
Low-Overhead Reinforcement Learning-Based Power Management Using 2QoSM †


Abstract
:1. Introduction
2. Related Work
2.1. Dynamic Voltage and Frequency Scaling
2.2. Modern Power Managers
2.3. Machine Learning in Power Management
3. Motivation
4. System Overview
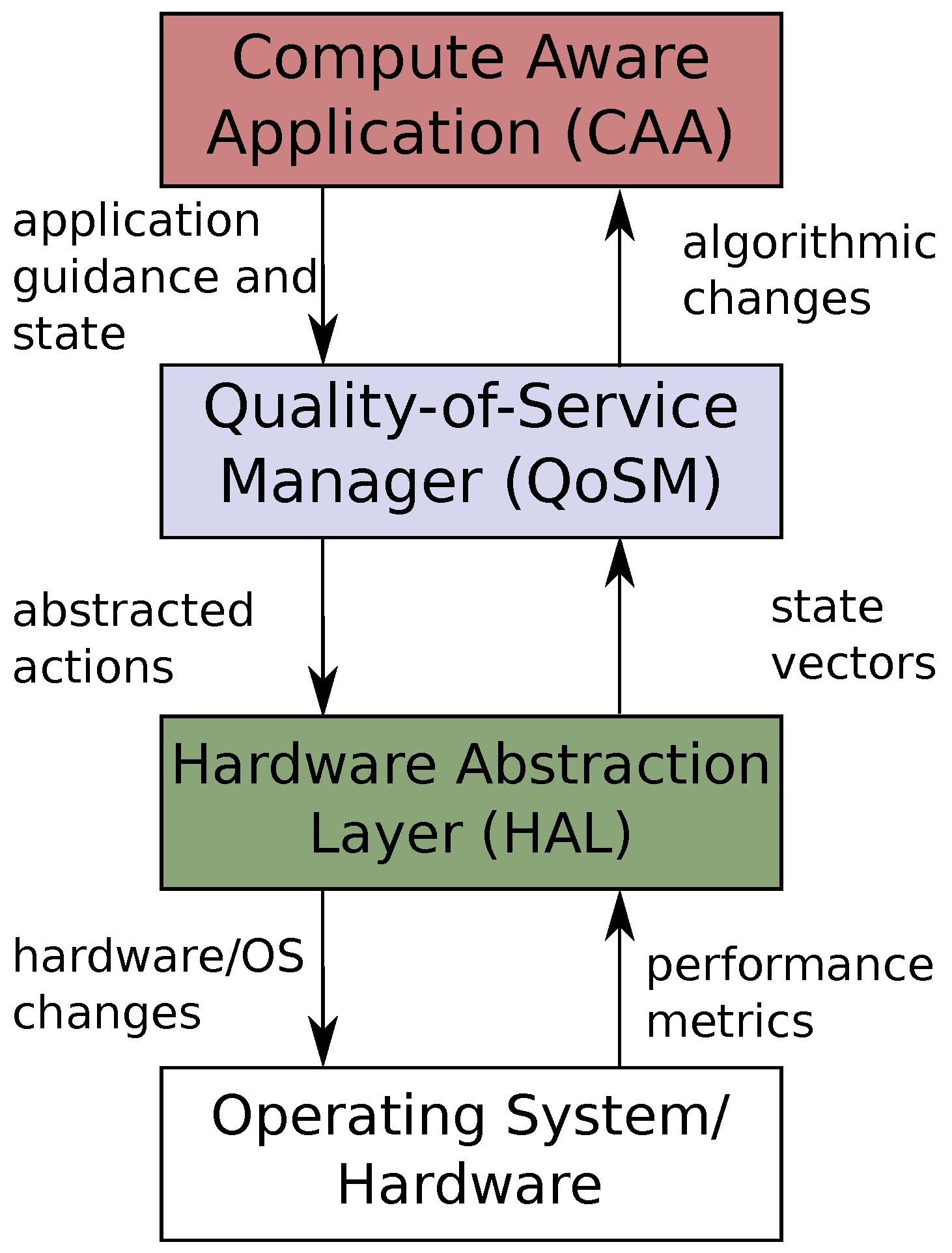
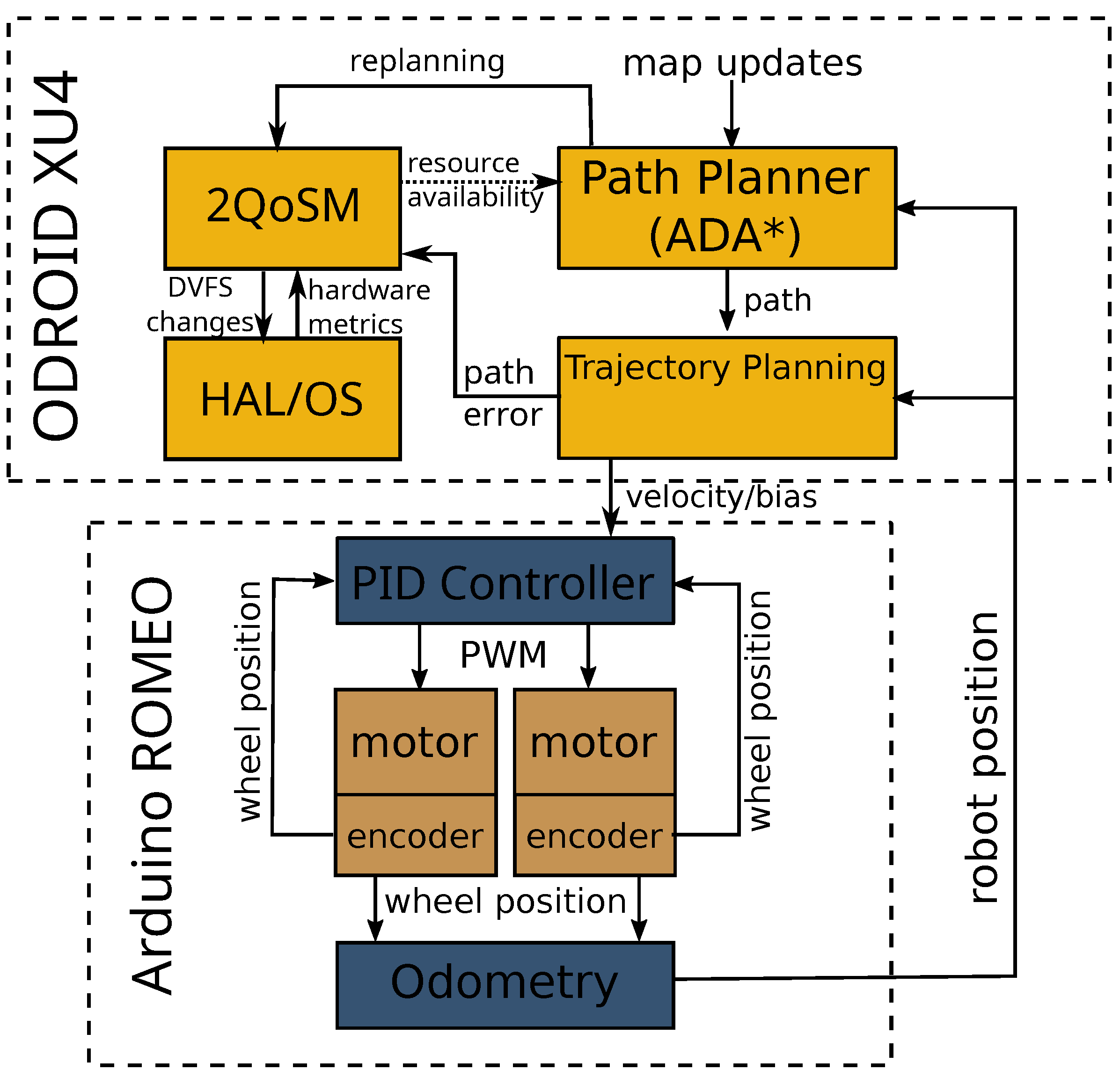
4.1. Software Architecture
4.2. Q-Learner Quality of Service Manager (2QoSM)
| Algorithm 1 Q-Learning Update |
|
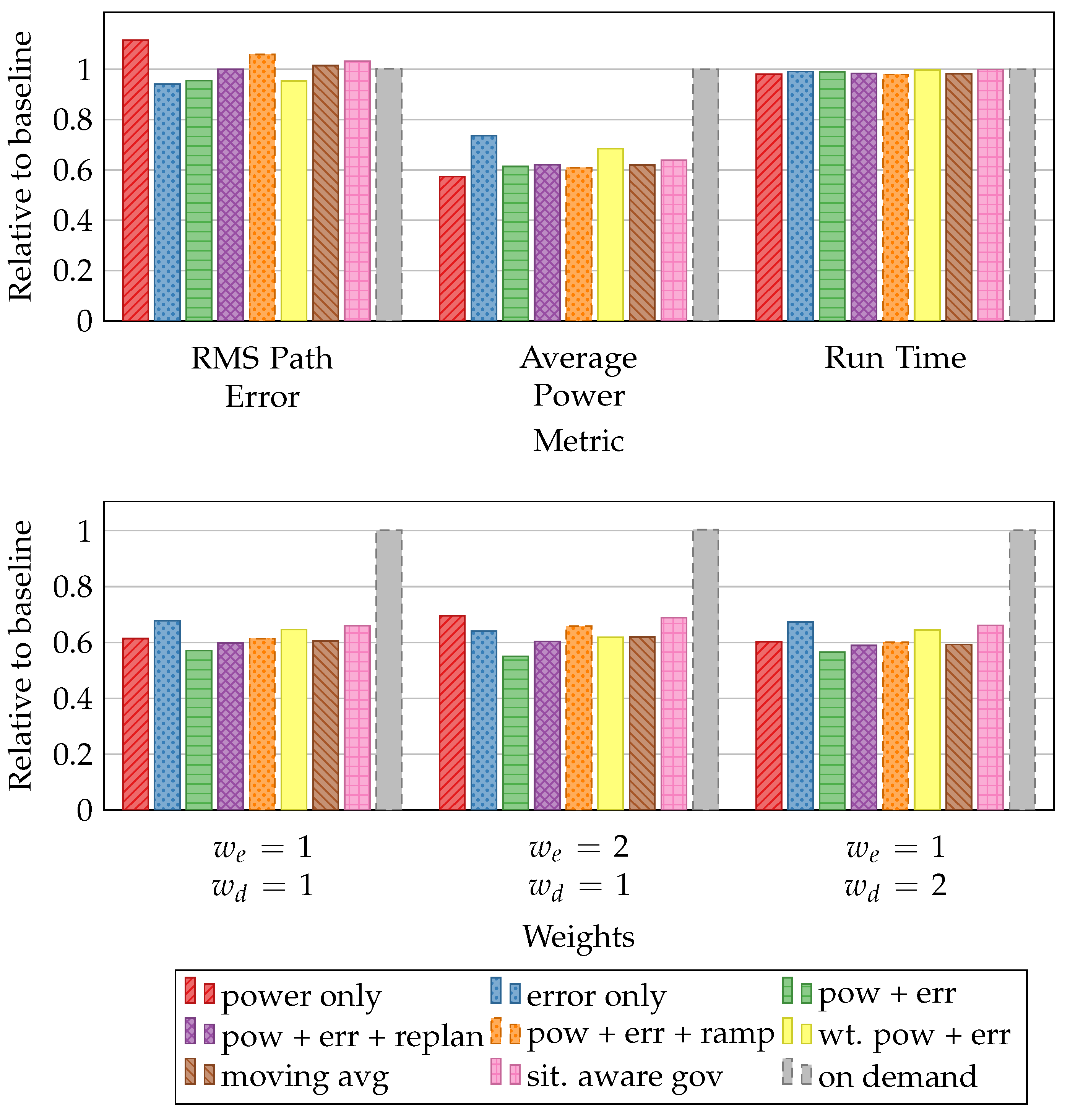
5. Experimental Results
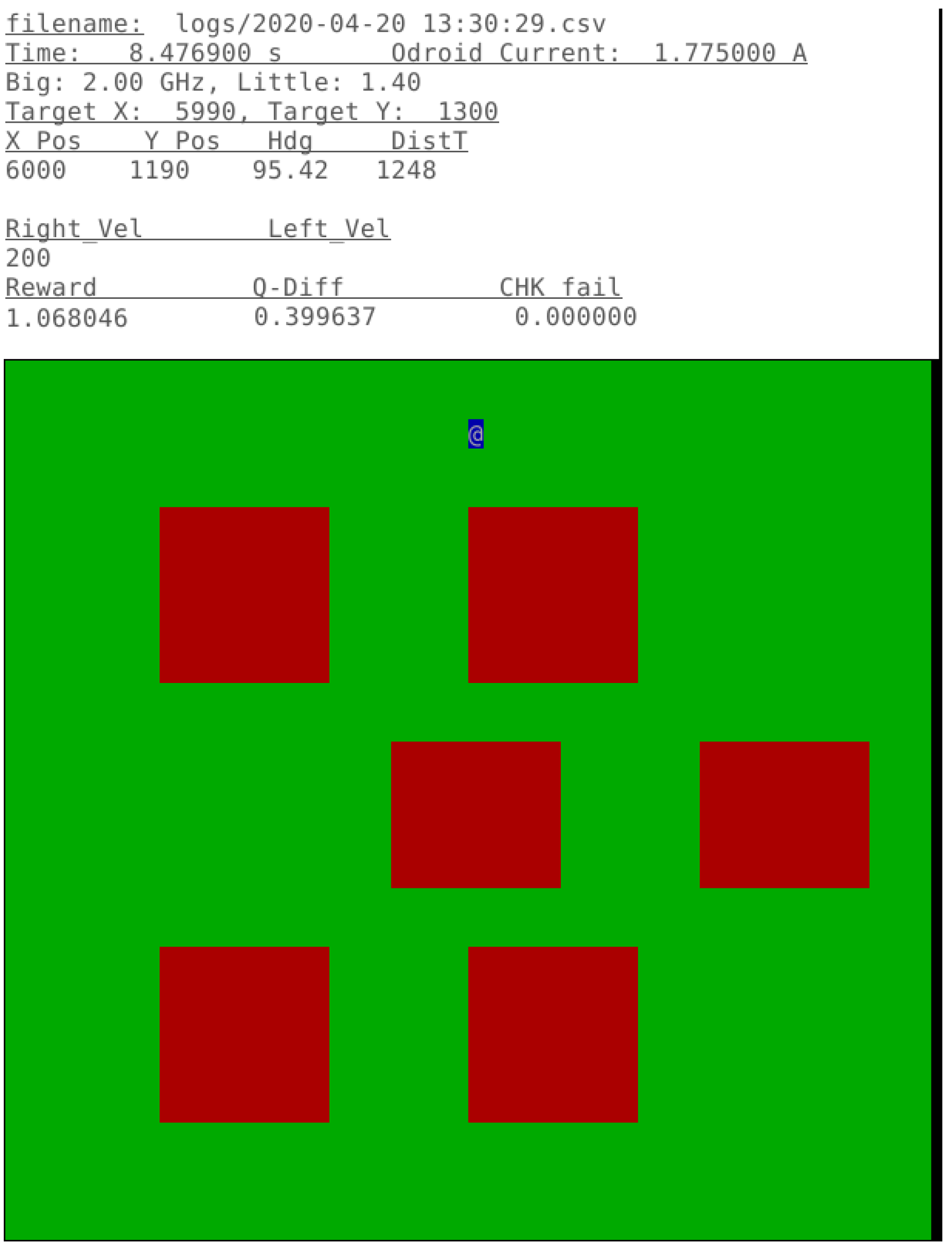
