A Deep Learning Method for 3D Object Classification Using the Wave Kernel Signature and A Center Point of the 3D-Triangle Mesh


Abstract
:1. Introduction
2. Related Works
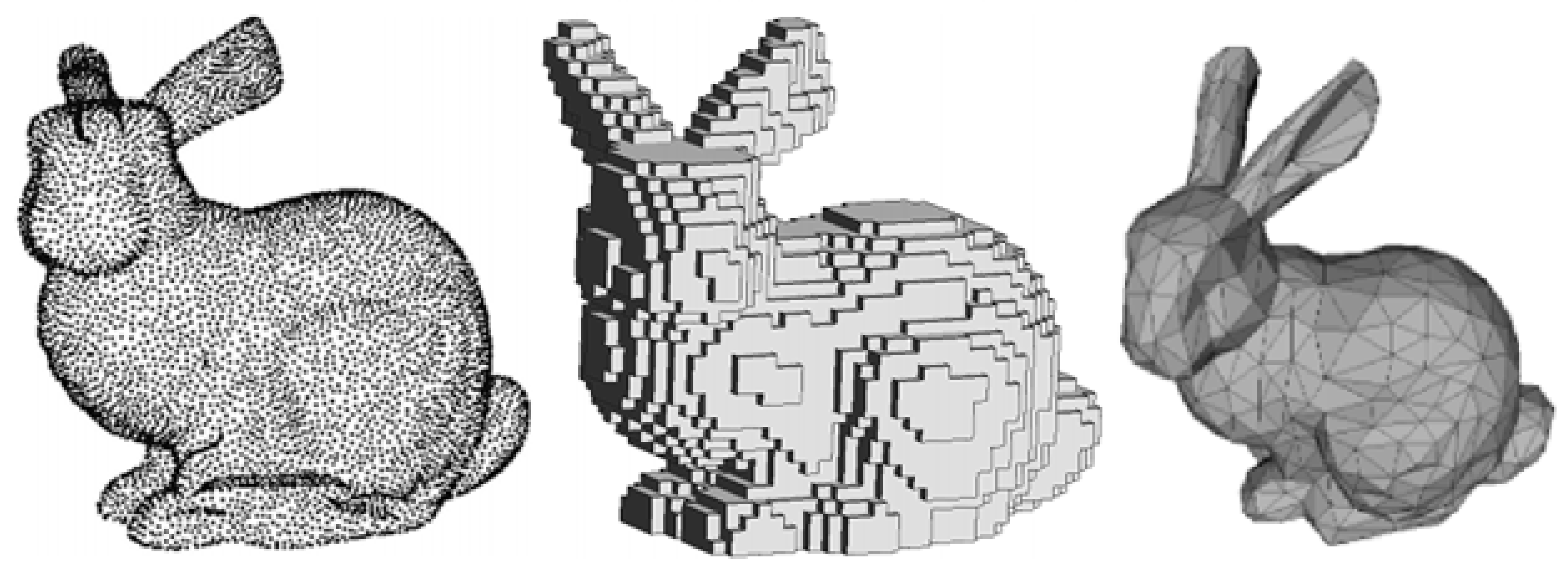
