Implementation of Pattern Recognition Algorithms in Processing Incomplete Wind Speed Data for Energy Assessment of Offshore Wind Turbines



Abstract
1. Introduction
1.1. Motivation and State-of-the-Art
1.2. Contribution of the Present Paper
- (a)
- This study is structured around the problem of working with incomplete and/or missing data; since this situation is frequent in renewable energy assessment preliminary studies. Incomplete and missing data pose restrictions on the techno-economic assessment of renewable energy projects. With the present paper, methodologies on investigating methods to overcome the aforementioned restrictions are developed and proposed. Two novel proposed methods for filling missing and incomplete wind speed data are developed, implemented and tested against real measured data that are obtained from a monitoring system installed in Neos Marmaras, Greece.
- (b)
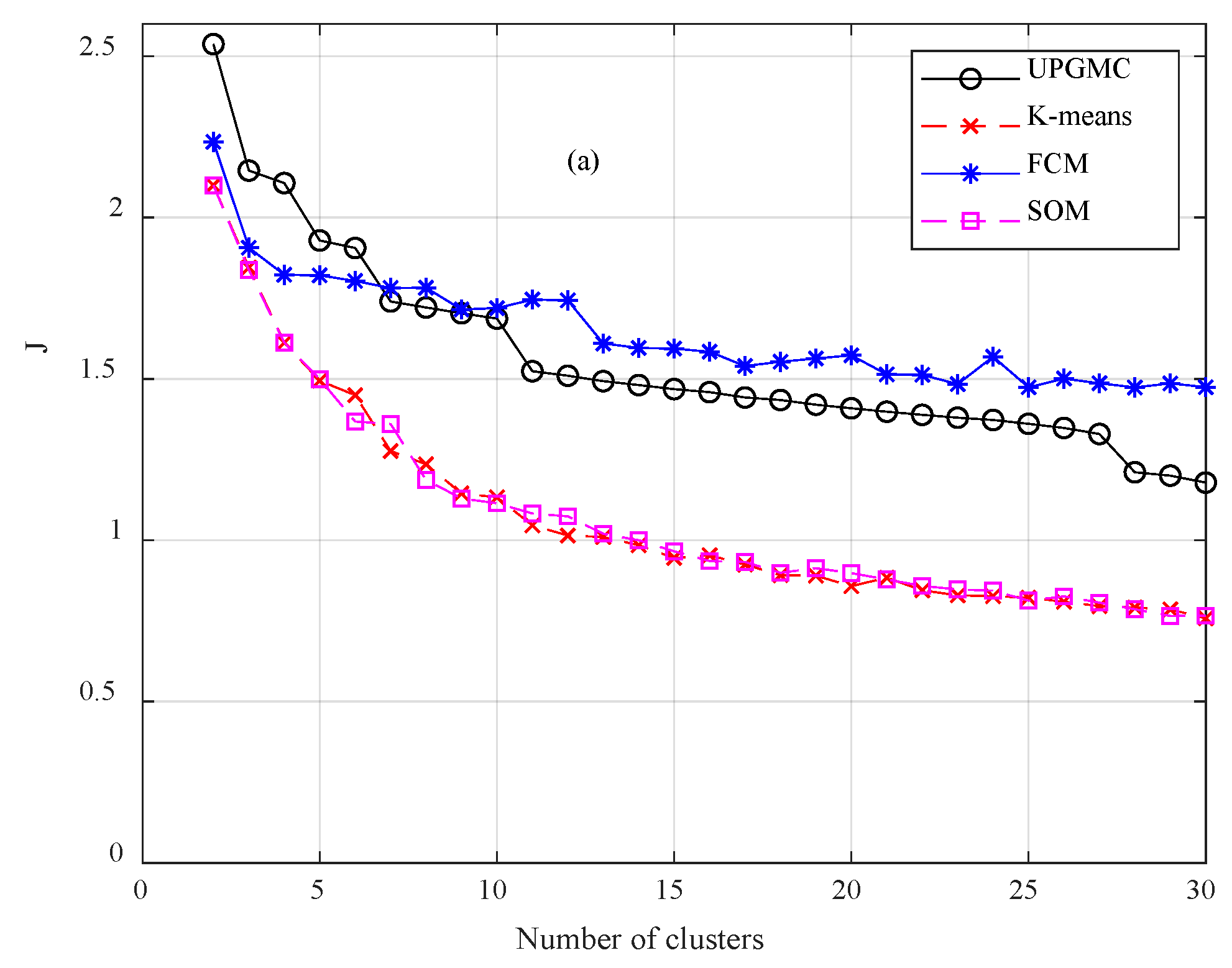
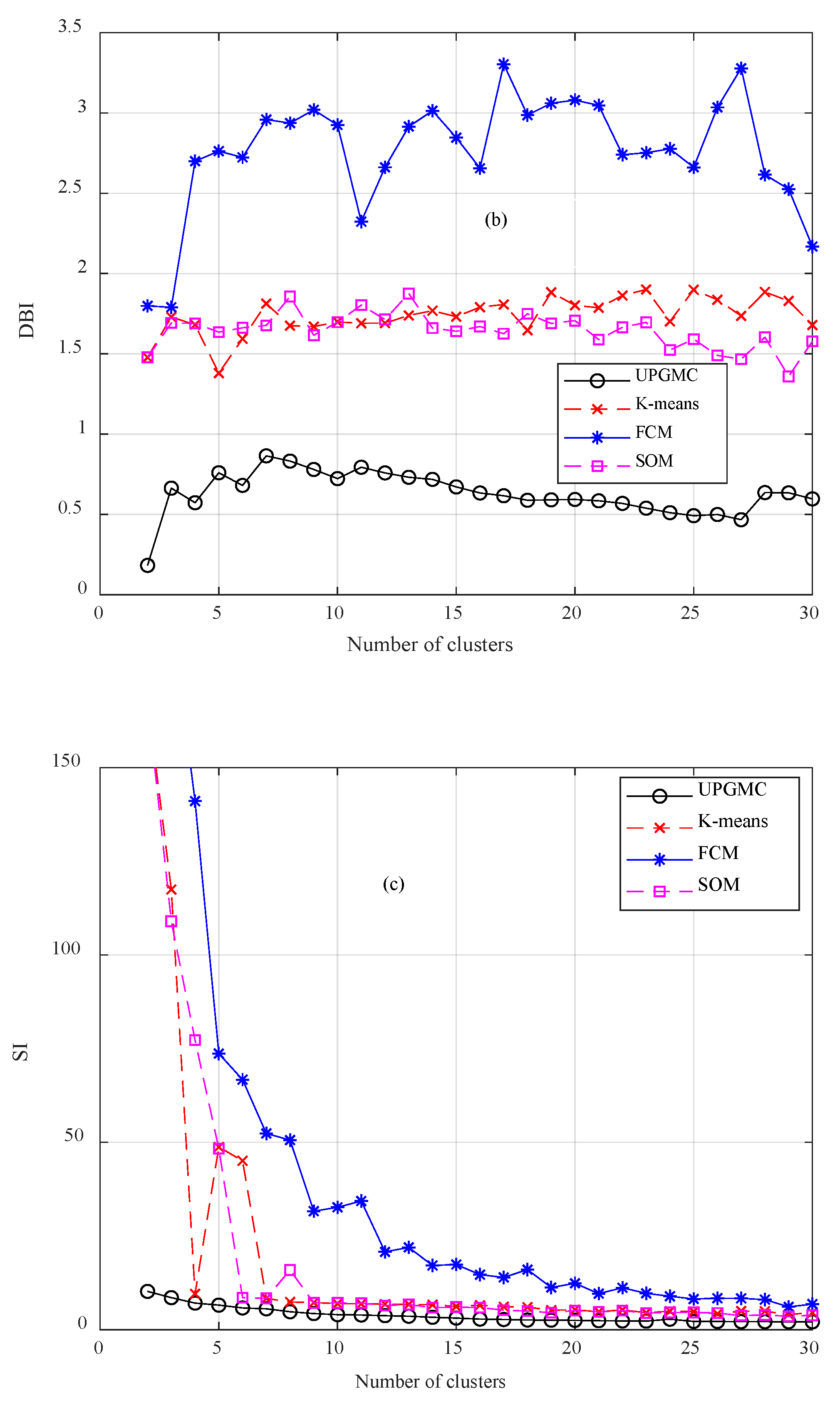
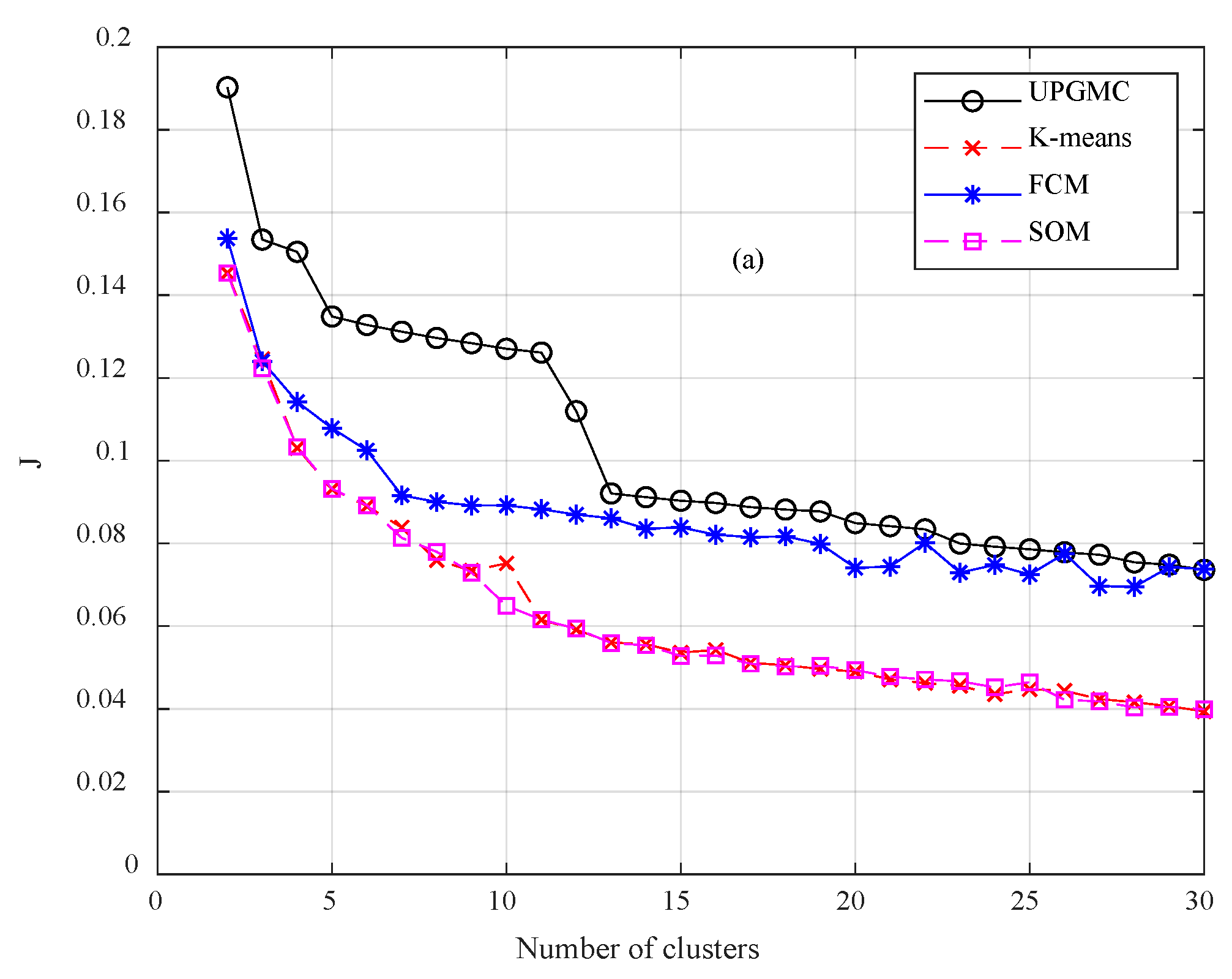
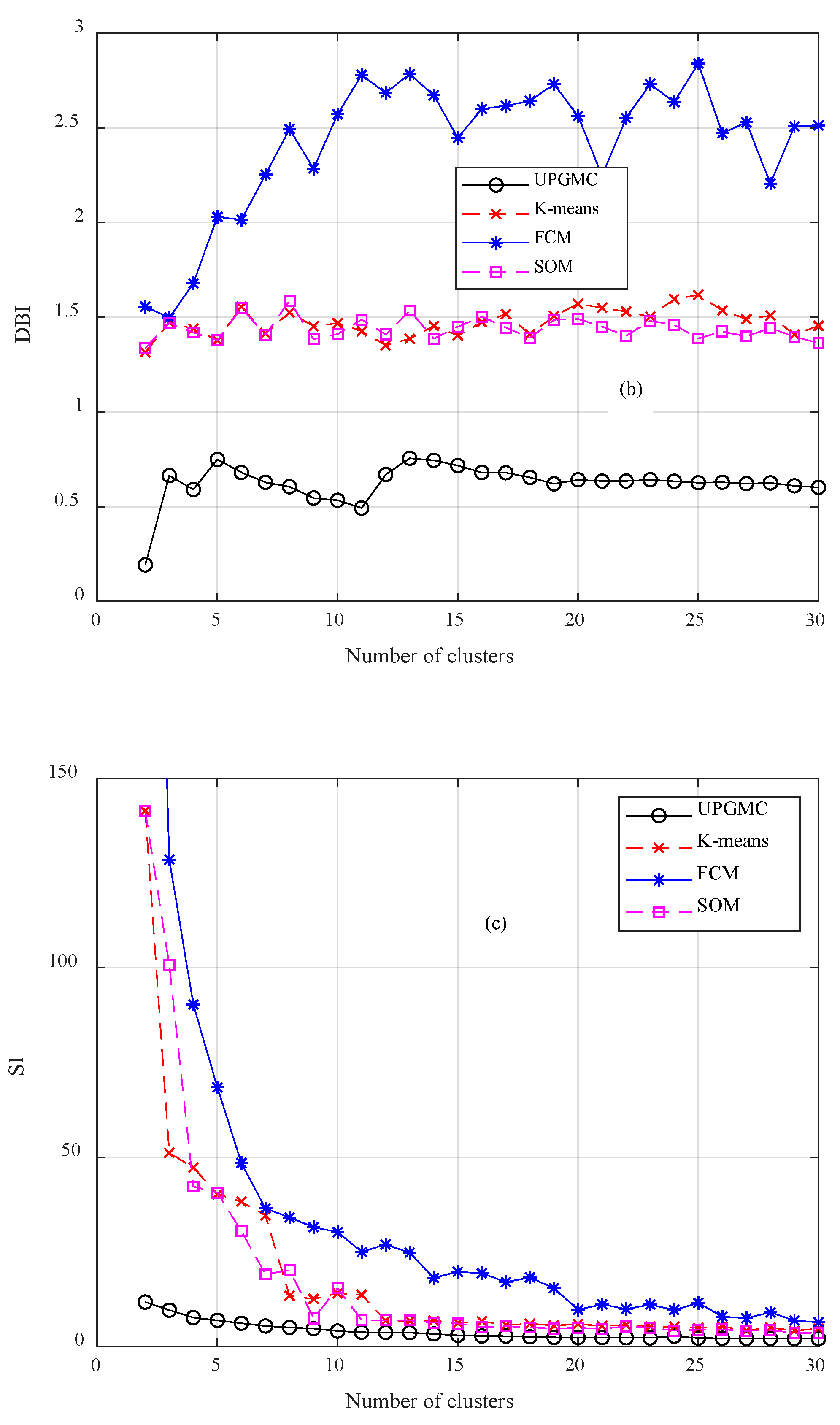
- The utilization of clustering algorithms in wind speed data partitioning has not sufficiently examined in the technical literature. Clustering leads to several advantages in time series modeling. In this study, a comparative analysis takes place between four well researched algorithms. By examining the outputs of clustering, useful conclusions can be drawn for the variations and special attributes of the speed data.
- (c)
- After the completion of the missing and incomplete data, the energy potential of the specific offshore site is estimated.
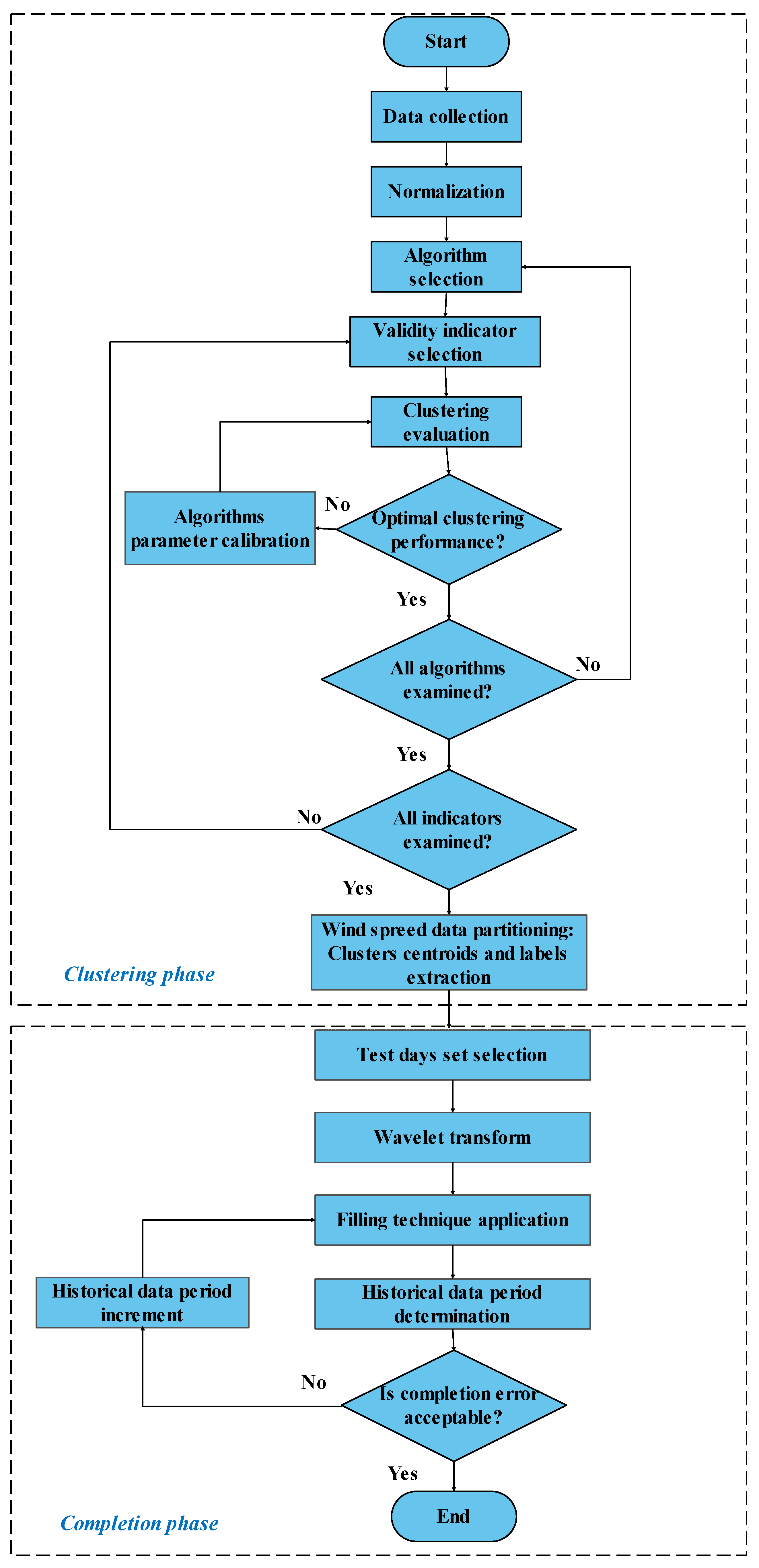
2. Materials and Methods
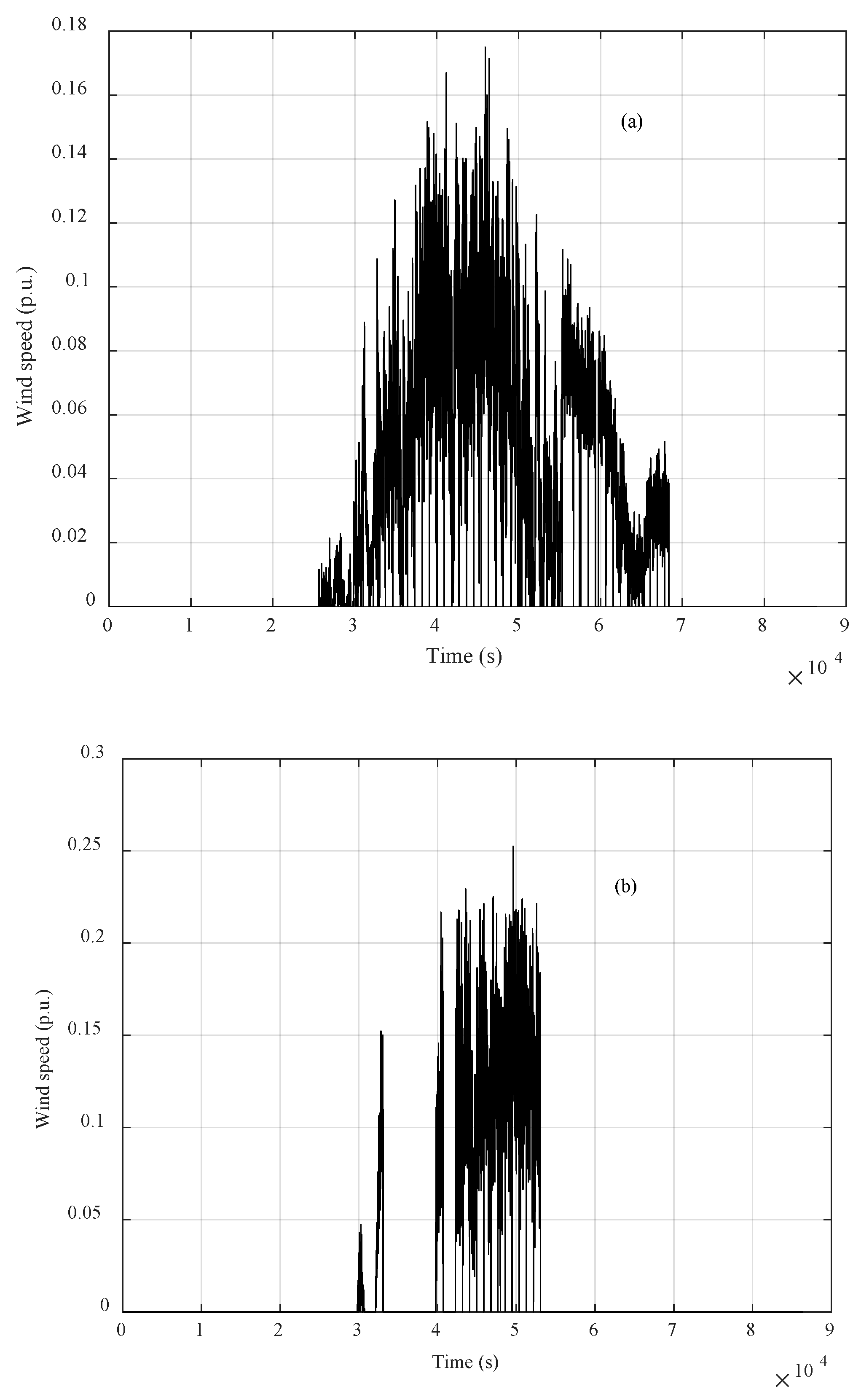
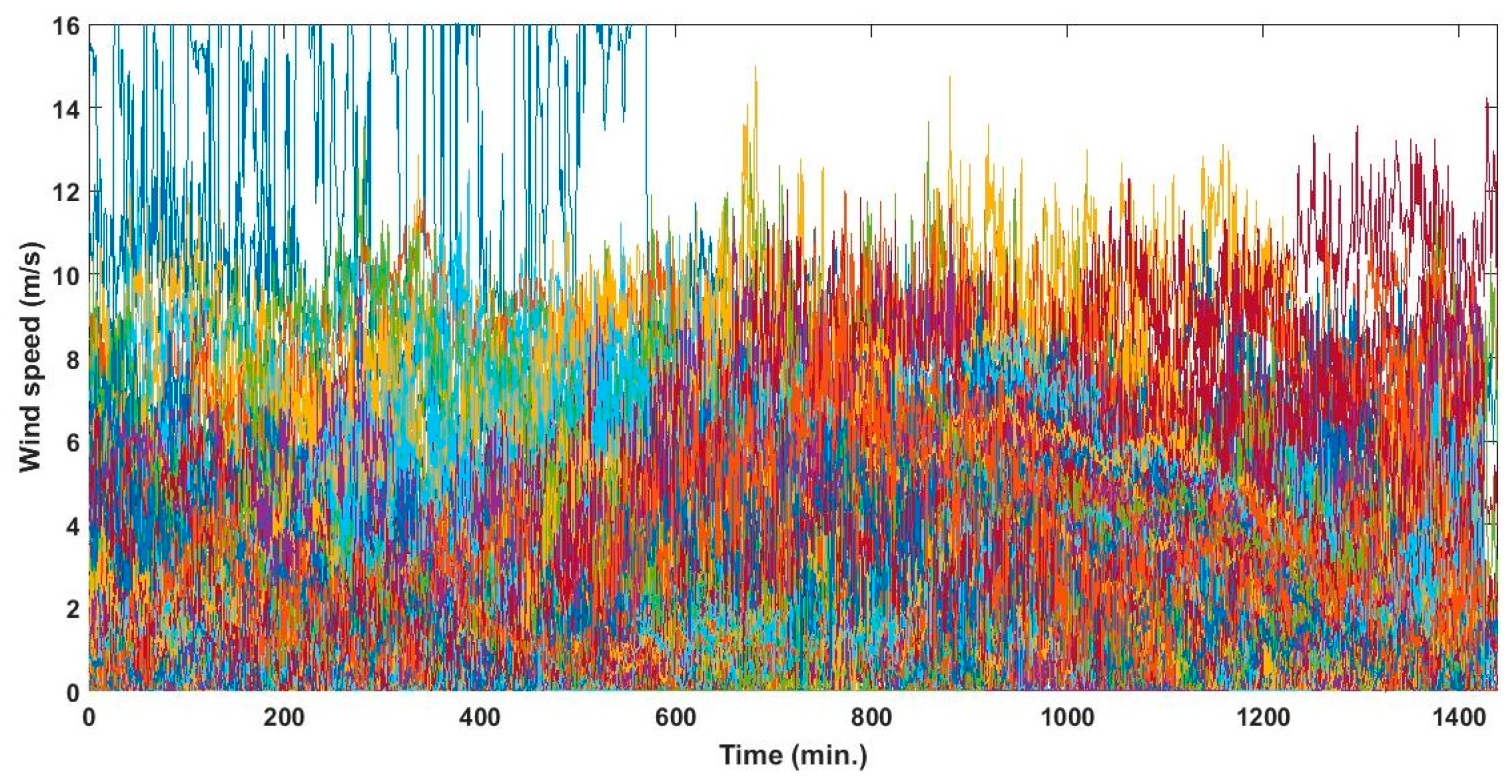
2.1. Description of the Available Data
2.2. Introduction with Regard to Clustering Process
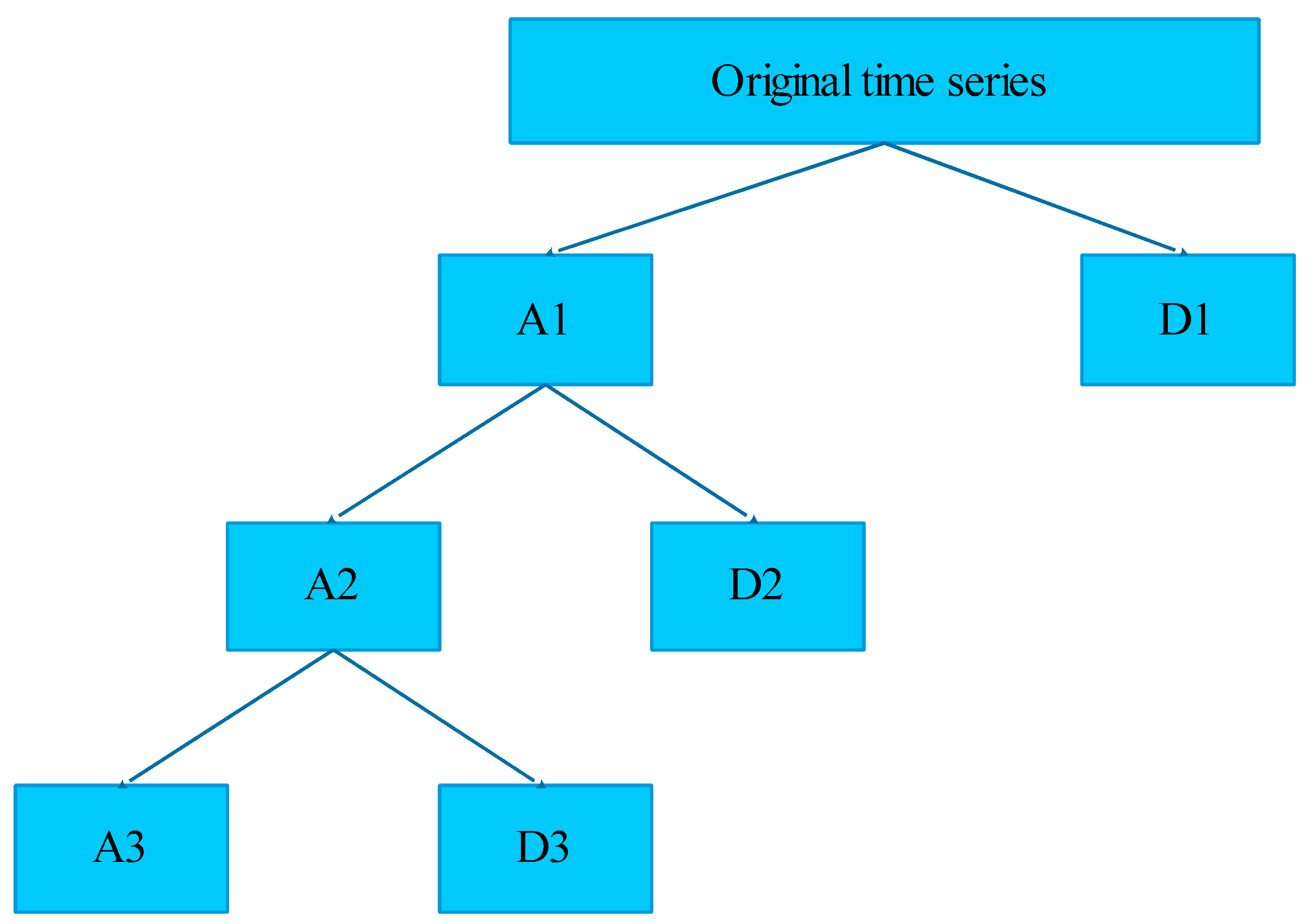
2.3. Patterns Representation
2.4. Algorithms Description
2.5. Cluster Validation Framework
2.6. Proposed Methodology for Filling Missing Data for Days with Complete Absence of Data
2.7. Proposed Methodology for Filling Incomplete Data for Days with Partial Absence of Data
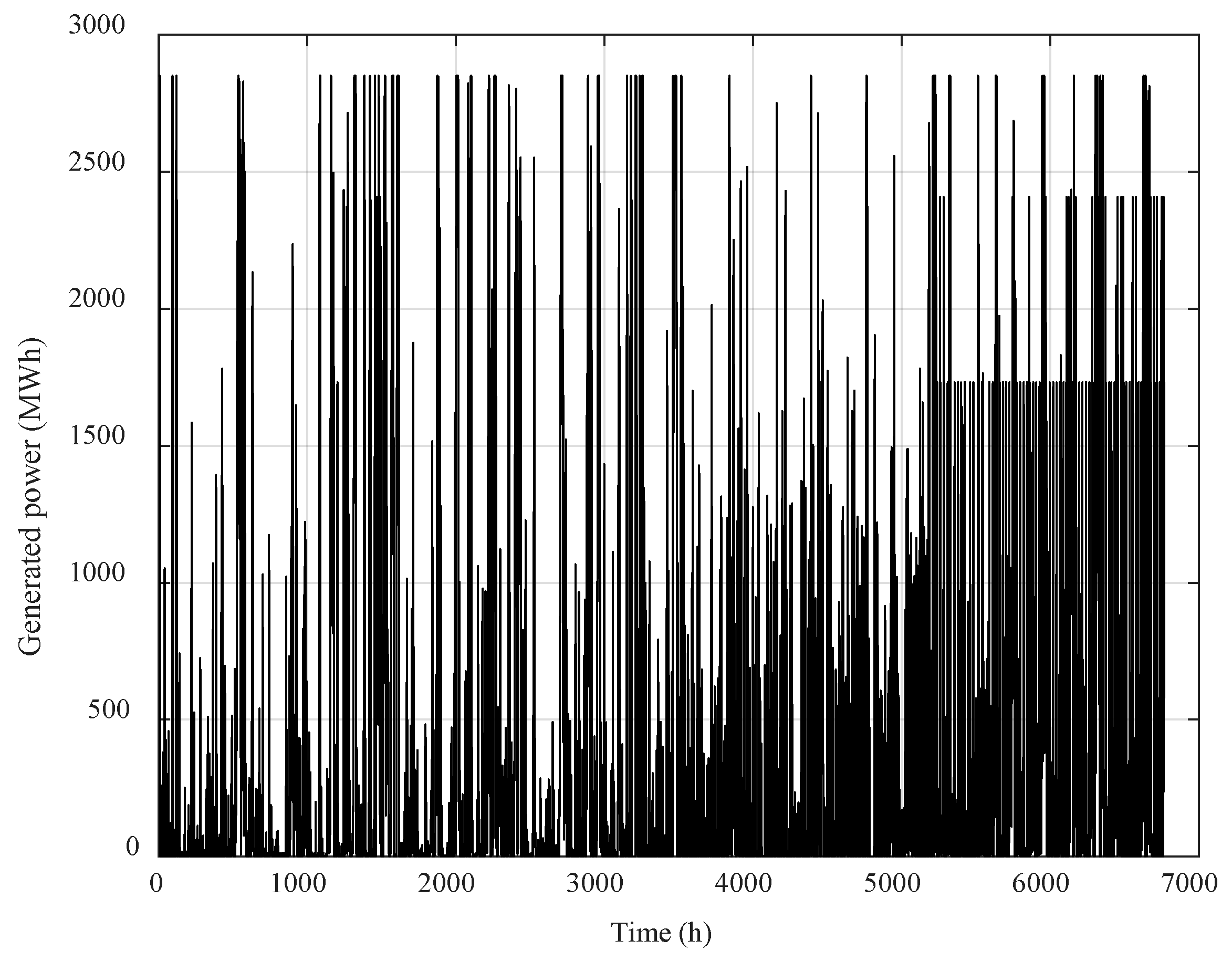
3. Results
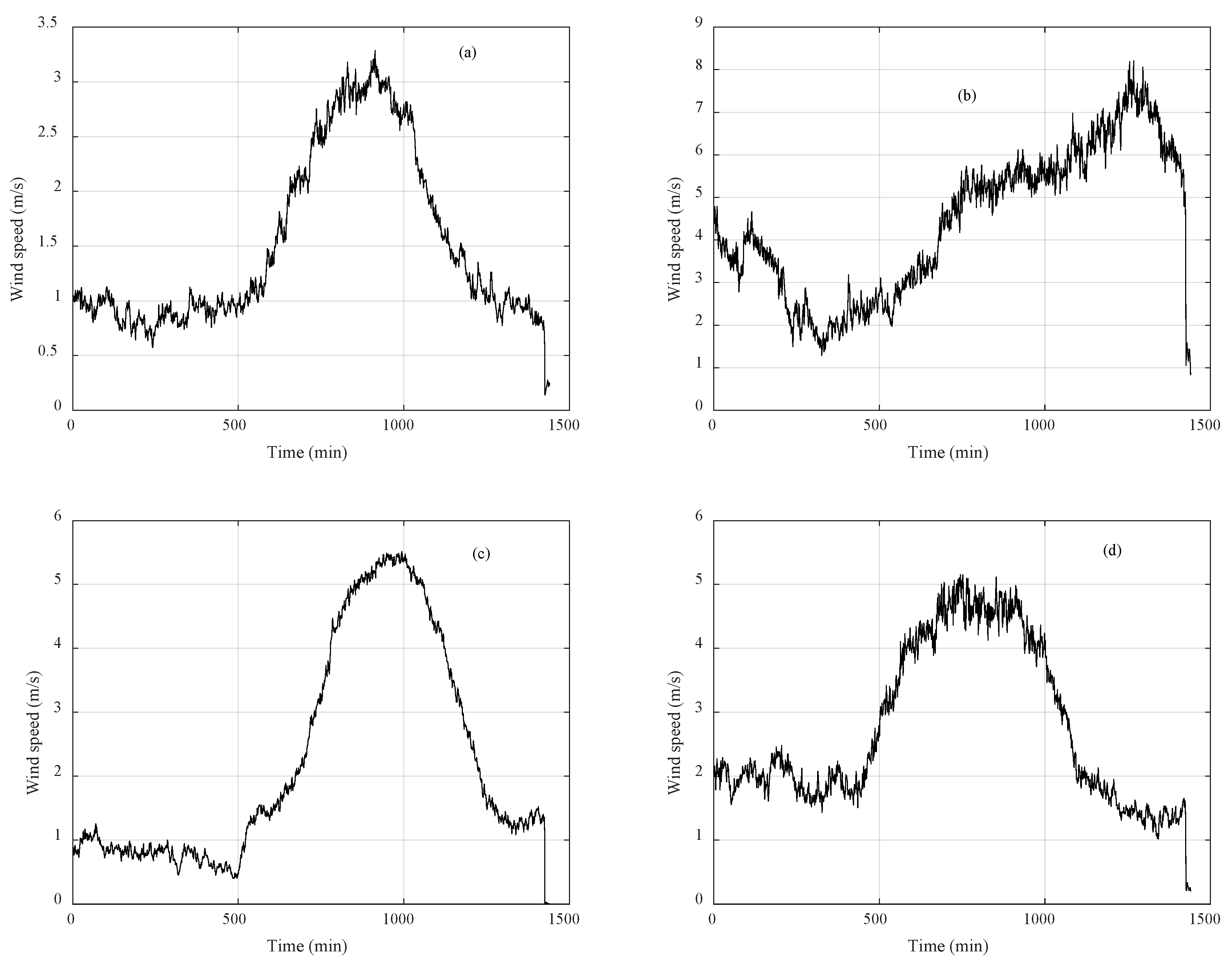
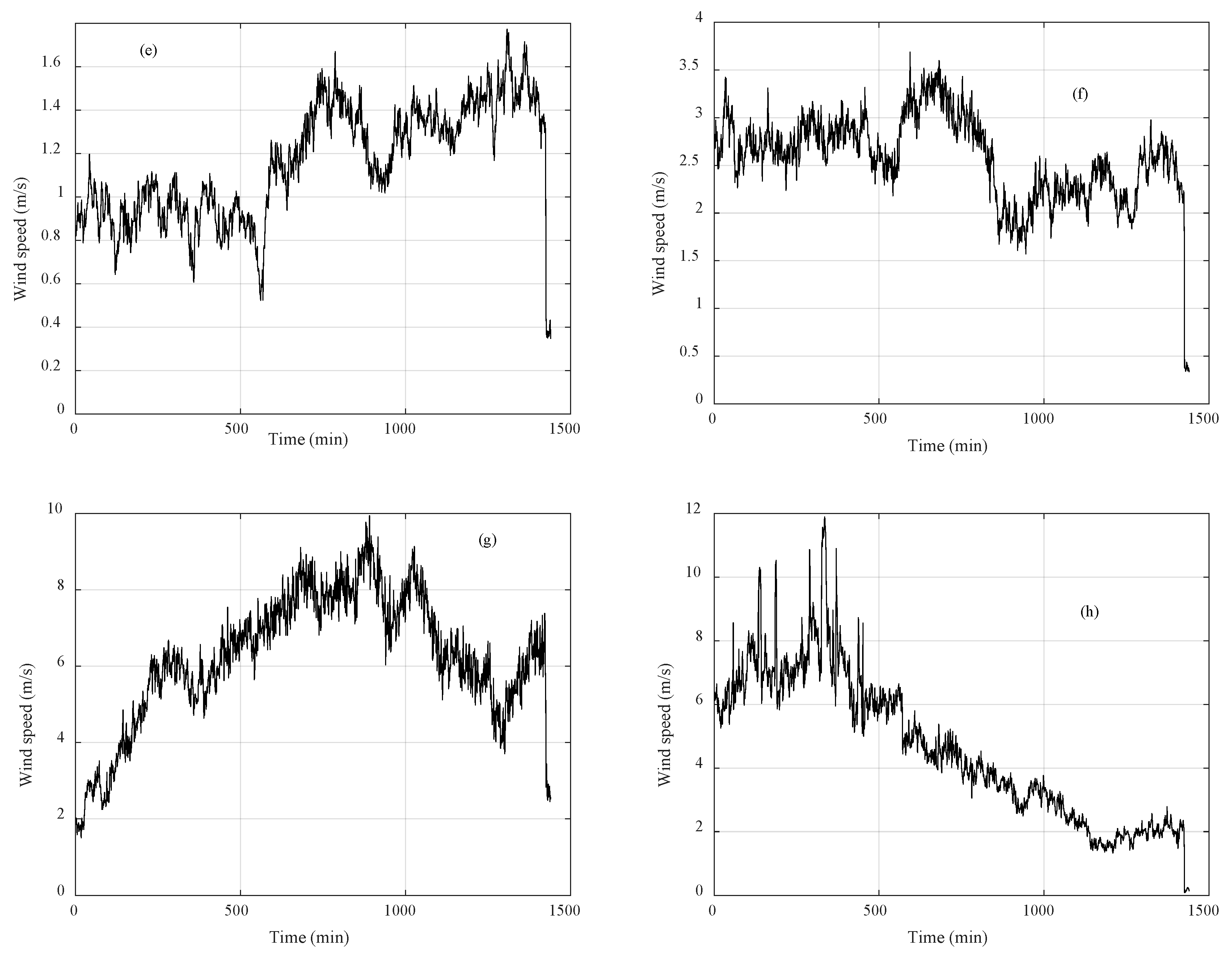
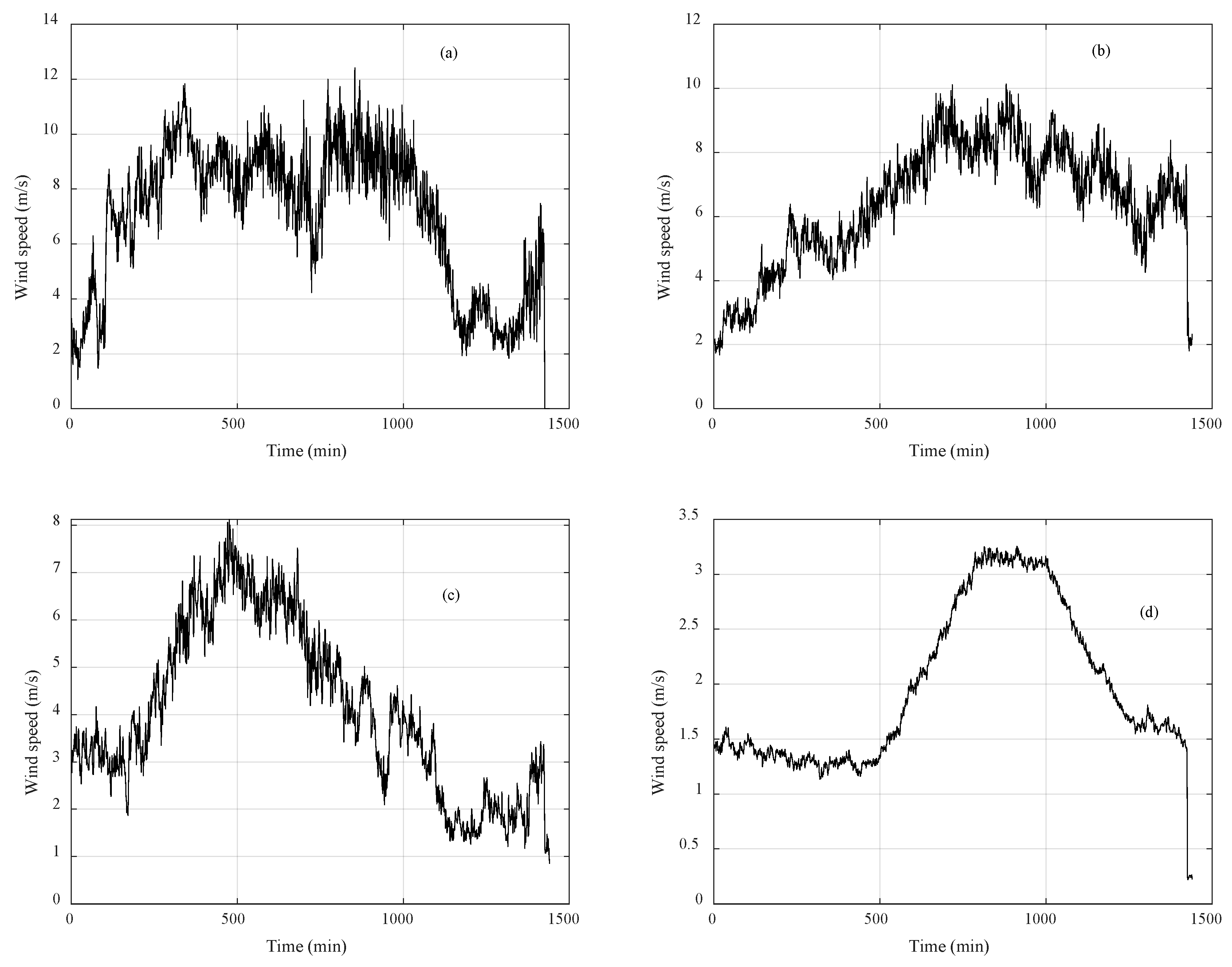
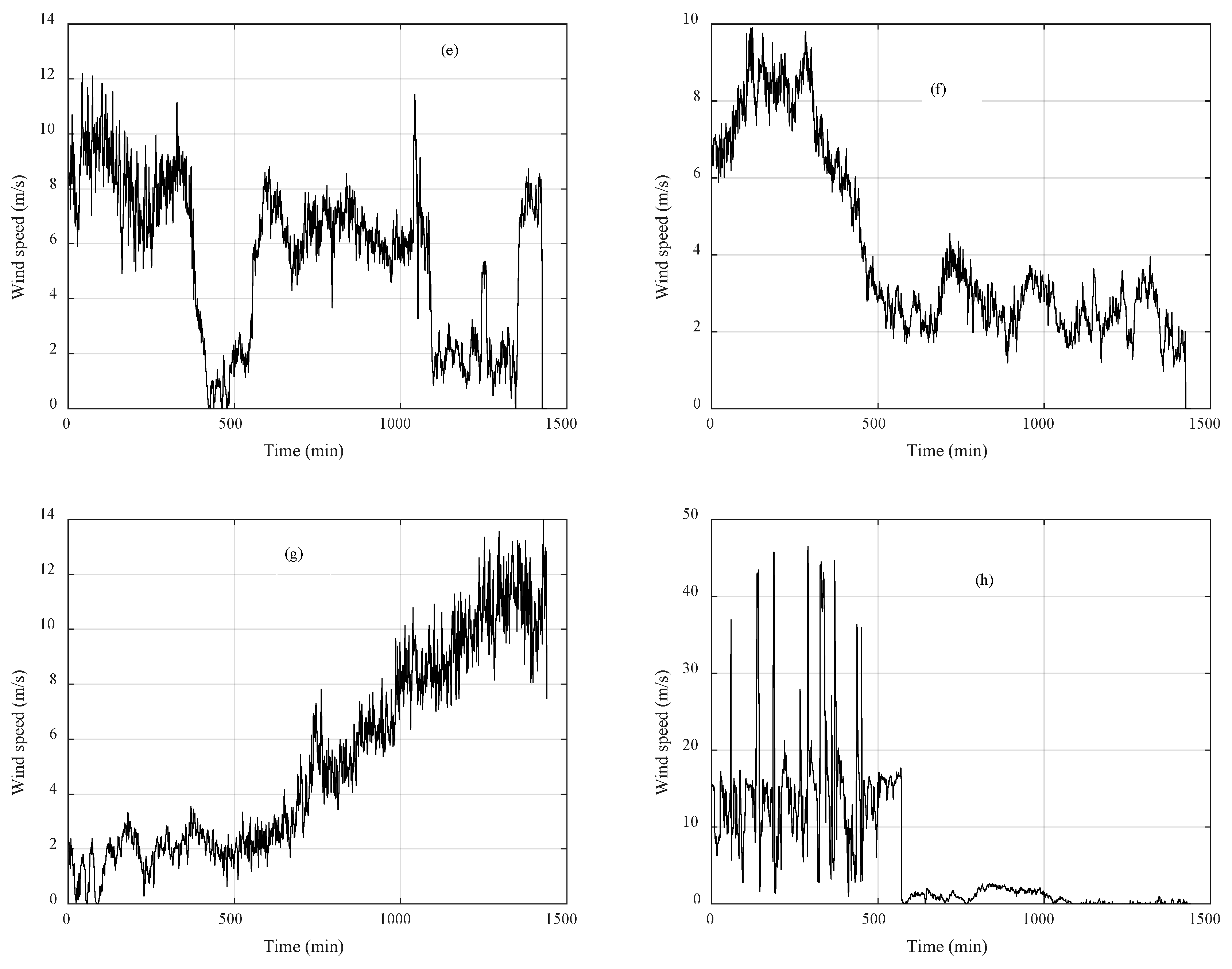
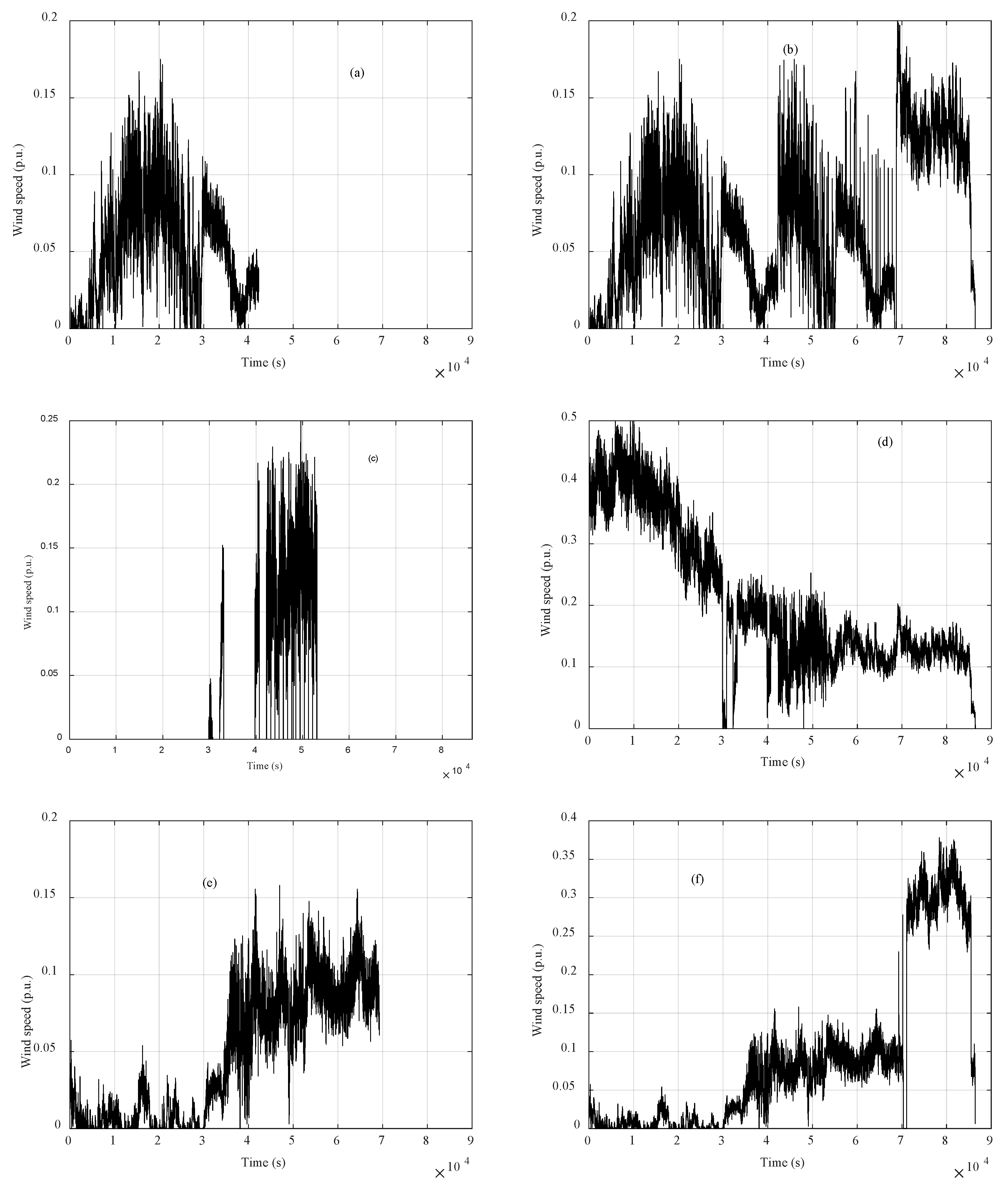
