1. Introduction
It has long been known that classical inference methods based on first-order asymptotic theory, when applied to the generalized method of moments estimator, may lead to unreliable results, in the form of substantial finite sample biases and variances, and incorrect coverage of confidence intervals, especially when the model is overidentified (
Donald et al. 2009;
Hall and Horowitz 1996;
Hansen et al. 1996;
Tauchen 1986). In another strand of the literature,
Chernozhukov and Hong (
2003) introduced Laplace-type estimators, which allow for estimation and inference with classical statistical methods (those which are defined by optimization of an objective function) to be done by working with the elements of a tuned Markov chain, so that potentially difficult or unreliable steps such as optimization or computation of asymptotic standard errors, etc., may be avoided. A third important strand of literature is simulation-based estimation. The strands of moment-based estimation, simulation, and Laplace-type methods meet in certain applications. The code by Gallant and Tauchen (
Gallant and Tauchen 2010) for efficient method of moments estimation (
Gallant and Tauchen 1996), which has been used in numerous papers, is an example. Another is
Christiano et al. (
2010) (see also
Christiano et al. 2016), which proposes a Laplace-type estimation methodology that uses simulated moments which are defined in terms of impulse response functions for estimation of macroeconomic modes. Very similar methodologies may be found in the broad Approximate Bayesian Computing literature, some of which uses MCMC methods and criteria functions that involve simulated moments (e.g.,
Marjoram et al. 2003).
Given the uneven performance of inference in classical GMM applications, one may wonder how reliable are inferences made using the combination of Laplace-type methods and simulated moments. Henceforth, this combination is referred to as MSM-MCMC, because the specific Laplace-type method considered here is to use the criteria function of the MSM estimator to define the likelihood that determines acceptance/rejection in Metropolis-Hastings MCMC, as was the focus of
Chernozhukov and Hong (
2003). This paper provides experimental evidence that confidence intervals derived from such estimators may have poor coverage when the moments over-identify the parameters, a result that parallels the above cited results for classical GMM estimators. It goes on to provide evidence that the simulated neural moments that were introduced in
Creel (
2017), which are just-identifying, when used with MSM-MCMC techniques, cause inferences to become much more reliable, especially when the continuously updating version of the GMM criteria is used. This paper is a continuation of the line of research in
Creel (
2017), its main new contribution being the experimental confirmation that inferences based upon simulated neural moments are reliable. The paper concludes with an example that uses the methods to estimate a jump-diffusion model for returns of the S&P 500 index.
Section 2 reviews how Laplace-type methods may be used with simulated moments, giving the MSM-MCMC combination, and
Section 3 then discusses how neural networks may be used to reduce the dimension of the moment conditions.
Section 4 presents four test models, and
Section 5 gives results for these models.
Section 6 illustrates the methods in the context of an empirical analysis of a model of more complexity, concretely, a jump-diffusion model for financial returns, and
Section 7 summarizes the conclusions. The
SNM archive (release version 1.2) contains all the code and results reported in this paper. These results were obtained using the Julia package
SimulatedNeuralMoments.jl (release version 0.1.0), which provides a convenient way to use the methods for other research projects.
2. Simulated Moments, Indirect Likelihood, and MSM-MCMC Inference
This section summarizes results from the part of the simulation-based estimation literature that bases estimation on a statistic, including (
Gallant and Tauchen 1996;
Gouriéroux et al. 1993;
McFadden 1989;
Smith 1993), among others, which is reviewed in (
Jiang and Turnbull 2004). Suppose there is a model
which generates data from a probability distribution
which depends on the unknown parameter vector
.
is fully known up to
, so that we can make draws of the data from the model, given
. Let
be a sample drawn at the parameter vector
, where
and
is a known parameter space. Suppose we have selected a finite-dimensional statistic
upon which to base estimation, and assume that the statistic satisfies a central limit theorem, uniformly, for all values of
of interest:
Let
be the statistic evaluated using an artificial sample drawn from the model at the parameter value
. This statistic has the same asymptotic distribution as does
, and furthermore, the two statistics are independent of one another. With
S such simulated statistics, define
and
We can easily obtain
Now, suppose we have a real sample which was generated at the unknown true parameter value
, and let
be the associated value of the statistic. Define
. With this, and Equation (
2), we can define the indirect likelihood function
1
where
where
is a consistent estimate of
.
