


Spatiotemporal Typhoon Damage Assessment: A Multi-Task Learning Method for Location Extraction and Damage Identification from Social Media Texts




Abstract
1. Introduction
2. Materials and Methods
2.1. Experimental Data
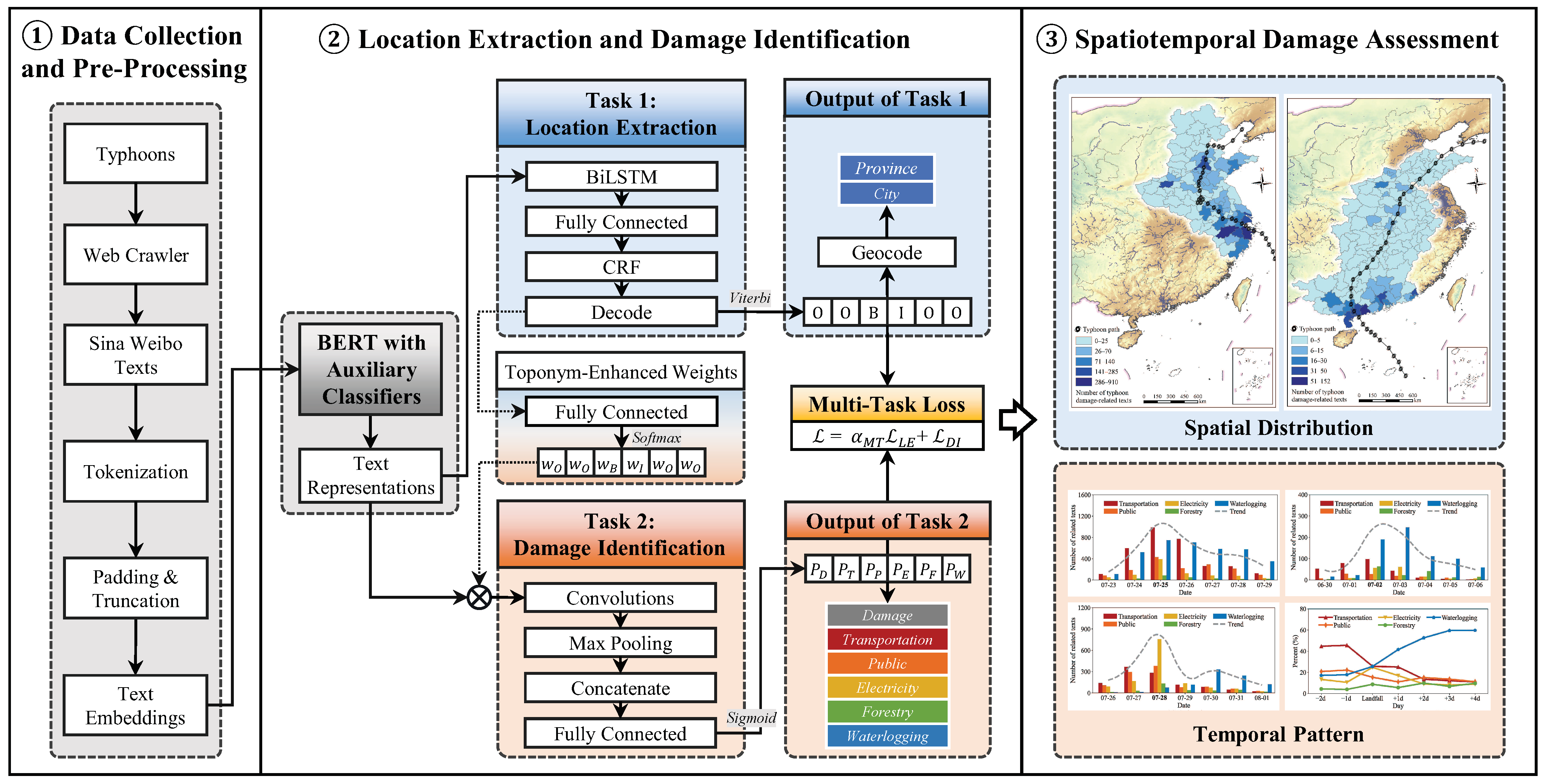
2.1.1. Data Collection and Pre-Processing
2.1.2. Experimental Datasets
2.2. Methodology
2.2.1. BERT with Auxiliary Classifiers
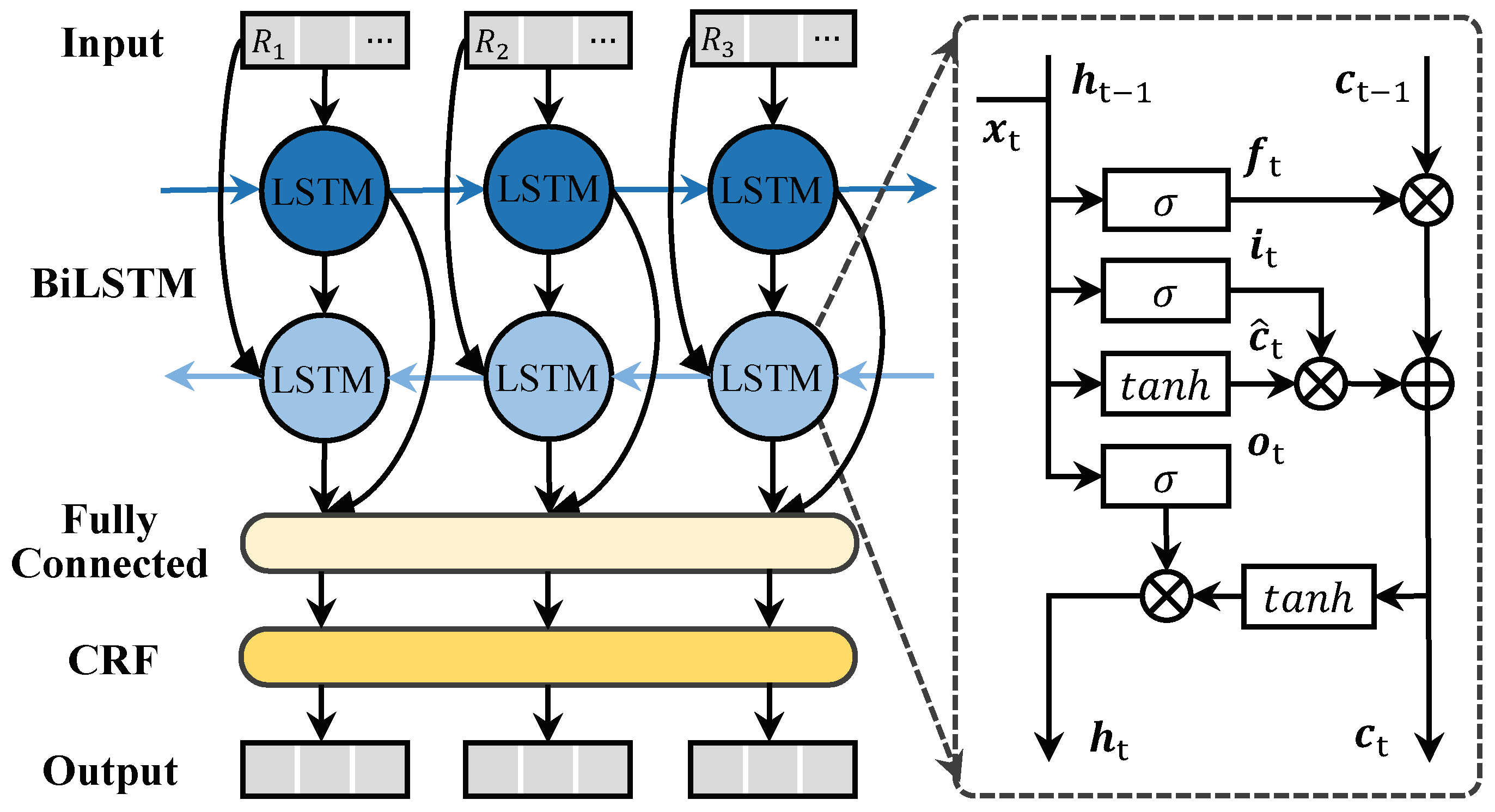
2.2.2. Location Extraction
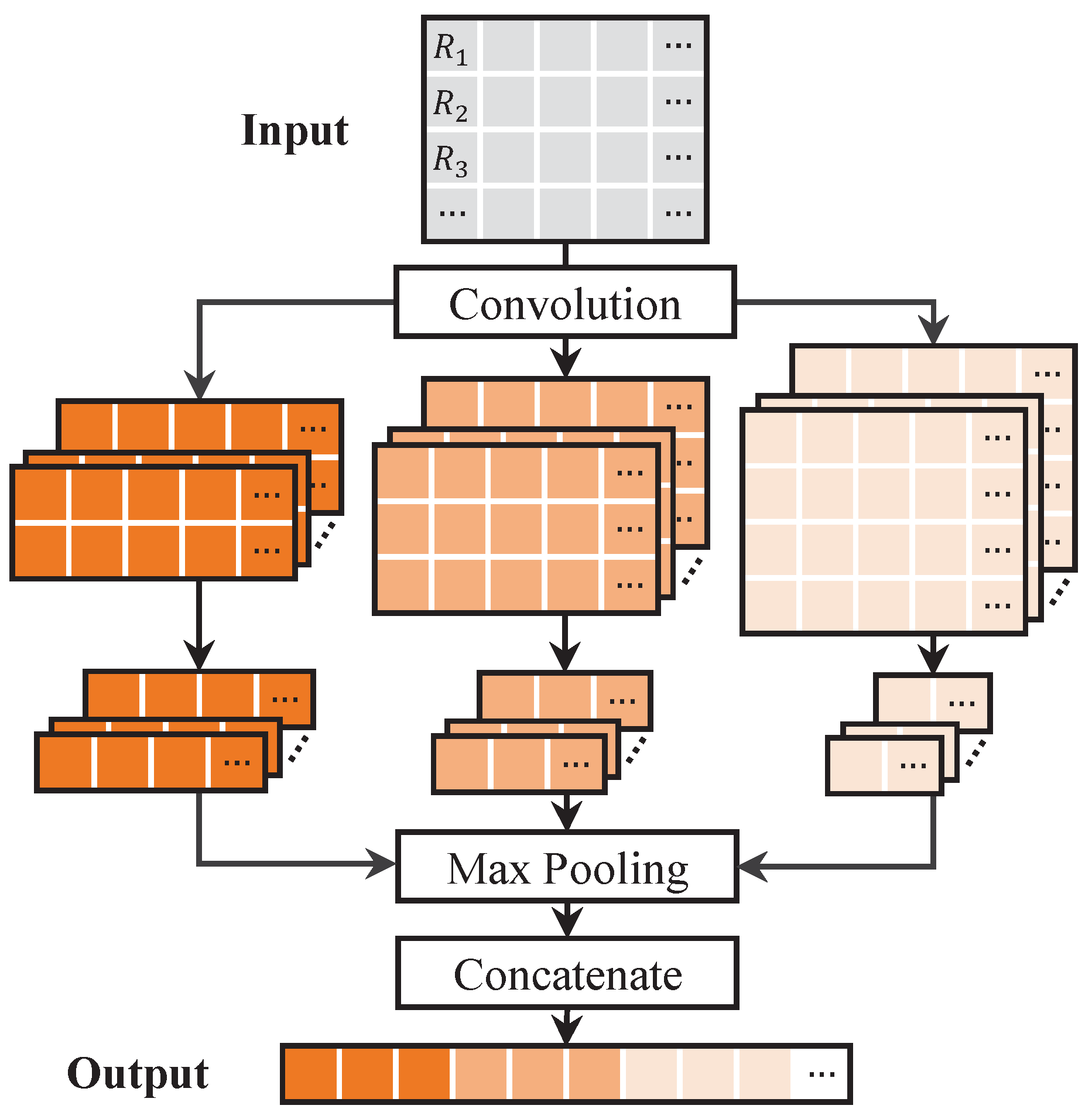
2.2.3. Damage Identification
2.2.4. Multi-Task Learning Framework
2.2.5. Experiment Designs and Model Evaluation
3. Results
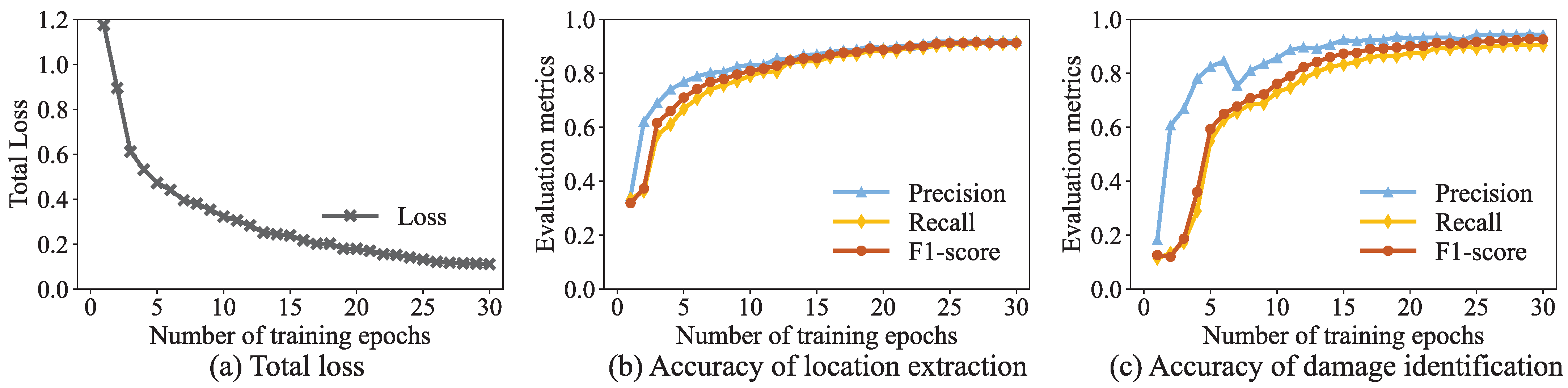
3.1. Model Performance
3.2. Spatial Distribution of Typhoon Damage
3.3. Temporal Pattern of Typhoon Damage
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cao, T.M.; Lee, S.H.; Lee, J.Y. The Impact of Natural Disasters and Pest Infestations on Technical Efficiency in Rice Production: A Study in Vietnam. Sustainability 2023, 15, 11633. [Google Scholar] [CrossRef]
- Bachmann, L.; Lex, R.; Regli, F.; Vögeli, S.; Mühlhofer, E.; McCaughey, J.W.; Hanger-Kopp, S.; Bresch, D.N.; Kropf, C.M. Climate-Resilient Strategy Planning Using the Swot Methodology: A Case Study of the Japanese Wind Energy Sector. Clim. Risk Manag. 2024, 46, 100665. [Google Scholar] [CrossRef]
- Jalloul, H.; Choi, J.; Yesiller, N.; Manheim, D.; Derrible, S. A Systematic Approach to Identify, Characterize, And Prioritize the Data Needs for Quantitative Sustainable Disaster Debris Management. Resour. Conserv. Recycl. 2022, 180, 106174. [Google Scholar] [CrossRef]
- Sahana, M.; Patel, P.P.; Rehman, S.; Rahaman, M.H.; Masroor, M.; Imdad, K.; Sajjad, H. Assessing the Effectiveness of Existing Early Warning Systems and Emergency Preparedness Towards Reducing Cyclone-Induced Losses in the Sundarban Biosphere Region, India. Int. J. Disaster Risk Reduct. 2023, 90, 103645. [Google Scholar] [CrossRef]
