1. Introduction
The past decade has witnessed the transformative impact of artificial intelligence (AI) combined with aerial imagery across various sectors, with the transportation industry standing out as a prominent beneficiary [
1,
2]. This development has unlocked new potentials for timely design, maintenance, infrastructure management, and the promotion of sustainable transportation systems [
3,
4]. This development consequently improves route optimizations and traffic management systems, leading to reduced fuel consumption and improved air quality and subsequently making cycling and walking safer in the environment [
5]. Recently, the encouragement of bicycle and pedestrian lane usage across the United States has increased remarkably, driven by a growing recognition of their health, environmental, and mobility benefits [
6,
7]. Unfortunately, the United States (U.S.) has not been particularly outstanding in terms of pedestrian and cyclist usage, partly due to safety concerns and more. A multimodal survey conducted by researchers in [
8] highlighted that more than 50% of a sample group agreed that cycling from one place to another within their neighborhood was dangerous. Many urban areas have experienced higher rates of cycling crashes, particularly among lower-income populations, who often rely on bicycles as a primary means of transportation due to economic constraints [
6,
7]. While urban areas face heightened risks due to inadequate cycling infrastructure, high traffic volumes, and insufficient safety measures [
9], rural areas, however, frequently struggle with the development and maintenance of adequate lane infrastructure due to limited financial resources and geographic isolation despite having lower traffic densities [
10,
11]. This lack of resources often results in poorly maintained or absent pedestrian and bicycle pathways, further compromising safety [
12].
The recent push for enhanced bicycle and pedestrian lanes aims to address these disparities by improving infrastructure quality and safety measures, thereby fostering a safer and more inclusive environment for all cyclists and pedestrians. This includes investing in protected bike and pedestrian lanes, pedestrian crossings, and traffic calming measures, which are critical for reducing crash rates and encouraging the adoption of non-motorized transportation options across both urban and rural landscapes. It is, therefore, critical to spatially identify the positions of bicycle and pedestrian lanes to enhance various traffic safety studies.
Several Departments of Transportation (DOTs) have made roadway safety a top priority since the Highway Safety Manual (HSM) was introduced in 2010 by meeting the safety manual’s standards for roadway geometric data collection [
13]. However, gathering these data manually across extensive roadway networks poses substantial challenges for many state and local transportation agencies, which need accurate, current data for effective planning, maintenance, design, and infrastructure rehabilitation [
14]. To overcome these obstacles, DOTs have adopted a range of Roadway Characteristics Inventory (RCI) methods for geometric data collection, such as static terrestrial laser scanning, mobile and airborne Light Detection and Ranging (LiDAR), satellite imagery, Geographic Information Science/Global Positioning System (GIS/GPS) mapping, photo and video logging, and direct field surveys [
13]. Each of these methods offers specific pros and cons related to cost, accuracy, data quality, labor intensity, storage requirements, time investment, and crew safety. Direct field observations remain common for DOTs and highway agencies when collecting roadway data [
14], yet these traditional methods can be slow, hazardous, and impractical under harsh weather conditions. A particular challenge lies in inspecting and maintaining pavement markings, which typically have a service life of only 0.5 to 3 years [
15]. Road inspectors are often required to perform frequent, manual inspections to monitor these markings, a task that is both labor-intensive and potentially unsafe.
To address these issues, it has become critical to identify alternative approaches that are more efficient for roadway geometric data collection. Recently, researchers have increasingly turned to advanced technologies like computer vision and image processing [
13]. Satellite and aerial imagery, specifically, have gained popularity as effective tools for gathering geospatial data [
13]. Images from satellites and aircraft can be rapidly processed to generate RCI data, providing a timely and detailed view of roadway conditions [
16,
17,
18].
One example of the most promising aerial imagery and deep learning applications in transportation is the creation of transportation infrastructure inventories [
3]. State and local agencies have successfully employed these technologies to rapidly assess the condition of extensive road networks, thereby contributing significantly to the enhancement of pedestrian and cyclist safety. There is a pressing need to investigate more efficient alternative methods for gathering roadway geometry data. For example, using Single Shot Detectors (SSDs), researchers analyzed aerial imagery captured by drones in real-time to identify and classify road surface defects, for instance, potholes, cracks, and wear [
19]. Another study [
18] utilized a deep learning algorithm to identify school zones, contributing to safer commuting. This automated approach not only facilitates proactive maintenance by reducing the need for labor-intensive manual inspections but also enables quicker responses to infrastructure deterioration. When models are well-trained, they can notably enhance output accuracy, and it is advantageous economically since this technique requires minimal to no field costs. While a challenge lies in identifying and extracting small or obscure objects, the recent development in machine learning has mitigated this constraint. Researchers have delved into novel and emerging technologies for the acquisition of roadway inventory data, including computer vision and image processing methods. A critical area of application is the optimization of traffic flow and congestion management [
20,
21]. By applying deep learning algorithms to aerial imagery, traffic patterns, bottlenecks, and other essential movement insights of people and vehicles can be identified. These developments allow traffic authorities to dynamically adjust traffic signal timings and deploy responsive measures to alleviate congestion. As a result, overall traffic efficiency improves, and both emissions and travel time are reduced [
20,
21].
RCI data include essential roadway elements like pedestrian and bicycle lanes, which are crucial for supporting traffic safety and operations for both state and local transportation agencies. Positioned along roadsides, these markings define specific lanes for pedestrians and cyclists, facilitating traffic flow and ensuring proper positioning, as highlighted in a USDOT study [
22]. Recognizing this importance, many DOTs have shown a growing interest in using automated methods to detect and evaluate lane markings [
23]. However, despite their role in enhancing roadway efficiency and reducing crashes, there is currently no comprehensive geospatial inventory of these features across Florida’s state and locally managed roadways. As such, developing new, efficient, and rapid data collection methods is critical. For DOTs, this information is invaluable, supporting objectives like locating faded or outdated markings and comparing the alignment of pedestrian and bicycle lanes with school zones, crosswalks, and turning lanes. Accordingly, crash trends within these areas and intersections can also be analyzed.
This study presents a novel application of deep learning-based object detection models—specifically, Multi-task Road Extractor (MTRE) and You Only Look Once (YOLO)—to systematically identify and extract pedestrian and bicycle lanes from high-resolution aerial imagery. Unlike previous studies that primarily focused on detecting broader roadway features, this research is the first to develop a comprehensive, AI-driven geospatial model for inventorying pedestrian and bicycle lanes across Florida’s rural and urban roadways. The innovation lies in the integration of advanced image processing techniques with high-resolution aerial imagery, enabling automated, large-scale mapping of critical transportation infrastructure with greater efficiency and accuracy than traditional methods. By leveraging AI-driven models, this framework offers a scalable, cost-effective, and adaptable approach to roadway inventory management, which is essential for transportation agencies aiming to enhance traffic safety and infrastructure planning. To the authors’ knowledge, no prior research has created a comprehensive, state-wide, or county-level inventory of pedestrian and bicycle lanes using high-resolution aerial images and AI-based techniques. This study aims to address this gap by introducing automated tools that leverage deep learning-based object detection models to detect and extract these key roadway elements. Specifically, this study develops a framework based on Multi-task Road Extractor (MTRE) and You Only Look Once (YOLO) models, designed to detect and extract pedestrian and bicycle lane markings from high-resolution aerial images. Primarily, the objective is to create advanced object detection and image processing algorithms to locate and map pedestrian and bicycle lanes across rural counties in Florida using the obtained high-resolution aerial images. Specifically, this research will focus on the following:
developing YOLO and MTRE object detection models;
evaluating the performance of the models with ground truth data;
applying detection models that can locate and map an inventory of pedestrian and bicycle lanes to Florida’s public roadways as a test case scenario.
This initiative is significantly important to USDOT and various transportation agencies for several reasons. It plays a key role in improving infrastructure management by enabling the identification of aging or obscured bicycle markings, which are vital for maintaining safe and efficient transportation networks. Furthermore, the ability to automatically extract roadway geometry data that can be easily integrated with crash data and traffic information offers valuable insights to roadway users and policymakers, facilitating better decision-making and enhancing overall transportation safety.