5.1. Experimental Platform
5.2. Quality-of-Service Manager Implementation
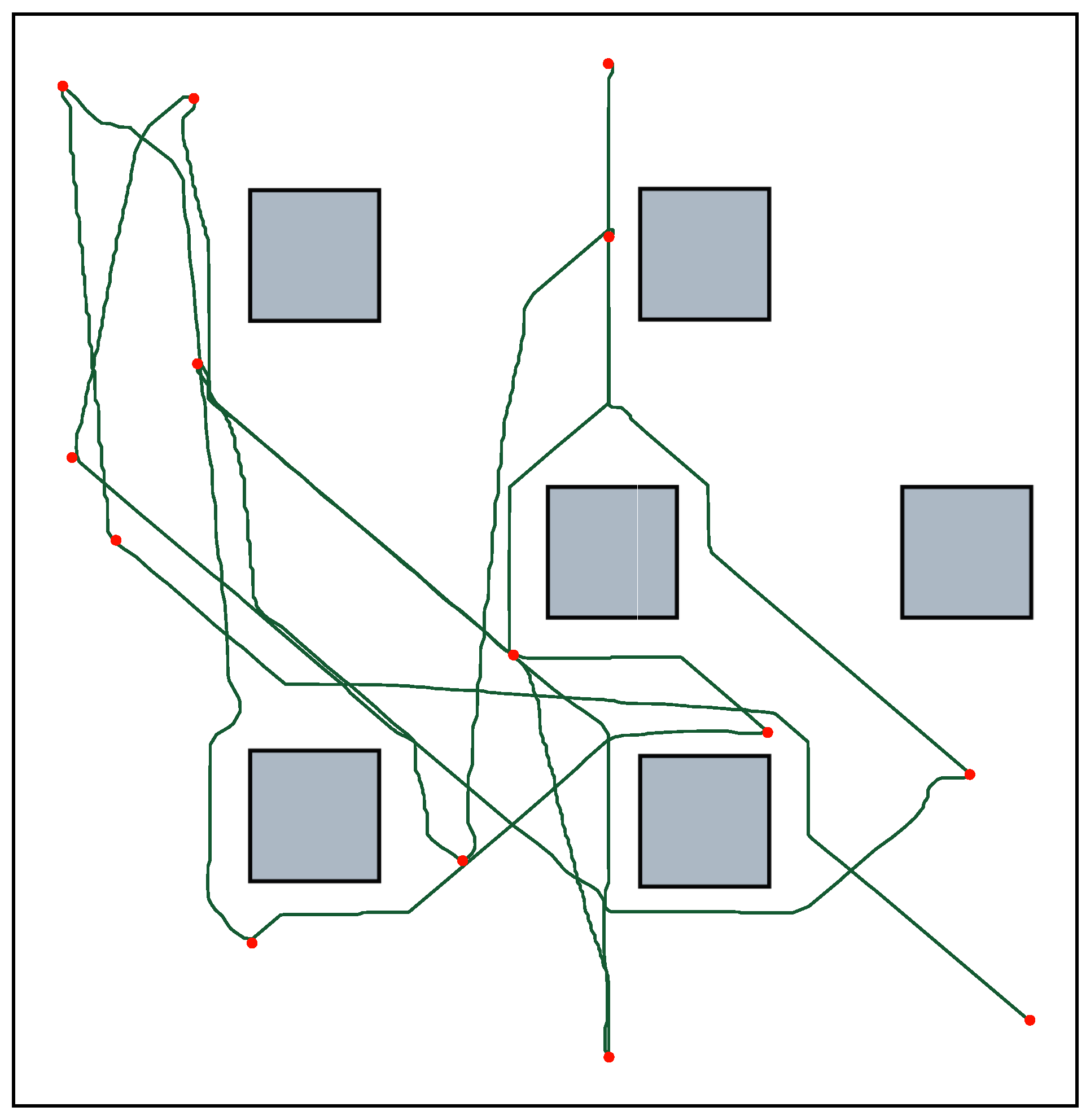
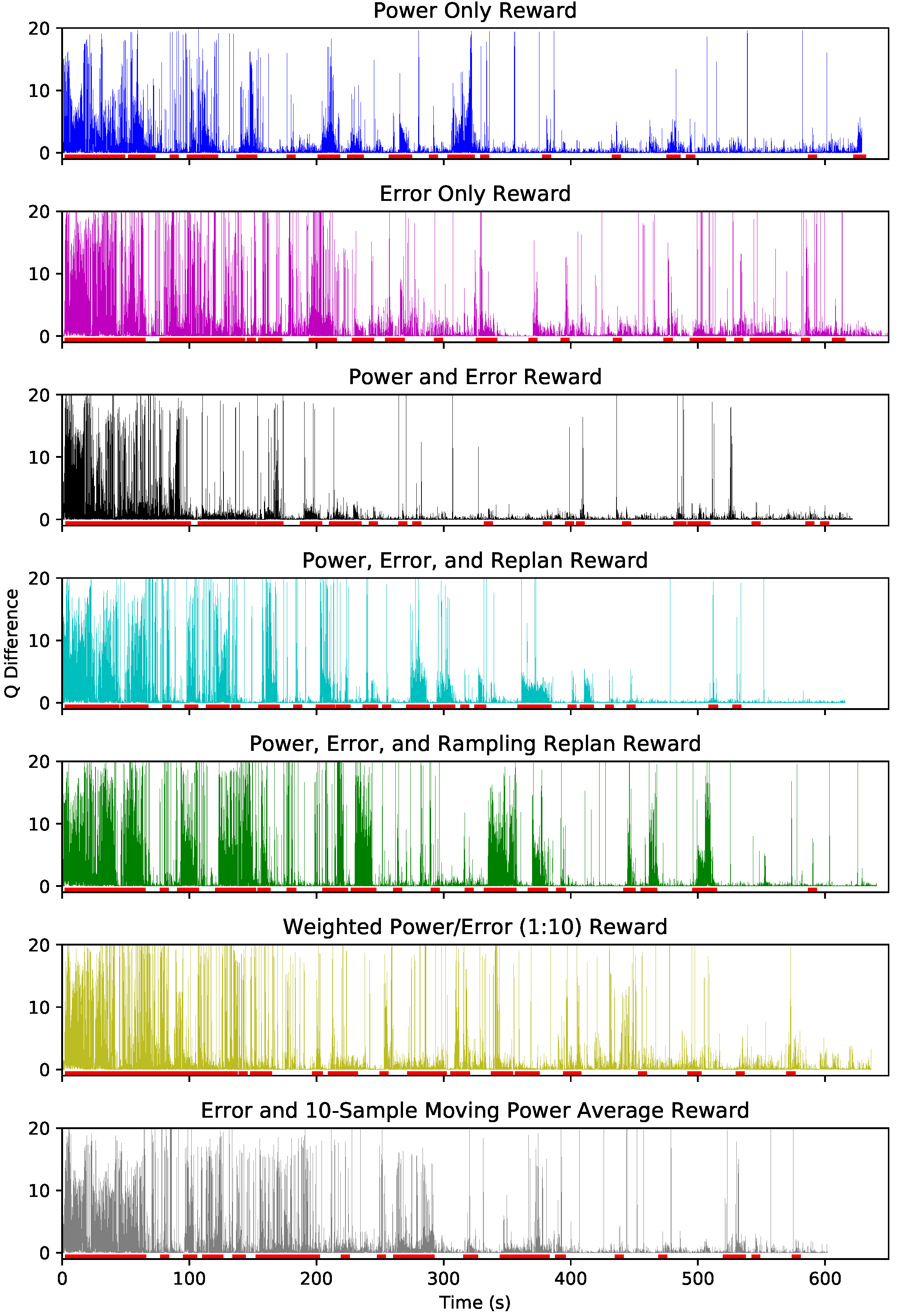
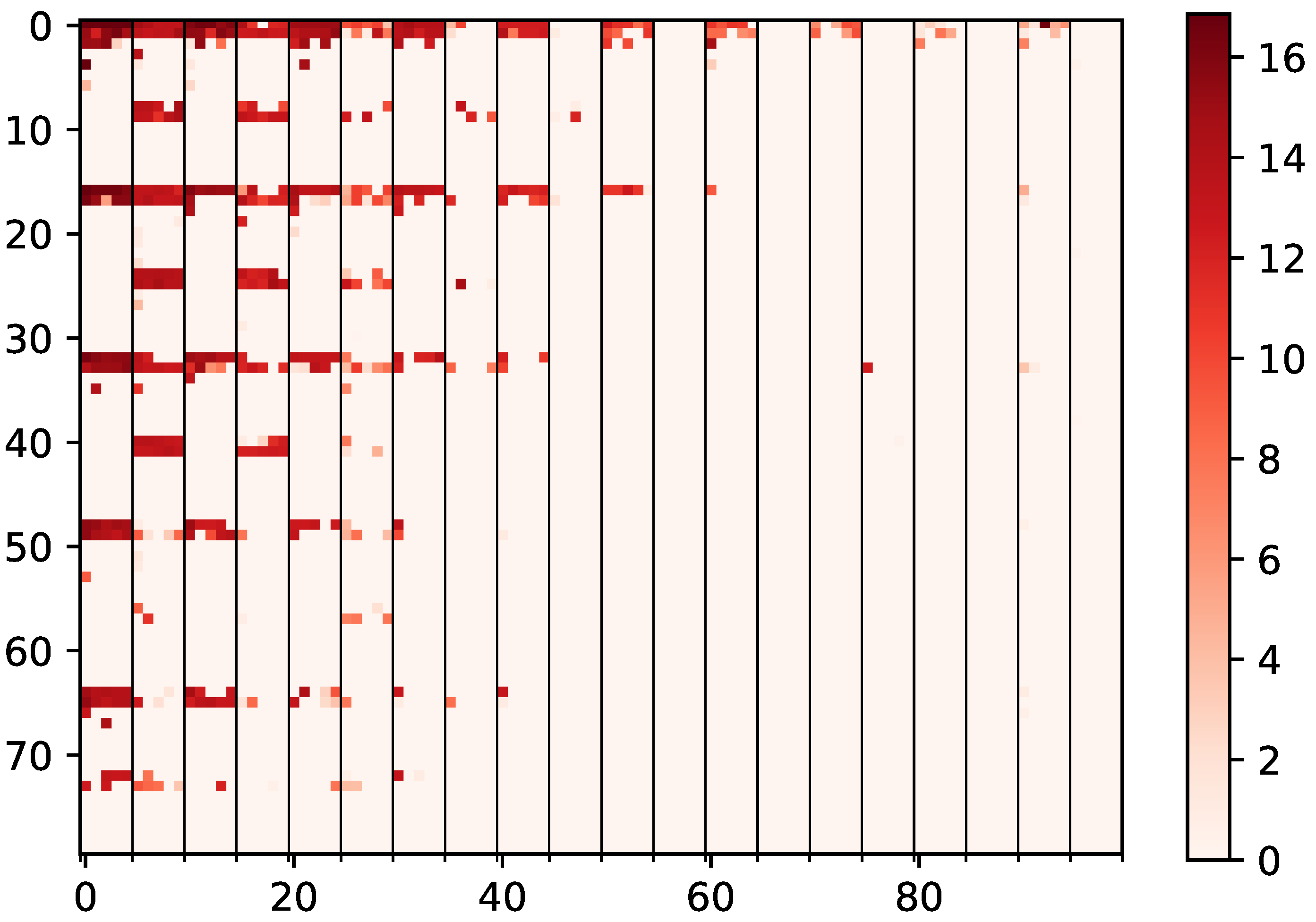
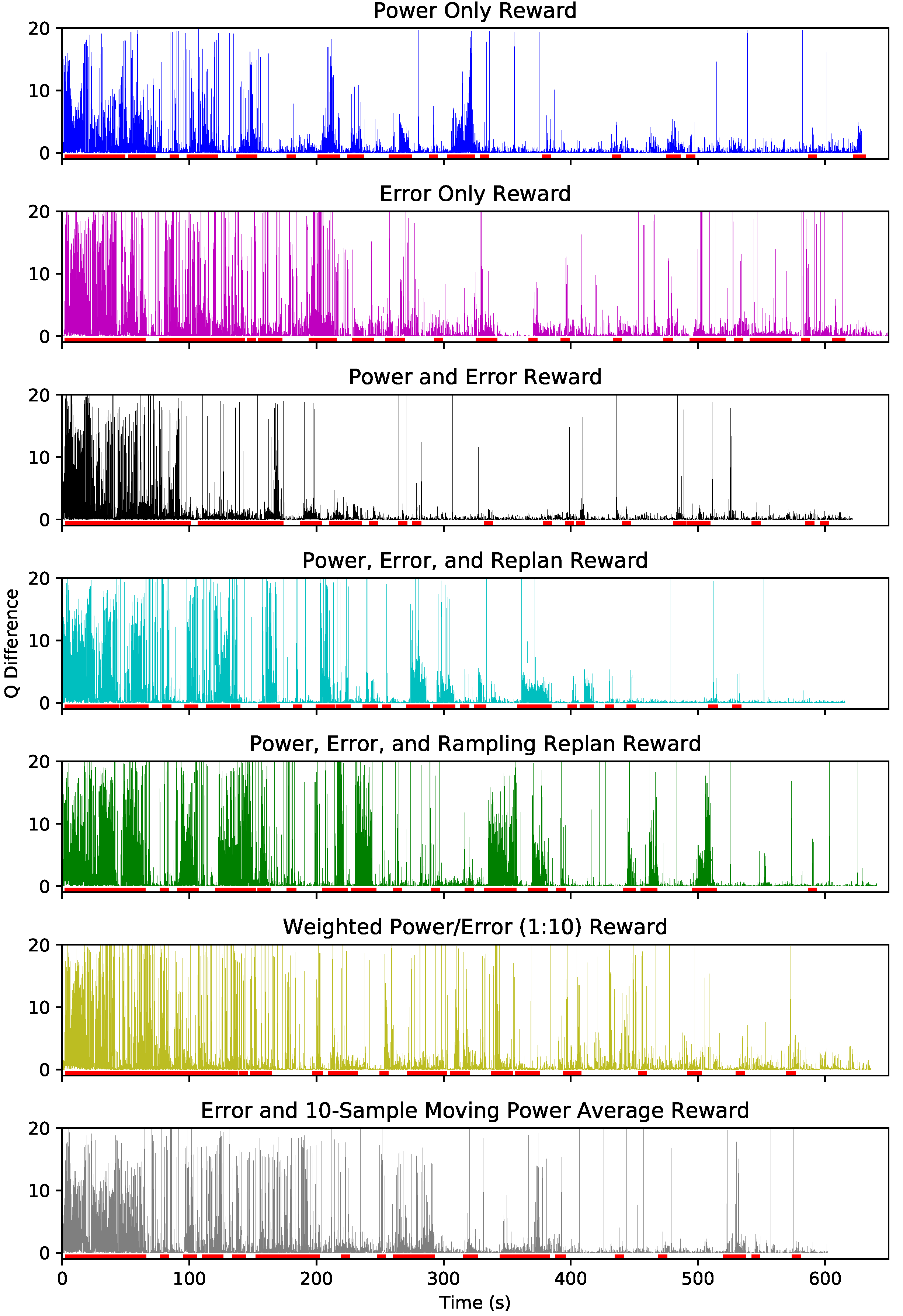
5.3. Training and Convergence
5.4. Metrics
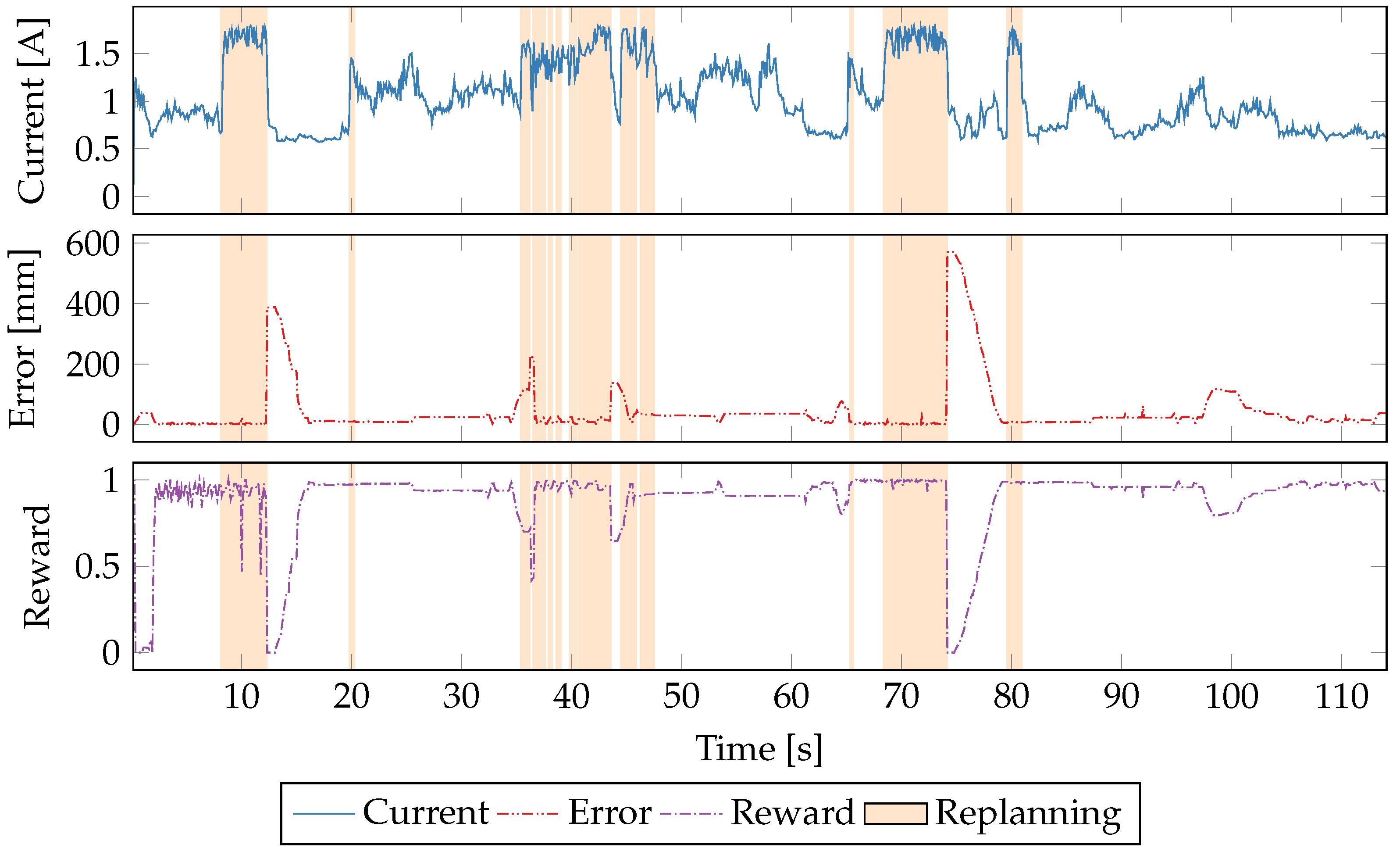
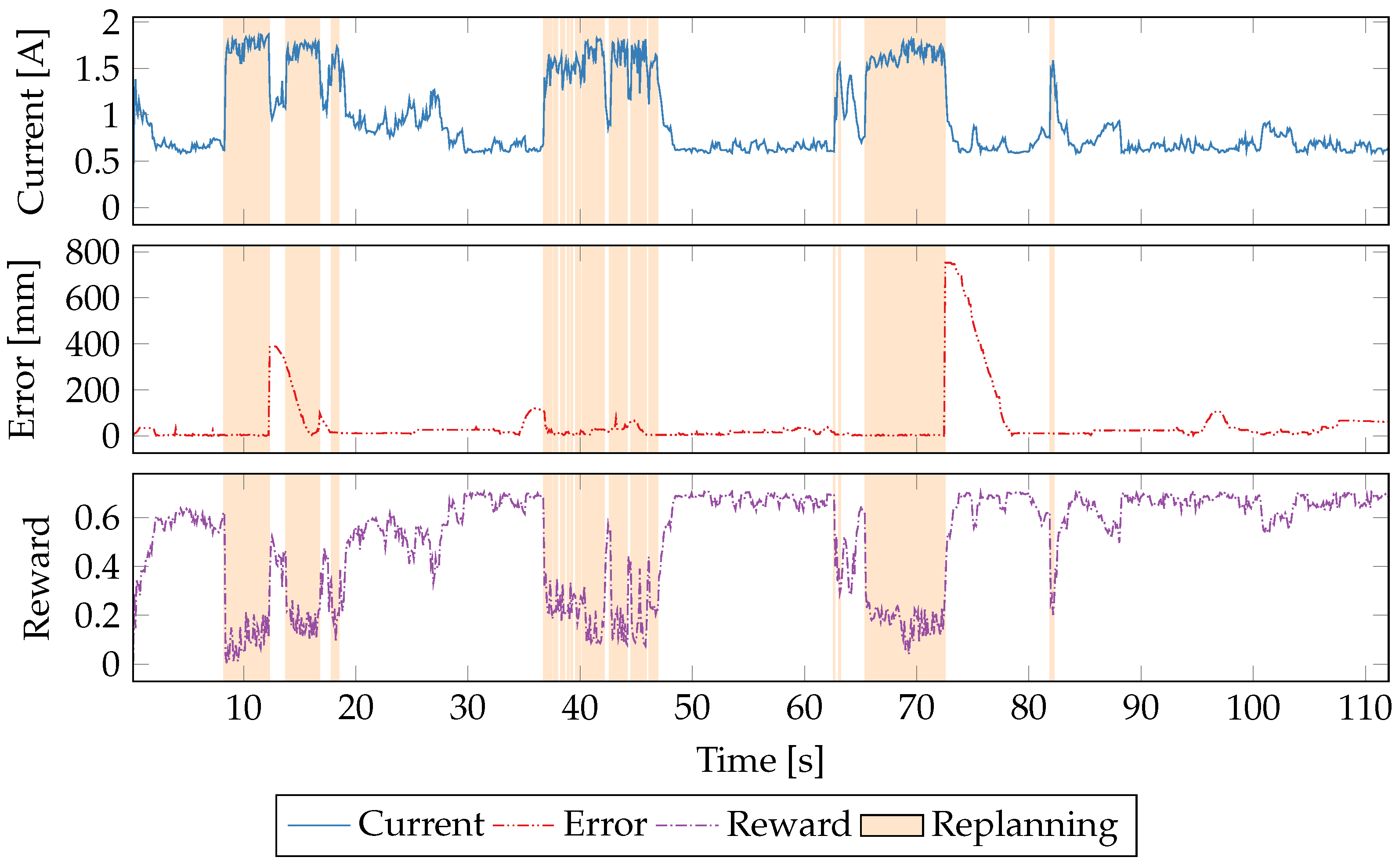
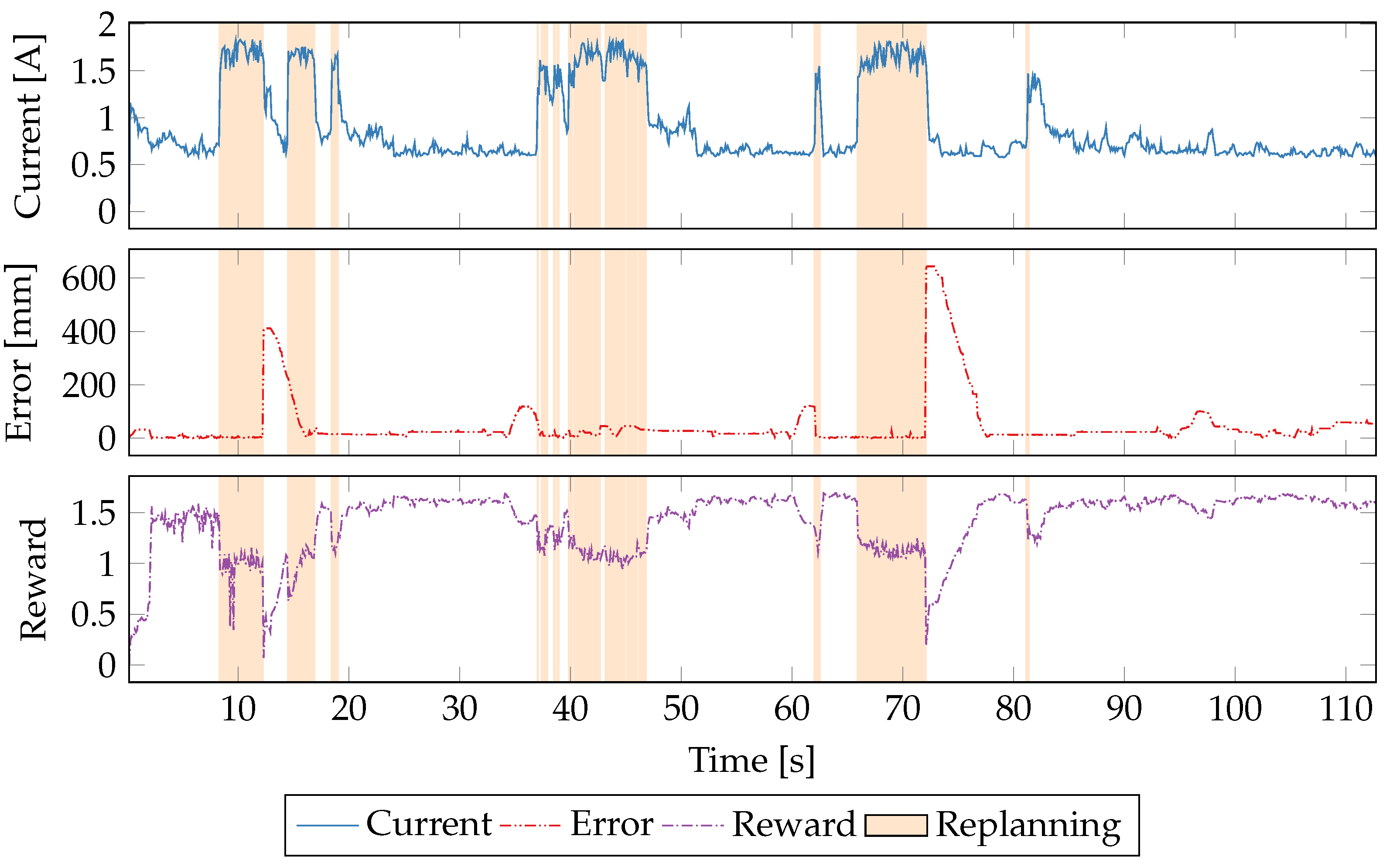
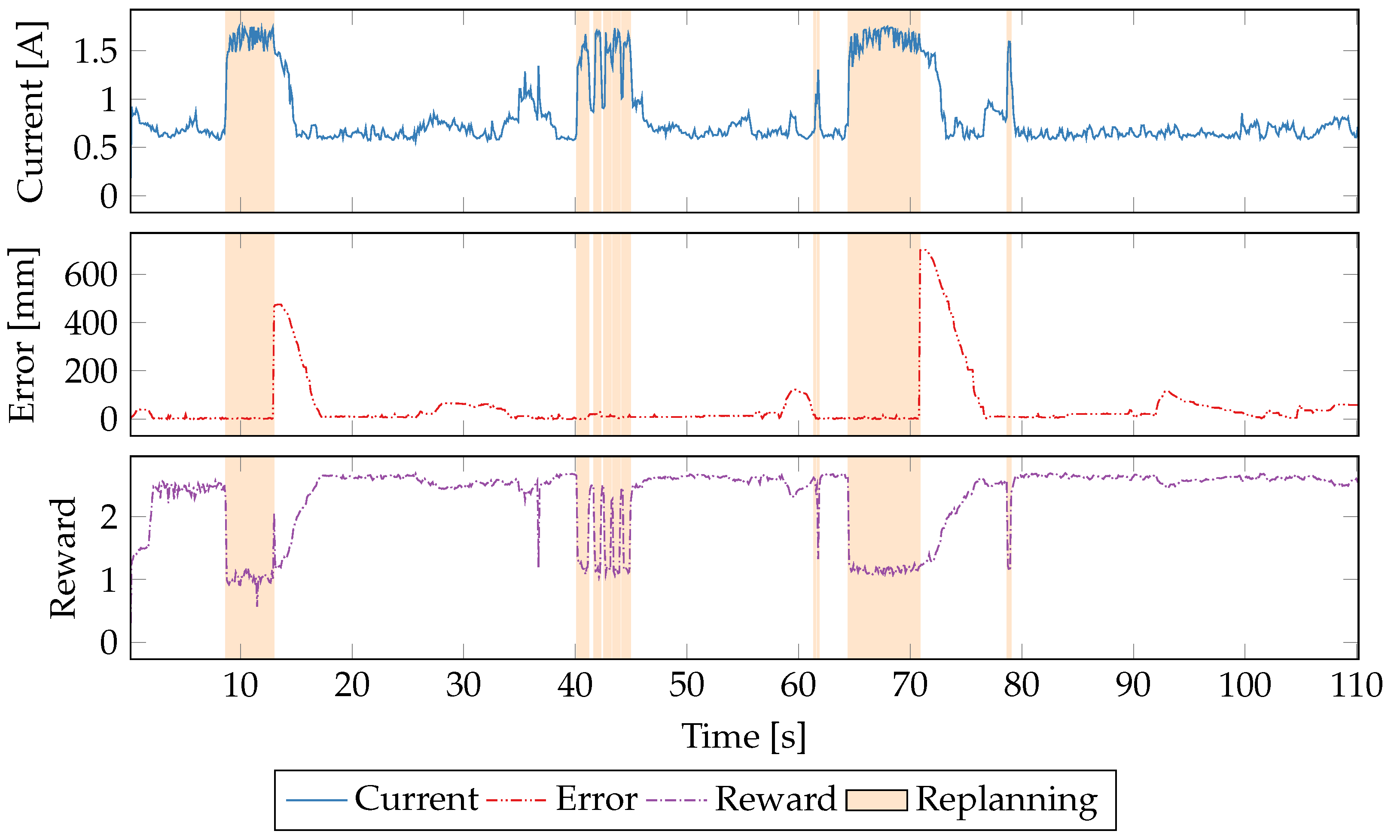
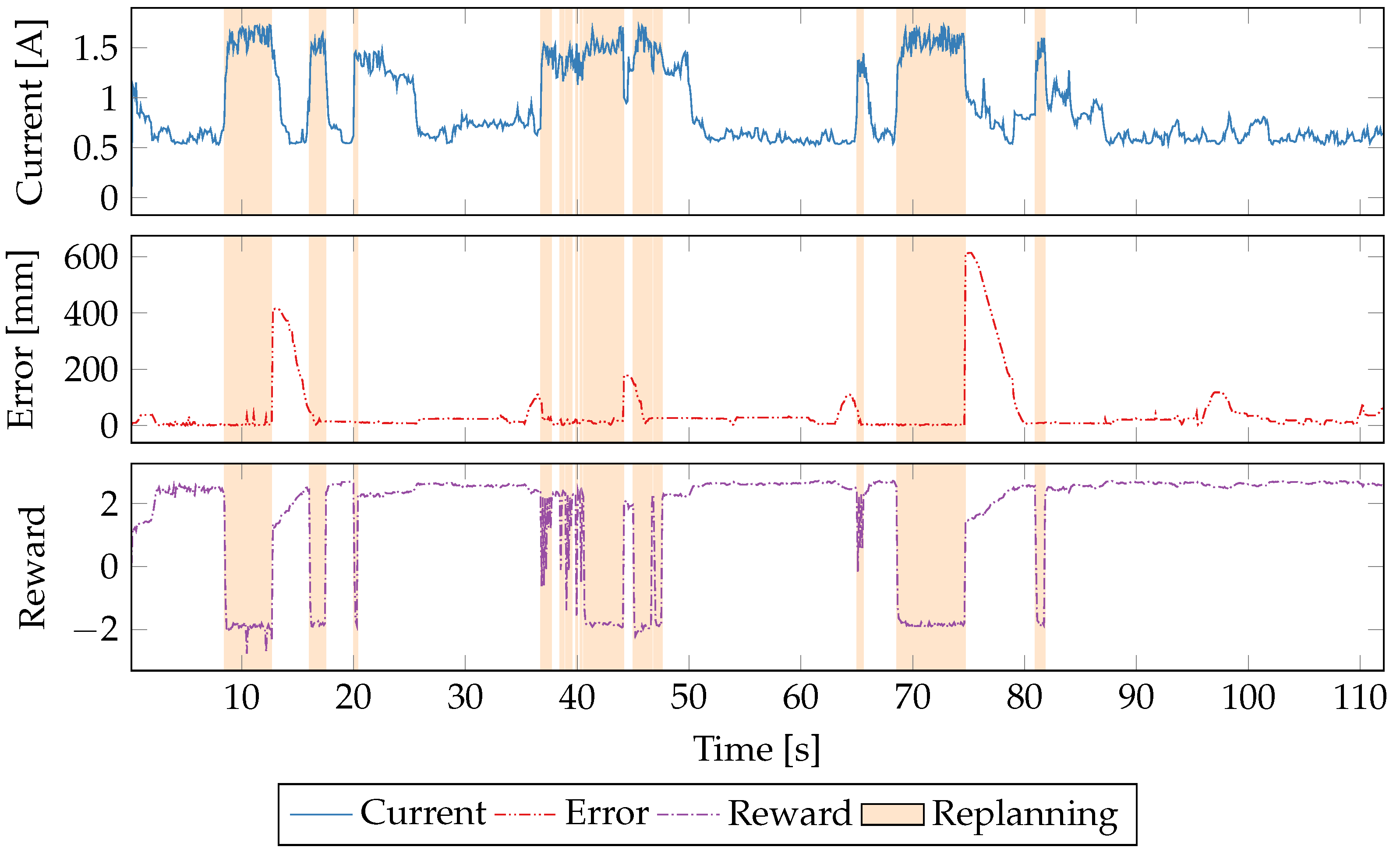
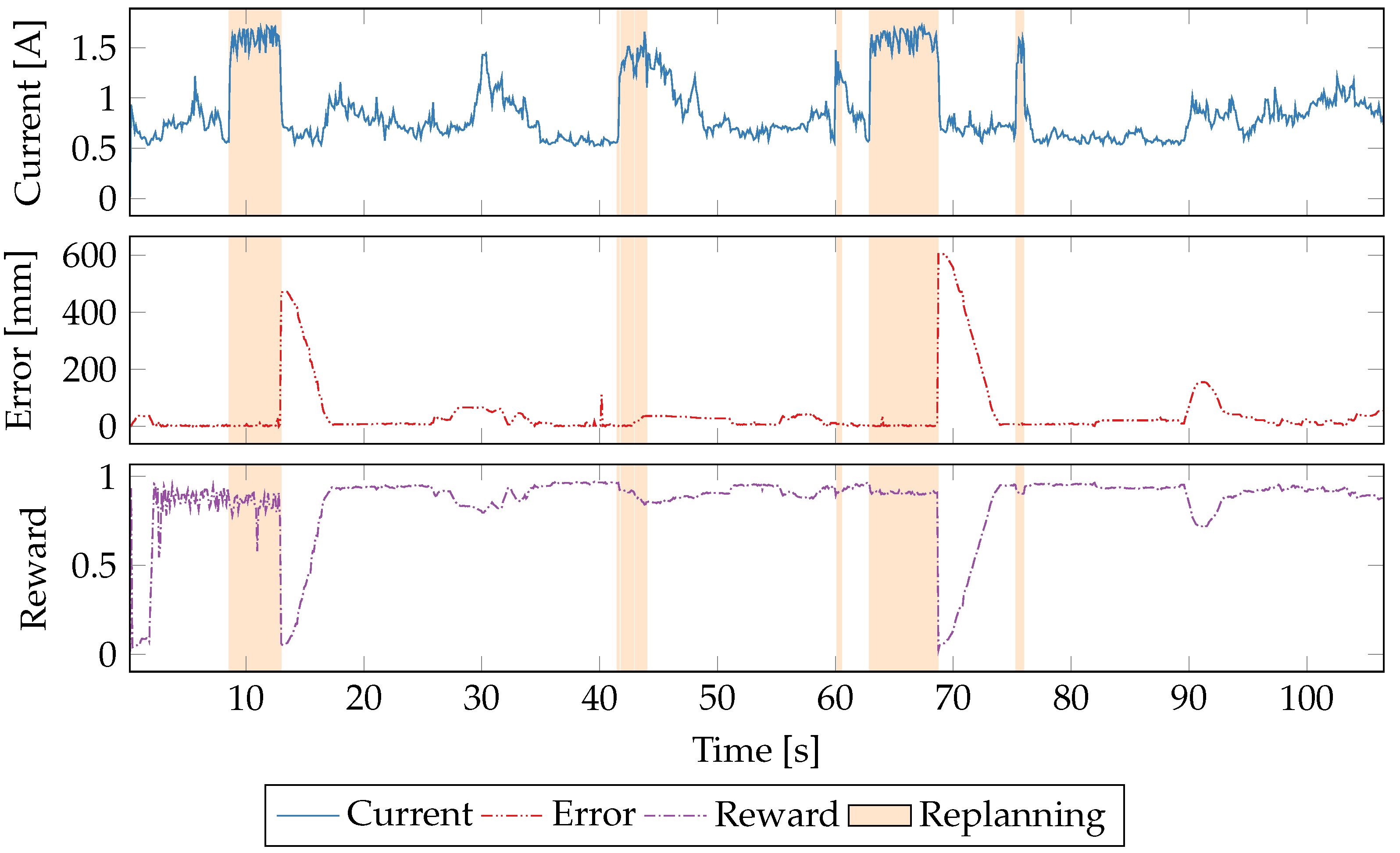
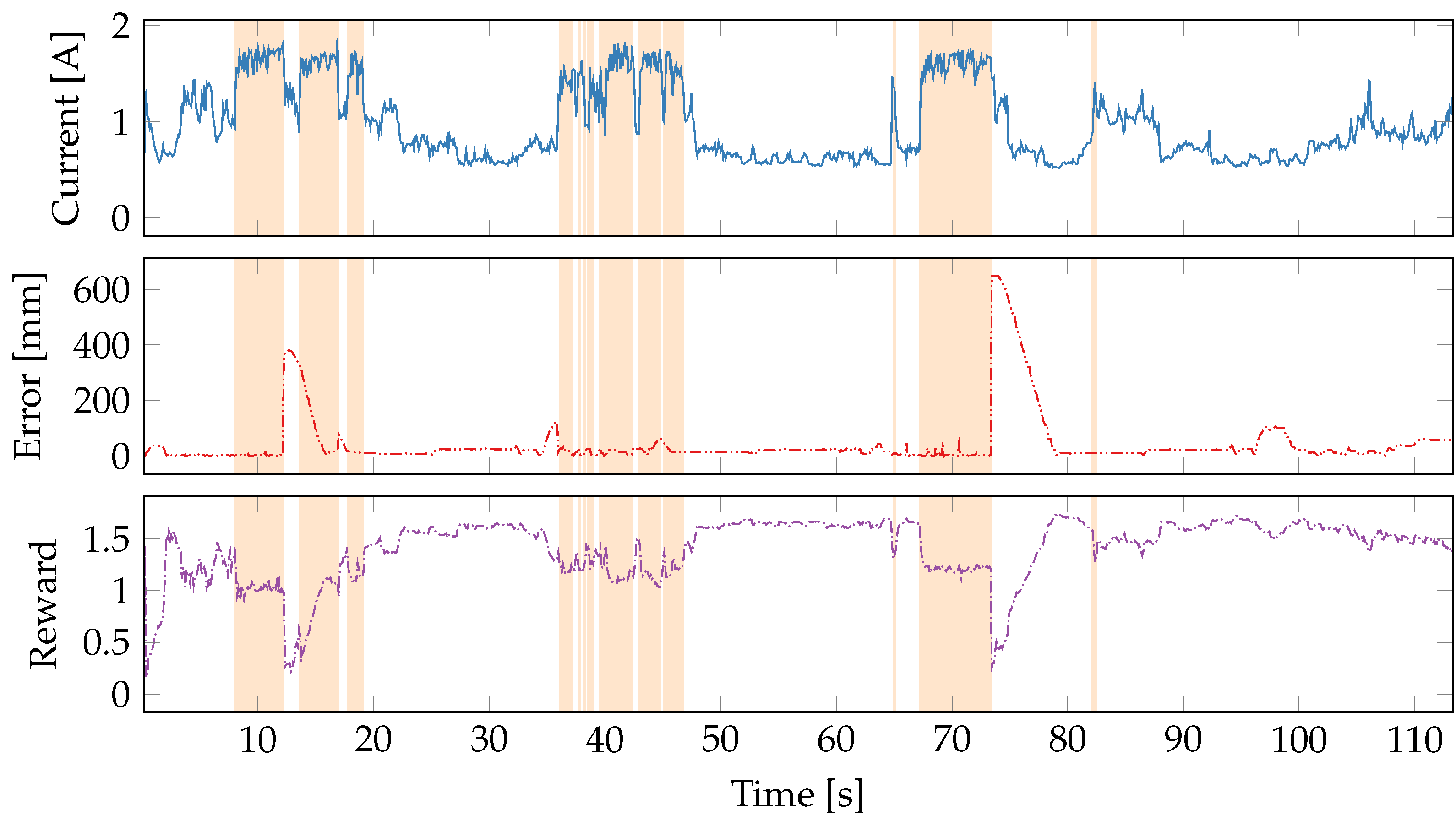