- Lam, N.S.; Meyer, M.; Reams, M.; Yang, S.; Lee, K.; Zou, L.; Mihunov, V.; Wang, K.; Kirby, R.; Cai, H. Improving Social Media Use for Disaster Resilience: Challenges and Strategies. Int. J. Digit. Earth 2023, 16, 3023–3044. [Google Scholar] [CrossRef]
- Robinson, S.a. Patterns of Hurricane Induced Displacement in the Bahamas: Building Equitable Resilience in Small Island Developing States. Clim. Risk Manag. 2024, 45, 100634. [Google Scholar] [CrossRef]
- Rodríguez, O.; Bech, J.; Soriano, J.d.D.; Gutiérrez, D.; Castán, S. A Methodology to Conduct Wind Damage Field Surveys for High-Impact Weather Events of Convective Origin. Nat. Hazards Earth Syst. Sci. 2020, 20, 1513–1531. [Google Scholar] [CrossRef]
- Chen, X.; Avtar, R.; Umarhadi, D.A.; Louw, A.S.; Shrivastava, S.; Yunus, A.P.; Khedher, K.M.; Takemi, T.; Shibata, H. Post-Typhoon Forest Damage Estimation Using Multiple Vegetation Indices and Machine Learning Models. Weather Clim. Extrem. 2022, 38, 100494. [Google Scholar] [CrossRef]
- Zhou, C.; He, Z.; Lai, G.; Plaza, A. A Selective Semantic Transformer for Spectral Super-Resolution of Multispectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 7436–7450. [Google Scholar] [CrossRef]
- Li, S.; Lin, Y.; Huang, H. Relief Supply-Demand Estimation Based on Social Media in Typhoon Disasters Using Deep Learning and a Spatial Information Diffusion Model. ISPRS Int. J. Geo-Inf. 2024, 13, 29. [Google Scholar] [CrossRef]
- Hou, R.; Lian, P.; Han, Z.; Yan, A. Differences in Disaster Warning and Community Engagement Between Families with and Without Members Suffering from Chronic Diseases: The Mediating Role of Satisfaction with Warning Service. Clim. Risk Manag. 2024, 44, 100607. [Google Scholar] [CrossRef]
- Shen, S.; Huang, J.; Cheng, C.; Zhang, T.; Murzintcev, N.; Gao, P. Spatiotemporal evolution of the online social network after a natural disaster. ISPRS Int. J. Geo-Inf. 2021, 10, 744. [Google Scholar] [CrossRef]