To estimate
, one possibility is to use a fixed sample-based estimate that does not rely on an estimate of
(see, for example,
Christiano et al. 2010,
2016). Another possibility is to (1) compute the estimate
of the covariance matrix in expression (
1) as the sample covariance of
R draws of
:
where
is the sample mean of the draws, and then (2) multiply the result by
to obtain the estimate
This estimator may be used in a continuously updating fashion, by updating
in Equations (
3) or (
4) every time the respective function is evaluated. Alternatively, if we obtain an initial consistent estimator of
then
can be computed at this estimate, and kept fixed in subsequent computations, in the usual two-step manner. Please note that if a fixed covariance estimator is used, then the maximizer of
L is the same as the minimizer of
H.
Extremum estimators may be obtained by maximizing
or minimizing
Laplace-type estimators, as defined by
Chernozhukov and Hong (
2003), may be defined by setting their general criteria function,
, as defined in their Section 3.1, to either
, or
Once this is done, then the practical methodology is to use Markov chain Monte Carlo (MCMC) methods to draw a chain
given the sample statistic
where acceptance/rejection is determined using the chosen
, along with a prior, and standard proposal methods
2. This specific version of Laplace-type methods is referred to as MSM-MCMC in this paper. This paper will rely directly on the theory and methods of
Chernozhukov and Hong (
2003), as MSM-MCMC falls within the class of methods they study. In the following, a primary use of the
Chernozhukov and Hong (
2003) methodology will be in order to obtain confidence intervals. For a function
, Theorem 3 of
Chernozhukov and Hong (
2003) proves that a valid confidence interval can be obtained using the quantiles of
, based on the final chain
. For example, a 95% confidence interval for a parameter
is given by the interval
), where
is the
th quantile of the
R values of the parameter
in the chain
3. Neural Moments
The dimension of the statistics used for estimation,
can be made minimal (equal to the dimension of the parameter to estimate,
by filtering an initial set of statistics, say,
W, through a trained neural net. Details of this process are explained in
Creel (
2017) and references cited therein, and the process is made explicit in the code which accompanies this paper
3. A summary of this process is: Suppose that
W is a
p vector of statistics
, with
where
. We may generate a large sample of
pairs, following:
Draw from the parameter space using some prior distribution.
Draw a sample from the model at .
Compute the vector of raw statistics
We can repeat this process to generate a large data set
, which can be used to train a neural network which predicts
, given
W. This process can be done without knowledge of the real sample data, and can in fact be done before the real sample data are gathered. The prediction from the net will be of the same dimension as
, and, according to results collectively known as the universal approximation theorem, will be a very accurate approximation to the posterior mean of
conditional on
W (
Hornik et al. 1989;
Lu et al. 2017). The output of the net may be represented as
where
is the neural net, with parameters
, that takes as inputs the
p statistics
and has
outputs. The parameters of the net,
, are adjusted using standard training methods from the neural net literature to obtain the trained parameters,
. Then we can think of
as a
dimensional statistic which can be computed essentially instantaneously once provided with
W. We will use this statistic
as the
Z of the previous section. Because the statistic is an accurate approximation to the posterior mean conditional on
W (supposing the net was well trained), it has two virtues: it is informative for
(supposing that the initial statistics
W contain information on
) and it has the minimal dimension needed to identify
. From the related GMM literature, GMM methods are known to lead to inaccurate inference when the dimension of the moments is large relative to the dimension of the parameter vector (
Donald et al. 2009). Use of a neural net as described here reduces the dimension of the statistic to the minimum required for identification.
