


A Modification Method for Domain Shift in the Hidden Semi-Markov Model and Its Application

 , , , , ,
, , , , ,  and
and
Abstract
1. Introduction
2. Methods
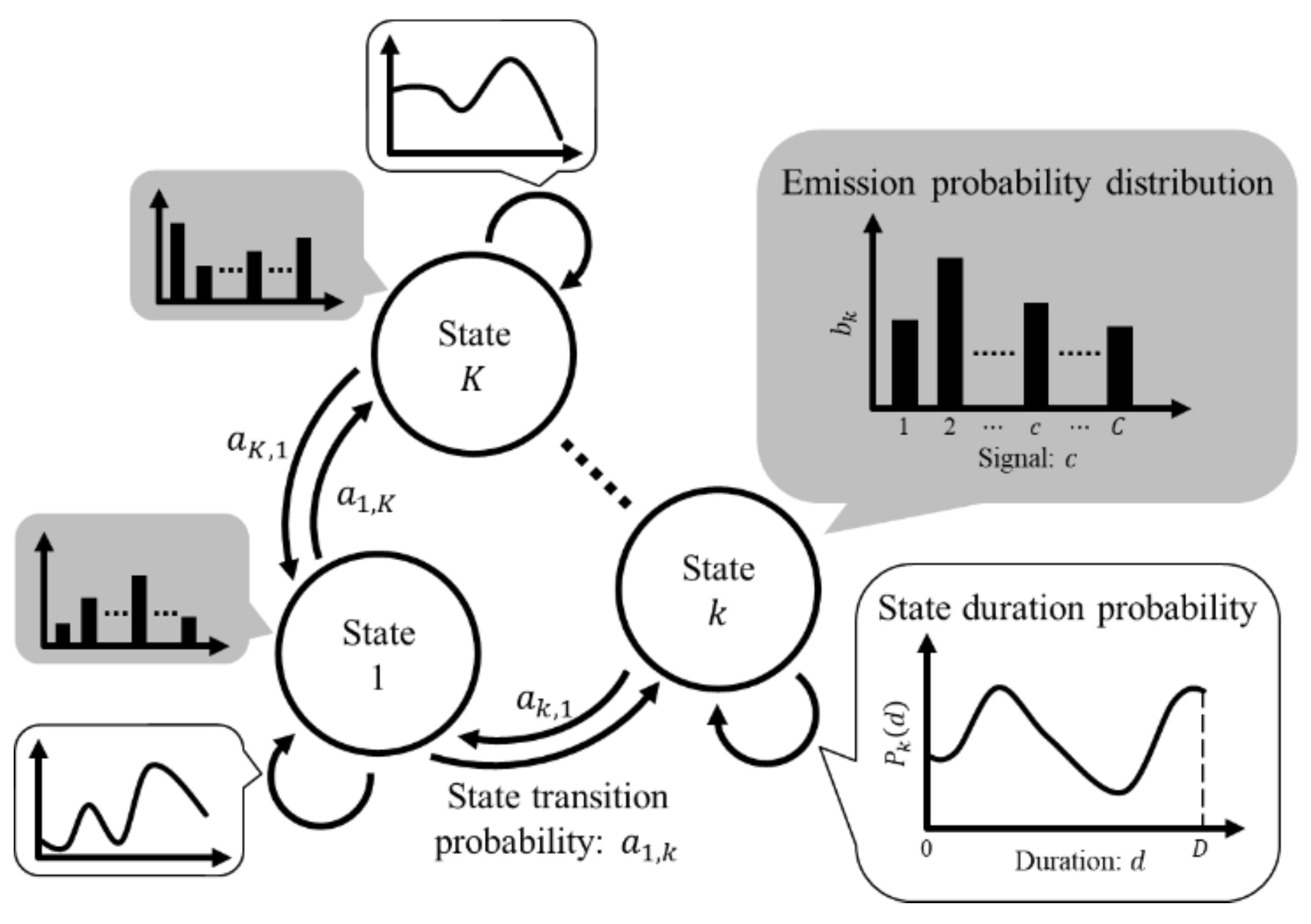
2.1. Outline: Pattern Recognition of HSMM
2.2. Modification of Emission Probability Distributions
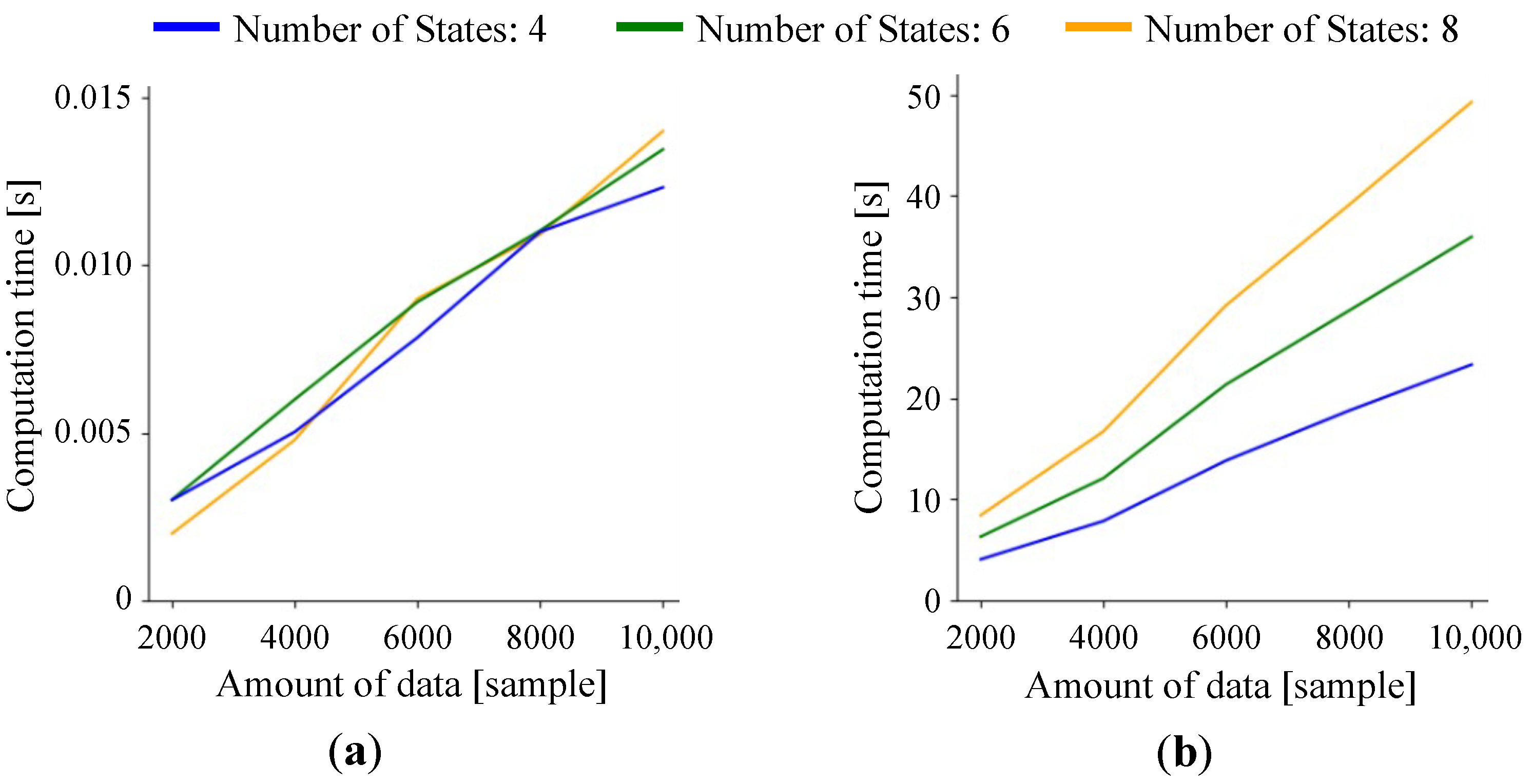
3. Experiments and Results
3.1. Experimental Setup
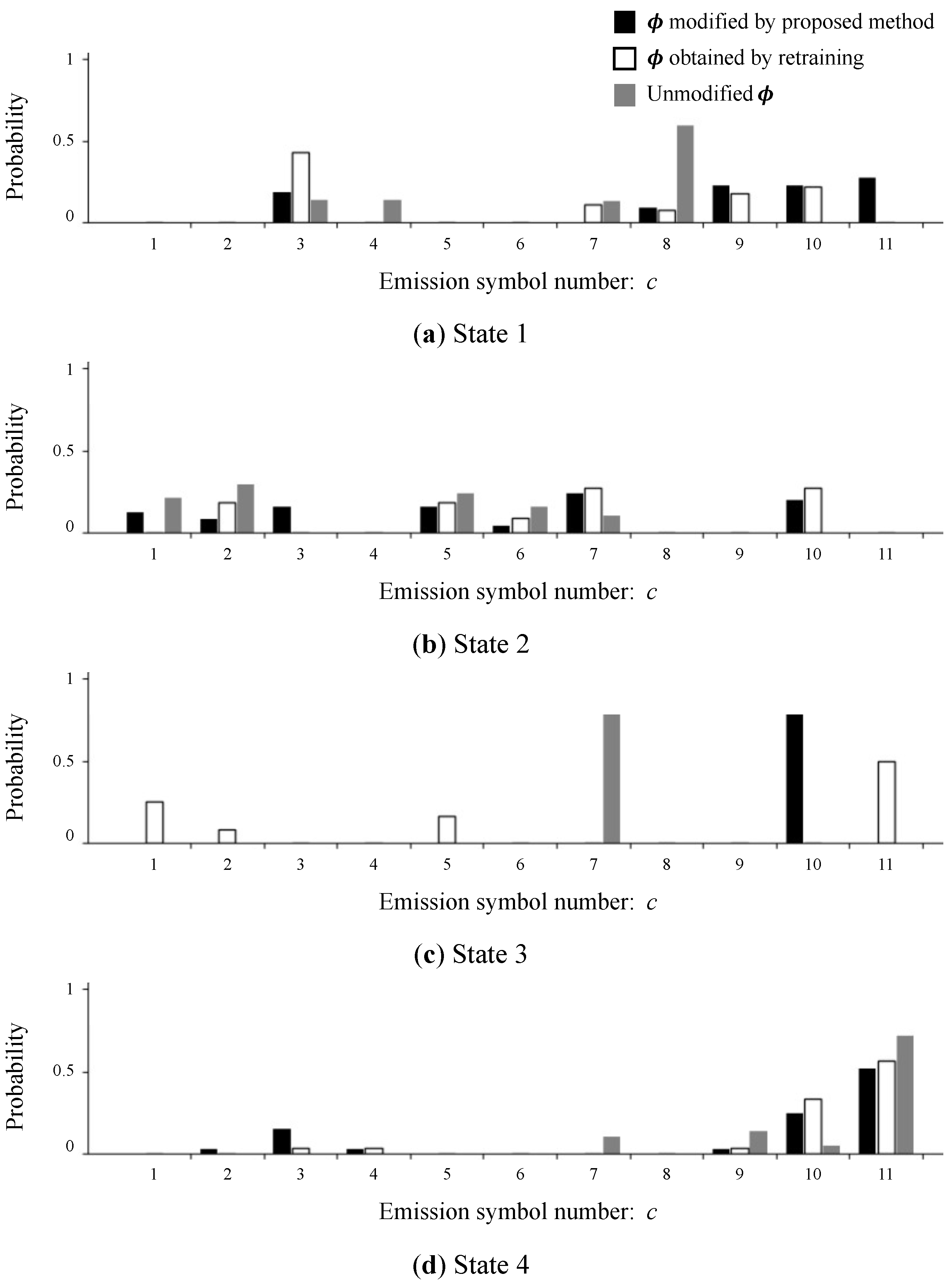
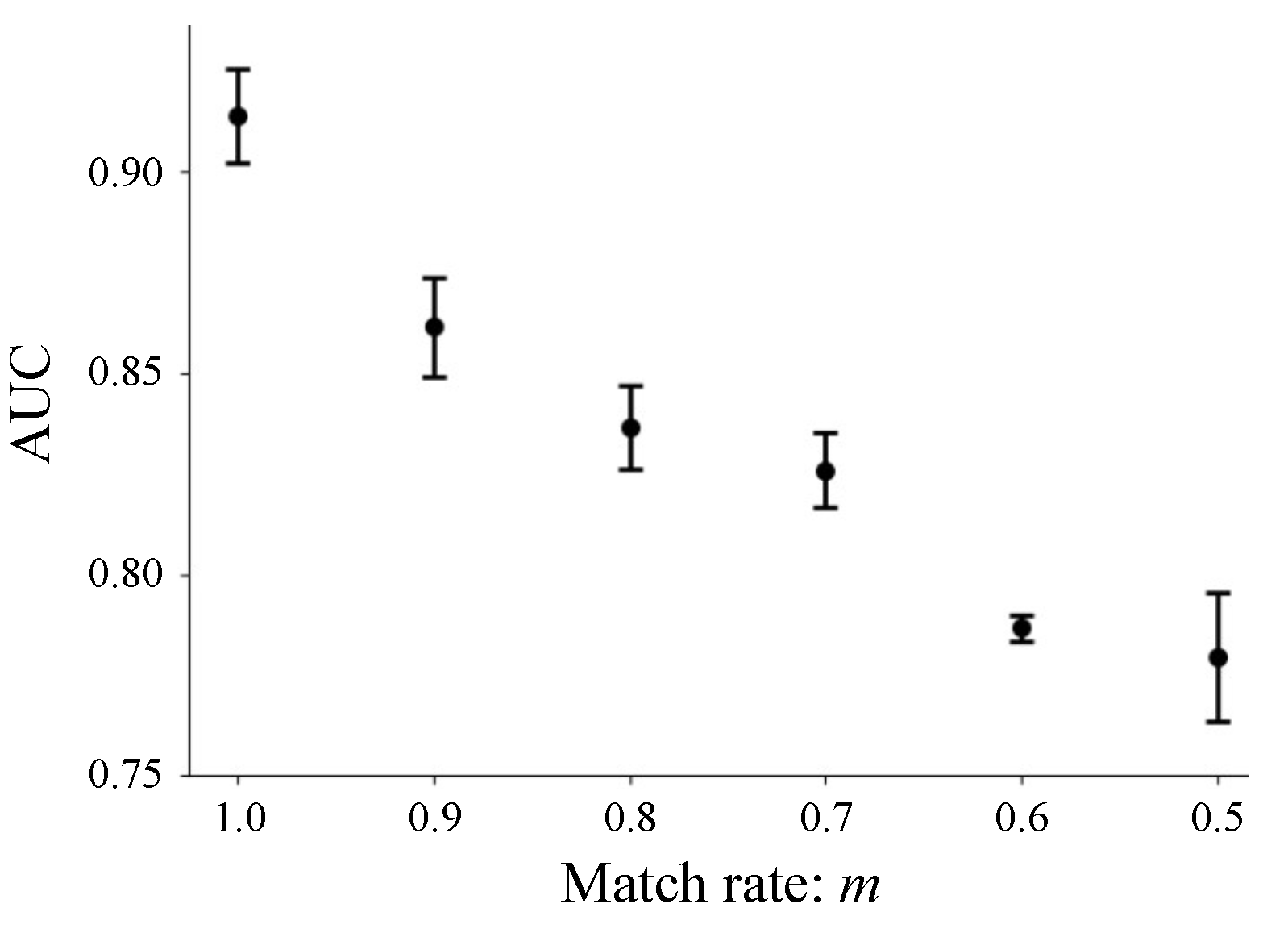
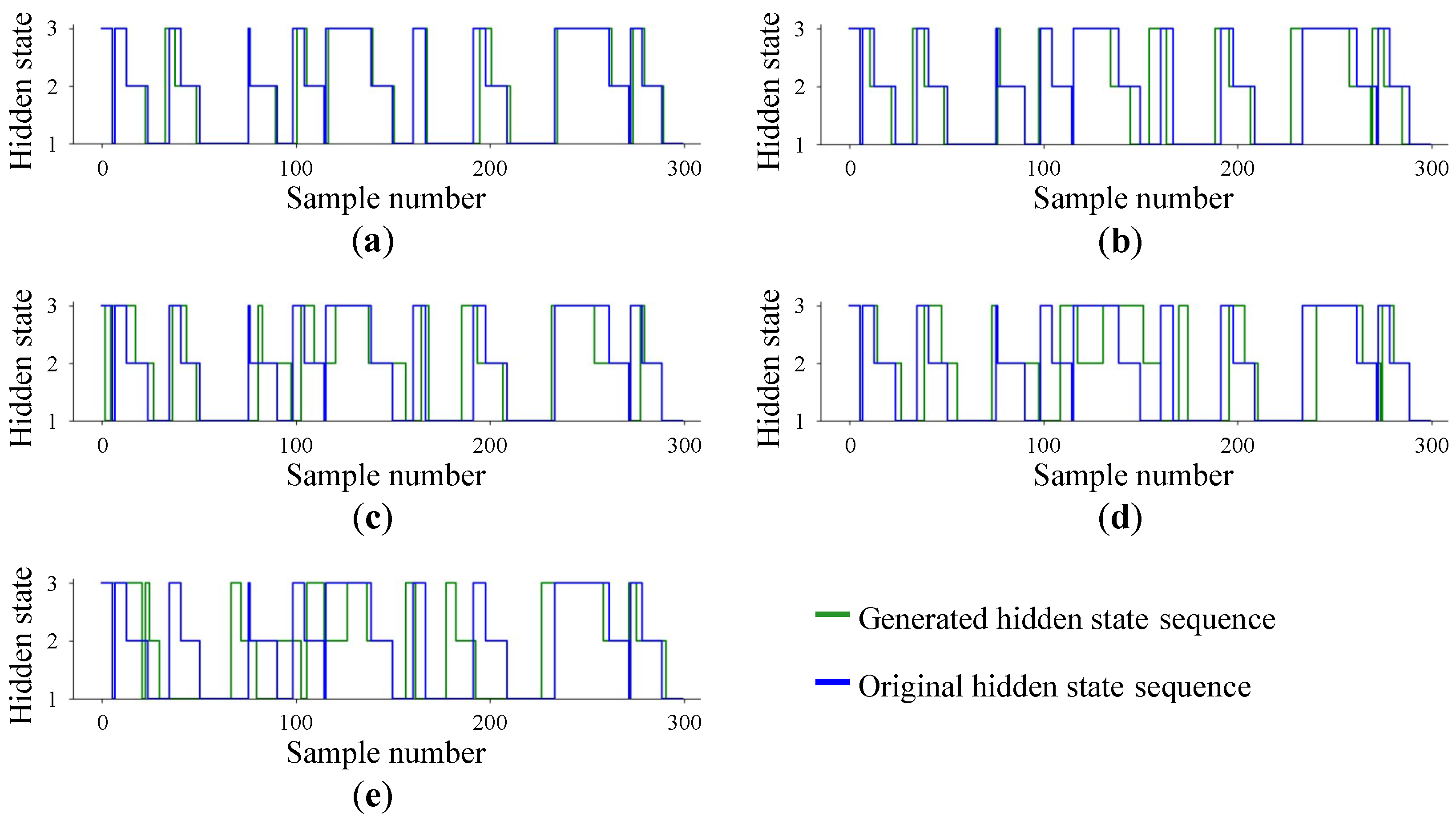
3.2. Results
4. Discussion and Application
4.1. Discussion
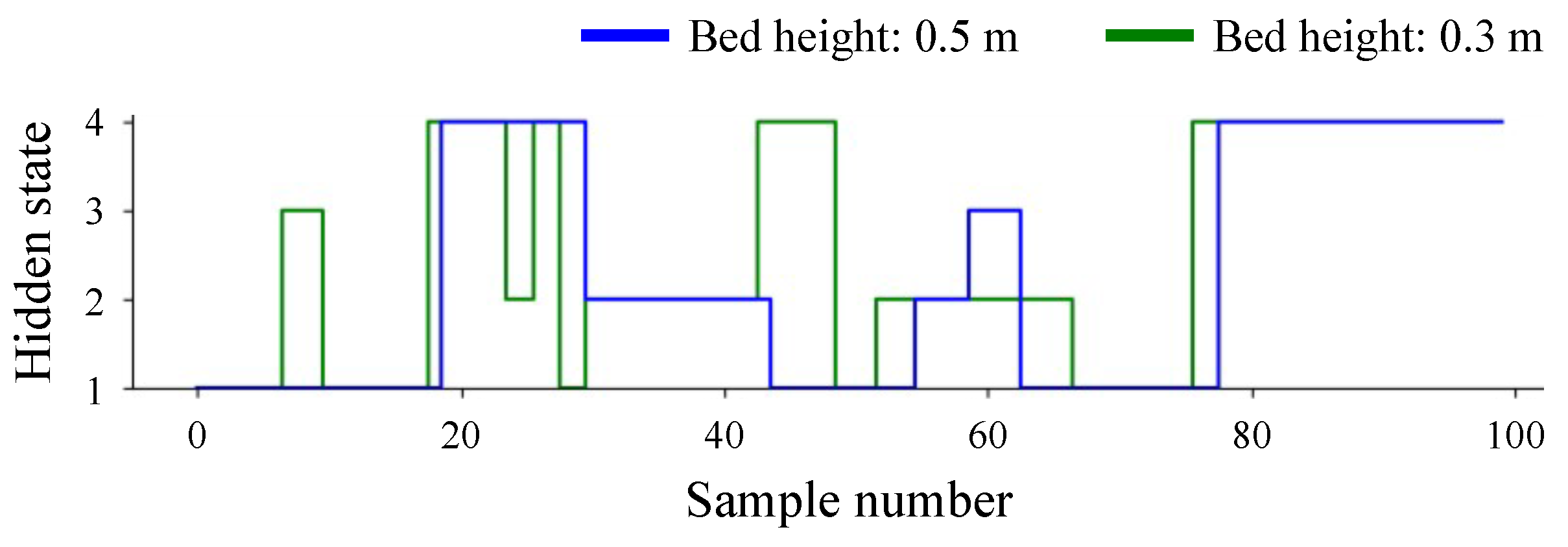
4.2. Application for Care Work Recognition
4.3. Limitation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Oscar, D.L.; Miguel, A.L. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2006, 54, 1947–1951. [Google Scholar] [CrossRef]
- Pavan, T.; Rama, C.; Subrahmanian, V.S.; Octavian, U. Machine Recognition of Human Activities: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1473–1488. [Google Scholar] [CrossRef]