- Karimiziarani, M.; Shao, W.; Mirzaei, M.; Moradkhani, H. Toward Reduction of Detrimental Effects of Hurricanes Using a Social Media Data Analytic Approach: How Climate Change Is Perceived? Clim. Risk Manag. 2023, 39, 100480. [Google Scholar] [CrossRef]
- Lu, X.; Chan, F.K.S.; Chan, H.K.; Chen, W.Q. Mitigating Flood Impacts on Road Infrastructure and Transportation by Using Multiple Information Sources. Resour. Conserv. Recycl. 2024, 206, 107607. [Google Scholar] [CrossRef]
- Du, W.; Xia, Q.; Cheng, B.; Xu, L.; Chen, Z.; Zhang, X.; Huang, M.; Chen, N. Flood Inundation Probability Estimation by Integrating Physical and Social Sensing Data: Case Study of 2021 Heavy Rainfall in Henan, China. Remote Sens. 2024, 16, 2734. [Google Scholar] [CrossRef]
- Huang, S.; Du, Y.; Yi, J.; Liang, F.; Qian, J.; Wang, N.; Tu, W. Understanding human activities in response to typhoon Hato from multi-source geospatial big data: A case study in Guangdong, China. Remote Sens. 2022, 14, 1269. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Preprint, 2018; work in progress. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Koroteev, M.V. BERT: A Review of Applications in Natural Language Processing and Understanding. arXiv 2021, arXiv:2103.11943. [Google Scholar] [CrossRef]
- Zhou, C.; Li, Q.; Li, C.; Yu, J.; Liu, Y.; Wang, G.; Zhang, K.; Ji, C.; Yan, Q.; He, L.; et al. A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT. arXiv 2023, arXiv:2302.09419. [Google Scholar] [CrossRef]
- Liu, N.F.; Gardner, M.; Belinkov, Y.; Peters, M.E.; Smith, N.A. Linguistic Knowledge and Transferability of Contextual Representations. arXiv 2019, arXiv:1903.08855. [Google Scholar] [CrossRef]
- Zou, L.; He, Z.; Zhou, C.; Zhu, W. Multi-class Multi-label Classification of Social Media Texts for Typhoon Damage Assessment: A Two-Stage Model Fully Integrating the Outputs of the Hidden Layers of BERT. Int. J. Digit. Earth 2024, 17, 2348668. [Google Scholar] [CrossRef]