2. A Literature Review
2.1. Advancements in AI-Based Roadway Feature Detection
Research focused on using artificial intelligence (AI) techniques to extract Roadway Characteristics Inventory (RCI) data, particularly pavement markings, has significantly increased in recent years. AI approaches, especially detection models, are crucial for extracting roadway information from remotely sensed data [
3,
24,
25]. Deep learning methodologies continue to advance, making AI an increasingly effective tool for addressing complex tasks across various fields, including Natural Language Processing (NLP) and generative models [
26,
27]. These advancements have led to the integration of AI in transportation-related applications, including the identification of roadway features.
Previous research has largely relied on conventional methods for roadway data collection, which often involve extensive field surveys that are time-consuming, disrupt traffic, and pose safety risks to field crews. In contrast, deep learning and computer vision techniques offer a more efficient alternative by allowing roadway features to be identified from aerial imagery, eliminating the need for prolonged fieldwork. These technologies provide easily accessible data, enable rapid assessments over large areas, and enhance crew safety by reducing traffic exposure. However, despite these advantages, limited attention has been given to their application in capturing roadway geometry elements from high-resolution aerial images [
28].
Recent advancements in autonomous driving research have integrated sensor technology, computer vision methods, and AI techniques to identify pavement markings for vehicle navigation [
29,
30,
31,
32,
33]. Convolutional Neural Networks (CNNs) and Single Shot Detectors (SSDs) have significantly improved object detection, classification, instance segmentation, and feature extraction in aerial imagery [
34]. By automating complex analyses, deep learning minimizes human effort, making the assessment and management of pedestrian and bicycle lanes timelier and more accurate. However, while AI-based approaches have gained traction in roadway data extraction, much of the existing research has focused on vehicle-centric applications rather than pedestrian and cyclist infrastructure.
Although studies have explored the use of LiDAR for RCI data collection, this approach has notable limitations, including high equipment costs and complex, time-consuming data processing. For example, a study [
14] utilized LiDAR-enabled high-performance computers and precision navigation to create roadway inventories, while others have employed Mobile Terrestrial Laser Scanning (MTLS) for highway inventory collection [
16]. These methods, while effective, require significant resources and may not be feasible for widespread adoption. Given the critical role of pedestrian and bicycle lanes in sustainable mobility, there is a need for alternative approaches that balance accuracy, efficiency, and cost-effectiveness.
This study aims to fill this gap by leveraging object detection models to classify and identify cycling and pedestrian lanes in Florida using high-resolution aerial imagery. By employing deep learning techniques—specifically YOLOv5 and MTRE-based models—this approach not only addresses local needs but also introduces a globally applicable methodology for enhancing walking and cycling infrastructure. Unlike traditional data collection techniques, AI-driven aerial imagery analysis enables rapid, large-scale assessments of roadway features, providing transportation agencies with a scalable, efficient, and cost-effective solution.
2.2. Applying Deep Learning and Computer Vision to Extract Roadway Geometry Features
Human efforts to identify, classify, and quantify features rely heavily on the expertise and experience of specialists. Machine learning aims to mimic this process by using algorithms to process various inputs, make predictions or estimates, and then interpret these as decisions [
35]. Despite its remarkable advancements, machine learning has not yet achieved the human brain’s level of capability on a one-to-one scale [
36,
37]. However, it can perform certain tasks that may be challenging for human experts. For more complex problems that traditional machine learning methods cannot address, neural networks—models with many interconnected layers—are employed. This approach, known as deep learning, has multiple layers in the network hierarchy [
38,
39,
40]. Deep learning excels in making refined predictions and estimates by capturing complex, non-linear relationships. It utilizes mathematical techniques, such as the chain rule in differentiation, to backpropagate errors and adjust neuron weights during training [
41,
42]. Deep learning is a powerful subset of machine learning that achieves superior performance on intricate tasks.
A pivotal moment in deep learning’s evolution occurred in 2012 during the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [
43,
44]. The deep convolutional neural network AlexNet demonstrated groundbreaking performance, significantly outperforming traditional methods. This success highlighted the exceptional ability of deep learning models, specifically CNNs, in managing complex visual data. AlexNet’s architecture, notable for its depth and multiple convolutional layers, showcased how deep learning could effectively handle and interpret large and intricate image datasets, marking a major advancement in computer vision [
45]. Building on AlexNet’s foundations, further developments in CNNs and other deep learning techniques, such as SSDs and more advanced network architectures, have continued to enhance our ability to process and interpret visual information [
46,
47]. CNNs have become the preferred models for many tasks, including object detection, instance segmentation, classification, and feature extraction [
46,
47]. These models automate complex analyses, significantly reducing the need for extensive human labor and improving the efficiency and accuracy of applications such as assessing and managing RCI for pedestrians and cyclists.
Transportation professionals are increasingly recognizing the value of Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) as powerful tools in advanced computer vision and deep learning [
48]. These methods have demonstrated effectiveness in rapidly recognizing, detecting, and mapping roadway features across large areas without human involvement. Recent advancements in CNNs have underscored their strength in object detection, with notable progress from region-based CNNs (R-CNN) to Fast R-CNN [
49] and, ultimately, Faster R-CNN [
50]. The CNN process begins by calculating features from region proposals that indicate possible object locations, while Faster R-CNN optimizes this by introducing a Region Proposal Network (RPN) to enhance detection performance further.
Studies have applied CNNs across various transportation contexts. For instance, CNNs have been used to recognize roadway geometry and detect lane markings in inverse perspective-mapped images [
30]. Another study utilized CNNs to identify, measure, and map geometric attributes of concealed road cracks via ground-penetrating radar [
51]. Additionally, CNNs have extracted roadway features from remotely sensed images [
52], and this approach is used in applications like enabling autonomous vehicles to identify objects and infrastructure in real time. In a study using Google Maps photogrammetric data, CNNs were employed to detect pavement marking defects on roads, achieving an accuracy of 30% using R-CNN to identify defects such as misalignment, ghost markings, fading, and cracks [
15]. Further comparisons of machine learning models have shown that Faster R-CNN outperforms Aggregate Channel Features (ACF) in vehicle detection and tracking [
53]. In other research, ground-level images were analyzed using ROI-wise reverse reweighting combined with multi-layer pooling operations in Faster R-CNN to detect road markers, achieving a 69.95% detection accuracy by focusing on multi-layered features [
54]. Another study introduced a hybrid local multiple CNN-SVM system (LM-CNN-SVM) using Caltech-101 and Caltech pedestrian datasets for object and pedestrian detection [
55]. This system divided full images into local regions for CNNs to learn feature characteristics, which were then processed by multiple support vector machines (SVMs) using empirical and structural risk reduction. This hybrid model, integrating a CNN architecture with AlexNet and SVM outputs, yielded an accuracy range between 89.80% and 92.80%.
2.3. Obtaining Roadway Geometry Data Through Aerial Imagery Techniques
Aerial imagery offers significant advantages over traditional ground-based survey methods, such as total stations, Global Navigation Satellite Systems (GNSS), dash cams, and mobile laser scanning [
56]. Firstly, aerial imagery can be quickly obtained due to the availability of fully automated image processing methods. Additionally, it provides a broader and more comprehensive view of a study area. Unlike ground-based methods, which often capture data from limited vantage points and are prone to blind spots or incomplete coverage, aerial imagery can cover extensive geographic regions in a single pass [
2]. This extensive coverage allows for the simultaneous assessment of various infrastructural elements, including road networks, pedestrian walkways, and surrounding landscapes, which would otherwise require multiple ground-based surveys [
57]. Furthermore, aerial surveys mitigate many logistical challenges associated with ground-based methods, such as accessing remote or hazardous locations, thus reducing risks to survey crews and minimizing traffic disruptions. Road markings are highly suitable for extraction from images due to their reflective properties. In one study [
58], researchers applied a CNN-based semantic segmentation technique to detect highway markers from aerial images. This approach introduced a new process for handling high-resolution images by integrating a discrete wavelet transform (DWT) with a fully convolutional neural network (FCNN). By utilizing high-frequency information, the DWT-FCNN combination improved lane detection accuracy. Another study [
59] developed an algorithm to identify and locate road markings using pixel extraction from images taken by vehicle-mounted cameras. This method used a median local threshold (MLT) filtering technique to isolate marking pixels, followed by a recognition algorithm that classified the markings based on shape and size. This system achieved an average true positive rate of 84% for detected markings.
