
PassRecover: A Multi-FPGA System for End-to-End Offline Password Recovery Acceleration


Abstract
1. Introduction
- (1)
- A multi-FPGA system containing one XCZU7EV and two XCVU9P FPGAs is proposed. The system provides the ability to recovery password in an end-to-end manner. As far as we know, it is the first work to accelerate both the deep learning-based password generation algorithm and the encryption algorithm on a multi-FPGA system.
- (2)
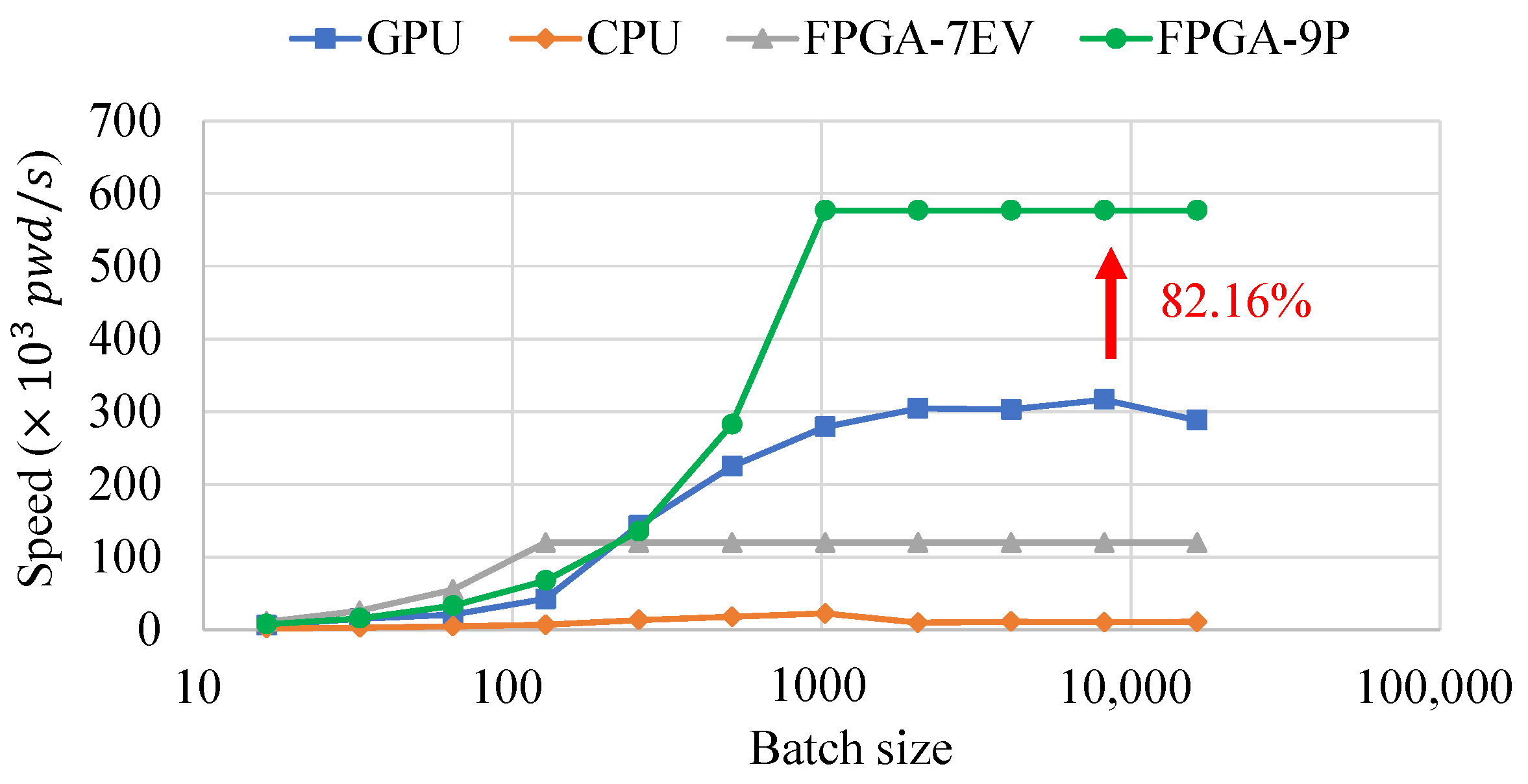
- An NPU architecture for deep learning-based password generation is proposed. PassGAN algorithm is taken as a case study to evaluate the NPU performance. Experimental results show a 82.16% and 155.22% improvement in speed and energy efficiency, respectively, compared to Tesla V100 GPU.