- Ronald, P. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Wang, X.; Cui, P.; Zhu, W. Out-of-distribution Generalization and Its Applications for Multimedia. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 5681–5682. [Google Scholar] [CrossRef]
- Pang, W.K.; Shiori, S.; Henrik, M.; Sang, M.X.; Marvin, Z.; Akshay, B.; Weihua, H.; Michihiro, Y.; Richard, L.P.; Irena, G.; et al. WILDS: A Benchmark of in-the-Wild Distribution Shifts. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 5637–5664. [Google Scholar]
- Joaquin, Q.C.; Masashi, S.; Anton, S.; Neil, D.L. Dataset Shift in Machine Learning; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Ganin, Y.; Lempistky, V. Unsupervised domain adaptation by backpropagation. In International Conference on Machine Learning; PMLR: Birmingham, UK, 2015; Volume 37, pp. 1180–1189. [Google Scholar]
- Saito, K.; Kim, D.; Sclaroff, S.; Darrell, T.; Saenko, K. Semi-supervised domain adaptation via minimax entropy. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8050–8058. [Google Scholar]
- Motiian, S.; Piccirilli, M.; Adjeroh, D.A.; Doretto, G. Unified deep supervised domain adaptation and generalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5715–5725. [Google Scholar]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 443–450. [Google Scholar] [CrossRef]
- Yan, H.; Dong, Y.; Li, P.; Wang, Q.; Xu, Y.; Zuo, W. Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2272–2281. [Google Scholar]
- Kang, G.; Jiang, L.; Yang, Y.; Hauptmann, A.G. Contrastive adaptation network for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 493–4902. [Google Scholar]
- Liu, M.Y.; Tuzel, O. CCoupled Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2016, 29, 469–477. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7167–7176. [Google Scholar]
- Pei, Z.; Cao, Z.; Long, M.; Wang, J. Multi-Adversarial Domain Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Ian, J.G.; Jean, P.A.; Mehdi, M.; Bing, X.; David, W.F.; Sherjil, O.; Aaron, C.; Yoshua, B. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar] [CrossRef]
- Ghifary, M.; Kleijn, W.B.; Zhang, M.; Balduzzi, D.; Li, W. Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 597–613. [Google Scholar] [CrossRef]
