for the positive constants and .
As a result of Theorem 1, the disturbance observer (
20) can successfully estimate the compound disturbance
D and the estimation error of compound disturbance
can converge to zero. Therefore, it is possible to neglect
in the error system (
27) for the optimal control design [
41,
42]. However,
would still be considered in the stability analysis. Then, the nominal error system is represented by
Define the cost function as
where
and
are the designed symmetric positive definite matrices.
The nonlinear Lyapunov equation for (
29) is achieved as
where
and
.
Definition 2 ([
43])
. A control policy is said to be admissible on the compact set Ø for (29) if is continuous on Ø, , stabilizes (28) on Ø and is finite . This is represented by , where denotes the set of admissible control policies. The Hamiltonian function takes the following form
The optimal cost function is represented by
and the following relation is satisfied
where
.
Under the existence condition of the optimal solution
, the optimal feedback control input is derived by
Substituting (
34) and (
31) into (
33), the HJB equation is developed as
3.3. Approximate Optimal Control Design
Clearly, it is necessary to derive
by solving the HJB Equation (
35) for deriving the optimal feedback control input (
34). However, (
35) is a typical nonlinear partial differential equation and its solution is difficult to derive in the analytic form [
44,
45]. To overcome the difficulty, the ADP method relying on the policy iteration technique is utilized to derive the approximate solution.
Assumption 4 ([
46])
. The continuously differentiable Lyapunov function candidate for the nominal error system (28) satisfies , where . Meanwhile, there exists a symmetric positive definite matrix such that . Moreover, the relation holds for positive constants , . Remark 3. Assumption 4 is a common assumption that has been used for the ADP method. Generally, it is assumed that the closed-loop dynamics with the optimal feedback control is bounded by a function of the system state on the compact set. In such a situation, there exists a positive constant such that . Hence, we can further derive . Furthermore, the function can be correctly selected as a quadratic polynomial [47], such as . Considering the uniform estimation property of neural networks, the optimal cost function is approximated by
where
represents the unknown ideal constant weight,
represents the activation function,
represents the approximate error, and
N represents the number of neurons. This neural network is called the critic network in the ADP method.
Lemma 2 ([
48])
. The estimation error
is expected to be bounded when the approximated function
is bounded.
Then, by the definition of
, it is developed as follows
where
and
.
Invoking (
37), the optimal feedback control input (
34) is developed as
Substituting (
37) into (
35), the HJB equation is developed as
where
.
represents the residual error, which takes the form of
Since is bounded, there exists the positive constants and such that .
Define the estimate of
as
, then the estimate of
is derived as follows:
Moreover, the approximate optimal feedback control input is derived as
Remark 4. The classical ADP method utilizes the critic network and the actor network to approximate the optimal cost function and the optimal feedback control, respectively [43,49,50]. Considering the association between the optimal cost function and the optimal feedback control for the continuous affine nonlinear system, it is possible to omit the actor network and only use the critic network [51,52]. This framework provides smaller computational effort, faster convergence and compared to the actor–critic network framework, which has a better practical value. Combining (
31), (
41) and (
42), the approximate Hamiltonian function is developed as
Define the objective function as
Moreover, the weight update law is designed as
where
,
are the learning rates to be designed.
and
.
is given in Assumption 4.
in the last term is defined as
where
is a designed positive constant.
Remark 5. The first term in (45) is employed for minimizing the objective function (44). To ensure that will converge to , the existence of the persistence of excitation (PE) condition is essential during the learning process is necessary [49]. In addition, the probing noise is typically introduced to the control input for satisfying this condition, which may enable the closed-loop system to become unstable during the learning process [53,54]. The second term in (45) is employed for the stability of the closed-loop system. Define the weight estimation error as
. Observing that
,
where
, and using (
39) and (
45), we have
3.4. Stability Analysis
Assumption 5 ([
50])
. The ideal weight have bound over the compact set Ø such that for a positive constant . Meanwhile, the activation function and the approximate error are bounded such that , for positive constants and , and their derivatives are also bounded such that and for positive constants and . Moreover, the residual error will converge to zero when the number of neurons N is sufficiently large, as suggested by Remark 3 and the bound of . That is, the relation exists for the positive constant . Theorem 2. Considering System (14), the robust approximate optimal controller for the trajectory tracking control is designed as (15), which consists of the robust compensation input (23) and the nominal system control input (16), and the weight update law is designed as (45) for the critic network, then it is ensured that the tracking error E of the closed-loop system and the weight estimation error are UUB. Proof. Select the candidate Lyapunov function as follows
where
is designed as (
20),
and
.