- (3)
- Five representative encryption algorithms, including Office 2010, Office2013, PDF 1.7, WINZIP, and RAR5 from Hashcat, are implemented by specific architecture to co-accelerate with PassGAN in an end-to-end manner. Results show that the speed and energy efficiency are and the GPU’s solution. Compared to the latest work that only accelerates encryption algorithms, the proposed architecture achieves an average of 101.50% higher speed and 22.11% higher energy efficiency.
2. Prerequisite
2.1. Why PassGAN Is Selected as the Study Case
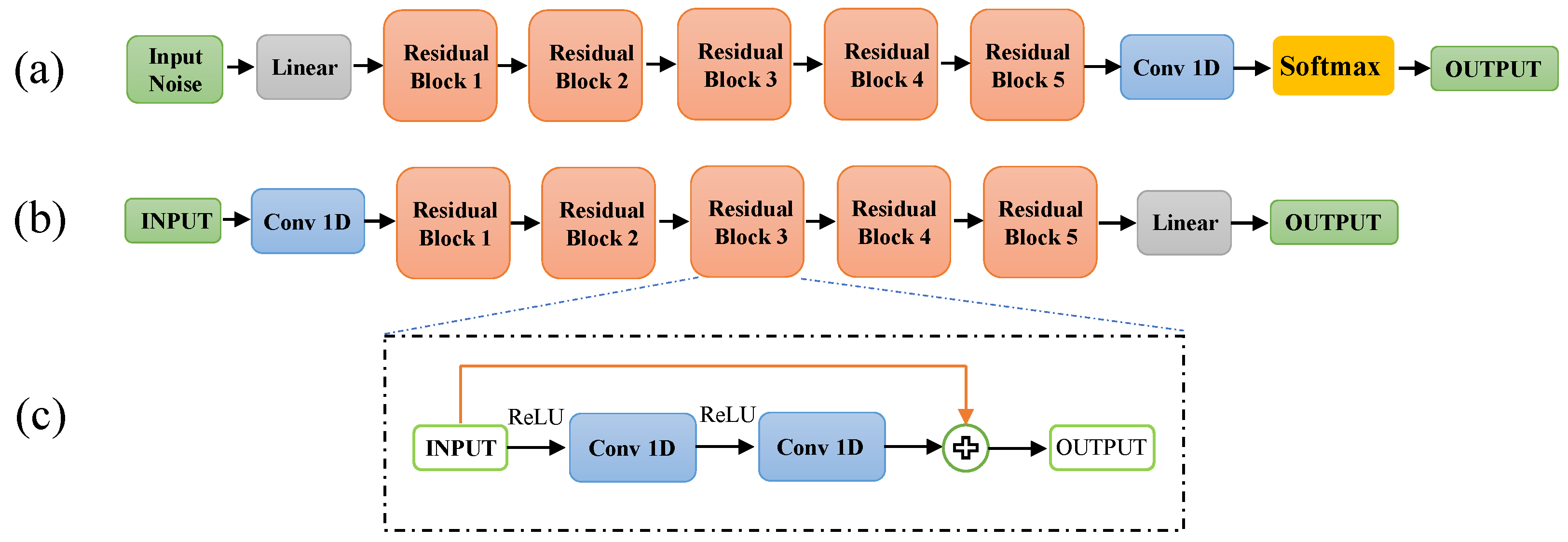
2.2. PassGAN Overview
| Algorithm 1: Pseudocode of the n-th Conv1D layer. |
 |
2.3. Characteristics of Application Encryption Algorithms
3. Proposed Architecture
3.1. PassRecover: System Architecture with Multi-FPGA
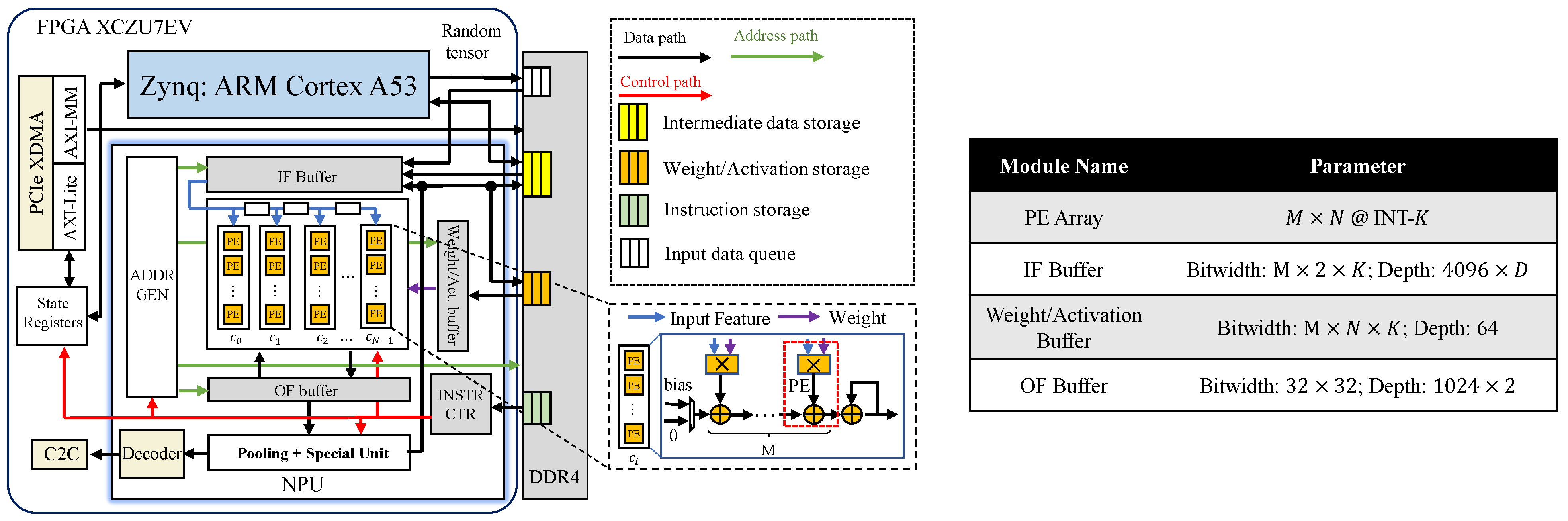
3.2. NPU
3.2.1. Overall Architecture
3.2.2. Tiling
| Algorithm 2: Pseudocode of tiling scheme in the n-th Conv1D layer. |
 |
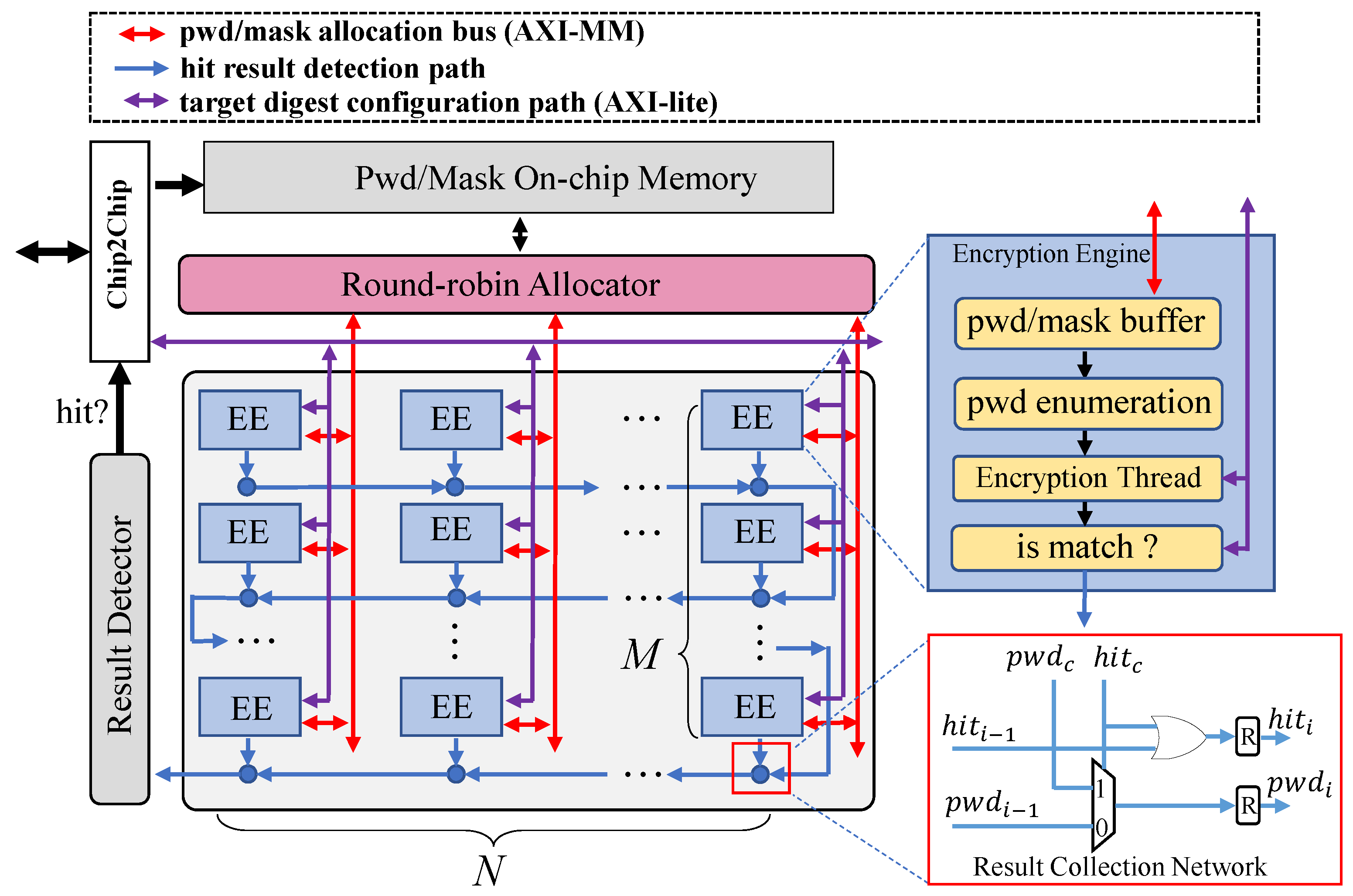
3.3. Encryption Algorithm Accelerator
3.3.1. Unified Hardware Architecture Template
3.3.2. Customization Methodology for Encryption Thread
| Algorithm 3: Pseudocode of SHA_512. |
 |
3.3.3. Architecture of Encryption Thread
- Stage 1 involves 100,000 iterations of SHA-512 computations. During each iteration n, the input password is dynamically padded with the iteration index n and intermediate value to construct —the initial message input for SHA-512 processing.