- Hu, X.; Zhou, Z.; Li, H.; Hu, Y.; Gu, F.; Kersten, J.; Fan, H.; Klan, F. Location Reference Recognition from Texts: A Survey and Comparison. ACM Comput. Surv. 2023, 56, 1–37. [Google Scholar] [CrossRef]
- Al-Olimat, H.S.; Thirunarayan, K.; Shalin, V.; Sheth, A. Location Name Extraction from Targeted Text Streams Using Gazetteer-Based Statistical Language Models. arXiv 2017, arXiv:1708.03105. [Google Scholar]
- Hu, X.; Al-Olimat, H.S.; Kersten, J.; Wiegmann, M.; Klan, F.; Sun, Y.; Fan, H. GazPNE: Annotation-Free Deep Learning for Place Name Extraction from Microblogs Leveraging Gazetteer and Synthetic Data by Rules. Int. J. Geogr. Inf. Sci. 2022, 36, 310–337. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, J.P. Location Reference Identification from Tweets During Emergencies: A Deep Learning Approach. Int. J. Disaster Risk Reduct. 2019, 33, 365–375. [Google Scholar] [CrossRef]
- Zhou, B.; Zou, L.; Hu, Y.; Qiang, Y.; Goldberg, D. TopoBERT: A Plug and Play Toponym Recognition Module Harnessing Fine-Tuned BERT. Int. J. Digit. Earth 2023, 16, 3045–3064. [Google Scholar] [CrossRef]
- Mao, H.; Thakur, G.; Sparks, K.; Sanyal, J.; Bhaduri, B. Mapping Near-Real-Time Power Outages from Social Media. In Social Sensing and Big Data Computing for Disaster Management; Routledge: Abingdon, UK, 2020; pp. 88–102. [Google Scholar]
- Qiu, Q.; Zheng, S.; Tian, M.; Li, J.; Ma, K.; Tao, L.; Xie, Z. A Deep Neural Network Model for Chinese Toponym Matching with Geographic Pre-Training Model. Int. J. Digit. Earth 2024, 17, 2353111. [Google Scholar] [CrossRef]
- Ma, K.; Tan, Y.; Xie, Z.; Qiu, Q.; Chen, S. Chinese Toponym Recognition with Variant Neural Structures from Social Media Messages Based on BERT Methods. J. Geogr. Syst. 2022, 24, 143–169. [Google Scholar] [CrossRef]