Aerial imagery significantly improves efficiency and data accuracy compared to traditional ground-based techniques. Ground-based surveys, such as those using total stations and GNSS, often involve lengthy setup times, precise alignment requirements, and manual data collection, making them time-consuming and labor-intensive [
3,
56]. While dash cams and mobile laser scanning offer advanced capabilities, they still depend on vehicle mobility and can be affected by obstructions, traffic conditions, and varying light levels [
60]. In contrast, aerial imagery, captured by drones or aircraft equipped with high-resolution cameras, can swiftly cover large areas with consistent accuracy, unaffected by terrestrial obstructions. This makes aerial imagery the most suitable technology for capturing geographic information within a given timeframe [
61]. Advanced processing techniques, such as stereo-photogrammetry and orthorectification, convert these images into precise geospatial datasets, allowing for accurate measurement and analysis of surface features [
62]. Compared to most publicly available satellite imagery, modern aerial imagery provides detailed geospatial datasets due to its near sub-decimeter resolution [
63,
64]. This high level of detail facilitates a more accurate assessment of infrastructure conditions, land use patterns, and potential safety hazards, thereby offering timelier information for informed decision-making and planning [
65,
66].
In one study [
14], researchers used a two-meter resolution aerial imagery and six-inch accuracy LiDAR data to collect and store roadway data in ASCII text file format. They used ArcView to integrate height data into LiDAR point shapefiles and transformed these points into Triangular Irregular Networks (TIN). The analysis involved merging the aerial photographs with LiDAR boundaries to create a cohesive dataset. Another study [
67] introduced a deep learning algorithm using 3D pavement profiles collected via laser scanning to automate the identification and extraction of road markings, reaching a 90.8% detection accuracy. This method used a step-shaped operator to locate potential edges of pavement markings, followed by a CNN that combined geometric properties with convolutional data for accurate extraction. Additionally, in study [
68], computer vision techniques were applied to assess pavement conditions and extract markings from camera images. Videos captured from a vehicle’s forward-facing perspective were preprocessed, and a hybrid detector using color and gradient attributes was used to locate markings. These were then identified through image segmentation and classified as edge lines, dividers, barriers, or continuity lines based on their properties. In this study, image processing techniques, along with YOLO and MTRE models, will be applied to extract pedestrian and bicycle lane features from high-resolution aerial images, focusing specifically on Leon County, Florida.
To the best of the authors’ knowledge, no research has yet explored the creation of a comprehensive inventory of pedestrian and bicycle lane markings on a county- or state-wide scale using integrated image processing and AI techniques with very high-resolution aerial images. This study aims to address this gap by developing automated methods for identifying these markings on a large scale from high-resolution images. Specifically, this research will focus on developing AI models based on MTRE and YOLO methodologies.
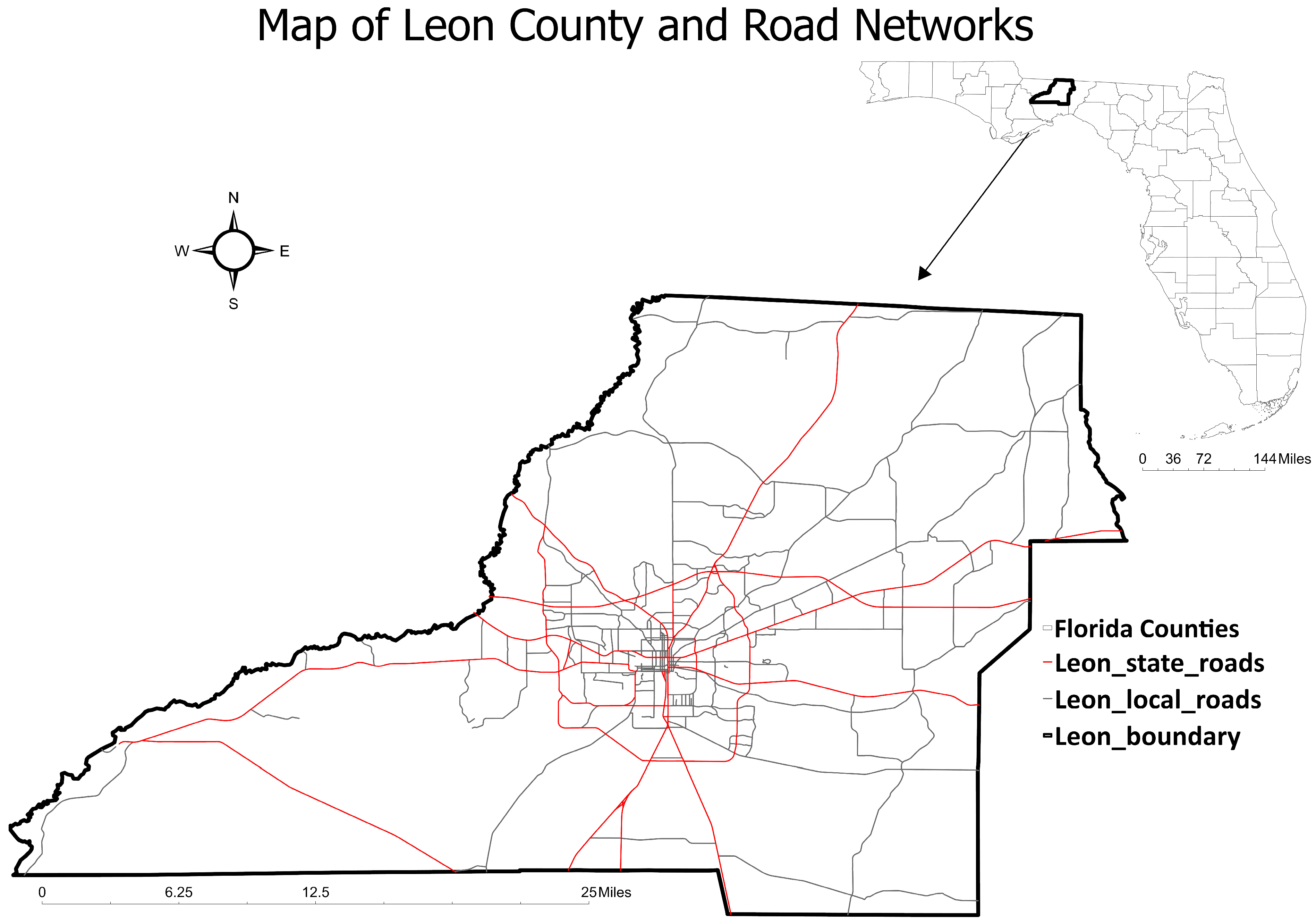
3. Study Area
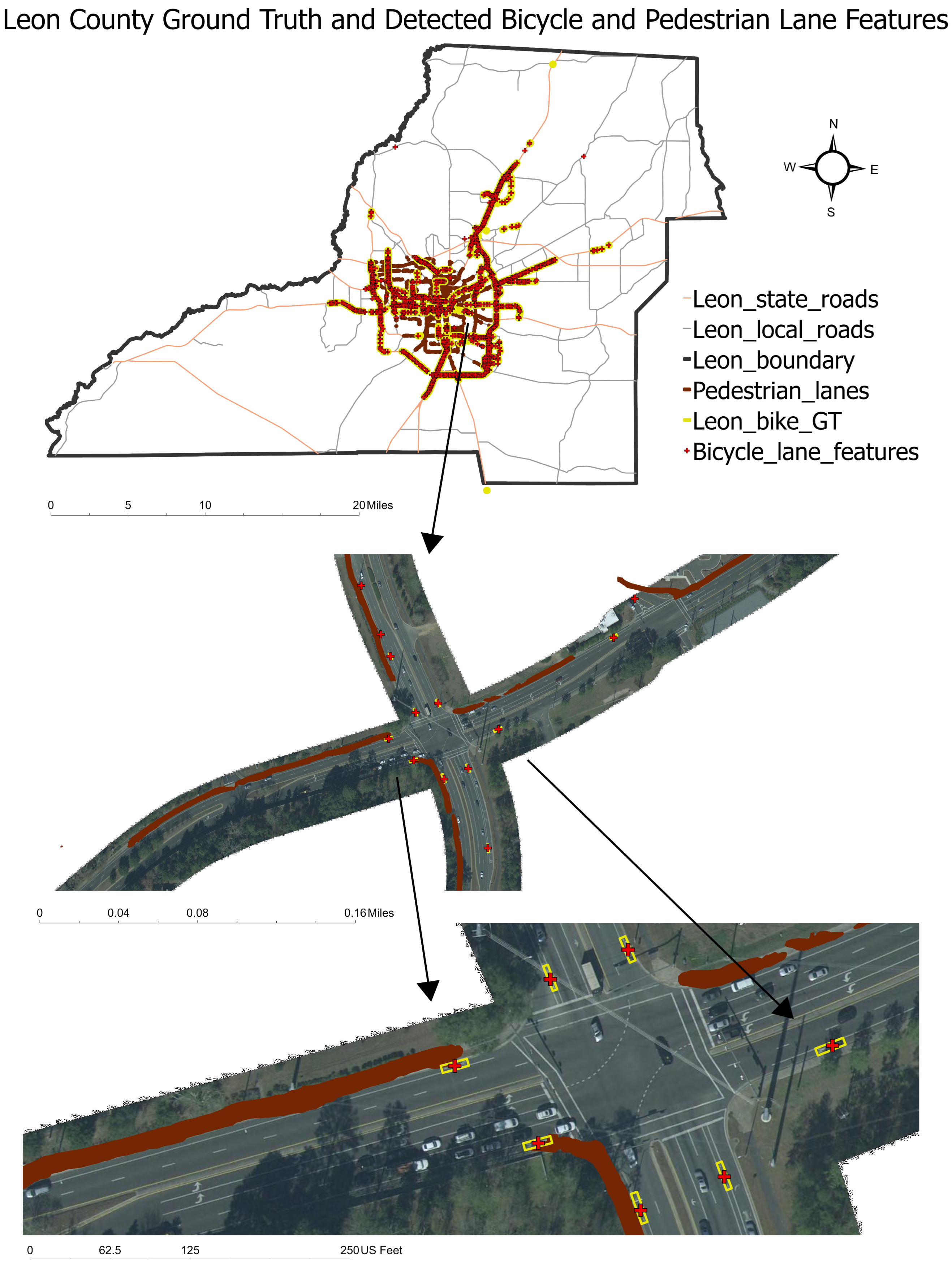
The study area for bicycle and pedestrian lane detection is Leon County, Florida (
Figure 1). Located in the Florida Panhandle, Leon County spans approximately 668 square miles and has a population of 292,198 residents [
69]. It is home to Tallahassee, the capital city of Florida, which serves as a political, educational, and economic hub for the region. The county shares its borders with Gadsden, Wakulla, Liberty, and Jefferson Counties in Florida, as well as Grady and Thomas Counties in Georgia.
Leon County features a diverse transportation infrastructure, ranging from dense urban road networks in Tallahassee to more rural and suburban roadways in outlying areas. This variation makes it an ideal location for studying the effectiveness of AI-driven roadway feature detection, as it includes a mix of major highways, arterial roads, local streets, and bicycle–pedestrian pathways. Also, the presence of Florida State University (FSU) and Florida A&M University (FAMU) contributes to high pedestrian and cycling activity, particularly in areas surrounding university campuses, government offices, and commercial centers.
This study selected Leon County due to its diverse roadway infrastructure and the need for improved pedestrian and bicycle lane inventories. The developed deep learning models were validated using ground truth data collected from Leon County, ensuring that this methodology is tested across a range of urban and suburban environments. By leveraging high-resolution aerial imagery, this research aims to enhance the accuracy and efficiency of pedestrian and bicycle lane detection, providing valuable insights for transportation agencies in managing and improving non-motorized infrastructure.
4. Materials and Methodology
4.1. Data Description
The choice of methodology for collecting roadway inventory data depends on several factors, such as the time required for collection of data, reduction, and processing, as well as the associated costs and demands for accuracy, safety, and data storage. This study focuses on developing single-class object detection models using YOLO and MTRE. The goal is to develop AI-based object detection models that can automatically detect and compile a geocoded inventory of bicycle and pedestrian lanes from high-resolution aerial images across counties in Florida and evaluate the performances of these models using ground truth data.