- Stage 2 executes post-processing transformations using the Stage 1 output. Through specialized message padding routines, two derived messages and are generated for subsequent SHA-512 computations. The resulting hash values and undergo one time AES-256 CBC decryption and encryption using the salt value and verification hash as encryption parameters, ultimately producing the final authentication digest.
| Algorithm 4: Pseudocode of Office2013 encryption algorithm. |
 |
3.4. Putting It All Together
4. Experimental Results
4.1. Experimental Setting
4.2. NPU Performance
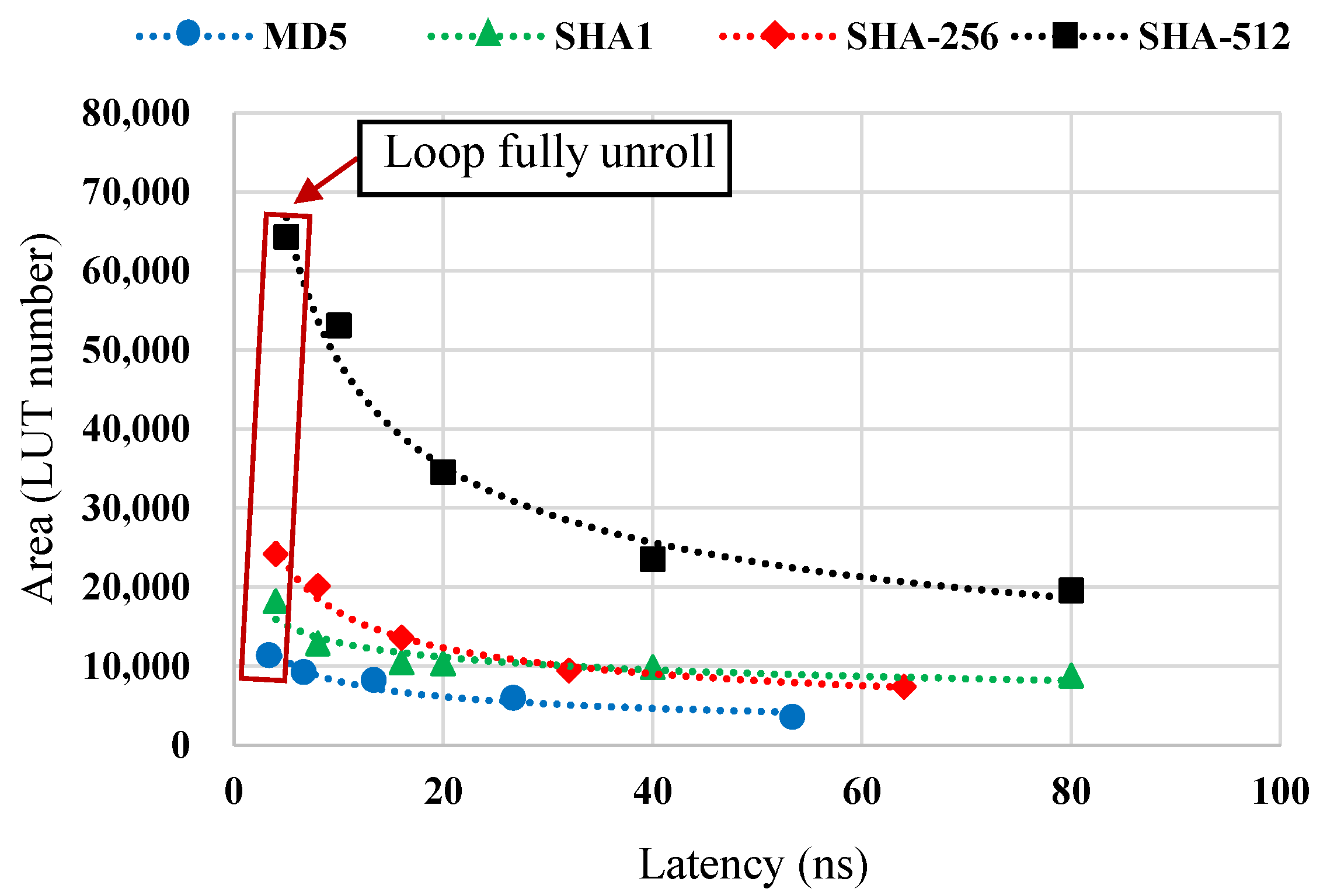
4.3. Implementation of Encryption Algorithm Accelerator
4.4. End-to-End Password Recovery
4.5. Scalability
4.5.1. The Scalability of PassRecover
4.5.2. The Scalability of Reconfiguration
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| NPU | Neural Processing Unit |
| FPGA | Filed-programmable Gate Array |
| GPU | Graphics Processing Unit |
| CPU | Central Processing Unit |
| HPC | High-performance Computing |
| GAN | Generative Adversarial Network |
| VLIW | Very Long Instruction Word |
| PE | Processing Element |
| EE | Encryption Engine |
| AXI | Advanced Extensible Interface |
| N/A | Not Applicable |
| LUT | Lookup Table |
| RAM | Random Access Memory |
| E2E | End-to-End |
| EO | Encryption Only |
| H2E | Host-to-Encryption |