Considering the second term in (
48) and using (
27), the time derivative is developed as
Considering the third term in (
48) and according to (
47), the time derivative is developed as
Since the first two terms in the final form of (
50) are negative semi-definite, we then derive
According to Remark 3 and Assumption 5, and considering the bound of
, we assume that
,
,
,
,
and
. Noticing that the PE condition guarantees
to be bounded, there exists a positive constant
such that
. In addition, based on Young’s inequality, there exists the relation
, where
c is a nonzero constant. Then, we have
Then, (
51) is developed as
where
and
are all non-zero constants whose selection guarantees
. Combining the results of (
22), (
49) and (
51), we have
By using Young’s inequality, the relation
exists. Then, (
61) is developed as
The following discussion is divided into two cases.
Case 1. In this case, . Since , we can derive that . According to the dense property of , there exists a positive constant such that for all . Then, (62) becomes By selecting and , such that , then is satisfied provided that one of the following conditions holds:or Case 2. Considering the case , (62) is developed as Based on Assumption 4, and considering , we have Similarly, by selecting and such that and , then it means that holds as long asor In conclusion,
when
or
. Relying on Lemma 1 and the standard Lyapunov extension theorem [
55], it is further concluded that the tracking error
E of the closed-loop system and the weight estimation error
are UUB. This completes the proof. □
Remark 6. As a result of Theorem 2, the approximate optimal cost function in (41) and the approximate optimal feedback control input in (42) can, respectively, converge to the neighborhoods of the optimal cost function and the optimal feedback control input within finite bounds when the PE condition holds [41]. 5. Simulation Results
In this section, the robustness and effectiveness of the designed controller are evaluated through numerical simulations. The quadrotor is considered to be in a flight environment with slow-changing disturbances. The parameters of the quadrotor model are presented in
Table 1 [
24].
A representative desired trajectory is selected to emulate the trajectory tracking performance of the quadrotor. The desired trajectory is designed as