When the statistic
Z is the output of a neural net
, where the parameter vector of the net,
, can have a very high dimension (hundreds or thousands of parameters are not uncommon), the simulated likelihood of Equation (
3) will be a wavy function, with many local maxima. This will occur even if the net is trained using regularization methods. Because of this waviness, gradient-based methods will not be effective when attempting to maximize
or to minimize
H (Equations (
3) and (
4)), and attempts to compute the covariance matrix of the estimator that rely on derivatives of the log likelihood function will also be unlikely to succeed. However, derivative free methods can be used to compute extremum estimators, to obtain point estimators or to initialize a MCMC chain, and the simulation-based estimator of the covariance matrix
of Equation (
1) discussed in the previous section does not depend on derivatives. A major motivation of using Laplace-type estimators in the first place is to overcome problems of local extrema, as
Chernozhukov and Hong (
2003) emphasize. It is worth noting that the output of the net evaluated at the real sample statistic,
, will also provide an excellent starting value for computing extremum estimators, or for initializing a MCMC chain. Likewise, the covariance estimator of Equation (
6) can be used to define a random walk multivariate normal proposal density for MCMC, by drawing the trial value
from
, where
is the current value of the chain. Experience with this proposal density, as reported below, is that it is easy to tune, by scaling the covariance by a scalar, to achieve an acceptance rate withing the desired limits
4.
Creel (
2017) used neural moments to compute a Laplace-type estimator, similarly to what is done here. That paper used nonparametric regression quantiles applied to the set of draws from the Laplace-type posterior to compute confidence intervals, and the posterior draws were generated by a procedure similar to sequential Monte Carlo, rather than MCMC. Additionally, the metric used for selection of particles was different from the GMM criteria, which were used here. The use of nonparametric regression quantiles is very costly to study by Monte Carlo. Thus, this paper focuses on straightforward use of the methods that
Chernozhukov and Hong (
2003) focus on: traditional MCMC using the GMM criteria function, with confidence intervals computed using the direct quantiles from the posterior sample. These simplifications give a simpler and more tractable procedure that can reasonably be studied and verified by Monte Carlo. For theoretical support, we can note that the methods fall within the class of methods studied by Chernozhukhov and Hong, with the only innovation being the use of statistics filtered through a previously trained neural net. The neural nets used here consist of a finite series of nonstochastic nonlinear mappings to the (−1, 1) interval, followed by a final linear transformation. As such, the conjecture that the final statistics that are the output of the net follow a uniform law of large numbers and a uniform central limit theorem seems reasonable, but this is not formally verified in this paper.
5. Monte Carlo Results
This section reports results for MSM-MCMC estimation of each of the test models, using the GMM-like criteria function
H (Equation (
4)) as the
of
Chernozhukov and Hong (
2003). Results using the criterion
L (Equation (
3)) were qualitatively very similar in all cases where the two versions were computed, and are thus not reported
10. In all cases, 500 Monte Carlo replications were done. For all the test models, the number of artificial samples used to train the neural net was 20,000 times the number of parameters of the model. This is actually a fairly small number, given that generating the samples and training the nets is an operation that takes only 10 min or less for the test models, other than the DSGE model. The reason that a larger number of samples was not used is that it was desired to obtain results that may be more relevant for cases where it is more costly to simulate from the model, as is the case of the jump diffusion model studied below.
First, we report results for the SV and ARMA models, where MSM-MCMC estimators were computed using both the overidentifying statistic,
and the exactly identifying neural moments,
For the plain overidentifying statistics, the results are computed using the CUE GMM criteria. For the neural moments, both the two-step and the CUE criteria were used.
Table 1 reports RMSE. The three versions of the MSM-MCMC estimators lead to similar RMSEs, generally speaking. The version that uses the raw statistics has somewhat higher RMSE than do the versions based on the neural statistics,
Z, in most cases, but the differences are not important.
Table 2,
Table 3 and
Table 4 address the main point of the paper, inference, reporting confidence interval coverage, which is the proportion of times that the true parameter lies inside the computed confidence interval. Critical coverage proportions that would lead one to reject correct coverage may be computed from the binomial(500,
distribution, where
p is the significance level associated with the respective confidence interval. These critical coverage proportions are 0.864 and 0.932 for 90% intervals, 0.924 and 0.974 for 95% intervals, and 0.976–1.0 for 99% intervals. Looking at the column labeled
W (CUE) in these tables, we see that the results on the unreliability of inferences for overidentified GMM estimators, which were reviewed in the Introduction, carry over to Bayesian MCMC methods, at least for the models considered. In all entries but one, the coverage is significantly different from correct coverage, erring on the side of being too low, and, in many cases, considerably so. This implies that the probability of Type-I error is higher than the associated nominal significance level. For the neural net statistics,
Z, coverage is improved. For the two-step version, coverage is in all cases closer to the correct proportion than when the raw statistics,
are used. In several cases, correct coverage is also statistically rejected, but now, the error is on the side of conservative confidence intervals, which contain the true parameters more often than the nominal coverage. In this case, the probability of Type-I error will be less than the nominal significance level associated with the confidence intervals. For the CUE version that uses the neural statistics,
coverage is very good, and is close to the nominal proportion in all cases. Statistically correct coverage is never rejected when neural moments and the CUE criteria are used.