| LLM | Large Language Model |
References
- Wang, D.; Zhang, Z.; Wang, P.; Yan, J.; Huang, X. Targeted Online Password Guessing: An Underestimated Threat. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1242–1254. [Google Scholar] [CrossRef]
- Yang, X.; Yue, C.; Zhang, W.; Liu, Y.; Ooi, B.C.; Chen, J. SecuDB: An In-enclave Privacy-preserving and Tamper-resistant Relational Database. Proc. VLDB Endow. 2024, 17, 3906–3919. [Google Scholar] [CrossRef]
- Houshmand, S.; Aggarwal, S.; Flood, R. Next Gen PCFG Password Cracking. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1776–1791. [Google Scholar] [CrossRef]
- Garg, V.; Ahuja, L. Password Guessing Using Deep Learning. In Proceedings of the 2019 2nd International Conference on Power Energy, Environment and Intelligent Control (PEEIC), Greater Noida, India, 18–19 October 2019; pp. 38–40. [Google Scholar] [CrossRef]
- Dürmuth, M.; Angelstorf, F.; Castelluccia, C.; Perito, D.; Abdelberi, C. OMEN: Faster Password Guessing Using an Ordered Markov Enumerator. In Proceedings of the Engineering Secure Software and Systems - 7th International Symposium, ESSoS 2015, Milan, Italy, 4–6 March 2015; Lecture Notes in Computer Science; Proceedings. Springer: Berlin/Heidelberg, Germany, 2015; Volume 8978, pp. 119–132. [Google Scholar] [CrossRef]