- Qiu, Q.; Xie, Z.; Wang, S.; Zhu, Y.; Lv, H.; Sun, K. ChineseTR: A Weakly Supervised Toponym Recognition Architecture Based on Automatic Training Data Generator and Deep Neural Network. Trans. GIS. 2022, 26, 1256–1279. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning–Based Text Classification: A Comprehensive Review. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Liu, W.; Wang, H.; Shen, X.; Tsang, I.W. The Emerging Trends of Multi-label Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7955–7974. [Google Scholar] [CrossRef]
- Huang, X.; Li, Z.; Wang, C.; Ning, H. Identifying Disaster Related Social Media for Rapid Response: A Visual-Textual Fused CNN Architecture. Int. J. Digit. Earth 2020, 13, 1017–1039. [Google Scholar] [CrossRef]
- Magalhães, D.; Lima, R.H.; Pozo, A. Creating Deep Neural Networks for Text Classification Tasks Using Grammar Genetic Programming. Appl. Soft Comput. 2023, 135, 110009. [Google Scholar] [CrossRef]
- Du, J.; Vong, C.M.; Chen, C.P. Novel Efficient RNN and LSTM-Like Architectures: Recurrent and Gated Broad Learning Systems and Their Applications for Text Classification. IEEE Trans. Cybern. 2020, 51, 1586–1597. [Google Scholar] [CrossRef]
- Wu, M.; Long, R.; Chen, F.; Chen, H.; Bai, Y.; Cheng, K.; Huang, H. Spatio-Temporal Difference Analysis in Climate Change Topics and Sentiment Orientation: Based on LDA and BiLSTM Model. Resour. Conserv. Recycl. 2023, 188, 106697. [Google Scholar] [CrossRef]
- Huang, H.; Long, R.; Chen, H.; Sun, K.; Sun, Q.; Li, Q. Examining Public Attitudes and Perceptions of Waste Sorting in China Through an Urban Heterogeneity Lens: A Social Media Analysis. Resour. Conserv. Recycl. 2023, 199, 107233. [Google Scholar] [CrossRef]
- Fan, K.; Li, D.; Wu, H.; Wang, Y.; Yu, H.; Zeng, Z. Extracting and Evaluating Typical Characteristics of Rural Revitalization Using Web Text Mining. Int. J. Geogr. Inf. Sci. 2024, 38, 297–321. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. A Survey on Multi-task Learning. IEEE Trans. Knowl. Data Eng. 2021, 34, 5586–5609. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhang, Z.; Tang, P.; Wang, X.; Cui, L. MT-GN: Multi-task-Learning-Based Graph Residual Network for Tropical Cyclone Intensity Estimation. Remote Sens. 2024, 16, 215. [Google Scholar] [CrossRef]