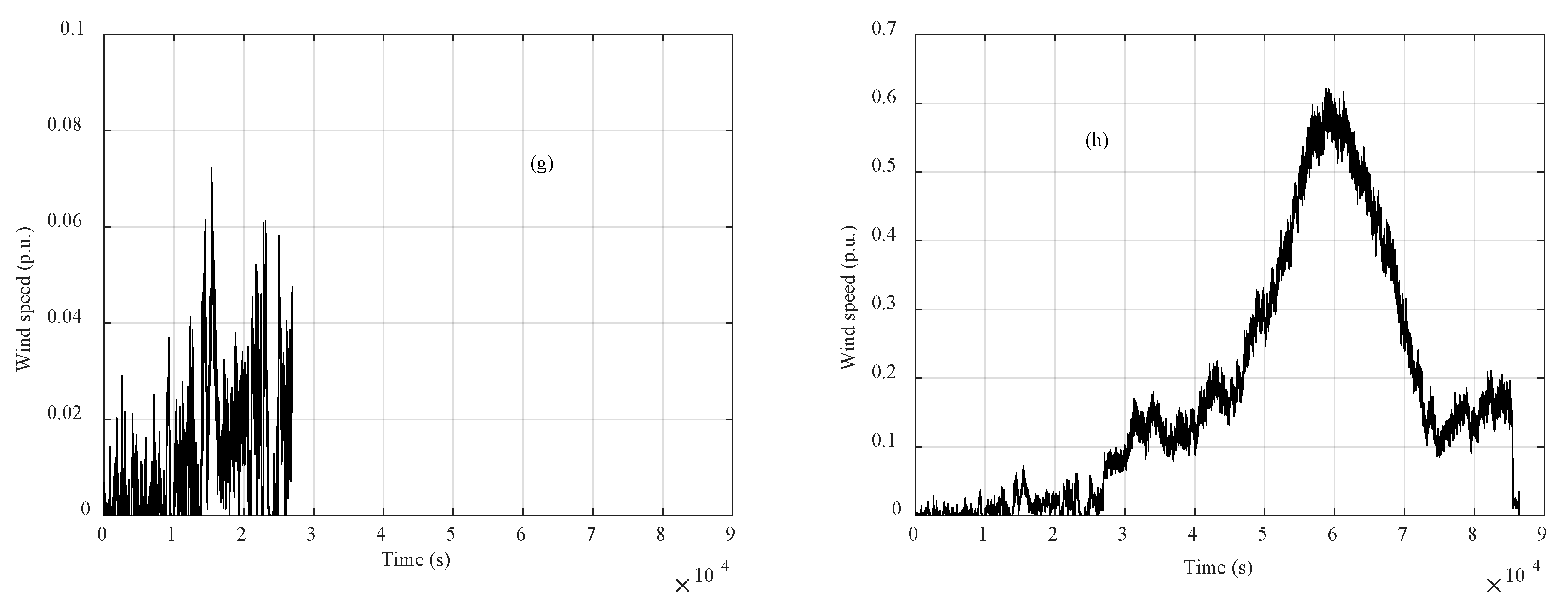
3.1. Clustering Algorithms Comparison and Wind Speed Profiles
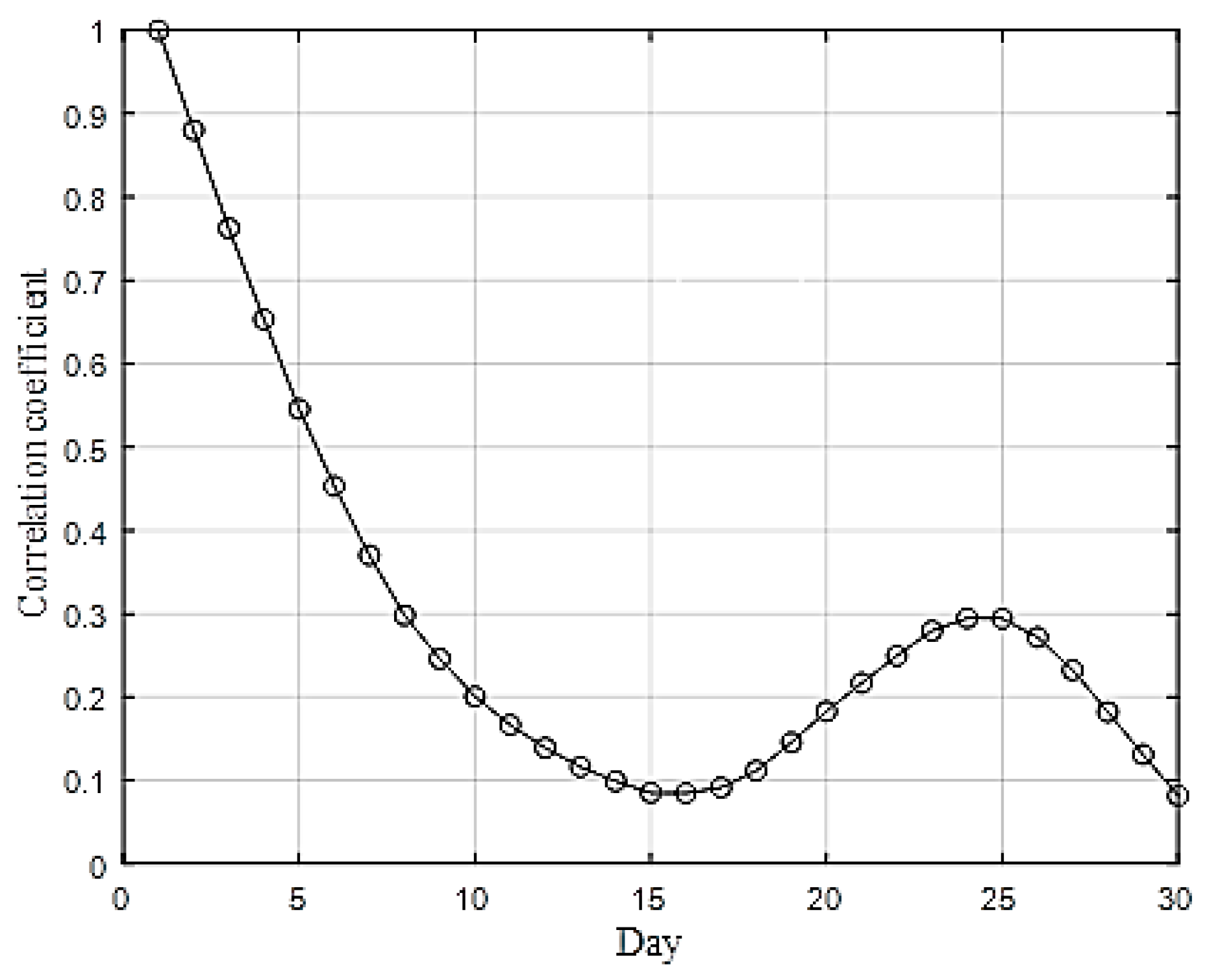
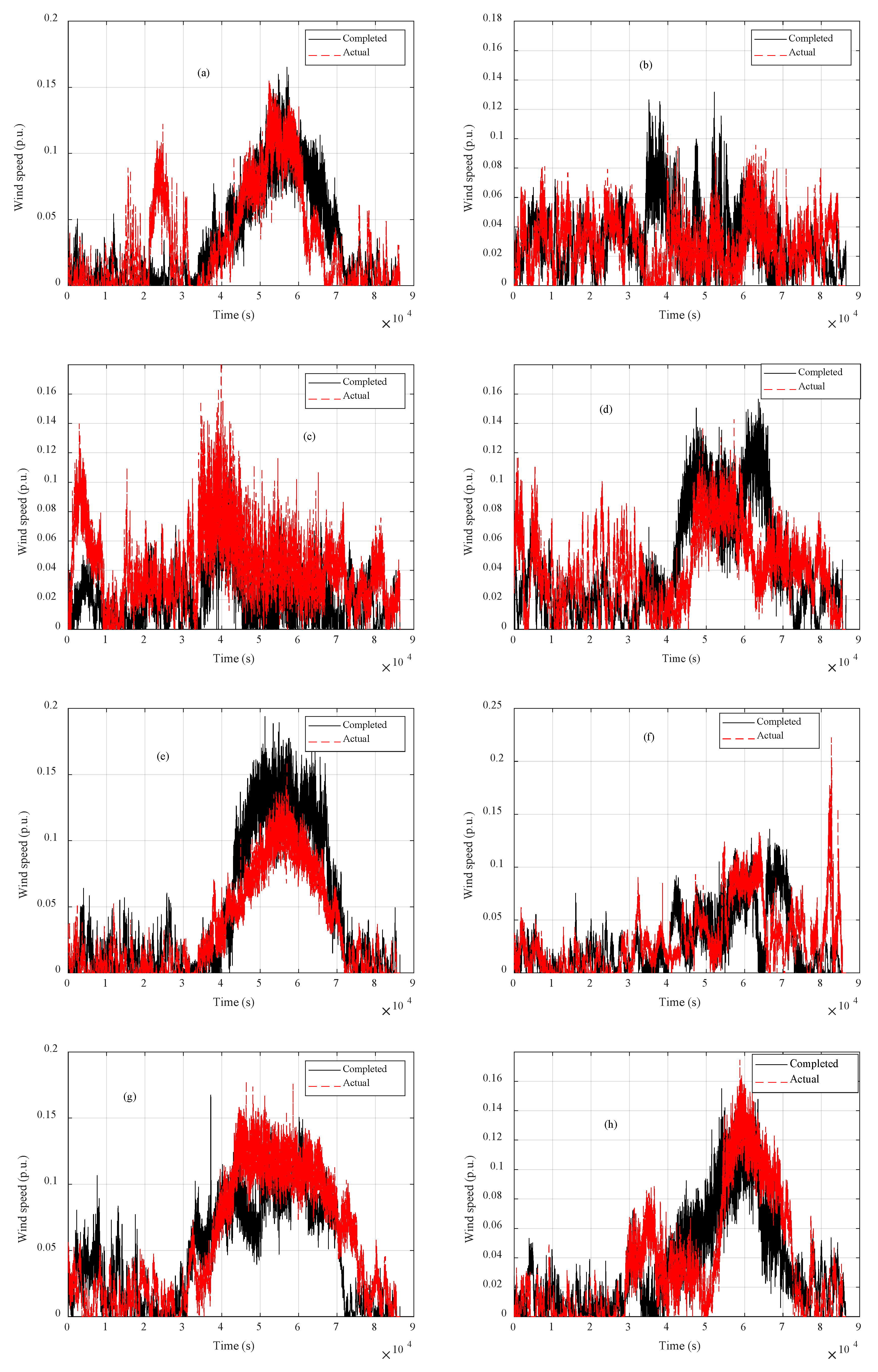
3.2. Missing Data Completion
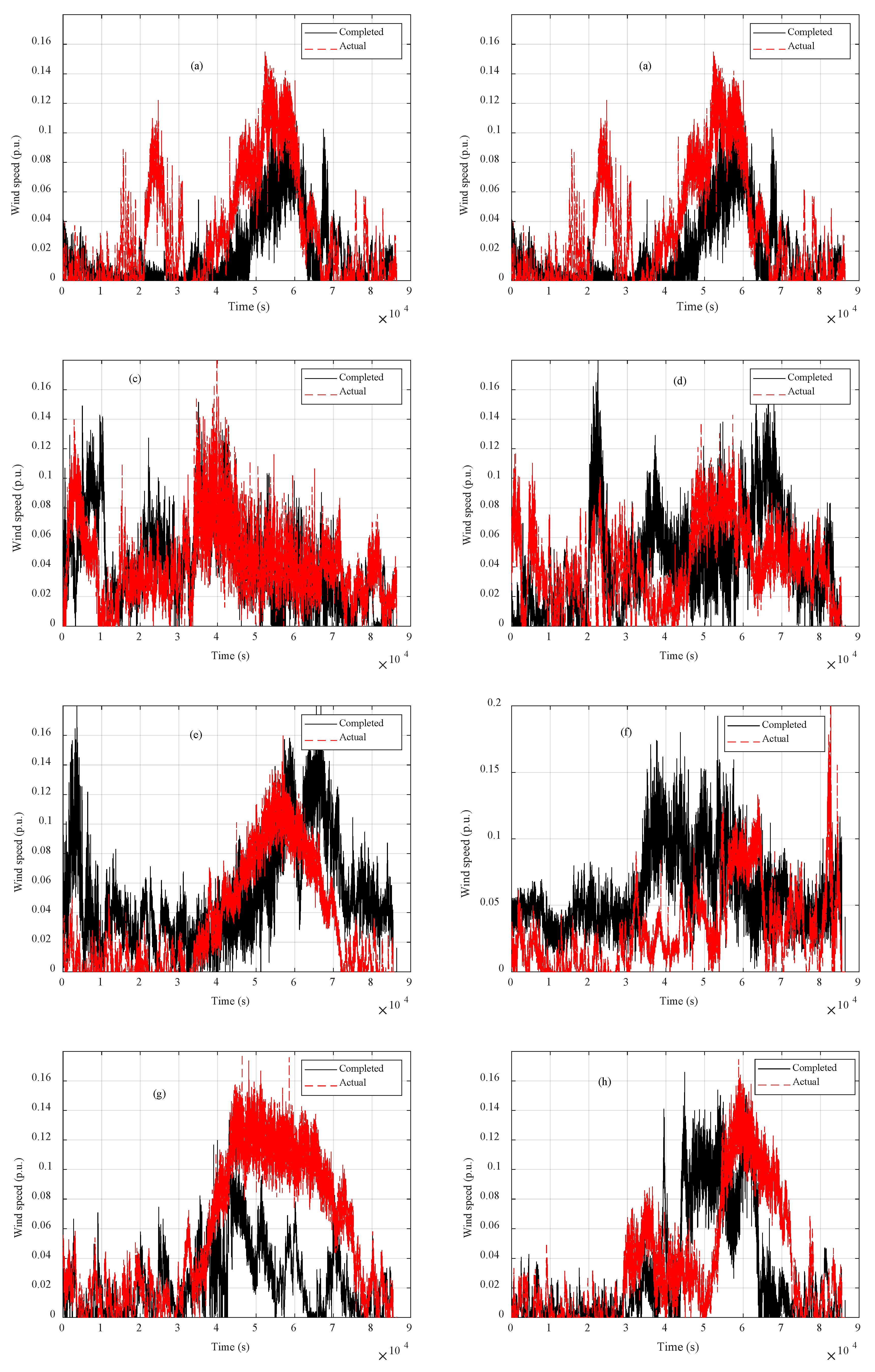
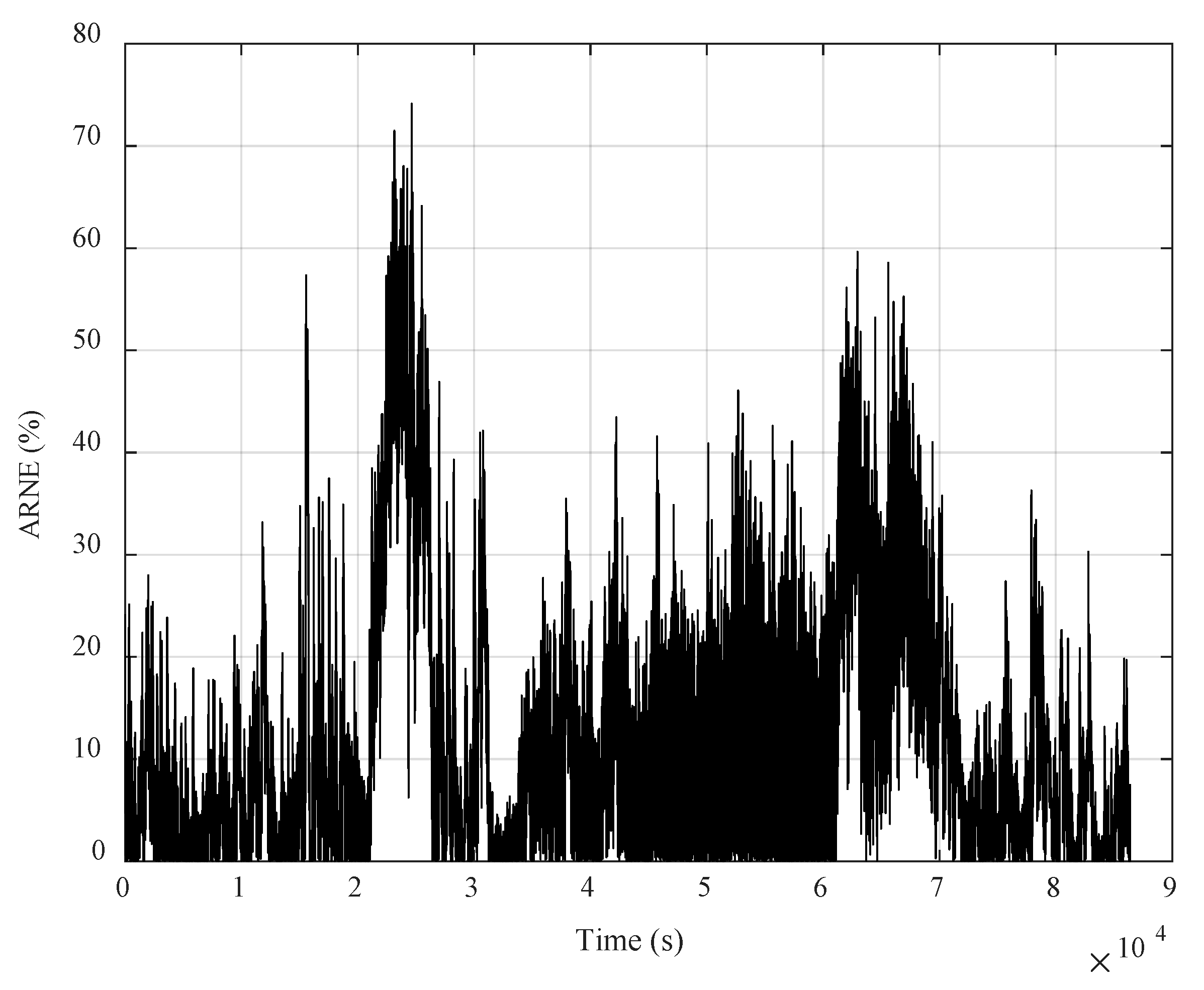
3.3. Incomplete Data Completion
4. Discussion
- A set of validity indicators is required for determining the optimal algorithm. Clustering is application driven. Therefore, there is no universally acclaimed algorithm for all clustering problems.
- The comparative analysis indicates that UPGMC is more appropriate for wind speed data clustering; FCM and SOM correspond to poor performance.
- With respect to execution time, UPGMC requires the less time. SOM corresponds to high execution time and its utilization is not recommended for the problem under study.
- The indicator J and SI are appropriate for determining the optimal number of clusters. This number differs among the time scales (second, minute and hour) of wind speed time series.Clustering is the core of the missing data completion techniques. Regarding the completion of days with a complete absence of data, the main conclusions can be summarized in the following:
- The K-means leads to increased errors in all days of the test set compared to the UPGMC.
- No strong correlation is observed between the seasonality of the day and the completion error.
- A set of various clustering algorithms have been compared for the analysis of the wind speed data. Contrary to the existing literature, the patterns for clustering refer to daily wind speed series. Apart from validity indicators, the algorithms have been checked in terms of complexity, i.e., the required execution time.
- Two novel techniques of missing data filling have been proposed.The analysis of the present paper can be expanded to the following areas:
- Examination of other clustering algorithms for the problem under study.
- Development of new algorithms (i.e., multi-objective optimization) that aim to satisfy two criteria, for example the distances between patterns in the same cluster and the distances between the centroids among the clusters.
- The utilization of new indicators for algorithm assessment, both for measuring the clustering error and complexity.
- Examination of other mother wavelets of the DWT.
- Implementation of the proposed missing data filling techniques in the variables that are related to the structural health monitoring of offshore installations.