For the other two test models, MN and DSGE, results were computed only for the neural moments, as the results for the SV and ARMA models, as well as the results from the GMM literature, already indicated that inferences based on the raw statistics,
were very likely to be unreliable.
Table 5 has the RMSE results for the MN and DSGE models. We can see that the use of the two-step or CUE criteria makes little difference for RMSE, in common with the above results for the SV and ARMA models.
Table 6,
Table 7 and
Table 8 hold the confidence interval coverage results for these two models. Again, the intervals based on the two-step criteria often contain the true parameters more often than they should. The coverage of intervals based on the CUE criteria is very good in all cases, and is never statistically significantly different from correct.
In summary, this section has shown that confidence intervals based on raw overidentifying statistics may be unreliable, rejecting the true parameter values more often than they should. Intervals based on exactly identifying neural moments are more reliable, in general. When the two-step version is used, the intervals are often too broad, so the probability of Type-I error is less than what it should be, and power to reject false hypotheses is lower than it could be. When the CUE version is used, coverage is very accurate: correct coverage was never rejected in any of the cases.
It is to be noted that the CUE version is computationally more demanding than is the two-step version, as the weight matrix must be estimated at each MCMC trial vector. Each of these estimations requires a reasonably large number of simulations to be drawn, to estimate the covariance matrix accurately. If a researcher is primarily concerned with limiting the probability of Type-I error, and is willing to accept a loss of power to accelerate computations, then the two-step version might be preferred. If one is willing to accept more costly computations, all the examples considered here indicate that the CUE version will lead to accurate confidence intervals.
6. Application: A Jump-Diffusion Model of S&P 500 Returns
The previous examples are mostly small models that are not costly to simulate, except for the DSGE example. As an example of a more computationally challenging model that may be more representative of actual research problems, this section presents results for estimation of a jump-diffusion model of S&P 500 returns. Solving and simulating
11 the model for each MCMC trial parameter acceptance/rejection decision takes about 15 s, when the CUE criteria are used, so training a net and estimation by MCMC is somewhat costly, requiring approximately 2.5 days to complete using a moderate power workstation
12 and threads-based parallelization, where possible. This example is intended to show that the methods are feasible for moderately complex models.
The jump-diffusion model is
where
is 100 times log price,
is log volatility,
is jump size, and
is a Poisson process with jump intensity
.
and
are two standard Brownian motions with correlation
. When a jump occurs, its size is
, where
a is 1 with probability
and
with probability
Therefore, jump size depends on the current standard deviation, and jumps are positive or negative with equal probability. Log price,
is simulated using 10-minute tics, and the observed log price adds a
measurement error to
, when
is greater than zero. From this model, 1000 daily observations on returns, realized volatility (RV), and bipower variation (BV) are generated. Because log price has been scaled by 100 in the parameterization of the model, returns, computed as the first difference of
at the close of trading days, are directly in percentage terms. Both RV and BV are informative about volatility, and, because BV is somewhat robust to jumps, while RV is not, the difference between the two can help to identify the frequency and size of jumps (
Barndorff-Nielsen and Shephard 2002). The model is simulated on a continuous 24-hour basis, and returns are computed using the change in daily log closing price, for trading days only. Overnight periods and weekends are simulated, but returns, RV and BV are recorded only at the close of trading days. In summary, the seven parameters are
, and simulated data consists of 1000 daily observations on returns, RV and BV. The model studied here is quite similar to that studied in (
Creel 2017;
Creel and Kristensen 2015), except that the drift process is simplified to be constant, and the jump process is modeled somewhat differently, with constant intensity, and with the magnitude of a jump depending on the current instantaneous volatility. These changes were motivated by the results of the previous papers, and by the better tractability of the present specification.