- Myint, P.Y.W.; Lo, S.L.; Zhang, Y. Unveiling the Dynamics of Crisis Events: Sentiment and Emotion Analysis via Multi-Task Learning with Attention Mechanism and Subject-Based Intent Prediction. Inf. Process. Manag. 2024, 61, 103695. [Google Scholar] [CrossRef]
- Xie, J.; Zhou, K.; Chen, H.; Han, L.; Guan, L.; Wang, M.; Zheng, Y.; Chen, H.; Mao, J. Multi-Task Learning for Tornado Identification Using Doppler Radar Data. Geophys. Res. Lett. 2024, 51, e2024GL108809. [Google Scholar] [CrossRef]
- Shi, Y.; Shi, Y.; Yao, D.; Lu, M.; Liang, Y. Adaptive Transformer-Based Multi-Task Learning Framework for Synchronous Prediction of Substation Flooding and Outage Risks. Electr. Power Syst. Res. 2025, 242, 111450. [Google Scholar] [CrossRef]
- Hu, Y.; Mai, G.; Cundy, C.; Choi, K.; Lao, N.; Liu, W.; Lakhanpal, G.; Zhou, R.Z.; Joseph, K. Geo-Knowledge-Guided GPT Models Improve the Extraction of Location Descriptions from Disaster-Related Social Media Messages. Int. J. Geogr. Inf. Sci. 2023, 37, 2289–2318. [Google Scholar] [CrossRef]
- Zhang, T.; Cheng, C. Temporal and Spatial Evolution and Influencing Factors of Public Sentiment in Natural Disasters—A Case Study of Typhoon Haiyan. ISPRS Int. J. Geo-Inf. 2021, 10, 299. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, X.; Li, S.; Ding, S.; Tan, C.; Wu, C.; Shen, Y.S.; Xu, L. Do Typhoon Disasters Foster Climate Change Concerns? Evidence from Public Discussions on Social Media in China. Int. J. Disaster Risk Reduct. 2024, 111, 104693. [Google Scholar] [CrossRef]
- Li, J.; He, Z.; Plaza, J.; Li, S.; Chen, J.; Wu, H.; Wang, Y.; Liu, Y. Social Media: New Perspectives to Improve Remote Sensing for Emergency Response. Proc. IEEE 2017, 105, 1900–1912. [Google Scholar] [CrossRef]