Author Contributions
Funding
Conflicts of Interest
References
- International Energy Agency. Renewables Information 2016; IEA: Paris, France, 2016. [Google Scholar]
- Esteban, M.D.; Diez, J.J.; López, J.D.; Negro, V. Why offshore wind energy? Renew. Energy 2011, 36, 444–450. [Google Scholar] [CrossRef]
- Breton, S.M.; Moe, G. Status, plans and technologies for offshore wind turbines in Europe and North America. Renew. Energy 2009, 34, 646–654. [Google Scholar] [CrossRef]
- Bilgili, M.; Yasar, A.; Simsek, E. Offshore wind power development in Europe and its comparison with onshore counterpart. Renew. Sustain. Energy Rev. 2011, 15, 905–915. [Google Scholar] [CrossRef]
- Snyder, B.; Kaiser, M.J. Ecological and economic cost-benefit analysis of offshore wind energy. Renew. Energy 2009, 34, 1567–1578. [Google Scholar] [CrossRef]
- Karimirad, M.; Michailides, C. V-shaped semisubmersible offshore wind turbine: An alternative concept for offshore wind technology. Renew. Energy 2015, 83, 126–143. [Google Scholar] [CrossRef]
- Karimirad, M.; Michailides, C. V-shaped Semisubmersible Offshore Wind Turbine Subjected to Misaligned Wave and Wind. J. Renew. Sustain. Energy 2016, 8, 023305. [Google Scholar] [CrossRef]
- Michailides, C.; Gao, Z.; Moan, T. Experimental Study of the Functionality of a Semisubmersible Wind Turbine Combined with Flap-Type Wave Energy Converters. Renew. Energy 2016, 93, 675–690. [Google Scholar] [CrossRef]
- Michailides, C.; Gao, Z.; Moan, T. Experimental and numerical study of the response of the offshore combined wind/wave energy concept SFC in extreme environmental conditions. Mar. Struct. 2016, 50, 35–54. [Google Scholar] [CrossRef]
- Pérez-Collazo, C.; Greaves, D.; Iglesias, G. A review of combined wave and offshore wind energy. Renew. Sustain. Energy Rev. 2015, 42, 141–153. [Google Scholar] [CrossRef]
- Rodrigues, S.; Restrepo, C.; Kontos, E.; Teixeira Pinto, R.; Bauer, P. Trends of offshore wind projects. Sustain. Energy Rev. 2015, 49, 1114–1135. [Google Scholar] [CrossRef]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley and Sons: New York, NY, USA, 1987. [Google Scholar]
- Batista, P.A.; Monard, M.C. An analysis of four missing data treatment methods for supervised learning. Appl. Artif. Intell. 2003, 17, 519–533. [Google Scholar] [CrossRef]
