1. Introduction
During the last few years, interest in the world of cryptocurrencies has exploded, as underlined by the huge rise in Google queries concerning digital currencies. Unlike a standard currency, which is supported by a government or central bank, a digital currency has the feature of allowing online payments linking the giver and the recipient directly, without using a financial institution. The first digital currency, named Bitcoin, dates back to 2008. It was developed in the middle of the Great Recession period based on the paper of
Nakamoto (
2008). At that time, the stability of the global banking system was highly strained. As pointed out by
Weber (
2016), Bitcoin took advantage of these circumstances and gained popularity among practitioners, academics, and the financial press. After the European sovereign debt crisis (2010–2013), the confidence in the banking system’s stability sharply reduced. As a consequence, Bitcoin notably rose in value. At present, the diffusion of cryptocurrencies has reached unprecedented levels. The popularity of cryptocurrencies has been underlined by several works. For instance,
ElBahrawy et al. (
2017) analyzed the statistical properties of the whole cryptocurrency market,
Hileman and Rauchs (
2017) focused on the cryptocurrency industry and how these digital currencies can be used, and
Gandal and Halaburda (
2016) investigated the appreciation and depreciation of six different cryptocurrencies.
According to the site
https://coinmarketcap.com/ accessed on 30 June 2021, at the time of writing, there were 8525 cryptocurrencies, with a market value of approximately USD 1676 billion. Among all these cryptocurrencies, Bitcoin has the largest market share (around 61%), followed by Ethereum (13%). The reason behind this increasing popularity remains debatable, but probably lies in the heterogeneous nature of digital currencies. In fact, the question of whether cryptocurrencies are a real currency (
Yermack 2015), a speculative investment (
Baek and Elbeck 2015), a safe haven (
Bouri et al. 2017,
2020) or even a general financial asset (
Elendner et al. 2018) is still debated. Because of this, investigating the volatility and co-volatility among the cryptocurrencies is crucial and of primary interest for investors and portfolio managers.
Since the seminal paper of
Engle (
1982), the literature on financial econometrics has focused on volatility modeling and forecasting through the Generalized AutoRegressive Conditional Heteroskedasticity (GARCH) model, surveyed by
Teräsvirta (
2009). Modeling cryptocurrencies’ volatility using the GARCH specification has become standard among practitioners and scholars. For instance,
Chu et al. (
2017) analyzed the volatility of seven cryptocurrencies using twelve GARCH specifications;
Catania et al. (
2018), using GARCH and other models, predicted the volatility of four cryptocurrencies (Bitcoin, Ethereum, Litecoin, and Ripple) and
Caporale and Zekokh (
2019) used more than one thousand GARCH models for four cryptocurrencies. Taking advantage of the Mixing-Data Sampling (MIDAS) methods (
Ghysels et al. 2007), the GARCH–MIDAS (
Engle et al. 2013) models have also been used within the cryptocurrency framework.
Conrad et al. (
2018) investigated Bitcoin’s volatility in detail by including additional macroeconomic and financial variables (observed at a monthly frequency) as potential drivers of the volatility.
Walther et al. (
2019) used GARCH–MIDAS to forecast the volatility of five cryptocurrencies (Bitcoin, Etherium, Litecoin, Ripple, and Stellar) by including some monthly economic and financial drivers.
Recently, the literature has also been interested in the interdependencies among cryptocurrencies and other financial assets. For instance,
Cebrián-Hernández and Jiménez-Rodríguez (
2021) used the Dynamic Conditional Correlation (DCC) model of
Engle (
2002) on a mixed portfolio composed of Bitcoin and ten other assets.
Mensi et al. (
2020) applied the DCC model to four cryptocurrencies (Bitcoin, Ethereum, Litecoin, and Ripple).
Katsiampa et al. (
2019) applied the Diagonal BEKK (
Engle and Kroner 1995) and its asymmetric version to eight cryptocurrencies. Using a multivariate factor stochastic volatility model in a Bayesian framework,
Shi et al. (
2020) investigated the dynamic correlations among six cryptocurrencies.
García-Medina and Chaudary (
2020) studied the interconnections of cryptocurrencies in a network context by estimating the multivariate transfer entropy.
Ji et al. (
2019) investigated the volatility spillovers among six cryptocurrencies, finding that Bitcoin and Litecoin played a prominent role.
Despite the literature on multivariate analysis of cryptocurrencies is rich, some questions still remain: (i) how to deal with the inclusion of the variables observed at lower frequencies, with a potential separate effect if positive or negative, and influencing daily cryptocurrencies in a multivariate context; (ii) what benefit these variables can give from statistical and economic points of view. The present paper aims to address these points. In particular, the contribution of this work is twofold. First, we analyze the interdependencies among seven cryptocurrencies for the period 2017–2020 by using a set of popular DCC specifications—that is, the corrected DCC (cDCC) of
Aielli (
2013), the DCC-MIDAS of
Colacito et al. (
2011), and the Dynamic Equicorrelation (DECO) of
Engle and Kelly (
2012), as well as a popular non-parametric specification, the RiskMetrics (RM) model, which is also used in
Amendola et al. (
2020). The DCC class of models is a standard tool for investigating the dynamic interdependencies between financial assets (
Hemche et al. 2016). In this paper, the DCC models also include a monthly variable in a context where the dependent variable—that is, the digital currency—is observed daily. The chosen monthly variable is the Google searches of each digital currency. This choice is motivated by
Kristoufek (
2013), who argued that the Google queries on the digital currencies are the factors determining the cryptocurrencies’ prices. The specification used for including the Google trend data on cryptocurrencies in the univariate specifications is the Double Asymmetric GARCH–MIDAS (DAGM), which was recently proposed by
Amendola et al. (
2019). The DAGM model is able to take into account the separate effects that positive and negative variations in the low-frequency variable—in this case, the monthly Google searches—may have on the daily (cryptocurrency) volatility. The second contribution of our work is that we evaluate the models from statistical and economic perspectives, as has been done by
Amendola and Candila (
2017), among others. The statistical evaluation is based on the distance between each predicted conditional covariance matrix and a covariance proxy. The economic evaluation refers to the portfolio Value-at-Risk (VaR) obtained from the global minimum variance (GMV) strategy. As in
Elendner et al. (
2018), we analyzed a portfolio entirely composed of cryptocurrencies.
The estimation of all the models employed in this work was carried out using the Gaussian distribution. The fat tails and severe skewness are very well-known features of cryptocurrency returns (see, for instance, the works of
Bariviera et al. (
2017),
Zhang et al. (
2018), and
Näf et al. (
2019), among others). The univariate analysis can involve distributions, different from the Normal one, handling efficiently these stylized facts. However, as stated by
Pesaran and Pesaran (
2010), when the DCC models are estimated using a non-normal distribution, some problems may arise. First of all, there could exist different local maxima. Moreover, the possibility of splitting the estimate stage into two steps is lost. This aspect means that the DCC models’ estimation is problematic, as many parameters have to be optimized jointly. Recently, a viable approach that addresses and solves this issue was proposed in
Paolella and Polak (
2015) and
Paolella et al. (
2019). This is accomplished via the use of an expectation–maximization algorithm to jointly estimate all model parameters amid a non-Gaussian distribution. Thus, it is also applicable to high dimensions. We did not pursue this methodology in this paper, leaving it for future work. Instead, we continued to use the Gaussian distribution, because it is the dominant choice in this context (it has been recently used in
Canh et al. (
2019),
Guesmi et al. (
2019), and
Kumar and Anandarao (
2019), for instance).