and
. In addition, referring to [
57,
58], the unknown compound disturbances considered are described as
and
. In this way, the performance of the disturbance observers is reflected by comparing them with the estimates. The initial states of the quadrotor are all set to zero.
The vector-valued functions of the disturbance observers are designed as
,
, while the observer gains are selected as
Clearly, and are positive definite and satisfy the design requirements of Theorem 1. To derive the appropriate dynamic performance, the parameters of the performance index functions are designed as , , . The activation functions are designed as , . The relevant constants of the weight update laws are selected as , , , , , . The Lyapunov function candidates are selected as and . The initial weights are assigned values within the interval .
The PE condition is ensured by the method mentioned in Remark 5 to excite the system states. The weights gradually vary to become slower and stabilize during the learning process. The converged weights are already very close to the ideal weights after sufficient learning. The convergence of the whole critic network weights
,
in the learning processes are depicted in
Figure 3. The final converged values of
,
are as follows
The converged weights are used to design the approximate feedback optimal control inputs.
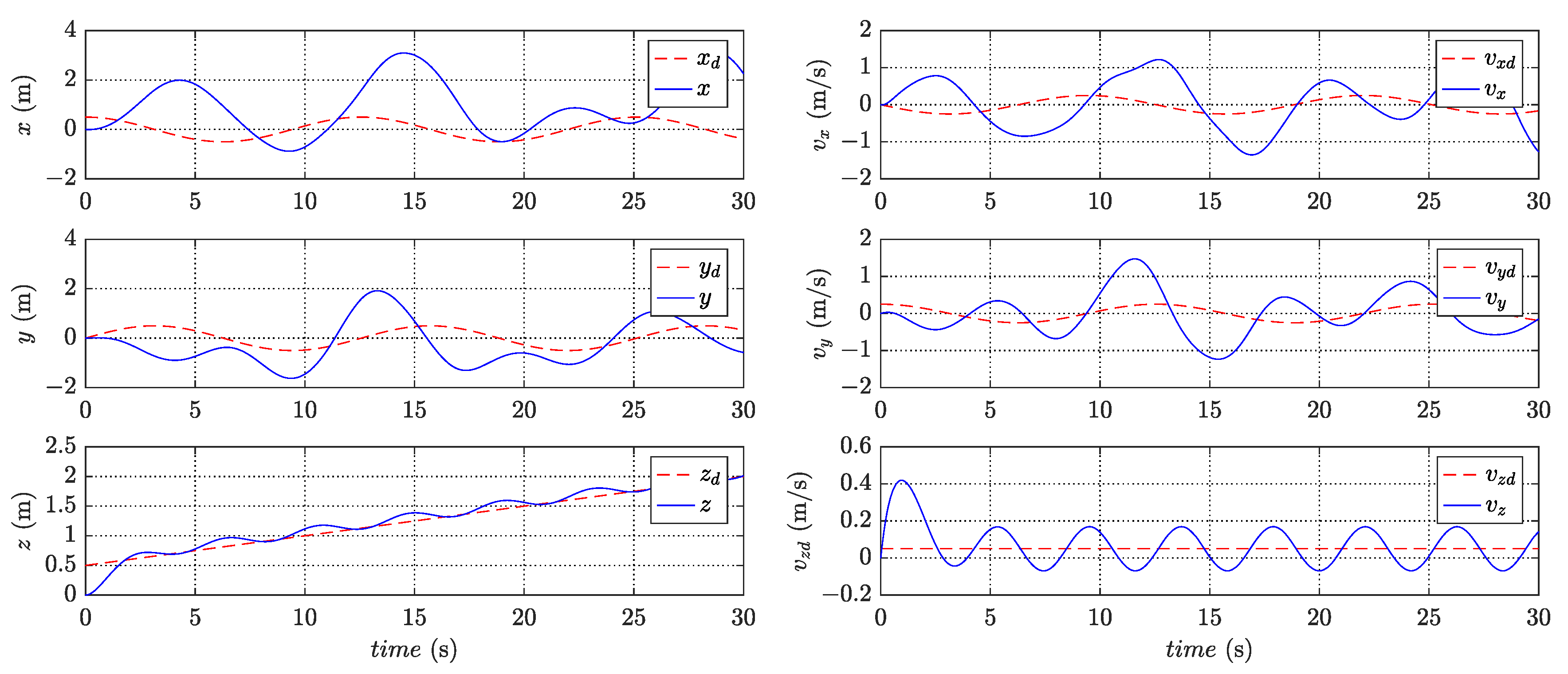
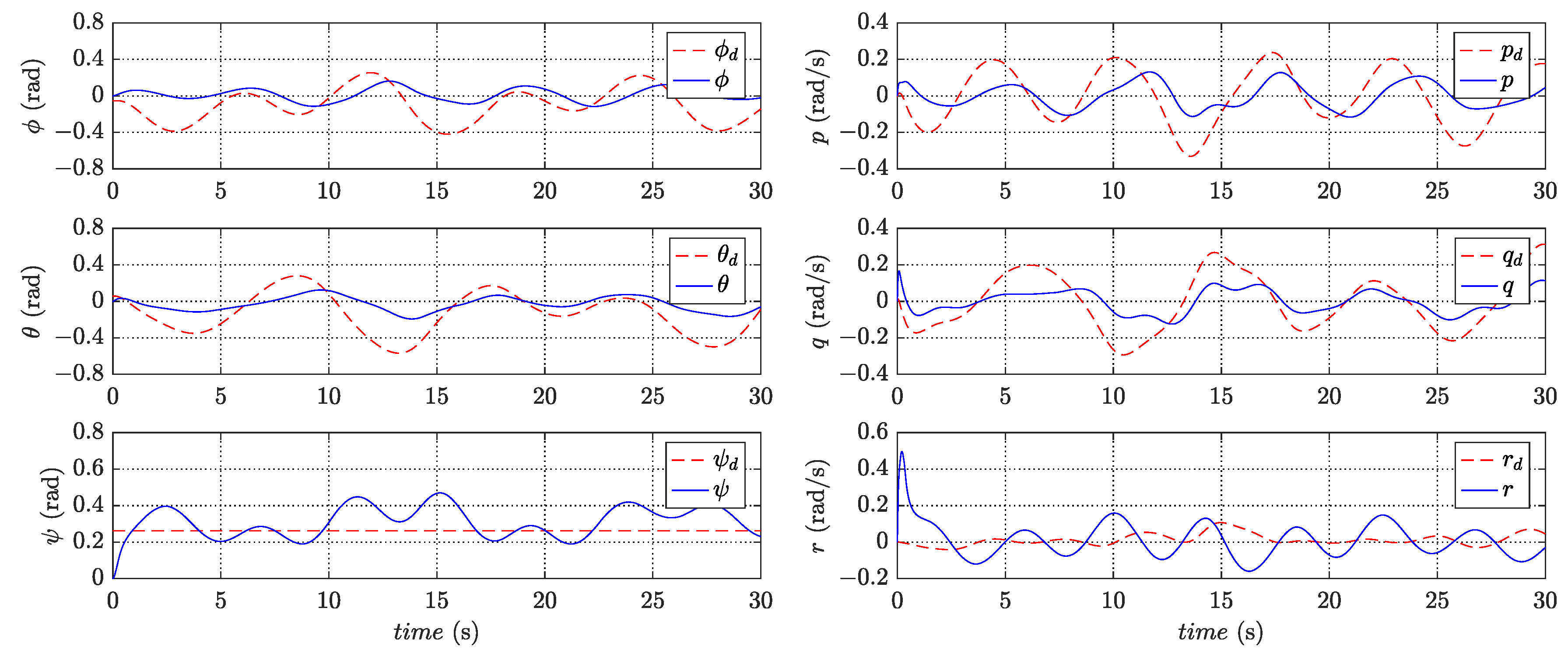