- Rando, J.; Pérez-Cruz, F.; Hitaj, B. PassGPT: Password Modeling and (Guided) Generation with Large Language Models. In Proceedings of the Computer Security - ESORICS 2023 - 28th European Symposium on Research in Computer Security, The Hague, The Netherlands, 25–29 September 2023; Lecture Notes in Computer Science; Proceedings, Part IV. Springer: Berlin/Heidelberg, Germany, 2023; Volume 14347, pp. 164–183. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, P.; Wang, W.; Jiang, Y. RUPA: A High Performance, Energy Efficient Accelerator for Rule-Based Password Generation in Heterogenous Password Recovery System. IEEE Trans. Comput. 2023, 72, 900–913. [Google Scholar] [CrossRef]
- Liu, P.; Li, S.; Ding, Q. An Energy-Efficient Accelerator Based on Hybrid CPU-FPGA Devices for Password Recovery. IEEE Trans. Comput. 2019, 68, 170–181. [Google Scholar] [CrossRef]
- Ding, Q.; Zhang, Z.; Li, S.; Liu, P. Energy-Efficient RAR3 Password Recovery with Dual-Granularity Data Path Strategy. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Li, B.; Feng, F.; Chen, X.; Cao, Y. Reconfigurable and High-Efficiency Password Recovery Algorithms Based on HRCA. IEEE Access 2021, 9, 18085–18111. [Google Scholar] [CrossRef]
- Li, B.; Zhou, Q.; Cao, Y.; Si, X. Cognitively Reconfigurable Mimic-based Heterogeneous Password Recovery System. Comput. Secur. 2022, 116, 102667. [Google Scholar]
- Hashcat. Mask Attack. Available online: https://hashcat.net/wiki/doku.php?id=mask_attack (accessed on 1 February 2025).