In terms of results, the inclusion of the monthly Google searches as additional determinants for the daily volatilities of the chosen digital currencies is extremely important. In fact, only the models using Google searches belong to the set of superior models (SSM), identified through the Model Confidence Set (MCS,
Hansen et al. 2011) procedure. These results hold both for the statistical and economic evaluations. Moreover, only the models employing the Google trends and the RM model have satisfactory residual diagnostics. Finally, all the estimated time-varying conditional correlations obtained from the models within the SSM are relatively high, approximately ranging between 0.6 and 0.8 in the last part of the sample.
The rest of the paper is structured as follows.
Section 2 illustrates the methodology used.
Section 3 is devoted to the empirical analysis. Finally,
Section 4 provides the concluding remarks.
2. Methodology
Let
be the vector of
n daily log-returns observed at time
i of period
t. Typically, the frequency of period
i is higher than the frequency of
t in order to take into account the additional volatility determinants which, in this work, will be observed at a monthly frequency. Globally, there are
days within each period
t, and there are
T low-frequency periods. Then, we assume that:
where
is the multivariate normal distribution;
is the
conditional covariance matrix;
is the diagonal matrix, which includes the conditional standard deviations on the main diagonal; and
is the correlation matrix, which is formulated as:
In Equation (
3),
denotes the conditional expectation made at time
of the period
t. By means of this formulation,
are the standardized residuals obtained from the univariate volatility models. Therefore, under the Equations (
1)–(4), we have that:
where
is the
dimensional identity matrix.
The main appeal of DCC models is the possibility of splitting the estimation phase into two steps. In the first step, the univariate models are separately estimated in order to form the matrix