This study aims to detect bicycle and pedestrian lanes on roadways managed by state, county, and city agencies, excluding interstate highways. According to the Florida Department of Transportation (FDOT) classification, state highway system roads are categorized as “ON system roadways”, while roads under county and city jurisdiction are designated as “OFF system roadways” or local roads. This methodology integrates centerline data from shapefiles of both local and state-managed roads, leveraging this information to enhance lane detection. While FDOT’s GIS database provides key geometric data points for mobility and safety analysis, it does not include the specific locations of bicycle and pedestrian lanes on local roads. To address this gap, this research applies an advanced object detection model to inventory bicycle and pedestrian lane markings, with an initial focus on Leon County, Florida.
The detection algorithm utilizes high-resolution aerial imagery and state-of-the-art advancements in computer vision and object detection. The objective is to automate the identification of bicycle lane markings and segment pedestrian lanes based on their reflectance properties, offering a practical solution for transportation agencies. Aerial imagery for this study was sourced from the Florida Aerial Photo Look-Up System (APLUS) and maintained by FDOT’s Surveying and Mapping Office. Images from Sarasota (2017), Hillsborough (2017), Gilchrist (2019), Gulf (2019), Leon (2018), and Miami-Dade (2017) counties were analyzed. With resolutions ranging from 0.25 to 1.5 feet, these images provided sufficient detail for accurate detection of pedestrian and bicycle lanes. The majority of the images had a resolution of 0.5 feet per pixel, with dimensions of 5000 × 5000 and a 3-band (RGB) format, although specific resolutions varied by county. The imagery was supplied in MrSID format, enabling GIS projection onto maps and facilitating spatial analysis. State and local roadway shapefiles from FDOT’s GIS database further enriched the dataset used in the detection algorithm. Notably, the model’s resolution requirement allows it to process any imagery that meets or exceeds the specified resolution threshold. This integration of aerial imagery and GIS data ensures a robust framework for identifying bicycle and pedestrian lanes and addressing a critical data gap for transportation agencies.
4.2. Preprocessing
Preprocessing is a crucial step in managing large datasets and meeting the complex demands of object recognition. This process begins by filtering out images that do not intersect with roadway centerlines and masking regions outside a designated buffer zone. Specifically, objects located more than 100 feet from state and local roadways are excluded (
Figure 2). This step reduces the dataset size and narrows the analysis to relevant areas. A 100-feet buffer was determined based on the characteristics of the roadway shapefile data used in the image masking process. Since the roadway centerline shapefile data were unidirectional, instances where roadways had wide medians posed a challenge, as smaller buffer values tended to crop out portions of the roadway that were crucial for analysis. To mitigate this issue, a standard 100-feet buffer was applied to ensure that all roadways were fully captured without inadvertently excluding relevant sections. At the same time, this threshold was chosen to balance completeness and noise reduction, ensuring that the masked images did not introduce excessive background elements that could interfere with the detection models. This approach optimized the effectiveness of the image masking process while maintaining focus on the intended roadway features. A buffer is first applied to the roadway shapefile, generating overlapping polygons that act as reference zones for cropping intersecting regions in the aerial images. Pixels lying outside this buffer are masked, producing cropped images with fewer pixels for streamlined analysis. These cropped images are then mosaiced into a single raster file to facilitate data management.
The workflow involves importing aerial imagery from selected counties into a mosaic dataset within ArcGIS Pro. These geocoded images are organized and visualized in the mosaic database, enabling intersections with vector data to identify specific image tiles by location. From this dataset, only images intersecting roadway centerlines are extracted for further processing. An automated masking tool, developed using ArcGIS Pro’s ModelBuilder, applies a 100-foot buffer around the roadway centerlines and processes each image systematically. The masked outputs are saved as JPG files and optimized for the subsequent object detection phase. These final exported images undergo additional preparation for model training and detection tasks, ensuring compatibility with advanced recognition algorithms.
4.3. Data Preparation for Model Training and Evaluation
High-resolution image data are essential for effectively training deep learning models to detect various features. The image preparation process involves identifying features, extracting training data, and generating labels. Considerable time and effort were devoted to creating a robust training dataset, as model performance largely depends on the quality, quantity, and diversity of these data. Also, significant effort went into model training, which involved testing various parameters to determine the most effective ones.