2.1. 3D Data Representation
2.2. 3D Shape Analysis
2.3. 3D Object Classification
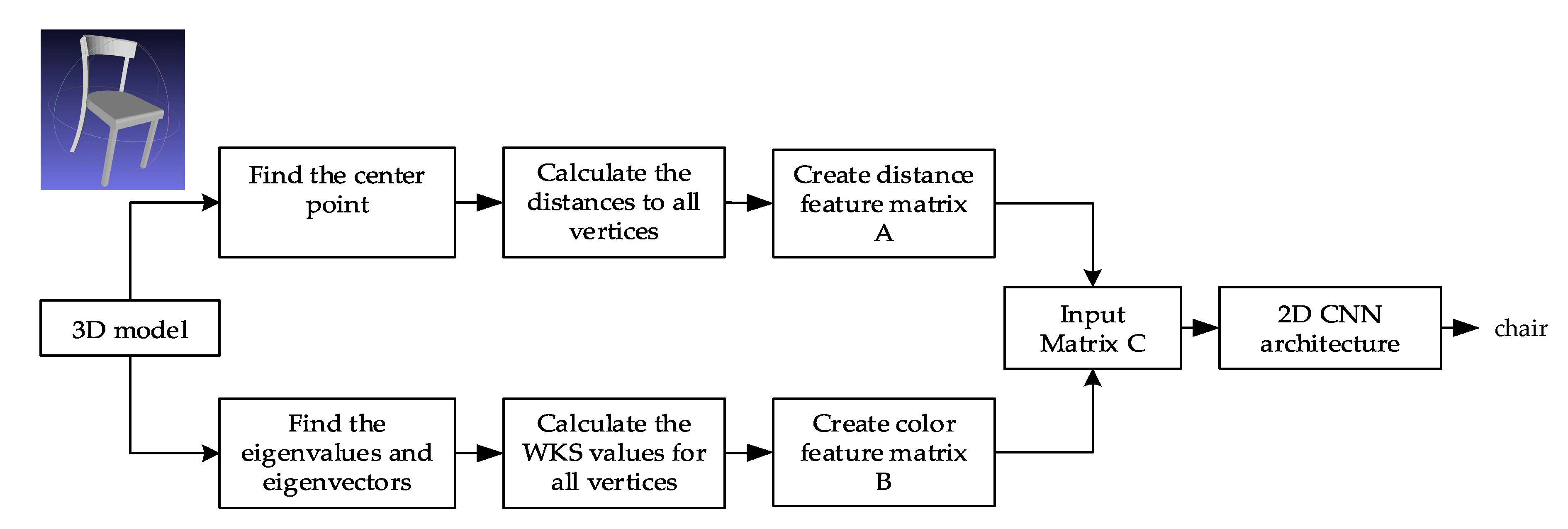
3. Methodology
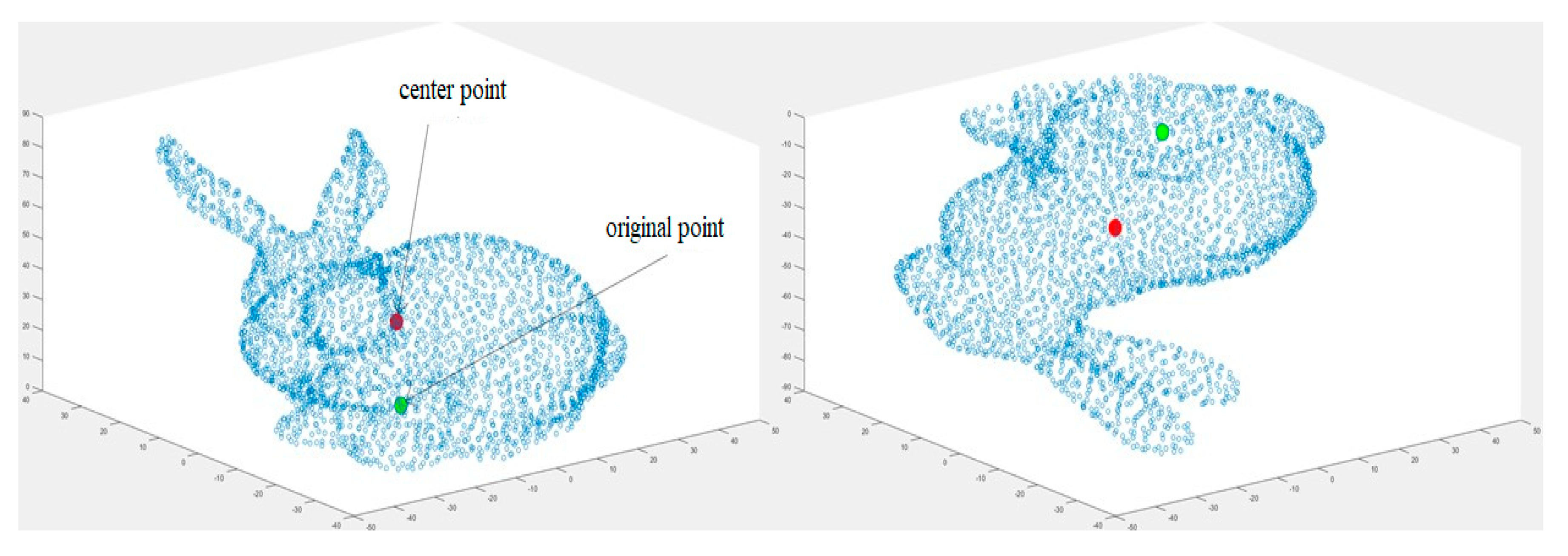
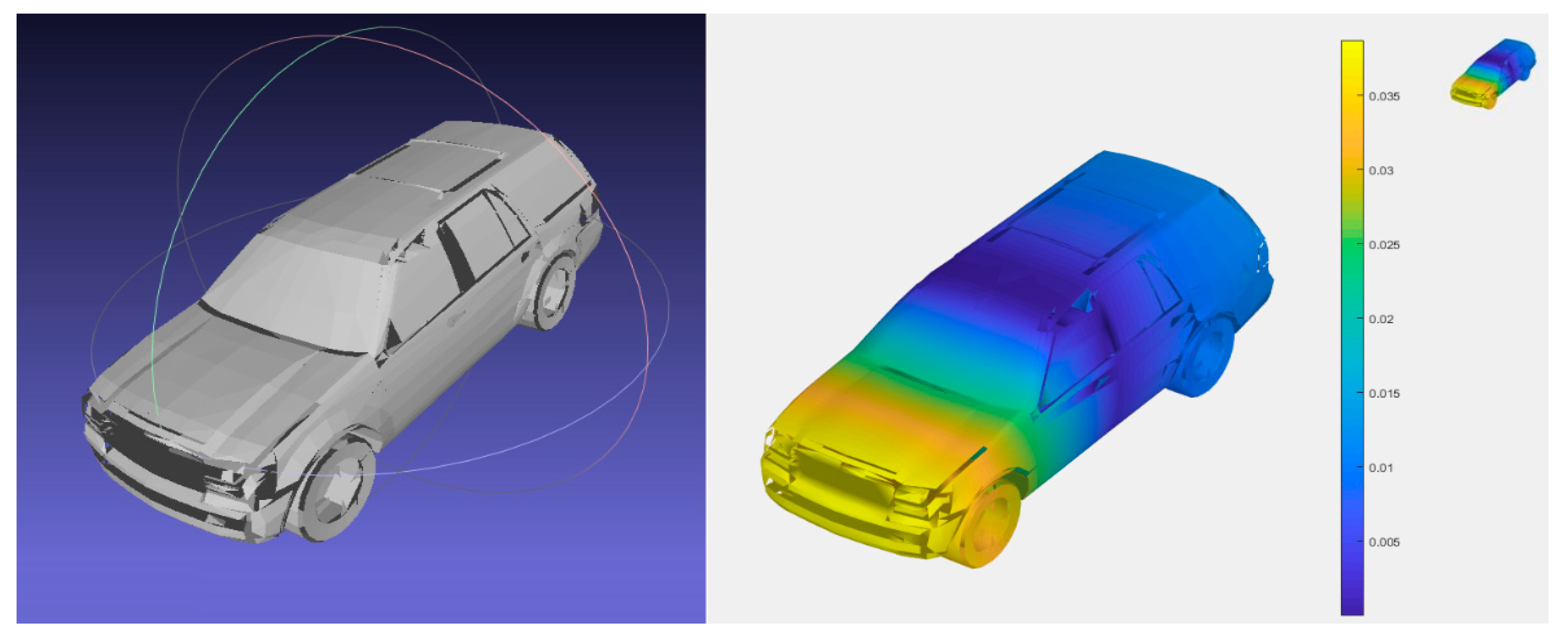