. Then, in the second step, the correlation models are estimated. The advantage of such a procedure is that it makes the estimation feasible even for moderately large portfolios of assets. In particular, let
and
be the parameter spaces of the volatility and correlation models, respectively, with
. Hence, following
Engle (
2002), the global log-likelihood function, labelled as
, can be written as:
The univariate specifications used in this work are the GARCH and the DAGM models. In the first case, the volatility dynamics of each asset is:
In the case of the DAGM model, the volatility of each asset is decomposed into two multiplicative components, short-run and long-run terms. The former is labeled as
and varies each day
i. The long-run component instead, labeled as
, varies with the same frequency as the additional variable
. Formally, the model for
is:
where
follows a standard normal distribution. Note that Equation (12) considers the influence of positive and negative
realizations separately via
and
. These two parameters, respectively, give the contribution to
of the positive and negative weighted summation of the
K lagged realizations. The specifications in Equations (
9) and (11) could be further enriched by the inclusion of some asymmetric terms, linked to negative returns, as was implemented by
Conrad and Loch (
2015), for instance.
The three parametric specifications for the correlations used in this work, belonging to the class of DCC models, are the cDCC, DCC-MIDAS, and DECO models. Another popular specification is the RiskMetrics model, which does not require any estimation. All the functional forms of the models are illustrated in
Table 1. It is worth noting that the cDCC, DCC-MIDAS, and DECO models employed in this work use the standardized residuals coming from the univariate GARCH and DAGM models. Therefore, the model universe consists of six parametric models and one non-parametric model.
Once estimating