The raw statistics,
which are used to train the net and to do estimation, are a combination of coefficients from auxiliary regressions between the three observed variables, summary statistics, and functions of quantiles of the variables. The details of the 25 statistics are found in the file
JDlib.jl (this same file also gives details of the priors, which are uniform over fairly broad supports, for all parameters). The neural net was fit using 160,000 draws from the prior to generate the training and testing data. The importance of each of the statistics can be assessed by examining the maximal absolute weights on each of the raw statistics in the first layer of the neural net, as is discussed in
Creel (
2017). These may be seen in
Figure 1. We see that most of the 25 statistics have a non-negligible importance, which means that these statistics are contributing information to the fit of the neural net. The output of the net is of dimension 8, the same as the dimension of the parameters of the model. The net is combining the information of the overidentifying statistics to construct a just-identifying vector of statistics, which is then used to define the moments for MSM-MCMC estimation.
The model was fit, using MSM-MCMC and the CUE criteria, to S&P 500 data
13 from 16 December 2013 to 4 December 2017, which is an interval of 1000 trading days, the same as was used to train the neural net. The data may be seen in
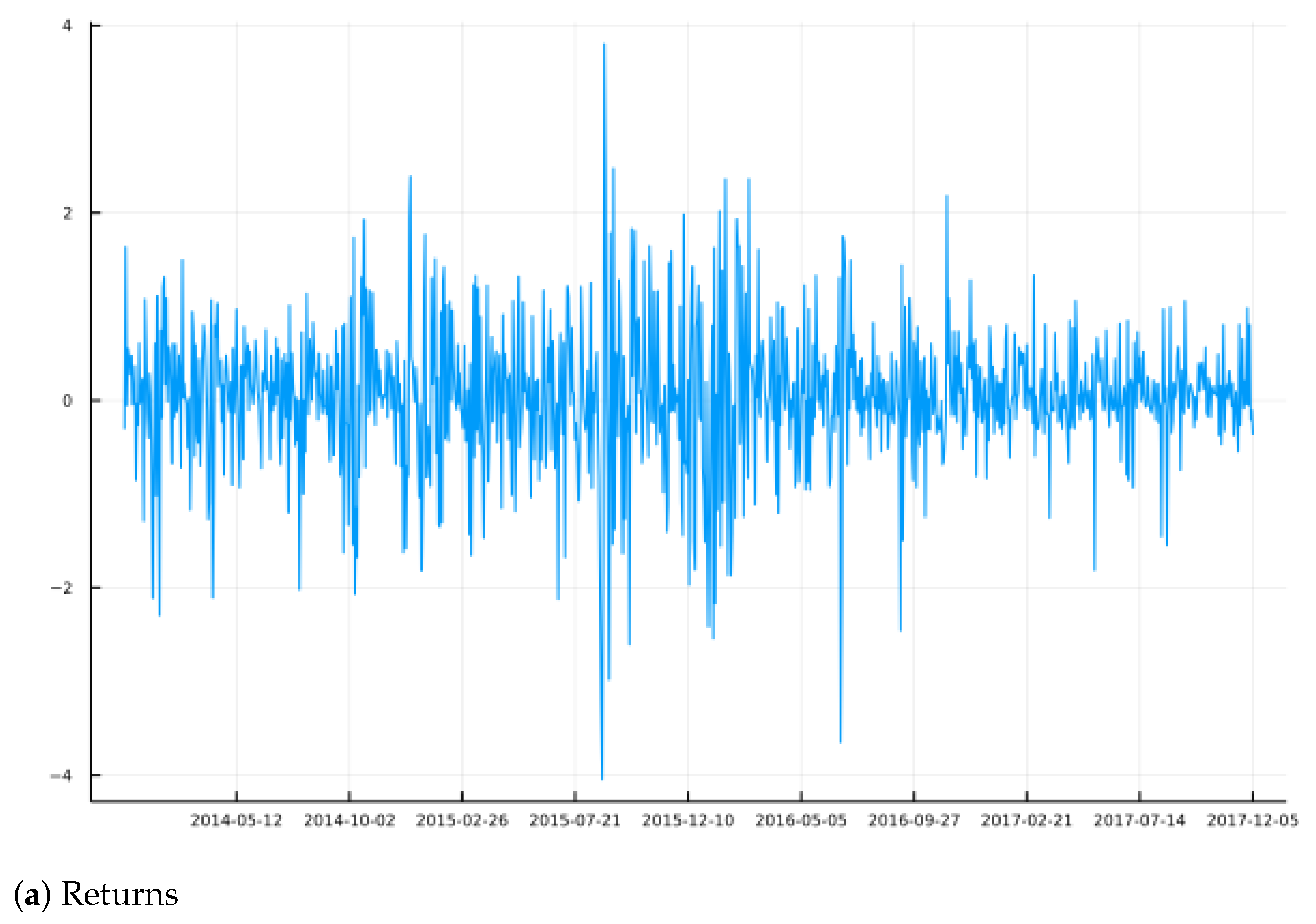
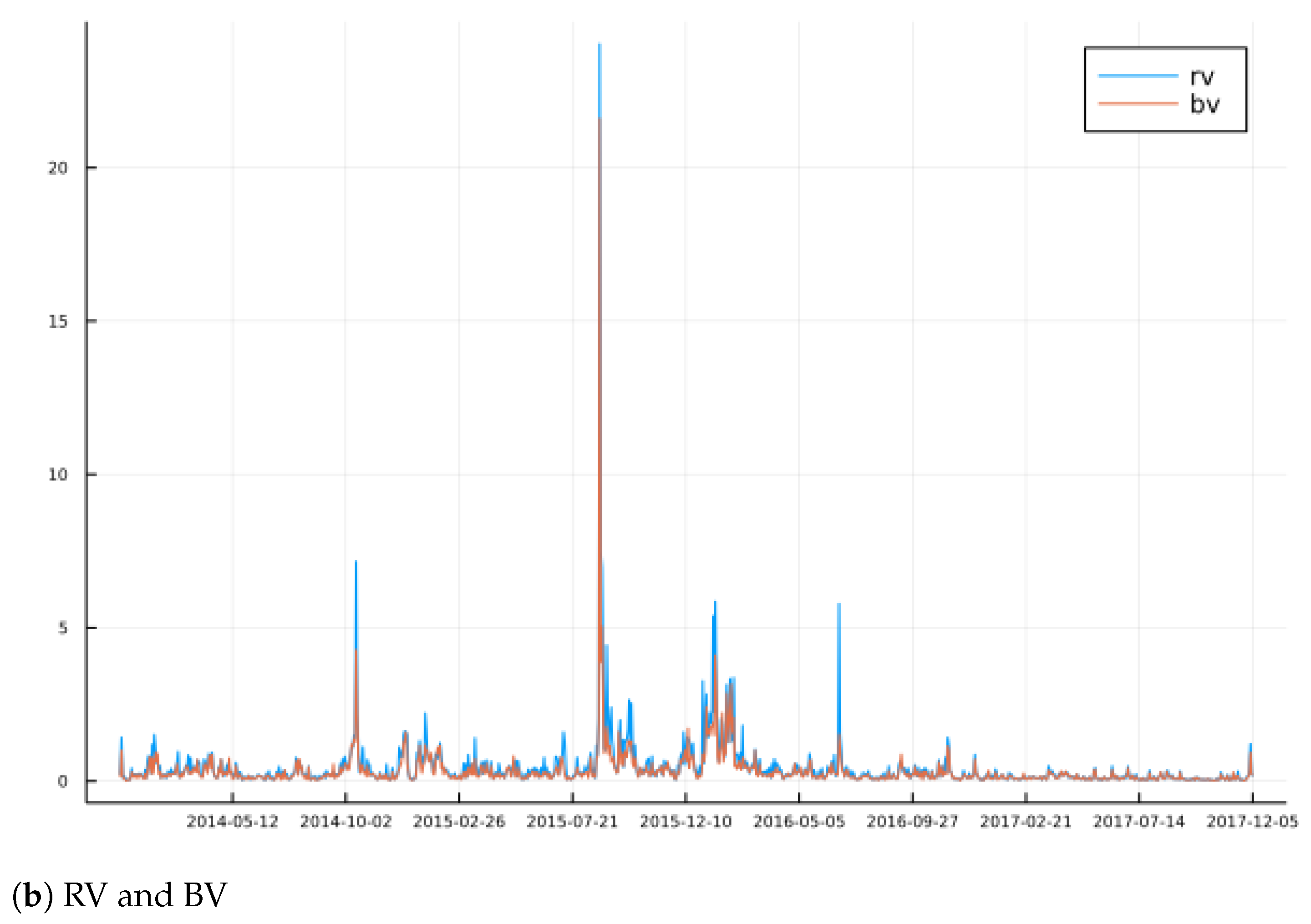
Figure 2, where we observe typical volatility clusters and some jumps. For example, the Brexit drop of June 2016 is clearly seen, and the more extreme spike in RV versus BV at this point illustrates the fact that jumps can be identified by comparing the two. Over the sample period, this price index climbed from about 1800 to 2600, which is approximately a 44% increase, or approximately 0.04% per trading day.