- Yoo, D.; Kim, N.; Park, S.; Paek, A.S.; Kweon, I.S. Pixel-Level Domain Transfer. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 517–532. [Google Scholar] [CrossRef]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In International Conference on Machine Learning; PMLR: Birmingham, UK, 2018; pp. 1989–1998. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Yu, S.Z. Hidden semi-Markov models. Artif. Intell. 2010, 174, 215–243. [Google Scholar] [CrossRef]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Mozafari, K.; Moghadam, C.N.; Shayegh, B.H.; Behrouzifar, M. A Novel Fuzzy HMM Approach for Human Action Recognition in Video. Commun. Comput. Inf. Sci. 2012, 295, 184–193. [Google Scholar] [CrossRef]
- Bae, J.; Tomizuka, M. Gait phase analysis based on a Hidden Markov Model. Mechatronics 2011, 21, 961–970. [Google Scholar] [CrossRef]
- Gao, X.; Wang, Z.; Wang, C.; Zhuang, S. Multi-scale Profile-HMM action recognition based on double matching states. In Proceedings of the 2021 International Conference on Information Technology and Biomedical Engineering, Tokyo, Japan, 17–20 March 2021; pp. 123–130. [Google Scholar] [CrossRef]
- Gedat, E.; Fechner, P.; Fiebelkorn, R.; Vandenhouten, R. Human action recognition with hidden Markov models and neural network derived poses. In Proceedings of the 2017 IEEE 15th International Symposium on Intelligent Systems and Informatics, Subotica, Serbia, 14–16 September 2017; pp. 000157–000162. [Google Scholar] [CrossRef]
- Mor, B.; Garhwal, S.; Kumar, A. A Systematic Review of Hidden Markov Models and Their Applications. Arch. Comput. Methods Eng. 2021, 28, 1429–1448. [Google Scholar] [CrossRef]
- Shimada, Y.; Mukaeda, T.; Kusaka, T.; Yui, E.; Mitsunori, T.; Natsuki, M.; Tanaka, T. Complementary event motion classification for robust identification and care work identification using Hidden Semi-Markov Model. Trans. Soc. Instrum. Control Eng. 2024, 60, 620–630. (In Japanese) [Google Scholar] [CrossRef]
- Mukaeda, T.; Shima, K.; Miyajima, S.; Hashimoto, Y.; Tanaka, T.; Tani, N.; Izumi, H. Development of an anomaly detection method with a novel hidden semi-Markov model incorporating unlearned states. In Proceedings of the IEEE/SICE International Symposiumon System Integration, Honolulu, HI, USA, 12–15 January 2020; pp. 1270–1275. [Google Scholar] [CrossRef]