, it would be necessary to test the adequacy of the model used in terms of the remaining presence of conditional heteroscedasticity in the (standardized) residuals. However, as argued by
Bauwens et al. (
2006), the tests at disposal for this aim are still at a preliminary stage, with respect to those for the univariate case. Among these works, the test proposed by
Ling and Li (
1997) (
) has some undoubted advantages. The test uses the squared standardized residuals to test the null of no conditional heteroscedasticity. Formally, the
test statistic is:
where
N is the total number of days used, obtained as
, and
represents the residual autocorrelation at lag
h—that is:
The test, under the null, is asymptotically distributed as a . Interestingly, the asymptotic distribution of the test statistic does not require the normality assumption of the error term, meaning that the test also appears to be robust in the presence of misspecified distribution.
3. Empirical Analysis
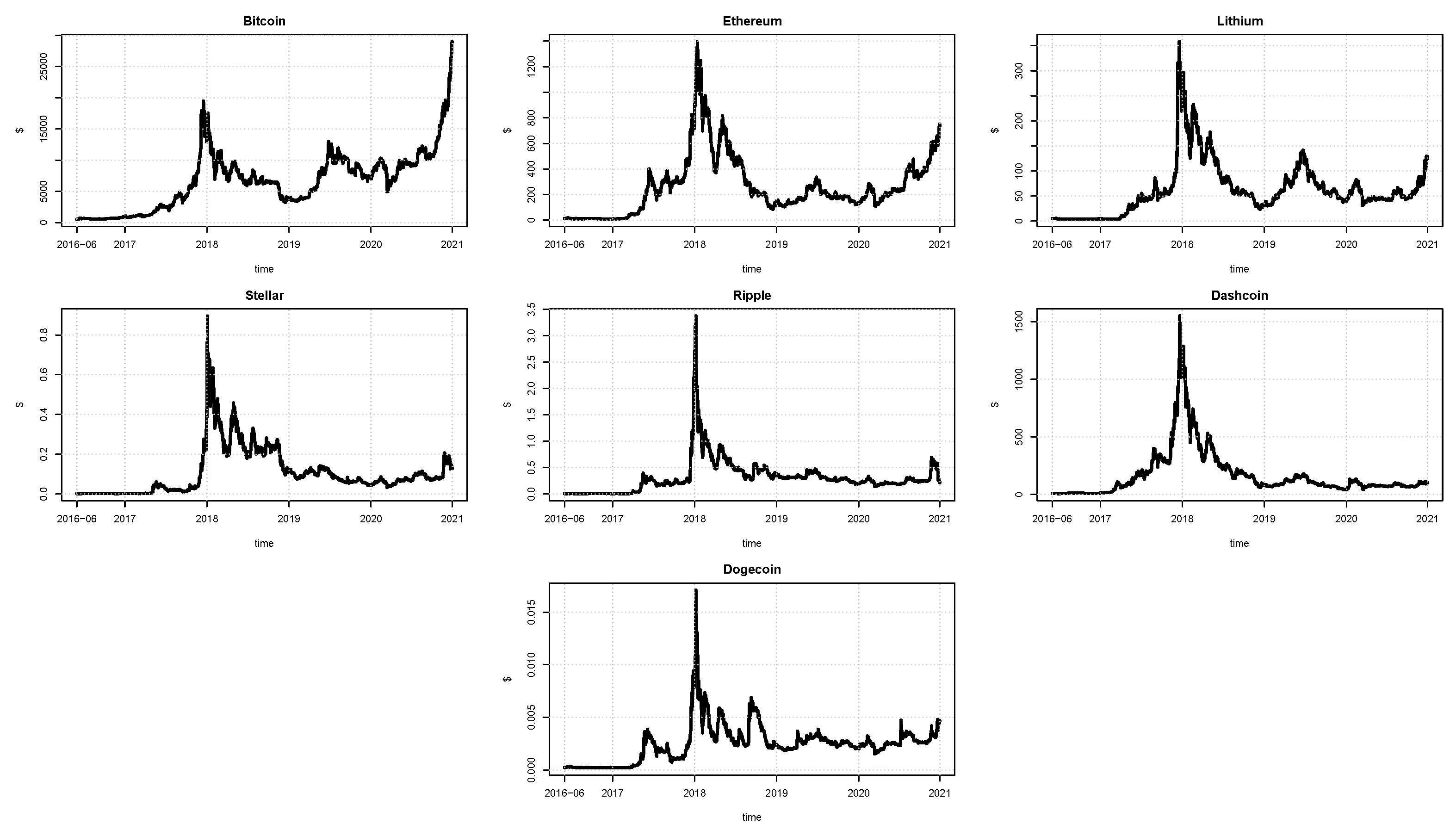
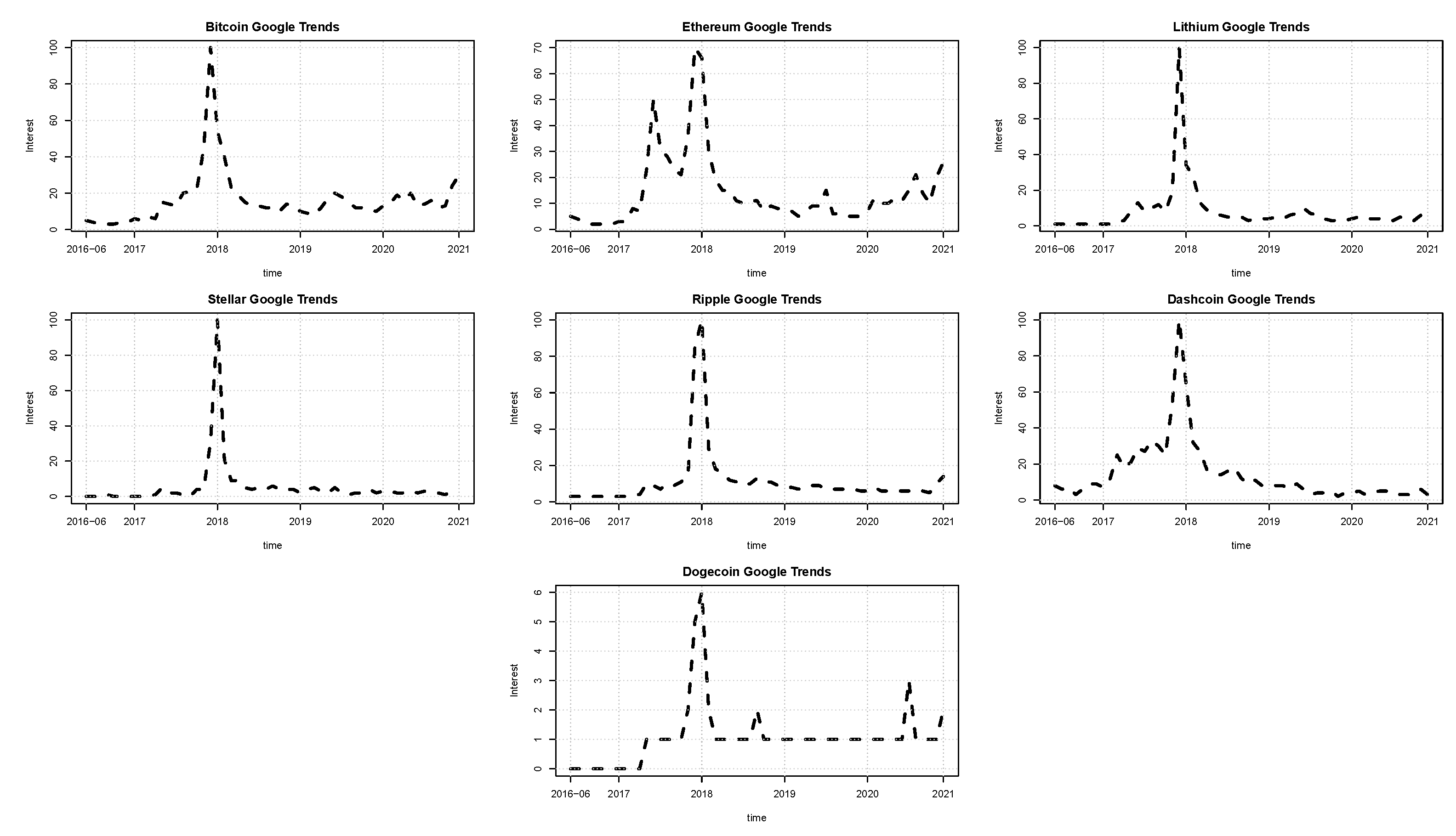
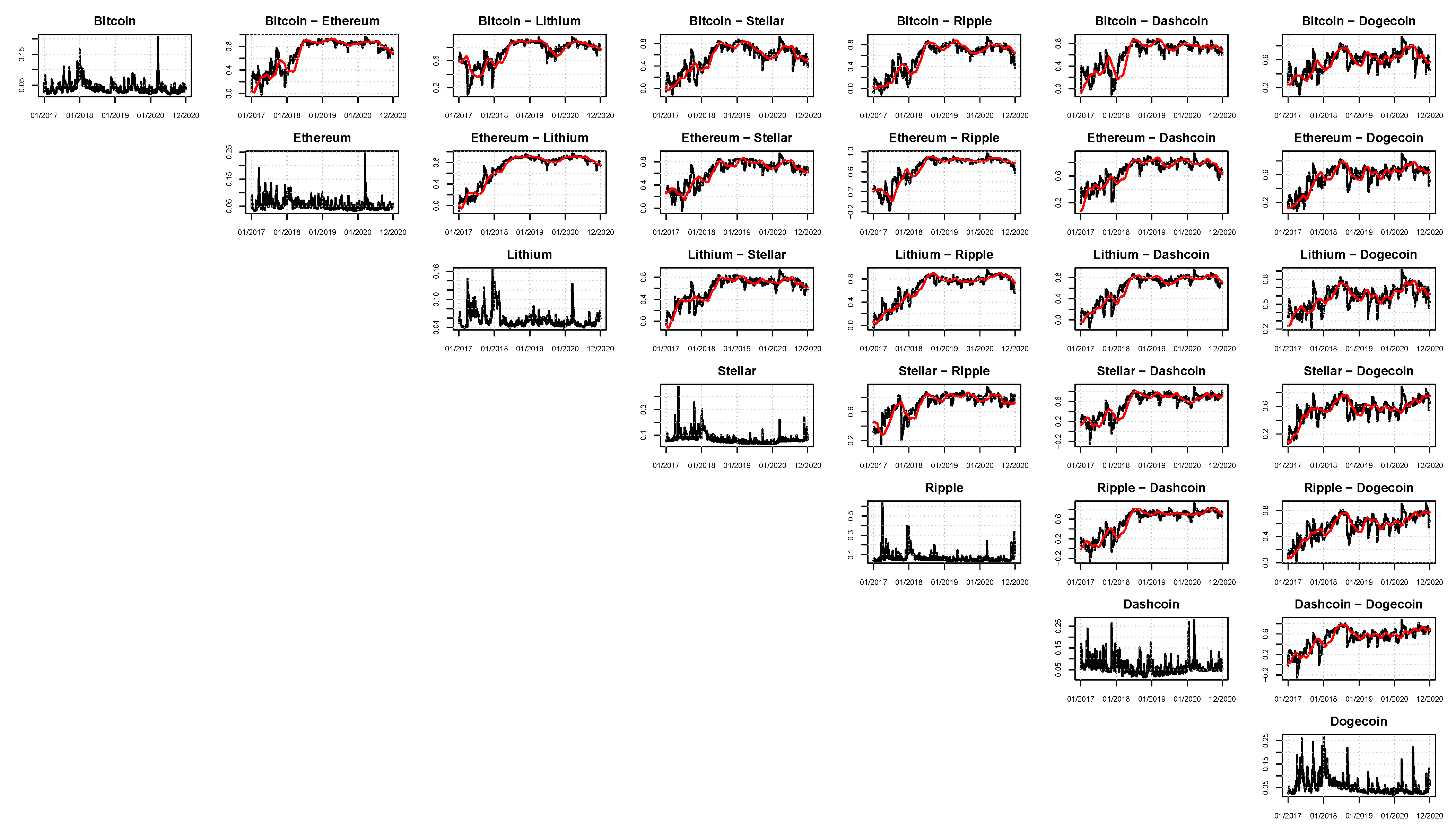
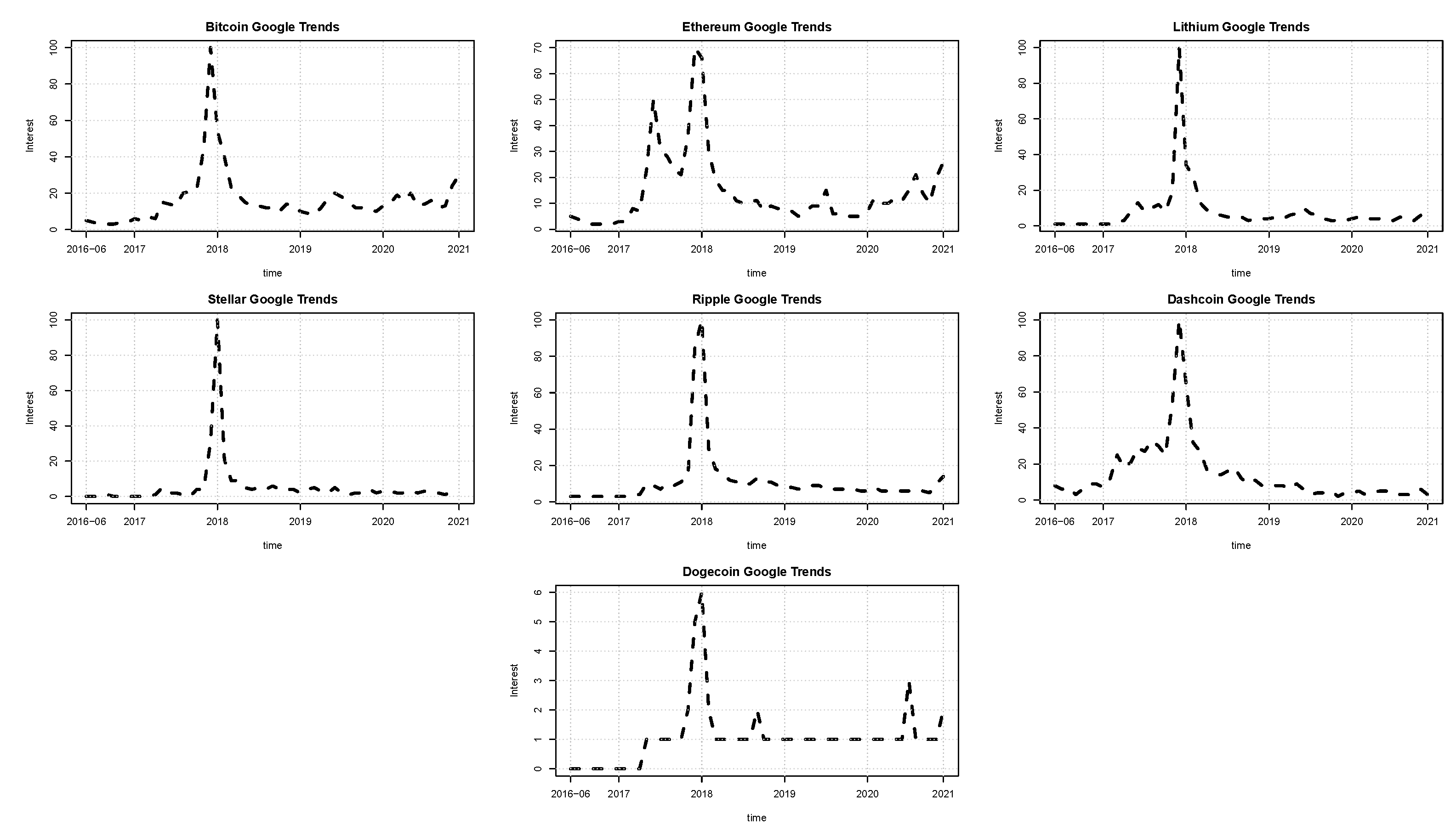
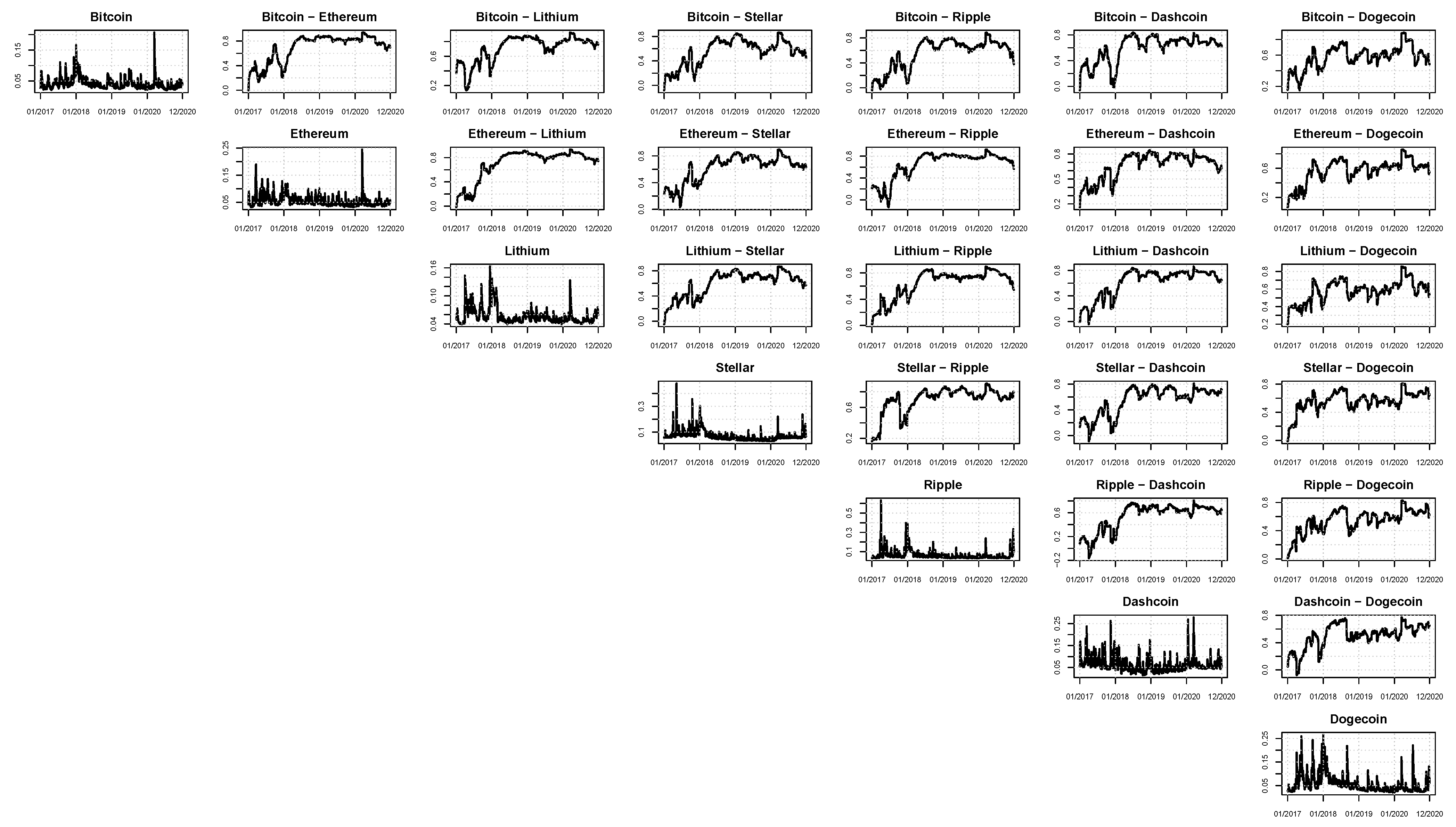
In this work, seven cryptocurrencies were used: Bitcoin, Ethereum, Lithium, Stellar, Ripple, Dashcoin, and Dogecoin. All the quotes for these series were collected from the Yahoo Finance site. The sample period is from June 2016 up to December 2020 for 1671 daily observations. The additional low-frequency volatility determinant is the Google trend series for each cryptocurrency. These Google trend series are reported monthly and enter Equation (12) as the first difference. The patterns of the cryptocurrencies and Google trend prices are illustrated in
Figure 1 and
Figure 2, respectively. In line with the literature, the connection between online searches and the prices’ movements appears evident. As of January 2018, all the online searches present a peak. Correspondingly, all the prices observed in January 2018 are at their maximum.