- Grzymala-Busse, J.W.; Goodwin, L.K. Handling missing attribute values in preterm birth data sets. In Lecture Notes in Computer Science: Volume 3642. Rough Sets, Fuzzy Sets, Data Mining, and Granular Computing (RSFDGrC 2005); Slezak, D., Yao, J., Peters, J.F., Ziarko, W., Hu, X., Eds.; Springer: Regina, Canada, 2005; p. 3420351. [Google Scholar]
- Li, D.; Deogun, J.; Spaulding, W.; Shuart, B. Towards missing data imputation: A study of fuzzy K-means clustering method. In Lecture Notes in Computer Science: Volume 3066. Rough Sets and Current Trends in Computing (RSCTC 2004); Tsumoto, S., Slowinski, R., Komorowski, J., Grzymala-Busse, J.W., Eds.; Springer: Uppsala, Sweden, 2004; p. 573579. [Google Scholar]
- Acuna, E.; Rodriguez, C. The treatment of missing values and its effect in the classifier accuracy. In Classification, Clustering and Data Mining Applications; Banks, D., House, L., McMorris, F.R., Arabie, P., Gaul, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 639–648. [Google Scholar]
- Wong, A.K.C.; Chiu, D.K.Y. Synthesizing statistical knowledge from incomplete mixed-mode data. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 796–805. [Google Scholar] [CrossRef]
- Schneider, T. Analysis of incomplete climate data: Estimation of mean values and covariance matrices and imputation of missing values. J. Clim. 2001, 14, 853–871. [Google Scholar] [CrossRef]
- Feng, H.A.B.; Chen, G.C.; Yin, C.D.; Yang, B.B.; Chen, Y.E. A SVM regression based approach to filling in missing values. In Lecture Notes in Artificial Intelligence: Volume 3683. Knowledge-Based Intelligent Information and Engineering Systems (KES 2005); Khosla, R., Howlett, R.J., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 581–587. [Google Scholar]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef]
- Oba, S.; Sato, M.; Takemasa, I.; Monden, M.; Matsubara, K.; Ishii, S. A Bayesian missing value estimation method for gene expression profile data. Bioinformatics 2003, 19, 2088–2096. [Google Scholar] [CrossRef]
- Luengo, J.; García, S.; Herrera, F. A study on the use of imputation methods for experimentation with Radial Basis Function Network classifiers handling missing attribute values: The good synergy between RBFNs and Event Covering method. Neural Netw. 2010, 23, 406–418. [Google Scholar] [CrossRef]
- Luengo, J.; García, S.; Herrera, F. On the choice of the best imputation methods for missing values considering three groups of classification methods. Knowl. Inf. Syst. 2012, 32, 77–108. [Google Scholar] [CrossRef]