3.1. The Center Point of 3D Triangle Mesh (CP)
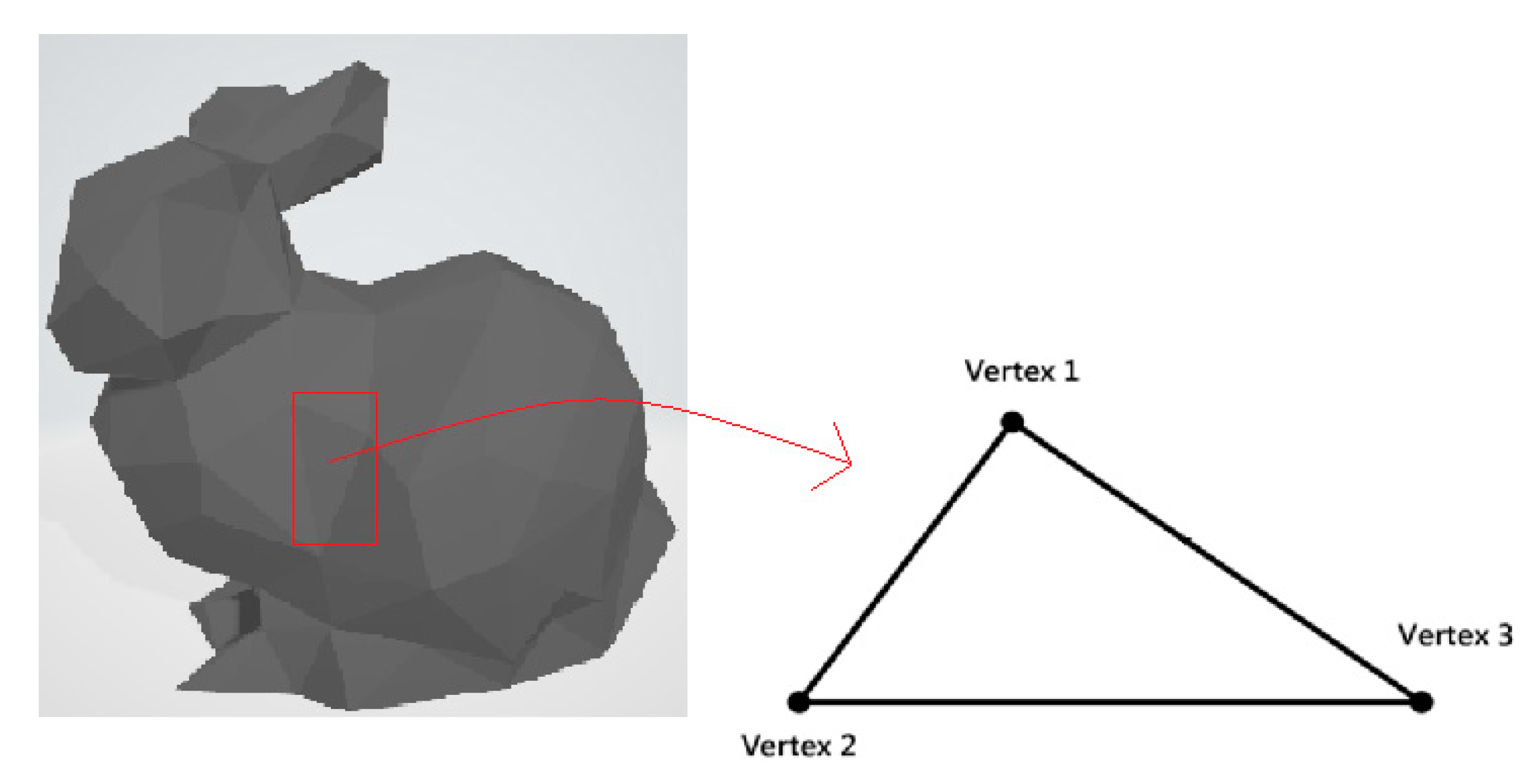
3.2. Wave Kernel Signature on the 3D Triangle Mesh (WKS)
3.3. The Architecture of Convolution Neural Network
4. Experimental Results
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Shen, X. A Survey of Object Classification and Detection Based on 2D/3D Data. Available online: https://arxiv.org/abs/1905.12683 (accessed on 20 September 2019).