The main summary statistics for the close-to-close log-returns are reported in
Table 2. All the returns exhibit a high kurtosis, sometimes a very high kurtosis, probably due to some exceptional values. Except for Bitcoin and Ethereum, all the returns are positively skewed. As also discussed in the Introduction, even though alternative approaches dealing with the fat tails and severe skewness are available in the literature, we use the Gaussian distribution for the estimation. Moreover, it has to be remarked that all the standard errors reported are based on Quasi-Maximum Likelihood methods, as was recently done by
Guesmi et al. (
2019), among others. Moreover, once
is achieved, the resulting portfolio VaR will take care of the fat tails of the cryptocurrencies.
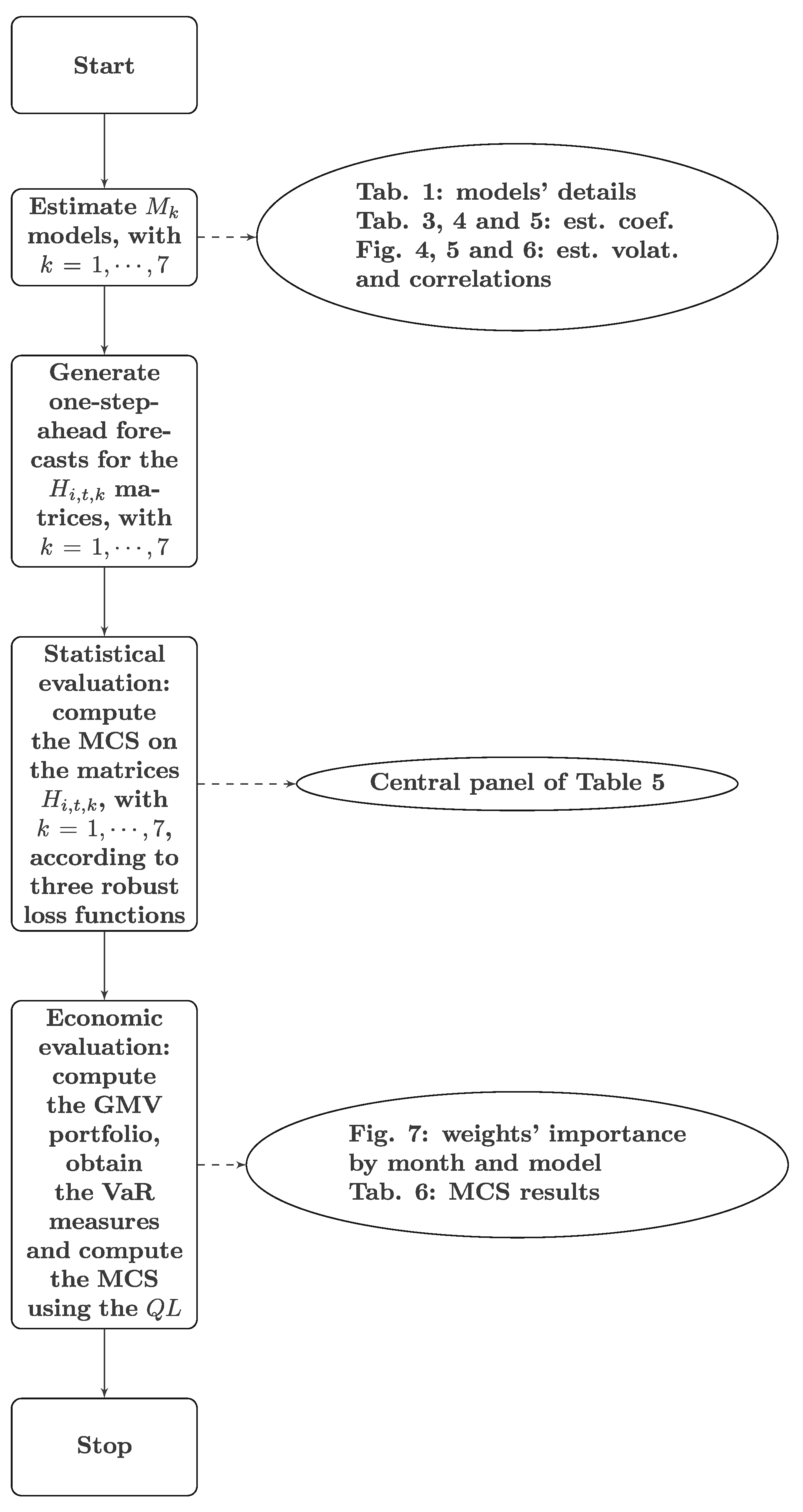
All the estimations performed in this work were executed in R using the package
dccmidas (
Candila 2021). The summary diagram in
Figure 3 illustrates the phases of our research.
The results of the first step, concerning the univariate models, are reported in
Table 3 and
Table 4. The number of lagged realizations of the Google searches entering the long-run equation is
. Interestingly, the parameters associated with the Google searches are almost always all significant. This means that such queries effectively help in estimating the volatility of digital currencies.