- Stefanakos, S.N.; Athanassoulis, G.A. A unified methodology for the analysis, completion and simulation of nonstationary time series with missing values, with application to wave data. Appl. Ocean Res. 2001, 23, 207–220. [Google Scholar] [CrossRef]
- Nikolaidis, A.; Georgiou, G.C.; Hadjimitsis, D.; Akylas, E. Filling in Missing Sea-Surface Temperature Satellite Data Over the Eastern Mediterranean Sea Using the DINEOF Algorithm. Cent. Eur. J. Geosci. 2014, 6, 27–41. [Google Scholar] [CrossRef][Green Version]
- Xu, R.; Wunsch, D. Clustering; John Wiley & Sons. Inc.: Hoboken, NJ, USA, 2006. [Google Scholar]
- Dar, K.M.; Javed, I.; Amjad, W.; Aslam, S.; Shamim, A. Survey of clustering applications. J. Netw. Commun. Emerg. Technol. 2015, 4, 10–14. [Google Scholar]
- Steinley, D. K-means clustering: A half-century synthesis. Br. J. Math. Stat. Psychol. 2006, 59, 1–34. [Google Scholar] [CrossRef]
- Fortuna, L. Clustering Daily Wind Speed Time Series. Book Chapter: Nonlinear Modeling of Solar Radiation and Wind Speed Time Series; Springer: Berlin/Heidelberg, Germany, June 2016; pp. 79–89. [Google Scholar]
- Ouyang, T.; Kusiak, A.; He, Y. Modeling wind-turbine power curve: A data partitioning and mining approach. Renew. Energy 2017, 102, 1–8. [Google Scholar] [CrossRef]
- Tamah Al-Shammari, E.; Shamshirband, S.; Petkovi, D.; Zalnezhad, E.; Yee, P.L.; Taher, R.S.; Cojba, Z. Comparative study of clustering methods for wake effect analysis in wind farm. Energy 2016, 95, 573–579. [Google Scholar] [CrossRef]
- Di Piazza, A.; Di Piazza, M.C.; Ragusa, A.; Vitale, G. Statistical processing of wind speed data for energy forecast and planning. In Proceedings of the International Conference on Renewable Energies and Power Quality, Granada, Spain, 23–25 March 2010; pp. 1417–1422. [Google Scholar]
- Sánchez-Pérez, P.A.; Robles, M.; Jaramill, O.A. Real time Markov chains: Wind states in anemometric data. J. Renew. Sustain. Energy 2016, 8, 023304. [Google Scholar] [CrossRef]
- Carreón-Sierra, S.; Salcido, A.; Castro, T.; Celada-Murillo, A.T. Cluster analysis of the wind events and seasonal wind circulation patterns in the Mexico city region. Atmosphere 2015, 6, 1006–1031. [Google Scholar] [CrossRef]
- Lorenzo, J.; Mendez, J.; Castrillon, M.; Hernandez, D. Short-Term Wind Power Based on Cluster Analysis and Artificial Neural Networks. Volume 6691 of the Series Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 191–198. [Google Scholar]