In the initial phase, single-class object detection models were developed to identify bicycle and pedestrian lanes specifically. The training data consisted of “bicycle” and “pedestrian” classes, annotated by rectangular bounding boxes around the respective features (
Table 1). For YOLO and MTRE models, a total of 8628 bicycle features and 8766 pedestrian features were manually labeled on aerial images from Miami-Dade, Sarasota, Hillsborough, Gulf, and Gilchrist counties using ArcGIS Pro’s Deep Learning Toolbox. To enhance data diversity, augmentation techniques like rotation were applied, rotating training data at various angles (e.g., 90 degrees) to help the model identify features in different orientations. Ultimately, 26,728 image chips with 32,852 bicycle features and 18,792 image chips with 32,023 pedestrian features were collected for the training detection model. Metadata for the labels, including information such as image chip size, object classes, and bounding box dimensions, was stored in XML files. Bicycle and pedestrian data were formatted according to the Pascal Visual Objects and Classified Tiles standards, respectively. To facilitate compatibility with YOLOv5, a custom function was developed to convert the bicycle model metadata. This function recalculated the bounding box center coordinates, width, and height to align with the YOLOv5 format requirements. The bounding box coordinates were normalized according to the image dimensions, maintaining accuracy relative to the input image. The original metadata in Pascal Visual Objects format was converted to YOLOv5 format before final training. High-resolution aerial images from selected Florida counties, with tile sizes ranging from 5000 × 5000 to 10,000 × 10,000 square feet, served as the input mosaic data.
4.4. YOLOv5 and MTRE Detection Models
The You Only Look Once (YOLO) model is widely used for its remarkable speed and efficiency in real-time object detection, making it a popular choice over models like R-CNN and Faster R-CNN. Unlike these architectures, which first classify image regions before identifying objects, YOLO processes the entire image in a single network evaluation. This streamlined approach enables YOLO to be significantly faster, outperforming R-CNN and Faster R-CNN by factors of 1000 and 100, respectively [
70]. Since its introduction in 2016 [
71], YOLO has undergone continuous improvement across multiple versions. YOLOv2 [
72] and YOLOv3 incorporated multi-scale predictions to enhance detection capabilities. More recently, YOLOv4 (2020) and YOLOv5 (2022) have further advanced both speed and accuracy, cementing YOLO’s status as a leading tool in object detection [
73,
74]. While more recent official versions of YOLO (e.g., YOLOv8) have been developed with certain improvements, the selection of YOLOv5m was based on several key factors such as computational efficiency and memory considerations, competitive performance, robustness and familiarity, and scalability in real-world applications. Given the scale of the detections and the available computational resources, YOLOv5m provided an optimal balance between accuracy and efficiency. Larger models or newer versions often require significantly higher computational power, which may not be practical for large-scale aerial image processing without access to extensive GPU resources. While newer YOLO versions introduce refinements, studies have shown that YOLOv5, particularly the medium (m) variant, maintains competitive performance in terms of accuracy and speed for object detection tasks. The marginal improvements in detection precision in newer versions did not justify the increased computational demand for this specific application. The YOLOv5 architecture is composed of three main components: the backbone (CSP-Darknet), the neck (Path Aggregation Network, or PANet), and the head (output layer). YOLOv5’s backbone uses a Cross-Stage Partial (CSP) network—an improved version of YOLOv3’s Darknet-53 backbone—which achieves higher accuracy and processing speed [
74]. Its backbone and 6 × 6 convolution structure increase the model’s efficiency, allowing the feature extractor to outperform previous YOLO versions and other models in terms of speed and precision [
75,
76]. YOLOv5 achieves a level of accuracy and speed that is double that of ResNet152 [
70]. This model incorporates multiple pooling and convolution layers, enabling feature extraction at different levels using CSP and Spatial Pyramid Pooling (SPP) to detect varied object sizes within an image [
77].
YOLOv5’s design significantly reduces computational complexity through its BottleneckCSP structure, which optimizes inference speed, and SPP, which extracts features across different image regions to create three-scale feature maps that improve detection quality. The model’s neck, a series of layers between the input and output, uses Feature Pyramid Network (FPN) and PAN structures. FPN passes high-level semantic features to lower feature maps, while PAN conveys accurate localization features to higher feature maps. This multi-scale detection process culminates in the output head, which generates target predictions across three distinct feature map sizes [
77].
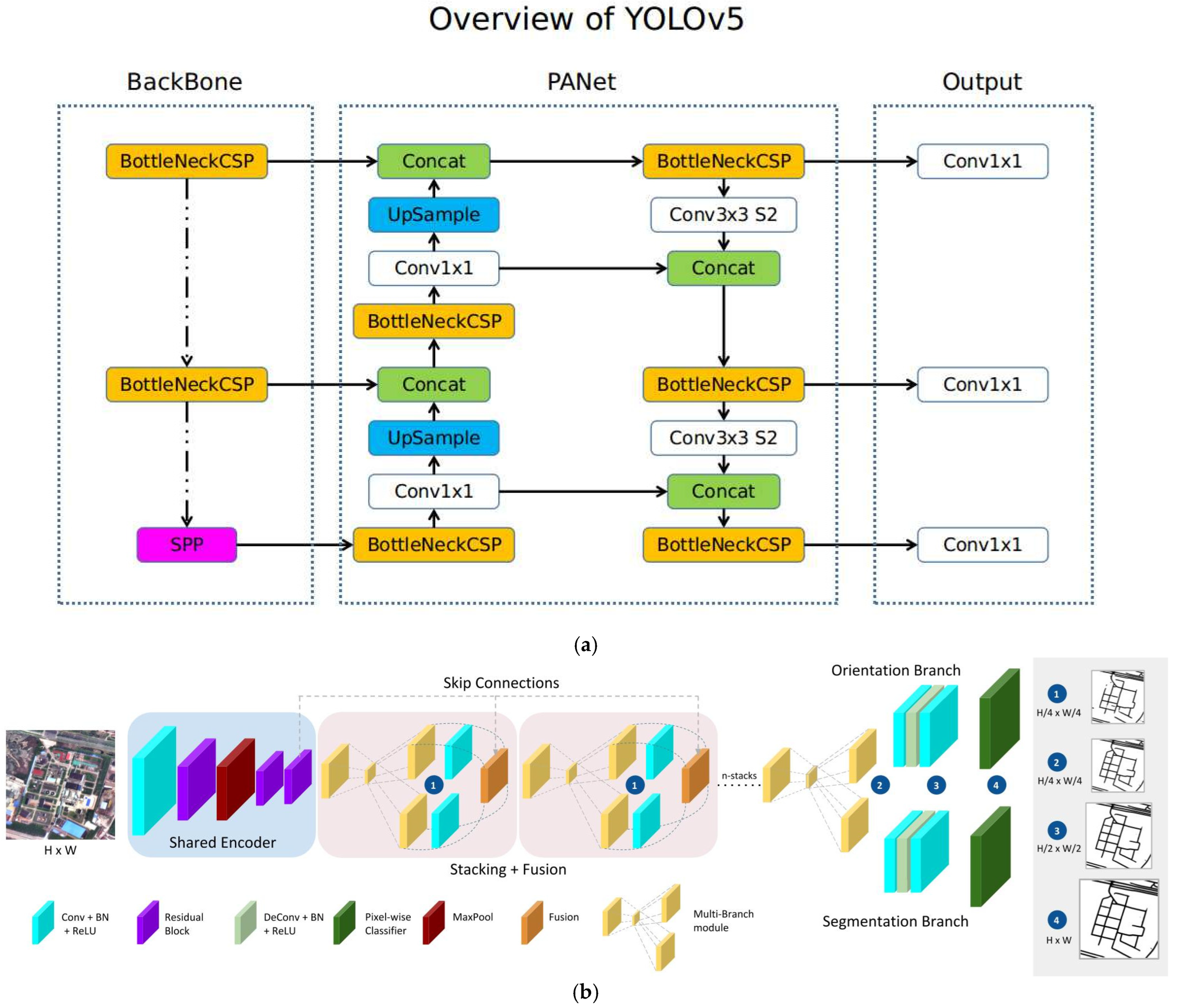
Figure 3a illustrates YOLOv5’s architecture, showing how the model applies a 1 × 1 detection kernel on feature maps at three scales within the network.