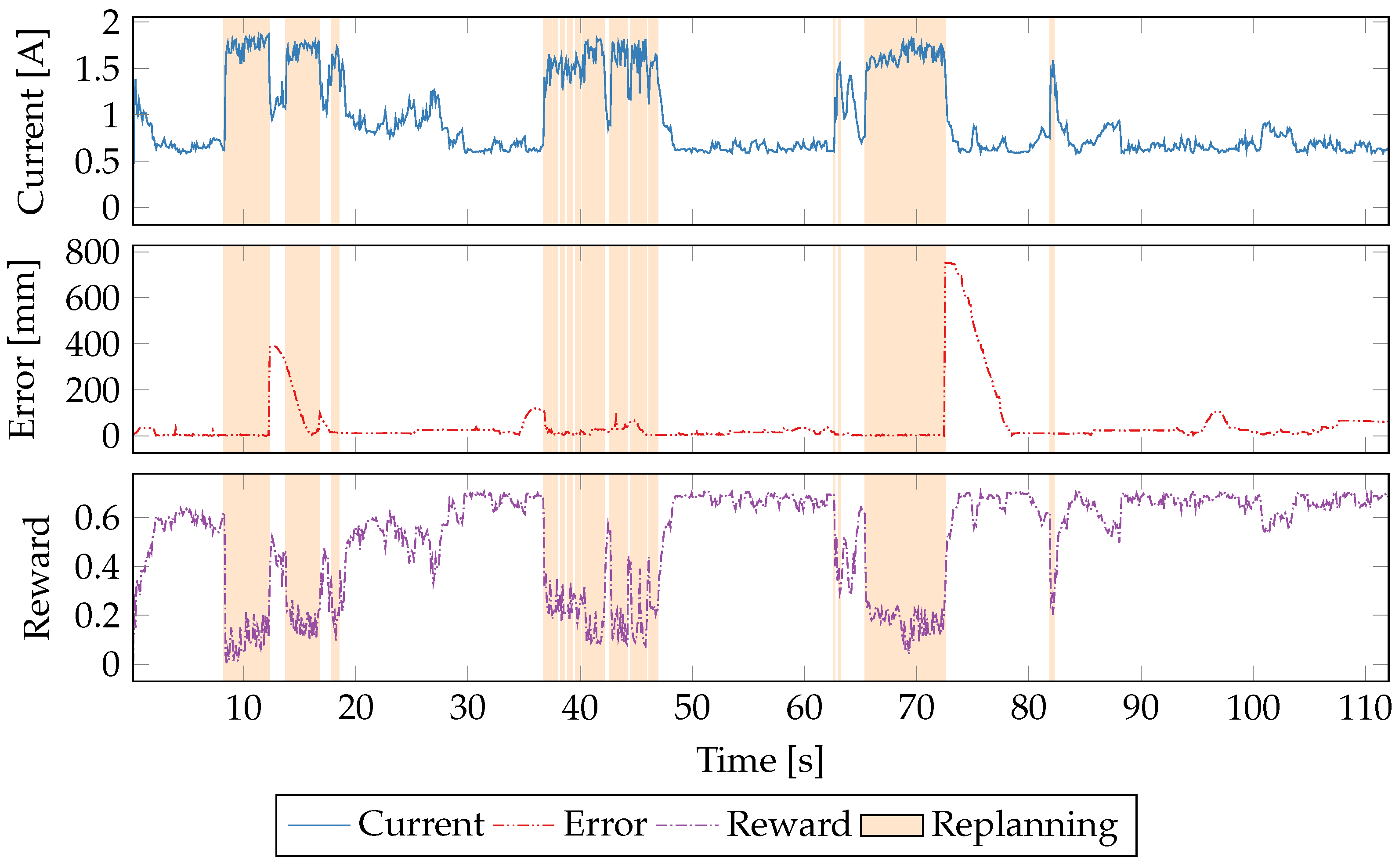
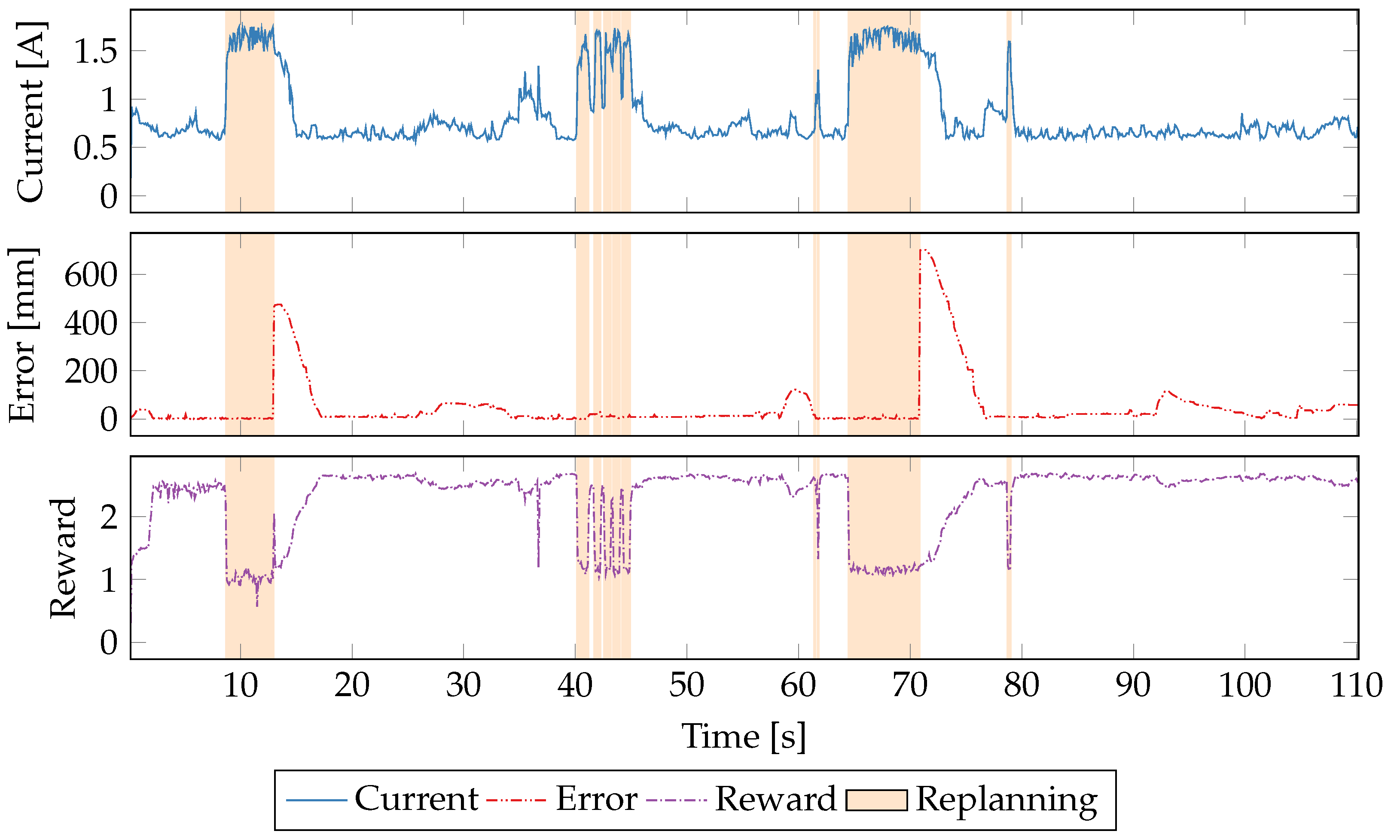
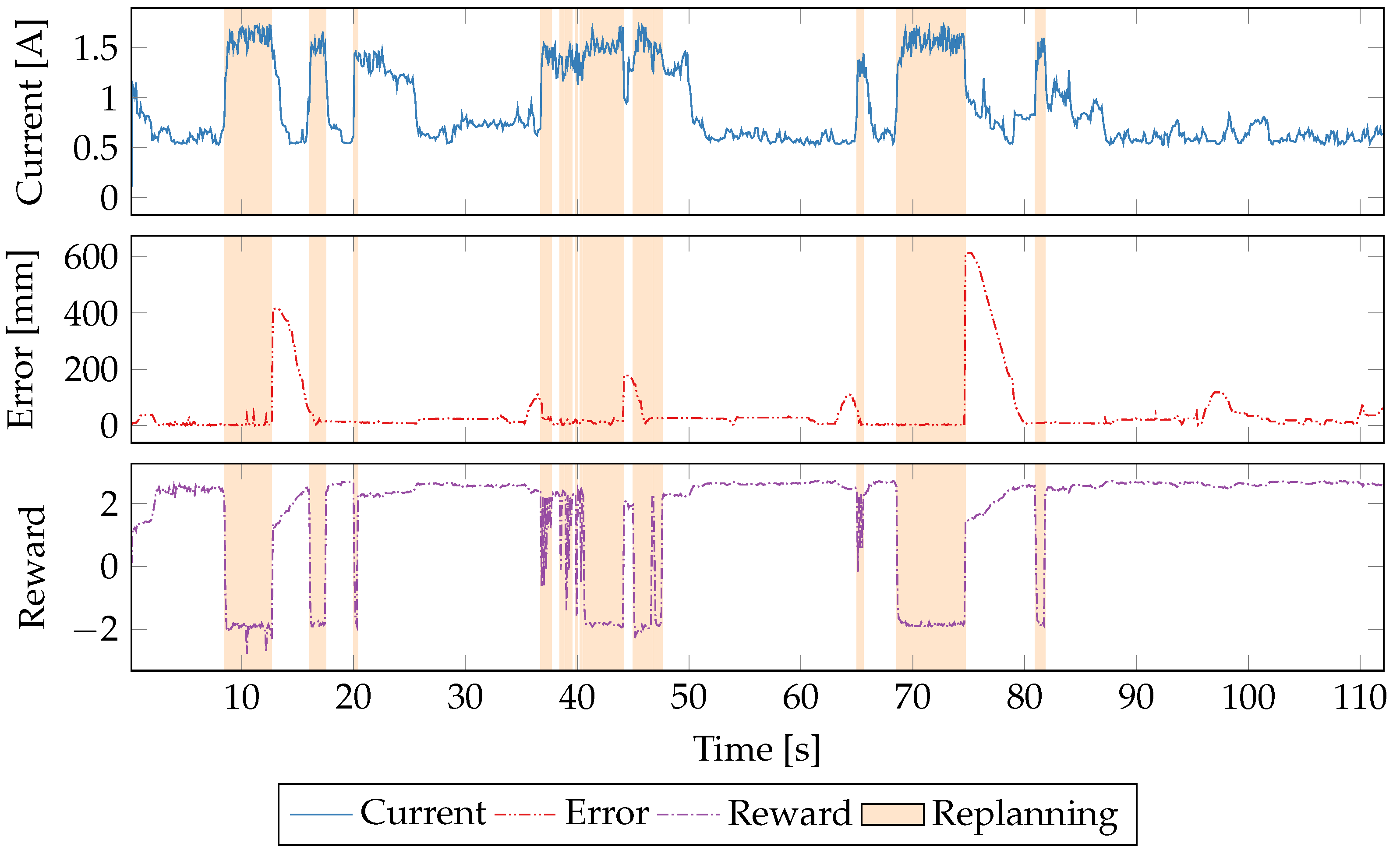
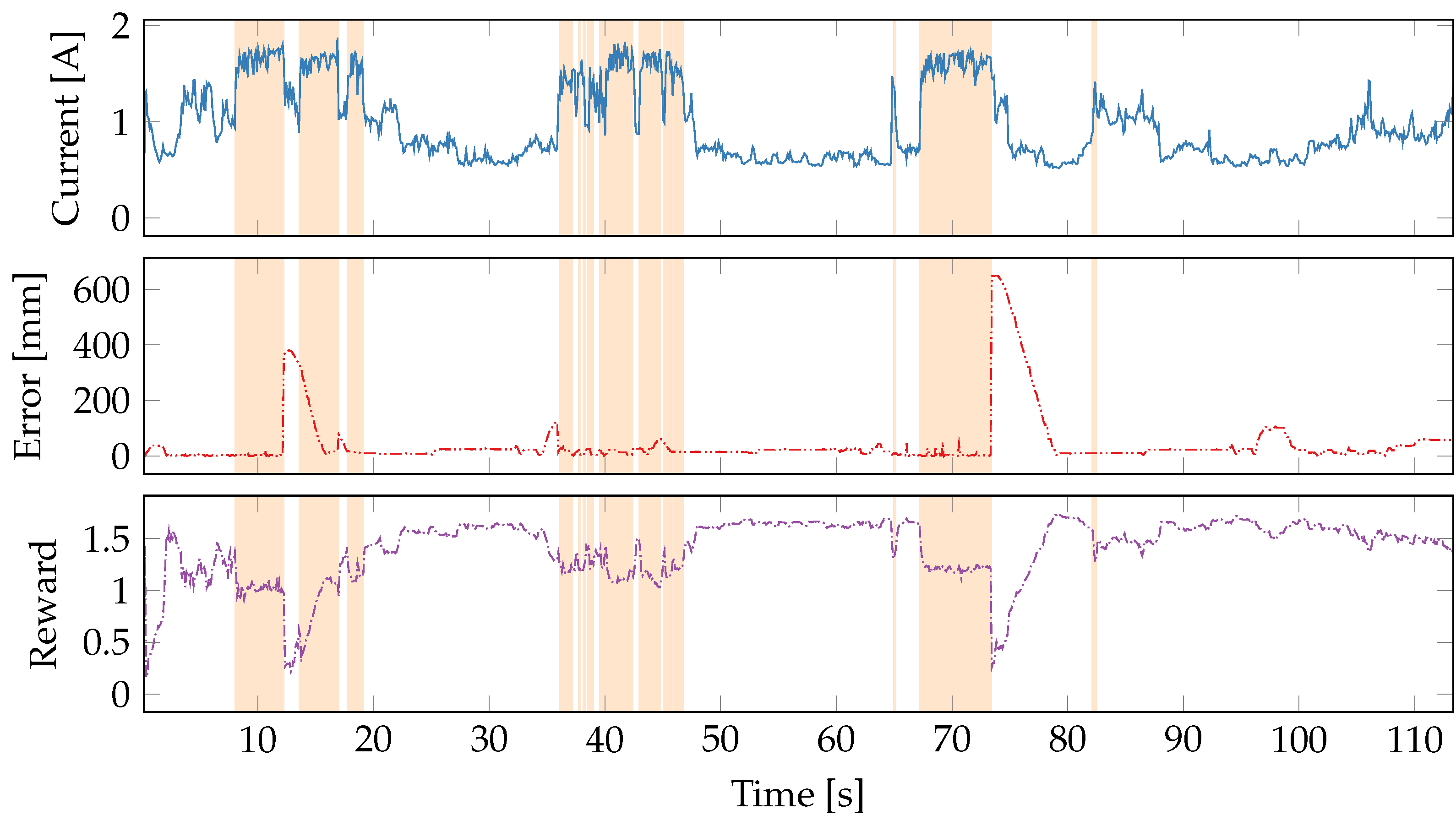
5.5. Time Series Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Govil, K.; Chan, E.; Wasserman, H. Comparing Algorithm for Dynamic Speed-setting of a Low-power CPU. In Proceedings of the MobiCom ’95: 1st Annual International Conference on Mobile Computing and Networking, Berkeley, CA, USA, 13–15 November 1995; ACM: New York, NY, USA, 1995; pp. 13–25. [Google Scholar] [CrossRef]