- Esmaeili, M.A.; Twomey, J. Self-Organizing Map (SOM) in wind speed forecasting: A new approach in computational intelligence (CI) forecasting methods. In Proceedings of the ASME/ISCIE 2012 International Symposium on Flexible Automation, St. Louis, MO, USA, 18–20 June 2012; pp. 405–409. [Google Scholar]
- Michailides, C.; Loukogeorgaki, E.; Angelides, D.C. Monitoring the response of connected moored floating modules. In Proceedings of the Twenty-third International Offshore and Polar Engineering, Anchorage, AK, USA, 30 June–5 July 2013; pp. 869–876, ISBN 978-1-880653-99-9. [Google Scholar]
- Tseranidis, S.; Theodoridis, L.; Loukogeorgaki, E.; Angelides, D.C. Investigation of the condition and the behavior of a modular floating structure by harnessing monitoring data. Mar. Struct. 2016, 50, 224–242. [Google Scholar] [CrossRef]
- Chicco, G. Overview and performance assessment of the clustering methods for electrical load pattern. Energy 2012, 42, 68–80. [Google Scholar] [CrossRef]
- Greenlaw, R.; Kantabutra, S. Survey of clustering: Algorithms and applications. Int. J. Inf. Retr. Res. 2013, 3, 1–29. [Google Scholar] [CrossRef]
- Dharmarajan, A.; Velmurugan, T. Applications of partition based clustering algorithms: A survey. In Proceedings of the 2013 IEEE International Conference on Computational Intelligence and Computing Research, Tamilnadu, India, 26–28 December 2013; pp. 703–707. [Google Scholar]
- Neha, D.; Vidyavathi, B.M. A survey on applications of data mining using clustering techniques. Int. J. Comput. Appl. 2015, 126, 7–12. [Google Scholar]
- Mallat, S. A theory for multiresolution signal decomposition-the wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Amjady, N.; Keynia, F. Short-term load forecasting of power systems by combination of wavelet transform and neuro-evolutionary algorithm. Energy 2009, 34, 46–57. [Google Scholar] [CrossRef]
- Soldo, B.; Potocnik, P.; Simunovi, G.; Sari, T.; Govekar, E. Improving the residential natural gas consumption forecasting models by using solar radiation. Energy Build. 2014, 69, 498–506. [Google Scholar] [CrossRef]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamr, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Boura, A. A survey of clustering algorithms for Big Data: Taxonomy and empirical analysis. IEEE Trans. Emerg. Top. Comput. 2014, 3, 267–279. [Google Scholar] [CrossRef]