- Kazhdan, M.; Funkhouser, T.; Rusinkiewicz, S. Rotation invariant spherical harmonic representation of 3D shape descriptors. In Proceedings of the Eurographics/ACM SIGGRAPH Symposium on geometry processing, Aachen, Germany, 23–25 June 2003; pp. 156–164. [Google Scholar]
- Chen, D.-Y.; Tian, X.-P.; Shen, Y.-T.; Ouhyoung, M. On visual similarity based 3D model retrieval. Comput. Graph. Forum 2003, 22, 223–232. [Google Scholar] [CrossRef]
- Ioannidou, A.; Chatzilari, E.; Nikolopoulos, S.; Kompatsiaris, I. Deep learning advances in computer vision with 3D data: A survey. ACM Comput. Surv. 2017, 50, 1–38. [Google Scholar] [CrossRef]
- Wu, W.; Qi, Z.; Fuxin, L. PointConv: Deep convolutional networks on 3D point clouds. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; pp. 9621–9630. [Google Scholar]
- Karmakar, N.; Biswas, A.; Bhowmick, P.; Bhattacharya, B.B. A combinatorial algorithm to construct 3D isothetic covers. Int. J. Comput. Math. 2013, 90, 1571–1606. [Google Scholar] [CrossRef]
- Hamidi, M.; Chetouani, A.; El Haziti, M.; El Hassouni, M.; Cherifi, H. Blind robust 3D mesh watermarking based on mesh saliency and wavelet transform for copyright protection. Inf. 2019, 10, 67. [Google Scholar] [CrossRef]
- Agarwal, P.; Prabhakaran, B. Robust blind watermarking of point-sampled geometry. IEEE Trans. Inf. Forensics Secur. 2009, 4, 36–48. [Google Scholar] [CrossRef]
- Construction of 3D Orthogonal Cover. Available online: http://cse.iitkgp.ac.in/~pb/research/3dpoly/3dpoly.html (accessed on 20 September 2019).
- Triangle Mesh Processing. Available online: http://www.lix.polytechnique.fr/~maks/Verona_MPAM/TD/TD2/ (accessed on 20 September 2019).
- Fernández, F. On the Symmetry of the Quantum-Mechanical Particle in a Cubic Box. Available online: https://arxiv.org/abs/1310.5136 (accessed on 20 September 2019).
- Su, Y.; Shan, S.; Chen, X.; Gao, W. Hierarchical ensemble of global and local classifiers for face recognition. IEEE Trans. Image Process. 2009, 18, 1885–1896. [Google Scholar] [CrossRef] [PubMed]
- Aubry, M.; Schlickewei, U.; Cremers, D. The wave kernel signature: A quantum mechanical approach to shape analysis. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops 2011), Barcelona, Spain, 6–13 November 2011; pp. 1626–1633. [Google Scholar] [CrossRef]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J. 3D object recognition in cluttered scenes with local surface features: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2270–2287. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar] [CrossRef]
- Garcia, A.; Donoso, F.; Rodriguez, J.; Escolano, S.; Cazorla, M.; Lopez, J. PointNet: A 3D convolutional neural network for real-time object class recognition. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN 2016), Vancouver, BC, Canada, 24–29 July 2016; pp. 1578–1584. [Google Scholar] [CrossRef]
- Sinha, A.; Bai, J.; Ramani, K. Deep learning 3D shape surfaces using geometry images. In Proceedings of the 2016 European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; pp. 223–240. [Google Scholar] [CrossRef]
- Shi, B.; Bai, S.; Zhou, Z.; Bai, X. DeepPano: Deep panoramic representation for 3-D shape recognition. IEEE Signal Process. Lett. 2015, 22, 2339–2343. [Google Scholar] [CrossRef]
- Sun, G.; Huang, H.; Zhang, A.; Li, F.; Zhao, H.; Fu, H. Fusion of multiscale convolutional neural networks for building extraction in very high-resolution images. Remote. Sens. 2019, 11, 227. [Google Scholar] [CrossRef]