In addition to YOLOv5, the MTRE framework, based on a CNN architecture, supports two configurations: LinkNet and Hourglass. For this study, the MTRE model’s Hourglass architecture with a ResNet50 backbone was utilized [
78]. The framework consists of three main components: the shared encoder, the stacking and fusion block, and the prediction heads (
Figure 3b). The stacking and fusion block progressively combines segmentation and orientation predictions, while the prediction heads include separate branches for each task. By integrating intermediate predictions at smaller scales, the Hourglass architecture enhances information flow between tasks, ultimately improving segmentation and orientation accuracy across the model.
4.5. Training and Evaluation of Bicycle and Pedestrian Lane Detection Models
The adjustable parameters and hyperparameters in the object detection model include factors like batch size, training-test data split, epochs, input image dimensions, learning rate, anchor box sizes, and ratios. The evaluation metrics were visualized using training loss, validation loss, precision, F1, confidence and recall graphs, and confusion matrices. Validation loss and mean average precision (mAP) were computed using a validation dataset that represented 15% of the total input data. The learning rate controls how quickly the model adapts during training, balancing convergence speed with detection precision.
In this study, learning rates of 3.0 × 10
−4 and 8.3 × 10
−4 were chosen for the YOLO and MTRE models, respectively, to achieve optimal performance. Batch size, which determines the number of samples processed per iteration, was set to 64 for training the bicycle lane model to ensure efficient processing. However, due to memory limitations, a batch size of 20 was used for the pedestrian lane model. Larger batch sizes enable faster computation but demand more memory, while smaller batch sizes add randomness, potentially improving generalization to new data. Anchor boxes, which define the size, shape, and position of detected objects, were initialized with four sizes for training the YOLO model. The number of epochs, representing the total passes through the entire training dataset, was fixed at 100 for this study. For data partitioning, 70% of the input dataset was allocated for training, while the remaining 30% was split between validation (15%) and testing (15%) to assess the model’s performance. Metrics such as precision, F1, accuracy, and recall were computed using the test set after training. The data split ratio was adjusted based on dataset size; for datasets exceeding 10,000 samples, allocating 20–30% for validation provided a sufficient randomized sample for robust evaluation. Predictions were deemed valid if there was at least a 50% overlap between the detection and label-bounding boxes. Precision and recall metrics were calculated to quantify detection accuracy relative to both the ground truth labels and all predicted outputs. During YOLO model training, binary cross-entropy loss was used for classification, replacing mean square error. This allowed for the use of logistic regression to predict object confidence and class labels, reducing computational overhead while improving performance. In YOLOv5, the total loss function integrated class loss, object confidence loss, and box location loss weighted by their respective coefficients,
,
,
. The full loss function is given by [
70,
74] as follows:
, , : Weight factors for each of the loss components that balance their contribution to the total loss during optimization;
: Classification loss, which calculates the error in object class prediction;
: Object confidence loss, which evaluates the predicted confidence for an object in the grid cell;
: Location or bounding box loss, which measures the difference between the predicted bounding box and the ground truth.
: Grid size, where the input image is divided into grid cells;
: The number of bounding boxes predicted per grid cell;
: Probability that an object exists in grid cell ;
: Probability of no object being present in grid cell ;
: Diagonal distance of the smallest enclosing area containing both the predicted and ground truth boxes;
: Confidence score for the predicted bounding box;
: Confidence score for the predicted bounding box in relation to the ground truth box.
The Intersection over Union (IoU) is a key evaluation metric for the localization accuracy of predicted bounding boxes. It is calculated as
The center point of the predicted bounding box;
The center point of the ground truth bounding box;
: Measures the overlap between the predicted and ground truth boxes; a higher
indicates better alignment.
α: The positive trade-off parameter that helps balance the competing objectives of the loss function.
: Evaluates the aspect ratio consistency;
, : The width and height of the ground truth bounding box;
, : The width and height of the predicted bounding box.
The overall Loss function is composed of three main components: classification loss, , the object confidence loss, , and the location or box loss, . These components are weighted by factors , , , respectively, which balance the contribution of each loss type to the overall model optimization. The grid size, denoted by , represents the division of the input image into grid cells, while indicates the number of bounding boxes predicted per grid cell. The probability of an object belonging to a specific category is represented by , and refers to the probability of a classification error. Key geometric terms include , which is the diagonal distance of the smallest enclosing area that contains both the predicted box and the ground truth box, and is the confidence score for a prediction. The term represents the intersection between the predicted bounding box and the ground truth box. The intersection over union, measures the overlap between these two boxes, providing a critical evaluation metric for localization accuracy. Additional parameters include , which calculates the Euclidean distance between the centroids of the predicted and ground truth boxes. denote the center points of the predicted and ground truth boxes, respectively. The aspect ratio consistency is evaluated using , which considers the target and predicted aspect ratios, and . The positive trade-off parameter α helps balance the competing objectives within the loss function. Lastly, is a weight that penalizes classification errors in grid cells without objects.
The loss function for the MTRE model is the sum of the segmentation loss and orientation loss [
78]:
: The segmentation loss function, which measures the error in segmenting the roadway features;
: The orientation loss function, which evaluates the accuracy of the predicted orientation;
, : Prediction functions for segmentation and orientation tasks, respectively.
The is the total loss; is the segmentation loss; is the orientation loss; is the scale, and is the number of bins in the orientation. Let be a labeled sample from the dataset, represent the prediction function of the model, and and be the refined predictions for the roads and orientation, respectively.
Following the training process, the model’s performance was evaluated. For the YOLO model, metrics such as precision–recall, confusion matrix, validation and training loss, and F1 confidence were used. The MTRE model was assessed using metrics, including IoU, accuracy, dice/F1 score, and training and validation loss. The confusion matrix provided insights into the model’s true positive rate and misclassification rate. Notably, the diagonal of the matrix showed a high rate of true positive predictions for the bicycle feature class (
Figure 4a). A distinct background class was also observed, representing areas where no objects were detected. This accounted for regions in the dataset with no identifiable features, and the model exhibited very few unclassified features overall.