- Hu, Z.; Buyuktosunoglu, A.; Srinivasan, V.; Zyuban, V.; Jacobson, H.; Bose, P. Microarchitectural Techniques for Power Gating of Execution Units. In Proceedings of the 2004 International Symposium on Low Power Electronics and Design (ISLPED ’04), Newport Beach, CA, USA, 11 August 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 32–37. [Google Scholar] [CrossRef]
- Agarwal, K.; Deogun, H.; Sylvester, D.; Nowka, K. Power gating with multiple sleep modes. In Proceedings of the 7th International Symposium on Quality Electronic Design (ISQED’06), San Jose, CA, USA, 27–29 March 2006. [Google Scholar] [CrossRef]
- Liu, S.; Pattabiraman, K.; Moscibroda, T.; Zorn, B.G. Flikker: Saving DRAM Refresh-Power through Critical Data Partitioning. In Proceedings of the Sixteenth International Conference on Architectural Support for Programming Languages and Operating Systems, Newport Beach, CA, USA, 5–11 March 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 213–224. [Google Scholar] [CrossRef]
- Liu, J.; Jaiyen, B.; Veras, R.; Mutlu, O. RAIDR: Retention-Aware Intelligent DRAM Refresh. SIGARCH Comput. Archit. News 2012, 40, 1–12. [Google Scholar] [CrossRef]
- Li, K.; Kumpf, R.; Horton, P.; Anderson, T. A Quantitative Analysis of Disk Drive Power Management in Portable Computers. In Proceedings of the USENIX Winter 1994 Technical Conference (WTEC’94), San Francisco, CA, USA, 17–21 January 1994; USENIX Association: Berkeley, CA, USA, 1994; p. 22. [Google Scholar]
- Intel Corporation. Intel Automated Relational Knowledge Base (ARK). 2020. Available online: https://ark.intel.com/content/www/us/en/ark.html (accessed on 31 January 2022).