- Wieland, M.; Schmidt, S.; Resch, B.; Abecker, A.; Martinis, S. Fusion of Geospatial Information from Remote Sensing and Social Media to Prioritise Rapid Response Actions in Case of Floods. Nat. Hazard. 2025, 1–28. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Typhoon | Landfall Time | Time Scope | Number of Texts |
|---|---|---|---|
| In-fa | 25 July 2021 | 23–29 July 2021 | 11,020 |
| Chaba | 2 July 2022 | 30 June–6 July 2022 | 13,391 |
| Doksuri | 28 July 2023 | 26 July–1 August 2023 | 6968 |
| Category | Description | Example |
|---|---|---|
| Damage | Impact on natural environment and societal function |
台风好强,树倒路塌,只能在家里避风。 (The typhoon is so strong that the trees fall down and the roads collapse, so we have to take shelter at home.) |
| Transportation | Suspension of public transport, traffic jam |
风大雨大,地铁停运了。 (It’s windy and rainy. The underground is out of service.) |
| Public | Suspension of work, production, or school, event postponed |
台风快要来了,我们暑假补习班通知停课。 (The typhoon is coming soon, our tutorial classes are closed.) |
| Electricity | Power outage |
小区两栋楼停电,台风天真倒霉。 (Two buildings in the neighbourhood are without power. It’s bad luck on a typhoon day.) |
| Forestry | Destruction of forest or trees |
台风过境,大片路树倒伏。 (A large number of roadside trees fall down as the typhoon passes through.) |
| Waterlogging | Flooded ground |
隧道积水,请过往司机绕路通行。 (The tunnel is waterlogged and passing drivers are advised to take a detour.) |
| Text | D | T | P | E | F | W |
|---|---|---|---|---|---|---|
| 最近要来台风,出门记得带雨伞,注意防范。 (A typhoon is coming lately, so remember to bring an umbrella when you go out and take precautions.) | 0 | 0 | 0 | 0 | 0 | 0 |
| 台风虽然让我提前结束工作,但回家路上树倒了好多,桥被封了,家里还停电。台风快结束吧! (The typhoon ended my work early, but there were so many trees down on the way home, bridges were closed, and the power was out at home. Let the typhoon end soon!) | 1 | 1 | 1 | 1 | 1 | 0 |
| 公路积水,无法通行,路边的树一路倒,这台风来势真凶。 (The roads are waterlogged and impassable, trees are falling all the way along the roadside, this typhoon is really fierce.) | 1 | 1 | 0 | 0 | 1 | 1 |