Figure 4 and
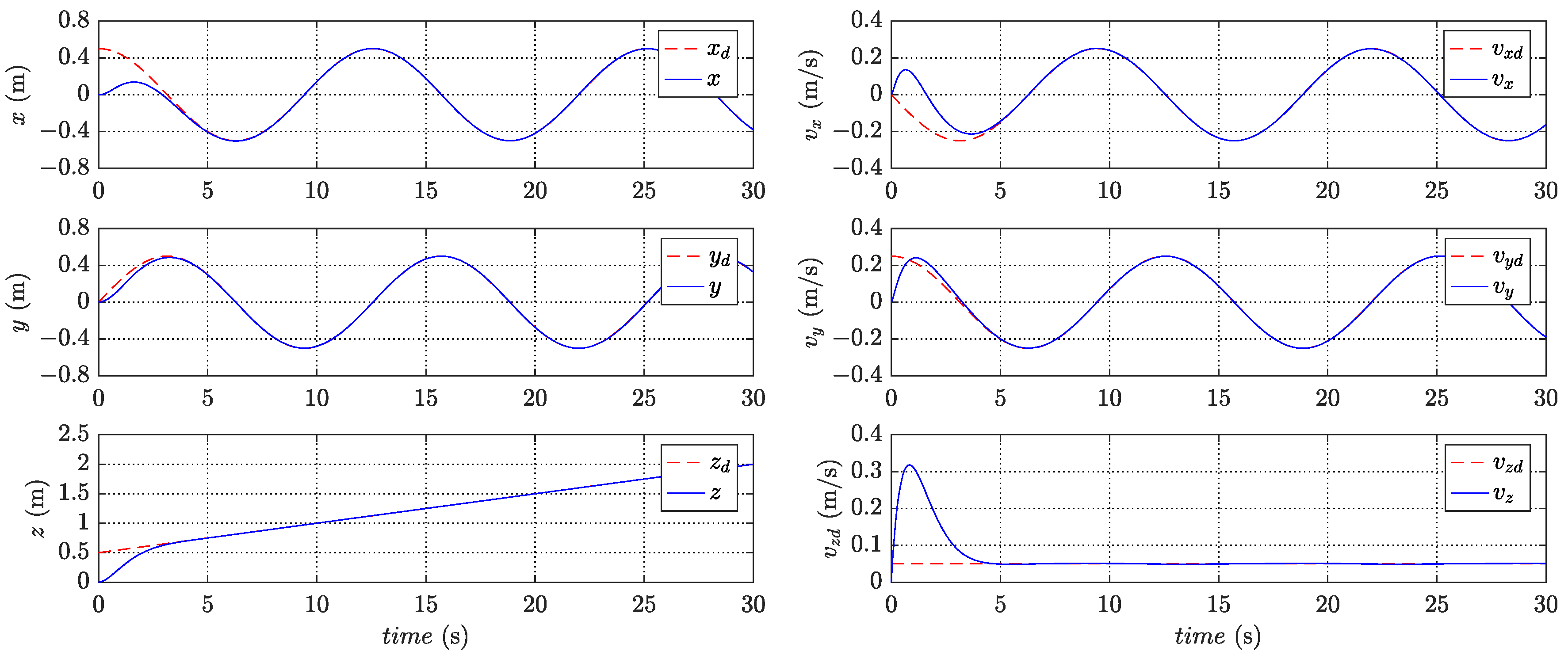
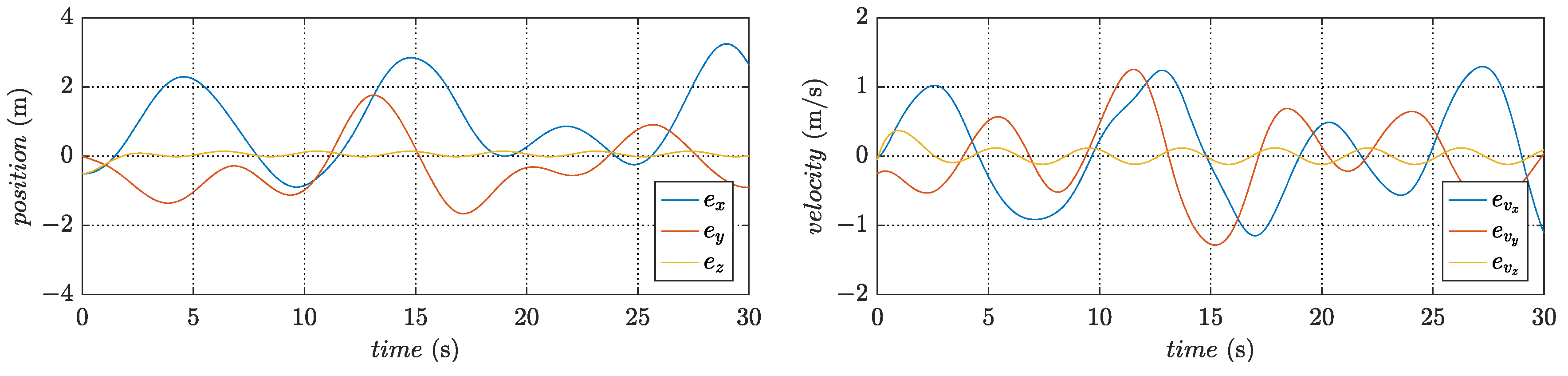
Figure 5 present the variation of states in trajectory tracking control, revealing the corresponding tracking errors in
Figure 6 and
Figure 7. In addition,
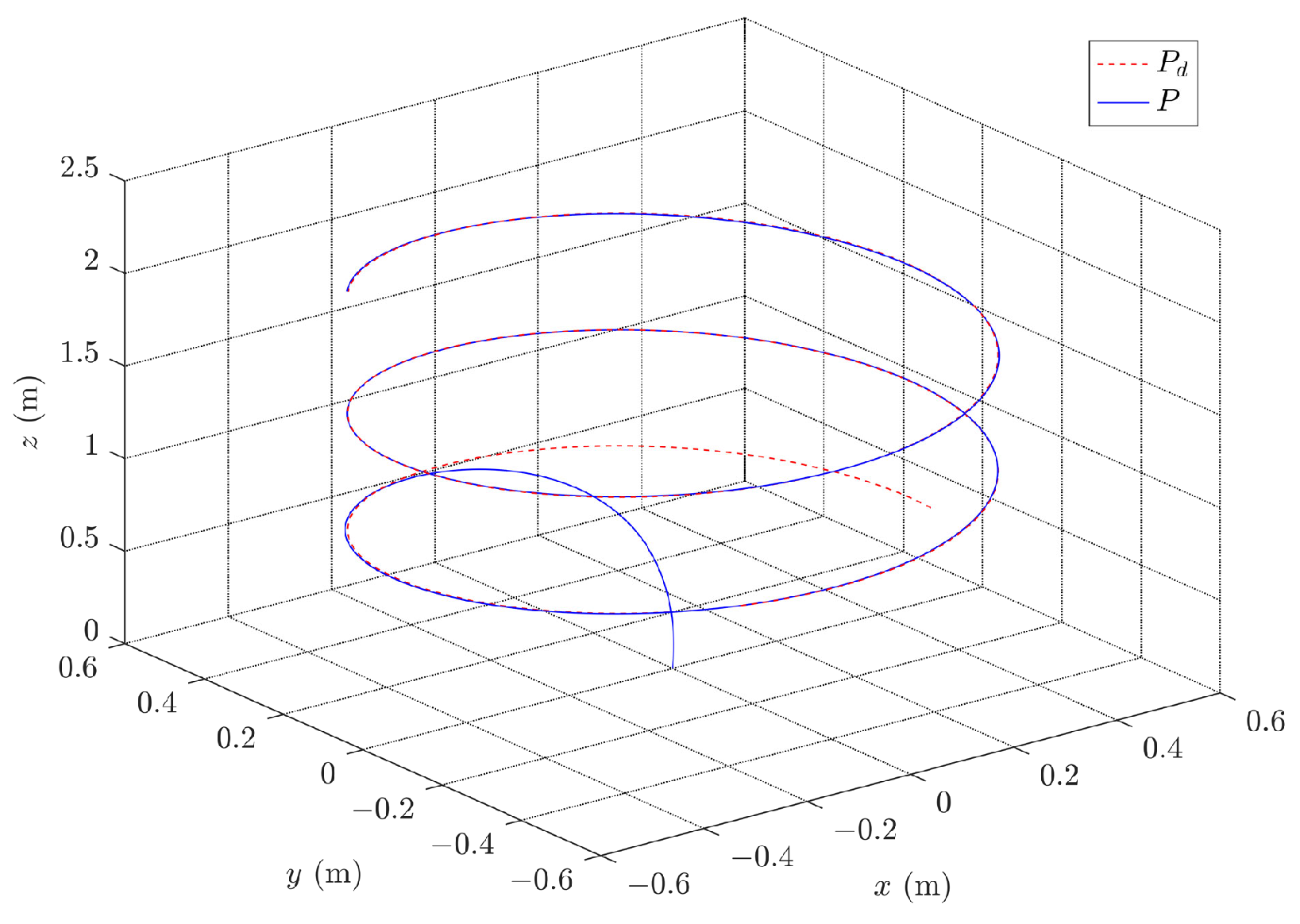
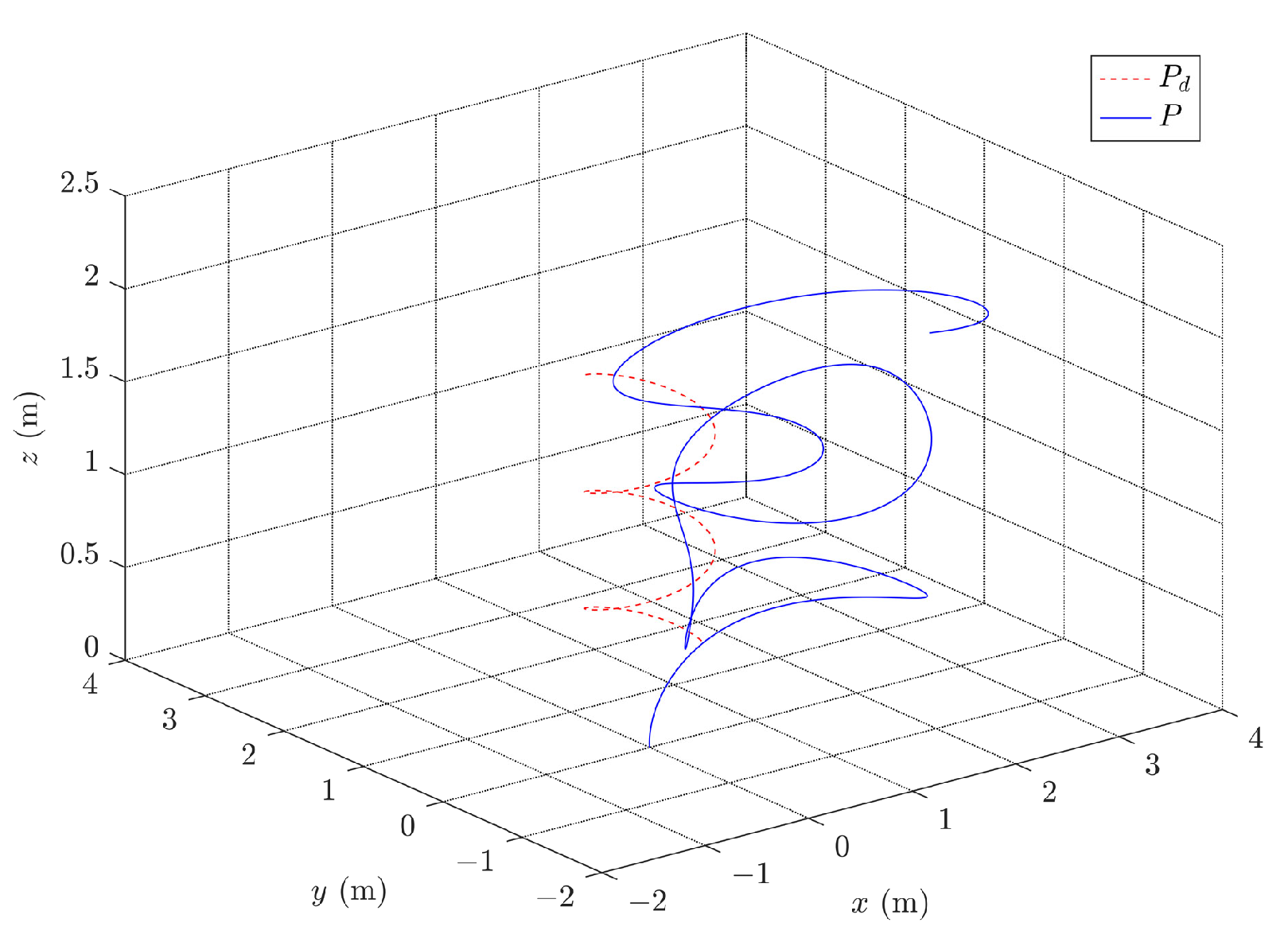
Figure 8 visualizes the path in three-dimensional space, whereas
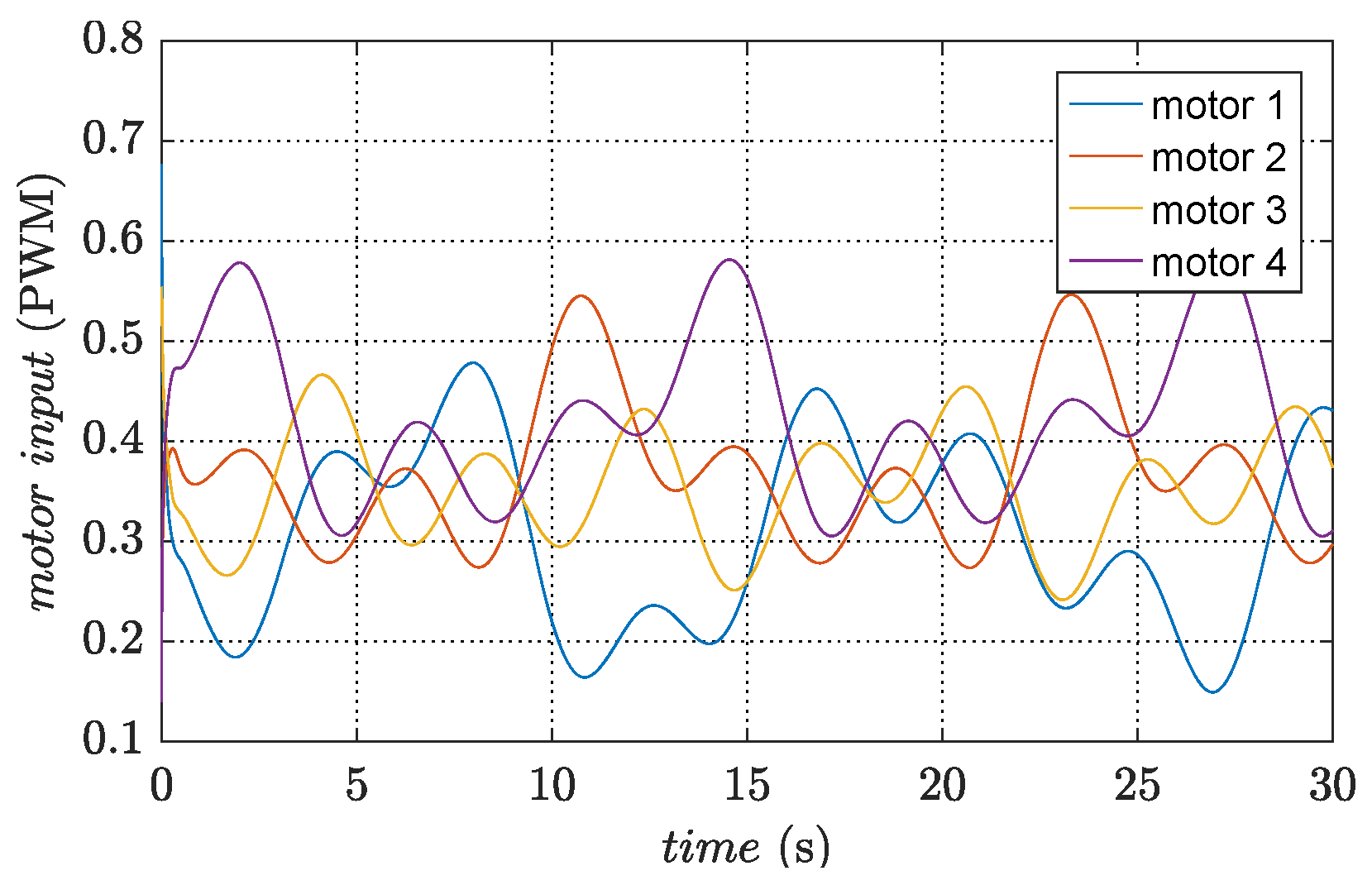
Figure 9 illustrates the PWM signals for the motors. The figures clearly demonstrate that the quadrotor system effectively tracks the desired trajectory and achieves a small convergence bound for the tracking error. These results highlight the rapidity and accuracy of the designed controller in the control process.