- Ghose, S.; Yaglikçi, A.G.; Gupta, R.; Lee, D.; Kudrolli, K.; Liu, W.X.; Hassan, H.; Chang, K.K.; Chatterjee, N.; Agrawal, A.; et al. What Your DRAM Power Models Are Not Telling You: Lessons from a Detailed Experimental Study. Proc. ACM Meas. Anal. Comput. Syst. 2018, 2, 1–41. [Google Scholar] [CrossRef]
- Ahmadoh, E.; Tawalbeh, L.A. Power consumption experimental analysis in smart phones. In Proceedings of the 2018 Third International Conference on Fog and Mobile Edge Computing (FMEC), Barcelona, Spain, 23–26 April 2018; pp. 295–299. [Google Scholar] [CrossRef]
- Riaz, M.N. Energy consumption in hand-held mobile communication devices: A comparative study. In Proceedings of the 2018 Int’l Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 3–4 March 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Bai, G.; Mou, H.; Hou, Y.; Lyu, Y.; Yang, W. Android Power Management and Analyses of Power Consumption in an Android Smartphone. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, Zhangjiajie, China, 13–15 November 2013; pp. 2347–2353. [Google Scholar] [CrossRef]
- Martinez, B.; Montón, M.; Vilajosana, I.; Prades, J.D. The Power of Models: Modeling Power Consumption for IoT Devices. IEEE Sens. J. 2015, 15, 5777–5789. [Google Scholar] [CrossRef] [Green Version]
- Intel Corporation and Microsoft Corporation. Advanced Power Management (APM) BIOS Interface Specification v1.2. Available online: https://cupdf.com/document/advanced-power-management-apm-bios-interface-specification-revision-12-february.html (accessed on 31 January 2022).
- UEFI Forum. Advanced Configuration and Power Interface Specification v6.3; UEFI Forum: Beaverton, OR, USA, 2019. [Google Scholar]
- Chandrakasan, A.P.; Sheng, S.; Brodersen, R.W. Low-power CMOS digital design. IEICE Trans. Electron. 1992, 27, 473–484. [Google Scholar] [CrossRef] [Green Version]
- Wakerly, J. Digital Design: Principles and Practices, 4th ed.; Prentice-Hall, Inc.: Hoboken, NJ, USA, 2005. [Google Scholar]
- Kim, N.S.; Austin, T.; Baauw, D.; Mudge, T.; Flautner, K.; Hu, J.S.; Irwin, M.J.; Kandemir, M.; Narayanan, V. Leakage current: Moore’s law meets static power. Computer 2003, 36, 68–75. [Google Scholar] [CrossRef]
- Veendrick, H.J.M. Short-circuit dissipation of static CMOS circuitry and its impact on the design of buffer circuits. IEEE J. Solid-State Circuits 1984, 19, 468–473. [Google Scholar] [CrossRef] [Green Version]
- Pallipadi, V.; Starikovskiy, A. The ondemand governor. In Proceedings of the Linux Symposium, Ottawa, ON, Canada, 19–22 July 2006; Volume 2, pp. 215–230. [Google Scholar]
- Brodowsk, D.; Golde, N.; Wysocki, R.J.; Kumar, V. CPU Frequency and Voltage Scaling Code in the Linux(TM) Kernel. Available online: https://www.mikrocontroller.net/attachment/529080/Linux-CPU-freq-governors.pdf (accessed on 31 January 2022).
- Ahmed, S.; Ferri, B.H. Prediction-Based Asynchronous CPU-Budget Allocation for Soft-Real-Time Applications. IEEE Trans. Comput. 2014, 63, 2343–2355. [Google Scholar] [CrossRef]
- Ge, R.; Feng, X.; Feng, W.C.; Cameron, K.W. CPU MISER: A Performance-Directed, Run-Time System for Power-Aware Clusters. In Proceedings of the 2007 Int’l Conference on Parallel Processing (ICPP 2007), Xi’an, China, 10–14 September 2007. [Google Scholar] [CrossRef] [Green Version]
- Deng, Q.; Meisner, D.; Bhattacharjee, A.; Wenisch, T.F.; Bianchini, R. CoScale: Coordinating CPU and Memory System DVFS in Server Systems. In Proceedings of the 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture, Vancouver, BC, Canada, 1–5 December 2012; pp. 143–154. [Google Scholar] [CrossRef]
- David, H.; Gorbatov, E.; Hanebutte, U.R.; Khanna, R.; Le, C. RAPL: Memory power estimation and capping. In Proceedings of the 2010 ACM/IEEE International Symposium on Low-Power Electronics and Design (ISLPED), Austin, TX, USA, 18–20 August 2010; pp. 189–194. [Google Scholar] [CrossRef]
- Albers, S.; Antoniadis, A. Race to Idle: New Algorithms for Speed Scaling with a Sleep State. ACM Trans. Algorithms 2014, 10, 1–31. [Google Scholar] [CrossRef]
- Das, A.; Merrett, G.V.; Al-Hashimi, B.M. The slowdown or race-to-idle question: Workload-aware energy optimization of SMT multicore platforms under process variation. In Proceedings of the 2016 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 535–538. [Google Scholar]
- Awan, M.A.; Petters, S.M. Enhanced Race-To-Halt: A Leakage-Aware Energy Management Approach for Dynamic Priority Systems. In Proceedings of the 23rd Euromicro Conference on Real-Time Systems, Porto, Portugal, 5–8 July 2011; pp. 92–101. [Google Scholar] [CrossRef]
- Giardino, M.; Ferri, B. Correlating Hardware Performance Events to CPU and DRAM Power Consumption. In Proceedings of the 2016 IEEE International Conference on Networking, Architecture and Storage (NAS), Long Beach, CA, USA, 8–10 August 2016; pp. 1–2. [Google Scholar] [CrossRef]
- Kumar, K.; Doshi, K.; Dimitrov, M.; Lu, Y.H. Memory energy management for an enterprise decision support system. In Proceedings of the IEEE/ACM International Symposium on Low Power Electronics and Design, Fukuoka, Japan, 1–3 August 2011; pp. 277–282. [Google Scholar] [CrossRef]
- Tolentino, M.E.; Turner, J.; Cameron, K.W. Memory MISER: Improving Main Memory Energy Efficiency in Servers. IEEE Trans. Comput. 2009, 58, 336–350. [Google Scholar] [CrossRef]
- Ghosh, M.; Lee, H.H.S. Smart Refresh: An Enhanced Memory Controller Design for Reducing Energy in Conventional and 3D Die-Stacked DRAMs. In Proceedings of the 40th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO 40), Chicago, IL, USA, 1–5 December 2007; IEEE Computer Society: Washington, DC, USA, 2007; pp. 134–145. [Google Scholar] [CrossRef] [Green Version]
- Qureshi, M.K.; Srinivasan, V.; Rivers, J.A. Scalable High Performance Main Memory System Using Phase-change Memory Technology. In Proceedings of the ISCA ’09: 36th Annual International Symposium on Computer Architecture, Austin, TX, USA, 20–24 June 2009; ACM: New York, NY, USA, 2009; pp. 24–33. [Google Scholar] [CrossRef]
- Giardino, M.; Doshi, K.; Ferri, B. Soft2LM: Application Guided Heterogeneous Memory Management. In Proceedings of the 2016 IEEE International Conference on Networking, Architecture and Storage (NAS), Long Beach, CA, USA, 8–10 August 2016; pp. 1–10. [Google Scholar] [CrossRef]
- Li, B.; León, E.A.; Cameron, K.W. COS: A Parallel Performance Model for Dynamic Variations in Processor Speed, Memory Speed, and Thread Concurrency. In Proceedings of the HPDC ’17: 26th International Symposium on High-Performance Parallel and Distributed Computing, Washington, DC, USA, 26–30 June 2017; ACM: New York, NY, USA, 2017; pp. 155–166. [Google Scholar] [CrossRef]
- Li, B.; Nahrstedt, K. A control-based middleware framework for quality-of-service adaptations. IEEE J. Sel. Areas Commun. 1999, 17, 1632–1650. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Lu, C.; Abdelzaher, T.F.; Stankovic, J.A. ControlWare: A Middleware Architecture for Feedback Control of Software Performance. In Proceedings of the 22nd International Conference on Distributed Computing Systems (ICDCS’02), Vienna, Austria, 2–5 July 2002; IEEE Computer Society: Washington, DC, USA, 2002; pp. 301–310. [Google Scholar]
- Hoffmann, H. CoAdapt: Predictable Behavior for Accuracy-Aware Applications Running on Power-Aware Systems. In Proceedings of the 2014 26th Euromicro Conference on Real-Time Systems, Madrid, Spain, 8–11 July 2014; pp. 223–232. [Google Scholar] [CrossRef]
- Shahhosseini, S.; Moazzemi, K.; Rahmani, A.M.; Dutt, N. On the feasibility of SISO control-theoretic DVFS for power capping in CMPs. Microprocess. Microsyst. 2018, 63, 249–258. [Google Scholar] [CrossRef]
- Rahmani, A.M.; Donyanavard, B.; Mück, T.; Moazzemi, K.; Jantsch, A.; Mutlu, O.; Dutt, N. SPECTR: Formal Supervisory Control and Coordination for Many-core Systems Resource Management. In Proceedings of the ASPLOS ’18: Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems, Williamsburg, VA, USA, 24–28 March 2018; ACM: New York, NY, USA, 2018; pp. 169–183. [Google Scholar] [CrossRef]
- Muthukaruppan, T.S.; Pricopi, M.; Venkataramani, V.; Mitra, T.; Vishin, S. Hierarchical Power Management for Asymmetric Multi-core in Dark Silicon Era. In Proceedings of the DAC ’13: 50th Annual Design Automation Conference, Austin, TX, USA, 29 May–7 June 2013; ACM: New York, NY, USA, 2013; pp. 174:1–174:9. [Google Scholar] [CrossRef]
- Somu Muthukaruppan, T.; Pathania, A.; Mitra, T. Price Theory Based Power Management for Heterogeneous Multi-cores. SIGARCH Comput. Archit. News 2014, 42, 161–176. [Google Scholar] [CrossRef]
- Giardino, M.; Maxwell, W.; Ferri, B.; Ferri, A. Speculative Thread Framework for Transient Management and Bumpless Transfer in Reconfigurable Digital Filters. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018; pp. 3786–3791. [Google Scholar] [CrossRef] [Green Version]
- Imes, C.; Kim, D.H.K.; Maggio, M.; Hoffmann, H. POET: A portable approach to minimizing energy under soft real-time constraints. In Proceedings of the 21st IEEE Real-Time and Embedded Technology and Applications Symposium, Seattle, WA, USA, 13–16 April 2015; pp. 75–86. [Google Scholar] [CrossRef]