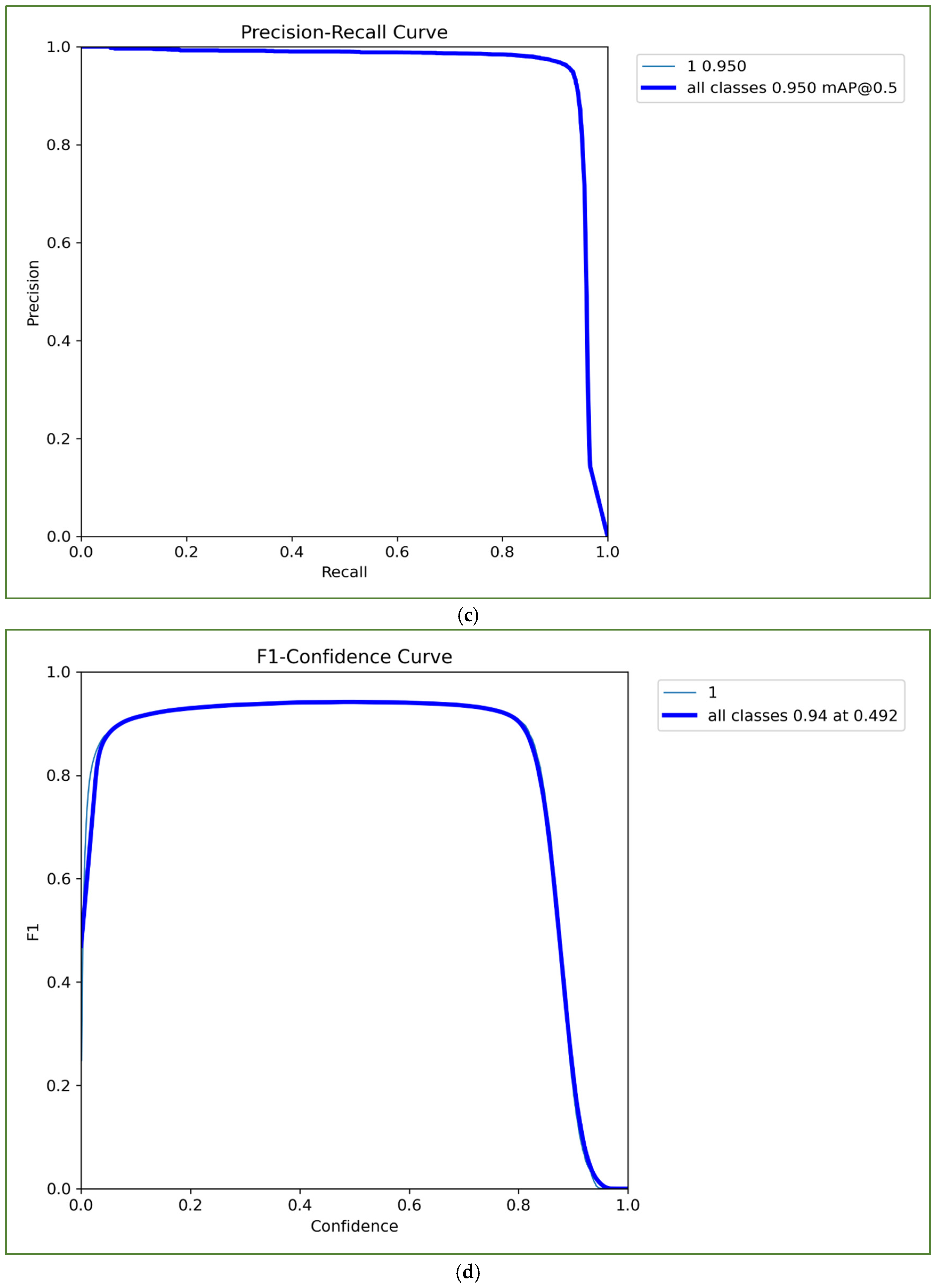
Figure 4b illustrates the training–validation loss curve for the YOLO model. Training loss measured the model’s fit to the training data, while validation loss indicated its performance on the validation dataset. A high loss suggested greater errors, whereas a low loss reflected better accuracy and fewer errors. Throughout the training process, the YOLO model demonstrated a minimal difference between training and validation loss. Initially, training loss was slightly higher, but by the end of this process, validation loss marginally surpassed training loss. This trend indicates that the YOLO model is highly accurate, performing slightly better on the training data than the validation set. The precision–recall curve for the YOLO model, shown in
Figure 4c, highlights its sensitivity in identifying true positives and its ability to predict positive values accurately. A robust classifier exhibits high precision and recall across the curve. The YOLO model achieved a precision of 0.958 and a recall of 0.927, indicating strong performance. The F1 score, calculated as the harmonic mean of precision and recall, serves as a critical metric for evaluating model effectiveness. Higher F1 scores correspond to better performance. From the F1 confidence curve (
Figure 4d), the YOLO model performed exceptionally well, achieving an F1 score between 0.90 and 0.97 when the confidence threshold ranged from 0.05 to 0.8. An optimal threshold of 0.49 yielded an F1 value of 0.94 for the bicycle class. The precision–confidence curve, depicted in
Figure 4e, revealed that precision steadily increased with higher confidence thresholds. Even at a confidence level of 0.2, this model demonstrated strong precision, peaking at an ideal precision value of 0.94. Overall, the developed YOLO model achieved an accuracy of 0.950, showcasing its high precision and reliable performance in detecting bicycle features.
The train–validation loss for the MTRE model is shown in
Figure 4f. It can be observed from the graph that the validation data were higher than the training data, indicating better performance with training data. The IoU metric is the area of intersection divided by the area of the union. This measures the ratio of how much of the predicted area falls within the ground truth area and the union of the two. On the other hand, the dice coefficient is two times the intersection between the prediction and ground truth areas divided by the sum of the prediction and ground truth areas. In segmentation tasks, the dice is also referred to as the F1 value. The value is 1 when there is a 100% overlap and 0 when there is a 0% overlap between the prediction area and ground truth area. The IoU of the MTRE model is 0.856; the dice is 0.781, whereas the accuracy is 0.985.
Figure 4g shows a graph of the accuracy, IoU, and the dice coefficients.
4.6. Mapping Bicycle and Pedestrian Lanes
The bicycle and pedestrian lane detectors were initially tested on individual images.
Figure 5 shows the YOLO detector accurately identifying bicycle lane features with bounding boxes based on the confidence score while also segmenting pedestrian lanes within the images. A confidence threshold of 0.1 was set to ensure the detection of all features, including those with very low confidence scores. While this approach enhances the model’s ability to identify faint or partially visible features, thereby improving recall and reducing missed detections, it comes with trade-offs. Lowering the detection threshold increases the likelihood of false positives, which can negatively impact precision. Additionally, it raises computational demands and prolongs detection time by introducing irrelevant features or noise into the analysis. To avoid duplicate detections, overlapping bounding boxes with more than 10% overlap were minimized. The detectors were trained on sub-images with a resolution of 512 × 512 pixels at 0.5 feet per pixel. Using large images for object detection is impractical due to the high computational cost. To facilitate detection, the images were divided into tiles measuring 512 × 512 pixels or smaller, enabling the model to process each tile individually. The resulting detection labels, along with their corresponding coordinates, were subsequently transformed into shapefiles for visualization and advanced analysis within ArcGIS.
Since the detectors performed well on individual images, the detection and mapping process was scaled to the county level. For this process, each input image was processed iteratively through the detector. For the YOLO model, an output shapefile containing all detected features within a county was generated after processing all images, while the MTRE model produced a segmented raster of pedestrian lanes. The detection confidence scores were included in the output files, which were subsequently used to map bicycle and pedestrian lane features. These models were shown to effectively detect features from images with resolutions ranging from 1.5 feet to 0.25 feet per pixel. However, they have not yet been tested on images with resolutions lower than those provided by the Florida APLUS system. Initial observations after model training revealed occasional false detections by the models, which are addressed in the
Section 5.
4.7. Post-Processing
Following the application of the YOLO and MTRE models to the aerial imagery from Leon County, a total of 1702 bicycle features and 1391 pedestrian lane detections were identified. During post-processing, overlapping detections caused by the proximity of image tiles were eliminated. Features on state and local roadways were further classified into groups based on the specific analytical goals. Non-Maximum Suppression (NMS) was employed to resolve duplicate detections, retaining only those with the highest confidence levels while removing any detections with over 10% overlap and lower confidence scores. To facilitate further analysis, the identified bicycle features were converted from polygon shapefiles to point shapefiles.
5. Results and Discussions
The performance of the models was evaluated during training using precision, recall, IoU, and F1 scores. Subsequently, Leon County was selected as the case study area for collecting GT data and assessing the models’ performance in terms of completeness, correctness, quality, and F1 score. The GT dataset, comprising bicycle features and pedestrian lanes on Leon County roadways, served as a proof of concept. After detection, 1702 bicycle features and 1391 pedestrian lane features were observed. A visual inspection followed, during which 1561 visible bicycle feature markings and 1091 pedestrian lane polygons were identified in the GT dataset using masked images as the reference background. The evaluation involved direct comparisons of individual features detected in the aerial images.
Figure 6 illustrates the GT dataset alongside the detected pedestrian and bicycle lane markings in Leon County. For this case study, the YOLO model identified bicycle lane markers with a minimum confidence threshold of 10%. Bicycle lane markers (M) detected on local roads in Leon County were selected for analysis. A similar location-based methodology was applied to the GT dataset. The model’s performance was assessed by comparing detected points within the polygons and vice versa across confidence thresholds of 90%, 75%, 50%, 25%, and 10% (
Table 2). A confusion matrix provided a visual representation of the model’s accuracy compared to the GT dataset (
Figure 7).
The primary objective of this study was to evaluate the accuracy and reliability of the proposed models’ predictions by comparing them against the GT dataset. Separate evaluations were conducted for bicycle and pedestrian detections, analyzing the models’ precision (correctness) and recall (completeness). The F1 score, calculated as the harmonic mean of precision and recall, was used as the primary evaluation metric. This measure is particularly effective for imbalanced datasets, where the cost of missing actual objects is higher than misclassifying background regions as objects.
Finally, the YOLO model’s performance was assessed using completeness (recall), correctness (precision), quality (IoU), and F1 score. These evaluation metrics, originally applied in highway extraction studies [
79,
80], are now standard for performance assessment in related object detection models [
81,
82]. Specific criteria were applied to calculate these metrics, providing a comprehensive evaluation of the model’s effectiveness:
GT: Number of bicycle feature polygons (Ground Truth);
M: Number of Model detected bicycle feature points;
False Negative (FN): Number of GT bicycle feature polygons without M bicycle feature points;
False Positive (FP): Number of M bicycle feature points not found within GT bicycle feature polygons;
True Positive (TP): Number of M bicycle feature points within GT bicycle feature polygons.