Ten MCMC chains of length 1000 were drawn independently using threads-based parallelization, for a final chain of length 10,000. The estimation results are in
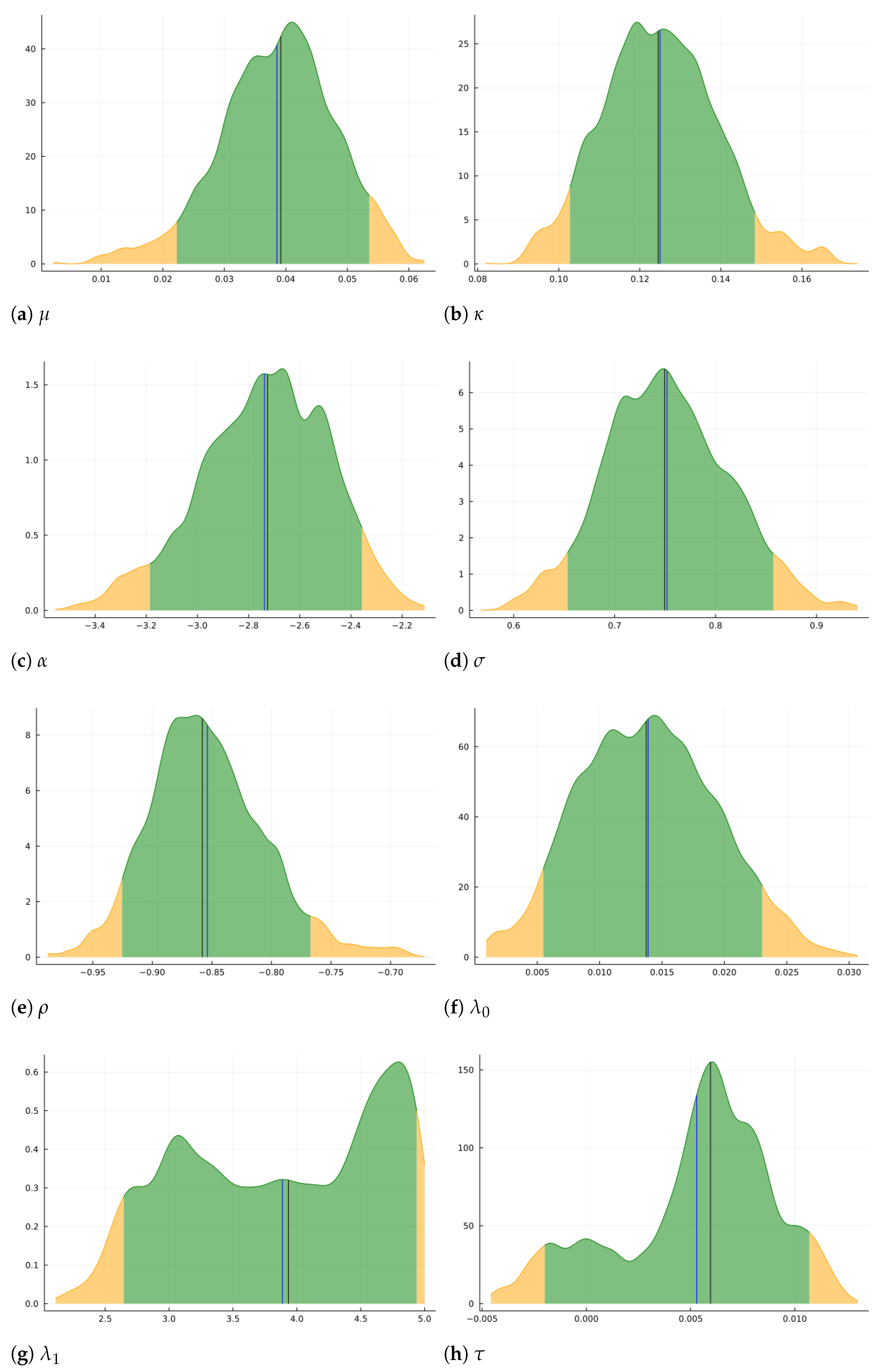
Figure 3, which shows nonparametric plots of the marginal posterior density for each parameter, along with posterior means and medians, and 90% confidence intervals defined by the limits of the green areas. All posteriors are considerably more concentrated than are the priors. Drift (
) is concentrated around a value slightly below 0.04, which is consistent with the average daily returns over the sample period. There is quite a bit of persistence in volatility, as mean reversion,
, is estimated to be quite low, concentrated around 0.125. Leverage (
) is quite strong, concentrated around −0.85. The jump probability per day (
) is concentrated around 0.014, and is significantly different from zero. Therefore, jumps are a statistically important feature of the model. When a jump does occur, its magnitude (
) is approximately 4 times the current instantaneous standard deviation, but this parameter is not very well identified, as the posterior is quite dispersed. An interesting result is that
, the standard deviation of measurement error of log price, is concentrated around 0.0055. It is not significantly different from zero at the 0.10 significance level, but it is close to being so. From the Figure, one can see that
would be very close to being rejected at the 10% significance level. The parameterization of the model is such that there is no measurement error when
. Thus, it appears that it is a safer option to allow for measurement error in the model, as the evidence suggests that it is very likely present, and its omission could bias the estimates of the other parameters.
7. Conclusions
This paper has shown, through Monte Carlo experimentation, that confidence intervals based upon quantiles of a tuned MCMC chain may have coverage which is far from the nominal level, even for simple models with few parameters. The results on poor reliability of inferences when using overidentified GMM estimators, which were referenced in the Introduction, carry over to a Bayesian version of overidentified MSM, implemented using the
Chernozhukov and Hong (
2003) methodology, for the models considered in this paper. The paper proposes to use neural networks to reduce the dimension of an initial set of moments to the minimum number of moments needed to maintain identification, following