Once we obtained the standardized residuals, the second step of the estimation concerns the correlation models, whose estimated coefficients are reported in
Table 5. The same table presents the averages of three robust (
Laurent et al. 2013) loss functions—namely, the Euclidean, Squared Frobenius, and Root Mean Squared Error (RMSE). The losses evaluate the distance of the estimated
1 conditional covariance matrix from the covariance proxy, which is represented by the matrix of the cross-products of
. Finally, the SSM obtained from the MCS is highlighted in shades of gray. Surprisingly, under two out of three losses (i.e., the Euclidean and the Squared Frobenius), all the models using DAGM in the first step are in the SSM. When the RMSE is used, the DAGM-cDCC specification (that is, the model labeled as M4) is the only model belonging to the SSM. Therefore, it appears evident that including the (monthly) Google searches in the first step through a mixed-frequency approach results in better conditional covariance predictions. This observation is corroborated by the results of the
test, which was applied to the standardized residuals obtained after the estimation of the conditional covariance matrix. Remarkably, the null hypothesis of no conditional heteroscedasticity was rejected for models M1, M2, and M3—that is, the parametric models without the Google trend information. Instead, both the parametric models using the MIDAS variable and the RM model do not reject the null hypothesis.
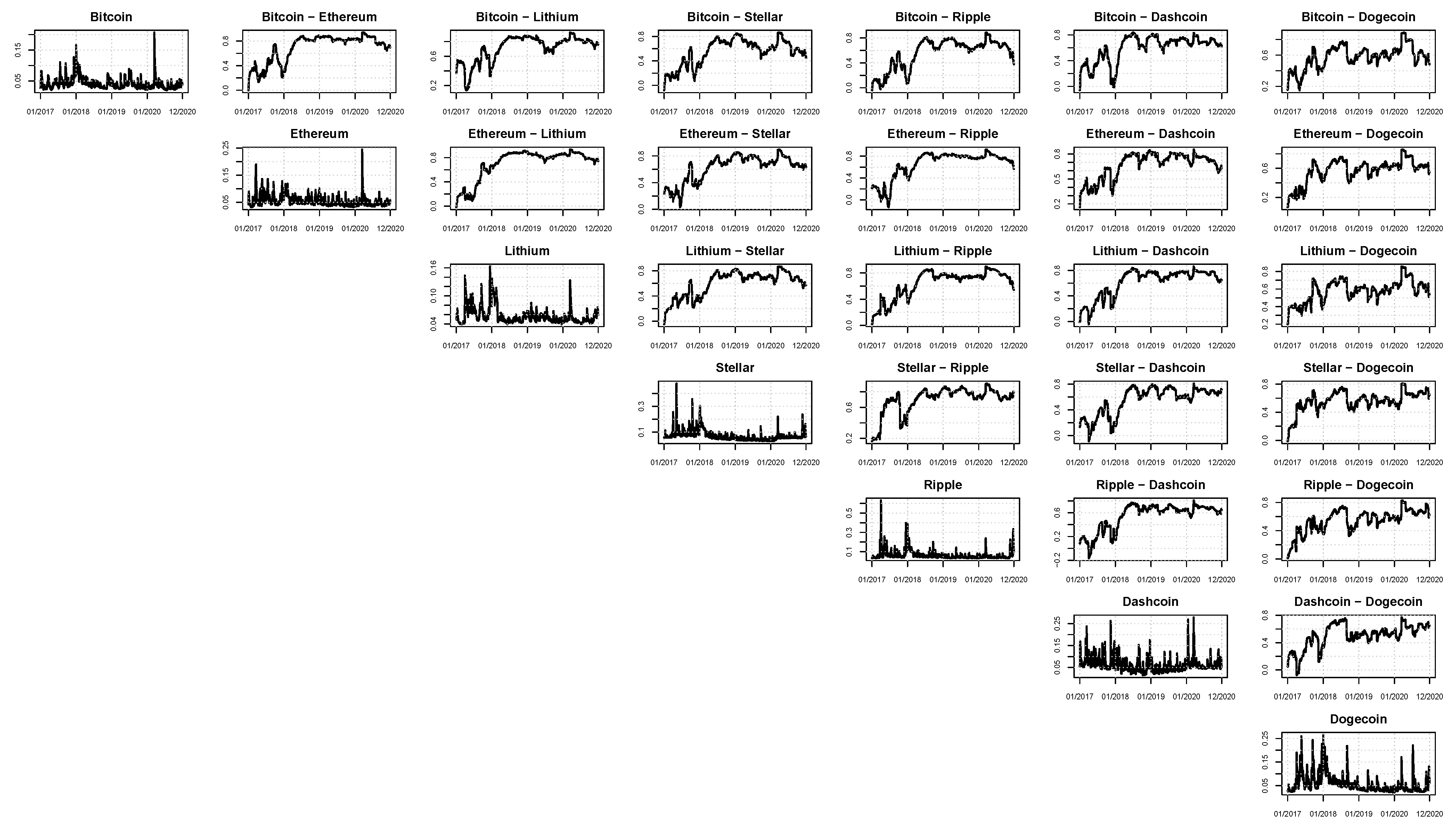
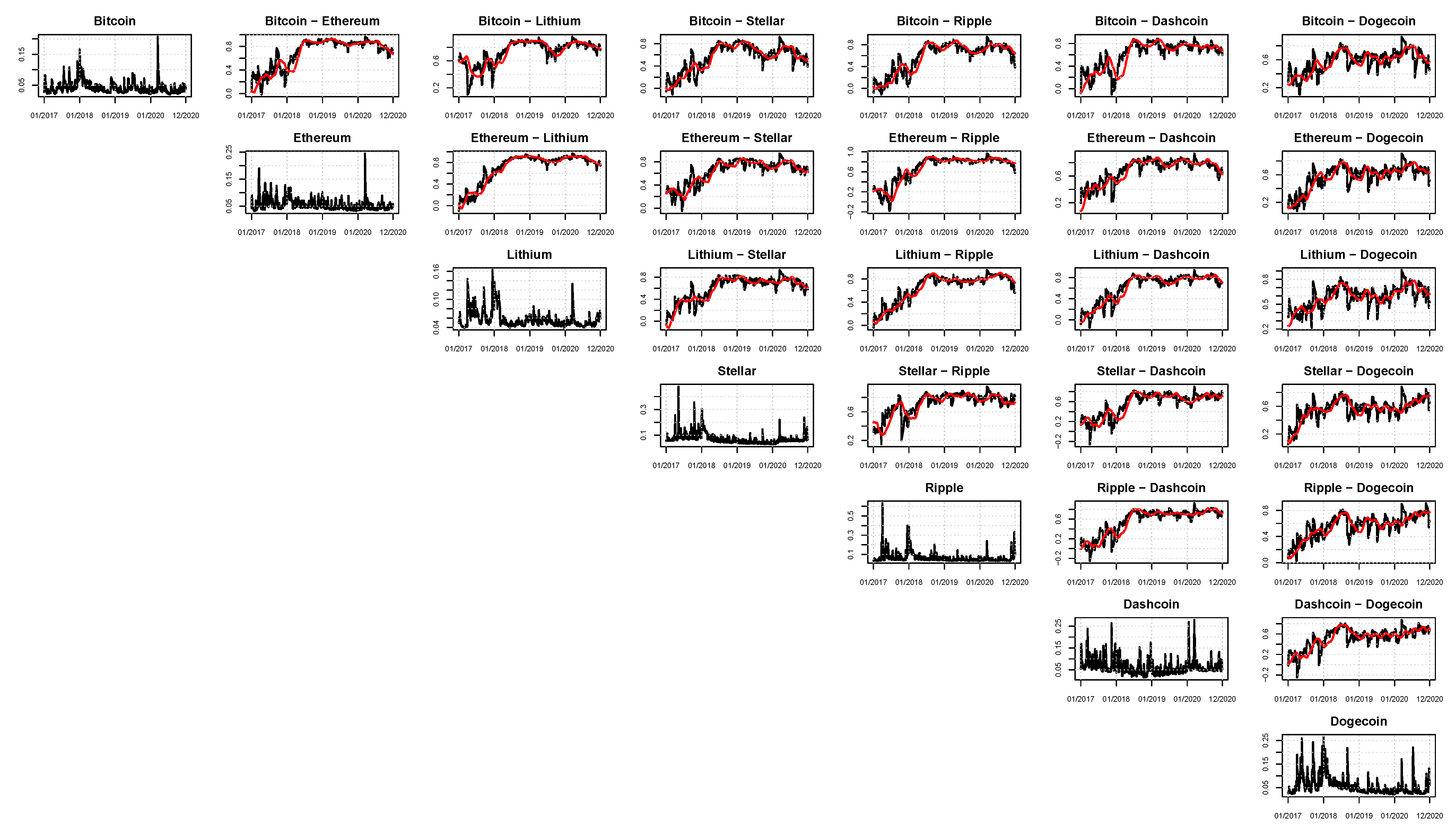
A graphical analysis of the correlation plots of the models belonging to the SSM (according to Euclidean and Squared Frobenius loss functions) is fundamental to visualize the time-varying patterns of the estimated correlations.