- Luo, Y.; Liu, J.; Gong, C.; Li, T. An Efficient Heterogeneous Parallel Password Recovery System on MT-3000. J. Supercomput. 2025, 81, 38. [Google Scholar] [CrossRef]
- Guardian. Standard Forensics & Data Recovery Rates. Available online: https://guardian-forensics.com/digital-forensics-rates/ (accessed on 1 February 2025).
- RockYou. RockYou. 2010. Available online: http://downloads.skullsecurity.org/passwords/rockyou.txt.bz2 (accessed on 1 February 2025).
- Hashes.org. Linkedin Leak. Available online: https://github.com/brannondorsey/PassGAN/releases/download/data/68_linkedin_found_hash_plain.txt.zip (accessed on 1 February 2025).
- SkullSecurity. Wiki: Passwords. Available online: http://downloads.skullsecurity.org/passwords/hotmail.txt.bz2 (accessed on 1 February 2025).
- Pasquini, D.; Gangwal, A.; Ateniese, G.; Bernaschi, M.; Conti, M. Improving Password Guessing via Representation Learning. In Proceedings of the 42nd IEEE Symposium on Security and Privacy (SP 2021), San Francisco, CA, USA, 24–27 May 2021; pp. 1382–1399. [Google Scholar] [CrossRef]
- Brannondorsey. PassGAN. 2017. Available online: https://github.com/brannondorsey/PassGAN (accessed on 1 February 2025).
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein GANs. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Wiki. Embarrassingly Parallel. Available online: https://en.wikipedia.org/wiki/Embarrassingly_parallel (accessed on 1 February 2025).
- AMD. Aurora 64B66B Protocal Specification, SP011(v3). 2013. Available online: https://docs.amd.com/v/u/en-US/aurora_64b66b_protocol_spec_sp011 (accessed on 1 February 2025).
- AMD. UltraScale Architecture Configuration User Guide (UG570). Available online: https://docs.amd.com/r/en-US/ug570-ultrascale-configuration/Introduction?tocId=__uoAGvOd16yWRXoFejPDQ (accessed on 1 February 2025).
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.A.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-Datacenter Performance Analysis of a Tensor Processing Unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, ISCA 2017, Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Chen, Y.; Emer, J.S.; Sze, V. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks. In Proceedings of the 43rd ACM/IEEE Annual International Symposium on Computer Architecture (ISCA 2016), Seoul, Republic of Korea, 18–22 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 367–379. [Google Scholar] [CrossRef]
- Li, T.; Zhang, F.; Xie, G.; Fan, X.; Gao, Y.; Sun, M. A High Speed Reconfigurable Architecture for Softmax and GELU in Vision Transformer. Electron. Lett. 2023, 59, e12751. [Google Scholar] [CrossRef]
- Pub, F. Secure Hash Standard (SHS). Fips Pub 2012, 180.4, 10–23. [Google Scholar]
- Dask. Scale the Python Tools You Love. Available online: https://www.dask.org/ (accessed on 1 February 2025).