Performance evaluation metrics:
Completeness = is a true detection rate among GT bicycle features (recall);
Correctness = is a true detection rate among M bicycle feature (precision);
Quality = is a true detection among the M bicycle feature plus the undetected GT bicycle feature (Intersection over Union: IoU).
This analysis revealed that the automated pedestrian lane detection and mapping model successfully identified and mapped 73% of pedestrian lanes with an average precision of 72% and an F1 score of 62%. Conversely, the bicycle feature detection model demonstrated a detection rate of 58% at a confidence level of 75%, achieving a precision of 99% and an F1 score of 74%. When the confidence threshold was lowered to 25%, the model detected approximately 82% of bicycle features, with a precision of 89% and an F1 score of 85%.
Improved accuracy at lower confidence thresholds is attributed to higher recall rates, which allow for increased detections. Observations indicated that features such as occluded bicycle markings—obstructed by vehicles, trees, or shadows—or those with faded markings typically had lower confidence scores. Lowering the confidence threshold incorporates these detections into the results, thereby increasing the total number of identified features. This process tends to introduce more true positives while maintaining or reducing false positives and false negatives. Consequently, as the number of true positives rises with decreasing confidence, the model’s accuracy improves since accuracy depends on the proportion of true positives relative to the total detections.
Bicycle feature detections were categorized by varying confidence levels, as detailed in
Table 2. From the assessments, we can conclude that the developed bicycle feature and pedestrian lane detectors perform quite well. The extracted roadway geometry data hold potential for integration with crash and traffic datasets, particularly at intersections, to inform policymakers and roadway users. These data can support a range of applications, such as identifying worn or invisible markings, comparing bicycle feature locations with other geometric elements like crosswalks and school zones, and analyzing crash patterns in these areas.
The discrepancy in detection accuracy between bicycle lanes (89%) and pedestrian paths (73%) can be attributed to several key factors related to model type, feature characteristics, and assessment methodology. It is important to mention that the difference in accuracy is partially influenced by the nature of the output data from the two models. The YOLO model generates vector-based object detections, making it highly effective at identifying distinct, well-defined features like bicycle lane markings, which often appear as clear, linear elements with high contrast against the roadway background. In contrast, the MTRE model operates on raster-based segmentation, which is inherently more complex, especially when dealing with continuous features like pedestrian paths. Since segmentation models assess each pixel individually, they are more susceptible to inconsistencies in pavement texture, shading, and occlusions, which can impact detection accuracy. Also, the assessment methodologies for the two models differ. YOLO’s performance was evaluated using the F1 score, which measures precision and recall based on discrete object detection. Meanwhile, the MTRE model was assessed using Intersection over Union (IoU) and dice coefficient, which focus on the pixel-wise overlap between predicted and ground truth segmentations. Since pedestrian paths tend to be wider, more variable in appearance, and often partially occluded by shadows or surrounding infrastructure, they introduce greater segmentation challenges, leading to a lower IoU and Dice score compared to the well-structured and highly reflective bicycle lane markings. Furthermore, geometric and reflective differences between bicycle lanes and pedestrian paths contribute to the observed performance gap. Bicycle lane markings are typically standardized, featuring brightly painted, high-contrast symbols or solid lines, making them easier for the model to detect. Pedestrian paths, on the other hand, often lack consistent visual cues (e.g., some are simple sidewalks with no explicit markings) and may be more integrated into the surrounding pavement, making segmentation more challenging. Additionally, the presence of shadows from trees, buildings, and other urban elements disproportionately affects pedestrian paths, reducing the model’s ability to achieve high segmentation accuracy.
6. Conclusions and Future Work
This research investigates the use of computer vision techniques to extract roadway geometry, with a particular emphasis on bicycle and pedestrian lanes in Florida as a proof of concept. By harnessing the capabilities of computer vision, this method offers a modern alternative to traditional manual inventory processes, which are typically time-consuming and susceptible to human error. The findings of this study highlight the transformative potential of deep learning models in roadway infrastructure mapping, particularly for pedestrian and bicycle lane detection. The developed framework, utilizing YOLO and MTRE models, significantly enhances the automation of geospatial data extraction, reducing reliance on time-intensive and hazardous manual data collection processes. This approach not only improves the efficiency of transportation agencies in maintaining up-to-date roadway inventories but also provides a replicable methodology that can be adapted for use in other regions with similar transportation needs. The integration of AI with high-resolution aerial imagery represents a major advancement in transportation data science, demonstrating how automated detection techniques can support safer, more sustainable multimodal transportation systems. Future applications of this research could extend to other roadway elements, such as crosswalks and traffic signs, further broadening the impact of AI-driven transportation analytics. The developed system demonstrates the ability to automatically and accurately identify bicycle markings and pedestrian lanes from high-resolution imagery, achieving an F1 score of 85.48% for bicycle lanes and 61.50% for pedestrian lanes when validated against ground truth data from Leon County, Florida.
At a 50% confidence threshold, the bicycle lane model achieved completeness of 73.29%, correctness of 95.65%, and an F1 score of 82.99%, reflecting strong model performance in minimizing false negatives while maintaining high precision. Even at a lower 25% confidence threshold, the model maintained high completeness (81.87%) and correctness (89.43%), resulting in an overall quality of 74.65%. Meanwhile, for pedestrian lanes, this model exhibited a completeness of 73.42%, correctness of 52.91%, and quality of 45.88%, highlighting the challenges associated with detecting pedestrian features in high-resolution aerial imagery, particularly due to occlusions and complex background textures.
By eliminating the need for manual inventory, this system not only improves the accuracy of roadway geometry data but also offers significant cost savings for stakeholders by reducing errors associated with manual data entry.
The implications of this approach extend beyond cost and efficiency. For transportation agencies, the ability to extract and analyze roadway data from imagery offers numerous advantages. It can help identify outdated or obscured markings, which are critical for maintaining safety and regulatory compliance. Furthermore, this system allows for the comparison of geometric features, such as the alignment of turning lanes with crosswalks and school zones, providing agencies with insights into areas that may require redesign or safety improvements. These data can also be used in crash analysis, helping to identify patterns or hazards near these features and contributing to better-informed safety interventions.
This study highlights several limitations and provides suggestions for future research. One significant challenge is the difficulty in detecting feature markings on roadways obscured by tree canopies in aerial imagery. Also, the geographical scope of this study was intentionally limited to Florida public roadways, with a focus on Leon County due to its diverse transportation infrastructure. This area encompasses a range of roadway types, from dense urban networks in Tallahassee to more rural and suburban roadways, making it an ideal testbed for evaluating the effectiveness of object detection models in various contexts. Additionally, the training dataset included roadway data from multiple Florida counties—such as Sarasota, Hillsborough, Gilchrist, Gulf, and Miami-Dade—ensuring that the models were exposed to a variety of road layouts, markings, and conditions. While the models are expected to generalize well to other areas with diverse road networks, their performance may vary in regions with significantly different roadway structures, markings, and environmental conditions. For instance, road designs in European or Asian countries often differ from U.S. standards in terms of lane markings, signage conventions, and traffic flow patterns. Similarly, variations in topography and vegetation could affect how features are detected in aerial imagery. To adapt the models for broader applicability, retraining with region-specific datasets would be necessary to ensure that they capture local road characteristics. Acknowledging these limitations, future research will explore the models’ adaptability to international roadway systems and assess potential modifications to improve its generalizability across different regions. Moving forward, the proposed models could be incorporated into comprehensive roadway geometry inventory frameworks, including the HSM and the Model Inventory of Roadway Elements (MIRE). By doing so, it could play a key role in ensuring that datasets are updated to reflect the current state of bicycle and pedestrian infrastructure. This would enable transportation agencies to more effectively manage roadway assets, enhance safety, and improve planning and operational decisions. Future research will aim to enhance the model’s functionality by enabling the detection and extraction of additional continuous roadway features, such as guardrails, shoulders, and medians. Furthermore, efforts will be made to combine the identified bicycle and pedestrian lanes with crash statistics, traffic data, and demographic information to facilitate a more comprehensive analysis.



 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}