- Panapakidis, I.P.; Alexiadis, M.C.; Papagiannis, G.K. Deriving the optimal number of clusters in the electricity consumer segmentation procedure. In Proceedings of the 10th European Energy Market Conference (EEM13), Stockholm, Sweden, 27–31 May 2013; pp. 1–8. [Google Scholar]
- Vestas V112-3.0 MW. Available online: http://www.vestas.cz/ (accessed on 26 March 2019).
- Hsu, S.A.; Meindl, E.A.; Gilhouse, D.B. Determining the power-law wind-profile exponent under near-neutral stability conditions at sea. J. Appl. Meteorol. 1994, 33, 757–765. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Time (s) | Ratio |
|---|---|---|
| K-means | 33.24 | 1 |
| UPGMC | 5.28 | 0.15 |
| FCM | 282.49 | 8.49 |
| SOM | 658.31 | 19.80 |
| Cluster | Number of Days Per Clusters | General Description of the Day Types |
|---|---|---|
| 1 | 60 | Most days October 2012, six days of March 2013, most days of April 2013, six days of May 2013, six days of June 2013, three days of July 2013 and six days of August 2013 |
| 2 | 9 | One day per the following months: October 2012, December 2012, January 2013, May 2013 and June 203. Two days of the following moths: February 2013 and March 2013 |
| 3 | 41 | Two days of March 2013, five days of April 2013, most days of May 2013, June 2013 and July 2013 |
| 4 | 27 | Five days of October 2012, 3 days of November 2012, few days of February 2013 and March 2013, seven days of July 2013 |
| 5 | 51 | Eight days of October 2012, twelve days of November 2012, four days of December 2012, seven days of January 2013, five days of February 2013, eight days of March 2013, few days of April 2013, May 2013 and June 2013 |
| 6 | 28 | Five days of November 2012, few days of December 2012, January 2013 and February 2013, five days of March 2013, five days of May 2013 |
| 7 | 7 | Few days of December 2012 and March 2013 |
| 8 | 11 | Few days of February 2013 and May 2013, one day of August 2013 |
| Cluster | Number of Days Per Clusters | General Description of the Day Types |
|---|---|---|
| 1 | 1 | One day of September 2012 |
| 2 | 5 | Two days of September 2012, three days of October 2012 |
| 3 | 7 | Seven days of October 2012 |
| 4 | 214 | All the rest days |
| 5 | 1 | One day of July 2013 |
| 6 | 4 | Four days of August 2013 |
| 7 | 1 | One day of August 2013 |
| 8 | 1 | One day of August 2013 |
| Day Number | Date | MARNE (%) | MARNE (%) Improvement | |
|---|---|---|---|---|
| UPGMC | K-means | |||
| 1 | 01/10/2012 | 11.64 | 15.24 | 23.62 |