- Anders, M.A.; Kaul, H.; Mathew, S.; Suresh, V.B.; Satpathy, S.; Agarwal, A.; Hsu, S.; Krishnamurthy, R. 2.9TOPS/W Reconfigurable Dense/Sparse Matrix-Multiply Accelerator with Unified INT8/INTI6/FP16 Datapath in 14NM Tri-Gate CMOS. In Proceedings of the 2018 IEEE Symposium on VLSI Circuits, Honolulu, HI, USA, 18–22 June 2018; pp. 39–40. [Google Scholar] [CrossRef]
- Liu, C.; Yang, Z.; Zhang, X.; Zhu, Z.; Chu, H.; Huan, Y.; Zheng, L.; Zou, Z. A Low-Power Hybrid-Precision Neuromorphic Processor With INT8 Inference and INT16 Online Learning in 40-nm CMOS. IEEE Trans. Circuits Syst. I Regul. Pap. 2023, 70, 4028–4039. [Google Scholar] [CrossRef]
- Fan, X.; Xie, G.; Huang, Z.; Cao, W.; Wang, L. Acceleration of Rotated Object Detection on FPGA. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 2296–2300. [Google Scholar] [CrossRef]
- Fu, Y.; Wu, E.; Sirasao, A.; Attia, S.; Khan, K.; Wittig, R. Deep Learning with INT8 Optimization on Xilinx Devices. 2017. Available online: https://www.origin.xilinx.com/content/dam/xilinx/support/documents/white_papers/wp486-deep-learning-int8.pdf (accessed on 1 February 2025).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | Hardware Platform | Attacking Method | Support Deep Learning Password Generator Acceleration | Encryption Algorithm Acceleration |
|---|---|---|---|---|
| [7] | FPGA | Rule | ✗ | ✓ |
| [8] | CPU-FPGA hybrid architecture | Mask/Dictionary | ✗ | ✓ |
| [9] | FPGA | Mask/Dictionary | ✗ | ✓ |
| [10] | FPGA | Mask/Dictionary | ✗ | ✓ |
| [11] | FPGA | Mask/Dictionary | ✗ | ✓ |
| [13] | MT-3000 (HPC processor) | Rule/Mask/Dictionary | ✗ | ✓ |
| This work | FPGA | PassGAN/Mask/Dictionary | ✓ | ✓ |
| Layer Name | Data Dimension (Batch × Channel × Width) | Weight Dimension |
|---|---|---|
| Input | batch × 128 × 1 | 0 |
| Linear | batch × 1280 × 1 | 128 × 1280 |
| Reshape | batch × 128 × 10 | 0 |
| ResBlock1 | batch × 128 × 10 | |
| ResBlock2 | batch × 128 × 10 | |
| ResBlock3 | batch × 128 × 10 | |
| ResBlock4 | batch × 128 × 10 | |
| ResBlock5 | batch × 128 × 10 | |
| Conv1D | batch × 97 × 10 | |
| Softmax | batch × 97 × 10 | 0 |
| Intel Xeon Gold 5218 CPU | Tesla V100 GPU | |
|---|---|---|
| PassGAN | TensorFlow 1.15 oneDNN 2.2.4 | TensorFlow 1.15 CUDA 10.0 cuDNN 7.6 |
| Hashcat 6.2.6 | Intel OpenCL 2.1 | CUDA 12.4 |
| Power detection tool | Intel-pcm 202409 | Nvidia-smi |
| XCZU7EV | XCVU9P | |||||
|---|---|---|---|---|---|---|
| Used | Available | Percentage | Used | Available | Percentage | |
| LUTs | 142,374 | 230,400 | 61.79% | 712,747 | 1,182,240 | 60.29% |
| FFs | 234,986 | 460,800 | 51.00% | 1,164,242 | 2,364,480 | 49.24% |
| BRAMs | 68 | 312 | 21.79% | 1105 | 2160 | 51.16% |
| URAMs | 88 | 96 | 91.67% | 704 | 960 | 73.33% |
| DSPs | 1283 | 1728 | 74.25% | 5129 | 6840 | 74.99% |
| CPU | GPU | FPGA-9P | FPGA-7EV | |
|---|---|---|---|---|
| Platform | Xeon Gold 5218 | Tesla V100 | Ultrascale+ XCVU9P | Ultrascale+ XCZU7EV |
| Process | 14 nm | 12 nm | 16 nm | 16 nm |
| Device number | 2 | 1 | 1 | 1 |
| Frequency (GHz) | 2.3 | 1.3 | 0.3/0.6 | 0.25/0.5 |
| Batch size | 1024 | 8192 | 1024 | 128 |
| Speed (pwd/s) | 22,547 | 316,656 | 576,820 | 120,192 |
| Power (W) | 278.62 | 189 | 134.92 | 23.25 |
| Speedup | 1× | 28.08× | 51.16× | 10.66× |
| Energy efficiency (pwd/J) | 80.92 | 1675.43 | 4275.27 | 5169.55 |
| Energy efficiency ratio | 1× | 20.70× | 52.83× | 63.88× |
| LUTs (%) | FFs (%) | BRAMs (%) | |||
|---|---|---|---|---|---|