Creel (
2017). When estimation and inference using the MSM-MCMC methodology is based on neural moments, which are exactly identifying, confidence intervals have statistically correct coverage in all cases studied by Monte Carlo, when the CUE version of MSM is used. Thus, there seems to be no generic problems with the MSM-MCMC methodology for the purpose of inference. A potential problem has to do with the choice of moments upon which MSM is based. Too much over-identification results in poor inferences, for the models studied. The use of neural moments solves this problem, by reducing the number of moments, without losing the information that they contain. The fact that RMSE does not rise when one moves from raw to neural moments illustrates that the neural moments do not lose the information that is contained in the larger set. The methods have been illustrated empirically by the estimation of a jump-diffusion model for S&P 500 data. An interesting result of the empirical work is that measurement error in log prices is likely to be present.
It is to be noted that the step of filtering moments though a neural net is very easy and quick to perform using modern deep learning software environments. The software archive that accompanies this paper provides a function for automatic training, requiring no human intervention. It only requires functions that provide simulated moments computed using data drawn from the model at parameter values drawn from the prior. Filtering moments through a neural net gives an informative, minimal dimension statistic as the output. This provides a convenient and automatic alternative to moment selection procedures. Uninformative moments are essentially removed, and correlated moments are combined.
This paper has examined how inference using the MSM-MCMC estimator may be improved when neural moments are used instead of a vector of overidentifying moments. It seems likely that other inference methods which are used with simulation-based estimators, such as Hamiltonian Monte Carlo and sequential Monte Carlo, among others, may be made more reliable if neural moments are used, as dimension reduction while maintaining relevant information is likely to be generally beneficial.








{kind=link}
{kind=link}
{kind=link}
{kind=link}