| 2 | 09/10/2012 | 14.09 | 14.09 | 0 |
| 3 | 16/10/2012 | 13.92 | 16.84 | 17.33 |
| 4 | 01/11/2012 | 18.25 | 18.44 | 1.03 |
| 5 | 09/11/2012 | 20.64 | 25.11 | 17.80 |
| 6 | 16/11/2012 | 19.88 | 22.68 | 12.34 |
| 7 | 01/12/2012 | 19.67 | 22.38 | 12.10 |
| 8 | 09/12/2012 | 17.27 | 18.64 | 7.34 |
| 9 | 17/12/2012 | 16.51 | 29.61 | 44.24 |
| 10 | 09/01/2013 | 12.37 | 13.38 | 7.54 |
| 11 | 16/01/2013 | 27.67 | 30.10 | 8.07 |
| 12 | 01/02/2013 | 18.09 | 21.66 | 16.48 |
| 13 | 09/02/2013 | 17.90 | 47.46 | 62.28 |
| 14 | 13/02/2013 | 19.49 | 20.60 | 5.38 |
| 15 | 01/03/2013 | 24.06 | 24.74 | 2.74 |
| 16 | 09/03/2013 | 19.51 | 19.52 | 0.05 |
| 17 | 16/03/2013 | 18.79 | 39.17 | 52.02 |
| 18 | 01/04/2013 | 36.37 | 36.67 | 0.81 |
| 19 | 16/04/2013 | 16.62 | 18.31 | 9.22 |
| 20 | 23/04/2013 | 12.03 | 19.84 | 39.36 |
| 21 | 01/05/2013 | 14.35 | 28.69 | 49.98 |
| 22 | 09/05/2013 | 10.65 | 14.26 | 25.31 |
| 23 | 16/05/2013 | 9.90 | 16.47 | 39.89 |
| 24 | 01/06/2013 | 18.89 | 27.71 | 31.82 |
| 25 | 09/06/2013 | 12.48 | 21.02 | 40.62 |
| 26 | 16/06/2013 | 11.03 | 16.21 | 31.95 |
| 27 | 01/07/2013 | 17.03 | 32.01 | 46.79 |
| 28 | 09/07/2013 | 14.07 | 14.97 | 6.01 |
| 29 | 15/07/2013 | 9.14 | 10.50 | 12.95 |
| 30 | 01/08/2013 | 17.46 | 18.33 | 4.74 |
| 31 | 09/08/2013 | 12.83 | 20.34 | 36.92 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panapakidis, I.P.; Michailides, C.; Angelides, D.C. Implementation of Pattern Recognition Algorithms in Processing Incomplete Wind Speed Data for Energy Assessment of Offshore Wind Turbines. Electronics 2019, 8, 418. https://doi.org/10.3390/electronics8040418
Panapakidis IP, Michailides C, Angelides DC. Implementation of Pattern Recognition Algorithms in Processing Incomplete Wind Speed Data for Energy Assessment of Offshore Wind Turbines. Electronics. 2019; 8(4):418. https://doi.org/10.3390/electronics8040418
Chicago/Turabian StylePanapakidis, Ioannis P., Constantine Michailides, and Demos C. Angelides. 2019. "Implementation of Pattern Recognition Algorithms in Processing Incomplete Wind Speed Data for Energy Assessment of Offshore Wind Turbines" Electronics 8, no. 4: 418. https://doi.org/10.3390/electronics8040418
APA StylePanapakidis, I. P., Michailides, C., & Angelides, D. C. (2019). Implementation of Pattern Recognition Algorithms in Processing Incomplete Wind Speed Data for Energy Assessment of Offshore Wind Turbines. Electronics, 8(4), 418. https://doi.org/10.3390/electronics8040418