- Imes, C.; Hoffmann, H. Bard: A unified framework for managing soft timing and power constraints. In Proceedings of the 2016 International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation (SAMOS), Agios Konstantinos, Greece, 17–21 July 2016; pp. 31–38. [Google Scholar] [CrossRef]
- Giardino, M.; Klawitter, E.; Ferri, B.; Ferri, A. A Power- and Performance-Aware Software Framework for Control System Applications. IEEE Trans. Comput. 2020, 69, 1544–1555. [Google Scholar] [CrossRef]
- Das, A.; Walker, M.J.; Hansson, A.; Al-Hashimi, B.M.; Merrett, G.V. Hardware-software interaction for run-time power optimization: A case study of embedded Linux on multicore smartphones. In Proceedings of the 2015 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Rome, Italy, 22–24 July 2015; pp. 165–170. [Google Scholar]
- Martinez, J.F.; Ipek, E. Dynamic Multicore Resource Management: A Machine Learning Approach. IEEE Micro 2009, 29, 8–17. [Google Scholar] [CrossRef]
- Sheng, Y.; Shafik, R.A.; Merrett, G.V.; Stott, E.; Levine, J.M.; Davis, J.; Al-Hashimi, B.M. Adaptive energy minimization of embedded heterogeneous systems using regression-based learning. In Proceedings of the 2015 25th International Workshop on Power and Timing Modeling, Optimization and Simulation (PATMOS), Salvador, Brazil, 1–4 September 2015; pp. 103–110. [Google Scholar] [CrossRef] [Green Version]
- Ye, R.; Xu, Q. Learning-Based Power Management for Multicore Processors via Idle Period Manipulation. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2014, 33, 1043–1055. [Google Scholar] [CrossRef] [Green Version]
- Shen, H.; Tan, Y.; Lu, J.; Wu, Q.; Qiu, Q. Achieving Autonomous Power Management Using Reinforcement Learning. ACM Trans. Des. Autom. Electron. Syst. 2013, 18, 1–32. [Google Scholar] [CrossRef]
- Ge, Y.; Qiu, Q. Dynamic Thermal Management for Multimedia Applications Using Machine Learning. In Proceedings of the 48th Design Automation Conference (DAC ’11), San Diego, CA, USA, 5–9 June 2011; ACM: New York, NY, USA, 2011; pp. 95–100. [Google Scholar] [CrossRef]
- Das, A.; Al-Hashimi, B.M.; Merrett, G.V. Adaptive and Hierarchical Runtime Manager for Energy-Aware Thermal Management of Embedded Systems. ACM Trans. Embed. Comput. Syst. 2016, 15, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Gupta, U.; Mandal, S.K.; Mao, M.; Chakrabarti, C.; Ogras, U.Y. A Deep Q-Learning Approach for Dynamic Management of Heterogeneous Processors. IEEE Comput. Archit. Lett. 2019, 18, 14–17. [Google Scholar] [CrossRef]
- Bienia, C.; Kumar, S.; Singh, J.P.; Li, K. The PARSEC benchmark suite: Characterization and architectural implications. In Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques, Toronto, ON, Canada, 25–29 October 2008; pp. 72–81. [Google Scholar]
- Gupta, U.; Campbell, J.; Ogras, U.Y.; Ayoub, R.; Kishinevsky, M.; Paterna, F.; Gumussoy, S. Adaptive Performance Prediction for Integrated GPUs. In Proceedings of the 35th International Conference on Computer-Aided Design (ICCAD ’16), Austin, TX, USA, 7–10 November 2016; ACM: New York, NY, USA, 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Gupta, U.; Babu, M.; Ayoub, R.; Kishinevsky, M.; Paterna, F.; Ogras, U.Y. STAFF: Online Learning with Stabilized Adaptive Forgetting Factor and Feature Selection Algorithm. In Proceedings of the 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G.; Williams, R.J. Reinforcement learning is direct adaptive optimal control. IEEE Control Syst. Mag. 1992, 12, 19–22. [Google Scholar] [CrossRef]
- Chi-Hyon, O.; Nakashima, T.; Ishibuchi, H. Initialization of Q-values by fuzzy rules for accelerating Q-learning. In Proceedings of the 1998 IEEE International Joint Conference on Neural Networks Proceedings, World Congress on Computational Intelligence (Cat. No.98CH36227), Anchorage, AK, USA, 4–9 May 1998; Volume 3, pp. 2051–2056. [Google Scholar]
- Song, Y.; Li, Y.; Li, C.; Zhang, G. An efficient initialization approach of Q-learning for mobile robots. Int. J. Control. Autom. Syst. 2012, 10, 166–172. [Google Scholar] [CrossRef]
- Even-Dar, E.; Mansour, Y. Learning Rates for Q-learning. J. Mach. Learn. Res. 2004, 5, 1–25. [Google Scholar]
- DFRobot. Cherokey 4WD Datasheet. Available online: https://wiki.dfrobot.com/Cherokey_4WD_Mobile_Platform__SKU_ROB0102_ (accessed on 27 March 2021).
- DFRobot. ROMEO BLE Datasheet. Available online: https://wiki.dfrobot.com/RoMeo_BLE__SKU_DFR0305_ (accessed on 27 March 2021).
- Roy, R.; Bommakanti, V. ODROID XU4 User Manual. Available online: https://magazine.odroid.com/wp-content/uploads/odroid-xu4-user-manual.pdf (accessed on 31 January 2022).
- Gupta, U.; Patil, C.A.; Bhat, G.; Mishra, P.; Ogras, U.Y. DyPO: Dynamic Pareto-Optimal Configuration Selection for Heterogeneous MPSoCs. ACM Trans. Embed. Comput. Syst. 2017, 16, 1–20. [Google Scholar] [CrossRef]
- Butko, A.; Bruguier, F.; Gamatie, A.; Sassatelli, G.; Novo, D.; Torres, L.; Robert, M. Full-System Simulation of big.LITTLE Multicore Architecture for Performance and Energy Exploration. In Proceedings of the 2016 IEEE 10th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSOC), Lyon, France, 21–23 September 2016; pp. 201–208. [Google Scholar]
- Chung, H.; Kang, M.; Cho, H.D. Heterogeneous Multi-Processing Solution of Exynos 5 Octa with ARM® big.LITTLE™ Technology. Available online: https://s3.ap-northeast-2.amazonaws.com/global.semi.static/HeterogeneousMulti-ProcessingSolutionofExynos5OctawithARMbigLITTLETechnology.pdf (accessed on 31 January 2022).
- ARM. big.LITTLE Technology: The Future of Mobile. Available online: https://img.hexus.net/v2/press_releases/arm/big.LITTLE.Whitepaper.pdf (accessed on 31 January 2022).
- Likhachev, M.; Ferguson, D.; Gordon, G.; Stentz, A.; Thrun, S. Anytime Dynamic A*: An Anytime, Replanning Algorithm. In Proceedings of the 15th International Conference on Automated Planning and Scheduling, Monterey, CA, USA, 5–10 June 2005; pp. 262–271. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Gough, B. GNU Scientific Library Reference Manual, 3rd ed.; Network Theory Ltd.: Scotland, Galloway, UK, 2009. [Google Scholar]
- Murao, H.; Kitamura, S. Q-Learning with adaptive state segmentation (QLASS). In Proceedings of the 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation CIRA’97, ‘Towards New Computational Principles for Robotics and Automation’, Monterey, CA, USA, 10–11 July 1997; pp. 179–184. [Google Scholar]
- Gama, J.; Torgo, L.; Soares, C. Dynamic Discretization of Continuous Attributes. In Proceedings of the Progress in Artificial Intelligence—IBERAMIA 98, Lisbon, Portugal, 5–9 October 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 160–169. [Google Scholar]
- Gonzalez, R.; Horowitz, M. Energy dissipation in general purpose microprocessors. IEEE J. Solid-State Circuits 1996, 31, 1277–1284. [Google Scholar] [CrossRef] [Green Version]
- Brooks, D.M.; Bose, P.; Schuster, S.E.; Jacobson, H.; Kudva, P.N.; Buyuktosunoglu, A.; Wellman, J.; Zyuban, V.; Gupta, M.; Cook, P.W. Power-aware Microarchitecture: Design and modeling challenges for next-generation microprocessors. IEEE Micro 2000, 20, 26–44. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| high-level controller | board | ODROID XU4 [64] |
| processor | Samsung Exynos5422 8-core big.LITTLE [68] | |
| DRAM | 2 GB | |
| storage | 16 GB eMMC | |
| network | 802.11b wireless via USB | |
| operating system | Ubuntu 18.04 | |
| kernel | Linux 4.14.5-92 | |
| low-level controller | board | Arduino ROMEO [63] |
| processor | ATMega 328P |
| Metric | Discretization Levels | Cumulative States | Size (B) |
|---|---|---|---|
| error | 10 | 10 | 400 B |
| power consumption | 10 | 100 | 4000 B |
| replanning mode | 2 | 200 | 8000 B |
| checksum error | 4 | 400 | 16,000 B |
| map updates | 2 | 1600 | 64,000 B |
| Symbol | Description |
|---|---|
| t | Time of sample |
| Instantaneous Power at time t | |
| Maximum measured power | |
| Error measured at time t | |
| Maximum measured error | |
| r | ADA* replanning active (0, 1) |
| Accumulating sum of replanning | |
| n-Sample moving Average of Power |
| Number | Reward Description | Reward Function |
|---|---|---|
| 1 | Power Only | |
| 2 | Error Only | |
| 3 | Power + Error | |
| 4 | Power + Error + Replan Flag | |
| 5 | Power + Error + Accumulating Replan Flag | |
| 6 | Weighted 1:10 power to error | |
| 7 | Error + 10-sample Moving Average of Power |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giardino, M.; Schwyn, D.; Ferri, B.; Ferri, A. Low-Overhead Reinforcement Learning-Based Power Management Using 2QoSM. J. Low Power Electron. Appl. 2022, 12, 29. https://doi.org/10.3390/jlpea12020029
Giardino M, Schwyn D, Ferri B, Ferri A. Low-Overhead Reinforcement Learning-Based Power Management Using 2QoSM. Journal of Low Power Electronics and Applications. 2022; 12(2):29. https://doi.org/10.3390/jlpea12020029
Chicago/Turabian StyleGiardino, Michael, Daniel Schwyn, Bonnie Ferri, and Aldo Ferri. 2022. "Low-Overhead Reinforcement Learning-Based Power Management Using 2QoSM" Journal of Low Power Electronics and Applications 12, no. 2: 29. https://doi.org/10.3390/jlpea12020029
APA StyleGiardino, M., Schwyn, D., Ferri, B., & Ferri, A. (2022). Low-Overhead Reinforcement Learning-Based Power Management Using 2QoSM. Journal of Low Power Electronics and Applications, 12(2), 29. https://doi.org/10.3390/jlpea12020029