Figure 4,
Figure 5 and
Figure 6 are dedicated to these plots, respectively, for models M4 (DAGM + cDCC), M5 (DAGM + DCC-MIDAS), and M6 (DAGM + DECO). Independently of the model adopted for the correlations, all the cryptocurrencies appear to be highly correlated. In particular, if the correlations seem low at the beginning of the considered sample, during the last period the digital currencies exhibit larger and generally very high interdependencies, almost always ranging between 0.6 and 0.8. From a portfolio manager’s perspective, these interconnections are fundamental to deciding the assets in which to invest.
The last part of our analysis concerns the economic evaluation of the models. In particular, starting from each conditional covariance matrix
, we calculated the optimal (daily) weights minimizing the portfolio variance (
Markowitz 1952), as has also been done by
Symitsi and Chalvatzis (
2019), where the portfolio investigated consists of Bitcoin and other asset classes.
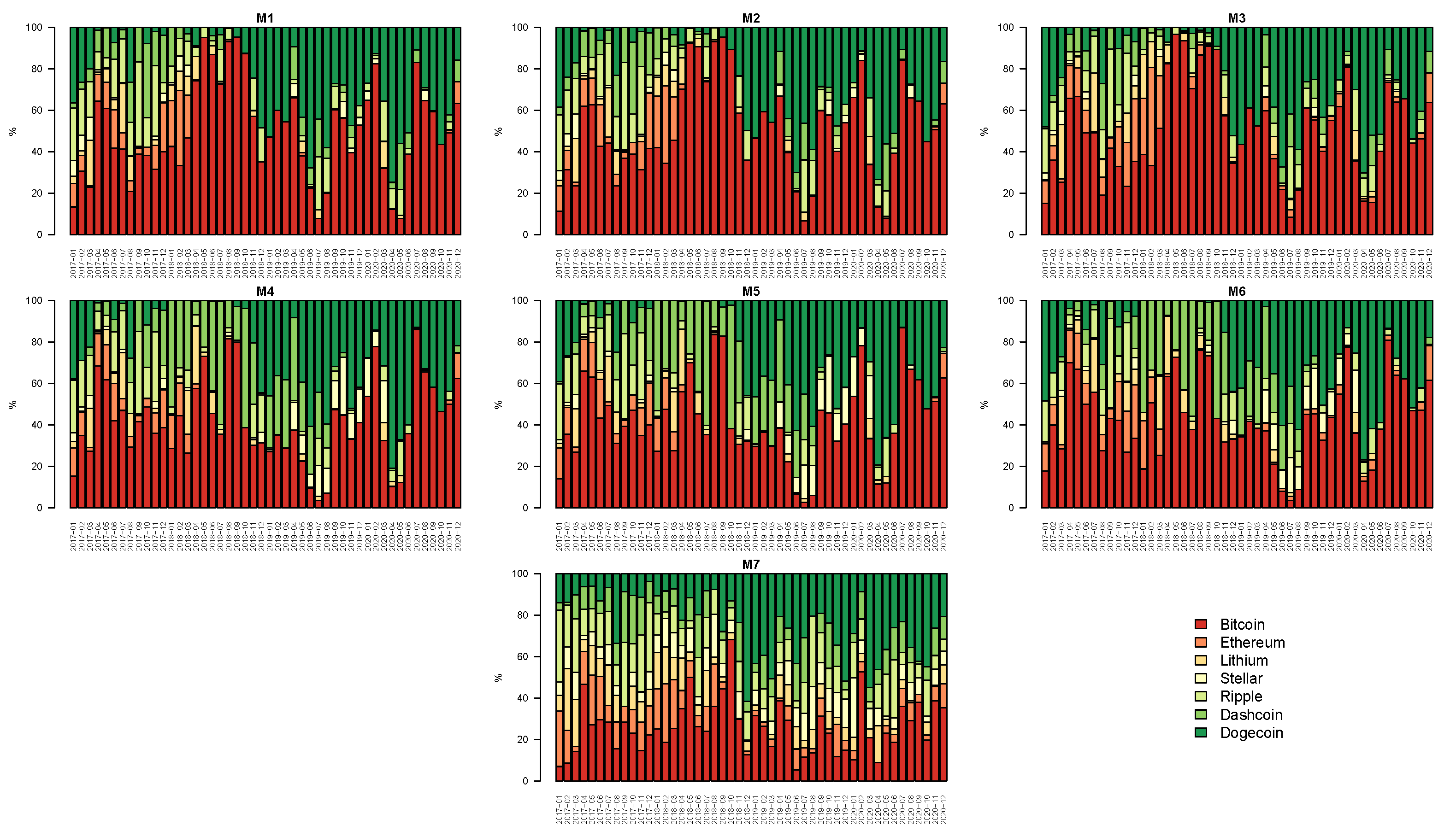
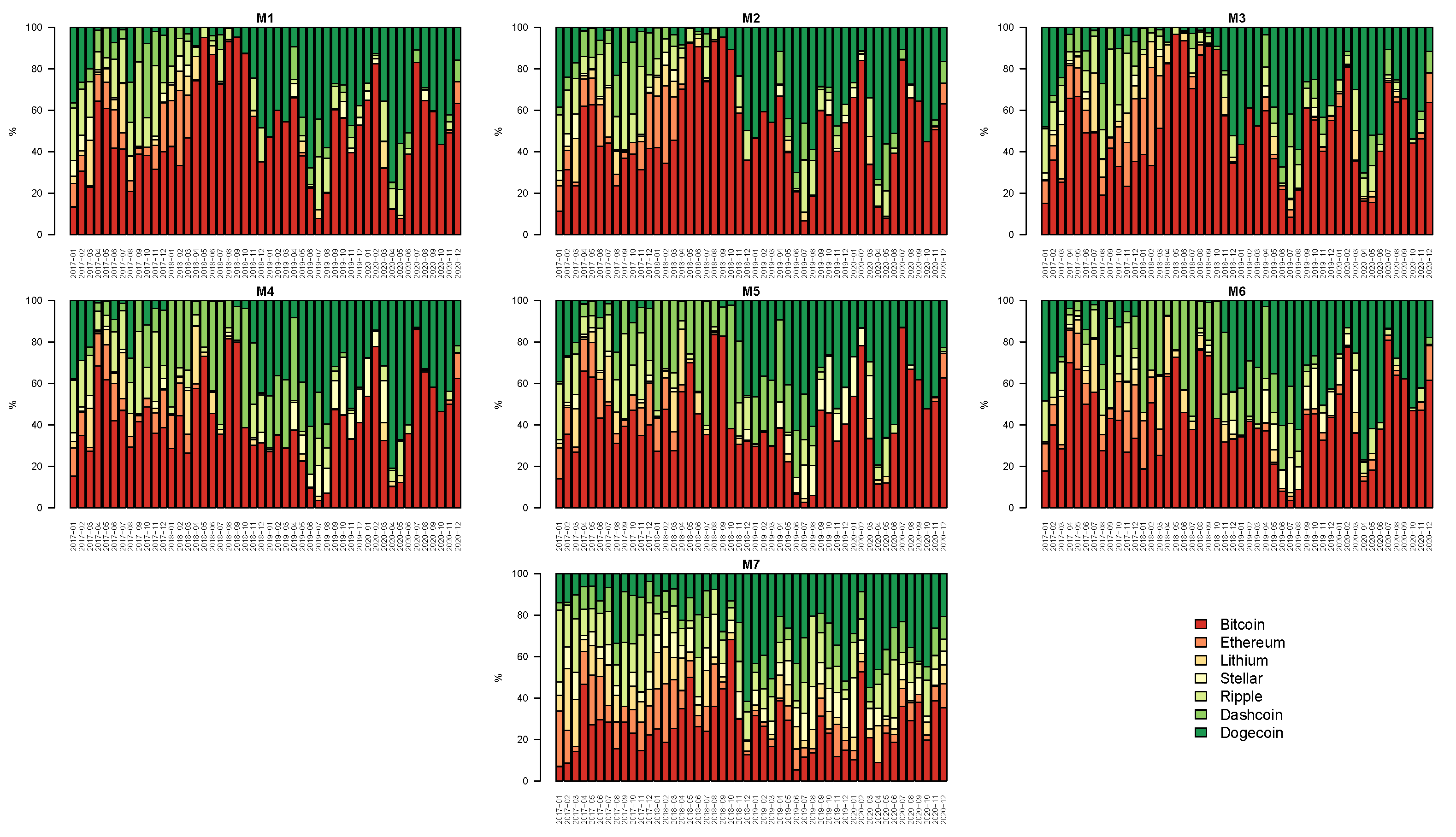
Figure 7 summarizes the patterns of the estimated weights across time, cryptocurrencies, and models. Similar to
Cipollini et al. (
2021), each bar in the figure represents the rescaled summation of the daily weights by month. Overall, it can be noted that the GMV portfolio is mainly made up of Bitcoin for the parametric models. In other words, Bitcoin has the largest importance relative to the other digital currencies in the GMV portfolio. The optimal weights are then used for obtaining the portfolio return and variance. In particular, we calculated the VaR at
level using the following parametric (
Jorion 1997) approach:
where
is the conditional mean of the portfolio,
is the portfolio standard deviation, and
is the inverse of Student’s
t cumulative density function with
degrees of freedom. Note that in Equation (
15), we use a Student’s
t distribution to explicitly take into account the fat tails of the cryptocurrencies. Finally, each VaR series coming from models M1 to M7 is evaluated through the MCS procedure using the following quantile loss (
), as in
González-Rivera et al. (
2004):
where
is the portfolio return and
is an indicator function that is equal to one if the argument is true. The estimations of the degrees of freedom
, as well as the results of the MCS tests, are reported in
Table 6. The VaR series are calculated according to three different
levels: 0.01, 0.05, and 0.10. The estimated degrees of freedom
are very low, which is in agreement with the fat tails reported in
Table 2. Interestingly, all the models belonging to the SSM as described by the statistical evaluation are again included in the SSM. To conclude, the inclusion of the Google trends in the univariate part of the DCC specifications dramatically improves the performance of the models from statistical and economic points of view.
4. Conclusions
The literature on financial econometrics has recently shown an enormous interest in cryptocurrencies. The first and most well-known digital currency, Bitcoin, dates back to 2009; today, thousands of cryptocurrencies are traded. From this aspect, cryptocurrencies can be used for speculative or hedging purposes. For this reason, investigating the volatility as well as the correlations of digital currencies appears to be extremely important. Although there are several contributions concerning the cryptocurrencies’ single variability and co-movements, the interdependencies of the daily cryptocurrencies