- Yu, S.Z.; Kobayashi, H. Practical Implementation of an Efficient Forward-backward Algorithm for an Explicitduration Hidden Markov Model. IEEE Trans. Signal Process. 2006, 54, 1947–1951. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Samples | Parameters of ED-HMM Used for Data Generation |
|---|---|---|
| For training | 300 | Uniform random values |
| For modifying | 300 | Emission probability: Same as data for training |
| Other parameters: Uniform random values | ||
| For validation (Positivee class) | 150 | Same as data for modifying |
| For validation (Negative class) | 150 | Uniform random values |
| State | Cosine Similarityr |
|---|---|
| 1 | 0.872 |
| 2 | 0.906 |
| 3 | 0.922 |
| Model | AUC |
|---|---|
| Modified (Proposed method) | 0.911 |
| Retrained | 0.920 |
| Original | 0.463 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| Modified (Proposed method) | 0.917 | 0.647 | 0.759 |
| Retrained | 0.875 | 0.824 | 0.848 |
| Original | 0.333 | 0.176 | 0.231 |
| Method | Computational Cost | Accuracy | Data Requirement |
|---|---|---|---|
| Proposed method | Very low | Moderate | Low |
| Retraining | Very high | Very high | Very high |
| Fine-tuning | High | High | High |
| GAN-based domain adaptation | Moderate | Very high | Moderate |
| Label | Upper Body | Lower Body |
|---|---|---|
| 01 | Standing | Standing |
| 02 | Foward bending | Open left leg |
| 03 | Backward bending | Open right leg |
| 04 | Left rotation/lateral flexion | Close left leg |
| 05 | Right rotation/lateral flexion | Clsoe right leg |
| 06 | Left rotation/lateral flexion while bending forward | Stationary in open leg posture |
| 07 | Right rotation/lateral flexion while bending forward | Bend knee |
| 08 | Left rotation/lateral flexion while bending backward | Extend knee |
| 09 | Right rotation/lateral flexion while bending backward | Stationary in crouching posture |
| 10 | Stationary in forward bending/rotating/lateral bending | - |
| State | Cosine Similarity |
|---|---|
| 1 | 0.705 |
| 2 | 0.806 |
| 3 | 0 |