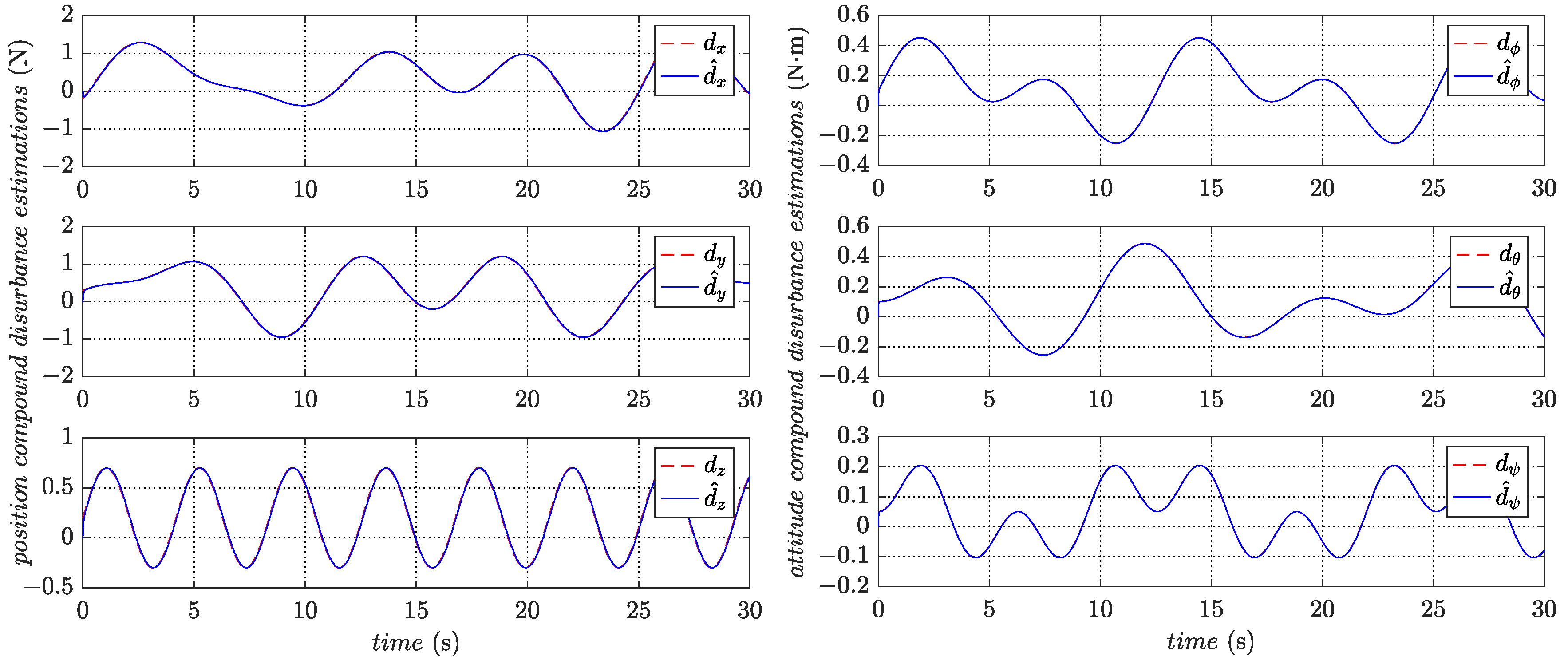
The estimates for the compound disturbances are depicted in
Figure 10. It shows that the estimated values from the disturbance observers can quickly follow the actual compound disturbances. Moreover, the trajectory tracking control performs well in the presence of compound disturbances, which implies the robustness of the designed controller.
In order to verify that the designed controller rejects the compound disturbances, a comparative simulation is performed without the disturbance observers in the position subsystem and the attitude subsystem. The control inputs use only the control inputs designed for the nominal system. Under such control, the variation of states is presented in
Figure 11 and
Figure 12, while
Figure 13 and
Figure 14 show the corresponding tracking errors.
By comparing the simulation results, it is clear that the trajectory tracking control of the quadrotor cannot be realized without the robust compensation inputs. Thus, further demonstrating the robustness of the designed controller. Moreover, the corresponding path in three-dimensional space and the PWM signals of the motors are shown in
Figure 15 and
Figure 16, respectively.
In summary, the controller designed for quadrotor trajectory tracking control has good dynamic performance, high tracking accuracy and strong robustness when the quadrotor is subjected to compound disturbances.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}