potentially driven by additional variables, observed at lower frequencies, still remain unexplored. This paper aims to fill this gap. In particular, this work aims to estimate the conditional covariance matrix for a panel of cryptocurrencies using some specifications belonging to the Dynamic Conditional Correlation (DCC) class of models. The original contribution of this paper is the inclusion of the monthly Google queries regarding the cryptocurrencies as an additional volatility determinant in the DCC models’ univariate step. The inclusion of the monthly Google searches in models where the dependent variable is observed daily took place using the mixed-frequency proposed by
Ghysels et al. (
2007). In particular, for the first time, the Double Asymmetric GARCH–MIDAS (
Amendola et al. 2019) was inserted within some DCC specifications. In doing so, the daily conditional covariance matrices also depended on the additional MIDAS variable—that is, the (first difference of the) Google trends. Once the time series of the conditional covariance matrices were obtained, statistical and economic evaluations of all the specifications employed were carried out. Both the evaluations were based on the selection of the set of superior models (SSM) according to the Model Confidence Set (MCS,
Hansen et al. 2011) procedure. The statistical evaluation used robust (
Laurent et al. 2013) loss functions. The economic evaluation was based on the estimation of the global minimum variance (GMV) portfolio, and then, on the analysis of the resulting Value-at-Risk (VaR). In terms of results, we found that the mixed-frequency approach provided good performances from both the statistical and economic perspectives. In particular, only the models employing the monthly Google searches belonged to the SSM. Instead, the excluded models were the DCC-based models using the simple GARCH specification for the univariate step and the RiskMetrics specification. The time-varying correlations of the models from the SSM showed that all the cryptocurrencies co-move together, mainly in the last part of the considered sample (June 2016–December 2020). In particular, the estimated correlations generally varied between 0.6 and 0.8, mainly in 2020. The economic analysis largely confirmed what was found in the statistical evaluation. In greater detail, the parametric approach was used to calculate the VaR of the GMV portfolio, with specific attention paid to the fat tails of the cryptocurrencies. Then, the VaR measures were evaluated through the MCS procedure according to the quantile loss (
González-Rivera et al. 2004). Interestingly, again all the models based on a mixed-frequency approach entered the SSM. Last but not least, Bitcoin was the digital currency with the largest share in the considered GMV portfolio, independently of the specifications adopted.
Future research could enlarge the set of assets under investigation by including, for instance, standard currencies as well. Moreover, using different portfolio strategies could also be extremely useful. Furthermore, adopting some rolling forecasting schemes would be interesting. Finally, the multivariate models could also include specifications able to deal with the typical skewness and high kurtosis of the cryptocurrencies, such as the copula-based multivariate GARCH model of
Lee and Long (
2009) or the approach proposed by
Paolella and Polak (
2015) and then generalized in
Paolella et al. (
2019).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}