| LUTs as Logic | LUTs as Memory | Total | |||
| Office2010 | 618,512 | 122,971 | 741,483 (62.72%) | 1,242,526 (52.55%) | 774 (35.83%) |
| Office2013 | 510,132 | 37,321 | 547,453 (46.31%) | 698,230 (29.53%) | 120 (5.56%) |
| PDF1.7 | 719,770 | 49,732 | 769,502 (65.09%) | 925,181 (39.13%) | 106.5 (4.93%) |
| Winzip | 628,879 | 154,342 | 783,221 (66.25%) | 1,171,776 (49.56%) | 1525.5 (70.63%) |
| RAR5 | 669,664 | 122,548 | 792,212 (67.01%) | 873,070 (36.92%) | 97.5 (4.51%) |
| Hashcat | TC2019 [8] | C&S [11] | This Work | |||
|---|---|---|---|---|---|---|
| Platform | CPU | GPU | FPGA | FPGA | FPGA | |
| Chip type | Xeon Gold 5218 | Tesla V100 | XC7Z030 | XCKU060 | XCVU9P | |
| Process | 14 nm | 12 nm | 28 nm | 20 nm | 16 nm | |
| Chip number | 2 | 1 | 1 | 4 | 2 | |
| Office2010 | Frequency (MHz) | 3000 | 1530 | 190 | 250 | 250 |
| Speed (KH/s) | 12.74 | 144.70 | 9.84 | 140 | 220 | |
| Power (W) | 231.56 | 288 | 12.55 | 117.5 | 177.0 | |
| Energy efficiency (H/J) | 55.01 | 502.43 | 783.82 | 1191.49 | 1242.94 | |
| Speedup | 1× | 11.36× | 0.77× | 10.99× | 17.27× | |
| Energy efficiency ratio | 1× | 9.13× | 14.25× | 21.66× | 22.59× | |
| Office2013 | Frequency (MHz) | 3000 | 1530 | 190 | 150 | 150 |
| Speed (KH/s) | 1.897 | 17.6 | 0.979 | 18 | 27 | |
| Power (W) | 225.77 | 250 | 10.65 | 104.33 | 134.8 | |
| Energy efficiency (H/J) | 8.4 | 70.4 | 91.92 | 172.53 | 200.3 | |
| Speedup | 1× | 9.28× | 0.52× | 9.49× | 14.23× | |
| Energy efficiency ratio | 1× | 8.38× | 10.94× | 20.54× | 23.85× | |
| PDF1.7 (Acrobat 9) | Frequency (MHz) | 3000 | 1530 | N/A | N/A | 200 |
| Speed (MH/s) | 359.8 | 5029.5 | 13,200 | |||
| Power (W) | 201.53 | 289 | 196.48 | |||
| Energy efficiency (MH/J) | 1.79 | 17.4 | 67.18 | |||
| Speedup | 1× | 13.98× | 36.69× | |||
| Energy efficiency ratio | 1× | 9.72× | 37.53× | |||
| Winzip | Frequency (MHz) | 3000 | 1530 | N/A | 200 | 250 |
| Speed (KH/s) | 536.4 | 5810 | 4341.22 | 8250 | ||
| Power (W) | 222.7 | 272 | 105.71 | 152.36 | ||
| Energy efficiency (KH/J) | 2.41 | 21.36 | 41.07 | 54.15 | ||
| Speedup | 1× | 10.83× | 8.09× | 15.38× | ||
| Energy efficiency ratio | 1× | 8.86× | 17.04× | 22.47× | ||
| RAR5 | Frequency (MHz) | 3000 | 1530 | 190 | 200 | 200 |
| Speed (KH/s) | 8.591 | 85.109 | 5.711 | 121.96 | 207.33 | |
| Power (W) | 238.75 | 283 | 12.95 | 106.59 | 176.94 | |
| Energy efficiency (H/J) | 35.98 | 300.74 | 441 | 1144.15 | 1171.75 | |
| Speedup | 1× | 9.91× | 0.66× | 14.20× | 24.13× | |
| Energy efficiency ratio | 1× | 8.36× | 12.26× | 31.80× | 32.57× | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, G.; Fan, X.; Huang, Z.; Cao, W.; Zhang, F. PassRecover: A Multi-FPGA System for End-to-End Offline Password Recovery Acceleration. Electronics 2025, 14, 1415. https://doi.org/10.3390/electronics14071415
Xie G, Fan X, Huang Z, Cao W, Zhang F. PassRecover: A Multi-FPGA System for End-to-End Offline Password Recovery Acceleration. Electronics. 2025; 14(7):1415. https://doi.org/10.3390/electronics14071415
Chicago/Turabian StyleXie, Guangwei, Xitian Fan, Zhongchen Huang, Wei Cao, and Fan Zhang. 2025. "PassRecover: A Multi-FPGA System for End-to-End Offline Password Recovery Acceleration" Electronics 14, no. 7: 1415. https://doi.org/10.3390/electronics14071415
APA StyleXie, G., Fan, X., Huang, Z., Cao, W., & Zhang, F. (2025). PassRecover: A Multi-FPGA System for End-to-End Offline Password Recovery Acceleration. Electronics, 14(7), 1415. https://doi.org/10.3390/electronics14071415