- Cheng, Y.-C.; Chen, S.-Y. Image classification using color, texture and regions. Image Vision Comput. 2003, 21, 759–776. [Google Scholar] [CrossRef]
- Castellani, U.; Mirtuono, P.; Murino, V.; Bellani, M.; Rambaldelli, G.; Tansella, M.; Brambilla, P. A new shape diffusion descriptor for brain classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2011), Toronto, ON, Canada, 18–22 September 2011; pp. 426–433. [Google Scholar] [CrossRef]
- Yang, J.; Yang, G. Modified convolutional neural network based on dropout and the stochastic gradient descent optimizer. Algorithms 2018, 11, 28. [Google Scholar] [CrossRef]
- Zheng, Q.; Sun, J.; Zhang, L.; Chen, W.; Fan, H. An improved 3D shape recognition method based on panoramic view. Math. Probl. Eng. 2018, 2018, 1–11. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Train | Test | Total |
|---|---|---|---|
| bathtub | 106 | 50 | 156 |
| bed | 515 | 100 | 615 |
| chair | 889 | 100 | 989 |
| desk | 200 | 86 | 286 |
| dresser | 200 | 86 | 286 |
| monitor | 465 | 100 | 565 |
| nightstand | 200 | 86 | 286 |
| sofa | 680 | 100 | 780 |
| table | 392 | 100 | 492 |
| toilet | 344 | 100 | 444 |
| total | 3991 | 908 | 4899 |
| Algorithm | ModelNet10 | ModelNet40 |
|---|---|---|
| PointNet [17] | 77.60% | N/A |
| 3D ShapeNets [16] | 83.54% | 77.32% |
| Geometry Image [18] | 88.40% | 83.90% |
| DeepPano [19] | 88.66% | 82.54% |
| PanoramicView [24] | 89.80% | 82.47% |
| Our Method | 90.20% | 84.64% |
| Layers | DeepPano | Parameters | PanoView | Parameters | Our Method | Parameters |
|---|---|---|---|---|---|---|
| Input | 160 × 64 | 0 | 108 × 36 | 0 | 32 × 32 × 6 | 0 |
| Conv1 | (5, 96) | 2496 | (1, 64) | 128 | Two (3, 16) | 320 |
| Conv2 | (5, 256) | 6656 | (2, 80) | 400 | Two (3, 32) | 640 |
| Conv3 | (3, 384) | 3840 | (4, 160) | 2720 | Two (3, 64) | 1280 |
| Conv4 | (3, 512) | 5120 | (6, 320) | 11,840 | Two (3, 128) | 2560 |
| FC1 | N. Available | N. Available | 512 | N. Available | 128 | N. Available |
| FC2 | N. Available | N. Available | 1024 | N. Available | 10 or 40 | N. Available |
| Total | 18,112 | 15,088 | 4800 |
| Class | PointNet | Our Method | Class | PointNet | Our Method |
|---|---|---|---|---|---|
| bathtub | 34 | 39 | monitor | 87 | 100 |
| bed | 80 | 99 | nightstand | 60 | 63 |
| chair | 90 | 100 | sofa | 88 | 94 |
| desk | 52 | 67 | table | 69 | 80 |
| dresser | 61 | 77 | toilet | 84 | 100 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoang, L.; Lee, S.-H.; Kwon, O.-H.; Kwon, K.-R. A Deep Learning Method for 3D Object Classification Using the Wave Kernel Signature and A Center Point of the 3D-Triangle Mesh. Electronics 2019, 8, 1196. https://doi.org/10.3390/electronics8101196
Hoang L, Lee S-H, Kwon O-H, Kwon K-R. A Deep Learning Method for 3D Object Classification Using the Wave Kernel Signature and A Center Point of the 3D-Triangle Mesh. Electronics. 2019; 8(10):1196. https://doi.org/10.3390/electronics8101196
Chicago/Turabian StyleHoang, Long, Suk-Hwan Lee, Oh-Heum Kwon, and Ki-Ryong Kwon. 2019. "A Deep Learning Method for 3D Object Classification Using the Wave Kernel Signature and A Center Point of the 3D-Triangle Mesh" Electronics 8, no. 10: 1196. https://doi.org/10.3390/electronics8101196
APA StyleHoang, L., Lee, S.-H., Kwon, O.-H., & Kwon, K.-R. (2019). A Deep Learning Method for 3D Object Classification Using the Wave Kernel Signature and A Center Point of the 3D-Triangle Mesh. Electronics, 8(10), 1196. https://doi.org/10.3390/electronics8101196