| 4 | 0.974 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shimada, Y.; Kusaka, T.; Mukaeda, T.; Endo, Y.; Tada, M.; Miyata, N.; Tanaka, T. A Modification Method for Domain Shift in the Hidden Semi-Markov Model and Its Application. Electronics 2025, 14, 1579. https://doi.org/10.3390/electronics14081579
Shimada Y, Kusaka T, Mukaeda T, Endo Y, Tada M, Miyata N, Tanaka T. A Modification Method for Domain Shift in the Hidden Semi-Markov Model and Its Application. Electronics. 2025; 14(8):1579. https://doi.org/10.3390/electronics14081579
Chicago/Turabian StyleShimada, Yunosuke, Takashi Kusaka, Takayuki Mukaeda, Yui Endo, Mitsunori Tada, Natsuki Miyata, and Takayuki Tanaka. 2025. "A Modification Method for Domain Shift in the Hidden Semi-Markov Model and Its Application" Electronics 14, no. 8: 1579. https://doi.org/10.3390/electronics14081579
APA StyleShimada, Y., Kusaka, T., Mukaeda, T., Endo, Y., Tada, M., Miyata, N., & Tanaka, T. (2025). A Modification Method for Domain Shift in the Hidden Semi-Markov Model and Its Application. Electronics, 14(8), 1579. https://doi.org/10.3390/electronics14081579