| 好烦哦,为了预防台风已经停课了,但今天只停电没下雨。 (It’s so annoying that classes have been closed in case of a typhoon, but today it’s only power outages and no rain.) | 1 | 0 | 1 | 1 | 0 | 0 |
| Component | Location Extraction | Damage Identification | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Multi-Task Learning | Auxiliary Classifiers | Toponym-Enhanced Weights | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| 1 | ✗ | ✗ | ✗ | 0.875 | 0.834 | 0.854 | 0.885 | 0.872 | 0.876 |
| 2 | ✓ | ✗ | ✗ | 0.880 | 0.843 | 0.860 | 0.889 | 0.869 | 0.875 |
| 3 | ✓ | ✓ | ✗ | 0.885 | 0.869 | 0.876 | 0.905 | 0.884 | 0.893 |
| 4 | ✓ | ✗ | ✓ | 0.876 | 0.884 | 0.880 | 0.891 | 0.879 | 0.885 |
| 5 | ✓ | ✓ | ✓ | 0.898 | 0.882 | 0.891 | 0.901 | 0.895 | 0.898 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, L.; He, Z.; Wang, X.; Liang, Y. Spatiotemporal Typhoon Damage Assessment: A Multi-Task Learning Method for Location Extraction and Damage Identification from Social Media Texts. ISPRS Int. J. Geo-Inf. 2025, 14, 189. https://doi.org/10.3390/ijgi14050189
Zou L, He Z, Wang X, Liang Y. Spatiotemporal Typhoon Damage Assessment: A Multi-Task Learning Method for Location Extraction and Damage Identification from Social Media Texts. ISPRS International Journal of Geo-Information. 2025; 14(5):189. https://doi.org/10.3390/ijgi14050189
Chicago/Turabian StyleZou, Liwei, Zhi He, Xianwei Wang, and Yutian Liang. 2025. "Spatiotemporal Typhoon Damage Assessment: A Multi-Task Learning Method for Location Extraction and Damage Identification from Social Media Texts" ISPRS International Journal of Geo-Information 14, no. 5: 189. https://doi.org/10.3390/ijgi14050189
APA StyleZou, L., He, Z., Wang, X., & Liang, Y. (2025). Spatiotemporal Typhoon Damage Assessment: A Multi-Task Learning Method for Location Extraction and Damage Identification from Social Media Texts. ISPRS International Journal of Geo-Information, 14(5), 189. https://doi.org/10.3390/ijgi14050189